Recommendation Systems (5): Embedding and Representation Learning
Chen KaiBOSS
2026-02-03 23:11:112026-02-03 23:1110.4k Words64 Mins
permalink: "en/recommendation-systems-5-embedding-techniques/" date:
2024-05-22 09:15:00 tags: - Recommendation Systems - Embedding -
Representation Learning categories: Recommendation Systems mathjax: true
--- When you browse Netflix, each movie recommendation feels
personalized — not just because the algorithm knows your viewing
history, but because it has learned dense vector representations
(embeddings) that capture subtle relationships between movies, genres,
and your preferences. These embeddings transform sparse,
high-dimensional user-item interactions into compact, semantically rich
vectors that enable efficient similarity search and recommendation.
Embedding techniques form the backbone of modern recommendation
systems, from Word2Vec-inspired Item2Vec that treats user sequences as
"sentences," to graph-based Node2Vec that captures complex item
relationships, to deep two-tower architectures like DSSM and YouTube DNN
that learn separate user and item embeddings. These methods solve
fundamental challenges: how to represent items and users in a way that
preserves their relationships, how to handle millions of items
efficiently, and how to learn from implicit feedback signals like clicks
and views.
This article provides a comprehensive exploration of embedding
techniques for recommendation systems, covering theoretical foundations,
sequence-based methods (Item2Vec, Word2Vec), graph-based approaches
(Node2Vec), two-tower architectures (DSSM, YouTube DNN), negative
sampling strategies, approximate nearest neighbor search (FAISS, Annoy,
HNSW), embedding quality evaluation, and practical implementation with
10+ code examples and detailed Q&A sections.
Foundations of Embedding
Theory
What Are Embeddings?
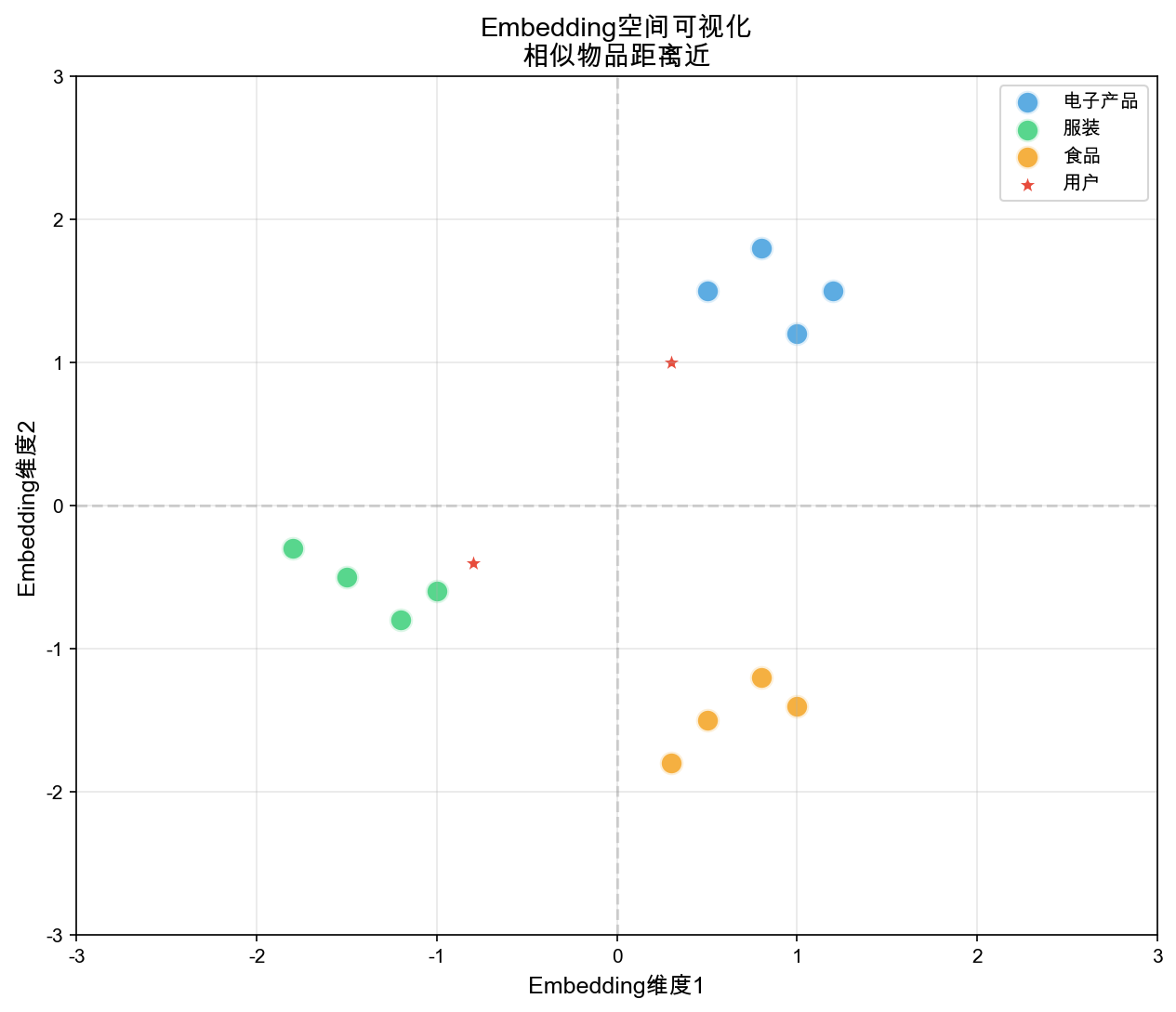
An embedding is a dense, low-dimensional vector
representation of a high-dimensional, often sparse, object. In
recommendation systems, embeddings transform users and items into
continuous vector spaces where similar entities are close together and
dissimilar ones are far apart.
Formally, given a set of items \(I = \{i_1,
i_2, \dots, i_n\}\), an embedding function\(f: I \rightarrow \mathbb{R}^d\)maps each
item\(i\)to a\(d\)-dimensional vector\(\mathbf{e}_i \in \mathbb{R}^d\), where\(d \ll |I|\) (typically\(d \in [64, 512]\)).
Why Embeddings Matter
Dimensionality Reduction: User-item interaction
matrices are extremely sparse. For a platform with 100 million users and
10 million items, the interaction matrix has\(10^{15}\)entries, but typically less than
0.01% are observed. Embeddings compress this into manageable dense
vectors.
Semantic Relationships: Embeddings capture semantic
relationships. If movies\(A\)and\(B\)are similar, their embeddings\(\mathbf{e}_A\)and\(\mathbf{e}_B\)should be close in vector
space. This enables: - Similarity search: Find items
similar to a given item - Recommendation: Recommend
items close to a user's embedding - Clustering: Group
similar items together
Computational Efficiency: Dense vectors enable fast
similarity computation via dot products or cosine similarity, making
real-time recommendation feasible at scale.
