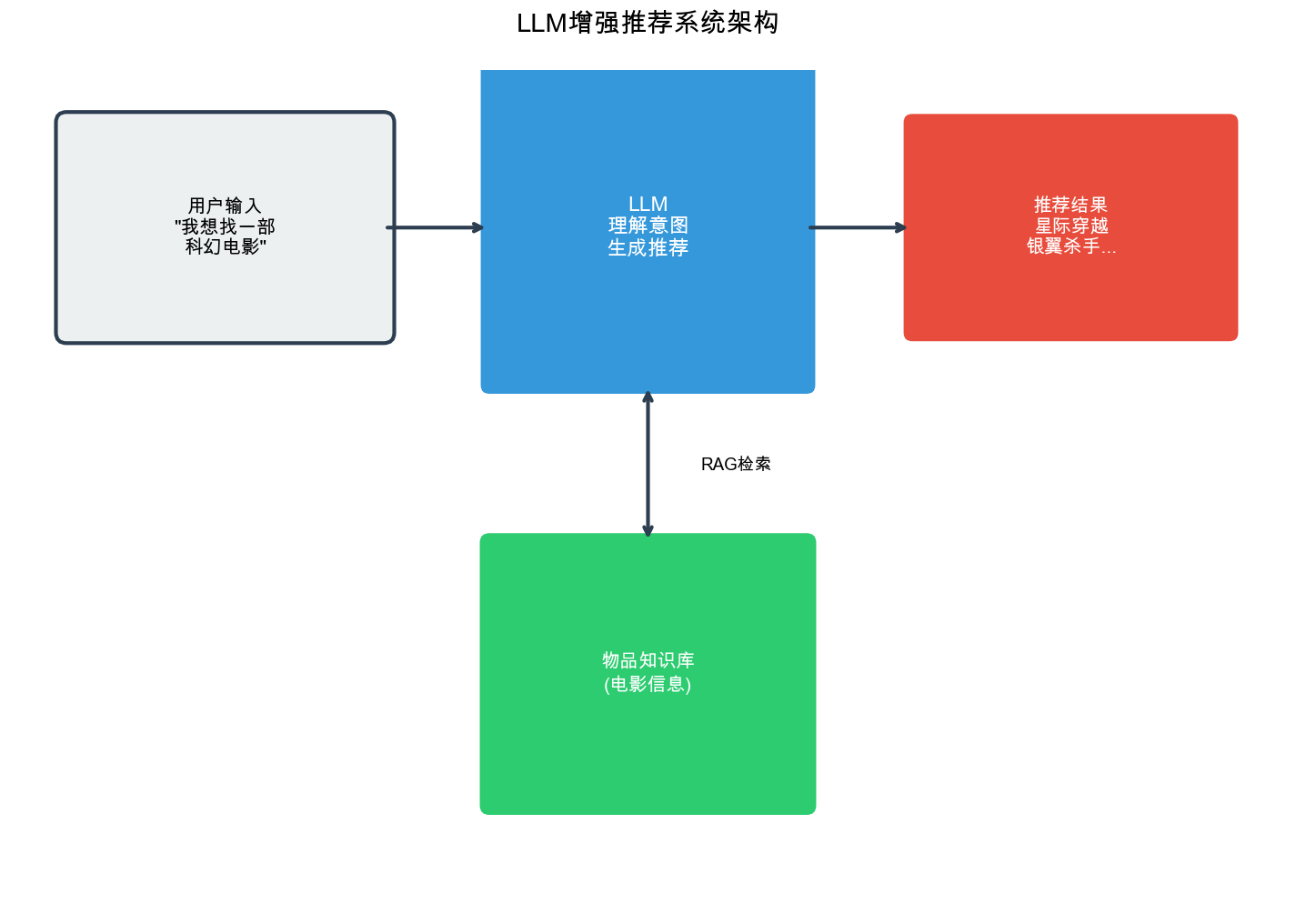
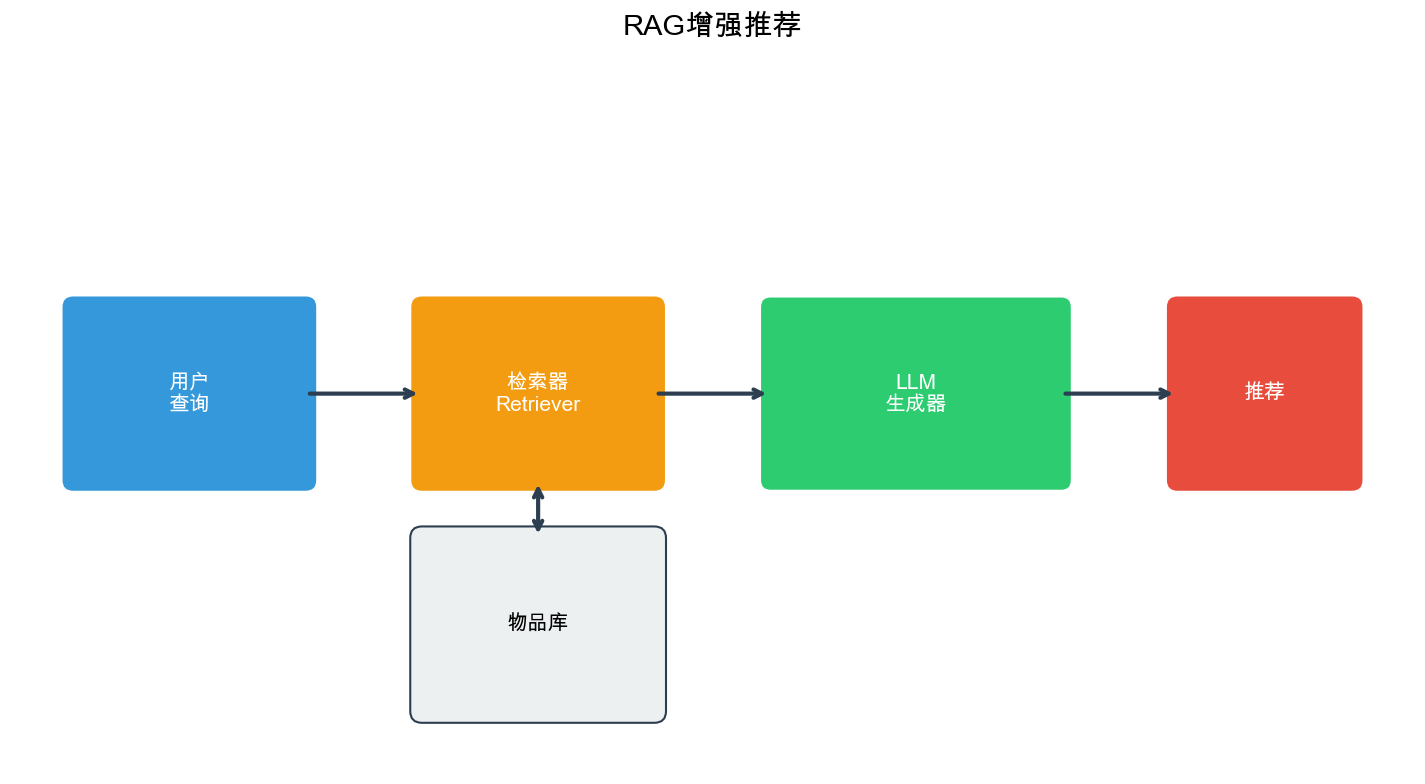
Recommendation Systems (12): Large Language Models and Recommendation
Chen KaiBOSS
2026-02-03 23:11:112026-02-03 23:118.4k Words52 Mins
permalink: "en/recommendation-systems-12-llm-recommendation/" date:
2024-06-26 14:30:00 tags: - Recommendation Systems - LLM - Large
Language Models categories: Recommendation Systems mathjax: true--- When
you ask ChatGPT "What movies should I watch if I liked The Matrix?" it
doesn't just match keywords — it understands the philosophical themes,
visual style, and narrative structure that made The Matrix compelling,
then reasons about similar films across genres and decades. This
capability represents a paradigm shift in recommendation systems: moving
from statistical pattern matching to semantic understanding and
reasoning. Large Language Models (LLMs) like GPT-4, Claude, and LLaMA
have revolutionized natural language processing, and their integration
into recommendation systems is transforming how we understand user
preferences, generate explanations, and handle cold-start scenarios.
Traditional recommendation systems excel at finding patterns in
user-item interaction matrices, but they struggle with understanding
rich textual content, explaining recommendations naturally, and adapting
to conversational contexts. LLMs bridge these gaps by bringing world
knowledge, semantic understanding, and natural language generation to
recommendation. From prompt-based zero-shot recommendation that requires
no training data, to LLM-enhanced feature extraction that enriches item
representations, to conversational recommenders that engage users in
natural dialogue, LLMs are reshaping the recommendation landscape.
This article provides a comprehensive exploration of LLM-powered
recommendation systems, covering the fundamental roles LLMs play (as
rankers, feature enhancers, and conversational agents), prompt
