permalink: "en/recommendation-systems-1-fundamentals/" date: 2024-05-02 09:00:00 tags: - Recommendation Systems - Collaborative Filtering - Introduction categories: Recommendation Systems mathjax: true --- Imagine opening Netflix and seeing a carefully curated row of shows that perfectly match your taste, or scrolling through Amazon and discovering products you didn't even know you needed. Behind these experiences lies one of the most commercially successful applications of machine learning: recommendation systems. From e-commerce giants like Amazon generating 35% of their revenue through recommendations, to streaming platforms like Spotify keeping users engaged with personalized playlists, recommendation systems have become the invisible force driving modern digital experiences.
But what exactly makes a good recommendation system? How do these systems learn your preferences without explicitly asking you? And more importantly, how can you build one from scratch? This article takes you from the fundamental concepts to practical implementations, covering the three major paradigms (collaborative filtering, content-based filtering, and hybrid approaches), evaluation metrics that matter in production, real-world system architectures, and the core challenges that every recommendation engineer must face.
Whether you're a data scientist looking to understand the theory, a software engineer tasked with building a recommender, or simply curious about how Netflix knows you better than your friends do, this guide provides the foundation you need. We'll explore not just the "what" and "how," but critically, the "why" – understanding the trade-offs, failure modes, and design decisions that separate academic toys from production-grade systems handling billions of users.
Why Recommendation Systems Matter
Before diving into algorithms and architectures, let's understand why recommendation systems have become mission-critical infrastructure for modern platforms.
The Information Overload Problem
In 2025, the average user faces an overwhelming amount of choice: - Netflix hosts over 15,000 titles across all regions - Amazon lists hundreds of millions of products - YouTube sees 500 hours of video uploaded every minute - Spotify contains over 100 million tracks
Without intelligent filtering, users would spend more time searching than consuming. The paradox of choice is real: more options can lead to decision paralysis and user dissatisfaction. Recommendation systems solve this by acting as intelligent filters, surfacing the tiny fraction of content that's actually relevant to each individual user.
Business Impact: The Numbers That Matter
The commercial impact of recommendation systems is staggering:
Revenue Generation: Amazon reports that 35% of their revenue comes from recommendation-driven purchases. For a company with$500+ billion in annual revenue, that's over$175 billion directly attributable to recommendations.
User Engagement: YouTube reports that 70% of watch time comes from recommendations. Without their recommendation engine, user engagement would plummet, directly impacting ad revenue.
Customer Retention: Netflix estimates that their recommendation system saves$1 billion per year by reducing churn. Users who receive good recommendations are significantly more likely to continue their subscriptions.
Conversion Rates: E-commerce platforms see 2-3x higher conversion rates on recommended products compared to organic search results.
These aren't marginal improvements – recommendation systems are often the difference between a thriving platform and a failed one.
Real-World Examples: Where You See Recommendations Daily
examine how different platforms use recommendations:
E-commerce (Amazon, Alibaba) - "Customers who bought this also bought..." (item-to-item collaborative filtering) - "Recommended for you" on homepage (personalized recommendations) - "Complete the look" fashion bundles (multi-item recommendations)
Streaming Video (Netflix, YouTube) - Personalized homepage rows organized by taste clusters - "Because you watched..." explanations - Auto-playing next episode (engagement optimization)
Music (Spotify, Apple Music) - Discover Weekly (cold-start handling for new content) - Daily Mix playlists (user preference clustering) - Radio stations (similar item exploration)
Social Media (Facebook, Instagram, TikTok) - News feed ranking (engagement prediction) - "People you may know" (social network analysis) - Explore page (diversity-aware recommendations)
Professional Networks (LinkedIn) - Job recommendations (multi-criteria matching) - Connection suggestions (graph-based recommendations) - Content feed ranking (expertise-based relevance)
Each of these use cases has different requirements and constraints, which we'll explore throughout this article.
The Three Paradigms of Recommendation
At the highest level, all recommendation systems fall into three fundamental paradigms. Understanding these paradigms is crucial because they represent different philosophies about what makes a good recommendation and what data we use to generate it.
Collaborative Filtering: "Users Like You Liked This"
Collaborative filtering is based on a beautifully simple idea: if two users agreed in the past, they're likely to agree in the future. The system doesn't need to understand what a movie is about or why you liked it – it just needs to find patterns in collective behavior.
Core Intuition
Imagine you and your friend Sarah have watched 50 movies together, and you've rated them almost identically. Sarah is your "taste twin." Now Sarah watches a new movie you haven't seen yet and loves it. There's a good chance you'll love it too – even if the recommendation system has no idea what the movie is about.
This is collaborative filtering: using the collective wisdom of the crowd to make predictions. The "collaboration" happens implicitly through user behavior data.
Two Flavors: User-Based vs. Item-Based
Collaborative filtering comes in two main variants:
- User-Based Collaborative Filtering (User-CF)
- Find users similar to you
- Recommend items those similar users liked
- Example: "Users with similar taste also enjoyed..."
- Item-Based Collaborative Filtering (Item-CF)
- Find items similar to ones you liked
- Recommend those similar items
- Example: "If you liked Movie A, you'll like Movie B"
The mathematical foundation is the same, but the practical implications differ significantly. Item-based methods tend to be more stable (items' characteristics don't change much over time, but users' tastes evolve) and more scalable (fewer items than users in most systems).
Mathematical Formulation
formalize this. We have: -\(U = \{u_1, u_2, \dots, u_m\}\): set of\(m\)users -\(I = \{i_1, i_2, \dots, i_n\}\): set of\(n\)items -\(R \in \mathbb{R}^{m \times n}\): user-item rating matrix, where\(r_{ui}\)is user\(u\)'s rating for item\(i\)The matrix\(R\)is sparse – most users have rated only a tiny fraction of items. The goal of collaborative filtering is to predict missing entries in\(R\).
For user-based CF, we predict user\(u\)'s rating for item\(i\)as:\[\hat{r}_{ui} = \bar{r}_u + \frac{\sum_{v \in N(u)} \text{sim}(u,v) \cdot (r_{vi} - \bar{r}_v)}{\sum_{v \in N(u)} |\text{sim}(u,v)|}\]Where: -\(\bar{r}_u\)is user\(u\)'s average rating (bias correction) -\(N(u)\)is the set of\(k\)most similar users to\(u\)who rated item\(i\) -\(\text{sim}(u,v)\)is the similarity between users\(u\)and\(v\)Key: computing\(\text{sim}(u,v)\). Common similarity metrics include:
Cosine Similarity:\[\text{sim}_{\text{cos }}(u,v) = \frac{\sum_{i \in I_{uv }} r_{ui} \cdot r_{vi }}{\sqrt{\sum_{i \in I_{uv }} r_{ui}^2} \cdot \sqrt{\sum_{i \in I_{uv }} r_{vi}^2 }}\]Where\(I_{uv}\)is the set of items both users have rated.
Pearson Correlation:\[\text{sim}_{\text{pearson }}(u,v) = \frac{\sum_{i \in I_{uv }} (r_{ui} - \bar{r}_u)(r_{vi} - \bar{r}_v)}{\sqrt{\sum_{i \in I_{uv }} (r_{ui} - \bar{r}_u)^2} \cdot \sqrt{\sum_{i \in I_{uv }} (r_{vi} - \bar{r}_v)^2 }}\]Pearson correlation is centered (accounts for different rating scales between users), making it more robust in practice.
Strengths and Weaknesses
Strengths: - Domain-free: Works without understanding item content - Serendipity: Can recommend surprising items you wouldn't have found yourself - Quality: Leverages collective intelligence, often producing high-quality recommendations
Weaknesses: - Cold-start problem: Cannot recommend new items with no ratings or to new users with no history - Sparsity: Requires sufficient overlap between users/items to compute meaningful similarities - Scalability: Computing similarities between millions of users/items is computationally expensive - Grey sheep problem: Users with unique tastes don't have similar neighbors, leading to poor recommendations - Popularity bias: Tends to recommend popular items because they have more data
Content-Based Filtering: "You'll Like This Because It's Similar to What You Liked"
If collaborative filtering asks "who else liked this?", content-based filtering asks "what is this thing, and have you liked similar things before?"
Core Intuition
Content-based filtering builds a profile of your preferences based on the attributes of items you've interacted with. If you've consistently rated action movies highly, the system learns you like the "action" attribute and recommends more action movies.