The Embedding Learning
Objective
The core principle of embedding learning is: items that
appear in similar contexts should have similar embeddings. This
is formalized through different objectives:
Pointwise: Learn embeddings that predict
ratings/scores directly
Pairwise: Learn embeddings that preserve relative
order (item\(A\)preferred over
item\(B\))
Listwise: Learn embeddings that optimize entire
recommendation lists
Most embedding methods optimize a loss function that encourages: -
Positive pairs (user-item interactions) to have high similarity -
Negative pairs (non-interactions) to have low similarity
Sequence-Based
Embeddings: Word2Vec and Item2Vec
Word2Vec: The Foundation
Word2Vec, introduced by Mikolov et al. in 2013, learns word
embeddings by predicting words from their context. It comes in two
architectures:
Skip-gram: Predict context words from a target
word
CBOW (Continuous Bag of Words): Predict target word
from context words
For recommendation systems, we adapt Word2Vec to learn item
embeddings from user interaction sequences.
Item2Vec:
Adapting Word2Vec for Recommendations
Item2Vec treats user interaction sequences as "sentences" and items
as "words." If a user's interaction sequence is\([i_1, i_2, i_3, i_4]\), we learn embeddings
such that items appearing close together have similar embeddings.
Key Insight: Items frequently co-occurring in user
sequences are likely similar and should be recommended together.
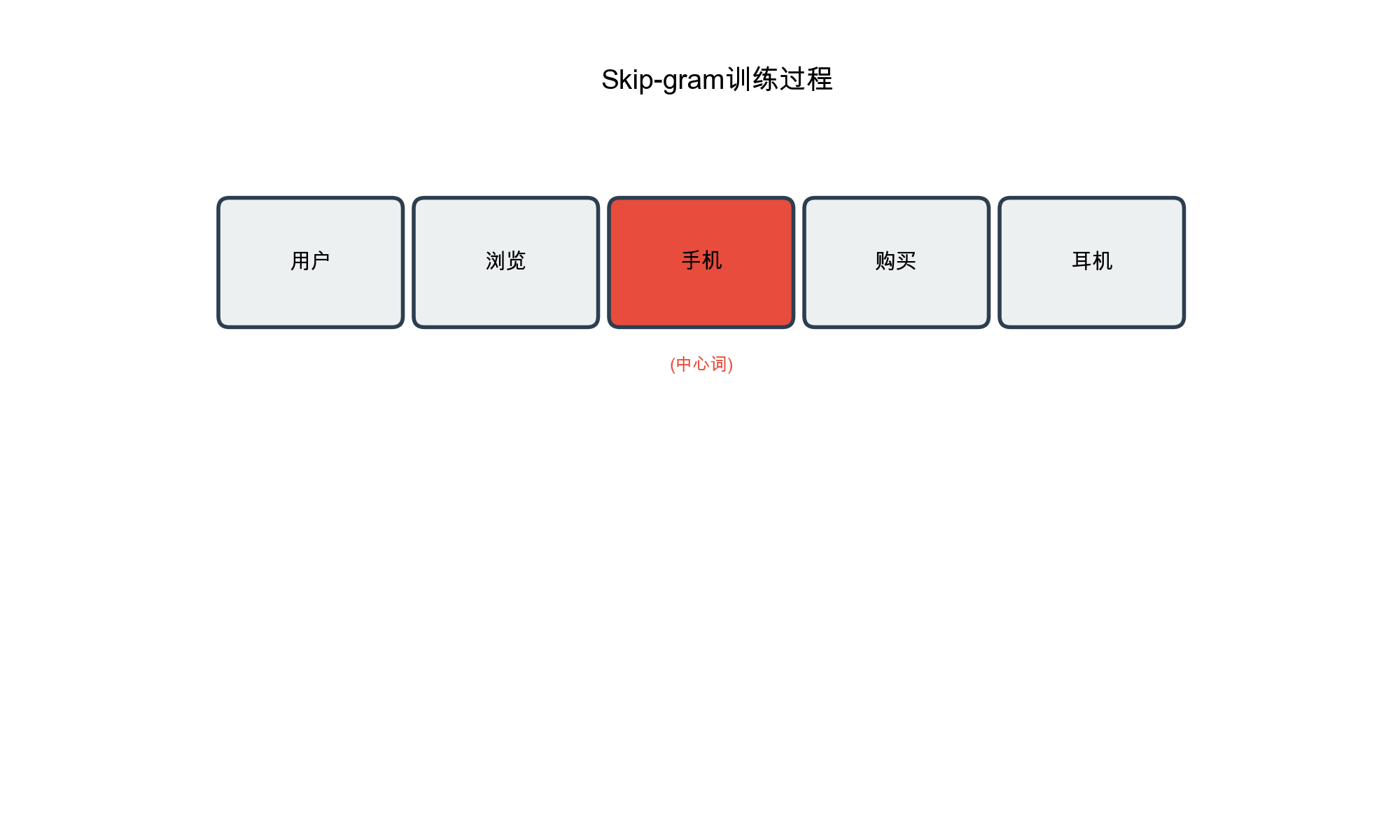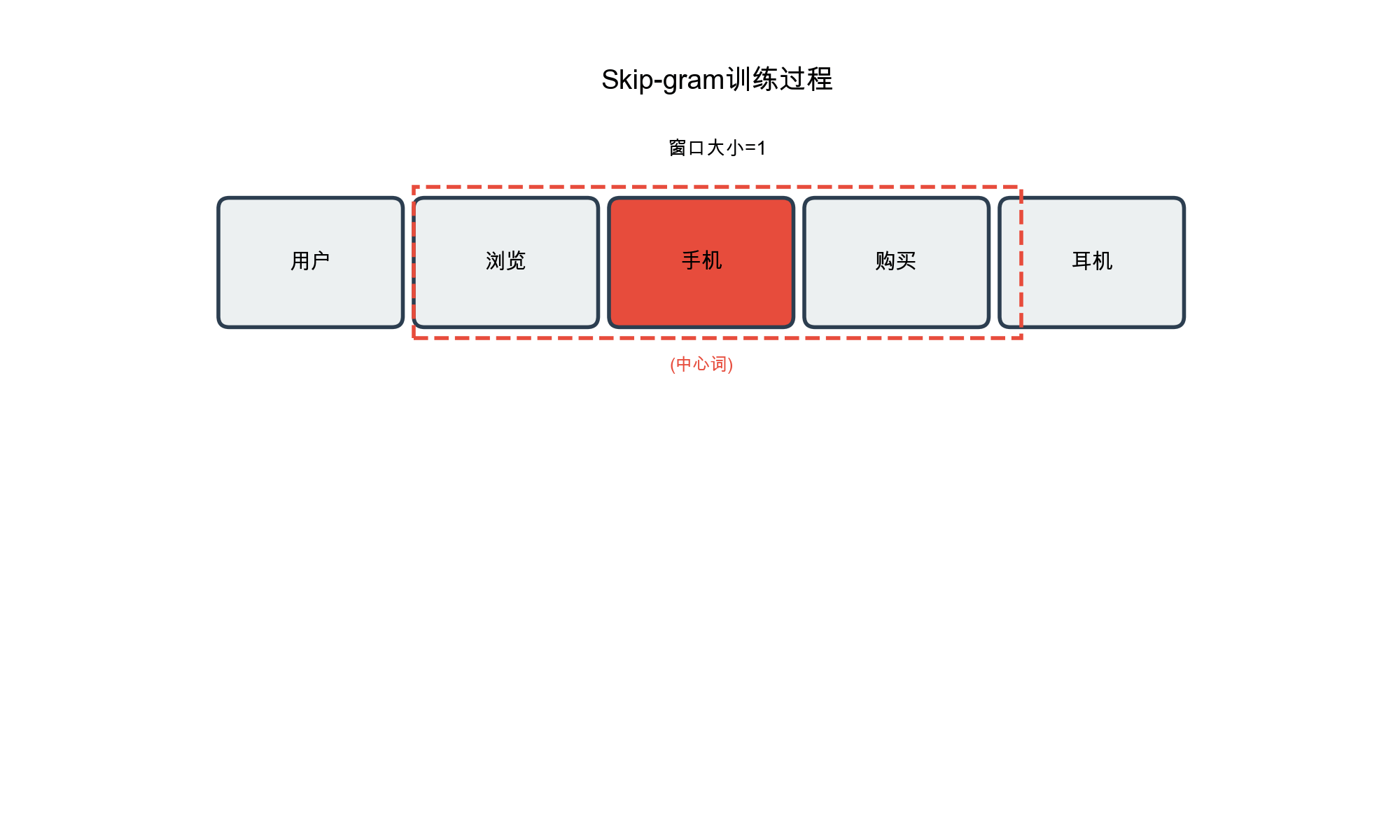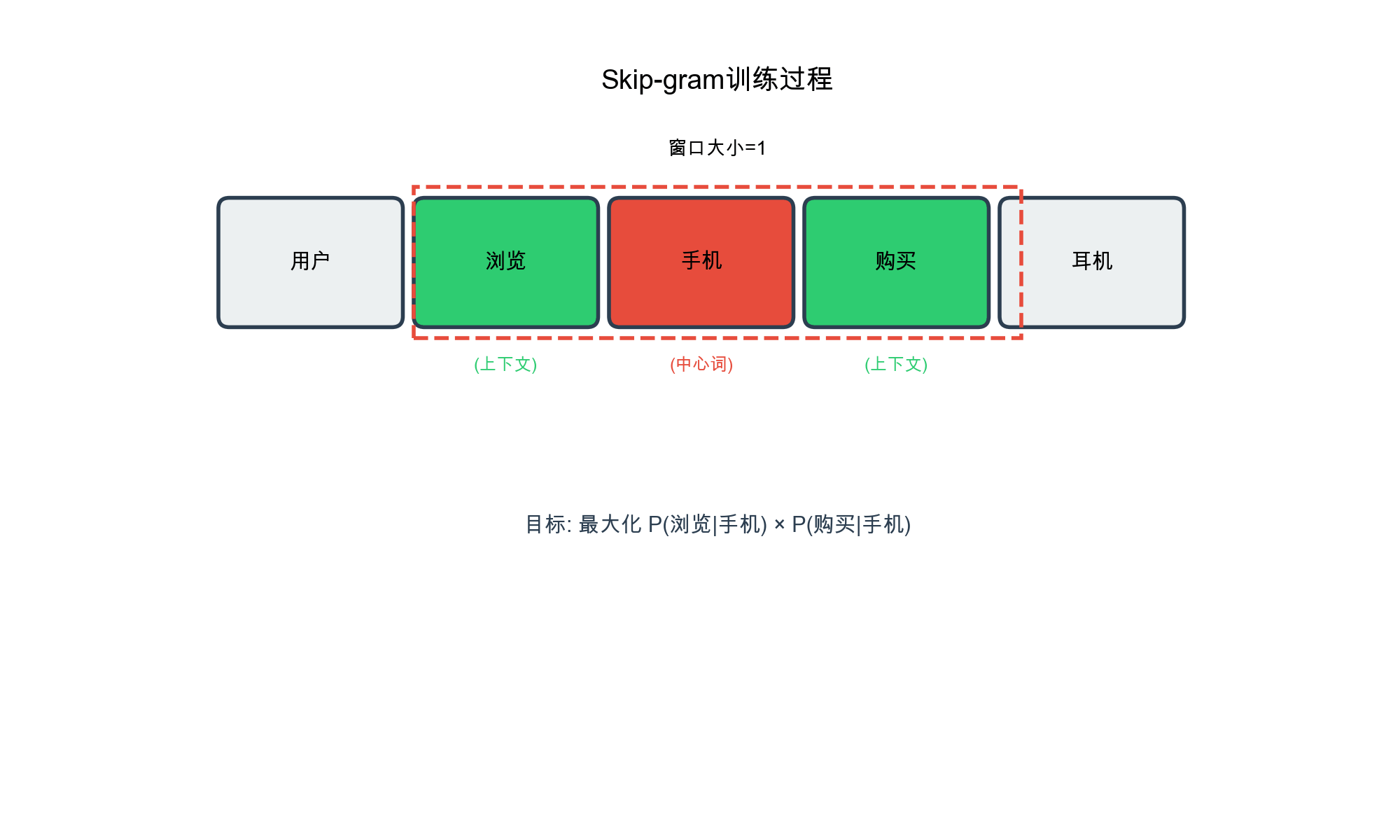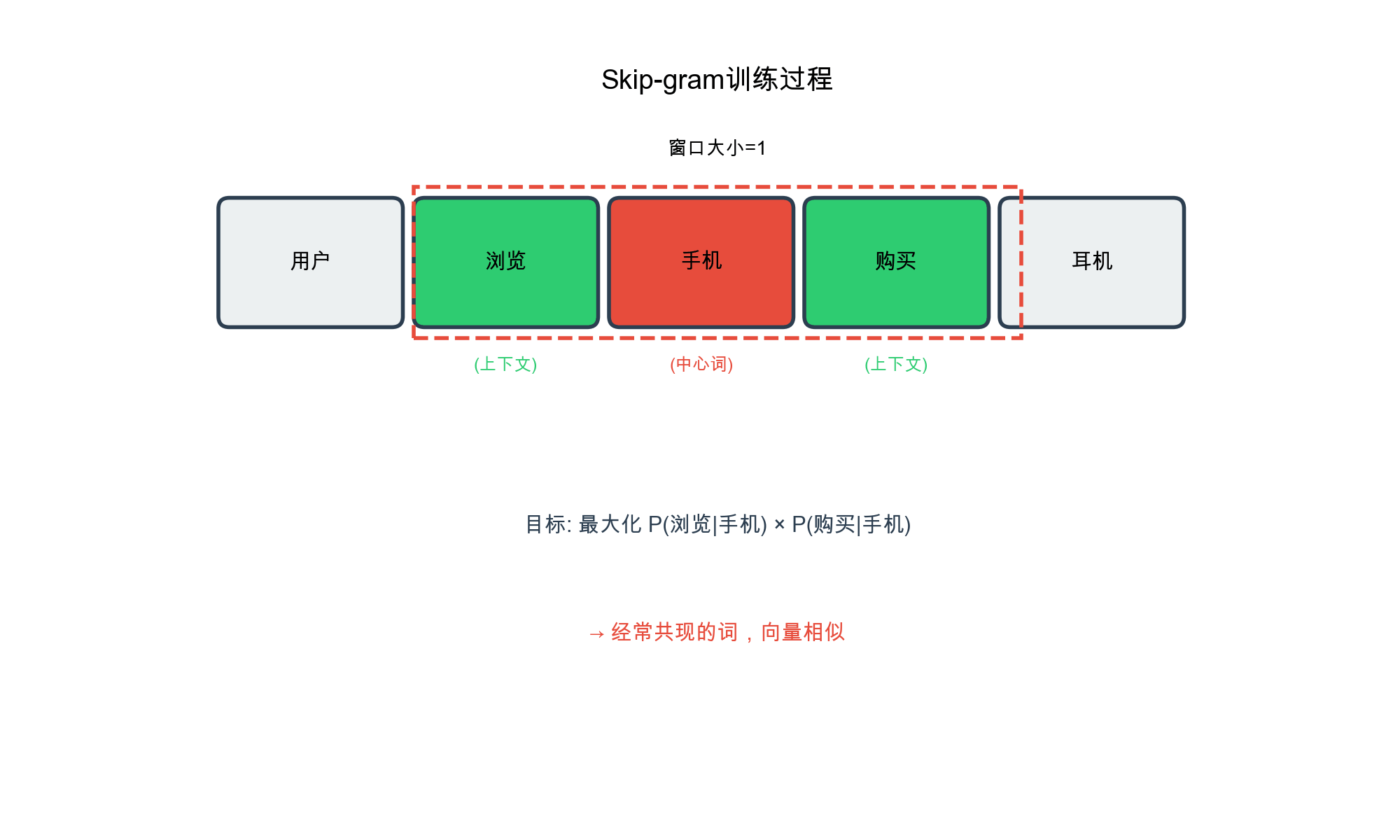
Skip-gram Objective for
Item2Vec
Given a sequence of items\(S = [i_1, i_2,
\dots, i_T]\), the Skip-gram objective maximizes:\[L = \sum_{t=1}^{T} \sum_{-c \leq j \leq c, j \ne
0} \log p(i_{t+j} | i_t)\]where\(c\)is the context window size, and the
probability is defined using softmax:\[p(i_{t+j} | i_t) = \frac{\exp(\mathbf{e}_{i_t}^T
\mathbf{e}_{i_{t+j }}')}{\sum_{k=1}^{|I|} \exp(\mathbf{e}_{i_t}^T
\mathbf{e}_k')}\]Here,\(\mathbf{e}_i\)is the embedding of item\(i\) (input), and\(\mathbf{e}_i'\)is the context embedding
(output). In practice, we often use only one set of embeddings.
Negative Sampling
Computing the full softmax over millions of items is computationally
expensive. Negative sampling approximates the objective
by sampling negative examples:\[L =
\sum_{t=1}^{T} \sum_{-c \leq j \leq c, j \ne 0} \left[ \log
\sigma(\mathbf{e}_{i_t}^T \mathbf{e}_{i_{t+j }}') + \sum_{k=1}^{K}
\mathbb{E}_{i_k \sim P_n} \log \sigma(-\mathbf{e}_{i_t}^T
\mathbf{e}_{i_k}') \right]\]where\(\sigma(x) = 1/(1 + e^{-x})\)is the sigmoid