engineering techniques for recommendation tasks, state-of-the-art
architectures like A-LLMRec and XRec, conversational recommendation
systems (ChatREC, RA-Rec, ChatCRS), token efficiency optimization
strategies, and practical implementations with 10+ code examples and
detailed Q&A sections addressing common challenges and design
decisions.
The Role of LLMs in
Recommendation Systems
Why LLMs for Recommendation?
Traditional recommendation systems face several fundamental
limitations that LLMs address:
Semantic Understanding Gap: Collaborative filtering
and content-based methods rely on explicit features (genres, tags,
ratings) but miss nuanced semantic relationships. LLMs understand that
"The Matrix" and "Blade Runner" share cyberpunk themes even if they're
tagged differently.
Cold-Start Problem: New items and users lack
interaction history. LLMs can generate recommendations based solely on
item descriptions, user profiles, or natural language queries without
requiring historical data.
Explainability: Traditional systems struggle to
explain why they recommend an item. LLMs can generate natural language
explanations that reference specific aspects of user preferences and
item characteristics.
Conversational Interaction: Most recommendation
systems are one-shot: input preferences, get recommendations. LLMs
enable multi-turn conversations where users can refine preferences, ask
questions, and explore recommendations interactively.
Cross-Domain Knowledge: LLMs bring world knowledge
that traditional systems lack. They understand that users who like "The
Godfather" might appreciate "Goodfellas" because both are mafia films,
even without explicit genre tags.
Three Primary Roles of LLMs
LLMs serve three main roles in recommendation systems:
1. LLM as Ranker: The LLM directly generates or
ranks recommendations based on user preferences and item descriptions.
This is the most direct application, often using few-shot prompting or
fine-tuning.
