permalink: "en/recommendation-systems-4-ctr-prediction/" date: 2024-05-17 15:45:00 tags: - Recommendation Systems - CTR Prediction - Click-Through Rate categories: Recommendation Systems mathjax: true--- When you scroll through your social media feed, click on a product recommendation, or watch a suggested video, you're interacting with one of the most critical components of modern recommendation systems: the CTR (Click-Through Rate) prediction model. These models answer a deceptively simple question: "What's the probability this user will click on this item?" But behind this simplicity lies a complex machine learning challenge that directly impacts billions of dollars in revenue for platforms like Facebook, Google, Amazon, and Alibaba.
CTR prediction sits at the heart of the ranking stage in recommendation systems. After candidate generation retrieves thousands of potential items, CTR models score each candidate to determine the final ranking order. A 1% improvement in CTR prediction accuracy can translate to millions of dollars in additional revenue for large-scale platforms. This makes CTR prediction one of the most researched and optimized problems in machine learning.
This article takes you on a journey through the evolution of CTR prediction models, from the foundational Logistic Regression baseline to state-of-the-art deep learning architectures like DeepFM, xDeepFM, DCN, AutoInt, and FiBiNet. We'll explore not just how these models work mathematically, but why they were designed the way they were, what problems they solve, and how to implement them from scratch. Along the way, we'll cover feature engineering techniques, training strategies, and practical considerations that separate academic prototypes from production-ready systems.
Whether you're building a recommendation system for the first time or optimizing an existing one, understanding CTR prediction models is essential. These models have evolved dramatically over the past decade, incorporating insights from factorization machines, deep learning, attention mechanisms, and feature interaction modeling. By the end of this article, you'll have a comprehensive understanding of the field and the practical skills to implement these models yourself.
Understanding the CTR Prediction Problem
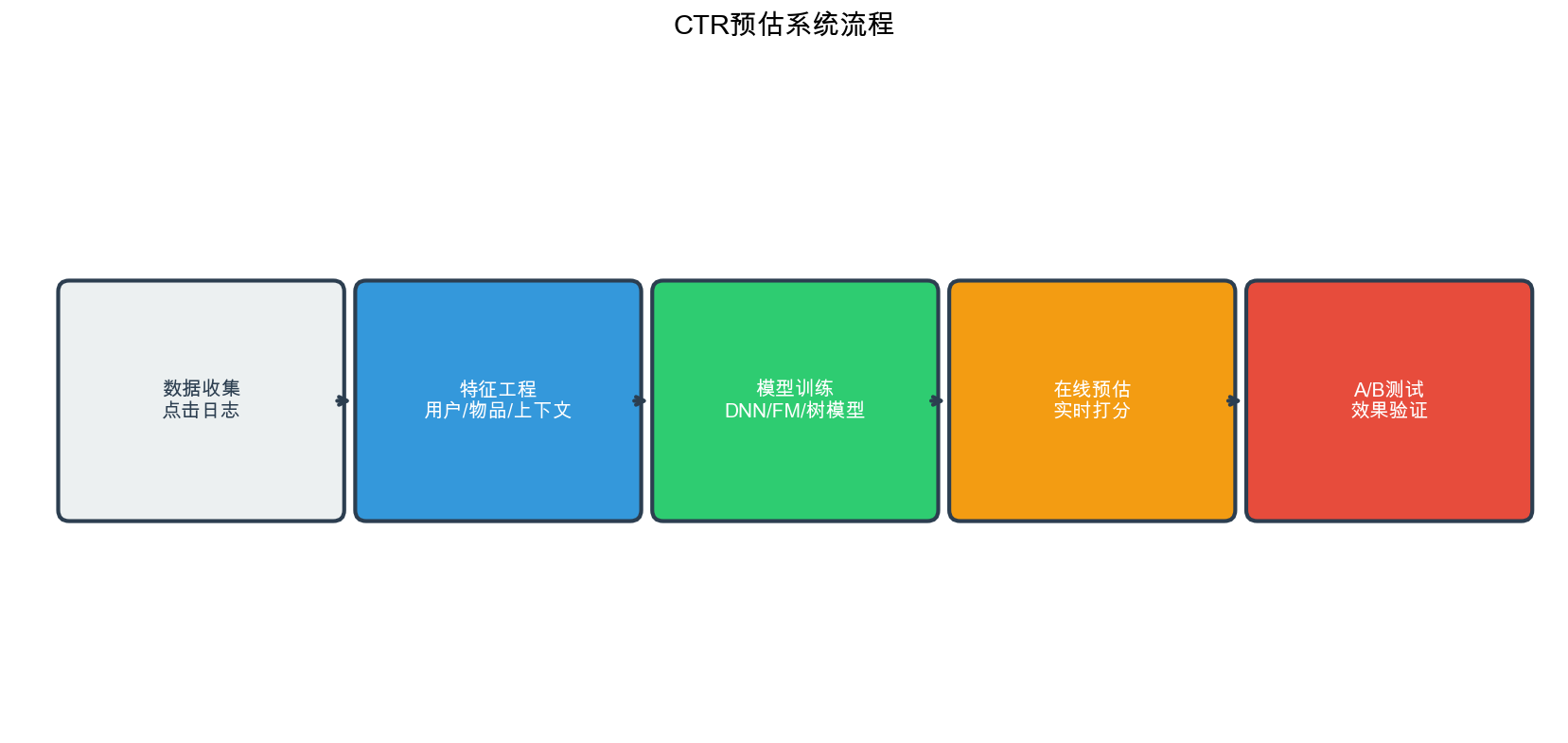
Before diving into specific models, let's establish a clear understanding of what CTR prediction is, why it matters, and what makes it uniquely challenging.
What is CTR Prediction?