function, and\(P_n\)is the noise
distribution (typically unigram distribution raised to\(3/4\)power).
Implementation:
Item2Vec with Negative Sampling
Problem Background
In recommendation systems, learning effective item representations is
a core challenge. Traditional collaborative filtering methods require
explicit user-item interaction matrices, but in practice, we often only
have user behavior sequences (e.g., click sequences, purchase
sequences). These sequences contain rich co-occurrence information: if
two items frequently appear in the same user's behavior sequence, they
likely share similar properties or satisfy similar user needs. However,
extracting semantic representations from these sequences and capturing
item similarities remains challenging.
Solution Approach
Item2Vec adapts Word2Vec's approach to recommendation systems by
treating user behavior sequences as "sentences" and items as "words."
The core insight is that if two items frequently co-occur in sequences
(appear in nearby positions), their embedding vectors should be similar.
Specifically, Item2Vec uses the Skip-gram architecture: for each center
item in a sequence, the model learns to predict its context items (other
items within a window). By maximizing similarity for positive pairs and
minimizing similarity for negative pairs, the model learns item vector
representations where semantically similar items are closer in vector
space.
Design Considerations
When implementing Item2Vec, several key design decisions must be
considered:
Two Embedding Matrices: Similar to Word2Vec, we
use two independent embedding matrices — center item embeddings and
context item embeddings. This design provides greater model capacity,
allowing more flexible learning of different roles. Ultimately, we only
use the center item embeddings as the final item
representations.
Negative Sampling Strategy: Computing the full
softmax over all items is computationally expensive when the number of
items is large. Negative sampling approximates the objective by randomly
sampling a small number of negative examples (typically 5-20),
dramatically improving training efficiency. The negative sampling
distribution uses the 3/4 power of item frequencies, avoiding
over-sampling of high-frequency items while giving low-frequency items
learning opportunities.
Window Size Selection: The context window size
determines how far co-occurrence relationships are considered. A small
window (e.g., 1-2) only captures local co-occurrence, while a large
window (e.g., 10+) may introduce noise. Typically, window sizes are set
