Recommendation Systems (16): Industrial Architecture and Best Practices
Chen KaiBOSS
2026-02-03 23:11:112026-02-03 23:117.7k Words48 Mins
permalink: "en/recommendation-systems-16-industrial-practice/" date:
2024-07-16 14:00:00 tags: - Recommendation Systems - Industrial Practice
- System Architecture categories: Recommendation Systems mathjax:
true---
Building production-grade recommendation systems requires navigating
a complex landscape of architectural decisions, performance constraints,
and business requirements. This article explores the industrial practice
of recommendation systems, covering everything from multi-channel recall
strategies to deployment pipelines and monitoring infrastructure.
Introduction
Industrial recommendation systems differ fundamentally from academic
prototypes. While research papers focus on novel algorithms and metrics,
production systems must handle millions of requests per second, maintain
sub-100ms latency, and continuously adapt to changing user behavior. The
architecture must balance accuracy, scalability, and operational
complexity.
This article synthesizes best practices from leading tech companies,
including Alibaba's EasyRec framework and ByteDance's LONGER system.
We'll examine the complete pipeline: recall, ranking, reranking, feature
engineering, A/B testing, and production deployment.
Industrial
Recommendation System Landscape
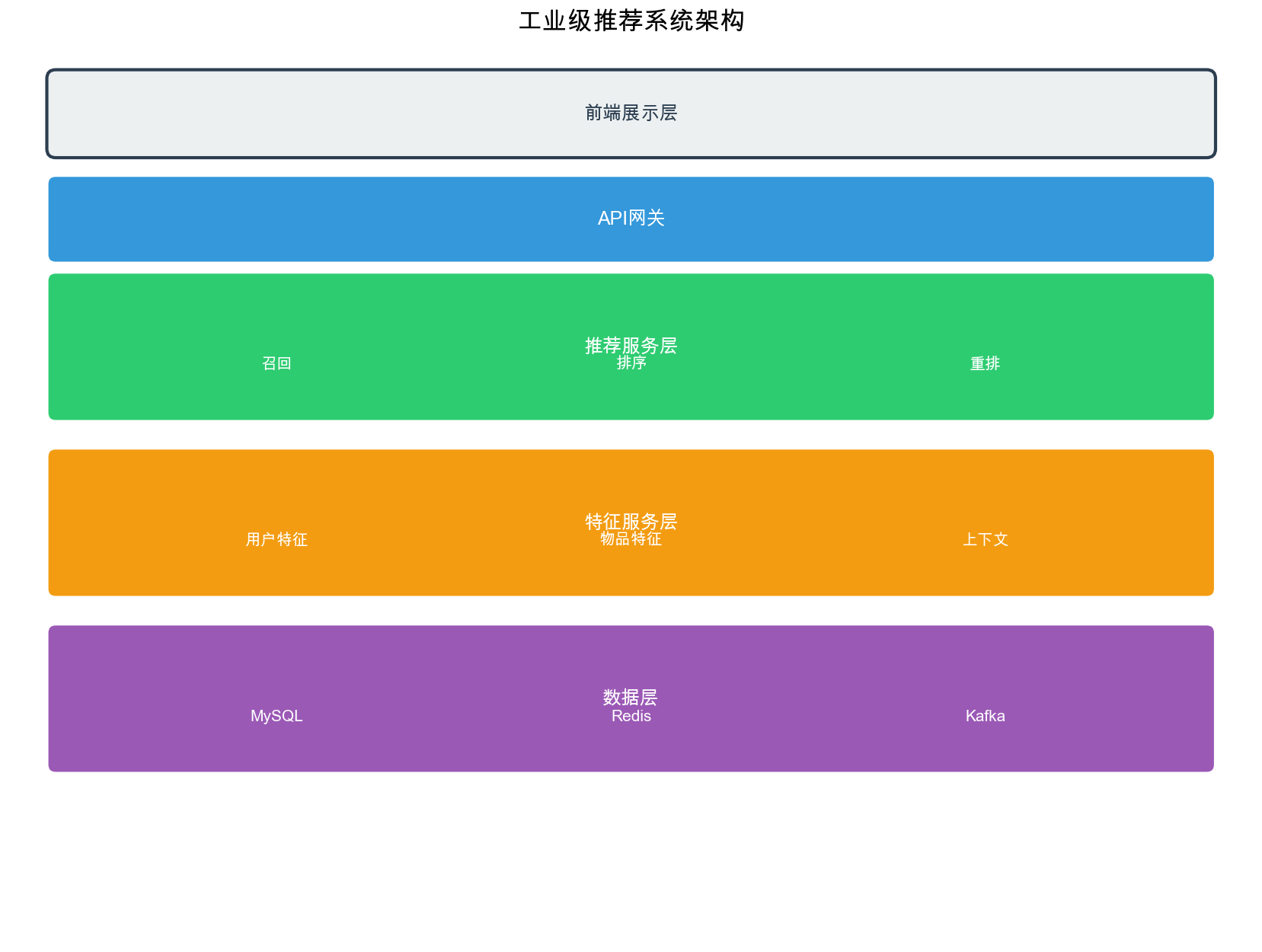
Architecture Overview
Modern industrial recommendation systems follow a multi-stage
pipeline architecture:
1
User Request → Recall (Multi-Channel) → Coarse Ranking → Fine Ranking → Reranking → Response
Each stage serves a specific purpose:
Recall: Reduces the candidate space from millions
to thousands
Coarse Ranking: Quick filtering using lightweight
models
Fine Ranking: Detailed scoring with complex
models
Reranking: Business rules, diversity, and freshness
adjustments
Key Design Principles
1. Scalability First
Production systems must handle traffic spikes. Horizontal scaling and
stateless services are essential:
classFaultTolerantRecall: def__init__(self, recall_channels): self.channels = recall_channels self.fallback = PopularItemsRecall() defrecall(self, user_id, context): results = [] for channel in self.channels: try: channel_results = channel.recall(user_id, context, timeout=20) results.extend(channel_results) except Exception as e: logger.warning(f"Channel {channel.name} failed: {e}") # Continue with other channels ifnot results: return self.fallback.recall(user_id, context) return deduplicate(results)
Multi-Channel Recall Design
Recall is the most critical stage — it determines the upper bound of
recommendation quality. Industrial systems employ multiple recall
channels in parallel.
Channel Types
1. Collaborative Filtering Recall
