Recommendation Systems (10): Deep Interest Networks and Attention Mechanisms
Chen KaiBOSS
2026-02-03 23:11:112026-02-03 23:116.5k Words40 Mins
permalink: "en/recommendation-systems-10-deep-interest-networks/"
date: 2024-06-16 15:15:00 tags: - Recommendation Systems - DIN -
Attention Mechanism categories: Recommendation Systems mathjax: true---
When you browse Alibaba's e-commerce platform, the recommendation system
doesn't treat all your past clicks equally. That vintage leather jacket
you viewed last week matters more when you're looking at similar jackets
today than the random phone charger you clicked months ago. This
selective focus — understanding which historical behaviors are relevant
to the current recommendation — is the core insight behind Deep Interest
Networks (DIN), a breakthrough architecture that introduced attention
mechanisms to recommendation systems and revolutionized how we model
user interests.
Traditional recommendation models treat user behavior sequences as
fixed-length vectors, averaging or pooling all historical interactions
regardless of their relevance to the current item. DIN changed this
paradigm by introducing target attention: dynamically weighting
historical behaviors based on their similarity to the candidate item.
This simple but powerful idea, combined with Alibaba's massive scale
(billions of users, millions of items, terabytes of daily data), led to
significant improvements in click-through rates and revenue. The success
of DIN spawned a family of attention-based architectures: DIEN (Deep
Interest Evolution Network) models how interests evolve over time, DSIN
(Deep Session Interest Network) captures session-level patterns, and
various attention variants address different aspects of the
recommendation problem.
This article provides a comprehensive exploration of Deep Interest
Networks and attention mechanisms in recommendation systems, covering
the theoretical foundations of attention, DIN's target attention
mechanism, DIEN's interest evolution modeling, DSIN's session-aware
architecture, attention variants (multi-head, self-attention,
co-attention), Alibaba's production practices and optimizations,
training techniques for large-scale systems, and practical
implementations with 10+ code examples and detailed Q&A sections
addressing common questions and challenges.
The
Attention Revolution in Recommendation Systems
Why Attention Matters
Traditional recommendation models face a fundamental limitation: they
treat all historical user behaviors as equally important. Consider a
user who has clicked on: - 5 action movies - 3 romantic comedies
- 2 documentaries - 1 horror film
When recommending a new action movie, the system should emphasize
those 5 action movie clicks, not treat them equally with the horror film
click. This selective focus is exactly what attention mechanisms
provide.
The Core Problem
Given a user's behavior sequence\(\mathbf{B}_u = [b_1, b_2, \dots,
b_T]\)where each\(b_i\)represents a historical interaction
(click, purchase, view), and a candidate item\(i\), traditional models compute:\[\mathbf{v}_u = \text{Pool}(\mathbf{B}_u) =
\frac{1}{T} \sum_{j=1}^{T} \mathbf{e}_{b_j}\]where\(\mathbf{e}_{b_j}\)is the embedding of
behavior\(b_j\). This averaging loses
the relevance information — all behaviors contribute equally regardless
of how similar they are to the candidate item.
Attention Solution
Attention mechanisms compute a relevance score\(\alpha_j\)for each historical behavior\(b_j\)with respect to the candidate
item\(i\):\[\alpha_j = \text{Attention}(\mathbf{e}_{b_j},
\mathbf{e}_i)\]The user representation becomes a weighted
sum:\[\mathbf{v}_u = \sum_{j=1}^{T} \alpha_j
\mathbf{e}_{b_j}\]where behaviors similar to the candidate item
receive higher weights, allowing the model to focus on relevant
historical patterns.
Attention Mechanism
Fundamentals
Basic Attention
The attention mechanism computes a compatibility score between a
query\(\mathbf{q}\)and a set of
keys\(\mathbf{K} = [\mathbf{k}_1,
\mathbf{k}_2, \dots, \mathbf{k}_n]\):\[\text{Attention}(\mathbf{q}, \mathbf{K},
\mathbf{V}) = \sum_{i=1}^{n} \alpha_i \mathbf{v}_i\]where the
attention weights\(\alpha_i\)are
computed as:\[\alpha_i =
\frac{\exp(\text{score}(\mathbf{q}, \mathbf{k}_i))}{\sum_{j=1}^{n}
\exp(\text{score}(\mathbf{q}, \mathbf{k}_j))}\]Common scoring
functions include:
In recommendation systems, we use target attention
(also called query attention), where: - Query:
candidate item embedding\(\mathbf{e}_i\) - Keys: historical behavior
embeddings\(\mathbf{e}_{b_j}\) -
Values: historical behavior embeddings\(\mathbf{e}_{b_j}\)(self-attention)
The attention weight measures how relevant each historical behavior
is to the current candidate item.