Click-Through Rate (CTR) prediction is a binary classification problem: given a user-item pair and contextual features, predict the probability that the user will click on the item. Formally, we want to estimate:
\[P(y = 1 | \mathbf{x})\]Where: -\(y \in \{0, 1\}\)is the binary label (1 = click, 0 = no click) -\(\mathbf{x}\)is the feature vector representing the user, item, and context
The CTR is then:\[\text{CTR} = \frac{\text{Number of clicks }}{\text{Number of impressions }}\]In recommendation systems, CTR prediction is used to: 1. Rank items: Higher predicted CTR → higher position in recommendation list 2. Filter low-quality candidates: Remove items with very low predicted CTR 3. Optimize business metrics: Balance CTR with other objectives (revenue, diversity, etc.)
Why CTR Prediction is Challenging
CTR prediction presents several unique challenges that distinguish it from standard classification problems:
1. Extreme Class Imbalance
In most real-world scenarios, CTR is extremely low: - Display ads: 0.1% - 2% CTR - E-commerce recommendations: 1% - 5% CTR - News feed: 2% - 10% CTR
This means we have far more negative examples (no clicks) than positive examples (clicks). Standard accuracy metrics are misleading – a model that always predicts "no click" would achieve 95%+ accuracy but be completely useless.
2. High-Dimensional Sparse Features
CTR prediction typically involves: - Categorical features: User ID, Item ID, Category, Brand, etc. - Numerical features: Price, Age, Time of day, etc. - Contextual features: Device type, Location, Day of week, etc.
After one-hot encoding categorical features, the feature space becomes extremely high-dimensional (millions or billions of dimensions) but sparse (each sample activates only a tiny fraction of features).
3. Feature Interactions
The most important signals often come from interactions between features: - User age × Item category: Young users might prefer different categories - Item price × User purchase history: Price sensitivity varies by user - Time of day × Item type: Different items are popular at different times
Capturing these interactions is crucial but computationally expensive.
4. Data Distribution Shift
User behavior changes over time: - Seasonal effects (holiday shopping, summer content) - Trending items (viral content, new releases) - User preference evolution
Models must be robust to these shifts and frequently retrained.
5. Real-Time Requirements
CTR prediction often happens in real-time: - Latency requirements: < 10ms per prediction - Throughput requirements: Millions of predictions per second - Model size constraints: Must fit in memory for fast inference
The CTR Prediction Pipeline
A typical CTR prediction pipeline consists of:
1 | Raw Data → Feature Engineering → Feature Encoding → Model Training → Model Serving |
Feature Engineering: - Extract features from user behavior, item attributes, context - Create interaction features (e.g., user_category combinations) - Handle missing values, outliers, normalization
Feature Encoding: - One-hot encoding for categorical features - Embedding layers for high-cardinality categorical features - Normalization for numerical features
Model Training: - Use appropriate loss function (binary cross-entropy) - Handle class imbalance (weighted loss, sampling) - Regularization to prevent overfitting
Model Serving: - Deploy model for real-time inference - Monitor performance metrics - A/B test new models
explore the evolution of CTR prediction models, starting with the simplest baseline.
Logistic Regression: The Foundation
Logistic Regression serves as the baseline for CTR prediction. Despite its simplicity, it's still widely used in production systems due to its interpretability, efficiency, and robustness.
Mathematical Formulation
Logistic Regression models the probability of a click as:\[P(y = 1 | \mathbf{x}) = \sigma(\mathbf{w}^T \mathbf{x} + b) = \frac{1}{1 + e^{-(\mathbf{w}^T \mathbf{x} + b) }}\]Where: -\(\mathbf{w} \in \mathbb{R}^d\)are the model weights -\(b \in \mathbb{R}\)is the bias term -\(\sigma(z) = \frac{1}{1 + e^{-z }}\)is the sigmoid function -\(\mathbf{x} \in \mathbb{R}^d\)is the feature vector
The sigmoid function maps the linear combination\(\mathbf{w}^T \mathbf{x} + b\)to a probability between 0 and 1.
Training Objective
We minimize the binary cross-entropy loss:\[\mathcal{L} = -\frac{1}{N} \sum_{i=1}^{N} \left[ y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i) \right]\]Where\(\hat{y}_i = P(y_i = 1 | \mathbf{x}_i)\)is the predicted probability.
Implementation
Here's a complete implementation of Logistic Regression for CTR prediction:
1 | import numpy as np |
Limitations of Logistic Regression
While Logistic Regression is simple and effective, it has significant limitations:
No Feature Interactions: It assumes features are independent. The model can't learn that "young users clicking on action movies" is different from the sum of "young users" and "action movies" effects.
Manual Feature Engineering Required: To capture interactions, engineers must manually create interaction features (e.g.,
user_age × item_category), which is:- Time-consuming and error-prone
- Doesn't scale to high-order interactions
- May miss important interactions
Linear Decision Boundary: The model can only learn linear relationships, limiting its expressiveness.
These limitations motivated the development of Factorization Machines, which automatically learn feature interactions.
Factorization Machines (FM): Learning Feature Interactions
Factorization Machines, introduced by Steffen Rendle in 2010, were a breakthrough in CTR prediction. They automatically model pairwise feature interactions without requiring manual feature engineering.

Intuition
The key insight of FM is to model interactions between features using factorized parameters. Instead of learning a separate weight\(w_{ij}\)for each pair of features\((i, j)\)(which would require\(O(d^2)\)parameters), FM learns a low-rank factorization:\[w_{ij} \approx \langle \mathbf{v}_i, \mathbf{v}_j \rangle = \sum_{f=1}^{k} v_{i,f} \cdot v_{j,f}\]Where: -\(\mathbf{v}_i \in \mathbb{R}^k\)is the embedding vector for feature\(i\) -\(k\)is the embedding dimension (typically 8-64) -\(\langle \cdot, \cdot \rangle\)denotes the dot product
This reduces the number of parameters from\(O(d^2)\)to\(O(d \cdot k)\), making FM scalable to high-dimensional sparse data.
