permalink: "en/recommendation-systems-7-graph-neural-networks/" date: 2024-06-01 10:30:00 tags: - Recommendation Systems - GNN - Social Recommendation categories: Recommendation Systems mathjax: true --- When Netflix recommends a movie, it's not just looking at what you've watched — it's analyzing a complex web of relationships: which movies are similar to each other, which users share your taste, and how these connections form patterns across millions of interactions. This intricate network of relationships is exactly what graph neural networks (GNNs) excel at modeling. Unlike traditional recommendation approaches that treat users and items as isolated entities, GNNs capture the rich structural information encoded in user-item interaction graphs, social networks, and knowledge graphs.
Graph neural networks have revolutionized recommendation systems by explicitly modeling the graph structure underlying collaborative filtering. From the foundational Graph Convolutional Networks (GCN) that aggregate neighbor information, to Graph Attention Networks (GAT) that learn adaptive importance weights, to GraphSAGE that enables inductive learning on large-scale graphs, GNNs provide a principled framework for leveraging relational data in recommendations. In recommendation systems, these techniques have given rise to models like PinSage (Pinterest's billion-scale recommender), LightGCN (a simplified yet powerful approach), and NGCF (Neural Graph Collaborative Filtering) that achieve state-of-the-art performance by learning high-quality embeddings through graph convolution operations.
This article provides a comprehensive exploration of graph neural networks for recommendation, covering foundational GNN architectures (GCN, GAT, GraphSAGE), graph modeling strategies for recommendation scenarios, key models (PinSage, LightGCN, NGCF), social recommendation techniques, graph sampling methods for scalability, training strategies, implementation details with 10+ code examples, and detailed Q&A sections addressing common questions and practical challenges.
Why Graph Neural Networks for Recommendation?
The Graph Structure of Recommendation Data
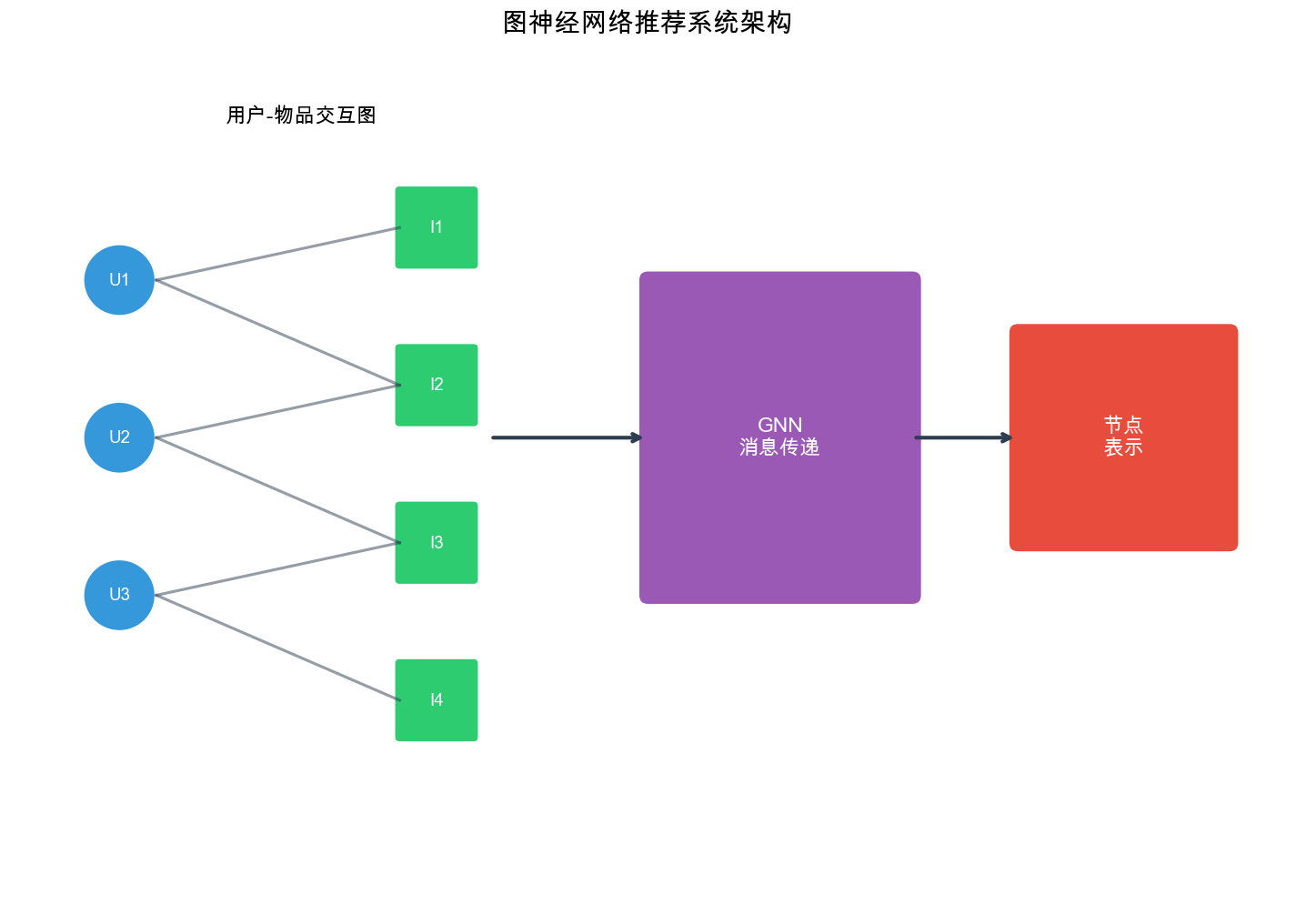
Recommendation systems naturally operate on graph-structured data. Consider a user-item interaction matrix: each row represents a user, each column represents an item, and each entry indicates an interaction (click, purchase, rating). This matrix can be viewed as a bipartite graph where: - Nodes are users and items - Edges represent interactions (with optional weights/features) - The graph structure encodes collaborative signals: users with similar interaction patterns are implicitly connected through shared items
Example: In a movie recommendation scenario: - User \(u_1\)watched movies\(m_1\),\(m_2\),\(m_3\) - User\(u_2\)watched movies\(m_2\),\(m_3\),\(m_4\) - The graph structure reveals that\(u_1\)and\(u_2\)share preferences (through\(m_2\)and\(m_3\)), even if they never directly interacted
Limitations of Traditional Approaches
Traditional collaborative filtering methods have limitations when dealing with graph-structured data:
Matrix Factorization: Learns low-dimensional embeddings but doesn't explicitly model the graph structure. The collaborative signal is implicit in the dot product\(u_i^T v_j\), but there's no mechanism to aggregate information from neighboring nodes.