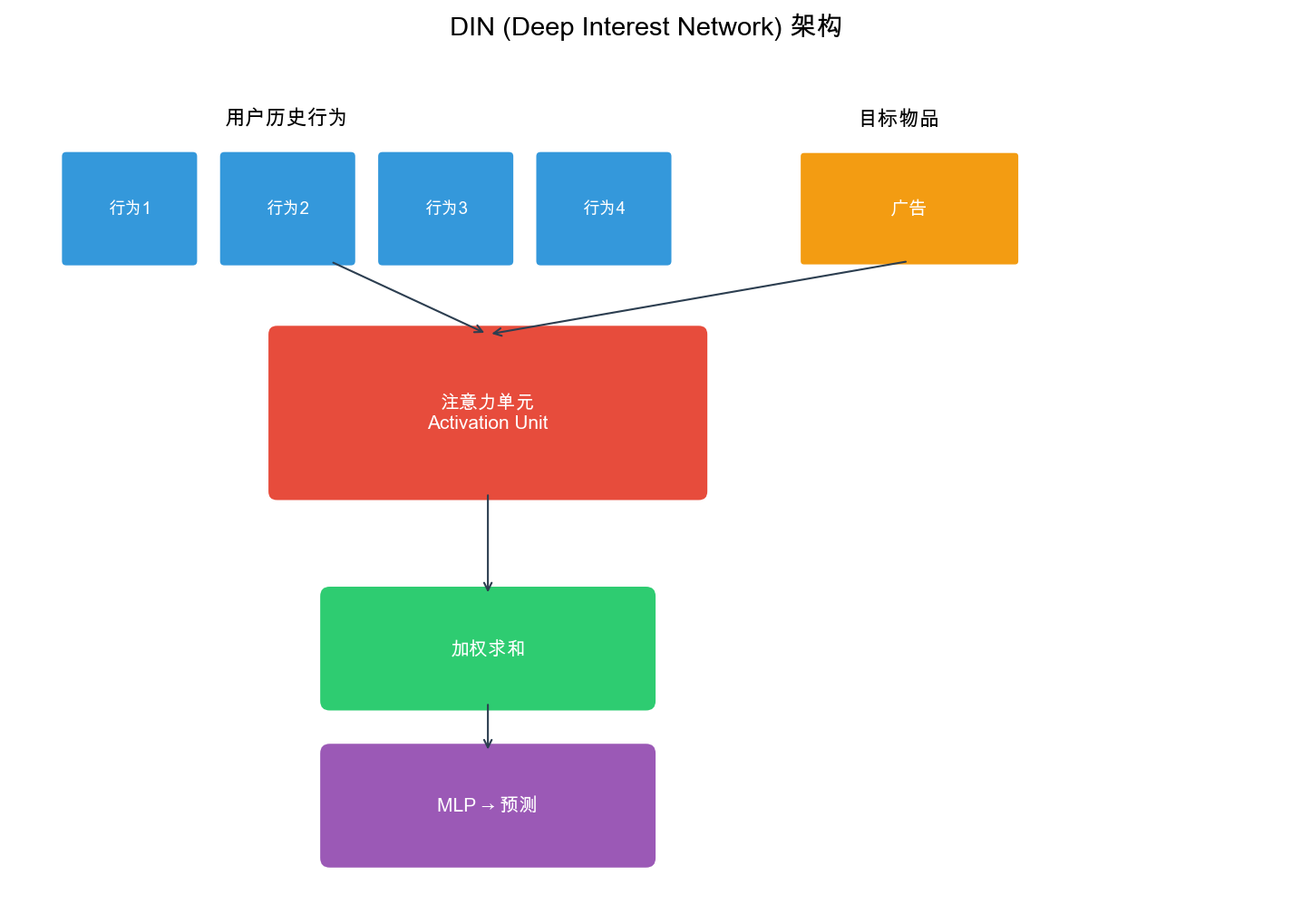
Deep Interest Network (DIN)
Architecture Overview
DIN was introduced by Alibaba in 2018 to address the limitation of
fixed-length user representations in CTR prediction. The key innovation
is the Local Activation Unit that adaptively computes
attention weights based on the candidate item.
Problem Formulation
Given: - User profile features:\(\mathbf{x}_u\)(age, gender, city, etc.) -
User behavior sequence:\(\mathbf{B}_u = [b_1,
b_2, \dots, b_T]\)(clicked items) - Candidate item:\(i\)with features\(\mathbf{x}_i\) - Context features:\(\mathbf{x}_c\)(time, device, etc.)
User Features → Embedding Layer Behavior Sequence → Embedding Layer → Local Activation Unit (Attention) Candidate Item → Embedding Layer Context Features → Embedding Layer ↓ Concatenate All Features ↓ MLP Layers ↓ Output (CTR)
Local Activation Unit
The Local Activation Unit computes attention weights for each
behavior in the sequence:\[\alpha_j =
\text{Attention}(\mathbf{e}_{b_j}, \mathbf{e}_i) =
\frac{\exp(\text{score}(\mathbf{e}_{b_j}, \mathbf{e}_i))}{\sum_{k=1}^{T}
\exp(\text{score}(\mathbf{e}_{b_k}, \mathbf{e}_i))}\]The scoring
function uses an MLP:\[\text{score}(\mathbf{e}_{b_j}, \mathbf{e}_i) =
\mathbf{W}^T \text{ReLU}(\mathbf{W}_1 \mathbf{e}_{b_j} + \mathbf{W}_2
\mathbf{e}_i + \mathbf{b}) + c\]The activated user representation
is:\[\mathbf{v}_u = \sum_{j=1}^{T} \alpha_j
\mathbf{e}_{b_j}\]
Key Properties
Adaptive: Attention weights change based on the
candidate item
Sparse: Only relevant behaviors get high
weights
Interpretable: Attention weights show which
behaviors matter
DIN uses binary cross-entropy loss for CTR prediction:\[\mathcal{L} = -\frac{1}{N} \sum_{i=1}^{N} [y_i
\log(\hat{y}_i) + (1-y_i) \log(1-\hat{y}_i)]\]where\(y_i \in \{0, 1\}\)is the true label (click
or not) and\(\hat{y}_i\)is the
predicted CTR.