This approach is fundamentally different from collaborative filtering: it doesn't care what other users think. It only cares about you and the characteristics of the items.
Feature Representation
The critical step in content-based filtering is representing items as feature vectors. The approach depends on the domain:
Text Content (news, articles, product descriptions) - TF-IDF vectors: Weight words by how distinctive they are - Word embeddings: Dense semantic representations (Word2Vec, GloVe, BERT) - Topic models: Latent topic distributions (LDA)
Images (products, artwork) - CNN embeddings: Features from pre-trained networks (ResNet, EfficientNet) - Color histograms: Distribution of colors - Visual attributes: Tags like "formal," "casual," "vintage"
Audio (music, podcasts) - Spectral features: MFCCs, chroma features - Music embeddings: Audio2Vec representations - Metadata: Genre, mood, tempo, key
Structured Data (movies, products) - Categorical features: Genre, brand, category - Numerical features: Price, year, duration - Graphs: Actor/director networks, knowledge graphs
Mathematical Formulation
Let\(\mathbf{x}_i \in \mathbb{R}^d\)be the feature vector for item\(i\), and\(\mathbf{w}_u \in \mathbb{R}^d\)be user\(u\)'s preference weights. The predicted rating is:\[\hat{r}_{ui} = \mathbf{w}_u^T \mathbf{x}_i + b_u\]We learn\(\mathbf{w}_u\)by minimizing the squared error over items the user has rated:\[\min_{\mathbf{w}_u, b_u} \sum_{i \in I_u} (r_{ui} - \mathbf{w}_u^T \mathbf{x}_i - b_u)^2 + \lambda ||\mathbf{w}_u||^2\]Where\(I_u\)is the set of items user\(u\)has rated, and\(\lambda\)is a regularization parameter to prevent overfitting.
Example: Movie Recommendation
say we represent movies with features:\[\mathbf{x}_{\text{movie }} = [\text{action}, \text{comedy}, \text{drama}, \text{year}, \text{director\_quality}]\]For "The Dark Knight" (2008):\[\mathbf{x}_{\text{TDK }} = [1.0, 0.1, 0.3, 2008, 0.9]\]If your preference vector is:\[\mathbf{w}_u = [0.8, -0.2, 0.5, 0.01, 0.7]\]The predicted rating is:\[\hat{r}_{u,\text{TDK }} = 0.8(1.0) + (-0.2)(0.1) + 0.5(0.3) + 0.01(2008) + 0.7(0.9) = 22.16\]This high score indicates you'd likely enjoy this movie.
Strengths and Weaknesses
Strengths: - No cold-start for items: Can recommend new items immediately based on their features - Transparency: Recommendations are explainable (e.g., "Because it has similar actors") - No sparsity issues: Doesn't require user-user overlap - User independence: Can work with a single user's data
Weaknesses: - Feature engineering: Requires domain expertise to extract meaningful features - Limited novelty: Tends to recommend similar items (over-specialization) - New user cold-start: Still struggles with users who have no history - Content limitations: Some preferences are hard to capture with features (e.g., a movie's "vibe")
Hybrid Methods: Combining the Best of Both Worlds
Pure collaborative filtering and pure content-based methods each have blind spots. Hybrid methods combine them to leverage the strengths of both while mitigating their weaknesses.
Why Hybrid?
Consider these scenarios: 1. A new movie is released (cold-start for CF) with great features and actors you love (content-based can help) 2. You usually watch sci-fi (content-based predicts more sci-fi) but similar users also enjoy unexpected comedies (CF adds serendipity) 3. An item has few ratings (CF struggles) but rich metadata (content-based provides signal)
Hybrid methods provide graceful degradation: when one approach fails, the other can compensate.
Hybrid Architectures
There are several ways to combine collaborative and content-based approaches:
1. Weighted Hybrid
Simply combine predictions with learned weights:\[\hat{r}_{ui} = \alpha \cdot \hat{r}_{ui}^{\text{CF }} + (1-\alpha) \cdot \hat{r}_{ui}^{\text{CB }}\]The weight\(\alpha \in [0,1]\)can be: - Fixed (e.g., 0.7 for CF, 0.3 for content-based) - Learned globally from validation data - Adaptive per user (more CF for users with rich history, more content-based for new users) - Adaptive per item (more CF for popular items, more content-based for new items)
2. Switching Hybrid
Use heuristics to choose which method to apply:
1 | def predict(user, item): |
3. Feature Combination
Augment collaborative filtering with content features:\[\hat{r}_{ui} = \mathbf{w}_u^T \mathbf{x}_i + \sum_{v \in N(u)} \text{sim}(u,v) \cdot r_{vi}\]This treats collaborative signals as additional features in a unified model.
4. Cascade Hybrid
Use one method to refine candidates from another: 1. Use CF to generate top 100 candidates (fast, high recall) 2. Use content-based model to re-rank these candidates (precise, captures nuances)
This is common in industrial systems where you need to filter millions of items down to a small set efficiently.
5. Meta-Level Hybrid
Use content-based model to learn user/item representations, then apply CF on these learned representations:
1 | # Step 1: Learn item embeddings from content |
Modern deep learning approaches often fall into this category, using neural networks to learn representations from both content and behavior.
Example: Netflix's Approach
Netflix uses a sophisticated hybrid approach: - Content-based: Extract features from video thumbnails, titles, descriptions, cast, genre - Collaborative filtering: Matrix factorization on viewing history and ratings - Deep learning: Neural networks that fuse both types of signals - Context-aware: Time of day, device, viewing patterns - Business rules: Recency, diversity, freshness constraints
The final ranking is an ensemble of dozens of models, each capturing different aspects of the recommendation problem.
Matrix Factorization: The Workhorse of Collaborative Filtering
While neighborhood-based methods (user-CF and item-CF) are intuitive, matrix factorization (MF) methods have become the dominant approach in modern recommendation systems. They won the Netflix Prize and power many production systems today.
The Core Idea: Latent Factors
Matrix factorization assumes that user preferences and item characteristics can be represented by a small number of latent factors. These factors aren't explicitly defined (like "action" or "comedy") but emerge from the data.
Intuition
Think of movies. Instead of manually defining genres, MF discovers latent dimensions like: - Factor 1: "Blockbuster vs. Art House" - Factor 2: "Serious vs. Light-hearted" - Factor 3: "Classic vs. Modern"
Each movie has a position in this latent space (e.g., "The Dark Knight" is high on Factor 1, medium on Factor 2, high on Factor 3). Each user also has preferences in this space (e.g., you like high Factor 1, medium Factor 2, low Factor 3).
The predicted rating is the dot product of user and item vectors in this space:\[\hat{r}_{ui} = \mathbf{p}_u^T \mathbf{q}_i\]Where: -\(\mathbf{p}_u \in \mathbb{R}^k\): user\(u\)'s latent factor vector (user embedding) -\(\mathbf{q}_i \in \mathbb{R}^k\): item\(i\)'s latent factor vector (item embedding) -\(k\): number of latent factors (typically 20-200)
Mathematical Formulation
We want to factorize the rating matrix\(R \in \mathbb{R}^{m \times n}\)into two lower-rank matrices:\[R \approx P Q^T\]Where: -\(P \in \mathbb{R}^{m \times k}\): user latent factor matrix (each row is\(\mathbf{p}_u\)) -\(Q \in \mathbb{R}^{n \times k}\): item latent factor matrix (each row is\(\mathbf{q}_i\))
We learn\(P\)and\(Q\)by minimizing the squared error on observed ratings:\[\min_{P,Q} \sum_{(u,i) \in \Omega} (r_{ui} - \mathbf{p}_u^T \mathbf{q}_i)^2 + \lambda (||\mathbf{p}_u||^2 + ||\mathbf{q}_i||^2)\]Where: -\(\Omega\)is the set of observed (user, item) pairs -\(\lambda\)is the regularization parameter to prevent overfitting
Adding Biases
In practice, we add bias terms to capture systematic tendencies:\[\hat{r}_{ui} = \mu + b_u + b_i + \mathbf{p}_u^T \mathbf{q}_i\]Where: -\(\mu\): global average rating -\(b_u\): user\(u\)'s bias (some users rate everything high, others rate everything low) -\(b_i\): item\(i\)'s bias (some items are universally loved, others are polarizing)
The optimization becomes:\[\min_{P,Q,b} \sum_{(u,i) \in \Omega} (r_{ui} - \mu - b_u - b_i - \mathbf{p}_u^T \mathbf{q}_i)^2 + \lambda (||\mathbf{p}_u||^2 + ||\mathbf{q}_i||^2 + b_u^2 + b_i^2)\]
Optimization: SGD and ALS
Two main approaches exist for optimizing the MF objective:
1. Stochastic Gradient Descent (SGD)
For each observed rating\((u,i,r_{ui})\):
- Compute prediction error:\[e_{ui} = r_{ui} - \hat{r}_{ui}\]2. Update parameters in the direction of the gradient:\[\mathbf{p}_u \leftarrow \mathbf{p}_u + \eta (e_{ui} \mathbf{q}_i - \lambda \mathbf{p}_u)\] \[\mathbf{q}_i \leftarrow \mathbf{q}_i + \eta (e_{ui} \mathbf{p}_u - \lambda \mathbf{q}_i)\] \[b_u \leftarrow b_u + \eta (e_{ui} - \lambda b_u)\] \[b_i \leftarrow b_i + \eta (e_{ui} - \lambda b_i)\]Where\(\eta\)is the learning rate.
