In real-world recommendation systems, optimizing for a single
objective is rarely sufficient. When you browse an e-commerce platform,
the system needs to predict not just whether you'll click on a product,
but also whether you'll add it to cart, make a purchase, return it, or
write a review. Each of these actions represents a different task with
distinct patterns, yet they're all interconnected — a user who clicks is
more likely to purchase, and someone who purchases is more likely to
return. Multi-task learning (MTL) provides a powerful framework for
jointly optimizing multiple objectives by sharing representations across
related tasks, leading to improved performance on each individual task
while reducing computational overhead.
Multi-task learning has become a cornerstone of modern recommendation
systems, from Google's MMoE (Multi-gate Mixture-of-Experts) that handles
conflicting objectives, to Alibaba's ESMM (Entire Space Multi-Task
Model) that addresses sample selection bias in conversion prediction, to
Tencent's PLE (Progressive Layered Extraction) that explicitly separates
shared and task-specific knowledge. These architectures have
demonstrated significant improvements over single-task models by
leveraging the commonalities between tasks while preserving
task-specific nuances.
This article provides a comprehensive exploration of multi-task
learning for recommendation systems, covering foundational architectures
(Shared-Bottom, ESMM, MMoE, PLE, STEM-Net), task relationship modeling
techniques, loss balancing strategies, industrial applications and case
studies, implementation details with 10+ code examples, and detailed
Q&A sections addressing common challenges and best practices.
Why Multi-Task
Learning for Recommendation?
The
Multi-Objective Nature of Recommendation
Recommendation systems in production face multiple, often conflicting
objectives:
Advertising Systems: - Click-through rate: Ad
relevance - Conversion rate: Purchase actions - Cost per acquisition
(CPA): Efficiency - User lifetime value (LTV): Long-term value
These objectives are interrelated but distinct:
optimizing for clicks might increase low-quality interactions, while
optimizing solely for conversions might reduce overall engagement.
Multi-task learning allows us to balance these objectives by learning
shared representations that capture common patterns while maintaining
task-specific heads that capture unique characteristics.
Sample Selection Bias
Problem
A critical challenge in recommendation is sample selection
bias. Consider conversion prediction:
Training data: Only contains samples where users
clicked (positive samples for CTR)
Test data: Contains all samples (both clicked and
non-clicked)
Problem: The model is trained on a biased
distribution, leading to poor generalization
Traditional single-task models trained on clicked samples only cannot
properly estimate the true conversion rate in the entire space. ESMM
addresses this by modeling the entire space through the chain rule:
.
Benefits of Multi-Task
Learning
Multi-task learning offers several advantages:
Data Efficiency: Shared representations allow tasks
with limited data to benefit from tasks with abundant data
Regularization: Learning shared features acts as
implicit regularization, reducing overfitting
Transfer Learning: Knowledge learned from one task
transfers to related tasks
Computational Efficiency: Shared bottom layers