Mini-batch Aware Regularization
For large-scale training with millions of items, DIN uses mini-batch
aware regularization for embedding layers:\[\mathcal{L}_{reg} = \sum_{j=1}^{K} \sum_{m=1}^{B}
\frac{\alpha_{mj }}{n_j} ||\mathbf{e}_j||^2\]where: -\(K\)is the number of embedding tables -\(B\)is the number of mini-batches -\(\alpha_{mj}\)is the number of times
feature\(j\)appears in batch\(m\) -\(n_j\)is the total frequency of feature\(j\)in the dataset
This avoids expensive full-batch regularization while maintaining
regularization benefits.
Training Tricks
Dice Activation: Adaptive activation function that
performs better than ReLU/PReLU
Data Adaptive: Normalizes inputs based on data
distribution
Gradient Clipping: Prevents gradient explosion in
long sequences
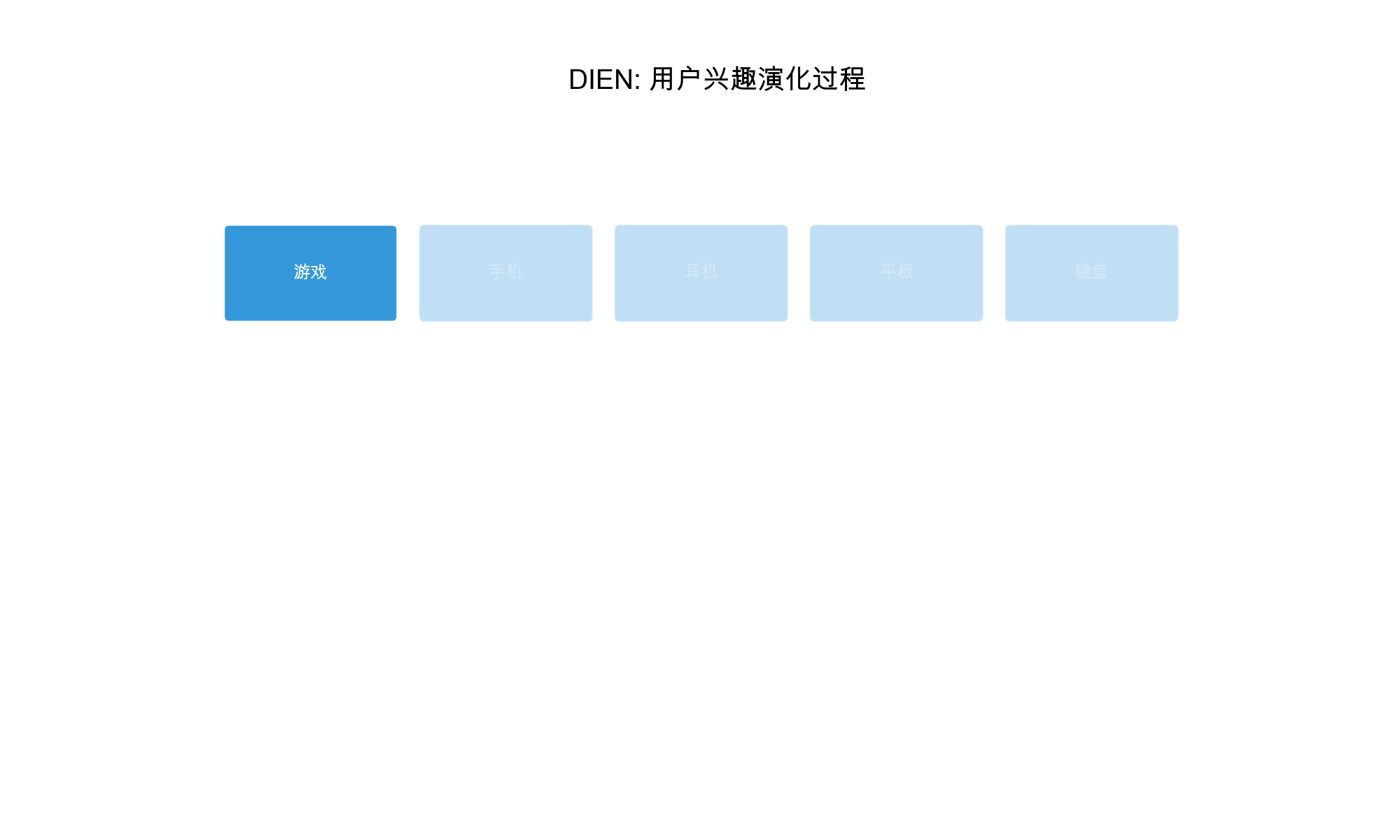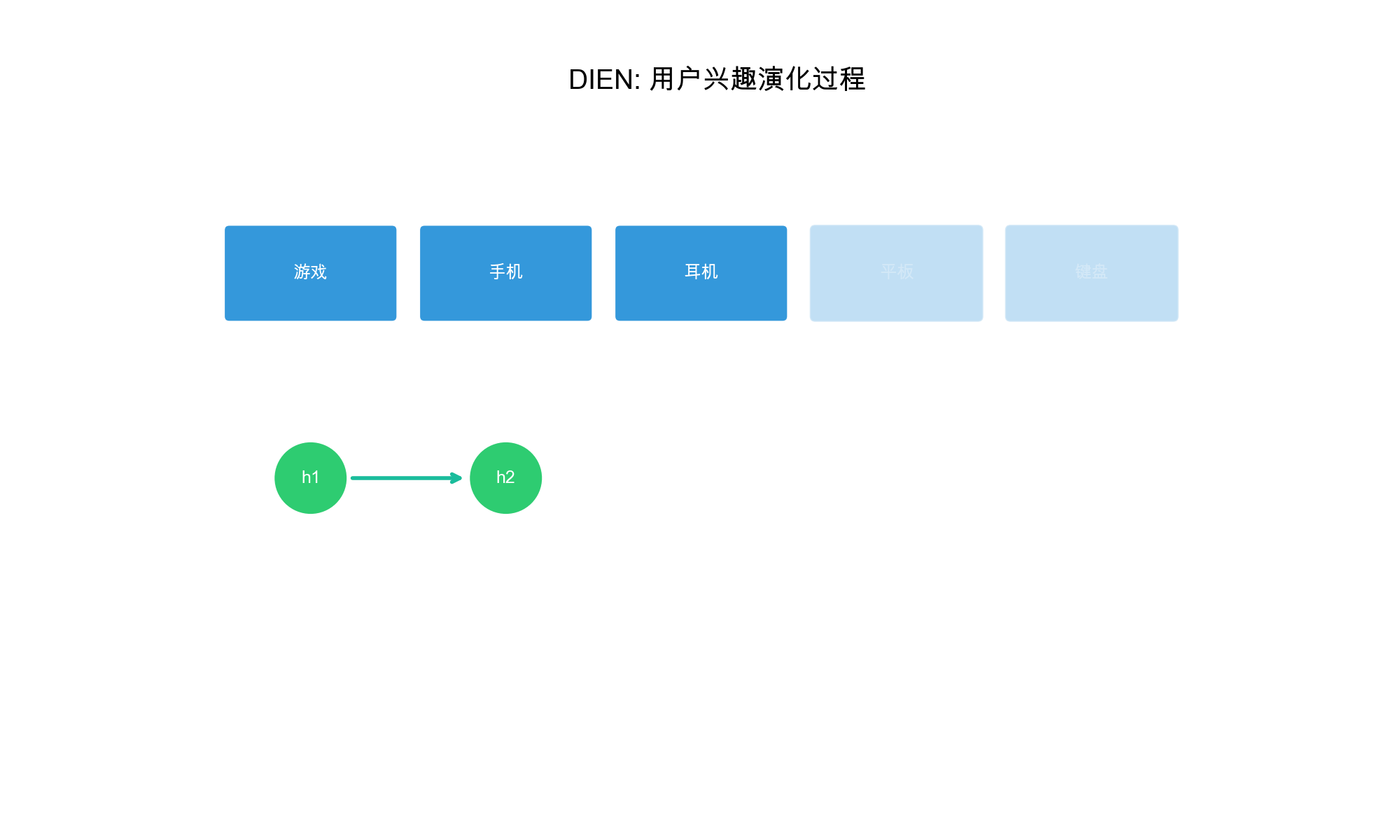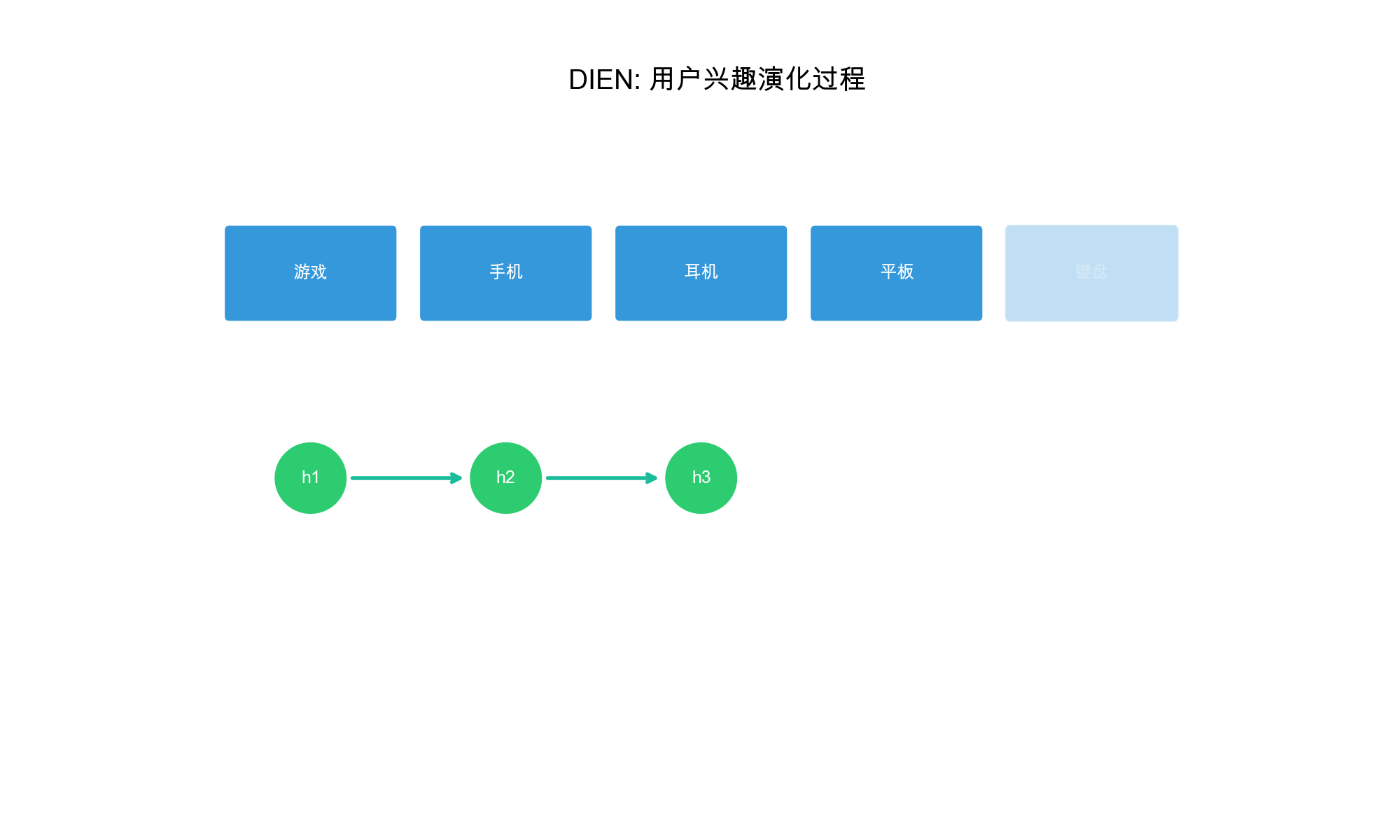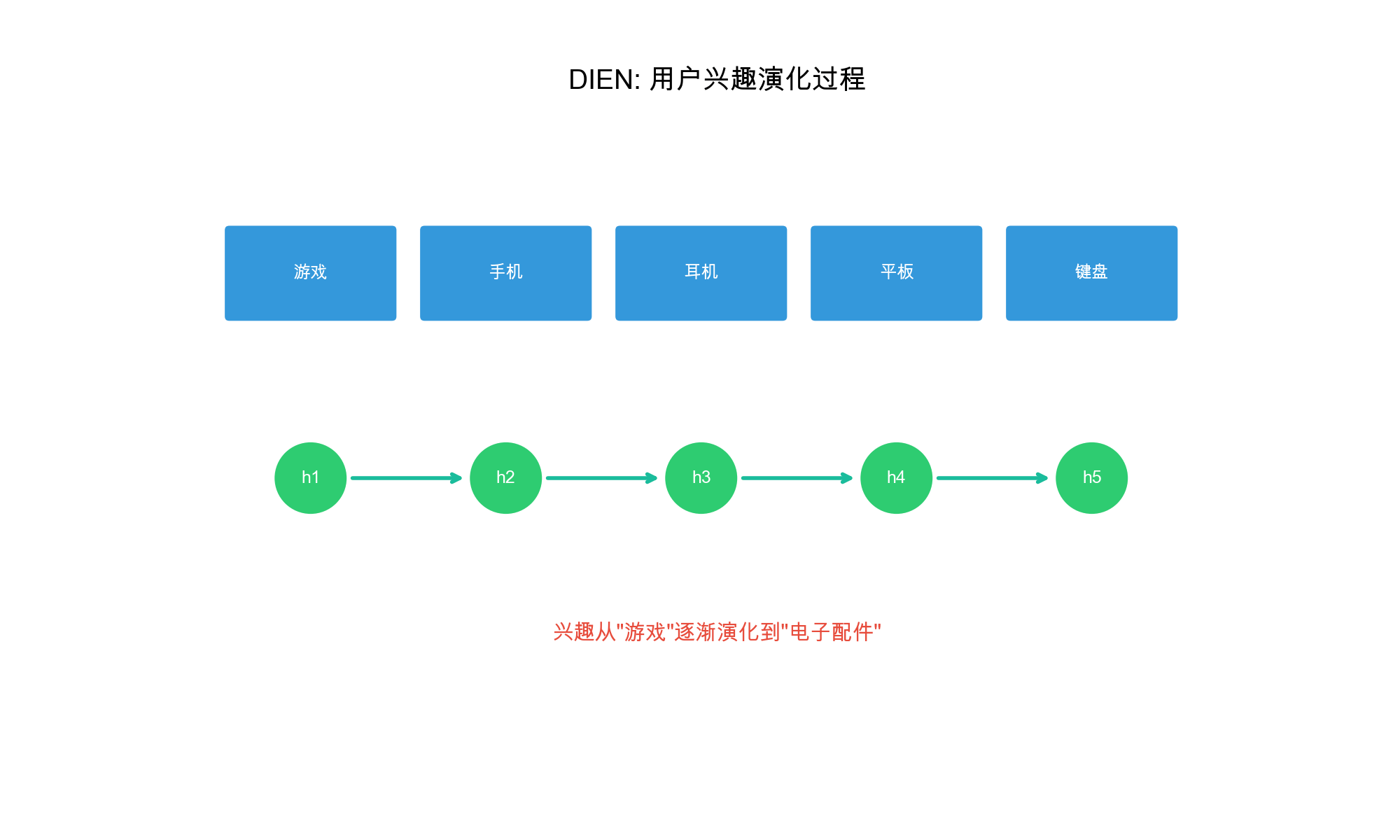
Deep Interest Evolution
Network (DIEN)
Motivation
DIN treats all historical behaviors as independent, ignoring the
temporal evolution of user interests. DIEN addresses this by modeling
how interests evolve over time using a two-layer structure: 1.