2. Alternating Least Squares (ALS)
ALS alternates between fixing\(P\)and optimizing\(Q\), then fixing\(Q\)and optimizing\(P\).
When\(Q\)is fixed, the problem becomes a least squares problem for each user:\[\mathbf{p}_u = (Q^T Q + \lambda I)^{-1} Q^T \mathbf{r}_u\]Similarly for items when\(P\)is fixed:\[\mathbf{q}_i = (P^T P + \lambda I)^{-1} P^T \mathbf{r}_i\]Where\(\mathbf{r}_u\)is user\(u\)'s rating vector.
ALS is advantageous when: - You can parallelize across users/items (each update is independent) - You have implicit feedback (can be adapted to weighted least squares) - You need a GPU-friendly algorithm (matrix operations)
Implementation: Basic Matrix Factorization
implement a complete matrix factorization system with SGD:
1 | import numpy as np |
Output explanation: This implementation demonstrates the core MF algorithm. In practice, you'd add: - Early stopping based on validation RMSE - Learning rate decay - Mini-batch updates instead of full SGD - More sophisticated initialization (e.g., SVD initialization)
Advanced: Implicit Feedback
Most real-world systems don't have explicit ratings. Instead, they have implicit feedback: clicks, views, purchases, play time. The challenge is that absence of interaction doesn't mean dislike – it might mean the user never saw the item.
Weighted Matrix Factorization for Implicit Feedback
Instead of predicting ratings, we predict confidence in preference. The objective becomes:\[\min_{P,Q} \sum_{u,i} c_{ui}(p_{ui} - \mathbf{p}_u^T \mathbf{q}_i)^2 + \lambda (||\mathbf{p}_u||^2 + ||\mathbf{q}_i||^2)\]Where: -\(p_{ui} \in \{0,1\}\): binary preference (1 if user interacted with item, 0 otherwise) -\(c_{ui}\): confidence in the observation (higher for repeated interactions)
A common confidence function:\[c_{ui} = 1 + \alpha \cdot f_{ui}\]Where\(f_{ui}\)is the interaction frequency (e.g., number of times user watched movie), and\(\alpha\)is a hyperparameter.
Key insight: We optimize over all user-item pairs (even unobserved ones), but with different confidence weights. Observed interactions get high confidence (we're sure the user likes this), while unobserved ones get low confidence (we're less sure the user dislikes this).
This formulation is solved efficiently with ALS, giving us one of the most powerful recommendation algorithms for implicit feedback data.
Evaluation Metrics: Measuring What Matters
Building a recommendation system is only half the battle – knowing whether it's actually good is the other half. Unlike supervised learning where accuracy is well-defined, recommendation systems need to balance multiple, often competing objectives.
The Challenge of Evaluation
Consider this: your recommendation system has 95% accuracy in predicting ratings. Is that good? Not necessarily: - If users only rate movies they like, predicting high ratings for everything might be "accurate" but useless - If the test set only includes popular movies, you're not measuring the hard cases - If recommendations lack diversity, users might be accurate satisfied initially but churned in the long run
Effective evaluation requires multiple metrics capturing different aspects of quality.
Classification-Based Metrics: Precision and Recall
When recommendations are binary (recommend vs. not recommend), we can use classic classification metrics.
Setup
For user\(u\), let: -\(R_u\): set of items recommended to user\(u\)(top-N recommendations) -\(T_u\): set of truly relevant items for user\(u\)(test set items the user liked)
Precision@N
What fraction of recommendations are relevant?\[\text{Precision@N} = \frac{|R_u \cap T_u|}{|R_u|}\]Example: You recommend 10 movies, user likes 7 of them → Precision@10 = 0.7
Recall@N
What fraction of relevant items did we recommend?\[\text{Recall@N} = \frac{|R_u \cap T_u|}{|T_u|}\]Example: User likes 20 movies total, you recommended 7 of them → Recall@10 = 0.35
F1@N
Harmonic mean of precision and recall:\[\text{F1@N} = 2 \cdot \frac{\text{Precision@N} \cdot \text{Recall@N }}{\text{Precision@N} + \text{Recall@N }}\]
When to use: These metrics are intuitive and easy to explain to stakeholders. Use them when: - You have binary feedback (like/dislike, click/no-click) - You care about set-level accuracy - You need metrics that non-technical stakeholders can understand
Limitations: - Don't consider ranking order within top-N - Don't account for rating scale (if available) - Precision and recall often trade off (hard to optimize both)
Ranking-Based Metrics: Position Matters
In reality, position matters immensely. A relevant item at position 1 is worth much more than at position 10. Ranking metrics capture this.
Mean Average Precision (MAP)
For a single user, Average Precision (AP) is:\[\text{AP}@N = \frac{1}{|T_u|} \sum_{k=1}^{N} \text{Precision}@k \cdot \text{rel}(k)\]Where\(\text{rel}(k) = 1\)if the item at position\(k\)is relevant, 0 otherwise.
MAP averages AP across all users:\[\text{MAP} = \frac{1}{|U|} \sum_{u \in U} \text{AP}_u\]
Intuition: MAP rewards systems that rank relevant items higher. If all relevant items are at the top, MAP is high. If they're scattered, MAP is lower even if Precision@N is the same.
Example: - Recommendations: [relevant, relevant, irrelevant, relevant, irrelevant] -\(\text{Precision}@1 = 1.0\),\(\text{Precision}@2 = 1.0\),\(\text{Precision}@4 = 0.75\) -\(\text{AP}@5 = \frac{1}{3}(1.0 + 1.0 + 0.75) = 0.917\) Normalized Discounted Cumulative Gain (NDCG)
NDCG is the gold standard for ranking evaluation when you have graded relevance (ratings, not just binary).
Discounted Cumulative Gain (DCG):\[\text{DCG}@N = \sum_{k=1}^{N} \frac{2^{\text{rel}_k} - 1}{\log_2(k+1)}\]Where\(\text{rel}_k\)is the relevance (e.g., rating) of the item at position\(k\).
The\(\log_2(k+1)\)discount means items at lower positions contribute less to the score.
Ideal DCG (IDCG):
DCG of the perfect ranking (all items sorted by true relevance):\[\text{IDCG}@N = \sum_{k=1}^{N} \frac{2^{\text{rel}_k^*} - 1}{\log_2(k+1)}\]Where\(\text{rel}_k^*\)is the\(k\)-th highest relevance score.
Normalized DCG:\[\text{NDCG}@N = \frac{\text{DCG}@N}{\text{IDCG}@N}\]NDCG ranges from 0 to 1, where 1 is perfect ranking.
Example: - True ratings: [5, 4, 3, 2, 1] - Predicted order: [5, 3, 4, 2, 1]\[\text{DCG}@5 = \frac{31}{1} + \frac{7}{1.585} + \frac{15}{2} + \frac{3}{2.322} + \frac{1}{2.585} = 44.93\] \[\text{IDCG}@5 = \frac{31}{1} + \frac{15}{1.585} + \frac{7}{2} + \frac{3}{2.322} + \frac{1}{2.585} = 45.32\] \[\text{NDCG}@5 = \frac{44.93}{45.32} = 0.991\]
When to use: NDCG is ideal when: - You have graded relevance (ratings, engagement scores) - Ranking order is critical to user experience - You want a metric used widely in research (for comparability)
Implementation: Ranking Metrics
1 | import numpy as np |
Beyond Accuracy: Coverage and Diversity
High accuracy metrics don't tell the whole story. A system that only recommends the top 10 most popular items might have high precision (because popular items are widely liked) but provides a terrible user experience.