2. LLM as Feature Enhancer: The LLM enriches item
and user representations by extracting semantic features from text
descriptions, generating embeddings, or creating structured metadata
that traditional models can use.
3. LLM as Conversational Agent: The LLM engages
users in natural language dialogue to understand preferences, provide
recommendations, explain choices, and handle follow-up questions.
explore each role in detail.
Prompt-Based Recommendation
Prompt-based recommendation leverages LLMs' in-context learning
capabilities to generate recommendations without fine-tuning. By
carefully crafting prompts that include user preferences, item
descriptions, and examples, we can guide LLMs to produce relevant
recommendations.
Basic Prompt Structure
A typical prompt for recommendation consists of:
Task Description: What the LLM should do
User Profile: User preferences, history, or
query
Item Catalog: Available items with
descriptions
Examples (few-shot): Example input-output
pairs
Output Format: How recommendations should be
structured
Zero-Shot Recommendation
Zero-shot recommendation uses no training examples, relying entirely
on the LLM's pre-trained knowledge:
defzero_shot_recommendation(user_query, items, llm_client): """ Generate recommendations using zero-shot prompting. Args: user_query: Natural language query (e.g., "I want action movies") items: List of items with descriptions llm_client: LLM API client (OpenAI, Anthropic, etc.) """ item_descriptions = "\n".join([ f"{i+1}. {item['title']}: {item['description']}" for i, item inenumerate(items) ]) prompt = f"""You are a movie recommendation expert. Based on the user's request, recommend the top 5 most relevant movies from the catalog below. User Request: {user_query} Available Movies: {item_descriptions} Please provide your recommendations in the following format: 1. Movie Title - Brief reason 2. Movie Title - Brief reason ... Recommendations:""" response = llm_client.generate(prompt) return parse_recommendations(response)
Few-Shot Recommendation
Few-shot recommendation includes examples to guide the LLM's
behavior:
deffew_shot_recommendation(user_query, items, llm_client): """ Generate recommendations using few-shot prompting with examples. """ examples = """ Example 1: User Request: I like psychological thrillers with plot twists Recommendations: 1. Shutter Island - Complex psychological mystery with unexpected revelations 2. The Prestige - Mind-bending narrative with multiple twists 3. Memento - Non-linear storytelling that keeps you guessing Example 2: User Request: I want romantic comedies set in New York Recommendations: 1. When Harry Met Sally - Classic NYC rom-com with witty dialogue 2. You've Got Mail - Modern NYC romance with bookstore setting 3. Serendipity - Magical NYC love story """ item_descriptions = "\n".join([ f"{i+1}. {item['title']}: {item['description']}" for i, item inenumerate(items) ]) prompt = f"""{examples} Now, based on the following user request, recommend the top 5 movies: User Request: {user_query} Available Movies: {item_descriptions} Recommendations:""" response = llm_client.generate(prompt) return parse_recommendations(response)
Chain-of-Thought
Recommendation
Chain-of-thought prompting helps LLMs reason through the
recommendation process:
defchain_of_thought_recommendation(user_history, items, llm_client): """ Use chain-of-thought reasoning for recommendations. """ history_str = "\n".join([ f"- {item['title']} ({item['rating']}/5): {item['review']}" for item in user_history ]) item_descriptions = "\n".join([ f"{i+1}. {item['title']}: {item['description']}" for i, item inenumerate(items) ]) prompt = f"""Analyze the user's viewing history and recommend movies they would enjoy. User's Viewing History: {history_str} Available Movies: {item_descriptions} Think step by step: 1. What patterns do you notice in the user's preferences? 2. What genres, themes, or styles do they prefer? 3. Which movies from the catalog match these preferences? 4. Rank them by relevance. Analysis: """ response = llm_client.generate(prompt) # Continue with recommendation request follow_up = f"""{response} Based on this analysis, provide your top 5 recommendations:""" recommendations = llm_client.generate(follow_up) return parse_recommendations(recommendations)
Prompt Template Design
Effective prompt templates balance specificity with flexibility:
classRecommendationPromptTemplate: """Template for recommendation prompts.""" def__init__(self, task_type="zero_shot"): self.task_type = task_type self.templates = { "zero_shot": self._zero_shot_template, "few_shot": self._few_shot_template, "conversational": self._conversational_template } def_zero_shot_template(self, user_context, items): returnf"""Task: Recommend items based on user preferences. User Context: {user_context} Available Items: {self._format_items(items)} Instructions: - Analyze the user's preferences - Select the top 5 most relevant items - Provide brief explanations for each recommendation Recommendations:""" def_few_shot_template(self, user_context, items, examples): returnf"""Task: Recommend items based on user preferences. Examples: {self._format_examples(examples)} User Context: {user_context} Available Items: {self._format_items(items)} Recommendations:""" def_conversational_template(self, conversation_history, items): returnf"""You are a helpful recommendation assistant. Based on the conversation, recommend items. Conversation History: {conversation_history} Available Items: {self._format_items(items)} Your response:""" def_format_items(self, items): return"\n".join([ f"{i+1}. {item.get('title', item.get('name'))}: {item.get('description', '')}" for i, item inenumerate(items) ]) def_format_examples(self, examples): return"\n\n".join([ f"Example {i+1}:\n{ex['input']}\nRecommendations: {ex['output']}" for i, ex inenumerate(examples) ])
A-LLMRec: Augmented
LLM for Recommendation
A-LLMRec (Augmented LLM for Recommendation) enhances LLMs with
external knowledge and structured data to improve recommendation
accuracy. It addresses LLMs' limitations in handling numerical features,
temporal patterns, and domain-specific knowledge.
