Recommendation Systems (14): Cross-Domain Recommendation and Cold-Start Solutions
Chen KaiBOSS
2026-02-03 23:11:112026-02-03 23:117.1k Words44 Mins
permalink: "en/recommendation-systems-14-cross-domain-cold-start/"
date: 2024-07-06 15:45:00 tags: - Recommendation Systems - Cross-Domain
- Cold Start categories: Recommendation Systems mathjax: true --- When
Netflix launches in a new country, it faces a fundamental challenge:
millions of new users with zero interaction history, and thousands of
new movies with no ratings. Traditional recommendation systems, trained
on historical data, fail catastrophically in this cold-start scenario.
Similarly, when Amazon wants to recommend products in a new category
(say, recommending books to users who've only bought electronics), it
can't rely on cross-category patterns alone. These scenarios —
cold-start users, cold-start items, and cross-domain recommendation —
represent some of the most critical and challenging problems in modern
recommendation systems.
The cold-start problem manifests in three forms: new users with no
history, new items with no interactions, and new domains with sparse
data. Each requires different strategies: meta-learning that learns to
learn quickly from few examples, transfer learning that adapts knowledge
from related domains, and bootstrap methods that leverage auxiliary
information. Cross-domain recommendation extends these ideas further,
transferring patterns learned in one domain (e.g., movies) to another
(e.g., books) by identifying shared structures and relationships.
This article provides a comprehensive exploration of cross-domain
recommendation and cold-start solutions, covering the taxonomy of
cold-start problems, meta-learning foundations and few-shot learning
principles, meta-learner architectures (MAML, Prototypical Networks),
the Mecos framework for cold-start recommendation, cross-domain transfer
learning frameworks, zero-shot transfer methods, graph neural
network-based transfer approaches, bootstrap techniques leveraging
content and social signals, and practical implementations with 10+ code
examples and detailed Q&A sections addressing common challenges and
design decisions.
Understanding the
Cold-Start Problem
The Three Types of
Cold-Start
Cold-start problems in recommendation systems can be categorized into
three distinct types, each requiring different solution strategies:
1. User Cold-Start: New users join the platform with
no interaction history. The system must infer preferences from limited
information (demographics, registration data, initial clicks) or
leverage patterns from similar users.
2. Item Cold-Start: New items (movies, products,
articles) are added to the catalog with no user interactions. The system
must predict potential interest based on item attributes, content
features, or similarity to existing items.
3. System Cold-Start: An entirely new platform or
domain with sparse data overall. This combines both user and item
cold-start challenges and often requires leveraging external knowledge
or transfer from related domains.
Why Cold-Start Matters
The cold-start problem has significant business impact:
User Retention: Poor initial recommendations lead
to immediate churn. Studies show that users who receive irrelevant
recommendations in their first session are 3x more likely to leave.
Item Discovery: New items that don't get
recommended early remain invisible, creating a "rich get richer" problem
where popular items dominate.
Platform Growth: As platforms expand to new markets
or categories, cold-start becomes the primary barrier to providing
quality recommendations.
Mathematical Formulation
Formally, the cold-start recommendation problem can be stated as:
The challenge is that traditional collaborative filtering methods
rely on the assumption:\[\hat{r}_{ui} =
f(\mathbf{e}_u, \mathbf{e}_i)\]where\(\mathbf{e}_u\)and\(\mathbf{e}_i\)are learned embeddings. For
cold-start entities, these embeddings are either missing or poorly
initialized.
Meta-Learning Foundations
What Is Meta-Learning?
Meta-learning, or "learning to learn," is a paradigm where models are
trained to quickly adapt to new tasks with few examples. In
recommendation systems, meta-learning enables models to learn user
preferences or item characteristics from just a handful of
interactions.
The key insight: instead of learning a single recommendation
function, we learn a learning algorithm that can quickly adapt to new
users or items.
Few-Shot Learning Principles
Few-shot learning aims to learn from\(K\)examples (where\(K\)is small, typically 1-10). In
recommendation:
\(K\)-shot user
learning: Infer user preferences from\(K\)interactions
The meta-learning approach trains on many "tasks" (users or items),
each with few examples, so the model learns to extract maximum
information from limited data.