Interest Extractor Layer: Extracts interests from
behavior sequences 2. Interest Evolution Layer: Models
how interests evolve
Architecture
Interest Extractor Layer
Uses GRU to extract interest representations from behavior
sequences:\[\mathbf{h}_t =
\text{GRU}(\mathbf{e}_{b_t}, \mathbf{h}_{t-1})\]where\(\mathbf{e}_{b_t}\)is the embedding of
behavior at time\(t\)and\(\mathbf{h}_t\)is the hidden state
representing interest at time\(t\).
Interest Evolution Layer
Models interest evolution using an Auxiliary Loss to
help the GRU learn meaningful interest representations:
Auxiliary Loss: For each time step, predict the
next behavior using the current interest representation:\[\mathcal{L}_{aux} = -\frac{1}{N} \sum_{i=1}^{N}
\sum_{t=1}^{T} \log \sigma(\mathbf{h}_t^T \mathbf{e}_{b_{t+1 }}^+) +
\log(1 - \sigma(\mathbf{h}_t^T \mathbf{e}_{b_{t+1
}}^-))\]where\(\mathbf{e}_{b_{t+1
}}^+\)is the embedding of the actual next behavior and\(\mathbf{e}_{b_{t+1 }}^-\)is a negative
sample.
Attention-based GRU: Uses attention mechanism to
focus on relevant historical interests:\[\alpha_t = \text{Attention}(\mathbf{h}_t,
\mathbf{e}_i)\]\[\mathbf{h}_t' =
\text{GRU}(\mathbf{h}_t, \mathbf{h}_{t-1}', \alpha_t)\]The
final user representation is:\[\mathbf{v}_u =
\sum_{t=1}^{T} \alpha_t \mathbf{h}_t'\]
User behaviors often occur in sessions — short periods of focused
activity. DSIN models session-level patterns by: 1. Splitting behavior
sequences into sessions 2. Extracting session-level interests 3.
Modeling session evolution 4. Using self-attention within sessions
Architecture
Session Division
Split user behavior sequence into sessions based on time gaps:\[\mathbf{B}_u = [\mathbf{S}_1, \mathbf{S}_2,
\dots, \mathbf{S}_K]\]where each session\(\mathbf{S}_k = [b_{k,1}, b_{k,2}, \dots,
b_{k,|S_k|}]\)contains behaviors within a time window.
Session Interest Extractor
Uses self-attention within each session to extract session-level
interests:\[\text{Attention}(\mathbf{Q},
\mathbf{K}, \mathbf{V}) =
\text{softmax}\left(\frac{\mathbf{Q}\mathbf{K}^T}{\sqrt{d
}}\right)\mathbf{V}\]where\(\mathbf{Q}
= \mathbf{K} = \mathbf{V} = \mathbf{S}_k\)(self-attention).
The session interest is:\[\mathbf{s}_k =
\text{Attention}(\mathbf{S}_k, \mathbf{S}_k, \mathbf{S}_k)\]
Bias Encoding
Adds positional and session bias to capture temporal patterns:\[\mathbf{S}_k' = \mathbf{S}_k +
\mathbf{B}_{pos} + \mathbf{B}_{session}\]
Multi-head attention allows the model to attend to different aspects
simultaneously:\[\text{MultiHead}(\mathbf{Q},
\mathbf{K}, \mathbf{V}) = \text{Concat}(\text{head}_1, \dots,
\text{head}_h)\mathbf{W}^O\]where each head is:\[\text{head}_i =
\text{Attention}(\mathbf{Q}\mathbf{W}_i^Q, \mathbf{K}\mathbf{W}_i^K,
\mathbf{V}\mathbf{W}_i^V)\]
Self-attention uses the same sequence as query, key, and value:\[\text{SelfAttention}(\mathbf{X}) =
\text{Attention}(\mathbf{X}, \mathbf{X}, \mathbf{X})\]This
captures relationships within the sequence itself.