Catalog Coverage
What fraction of items can the system recommend?\[\text{Coverage} = \frac{|\{i : \exists u, i \in R_u} |}{|I|}\]Where\(R_u\)is the set of items recommended to any user\(u\).
Example: If your system only ever recommends 1000 out of 100,000 items, coverage = 0.01. This is the long-tail problem: obscure but relevant items never get surfaced.
Intra-List Diversity
How different are items within a single recommendation list?\[\text{Diversity}(R_u) = \frac{2}{|R_u|(|R_u|-1)} \sum_{i,j \in R_u, i \ne j} (1 - \text{sim}(i,j))\]Where\(\text{sim}(i,j)\)is similarity between items (e.g., cosine similarity of features).
Example: If you recommend 10 sci-fi movies that are all sequels to each other, diversity is low. Users want some variety.
Serendipity
How surprising yet relevant are recommendations?\[\text{Serendipity} = \frac{1}{|R_u|} \sum_{i \in R_u} \text{relevance}(i) \cdot (1 - \text{expected}(i))\]Where\(\text{expected}(i)\)measures how obvious the recommendation is (e.g., based on popularity or content similarity).
High serendipity means the system finds relevant items the user wouldn't have discovered on their own.
Trade-offs
These metrics often conflict: - High accuracy → Low coverage (recommend safe, popular items) - High diversity → Lower accuracy (users prefer some redundancy) - High serendipity → Higher risk (unexpected recommendations might be wrong)
Production systems use multi-objective optimization or business rules to balance these trade-offs.
Online Metrics: What Matters in Production
Offline metrics (evaluated on historical data) are useful for development, but online metrics (measured from real users) are what truly matter.
Click-Through Rate (CTR)\[\text{CTR} = \frac{\text{Number of clicks on recommendations }}{\text{Number of recommendations shown }}\]
