Recommendation Systems (2): Collaborative Filtering and Matrix Factorization
Chen KaiBOSS
2026-02-03 23:11:112026-02-03 23:1110k Words62 Mins
permalink: "en/recommendation-systems-2-collaborative-filtering/"
date: 2024-05-07 14:30:00 tags: - Recommendation Systems - Collaborative
Filtering - Matrix Factorization categories: Recommendation Systems
mathjax: true --- Imagine you've just finished watching The
Shawshank Redemption and want to find a similar movie. Traditional
approaches might filter by genre, director, or actors, but collaborative
filtering takes a different path — it doesn't care about the movie's
attributes. Instead, it observes what "users with similar taste to you
also liked." If user A and user B both loved The Shawshank
Redemption and Forrest Gump, and user A also enjoyed
The Pursuit of Happyness, the system will recommend that movie
to user B.
Collaborative filtering is the cornerstone of recommendation systems,
from the GroupLens system in the 1990s to the Netflix Prize competition,
to today's personalized recommendations on major platforms. Matrix
factorization is the mathematical core of collaborative filtering,
decomposing the user-item rating matrix into low-dimensional vectors and
using vector inner products to predict ratings. This approach solves the
data sparsity problem while laying the foundation for deep
learning-based recommendation systems.
This article provides an in-depth exploration of collaborative
filtering's two paradigms (User-CF and Item-CF), similarity calculation
methods, the mathematical principles of matrix factorization, SVD/SVD++
algorithms, ALS optimization methods, BPR ranking learning, FM
factorization machines, implicit feedback handling, bias term design,
and complete Python implementation code. Each algorithm includes
detailed mathematical derivations, code examples, and Q&A sections
to help you master recommendation system core algorithms from theory to
practice.
The Core Idea of
Collaborative Filtering
What is Collaborative
Filtering?
Collaborative Filtering (CF) is based on a core assumption:
similar users will have similar preferences, and similar items
will be liked by similar users. It doesn't need to know item
content features (like movie genres or actors) or user profiles (like
age or gender)— it only requires user historical behavior data (ratings,
clicks, purchases, etc.) to make recommendations.
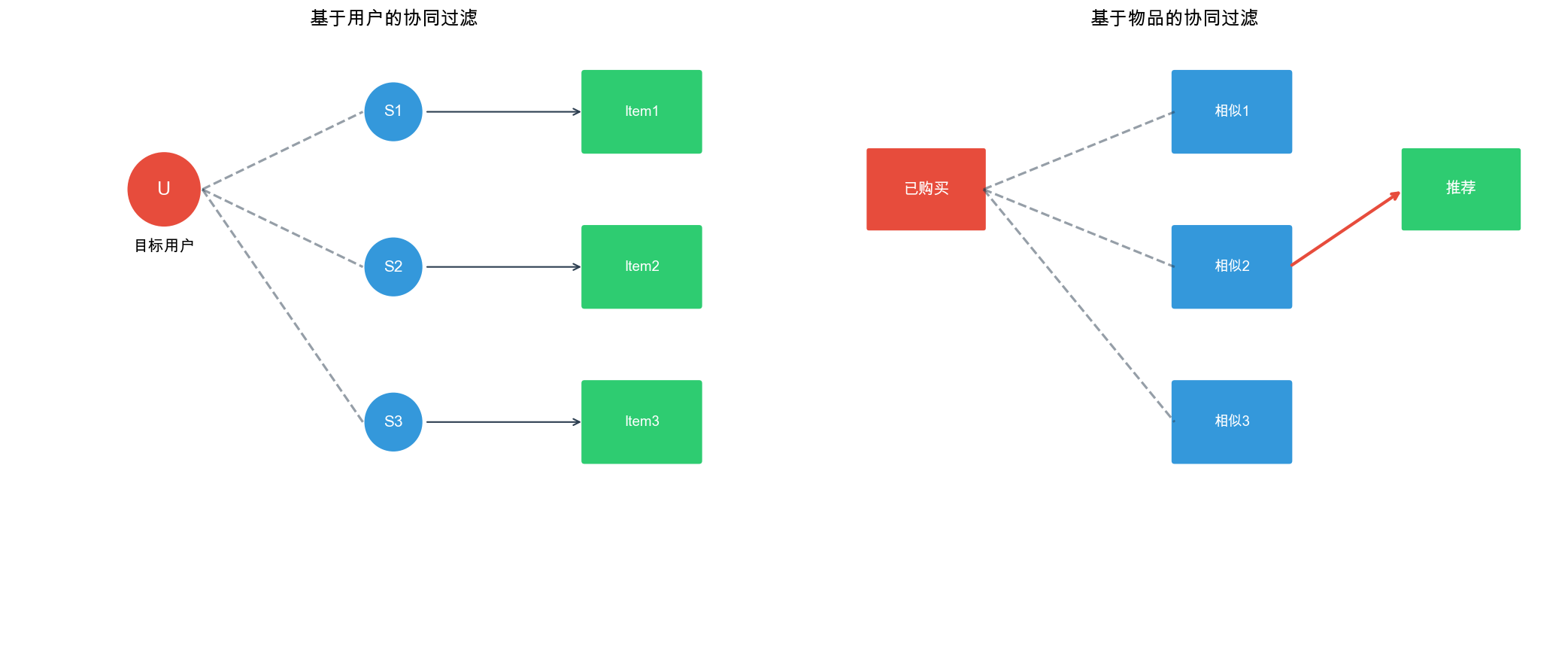
Collaborative filtering falls into two main categories:
User-Based Collaborative Filtering (User-CF): Find
users similar to the target user and recommend items those similar users
liked.