Deep Learning Approaches: Neural collaborative filtering and autoencoders can capture non-linear patterns but still treat interactions as independent, missing the structural relationships encoded in the graph.
Graph-Agnostic Embeddings: Traditional methods learn embeddings independently for each user/item, ignoring that similar users/items should have similar embeddings based on their graph neighborhoods.
Advantages of Graph Neural Networks
GNNs address these limitations by:
- Explicit Graph Modeling: Directly operate on the graph structure, allowing models to leverage topological information
- Neighborhood Aggregation: Aggregate information from neighboring nodes, enabling collaborative signal propagation
- Multi-Hop Reasoning: Through multiple layers, GNNs can capture multi-hop relationships (e.g., "users who liked items similar to items you liked")
- Inductive Learning: Some GNN variants (like GraphSAGE) can generalize to unseen nodes, crucial for handling new users/items
- Heterogeneous Graphs: Can model complex relationships including social networks, knowledge graphs, and item attributes
Graph Neural Network Fundamentals
Graph Basics
A graph\(G = (V, E)\)consists of: - Vertices (Nodes):\(V = \{v_1, v_2, \dots, v_n\}\)representing entities (users, items) - Edges:\(E \subseteq V \times V\)representing relationships (interactions, similarities) - Adjacency Matrix:\(A \in \{0,1\}^{n \times n}\)where\(A_{ij} = 1\)if edge\((v_i, v_j)\)exists