Mathematical Formulation
The FM model prediction is:\[\hat{y}(\mathbf{x}) = w_0 + \sum_{i=1}^{d} w_i x_i + \sum_{i=1}^{d} \sum_{j=i+1}^{d} \langle \mathbf{v}_i, \mathbf{v}_j \rangle x_i x_j\]Where: -\(w_0\)is the global bias -\(w_i\)are the linear weights for individual features -\(\langle \mathbf{v}_i, \mathbf{v}_j \rangle x_i x_j\)models pairwise interactions
The interaction term can be computed efficiently in\(O(k \cdot d)\)time using:\[\sum_{i=1}^{d} \sum_{j=i+1}^{d} \langle \mathbf{v}_i, \mathbf{v}_j \rangle x_i x_j = \frac{1}{2} \left[ \left( \sum_{i=1}^{d} \mathbf{v}_i x_i \right)^2 - \sum_{i=1}^{d} (\mathbf{v}_i x_i)^2 \right]\]This reformulation avoids the nested loop and makes FM computationally efficient.
Implementation
Here's a complete implementation of Factorization Machines:
1 | import torch |
Advantages of FM
Automatic Feature Interactions: Learns pairwise interactions without manual engineering
Scalability:\(O(k \cdot d)\)complexity instead of\(O(d^2)\)
Sparse Data Handling: Works well with high-dimensional sparse features
Interpretability: Can analyze learned embeddings to understand feature relationships
Limitations
- Only Pairwise Interactions: Cannot model higher-order interactions (3-way, 4-way, etc.)
- Same Embedding for All Interactions: All features share the same embedding space, which may not be optimal
These limitations led to the development of Field-aware Factorization Machines.
Field-aware Factorization Machines (FFM)
Field-aware Factorization Machines extend FM by introducing the concept of "fields." A field is a group of related features (e.g., all user-related features form one field, all item-related features form another).
Key Innovation
In FFM, each feature has multiple embedding vectors, one for each field it interacts with. This allows the model to learn field-specific interaction patterns.
Mathematical Formulation
The FFM prediction is:\[\hat{y}(\mathbf{x}) = w_0 + \sum_{i=1}^{d} w_i x_i + \sum_{i=1}^{d} \sum_{j=i+1}^{d} \langle \mathbf{v}_{i, f_j}, \mathbf{v}_{j, f_i} \rangle x_i x_j\]Where: -\(f_i\)is the field that feature\(i\)belongs to -\(\mathbf{v}_{i, f_j}\)is the embedding vector of feature\(i\)when interacting with field\(f_j\)The key difference from FM is that\(\mathbf{v}_{i, f_j} \ne \mathbf{v}_{i, f_k}\)for\(j \ne k\)– each feature has different embeddings for different fields.
Implementation
1 | class FieldAwareFactorizationMachine(nn.Module): |
FFM vs FM
FFM Advantages: - More expressive: Field-specific embeddings capture domain knowledge - Better performance on datasets with clear field structure
FFM Disadvantages: - More parameters:\(O(d \cdot F \cdot k)\)vs\(O(d \cdot k)\)where\(F\)is number of fields - More complex: Harder to train and tune - Field definition required: Need domain knowledge to define fields
In practice, FFM often performs better than FM but requires more careful tuning. However, both FM and FFM are limited to pairwise interactions. The next generation of models uses deep learning to automatically learn higher-order interactions.
DeepFM: Combining Factorization Machines with Deep Learning
DeepFM, introduced by Huawei in 2017, combines the strengths of Factorization Machines (for low-order interactions) with deep neural networks (for high-order interactions). It's one of the most widely used CTR prediction models in industry.
Architecture Overview
DeepFM consists of two components:
- FM Component: Models low-order (especially pairwise) feature interactions
- Deep Component: A multi-layer neural network that models high-order feature interactions
Both components share the same embedding layer, which reduces model complexity and improves training efficiency.
Mathematical Formulation
The DeepFM prediction is:\[\hat{y}(\mathbf{x}) = \sigma(y_{FM} + y_{Deep})\]Where: -\(y_{FM}\)is the FM component output (same as standard FM) -\(y_{Deep}\)is the deep component output -\(\sigma\)is the sigmoid function
The deep component processes the concatenated embeddings through multiple fully-connected layers:\[\mathbf{h}_0 = [\mathbf{v}_1, \mathbf{v}_2, \ldots, \mathbf{v}_d]\] \[\mathbf{h}_l = \text{ReLU}(\mathbf{W}_l \mathbf{h}_{l-1} + \mathbf{b}_l), \quad l = 1, 2, \ldots, L\] \[y_{Deep} = \mathbf{W}_{L+1} \mathbf{h}_L + b_{L+1}\]
Implementation
Here's a complete implementation of DeepFM:
1 | class DeepFM(nn.Module): |
Why DeepFM Works
- Complementary Strengths: FM captures low-order interactions explicitly, while the deep network captures high-order interactions implicitly
- Shared Embeddings: Reduces parameters and improves training stability
- End-to-End Learning: Both components are trained jointly, allowing them to complement each other
DeepFM has become a standard baseline in CTR prediction competitions and production systems. However, researchers noticed that the deep component's ability to learn feature interactions might be limited. This led to the development of xDeepFM, which explicitly models feature interactions in the deep component.
xDeepFM: Explicit High-Order Feature Interactions
xDeepFM (eXtreme Deep Factorization Machine) addresses a key limitation of DeepFM: while the deep network can theoretically learn high-order interactions, it doesn't explicitly model them. xDeepFM introduces the Compressed Interaction Network (CIN) to explicitly learn high-order feature interactions.