Co-Attention
Co-attention models interactions between two sequences (e.g., user
behaviors and item features):\[\mathbf{A} =
\text{softmax}(\mathbf{X}_1 \mathbf{W}_1 (\mathbf{X}_2
\mathbf{W}_2)^T)\]\[\mathbf{X}_1'
= \mathbf{A} \mathbf{X}_2\]\[\mathbf{X}_2' = \mathbf{A}^T
\mathbf{X}_1\]
deftrain_distributed(model, train_loader, optimizer): model = DistributedDataParallel(model) for epoch inrange(num_epochs): for batch in train_loader: optimizer.zero_grad() loss = model(batch) loss.backward() optimizer.step()
Mixed Precision Training
1 2 3 4 5 6 7 8 9 10 11 12 13
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for batch in train_loader: optimizer.zero_grad() with autocast(): loss = model(batch) scaler.scale(loss).backward() scaler.step(optimizer) scaler.update()
Gradient Accumulation
1 2 3 4 5 6 7 8 9
accumulation_steps = 4
for i, batch inenumerate(train_loader): loss = model(batch) / accumulation_steps loss.backward() if (i + 1) % accumulation_steps == 0: optimizer.step() optimizer.zero_grad()
Training Techniques
Dice Activation Function
Dice is an adaptive activation function that performs better than
ReLU/PReLU:\[\text{Dice}(x) = x \cdot
\sigma(\alpha(x - \bar{x}))\]where\(\bar{x}\)is the mean of\(x\)in the mini-batch and\(\alpha\)is a learnable parameter.
Implementation
1 2 3 4 5 6 7 8 9 10 11 12
classDice(nn.Module): """Dice activation function""" def__init__(self, embedding_dim): super(Dice, self).__init__() self.alpha = nn.Parameter(torch.zeros(embedding_dim)) self.bn = nn.BatchNorm1d(embedding_dim) defforward(self, x): x_norm = self.bn(x) p = torch.sigmoid(self.alpha * x_norm) return x * p
Label Smoothing
Label smoothing prevents overconfidence:\[y_{smooth} = (1 - \epsilon) \cdot y + \epsilon /
K\]where\(\epsilon\)is the
smoothing factor and\(K\)is the number
of classes.
Focal Loss
Focal loss addresses class imbalance:\[\text{FL}(p_t) = -\alpha_t (1 - p_t)^{\gamma}
\log(p_t)\]where\(\alpha_t\)balances class importance
and\(\gamma\)focuses on hard
examples.
Q1:
Why does DIN use target attention instead of self-attention?
A: Target attention allows the model to focus on
historical behaviors that are relevant to the current candidate item.
Self-attention would only capture relationships within the behavior
sequence itself, but wouldn't connect behaviors to the candidate. For
example, if a user clicked on "laptop" and "phone" in the past, and the
candidate is "laptop charger", target attention would give higher weight
to the "laptop" click, while self-attention might just learn that
"laptop" and "phone" are related (both electronics) but wouldn't connect
them to "laptop charger".
Q2: How does
DIEN's auxiliary loss help training?
A: The auxiliary loss encourages the GRU to learn
meaningful interest representations by predicting the next behavior.
This acts as a regularizer: if the interest representation\(\mathbf{h}_t\)can predict what the user
will click next, it must have captured useful information about the
user's current interest state. Without this loss, the GRU might learn
trivial representations that don't capture interest evolution.
Q3: What's
the difference between DIN, DIEN, and DSIN?
A: - DIN: Models user interests as
a weighted sum of historical behaviors using target attention. Treats
behaviors as independent. - DIEN: Models how interests
evolve over time using GRU, capturing temporal dependencies in user
behavior. - DSIN: Splits behaviors into sessions and
models session-level patterns using self-attention within sessions and
Bi-LSTM across sessions.
Q4: How
do you handle variable-length behavior sequences?
A: Common approaches: 1. Padding:
Pad shorter sequences with zeros and use masking to ignore padding in
attention 2. Truncation: Keep only the last N behaviors
3. Sampling: Randomly sample N behaviors from the
sequence 4. Hierarchical: Use RNN/LSTM to encode
variable-length sequences into fixed-length vectors
defcreate_attention_mask(sequence_lengths, max_len): """ Create attention mask for variable-length sequences Args: sequence_lengths: [batch_size] (actual lengths) max_len: maximum sequence length Returns: mask: [batch_size, max_len] (1 for valid, 0 for padding) """ batch_size = len(sequence_lengths) mask = torch.zeros(batch_size, max_len) for i, length inenumerate(sequence_lengths): mask[i, :length] = 1 return mask
# In attention computation attention_scores = attention_scores.masked_fill(mask == 0, -1e9)
Q5: How
does multi-head attention help in recommendation?
A: Multi-head attention allows the model to attend
to different aspects simultaneously. For example, one head might focus
on item categories (laptop → laptop charger), another on brands (Apple →
Apple accessories), another on price ranges (budget items → budget
items), and another on temporal patterns (recent clicks → similar recent
items). This captures richer relationships than single-head
attention.
Q6:
What are the computational costs of attention mechanisms?
For long sequences (e.g., 1000+ behaviors), this becomes expensive.
Solutions: 1. Truncation: Keep only recent N behaviors
2. Sampling: Sample N behaviors instead of using all 3.
Sparse attention: Only attend to a subset of positions
4. Linear attention: Use approximations to reduce
complexity
Q7:
How do you handle cold-start users with few behaviors?
A: For users with sparse behavior histories: 1.