Conversion Rate\[\text{Conversion} = \frac{\text{Number of purchases/views }}{\text{Number of clicks }}\]
Engagement Metrics - Watch time (video platforms) - Time to click (speed of engagement) - Session length (does the user continue browsing?)
Business Metrics - Revenue per user - Customer lifetime value (LTV) - Churn rate
A/B Testing
The gold standard for evaluation is A/B testing: 1. Split users randomly into control (old system) and treatment (new system) 2. Run both systems in parallel for a statistically significant period 3. Compare online metrics 4. Ship the better system
This accounts for all the complexity that offline metrics miss: user interface effects, temporal dynamics, network effects, etc.
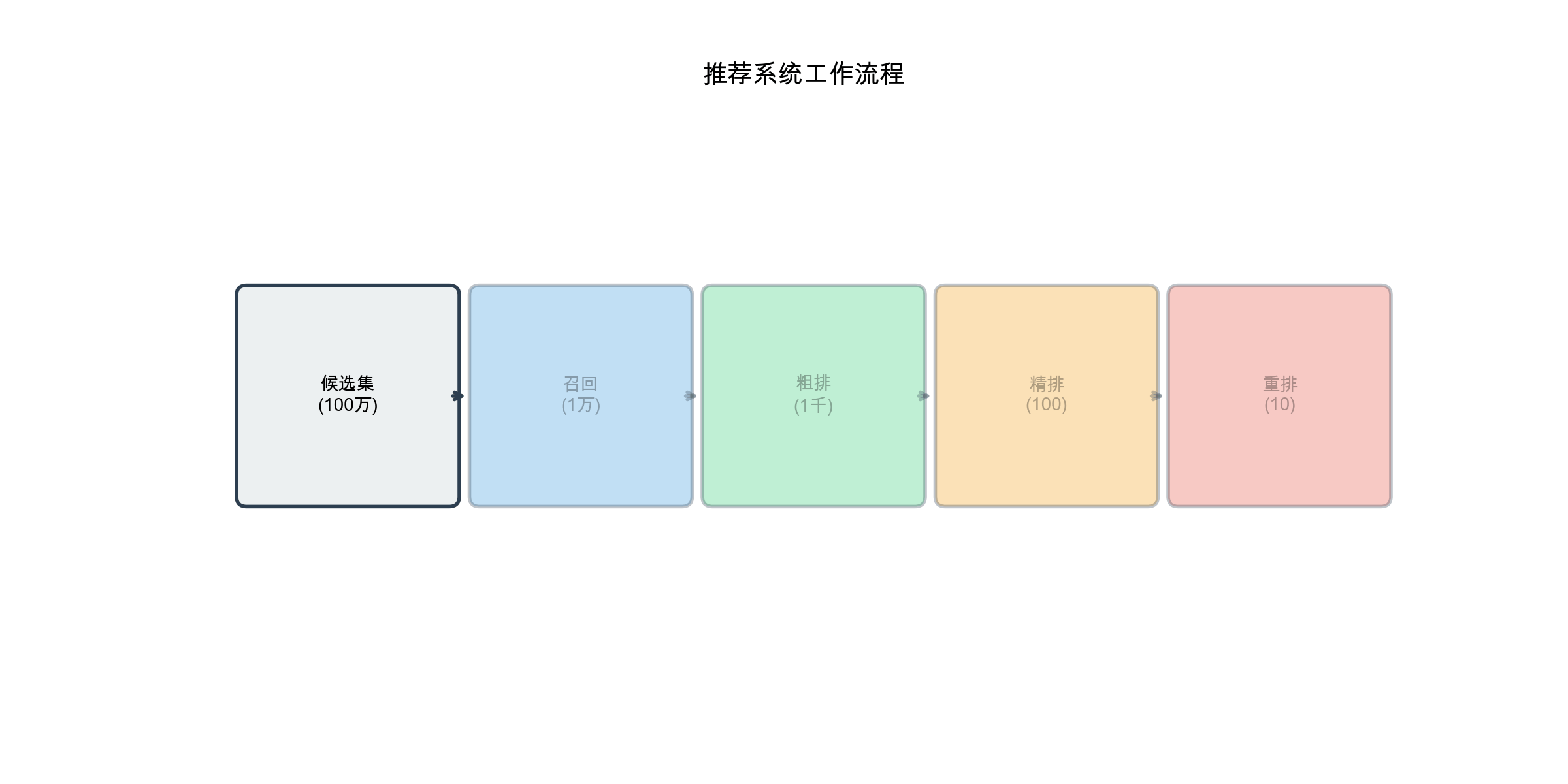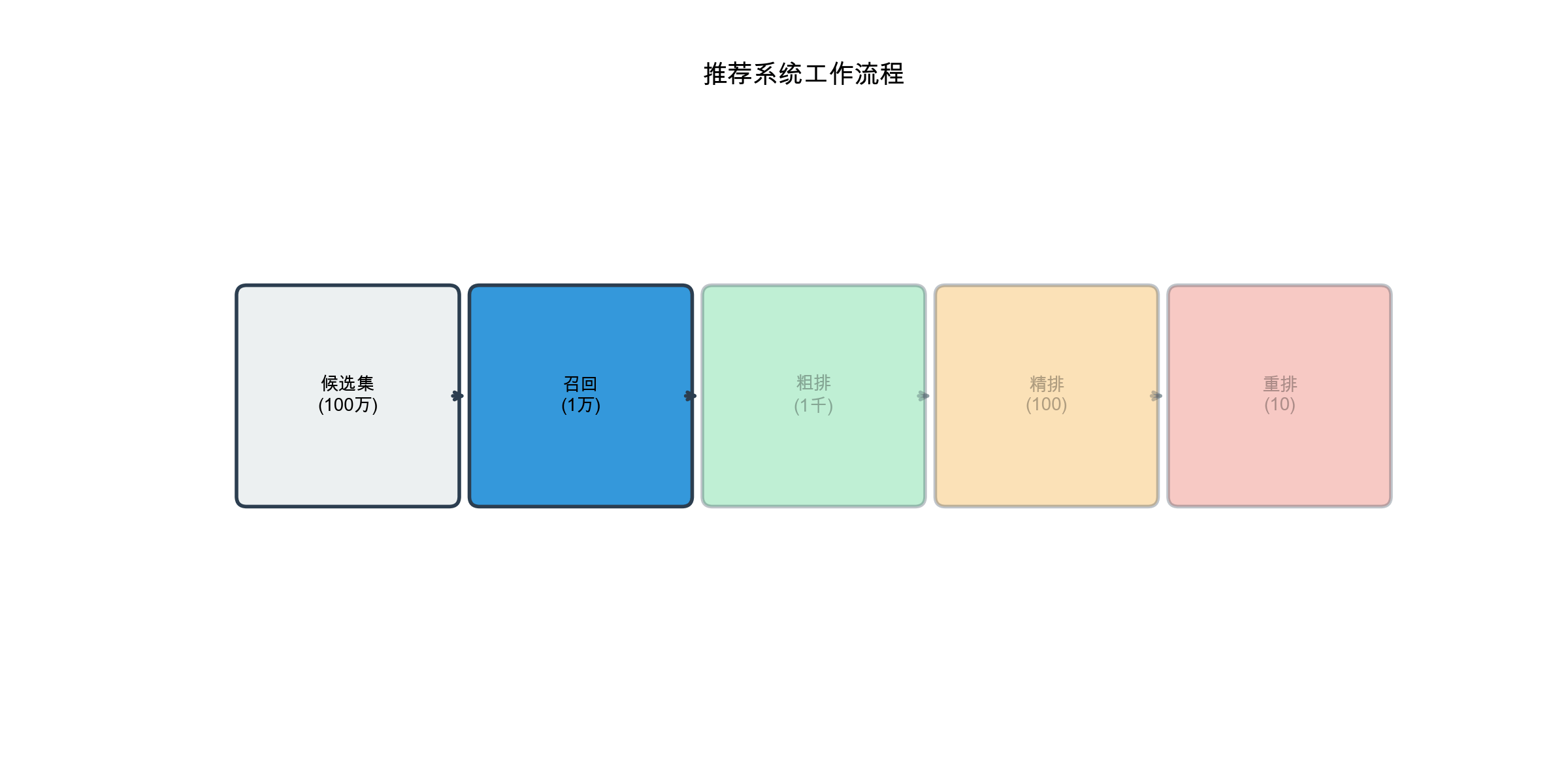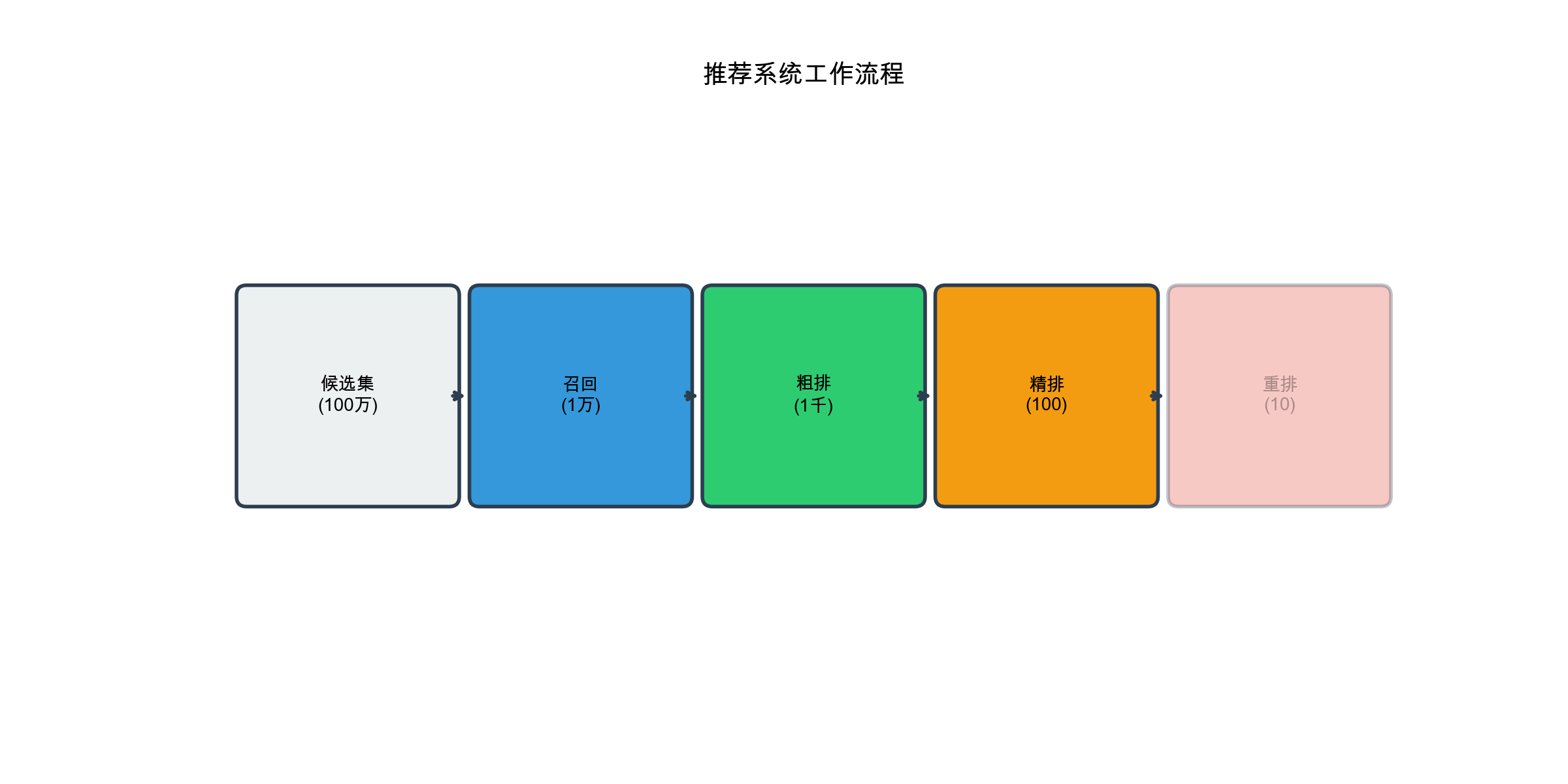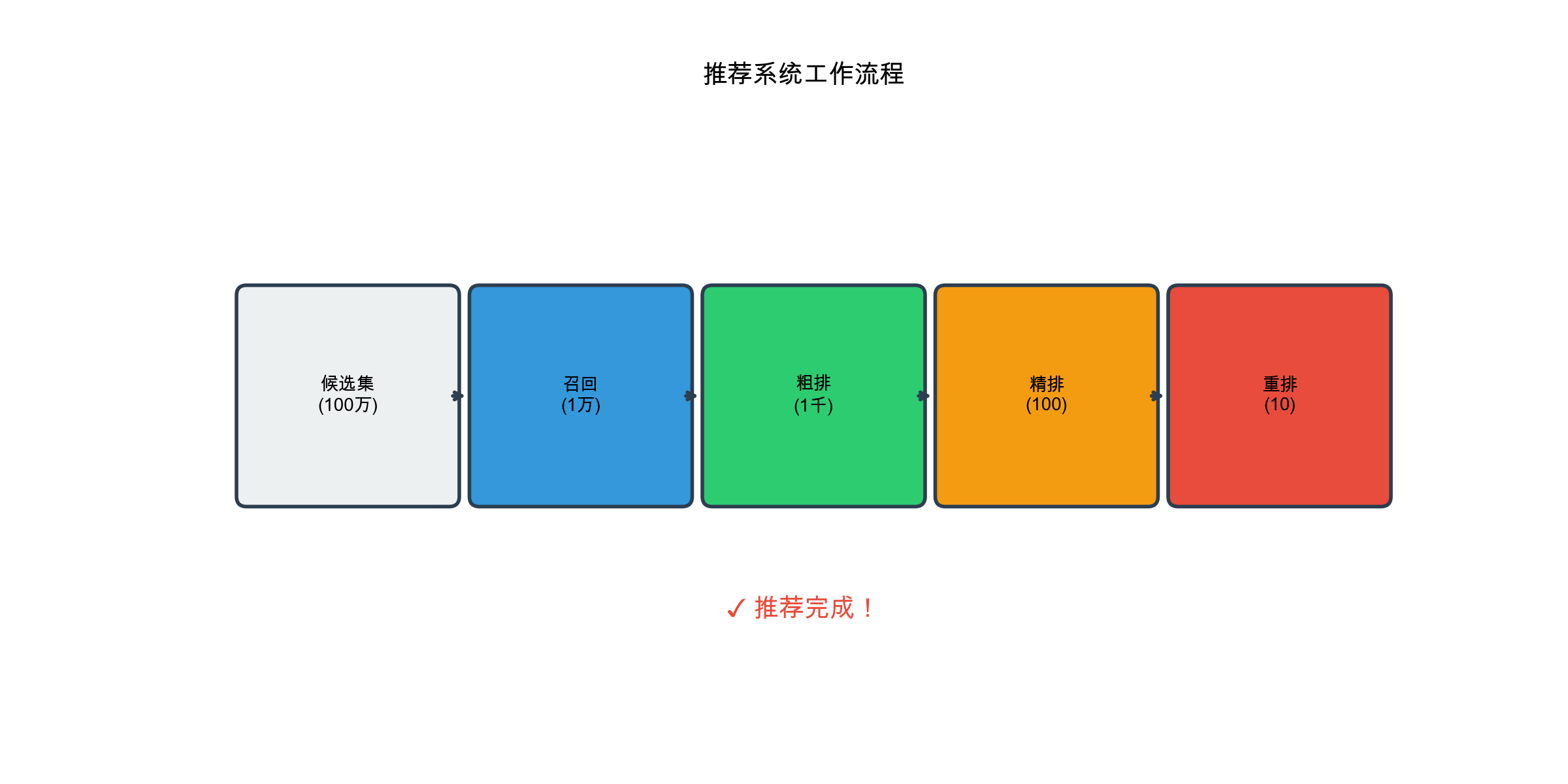
System Architecture: From Million Items to Top-10 Recommendations
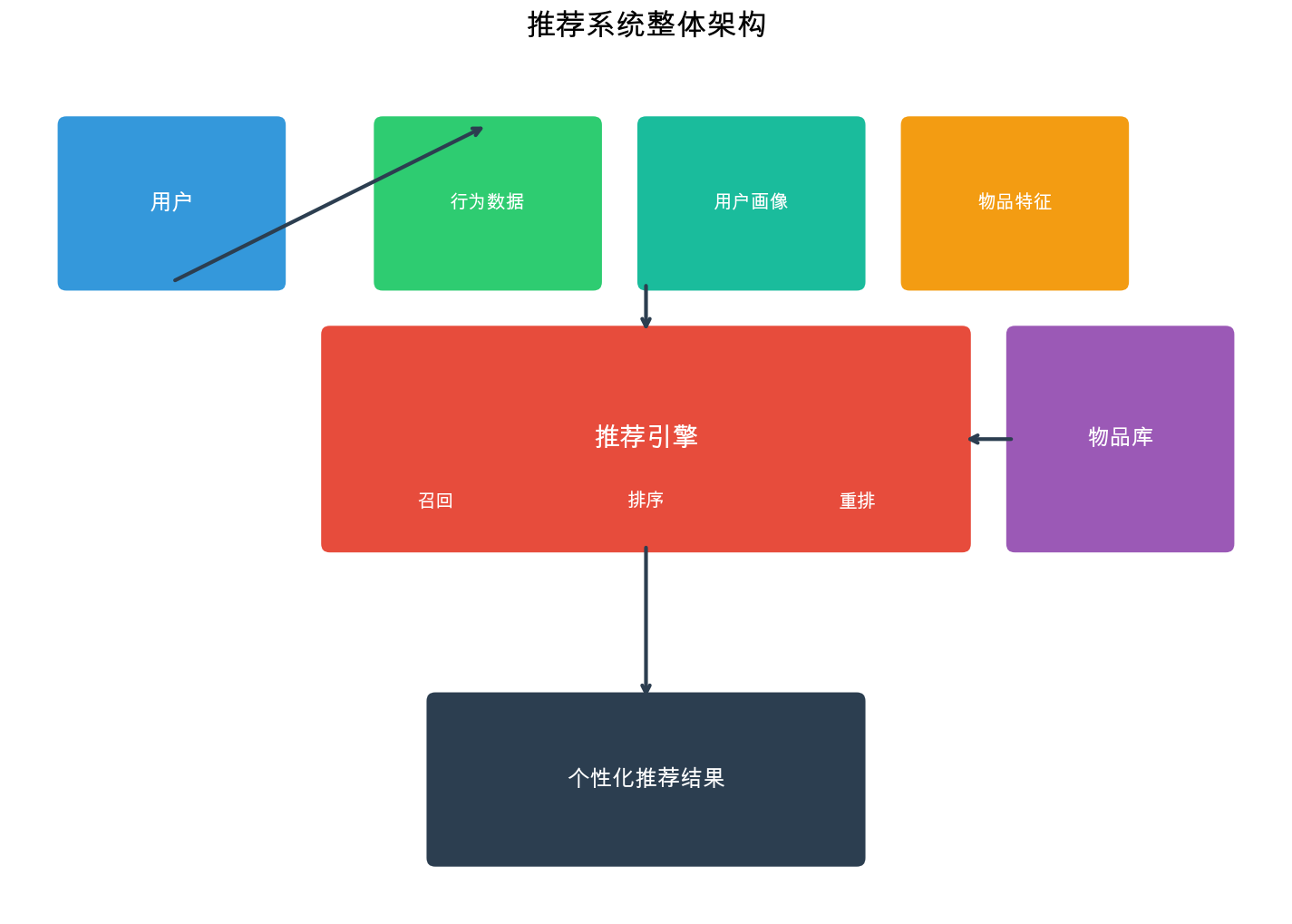
Real-world recommendation systems face a daunting challenge: how do you select 10 items to recommend from a catalog of millions or billions, with milliseconds of latency, for hundreds of millions of users?
The answer is a multi-stage architecture that progressively narrows down candidates while applying increasingly expensive models.
The Funnel Architecture
Modern recommendation systems use a 4-stage funnel:
1 | Stage 1: Candidate Generation (Recall) |
examine each stage in detail.
Stage 1: Candidate Generation (Recall)
Goal: Quickly filter millions of items down to a few thousand candidates that are likely to be relevant.
Methods:
- Collaborative Filtering Recall
- User-CF: Find similar users, retrieve their liked items
- Item-CF: Find items similar to user's history
- Matrix Factorization: Nearest neighbor search in embedding space
- Content-Based Recall