Key Innovation: Compressed Interaction Network (CIN)
CIN explicitly models feature interactions at each layer, similar to how CNNs learn spatial patterns in images. At each layer, CIN: 1. Computes interactions between the current layer's features and the original embeddings 2. Compresses the interaction results to a fixed dimension 3. Passes the compressed interactions to the next layer
Mathematical Formulation
Let\(\mathbf{X}^0 \in \mathbb{R}^{m \times D}\)be the embedding matrix where\(m\)is the number of fields and\(D\)is the embedding dimension. The\(k\)-th layer of CIN computes:\[\mathbf{X}^k_{h,*} = \sum_{i=1}^{H_{k-1 }} \sum_{j=1}^{m} \mathbf{W}^{k,h}_{i,j} (\mathbf{X}^{k-1}_{i,*} \circ \mathbf{X}^0_{j,*})\]Where: -\(H_k\)is the number of feature maps in layer\(k\) -\(\circ\)denotes element-wise product (Hadamard product) -\(\mathbf{W}^{k,h}\)are learnable parameters
The final CIN output is the sum of all layers' outputs (after pooling):\[\mathbf{p}^+ = [\mathbf{p}^1, \mathbf{p}^2, \ldots, \mathbf{p}^H]\]Where\(\mathbf{p}^h\)is the sum-pooling of the\(h\)-th feature map.
Implementation
1 | class CompressedInteractionNetwork(nn.Module): |
xDeepFM vs DeepFM
xDeepFM Advantages: - Explicit high-order interactions through CIN - Better interpretability (can analyze CIN layers) - Often achieves better performance on complex datasets
xDeepFM Disadvantages: - More complex architecture - Higher computational cost (CIN layers) - More hyperparameters to tune
xDeepFM represents a significant advancement in explicitly modeling feature interactions. However, another important direction in CTR prediction is learning cross-features automatically, which is the focus of DCN.
Deep & Cross Network (DCN): Learning Cross-Features Automatically
The Deep & Cross Network (DCN), introduced by Google in 2017, addresses feature interaction learning from a different angle. Instead of using factorization machines or CIN, DCN uses a "cross network" that explicitly learns bounded-degree feature interactions.
Architecture Overview
DCN consists of two components:
- Cross Network: Learns explicit feature interactions of bounded degree
- Deep Network: Standard MLP for implicit high-order interactions
The outputs of both networks are combined for the final prediction.
Cross Network Formulation
