Recommendation Systems (8): Knowledge Graph-Enhanced Recommendation
Chen KaiBOSS
2026-02-03 23:11:112026-02-03 23:118.8k Words54 Mins
permalink: "en/recommendation-systems-8-knowledge-graph/" date:
2024-06-06 16:00:00 tags: - Recommendation Systems - Knowledge Graph -
KG-enhanced categories: Recommendation Systems mathjax: true --- When
you search for "The Dark Knight" on a movie recommendation platform, the
system doesn't just know you watched it — it understands that Christian
Bale played Batman, Christopher Nolan directed it, it's part of the
Batman trilogy, and it's similar to other superhero films. This rich
semantic understanding comes from knowledge graphs, structured
representations that encode entities (movies, actors, directors) and
their relationships (acted_in, directed_by, similar_to) as a graph.
Knowledge graph-enhanced recommendation systems leverage these semantic
relationships to provide more accurate, explainable, and diverse
recommendations, especially for cold-start items and users with sparse
interaction histories.
Knowledge graphs transform recommendation from pure pattern matching
to semantic reasoning. Traditional collaborative filtering methods
struggle when items have few interactions, but knowledge graphs provide
rich auxiliary information: if a new movie shares actors or directors
with movies you've enjoyed, the system can confidently recommend it even
without historical interaction data. This article provides a
comprehensive exploration of knowledge graph-enhanced recommendation
systems, covering knowledge graph fundamentals, their role in
recommendation, propagation-based methods like RippleNet, graph
convolutional approaches (KGCN), attention mechanisms (KGAT, HKGAT),
collaborative knowledge embedding (CKE), recent advances in RecKG, and
practical implementations with 10+ code examples and detailed Q&A
sections.
Foundations of Knowledge
Graphs
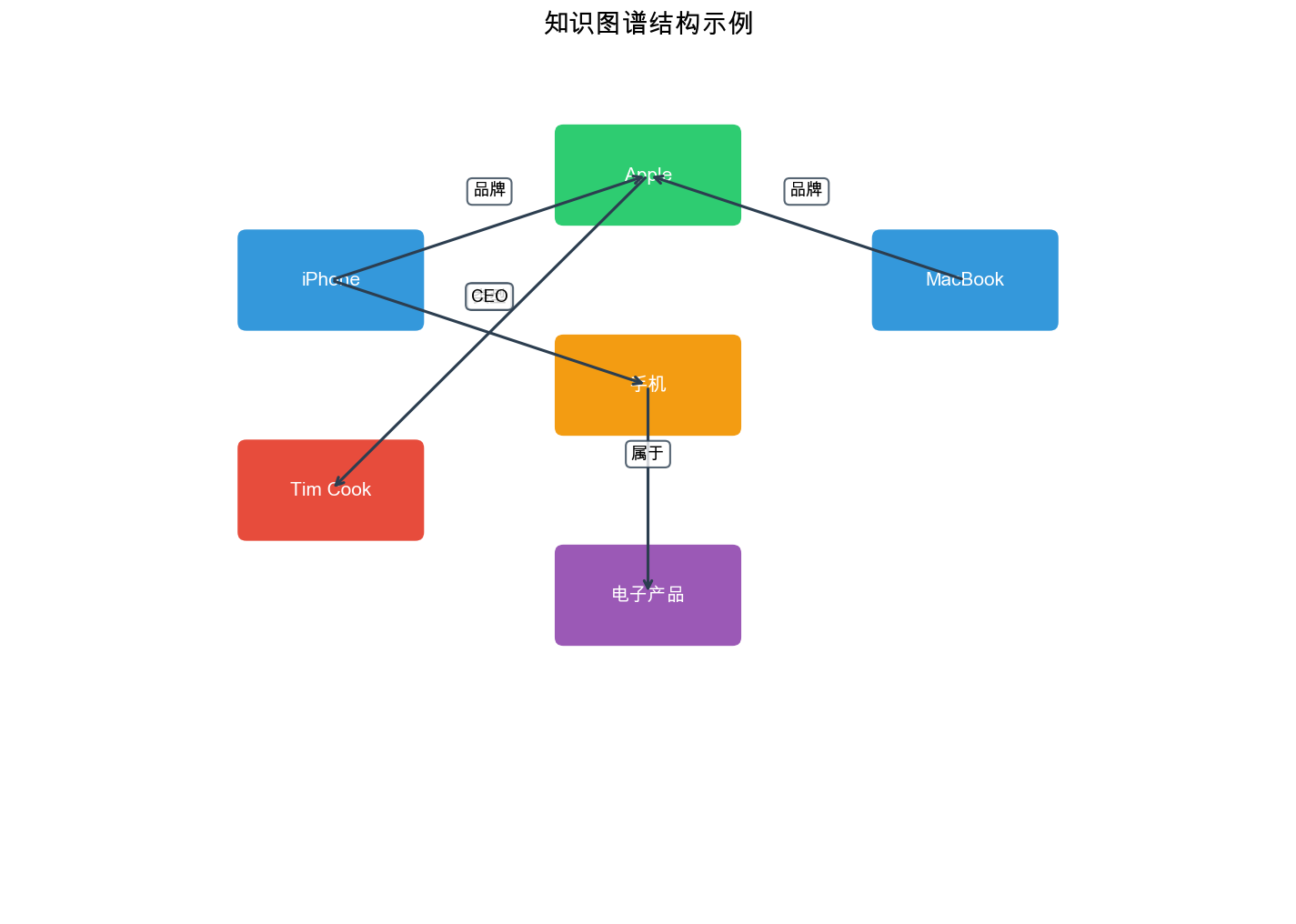
What Is a Knowledge Graph?