to 3-5, balancing co-occurrence capture and computational
efficiency.
Numerical Stability: Dot product computations
may produce large values, causing sigmoid function overflow. Scores must
be clamped to a reasonable range (e.g., [-10, 10]) before computing the
loss.
defbuild_vocab(sequences): """Build vocabulary from sequences.""" item_counts = Counter() for seq in sequences: item_counts.update(seq) # Create item to index mapping vocab = {item: idx for idx, item inenumerate(item_counts.keys())} return vocab, item_counts
defgenerate_training_pairs(sequences, vocab, window_size=5): """Generate (target, context) pairs from sequences.""" pairs = [] for seq in sequences: # Convert items to indices indices = [vocab[item] for item in seq if item in vocab] for i, target inenumerate(indices): # Context window start = max(0, i - window_size) end = min(len(indices), i + window_size + 1) for j inrange(start, end): if j != i: pairs.append((target, indices[j])) return pairs
defsample_negatives(item_counts, num_samples, num_negatives=5): """Sample negative items based on unigram distribution.""" # Unigram distribution raised to 3/4 power items = list(item_counts.keys()) probs = np.array([item_counts[item] ** 0.75for item in items]) probs = probs / probs.sum() negatives = np.random.choice(len(items), size=(num_samples, num_negatives), p=probs) return negatives
# Example usage if __name__ == "__main__": # Sample user sequences sequences = [ [1, 2, 3, 4, 5], [2, 3, 4, 6, 7], [1, 3, 5, 8, 9], [4, 5, 6, 10, 11], ] # Build vocabulary vocab, item_counts = build_vocab(sequences) vocab_size = len(vocab) # Generate training pairs pairs = generate_training_pairs(sequences, vocab, window_size=2) # Initialize model model = Item2Vec(vocab_size=vocab_size, embedding_dim=64, num_negatives=5) optimizer = optim.Adam(model.parameters(), lr=0.001) # Training loop batch_size = 32 num_epochs = 10 for epoch inrange(num_epochs): total_loss = 0 random.shuffle(pairs) for i inrange(0, len(pairs), batch_size): batch_pairs = pairs[i:i+batch_size] targets = torch.LongTensor([p[0] for p in batch_pairs]) contexts = torch.LongTensor([p[1] for p in batch_pairs]) negatives = torch.LongTensor( sample_negatives(item_counts, len(batch_pairs), num_negatives=5) ) optimizer.zero_grad() loss = model(targets, contexts, negatives) loss = loss.mean() loss.backward() optimizer.step() total_loss += loss.item() print(f"Epoch {epoch+1}/{num_epochs}, Loss: {total_loss/len(pairs)*batch_size:.4f}") # Get embeddings item_embedding = model.get_item_embedding(0) print(f"Embedding for item 0: {item_embedding[:5]}...")