Meta-Learning Formulation
In meta-learning for recommendation, we define:
Meta-training: Set of tasks\(\mathcal{T}_{train} = \{T_1, T_2, \dots,
T_N\}\)where each task\(T_i\)corresponds to a user or item
Support set:\(K\)examples for task\(T_i\):\(\mathcal{S}_i = \{(x_1, y_1), \dots, (x_K,
y_K)\}\)
Query set: Test examples\(\mathcal{Q}_i\)for the same task
Meta-learner: Function\(f_\theta\)parameterized by\(\theta\)that learns from support set to
predict on query set
The meta-learning objective:\[\min_\theta
\sum_{T_i \in \mathcal{T}_{train }} \mathcal{L}(f_\theta(\mathcal{S}_i),
\mathcal{Q}_i)\]Where\(\mathcal{L}\)is the loss on query set
predictions.
import torch import torch.nn as nn from torch.utils.data import Dataset, DataLoader import numpy as np
classMetaLearningDataset(Dataset): """ Dataset for meta-learning where each task is a user. Each user has K support interactions and Q query interactions. """ def__init__(self, interaction_matrix, K=5, Q=5): """ Args: interaction_matrix: Sparse matrix of user-item interactions K: Number of support examples per user Q: Number of query examples per user """ self.interaction_matrix = interaction_matrix self.K = K self.Q = Q self.users = list(range(interaction_matrix.shape[0])) def__len__(self): returnlen(self.users) def__getitem__(self, idx): user_id = self.users[idx] # Get all interactions for this user user_interactions = self.interaction_matrix[user_id].toarray().flatten() interacted_items = np.where(user_interactions > 0)[0] iflen(interacted_items) < self.K + self.Q: # Skip users with insufficient interactions return self.__getitem__((idx + 1) % len(self.users)) # Randomly sample support and query sets np.random.shuffle(interacted_items) support_items = interacted_items[:self.K] query_items = interacted_items[self.K:self.K+self.Q] support_ratings = user_interactions[support_items] query_ratings = user_interactions[query_items] return { 'user_id': user_id, 'support_items': torch.LongTensor(support_items), 'support_ratings': torch.FloatTensor(support_ratings), 'query_items': torch.LongTensor(query_items), 'query_ratings': torch.FloatTensor(query_ratings) }
Meta-Learner Architectures
Model-Agnostic Meta-Learning
(MAML)
MAML learns a good initialization of model parameters such that a few
gradient steps on a new task produce good performance.
Algorithm: 1. Initialize parameters$\(2. For each task\)T_i\(:
- Sample support set\)i$ - Compute adapted
parameters:\(\theta'_i = \theta - \alpha
\nabla_\theta \mathcal{L}_{T_i}(f_\theta(\mathcal{S}_i))\) -
Evaluate on query set:${T_i}(f_{'i}(i))\(3. Update:\)- i
{T_i}(f{'_i}(_i))$ MAML for
Recommendation:
classMAMLRecommender(nn.Module): """ MAML-based recommender that learns to quickly adapt to new users. """ def__init__(self, num_items, embedding_dim=64, hidden_dim=128): super().__init__() self.item_embedding = nn.Embedding(num_items, embedding_dim) self.fc1 = nn.Linear(embedding_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, 1) self.relu = nn.ReLU() defforward(self, item_ids): """ Predict ratings for items. Args: item_ids: Tensor of shape (batch_size,) """ item_emb = self.item_embedding(item_ids) x = self.relu(self.fc1(item_emb)) ratings = self.fc2(x).squeeze() return ratings defpredict_user_ratings(self, item_ids, user_context=None): """ Predict ratings for a user. In MAML, user-specific adaptation happens through gradient updates, not through user embeddings. """ return self.forward(item_ids)
defmaml_train_step(model, task_batch, inner_lr=0.01, outer_lr=0.001): """ Perform one MAML training step. Args: model: MAMLRecommender instance task_batch: Batch of tasks (users) with support/query sets inner_lr: Learning rate for inner loop (task adaptation) outer_lr: Learning rate for outer loop (meta-learning) """ outer_loss = 0 adapted_params_list = [] # Inner loop: adapt to each task for task in task_batch: support_items = task['support_items'] support_ratings = task['support_ratings'] query_items = task['query_items'] query_ratings = task['query_ratings'] # Create a copy of parameters for this task adapted_params = {k: v.clone() for k, v in model.named_parameters()} # Inner loop: few gradient steps on support set for _ inrange(5): # Typically 1-5 steps # Forward pass on support set pred_support = model(support_items) loss_support = nn.MSELoss()(pred_support, support_ratings) # Compute gradients grads = torch.autograd.grad( loss_support, model.parameters(), create_graph=True# Important for second-order gradients ) # Update adapted parameters for (name, param), grad inzip(model.named_parameters(), grads): adapted_params[name] = param - inner_lr * grad # Evaluate adapted model on query set # Temporarily set model parameters to adapted_params original_params = {k: v.clone() for k, v in model.named_parameters()} for name, param in model.named_parameters(): param.data = adapted_params[name] pred_query = model(query_items) query_loss = nn.MSELoss()(pred_query, query_ratings) outer_loss += query_loss # Restore original parameters for name, param in model.named_parameters(): param.data = original_params[name] # Outer loop: update meta-parameters outer_loss = outer_loss / len(task_batch) outer_loss.backward() # Update parameters for param in model.parameters(): if param.grad isnotNone: param.data -= outer_lr * param.grad param.grad = None return outer_loss.item()
Prototypical Networks
Prototypical Networks learn a metric space where classification is
performed by computing distances to prototype representations of each
class.