A knowledge graph (KG) is a structured
representation of knowledge as a graph, where nodes represent entities
(objects, concepts, events) and edges represent relationships between
entities. Formally, a knowledge graph is defined as\(\mathcal{G} = \{(h, r, t)\}\), where:
-\(h \in\)\(is the head entity
-\)r \(\mathcal{R}\)is the
relation type -\(t \in\)\(is the tail entity
-\)\(is the set of entities
-\)$is the set of relation types
Each triple\((h, r, t)\)represents a
fact: "head entity\(h\)has
relation\(r\)with tail entity\(t\)." For example, in a movie knowledge
graph: -\((TheDarkKnight, directed_by,
ChristopherNolan)\) -\((TheDarkKnight,
starred_in, ChristianBale)\) -\((TheDarkKnight, genre, Action)\) -\((ChristianBale, acted_in,
ThePrestige)\)
Knowledge Graph Structure
Knowledge graphs can be homogeneous (single
entity/relation type) or heterogeneous (multiple
entity/relation types). Recommendation systems typically use
heterogeneous knowledge graphs that include:
# Get neighbors dark_knight_id = kg.entities["TheDarkKnight"] neighbors = kg.get_neighbors(dark_knight_id) print(f"Neighbors of TheDarkKnight: {neighbors}")
The Role of
Knowledge Graphs in Recommendation
Why Knowledge Graphs
Help Recommendation
Knowledge graphs address several fundamental limitations of
traditional recommendation methods:
Cold Start Problem: New items with no interaction
history can't be recommended by collaborative filtering. Knowledge
graphs provide rich semantic information: if a new movie shares actors,