The cross network applies the following transformation at each layer:\[\mathbf{x}_{l+1} = \mathbf{x}_0 \mathbf{x}_l^T \mathbf{w}_l + \mathbf{b}_l + \mathbf{x}_l\]Where: -\(\mathbf{x}_0\)is the input embedding -\(\mathbf{x}_l\)is the output of layer\(l\) -\(\mathbf{w}_l, \mathbf{b}_l\)are learnable parameters
The key insight is that each cross layer increases the polynomial degree of interactions by 1. After\(L\)layers, the model can learn interactions up to degree\(L+1\).
Implementation
1 | class CrossNetwork(nn.Module): |
DCN Advantages
- Bounded Interaction Degree: The number of cross layers directly controls the maximum interaction degree, providing interpretability
- Efficient: Cross network is computationally efficient
- Automatic Feature Learning: Learns cross-features automatically without manual engineering
DCN has been successfully deployed in production at Google and other companies. However, another important direction is using attention mechanisms to automatically identify important feature interactions, which is the focus of AutoInt.
AutoInt: Automatic Feature Interaction Learning via Attention
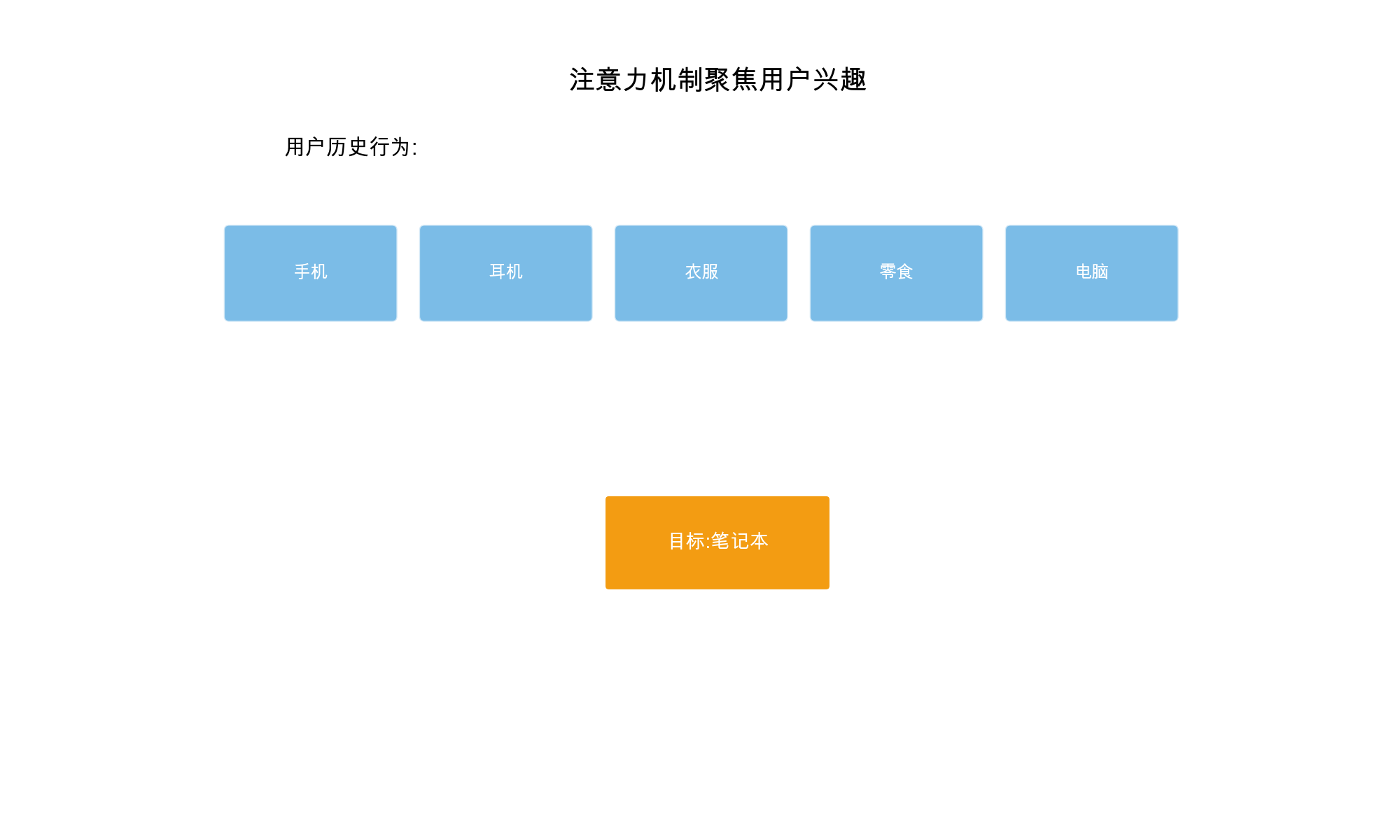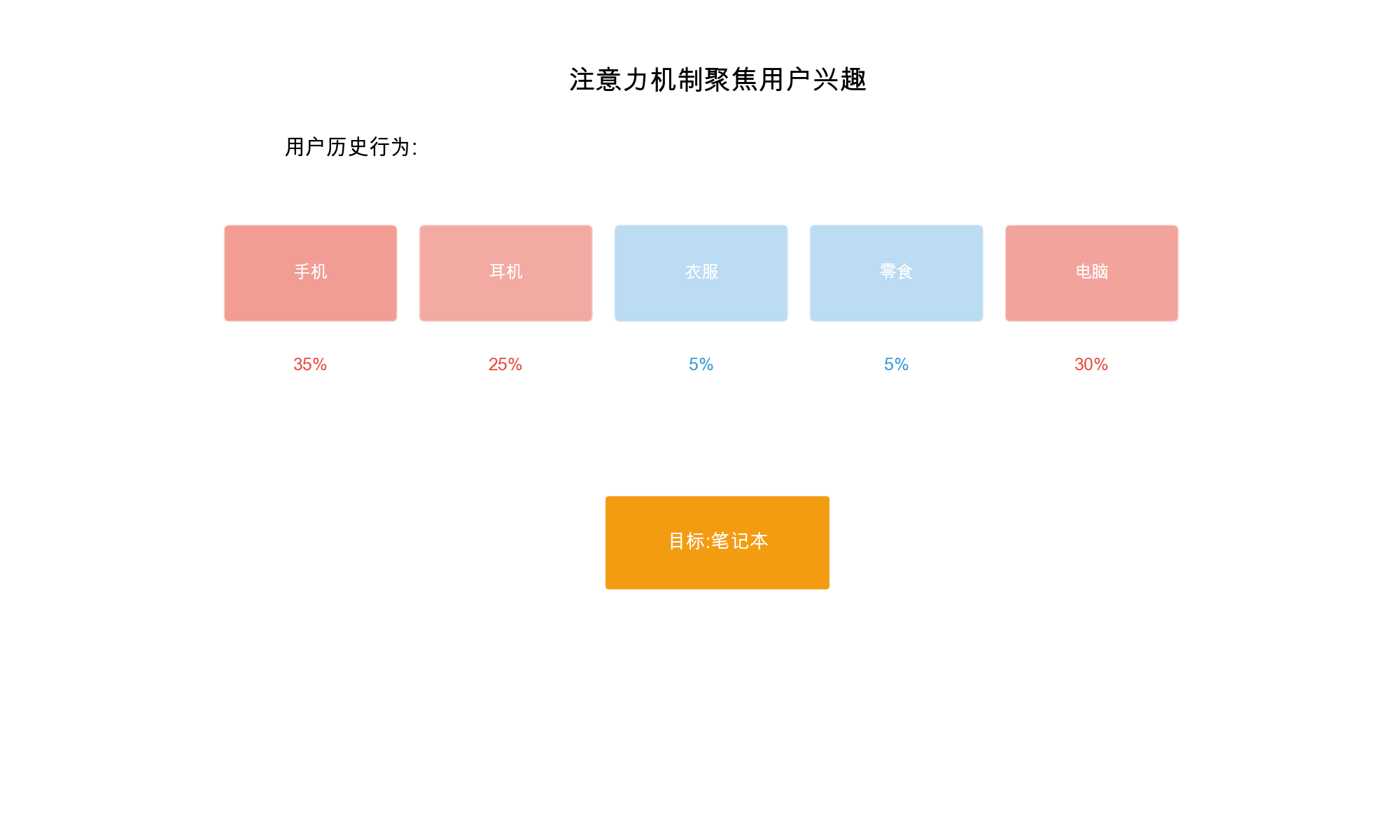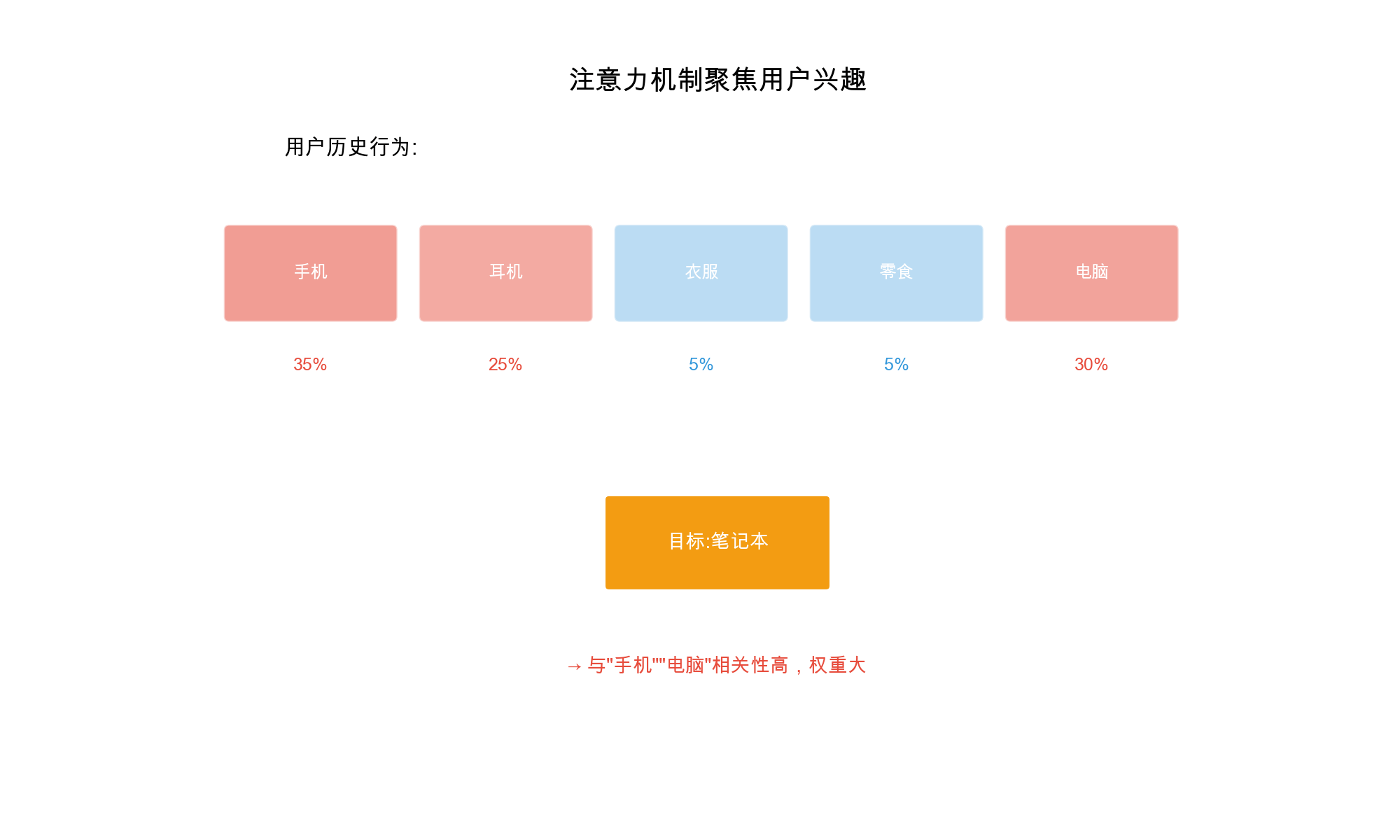
AutoInt, introduced in 2019, uses multi-head self-attention to automatically identify and model important feature interactions. The key insight is that not all feature interactions are equally important, and attention mechanisms can learn to focus on the most relevant ones.
Key Innovation: Multi-Head Self-Attention for Features
AutoInt treats each feature's embedding as a "token" and uses self-attention to learn which features should interact. This allows the model to: 1. Automatically discover important feature interactions 2. Assign different importance weights to different interactions 3. Model complex interaction patterns
Mathematical Formulation
Given feature embeddings\(\mathbf{E} = [\mathbf{e}_1, \mathbf{e}_2, \ldots, \mathbf{e}_m] \in \mathbb{R}^{m \times d}\), where\(m\)is the number of fields and\(d\)is the embedding dimension, the multi-head self-attention computes:\[\text{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{softmax}\left(\frac{\mathbf{Q}\mathbf{K}^T}{\sqrt{d_k }}\right)\mathbf{V}\]Where\(\mathbf{Q} = \mathbf{E}\mathbf{W}_Q\),\(\mathbf{K} = \mathbf{E}\mathbf{W}_K\),\(\mathbf{V} = \mathbf{E}\mathbf{W}_V\)are query, key, and value matrices.