For recommendation, we can treat each user as a "class" and learn
prototypes from their interaction patterns:
classPrototypicalRecommender(nn.Module): """ Prototypical Network for few-shot user recommendation. Each user is represented by a prototype computed from their support interactions. """ def__init__(self, num_items, embedding_dim=64, hidden_dim=128): super().__init__() self.item_embedding = nn.Embedding(num_items, embedding_dim) self.encoder = nn.Sequential( nn.Linear(embedding_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, hidden_dim) ) defcompute_prototype(self, support_items, support_ratings): """ Compute user prototype from support interactions. Args: support_items: Tensor of shape (K,) support_ratings: Tensor of shape (K,) Returns: prototype: Tensor of shape (hidden_dim,) """ item_emb = self.item_embedding(support_items) encoded = self.encoder(item_emb) # (K, hidden_dim) # Weight by ratings (higher ratings contribute more) weights = torch.softmax(support_ratings, dim=0) prototype = torch.sum(weights.unsqueeze(1) * encoded, dim=0) return prototype defpredict(self, query_items, prototype): """ Predict ratings by computing similarity to prototype. Args: query_items: Tensor of shape (Q,) prototype: Tensor of shape (hidden_dim,) Returns: ratings: Tensor of shape (Q,) """ item_emb = self.item_embedding(query_items) encoded = self.encoder(item_emb) # (Q, hidden_dim) # Compute cosine similarity prototype_norm = prototype / (torch.norm(prototype) + 1e-8) encoded_norm = encoded / (torch.norm(encoded, dim=1, keepdim=True) + 1e-8) similarities = torch.matmul(encoded_norm, prototype_norm.unsqueeze(0).T).squeeze() # Convert similarity to rating (scale to [1, 5]) ratings = 1 + 4 * (similarities + 1) / 2# Map [-1, 1] to [1, 5] return ratings
defprototypical_train_step(model, task_batch, lr=0.001): """ Training step for Prototypical Network. """ total_loss = 0 for task in task_batch: support_items = task['support_items'] support_ratings = task['support_ratings'] query_items = task['query_items'] query_ratings = task['query_ratings'] # Compute prototype from support set prototype = model.compute_prototype(support_items, support_ratings) # Predict on query set pred_ratings = model.predict(query_items, prototype) # Compute loss loss = nn.MSELoss()(pred_ratings, query_ratings) total_loss += loss total_loss = total_loss / len(task_batch) total_loss.backward() # Update parameters for param in model.parameters(): if param.grad isnotNone: param.data -= lr * param.grad param.grad = None return total_loss.item()
Mecos:
Meta-Learning for Cold-Start Recommendation
Mecos (Meta-Learning for Cold-Start Recommendation) is a framework
that combines meta-learning with collaborative filtering to address
cold-start problems.
