Recommendation Systems (13): Fairness, Debiasing, and Explainability
Chen KaiBOSS
2026-02-03 23:11:112026-02-03 23:1110k Words62 Mins
permalink: "en/recommendation-systems-13-fairness-explainability/"
date: 2024-07-01 09:00:00 tags: - Recommendation Systems - Fairness -
Explainability categories: Recommendation Systems mathjax: true--- When
Netflix recommends "The Crown" to a user who watched "The Queen," the
system might appear to understand historical dramas, but hidden biases
could be at play: are historical dramas featuring women being
systematically under-recommended? When Amazon suggests products, are
certain demographics receiving lower-quality recommendations? These
questions highlight two critical challenges in modern recommendation
systems: fairness and explainability. As recommendation systems
increasingly influence what we watch, buy, and discover, ensuring they
are fair (treating all users and items equitably) and explainable
(providing transparent reasoning for recommendations) has become not
just an ethical imperative but a business necessity.
Fairness in recommendation systems addresses systematic biases that
can disadvantage certain user groups or item categories. These biases
can emerge from imbalanced training data, algorithmic design choices, or
feedback loops that amplify existing inequalities. Explainability, on
the other hand, addresses the "black box" problem: users and
stakeholders need to understand why recommendations are made, not just
accept them blindly. Together, fairness and explainability form the
foundation of trustworthy recommendation systems that users can rely on
and regulators can audit.
This article provides a comprehensive exploration of fairness and
explainability in recommendation systems, covering bias types and their
sources, causal inference foundations for understanding recommendation
effects, counterfactual reasoning for fair recommendation, CFairER