- Query user's profile (learned preferences) against item features
- "More like this" based on last N interactions
- Popular Items
- Global trending items
- Category-level popular items
- Time-decayed popularity
- Sequential Models
- Based on last item viewed (session-based)
- Sequence models predicting next item
- Social/Network-Based
- Items friends liked
- Following/follower recommendations
Key Property: Each recall source is independent and runs in parallel. You might have 10-20 different recall sources, each retrieving 100-500 candidates. The union of all sources gives you 2000-5000 candidates total.
Efficiency: This stage must be extremely fast. Techniques include: - Pre-computed indexes (e.g., FAISS for embedding search) - Caching popular results - Approximate nearest neighbor search - Inverted indexes for sparse features
Example Architecture:
1 | class CandidateGenerator: |
Stage 2: Coarse Ranking
Goal: Apply a relatively cheap model to rank the thousands of candidates and filter down to a few hundred.
Methods:
- Lightweight Models
- Logistic regression on hand-crafted features
- Small neural networks (< 100k parameters)
- Boosted trees (e.g., XGBoost with limited depth)
- Features:
- User features: demographics, historical preferences, activity level
- Item features: category, popularity, recency
- User-item features: CF scores, content similarity, recall source
- Context features: time of day, device, location
Why not skip this stage? Running a complex ranking model on thousands of items per user, millions of times per second, is prohibitively expensive. Coarse ranking eliminates candidates that clearly won't make the final cut, leaving only the promising ones for expensive processing.
Example:
1 | class CoarseRanker: |
Stage 3: Fine Ranking
Goal: Apply your best, most expensive model to precisely rank the remaining few hundred candidates.