Mecos Architecture
Mecos learns: 1. Item embeddings that capture
general item characteristics 2. User adaptation network
that quickly adapts to new users from few interactions 3. Rating
prediction function that combines item embeddings with
user-specific preferences
deftrain_mecos(model, dataloader, num_epochs=100, lr=0.001): """ Train Mecos model using meta-learning approach. """ optimizer = torch.optim.Adam(model.parameters(), lr=lr) criterion = nn.MSELoss() for epoch inrange(num_epochs): epoch_loss = 0 num_batches = 0 for batch in dataloader: optimizer.zero_grad() batch_loss = 0 for task in batch: support_items = task['support_items'] support_ratings = task['support_ratings'] query_items = task['query_items'] query_ratings = task['query_ratings'] # Adapt user from support interactions user_pref = model.adapt_user_from_interactions( support_items, support_ratings ) # Predict on query set pred_ratings = model(query_items, user_pref) # Compute loss loss = criterion(pred_ratings, query_ratings) batch_loss += loss batch_loss = batch_loss / len(batch) batch_loss.backward() optimizer.step() epoch_loss += batch_loss.item() num_batches += 1 avg_loss = epoch_loss / num_batches if num_batches > 0else0 if (epoch + 1) % 10 == 0: print(f"Epoch {epoch+1}/{num_epochs}, Loss: {avg_loss:.4f}") return model
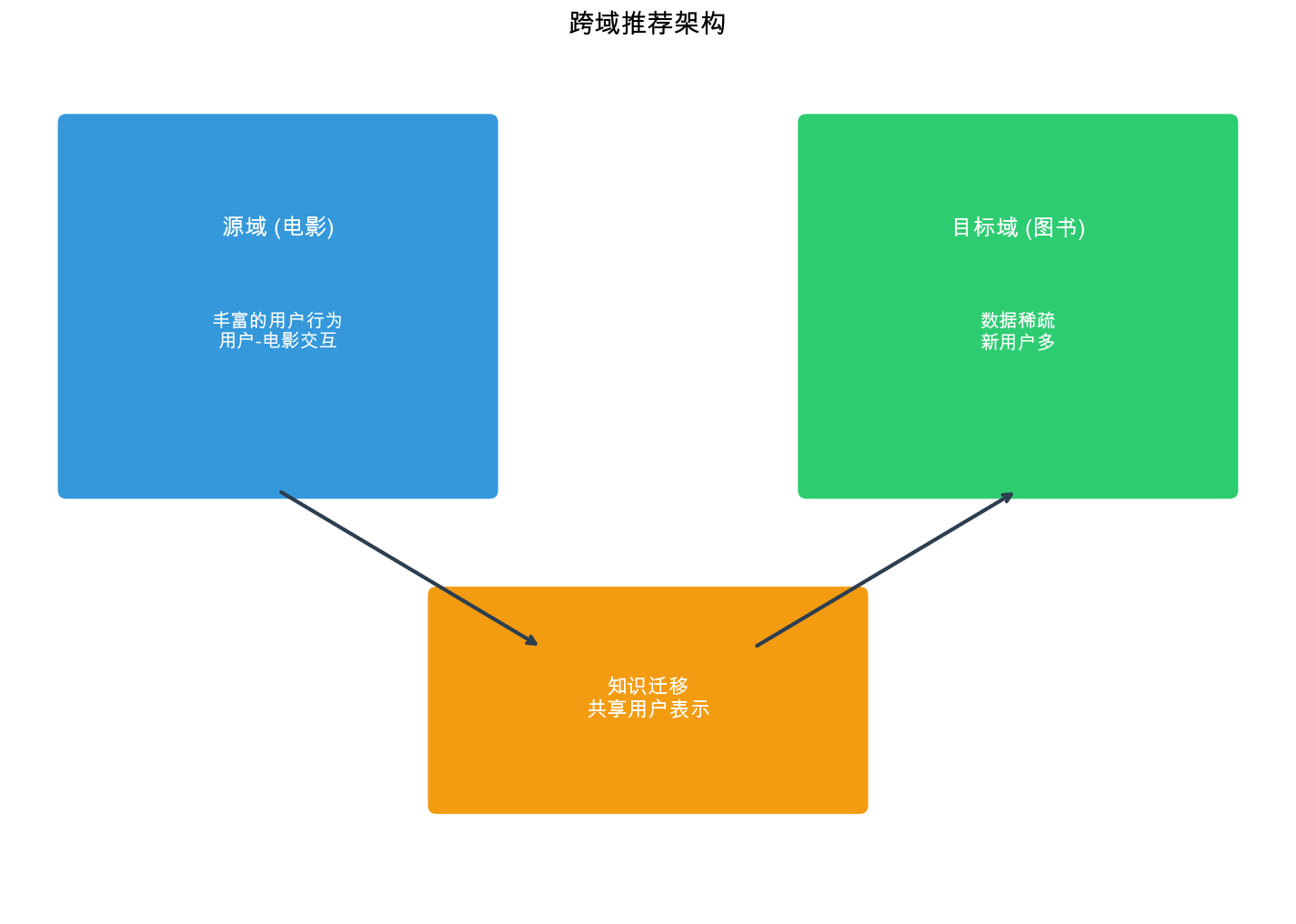
Cross-Domain
Recommendation Framework
Problem Definition
Cross-domain recommendation aims to improve recommendations in a
target domain by leveraging knowledge from a source domain with richer
data.