For recommendation, we typically work with: - Bipartite Graphs:\(G = (U \cup I, E)\)where\(U\)are users,\(I\)are items, and edges only connect users to items - Weighted Graphs: Edges have weights (e.g., rating scores, interaction frequencies) - Attributed Graphs: Nodes/edges have feature vectors
Message Passing Framework
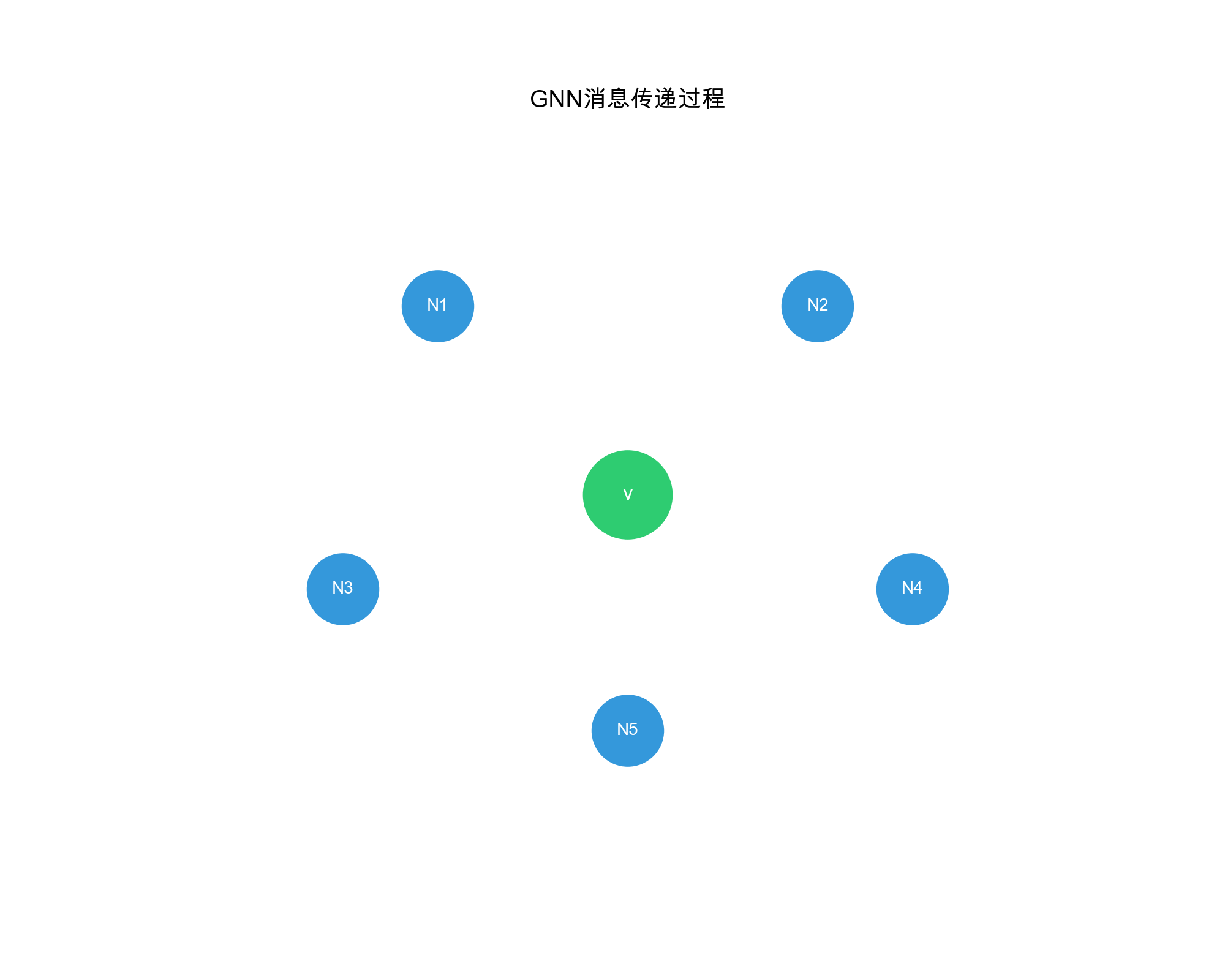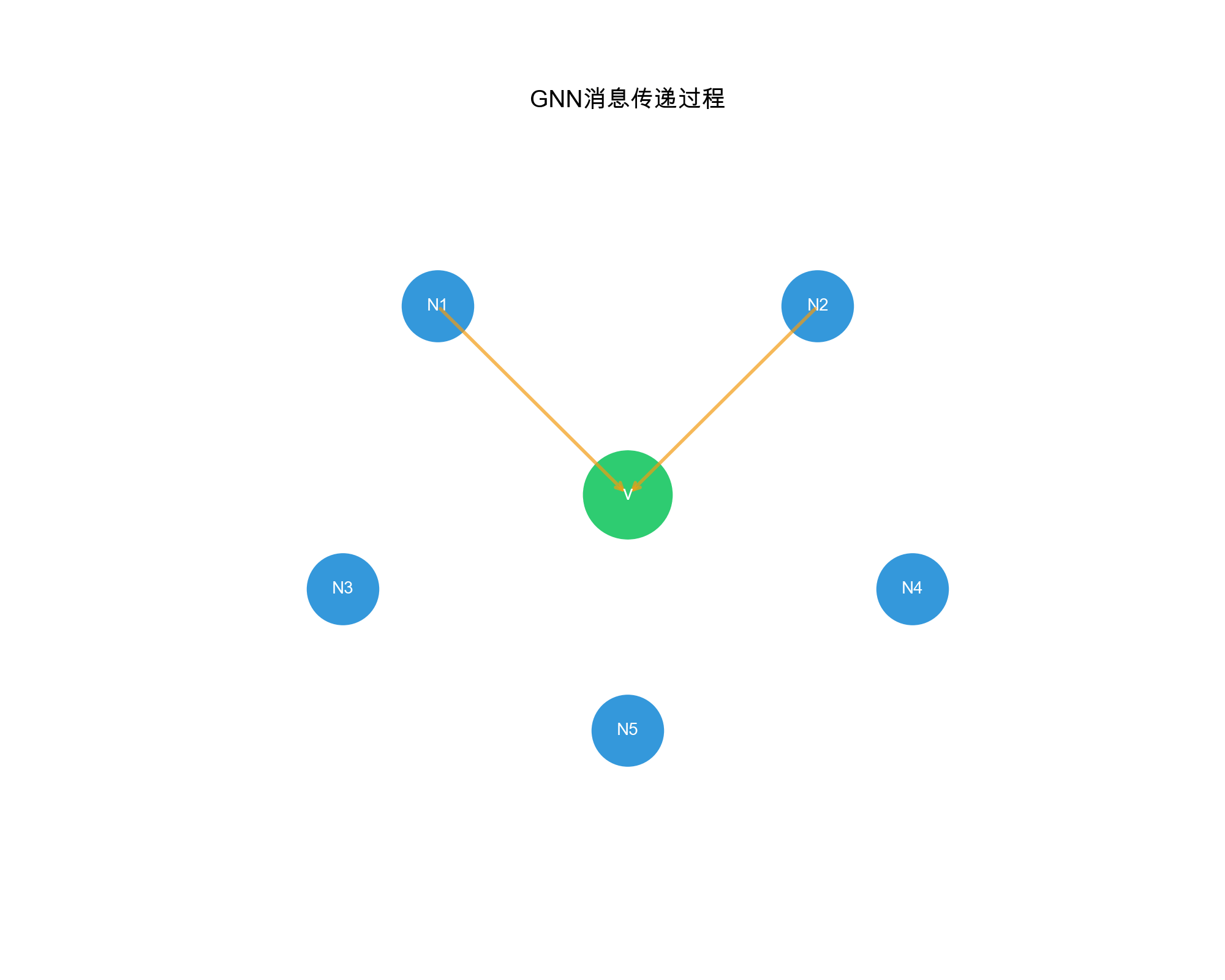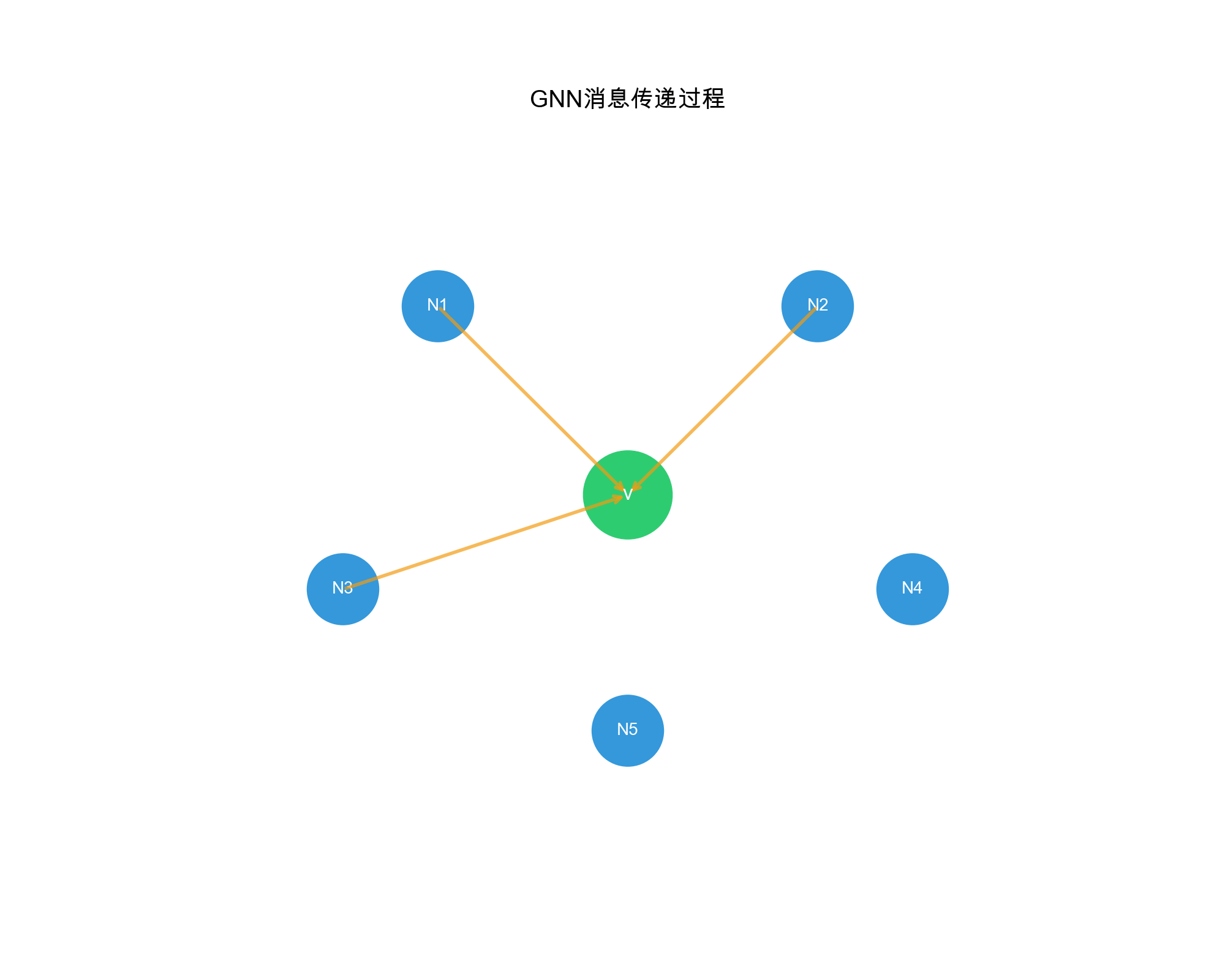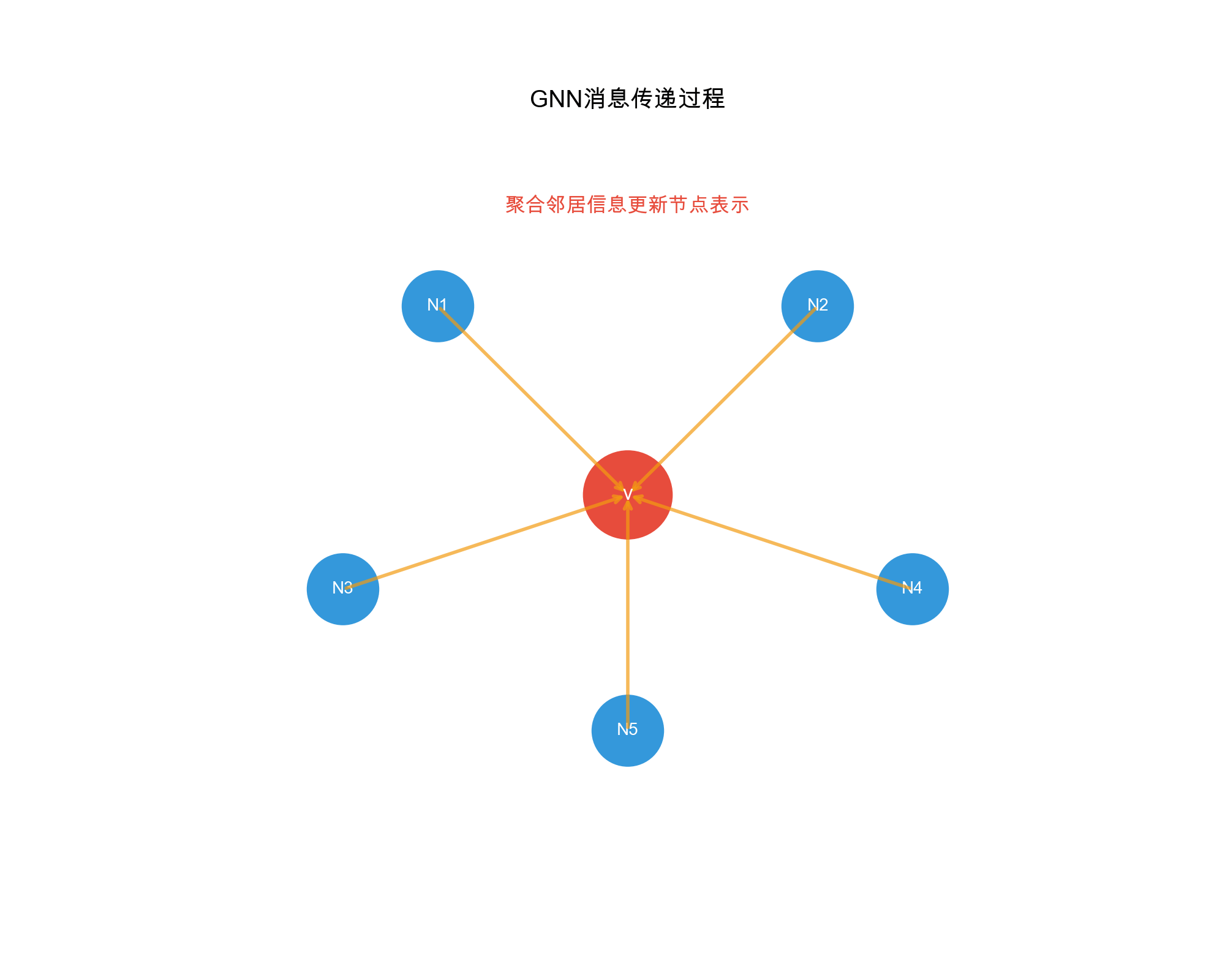
GNNs operate through message passing: nodes aggregate information from their neighbors to update their representations. The general framework:
- Message Computation: Each node computes messages to send to neighbors
- Message Aggregation: Each node aggregates messages received from neighbors
- Node Update: Each node updates its representation based on aggregated messages
Formally, for node\(v\)at layer\(l\):\[\mathbf{m}_v^{(l)} = \text{AGGREGATE}^{(l)}(\{\mathbf{h}_u^{(l-1)} : u \in \mathcal{N}(v)\})\] \[\mathbf{h}_v^{(l)} = \text{UPDATE}^{(l)}(\mathbf{h}_v^{(l-1)}, \mathbf{m}_v^{(l)})\]where\(\mathcal{N}(v)\)is the neighborhood of\(v\),\(\mathbf{h}_v^{(l)}\)is the representation of\(v\)at layer\(l\), and\(\text{AGGREGATE}\)and\(\text{UPDATE}\)are learnable functions.