Architecture Overview
A-LLMRec combines: 1. LLM backbone for semantic
understanding 2. External knowledge bases for
domain-specific information 3. Structured feature
extractors for numerical/categorical data 4. Hybrid
ranking that combines LLM scores with traditional signals
XRec focuses on generating natural language explanations for
recommendations, addressing the explainability gap in traditional
systems. It uses LLMs to create personalized explanations that reference
specific user preferences and item characteristics.
Architecture
XRec consists of: 1. Recommendation Module:
Generates candidate recommendations 2. Explanation
Generator: LLM-based module that creates explanations 3.
Explanation Ranker: Ranks explanations by quality and
relevance
classXRecExplainer: """ Explainable recommendation system using LLMs. """ def__init__(self, llm_client, recommendation_model): self.llm_client = llm_client self.recommendation_model = recommendation_model defrecommend_with_explanation(self, user_id, user_profile, top_k=5): """ Generate recommendations with explanations. Args: user_id: User identifier user_profile: User profile (preferences, history, etc.) top_k: Number of recommendations """ # Get recommendations recommendations = self.recommendation_model.recommend( user_id, top_k=top_k ) # Generate explanations explanations = [] for item in recommendations: explanation = self._generate_explanation( user_profile, item ) explanations.append({ 'item': item, 'explanation': explanation, 'score': item['score'] }) return explanations def_generate_explanation(self, user_profile, item): """Generate explanation for a single recommendation.""" prompt = f"""You are a recommendation system that explains why items are recommended to users. User Profile: - Preferences: {user_profile.get('preferences', [])} - Past Interactions: {user_profile.get('history', [])} - Demographics: {user_profile.get('demographics', {})} Recommended Item: - Title: {item['title']} - Description: {item['description']} - Features: {item.get('features', [])} Generate a natural, personalized explanation (2-3 sentences) explaining why this item is recommended. Reference specific aspects of the user's preferences and the item's characteristics. Explanation:""" explanation = self.llm_client.generate(prompt) return explanation.strip() defgenerate_comparative_explanation(self, user_profile, items): """Generate explanation comparing multiple items.""" items_str = "\n".join([ f"{i+1}. {item['title']}: {item['description']}" for i, item inenumerate(items) ]) prompt = f"""Compare these items and explain which one best matches the user's preferences. User Profile: {user_profile} Items: {items_str} Provide: 1. A comparison of the items 2. Which item best matches the user and why 3. When the other items might be preferred Analysis:""" return self.llm_client.generate(prompt)
defgenerate_multi_aspect_explanation(user_profile, item, llm_client): """ Generate explanation covering multiple aspects. """ prompt = f"""Explain why this item is recommended, covering: 1. Content similarity (how it matches user preferences) 2. Popularity signals (why others like it) 3. Diversity (how it adds variety to recommendations) 4. Temporal relevance (why it's relevant now) User Profile: {user_profile} Item: {item} Explanation:""" explanation = llm_client.generate(prompt) # Parse into aspects aspects = { 'content': extract_aspect(explanation, 'content'), 'popularity': extract_aspect(explanation, 'popularity'), 'diversity': extract_aspect(explanation, 'diversity'), 'temporal': extract_aspect(explanation, 'temporal') } return aspects
LLM as Feature Enhancer
LLMs excel at extracting semantic features from unstructured text,
enriching item and user representations that traditional recommendation
models can use.
classLLMFeatureExtractor: """ Extract semantic features from text using LLMs. """ def__init__(self, llm_model_name, feature_dim=768): self.model = AutoModel.from_pretrained(llm_model_name) self.tokenizer = AutoTokenizer.from_pretrained(llm_model_name) self.feature_dim = feature_dim defextract_item_features(self, item_description, item_metadata=None): """ Extract features from item description. Args: item_description: Text description of the item item_metadata: Additional metadata (optional) """ # Combine description and metadata if item_metadata: text = f"{item_description}\nMetadata: {item_metadata}" else: text = item_description # Tokenize and encode inputs = self.tokenizer( text, return_tensors="pt", padding=True, truncation=True, max_length=512 ) with torch.no_grad(): outputs = self.model(**inputs) # Mean pooling over sequence features = outputs.last_hidden_state.mean(dim=1) return features.squeeze().numpy() defextract_user_features(self, user_profile_text, interaction_history=None): """ Extract features from user profile and history. """ # Combine profile and history if interaction_history: history_text = "\n".join([ f"Interacted with: {item['title']} ({item.get('rating', 'N/A')})" for item in interaction_history[:10] # Last 10 interactions ]) text = f"{user_profile_text}\n\nInteraction History:\n{history_text}" else: text = user_profile_text inputs = self.tokenizer( text, return_tensors="pt", padding=True, truncation=True, max_length=512 ) with torch.no_grad(): outputs = self.model(**inputs) features = outputs.last_hidden_state.mean(dim=1) return features.squeeze().numpy()
defgenerate_structured_features(item_text, llm_client): """ Use LLM to generate structured features from unstructured text. """ prompt = f"""Extract structured features from this item description. Item Description: {item_text} Extract the following information in JSON format: {{ "genre": ["genre1", "genre2"], "themes": ["theme1", "theme2"], "target_audience": "audience description", "mood": ["mood1", "mood2"], "keywords": ["keyword1", "keyword2", "keyword3"] }} JSON:""" response = llm_client.generate(prompt) # Parse JSON response features = json.loads(extract_json(response)) return features
classHybridFeatureModel(nn.Module): """ Model that combines LLM-extracted features with traditional features. """ def__init__(self, llm_feature_dim, traditional_feature_dim, hidden_dim=256): super(HybridFeatureModel, self).__init__() self.llm_feature_proj = nn.Linear(llm_feature_dim, hidden_dim) self.traditional_feature_proj = nn.Linear(traditional_feature_dim, hidden_dim) self.fusion = nn.Sequential( nn.Linear(hidden_dim * 2, hidden_dim), nn.ReLU(), nn.Dropout(0.1), nn.Linear(hidden_dim, hidden_dim // 2) ) self.output = nn.Linear(hidden_dim // 2, 1) defforward(self, llm_features, traditional_features): """ Args: llm_features: Features extracted by LLM traditional_features: Traditional features (e.g., one-hot, embeddings) """ llm_proj = self.llm_feature_proj(llm_features) trad_proj = self.traditional_feature_proj(traditional_features) combined = torch.cat([llm_proj, trad_proj], dim=-1) fused = self.fusion(combined) score = self.output(fused) return score
LLM as Reranker
LLMs can serve as powerful rerankers, taking candidate items from a
first-stage retrieval system and reordering them based on semantic
understanding and user context.