Item-Based Collaborative Filtering (Item-CF): Find
items similar to the target item. If a user likes a certain item,
recommend similar items.
An Intuitive Example
Suppose we have a rating matrix (1-5 scale) of 5 users for 5
movies:
User
Shawshank
Forrest Gump
Pursuit
Titanic
Godfather
Alice
5
5
?
3
4
Bob
5
5
4
2
?
Carol
4
4
3
5
5
David
2
1
?
4
3
Eve
?
?
2
3
4
User-CF approach: Alice and Bob both gave high
ratings to The Shawshank Redemption and Forrest Gump,
indicating similar taste. Bob rated The Pursuit of Happyness 4,
so recommend this movie to Alice.
Item-CF approach: The Shawshank Redemption
and Forrest Gump both received high ratings from Alice, Bob,
and Carol, indicating these movies are similar. If a user likes The
Shawshank Redemption, recommend Forrest Gump.
Advantages
and Limitations of Collaborative Filtering
Advantages: - No content features
needed: Doesn't require movie genres, actors, etc. -
Discovers unexpected associations: May find
non-intuitive correlations like "people who buy diapers also buy beer" -
Cross-domain recommendations: Can recommend items
across different categories
Limitations: - Cold start problem:
New users or items lack historical data - Data
sparsity: User-item matrices are typically very sparse (over
99% missing values) - Scalability: Similarity
computation cost increases with user and item counts -
Popularity bias: Popular items are easily recommended,
long-tail items are ignored
User-Based
Collaborative Filtering (User-CF)
Algorithm Flow
The core steps of User-CF:
Calculate user similarity: Find the \(k\)users most similar to target user\(u\) (called "neighbors")
Predict ratings: Based on these\(k\)neighbors' ratings for item\(i\), predict user\(u\)'s rating for item\(i\)
Generate recommendations: Select the\(N\)items with highest predicted ratings to
recommend to the user
Similarity Calculation
Methods
Similarity measures how close two users' rating vectors are. Let
user\(u\)and\(v\)'s rating vectors for item set\(I_{uv}\) (items both users rated) be\(\mathbf{r}_u\)and\(\mathbf{r}_v\).
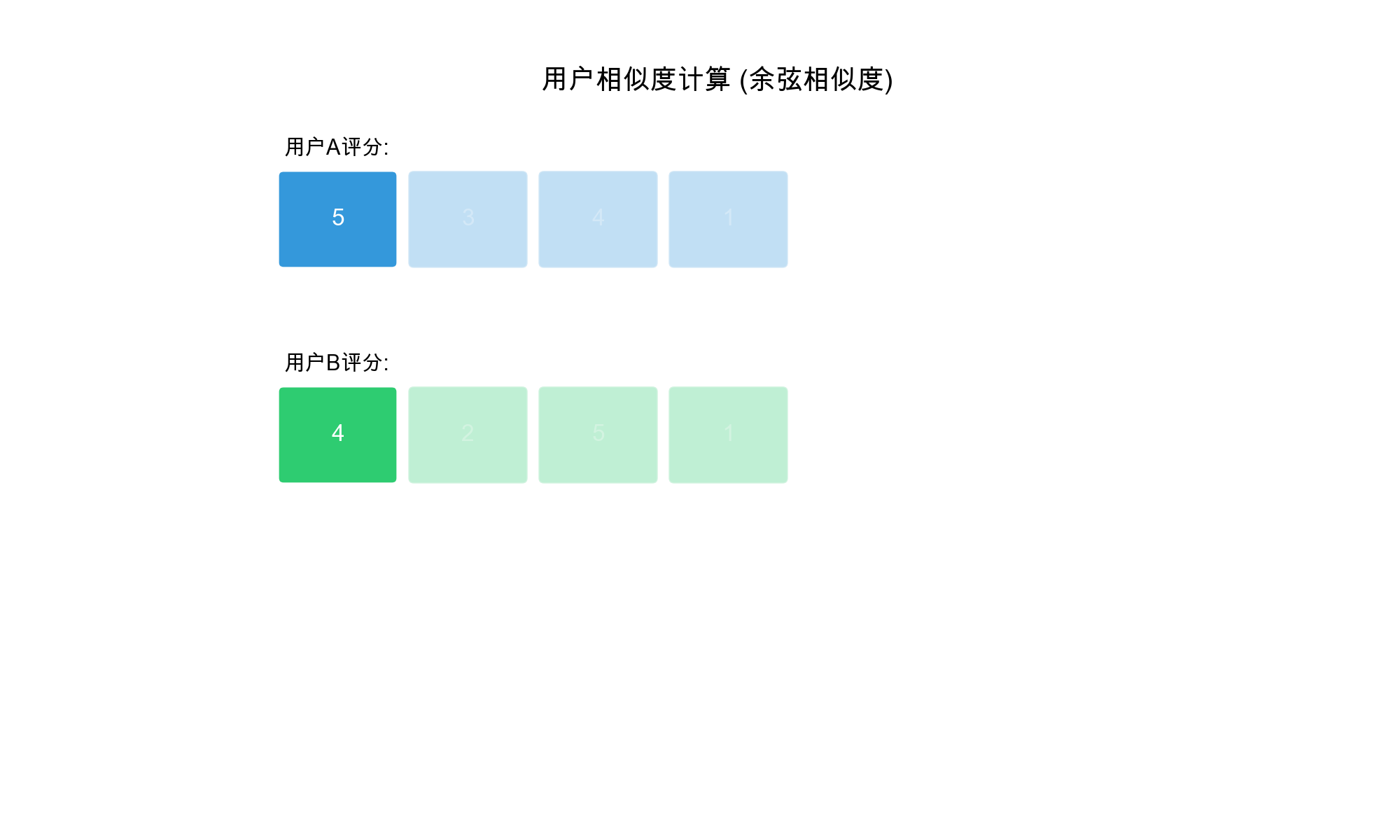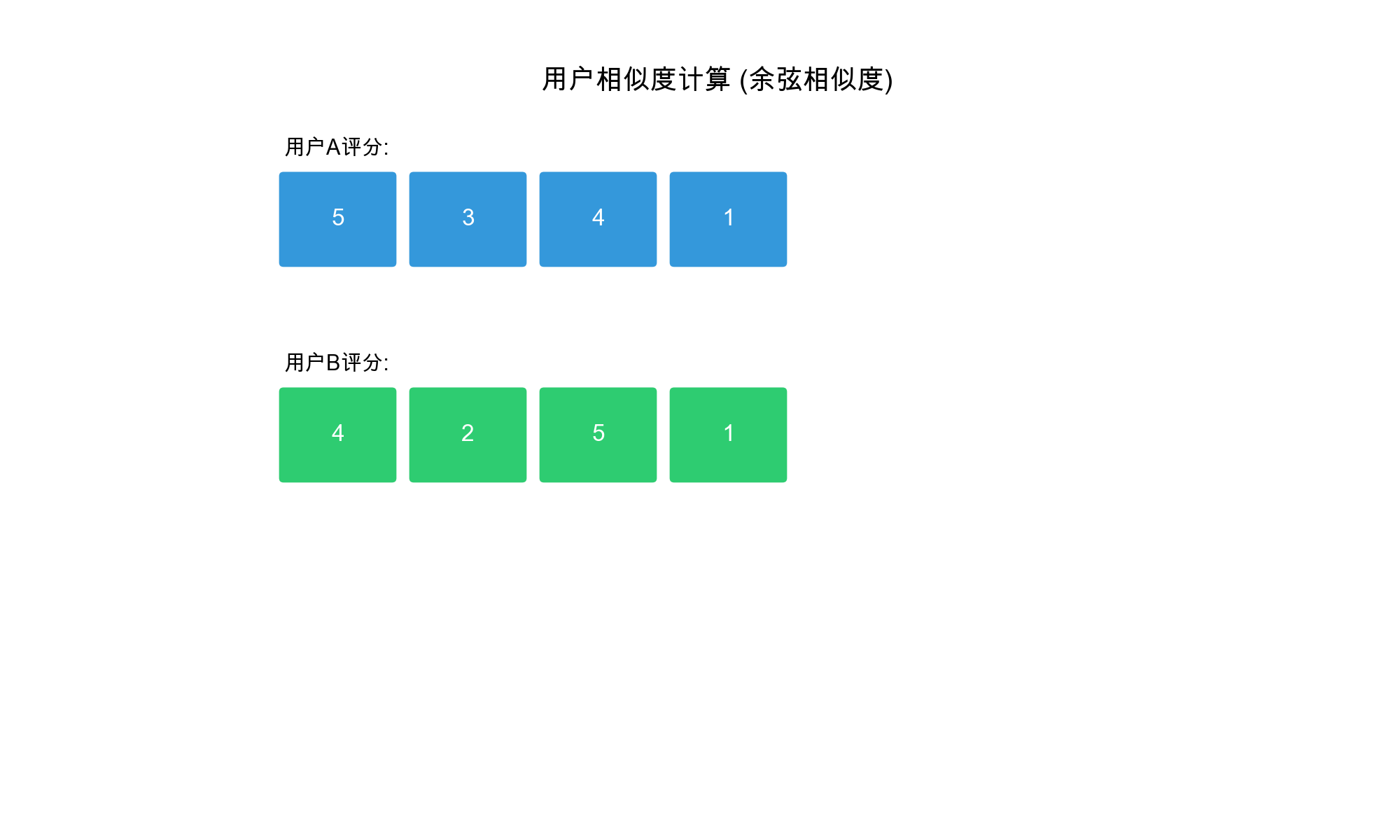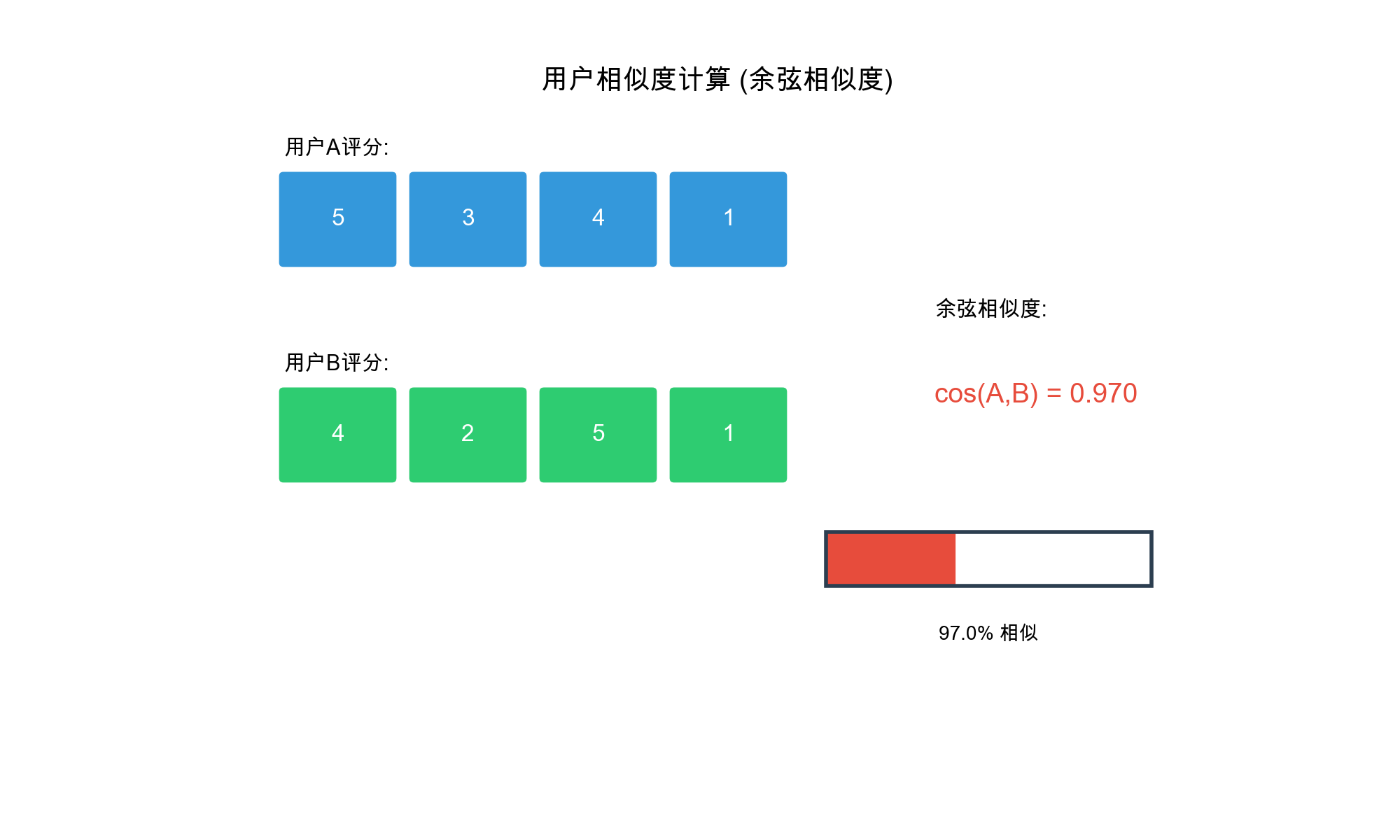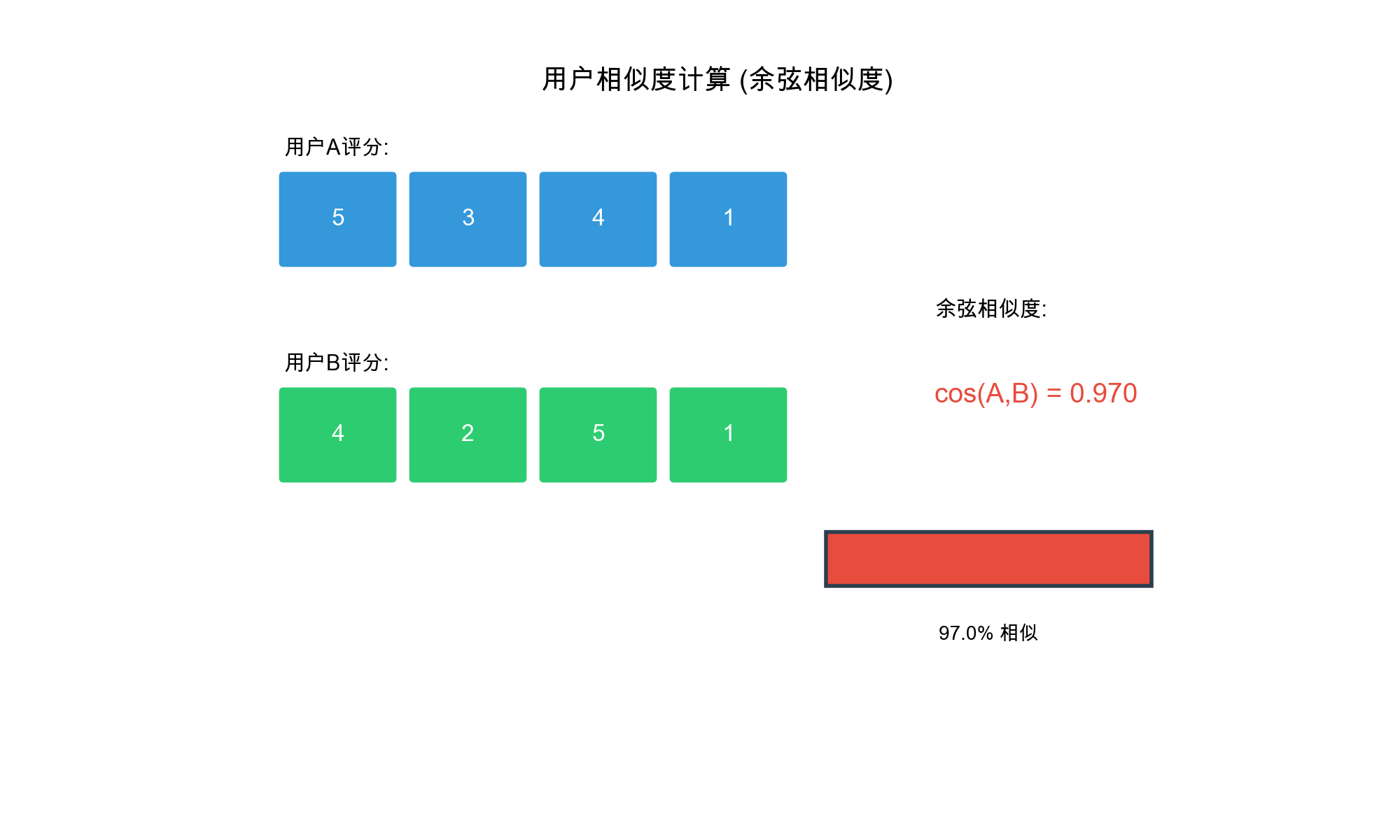
1. Cosine Similarity
Treat user ratings as vectors and calculate the cosine of the angle
between them:\[\text{sim}(u, v) =
\cos(\mathbf{r}_u, \mathbf{r}_v) = \frac{\mathbf{r}_u \cdot
\mathbf{r}_v}{|\mathbf{r}_u| \cdot |\mathbf{r}_v|} = \frac{\sum_{i \in
I_{uv}} r_{ui} \cdot r_{vi}}{\sqrt{\sum_{i \in I_{uv}} r_{ui}^2} \cdot
\sqrt{\sum_{i \in I_{uv}} r_{vi}^2}}\]Cosine similarity ranges
from\([-1, 1]\), with larger values
indicating greater similarity.
