Recommendation Systems (11): Contrastive Learning and Self-Supervised Learning
Chen KaiBOSS
2026-02-03 23:11:112026-02-03 23:118k Words50 Mins
permalink: "en/recommendation-systems-11-contrastive-learning/" date:
2024-06-21 10:00:00 tags: - Recommendation Systems - Contrastive
Learning - Self-Supervised categories: Recommendation Systems mathjax:
true---
Traditional recommendation systems rely heavily on explicit user
feedback — ratings, clicks, purchases — to learn user preferences. But
what happens when this data is sparse? What if you're launching a new
platform with no historical interactions? Or trying to recommend items
that have never been interacted with? These cold-start problems have
plagued recommendation systems for decades, limiting their effectiveness
and requiring massive amounts of labeled data to achieve reasonable
performance.
Contrastive learning offers a paradigm shift. Instead of requiring
explicit labels, it learns representations by contrasting similar and
dissimilar examples — teaching the model that augmented views of the
same user should be close in embedding space, while different users
should be far apart. This self-supervised approach has revolutionized
computer vision (SimCLR, MoCo), natural language processing (BERT, GPT),
and now recommendation systems.
In this comprehensive guide, we'll explore how contrastive learning
transforms recommendation systems. We'll start with the fundamental
principles of self-supervised learning, dive deep into landmark methods
like SimCLR and SGL, examine graph augmentation strategies, explore