classLLMReranker: """ LLM-based reranker for recommendation. """ def__init__(self, llm_client, max_candidates=100): self.llm_client = llm_client self.max_candidates = max_candidates defrerank(self, user_context, candidates, top_k=10): """ Rerank candidate items. Args: user_context: User preferences/history candidates: List of candidate items with initial scores top_k: Number of items to return """ # Limit candidates for efficiency candidates = candidates[:self.max_candidates] # Format candidates candidates_str = self._format_candidates(candidates) # Generate reranking prompt prompt = f"""You are a recommendation reranker. Given a user's context and candidate items, rank them by relevance. User Context: {user_context} Candidate Items (with initial scores): {candidates_str} Rank these items from most relevant to least relevant. Return only the item IDs in order, separated by commas. Ranked IDs:""" # Get reranking from LLM ranked_ids = self._parse_ranked_ids( self.llm_client.generate(prompt) ) # Map back to candidates id_to_item = {item['id']: item for item in candidates} reranked = [ id_to_item[id] foridin ranked_ids ifidin id_to_item ] # Fill remaining slots with original order remaining = [ item for item in candidates if item['id'] notin ranked_ids ] reranked.extend(remaining) return reranked[:top_k] def_format_candidates(self, candidates): """Format candidates for prompt.""" return"\n".join([ f"{i+1}. ID: {item['id']}, Title: {item['title']}, " f"Score: {item.get('score', 0):.3f}, " f"Description: {item.get('description', '')[:100]}" for i, item inenumerate(candidates) ]) def_parse_ranked_ids(self, response): """Parse ranked IDs from LLM response.""" # Extract IDs from response import re ids = re.findall(r'\d+', response) return [int(id) foridin ids]
defbatch_rerank(user_context, candidate_batches, llm_client, batch_size=20): """ Rerank candidates in batches for efficiency. """ all_reranked = [] for batch in candidate_batches: batch_str = "\n".join([ f"{i+1}. {item['title']}: {item.get('description', '')[:50]}" for i, item inenumerate(batch) ]) prompt = f"""Rank these items by relevance to the user. User Context: {user_context} Items: {batch_str} Return ranked item numbers (1-N) separated by commas:""" ranked_indices = parse_ranked_indices( llm_client.generate(prompt) ) reranked_batch = [batch[i-1] for i in ranked_indices if1 <= i <= len(batch)] all_reranked.extend(reranked_batch) return all_reranked
Conversational
Recommendation: ChatREC
ChatREC enables natural language conversations for recommendation,
allowing users to refine preferences, ask questions, and explore
recommendations interactively.
Architecture
ChatREC combines: 1. Conversation Manager: Maintains
dialogue state 2. Preference Extractor: Extracts
preferences from conversation 3. Recommendation Engine:
Generates recommendations 4. Response Generator:
Creates natural language responses
classRARec: """ Retrieval-Augmented Recommendation system. """ def__init__(self, llm_client, retriever, knowledge_base): self.llm_client = llm_client self.retriever = retriever self.knowledge_base = knowledge_base defrecommend(self, user_query, top_k=5): """ Generate recommendations using retrieval augmentation. """ # Retrieve relevant knowledge retrieved_items = self.retriever.retrieve( query=user_query, top_k=20 ) # Retrieve relevant knowledge graph facts kg_facts = self.knowledge_base.retrieve_facts( entities=[item['id'] for item in retrieved_items], top_k=10 ) # Augment context augmented_context = self._augment_context( user_query, retrieved_items, kg_facts ) # Generate recommendations prompt = f"""Generate recommendations based on the user query and retrieved information. User Query: {user_query} Retrieved Items: {self._format_items(retrieved_items)} Knowledge Graph Facts: {self._format_kg_facts(kg_facts)} Generate top {top_k} recommendations with explanations:""" recommendations = self.llm_client.generate(prompt) return self._parse_recommendations(recommendations) def_augment_context(self, query, items, kg_facts): """Augment context with retrieved information.""" context = { 'query': query, 'items': items, 'kg_facts': kg_facts, 'item_relationships': self._extract_relationships(items, kg_facts) } return context def_extract_relationships(self, items, kg_facts): """Extract relationships between items.""" relationships = [] for fact in kg_facts: if fact['relation'] in ['similar_to', 'related_to', 'sequel_of']: relationships.append(fact) return relationships def_format_items(self, items): """Format items for prompt.""" return"\n".join([ f"- {item['title']}: {item.get('description', '')}" for item in items ]) def_format_kg_facts(self, facts): """Format knowledge graph facts.""" return"\n".join([ f"- {fact['head']}{fact['relation']}{fact['tail']}" for fact in facts ]) def_parse_recommendations(self, text): """Parse recommendations from LLM output.""" # Simple parsing - can be enhanced lines = text.strip().split('\n') recommendations = [] for line in lines: if line.strip() and (line[0].isdigit() or line.startswith('-')): recommendations.append(line.strip()) return recommendations
ChatCRS:
Conversational Recommendation System
ChatCRS is a comprehensive conversational recommendation system that
handles multi-turn dialogues, preference elicitation, and recommendation
generation.