Matrix factorization and item-based collaborative filtering remain
effective:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
import numpy as np from scipy.sparse import csr_matrix
import networkx as nx from collections import defaultdict
classGraphRecall: def__init__(self, interaction_graph): self.graph = interaction_graph self.item_similarity = self._compute_item_similarity() def_compute_item_similarity(self): """Compute item-item similarity using graph structure""" similarity = defaultdict(dict) items = [n for n in self.graph.nodes() if self.graph.nodes[n]['type'] == 'item'] for item1 in items: neighbors1 = set(self.graph.neighbors(item1)) for item2 in items: if item1 != item2: neighbors2 = set(self.graph.neighbors(item2)) intersection = len(neighbors1 & neighbors2) union = len(neighbors1 | neighbors2) if union > 0: similarity[item1][item2] = intersection / union return similarity defrecall(self, user_id, top_k=1000): """Recall items connected to user's interacted items""" user_items = [ n for n in self.graph.neighbors(user_id) if self.graph.nodes[n]['type'] == 'item' ] candidate_scores = defaultdict(float) for item in user_items: for similar_item, sim_score in self.item_similarity.get(item, {}).items(): candidate_scores[similar_item] += sim_score top_items = sorted( candidate_scores.items(), key=lambda x: x[1], reverse=True )[:top_k] return [item_id for item_id, _ in top_items]
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity
classContentBasedRecall: def__init__(self, item_features): self.item_features = item_features self.vectorizer = TfidfVectorizer(max_features=1000) self.item_vectors = self._vectorize_items() def_vectorize_items(self): """Convert item features to vectors""" texts = [ ' '.join(str(v) for v in features.values()) for features in self.item_features.values() ] return self.vectorizer.fit_transform(texts) defrecall(self, user_profile, top_k=1000): """Recall items matching user profile""" user_vector = self.vectorizer.transform([' '.join(str(v) for v in user_profile.values())]) similarities = cosine_similarity(user_vector, self.item_vectors)[0] top_indices = np.argsort(similarities)[-top_k:][::-1] return top_indices.tolist()
classMultiChannelRecall: def__init__(self, channels, channel_weights=None): self.channels = channels self.channel_weights = channel_weights or {ch.name: 1.0for ch in channels} defrecall(self, user_id, context, target_size=2000): """Fuse results from multiple channels""" channel_results = {} # Parallel execution with ThreadPoolExecutor(max_workers=len(self.channels)) as executor: futures = { executor.submit(ch.recall, user_id, context): ch.name for ch in self.channels } for future in as_completed(futures): channel_name = futures[future] try: results = future.result(timeout=25) channel_results[channel_name] = results except Exception as e: logger.error(f"Channel {channel_name} failed: {e}") # Weighted fusion candidate_scores = defaultdict(float) for channel_name, items in channel_results.items(): weight = self.channel_weights.get(channel_name, 1.0) for rank, item_id inenumerate(items): # Rank-based scoring with channel weight score = weight * (1.0 / (rank + 1)) candidate_scores[item_id] += score # Select top candidates top_candidates = sorted( candidate_scores.items(), key=lambda x: x[1], reverse=True )[:target_size] return [item_id for item_id, _ in top_candidates]
Q&A: Multi-Channel Recall
Q1: How many recall channels should we use?
A: Typically 5-10 channels. Too few limits diversity; too many
increases latency and complexity. Start with 3-5 core channels (CF, deep
learning, real-time behavior) and add specialized channels based on
business needs.
Q2: How to handle channel failures?
A: Implement circuit breakers and fallbacks. Each channel should have
a timeout (20-30ms). If a channel fails, continue with others. Always
maintain a fallback channel (e.g., popular items) that never fails.
Q3: Should we deduplicate across channels?
A: Yes, but after fusion. Deduplication before fusion loses
information about item importance across channels. Fuse first, then
deduplicate based on final scores.
Coarse Ranking
Coarse ranking filters recall results using lightweight models,
reducing candidates from thousands to hundreds.
classCoarseRankingFeatures: defextract(self, user_id, item_id, context): """Extract lightweight features""" features = {} # User features features['user_click_count_7d'] = self.get_user_stat(user_id, 'click_count', days=7) features['user_purchase_count_30d'] = self.get_user_stat(user_id, 'purchase_count', days=30) features['user_avg_price'] = self.get_user_stat(user_id, 'avg_price') # Item features features['item_popularity'] = self.get_item_stat(item_id, 'popularity') features['item_ctr_7d'] = self.get_item_stat(item_id, 'ctr', days=7) features['item_price'] = self.get_item_stat(item_id, 'price') # Interaction features features['user_item_click_count'] = self.get_interaction_count(user_id, item_id, 'click') features['user_category_click_count'] = self.get_category_interaction(user_id, item_id, 'click') # Context features features['hour'] = context.get('hour', 0) features['day_of_week'] = context.get('day_of_week', 0) features['device_type'] = self.encode_device(context.get('device', 'unknown')) return np.array([features[k] for k insorted(features.keys())])
Q&A: Coarse Ranking
Q4: What's the ideal candidate reduction ratio?
A: Typically 10:1 (e.g., 2000 → 200). Too aggressive loses good
candidates; too conservative wastes fine ranking resources. Monitor
recall@K metrics to find the sweet spot.