Characteristics: - Only considers rating direction
(preference), not absolute values - Insensitive to rating scale -
Suitable for scenarios with different rating ranges
Characteristics: - Accounts for user rating habits
(some users tend to rate high, others low) - Range\([-1, 1]\) - More commonly used than cosine
similarity
3. Adjusted Cosine Similarity
Subtract user average rating from cosine similarity:\[\text{sim}(u, v) = \frac{\sum_{i \in I_{uv }}
(r_{ui} - \bar{r}_u)(r_{vi} - \bar{r}_v)}{\sqrt{\sum_{i \in I_{uv }}
(r_{ui} - \bar{r}_u)^2} \cdot \sqrt{\sum_{i \in I_{uv }} (r_{vi} -
\bar{r}_v)^2 }}\]In practice, adjusted cosine similarity is
mathematically equivalent to Pearson correlation.
4. Euclidean Distance
Calculate Euclidean distance between rating vectors, then convert to
similarity:\[d(u, v) = \sqrt{\sum_{i \in
I_{uv }} (r_{ui} - r_{vi})^2}\]\[\text{sim}(u, v) = \frac{1}{1 + d(u,
v)}\]
Characteristics: - Smaller distance means higher
similarity - Sensitive to outliers
Rating Prediction Formula
After finding\(k\)most similar
users, predict user\(u\)'s rating for
item\(i\):\[\hat{r}_{ui} = \bar{r}_u + \frac{\sum_{v \in
N_k(u)} \text{sim}(u, v) \cdot (r_{vi} - \bar{r}_v)}{\sum_{v \in N_k(u)}
|\text{sim}(u, v)|}\]where: -\(\bar{r}_u\)is user\(u\)'s average rating -\(N_k(u)\)is the set of\(k\)users most similar to user\(u\) -\(\text{sim}(u, v)\)is similarity between
users\(u\)and\(v\) -\(r_{vi} -
\bar{r}_v\)is user\(v\)'s rating
deviation for item\(i\)relative to
their average
Formula explanation: - Base score is user\(u\)'s average rating - Weighted average of
similar users' rating deviations for item\(i\) - Weights are similarities — higher
similarity means greater influence
import numpy as np from collections import defaultdict from scipy.spatial.distance import cosine from scipy.stats import pearsonr
classUserBasedCF: def__init__(self, k=20, similarity='pearson'): """ User-Based Collaborative Filtering Parameters: ----------- k : int Number of neighbors similarity : str Similarity method: 'cosine', 'pearson', 'euclidean' """ self.k = k self.similarity = similarity self.user_item_matrix = None self.user_means = None self.similarity_matrix = None deffit(self, user_item_matrix): """ Train the model Parameters: ----------- user_item_matrix : dict {user_id: {item_id: rating }} """ self.user_item_matrix = user_item_matrix self.user_means = {} # Calculate each user's average rating for user_id, items in user_item_matrix.items(): ratings = list(items.values()) self.user_means[user_id] = np.mean(ratings) if ratings else0 # Calculate user similarity matrix self._compute_similarity_matrix() def_compute_similarity_matrix(self): """Calculate user similarity matrix""" users = list(self.user_item_matrix.keys()) n_users = len(users) self.similarity_matrix = np.zeros((n_users, n_users)) self.user_to_idx = {user: idx for idx, user inenumerate(users)} self.idx_to_user = {idx: user for idx, user inenumerate(users)} for i inrange(n_users): for j inrange(i + 1, n_users): sim = self._compute_similarity(users[i], users[j]) self.similarity_matrix[i][j] = sim self.similarity_matrix[j][i] = sim def_compute_similarity(self, user1, user2): """Calculate similarity between two users""" items1 = set(self.user_item_matrix[user1].keys()) items2 = set(self.user_item_matrix[user2].keys()) common_items = items1 & items2 iflen(common_items) == 0: return0 ratings1 = [self.user_item_matrix[user1][item] for item in common_items] ratings2 = [self.user_item_matrix[user2][item] for item in common_items] if self.similarity == 'cosine': # Cosine similarity return1 - cosine(ratings1, ratings2) elif self.similarity == 'pearson': # Pearson correlation coefficient iflen(ratings1) < 2: return0 corr, _ = pearsonr(ratings1, ratings2) return corr ifnot np.isnan(corr) else0 elif self.similarity == 'euclidean': # Euclidean distance converted to similarity dist = np.sqrt(np.sum((np.array(ratings1) - np.array(ratings2))**2)) return1 / (1 + dist) else: raise ValueError(f"Unknown similarity: {self.similarity}") defpredict(self, user_id, item_id): """ Predict user's rating for an item Parameters: ----------- user_id : int/str User ID item_id : int/str Item ID Returns: -------- float Predicted rating """ if user_id notin self.user_item_matrix: return self.user_means.get(user_id, 3.0) # Default rating # Find users who rated item_id users_rated_item = [] for user, items in self.user_item_matrix.items(): if item_id in items: users_rated_item.append(user) iflen(users_rated_item) == 0: return self.user_means.get(user_id, 3.0) # Calculate similarity with these users similarities = [] ratings = [] user_idx = self.user_to_idx[user_id] for other_user in users_rated_item: other_user_idx = self.user_to_idx[other_user] sim = self.similarity_matrix[user_idx][other_user_idx] if sim > 0: # Only consider positive similarity similarities.append(sim) ratings.append(self.user_item_matrix[other_user][item_id]) iflen(similarities) == 0: return self.user_means.get(user_id, 3.0) # Select top-k similar users iflen(similarities) > self.k: top_k_indices = np.argsort(similarities)[-self.k:] similarities = [similarities[i] for i in top_k_indices] ratings = [ratings[i] for i in top_k_indices] # Weighted average prediction user_mean = self.user_means[user_id] numerator = sum(sim * (rating - self.user_means[other_user]) for sim, rating, other_user inzip(similarities, ratings, users_rated_item)) denominator = sum(abs(sim) for sim in similarities) if denominator == 0: return user_mean return user_mean + numerator / denominator defrecommend(self, user_id, n=10): """ Recommend items to user Parameters: ----------- user_id : int/str User ID n : int Number of items to recommend Returns: -------- list [(item_id, predicted_rating), ...] """ if user_id notin self.user_item_matrix: return [] user_items = set(self.user_item_matrix[user_id].keys()) all_items = set() for items in self.user_item_matrix.values(): all_items.update(items.keys()) candidate_items = all_items - user_items predictions = [] for item_id in candidate_items: pred_rating = self.predict(user_id, item_id) predictions.append((item_id, pred_rating)) # Sort by predicted rating predictions.sort(key=lambda x: x[1], reverse=True) return predictions[:n]
# Usage example if __name__ == "__main__": # Construct example data user_item_matrix = { 'Alice': {'Shawshank': 5, 'Forrest Gump': 5, 'Titanic': 3, 'Godfather': 4}, 'Bob': {'Shawshank': 5, 'Forrest Gump': 5, 'Pursuit': 4, 'Titanic': 2}, 'Carol': {'Shawshank': 4, 'Forrest Gump': 4, 'Pursuit': 3, 'Titanic': 5, 'Godfather': 5}, 'David': {'Shawshank': 2, 'Forrest Gump': 1, 'Titanic': 4, 'Godfather': 3}, 'Eve': {'Pursuit': 2, 'Titanic': 3, 'Godfather': 4} } # Train model model = UserBasedCF(k=2, similarity='pearson') model.fit(user_item_matrix) # Predict Alice's rating for "Pursuit" pred = model.predict('Alice', 'Pursuit') print(f"Alice's predicted rating for 'Pursuit': {pred:.2f}") # Recommend movies to Alice recommendations = model.recommend('Alice', n=3) print("\nMovies recommended to Alice:") for item, rating in recommendations: print(f" {item}: {rating:.2f}")
Advantages and
Disadvantages of User-CF
Advantages: - Intuitive and easy to understand,
aligns with human recommendation habits - Can discover users' latent
interests - Strong explainability of recommendations
Disadvantages: - High computational complexity:\(O(m^2 \cdot n)\), where\(m\)is number of users,\(n\)is number of items - Similarity matrix
storage and computation costs increase dramatically as user count grows
- Difficult to find users with common ratings when data is sparse -
Severe cold start problem for new users
Item-Based
Collaborative Filtering (Item-CF)
Algorithm Flow
The core steps of Item-CF:
Calculate item similarity: Find the\(k\)items most similar to target item\(i\)
Predict ratings: Based on user\(u\)'s ratings for these\(k\)similar items, predict user\(u\)'s rating for item\(i\)
Generate recommendations: Select the\(N\)items with highest predicted ratings to
recommend to the user
Why is Item-CF More Commonly
Used?
Compared to User-CF, Item-CF has the following advantages:
Item count is usually less than user count: Lower
cost to compute item similarity matrix
Item similarity is more stable: Item attributes
change slowly, similarity can be pre-computed and cached
More stable recommendations: When user interests
change, item similarity doesn't change immediately
Better explainability: "Because you liked A, we
recommend similar B"
Amazon's 2003 paper proved Item-CF outperforms User-CF and became the
mainstream method in industry.
Item Similarity Calculation
Let items\(i\)and\(j\)be rated by user set\(U_{ij}\)(users who rated both items).
2.
Adjusted Cosine Similarity (Commonly Used)\[\text{sim}(i, j) = \frac{\sum_{u \in U_{ij }}
(r_{ui} - \bar{r}_u)(r_{uj} - \bar{r}_u)}{\sqrt{\sum_{u \in U_{ij }}
(r_{ui} - \bar{r}_u)^2} \cdot \sqrt{\sum_{u \in U_{ij }} (r_{uj} -
\bar{r}_u)^2 }}\]Note: Here we subtract the user average
rating, not the item average rating. This eliminates the
influence of user rating habits.
Rating
Prediction Formula\[\hat{r}_{ui} =
\frac{\sum_{j \in N_k(i)} \text{sim}(i, j) \cdot r_{uj }}{\sum_{j \in
N_k(i)} |\text{sim}(i, j)|}\]where\(N_k(i)\)is the set of\(k\)items most similar to item\(i\).