classChatCRS: """ Comprehensive conversational recommendation system. """ def__init__(self, llm_client, recommendation_engine): self.llm_client = llm_client self.recommendation_engine = recommendation_engine self.sessions = {} # session_id -> session data defprocess_message(self, session_id, user_message): """ Process user message in a conversational context. """ # Get or create session if session_id notin self.sessions: self.sessions[session_id] = { 'history': [], 'preferences': {}, 'current_recommendations': None, 'state': 'greeting' } session = self.sessions[session_id] # Update history session['history'].append({ 'role': 'user', 'content': user_message, 'timestamp': datetime.now() }) # Determine system state state = self._determine_state(session, user_message) session['state'] = state # Generate response based on state response = self._generate_response(session, user_message, state) # Update history session['history'].append({ 'role': 'assistant', 'content': response, 'timestamp': datetime.now() }) return response def_determine_state(self, session, message): """Determine current conversation state.""" states = { 'greeting': 'User just started conversation', 'preference_elicitation': 'Collecting user preferences', 'recommendation_presentation': 'Presenting recommendations', 'clarification': 'Clarifying preferences or recommendations', 'exploration': 'User exploring items', 'feedback': 'Collecting feedback on recommendations' } prompt = f"""Determine the conversation state based on history and current message. Conversation History: {self._format_history(session['history'][-5:])} Current Message: {message} Current State: {session['state']} Possible States: {list(states.keys())} Respond with only the state name:""" state = self.llm_client.generate(prompt).strip().lower() return state if state in states else session['state'] def_generate_response(self, session, message, state): """Generate response based on state.""" if state == 'greeting': return self._greet_user(session) elif state == 'preference_elicitation': return self._elicit_preferences(session, message) elif state == 'recommendation_presentation': return self._present_recommendations(session, message) elif state == 'clarification': return self._clarify(session, message) elif state == 'exploration': return self._explore_items(session, message) elif state == 'feedback': return self._collect_feedback(session, message) else: return self._default_response(session, message) def_greet_user(self, session): """Greet user and start preference elicitation.""" prompt = """Generate a friendly greeting for a recommendation assistant. Introduce yourself and ask what the user is looking for. Keep it brief (2-3 sentences).""" return self.llm_client.generate(prompt).strip() def_elicit_preferences(self, session, message): """Elicit user preferences.""" # Extract preferences extracted = self._extract_preferences(message) session['preferences'].update(extracted) # Check if we have enough information if self._has_sufficient_preferences(session['preferences']): # Generate recommendations recommendations = self.recommendation_engine.recommend( preferences=session['preferences'], top_k=5 ) session['current_recommendations'] = recommendations # Present recommendations return self._present_recommendations(session, message) else: # Ask for more information prompt = f"""The user has provided some preferences. Ask for more specific information to provide better recommendations. Current Preferences: {session['preferences']} User Message: {message} Generate a natural question (1-2 sentences) asking for more preferences:""" return self.llm_client.generate(prompt).strip() def_present_recommendations(self, session, message): """Present recommendations to user.""" recommendations = session.get('current_recommendations') ifnot recommendations: recommendations = self.recommendation_engine.recommend( preferences=session['preferences'], top_k=5 ) session['current_recommendations'] = recommendations items_str = "\n".join([ f"{i+1}. {item['title']}" for i, item inenumerate(recommendations) ]) prompt = f"""Present these recommendations naturally to the user. User Preferences: {session['preferences']} Recommendations: {items_str} Generate a friendly response (3-4 sentences) that: 1. References the user's preferences 2. Presents the recommendations 3. Invites questions or feedback Response:""" return self.llm_client.generate(prompt).strip() def_clarify(self, session, message): """Handle clarification requests.""" prompt = f"""The user is asking for clarification. Provide a helpful response. Conversation History: {self._format_history(session['history'][-3:])} Current Message: {message} Response:""" return self.llm_client.generate(prompt).strip() def_explore_items(self, session, message): """Handle item exploration.""" # Extract item mention item = self._extract_item_mention(message) if item: prompt = f"""Provide detailed information about this item. Item: {item} User Question: {message} Provide helpful information:""" return self.llm_client.generate(prompt).strip() else: return"Which item would you like to know more about?" def_collect_feedback(self, session, message): """Collect feedback on recommendations.""" # Extract feedback feedback = self._extract_feedback(message) # Update preferences based on feedback if feedback.get('liked'): session['preferences']['liked_items'] = session['preferences'].get('liked_items', []) session['preferences']['liked_items'].extend(feedback['liked']) if feedback.get('disliked'): session['preferences']['disliked_items'] = session['preferences'].get('disliked_items', []) session['preferences']['disliked_items'].extend(feedback['disliked']) prompt = f"""Acknowledge the user's feedback and offer to refine recommendations. Feedback: {feedback} Current Recommendations: {session.get('current_recommendations', [])} Generate a response (2-3 sentences):""" return self.llm_client.generate(prompt).strip() def_default_response(self, session, message): """Default response handler.""" prompt = f"""Respond naturally to the user's message. Conversation History: {self._format_history(session['history'][-3:])} User Message: {message} Response:""" return self.llm_client.generate(prompt).strip() def_extract_preferences(self, message): """Extract preferences from message.""" prompt = f"""Extract user preferences from this message. Message: {message} Return JSON: {{ "genres": [], "themes": [], "constraints": {{ }}, "explicit_preferences": [] }} JSON:""" response = self.llm_client.generate(prompt) return json.loads(extract_json(response)) def_has_sufficient_preferences(self, preferences): """Check if we have enough preferences.""" returnlen(preferences.get('genres', [])) > 0orlen(preferences.get('themes', [])) > 0 def_extract_item_mention(self, message): """Extract item mention from message.""" # Simple implementation - can be enhanced with NER returnNone def_extract_feedback(self, message): """Extract feedback from message.""" prompt = f"""Extract feedback from this message. Message: {message} Return JSON: {{ "liked": ["item1", "item2"], "disliked": ["item3"], "rating": {{ "item1": 5 }} }} JSON:""" response = self.llm_client.generate(prompt) return json.loads(extract_json(response)) def_format_history(self, history): """Format conversation history.""" return"\n".join([ f"{turn['role']}: {turn['content']}" for turn in history ])
Token Efficiency
Optimization
LLM API calls are expensive, especially for recommendation systems
that need to process many items. Token efficiency is crucial for
production systems.
Strategies for Token
Efficiency
1. Prompt Compression: Reduce prompt size while
maintaining information
defcompress_prompt(user_context, items, max_tokens=1000): """ Compress prompt to fit within token limit. """ # Truncate item descriptions compressed_items = [] tokens_used = count_tokens(user_context) for item in items: item_tokens = count_tokens(item['description']) if tokens_used + item_tokens > max_tokens: # Truncate description truncated = truncate_to_tokens( item['description'], max_tokens - tokens_used - 50# Buffer ) item['description'] = truncated compressed_items.append(item) tokens_used += item_tokens return compressed_items
deftruncate_to_tokens(text, max_tokens): """Truncate text to fit within token limit.""" tokens = text.split() iflen(tokens) <= max_tokens: return text return' '.join(tokens[:max_tokens]) + '...'
2. Batch Processing: Process multiple requests
together
classSelectiveLLMRecommender: """ Use LLM only for complex cases, fallback to traditional methods. """ def__init__(self, llm_client, traditional_model): self.llm_client = llm_client self.traditional_model = traditional_model defrecommend(self, user_query, items): """ Use LLM only if query is complex or cold-start. """ # Check if traditional model can handle it if self._is_simple_query(user_query): return self.traditional_model.recommend(user_query, items) # Check if user has sufficient history if self._has_sufficient_history(user_query): return self.traditional_model.recommend(user_query, items) # Use LLM for complex/cold-start cases return self._llm_recommend(user_query, items) def_is_simple_query(self, query): """Check if query is simple enough for traditional model.""" # Simple heuristics: length, keyword matching, etc. returnlen(query.split()) < 5 def_has_sufficient_history(self, query): """Check if user has sufficient interaction history.""" # Implementation depends on your system returnFalse def_llm_recommend(self, query, items): """LLM-based recommendation.""" # Use LLM pass
5. Two-Stage Approach: Use LLM for ranking, not
retrieval
defevaluate_recommendations(recommended_items, ground_truth, k=10): """ Evaluate recommendations using traditional metrics. """ metrics = {} # Precision@K recommended_set = set(recommended_items[:k]) ground_truth_set = set(ground_truth) intersection = recommended_set & ground_truth_set metrics['precision@k'] = len(intersection) / k if k > 0else0 metrics['recall@k'] = len(intersection) / len(ground_truth_set) if ground_truth_set else0 # NDCG@K metrics['ndcg@k'] = compute_ndcg(recommended_items[:k], ground_truth) # MRR metrics['mrr'] = compute_mrr(recommended_items, ground_truth) return metrics
defcompute_ndcg(recommended, ground_truth, k=10): """Compute NDCG@K.""" dcg = 0 for i, item inenumerate(recommended[:k]): if item in ground_truth: relevance = 1# Binary relevance dcg += relevance / np.log2(i + 2) # Ideal DCG idcg = sum(1 / np.log2(i + 2) for i inrange(min(k, len(ground_truth)))) return dcg / idcg if idcg > 0else0
defcompute_mrr(recommended, ground_truth): """Compute Mean Reciprocal Rank.""" for i, item inenumerate(recommended): if item in ground_truth: return1 / (i + 1) return0