reduce computation compared to training separate models
Better Generalization: Joint optimization often
leads to more robust representations
Challenges in Multi-Task
Learning
However, MTL also introduces challenges:
Task Conflicts: Tasks may have conflicting
gradients, causing negative transfer
Loss Balancing: Different tasks have different
scales and importance
Task Relationships: Understanding which tasks
benefit from sharing vs. separation
Architecture Design: Balancing shared vs.
task-specific components
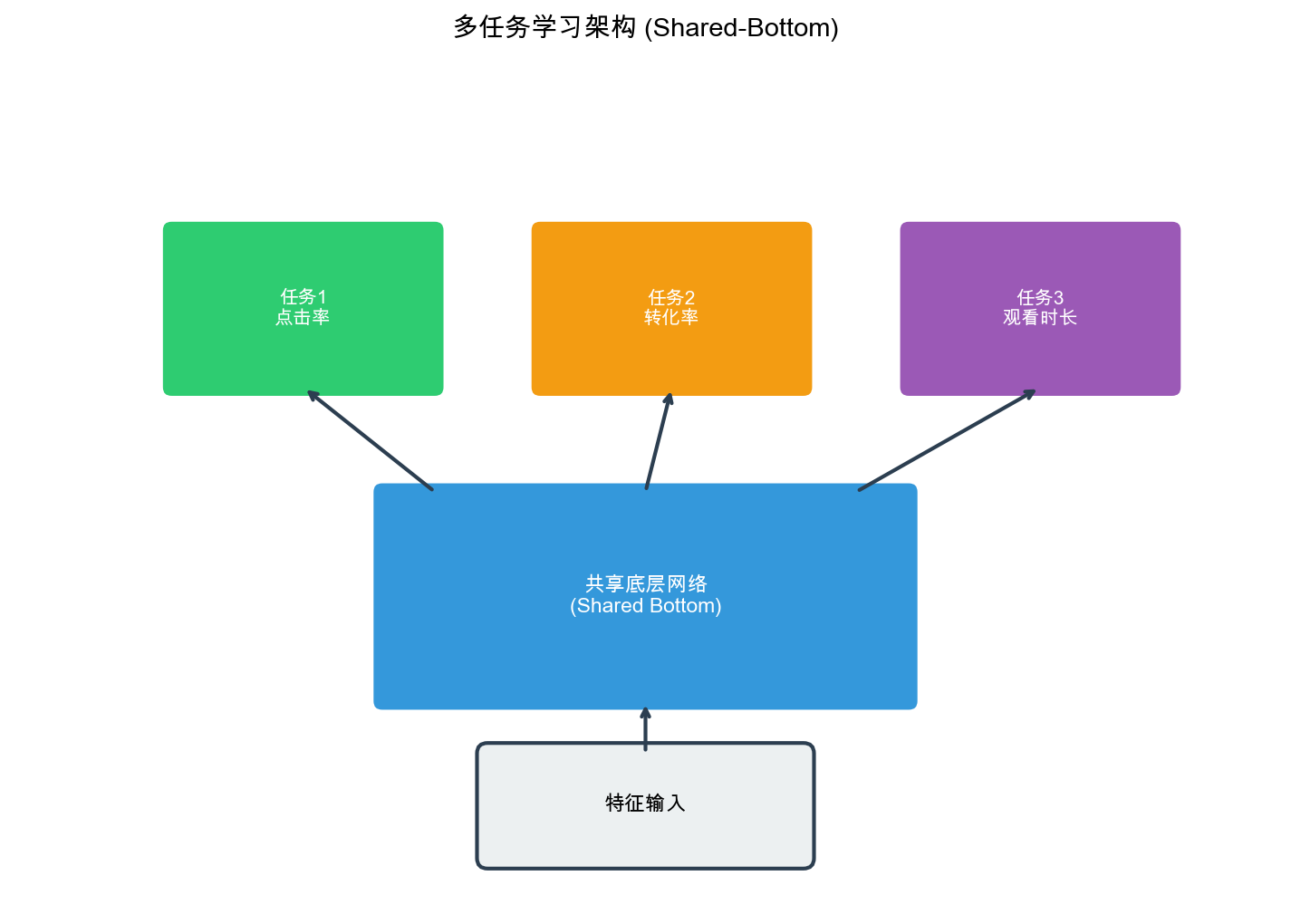
Shared-Bottom Architecture
Basic Structure
The Shared-Bottom architecture is the simplest
multi-task learning approach:
1 2 3 4 5 6 7
Input Features ↓ Shared Bottom Layers (shared across all tasks) ↓ Task-Specific Towers (one per task) ↓ Task Outputs
Mathematical Formulation:
Fortasks, the shared-bottom
model computes:where: -is the input feature vector
-is the shared
bottom network -is the
task-specific tower for task
-is the prediction for
task
The shared-bottom architecture has a fundamental limitation:
all tasks share the same representation, which can lead
to:
Negative Transfer: Conflicting tasks interfere with
each other
Insufficient Capacity: Shared layers may not
capture task-specific patterns
Gradient Conflicts: Tasks with conflicting
objectives create opposing gradients
This motivates more sophisticated architectures like MMoE and PLE
that allow selective sharing.
ESMM: Entire Space
Multi-Task Model
Problem Formulation
ESMM addresses the sample selection bias problem in
conversion prediction:
Traditional approach: Train CVR model only on clicked samples
Problem: Test on entire space (clicked + non-clicked), causing
distribution mismatch
Solution: Model the entire space using the chain rule
Mathematical Foundation:This decomposition allows us
to: 1. Train CTR model on all impressions 2. Train CVR model on clicked
samples only 3. Combine them to get conversion probability in entire
space
Data Efficiency: CTR model benefits from all
samples, CVR from clicked samples
Practical: Simple architecture, easy to deploy
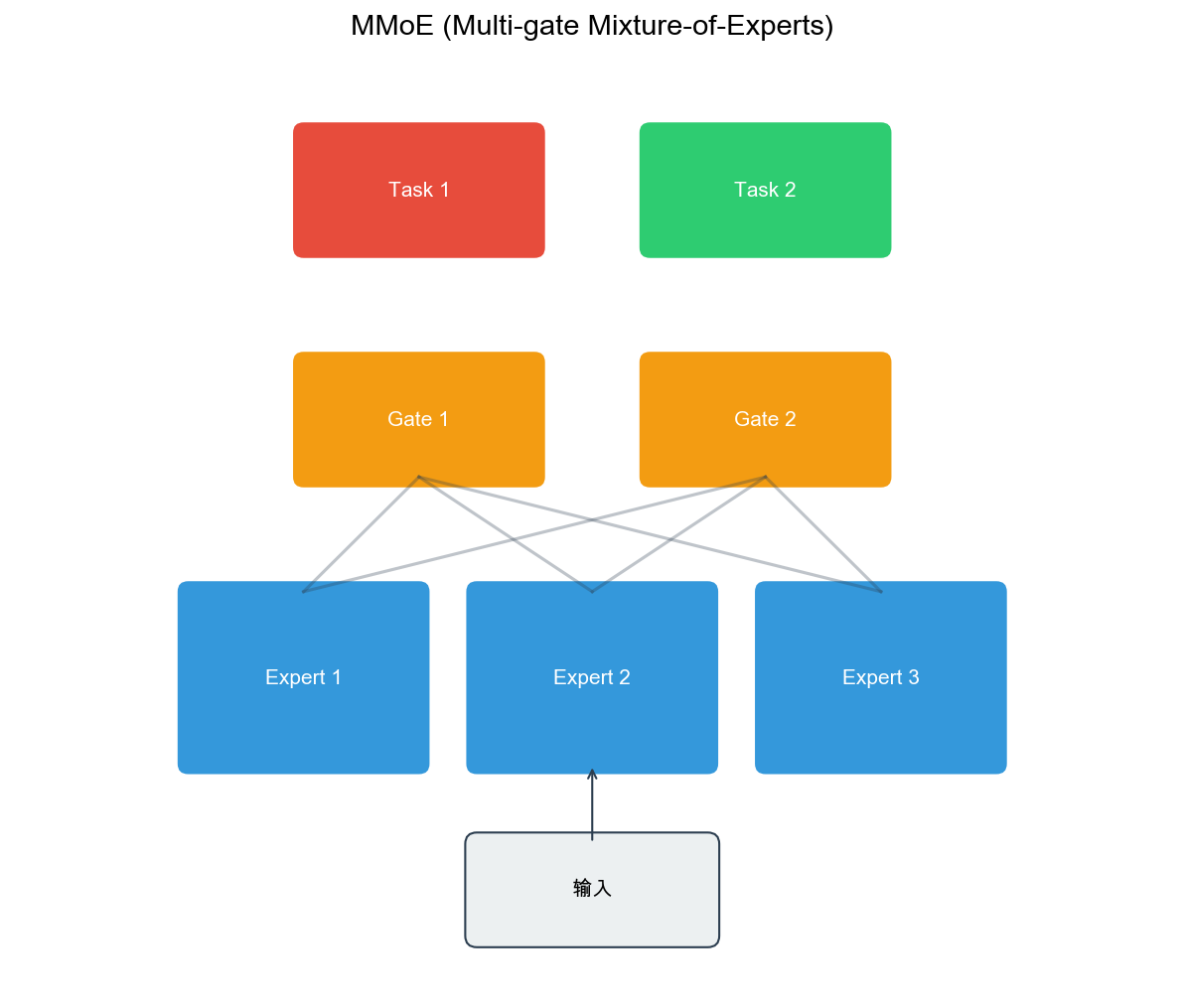
MMoE: Multi-gate
Mixture-of-Experts
Motivation
MMoE addresses the negative transfer problem in
shared-bottom architectures. When tasks conflict, forcing them to share
the same representation hurts performance. MMoE introduces:
Multiple Experts: Several expert networks that can
learn different patterns
Gating Networks: Task-specific gates that
selectively combine experts
Adaptive Sharing: Tasks can share experts when
beneficial, use different experts when conflicting
Architecture
MMoE consists of:
Expert Networks:that learn different feature
transformations
Gating Networks:for each taskthat learn to weight experts
Task Towers: Task-specific networks on top of
expert outputs
Mathematical Formulation:
For task:where: -is the output of
expert -is the gate weight for
taskand expert -(softmax normalization)
print(f"Task outputs: {[out.shape for out in outputs]}") print(f"Gate weights shape: {gate_weights[0].shape}") print(f"Sample gate weights for task 1: {gate_weights[0][0]}")
Advantages of MMoE
Adaptive Sharing: Tasks can selectively use experts
based on their needs
Conflict Handling: Conflicting tasks can use
different experts
Scalability: Easy to add new tasks or experts
Interpretability: Gate weights show which experts
each task uses
PLE: Progressive Layered
Extraction
Motivation