directors, or genres with movies a user likes, we can recommend it
confidently.
Data Sparsity: User-item interaction matrices are
extremely sparse. Knowledge graphs add dense semantic connections,
enabling the system to find relationships even when direct interactions
are missing.
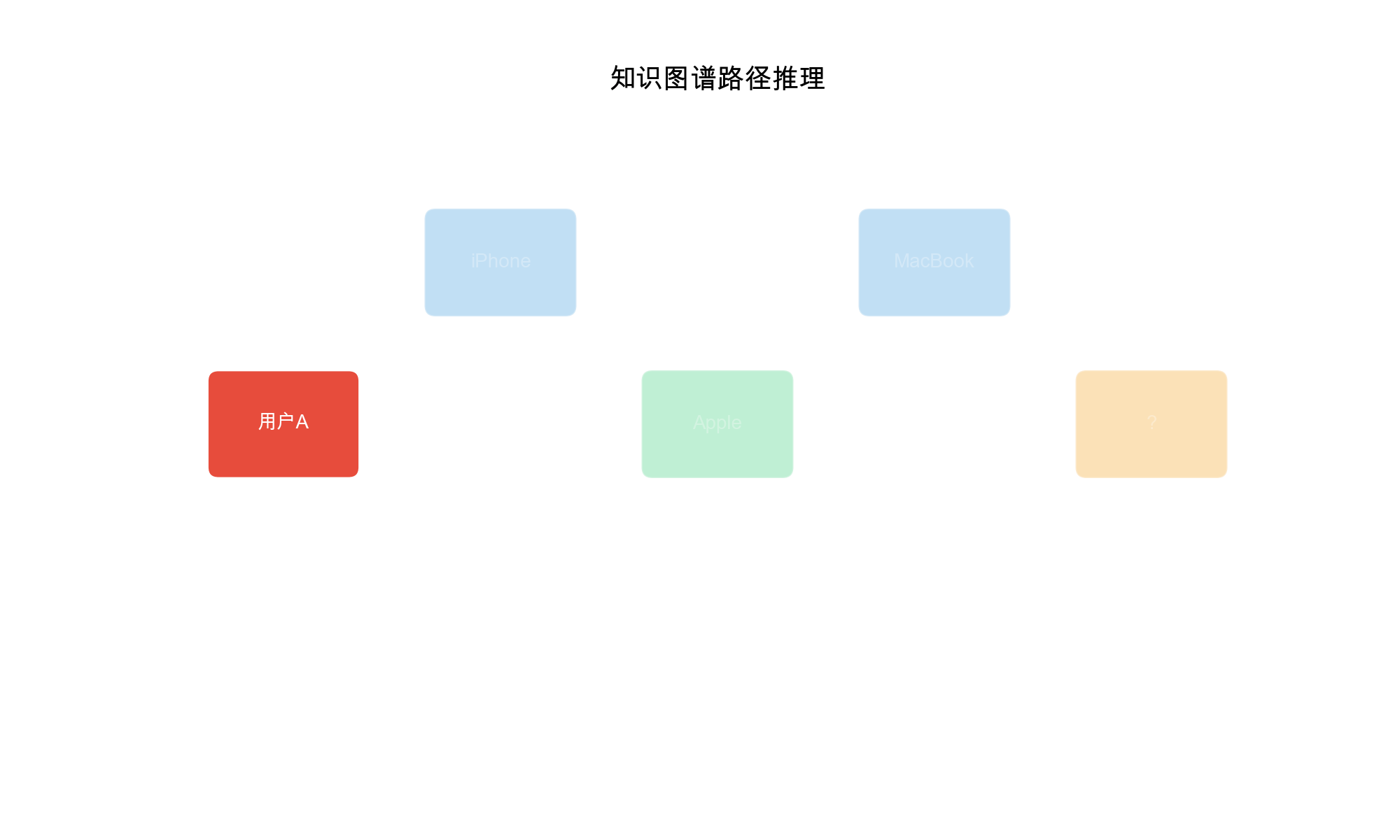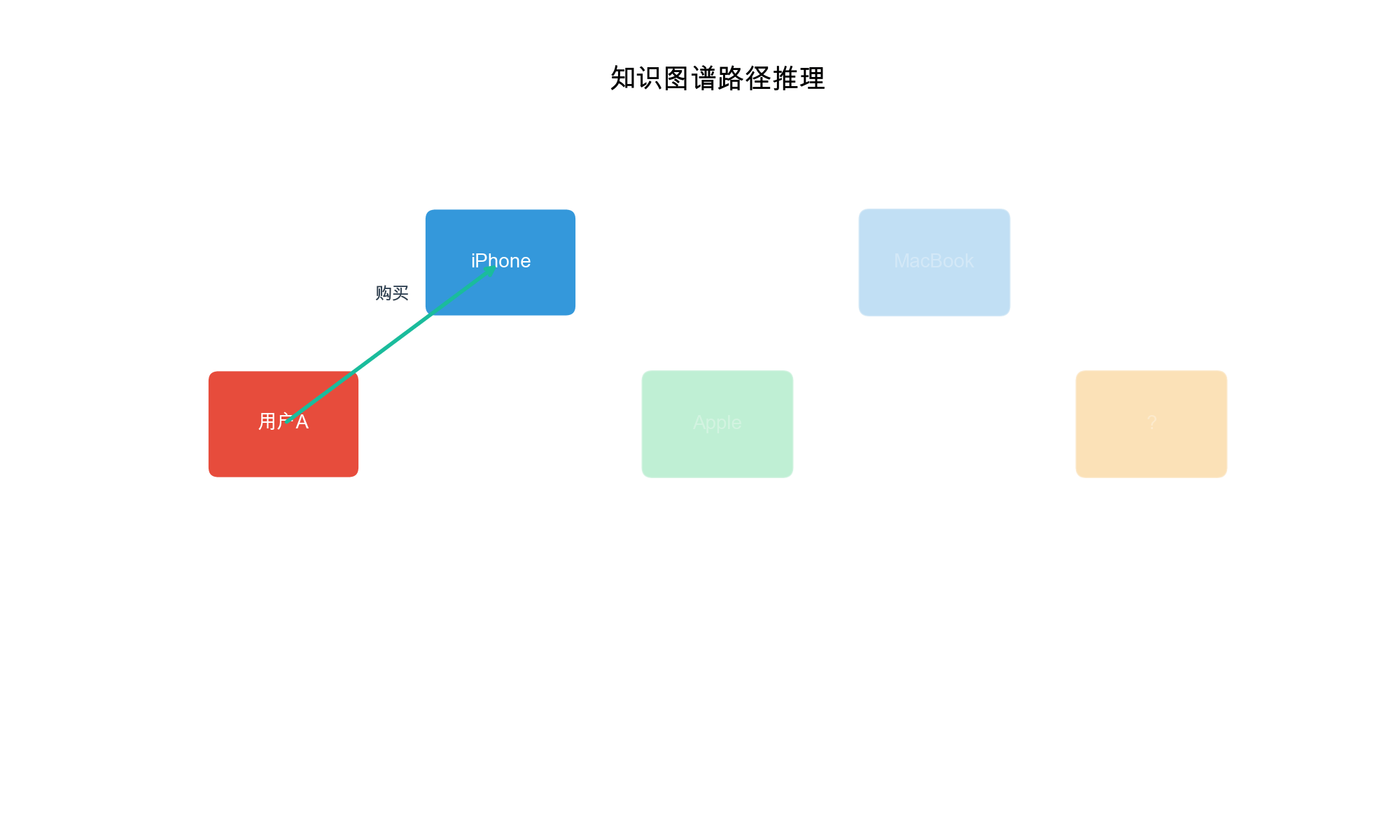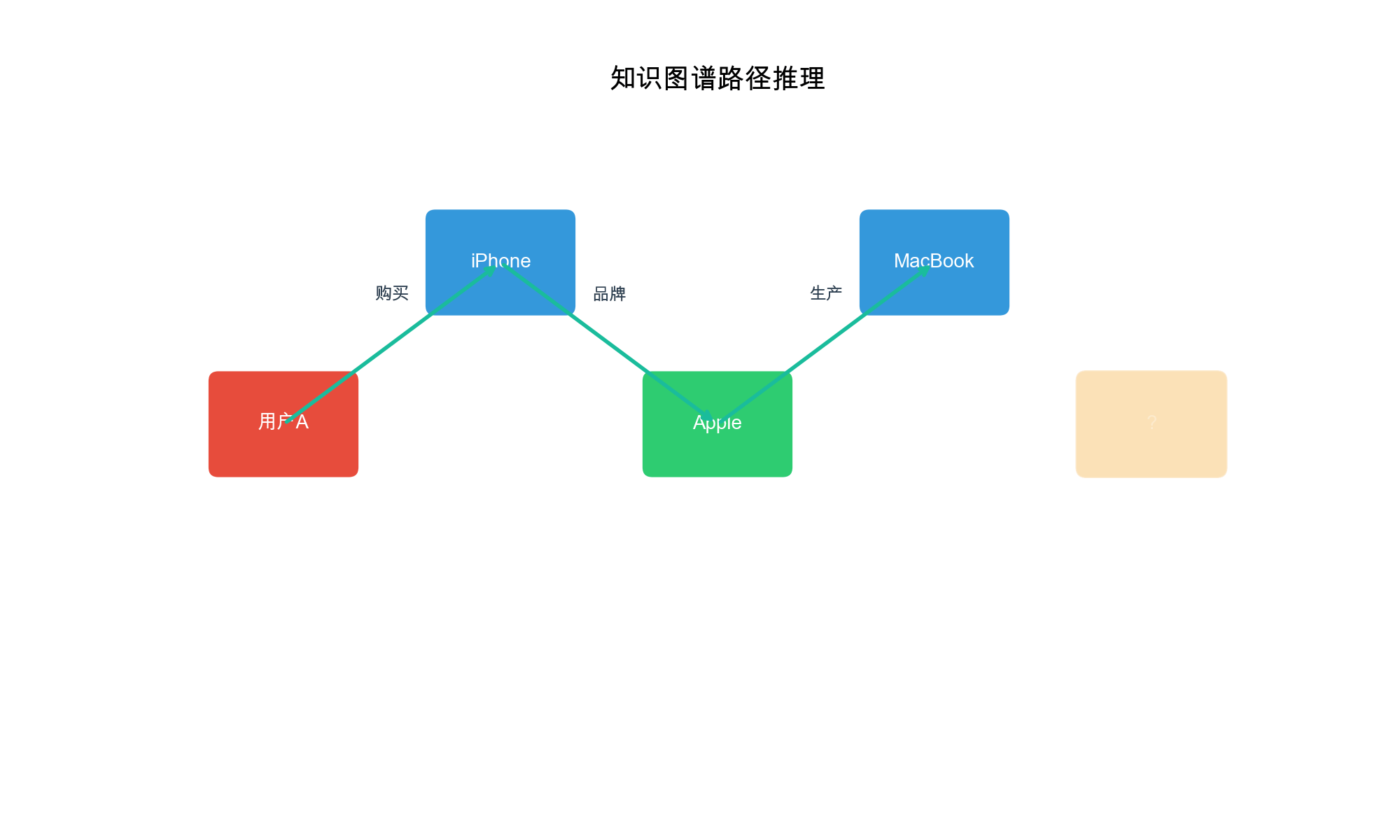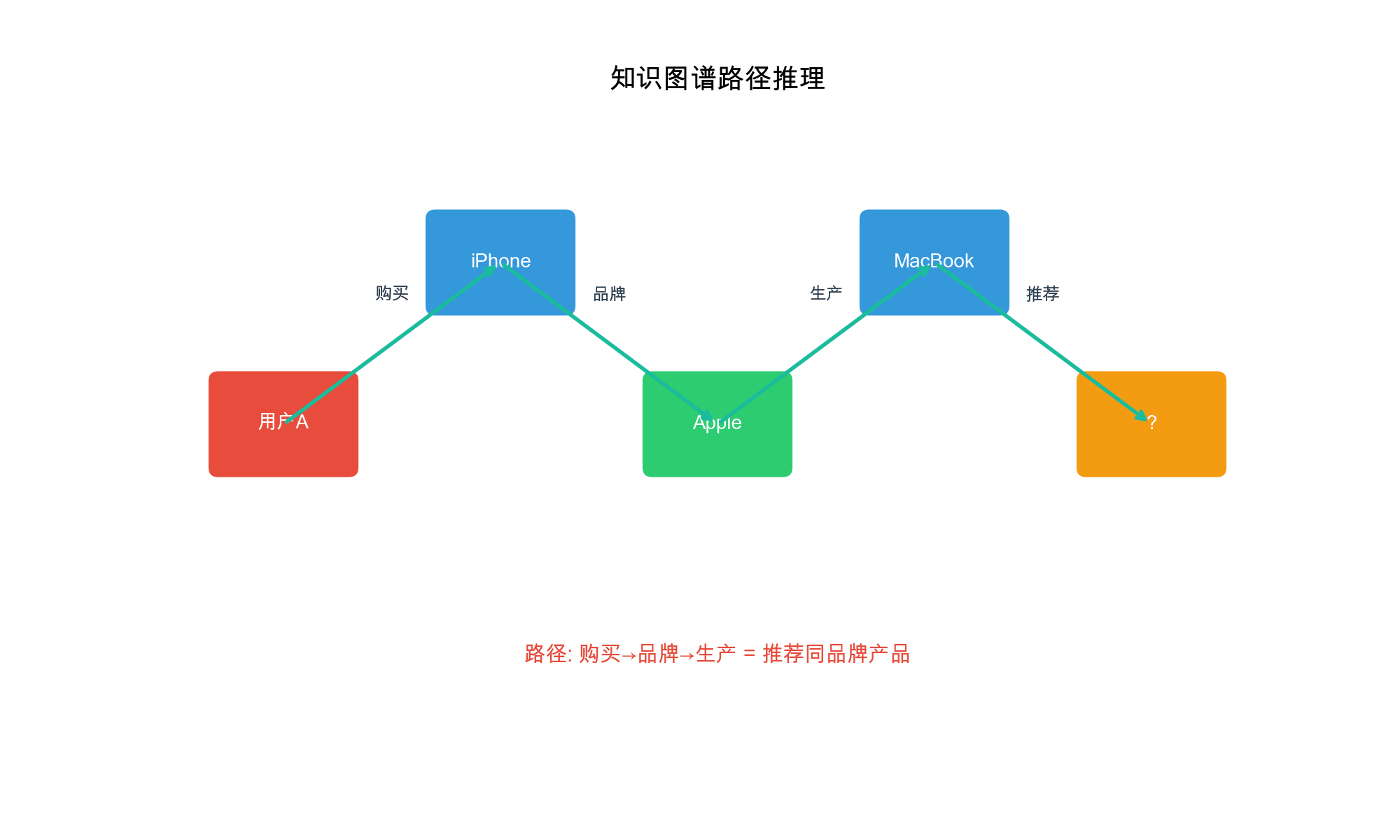
Explainability: Knowledge graphs provide
interpretable paths for recommendations. Instead of "users who liked
this also liked that," we can say "we recommend this because it's
directed by the same director as movies you've enjoyed."
Diversity: Knowledge graphs help discover diverse
recommendations by exploring different relation paths, avoiding the
filter bubble effect.
Knowledge
Graph-Enhanced Recommendation Pipeline
The typical pipeline for KG-enhanced recommendation:
Knowledge Graph Construction: Build KG from
structured data (DBpedia, Wikidata, domain-specific databases) or
extract from unstructured text
Entity Alignment: Link items/users in the
recommendation system to entities in the knowledge graph
Embedding Learning: Learn dense representations of
entities and relations
Recommendation: Use KG embeddings to enhance
user/item representations and generate recommendations
Types of
KG-Enhanced Recommendation Methods
Propagation-Based Methods: Propagate user
preferences through the knowledge graph (RippleNet)
Graph Convolutional Methods: Apply graph
convolutional networks to the knowledge graph (KGCN)