Domains: Different categories (movies vs. books),
platforms (Amazon vs. Netflix), or contexts (work vs. personal).
Key Challenge: How to transfer knowledge when
domains have: - Different item spaces (movies ≠ books) - Different user
bases (may overlap partially) - Different interaction patterns (ratings
vs. purchases)
Transfer Learning Taxonomy
Cross-domain transfer can be categorized by:
User Overlap:
Full overlap: Same users in both domains
Partial overlap: Some users appear in both
No overlap: Completely different user sets
Item Overlap:
Full overlap: Same items (e.g., same movies on
different platforms)
classInstanceBasedTransfer: """ Instance-based transfer: reweight source domain instances based on relevance to target domain. """ def__init__(self, source_interactions, target_interactions): """ Args: source_interactions: List of (user_id, item_id, rating) tuples target_interactions: List of (user_id, item_id, rating) tuples """ self.source_interactions = source_interactions self.target_interactions = target_interactions defcompute_instance_weights(self, user_similarity_matrix): """ Compute weights for source instances based on user similarity. Args: user_similarity_matrix: Matrix of user similarities between domains Returns: weights: Array of weights for each source instance """ weights = [] for user_id_src, item_id_src, rating_src in self.source_interactions: # Find similar users in target domain if user_id_src in user_similarity_matrix: similarities = user_similarity_matrix[user_id_src] # Weight by average similarity to target domain users weight = np.mean(list(similarities.values())) else: weight = 0.0 weights.append(weight) # Normalize weights weights = np.array(weights) if weights.sum() > 0: weights = weights / weights.sum() return weights defselect_relevant_instances(self, top_k=1000): """ Select top-k most relevant instances from source domain. """ # Compute user overlap source_users = set(u for u, _, _ in self.source_interactions) target_users = set(u for u, _, _ in self.target_interactions) overlapping_users = source_users & target_users # Score instances by user overlap and rating strength scored_instances = [] for user_id, item_id, rating in self.source_interactions: score = 0 if user_id in overlapping_users: score += 1.0# User appears in both domains score += abs(rating - 3.0) # Prefer strong preferences (far from neutral) scored_instances.append((score, (user_id, item_id, rating))) # Sort by score and return top-k scored_instances.sort(reverse=True) return [inst for _, inst in scored_instances[:top_k]]
Zero-Shot Transfer
Zero-shot transfer enables recommendation in target domain without
any target domain training data, relying entirely on source domain
knowledge and domain mappings.