Graph Convolutional Networks (GCN)
Spectral Convolution
GCN was introduced by Kipf & Welling (2017) as a spectral approach to graph convolution. The key idea is to define convolution in the spectral domain (eigenvalue decomposition of the graph Laplacian) and then approximate it efficiently.
The graph Laplacian is defined as:\[L = D - A\]where\(D\)is the degree matrix (\(D_{ii} = \sum_j A_{ij}\)). The normalized Laplacian is:\[L_{\text{norm}} = D^{-\frac{1}{2}} (D - A) D^{-\frac{1}{2}} = I - D^{-\frac{1}{2}} A D^{-\frac{1}{2}}\]
GCN Layer
A GCN layer performs the following operation:\[\mathbf{H}^{(l+1)} = \sigma(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} \mathbf{H}^{(l)} \mathbf{W}^{(l)})\]where: -\(\tilde{A} = A + I\) (add self-loops) -\(\tilde{D}_{ii} = \sum_j \tilde{A}_{ij}\) (degree matrix with self-loops) -\(\mathbf{H}^{(l)} \in \mathbb{R}^{n \times d_l}\)is the node feature matrix at layer\(l\) -\(\mathbf{W}^{(l)} \in \mathbb{R}^{d_l \times d_{l+1}}\)is a learnable weight matrix -\(\sigma\)is an activation function (e.g., ReLU)
The normalization\(\tilde{D}^{-\frac{1}{2 }} \tilde{A} \tilde{D}^{-\frac{1}{2 }}\)ensures that the aggregation is normalized by node degrees, preventing the exploding gradient problem.