Methods:
- Deep Neural Networks
- Wide & Deep models
- Deep & Cross networks
- Transformer-based models
- Multi-task learning (predicting click, conversion, engagement)
- Rich Features:
- Dense embeddings for all categorical features
- User sequential history (last N interactions)
- Cross features (2nd or 3rd order interactions)
- Real-time features (current session behavior)
- Example: Wide & Deep Model
1 | import torch |
Training Considerations: - Data: Millions to billions of (user, item, label) examples from logs - Labels: Click (binary), rating (regression), watch time (regression) - Sampling: Negative sampling (sample non-clicked items as negatives) - Loss: Binary cross-entropy for clicks, MSE for ratings
Stage 4: Reranking & Business Logic
Goal: Finalize the top-N list by applying constraints, diversity requirements, and business rules.
Operations:
- Diversity Injection
- MMR (Maximal Marginal Relevance): iteratively select items that are relevant but dissimilar to already selected items
- Submodular optimization: maximize relevance subject to diversity constraints
- Freshness Boost
- Boost recently released items
- Decay scores for items user has seen before
- Business Rules
- Remove out-of-stock items
- Apply content policy filters (age restrictions, etc.)
- Ensure paid placements or sponsored content appear in designated positions
- Fairness constraints (ensure diverse creator representation)
- Personalization Calibration
- Adjust for user's tolerance to niche content
- Apply explore-exploit trade-offs
Example: MMR for Diversification
1 | def maximal_marginal_relevance( |
Complete Pipeline Example
Here's how all stages come together:
1 | class RecommendationSystem: |
Core Challenges in Recommendation Systems
Despite decades of research and billions in commercial investment, recommendation systems still face fundamental challenges that have no perfect solutions. Understanding these challenges is crucial for building robust systems.
Challenge 1: The Cold-Start Problem
The cold-start problem comes in three flavors: new users, new items, and new systems.
New User Cold-Start
When a user first signs up, you have no behavioral history. How do you recommend anything?
Solutions:
- Onboarding: Explicitly ask users about preferences
- Show popular items, ask them to select favorites
- Ask demographic questions (age, location) to use stereotypes
- Gradual: start with 3-5 items, then refine
- Stereotype-based: Use demographic information
- Region-based (recommend local content)
- Age/gender-based (statistical preferences)
- Device-based (mobile users have different behavior patterns)
- Popular Items: Show globally popular or trending
items
- Safe bet: most people like popular items
- Gets early interactions to bootstrap personalization
- Content-based: If user gives any signal (e.g.,
signup context)
- Came from a blog post → recommend similar topics
- Clicked on an ad → recommend related products
New Item Cold-Start
You've just added 1000 new movies to your catalog. How do you know who will like them?
Solutions:
- Content-based: Use item metadata
- Genre, actors, director for movies
- Brand, category, attributes for products
- Match against users' historical preferences
- Explore-Exploit: Actively show new items to learn
about them
- Exploration bonus: boost scores for items with few ratings
- Thompson Sampling or Upper Confidence Bound (UCB)
- Example:\(\text{score}(i) = \hat{r}_i + \beta \sqrt{\frac{\log N}{n_i }}\)where\(n_i\)is item\(i\)'s rating count
- Transfer Learning: Use external signals
- If it's a movie sequel, transfer ratings from the original
- If it's a new product, use manufacturer reputation
- Use features from other platforms (e.g., IMDB ratings for Netflix)
- Expert Curation: Human-curated lists for new items
- "Staff Picks" or "New Releases You Might Like"
- Feature in prominent positions to gather data quickly
Example: Epsilon-Greedy Exploration
1 | def recommend_with_exploration(user_id: int, candidates: List[int], |
Challenge 2: Data Sparsity
Most users interact with a tiny fraction of items. The rating matrix is > 99.9% sparse. This makes similarity computation and pattern finding extremely difficult.
Magnitude of Sparsity
- Netflix: ~200M users, ~15K titles → ~3 trillion possible interactions
- Average user rates ~50 movies → 0.000002% density
- YouTube: billions of users, billions of videos → essentially infinite sparsity
Consequences: - User-user similarity is hard to compute (few common items) - Long-tail items have almost no data - Statistical estimates have huge variance
Solutions:
- Dimensionality Reduction: Matrix factorization
- Project into low-dimensional latent space
- Smooths estimates by sharing statistical strength
- Implicit Feedback: Expand your signal
- Don't rely only on explicit ratings
- Use clicks, views, time spent, mouse hovers
- More data, but noisier
- Multi-domain Learning: Transfer across domains
- User's music taste might inform movie taste
- Product purchases inform article interests
- Shared user embeddings across domains
- Regularization: Prevent overfitting to sparse data
- L2 regularization in matrix factorization
- Dropout in neural networks
- Early stopping
Challenge 3: Long-Tail Distribution
Item popularity follows a power law: a few items are extremely popular, most items have very few interactions. This creates multiple problems:
The Curve: - Top 1% of items account for 50% of interactions - Bottom 50% of items have < 10 interactions each - The "tail" extends very far
Problems:
- Popularity Bias: Models over-recommend popular
items
- Popular items have more data → better predictions → recommended more → get even more popular (rich get richer)
- Hurts diversity and user satisfaction over time
- Creator Fairness: Niche creators never get
discovered
- New/small creators can't get initial traction
- Reduces content diversity in ecosystem
- User Frustration: Users with niche tastes get poor
recommendations
- Their preferred content is in the tail
- System doesn't have enough data on those items
Solutions:
- Debiasing Techniques:
- Inverse Propensity Scoring: Weight training examples by\(\frac{1}{P(\text{observed})}\) - Popularity-dampened Loss:\(L = \sum (r - \hat{r})^2 / \log(1 + \text{popularity}(i))\) - Forces model to work harder on unpopular items
- Diversity Constraints: Explicitly limit popular
items
- "At most 3 blockbusters in top-10"
- Reserve slots for different popularity tiers
- Multi-armed Bandits: Active learning for tail items
- Intelligently explore tail items
- Show them to users likely to appreciate them
- Social Recommendations: Leverage network effects
- If someone in your network likes a niche item, you might too
- Word-of-mouth recommendations
Challenge 4: Temporal Dynamics
User preferences drift over time. Items' popularity changes. Models trained on old data become stale.
Types of Temporal Effects:
- User Preference Drift: You liked action movies 5 years ago, now you prefer documentaries
- Item Aging: Last year's trending items are old news
- Seasonal Patterns: Holiday movies in December, beach reads in summer
- Event-driven Spikes: Olympics → sports content, election → political content
Solutions:
- Time-Weighted Training:
- Exponential time decay: recent data weighted higher -\(w(t) = e^{-\lambda (t_{\text{now }} - t)}\) - Sliding window: only train on last N months
- Contextual Bandit Approaches:
- Continuously update models with new data
- Online learning algorithms (FTRL, online SGD)
- Temporal Features:
- Time since release (freshness)
- Day of week, hour of day
- Days until major event (e.g., Christmas)
- Session-based Models:
- Focus on recent session history, not all-time history
- RNNs or Transformers on sequential interactions
Example: Time-Decayed Matrix Factorization
1 | def fit_with_time_decay(self, ratings: List[Tuple[int, int, float, float]], |
Challenge 5: Scalability
Production systems need to serve millions of users per second with < 100ms latency. Training data grows to petabytes. Models have billions of parameters.
Scale Challenges:
- Online Serving: 10M+ requests per second
- Model Size: Billions of users × thousands of items = trillions of parameters
- Training Data: Petabytes of interaction logs
- Feature Computation: Real-time features for each request
Solutions:
- Distributed Systems:
- Sharding: partition users/items across machines
- Caching: cache popular predictions, user embeddings, item embeddings
- Load balancing: distribute requests evenly
- Model Compression:
- Quantization: 32-bit floats → 8-bit ints
- Knowledge distillation: train small model to mimic large model
- Pruning: remove low-importance parameters
- Approximate Algorithms:
- Approximate nearest neighbor (e.g., FAISS, ScaNN)
- Sampling negative examples instead of using all
- Blocking/chunking strategies
- Offline/Online Split:
- Precompute what you can offline (item embeddings, similarity matrices)
- Online: only compute user-specific and real-time features
Implementing Classic Algorithms from Scratch
Theory is essential, but nothing beats implementing algorithms yourself. build complete, production-quality implementations of the two foundational collaborative filtering approaches.
User-Based Collaborative Filtering
User-based CF finds users similar to you and recommends items they liked. Despite being one of the oldest recommendation algorithms, it's still used in practice for its interpretability and effectiveness.