Attention-Based Methods: Use attention mechanisms to
weight different relation paths (KGAT, HKGAT)
Embedding-Based Methods: Learn joint embeddings of
users, items, and KG entities (CKE)
RippleNet, introduced by Wang et al. in CIKM 2018, propagates user
preferences through the knowledge graph like ripples in water. When a
user interacts with an item, this preference "ripples" outward through
the KG, activating related entities at different hops.
Key Idea: User preferences propagate along relation
paths in the knowledge graph. Entities closer to the user's historical
items receive stronger signals.
RippleNet Algorithm
Given a user\(u\)with historical
items\(V_u = \{v_1, v_2, \dots\}\),
RippleNet:
Initializes the user's preference set as the
historical items:\(\mathcal{S}_u^0 =
V_u\)
Propagates preferences through\(H\)hops:
At hop\(h\), finds entities
connected to\(\mathcal{S}_u^{h-1}\)via
relations
Aggregates these entities to form\(\mathcal{S}_u^h\)
Aggregates preferences from all hops to form the
user embedding
Predicts user-item interaction
probability
Mathematical Formulation
At hop\(h\), for each historical
item\(v \in V_u\), RippleNet finds
related entities:\[\mathcal{S}_u^h = \{t |
(h, r, t) \in \mathcal{G}, h \in \mathcal{S}_u^{h-1}}\]The
relevance of entity\(t\)at hop\(h\)is computed as:\[p_i^h = \text{softmax}(\mathbf{v}^T \mathbf{R}_i
\mathbf{t})\]where\(\mathbf{v}\)is the item embedding,\(\mathbf{R}_i\)is the relation embedding
matrix, and\(\mathbf{t}\)is the entity
embedding.
