Recommendation Systems (15): Real-Time Recommendation and Online Learning
Chen KaiBOSS
2026-02-03 23:11:112026-02-03 23:117k Words43 Mins
permalink: "en/recommendation-systems-15-real-time-online/" date:
2024-07-11 10:15:00 tags: - Recommendation Systems - Real-Time - Online
Learning categories: Recommendation Systems mathjax: true--- In the era
of instant gratification, recommendation systems face an unprecedented
challenge: users expect personalized suggestions that adapt to their
current interests within milliseconds. Traditional batch-based
approaches, which retrain models every few hours or days, simply cannot
keep pace with rapidly changing user preferences, trending content, or
contextual shifts. This article explores real-time recommendation
architectures and online learning algorithms that enable systems to
learn and adapt continuously from streaming data, making decisions in
real-time while balancing exploration and exploitation.
Introduction:
The Need for Real-Time Adaptation
Consider a user browsing an e-commerce platform. At 2 PM, they're
searching for hiking gear. By 3 PM, they've shifted to looking at books.
A traditional recommendation system trained on yesterday's data would
still be suggesting hiking boots, completely missing the user's current
intent. Real-time recommendation systems solve this by continuously
updating their understanding of user preferences as new interactions
arrive, often processing thousands of events per second while
maintaining sub-100ms latency for serving recommendations.
The core challenge lies in the exploration-exploitation
dilemma: should the system exploit what it knows works well, or
explore new options to discover potentially better recommendations?
Online learning algorithms, particularly multi-armed bandits and their
contextual extensions, provide principled solutions to this problem,
enabling systems to learn optimal strategies while serving users.
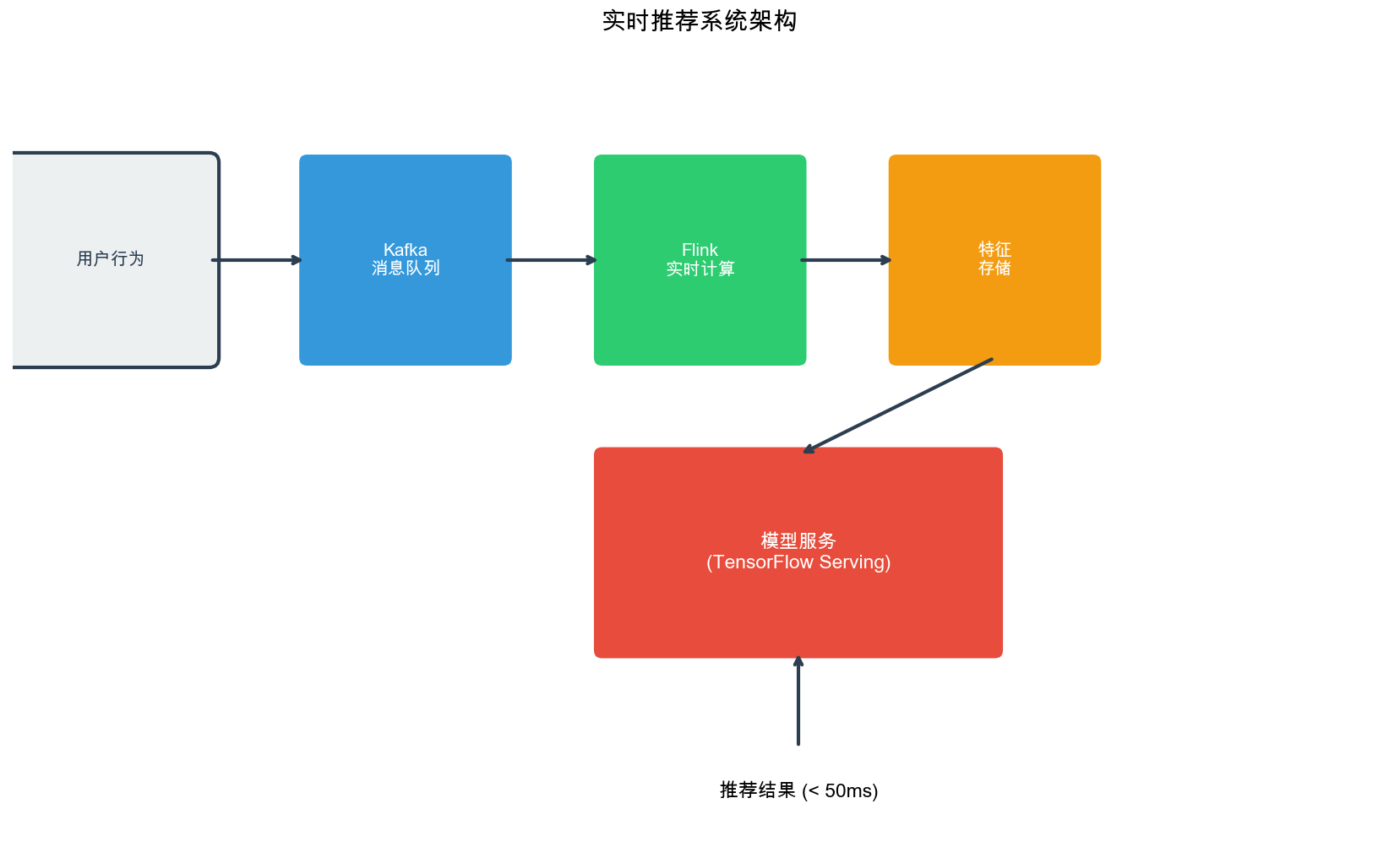
Real-Time Architecture
Fundamentals
System Components
A real-time recommendation system typically consists of several
interconnected components:
Event Ingestion Layer: Captures user interactions
(clicks, views, purchases) as they occur
Stream Processing Engine: Processes events in
real-time, updating feature stores and model parameters
Feature Store: Maintains up-to-date user and item
features accessible with low latency
Model Serving Layer: Serves predictions using the
latest model state
Feedback Loop: Ensures model updates influence