sequential and long-tail recommendation applications, and provide
extensive code examples. Whether you're building a new recommendation
system from scratch or improving an existing one, understanding
contrastive learning is essential for modern recommendation systems.
Before diving into algorithms, let's understand why contrastive
learning is particularly powerful for recommendation systems.
The Data Sparsity Challenge
Traditional recommendation systems face a fundamental problem: the
interaction matrix is extremely sparse. In a typical e-commerce
platform: - Users interact with less than 1% of available items - Most
items receive interactions from fewer than 0.1% of users - New users and
items have zero interaction history
This sparsity creates several problems: 1.
Cold-start: New users/items can't be effectively
recommended 2. Overfitting: Models memorize sparse
patterns instead of learning generalizable representations 3.
Bias amplification: Popular items dominate, making it
harder to discover long-tail content
How Contrastive Learning
Helps
Contrastive learning addresses these challenges by:
Learning from Structure: Instead of relying solely
on explicit interactions, contrastive methods learn from the inherent
structure of user-item graphs, sequences, and feature spaces.
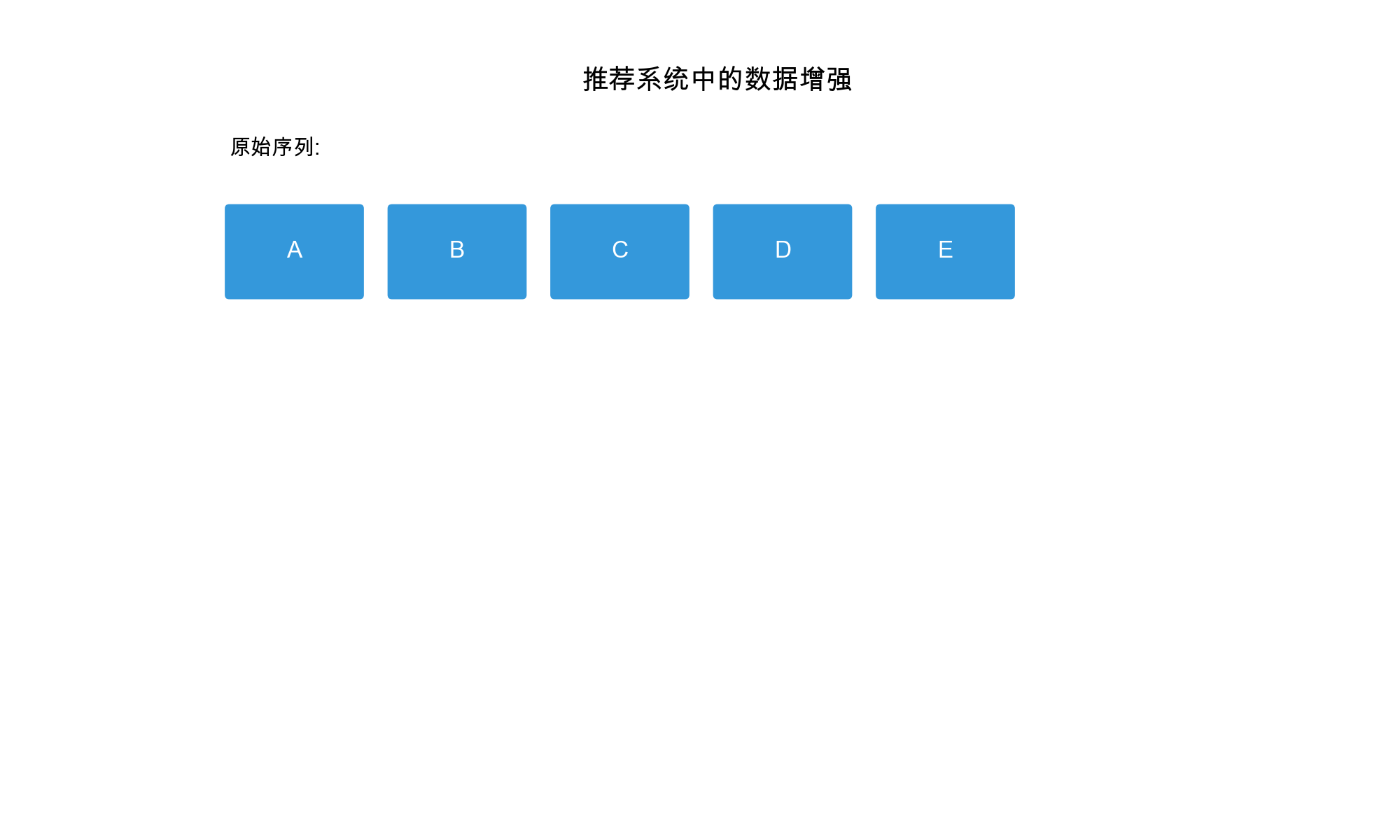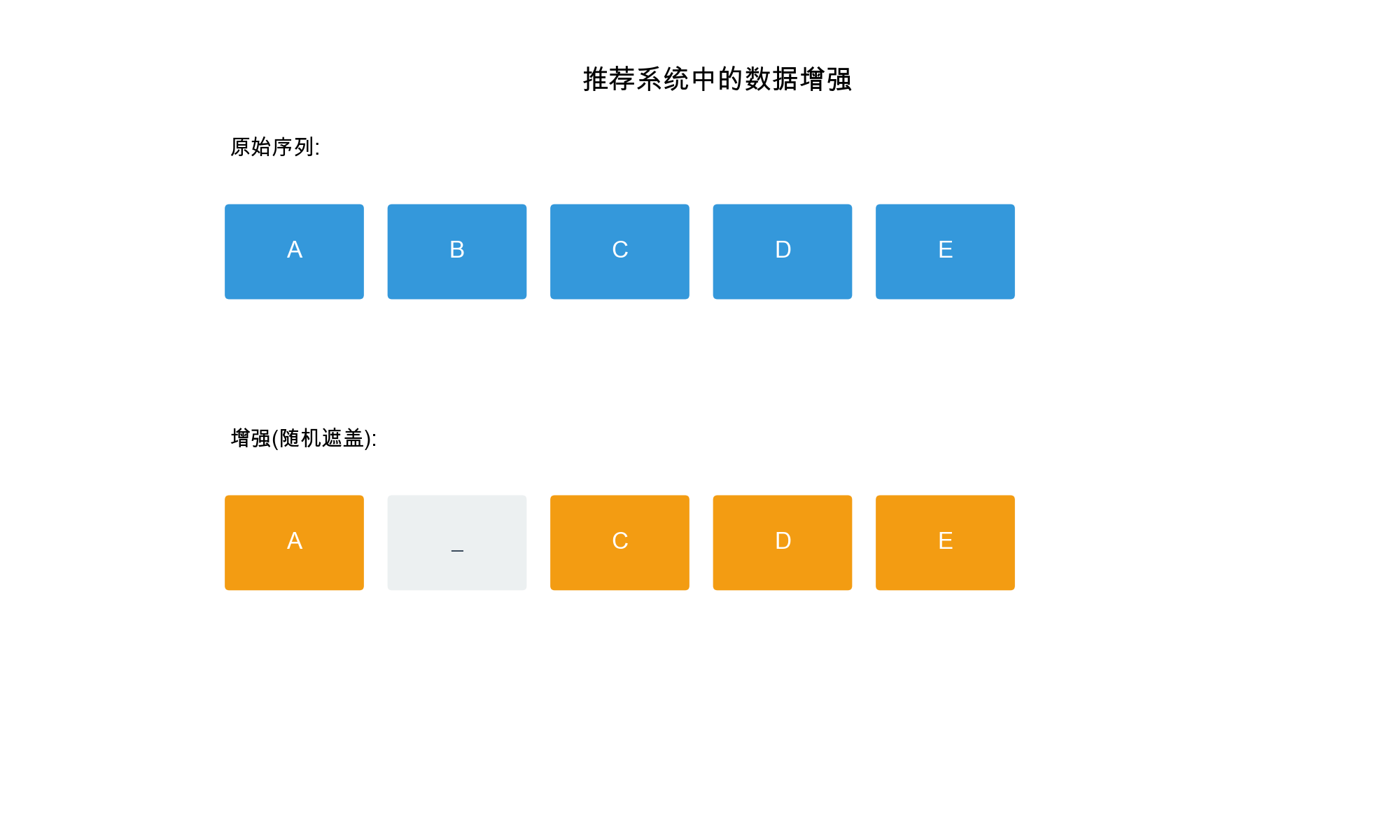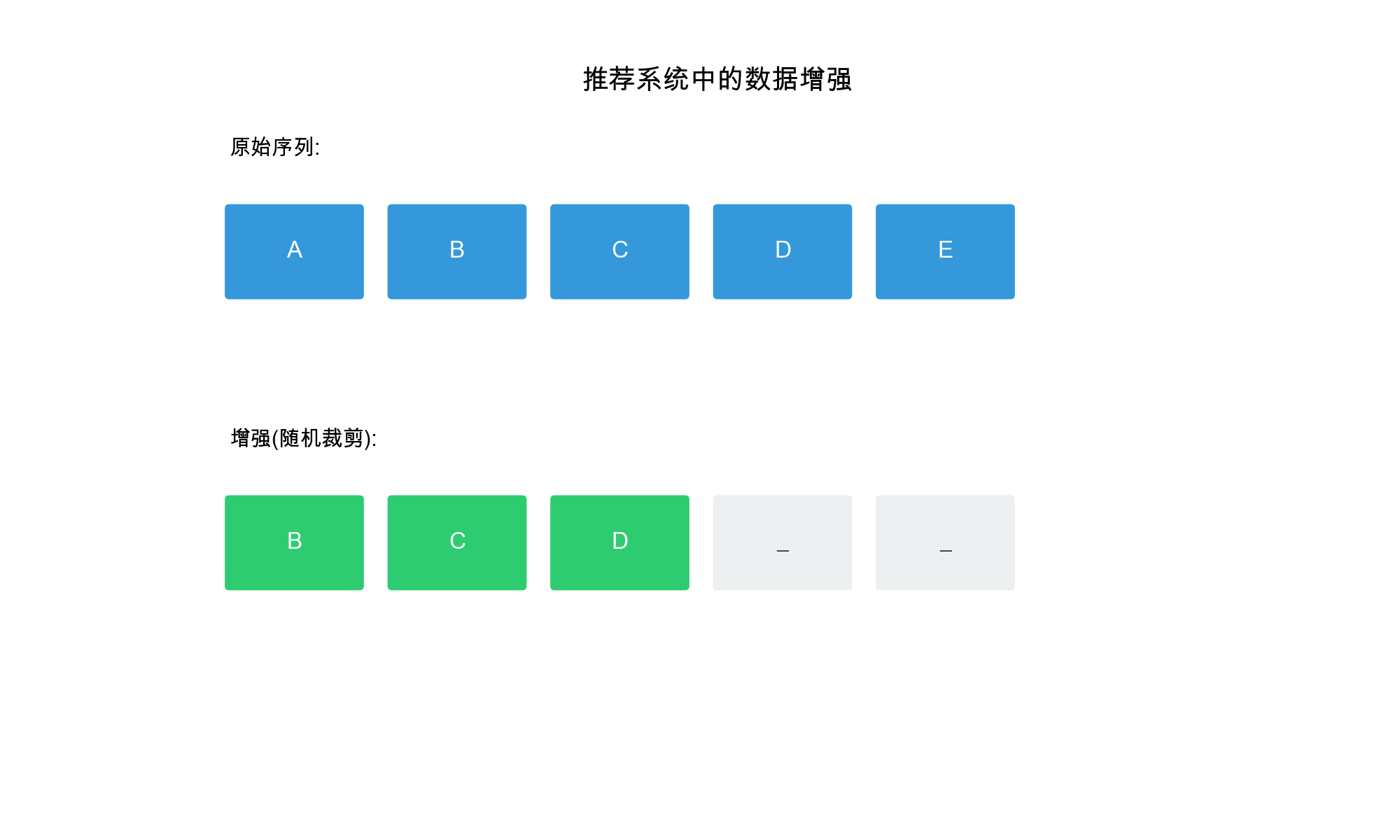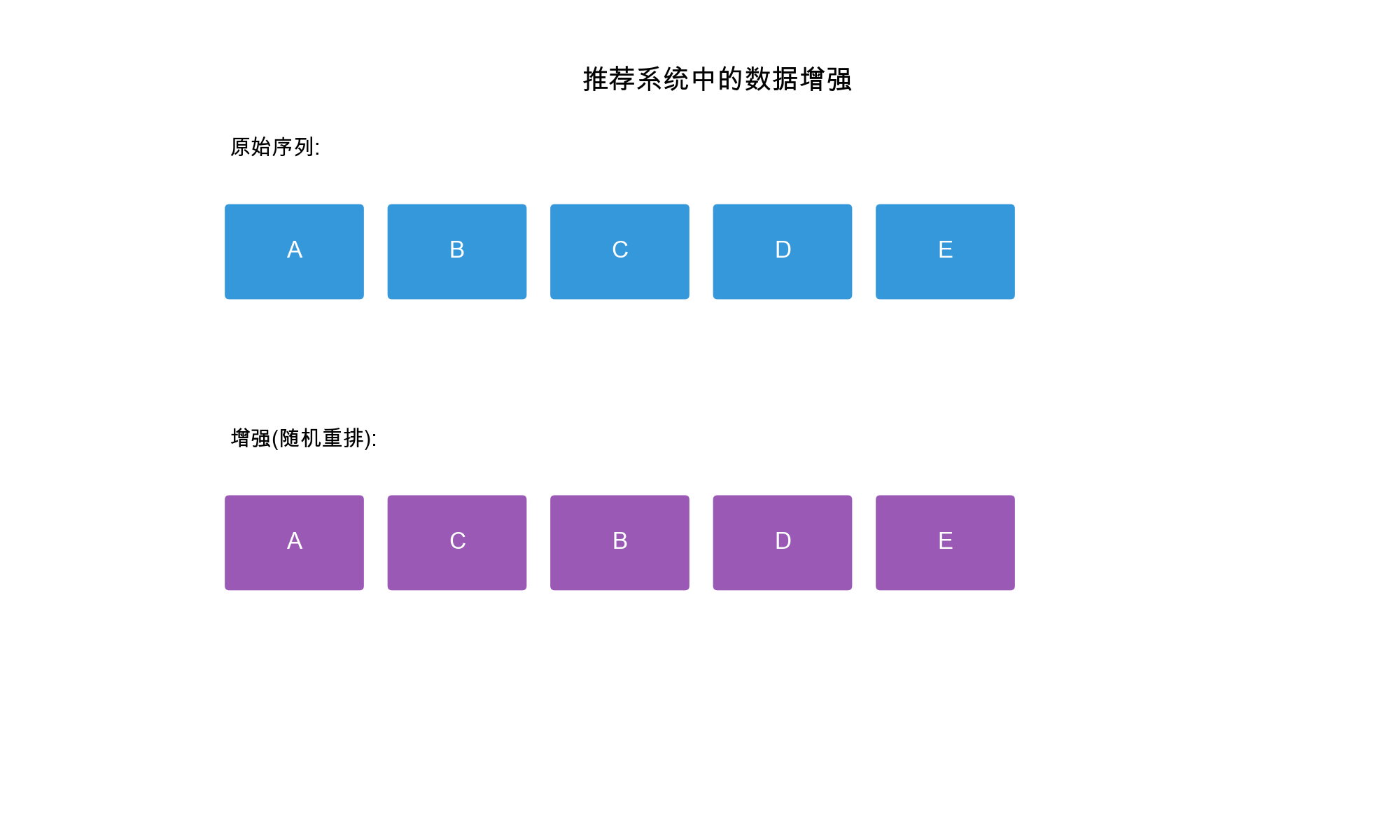
Data Augmentation: By creating multiple views of
the same data (e.g., dropping edges, masking items), we generate more
training signals from limited data.