Algorithm Overview:
The User-CF algorithm follows these key steps: 1. Build user-item rating matrix: Store which users rated which items and their ratings 2. Compute user similarities: For each user pair, calculate how similar their rating patterns are 3. Find neighbors: For a target user-item pair, find K users most similar to the target user who have rated the target item 4. Predict rating: Weighted average of neighbors' ratings, where weights are the similarity scores 5. Recommend: Rank all unrated items by predicted rating and return Top-N
Why User-CF Works:
The fundamental assumption is that users who agreed in the past will agree in the future. If you and another user gave similar ratings to 50 movies, when that user rates a new movie highly, there's a strong signal you'll like it too.
Implementation Considerations:
- Sparse data handling: Most users only rate a tiny fraction of items, so we use dictionaries instead of dense matrices
- Similarity metrics: Pearson correlation is preferred over cosine similarity because it accounts for different rating scales (some users rate 4-5, others rate 2-3)
- Minimum common items threshold: We only consider two users as neighbors if they've rated at least N items in common (default 3) to ensure statistical significance
- Top-K neighbors: Using all similar users would be slow and noisy; we only use the K most similar (default 50)
1 | import numpy as np |
Item-Based Collaborative Filtering
Item-based CF computes similarity between items and recommends items similar to ones you liked. It's generally more stable and scalable than user-based CF.
1 | class ItemBasedCF: |
Frequently Asked Questions
address common questions that arise when building recommendation systems.
Q1: When should I use collaborative filtering vs. content-based filtering?
Use collaborative filtering when: - You have substantial user-item interaction data - Items are hard to describe with features (e.g., what makes a song "good"?) - You want serendipitous recommendations (users discover unexpected items)
Use content-based filtering when: - You have rich item metadata but sparse interactions - Items are new (cold-start problem for CF) - You need explainable recommendations ("Because it has similar actors") - Privacy is a concern (content-based doesn't need other users' data)
In practice, use both (hybrid approach).
Q2: How do I handle implicit feedback (clicks, views) vs. explicit feedback (ratings)?
Implicit feedback is more abundant but noisier: - Positive class: User interacted (clicked, viewed, purchased) - Negative class: User didn't interact (but this could mean they never saw it!)
Approaches: 1. Treat all observations as positive, unobserved as negative with low confidence (weighted matrix factorization) 2. Sample negatives from unobserved items (negative sampling) 3. Use ranking losses instead of rating prediction (BPR, pairwise ranking)
Q3: What's the right dimensionality for matrix factorization?
Typical range: 20-200 latent factors.
- Too small (< 10): Underfitting, can't capture complexity
- Too large (> 500): Overfitting, slow, diminishing returns
Find the sweet spot using validation data. Start with 50-100 and tune.
Q4: How often should I retrain my model?
Depends on data velocity and user tolerance for staleness: - High velocity (TikTok, news): Every few hours or online learning - Medium velocity (Netflix, Spotify): Daily or weekly - Low velocity (Amazon products): Weekly to monthly
Use a freshness monitor: track how often recommendations include recently added items. If freshness drops, retrain more frequently.
Q5: How do I make recommendations explainable?
Explainability builds trust and helps users understand recommendations:
- Content-based: "Because it has similar genre/actors/attributes"
- Collaborative filtering: "Because users with similar taste enjoyed this"
- Hybrid: Combine both explanations
- Post-hoc: Train a separate model to generate explanations from features
Example implementation:
1 | def explain_recommendation(user_id: int, item_id: int) -> str: |
Q6: How do I balance exploitation (recommend what users like) vs. exploration (try new things)?
Pure exploitation leads to filter bubbles. Pure exploration annoys users.
Strategies: 1. Epsilon-greedy: With probability\(\epsilon\), recommend random items 2. Thompson Sampling: Bayesian approach that naturally balances exploitation/exploration 3. Upper Confidence Bound (UCB): Boost items with high uncertainty 4. Diversity in reranking: Reserve 1-2 spots in top-10 for "exploratory" items
Typical\(\epsilon\): 0.05-0.15 (5-15% exploration).
Q7: What about multi-criteria recommendations (price, location, etc.)?
For items with multiple attributes (price, location, availability):
- Filtering: Apply hard constraints first (price range, in-stock only)
- Multi-objective optimization: Pareto optimal solutions balancing multiple criteria
- Utility function: Learn a function that combines multiple criteria -\(\text{utility}(i) = \alpha \cdot \text{relevance}(i) + \beta \cdot \text{price\_score}(i) + \gamma \cdot \text{location\_score}(i)\) Q8: How do I prevent recommending the same item repeatedly?
Users don't want to see the same recommendations every time they visit.
Solutions: 1. Exclude recently seen: Don't recommend items shown in last N sessions 2. Decay seen items: Reduce scores for previously shown items 3. Session diversity: Track what's shown in current session, ensure variety 4. Fatigue modeling: Explicitly model probability user is "tired" of an item
1 | def apply_fatigue(item_scores: Dict[int, float], |
Q9: What about group recommendations (e.g., movie for family)?
Recommending for groups is challenging because individuals have different preferences.
Approaches: 1. Average: Aggregate individual scores -\(\text{score}(i) = \frac{1}{|G|} \sum_{u \in G} \text{score}_u(i)\)
Least misery: Optimize for the least satisfied member -\(\text{score}(i) = \min_{u \in G} \text{score}_u(i)\)
Most pleasure: Maximize the most satisfied member -\(\text{score}(i) = \max_{u \in G} \text{score}_u(i)\)
Fairness: Ensure each member gets some preferred items
- Alternate between optimizing for each member
Q10: How do I evaluate a recommendation system without A/B testing?
A/B tests are gold standard, but offline evaluation is useful during development:
- Temporal split: Train on data before time\(T\), test on data after
- Simulates production setting
- Leave-one-out: For each user, hide one item they liked, try to recommend it
- User-stratified split: Split by users (some users
for train, others for test)
- Tests generalization to new users
Be careful: offline metrics don't always correlate with online business metrics. A model with lower RMSE might have lower engagement. Always validate with A/B tests before shipping.
Summary and Next Steps
We've covered the foundational concepts of recommendation systems: from the three core paradigms (collaborative filtering, content-based, hybrid) to evaluation metrics (precision, recall, NDCG) to system architecture (multi-stage funnel) to critical challenges (cold-start, sparsity, long-tail) to practical implementations.
Key Takeaways:
- No single best algorithm: The right approach depends on your data, scale, and business goals
- Hybrid methods dominate: Combining multiple signals (collaborative + content + context) works best
- Architecture matters: Multi-stage systems balance quality and latency at scale
- Evaluation is multi-faceted: Accuracy, diversity, coverage, and business metrics all matter
- Production is different from research: Real systems must handle cold-start, scale, freshness, and business constraints
Where to Go from Here:
This article focused on fundamentals. The next articles in this series will cover:
- Part 2: Deep Learning for Recommendations: Neural collaborative filtering, attention mechanisms, graph neural networks, transformer-based models
- Part 3: Context-Aware Recommendations: Sequential models, session-based recommendations, multi-armed bandits, reinforcement learning
- Part 4: Advanced Topics: Multi-task learning, fairness & bias, explanation generation, real-time systems, large-scale serving
Resources for Further Learning:
Books: - "Recommender Systems: The Textbook" by Charu Aggarwal - "Deep Learning for Recommender Systems" by Heng-Tze Cheng et al.
Papers (foundational): - Matrix Factorization Techniques (Netflix Prize) - BPR: Bayesian Personalized Ranking (implicit feedback) - Wide & Deep Learning (Google) - Neural Collaborative Filtering (deep learning for CF)
Open-source libraries: - Surprise (Python, educational) - LightFM (hybrid models) - RecBole (comprehensive research toolkit) - TensorFlow Recommenders (production-grade)
The field of recommendation systems continues to evolve rapidly, with recent advances in foundation models, multi-modal recommendations, and conversational recommenders. But the fundamentals covered here remain essential – they're the building blocks upon which all modern systems are built. Master these concepts, and you'll have a solid foundation for understanding and building state-of-the-art recommendation systems.
- Post title:Recommendation Systems (1): Fundamentals and Core Concepts
- Post author:Chen Kai
- Create time:2026-02-03 23:11:11
- Post link:https://www.chenk.top/recommendation-systems-1-fundamentals/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.