PLE (Progressive Layered Extraction) extends MMoE by explicitly
separating:
Shared Experts: Capture common patterns across all
tasks
classPLELayer(nn.Module): """Single PLE layer with shared and task-specific experts""" def__init__(self, input_dim, num_shared_experts, num_task_experts, expert_hidden_dim, expert_output_dim, num_tasks): super(PLELayer, self).__init__() self.num_shared_experts = num_shared_experts self.num_task_experts = num_task_experts self.num_tasks = num_tasks self.expert_output_dim = expert_output_dim # Shared experts self.shared_experts = nn.ModuleList([ Expert(input_dim, expert_hidden_dim, expert_output_dim) for _ inrange(num_shared_experts) ]) # Task-specific experts self.task_experts = nn.ModuleList([ nn.ModuleList([ Expert(input_dim, expert_hidden_dim, expert_output_dim) for _ inrange(num_task_experts) ]) for _ inrange(num_tasks) ]) # Gating networks self.shared_gates = nn.ModuleList([ Gate(input_dim, num_shared_experts) for _ inrange(num_tasks) ]) self.task_gates = nn.ModuleList([ Gate(input_dim, num_task_experts) for _ inrange(num_tasks) ]) defforward(self, x): """ Forward pass through PLE layer Returns: task_outputs: List of task representations gate_info: Gate weights for analysis """ batch_size = x.size(0) # Shared expert outputs shared_expert_outputs = [] for expert in self.shared_experts: shared_expert_outputs.append(expert(x)) shared_expert_outputs = torch.stack(shared_expert_outputs, dim=1) # (batch_size, num_shared_experts, expert_output_dim) # Task-specific expert outputs task_expert_outputs_list = [] for task_idx inrange(self.num_tasks): task_expert_outputs = [] for expert in self.task_experts[task_idx]: task_expert_outputs.append(expert(x)) task_expert_outputs = torch.stack(task_expert_outputs, dim=1) # (batch_size, num_task_experts, expert_output_dim) task_expert_outputs_list.append(task_expert_outputs) # Combine shared and task-specific experts for each task task_outputs = [] gate_info = [] for task_idx inrange(self.num_tasks): # Gate weights shared_gate_weights = self.shared_gates[task_idx](x) # (batch_size, num_shared_experts) task_gate_weights = self.task_gates[task_idx](x) # (batch_size, num_task_experts) # Weighted combination shared_weighted = (shared_expert_outputs * shared_gate_weights.unsqueeze(2)).sum(dim=1) task_weighted = (task_expert_outputs_list[task_idx] * task_gate_weights.unsqueeze(2)).sum(dim=1) # Combine shared and task-specific (concatenate or add) task_output = shared_weighted + task_weighted # or torch.cat([shared_weighted, task_weighted], dim=1) task_outputs.append(task_output) gate_info.append({ 'shared_gate': shared_gate_weights, 'task_gate': task_gate_weights }) return task_outputs, gate_info
classPLE(nn.Module): """ Progressive Layered Extraction (PLE) Explicitly separates shared and task-specific experts with progressive knowledge extraction across layers. """ def__init__(self, input_dim, num_layers, num_shared_experts, num_task_experts, expert_hidden_dim, expert_output_dim, num_tasks, task_hidden_dims, task_types): super(PLE, self).