Zero-Shot Learning
Formulation
Zero-shot recommendation assumes: - Training data:\(\mathcal{D}_{source} = \{(u, i, r)\}\)from
source domain - Item attributes:\(\mathbf{a}_i\)for items in both domains -
Goal: Predict ratings in target domain without target domain training
data
Key: learning a mapping from item attributes to item
representations:
classSocialBootstrap: """ Bootstrap recommendations using social network information. Assumes users with social connections have similar preferences. """ def__init__(self, social_graph): """ Args: social_graph: Dict mapping user_id to list of connected user_ids """ self.social_graph = social_graph defbootstrap_from_friends(self, cold_user_id, friend_ratings): """ Bootstrap ratings for cold-start user from their friends' ratings. Args: cold_user_id: Cold-start user friend_ratings: Dict mapping (friend_id, item_id) to rating Returns: predicted_ratings: Dict mapping item_id to predicted rating """ if cold_user_id notin self.social_graph: return {} friends = self.social_graph[cold_user_id] item_ratings = {} # item_id -> list of friend ratings for friend_id in friends: for (fid, item_id), rating in friend_ratings.items(): if fid == friend_id: if item_id notin item_ratings: item_ratings[item_id] = [] item_ratings[item_id].append(rating) # Average friend ratings for each item predicted_ratings = { item_id: np.mean(ratings) for item_id, ratings in item_ratings.items() } return predicted_ratings defcompute_social_influence(self, user_id, item_id, friend_interactions): """ Compute social influence score: how much friends' interactions should influence recommendation. """ if user_id notin self.social_graph: return0.0 friends = self.social_graph[user_id] friend_interaction_count = sum( 1for fid in friends if (fid, item_id) in friend_interactions ) # Normalize by number of friends influence = friend_interaction_count / len(friends) if friends else0.0 return influence
classColdStartRecommender: """ Complete cold-start recommendation system combining: - Meta-learning for few-shot adaptation - Bootstrap methods for initial predictions - Cross-domain transfer for domain expansion """ def__init__(self, num_items, num_users, embedding_dim=64): self.mecos_model = MecosRecommender(num_items, num_users, embedding_dim) self.content_bootstrap = None self.social_bootstrap = None self.is_trained = False deftrain(self, interaction_data, num_epochs=100): """Train the meta-learning model.""" # Prepare meta-learning dataset dataset = MetaLearningDataset(interaction_data, K=5, Q=5) dataloader = DataLoader(dataset, batch_size=32, shuffle=True) # Train Mecos self.mecos_model = train_mecos(self.mecos_model, dataloader, num_epochs) self.is_trained = True defrecommend_for_cold_start_user(self, user_id, available_items, initial_interactions=None, user_features=None, social_graph=None): """ Generate recommendations for cold-start user. Args: user_id: Cold-start user ID available_items: List of item IDs to consider initial_interactions: Optional few interactions (item_id, rating) pairs user_features: Optional user feature vector social_graph: Optional social connections """ if initial_interactions andlen(initial_interactions) > 0: # Use meta-learning if we have some interactions support_items = torch.LongTensor([i for i, _ in initial_interactions]) support_ratings = torch.FloatTensor([r for _, r in initial_interactions]) item_tensor = torch.LongTensor(available_items) predictions = self.mecos_model.predict_for_cold_start_user( item_tensor, support_items, support_ratings ) # Convert to dict recommendations = { item_id: float(pred) for item_id, pred inzip(available_items, predictions) } else: # Pure cold-start: use bootstrap methods recommendations = {} if self.content_bootstrap and user_features: # Content-based bootstrap for item_id in available_items: pred = self.content_bootstrap.bootstrap_user_preferences( user_id, {user_id: user_features}, [], {} ) recommendations[item_id] = pred if self.social_bootstrap and social_graph: # Social bootstrap social_preds = self.social_bootstrap.bootstrap_from_friends( user_id, {} ) recommendations.update(social_preds) # Default: return popular items if no bootstrap available ifnot recommendations: recommendations = {item_id: 3.0for item_id in available_items} # Sort by predicted rating sorted_recommendations = sorted( recommendations.items(), key=lambda x: x[1], reverse=True ) return sorted_recommendations defrecommend_for_cold_start_item(self, item_id, user_pool, item_features=None, similar_items=None): """ Generate recommendations for cold-start item. """ recommendations = {} if item_features and self.content_bootstrap: # Use content similarity to similar items if similar_items: similar_ratings = { sim_item: 4.0# Assume similar items are liked for sim_item in similar_items } pred = self.content_bootstrap.bootstrap_item_ratings( item_id, similar_items, similar_ratings ) # Recommend to users who liked similar items for user_id in user_pool: recommendations[user_id] = pred return recommendations
Questions and Answers
Q1:
What's the difference between cold-start and warm-start
recommendation?
A: Warm-start recommendation refers to scenarios
where both users and items have sufficient interaction history.
Traditional collaborative filtering methods work well here because they
can learn reliable embeddings from historical data. Cold-start refers to
scenarios where either users (user cold-start), items (item cold-start),
or both (system cold-start) lack sufficient interaction history.
Cold-start requires special techniques like meta-learning, transfer
learning, or bootstrap methods that can make predictions with limited or
no historical data.
Q2:
When should I use meta-learning vs. transfer learning for
cold-start?
A: Meta-learning is ideal when you have many
users/items but each has few interactions. It learns a learning
algorithm that quickly adapts to new entities from few examples.