(Counterfactual Fairness in Recommendation), debiasing methods
(pre-processing, in-processing, and post-processing), explainable
recommendation techniques, attention visualization, LIME and SHAP for
model interpretation, trust-building strategies, and practical
implementations with 10+ code examples and detailed Q&A sections
addressing common challenges and design decisions.
Understanding Bias
in Recommendation Systems
Types of Bias in
Recommendation Systems
Bias in recommendation systems manifests in multiple forms, each with
distinct causes and consequences:
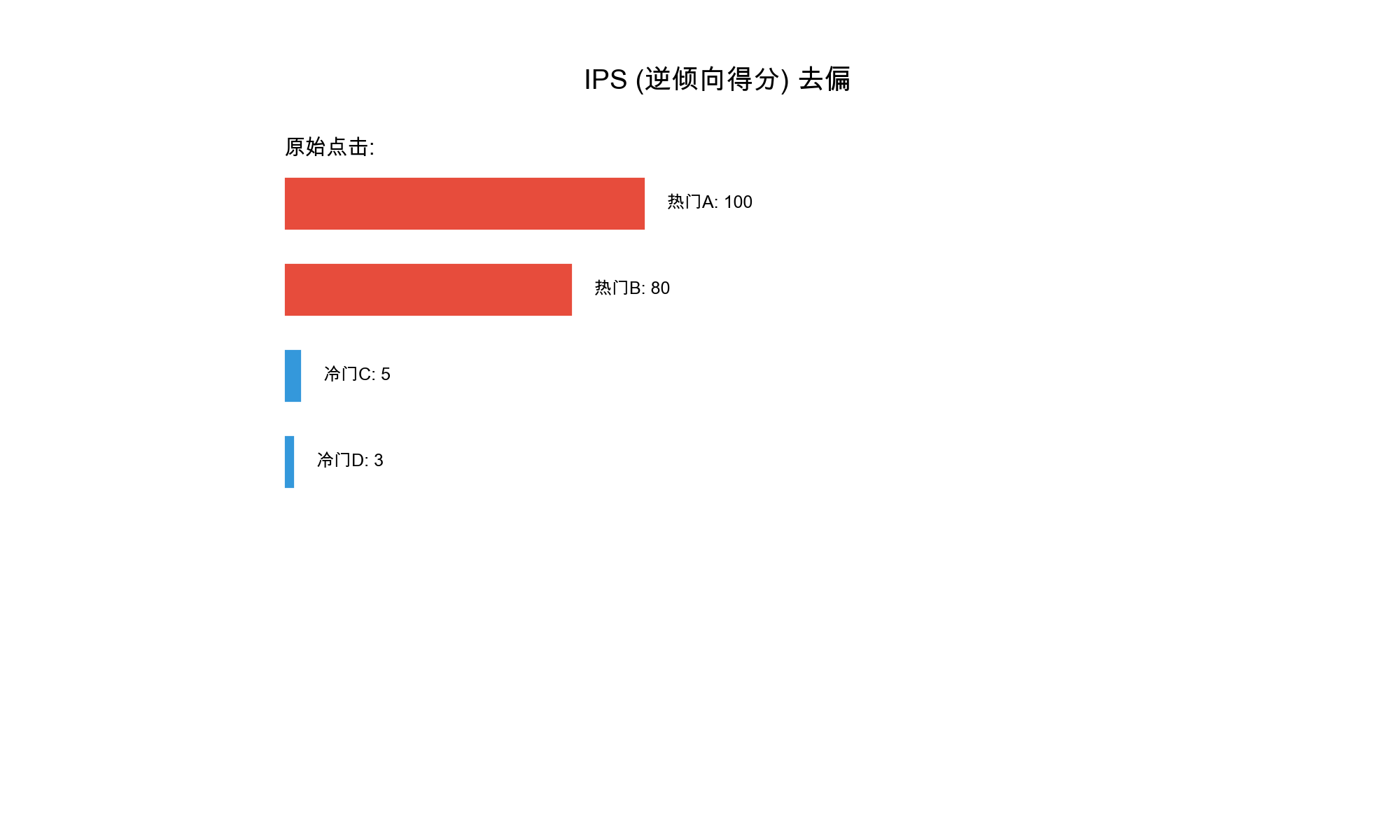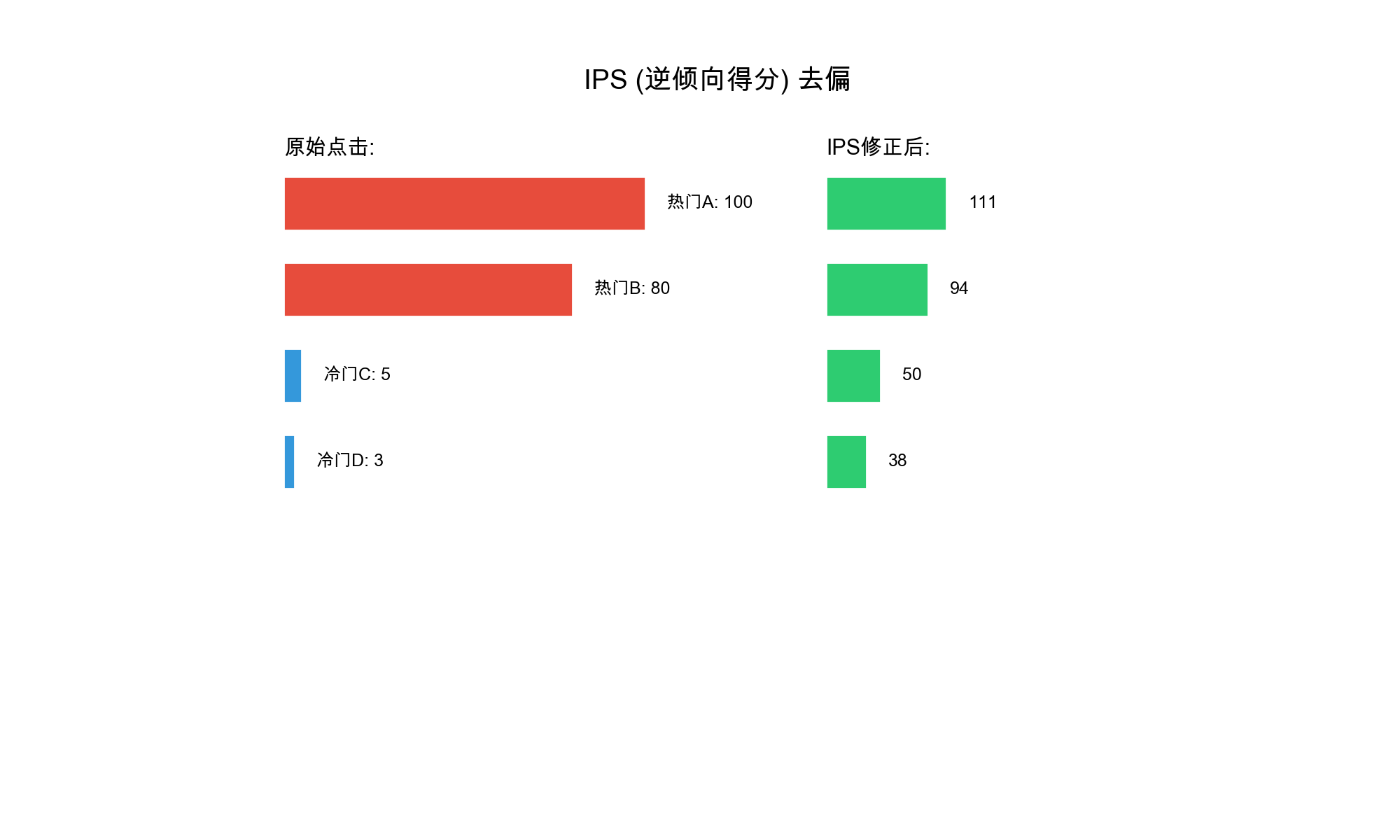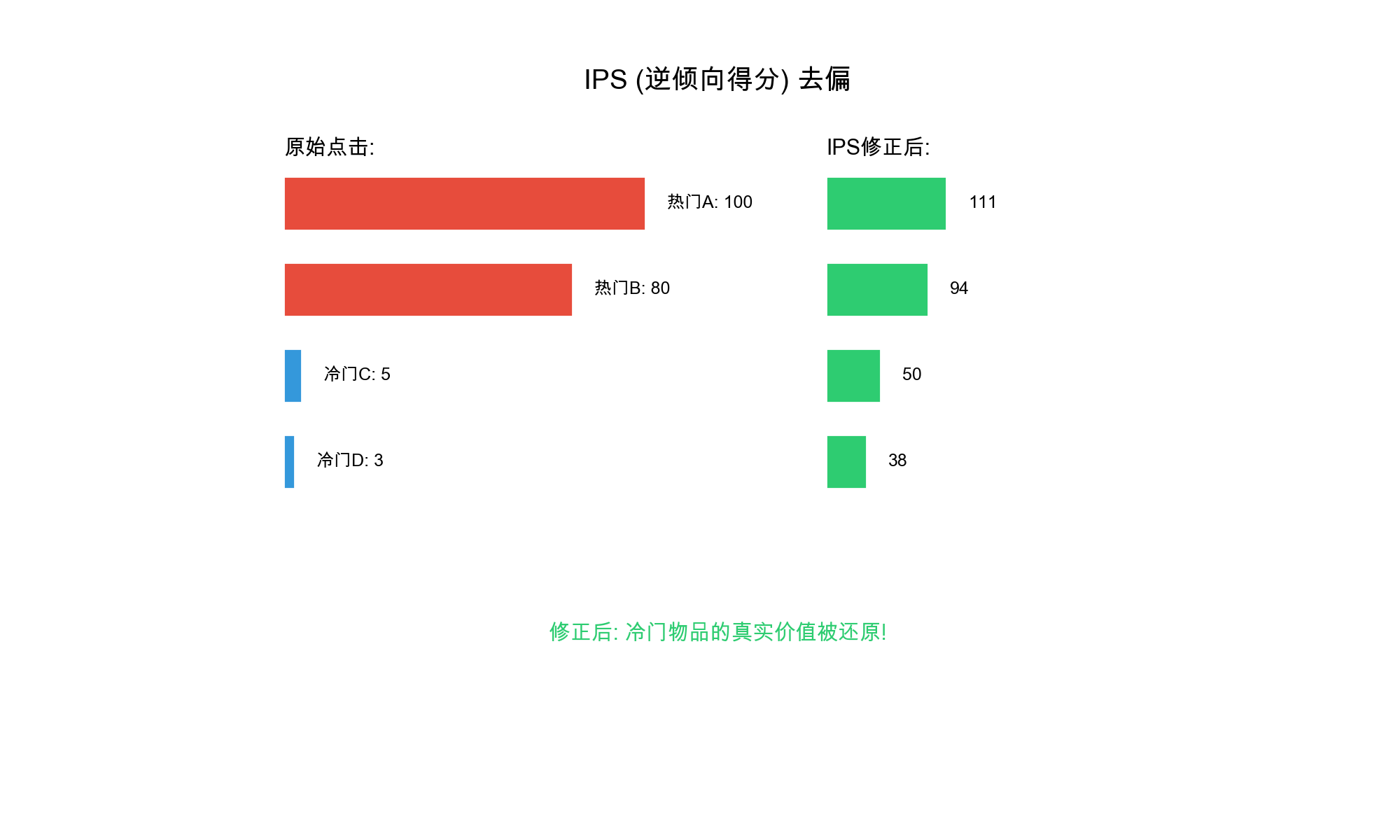
1. Popularity Bias
Popularity bias occurs when recommendation systems disproportionately
favor popular items, creating a "rich get richer" effect where popular
items receive even more exposure while less popular items remain
obscure.
Mathematically, if \(p(i)\)is the
popularity of item\(i\)(e.g., number of
interactions), and\(\hat{r}_{ui}\)is
the predicted rating, popularity bias can be measured as:\[\text{Popularity Bias} = \frac{\sum_{i \in
I_{\text{rec }}} p(i)}{|I_{\text{rec }}|} - \frac{\sum_{i \in I}
p(i)}{|I|}\]where\(I_{\text{rec
}}\)is the set of recommended items and\(I\)is the entire item catalog.
2. Gender Bias
Gender bias occurs when recommendations systematically differ based
on user gender or when items associated with certain genders receive
unequal treatment. For example, a system might recommend action movies
more frequently to male users and romance movies to female users,
reinforcing stereotypes.
3. Demographic Bias
Demographic bias extends beyond gender to include race, age,
location, and other protected attributes. Systems may provide
lower-quality recommendations to certain demographic groups due to
imbalanced training data or algorithmic design.