future recommendations
Latency Requirements
Different components have different latency budgets:
Event ingestion: < 10ms (must not block user
interactions)
from pyflink.datastream import StreamExecutionEnvironment from pyflink.table import StreamTableEnvironment from pyflink.datastream.functions import MapFunction, KeyedProcessFunction from pyflink.common.typeinfo import Types from pyflink.common.time import Time import json
# Process with Flink SQL result = table_env.execute_sql(""" SELECT user_id, COUNT(CASE WHEN event_type = 'click' THEN 1 END) as clicks, COUNT(CASE WHEN event_type = 'view' THEN 1 END) as views, COUNT(CASE WHEN event_type = 'click' THEN 1 END) * 1.0 / COUNT(CASE WHEN event_type = 'view' THEN 1 END) as ctr FROM user_interactions GROUP BY user_id, TUMBLE(event_time, INTERVAL '1' MINUTE) """)
Online Learning Basics
Batch vs. Online Learning
Batch learning processes all training data at once:
- Requires full dataset before training - Computationally expensive for
large datasets - Cannot adapt to new patterns quickly - Suitable for
stable environments
Online learning processes data one example (or
mini-batch) at a time: - Updates model incrementally - Adapts to
distribution shifts - Lower memory footprint - Suitable for dynamic
environments
Stochastic Gradient Descent
(SGD)
The foundation of online learning, SGD updates model parameters after
each example:
\[\theta_{t+1} = \theta_t - \eta_t
\nabla_\theta L(f(x_t, \theta_t), y_t)\]where\(\eta_t\)is the learning rate at time\(t\), and\(L\)is the loss function.
classAdaGrad: """AdaGrad with per-coordinate adaptive learning rates.""" def__init__(self, n_features, learning_rate=0.01, epsilon=1e-8): self.theta = np.zeros(n_features) self.learning_rate = learning_rate self.epsilon = epsilon self.G = np.zeros(n_features) # Sum of squared gradients defupdate(self, x: np.ndarray, y: float): """Update with AdaGrad.""" pred = np.dot(self.theta, x) error = pred - y gradient = error * x # Update sum of squared gradients self.G += gradient ** 2 # Per-coordinate learning rates adaptive_lr = self.learning_rate / (np.sqrt(self.G) + self.epsilon) # Update parameters self.theta -= adaptive_lr * gradient return pred, error
Multi-Armed
Bandits: Exploration vs. Exploitation
The multi-armed bandit problem formalizes the
exploration-exploitation trade-off. Imagine a slot machine with multiple
arms, each with an unknown reward distribution. The goal is to maximize
cumulative reward while learning which arms are best.