The user's preference at hop\(h\)is:\[\mathbf{o}_u^h = \sum_{(h,r,t) \in
\mathcal{S}_u^h} p_i^h \mathbf{t}\]The final user embedding
aggregates all hops:\[\mathbf{u} =
\sum_{h=1}^{H} \alpha_h \mathbf{o}_u^h + \mathbf{u}_0\]where\(\alpha_h\)are learnable weights and\(\mathbf{u}_0\)is the base user
embedding.
import torch import torch.nn as nn import torch.nn.functional as F from typing importList, Dict, Set
classRippleNet(nn.Module): """ RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems. """ def__init__(self, num_users, num_items, num_entities, num_relations, embedding_dim=64, n_hop=2, n_memory=32, kg_adj=None): super(RippleNet, self).__init__() self.num_users = num_users self.num_items = num_items self.num_entities = num_entities self.num_relations = num_relations self.embedding_dim = embedding_dim self.n_hop = n_hop self.n_memory = n_memory self.kg_adj = kg_adj # Knowledge graph adjacency: {entity_id: [(relation_id, tail_id), ...]} # Embeddings self.user_embeddings = nn.Embedding(num_users, embedding_dim) self.item_embeddings = nn.Embedding(num_items, embedding_dim) self.entity_embeddings = nn.Embedding(num_entities, embedding_dim) self.relation_embeddings = nn.Embedding(num_relations, embedding_dim) # Hop weights self.hop_weights = nn.Parameter(torch.ones(n_hop + 1) / (n_hop + 1)) # Initialize embeddings nn.init.xavier_uniform_(self.user_embeddings.weight) nn.init.xavier_uniform_(self.item_embeddings.weight) nn.init.xavier_uniform_(self.entity_embeddings.weight) nn.init.xavier_uniform_(self.relation_embeddings.weight) defforward(self, user_ids, item_ids, ripple_sets): """ Args: user_ids: (batch_size,) - user indices item_ids: (batch_size,) - item indices ripple_sets: List of ripple sets for each user Each ripple set: List of n_hop sets Each set: List of (relation_id, tail_id) tuples """ # Get base embeddings user_emb = self.user_embeddings(user_ids) # (batch_size, embedding_dim) item_emb = self.item_embeddings(item_ids) # (batch_size, embedding_dim) # Propagate preferences through KG user_emb_enhanced = self._ripple_propagate(user_emb, item_emb, ripple_sets) # Predict interaction probability scores = torch.sum(user_emb_enhanced * item_emb, dim=1) # (batch_size,) return scores def_ripple_propagate(self, user_emb, item_emb, ripple_sets): """ Propagate user preferences through knowledge graph. """ batch_size = user_emb.size(0) memories = [user_emb] # Start with base user embedding for hop inrange(self.n_hop): # Get ripple set for this hop hop_memories = [] for i inrange(batch_size): ripple_set = ripple_sets[i][hop] if hop < len(ripple_sets[i]) else [] iflen(ripple_set) == 0: # No neighbors at this hop, use zero vector hop_memories.append(torch.zeros(self.embedding_dim)) continue # Sample n_memory entities if too many iflen(ripple_set) > self.n_memory: ripple_set = ripple_set[:self.n_memory] # Get embeddings relations = torch.LongTensor([r for r, t in ripple_set]) tails = torch.LongTensor([t for r, t in ripple_set]) relation_emb = self.relation_embeddings(relations) # (n_mem, embedding_dim) tail_emb = self.entity_embeddings(tails) # (n_mem, embedding_dim) # Compute relevance scores # p = softmax(v^T R t) item_emb_i = item_emb[i].unsqueeze(0) # (1, embedding_dim) scores = torch.sum(item_emb_i * relation_emb * tail_emb, dim=1) # (n_mem,) probs = F.softmax(scores, dim=0) # (n_mem,) # Weighted aggregation hop_memory = torch.sum(probs.unsqueeze(1) * tail_emb, dim=0) # (embedding_dim,) hop_memories.append(hop_memory) hop_memories = torch.stack(hop_memories) # (batch_size, embedding_dim) memories.append(hop_memories) # Aggregate all hops memories = torch.stack(memories, dim=1) # (batch_size, n_hop+1, embedding_dim) weights = F.softmax(self.hop_weights, dim=0) # (n_hop+1,) user_emb_enhanced = torch.sum(weights.unsqueeze(0).unsqueeze(2) * memories, dim=1) # (batch_size, embedding_dim) return user_emb_enhanced defget_ripple_sets(self, user_id, user_items, kg_adj, max_hops=2): """ Generate ripple sets for a user. Args: user_id: User ID user_items: List of item IDs the user has interacted with kg_adj: Knowledge graph adjacency max_hops: Maximum number of hops Returns: List of ripple sets: [hop_0_set, hop_1_set, ...] """ ripple_sets = [] current_set = set(user_items) # Start with user's items for hop inrange(max_hops): next_set = [] for entity_id in current_set: if entity_id in kg_adj: for relation_id, tail_id in kg_adj[entity_id]: next_set.append((relation_id, tail_id)) ripple_sets.append(next_set) current_set = set([t for _, t in next_set]) return ripple_sets
# Example usage if __name__ == "__main__": num_users = 1000 num_items = 500 num_entities = 2000# Includes items + attributes num_relations = 10 embedding_dim = 64 # Build knowledge graph adjacency kg_adj = { 0: [(0, 100), (1, 101)], # Item 0 connected to entities 100, 101 1: [(0, 102), (2, 103)], } model = RippleNet( num_users=num_users, num_items=num_items, num_entities=num_entities, num_relations=num_relations, embedding_dim=embedding_dim, n_hop=2, n_memory=32, kg_adj=kg_adj ) # Generate ripple sets for a user user_items = [0, 1] # User interacted with items 0 and 1 ripple_sets = model.get_ripple_sets(0, user_items, kg_adj, max_hops=2) # Forward pass user_ids = torch.LongTensor([0]) item_ids = torch.LongTensor([2]) batch_ripple_sets = [ripple_sets] scores = model(user_ids, item_ids, batch_ripple_sets) print(f"Prediction score: {scores.item():.4f}")
KGCN: Knowledge
Graph Convolutional Networks
KGCN Architecture
KGCN (Knowledge Graph Convolutional Network), introduced by Wang et
al. in WWW 2019, applies graph convolutional networks directly to the
knowledge graph to learn item embeddings. Unlike RippleNet which
propagates user preferences, KGCN learns item representations by
aggregating information from neighboring entities in the KG.