If considering user average rating:\[\hat{r}_{ui} = \bar{r}_u + \frac{\sum_{j \in
N_k(i)} \text{sim}(i, j) \cdot (r_{uj} - \bar{r}_u)}{\sum_{j \in N_k(i)}
|\text{sim}(i, j)|}\]
From
Collaborative Filtering to Matrix Factorization
Traditional collaborative filtering methods (User-CF and Item-CF)
have obvious scalability issues: when user and item counts reach
millions, the cost of computing and storing similarity matrices becomes
unacceptable. Matrix Factorization (MF) solves the sparsity problem and
dramatically reduces computational complexity by decomposing
high-dimensional sparse matrices into products of low-dimensional dense
matrices.
The Basic Idea of Matrix
Factorization
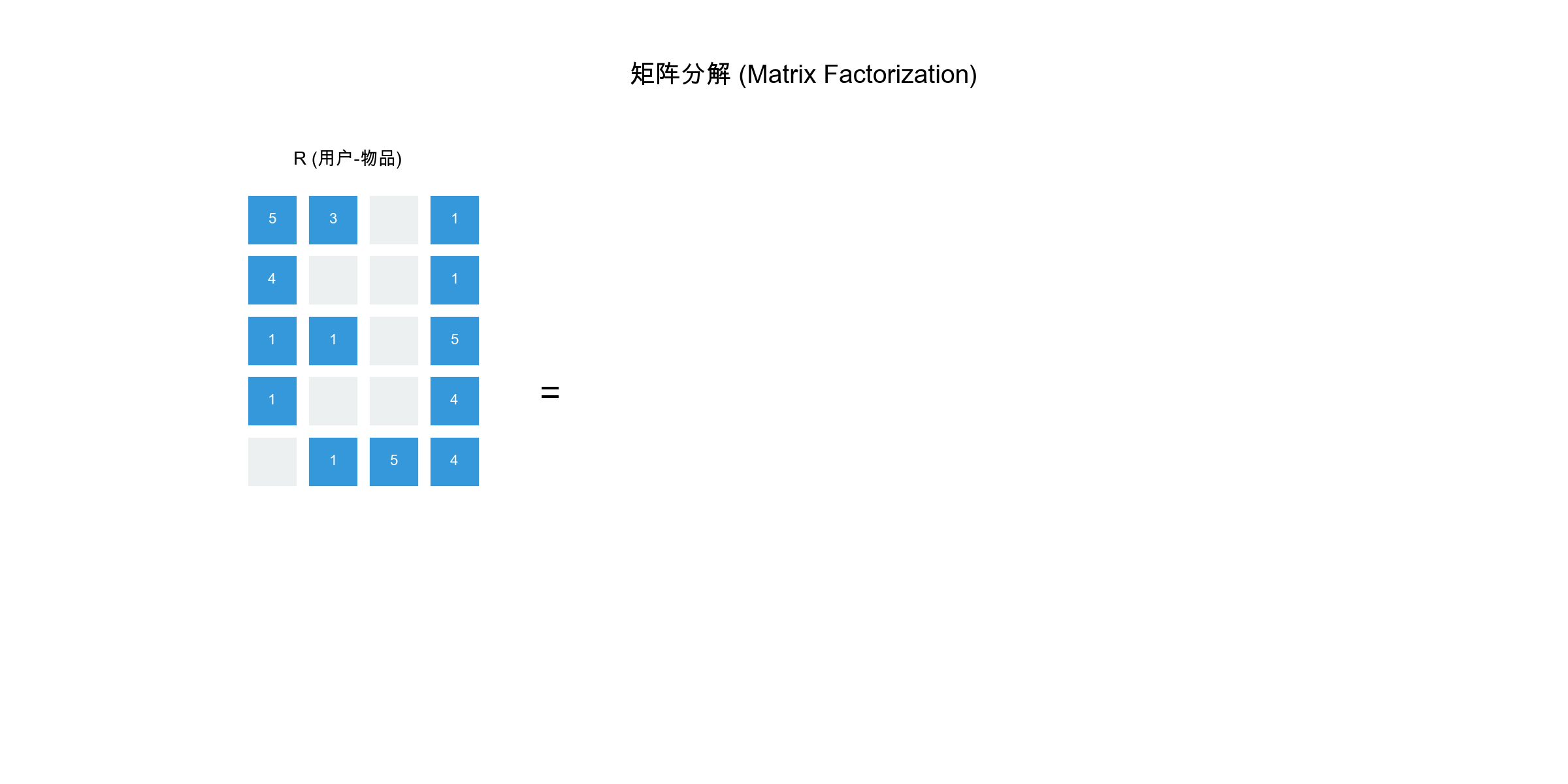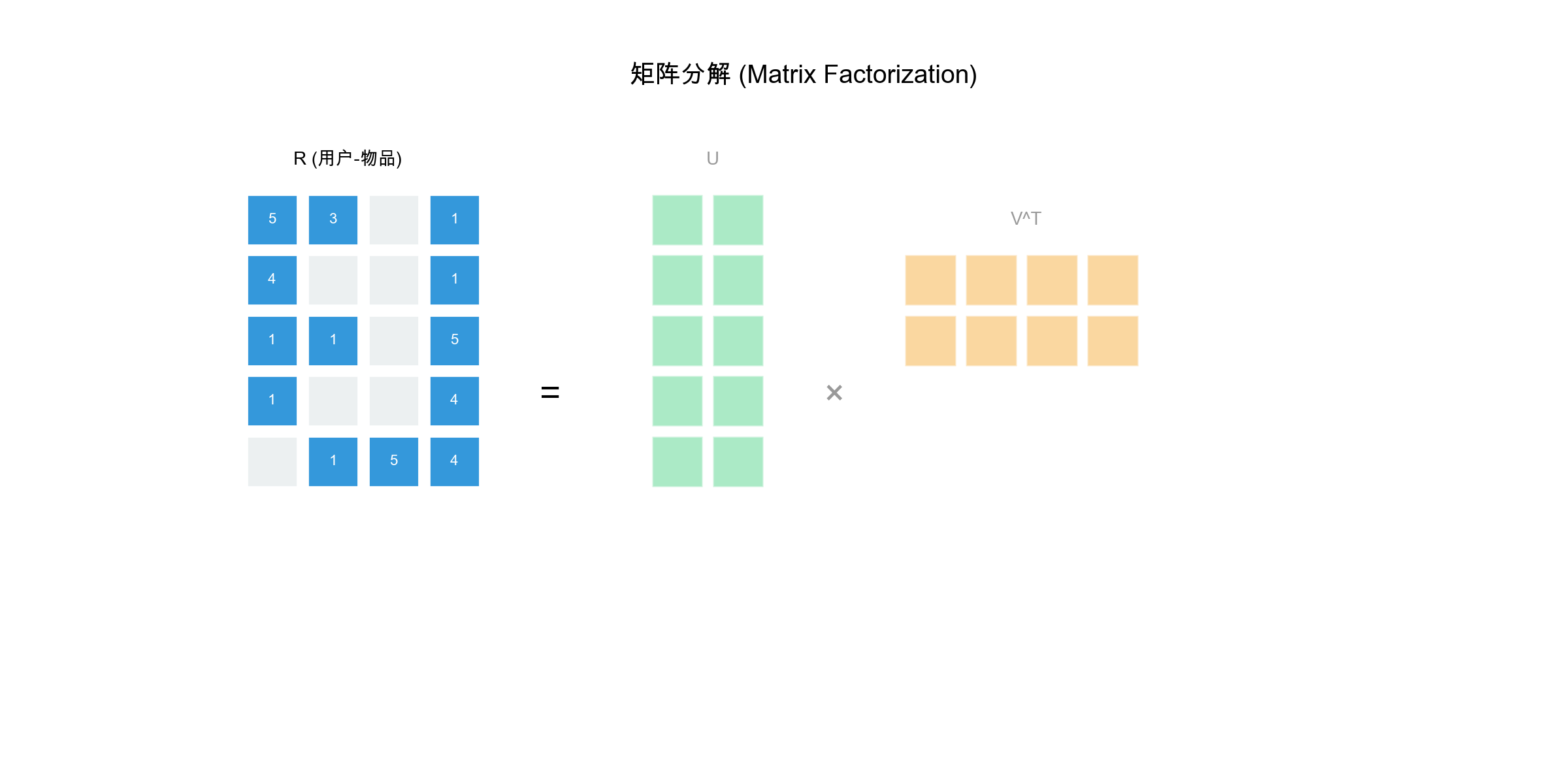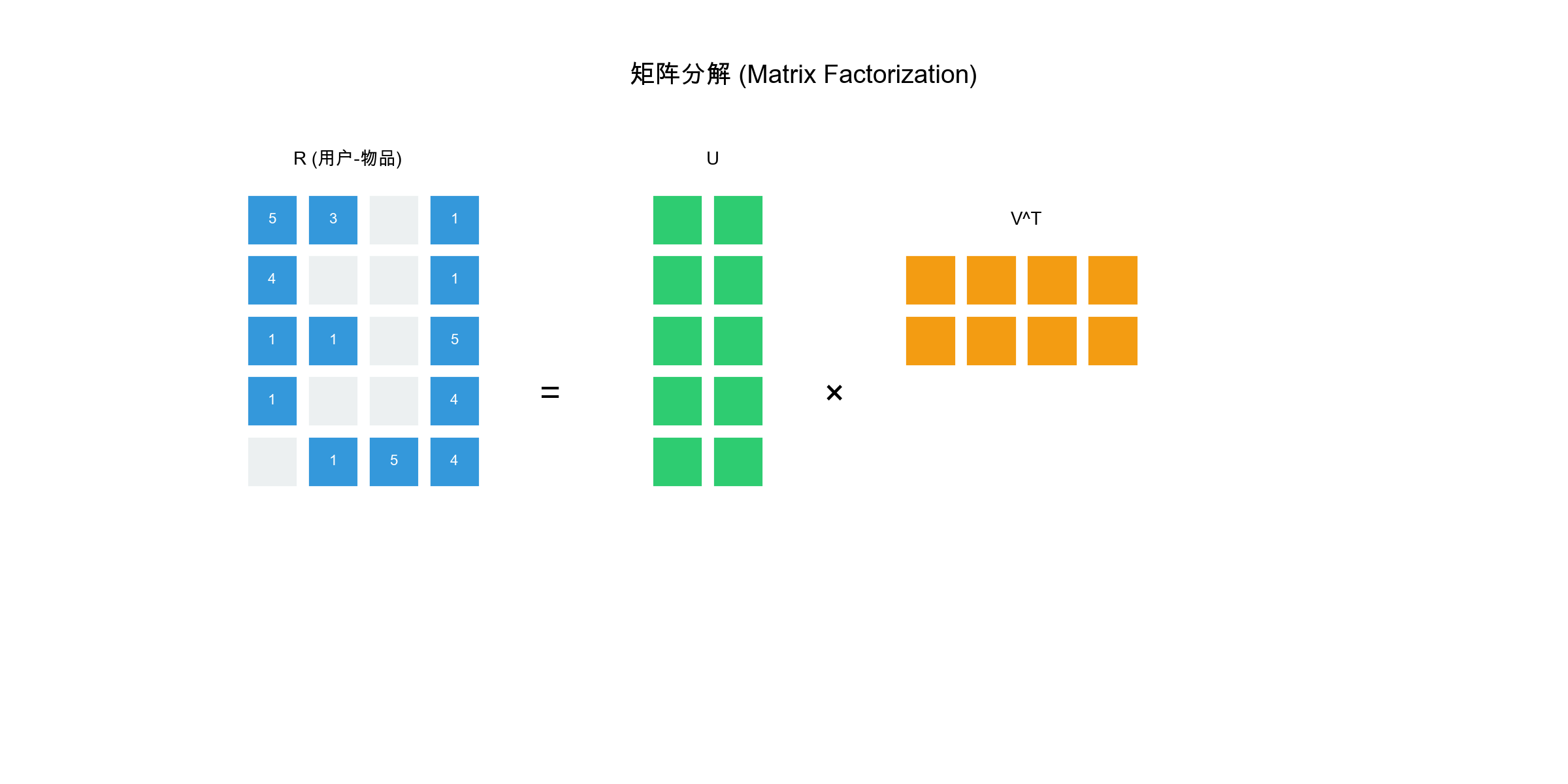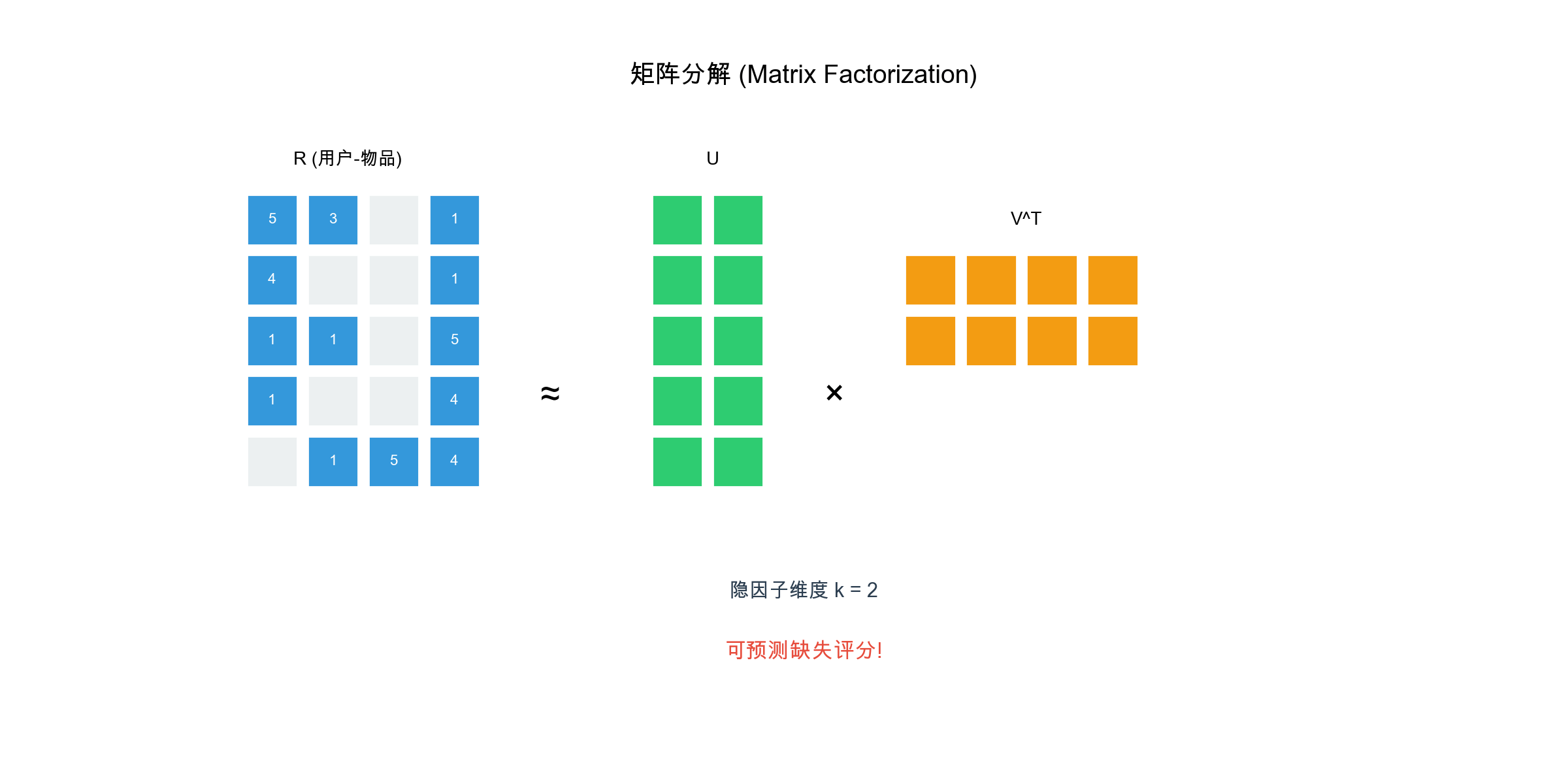
The core of matrix factorization is decomposing the user-item rating
matrix\(R \in \mathbb{R}^{m \times
n}\)(\(m\)users,\(n\)items) into the product of two
low-dimensional matrices:\[R \approx P \cdot
Q^T\]where: -\(P \in \mathbb{R}^{m
\times k}\)is the user feature matrix, each row\(\mathbf{p}_u\)represents user\(u\)'s\(k\)-dimensional latent feature vector
-\(Q \in \mathbb{R}^{n \times k}\)is
the item feature matrix, each row\(\mathbf{q}_i\)represents item\(i\)'s\(k\)-dimensional latent feature vector
-\(k\)is the latent feature dimension
(typically\(k \ll \min(m, n)\), e.g.,
50, 100)
Matrix factorization can be understood as: - User
vector\(\mathbf{p}_u\): User's
preference strength on\(k\)latent
dimensions - Item vector\(\mathbf{q}_i\): Item's feature strength
on\(k\)latent dimensions -
Inner product\(\mathbf{p}_u
\cdot \mathbf{q}_i\): Match degree between user preference and
item features
For example, if\(k=3\), it might
correspond to: - Dimension 1: Action vs. Art films - Dimension 2: Comedy
vs. Tragedy - Dimension 3: Modern vs. Classical
User Alice's vector might be\([0.8, 0.2,
0.6]\)(likes action, doesn't like comedy much, prefers modern),
and movie The Shawshank Redemption's vector might be\([0.3, 0.1, 0.9]\)(more art, less comedy,
modern), with inner product\(0.8 \times 0.3 +
0.2 \times 0.1 + 0.6 \times 0.9 = 0.68\), indicating high
match.
Objective Function
Matrix factorization aims to find\(P\)and\(Q\)such that predicted ratings are as close
as possible to true ratings. Define the loss function:\[\mathcal{L} = \sum_{(u,i) \in \mathcal{R }}
(r_{ui} - \hat{r}_{ui})^2 + \lambda (\|\mathbf{p}_u\|^2 +
\|\mathbf{q}_i\|^2)\]where: -\(\mathcal{R}\)is the set of known ratings -
First term is squared error loss (MSE) - Second term is regularization
to prevent overfitting -\(\lambda\)is
the regularization coefficient
import numpy as np from collections import defaultdict import random