Key Points Interpretation
The Item2Vec implementation includes several key components, each
with specific roles:
Sequence Construction and Window Sampling: User
historical interactions are sorted chronologically to form item
sequences, which serve as the foundation data. For each center item in a
sequence, we extract other items within its window as context.
window_size=2 means considering 2 items before and after,
capturing local co-occurrence without introducing excessive noise.
Window size selection requires balancing co-occurrence capture and
computational efficiency: larger windows generate more training samples
but may introduce irrelevant co-occurrences.
Negative Sampling Mechanism: Negative sampling
is key to Item2Vec's training efficiency. Each positive pair (center
item-context item) requires multiple negative pairs (center item-random
item). num_negatives=5 means 5 negative samples per
positive sample, typically set between 5-20. More negative samples
improve the model's ability to distinguish dissimilar items but linearly
increase training time.
Two Embedding Matrices: Center items and context
items use independent embedding matrices, following Word2Vec's design.
This design provides greater model capacity, allowing learning of
different role representations. Although this increases parameters,
experiments show this design improves model performance. Ultimately, we
only use center item embeddings as final item representations.
Loss Function Design: The negative
log-likelihood loss maximizes sigmoid(dot product) for positive samples
and minimizes sigmoid(dot product) for negative samples. This design
increases dot products for similar items and decreases them for
dissimilar items, learning meaningful embeddings.
Design Trade-offs
In Item2Vec's implementation, several design trade-offs exist:
Window Size vs Computational Efficiency: Larger
windows capture more distant co-occurrence relationships but
quadratically increase training samples (O(n ²)). Typically, window
sizes are set to 3-5, balancing effectiveness and efficiency.
Negative Sample Count vs Training Time: More
negative samples improve the model's ability to distinguish negative
samples but linearly increase per-batch computation time. Typically set
to 5-20, balancing effectiveness and efficiency.
Embedding Dimension vs Expressiveness: Higher
dimensions provide stronger model expressiveness but increase parameters
and may cause overfitting. Typically set to 64-256 dimensions, chosen
based on item count and computational resources.
Frequency Distribution vs Uniform Distribution:
Negative sampling uses the 3/4 power of frequency distribution, avoiding
over-sampling of high-frequency items while giving low-frequency items
learning opportunities. Uniform distribution would over-sample
low-frequency items; direct frequency would over-sample high-frequency
items.
Common Issues
How to Handle Cold-Start Items? For new items
not in the training set, Item2Vec cannot directly learn their
embeddings. Common solutions include: (1) Using item content features
(e.g., category, tags) to generate initial embeddings through additional
neural networks; (2) Using similar items' embeddings as initialization;
(3) Assigning randomly initialized embeddings to new items during
training, learning quickly through few interactions.
Numerical Overflow Issues: Dot product
computations may produce large values (especially when embeddings are
not normalized), causing sigmoid function overflow. Code uses
torch.clamp to limit scores to [-10, 10], an important
numerical stability technique.
Negative Sample Duplication: Random negative
sampling may sample positive samples (items within the context window).
Strictly speaking, positive samples should be excluded, but when item
counts are large (e.g., millions), the probability of sampling positive
samples is very small (<0.1%) and can be ignored. If item counts are
small, positive samples can be excluded during sampling.
Inconsistent Sequence Lengths: In practice, user
sequence lengths vary greatly, from a few items to hundreds of items.
Common approaches include: (1) Truncation: Keep only the most recent N
items (e.g., last 50); (2) Padding: Pad short sequences to fixed length;
(3) Dynamic batching: Group sequences of similar lengths in the same
batch.
How to Handle Temporal Information? Item2Vec
ignores temporal information in sequences, treating all items within a
window equally. If temporal decay is needed, different weights can be
assigned to context items at different positions in the loss function,
with weights decreasing as distance from the center item
increases.
Usage Example
The following example demonstrates how to use Item2Vec for training
and obtaining item embeddings:
# Prepare user behavior sequence data sequences = [ [0, 1, 2, 3, 4], # User 1's interaction sequence [1, 2, 5, 6, 7], # User 2's interaction sequence [0, 3, 4, 8, 9], # User 3's interaction sequence ]
# Create trainer and train model trainer = Item2VecTrainer( sequences=sequences, vocab_size=12, embedding_dim=64, window_size=2, num_negatives=5, batch_size=32, learning_rate=0.01 )
# Train model (typically 5-20 epochs) embeddings = trainer.train(num_epochs=10)
# Use embeddings for similar item recommendation item_emb = embeddings[0] # Get item 0's embedding similarities = [cosine_similarity(item_emb, embeddings[i]) for i inrange(12)] top_k_items = np.argsort(similarities)[::-1][:5] # Find 5 most similar items
In practice, Item2Vec is typically used as a feature extractor, with
learned embeddings used for: (1) Similar item recommendation; (2) Input
features for downstream models; (3) Item clustering and visualization
analysis.
CBOW Variant for Item2Vec
The CBOW (Continuous Bag of Words) variant predicts the target item
from its context:
While Item2Vec captures sequential patterns, many recommendation
scenarios involve complex item relationships that aren't purely
sequential. Graph-based embeddings model items as nodes in a graph,
where edges represent relationships (co-purchase, co-view, similarity,
etc.).
Node2Vec, introduced by Grover and Leskovec in 2016,
learns node embeddings by exploring the graph through biased random
walks, balancing between breadth-first search (BFS) and depth-first
search (DFS) exploration.
Node2Vec Algorithm
Node2Vec uses biased random walks with two
parameters: - \(p\)(return
parameter): Controls likelihood of returning to previous node -
\(q\)(in-out
parameter): Controls exploration of distant vs. nearby
nodes
The transition probability from node\(v\)to node\(x\)is:\[\alpha_{pq}(t, x) = \begin{cases}
\frac{1}{p} & \text{if } d_{tx} = 0 \\
1 & \text{if } d_{tx} = 1 \\
\frac{1}{q} & \text{if } d_{tx} = 2
\end{cases}\]where\(d_{tx}\)is
the shortest path distance between nodes\(t\)(previous node) and\(x\).
\(p < 1\): More
likely to return (BFS-like, local exploration)
\(p > 1\): Less
likely to return (DFS-like, global exploration)
\(q < 1\):
Prefer distant nodes (DFS-like)
\(q > 1\):
Prefer nearby nodes (BFS-like)
Implementation:
Node2Vec for Recommendation
Problem Background
In recommendation systems, user-item interactions can be naturally
modeled as graph structures: users and items are two types of nodes, and
interactions are edges. This graph structure contains rich semantic
information: users with similar connections (e.g., purchasing the same
items) may have similar interests; items with similar structures (e.g.,
purchased by similar users) may have similar properties. However,
learning effective representations of nodes (users and items) from graph
structures, such that similar nodes are closer in vector space, remains
challenging. Traditional graph embedding methods (e.g., DeepWalk) use
standard random walks to generate node sequences, but this approach
cannot flexibly control walk strategies, making it difficult to
simultaneously capture local structures (e.g., communities) and global
structures (e.g., node roles).