Q5: Should coarse ranking use the same features as fine
ranking?
A: No. Coarse ranking prioritizes speed, so use fewer, simpler
features. Fine ranking can use complex, expensive features. Overlap is
fine, but coarse ranking should avoid heavy computations.
Fine Ranking
Fine ranking uses complex models to score the remaining candidates
precisely.
A: Balance accuracy and latency. Start with Wide & Deep or
DeepFM. Add complexity (e.g., DIN, DIEN) only if it improves metrics
significantly. Monitor inference time — complex models may require model
compression.
Q7: How to handle feature engineering
complexity?
A: Use feature stores and automated feature engineering. Store
precomputed features in Redis/feature store. Use tools like Feast or
Tecton for feature management. Consider automated feature selection to
reduce dimensionality.
Reranking
Reranking applies business rules, diversity constraints, and
freshness adjustments to the final ranking.
A: Use MMR (Maximal Marginal Relevance) or similar algorithms. Start
with diversity_weight=0.2-0.3. A/B test different weights and monitor
both CTR and diversity metrics (e.g., category diversity, price
diversity).
Q9: Should reranking be model-based or
rule-based?
A: Hybrid approach works best. Use rules for hard constraints (e.g.,
exclude out-of-stock items) and model-based reranking for soft
optimization (e.g., diversity, freshness). Consider learning-to-rank
models for reranking if you have sufficient data.
Alibaba EasyRec Framework
EasyRec is Alibaba's open-source recommendation framework, providing
end-to-end tools for building production systems.
Architecture Overview
EasyRec provides:
Feature Engineering: Automated feature extraction
and transformation
Model Training: Pre-built models (Wide&Deep,
DeepFM, DIN, etc.)
Serving: High-performance inference engine
Evaluation: Comprehensive metrics and A/B testing
tools
Feature Engineering: Use EasyRec's feature
transformations (normalization, bucketization, etc.)
Model Selection: Start with DeepFM, upgrade to
DIN/DIEN if needed
Distributed Training: Use EasyRec's distributed
training for large datasets
Model Versioning: Leverage EasyRec's model
versioning for A/B testing
Q&A: EasyRec
Q10: How does EasyRec compare to TensorFlow
Recommenders?
A: EasyRec is more production-oriented with built-in serving, feature
engineering, and A/B testing. TensorFlow Recommenders is more flexible
but requires more custom code. EasyRec is better for rapid deployment;
TF Recommenders for research.
ByteDance LONGER System
LONGER (Learning to Optimize Recommendation with Graph Enhanced
Ranking) is ByteDance's graph-enhanced ranking system.
Q11: When should we use graph-based approaches like
LONGER?
A: Use graph methods when you have rich interaction data and need to
model complex relationships. They're especially effective for cold start
problems and multi-hop reasoning. However, they require more
computational resources than traditional methods.
Feature Engineering
Automation
Manual feature engineering is time-consuming and error-prone.
Automation is essential for scale.
classFeatureStore: def__init__(self, redis_client, feature_ttl=3600): self.redis = redis_client self.ttl = feature_ttl defget_feature(self, entity_type, entity_id, feature_name): """Get feature value""" key = f"{entity_type}:{entity_id}:{feature_name}" value = self.redis.get(key) if value: return json.loads(value) returnNone defset_feature(self, entity_type, entity_id, feature_name, value): """Set feature value""" key = f"{entity_type}:{entity_type}:{feature_name}" self.redis.setex( key, self.ttl, json.dumps(value) ) defbatch_get_features(self, entity_type, entity_ids, feature_names): """Batch get features""" keys = [ f"{entity_type}:{eid}:{fname}" for eid in entity_ids for fname in feature_names ] values = self.redis.mget(keys) # Reshape to [num_entities, num_features] num_features = len(feature_names) return [ [json.loads(v) if v elseNonefor v in values[i:i+num_features]] for i inrange(0, len(values), num_features) ]
Q&A: Feature Engineering
Q12: How to balance feature engineering automation and manual
curation?