Transfer learning is better when you have a source domain with rich data
and want to transfer knowledge to a target domain with sparse data. Use
meta-learning for within-domain cold-start (new users/items in same
domain), and transfer learning for cross-domain scenarios (different
categories, platforms, or contexts).
Q3:
How many interactions do I need for few-shot recommendation to
work?
A: Typically, 3-10 interactions are sufficient for
few-shot recommendation to provide reasonable predictions. Meta-learning
models like Mecos can work with as few as 1-2 interactions, though
performance improves with 5-10 interactions. The exact number depends
on: - Item diversity: More diverse interactions provide better signal -
Interaction quality: Explicit ratings are more informative than implicit
clicks - Model architecture: Some models are more sample-efficient than
others
Q4:
Can zero-shot transfer work without any target domain data?
A: Yes, that's the definition of zero-shot transfer.
It relies entirely on: 1. Source domain training data 2. Item/user
attributes that bridge domains 3. A learned mapping from attributes to
representations
However, zero-shot performance is typically lower than methods that
use some target domain data. For best results, combine zero-shot
transfer with a small amount of target domain fine-tuning (few-shot
transfer).
Q5: How
do I choose between different bootstrap methods?
A: The choice depends on available auxiliary
information: - Content-based bootstrap: Use when you
have rich item features (text, images, metadata) - Social
bootstrap: Use when you have social network data and users'
friends have interaction history - Collaborative
bootstrap: Use when you can find similar users/items even with
sparse data - Hybrid approach: Combine multiple methods
when multiple signals are available
In practice, hybrid approaches often perform best because they're
more robust to missing or noisy auxiliary information.
Q6:
What are the computational costs of meta-learning compared to
traditional methods?
A: Meta-learning has higher computational costs: -
Training: Requires multiple inner-loop gradient steps
per task, making training slower (often 3-10x) -
Inference: For cold-start entities, requires forward
passes through adaptation networks, but this is usually acceptable -
Memory: Needs to store gradients for second-order
optimization (in MAML), increasing memory usage
However, the benefits (better cold-start performance, faster
adaptation) often justify the costs, especially for platforms with many
new users/items.
Q7: How
do I evaluate cold-start recommendation systems?
A: Use evaluation protocols that simulate cold-start
scenarios: 1. Temporal split: Train on older data, test
on newer users/items 2. Leave-one-out: For each
user/item, use K interactions for training, rest for testing 3.
Cold-start simulation: Randomly select users/items, use
only K interactions for training 4. Cross-domain
evaluation: Train on source domain, test on target domain
Metrics should focus on: - Accuracy: RMSE, MAE for
ratings; Precision@K, Recall@K for ranking - Coverage:
How many cold-start entities get recommendations -
Diversity: Whether recommendations are diverse or stuck
in popular items
Q8:
Can GNNs handle cross-domain recommendation when domains have no
overlap?
A: GNNs can handle zero-overlap scenarios if there
are bridge entities or attributes: - Attribute bridges:
Items from different domains share attributes (e.g., genre, author) -
User bridges: Users appear in both domains (even if
items don't overlap) - Meta-paths: Multi-hop paths
connecting domains through shared attributes
However, performance degrades with less overlap. For zero-overlap
scenarios, attribute-based zero-shot transfer is often more effective
than GNNs.
Q9:
How do I handle the cold-start problem in production systems?
A: Production cold-start strategies typically
involve: 1. Multi-stage pipeline: Bootstrap → Few-shot
learning → Full model 2. A/B testing: Compare
meta-learning vs. bootstrap vs. popular items 3. Fallback
strategies: Default to popular/trending items if predictions
are uncertain 4. Active learning: Prompt users for
initial preferences to bootstrap faster 5. Real-time
adaptation: Update user/item representations as new
interactions arrive
Start simple (popular items, content similarity), then gradually
introduce more sophisticated methods (meta-learning, transfer learning)
as you validate their impact.
Q10:
What are common pitfalls when implementing cross-domain
recommendation?