Representation Quality: Contrastive objectives
encourage the model to learn rich, discriminative representations that
capture semantic similarity rather than just memorizing
interactions.
Robustness: Models trained with contrastive
learning are more robust to noise and missing data, crucial for
real-world recommendation scenarios.
Real-World Impact
Companies deploying contrastive learning in recommendations report: -
30-50% improvement in cold-start recommendation quality
- 20-30% increase in long-tail item discovery -
15-25% boost in overall recommendation diversity -
Reduced training data requirements by 40-60% while
maintaining performance
Foundations:
Self-Supervised Learning Basics
What is Self-Supervised
Learning?
Self-supervised learning (SSL) is a paradigm where models learn
representations from unlabeled data by solving pretext tasks. Unlike
supervised learning that requires explicit labels, SSL creates
supervisory signals from the data itself.
Key Intuition: The structure of the data contains
rich information. If we can design tasks that require understanding this
structure, the model will learn useful representations.
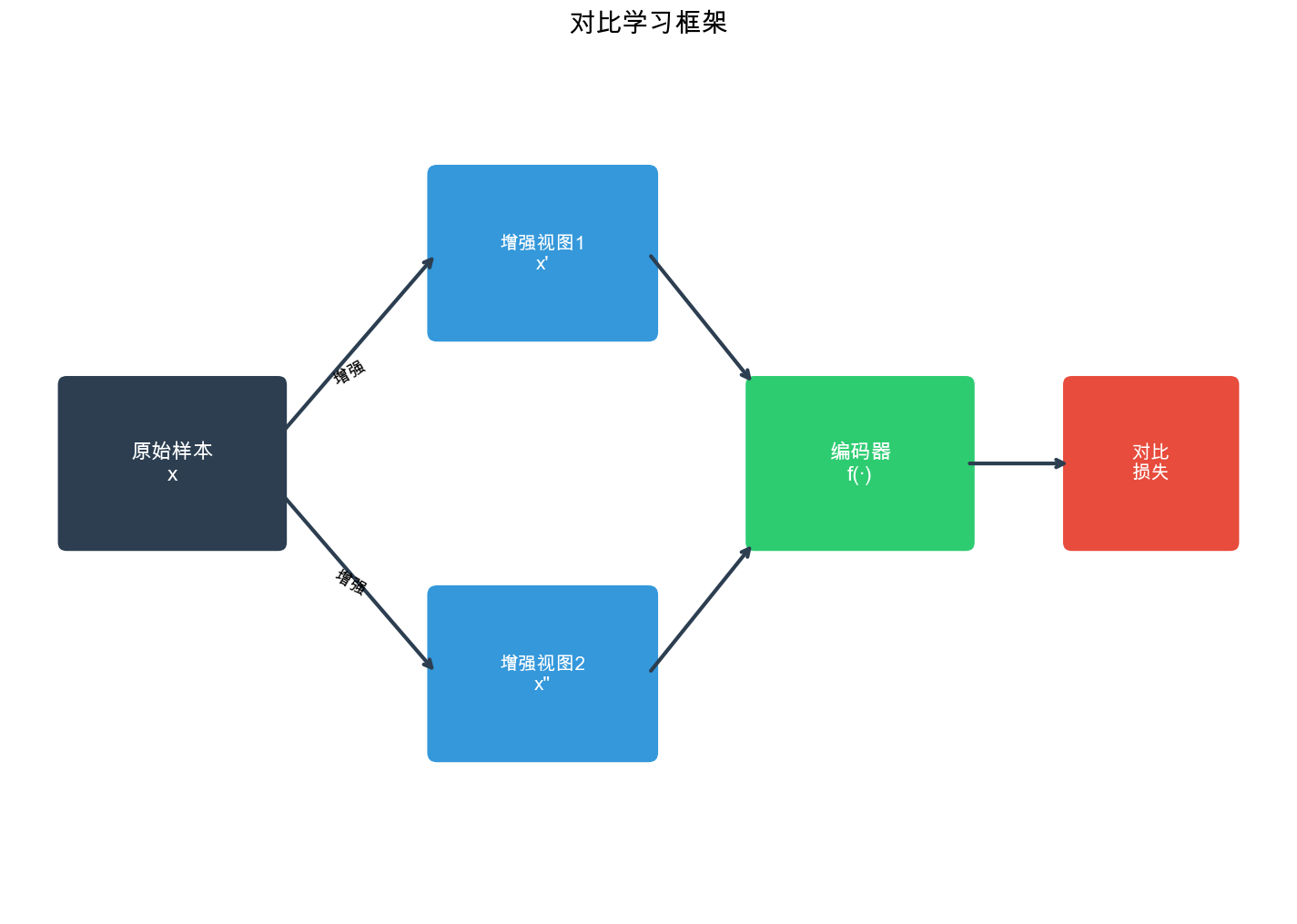
Contrastive Learning
Framework
Contrastive learning is a specific type of SSL that learns by
contrasting positive and negative pairs:
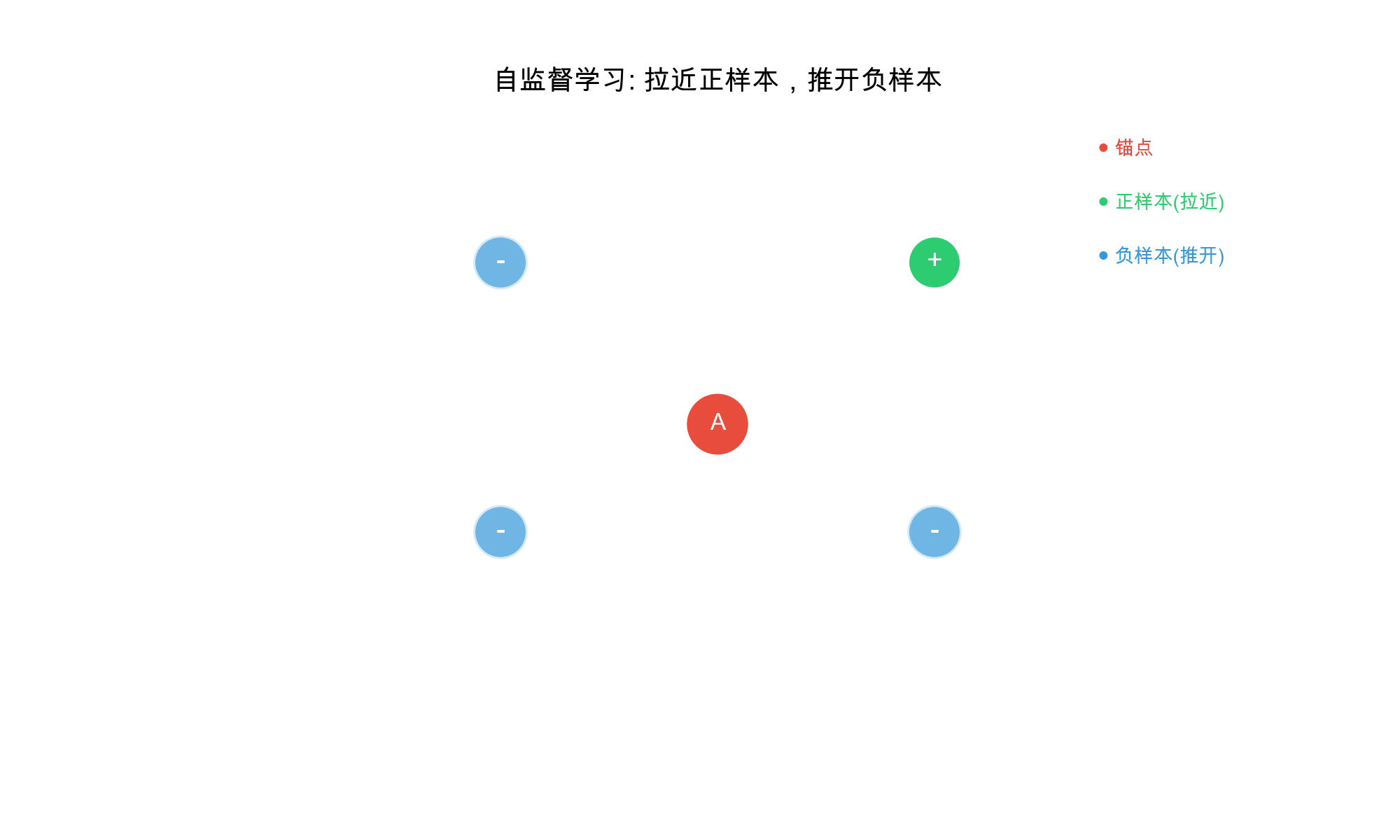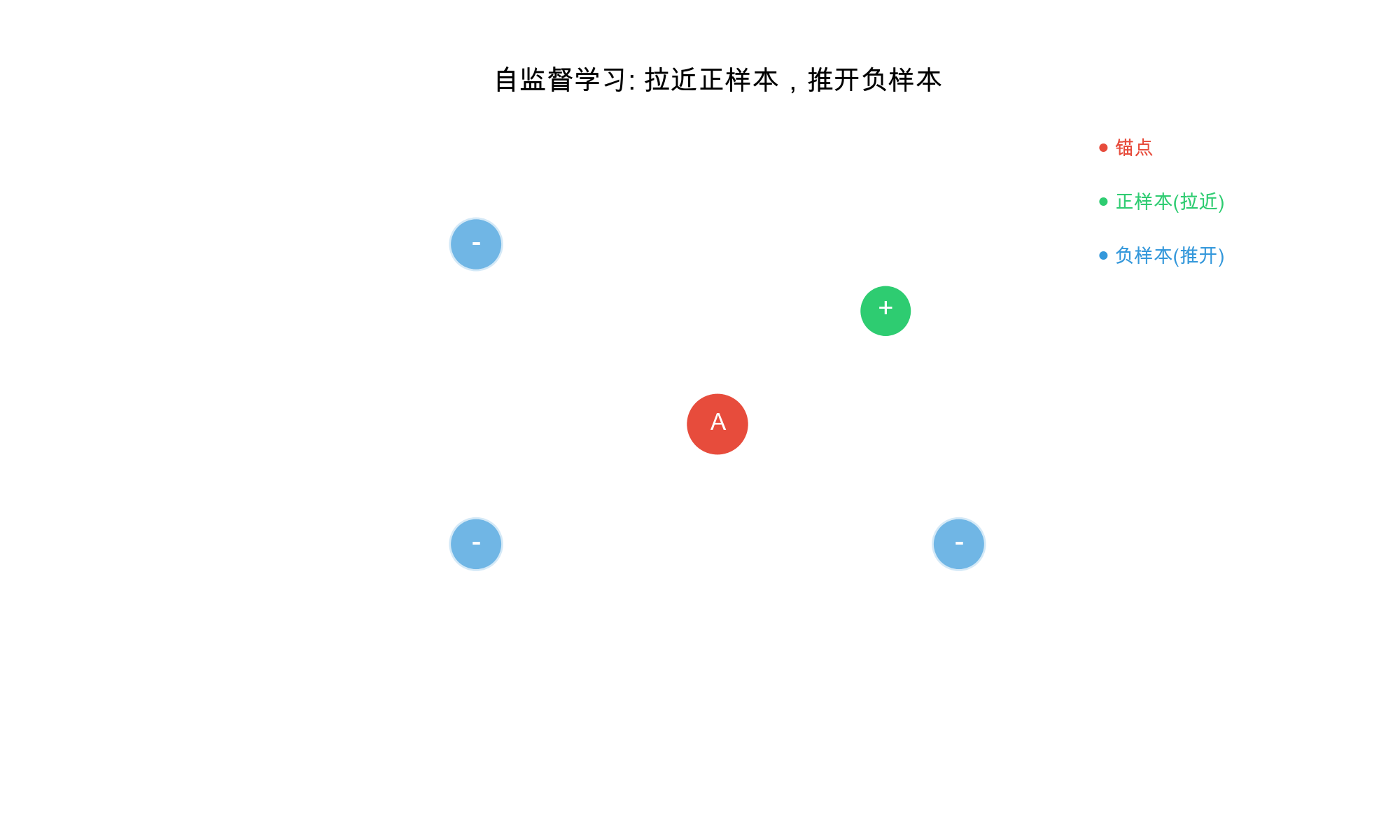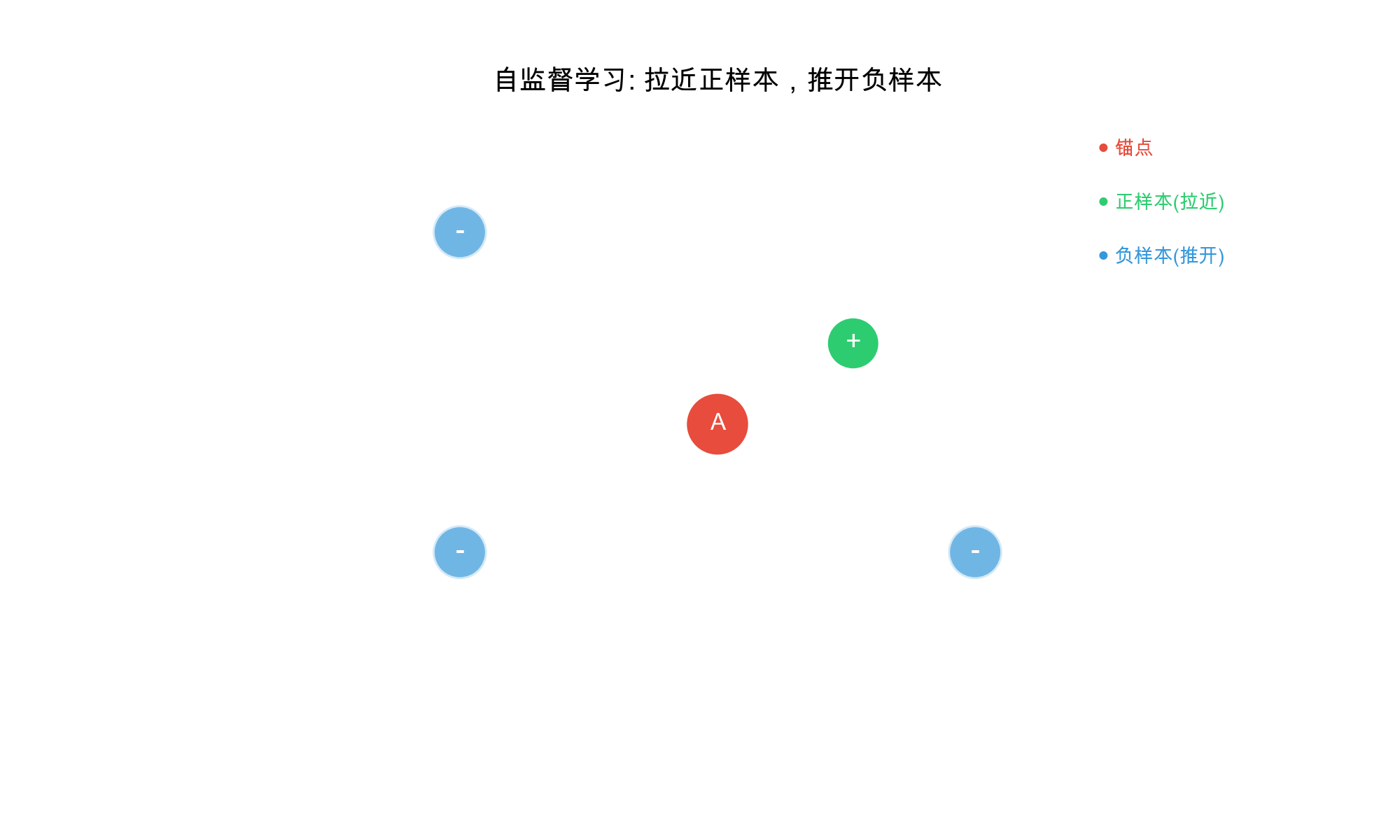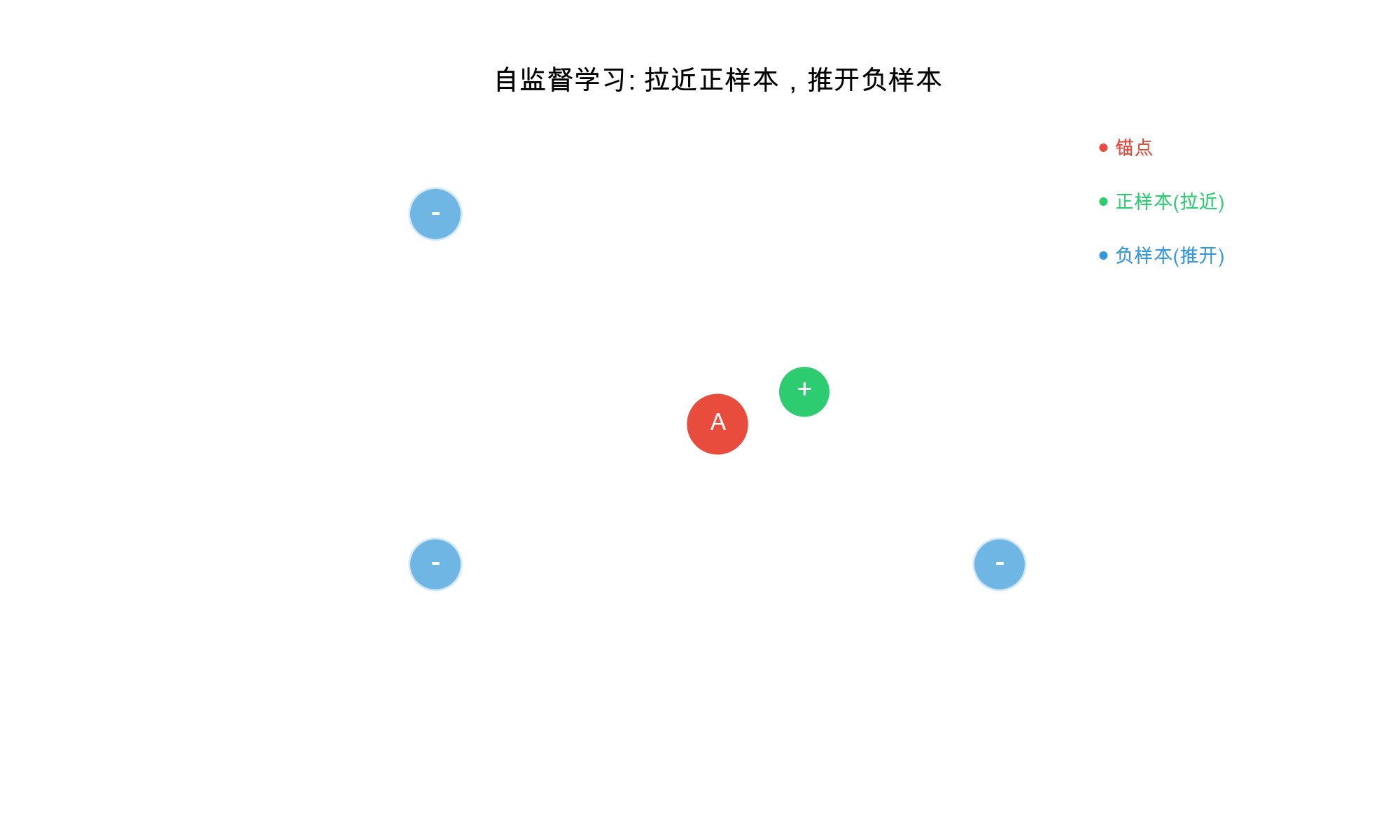
Core Principle: Pull similar examples (positives)
together in embedding space, push dissimilar examples (negatives)
apart.
Mathematically, given an anchor sample \(x\), a positive sample\(x^+\), and negative samples\(\{x_i^-\}_{i=1}^N\), contrastive learning
optimizes:\[\mathcal{L}_{contrastive} = -\log
\frac{\exp(\text{sim}(f(x), f(x^+)) / \tau)}{\exp(\text{sim}(f(x),
f(x^+)) / \tau) + \sum_{i=1}^N \exp(\text{sim}(f(x), f(x_i^-)) /
\tau)}\]where: -\(f(\cdot)\)is
the encoder function -\(\text{sim}(\cdot,
\cdot)\)is a similarity function (typically cosine similarity)
-\(\tau\)is a temperature parameter
controlling the concentration of the distribution
Key Components
Data Augmentation: Creating multiple views of the
same data
For images: rotation, cropping, color jittering