4. Confirmation Bias
Confirmation bias occurs when systems reinforce users' existing
preferences without introducing diversity, creating "filter bubbles"
that limit exposure to new content.
5. Position Bias
Position bias refers to the tendency of users to interact more with
items shown at the top of recommendation lists, regardless of relevance.
This creates a feedback loop where top positions become
self-reinforcing.
6. Selection Bias
Selection bias arises from the fact that observed interactions are
not random — users only interact with items they're exposed to, creating
a biased sample of true preferences.
7. Exposure Bias
Exposure bias occurs when certain items or user groups receive
systematically less exposure in recommendations, leading to unfair
treatment.
Sources of Bias
Bias can originate from multiple sources:
Data-Level Bias: - Historical discrimination
reflected in training data - Imbalanced representation of user groups or
item categories - Missing data from underrepresented groups
Algorithm-Level Bias: - Optimization objectives that
favor popular items - Collaborative filtering amplifying existing
patterns - Lack of diversity constraints
Feedback Loop Bias: - Users interact more with
recommended items - These interactions reinforce the recommendation
patterns - Creates a self-perpetuating cycle
Evaluation Bias: - Metrics that don't account for
fairness - Test sets that don't represent all user groups - Offline
metrics that don't reflect real-world fairness
Measuring Bias
To address bias, we must first measure it. Here's a comprehensive
bias measurement framework:
Code Purpose: This code implements a comprehensive
bias measurement framework for recommendation systems. It provides
multiple metrics to quantify different types of biases (popularity bias,
demographic bias, diversity, etc.), enabling systematic evaluation of
fairness in recommendation systems.