Rewards: Each arm\(i\)has expected reward\(\mu_i\)
Objective: Maximize\(\sum_{t=1}^T r_{a_t}\)where\(a_t\)is the arm chosen at time\(t\)The regret measures
performance:\[R_T = T \mu^* - \sum_{t=1}^T
\mu_{a_t}\]where\(\mu^* = \max_i
\mu_i\)is the optimal arm's expected reward.
Upper Confidence Bound (UCB)
UCB balances exploration and exploitation by choosing arms with high
upper confidence bounds:\[a_t =
\arg\max_{i=1,\dots,K} \left( \hat{\mu}_i + c \sqrt{\frac{\ln t}{n_i }}
\right)\]where: -\(\hat{\mu}_i\)is the empirical mean reward
for arm\(i\) -\(n_i\)is the number of times arm\(i\)has been pulled -\(c\)is the exploration parameter
(typically\(c = \sqrt{2}\))
classThompsonSampling: """Thompson Sampling for Bernoulli bandits.""" def__init__(self, n_arms, alpha=1.0, beta=1.0): self.n_arms = n_arms self.alpha = np.ones(n_arms) * alpha # Success counts self.beta = np.ones(n_arms) * beta # Failure counts defselect_arm(self): """Select arm by sampling from posterior distributions.""" samples = [] for arm inrange(self.n_arms): # Sample from Beta distribution sample = np.random.beta(self.alpha[arm], self.beta[arm]) samples.append(sample) return np.argmax(samples) defupdate(self, arm, reward): """Update Beta distribution parameters.""" if reward == 1: self.alpha[arm] += 1 else: self.beta[arm] += 1 defget_expected_rewards(self): """Get expected reward for each arm.""" return self.alpha / (self.alpha + self.beta)
# Example usage ts = ThompsonSampling(n_arms=5)
for t inrange(1000): arm = ts.select_arm() # Simulate reward (arm 2 is best with 50% success rate) true_probs = [0.1, 0.3, 0.5, 0.2, 0.15] reward = np.random.binomial(1, true_probs[arm]) ts.update(arm, reward) if t % 200 == 0: expected = ts.get_expected_rewards() print(f"Step {t}: Expected rewards = {expected}")
Contextual Bandits
Contextual bandits extend multi-armed bandits by incorporating
context (features) into decision-making. Instead of learning which arm
is best overall, we learn which arm is best given the current
context.
Linear Contextual Bandits
In linear contextual bandits, the expected reward is linear in the
context:\[E[r_{a_t} | x_t] = x_t^T
\theta_{a_t}\]where\(x_t\)is the
context vector and\(\theta_{a_t}\)is
the parameter vector for arm\(a_t\).
LinUCB: Linear Upper
Confidence Bound
LinUCB extends UCB to linear contextual bandits:\[a_t = \arg\max_{a \in A} \left( x_t^T
\hat{\theta}_a + \alpha \sqrt{x_t^T A_a^{-1} x_t} \right)\]where:
-\(\hat{\theta}_a\)is the estimated
parameter for arm\(a\) -\(A_a = D_a^T D_a + I_d\)is the regularized
design matrix -\(D_a\)is the matrix of
contexts where arm\(a\)was chosen
-\(\alpha\)controls exploration
import torch import torch.nn as nn import torch.optim as optim
classNeuralContextualBandit(nn.Module): """Neural network for contextual bandits.""" def__init__(self, n_features, n_arms, hidden_dim=64): super().__init__() self.n_arms = n_arms # Shared feature extractor self.feature_extractor = nn.Sequential( nn.Linear(n_features, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, hidden_dim), nn.ReLU() ) # Arm-specific heads self.arm_heads = nn.ModuleList([ nn.Linear(hidden_dim, 1) for _ inrange(n_arms) ]) defforward(self, context): """Forward pass.""" features = self.feature_extractor(context) rewards = torch.stack([ head(features) for head in self.arm_heads ], dim=1) return rewards.squeeze(-1) defselect_arm(self, context, exploration_bonus=1.0): """Select arm with exploration bonus.""" self.eval() with torch.no_grad(): rewards = self.forward(context) # Add exploration bonus (simplified) ucb_rewards = rewards + exploration_bonus * torch.randn_like(rewards) return torch.argmax(ucb_rewards).item()
# Training loop model = NeuralContextualBandit(n_features=10, n_arms=5) optimizer = optim.Adam(model.parameters(), lr=0.001)
contexts = [] arms = [] rewards = []
for t inrange(1000): # Generate context context = torch.randn(1, 10) # Select arm arm = model.select_arm(context) # Simulate reward reward = torch.rand(1).item() # Store for batch update contexts.append(context) arms.append(arm) rewards.append(reward) # Update every 32 steps iflen(contexts) >= 32: model.train() optimizer.zero_grad() batch_contexts = torch.cat(contexts[-32:], dim=0) batch_arms = torch.tensor(arms[-32:]) batch_rewards = torch.tensor(rewards[-32:]) predicted_rewards = model(batch_contexts) selected_rewards = predicted_rewards.gather(1, batch_arms.unsqueeze(1)).squeeze() loss = nn.MSELoss()(selected_rewards, batch_rewards) loss.backward() optimizer.step() contexts = [] arms = [] rewards = []
HyperBandit:
Hyperparameter Optimization for Bandits
HyperBandit addresses the challenge of selecting hyperparameters
(like exploration rate\(\alpha\)) for
bandit algorithms. Instead of fixing hyperparameters, we treat them as
arms in a meta-bandit problem.