__init__() self.num_layers = num_layers self.num_tasks = num_tasks # PLE layers self.ple_layers = nn.ModuleList() prev_dim = input_dim for layer_idx inrange(num_layers): layer = PLELayer( prev_dim, num_shared_experts, num_task_experts, expert_hidden_dim, expert_output_dim, num_tasks ) self.ple_layers.append(layer) prev_dim = expert_output_dim # Task-specific towers self.task_towers = nn.ModuleList() for task_idx inrange(num_tasks): tower_layers = [] prev_dim = expert_output_dim for hidden_dim in task_hidden_dims: tower_layers.extend([ nn.Linear(prev_dim, hidden_dim), nn.ReLU(), nn.Dropout(0.1) ]) prev_dim = hidden_dim if task_types[task_idx] == 'binary': tower_layers.append(nn.Linear(prev_dim, 1)) tower_layers.append(nn.Sigmoid()) elif task_types[task_idx] == 'regression': tower_layers.append(nn.Linear(prev_dim, 1)) self.task_towers.append(nn.Sequential(*tower_layers)) defforward(self, x): """ Forward pass through PLE layers Returns: task_outputs: Final task predictions all_gate_info: Gate information from all layers """ current_input = x all_gate_info = [] # Progressive extraction through layers for layer in self.ple_layers: current_input_list, gate_info = layer(current_input) all_gate_info.append(gate_info) # Use average or first task's output as input to next layer # (In practice, you might use a more sophisticated combination) current_input = current_input_list[0] # Simplified: use first task # Final task-specific towers final_outputs = [] for task_idx inrange(self.num_tasks): output = self.task_towers[task_idx](current_input_list[task_idx]) final_outputs.append(output) return final_outputs, all_gate_info
# Example usage model = PLE( input_dim=128, num_layers=2, num_shared_experts=2, num_task_experts=2, expert_hidden_dim=64, expert_output_dim=32, num_tasks=3, task_hidden_dims=[16], task_types=['binary', 'binary', 'regression'] )
x = torch.randn(32, 128) outputs, gate_info = model(x) print(f"Number of layers: {len(gate_info)}") print(f"Task outputs: {[out.shape for out in outputs]}")
STEM-Net:
Search-based Task Embedding for Multi-Task Learning
Motivation
STEM-Net introduces task embeddings to explicitly
model task relationships. Instead of hard-coding which tasks share
experts, STEM-Net learns task representations that guide expert
selection.
Key Ideas
Task Embeddings: Learnable representations for each
task
Search-Based Architecture: Use task embeddings to
search for relevant experts
Dynamic Expert Selection: Experts are selected
based on task-task and task-expert similarity
# Example usage model = STEMNet( input_dim=128, num_experts=4, expert_hidden_dim=64, expert_output_dim=32, num_tasks=3, task_embed_dim=16, task_hidden_dims=[16], task_types=['binary', 'binary', 'regression'] )
x = torch.randn(32, 128) outputs, attention_weights = model(x) print(f"Task outputs: {[out.shape for out in outputs]}") print(f"Attention weights shape: {attention_weights.shape}")
Task Relationship Modeling
Understanding Task
Relationships
Tasks in recommendation systems have different relationships:
Complementary Tasks: Benefit from sharing (e.g.,
CTR and CVR)
Conflicting Tasks: Hurt each other when sharing
(e.g., engagement vs. revenue)
Hierarchical Tasks: One task is a prerequisite for
another (e.g., click → conversion)
Different tasks have: - Different scales (CTR: 0.01-0.1, Revenue:
0-1000) - Different importance (business priorities) - Different
difficulty (some tasks are easier to learn)
Simply summing losses can lead to one task dominating training.
Key Insights: - Modeling entire space is crucial for
production systems - Chain rule ensures mathematical consistency -
Simple architecture enables easy deployment
Google: MMoE for
YouTube Recommendations
Problem: Multiple conflicting objectives (watch
time, engagement, revenue).
Solution: MMoE with multiple experts and
task-specific gates.