classMatrixFactorization: def__init__(self, n_factors=50, learning_rate=0.01, reg=0.01, n_epochs=20): """ Basic Matrix Factorization model Parameters: ----------- n_factors : int Latent feature dimension learning_rate : float Learning rate reg : float Regularization coefficient n_epochs : int Number of iterations """ self.n_factors = n_factors self.learning_rate = learning_rate self.reg = reg self.n_epochs = n_epochs self.user_factors = None self.item_factors = None self.global_mean = None deffit(self, user_item_matrix): """Train the model""" users = list(user_item_matrix.keys()) items = set() for items_dict in user_item_matrix.values(): items.update(items_dict.keys()) items = list(items) self.user_to_idx = {user: idx for idx, user inenumerate(users)} self.idx_to_user = {idx: user for idx, user inenumerate(users)} self.item_to_idx = {item: idx for idx, item inenumerate(items)} self.idx_to_item = {idx: item for idx, item inenumerate(items)} n_users = len(users) n_items = len(items) # Initialize user and item feature matrices self.user_factors = np.random.normal(scale=0.1, size=(n_users, self.n_factors)) self.item_factors = np.random.normal(scale=0.1, size=(n_items, self.n_factors)) # Calculate global mean all_ratings = [] for items_dict in user_item_matrix.values(): all_ratings.extend(items_dict.values()) self.global_mean = np.mean(all_ratings) if all_ratings else0 # Build training samples samples = [] for user_id, items_dict in user_item_matrix.items(): user_idx = self.user_to_idx[user_id] for item_id, rating in items_dict.items(): item_idx = self.item_to_idx[item_id] samples.append((user_idx, item_idx, rating)) # Training for epoch inrange(self.n_epochs): random.shuffle(samples) total_loss = 0 for user_idx, item_idx, rating in samples: # Predict rating pred = np.dot(self.user_factors[user_idx], self.item_factors[item_idx]) error = rating - pred # Update parameters user_factor = self.user_factors[user_idx].copy() item_factor = self.item_factors[item_idx].copy() self.user_factors[user_idx] += self.learning_rate * ( error * item_factor - self.reg * self.user_factors[user_idx] ) self.item_factors[item_idx] += self.learning_rate * ( error * user_factor - self.reg * self.item_factors[item_idx] ) total_loss += error ** 2 if (epoch + 1) % 5 == 0: rmse = np.sqrt(total_loss / len(samples)) print(f"Epoch {epoch + 1}, RMSE: {rmse:.4f}") defpredict(self, user_id, item_id): """Predict rating""" if user_id notin self.user_to_idx or item_id notin self.item_to_idx: return self.global_mean user_idx = self.user_to_idx[user_id] item_idx = self.item_to_idx[item_id] pred = np.dot(self.user_factors[user_idx], self.item_factors[item_idx]) return pred defrecommend(self, user_id, n=10): """Recommend items""" if user_id notin self.user_to_idx: return [] predictions = [] for item_idx inrange(len(self.item_factors)): item_id = self.idx_to_item[item_idx] pred = self.predict(user_id, item_id) predictions.append((item_id, pred)) predictions.sort(key=lambda x: x[1], reverse=True) return predictions[:n]
Matrix Factorization with
Bias Terms
Why Do We Need Bias Terms?