Solution Approach
Node2Vec addresses this by introducing biased random walks. The core
idea is to control walk strategies through two parameters p and q,
allowing walks to flexibly switch between depth-first search (DFS) and
breadth-first search (BFS). Specifically, p (return parameter) controls
the probability of returning to the previous node, and q (in-out
parameter) controls the probability of exploring nodes far from the
starting node. When p is small and q is large, walks tend toward BFS,
capturing local community structures; when p is large and q is small,
walks tend toward DFS, capturing global structures. Through this
flexible walk strategy, Node2Vec generates diverse node sequences, then
uses Skip-gram to learn node embeddings, making structurally similar or
similarly connected nodes closer in vector space.
Design Considerations
When implementing Node2Vec, several key design decisions must be
considered:
Biased Walk Strategy: Walk probability
calculations must consider the relationships between the previous node,
current node, and candidate nodes. For each candidate node, the shortest
distance to the previous node must be computed, then different weights
assigned based on distance. This design allows walks to flexibly balance
local exploration and global exploration.
Graph Preprocessing: To accelerate walk
generation, neighbor information for each node must be precomputed and
stored. This avoids repeated graph structure queries during training,
significantly improving walk generation speed. For large-scale graphs,
this preprocessing is necessary.
Walk Sequence Generation: Multiple walks are
performed for each node (typically 10-50), each generating a
fixed-length sequence (typically 50-100). More walks capture richer
graph structure information but increase computational cost.
Skip-gram Training: Generated walk sequences are
treated as "sentences," using Skip-gram to learn node embeddings. This
is similar to Item2Vec's training process but with different data
sources: Item2Vec uses user behavior sequences, while Node2Vec uses
graph walk sequences.
item_graph = build_item_graph_from_interactions(interactions, similarity_threshold=0.3) print(f"Graph has {item_graph.number_of_nodes()} nodes and {item_graph.number_of_edges()} edges")
Two-Tower
Models: Separate User and Item Embeddings
Architecture Overview
Two-tower models learn separate embedding towers for users and items,
then compute similarity via dot product or cosine similarity. This
architecture is scalable and enables efficient serving.
Key Components: 1. User Tower:
Encodes user features (ID, demographics, behavior history) into user
embedding 2. Item Tower: Encodes item features (ID,
content, metadata) into item embedding 3. Similarity
Function: Computes similarity between user and item
embeddings
Advantages of Two-Tower
Architecture
Scalability: Pre-compute item embeddings offline,
compute user embeddings online
Efficiency: Fast similarity search via approximate
nearest neighbor (ANN) algorithms
Flexibility: Can incorporate rich features in both
towers
Cold Start: Can handle new users/items through
feature-based towers
Deep Structured Semantic
Models (DSSM)
DSSM Architecture
DSSM (Deep Structured Semantic Model), introduced by Microsoft in
2013, was originally designed for web search but has been widely adopted
for recommendation systems.
Architecture: 1. Query Tower:
Multi-layer neural network encoding query (user) features 2.
Document Tower: Multi-layer neural network encoding
document (item) features 3. Similarity: Cosine
similarity between query and document embeddings 4.
Training: Maximize similarity for positive pairs,
minimize for negative pairs
Mathematical Formulation
Given a user\(u\)with features\(\mathbf{x}_u\)and an item\(i\)with features\(\mathbf{x}_i\):\[\mathbf{e}_u = f_u(\mathbf{x}_u; \theta_u)$
\]\(\mathbf{e}_i = f_i(\mathbf{x}_i;
\theta_i)\) $
\[s(u, i) = \cos(\mathbf{e}_u,
\mathbf{e}_i) = \frac{\mathbf{e}_u^T \mathbf{e}_i}{|\mathbf{e}_u| \cdot
|\mathbf{e}_i|}\]The training objective maximizes the probability
of positive pairs:\[P(i | u) =
\frac{\exp(s(u, i))}{\sum_{j \in \mathcal{N}_u} \exp(s(u,
j))}\]where\(\mathcal{N}_u\)includes positive items and
sampled negatives.
classFeatureEncoder: """ Encode various features for DSSM input. """ def__init__(self, vocab_sizes=None): """ Args: vocab_sizes: Dict mapping feature names to vocabulary sizes """ self.vocab_sizes = vocab_sizes or {} self.embeddings = {} # Initialize embeddings for categorical features for feat_name, vocab_size in self.vocab_sizes.items(): self.embeddings[feat_name] = nn.Embedding(vocab_size, 16) defencode_user_features(self, user_data): """ Encode user features into dense vector. Args: user_data: Dict with keys like 'user_id', 'age', 'gender', 'history' """ features = [] # User ID embedding if'user_id'in user_data: user_id_emb = self.embeddings['user_id'](user_data['user_id']) features.append(user_id_emb) # Numerical features (normalized) if'age'in user_data: age_normalized = user_data['age'] / 100.0# Normalize features.append(age_normalized.unsqueeze(1)) # Categorical features if'gender'in user_data: gender_emb = self.embeddings['gender'](user_data['gender']) features.append(gender_emb) # Historical behavior (average of item embeddings) if'history'in user_data: # Assume history is a list of item IDs history_emb = self.embeddings['item_id'](user_data['history']) history_emb = history_emb.mean(dim=1) # Average pooling features.append(history_emb) return torch.cat(features, dim=1) defencode_item_features(self, item_data): """ Encode item features into dense vector. Args: item_data: Dict with keys like 'item_id', 'category', 'price' """ features = [] # Item ID embedding if'item_id'in item_data: item_id_emb = self.embeddings['item_id'](item_data['item_id']) features.append(item_id_emb) # Category embedding if'category'in item_data: category_emb = self.embeddings['category'](item_data['category']) features.append(category_emb) # Numerical features if'price'in item_data: price_normalized = torch.log(item_data['price'] + 1) / 10.0 features.append(price_normalized.unsqueeze(1)) return torch.cat(features, dim=1)
YouTube
DNN: Deep Neural Network for Recommendations
YouTube DNN Architecture
YouTube DNN, introduced in 2016, is a two-tower model specifically
designed for large-scale video recommendation. It addresses several key
challenges:
Extreme Scale: Millions of videos, billions of
users
Freshness: New videos uploaded constantly
Implicit Feedback: Watch time, clicks, not explicit
ratings
Real-time Serving: Low-latency requirements
Architecture Details
User Tower: - Input: User watch history (sequence of
video IDs) - Processing: Average pooling over watched video embeddings -
Additional features: User demographics, search queries - Output: User
embedding
Item Tower: - Input: Video features (ID, category,
tags, etc.) - Processing: Concatenate and pass through MLP - Output:
Item embedding
Training: - Objective: Predict next video to watch -
Loss: Weighted logistic regression (weighted by watch time) - Negative
sampling: Sample from entire video corpus
In recommendation systems, we have far more negative examples
(non-interactions) than positive ones. Computing loss over all negatives
is computationally expensive. Negative sampling selects a small subset
of negatives for training.