Intuition
The GCN operation can be understood as: 1. Linear Transformation:\(\mathbf{H}^{(l)} \mathbf{W}^{(l)}\)transforms node features 2. Neighborhood Aggregation:\(\tilde{A} \mathbf{H}^{(l)} \mathbf{W}^{(l)}\)aggregates features from neighbors (and self) 3. Normalization:\(\tilde{D}^{-\frac{1}{2 }} \tilde{A} \tilde{D}^{-\frac{1}{2 }}\)normalizes by degrees 4. Non-linearity:\(\sigma\)applies activation
For a single node\(v\), the update is:\[\mathbf{h}_v^{(l+1)} = \sigma\left(\sum_{u \in \mathcal{N}(v) \cup \{v} } \frac{1}{\sqrt{d_v d_u }} \mathbf{h}_u^{(l)} \mathbf{W}^{(l)}\right)\]where\(d_v\)is the degree of node\(v\).
Implementation: Basic GCN Layer
1 | import torch |
Multi-Layer GCN
Stacking multiple GCN layers enables the model to capture multi-hop dependencies:
1 | class GCN(nn.Module): |
Graph Attention Networks (GAT)
Attention Mechanism
While GCN uses fixed weights based on node degrees, GAT (Veli č kovi ć et al., 2018) learns adaptive attention weights that determine how much importance to assign to each neighbor. This allows the model to focus on more relevant neighbors.
GAT Layer
A GAT layer computes attention coefficients for each edge:\[e_{ij} = \text{LeakyReLU}(\mathbf{a}^T [\mathbf{W}\mathbf{h}_i \| \mathbf{W}\mathbf{h}_j])\]where\(\mathbf{a}\)is a learnable attention vector,\(\mathbf{W}\)is a weight matrix, and\(\|\)denotes concatenation.
The attention coefficients are normalized using softmax:\[\alpha_{ij} = \frac{\exp(e_{ij})}{\sum_{k \in \mathcal{N}(i)} \exp(e_{ik})}\]The node update is then:\[\mathbf{h}_i^{(l+1)} = \sigma\left(\sum_{j \in \mathcal{N}(i) \cup \{i} } \alpha_{ij} \mathbf{W}^{(l)} \mathbf{h}_j^{(l)}\right)\]
Multi-Head Attention
GAT typically uses multi-head attention to stabilize learning:\[\mathbf{h}_i^{(l+1)} = \|{}_{k=1}^{K} \sigma\left(\sum_{j \in \mathcal{N}(i) \cup \{i} } \alpha_{ij}^{(k)} \mathbf{W}^{(k)} \mathbf{h}_j^{(l)}\right)\]where\(K\)is the number of attention heads and\(\|\)denotes concatenation. For the final layer, averaging is often used instead of concatenation.
Implementation: GAT Layer
1 | import torch |
GraphSAGE
Inductive Learning
GraphSAGE (Hamilton et al., 2017) addresses a key limitation of GCN: transductive learning. GCN requires the entire graph during training and cannot generalize to new nodes. GraphSAGE enables inductive learning by learning aggregation functions rather than fixed node embeddings.
Sampling and Aggregation
GraphSAGE uses two key ideas:
- Neighbor Sampling: Instead of using all neighbors, sample a fixed-size neighborhood
- Aggregation Functions: Learn functions to aggregate sampled neighbor features
The algorithm:
- Sample Neighbors: For each node, sample\(k\)neighbors at each hop
- Aggregate: Aggregate features from sampled neighbors using a learned function
- Combine: Combine aggregated neighbor features with node's own features
Formally, for node\(v\):\[\mathbf{h}_{\mathcal{N}(v)}^{(l)} = \text{AGGREGATE}^{(l)}(\{\mathbf{h}_u^{(l-1)} : u \in \mathcal{N}(v)} )\] \[\mathbf{h}_v^{(l)} = \sigma(\mathbf{W}^{(l)} \cdot [\mathbf{h}_v^{(l-1)} \| \mathbf{h}_{\mathcal{N}(v)}^{(l)}])\]where\(\|\)denotes concatenation.
Aggregation Functions
GraphSAGE supports several aggregation functions:
Mean Aggregator:\[\mathbf{h}_{\mathcal{N}(v)} = \frac{1}{|\mathcal{N}(v)|} \sum_{u \in \mathcal{N}(v)} \mathbf{h}_u\]
LSTM Aggregator: Uses an LSTM to process neighbors (requires ordering)
Pooling Aggregator:\[\mathbf{h}_{\mathcal{N}(v)} = \max(\{\sigma(\mathbf{W}_{\text{pool }} \mathbf{h}_u + \mathbf{b}) : u \in \mathcal{N}(v)} )\]
Implementation: GraphSAGE Layer
1 | import torch |
Neighbor Sampling
For large graphs, GraphSAGE uses neighbor sampling to control computational cost:
1 | import torch |
Graph Modeling for Recommendation
User-Item Bipartite Graph
The most common graph structure in recommendation is the user-item bipartite graph:
- Nodes: Users\(U = \{u_1, u_2, \dots, u_m\}\)and items\(I = \{i_1, i_2, \dots, i_n\}\)
- Edges: Interactions\((u, i)\)with optional weights (ratings, clicks, purchases)
- Adjacency Matrix:\[A = \begin{bmatrix} 0 & R \\ R^T & 0 \end{bmatrix}\]where\(R \in \mathbb{R}^{m \times n}\)is the user-item interaction matrix
Heterogeneous Graphs
Real-world recommendation often involves heterogeneous graphs with multiple node/edge types:
- Node Types: Users, items, attributes (categories, brands), entities (actors, directors)
- Edge Types: Interactions (click, purchase), relationships (friend, follow), attributes (belongs-to, has)
Example: A movie recommendation graph might have: - User nodes -
Movie nodes
- Actor nodes - Genre nodes - Edges: (user, watched, movie), (movie,
has_actor, actor), (movie, has_genre, genre)
Knowledge Graphs
Knowledge graphs encode structured knowledge about items:
- Entities: Items, attributes, concepts
- Relations: Semantic relationships (directed_by, produced_by, similar_to)
- Triples: (subject, relation, object)
Example: (The Matrix, directed_by, Wachowskis), (The Matrix, similar_to, Inception)
Knowledge graphs enable explainable recommendations by leveraging semantic relationships.
Multi-Relational Graphs
Some recommendation scenarios involve multi-relational graphs where edges have types:
- Social relations: friend, follow, trust
- Interaction types: view, click, purchase, rate
- Item relations: similar, co-purchased, co-viewed
Each relation type can have different semantics and should be modeled separately.
PinSage: Billion-Scale Recommendation
Overview
PinSage (Ying et al., 2018) is Pinterest's graph convolutional network for web-scale recommendation. It handles graphs with billions of nodes and edges, making it one of the largest GNN applications.