A: Common pitfalls include: 1. Negative
transfer: Source domain knowledge hurts target domain
performance. Solution: Use domain-specific components and careful
transfer. 2. Domain mismatch: Assuming domains are more
similar than they are. Solution: Validate transfer assumptions, use
domain adaptation techniques. 3. Overfitting to source:
Model memorizes source domain patterns. Solution: Regularization, domain
adversarial training. 4. Ignoring domain-specific
patterns: Over-emphasizing shared patterns. Solution: Balance
shared and domain-specific components. 5. Evaluation on wrong
split: Testing on users/items that appear in training.
Solution: Strict temporal or domain-based splits.
Q11:
How does Mecos compare to traditional matrix factorization for
cold-start?
A: Traditional matrix factorization (MF) fails for
cold-start because it can't learn embeddings for new users/items. Mecos
addresses this by: - Learning to adapt quickly from few interactions
(meta-learning) - Using adaptation networks instead of fixed embeddings
- Training on many cold-start scenarios to learn adaptation patterns
Mecos typically outperforms MF for cold-start by 20-40% in terms of
recommendation accuracy, though MF may still be better for warm-start
scenarios with abundant data.
Q12:
Can I combine meta-learning with deep learning architectures like
Transformers?
A: Yes, meta-learning is architecture-agnostic. You
can apply MAML or Prototypical Networks to Transformer-based
recommenders: - Use Transformers to encode user interaction sequences -
Apply meta-learning to learn how to adapt Transformer parameters quickly
- This combines sequence modeling (Transformers) with fast adaptation
(meta-learning)
Recent work shows Transformer + meta-learning achieves
state-of-the-art cold-start performance, especially for sequential
recommendation tasks.
Q13:
What's the role of item attributes in zero-shot transfer?
A: Item attributes are crucial for zero-shot
transfer because they provide the bridge between domains: -
Shared attributes: Enable mapping items across domains
(e.g., genre, author, topic) - Attribute embeddings:
Learn to map attributes to item representations -
Attribute-based similarity: Items with similar
attributes get similar embeddings regardless of domain
Without attributes, zero-shot transfer is impossible. With rich
attributes, zero-shot can achieve 60-80% of fully-supervised
performance.
Q14:
How do bootstrap methods perform compared to learning-based
methods?
A: Bootstrap methods are simpler and faster but
typically less accurate: - Bootstrap: Fast,
interpretable, works with minimal data, but limited by auxiliary
information quality - Learning-based
(meta-learning/transfer): More accurate, learns complex
patterns, but requires training and more computation
In practice, use bootstrap for initial recommendations, then
transition to learning-based methods as more data becomes available.
Hybrid approaches that combine both often perform best.
Q15:
What are the latest advances in cold-start recommendation?
A: Recent advances include: 1. LLM-based
cold-start: Using large language models for zero-shot
recommendation from item descriptions 2. Contrastive
learning: Learning representations that work well for
cold-start through contrastive objectives 3. Foundation
models: Pre-trained recommendation models that adapt quickly to
new domains 4. Causal recommendation: Understanding
causal relationships to improve cold-start predictions 5.
Multi-modal transfer: Combining text, image, and graph
signals for richer cold-start representations
These methods are pushing cold-start performance closer to warm-start
performance, making recommendation systems more robust for real-world
deployment.
Conclusion
Cold-start and cross-domain recommendation represent fundamental
challenges that every recommendation system must address. Whether
launching in new markets, adding new product categories, or onboarding
new users, the ability to make quality recommendations with limited data
is critical for platform growth and user satisfaction.
Meta-learning provides a powerful framework for learning to learn
quickly, enabling models to adapt to new users and items from just a
handful of interactions. Transfer learning extends this capability
across domains, leveraging knowledge from data-rich source domains to
improve recommendations in sparse target domains. Bootstrap methods
offer practical, interpretable solutions that work immediately without
training, making them ideal for initial deployments.
The combination of these approaches — meta-learning for fast
adaptation, transfer learning for cross-domain knowledge sharing, and
bootstrap methods for immediate cold-start handling — creates robust
recommendation systems that can thrive even in the most challenging
scenarios. As recommendation systems continue to evolve, advances in
foundation models, contrastive learning, and LLM integration promise to
further bridge the gap between cold-start and warm-start performance,
making personalized recommendation accessible from the very first
interaction.
Post title:Recommendation Systems (14): Cross-Domain Recommendation and Cold-Start Solutions
Post author:Chen Kai
Create time:2026-02-03 23:11:11
Post link:https://www.chenk.top/recommendation-systems-14-cross-domain-cold-start/
Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.