Overall Approach: 1. Multiple Bias
Metrics: Implements various bias measurement methods including
popularity bias, Gini coefficient, demographic parity, item coverage,
and diversity 2. Flexible Input: Accepts
recommendations, item popularity, and optional user/item group
information 3. Quantitative Analysis: Provides
numerical scores for each bias type, enabling comparison and tracking
over time 4. Comprehensive Coverage: Measures both
item-level biases (popularity, coverage) and user-level biases
(demographic parity)
Traditional recommendation systems learn correlations: "users who
watched X also watched Y." But correlations don't imply causation.
Causal inference helps us understand: - Why
recommendations work (causal mechanisms) - What would
happen if we changed the recommendation strategy
(counterfactuals) - Whether recommendations cause user
satisfaction or just correlate with it
Basic Causal Concepts
Potential Outcomes Framework
For a user\(u\)and item\(i\), we define: -\(Y_{ui}(1)\): outcome if item\(i\)is recommended (treatment = 1) -\(Y_{ui}(0)\): outcome if item\(i\)is not recommended (treatment = 0)
The Individual Treatment Effect (ITE) is:\[\text{ITE}_{ui} = Y_{ui}(1) -
Y_{ui}(0)\]Since we can only observe one outcome, we estimate the
Average Treatment Effect (ATE):\[\text{ATE} = \mathbb{E}[Y_{ui}(1) -
Y_{ui}(0)]\]
Confounding Variables
Confounders are variables that affect both treatment (recommendation)
and outcome (user satisfaction). For example: - User preference affects
both what gets recommended and satisfaction - Item popularity affects
both recommendation probability and user interaction
Causal Graph
A causal graph represents relationships between variables:
1 2 3
User Preference → Recommendation → User Satisfaction ↓ ↑ Item Quality ────────────────────┘
Causal Inference Methods
1. Randomized Controlled Trials (RCT)
The gold standard: randomly assign recommendations and measure
outcomes.
Code Purpose: This code implements a Randomized
Controlled Trial (RCT) framework for recommendation systems, which is
the gold standard for causal inference. RCTs randomly assign
recommendations to users, eliminating selection bias and providing
unbiased estimates of recommendation effects.
Overall Approach: 1. Random Treatment
Assignment: Randomly assign recommendations with a specified
probability 2. Outcome Recording: Track user outcomes
(ratings, clicks) for both treated and control groups 3. ATE
Estimation: Calculate Average Treatment Effect by comparing
treated and control group outcomes 4. ITE
Approximation: Estimate Individual Treatment Effect using
matching methods (simplified implementation)
classRCTRecommender: """Randomized Controlled Trial for recommendation""" def__init__(self, items: List[int], treatment_prob: float = 0.5): """ Args: items: List of item IDs treatment_prob: Probability of recommending each item """ self.items = items self.treatment_prob = treatment_prob self.treatment_assignment = {} self.outcomes = {} defassign_treatment(self, user_id: int, item_id: int) -> bool: """ Randomly assign treatment (recommendation). Returns: True if item is recommended, False otherwise """ np.random.seed(hash((user_id, item_id)) % 2**32) assigned = np.random.random() < self.treatment_prob self.treatment_assignment[(user_id, item_id)] = assigned return assigned defrecord_outcome(self, user_id: int, item_id: int, outcome: float): """Record user outcome (e.g., rating, click)""" self.outcomes[(user_id, item_id)] = outcome defestimate_ate(self) -> float: """ Estimate Average Treatment Effect. Returns: ATE estimate """ treatment_outcomes = [] control_outcomes = [] for (user_id, item_id), outcome in self.outcomes.items(): if self.treatment_assignment.get((user_id, item_id), False): treatment_outcomes.append(outcome) else: control_outcomes.append(outcome) ifnot treatment_outcomes ornot control_outcomes: return0.0 ate = np.mean(treatment_outcomes) - np.mean(control_outcomes) return ate defestimate_ite(self, user_id: int, item_id: int) -> float: """ Estimate Individual Treatment Effect using matching. Note: True ITE is unobservable, this is an approximation. """ # Find similar users who didn't receive treatment # This is simplified - real implementation would use matching treatment_outcome = self.outcomes.get((user_id, item_id), None) if treatment_outcome isNone: return0.0 # Estimate control outcome from similar users # (simplified - would use propensity score matching in practice) control_outcomes = [ outcome for (uid, iid), outcome in self.outcomes.items() if uid != user_id and iid == item_id andnot self.treatment_assignment.get((uid, iid), False) ] ifnot control_outcomes: return0.0 control_outcome = np.mean(control_outcomes) return treatment_outcome - control_outcome
2. Propensity Score Matching
Match treated and control units with similar propensity scores
(probability of treatment).
Code Purpose: This code implements Propensity Score
Matching (PSM), a causal inference method that matches treated and
control units with similar propensity scores (probability of receiving
treatment). This helps eliminate confounding bias when random assignment
is not possible.
Overall Approach: 1. Propensity Score
Estimation: Use logistic regression to estimate the probability
of treatment given covariates 2. Matching: Match each
treated unit with the nearest control unit based on propensity scores 3.