Results: - Significant improvement over
shared-bottom baseline - Better handling of task conflicts - Scalable to
many tasks
Key Insights: - Gating mechanism crucial for
handling conflicts - Expert diversity important for performance -
Architecture scales well with number of tasks
Tencent: PLE for Video
Recommendations
Problem: Balance multiple objectives with both
shared and conflicting patterns.
Solution: PLE with explicit shared/task-specific
expert separation.
Results: - 12% improvement in overall engagement -
Better balance across objectives - Improved long-term user
satisfaction
Q1:
When should I use multi-task learning vs. separate models?
A: Use multi-task learning when: - Tasks are related
and share underlying patterns - You have limited data for some tasks -
Tasks benefit from shared representations - You want to reduce
computational overhead
Use separate models when: - Tasks are completely independent - Tasks
have strong conflicts that can't be resolved - You have abundant data
for each task - Tasks require very different architectures
Q2: How
do I choose between Shared-Bottom, MMoE, and PLE?
A: - Shared-Bottom: Start here for
simple cases with complementary tasks - MMoE: Use when
tasks may conflict but you're unsure which ones - PLE:
Use when you know tasks have both shared and conflicting patterns
Generally, start simple and move to more complex architectures if
needed.
Q3: How many
experts should I use in MMoE/PLE?
A: Common choices: - 2-4 experts:
For 2-3 tasks - 4-8 experts: For 4-6 tasks - 8+