Algorithm Overview
Define a set of hyperparameter configurations
Treat each configuration as an arm
Use a bandit algorithm to select which configuration to use
Periodically evaluate and update configuration performance
for t inrange(1000): arm = hyper_bandit.select_arm() reward = np.random.binomial(1, 0.3) # Simulated reward hyper_bandit.update(arm, reward)
B-DES:
Bandit-Based Dynamic Exploration Strategy
B-DES adaptively adjusts exploration based on the uncertainty in
reward estimates. When uncertainty is high, it explores more; when
uncertainty is low, it exploits more.
Algorithm
B-DES uses adaptive confidence intervals:\[a_t = \arg\max_{a \in A} \left( \hat{\mu}_a +
\beta_t \sigma_a \right)\]where\(\beta_t\)adapts based on the current
uncertainty level:\[\beta_t = \beta_0 \cdot
\exp(-\lambda \cdot \text{avg\_uncertainty}_t)\]
Interest Clock models how user interests evolve over time,
recognizing that interests have temporal patterns (e.g., morning news,
evening entertainment).
Concept
Interest Clock maintains separate interest models for different time
periods:\[I_u(t) = \sum_{k=1}^K w_k(t) \cdot
I_u^{(k)}\]where\(I_u^{(k)}\)represents interest in
category\(k\), and\(w_k(t)\)are time-dependent weights.
import numpy as np from collections import defaultdict
classInterestClock: """Models temporal patterns in user interests.""" def__init__(self, n_categories, n_time_buckets=24): self.n_categories = n_categories self.n_time_buckets = n_time_buckets # Interest vectors for each time bucket self.interests = np.zeros((n_time_buckets, n_categories)) # Counts for smoothing self.counts = np.zeros((n_time_buckets, n_categories)) # Decay factor for forgetting old interests self.decay_factor = 0.95 defget_time_bucket(self, hour): """Get time bucket index (0-23 for hours).""" returnint(hour) % self.n_time_buckets defupdate_interest(self, category, hour, interaction_strength=1.0): """Update interest for a category at a specific time.""" bucket = self.get_time_bucket(hour) # Exponential moving average alpha = 1.0 / (self.counts[bucket, category] + 1) self.interests[bucket, category] = ( (1 - alpha) * self.interests[bucket, category] + alpha * interaction_strength ) self.counts[bucket, category] += 1 defget_current_interest(self, hour): """Get interest vector for current time.""" bucket = self.get_time_bucket(hour) return self.interests[bucket, :].copy() defpredict_preference(self, item_category, hour): """Predict user preference for an item category at given hour.""" bucket = self.get_time_bucket(hour) return self.interests[bucket, item_category] defapply_temporal_decay(self): """Apply decay to all interests (call periodically).""" self.interests *= self.decay_factor
# Example usage interest_clock = InterestClock(n_categories=10, n_time_buckets=24)
# Simulate user interactions throughout the day interactions = [ (0, 2, 1.0), # Category 2 at midnight (8, 0, 1.0), # Category 0 at 8 AM (news) (12, 5, 1.0), # Category 5 at noon (lunch) (18, 7, 1.0), # Category 7 at 6 PM (entertainment) (20, 7, 1.0), # Category 7 at 8 PM (entertainment) ]
for hour, category, strength in interactions: interest_clock.update_interest(category, hour, strength)
# Predict preferences at different times for hour in [8, 12, 18, 22]: interests = interest_clock.get_current_interest(hour) print(f"Hour {hour}: Top interests = {np.argsort(interests)[-3:]}")
Exploration-Exploitation
Strategies
Epsilon-Greedy
Simple strategy: with probability\(\epsilon\), explore randomly; otherwise,
exploit the best-known arm.