For graphs: edge dropping, node masking
For sequences: item masking, reordering
Encoder Architecture: Neural network that maps
inputs to embeddings
Should be expressive enough to capture complex patterns
Should be regularized to prevent collapse
Projection Head: Optional MLP that maps embeddings
to contrastive space
Often improves performance by allowing the encoder to learn more
general features
Typically discarded after training
Negative Sampling: Selecting negative examples
In-batch negatives: use other samples in the batch
Hard negatives: samples that are similar but should be
different
Easy negatives: obviously different samples
InfoNCE Loss
The most common contrastive loss is InfoNCE (Information Noise
Contrastive Estimation):\[\mathcal{L}_{InfoNCE} = -\mathbb{E} \left[ \log
\frac{\exp(\text{sim}(z_i, z_j^+) / \tau)}{\sum_{k=1}^{2N} \mathbb{1}_{k
\ne i} \exp(\text{sim}(z_i, z_k) / \tau)} \right]\]where: -\(z_i = f(x_i)\)is the embedding of anchor
-\(z_j^+\)is the embedding of positive
- The denominator includes all negatives in the batch -\(\mathbb{1}_{k \ne i}\)ensures we don't
compare an anchor with itself
Why InfoNCE works: It maximizes the mutual
information between positive pairs while minimizing it for negative
pairs. This encourages the model to learn representations that capture
the essential information needed to distinguish positives from
negatives.
SimCLR: A
Foundation for Contrastive Learning
SimCLR (Simple Contrastive Learning of Representations) introduced a
simple yet powerful framework that became the foundation for many
contrastive learning methods in recommendations.
SimCLR Architecture
SimCLR consists of four components:
Data Augmentation Module:\(\mathcal{T}\)
applies random augmentations
Base Encoder:\(f(\cdot)\)
extracts representations (e.g., ResNet)
Projection Head:\(g(\cdot)\)
maps to contrastive space
Contrastive Loss: InfoNCE loss
Algorithm Overview
For each sample\(x\): 1. Generate
two augmented views:\(\tilde{x}_i =
t(x)\),\(\tilde{x}_j =
t'(x)\)where\(t, t'
\sim\)\(2. Encode:\)h_i =
f(_i)\(,\)h_j = f(_j)\(3. Project:\)z_i = g(h_i)\(,\)z_j = g(h_j)\(4. Compute contrastive loss
between\)z_i\(and\)z_j$
Key Design Choices
Large Batch Sizes: SimCLR requires large batches
(4096+) because negatives come from other samples in the batch. Larger