experts: For many tasks or complex scenarios
Start with fewer experts and increase if needed. Too many experts can
lead to overfitting.
Q4: How do I balance
losses across tasks?
A: Several approaches: 1. Uniform:
Simple sum (works if tasks have similar scales) 2. Uncertainty
Weighting: Learn task-specific weights automatically 3.
GradNorm: Balance gradients instead of losses 4.
DWA: Dynamic weighting based on loss decrease rates 5.
Manual: Set weights based on business priorities
Start with uniform or uncertainty weighting, then try more
sophisticated methods if needed.
Q5: What if tasks
have very different scales?
A: Options: 1. Normalize labels:
Scale all labels to similar ranges (e.g., [0, 1]) 2. Use
appropriate loss functions: MSE for regression, BCE for
classification 3. Learn task-specific scales: Use
uncertainty weighting or learnable scales 4. Separate
normalization: Normalize each task's labels independently
Q6: How do I
handle missing labels for some tasks?
A: Strategies: 1. Masked loss: Only
compute loss for available labels 2. Imputation: Fill
missing labels with default values 3. Separate
sampling: Sample batches to ensure all tasks have labels 4.
Task-specific data loaders: Handle missing labels in
data loading
Most common: masked loss computation.
Q7:
Can I use multi-task learning with different input modalities?
A: Yes! Common approaches: 1. Shared
encoders: Encode each modality separately, then combine 2.
Cross-modal attention: Attend across modalities 3.
Modality-specific experts: Separate experts for each
modality