For\(H\)attention heads:\[\text{MultiHead}(\mathbf{E}) = \text{Concat}(\text{head}_1, \ldots, \text{head}_H)\mathbf{W}^O\]Where each head computes attention independently.
Implementation
1 | class MultiHeadSelfAttention(nn.Module): |
AutoInt Advantages
- Automatic Interaction Discovery: Attention mechanism automatically identifies important feature interactions
- Interpretability: Attention weights show which feature interactions are important
- Flexibility: Can model complex, non-linear interaction patterns
AutoInt demonstrates the power of attention mechanisms in CTR prediction. However, another important direction is improving feature representation itself, which is the focus of FiBiNet.
FiBiNet: Feature Importance and Bilinear Feature Interaction Network
FiBiNet (Feature Importance and Bilinear feature Interaction NETwork), introduced in 2019, addresses two key aspects of CTR prediction: 1. Feature Importance: Not all features are equally important 2. Feature Interactions: How features interact matters
FiBiNet introduces SENet (Squeeze-and-Excitation Network) for feature importance learning and bilinear interaction for feature interaction modeling.
Key Components
1. SENet for Feature Importance
SENet learns to reweight features based on their importance:
- Squeeze: Global average pooling to get feature importance scores
- Excitation: Two-layer MLP to learn importance weights
- Reweight: Multiply original features by importance weights
2. Bilinear Interaction
Instead of simple element-wise product (like in FM), FiBiNet uses bilinear interaction:\[f_{Bilinear}(\mathbf{v}_i, \mathbf{v}_j) = \mathbf{v}_i^T \mathbf{W} \mathbf{v}_j\]Where\(\mathbf{W}\)is a learnable matrix. This is more expressive than element-wise product.
Implementation
1 | class SENet(nn.Module): |
FiBiNet Advantages
- Feature Importance Learning: SENet automatically identifies important features
- Expressive Interactions: Bilinear interactions are more expressive than element-wise products
- Interpretability: Can analyze SENet weights to understand feature importance
FiBiNet demonstrates how improving feature representation can lead to better CTR prediction performance.