Basic matrix factorization assumes ratings are determined only by
user and item latent features, but in reality: - User
bias: Some users tend to rate high, others low - Item
bias: Popular items have higher average ratings, unpopular
items lower - Global bias: Overall rating level (e.g.,
average 3.5)
After introducing bias terms, the prediction formula becomes:\[\hat{r}_{ui} = \mu + b_u + b_i + \mathbf{p}_u
\cdot \mathbf{q}_i^T\]where: -\(\mu\)is the global average rating -\(b_u\)is user\(u\)'s bias (relative to global average)
-\(b_i\)is item\(i\)'s bias (relative to global average)
Calculation of Bias Terms
Initialization:\[b_u = \frac{1}{|I_u|}
\sum_{i \in I_u} (r_{ui} - \mu)\]\[b_i = \frac{1}{|U_i|} \sum_{u \in U_i} (r_{ui} -
\mu - b_u)\]where\(I_u\)is the
set of items rated by user\(u\),\(U_i\)is the set of users who rated
item\(i\).
classBiasedMatrixFactorization: def__init__(self, n_factors=50, learning_rate=0.01, reg=0.01, reg_bias=0.01, n_epochs=20): """Matrix Factorization model with bias terms""" self.n_factors = n_factors self.learning_rate = learning_rate self.reg = reg self.reg_bias = reg_bias self.n_epochs = n_epochs self.user_factors = None self.item_factors = None self.user_bias = None self.item_bias = None self.global_mean = None deffit(self, user_item_matrix): """Train the model""" users = list(user_item_matrix.keys()) items = set() for items_dict in user_item_matrix.values(): items.update(items_dict.keys()) items = list(items) self.user_to_idx = {user: idx for idx, user inenumerate(users)} self.idx_to_user = {idx: user for idx, user inenumerate(users)} self.item_to_idx = {item: idx for idx, item inenumerate(items)} self.idx_to_item = {idx: item for idx, item inenumerate(items)} n_users = len(users) n_items = len(items) # Initialize self.user_factors = np.random.normal(scale=0.1, size=(n_users, self.n_factors)) self.item_factors = np.random.normal(scale=0.1, size=(n_items, self.n_factors)) self.user_bias = np.zeros(n_users) self.item_bias = np.zeros(n_items) # Calculate global mean all_ratings = [] for items_dict in user_item_matrix.values(): all_ratings.extend(items_dict.values()) self.global_mean = np.mean(all_ratings) if all_ratings else0 # Initialize bias terms for user_id, items_dict in user_item_matrix.items(): user_idx = self.user_to_idx[user_id] ratings = list(items_dict.values()) self.user_bias[user_idx] = np.mean(ratings) - self.global_mean for item_idx inrange(n_items): item_id = self.idx_to_item[item_idx] ratings = [] for user_id, items_dict in user_item_matrix.items(): if item_id in items_dict: ratings.append(items_dict[item_id]) if ratings: self.item_bias[item_idx] = np.mean(ratings) - self.global_mean # Build training samples samples = [] for user_id, items_dict in user_item_matrix.items(): user_idx = self.user_to_idx[user_id] for item_id, rating in items_dict.items(): item_idx = self.item_to_idx[item_id] samples.append((user_idx, item_idx, rating)) # Training for epoch inrange(self.n_epochs): random.shuffle(samples) total_loss = 0 for user_idx, item_idx, rating in samples: # Predict rating pred = (self.global_mean + self.user_bias[user_idx] + self.item_bias[item_idx] + np.dot(self.user_factors[user_idx], self.item_factors[item_idx])) error = rating - pred # Update parameters user_factor = self.user_factors[user_idx].copy() item_factor = self.item_factors[item_idx].copy() self.user_factors[user_idx] += self.learning_rate * ( error * item_factor - self.reg * self.user_factors[user_idx] ) self.item_factors[item_idx] += self.learning_rate * ( error * user_factor - self.reg * self.item_factors[item_idx] ) self.user_bias[user_idx] += self.learning_rate * ( error - self.reg_bias * self.user_bias[user_idx] ) self.item_bias[item_idx] += self.learning_rate * ( error - self.reg_bias * self.item_bias[item_idx] ) total_loss += error ** 2 if (epoch + 1) % 5 == 0: rmse = np.sqrt(total_loss / len(samples)) print(f"Epoch {epoch + 1}, RMSE: {rmse:.4f}") defpredict(self, user_id, item_id): """Predict rating""" if user_id notin self.user_to_idx or item_id notin self.item_to_idx: return self.global_mean user_idx = self.user_to_idx[user_id] item_idx = self.item_to_idx[item_id] pred = (self.global_mean + self.user_bias[user_idx] + self.item_bias[item_idx] + np.dot(self.user_factors[user_idx], self.item_factors[item_idx])) return pred defrecommend(self, user_id, n=10): """Recommend items""" if user_id notin self.user_to_idx: return [] predictions = [] for item_idx inrange(len(self.item_factors)): item_id = self.idx_to_item[item_idx] pred = self.predict(user_id, item_id) predictions.append((item_id, pred)) predictions.sort(key=lambda x: x[1], reverse=True) return predictions[:n]
SVD and SVD++
Singular Value Decomposition
(SVD)
Traditional SVD requires a complete matrix, but rating matrices are
sparse. In the Netflix Prize competition, researchers proposed SVD
methods suitable for sparse matrices, which are essentially matrix
factorization with bias terms.
SVD++: Incorporating
Implicit Feedback
SVD++ introduces implicit feedback on top of SVD.
Implicit feedback refers to user behaviors that don't involve explicit
ratings but may express preferences, such as: - Browsing without
purchasing - Clicking without rating - Watch time - Favorites,
shares
SVD++ prediction formula:\[\hat{r}_{ui} =
\mu + b_u + b_i + \mathbf{q}_i^T \left( \mathbf{p}_u +
|I_u|^{-\frac{1}{2 }} \sum_{j \in I_u} \mathbf{y}_j
\right)\]where: -\(\mathbf{p}_u\)is user\(u\)'s explicit feedback feature vector
-\(I_u\)is the set of items with
implicit feedback from user\(u\) -\(\mathbf{y}_j\)is item\(j\)'s implicit feedback feature vector
-\(|I_u|^{-\frac{1}{2 }}\)is the
normalization factor
classSVDPlusPlus: def__init__(self, n_factors=50, learning_rate=0.01, reg=0.01, reg_bias=0.01, n_epochs=20): """SVD++ model""" self.n_factors = n_factors self.learning_rate = learning_rate self.reg = reg self.reg_bias = reg_bias self.n_epochs = n_epochs self.user_factors = None self.item_factors = None self.item_implicit_factors = None self.user_bias = None self.item_bias = None self.global_mean = None deffit(self, user_item_matrix, implicit_feedback=None): """Train the model""" users = list(user_item_matrix.keys()) items = set() for items_dict in user_item_matrix.values(): items.update(items_dict.keys()) if implicit_feedback: for item_list in implicit_feedback.values(): items.update(item_list) items = list(items) self.user_to_idx = {user: idx for idx, user inenumerate(users)} self.idx_to_user = {idx: user for idx, user inenumerate(users)} self.item_to_idx = {item: idx for idx, item inenumerate(items)} self.idx_to_item = {idx: item for idx, item inenumerate(items)} n_users = len(users) n_items = len(items) # Initialize self.user_factors = np.random.normal(scale=0.1, size=(n_users, self.n_factors)) self.item_factors = np.random.normal(scale=0.1, size=(n_items, self.n_factors)) self.item_implicit_factors = np.random.normal(scale=0.1, size=(n_items, self.n_factors)) self.user_bias = np.zeros(n_users) self.item_bias = np.zeros(n_items) # Calculate global mean all_ratings = [] for items_dict in user_item_matrix.values(): all_ratings.extend(items_dict.values()) self.global_mean = np.mean(all_ratings) if all_ratings else0 # Initialize bias for user_id, items_dict in user_item_matrix.items(): user_idx = self.user_to_idx[user_id] ratings = list(items_dict.values()) self.user_bias[user_idx] = np.mean(ratings) - self.global_mean for item_idx inrange(n_items): item_id = self.idx_to_item[item_idx] ratings = [] for user_id, items_dict in user_item_matrix.items(): if item_id in items_dict: ratings.append(items_dict[item_id]) if ratings: self.item_bias[item_idx] = np.mean(ratings) - self.global_mean # Build implicit feedback sets if implicit_feedback isNone: implicit_feedback = {} for user_id, items_dict in user_item_matrix.items(): implicit_feedback[user_id] = list(items_dict.keys()) self.user_implicit_items = {} for user_id in users: if user_id in implicit_feedback: self.user_implicit_items[user_id] = [ self.item_to_idx[item] for item in implicit_feedback[user_id] if item in self.item_to_idx ] else: self.user_implicit_items[user_id] = [] # Build training samples samples = [] for user_id, items_dict in user_item_matrix.items(): user_idx = self.user_to_idx[user_id] for item_id, rating in items_dict.items(): item_idx = self.item_to_idx[item_id] samples.append((user_idx, item_idx, rating)) # Training for epoch inrange(self.n_epochs): random.shuffle(samples) total_loss = 0 for user_idx, item_idx, rating in samples: # Calculate enhanced user feature vector user_id = self.idx_to_user[user_idx] implicit_items = self.user_implicit_items[user_id] iflen(implicit_items) > 0: implicit_sum = np.sum( [self.item_implicit_factors[j] for j in implicit_items], axis=0 ) norm_factor = 1.0 / np.sqrt(len(implicit_items)) enhanced_user_factor = self.user_factors[user_idx] + norm_factor * implicit_sum else: enhanced_user_factor = self.user_factors[user_idx] # Predict rating pred = (self.global_mean + self.user_bias[user_idx] + self.item_bias[item_idx] + np.dot(enhanced_user_factor, self.item_factors[item_idx])) error = rating - pred # Update parameters user_factor = self.user_factors[user_idx].copy() item_factor = self.item_factors[item_idx].copy() # Update explicit features self.user_factors[user_idx] += self.learning_rate * ( error * item_factor - self.reg * self.user_factors[user_idx] ) self.item_factors[item_idx] += self.learning_rate * ( error * enhanced_user_factor - self.reg * self.item_factors[item_idx] ) # Update implicit features iflen(implicit_items) > 0: norm_factor = 1.0 / np.sqrt(len(implicit_items)) for j in implicit_items: self.item_implicit_factors[j] += self.learning_rate * ( error * norm_factor * item_factor - self.reg * self.item_implicit_factors[j] ) # Update bias self.user_bias[user_idx] += self.learning_rate * ( error - self.reg_bias * self.user_bias[user_idx] ) self.item_bias[item_idx] += self.learning_rate * ( error - self.reg_bias * self.item_bias[item_idx] ) total_loss += error ** 2 if (epoch + 1) % 5 == 0: rmse = np.sqrt(total_loss / len(samples)) print(f"Epoch {epoch + 1}, RMSE: {rmse:.4f}") defpredict(self, user_id, item_id): """Predict rating""" if user_id notin self.user_to_idx or item_id notin self.item_to_idx: return self.global_mean user_idx = self.user_to_idx[user_id] item_idx = self.item_to_idx[item_id] # Calculate enhanced user feature vector implicit_items = self.user_implicit_items.get(user_id, []) iflen(implicit_items) > 0: implicit_sum = np.sum( [self.item_implicit_factors[j] for j in implicit_items], axis=0 ) norm_factor = 1.0 / np.sqrt(len(implicit_items)) enhanced_user_factor = self.user_factors[user_idx] + norm_factor * implicit_sum else: enhanced_user_factor = self.user_factors[user_idx] pred = (self.global_mean + self.user_bias[user_idx] + self.item_bias[item_idx] + np.dot(enhanced_user_factor, self.item_factors[item_idx])) return pred defrecommend(self, user_id, n=10): """Recommend items""" if user_id notin self.user_to_idx: return [] predictions = [] for item_idx inrange(len(self.item_factors)): item_id = self.idx_to_item[item_idx] pred = self.predict(user_id, item_id) predictions.append((item_id, pred)) predictions.sort(key=lambda x: x[1], reverse=True) return predictions[:n]
ALS: Alternating Least
Squares
Why Do We Need ALS?