classLLMRecommendationSystem: """ Complete LLM-based recommendation system. """ def__init__(self, config): self.config = config # Initialize components self.llm_client = self._init_llm_client(config['llm']) self.feature_extractor = LLMFeatureExtractor( config['llm']['model_name'] ) self.recommendation_model = self._init_recommendation_model(config) self.reranker = LLMReranker(self.llm_client) self.conversation_manager = ChatCRS( self.llm_client, self.recommendation_model ) defrecommend(self, user_id, user_query=None, top_k=10): """ Main recommendation interface. """ # Get user profile user_profile = self._get_user_profile(user_id) # Extract features if user_query: user_features = self.feature_extractor.extract_user_features( user_query, user_profile.get('history') ) else: user_features = self.feature_extractor.extract_user_features( user_profile.get('description', ''), user_profile.get('history') ) # Get initial recommendations recommendations = self.recommendation_model.recommend( user_features=user_features, user_id=user_id, top_k=top_k * 2# Get more for reranking ) # Rerank with LLM reranked = self.reranker.rerank( user_context=user_query or user_profile.get('description', ''), candidates=recommendations, top_k=top_k ) # Generate explanations explanations = [] for item in reranked: explanation = self._generate_explanation( user_profile, item ) explanations.append({ 'item': item, 'explanation': explanation }) return explanations defchat(self, session_id, user_message): """ Conversational recommendation interface. """ return self.conversation_manager.process_message( session_id, user_message ) def_init_llm_client(self, llm_config): """Initialize LLM client.""" # Implementation depends on LLM provider if llm_config['provider'] == 'openai': return OpenAIClient(llm_config['api_key']) elif llm_config['provider'] == 'anthropic': return AnthropicClient(llm_config['api_key']) # Add more providers def_init_recommendation_model(self, config): """Initialize recommendation model.""" # Can be traditional model or LLM-based return TraditionalRecommendationModel(config['model']) def_get_user_profile(self, user_id): """Get user profile from database.""" # Implementation depends on your data storage return {} def_generate_explanation(self, user_profile, item): """Generate explanation for recommendation.""" prompt = f"""Explain why this item is recommended. User Profile: {user_profile} Item: {item} Explanation:""" return self.llm_client.generate(prompt).strip()
Questions and Answers
Q1:
When should I use LLMs for recommendation vs. traditional methods?
A: Use LLMs when: - You have rich textual content
(descriptions, reviews, user profiles) - You need natural language
explanations - You're dealing with cold-start problems (new users/items)
- You want conversational recommendation interfaces - You need
cross-domain knowledge
Use traditional methods when: - You have abundant interaction data -
Latency and cost are critical constraints - You're working with
structured, numerical features - You need deterministic, reproducible
results
Hybrid approach: Use traditional methods for
retrieval, LLMs for reranking and explanation.
Q2:
How do I handle the cost of LLM API calls in production?
A: Several strategies:
Two-stage architecture: Use cheap retrieval
(traditional methods) to get candidates, then use LLM only for reranking
top candidates
Caching: Cache LLM responses for similar
queries
Batch processing: Combine multiple requests into
single API calls
Selective usage: Use LLMs only for complex queries
or cold-start cases
Prompt optimization: Minimize prompt size while
maintaining quality
Fine-tuning: Fine-tune smaller models for your
specific domain (cheaper than API calls)
Q3:
How do I ensure LLM recommendations are fair and unbiased?
A: LLMs can inherit biases from training data.
Mitigation strategies:
Bias detection: Monitor recommendations for
demographic biases
Prompt engineering: Include fairness constraints in
prompts
Post-processing: Apply fairness filters to LLM
outputs
Diverse sampling: Ensure diversity in
recommendations
User feedback: Collect and incorporate user
feedback on fairness
Regular audits: Periodically audit recommendations
for bias
Q4: Can I
fine-tune LLMs for recommendation tasks?
A: Yes, fine-tuning can improve performance:
Task-specific fine-tuning: Fine-tune on
recommendation datasets
Domain adaptation: Fine-tune on your specific
domain (movies, products, etc.)
Parameter-efficient methods: Use LoRA or adapter
layers to reduce costs
Instruction tuning: Fine-tune to follow
recommendation-specific instructions
Example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
from transformers import Trainer, TrainingArguments
Large Language Models are transforming recommendation systems by
bringing semantic understanding, natural language generation, and
conversational capabilities. From zero-shot prompt-based recommendation
to sophisticated conversational systems like ChatCRS, LLMs address
fundamental limitations of traditional methods while introducing new
possibilities for explainability and user interaction.
However, LLM-based recommendation is not a panacea. Cost, latency,
and reliability concerns require careful architecture design, often
combining LLMs with traditional methods in hybrid systems. Key: to
leverage LLMs where they add the most value — semantic understanding,
explanation generation, and conversational interaction — while using
efficient traditional methods for retrieval and ranking.
As LLM technology continues to evolve, we can expect more efficient
models, better fine-tuning techniques, and improved integration with
recommendation systems. The future of recommendation lies in combining
the pattern recognition strength of traditional methods with the
semantic understanding and natural language capabilities of LLMs,
creating systems that are both accurate and intuitive for users.
Post title:Recommendation Systems (12): Large Language Models and Recommendation
Post author:Chen Kai
Create time:2026-02-03 23:11:11
Post link:https://www.chenk.top/recommendation-systems-12-llm-recommendation/
Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.