Key Innovations
1. Random Walk Sampling Instead of using all neighbors, PinSage samples important neighbors using random walks:
- Start from target node
- Perform random walks to identify important neighbors
- Use top-\(k\)neighbors by visit frequency
2. Importance-Based Aggregation Aggregate neighbor features weighted by importance scores from random walks:\[\mathbf{h}_v^{(l)} = \sigma(\mathbf{W}^{(l)} \cdot \text{CONCAT}[\mathbf{h}_v^{(l-1)}, \text{AGGREGATE}(\{\alpha_{uv} \mathbf{h}_u^{(l-1)} : u \in \mathcal{N}(v)} )])\]where\(\alpha_{uv}\)is the importance score from random walks.
3. Efficient Training - Negative Sampling: Sample negative items for each positive interaction - Hard Negatives: Use difficult negative examples to improve learning - Multi-GPU Training: Distribute computation across GPUs
Implementation: PinSage Convolution
1 | import torch |
LightGCN: Simplifying GCN for Recommendation
Motivation
LightGCN (He et al., 2020) simplifies GCN by removing unnecessary components: - No feature transformation: Removes the linear transformation matrix - No non-linear activation: Removes ReLU activation - No self-connection: Removes explicit self-loops (handled by layer combination)
The key insight: feature transformation and non-linearity are not necessary for collaborative filtering — the graph structure itself provides sufficient signal.
LightGCN Architecture
LightGCN uses a simple aggregation rule:\[\mathbf{e}_u^{(l+1)} = \sum_{i \in \mathcal{N}(u)} \frac{1}{\sqrt{|\mathcal{N}(u)| |\mathcal{N}(i)| }} \mathbf{e}_i^{(l)}\] \[\mathbf{e}_i^{(l+1)} = \sum_{u \in \mathcal{N}(i)} \frac{1}{\sqrt{|\mathcal{N}(u)| |\mathcal{N}(i)| }} \mathbf{e}_u^{(l)}\]where\(\mathbf{e}_u^{(l)}\)and\(\mathbf{e}_i^{(l)}\)are user and item embeddings at layer\(l\).
The final embeddings are a weighted combination of all layers:\[\mathbf{e}_u = \sum_{l=0}^{L} \alpha_l \mathbf{e}_u^{(l)}, \quad \mathbf{e}_i = \sum_{l=0}^{L} \alpha_l \mathbf{e}_i^{(l)}\]where\(\alpha_l\)are learnable or fixed weights (often\(\alpha_l = \frac{1}{L+1}\)).
Why LightGCN Works
- Smoothing Effect: Multiple layers smooth embeddings, bringing similar nodes closer
- Collaborative Signal: Higher layers capture higher-order collaborative signals
- Simplicity: Fewer parameters reduce overfitting risk
Implementation: LightGCN
1 | import torch |
NGCF: Neural Graph Collaborative Filtering
Overview
NGCF (Wang et al., 2019) explicitly models the collaborative signal in user-item interactions through graph convolution. Unlike LightGCN, NGCF uses feature transformation and non-linear activation.
NGCF Architecture
NGCF performs the following operations at each layer:
Message Construction:\[\mathbf{m}_{u \leftarrow i} = \frac{1}{\sqrt{|\mathcal{N}(u)| |\mathcal{N}(i)| }} (\mathbf{W}_1 \mathbf{e}_i^{(l)} + \mathbf{W}_2 (\mathbf{e}_i^{(l)} \odot \mathbf{e}_u^{(l)}))\] \[\mathbf{m}_{i \leftarrow u} = \frac{1}{\sqrt{|\mathcal{N}(u)| |\mathcal{N}(i)| }} (\mathbf{W}_1 \mathbf{e}_u^{(l)} + \mathbf{W}_2 (\mathbf{e}_u^{(l)} \odot \mathbf{e}_i^{(l)}))\]
Message Aggregation:\[\mathbf{e}_u^{(l+1)} = \text{LeakyReLU}(\mathbf{m}_{u \leftarrow u} + \sum_{i \in \mathcal{N}(u)} \mathbf{m}_{u \leftarrow i})\] \[\mathbf{e}_i^{(l+1)} = \text{LeakyReLU}(\mathbf{m}_{i \leftarrow i} + \sum_{u \in \mathcal{N}(i)} \mathbf{m}_{i \leftarrow u})\]where\(\odot\)denotes element-wise product (captures feature interaction).
Key Components
- Self-Connection:\(\mathbf{m}_{u \leftarrow u}\)preserves node's own information
- Neighbor Aggregation: Aggregates messages from neighbors
- Feature Interaction:\(\mathbf{e}_i^{(l)} \odot \mathbf{e}_u^{(l)}\)captures user-item feature interactions
- Non-linearity: LeakyReLU enables non-linear transformations
Implementation: NGCF
1 | import torch |
Social Recommendation
Leveraging Social Networks
Social recommendation leverages social relationships to improve recommendations. The key idea: users with social connections (friends, followers) often have similar preferences.
Social Graph Structure
Social recommendation uses a heterogeneous graph with: - User nodes: Users in the system - Item nodes: Items to be recommended - Social edges:\((u_i, u_j)\)indicating social relationship (friend, follow, trust) - Interaction edges:\((u_i, i_j)\)indicating user-item interaction
Social Influence Models
Homophily: Users with social connections tend to have similar preferences. Modeled by: - Sharing embeddings between socially connected users - Aggregating preferences from social neighbors
Social Influence: Users influence each other's preferences. Modeled by: - Propagating preferences through social edges - Learning influence weights for different social connections
Implementation: Social GCN
1 | import torch |
Graph Sampling for Scalability
The Scalability Challenge
Full-batch GNN training requires storing the entire graph in memory and computing embeddings for all nodes, which is infeasible for large-scale graphs (millions/billions of nodes).
Sampling Strategies
1. Node Sampling Sample a subset of nodes and their neighbors for each batch: - Random node sampling - Importance-based sampling (e.g., PageRank)
2. Neighbor Sampling For each node, sample a fixed number of neighbors: - Uniform sampling - Importance-based sampling (e.g., random walk)
3. Layer-wise Sampling Sample neighbors independently at each layer: - FastGCN: Samples nodes at each layer - GraphSAGE: Samples neighbors for each node
4. Subgraph Sampling Sample connected subgraphs: - Cluster-GCN: Partition graph into clusters - GraphSAINT: Sample random subgraphs
Implementation: Neighbor Sampling
1 | import torch |
Cluster-GCN Sampling
1 | import torch |
Training Techniques
Loss Functions
BPR Loss (Bayesian Personalized Ranking):\[\mathcal{L}_{\text{BPR }} = -\sum_{(u,i,j) \in \mathcal{D }} \ln \sigma(\hat{r}_{ui} - \hat{r}_{uj}) + \lambda \|\Theta\|^2\]where\((u,i,j)\)are triplets: user\(u\)interacted with item\(i\)(positive) but not\(j\)(negative), and\(\hat{r}_{ui} = \mathbf{e}_u^T \mathbf{e}_i\).