Use side features: Rely more on user profile features
(demographics, location) 2. Content-based: Use item
features when behavior is insufficient 3. Transfer
learning: Use embeddings learned from similar users 4.
Default behaviors: Use popular items or category-level
behaviors as fallback
defhandle_sparse_behavior(behavior_sequence, user_features, min_behaviors=5): """ Handle sparse behavior sequences Args: behavior_sequence: [batch_size, seq_len, embedding_dim] user_features: [batch_size, feature_dim] min_behaviors: minimum behaviors required Returns: enhanced_sequence: [batch_size, seq_len, embedding_dim] """ batch_size, seq_len, emb_dim = behavior_sequence.shape # Count non-zero behaviors (assuming padding is zeros) behavior_counts = (behavior_sequence.sum(dim=-1) != 0).sum(dim=1) # For sparse users, use user features as additional "behavior" sparse_mask = behavior_counts < min_behaviors # Expand user features to match behavior dimension user_feature_expanded = user_features.unsqueeze(1).expand( batch_size, seq_len, -1 ) # Concatenate or replace for sparse users if sparse_mask.any(): # Option 1: Concatenate enhanced_sequence = torch.cat( [behavior_sequence, user_feature_expanded], dim=-1 ) # Option 2: Replace padding with user features # behavior_sequence[sparse_mask] = user_feature_expanded[sparse_mask] return enhanced_sequence
Q8: How
does DSIN's session division work in practice?
A: Sessions are typically divided based on: 1.
Time gaps: If time between behaviors > threshold
(e.g., 30 minutes), start new session 2. Category
changes: If user switches to different category, start new
session 3. Explicit signals: User closes app, starts
new search, etc.
defdivide_into_sessions(behaviors, timestamps, time_threshold=1800): """ Divide behavior sequence into sessions Args: behaviors: [seq_len, embedding_dim] timestamps: [seq_len] (Unix timestamps) time_threshold: seconds between behaviors to start new session Returns: sessions: List of sessions, each [session_len, embedding_dim] """ sessions = [] current_session = [behaviors[0]] for i inrange(1, len(behaviors)): time_gap = timestamps[i] - timestamps[i-1] if time_gap > time_threshold: # Start new session sessions.append(torch.stack(current_session)) current_session = [behaviors[i]] else: current_session.append(behaviors[i]) # Add last session if current_session: sessions.append(torch.stack(current_session)) return sessions
Q9: What's the role
of bias encoding in DSIN?
A: Bias encoding adds positional and session-level
information: 1. Positional bias: Captures that
behaviors at different positions in a session have different importance
(e.g., first click vs. last click) 2. Session bias:
Captures that different sessions have different characteristics (e.g.,
morning browsing vs. evening shopping)
This helps the model understand temporal patterns beyond just the
content of behaviors.
Q10:
How do you optimize attention for production serving?
A: Production optimizations:
Pre-compute attention: For fixed candidate items,
pre-compute attention weights
Cache embeddings: Cache item and user
embeddings
Approximate attention: Use low-rank approximations
or locality-sensitive hashing
Batch processing: Process multiple requests
together
Model quantization: Reduce precision (FP32 → FP16 →
INT8)
classCachedAttention(nn.Module): """Attention with caching for production""" def__init__(self, embedding_dim): super(CachedAttention, self).__init__() self.embedding_dim = embedding_dim self.attention_cache = {} defforward(self, behavior_embeddings, candidate_embedding, use_cache=True): # Create cache key from candidate embedding hash cache_key = hash(candidate_embedding.cpu().numpy().tobytes()) if use_cache and cache_key in self.attention_cache: attention_weights = self.attention_cache[cache_key] else: # Compute attention scores = torch.matmul( behavior_embeddings, candidate_embedding.unsqueeze(-1) ).squeeze(-1) attention_weights = F.softmax(scores, dim=1) if use_cache: self.attention_cache[cache_key] = attention_weights return attention_weights
Q11:
How does attention help with model interpretability?
A: Attention weights provide interpretability: 1.
Feature importance: Show which historical behaviors
matter most 2. Debugging: Identify why certain
recommendations were made 3. Business insights:
Understand user interest patterns 4. A/B testing:
Compare attention patterns between model versions
Deep Interest Networks and attention mechanisms have revolutionized
recommendation systems by enabling models to focus on relevant
historical behaviors. DIN's target attention, DIEN's interest evolution
modeling, and DSIN's session-aware architecture each address different
aspects of the recommendation problem, leading to significant
improvements in CTR prediction and user engagement.
The key insights are: 1. Not all behaviors are
equal: Target attention weights behaviors by relevance 2.
Interests evolve: Temporal modeling captures changing
preferences 3. Sessions matter: Session-level patterns
provide additional signal 4. Production matters:
Optimizations for scale and latency are crucial
As recommendation systems continue to evolve, attention mechanisms
remain a fundamental building block, enabling models to understand user
interests at increasingly granular levels while maintaining
interpretability and efficiency.
Post title:Recommendation Systems (10): Deep Interest Networks and Attention Mechanisms
Post author:Chen Kai
Create time:2026-02-03 23:11:11
Post link:https://www.chenk.top/recommendation-systems-10-deep-interest-networks/
Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.