Stochastic Gradient Descent (SGD) is simple but slow on large-scale
data. Alternating Least Squares (ALS) optimizes one variable while
fixing the other, enabling parallelization and significantly improving
training speed.
ALS Algorithm Principle
ALS alternates between optimizing user vectors and item vectors:
Fix item vectors\(Q\),
optimize user vectors\(P\):
For each user\(u\), solve the least
squares problem:\[\min_{\mathbf{p}_u} \sum_{i
\in I_u} (r_{ui} - \mathbf{p}_u \cdot \mathbf{q}_i^T)^2 + \lambda
\|\mathbf{p}_u\|^2\]
Analytical solution:\[\mathbf{p}_u =
(Q_u^T Q_u + \lambda I)^{-1} Q_u^T \mathbf{r}_u\]where\(Q_u\)is the feature matrix of items rated
by user\(u\),\(\mathbf{r}_u\)is the corresponding rating
vector.
Fix user vectors\(P\),
optimize item vectors\(Q\):
For each item\(i\), solve the least
squares problem:\[\min_{\mathbf{q}_i} \sum_{u
\in U_i} (r_{ui} - \mathbf{p}_u \cdot \mathbf{q}_i^T)^2 + \lambda
\|\mathbf{q}_i\|^2\]
Analytical solution:\[\mathbf{q}_i =
(P_i^T P_i + \lambda I)^{-1} P_i^T \mathbf{r}_i\]where\(P_i\)is the feature matrix of users who
rated item\(i\),\(\mathbf{r}_i\)is the corresponding rating
vector.
Alternate iterations: Repeat steps 1 and 2 until
convergence.
Advantages of ALS
Parallelizable: Optimization for different
users/items can be computed in parallel
Fast convergence: Each iteration has an analytical
solution
Suitable for large-scale data: Frameworks like
Spark MLlib implement ALS
classALSMatrixFactorization: def__init__(self, n_factors=50, reg=0.01, n_epochs=20): """ALS Matrix Factorization model""" self.n_factors = n_factors self.reg = reg self.n_epochs = n_epochs self.user_factors = None self.item_factors = None deffit(self, user_item_matrix): """Train the model""" users = list(user_item_matrix.keys()) items = set() for items_dict in user_item_matrix.values(): items.update(items_dict.keys()) items = list(items) self.user_to_idx = {user: idx for idx, user inenumerate(users)} self.idx_to_user = {idx: user for idx, user inenumerate(users)} self.item_to_idx = {item: idx for idx, item inenumerate(items)} self.idx_to_item = {idx: item for idx, item inenumerate(items)} n_users = len(users) n_items = len(items) # Initialize self.user_factors = np.random.normal(scale=0.1, size=(n_users, self.n_factors)) self.item_factors = np.random.normal(scale=0.1, size=(n_items, self.n_factors)) # Build user-item rating matrix (sparse) self.user_items = {} self.item_users = {} for user_id, items_dict in user_item_matrix.items(): user_idx = self.user_to_idx[user_id] self.user_items[user_idx] = {} for item_id, rating in items_dict.items(): item_idx = self.item_to_idx[item_id] self.user_items[user_idx][item_idx] = rating if item_idx notin self.item_users: self.item_users[item_idx] = {} self.item_users[item_idx][user_idx] = rating # ALS iteration lambda_eye = self.reg * np.eye(self.n_factors) for epoch inrange(self.n_epochs): # Fix item vectors, optimize user vectors for user_idx inrange(n_users): if user_idx notin self.user_items: continue items_rated = list(self.user_items[user_idx].keys()) ratings = [self.user_items[user_idx][i] for i in items_rated] iflen(items_rated) == 0: continue Q_u = self.item_factors[items_rated] r_u = np.array(ratings) # Solve (Q_u^T Q_u + lambda I) p_u = Q_u^T r_u A = Q_u.T.dot(Q_u) + lambda_eye b = Q_u.T.dot(r_u) self.user_factors[user_idx] = np.linalg.solve(A, b) # Fix user vectors, optimize item vectors for item_idx inrange(n_items): if item_idx notin self.item_users: continue users_rated = list(self.item_users[item_idx].keys()) ratings = [self.item_users[item_idx][u] for u in users_rated] iflen(users_rated) == 0: continue P_i = self.user_factors[users_rated] r_i = np.array(ratings) # Solve (P_i^T P_i + lambda I) q_i = P_i^T r_i A = P_i.T.dot(P_i) + lambda_eye b = P_i.T.dot(r_i) self.item_factors[item_idx] = np.linalg.solve(A, b) # Calculate RMSE if (epoch + 1) % 5 == 0: total_error = 0 count = 0 for user_idx, items_dict in self.user_items.items(): for item_idx, rating in items_dict.items(): pred = np.dot(self.user_factors[user_idx], self.item_factors[item_idx]) total_error += (rating - pred) ** 2 count += 1 rmse = np.sqrt(total_error / count) if count > 0else0 print(f"Epoch {epoch + 1}, RMSE: {rmse:.4f}") defpredict(self, user_id, item_id): """Predict rating""" if user_id notin self.user_to_idx or item_id notin self.item_to_idx: return0 user_idx = self.user_to_idx[user_id] item_idx = self.item_to_idx[item_id] pred = np.dot(self.user_factors[user_idx], self.item_factors[item_idx]) return pred defrecommend(self, user_id, n=10): """Recommend items""" if user_id notin self.user_to_idx: return [] predictions = [] for item_idx inrange(len(self.item_factors)): item_id = self.idx_to_item[item_idx] pred = self.predict(user_id, item_id) predictions.append((item_id, pred)) predictions.sort(key=lambda x: x[1], reverse=True) return predictions[:n]
BPR: Bayesian Personalized
Ranking
From Rating
Prediction to Ranking Learning
Traditional matrix factorization methods (MF, SVD++) are
rating prediction tasks: predicting user ratings for
items. But in real recommendation scenarios, we care more about
ranking: placing items users are most likely to like at
the top.
BPR (Bayesian Personalized Ranking) transforms the recommendation
problem into a ranking learning problem, directly
optimizing ranking metrics (like AUC, NDCG) rather than rating
prediction RMSE.
Core Idea of BPR
BPR assumes: users prefer items they've rated over items they haven't
rated.
For user\(u\), if they have positive
feedback (like rating, click) for item\(i\)but no feedback for item\(j\), then\(u\)prefers\(i\)over\(j\):\[r_{ui}
> r_{uj}\]
BPR Objective Function
BPR uses Bayesian methods to maximize posterior probability:\[p(\Theta | >_u) \propto p(>_u | \Theta)
p(\Theta)\]where: -\(>_u\)represents user\(u\)'s preference ranking -\(\Theta\)are model parameters (user and item
vectors)
Define:\[p(>_u | \Theta) =
\prod_{(u,i,j) \in D_S} p(i >_u j | \Theta)\]where\(D_S\)is the training sample set, each
sample is a triple\((u, i, j)\),
meaning user\(u\)prefers item\(i\)over\(j\).
classBPRMatrixFactorization: def__init__(self, n_factors=50, learning_rate=0.01, reg=0.01, n_epochs=20): """BPR Matrix Factorization model""" self.n_factors = n_factors self.learning_rate = learning_rate self.reg = reg self.n_epochs = n_epochs self.user_factors = None self.item_factors = None deffit(self, user_item_matrix): """Train the model""" users = list(user_item_matrix.keys()) items = set() for items_dict in user_item_matrix.values(): items.update(items_dict.keys()) items = list(items) self.user_to_idx = {user: idx for idx, user inenumerate(users)} self.idx_to_user = {idx: user for idx, user inenumerate(users)} self.item_to_idx = {item: idx for idx, item inenumerate(items)} self.idx_to_item = {idx: item for idx, item inenumerate(items)} n_users = len(users) n_items = len(items) # Initialize self.user_factors = np.random.normal(scale=0.1, size=(n_users, self.n_factors)) self.item_factors = np.random.normal(scale=0.1, size=(n_items, self.n_factors)) # Build training samples: for each user, positive items vs negative items self.user_items = {} for user_id, items_dict in user_item_matrix.items(): user_idx = self.user_to_idx[user_id] self.user_items[user_idx] = set(items_dict.keys()) all_items = set(items) # Training for epoch inrange(self.n_epochs): total_loss = 0 sample_count = 0 for user_idx inrange(n_users): if user_idx notin self.user_items: continue positive_items = self.user_items[user_idx] negative_items = all_items - positive_items iflen(positive_items) == 0orlen(negative_items) == 0: continue # For each positive sample, sample a negative sample for pos_item_id in positive_items: pos_item_idx = self.item_to_idx[pos_item_id] # Randomly sample negative sample neg_item_id = random.choice(list(negative_items)) neg_item_idx = self.item_to_idx[neg_item_id] # Calculate prediction r_ui = np.dot(self.user_factors[user_idx], self.item_factors[pos_item_idx]) r_uj = np.dot(self.user_factors[user_idx], self.item_factors[neg_item_idx]) r_uij = r_ui - r_uj # Calculate gradient x_uij = 1 / (1 + np.exp(r_uij)) # sigmoid derivative # Update parameters user_factor = self.user_factors[user_idx].copy() self.user_factors[user_idx] += self.learning_rate * ( x_uij * (self.item_factors[pos_item_idx] - self.item_factors[neg_item_idx]) - self.reg * self.user_factors[user_idx] ) self.item_factors[pos_item_idx] += self.learning_rate * ( x_uij * user_factor - self.reg * self.item_factors[pos_item_idx] ) self.item_factors[neg_item_idx] += self.learning_rate * ( -x_uij * user_factor - self.reg * self.item_factors[neg_item_idx] ) total_loss += np.log(1 / (1 + np.exp(-r_uij))) sample_count += 1 if (epoch + 1) % 5 == 0: avg_loss = total_loss / sample_count if sample_count > 0else0 print(f"Epoch {epoch + 1}, Average Loss: {avg_loss:.4f}") defpredict(self, user_id, item_id): """Predict user's preference score for an item""" if user_id notin self.user_to_idx or item_id notin self.item_to_idx: return0 user_idx = self.user_to_idx[user_id] item_idx = self.item_to_idx[item_id] pred = np.dot(self.user_factors[user_idx], self.item_factors[item_idx]) return pred defrecommend(self, user_id, n=10): """Recommend items""" if user_id notin self.user_to_idx: return [] predictions = [] for item_idx inrange(len(self.item_factors)): item_id = self.idx_to_item[item_idx] pred = self.predict(user_id, item_id) predictions.append((item_id, pred)) predictions.sort(key=lambda x: x[1], reverse=True) return predictions[:n]
Factorization Machines (FM)
Motivation for FM
Factorization Machines (FM), proposed by Steffen Rendle in 2010, were
initially designed to solve sparse feature regression
and classification problems. In recommendation systems, FM can
simultaneously utilize: - User features: Age, gender,
location, etc. - Item features: Category, price, brand,
etc. - User-item interactions: Historical ratings,
clicks, etc.