NCE Loss (Noise Contrastive Estimation):\[\mathcal{L}_{\text{NCE }} = -\sum_{(u,i) \in \mathcal{D }} \left[\ln \sigma(\hat{r}_{ui}) + \sum_{j \sim p_n} \ln \sigma(-\hat{r}_{uj})\right]\]where\(p_n\)is a negative sampling distribution.
Negative Sampling
Uniform Negative Sampling: Sample negative items uniformly at random.
Hard Negative Mining: Sample difficult negatives (items with high scores but not interacted).
Popularity-Based Sampling: Sample negatives proportional to item popularity (helps with long-tail items).
Implementation: Training Loop
1 | import torch |
Evaluation Metrics
Recall@K: Fraction of relevant items in top-K recommendations.
NDCG@K: Normalized Discounted Cumulative Gain, accounts for ranking position.
Hit Rate@K: Fraction of users with at least one relevant item in top-K.
1 | def evaluate(model, test_data, k=10): |
Complete Example: LightGCN on MovieLens
1 | import torch |
Questions and Answers
Q1: Why do GNNs work well for recommendation?
A: GNNs excel at recommendation because: 1. Graph Structure: Recommendation data is naturally graph-structured (user-item bipartite graph) 2. Collaborative Signal: GNNs explicitly propagate collaborative signals through graph convolution 3. Multi-Hop Reasoning: Multiple layers capture higher-order relationships (e.g., "users who liked items similar to items you liked") 4. Neighborhood Aggregation: Similar users/items naturally cluster in embedding space through neighborhood aggregation
Traditional methods like matrix factorization learn embeddings independently, missing the structural relationships. GNNs leverage these relationships to learn better representations.
Q2: What's the difference between GCN, GAT, and GraphSAGE?
A: Key differences:
| Aspect | GCN | GAT | GraphSAGE |
|---|---|---|---|
| Aggregation | Fixed weights (degree-based) | Learned attention weights | Learnable aggregation functions |
| Learning | Transductive (needs full graph) | Transductive | Inductive (generalizes to new nodes) |
| Neighbors | All neighbors | All neighbors | Sampled neighbors |
| Complexity | O(E) | O(E) | O(k · V) with sampling |
- GCN: Simple, efficient, but requires full graph
- GAT: More expressive (adaptive attention), but computationally expensive
- GraphSAGE: Scalable (sampling), inductive, good for large graphs
Q3: How does LightGCN differ from NGCF?
A: LightGCN simplifies NGCF by removing: - Feature transformation (no linear layers) - Non-linear activation (no ReLU) - Self-connections (handled by layer combination)
LightGCN's key insight: simplicity works better. The graph structure itself provides sufficient signal — adding complexity (transformation, activation) can hurt performance by overfitting.
NGCF uses: - Feature transformation:\(\mathbf{W}\mathbf{h}\) - Feature interaction:\(\mathbf{h}_i \odot \mathbf{h}_j\) - Non-linearity: LeakyReLU
LightGCN uses only normalized neighbor aggregation, achieving better or comparable performance with fewer parameters.
Q4: How do you handle cold-start users/items in GNN-based recommendation?
A: Several strategies:
GraphSAGE-style Inductive Learning: Learn aggregation functions rather than fixed embeddings. New nodes can use their neighbors' embeddings.
Feature Initialization: Initialize new user/item embeddings using:
- Side information (demographics, item attributes)
- Random initialization with small variance
- Mean of similar users/items
Meta-Learning: Use meta-learning to quickly adapt to new users/items (e.g., MAML).
Hybrid Approaches: Combine GNN with content-based features for cold-start items.
Example for new user: 1
2
3
4
5
6
7
8
9
10
11
12
13
14def initialize_new_user(user_features, neighbor_users, model):
"""
Initialize embedding for new user using features and neighbors.
"""
# Use feature-based initialization
feature_emb = model.feature_encoder(user_features)
# Aggregate from similar users (if available)
if neighbor_users:
neighbor_embs = model.user_embedding(neighbor_users)
neighbor_emb = neighbor_embs.mean(dim=0)
return (feature_emb + neighbor_emb) / 2
return feature_emb
Q5: What's the computational complexity of GNNs for recommendation?
A: Complexity depends on the architecture:
GCN/LightGCN: - Forward pass:\(O(L \cdot |E| \cdot d)\)where\(L\)is layers,\(|E|\)is edges,\(d\)is embedding dimension - Memory:\(O(|V| \cdot d + |E|)\) GAT: - Forward pass:\(O(L \cdot |E| \cdot d \cdot H)\)where\(H\)is attention heads - Memory:\(O(|V| \cdot d \cdot H + |E|)\) GraphSAGE (with sampling): - Forward pass:\(O(L \cdot |V| \cdot k \cdot d)\)where\(k\)is sampled neighbors - Memory:\(O(|V| \cdot d + k \cdot |V|)\)For large-scale graphs (billions of nodes), sampling (GraphSAGE, PinSage) or clustering (Cluster-GCN) is essential.
Q6: How do you choose the number of GNN layers?
A: The number of layers affects: - Receptive Field: More layers = larger neighborhood (higher-order collaborative signals) - Over-smoothing: Too many layers can make all embeddings similar (loss of discriminative power) - Computational Cost: More layers = more computation
Guidelines: - 2-3 layers: Common for recommendation (captures 2-3 hop relationships) - Monitor over-smoothing: Check if embeddings become too similar - Layer combination: Use weighted combination (like LightGCN) to balance different hop signals
Rule of thumb: Start with 2-3 layers, increase if performance improves, stop if over-smoothing occurs.
Q7: How does social recommendation improve performance?
A: Social recommendation leverages social relationships to: 1. Homophily: Users with social connections share preferences 2. Social Influence: Friends influence each other's preferences 3. Cold-start: Social connections help recommend to new users
Improvements come from: - Richer Signals: Combining interaction and social signals - Better Embeddings: Social neighbors provide additional context - Trust Propagation: Recommendations from friends are more trusted
Empirical studies show 5-15% improvement in recommendation quality when incorporating social signals.
Q8: What are the main challenges in training GNNs for recommendation?
A: Key challenges:
- Scalability: Large graphs (millions/billions of nodes) require sampling/clustering
- Over-smoothing: Deep GNNs make embeddings too similar
- Sparsity: User-item graphs are extremely sparse (most entries are 0)
- Negative Sampling: Choosing good negatives is crucial for BPR loss
- Hyperparameter Tuning: Many hyperparameters (layers, embedding dim, learning rate, etc.)
Solutions: - Sampling: GraphSAGE, Cluster-GCN - Layer combination: LightGCN's weighted combination - Data augmentation: Negative sampling strategies - Regularization: Dropout, L2 regularization
Q9: Can GNNs handle dynamic graphs (time-evolving interactions)?