Model Comparison and Selection
Now that we've covered the major CTR prediction models, let's compare them across different dimensions:
Computational Complexity
| Model | Parameters | Training Time | Inference Time |
|---|---|---|---|
| LR | \(O(d)\) | Fast | Very Fast |
| FM | \(O(d \cdot k)\) | Fast | Fast |
| FFM | \(O(d \cdot F \cdot k)\) | Medium | Medium |
| DeepFM | \(O(d \cdot k + MLP)\) | Medium | Medium |
| xDeepFM | \(O(d \cdot k + CIN + MLP)\) | Slow | Medium |
| DCN | \(O(d \cdot k + Cross + MLP)\) | Medium | Medium |
| AutoInt | \(O(d \cdot k + Attention + MLP)\) | Medium | Medium |
| FiBiNet | \(O(d \cdot k + SENet + Bilinear + MLP)\) | Medium | Medium |
Interaction Modeling Capability
| Model | Low-Order | High-Order | Explicit | Implicit |
|---|---|---|---|---|
| LR | Linear only | No | No | No |
| FM | Pairwise | No | Yes | No |
| FFM | Pairwise (field-aware) | No | Yes | No |
| DeepFM | Pairwise | Yes | Yes | Yes |
| xDeepFM | Pairwise | Yes (bounded) | Yes | Yes |
| DCN | Bounded degree | Yes | Yes | Yes |
| AutoInt | All orders | Yes | Yes (via attention) | Yes |
| FiBiNet | Pairwise (bilinear) | Yes | Yes | Yes |
When to Use Which Model?
Logistic Regression: - Baseline for comparison - When interpretability is critical - When data is very limited - When latency requirements are extreme
FM/FFM: - When you need explicit pairwise interactions - When computational resources are limited - When you have domain knowledge about fields (FFM)
DeepFM: - General-purpose choice for most scenarios - Good balance of performance and complexity - When you need both low-order and high-order interactions
xDeepFM: - When you need explicit high-order interactions - When interpretability of interactions matters - When you have sufficient computational resources
DCN: - When you want bounded interaction degree - When you need automatic cross-feature learning - Google-style production systems
AutoInt: - When you want automatic interaction discovery - When interpretability of attention weights is useful - When feature interactions are complex and non-linear
FiBiNet: - When feature importance varies significantly - When you need more expressive interactions than FM - When you want to understand which features matter
Training Strategies and Best Practices
Implementing the models is only half the battle. Here are essential training strategies for CTR prediction:
Handling Class Imbalance
CTR prediction suffers from extreme class imbalance. Here are effective strategies:
1. Weighted Loss Function
1 | def weighted_bce_loss(predictions, targets, pos_weight): |
2. Negative Sampling
Instead of using all negative examples, sample a subset:
1 | def sample_negatives(positive_samples, num_negatives_per_positive, item_pool): |
3. Focal Loss
Focal loss downweights easy examples and focuses on hard examples:
1 | class FocalLoss(nn.Module): |
Feature Engineering
1. Categorical Feature Encoding
1 | def encode_categorical_features(df, categorical_columns): |
2. Numerical Feature Normalization
1 | def normalize_numerical_features(df, numerical_columns): |
3. Feature Interaction Creation
1 | def create_interaction_features(df, field1, field2): |
Regularization Techniques
1. Dropout
Already included in our model implementations. Key points: - Use dropout in MLP layers (0.2-0.5) - Don't use dropout in embedding layers (can hurt performance) - Use dropout during training, disable during inference
2. L2 Regularization
1 | # Add L2 regularization to optimizer |
3. Early Stopping
1 | def train_with_early_stopping(model, train_loader, val_loader, |
Evaluation Metrics
For CTR prediction, standard classification metrics apply, but some are more important:
1. AUC-ROC
1 | from sklearn.metrics import roc_auc_score |
2. Log Loss
1 | from sklearn.metrics import log_loss |
3. Calibration
CTR predictions should be well-calibrated (predicted probability ≈ actual frequency):
1 | def evaluate_calibration(model, data_loader, num_bins=10): |
Complete Training Pipeline
Here's a complete training pipeline that brings everything together:
1 | import torch |
Frequently Asked Questions (Q&A)
Q1: Why is CTR prediction a binary classification problem instead of regression?
A: CTR prediction is fundamentally about estimating a probability (the probability of a click), which naturally maps to binary classification. While you could frame it as regression (predicting the actual CTR value), binary classification has several advantages: - Handles class imbalance better - More robust to outliers - Standard evaluation metrics (AUC, log loss) are well-established - Easier to interpret (probability vs. arbitrary score)
However, in some scenarios (e.g., predicting expected revenue), regression might be more appropriate.
Q2: How do I choose the embedding dimension?
A: Embedding dimension is a crucial hyperparameter. General guidelines: - Small datasets (< 1M samples): 4-8 dimensions - Medium datasets (1M-10M samples): 8-16 dimensions - Large datasets (> 10M samples): 16-64 dimensions
Start with 16 and tune based on validation performance. Larger embeddings can capture more information but require more parameters and computation. Use validation AUC/log loss to guide your choice.
Q3: What's the difference between FM and matrix factorization?
A: While both use factorization, they serve different purposes: - Matrix Factorization (MF): Decomposes user-item rating matrix into user and item embeddings. Used for collaborative filtering. - Factorization Machines (FM): Models feature interactions in general feature vectors. Used for any supervised learning task with categorical features.
FM is more general and can incorporate side features (user age, item category, etc.), while MF only uses user-item interactions.
Q4: When should I use DeepFM vs xDeepFM?
A: - DeepFM: Use when you want a good balance of performance and complexity. It's simpler, faster to train, and works well for most scenarios. - xDeepFM: Use when you need explicit high-order interactions and have sufficient computational resources. It's more complex but can achieve better performance on datasets with complex interaction patterns.
Start with DeepFM, and only move to xDeepFM if you need the extra expressiveness.
Q5: How do I handle cold-start items/users in CTR prediction?