A: Automate low-level features (statistical, temporal) and use
automation to discover crosses. Manually curate high-level business
features (e.g., user segments, item categories). Use feature importance
to guide manual efforts.
Q13: How often should we refresh features?
A: Real-time features (e.g., recent clicks) update continuously.
Statistical features refresh hourly or daily. Embedding features may
refresh weekly. Monitor feature drift and refresh when distributions
change significantly.
A/B Testing Framework
A/B testing is crucial for validating improvements and making
data-driven decisions.
A: Run until statistical significance is reached or minimum sample
size (typically 2-4 weeks). Use power analysis to determine required
sample size before starting. Don't stop early due to early positive
results — wait for full duration.
Q15: How to handle multiple simultaneous
experiments?
A: Use experiment layering and orthogonal assignment. Ensure
experiments don't interfere by using consistent hashing with experiment
IDs. Monitor for interactions between experiments.
Performance Optimization
Production systems require careful optimization to meet latency and
throughput requirements.
Model Optimization
1. Model Quantization
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
import torch.quantization as quantization
classModelQuantizer: defquantize_model(self, model, calibration_data): """Quantize model to INT8""" model.eval() # Prepare for quantization model.qconfig = quantization.get_default_qconfig('fbgemm') quantization.prepare(model, inplace=True) # Calibrate with torch.no_grad(): for batch in calibration_data: model(batch) # Convert to quantized quantized_model = quantization.convert(model, inplace=False) return quantized_model
2. Model Pruning
1 2 3 4 5 6 7 8 9 10 11
import torch.nn.utils.prune as prune
classModelPruner: defprune_model(self, model, pruning_ratio=0.3): """Prune model weights""" for name, module in model.named_modules(): ifisinstance(module, nn.Linear): prune.l1_unstructured(module, name='weight', amount=pruning_ratio) prune.remove(module, 'weight') return model
Q16: How to choose between quantization, pruning, and
distillation?
A: Quantization for fastest inference (2-4x speedup). Pruning for
model size reduction. Distillation for accuracy preservation with
smaller models. Often combine: distill → prune → quantize for maximum
optimization.
Q17: What's the trade-off between batch size and
latency?
A: Larger batches improve throughput but increase latency (waiting
for batch to fill). Find the sweet spot: typically batch_size=16-32 with
max_wait=5-10ms works well. Monitor p95 latency, not just average.
Deployment and Monitoring
Production deployment requires robust infrastructure and
comprehensive monitoring.
A: Use semantic versioning (major.minor.patch). Store models in a
model registry (MLflow, DVC, or custom). Tag models with metadata
(training data version, hyperparameters, metrics). Maintain version
compatibility for gradual rollouts.
Q19: What metrics should we monitor?
A: System metrics (latency p50/p95/p99, throughput, error rate),
prediction metrics (score distribution, prediction quality), business
metrics (CTR, conversion rate, revenue). Set up alerts for anomalies in
all metrics.
Complete Project Example
build a complete recommendation system from scratch.