Select arms with probabilities proportional to their estimated
values:\[P(a_t = i) = \frac{\exp(\hat{\mu}_i
/ \tau)}{\sum_{j=1}^K \exp(\hat{\mu}_j / \tau)}\]where\(\tau\)is the temperature parameter.
Q2:
What are the trade-offs between exploration and exploitation in
production systems?
A: The key trade-offs are:
More exploration: Better long-term learning, but
lower short-term engagement
More exploitation: Higher immediate engagement, but
may miss better options
UCB/Thompson Sampling: Provide principled balance
with theoretical guarantees
A/B testing: Essential for validating exploration
strategies
In practice, systems often use: - Higher exploration for new
users/items - Adaptive exploration rates based on uncertainty - Separate
exploration budgets for different user segments
Q3:
How do streaming frameworks ensure exactly-once processing?
A: Exactly-once semantics require:
Idempotent operations: Operations that produce the
same result when applied multiple times
Transactional writes: Atomic updates to state
stores
Checkpointing: Periodic snapshots of processing
state
Deduplication: Track processed event IDs
Flink provides exactly-once through: - Two-phase commit protocol for
sinks - Distributed snapshots (checkpoints) - State backend for fault
tolerance
Q4:
Can online learning algorithms converge to optimal solutions?
classProductionOnlineLearner: """Production-ready online learner with safety mechanisms.""" def__init__(self, base_model): self.model = base_model self.backup_model = copy.deepcopy(base_model) self.performance_history = [] self.update_count = 0 defsafe_update(self, x, y): """Update with safety checks.""" # Validate input ifnot self._validate_input(x, y): returnFalse # Make backup periodically if self.update_count % 1000 == 0: self.backup_model = copy.deepcopy(self.model) # Update model old_performance = self._evaluate_on_holdout() self.model.update(x, y) new_performance = self._evaluate_on_holdout() # Check for performance degradation if new_performance < 0.9 * old_performance: # Rollback self.model = copy.deepcopy(self.backup_model) returnFalse self.update_count += 1 returnTrue def_validate_input(self, x, y): """Validate input data.""" # Check for NaN, Inf, outliers if np.any(np.isnan(x)) or np.any(np.isinf(x)): returnFalse if np.abs(y) > 10: # Outlier threshold returnFalse returnTrue def_evaluate_on_holdout(self): """Evaluate on holdout set (simplified).""" # In practice, use a separate validation set return0.8# Placeholder
Conclusion
Real-time recommendation systems represent the frontier of
personalized user experiences, combining streaming data processing,
online learning algorithms, and principled exploration-exploitation
strategies. The key to success lies in:
Architecture: Robust streaming pipelines with
low-latency serving
Algorithms: Bandit algorithms that balance
exploration and exploitation
Features: Real-time feature computation and
temporal modeling
Monitoring: Comprehensive metrics and safety
mechanisms
Iteration: Continuous A/B testing and algorithm
refinement
As user expectations for personalization continue to rise, systems
that can adapt in real-time will become increasingly essential. The
algorithms and architectures discussed in this article provide a
foundation for building such systems, but success ultimately depends on
careful engineering, thorough testing, and continuous improvement based
on real-world feedback.
The field continues to evolve rapidly, with new techniques emerging
for handling non-stationary environments, improving exploration
efficiency, and ensuring fairness and diversity. Staying current with
these developments and understanding the fundamental principles
underlying online learning and bandit algorithms will be crucial for
building next-generation recommendation systems.
Post title:Recommendation Systems (15): Real-Time Recommendation and Online Learning
Post author:Chen Kai
Create time:2026-02-03 23:11:11
Post link:https://www.chenk.top/recommendation-systems-15-real-time-online/
Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.