ATE Estimation: Calculate Average Treatment Effect
using matched pairs, reducing bias from confounding variables
from sklearn.linear_model import LogisticRegression from sklearn.neighbors import NearestNeighbors
classPropensityScoreMatching: """Propensity score matching for causal inference""" def__init__(self): self.propensity_model = LogisticRegression() self.nn_model = NearestNeighbors(n_neighbors=1) deffit_propensity_model(self, X: np.ndarray, treatment: np.ndarray): """ Fit propensity score model. Args: X: User/item features treatment: Binary treatment indicator """ self.propensity_model.fit(X, treatment) defcompute_propensity_scores(self, X: np.ndarray) -> np.ndarray: """Compute propensity scores""" return self.propensity_model.predict_proba(X)[:, 1] defmatch(self, X_treated: np.ndarray, X_control: np.ndarray, propensity_treated: np.ndarray, propensity_control: np.ndarray) -> List[Tuple[int, int]]: """ Match treated and control units. Returns: List of (treated_idx, control_idx) pairs """ # Build nearest neighbor index on control units self.nn_model.fit(propensity_control.reshape(-1, 1)) matches = [] for i, ps inenumerate(propensity_treated): # Find nearest control unit distances, indices = self.nn_model.kneighbors( ps.reshape(1, -1) ) matches.append((i, indices[0][0])) return matches defestimate_ate(self, X_treated: np.ndarray, X_control: np.ndarray, y_treated: np.ndarray, y_control: np.ndarray) -> float: """Estimate ATE using propensity score matching""" # Compute propensity scores ps_treated = self.compute_propensity_scores(X_treated) ps_control = self.compute_propensity_scores(X_control) # Match matches = self.match(X_treated, X_control, ps_treated, ps_control) # Compute matched outcomes matched_diffs = [] for treated_idx, control_idx in matches: diff = y_treated[treated_idx] - y_control[control_idx] matched_diffs.append(diff) return np.mean(matched_diffs)
3. Instrumental Variables
Use variables that affect treatment but not outcome directly.
Code Purpose: This code implements Instrumental
Variable (IV) estimation using Two-Stage Least Squares (2SLS). IV
methods are used when treatment assignment is not random and there are
unobserved confounders. An instrumental variable affects treatment but
not outcome directly, allowing us to identify causal effects.
Overall Approach: 1. First Stage:
Predict treatment from instrumental variables and confounders 2.
Second Stage: Predict outcome from predicted treatment
and confounders 3. ATE Estimation: Extract the
treatment coefficient from the second stage model as the causal effect
estimate
classInstrumentalVariableEstimator: """Instrumental variable estimation for causal inference""" def__init__(self): self.first_stage_model = None self.second_stage_model = None deffit(self, Z: np.ndarray, X: np.ndarray, treatment: np.ndarray, outcome: np.ndarray): """ Two-stage least squares (2SLS). Args: Z: Instrumental variables X: Confounders treatment: Treatment variable outcome: Outcome variable """ from sklearn.linear_model import LinearRegression # First stage: predict treatment from instruments self.first_stage_model = LinearRegression() ZX = np.hstack([Z, X]) self.first_stage_model.fit(ZX, treatment) treatment_pred = self.first_stage_model.predict(ZX) # Second stage: predict outcome from predicted treatment self.second_stage_model = LinearRegression() treatment_X = np.hstack([treatment_pred.reshape(-1, 1), X]) self.second_stage_model.fit(treatment_X, outcome) defestimate_ate(self) -> float: """Estimate ATE from second stage model""" # Coefficient on treatment variable return self.second_stage_model.coef_[0]
Counterfactual Reasoning
What Are Counterfactuals?
Counterfactuals answer "what if" questions: "What would have happened
if we recommended a different item?" This is crucial for: -
Fairness: Ensuring recommendations would be similar for
similar users regardless of protected attributes -
Explainability: Understanding why recommendations were
made - Debiasing: Identifying and correcting unfair
patterns
Counterfactual Fairness
A recommendation system is counterfactually fair if, for any user,
changing their protected attributes (e.g., gender, race) while keeping
other attributes constant would not change the recommendations.
Formally, for protected attribute\(A\)and recommendation function\(f\):\[P(f(X,
A=a) = y | X=x, A=a) = P(f(X, A=a') = y | X=x, A=a')\]for
all\(a, a'\)and\(x, y\).
Implementing
Counterfactual Reasoning
Code Purpose: This code implements a counterfactual
reasoning framework for fair recommendation. It enables answering "what
if" questions: what would happen if we changed a user's protected
attributes (e.g., gender, race) while keeping other attributes constant?
This is crucial for ensuring counterfactual fairness.
Overall Approach: 1. Embedding-Based
Model: Use user and item embeddings to predict recommendation
scores 2. Protected Attribute Handling: Allow
specification of protected attributes for users 3.