Example: Text + image recommendations can share high-level
representations while keeping modality-specific encoders.
Q8: How do I evaluate
multi-task models?
A: Evaluate both: 1. Individual task
performance: Metrics for each task (AUC, MSE, etc.) 2.
Joint performance: Combined metrics (e.g., weighted
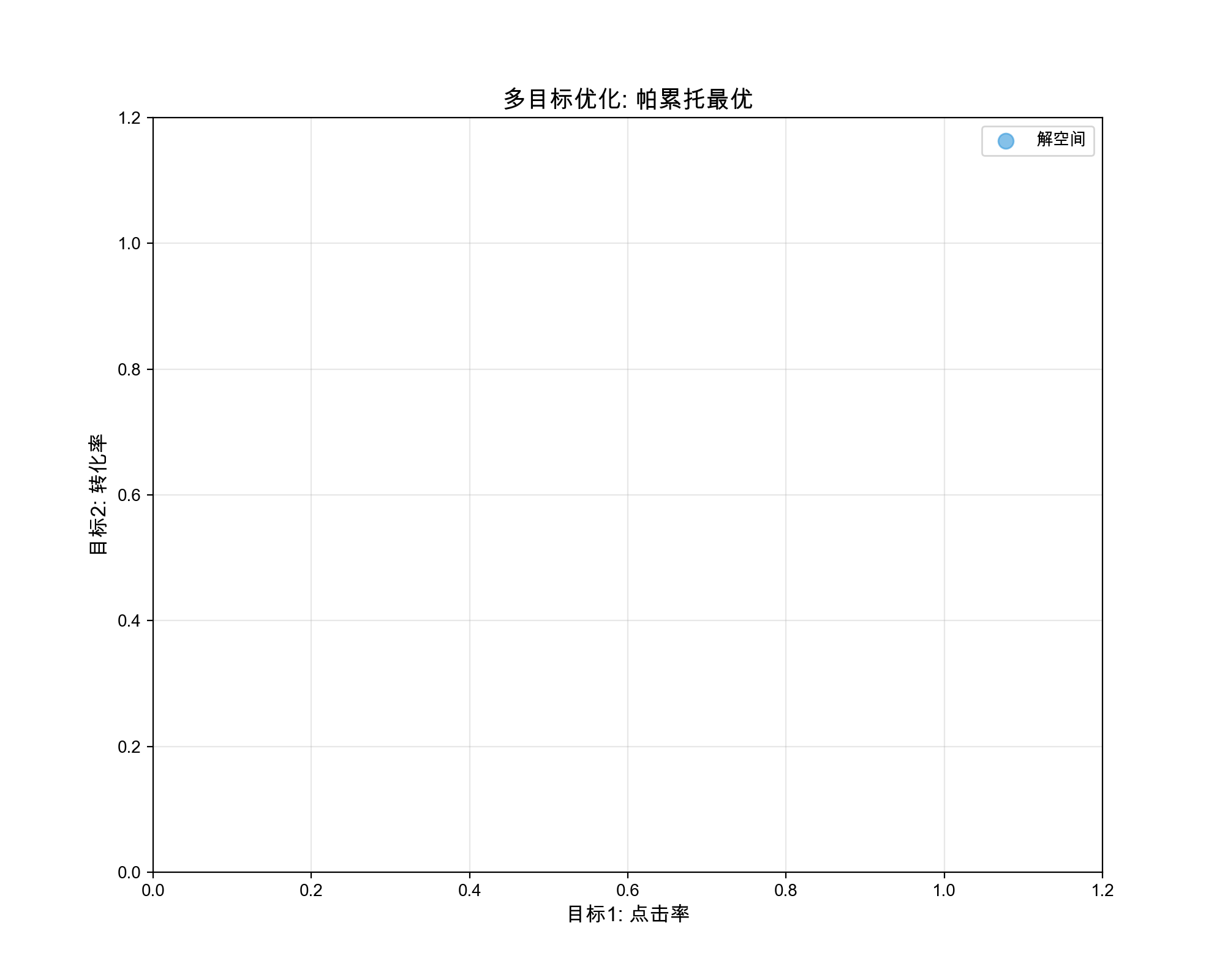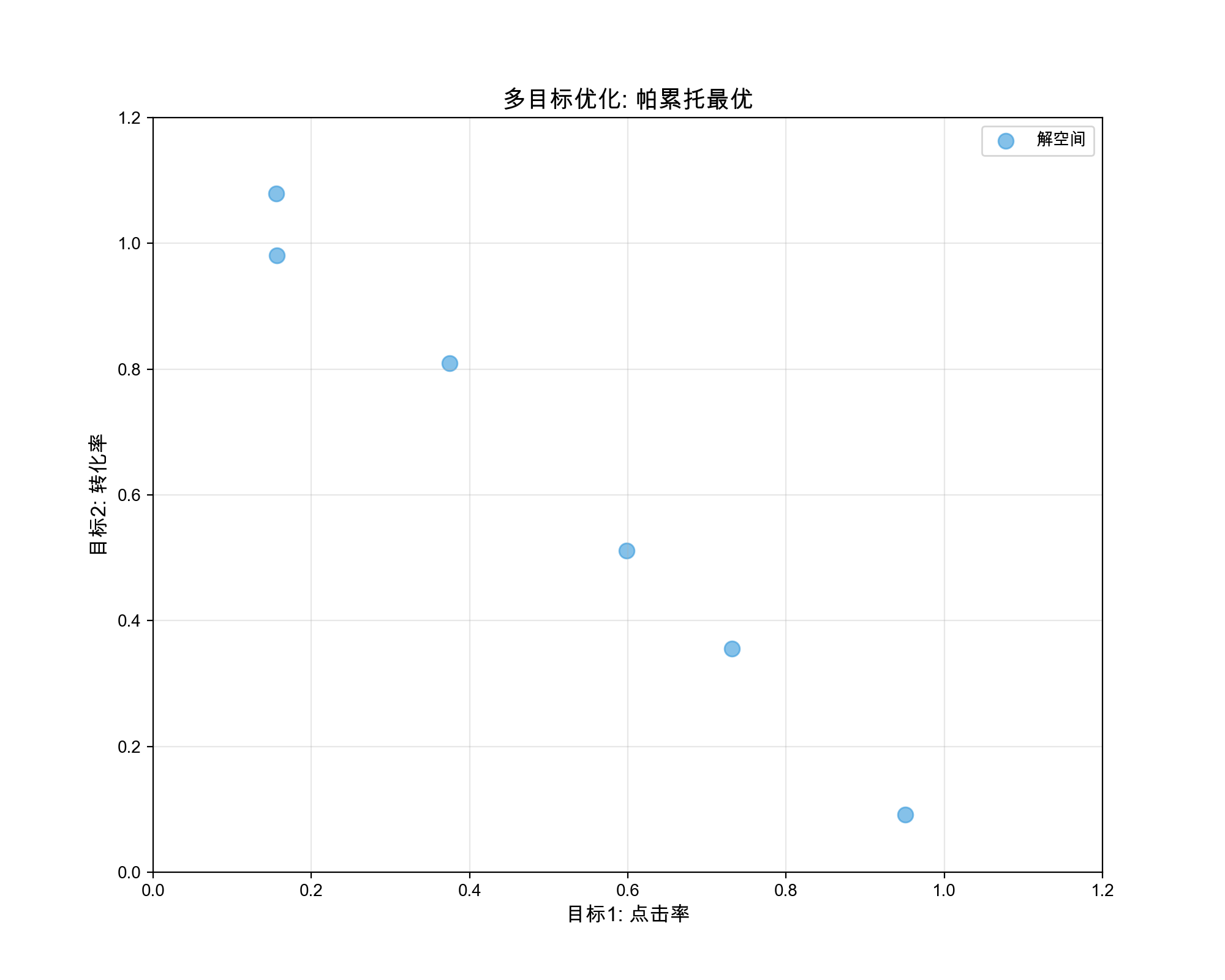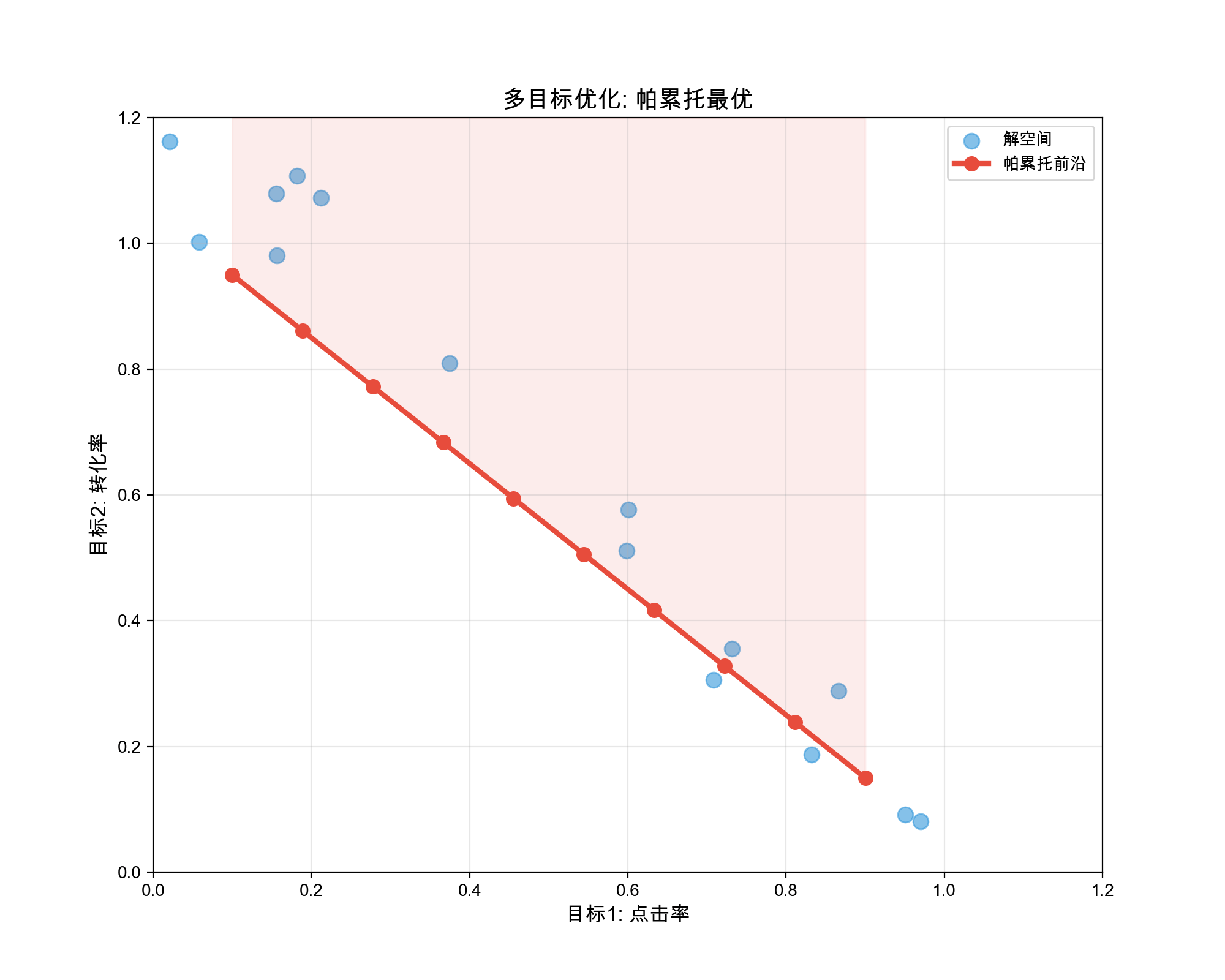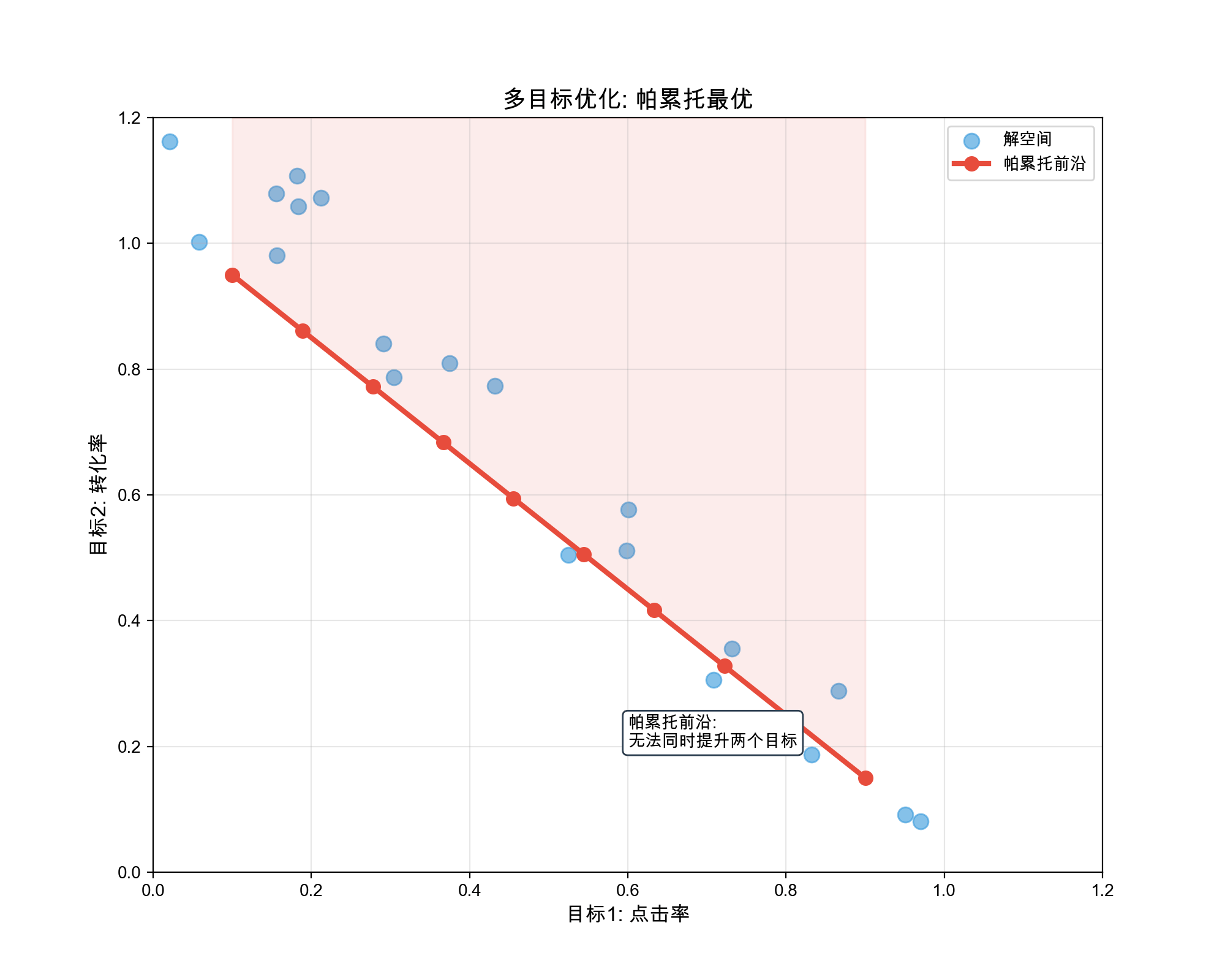
average) 3. Trade-off analysis: Pareto frontier if
objectives conflict
Don't just look at average performance — understand task-specific
improvements.
Q9: What are
common pitfalls in multi-task learning?
A: Common mistakes: 1. Ignoring task
conflicts: Forcing conflicting tasks to share 2. Poor
loss balancing: One task dominates training 3.
Insufficient capacity: Shared layers too small 4.
Over-sharing: Sharing when tasks should be separate 5.
Under-sharing: Not sharing when tasks benefit from
it
Q10: How do I debug
multi-task models?
A: Debugging strategies: 1. Check individual
task losses: Ensure all tasks are learning 2. Visualize
gate weights: Understand expert usage in MMoE/PLE 3.
Monitor gradients: Check for gradient conflicts 4.
Ablation studies: Remove tasks/experts to understand
contributions 5. Compare to single-task baselines:
Ensure MTL actually helps
Q11:
Can I add new tasks to an existing multi-task model?
A: Yes, but consider: 1.
Architecture: MMoE/PLE make this easier than
Shared-Bottom 2. Fine-tuning: Retrain or fine-tune when
adding tasks 3. Task relationships: New tasks may