batches = more negatives = better learning signal.
Projection Head: A 2-layer MLP with ReLU activation
significantly improves performance. The projection head can be discarded
after training.
Strong Augmentations: SimCLR showed that stronger
augmentations lead to better representations. The model learns to be
invariant to these transformations.
Temperature Parameter:\(\tau = 0.07\)was found to work well. Lower
temperatures make the distribution sharper (harder negatives matter
more).
SimCLR Implementation
for Recommendations
Here's how we can adapt SimCLR for recommendation systems:
# Example training for epoch inrange(100): user_ids = torch.randint(0, num_users, (64,)) item_ids = torch.randint(0, num_items, (64,)) edge_index = torch.randint(0, num_users, (2, 1000)) loss = train_simclr(model, user_ids, item_ids, edge_index, optimizer) if epoch % 10 == 0: print(f"Epoch {epoch}, Loss: {loss:.4f}")
Key Insights from SimCLR
Augmentation is Critical: The choice of
augmentation strategy directly impacts what the model learns. For
recommendations, this means carefully designing graph/sequence
augmentations.
Projection Head Matters: The projection head
allows the encoder to learn more general features while the projection
learns task-specific representations.
Batch Size vs. Performance: Larger batches
provide more negatives, improving the contrastive signal. However, this
must be balanced with memory constraints.
Temperature Tuning: The temperature parameter is
crucial. Too high (smooth distribution) or too low (sharp distribution)
both hurt performance.
SGL:
Self-Supervised Graph Learning for Recommendations
SGL (Self-supervised Graph Learning) adapts contrastive learning
specifically for graph-based recommendation systems. It's one of the
most influential methods for applying contrastive learning to
recommendations.
Motivation
Graph Neural Networks (GNNs) have shown great success in
recommendation systems by modeling user-item interactions as a bipartite
graph. However, GNNs suffer from: - Data sparsity:
Limited supervision signals - Over-smoothing: Node
embeddings become too similar after many layers -
Cold-start: New users/items have no connections
SGL addresses these by introducing self-supervised learning through
graph augmentation.