Key Idea: Items are represented by aggregating
features from their neighbors in the knowledge graph. Different
relations contribute differently to the final representation.
KGCN Algorithm
For an item\(i\)in the knowledge
graph, KGCN:
Samples neighbors:$_i = {(r, e) | (i, r, e) }
$
Aggregates neighbor embeddings with
relation-aware weights
Updates item embedding by combining its own
embedding with aggregated neighbors
Repeats for multiple layers to capture multi-hop
relationships
Mathematical Formulation
At layer\(l\), for item\(i\), KGCN aggregates neighbors:\[\mathbf{e}_{\mathcal{N}_i}^l = \sum_{(r,e) \in
\mathcal{N}_i} \pi_r^l(i, e) \mathbf{e}_e^{l-1}\]where\(\pi_r^l(i, e)\)is the attention weight for
relation\(r\)and neighbor\(e\):\[\pi_r^l(i,
e) = \frac{\exp(\mathbf{W}_r^l \mathbf{e}_i^{l-1} +
\mathbf{b}_r^l)}{\sum_{(r',e') \in \mathcal{N}_i}
\exp(\mathbf{W}_{r'}^l \mathbf{e}_i^{l-1} +
\mathbf{b}_{r'}^l)}\]The item embedding is updated as:\[\mathbf{e}_i^l = \sigma(\mathbf{W}^l
[\mathbf{e}_i^{l-1} || \mathbf{e}_{\mathcal{N}_i}^l] +
\mathbf{b}^l)\]where\(||\)denotes concatenation and\(\sigma\)is an activation function.
import torch import torch.nn as nn import torch.nn.functional as F from torch_geometric.nn import MessagePassing from torch_geometric.utils import add_self_loops, degree
classKGCNLayer(nn.Module): """ Single layer of Knowledge Graph Convolutional Network. """ def__init__(self, embedding_dim, num_relations, aggregator='sum'): super(KGCNLayer, self).__init__() self.embedding_dim = embedding_dim self.num_relations = num_relations self.aggregator = aggregator # Relation-specific transformation matrices self.relation_transforms = nn.ModuleList([ nn.Linear(embedding_dim, embedding_dim, bias=False) for _ inrange(num_relations) ]) # Attention weights self.attention_weights = nn.ModuleList([ nn.Linear(embedding_dim, 1) for _ inrange(num_relations) ]) # Aggregation function self.aggregate = nn.Linear(embedding_dim * 2, embedding_dim) defforward(self, item_embeddings, neighbors, relations): """ Args: item_embeddings: (num_items, embedding_dim) - current item embeddings neighbors: List of neighbor lists for each item neighbors[i] = [(relation_id, neighbor_id), ...] relations: Relation embeddings (num_relations, embedding_dim) """ num_items = item_embeddings.size(0) aggregated = [] for i inrange(num_items): iflen(neighbors[i]) == 0: # No neighbors, use zero vector aggregated.append(torch.zeros(self.embedding_dim)) continue # Get neighbor embeddings and relations neighbor_embs = [] attention_scores = [] for r_id, n_id in neighbors[i]: neighbor_emb = item_embeddings[n_id] # (embedding_dim,) # Transform neighbor embedding with relation transformed = self.relation_transforms[r_id](neighbor_emb) # (embedding_dim,) neighbor_embs.append(transformed) # Compute attention score # Attention based on item and relation compatibility item_emb = item_embeddings[i] # (embedding_dim,) relation_emb = relations[r_id] # (embedding_dim,) combined = item_emb + relation_emb # (embedding_dim,) score = self.attention_weights[r_id](combined) # (1,) attention_scores.append(score) neighbor_embs = torch.stack(neighbor_embs) # (num_neighbors, embedding_dim) attention_scores = torch.stack(attention_scores).squeeze() # (num_neighbors,) # Apply attention attention_weights = F.softmax(attention_scores, dim=0) # (num_neighbors,) aggregated_emb = torch.sum(attention_weights.unsqueeze(1) * neighbor_embs, dim=0) # (embedding_dim,) aggregated.append(aggregated_emb) aggregated = torch.stack(aggregated) # (num_items, embedding_dim) # Combine with original embeddings combined = torch.cat([item_embeddings, aggregated], dim=1) # (num_items, embedding_dim * 2) output = self.aggregate(combined) # (num_items, embedding_dim) return output
classKGCN(nn.Module): """ Knowledge Graph Convolutional Network for Recommendation. """ def__init__(self, num_users, num_items, num_entities, num_relations, embedding_dim=64, n_layers=2, aggregator='sum'): super(KGCN, self).__init__() self.num_users = num_users self.num_items = num_items self.num_entities = num_entities self.num_relations = num_relations self.embedding_dim = embedding_dim self.n_layers = n_layers # Embeddings self.user_embeddings = nn.Embedding(num_users, embedding_dim) self.item_embeddings = nn.Embedding(num_items, embedding_dim) self.entity_embeddings = nn.Embedding(num_entities, embedding_dim) self.relation_embeddings = nn.Embedding(num_relations, embedding_dim) # KGCN layers self.kgcn_layers = nn.ModuleList([ KGCNLayer(embedding_dim, num_relations, aggregator) for _ inrange(n_layers) ]) # Initialize embeddings nn.init.xavier_uniform_(self.user_embeddings.weight) nn.init.xavier_uniform_(self.item_embeddings.weight) nn.init.xavier_uniform_(self.entity_embeddings.weight) nn.init.xavier_uniform_(self.relation_embeddings.weight) defforward(self, user_ids, item_ids, item_neighbors): """ Args: user_ids: (batch_size,) - user indices item_ids: (batch_size,) - item indices item_neighbors: List of neighbor lists for each layer item_neighbors[l][i] = [(relation_id, neighbor_id), ...] """ # Get base embeddings user_emb = self.user_embeddings(user_ids) # (batch_size, embedding_dim) # Initialize item embeddings (use entity embeddings for items) item_emb = self.entity_embeddings(item_ids) # (batch_size, embedding_dim) # Apply KGCN layers relation_emb = self.relation_embeddings.weight # (num_relations, embedding_dim) # For simplicity, we'll use item_neighbors for the first layer # In practice, you'd propagate through multiple layers current_emb = self.entity_embeddings.weight[:self.num_items] # (num_items, embedding_dim) for layer_idx, kgcn_layer inenumerate(self.kgcn_layers): if layer_idx < len(item_neighbors): current_emb = kgcn_layer(current_emb, item_neighbors[layer_idx], relation_emb) current_emb = F.relu(current_emb) # Get item embeddings for batch item_emb_enhanced = current_emb[item_ids] # (batch_size, embedding_dim) # Predict interaction scores = torch.sum(user_emb * item_emb_enhanced, dim=1) # (batch_size,) return scores
KGAT (Knowledge Graph Attention Network), introduced by Wang et al.