A: Yes, with modifications:
- Temporal GNNs: Incorporate time information:
- Time-aware aggregation (weight by recency)
- Temporal encoding (add time embeddings)
- Incremental Updates: Update embeddings as new
interactions arrive:
- Fine-tune on new edges
- Retrain periodically
- Temporal Graph Networks: Models like TGN (Temporal Graph Networks) handle dynamic graphs natively.
Example time-aware aggregation: 1
2
3
4
5
6
7
8def temporal_aggregate(neighbor_embs, timestamps, current_time, decay_rate=0.1):
"""
Aggregate neighbors weighted by temporal recency.
"""
time_diffs = current_time - timestamps
weights = torch.exp(-decay_rate * time_diffs)
weights = weights / weights.sum()
return (neighbor_embs * weights.unsqueeze(1)).sum(dim=0)
Q10: How do you evaluate GNN-based recommendation systems?
A: Standard evaluation protocol:
Data Split:
- Train: 80% interactions
- Test: 20% interactions
- For each user, hold out some items
Metrics:
- Recall@K: Fraction of test items in top-K
- NDCG@K: Ranking quality (accounts for position)
- Hit Rate@K: Fraction of users with at least one hit
Negative Sampling: For each test positive, sample 100 negatives (or all non-interacted items)
Protocol:
- Rank all items for each user
- Compute metrics on top-K
- Average across users
Important: Use the same evaluation protocol as baselines for fair comparison.
Q11: What's the role of graph sampling in GNN training?
A: Graph sampling addresses scalability:
- Memory: Full-batch training requires storing entire graph (infeasible for large graphs)
- Computation: Processing all nodes/edges is expensive
- Batch Training: Enables mini-batch SGD (better convergence, parallelization)
Sampling strategies: - Node Sampling: Sample nodes and their neighbors (FastGCN) - Neighbor Sampling: Sample fixed number of neighbors per node (GraphSAGE) - Subgraph Sampling: Sample connected subgraphs (Cluster-GCN, GraphSAINT)
Trade-offs: - More sampling = faster training, but may lose information - Less sampling = more accurate, but slower
Q12: How do you handle heterogeneous graphs in recommendation?
A: Heterogeneous graphs have multiple node/edge types. Approaches:
- Type-specific Embeddings: Different embedding spaces for different types
- Type-aware Aggregation: Aggregate differently based on edge types
- Meta-paths: Define paths connecting nodes (e.g., user-item-user)
- Heterogeneous GNNs: Models like HAN (Heterogeneous Attention Network)
Example: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class HeterogeneousGCN(nn.Module):
def __init__(self, num_node_types, embedding_dim):
# Different embeddings per type
self.embeddings = nn.ModuleDict({
t: nn.Embedding(num_nodes[t], embedding_dim)
for t in num_node_types
})
# Type-specific transformations
self.transformations = nn.ModuleDict({
t: nn.Linear(embedding_dim, embedding_dim)
for t in num_node_types
})
def aggregate_by_type(self, node_type, neighbor_embs, edge_types):
# Aggregate differently based on edge type
aggregated = {}
for edge_type in set(edge_types):
mask = edge_types == edge_type
aggregated[edge_type] = neighbor_embs[mask].mean(dim=0)
return aggregated
Q13: What are the advantages of using attention in GAT for recommendation?
A: Attention in GAT provides:
- Adaptive Importance: Learn which neighbors are more important (not all neighbors are equally relevant)
- Interpretability: Attention weights show which users/items influence recommendations
- Flexibility: Different attention for different relationships
- Robustness: Less sensitive to noisy neighbors (low attention weights)
Example: In social recommendation, attention can learn that some friends' preferences are more relevant than others.
Trade-off: More expressive but computationally expensive (quadratic in neighborhood size).
Q14: How do you prevent overfitting in GNN-based recommendation?
A: Regularization techniques:
- Dropout: Drop nodes/edges during training (e.g., 0.5 dropout rate)
- L2 Regularization: Penalize large embedding values
- Early Stopping: Stop when validation performance plateaus
- Layer Combination: Use weighted combination (prevents over-relying on deep layers)
- Data Augmentation: Negative sampling, edge dropout
LightGCN's approach: Simplicity itself is a form of regularization — fewer parameters = less overfitting risk.
Q15: Can GNNs be combined with other recommendation techniques?
A: Yes, hybrid approaches are common:
- GNN + Content Features: Combine graph signals with item/user features
- GNN + Sequential Models: Use GNN for collaborative signal, RNN/Transformer for sequential patterns
- GNN + Knowledge Graphs: Incorporate semantic relationships from knowledge graphs
- Ensemble: Combine predictions from GNN and other models
Example GNN + Content: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class HybridGNN(nn.Module):
def __init__(self, num_users, num_items, content_dim, embedding_dim):
# GNN embeddings
self.gnn = LightGCN(num_users, num_items, embedding_dim)
# Content encoders
self.user_content_encoder = nn.Linear(content_dim, embedding_dim)
self.item_content_encoder = nn.Linear(content_dim, embedding_dim)
def forward(self, edge_index, user_features, item_features):
# GNN embeddings
user_emb_gnn, item_emb_gnn = self.gnn(edge_index)
# Content embeddings
user_emb_content = self.user_content_encoder(user_features)
item_emb_content = self.item_content_encoder(item_features)
# Combine
user_emb = user_emb_gnn + user_emb_content
item_emb = item_emb_gnn + item_emb_content
return user_emb, item_emb
Conclusion
Graph neural networks have transformed recommendation systems by explicitly modeling the graph structure underlying collaborative filtering. From foundational architectures like GCN, GAT, and GraphSAGE, to recommendation-specific models like PinSage, LightGCN, and NGCF, GNNs provide a powerful framework for learning high-quality embeddings through neighborhood aggregation and message passing.
Key takeaways: - Graph Structure: Recommendation data is naturally graph-structured — GNNs leverage this structure - Collaborative Signals: GNNs explicitly propagate collaborative signals through graph convolution - Scalability: Sampling and clustering enable GNNs to handle billion-scale graphs - Simplicity: LightGCN shows that simpler models can outperform complex ones - Social Signals: Incorporating social relationships improves recommendation quality
As recommendation systems continue to evolve, GNNs will play an increasingly important role in capturing complex relational patterns and delivering personalized recommendations at scale.
- Post title:Recommendation Systems (7): Graph Neural Networks and Social Recommendation
- Post author:Chen Kai
- Create time:2026-02-03 23:11:11
- Post link:https://www.chenk.top/recommendation-systems-7-graph-neural-networks/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.