Common Negative Sampling
Strategies
1. Uniform Random Sampling
Sample negatives uniformly from all items:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
defuniform_negative_sampling(item_set, num_negatives, exclude_items=None): """ Uniform random negative sampling. Args: item_set: Set of all item IDs num_negatives: Number of negatives to sample exclude_items: Set of items to exclude (e.g., positive items) """ if exclude_items: candidates = list(item_set - exclude_items) else: candidates = list(item_set) negatives = random.sample(candidates, min(num_negatives, len(candidates))) return negatives
2. Popularity-Based Sampling
Sample negatives proportional to item popularity (unigram
distribution):
defpopularity_negative_sampling(item_popularity, num_negatives, exclude_items=None): """ Sample negatives based on item popularity. Args: item_popularity: Dict mapping item_id to popularity count num_negatives: Number of negatives to sample exclude_items: Set of items to exclude """ if exclude_items: candidates = {k: v for k, v in item_popularity.items() if k notin exclude_items} else: candidates = item_popularity # Unigram distribution items = list(candidates.keys()) probs = np.array([candidates[item] for item in items]) probs = probs / probs.sum() negatives = np.random.choice(items, size=num_negatives, p=probs) return negatives.tolist()
3. Hard Negative Mining
Sample negatives that are "hard" (similar to positives but not
interacted):
defhard_negative_mining(user_embedding, item_embeddings, positive_items, num_negatives, top_k=100): """ Hard negative mining: sample negatives with high similarity to user. Args: user_embedding: User embedding vector item_embeddings: Dict mapping item_id to embedding positive_items: Set of positive item IDs num_negatives: Number of negatives to sample top_k: Consider top-k similar items as candidates """ # Compute similarities similarities = {} for item_id, item_emb in item_embeddings.items(): if item_id notin positive_items: sim = np.dot(user_embedding, item_emb) similarities[item_id] = sim # Get top-k similar items (hard negatives) sorted_items = sorted(similarities.items(), key=lambda x: x[1], reverse=True) candidates = [item_id for item_id, _ in sorted_items[:top_k]] # Sample from candidates negatives = random.sample(candidates, min(num_negatives, len(candidates))) return negatives
4. In-Batch Negatives
Use other items in the same batch as negatives:
1 2 3 4 5 6 7 8 9 10 11 12 13
defin_batch_negative_sampling(batch_items, positive_items): """ Use other items in batch as negatives. Args: batch_items: List of item IDs in current batch positive_items: Set of positive item IDs for current user """ negatives = [] for item in batch_items: if item notin positive_items: negatives.append(item) return negatives
Once we have embeddings, finding the most similar items requires
computing similarity with all items, which is\(O(n)\)per query. For millions of items,
this is too slow. Approximate Nearest Neighbor (ANN)
algorithms trade accuracy for speed.
FAISS: Facebook AI
Similarity Search
FAISS is a library for efficient similarity search and clustering of
dense vectors.
FAISS Index Types
Flat Index: Brute-force search (exact, but
slow)
IVF (Inverted File Index): Clusters vectors and
searches within clusters
HNSW (Hierarchical Navigable Small World):
Graph-based index
Product Quantization: Compresses vectors for memory
efficiency
defrecommendation_coverage(recommendations, all_items): """ Measure how many items are recommended (coverage). Args: recommendations: Dict mapping user_id to list of recommended item_ids all_items: Set of all items """ recommended_items = set() for user_id, items in recommendations.items(): recommended_items.update(items) coverage = len(recommended_items) / len(all_items) return coverage
defrecommendation_diversity(recommendations, item_embeddings): """ Measure diversity of recommendations (average pairwise distance). Args: recommendations: Dict mapping user_id to list of recommended item_ids item_embeddings: Dict mapping item_id to embedding """ diversities = [] for user_id, items in recommendations.items(): iflen(items) < 2: continue embeddings = [item_embeddings[item_id] for item_id in items if item_id in item_embeddings] iflen(embeddings) < 2: continue # Compute pairwise distances distances = [] for i inrange(len(embeddings)): for j inrange(i+1, len(embeddings)): dist = 1 - np.dot(embeddings[i], embeddings[j]) # Cosine distance distances.append(dist) diversity = np.mean(distances) diversities.append(diversity) return np.mean(diversities) if diversities else0.0
Complete Training Pipeline
Here's a complete example combining all components:
deftrain_dssm_model(model, train_loader, val_loader, num_epochs=10, lr=0.001): """Complete training pipeline for DSSM.""" device = torch.device('cuda'if torch.cuda.is_available() else'cpu') model = model.to(device) optimizer = optim.Adam(model.parameters(), lr=lr) criterion = DSSMLoss(temperature=1.0) for epoch inrange(num_epochs): # Training model.train() train_loss = 0 for batch in train_loader: user_features = batch['user_features'].to(device) item_features = batch['item_features'].to(device) labels = batch['label'].to(device) # Get positive and negative samples user_emb, pos_item_emb, _ = model(user_features, item_features) # Sample negatives (simplified: use other items in batch) batch_size = user_features.size(0) neg_indices = torch.randint(0, len(train_loader.dataset.item_features), (batch_size, 5)) neg_item_features = torch.stack([ train_loader.dataset.item_features[idx] for idx in neg_indices ]).to(device) neg_item_emb = model.get_item_embedding(neg_item_features.view(-1, neg_item_features.size(-1))) neg_item_emb = neg_item_emb.view(batch_size, 5, -1) # Compute loss loss = criterion(user_emb, pos_item_emb, neg_item_emb) optimizer.zero_grad() loss.backward() optimizer.step() train_loss += loss.item() # Validation model.eval() val_loss = 0 with torch.no_grad(): for batch in val_loader: user_features = batch['user_features'].to(device) item_features = batch['item_features'].to(device) user_emb, pos_item_emb, _ = model(user_features, item_features) # ... compute validation loss print(f"Epoch {epoch+1}/{num_epochs}, Train Loss: {train_loss/len(train_loader):.4f}")
# Example usage if __name__ == "__main__": # Prepare data num_users = 1000 num_items = 5000 user_feature_dim = 50 item_feature_dim = 30 # Generate synthetic data interactions = [ (np.random.randint(0, num_users), np.random.randint(0, num_items), 1) for _ inrange(10000) ] user_features = {i: torch.randn(user_feature_dim) for i inrange(num_users)} item_features = {i: torch.randn(item_feature_dim) for i inrange(num_items)} # Create datasets train_size = int(0.8 * len(interactions)) train_interactions = interactions[:train_size] val_interactions = interactions[train_size:] train_dataset = RecommendationDataset(train_interactions, user_features, item_features) val_dataset = RecommendationDataset(val_interactions, user_features, item_features) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False) # Initialize model model = DSSM( user_feature_dim=user_feature_dim, item_feature_dim=item_feature_dim, embedding_dim=128 ) # Train train_dssm_model(model, train_loader, val_loader, num_epochs=10)
Questions and Answers
Q1:
What's the difference between Item2Vec and collaborative filtering?