Handles sparse features: Captures feature
interactions through vector inner products, even when feature pairs
rarely appear in training data
Linear time complexity: Can be rewritten as
linear complexity:\[\sum_{i=1}^{n}
\sum_{j=i+1}^{n} \langle \mathbf{v}_i, \mathbf{v}_j \rangle x_i x_j =
\frac{1}{2} \sum_{f=1}^{k} \left[ \left( \sum_{i=1}^{n} v_{i,f} x_i
\right)^2 - \sum_{i=1}^{n} v_{i,f}^2 x_i^2 \right]\]
General purpose: Can be used for regression,
classification, ranking, and other tasks
FM Applications in
Recommendation Systems
In recommendation systems, feature vector\(\mathbf{x}\)typically includes: -
User one-hot encoding: e.g.,\([0, 0, 1, 0, ...]\)represents user 3 -
Item one-hot encoding: e.g.,\([0, 1, 0, 0, ...]\)represents item 2 -
Other features: User age, item category, etc.
classFactorizationMachine: def__init__(self, n_factors=10, learning_rate=0.01, reg=0.01, n_epochs=20): """Factorization Machine""" self.n_factors = n_factors self.learning_rate = learning_rate self.reg = reg self.n_epochs = n_epochs self.w0 = 0 self.w = None self.v = None deffit(self, X, y): """ Train the model Parameters: ----------- X : np.ndarray Feature matrix, shape=(n_samples, n_features) y : np.ndarray Labels, shape=(n_samples,) """ n_samples, n_features = X.shape # Initialize parameters self.w0 = np.mean(y) self.w = np.zeros(n_features) self.v = np.random.normal(scale=0.1, size=(n_features, self.n_factors)) # Training for epoch inrange(self.n_epochs): total_loss = 0 for idx inrange(n_samples): x = X[idx] y_true = y[idx] # Predict y_pred = self._predict_single(x) error = y_true - y_pred # Update w0 self.w0 += self.learning_rate * error # Update w for i inrange(n_features): if x[i] != 0: self.w[i] += self.learning_rate * (error * x[i] - self.reg * self.w[i]) # Update v for i inrange(n_features): if x[i] != 0: # Calculate gradient of interaction term w.r.t. v[i] sum_vx = np.sum([self.v[j] * x[j] for j inrange(n_features) if j != i], axis=0) grad_v = error * x[i] * sum_vx - self.reg * self.v[i] self.v[i] += self.learning_rate * grad_v total_loss += error ** 2 if (epoch + 1) % 5 == 0: rmse = np.sqrt(total_loss / n_samples) print(f"Epoch {epoch + 1}, RMSE: {rmse:.4f}") def_predict_single(self, x): """Predict single sample""" # Linear term linear = np.dot(self.w, x) # Interaction term (using optimized formula) interaction = 0 sum_vx = np.zeros(self.n_factors) sum_vx_sq = 0 for i inrange(len(x)): if x[i] != 0: vx = self.v[i] * x[i] sum_vx += vx sum_vx_sq += np.dot(vx, vx) interaction = 0.5 * (np.dot(sum_vx, sum_vx) - sum_vx_sq) return self.w0 + linear + interaction defpredict(self, X): """Predict""" predictions = [] for x in X: predictions.append(self._predict_single(x)) return np.array(predictions)
Implicit Feedback Handling
Explicit vs. Implicit
Feedback
Explicit feedback: User's explicit ratings (1-5
stars), likes, favorites, etc.
Implicit feedback: User behavior data, such as
clicks, view time, purchases, etc.
Characteristics of
Implicit Feedback
Large data volume: Implicit feedback is much more
abundant than explicit feedback
High noise: Clicks don't necessarily mean likes,
could be accidental
Only positive samples: No explicit negative samples
(no click doesn't mean dislike)
Methods for Handling
Implicit Feedback
1. Weighted Matrix
Factorization
Assign different weights to different implicit feedback:\[\mathcal{L} = \sum_{(u,i)} c_{ui} (r_{ui} -
\hat{r}_{ui})^2 + \lambda (\|\mathbf{p}_u\|^2 +
\|\mathbf{q}_i\|^2)\]where\(c_{ui}\)is confidence weight, typically: -
More clicks mean higher weight - Longer view time means higher
weight
2. Negative Sample Sampling
Sample negative samples from uninteracted items, pair with positive
samples for training.
3. Using BPR
BPR naturally suits implicit feedback, as it only needs positive vs.
negative sample comparisons.
classImplicitFeedbackMF: def__init__(self, n_factors=50, learning_rate=0.01, reg=0.01, n_epochs=20): """Implicit Feedback Matrix Factorization""" self.n_factors = n_factors self.learning_rate = learning_rate self.reg = reg self.n_epochs = n_epochs self.user_factors = None self.item_factors = None deffit(self, user_item_interactions, confidence_func=None): """ Train the model Parameters: ----------- user_item_interactions : dict {user_id: {item_id: interaction_count }} confidence_func : callable, optional Confidence function, converts interaction count to confidence """ if confidence_func isNone: # Default confidence function: c = 1 + alpha * log(1 + count) confidence_func = lambda count: 1 + 10 * np.log1p(count) users = list(user_item_interactions.keys()) items = set() for items_dict in user_item_interactions.values(): items.update(items_dict.keys()) items = list(items) self.user_to_idx = {user: idx for idx, user inenumerate(users)} self.idx_to_user = {idx: user for idx, user inenumerate(users)} self.item_to_idx = {item: idx for idx, item inenumerate(items)} self.idx_to_item = {idx: item for idx, item inenumerate(items)} n_users = len(users) n_items = len(items) # Initialize self.user_factors = np.random.normal(scale=0.1, size=(n_users, self.n_factors)) self.item_factors = np.random.normal(scale=0.1, size=(n_items, self.n_factors)) # Build training samples (with confidence) samples = [] for user_id, items_dict in user_item_interactions.items(): user_idx = self.user_to_idx[user_id] for item_id, count in items_dict.items(): item_idx = self.item_to_idx[item_id] confidence = confidence_func(count) samples.append((user_idx, item_idx, confidence)) # Training for epoch inrange(self.n_epochs): random.shuffle(samples) total_loss = 0 for user_idx, item_idx, confidence in samples: # Predict (assuming implicit feedback target value is 1) pred = np.dot(self.user_factors[user_idx], self.item_factors[item_idx]) error = 1 - pred # Target value is 1 # Update parameters (weighted) user_factor = self.user_factors[user_idx].copy() item_factor = self.item_factors[item_idx].copy() self.user_factors[user_idx] += self.learning_rate * confidence * ( error * item_factor - self.reg * self.user_factors[user_idx] ) self.item_factors[item_idx] += self.learning_rate * confidence * ( error * user_factor - self.reg * self.item_factors[item_idx] ) total_loss += confidence * error ** 2 if (epoch + 1) % 5 == 0: rmse = np.sqrt(total_loss / len(samples)) print(f"Epoch {epoch + 1}, Weighted RMSE: {rmse:.4f}") defpredict(self, user_id, item_id): """Predict user's preference for an item""" if user_id notin self.user_to_idx or item_id notin self.item_to_idx: return0 user_idx = self.user_to_idx[user_id] item_idx = self.item_to_idx[item_id] pred = np.dot(self.user_factors[user_idx], self.item_factors[item_idx]) return pred defrecommend(self, user_id, n=10): """Recommend items""" if user_id notin self.user_to_idx: return [] predictions = [] for item_idx inrange(len(self.item_factors)): item_id = self.idx_to_item[item_idx] pred = self.predict(user_id, item_id) predictions.append((item_id, pred)) predictions.sort(key=lambda x: x[1], reverse=True) return predictions[:n]
Frequently Asked Questions
(Q&A)
Q1: Which should I
choose, User-CF or Item-CF?
A: The choice depends on the specific scenario:
Item-CF is more commonly used: Item count is
usually less than user count, lower computation cost; item similarity is
more stable and can be pre-computed; recommendations are more
stable.
User-CF is suitable for: Relatively fewer users;
user interests change quickly, need real-time capture; want to discover
users' latent interests.
Practical advice: In most cases, choose Item-CF
unless there are special requirements.
Q2:
How to choose the latent feature dimension\(k\)for matrix factorization?
A: Choosing\(k\)requires trade-offs:
\(k\)too small:
Insufficient model expressiveness, underfitting
\(k\)too large:
Easy to overfit, high computation cost
Rule of thumb: - Small scale (< 100K users):\(k = 10-50\) - Medium scale (100K-1M
users):\(k = 50-100\) - Large scale
(> 1M users):\(k = 100-200\)Practice: Use cross-validation, test different\(k\)values on validation set, choose the one
with optimal RMSE/NDCG.
Q3: How to handle the
cold start problem?
A: Cold start is divided into user cold start and
item cold start:
User cold start: - Use user registration info (age,
gender, location) to initialize user vectors - Use popular item
recommendations as default strategy - Guide users to label interests
Item cold start: - Use item content features
(category, tags) to initialize item vectors - Use content similarity to
recommend similar items - Use item publisher, publish time, etc.
Hybrid strategy: Use content-based recommendations
during cold start, switch to collaborative filtering after accumulating
data.
Q4: Which is better, SGD or
ALS?
A: Each has advantages:
SGD: - Advantages: Simple implementation, low memory
usage, suitable for online learning - Disadvantages: Slow convergence,
hard to parallelize
ALS: - Advantages: Fast convergence, parallelizable,
suitable for large-scale data - Disadvantages: High memory usage (need
to store matrices), not suitable for online learning
Online metrics: - Click-through rate
(CTR): CTR of recommended items - Conversion
rate: Purchase/conversion rate of recommended items -
User retention: User retention after using
recommendation system
Practice advice: Offline metrics for model selection
and hyperparameter tuning, online A/B testing for final validation.
Q11:
What initialization methods are there for matrix factorization?
A: Common initialization methods:
Random initialization: Sample from normal
distribution\(\mathcal{N}(0,
0.1)\)
This article provides an in-depth exploration of collaborative
filtering and matrix factorization core algorithms:
Collaborative Filtering: Basic principles,
similarity calculations, and code implementations of User-CF and
Item-CF
Matrix Factorization: Mathematical principles and
implementations of basic MF, MF with bias, SVD++
Optimization Methods: Comparison and selection of
SGD and ALS
Ranking Learning: BPR's transformation from rating
prediction to ranking learning
Factorization Machines: FM's ability to handle
sparse features
Implicit Feedback: How to handle implicit feedback
data
Practical Techniques: Bias terms, regularization,
cold start, etc.
These algorithms form the foundation of recommendation systems.
Understanding them helps in learning more advanced deep learning
methods. In practice, choose appropriate algorithms based on data scale
and business scenarios, and validate effectiveness through
experiments.
References
Koren, Y., Bell, R., & Volinsky, C. (2009). Matrix factorization
techniques for recommender systems. Computer, 42(8), 30-37. IEEE
Rendle, S., Freudenthaler, C., Gantner, Z., & Schmidt-Thieme, L.
(2009). BPR: Bayesian personalized ranking from implicit feedback. UAI.
arXiv:1205.2618