SGL Architecture
SGL consists of three main components:
Graph Augmentation: Creates multiple views of the
user-item graph
GNN Encoder: Extracts node representations from
augmented graphs
Contrastive Learning: Trains encoder to be
invariant to augmentations
Graph Augmentation
Strategies
SGL proposes three augmentation strategies:
1. Node Dropout
Randomly masks out some nodes (users or items) and their associated
edges:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
defnode_dropout(edge_index, node_mask, num_nodes): """ Drop nodes and their associated edges. Args: edge_index: [2, E] edge tensor node_mask: [N] boolean mask (True = keep, False = drop) num_nodes: total number of nodes """ # Filter edges where both endpoints are kept row, col = edge_index mask = node_mask[row] & node_mask[col] return edge_index[:, mask]
import torch import torch.nn as nn import torch.nn.functional as F from torch_geometric.nn import LightGCNConv from torch_geometric.utils import add_self_loops, degree
classSGLRecommender(nn.Module): """ Self-Supervised Graph Learning for Recommendation. """ def__init__(self, num_users, num_items, embedding_dim=64, num_layers=3, aug_type='edge', drop_prob=0.1): super(SGLRecommender, self).__init__() self.num_users = num_users self.num_items = num_items self.embedding_dim = embedding_dim self.num_layers = num_layers self.aug_type = aug_type self.drop_prob = drop_prob # Embeddings self.user_embedding = nn.Embedding(num_users, embedding_dim) self.item_embedding = nn.Embedding(num_items, embedding_dim) # Initialize embeddings nn.init.normal_(self.user_embedding.weight, std=0.1) nn.init.normal_(self.item_embedding.weight, std=0.1) # LightGCN layers self.convs = nn.ModuleList([ LightGCNConv(embedding_dim, embedding_dim) for _ inrange(num_layers) ]) defget_embeddings(self): """Get initial user and item embeddings.""" return torch.cat([self.user_embedding.weight, self.item_embedding.weight], dim=0) defaugment_graph(self, edge_index, num_nodes): """ Apply graph augmentation. Args: edge_index: [2, E] edge tensor num_nodes: total number of nodes (users + items) """ ifnot self.training: return edge_index if self.aug_type == 'edge': # Edge dropout num_edges = edge_index.size(1) num_drop = int(num_edges * self.drop_prob) drop_indices = torch.randperm(num_edges, device=edge_index.device)[:num_drop] mask = torch.ones(num_edges, dtype=torch.bool, device=edge_index.device) mask[drop_indices] = False return edge_index[:, mask] elif self.aug_type == 'node': # Node dropout node_mask = torch.rand(num_nodes, device=edge_index.device) > self.drop_prob row, col = edge_index mask = node_mask[row] & node_mask[col] return edge_index[:, mask] elif self.aug_type == 'mixed': # Randomly choose between edge and node dropout if torch.rand(1).item() < 0.5: return self.augment_graph(edge_index, num_nodes, 'edge') else: return self.augment_graph(edge_index, num_nodes, 'node') return edge_index defforward(self, edge_index, aug_edge_index=None): """ Forward pass through GNN. Args: edge_index: original graph edges aug_edge_index: augmented graph edges (for contrastive learning) """ # Get embeddings x = self.get_embeddings() num_nodes = x.size(0) # Use augmented graph if provided if aug_edge_index isnotNone: edge_index = aug_edge_index # Add self-loops edge_index, _ = add_self_loops(edge_index, num_nodes=num_nodes) # LightGCN propagation embeddings = [x] for conv in self.convs: x = conv(x, edge_index) embeddings.append(x) # Average embeddings from all layers final_embedding = torch.mean(torch.stack(embeddings), dim=0) return final_embedding defcompute_contrastive_loss(self, z1, z2, temperature=0.2): """ Compute contrastive loss between two views. Args: z1, z2: [N, D] node embeddings from two augmented views temperature: temperature parameter """ # Normalize embeddings z1 = F.normalize(z1, dim=1) z2 = F.normalize(z2, dim=1) # Split into user and item embeddings user_emb_1 = z1[:self.num_users] user_emb_2 = z2[:self.num_users] item_emb_1 = z1[self.num_users:] item_emb_2 = z2[self.num_users:] # User-level contrastive loss user_sim = torch.matmul(user_emb_1, user_emb_2.T) / temperature user_labels = torch.arange(self.num_users, device=z1.device) user_loss = F.cross_entropy(user_sim, user_labels) # Item-level contrastive loss item_sim = torch.matmul(item_emb_1, item_emb_2.T) / temperature item_labels = torch.arange(self.num_items, device=z1.device) item_loss = F.cross_entropy(item_sim, item_labels) return user_loss + item_loss defpredict(self, user_ids, item_ids, edge_index): """Predict ratings for user-item pairs.""" embeddings = self.forward(edge_index) user_emb = embeddings[user_ids] item_emb = embeddings[self.num_users + item_ids] return torch.sum(user_emb * item_emb, dim=1)
# Training function deftrain_sgl(model, edge_index, optimizer, alpha=0.1): """ Train SGL model with contrastive learning. Args: model: SGL model edge_index: graph edges optimizer: optimizer alpha: weight for contrastive loss """ model.train() optimizer.zero_grad() num_nodes = model.num_users + model.num_items # Create two augmented views aug_edge_index_1 = model.augment_graph(edge_index, num_nodes) aug_edge_index_2 = model.augment_graph(edge_index, num_nodes) # Forward pass for both views z1 = model.forward(edge_index, aug_edge_index_1) z2 = model.forward(edge_index, aug_edge_index_2) # Contrastive loss contrastive_loss = model.compute_contrastive_loss(z1, z2) # Recommendation loss (BPR or other) # Here we use a simple dot product loss # In practice, you'd use BPR loss with sampled negative items recommendation_loss = compute_recommendation_loss(model, edge_index) # Total loss total_loss = recommendation_loss + alpha * contrastive_loss total_loss.backward() optimizer.step() return total_loss.item(), contrastive_loss.item(), recommendation_loss.item()
defcompute_recommendation_loss(model, edge_index): """ Compute recommendation loss (e.g., BPR loss). This is a simplified version - in practice, you'd sample negatives. """ # Get embeddings embeddings = model.forward(edge_index) user_emb = embeddings[:model.num_users] item_emb = embeddings[model.num_users:] # Sample positive and negative pairs row, col = edge_index user_ids = row[row < model.num_users] item_ids = col[col >= model.num_users] - model.num_users # Positive scores pos_scores = torch.sum(user_emb[user_ids] * item_emb[item_ids], dim=1) # Sample negative items neg_item_ids = torch.randint(0, model.num_items, (len(user_ids),), device=user_ids.device) neg_scores = torch.sum(user_emb[user_ids] * item_emb[neg_item_ids], dim=1) # BPR loss loss = -torch.log(torch.sigmoid(pos_scores - neg_scores) + 1e-10).mean() return loss
SGL Key Contributions
Graph-Specific Augmentations: SGL introduced
augmentations tailored for bipartite graphs (node dropout, edge dropout)
that preserve the graph structure while creating diverse views.
Multi-Level Contrastive Learning: SGL applies
contrastive learning at both user and item levels, learning better
representations for both entity types.
LightGCN Integration: SGL uses LightGCN as the
base encoder, combining the benefits of GNNs with contrastive
learning.
Empirical Success: SGL showed significant
improvements over traditional GNN-based recommenders, especially for
sparse data and cold-start scenarios.
RecDCL:
Recommendation via Dual Contrastive Learning
RecDCL introduces dual contrastive learning, applying contrastive
objectives at both the instance level and the prototype level.
Motivation
While SGL focuses on graph augmentation, RecDCL addresses a different
challenge: learning both fine-grained instance representations and
high-level prototype representations. This dual-level learning helps the
model capture both local patterns (specific user-item interactions) and
global patterns (user/item clusters).
Dual Contrastive Learning
Framework
RecDCL applies contrastive learning at two levels:
Instance-Level Contrastive Learning: Similar to
SGL, contrasts augmented views of the same instance
RCL (Robust Contrastive Learning) addresses the problem of noisy and
adversarial examples in contrastive learning for recommendations.
The Robustness Problem
Real-world recommendation data contains: - Noisy
interactions: Accidental clicks, bot traffic, mislabeled data -
Adversarial examples: Users trying to game the system -
Distribution shift: Training and test distributions
differ
Standard contrastive learning is sensitive to these issues, leading
to degraded performance.