Counterfactual Generation: Generate counterfactual
recommendations by changing protected attributes 4. Fairness
Evaluation: Compare factual and counterfactual recommendations
to assess fairness
import torch import torch.nn as nn from typing importDict, List, Tuple
classCounterfactualRecommender: """Counterfactual reasoning for fair recommendation""" def__init__(self, num_users: int, num_items: int, embedding_dim: int = 64): """ Args: num_users: Number of users num_items: Number of items embedding_dim: Embedding dimension """ self.user_embedding = nn.Embedding(num_users, embedding_dim) self.item_embedding = nn.Embedding(num_items, embedding_dim) self.predictor = nn.Sequential( nn.Linear(embedding_dim * 2, 128), nn.ReLU(), nn.Linear(128, 1), nn.Sigmoid() ) self.protected_attributes = {} # {user_id: protected_attr} defset_protected_attributes(self, protected_attrs: Dict[int, int]): """Set protected attributes for users""" self.protected_attributes = protected_attrs defforward(self, user_ids: torch.Tensor, item_ids: torch.Tensor, counterfactual_attrs: Dict[int, int] = None) -> torch.Tensor: """ Forward pass with optional counterfactual attributes. Args: user_ids: User IDs item_ids: Item IDs counterfactual_attrs: Counterfactual protected attributes Returns: Prediction scores """ user_emb = self.user_embedding(user_ids) item_emb = self.item_embedding(item_ids) # Apply counterfactual transformation if specified if counterfactual_attrs: user_emb = self._apply_counterfactual(user_emb, user_ids, counterfactual_attrs) combined = torch.cat([user_emb, item_emb], dim=1) scores = self.predictor(combined) return scores def_apply_counterfactual(self, user_emb: torch.Tensor, user_ids: torch.Tensor, counterfactual_attrs: Dict[int, int]) -> torch.Tensor: """ Apply counterfactual transformation to embeddings. This is a simplified version - real implementation would use more sophisticated methods like adversarial training. """ # In practice, this would involve: # 1. Learning attribute-specific transformations # 2. Removing attribute information from embeddings # 3. Adding counterfactual attribute information # Simplified: just return original embeddings # Real implementation would modify embeddings based on attributes return user_emb defcounterfactual_fairness_loss(self, user_ids: torch.Tensor, item_ids: torch.Tensor, scores: torch.Tensor) -> torch.Tensor: """ Compute counterfactual fairness loss. Ensures that changing protected attributes doesn't change predictions. """ # Get protected attributes protected_attrs = torch.tensor([ self.protected_attributes.get(uid.item(), 0) for uid in user_ids ]) # Generate counterfactual attributes (flip binary attributes) counterfactual_attrs = { uid.item(): 1 - self.protected_attributes.get(uid.item(), 0) for uid in user_ids } # Get counterfactual predictions counterfactual_scores = self.forward(user_ids, item_ids, counterfactual_attrs) # Fairness loss: minimize difference between factual and counterfactual fairness_loss = nn.MSELoss()(scores, counterfactual_scores) return fairness_loss defrecommend(self, user_id: int, top_k: int = 10, use_counterfactual: bool = False) -> List[int]: """ Generate recommendations for a user. Args: user_id: User ID top_k: Number of recommendations use_counterfactual: Whether to use counterfactual reasoning """ self.eval() user_tensor = torch.tensor([user_id]) all_items = torch.arange(self.item_embedding.num_embeddings) # Expand user tensor to match items user_ids_expanded = user_tensor.repeat(len(all_items)) counterfactual_attrs = None if use_counterfactual: # Use counterfactual attributes original_attr = self.protected_attributes.get(user_id, 0) counterfactual_attrs = {user_id: 1 - original_attr} with torch.no_grad(): scores = self.forward(user_ids_expanded, all_items, counterfactual_attrs) # Get top-k items top_scores, top_indices = torch.topk(scores.squeeze(), top_k) return top_indices.tolist()
CFairER:
Counterfactual Fairness in Recommendation
CFairER (Counterfactual Fairness in Recommendation) is a framework
that ensures recommendations are counterfactually fair by learning
representations that are invariant to protected attributes.
CFairER Architecture
CFairER consists of: 1. Encoder: Maps users and
items to embeddings 2. Predictor: Predicts ratings from
embeddings 3. Adversarial Discriminator: Tries to
predict protected attributes from embeddings 4. Fairness
Regularizer: Ensures embeddings don't encode protected
information
classFairSampler: """Sample interactions fairly across user/item groups""" def__init__(self, user_groups: Dict[int, str] = None, item_groups: Dict[int, str] = None): self.user_groups = user_groups or {} self.item_groups = item_groups or {} defsample(self, interactions: pd.DataFrame, sample_size: int, user_col: str = 'user_id', item_col: str = 'item_id') -> pd.DataFrame: """ Sample interactions ensuring fair representation. Args: interactions: Original interactions sample_size: Target sample size user_col: Column name for user ID item_col: Column name for item ID Returns: Fairly sampled DataFrame """ ifnot self.user_groups andnot self.item_groups: # No groups specified, random sample return interactions.sample(n=min(sample_size, len(interactions))) # Sample proportionally from each group sampled = [] if self.user_groups: # Sample by user groups for group inset(self.user_groups.values()): group_users = [ uid for uid, g in self.user_groups.items() if g == group ] group_interactions = interactions[ interactions[user_col].isin(group_users) ] group_size = int(sample_size * len(group_interactions) / len(interactions)) iflen(group_interactions) > 0: sampled.append( group_interactions.sample( n=min(group_size, len(group_interactions)) ) ) else: # Sample by item groups for group inset(self.item_groups.values()): group_items = [ iid for iid, g in self.item_groups.items() if g == group ] group_interactions = interactions[ interactions[item_col].isin(group_items) ] group_size = int(sample_size * len(group_interactions) / len(interactions)) iflen(group_interactions) > 0: sampled.append( group_interactions.sample( n=min(group_size, len(group_interactions)) ) ) result = pd.concat(sampled, ignore_index=True) # If we have fewer samples than requested, add random samples iflen(result) < sample_size: remaining = interactions[~interactions.index.isin(result.index)] additional = remaining.sample( n=min(sample_size - len(result), len(remaining)) ) result = pd.concat([result, additional], ignore_index=True) return result
In-Processing Methods
In-processing methods modify the training objective or model
architecture.