# src/serving/api.py from flask import Flask, request, jsonify from src.serving.predictor import RecommendationPredictor from src.utils.monitoring import RecommendationMonitor import time
# src/serving/predictor.py from src.recall.multi_channel import MultiChannelRecall from src.ranking.coarse_ranking import CoarseRankingModel from src.ranking.fine_ranking import FineRankingModel from src.ranking.reranking import DiversityReranker, BusinessRulesReranker from src.features.extractor import FeatureExtractor
classRecommendationPredictor: def__init__(self): # Initialize components self.recall = MultiChannelRecall(...) self.coarse_ranking = CoarseRankingModel(...) self.fine_ranking = FineRankingModel(...) self.reranker = DiversityReranker(...) self.business_rules = BusinessRulesReranker(...) self.feature_extractor = FeatureExtractor(...) defpredict(self, user_id, context, top_k=20): """Complete recommendation pipeline""" # 1. Recall candidates = self.recall.recall(user_id, context, target_size=2000) # 2. Coarse ranking coarse_features = [ self.feature_extractor.extract_coarse(user_id, item_id, context) for item_id in candidates ] coarse_scores = self.coarse_ranking.predict(coarse_features) coarse_ranked = sorted( zip(candidates, coarse_scores), key=lambda x: x[1], reverse=True )[:200] # Reduce to 200 # 3. Fine ranking fine_candidates = [item_id for item_id, _ in coarse_ranked] fine_features = [ self.feature_extractor.extract_fine(user_id, item_id, context) for item_id in fine_candidates ] fine_scores = self.fine_ranking.predict(fine_features) fine_ranked = sorted( zip(fine_candidates, fine_scores), key=lambda x: x[1], reverse=True ) # 4. Reranking rerank_candidates = [item_id for item_id, _ in fine_ranked[:50]] item_metadata = self.feature_extractor.get_item_metadata(rerank_candidates) # Diversity reranking diversity_ranked = self.reranker.rerank( rerank_candidates, [score for _, score in fine_ranked[:50]], item_metadata, top_k=top_k ) # Business rules final_ranked = self.business_rules.rerank( diversity_ranked, [score for item_id, score in fine_ranked if item_id in diversity_ranked], item_metadata ) # Format results return [ { 'item_id': item_id, 'score': next( score for iid, score in fine_ranked if iid == item_id ), 'rank': idx + 1 } for idx, item_id inenumerate(final_ranked) ]
deftrain(): # Load data train_dataset = RankingDataset('data/train.parquet', FeatureExtractor()) val_dataset = RankingDataset('data/val.parquet', FeatureExtractor()) train_loader = DataLoader(train_dataset, batch_size=256, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=256, shuffle=False) # Initialize model model = FineRankingModel(input_dim=500) optimizer = torch.optim.Adam(model.parameters(), lr=0.001) criterion = nn.BCEWithLogitsLoss() # Training loop for epoch inrange(10): model.train() train_loss = 0 for features, labels in train_loader: optimizer.zero_grad() predictions = model(features) loss = criterion(predictions, labels.float()) loss.backward() optimizer.step() train_loss += loss.item() # Validation model.eval() val_loss = 0 with torch.no_grad(): for features, labels in val_loader: predictions = model(features) loss = criterion(predictions, labels.float()) val_loss += loss.item() print(f"Epoch {epoch}: Train Loss={train_loss/len(train_loader):.4f}, " f"Val Loss={val_loss/len(val_loader):.4f}") # Save model torch.save(model.state_dict(), 'models/fine_ranking_model.pt')
if __name__ == '__main__': train()
Q&A: Complete System
Q20: How to handle cold start for new users?
A: Use content-based features and popular items as fallback. For new
items, use content features and category-based similarity. Consider
using graph methods (like LONGER) that can propagate information through
the graph.
Q21: How to ensure system reliability?
A: Implement circuit breakers, timeouts, and fallbacks at every
stage. Use health checks and graceful degradation. Monitor error rates
and latency. Have rollback procedures ready. Test failure scenarios
regularly.
Conclusion
Building industrial recommendation systems requires careful attention
to architecture, performance, and operations. The multi-stage pipeline
(recall → coarse ranking → fine ranking → reranking) provides a scalable
framework for handling millions of users and items.
Key takeaways:
Multi-channel recall is essential for diversity and
coverage
Monitoring and deployment practices ensure
reliability
The frameworks and practices discussed — from EasyRec to LONGER —
represent years of production experience. Adapt them to your specific
use case, and always measure the impact of changes through rigorous
experimentation.
As recommendation systems continue to evolve, new techniques like
graph neural networks, transformer-based models, and reinforcement
learning are pushing the boundaries. However, the fundamental principles
of scalable architecture, careful feature engineering, and rigorous
evaluation remain constant.