in KDD 2019, extends KGCN by using attention mechanisms to learn
relation-aware item embeddings. KGAT explicitly models high-order
connectivity in the knowledge graph through an attention-based
aggregator.
Key Innovation: KGAT uses attention to automatically
learn the importance of different relations and entities when
aggregating information in the knowledge graph.
KGAT Algorithm
KGAT builds a collaborative knowledge graph (CKG) that combines
user-item interactions with the knowledge graph:\[\mathcal{G}_1 = \{(u, interact, i) | u \in
\mathcal{U}, i \in \mathcal{I}}\]\[\mathcal{G}_2 = \{(h, r, t) | h, t \in
\mathcal{E}, r \in \mathcal{R}}\]\[\mathcal{G} = \mathcal{G}_1 \cup
\mathcal{G}_2\]For an entity\(e\)(user or item), KGAT aggregates
neighbors with attention:\[\mathbf{e}_{\mathcal{N}_e} = \sum_{(r,e') \in
\mathcal{N}_e} \pi(e, r, e') \mathbf{e}_{e'}\]where the
attention weight is:\[\pi(e, r, e') =
\frac{\exp(\text{LeakyReLU}(\mathbf{a}^T [\mathbf{e}_e || \mathbf{e}_r
|| \mathbf{e}_{e'}]))}{\sum_{(r',e'') \in \mathcal{N}_e}
\exp(\text{LeakyReLU}(\mathbf{a}^T [\mathbf{e}_e || \mathbf{e}_{r'}
|| \mathbf{e}_{e''}]))}\]The entity embedding is updated
as:\[\mathbf{e}_e^{(l)} =
\sigma(\mathbf{W}^{(l)} [\mathbf{e}_e^{(l-1)} ||
\mathbf{e}_{\mathcal{N}_e}^{(l-1)}] + \mathbf{b}^{(l)})\]
Multi-Head Attention
KGAT uses multi-head attention to capture different aspects:\[\mathbf{e}_{\mathcal{N}_e}^{(h)} =
\sum_{(r,e') \in \mathcal{N}_e} \pi^{(h)}(e, r, e')
\mathbf{e}_{e'}^{(h)}\]\[\mathbf{e}_{\mathcal{N}_e} = ||_{h=1}^{H}
\mathbf{e}_{\mathcal{N}_e}^{(h)}\]where\(H\)is the number of attention heads
and\(||\)denotes concatenation.
HKGAT (Hybrid Knowledge Graph Attention Network), introduced in
recent work, extends KGAT by explicitly modeling heterogeneous entity
types and relations. HKGAT uses type-specific attention mechanisms to
handle the heterogeneity in knowledge graphs.
Key Innovation: HKGAT distinguishes between
different entity types (users, items, attributes) and applies type-aware
transformations and attention mechanisms.
HKGAT Algorithm
HKGAT maintains separate embeddings for different entity types:
User embeddings:\(\mathbf{U} \in
\mathbb{R}^{|\mathcal{U}| \times d}\)
CKE (Collaborative Knowledge base Embedding), introduced by Zhang et
al. in KDD 2016, jointly learns embeddings for users, items, and
knowledge graph entities. CKE combines collaborative filtering signals
with knowledge graph structure through a unified embedding
framework.
Key Idea: Items are represented by combining their
collaborative filtering embeddings with their knowledge graph entity
embeddings, enabling the model to leverage both interaction patterns and
semantic relationships.
CKE Components
CKE consists of three components:
Collaborative Filtering Module: Learns user and
item embeddings from interaction data
Structural Knowledge Module: Learns entity
embeddings from knowledge graph structure
Textual Knowledge Module: Learns embeddings from
item descriptions/textual content
Mathematical Formulation
For an item\(i\), CKE represents it
as:\[\mathbf{i} = \mathbf{i}_{CF} +
\mathbf{i}_{KG} + \mathbf{i}_{text}\]where: -\(\mathbf{i}_{CF}\)is the collaborative
filtering embedding -\(\mathbf{i}_{KG}\)is the knowledge graph
entity embedding -\(\mathbf{i}_{text}\)is the textual content
embedding
The textual component uses a CNN or RNN to encode item
descriptions:\[\mathbf{i}_{text} =
\text{CNN}(\text{description}_i)\]The final loss combines all
components:\[\mathcal{L} = \mathcal{L}_{CF} +
\lambda_1 \mathcal{L}_{KG} + \lambda_2 \mathcal{L}_{text} + \lambda_3
\mathcal{L}_{reg}\]
❓
Q&A: Knowledge Graph-Enhanced Recommendation Common Questions
How do
knowledge graphs help with the cold start problem?
Knowledge graphs provide rich semantic information about items even
when they have no interaction history. For example, a new movie can be
recommended based on shared actors, directors, or genres with movies a
user has enjoyed. The knowledge graph creates connections between items
through attributes, enabling recommendations for cold-start items.