classCalibratedRecommender: """Calibrate recommendations to match user preferences""" defcalibrate(self, recommendations: Dict[int, List[Tuple[int, float]]], user_preferences: Dict[int, Dict[str, float]], top_k: int = 10) -> Dict[int, List[int]]: """ Calibrate recommendations to match user preference distribution. Args: recommendations: {user_id: [(item_id, score), ...]} user_preferences: {user_id: {category: proportion }} top_k: Number of recommendations Returns: Calibrated recommendations """ calibrated = {} for user_id, recs in recommendations.items(): if user_id notin user_preferences: # No preferences, return original calibrated[user_id] = [item_id for item_id, _ in recs[:top_k]] continue target_dist = user_preferences[user_id] calibrated[user_id] = self._calibrate_user( recs, target_dist, top_k ) return calibrated def_calibrate_user(self, recs: List[Tuple[int, float]], target_dist: Dict[str, float], top_k: int) -> List[int]: """Calibrate recommendations for a single user""" # This is simplified - real implementation would: # 1. Map items to categories # 2. Track current distribution # 3. Select items to match target distribution # Simplified: diversity-based selection selected = [] category_counts = defaultdict(int) target_total = sum(target_dist.values()) target_counts = { cat: int(prop * top_k / target_total) for cat, prop in target_dist.items() } for item_id, score insorted(recs, key=lambda x: x[1], reverse=True): iflen(selected) >= top_k: break # Simplified: assume we can map items to categories # In practice, this would use item metadata item_category = self._get_item_category(item_id) if category_counts[item_category] < target_counts.get(item_category, top_k): selected.append(item_id) category_counts[item_category] += 1 return selected def_get_item_category(self, item_id: int) -> str: """Get item category (simplified)""" # In practice, this would query item metadata returnf"category_{item_id % 3}"
Explainable Recommendation
Why Explainability Matters
Explainability in recommendation systems serves multiple purposes: -
Trust: Users trust recommendations more when they
understand the reasoning - Transparency: Stakeholders
can audit recommendation decisions - Debugging:
Engineers can identify and fix issues - User Control:
Users can provide feedback and adjust preferences
Types of Explanations
1. Feature-Based Explanations
Explain recommendations using item features (e.g., "Recommended
because you like action movies").
classFeatureBasedExplainer: """Generate feature-based explanations""" def__init__(self, item_features: Dict[int, Dict[str, float]]): """ Args: item_features: {item_id: {feature: value }} """ self.item_features = item_features defexplain(self, user_id: int, item_id: int, user_preferences: Dict[str, float], top_features: int = 3) -> str: """ Generate explanation based on matching features. Args: user_id: User ID item_id: Recommended item ID user_preferences: User's feature preferences top_features: Number of features to mention Returns: Explanation string """ if item_id notin self.item_features: return"This item matches your preferences." item_feats = self.item_features[item_id] # Find matching features matches = [] for feature, user_pref in user_preferences.items(): if feature in item_feats: item_value = item_feats[feature] match_score = min(user_pref, item_value) matches.append((feature, match_score)) # Sort by match score matches.sort(key=lambda x: x[1], reverse=True) ifnot matches: return"This item is recommended based on your preferences." # Generate explanation top_matches = matches[:top_features] feature_names = [feat for feat, _ in top_matches] iflen(feature_names) == 1: explanation = f"Recommended because you like {feature_names[0]}." eliflen(feature_names) == 2: explanation = f"Recommended because you like {feature_names[0]} and {feature_names[1]}." else: explanation = f"Recommended because you like {', '.join(feature_names[:-1])}, and {feature_names[-1]}." return explanation
2. Neighbor-Based Explanations
Explain using similar users or items (e.g., "Users like you also
liked this").