A: Cold-start is challenging for CTR prediction. Strategies: 1. Default embeddings: Use average embeddings or learned default embeddings for new items/users 2. Content features: Use item content features (category, brand, description) for new items 3. Popularity fallback: Use popularity-based scores for cold-start cases 4. Multi-armed bandits: Use exploration strategies for new items 5. Transfer learning: Pre-train on similar domains and fine-tune
Q6: How important is feature engineering vs. model architecture?
A: Both matter, but feature engineering often has more impact: - Feature engineering: Can improve performance by 10-30% - Model architecture: Can improve performance by 2-10%
Focus on feature engineering first (creating good features, handling missing values, normalization), then optimize model architecture. However, modern deep learning models (DeepFM, xDeepFM) can learn some feature interactions automatically, reducing manual engineering.
Q7: How do I handle missing features?
A: Strategies for missing features: 1. Default values: Use 0, mean, or mode for missing values 2. Learnable missing indicators: Add a binary feature indicating whether a feature is missing 3. Embedding for missing: Use a special "missing" embedding for categorical features 4. Imputation: Use statistical or ML-based imputation (mean, median, KNN, etc.)
The best approach depends on whether missingness is informative (missing itself is a signal) or random.
Q8: What's the relationship between CTR prediction and ranking?
A: CTR prediction is often used for ranking: 1. Score items: Use CTR model to predict click probability for each candidate 2. Rank by score: Sort items by predicted CTR (descending) 3. Return top-K: Return top K items to user
However, ranking can also consider other factors: - Diversity: Avoid showing similar items - Business rules: Promote certain items (new releases, high-margin products) - Multi-objective: Balance CTR, revenue, user satisfaction
Q9: How do I evaluate CTR models offline vs. online?
A: - Offline evaluation: Use historical data with train/validation/test splits. Metrics: AUC, log loss, precision@K, recall@K. Fast and cheap but may not reflect real-world performance. - Online evaluation: A/B testing with real users. Metrics: actual CTR, conversion rate, revenue. Slow and expensive but reflects true performance.
Always validate offline first, but final decisions should be based on online A/B tests.
Q10: How do I deploy CTR models in production?
A: Production deployment considerations: 1. Model serving: Use TensorFlow Serving, TorchServe, or custom serving infrastructure 2. Latency: Optimize for < 10ms inference time (batch predictions, model quantization, caching) 3. Scalability: Handle millions of requests per second (horizontal scaling, load balancing) 4. Monitoring: Track prediction distribution, latency, error rates 5. Retraining: Set up pipeline for regular retraining (daily/weekly) 6. Versioning: Version control for models and features
Q11: Can I use pre-trained embeddings for CTR prediction?
A: Yes, but with caution: - Item embeddings: Can use embeddings from collaborative filtering (MF, NCF) or content-based methods - User embeddings: Can use embeddings from user behavior modeling - Transfer learning: Pre-train on similar domains and fine-tune
However, end-to-end training usually works better because embeddings are optimized for the specific CTR prediction task.
Q12: How do I handle numerical and categorical features together?
A: Common approaches: 1. Separate embeddings: Use embeddings for categorical features, direct input for numerical features 2. Concatenate: Concatenate categorical embeddings with numerical features before MLP 3. Field-aware: Treat numerical features as a separate field in FFM/FiBiNet 4. Normalization: Always normalize numerical features (standardization, min-max scaling)
Our implementations focus on categorical features, but you can easily extend them to include numerical features.
Q13: What's the impact of data quality on CTR prediction?
A: Data quality is critical: - Label quality: Click labels can be noisy (accidental clicks, bot traffic). Use filtering and cleaning. - Feature quality: Missing values, outliers, inconsistent encoding hurt performance - Temporal effects: Data distribution shifts over time. Use time-based train/test splits. - Bias: Historical data may contain biases (popularity bias, position bias). Use techniques like inverse propensity weighting.
Always invest in data quality before optimizing models.
Q14: How do I interpret CTR model predictions?
A: Interpretation methods: 1. Feature importance: Analyze embedding norms or attention weights 2. SHAP values: Use SHAP to understand feature contributions 3. Ablation studies: Remove features and measure impact 4. Case studies: Analyze predictions for specific user-item pairs
Interpretability is important for debugging, trust, and regulatory compliance.
Q15: What are the latest trends in CTR prediction?
A: Recent trends (2024-2025): 1. Transformer-based models: Using transformers for feature interaction learning 2. Multi-task learning: Predicting CTR along with other objectives (conversion, revenue) 3. Graph neural networks: Modeling user-item relationships as graphs 4. AutoML: Automated feature engineering and architecture search 5. Causal inference: Addressing bias and understanding causal effects 6. Federated learning: Training on distributed data without centralization
The field continues to evolve rapidly, but the fundamentals (feature engineering, interaction modeling, handling imbalance) remain important.
Conclusion
CTR prediction is a fundamental problem in recommendation systems, directly impacting user experience and business revenue. We've covered the evolution from simple Logistic Regression to sophisticated deep learning models like DeepFM, xDeepFM, DCN, AutoInt, and FiBiNet.
Key takeaways: 1. Start simple: Begin with Logistic Regression or FM as a baseline 2. Understand your data: Feature engineering and data quality matter more than model complexity 3. Handle imbalance: Use appropriate loss functions, sampling, or focal loss 4. Choose the right model: Consider your requirements (latency, interpretability, performance) 5. Evaluate properly: Use both offline metrics and online A/B testing 6. Iterate: CTR prediction is an ongoing process of improvement
The models we've covered provide a solid foundation, but the field continues to evolve. Stay updated with recent research, experiment with new architectures, and always validate improvements with real-world data.
Remember: the best model is the one that works best for your specific use case, data, and constraints. Don't chase the latest architecture blindly – understand your problem first, then choose the appropriate solution.
- Post title:Recommendation Systems (4): CTR Prediction and Click-Through Rate Modeling
- Post author:Chen Kai
- Create time:2026-02-03 23:11:11
- Post link:https://www.chenk.top/recommendation-systems-4-ctr-prediction/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.