RCL Approach
RCL makes contrastive learning robust by:
Robust Negative Sampling: Identifies and
downweights hard negatives that might be false negatives
Adversarial Augmentation: Uses adversarial examples
during training to improve robustness
Confidence Weighting: Weights contrastive losses by
confidence scores
defsubgraph_sampling(edge_index, num_nodes, num_samples=2, subgraph_size=1000): """ Sample multiple subgraphs for contrastive learning. """ subgraphs = [] for _ inrange(num_samples): # Random walk to get subgraph nodes start_node = torch.randint(0, num_nodes, (1,)).item() visited = {start_node} current = start_node # Random walk for _ inrange(subgraph_size): neighbors = get_neighbors(edge_index, current) iflen(neighbors) == 0: break current = np.random.choice(neighbors) visited.add(current) # Extract subgraph edges subgraph_nodes = list(visited) subgraph_edges = extract_subgraph_edges(edge_index, subgraph_nodes) subgraphs.append(subgraph_edges) return subgraphs
Feature Masking
For feature-rich graphs, mask node features:
1 2 3 4 5 6 7 8
deffeature_masking(node_features, mask_prob=0.15): """ Randomly mask node features (similar to BERT). """ mask = torch.rand(node_features.size(0), device=node_features.device) > mask_prob masked_features = node_features.clone() masked_features[~mask] = 0# or use learnable mask token return masked_features
XSimGCL:
Simplified Graph Contrastive Learning
XSimGCL (eXtreme Simplified Graph Contrastive Learning) simplifies
contrastive learning by removing the projection head and using
cross-layer contrastive learning.
Key Innovation
XSimGCL makes two key simplifications:
No Projection Head: Directly contrasts embeddings
from different GNN layers
Cross-Layer Contrastive Learning: Contrasts
embeddings from different layers of the same view
classXSimGCL(nn.Module): """ eXtreme Simplified Graph Contrastive Learning. """ def__init__(self, num_users, num_items, embedding_dim=64, num_layers=3, temperature=0.2): super(XSimGCL, self).__init__() self.num_users = num_users self.num_items = num_items self.embedding_dim = embedding_dim self.num_layers = num_layers self.temperature = temperature # Embeddings self.user_embedding = nn.Embedding(num_users, embedding_dim) self.item_embedding = nn.Embedding(num_items, embedding_dim) # GCN layers self.convs = nn.ModuleList([ GCNConv(embedding_dim, embedding_dim) for _ inrange(num_layers) ]) defforward(self, edge_index, aug_edge_index=None): """Forward pass.""" x = torch.cat([self.user_embedding.weight, self.item_embedding.weight], dim=0) if aug_edge_index isnotNone: edge_index = aug_edge_index # Store embeddings from each layer layer_embeddings = [x] for conv in self.convs: x = conv(x, edge_index) x = F.relu(x) layer_embeddings.append(x) return layer_embeddings defcross_layer_contrastive_loss(self, layer_embeddings_1, layer_embeddings_2): """ Contrast embeddings from different layers. """ loss = 0 # Contrast corresponding layers from two views for i inrange(len(layer_embeddings_1)): z1 = F.normalize(layer_embeddings_1[i], dim=1) z2 = F.normalize(layer_embeddings_2[i], dim=1) # Positive pairs: same node, different views sim = torch.sum(z1 * z2, dim=1) / self.temperature loss += -torch.mean(sim) # Cross-layer contrastive: contrast different layers for i inrange(len(layer_embeddings_1)): for j inrange(i+1, len(layer_embeddings_1)): z_i = F.normalize(layer_embeddings_1[i], dim=1) z_j = F.normalize(layer_embeddings_1[j], dim=1) # Different layers should be similar (smoothness) sim = torch.sum(z_i * z_j, dim=1) / self.temperature loss += -torch.mean(sim) * 0.1# Smaller weight return loss
Why XSimGCL Works
Simplicity: Removing the projection head reduces
parameters and complexity
Layer Diversity: Cross-layer contrastive learning
encourages smooth but diverse representations across layers
Efficiency: Fewer parameters and simpler
architecture make training faster
Contrastive
Learning for Sequential Recommendations
Sequential recommendation systems model user behavior as sequences of
item interactions. Contrastive learning can be applied to learn better
sequence representations.
classContrastiveSequentialRecommender(nn.Module): """ Contrastive learning for sequential recommendations. """ def__init__(self, num_items, embedding_dim=64, hidden_dim=128, num_layers=2, temperature=0.2): super(ContrastiveSequentialRecommender, self).__init__() self.num_items = num_items self.embedding_dim = embedding_dim self.temperature = temperature # Item embeddings self.item_embedding = nn.Embedding(num_items, embedding_dim) # Sequence encoder (GRU or Transformer) self.encoder = nn.GRU(embedding_dim, hidden_dim, num_layers, batch_first=True) # Projection head self.projection = nn.Sequential( nn.Linear(hidden_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, embedding_dim) ) defaugment_sequence(self, sequence, aug_type='mask'): """ Augment sequence for contrastive learning. Args: sequence: [B, L] sequence of item IDs aug_type: 'mask', 'crop', 'reorder', or 'insert' """ if aug_type == 'mask': # Randomly mask items mask_prob = 0.15 mask = torch.rand(sequence.size(), device=sequence.device) > mask_prob augmented = sequence.clone() augmented[~mask] = 0# 0 is mask token return augmented elif aug_type == 'crop': # Random crop seq_len = sequence.size(1) crop_len = int(seq_len * 0.8) start_idx = torch.randint(0, seq_len - crop_len + 1, (1,)).item() return sequence[:, start_idx:start_idx+crop_len] elif aug_type == 'reorder': # Shuffle non-adjacent items (preserve some order) # Simplified: just shuffle augmented = sequence.clone() for i inrange(sequence.size(0)): perm = torch.randperm(sequence.size(1)) augmented[i] = sequence[i][perm] return augmented return sequence defforward(self, sequence): """Encode sequence.""" # Embed items item_emb = self.item_embedding(sequence) # Encode sequence output, hidden = self.encoder(item_emb) # Use last hidden state seq_emb = hidden[-1] # [B, H] # Project z = self.projection(seq_emb) return z defcontrastive_loss(self, z1, z2): """Compute contrastive loss.""" z1 = F.normalize(z1, dim=1) z2 = F.normalize(z2, dim=1) sim_matrix = torch.matmul(z1, z2.T) / self.temperature labels = torch.arange(z1.size(0), device=z1.device) loss = F.cross_entropy(sim_matrix, labels) return loss defcompute_loss(self, sequences): """Compute contrastive loss for sequences.""" # Create two augmented views seq_1 = self.augment_sequence(sequences, 'mask') seq_2 = self.augment_sequence(sequences, 'crop') # Encode z1 = self.forward(seq_1) z2 = self.forward(seq_2) # Contrastive loss loss = self.contrastive_loss(z1, z2) return loss
Sequential Contrastive
Learning Benefits
Temporal Invariance: Learns representations
invariant to minor sequence variations
Better Generalization: Augmented sequences help
model generalize to unseen patterns
Cold-Start: Better handling of short sequences (new
users)
Contrastive
Learning for Long-Tail Recommendations
Long-tail items (items with few interactions) are crucial for
diversity but challenging to recommend. Contrastive learning can help by
learning better representations for these items.
The Long-Tail Problem
In recommendation systems: - Head items (popular
items) dominate interactions - Long-tail items (niche
items) have few interactions but are important for diversity -
Traditional models overfit to head items, ignoring long-tail
Contrastive Learning
Solution
Contrastive learning helps by:
Learning from Structure: Even with few
interactions, graph structure provides signal
Augmentation: Creates more training examples for
long-tail items
Better Representations: Learns semantic similarity
beyond interaction frequency
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import numpy as np from sklearn.metrics import roc_auc_score, ndcg_score
Q1:
Why do we need contrastive learning for recommendations? Can't we just
use more data?
A: While more data helps, contrastive learning
provides several advantages beyond just data quantity:
Better Representations: Contrastive learning
learns representations that capture semantic similarity, not just
interaction patterns. This helps with generalization and cold-start
scenarios.
Data Efficiency: Contrastive learning can
achieve similar performance with less labeled data by leveraging
self-supervision signals from data augmentation.
Robustness: Models trained with contrastive
learning are more robust to noise and missing data, which is common in
real-world recommendation scenarios.
Long-Tail Discovery: Contrastive learning helps
discover and recommend long-tail items that traditional methods often
ignore.