A: Item2Vec learns item embeddings from sequential
user interactions, treating sequences as "sentences" and items as
"words." It captures temporal patterns and co-occurrence relationships.
Collaborative filtering (like matrix factorization) learns embeddings by
factorizing the user-item interaction matrix, capturing global
similarity patterns. Item2Vec is better for sequential data (e.g.,
playlist recommendations), while CF is better for general preference
modeling.
Q2: How do I choose
embedding dimension?
A: Embedding dimension is a trade-off between
expressiveness and efficiency. Common choices: - Small
datasets (< 10K items): 32-64 dimensions - Medium
datasets (10K-1M items): 64-128 dimensions - Large
datasets (> 1M items): 128-256 dimensions
Higher dimensions capture more information but increase memory and
computation. Use validation metrics (hit rate, NDCG) to select the
optimal dimension.
Q3: What's
the difference between Skip-gram and CBOW?
A: - Skip-gram: Predicts context
items from a target item. Better for rare items, slower training. -
CBOW: Predicts target item from context items. Faster
training, better for frequent items.
For recommendation systems, Skip-gram is often preferred because it
better handles long-tail items.
Q4: How does Node2Vec
differ from Item2Vec?
A: - Item2Vec: Assumes sequential
data, learns from item sequences. - Node2Vec: Works on
graphs, captures complex item relationships (not just sequential). Uses
biased random walks to explore the graph structure.
Use Node2Vec when you have rich item relationships (co-purchase,
co-view, similarity graphs) beyond just sequences.
Q5:
Why use two-tower architecture instead of single-tower?
A: Two-tower architecture enables: 1.
Offline pre-computation: Compute item embeddings
offline, update user embeddings online 2. Efficient
serving: Use ANN search on pre-computed item embeddings 3.
Scalability: Handle millions of items efficiently 4.
Feature flexibility: Different features for users vs.
items
Single-tower models (like neural collaborative filtering) compute
user-item similarity jointly, which is harder to scale.
Q6: How do I
handle cold start for new users/items?
A: - New users: Use feature-based
user tower (demographics, device, location) instead of ID-only embedding
- New items: Use content-based item tower (category,
tags, description embeddings) - Hybrid approach:
Combine ID embeddings with feature embeddings
For completely new entities, start with feature-based embeddings and
gradually incorporate ID embeddings as data accumulates.
Q7: What's the
best negative sampling strategy?
A: It depends on your data: - Uniform
sampling: Simple, works well for balanced datasets -
Popularity-based: Better for imbalanced datasets,
prevents model from only learning popular items - Hard negative
mining: Improves model discrimination, but computationally
expensive - In-batch negatives: Efficient, but may
introduce bias
In practice, combine strategies: use uniform/popularity-based for
most training, occasionally add hard negatives.
Q8: How do I
choose between FAISS, Annoy, and HNSW?
A: - FAISS: Best for very large
scale (> 10M items), supports GPU, many index types -
Annoy: Simple API, good for medium scale (< 1M
items), easy to deploy - HNSW: Best accuracy/speed
trade-off, good for medium-large scale
For production, FAISS is often preferred due to its flexibility and
performance optimizations.
Q9: How
do I evaluate embedding quality without labels?
A: Use intrinsic metrics: 1.
Coherence: Compare embedding similarity with domain
knowledge (e.g., items in same category should be similar) 2.
Clustering: Check if embeddings form meaningful
clusters 3. Visualization: t-SNE/UMAP visualization to
inspect embedding structure 4. Downstream tasks: Use
embeddings for classification/clustering tasks
Q10:
How do I update embeddings for new items without retraining?
A: 1. Feature-based: Use content
features to generate embeddings via item tower 2. Incremental
learning: Fine-tune model on new data periodically 3.
Online learning: Update embeddings incrementally using
techniques like online matrix factorization 4. Hybrid:
Combine feature-based embeddings with learned ID embeddings
For two-tower models, feature-based item tower naturally handles new
items.
Q11:
What's the relationship between embedding dimension and model
capacity?
A: Embedding dimension determines the model's
capacity to distinguish items. Higher dimensions: - Can capture more
nuanced relationships - Require more data to avoid overfitting -
Increase memory and computation
Rule of thumb: embedding dimension should be much smaller than the
number of items (typically < 1% of vocabulary size).
Q12: How
do I handle multi-modal features in embeddings?
A: 1. Early fusion: Concatenate
features before embedding layer 2. Late fusion: Learn
separate embeddings for each modality, then combine (average,
concatenate, attention) 3. Cross-modal attention: Use
attention to learn interactions between modalities
For recommendation systems, early fusion (concatenation) is often
sufficient, but late fusion with attention can improve performance.
Q13:
What's the difference between dot product and cosine similarity?
A: - Dot product:\(\mathbf{u}^T \mathbf{v}\), sensitive to
vector magnitude - Cosine similarity:\(\frac{\mathbf{u}^T \mathbf{v }}{|\mathbf{u}| \cdot
|\mathbf{v}|}\), normalized by magnitude
For embeddings, cosine similarity is often preferred because: - It
focuses on direction (semantic similarity) rather than magnitude -
Normalized embeddings have consistent scale - More interpretable (ranges
from -1 to 1)
However, if embeddings aren't normalized, dot product can work well
and is computationally cheaper.
Q14: How do
I handle temporal dynamics in embeddings?
A: 1. Time-aware embeddings:
Include time features (hour, day, week) in user/item towers 2.
Sequential models: Use RNN/Transformer to encode
temporal sequences 3. Time-decay: Weight recent
interactions more heavily 4. Periodic retraining:
Retrain embeddings periodically to capture changing preferences
For real-time systems, time-aware features + periodic retraining is a
practical approach.
Q15: What
are common pitfalls when training embeddings?
A: 1. Insufficient negative
sampling: Too few negatives leads to poor discrimination 2.
Data leakage: Including future data in training
sequences 3. Popularity bias: Model only learns popular
items (use popularity-based negative sampling) 4.
Overfitting: Too high embedding dimension for dataset
size 5. Cold start: Not handling new users/items
properly 6. Evaluation on training data: Always
evaluate on held-out test set
Always monitor training/validation metrics and use proper evaluation
protocols.
Conclusion
Embedding techniques are fundamental to modern recommendation
systems, enabling efficient similarity search, personalization, and
scalability. From sequence-based methods like Item2Vec to graph-based
Node2Vec, to deep two-tower architectures like DSSM and YouTube DNN,
each approach has its strengths and use cases.
Key takeaways: - Choose the right method for your
data: sequential (Item2Vec), graph-based (Node2Vec), or feature-rich
(DSSM/YouTube DNN) - Optimize negative sampling to
balance accuracy and efficiency - Use ANN search
(FAISS/Annoy/HNSW) for scalable serving - Evaluate
comprehensively using both intrinsic and extrinsic metrics -
Handle cold start through feature-based towers
As recommendation systems continue to evolve, embedding techniques
remain at the core, enabling systems to understand and leverage the
complex relationships between users, items, and their interactions.
Post title:Recommendation Systems (5): Embedding and Representation Learning
Post author:Chen Kai
Create time:2026-02-03 23:11:11
Post link:https://www.chenk.top/recommendation-systems-5-embedding-techniques/
Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.