What's the
difference between RippleNet and KGCN?
RippleNet propagates user preferences through the knowledge graph:
when a user interacts with an item, this preference "ripples" outward,
activating related entities. KGCN, on the other hand, learns item
embeddings by aggregating information from neighboring entities in the
knowledge graph. RippleNet is user-centric (propagates from user items),
while KGCN is item-centric (learns item representations).
How does KGAT improve upon
KGCN?
KGAT extends KGCN by using attention mechanisms to automatically
learn the importance of different relations and entities when
aggregating information. KGAT also builds a collaborative knowledge
graph that combines user-item interactions with the knowledge graph,
enabling joint learning of collaborative and semantic signals.
What is the advantage
of HKGAT over KGAT?
HKGAT explicitly models heterogeneous entity types (users, items,
attributes) and applies type-specific transformations and attention
mechanisms. This allows the model to better handle the heterogeneity in
knowledge graphs, where different entity types may require different
treatment.
How does CKE
combine different information sources?
CKE represents items as the sum of three components: collaborative
filtering embeddings (from interaction data), knowledge graph embeddings
(from KG structure), and textual embeddings (from item descriptions).
This allows the model to leverage multiple information sources
simultaneously.
What
are the computational challenges of knowledge graph-enhanced
recommendation?
Knowledge graphs can be very large (millions of entities and
relations), making neighbor sampling and aggregation computationally
expensive. Solutions include: sampling strategies (e.g., RippleNet's
n_memory parameter), hierarchical aggregation, and efficient graph
neural network implementations.
How
do you evaluate knowledge graph-enhanced recommendation systems?
Evaluation includes both recommendation metrics (Hit Rate, NDCG, MRR)
and knowledge graph metrics (link prediction accuracy, entity ranking).
Additionally, explainability can be evaluated by measuring the quality
of generated explanations based on knowledge graph paths.
Can
knowledge graphs improve recommendation diversity?
Yes, knowledge graphs help discover diverse recommendations by
exploring different relation paths. Instead of recommending only similar
items, the system can recommend items connected through different
attributes (e.g., same director but different genre), increasing
diversity.
How do
you handle missing or noisy knowledge graph data?
Missing data can be handled through: (1) learning embeddings that are
robust to missing relations, (2) using attention mechanisms that can
downweight noisy connections, (3) data augmentation through relation
inference, and (4) multi-task learning that shares information across
tasks.
What
are the latest trends in knowledge graph-enhanced recommendation?
Recent trends include: (1) temporal knowledge graphs that model
evolving preferences, (2) multi-modal knowledge graphs combining
structured data with images and text, (3) federated learning across
distributed knowledge graphs, (4) transformer-based architectures for
knowledge graphs, and (5) explainable AI using knowledge graph
paths.
How
do you choose the number of hops/layers in knowledge graph methods?
The number of hops/layers depends on the graph structure and task.
Too few hops may miss important relationships, while too many hops can
introduce noise. Common approaches: (1) start with 2-3 hops and tune
based on validation performance, (2) use attention mechanisms to
automatically weight different hops, (3) analyze the graph diameter to
determine maximum useful hops.
What's
the relationship between knowledge graphs and graph neural
networks?
Knowledge graphs provide the structure (entities and relations),
while graph neural networks provide the learning mechanism (how to
aggregate information from neighbors). Most modern KG-enhanced
recommendation methods use GNNs (GCN, GAT, GraphSAGE) to learn from
knowledge graphs.
How
do you align items in your recommendation system with entities in
external knowledge graphs?
Entity alignment methods include: (1) string matching (exact or
fuzzy), (2) embedding-based similarity (learn embeddings for both and
find nearest neighbors), (3) manual curation by domain experts, (4)
joint learning that aligns entities during training.
Can
knowledge graphs help with explainable recommendation?
Yes, knowledge graphs enable explainable recommendations by providing
interpretable paths. For example, "We recommend Movie X because it's
directed by Director Y, who also directed Movie Z that you rated
highly." These explanations are generated by finding paths in the
knowledge graph from user items to recommended items.
What
are the limitations of knowledge graph-enhanced recommendation?
Limitations include: (1) dependency on knowledge graph quality and
completeness, (2) computational cost for large graphs, (3) difficulty in
handling dynamic knowledge (new entities/relations), (4) potential bias
from knowledge graph construction, and (5) challenges in multi-domain
scenarios where knowledge graphs may not align well.
Summary
Knowledge graph-enhanced recommendation systems represent a
significant advancement in recommendation technology, combining the
pattern recognition capabilities of collaborative filtering with the
semantic reasoning enabled by structured knowledge. Methods like
RippleNet, KGCN, KGAT, HKGAT, and CKE demonstrate different approaches
to leveraging knowledge graphs: propagation-based methods spread user
preferences through the graph, convolutional methods learn item
representations from neighbors, attention-based methods weight different
relations, and embedding methods jointly learn from multiple information
sources.
The key advantages of knowledge graph-enhanced recommendation
include: addressing cold start problems through rich semantic
information, improving explainability through interpretable paths,
increasing diversity by exploring different relation types, and enabling
better handling of sparse data through dense semantic connections.
As research continues, we're seeing advances in temporal modeling,
multi-modal integration, federated learning, and explainable AI. These
developments promise to make knowledge graph-enhanced recommendation
systems even more powerful and practical for real-world
applications.
References and Further
Reading
Wang, H., et al. "RippleNet: Propagating User Preferences on the
Knowledge Graph for Recommender Systems." CIKM 2018. arXiv:1803.03467
Wang, X., et al. "KGCN: Knowledge Graph Convolutional Network for
Recommender Systems." WWW 2019. arXiv:1904.12575
Wang, X., et al. "KGAT: Knowledge Graph Attention Network for
Recommendation." KDD 2019. arXiv:1905.07854
Zhang, F., et al. "Collaborative Knowledge Base Embedding for
Recommender Systems." KDD 2016. DOI:10.1145/2939672.2939673
Post title:Recommendation Systems (8): Knowledge Graph-Enhanced Recommendation
Post author:Chen Kai
Create time:2026-02-03 23:11:11
Post link:https://www.chenk.top/recommendation-systems-8-knowledge-graph/
Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.