classNeighborBasedExplainer: """Generate explanations based on similar users/items""" def__init__(self, user_similarities: np.ndarray = None, item_similarities: np.ndarray = None): """ Args: user_similarities: User-user similarity matrix item_similarities: Item-item similarity matrix """ self.user_similarities = user_similarities self.item_similarities = item_similarities defexplain_user_based(self, user_id: int, item_id: int, user_history: Dict[int, List[int]], top_neighbors: int = 3) -> str: """ Generate user-based explanation. Args: user_id: User ID item_id: Recommended item ID user_history: {user_id: [item_ids]} - user interaction history top_neighbors: Number of neighbors to mention """ if self.user_similarities isNone: return"Users similar to you also liked this item." # Find similar users who interacted with this item similar_users = [] for other_user_id, items in user_history.items(): if other_user_id == user_id: continue if item_id in items: similarity = self.user_similarities[user_id, other_user_id] similar_users.append((other_user_id, similarity)) ifnot similar_users: return"This item matches your preferences." # Sort by similarity similar_users.sort(key=lambda x: x[1], reverse=True) neighbor_count = len(similar_users[:top_neighbors]) if neighbor_count == 1: return"A user similar to you also liked this item." else: returnf"{neighbor_count} users similar to you also liked this item." defexplain_item_based(self, user_id: int, item_id: int, user_history: Dict[int, List[int]], top_neighbors: int = 3) -> str: """ Generate item-based explanation. Args: user_id: User ID item_id: Recommended item ID user_history: User interaction history top_neighbors: Number of similar items to mention """ if self.item_similarities isNone: return"This item is similar to items you've liked." user_items = user_history.get(user_id, []) ifnot user_items: return"This item matches your preferences." # Find items similar to recommended item that user has interacted with similar_items = [] for hist_item_id in user_items: if hist_item_id == item_id: continue similarity = self.item_similarities[item_id, hist_item_id] similar_items.append((hist_item_id, similarity)) ifnot similar_items: return"This item matches your preferences." # Sort by similarity similar_items.sort(key=lambda x: x[1], reverse=True) neighbor_count = len(similar_items[:top_neighbors]) if neighbor_count == 1: return"This item is similar to an item you've liked." else: returnf"This item is similar to {neighbor_count} items you've liked."
3. Attention-Based Explanations
Use attention weights to identify important features or
interactions.
Q1:
What is the difference between fairness and explainability?
A: Fairness ensures that recommendations treat all
users and items equitably, without systematic bias toward certain
groups. Explainability ensures that users and stakeholders can
understand why recommendations are made. While related (explainability
can help identify unfair patterns), they address different concerns: -
Fairness: "Are recommendations fair?" (normative
question) - Explainability: "Why was this recommended?"
(descriptive question)
A system can be explainable but unfair (e.g., clearly explaining
biased recommendations), or fair but unexplainable (e.g., fair
recommendations from a black-box model).
Q2:
How do I choose between pre-processing, in-processing, and
post-processing debiasing methods?
A: The choice depends on your constraints:
Pre-processing (modify data): - ✅ Pros:
Model-agnostic, easy to implement - ❌ Cons: May lose information,
doesn't address algorithmic bias - Use when: You have
control over data collection, want model-agnostic solution
In-processing (modify training): - ✅ Pros:
Addresses root cause, can optimize fairness-accuracy trade-off - ❌
Cons: Requires model modification, more complex - Use
when: You can modify model architecture, want optimal
trade-offs
Post-processing (modify outputs): - ✅ Pros: No
model changes needed, fast to deploy - ❌ Cons: May reduce accuracy,
doesn't fix underlying bias - Use when: Model is
already trained, need quick solution
Best practice: Combine methods (e.g., pre-processing
+ in-processing).
Q3: How
do I measure fairness in recommendation systems?
A: Fairness can be measured at multiple levels:
User-level fairness: - Demographic parity: Equal
recommendation quality across user groups - Equalized odds: Equal
true/false positive rates across groups
Item-level fairness: - Exposure fairness: Equal
exposure across item groups - Quality fairness: High-quality items get
fair exposure
Q4:
What is counterfactual fairness and why is it important?
A: Counterfactual fairness ensures that changing a
user's protected attributes (e.g., gender, race) while keeping other
attributes constant would not change recommendations. This is important
because:
Causal understanding: It addresses "what if"
questions about fairness
Legal compliance: Aligns with anti-discrimination
laws
User trust: Users trust systems that treat similar
users similarly
Example: Two users with identical preferences except
gender should receive similar recommendations.
Q5: How do LIME and SHAP
differ?
A:
LIME: - Local explanations (explains individual
predictions) - Uses linear models locally - Faster, easier to implement
- May be inconsistent across similar inputs
SHAP: - Based on Shapley values (game theory) -
Theoretically grounded (additivity, efficiency) - More consistent -
Computationally expensive (exact) or approximate
Choose LIME for: Quick explanations, large feature
sets, when consistency isn't critical.
Q10: What are
the legal and ethical considerations?
A: Key considerations:
Legal: - Anti-discrimination laws (e.g., Title VII
in US, GDPR in EU) - Protected attributes (gender, race, age, etc.) -
Disparate impact vs. disparate treatment
Ethical: - Transparency: Users should know how
recommendations work - User autonomy: Users should control their
recommendations - Beneficence: Recommendations should benefit users -
Non-maleficence: Avoid harm (e.g., filter bubbles, addiction)
Best practices: - Document fairness decisions -
Regular audits - User consent for data use - Explainability for users -
Compliance with regulations
Summary
Fairness and explainability are critical for building trustworthy
recommendation systems. This article covered:
Practical Takeaways: 1. Measure bias comprehensively
before addressing it 2. Use multiple debiasing methods in combination 3.
Provide explanations that users can understand 4. Balance fairness and
accuracy carefully 5. Monitor fairness continuously in production 6.
Consider legal and ethical implications
Building fair and explainable recommendation systems is an ongoing
process that requires continuous monitoring, evaluation, and
improvement. By understanding the foundations and implementing the
techniques covered in this article, you can build recommendation systems
that users trust and that treat all stakeholders equitably.
Post title:Recommendation Systems (13): Fairness, Debiasing, and Explainability
Post author:Chen Kai
Create time:2026-02-03 23:11:11
Post link:https://www.chenk.top/recommendation-systems-13-fairness-explainability/
Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.