Q2:
How do I choose the right augmentation strategy for my recommendation
system?
A: The choice depends on your data type and
problem:
Graph-based (user-item interactions): Use edge
dropout, node dropout, or subgraph sampling (like SGL)
Sequential (user behavior sequences): Use item
masking, sequence cropping, or reordering
Feature-rich: Use feature masking or feature
dropout
Hybrid: Combine multiple augmentation
strategies
Best Practice: Start with simple augmentations (edge
dropout for graphs, masking for sequences) and experiment. Monitor
validation performance to find what works best for your specific
dataset.
Q3:
What's the difference between SimCLR, SGL, and XSimGCL? Which should I
use?
A:
SimCLR: General contrastive learning framework,
originally for images. Requires adaptation for recommendations. Good
starting point for understanding contrastive learning.
SGL: Specifically designed for graph-based
recommendations. Uses graph augmentations (edge/node dropout) and
LightGCN. Best for bipartite graph recommendation scenarios.
XSimGCL: Simplified version that removes
projection head and uses cross-layer contrastive learning. More
efficient and often performs similarly to SGL.
Recommendation: Start with SGL if
you have graph-structured data. Use XSimGCL if you want
a simpler, more efficient model. Use SimCLR as a
reference for understanding contrastive learning principles.
Q4: How do I set
the temperature parameter\(\tau\)?
A: The temperature parameter controls the
concentration of the similarity distribution:
Low\(\tau\)(0.05-0.1): Sharper
distribution, harder negatives matter more. Can be too aggressive.
Medium\(\tau\)(0.1-0.2): Balanced, works
well for most cases. Common default: 0.2.
High\(\tau\)(0.5+): Softer distribution,
easier negatives also contribute. May hurt performance.
Best Practice: Start with\(\tau = 0.2\)and tune based on validation
performance. Lower values often work better for fine-grained
distinctions, higher values for coarse-grained.
Q5: Do I
need a projection head? When should I use it?
A: The projection head is an MLP that maps encoder
outputs to contrastive space:
With Projection Head (SimCLR, SGL): - Allows encoder
to learn more general features - Projection learns task-specific
representations - Typically discarded after training - Usually improves
performance
Without Projection Head (XSimGCL): - Simpler
architecture - Fewer parameters - Direct contrastive learning on
embeddings - Can work well if embeddings are already well-structured
Recommendation: Use a projection head unless you
have strong reasons not to (e.g., efficiency constraints). It's a simple
addition that often improves performance.
Q6:
How do I handle negative sampling in contrastive learning?
A: Negative sampling strategies:
In-Batch Negatives: Use other samples in the
batch as negatives. Simple and efficient, but requires large
batches.
Hard Negatives: Samples that are similar but
should be different. More informative but harder to identify.
Easy Negatives: Obviously different samples.
Less informative but stable.
Mixed Strategy: Combine easy and hard
negatives.
Best Practice: Start with in-batch negatives
(simplest). For better performance, add hard negatives by sampling items
similar to positive items but not interacted with.
Q7:
Can contrastive learning work with implicit feedback (clicks, views) or
do I need explicit ratings?
A: Contrastive learning works excellently with
implicit feedback! In fact, it's often more suitable than explicit
ratings because:
Implicit feedback is more abundant (every click is a signal)
Contrastive learning doesn't require exact ratings, just
positive/negative pairs
Graph structure from implicit interactions provides rich
self-supervision signals
Most contrastive recommendation methods (SGL, XSimGCL) are designed
for implicit feedback scenarios.
Q8:
How do I combine contrastive learning with traditional recommendation
losses (BPR, NCF)?
A: The standard approach is multi-task
learning:\[\mathcal{L}_{total} =
\mathcal{L}_{recommendation} + \alpha \cdot
\mathcal{L}_{contrastive}\]where\(\alpha\)controls the weight of contrastive
loss.
Example:
1 2 3 4 5 6 7 8
# Recommendation loss (BPR) recommendation_loss = compute_bpr_loss(user_emb, pos_item_emb, neg_item_emb)
# Contrastive loss contrastive_loss = compute_contrastive_loss(z1, z2)
# Total loss total_loss = recommendation_loss + alpha * contrastive_loss
Tuning\(\alpha\):
Start with\(\alpha = 0.1\)and adjust
based on validation performance. Too high (\(>1.0\)) may hurt recommendation
performance, too low (\(<0.01\)) may
not help.
Q9:
How much data do I need for contrastive learning to be effective?
A: Contrastive learning is more data-efficient than
supervised learning, but still benefits from more data:
Minimum: A few thousand user-item interactions
Good Performance: 10K-100K interactions
Excellent Performance: 100K+ interactions
However, contrastive learning can work with less data than pure
supervised methods because: - Augmentation creates more training
examples - Self-supervision signals don't require explicit labels -
Graph structure provides additional signal
Key: Even with limited data, contrastive learning
often outperforms traditional methods, especially for cold-start
scenarios.
Q10:
How do I evaluate contrastive learning models? Are standard metrics
(AUC, NDCG) sufficient?
A: Standard metrics are still relevant, but consider
additional evaluations:
Standard Metrics: - AUC/ROC:
Overall ranking quality - NDCG@K: Top-K recommendation
quality - Recall@K: Coverage of relevant items -
Precision@K: Accuracy of top-K recommendations
Contrastive-Specific Evaluations: -
Cold-Start Performance: Test on new users/items -
Long-Tail Discovery: Measure recommendation diversity -
Representation Quality: Visualize embeddings (t-SNE,
UMAP) - Robustness: Test with noisy/missing data
Best Practice: Use standard metrics for comparison
with baselines, but also evaluate cold-start and long-tail performance
where contrastive learning shines.
Q11:
Can I use contrastive learning for multi-modal recommendations (text,
images, etc.)?
A: Yes! Contrastive learning is excellent for
multi-modal scenarios:
Cross-Modal Contrastive Learning: - Contrast text
and image representations of the same item - Learn aligned embeddings
across modalities - Handle missing modalities gracefully
Example: For an item with both image and text,
create positive pairs from the same item's modalities, negatives from
different items.
Implementation: Use separate encoders for each
modality, contrast embeddings in shared space.
Q12:
How do I handle the computational cost of contrastive learning?
A: Contrastive learning can be computationally
expensive. Optimization strategies:
Smaller Batches: Use gradient accumulation if
memory is limited
Fewer Negatives: Limit negative sampling instead of
using all in-batch negatives
Simpler Architecture: Use XSimGCL instead of SGL if
needed
Efficient Augmentation: Cache augmented graphs
instead of recomputing
Mixed Precision Training: Use FP16 to reduce memory
and speed up training
Trade-off: Some performance loss may occur, but
contrastive learning often still outperforms non-contrastive methods
even with these optimizations.
Conclusion
Contrastive learning has emerged as a powerful paradigm for
recommendation systems, addressing fundamental challenges like data
sparsity, cold-start problems, and long-tail item discovery. By learning
from data structure rather than relying solely on explicit labels,
contrastive methods achieve better generalization and robustness.
Key takeaways:
Self-Supervision is Powerful: Learning from data
structure provides rich signals even with limited labeled data.
Augmentation Matters: The choice of augmentation
strategy directly impacts what the model learns. Graph augmentations
(edge/node dropout) work well for recommendation graphs.
Simplicity Can Win: Methods like XSimGCL show
that simpler architectures can match or exceed complex ones.
Multi-Level Learning: Combining instance-level
and prototype-level contrastive learning (like RecDCL) captures both
fine-grained and coarse-grained patterns.
Practical Impact: Contrastive learning provides
significant improvements in cold-start scenarios, long-tail discovery,
and overall recommendation diversity.
As recommendation systems continue to evolve, contrastive learning
will likely play an increasingly important role. The methods we've
covered — SimCLR, SGL, RecDCL, RCL, XSimGCL — represent the current
state of the art, but the field is rapidly advancing. New techniques for
better augmentations, more efficient training, and improved robustness
are constantly being developed.
Whether you're building a new recommendation system or improving an
existing one, understanding and applying contrastive learning is
essential. Start with simple augmentations and standard methods like
SGL, then experiment with more advanced techniques based on your
specific needs and constraints.
The future of recommendation systems lies in learning better
representations, and contrastive learning provides a powerful framework
for achieving that goal.
Post title:Recommendation Systems (11): Contrastive Learning and Self-Supervised Learning
Post author:Chen Kai
Create time:2026-02-03 23:11:11
Post link:https://www.chenk.top/recommendation-systems-11-contrastive-learning/
Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.