change expert usage patterns 4. Loss balancing: May
need to rebalance weights
MMoE and PLE are more flexible for adding tasks.
Q12:
How do I handle tasks with different update frequencies?
A: Options: 1. Separate optimizers:
Different learning rates per task 2. Alternating
updates: Update tasks in rounds 3. Gradient
accumulation: Accumulate gradients across tasks 4.
Task-specific schedules: Different update
frequencies
Most common: separate optimizers or alternating updates.
Q13:
What's the relationship between multi-task learning and transfer
learning?
A: - Multi-task learning: Train
multiple tasks simultaneously with shared representations -
Transfer learning: Pre-train on one task, fine-tune on
another
MTL can be seen as simultaneous transfer learning across tasks. Both
leverage shared knowledge.
Q14: How do I
choose task-specific architectures?
A: Consider: 1. Task type:
Classification vs. regression vs. ranking 2. Task
complexity: Simple tasks need simpler towers 3. Data
availability: More data allows more complex architectures 4.
Computational budget: Balance capacity with
efficiency
Start with simple towers and increase complexity if needed.
Q15:
Can multi-task learning help with cold-start problems?
A: Yes! MTL can help by: 1. Transfer from
warm tasks: Warm tasks help cold tasks through shared
representations 2. Auxiliary tasks: Use easy-to-collect
signals (clicks) to help hard tasks (purchases) 3. Shared
embeddings: Cold users/items benefit from shared patterns
This is one of the key advantages of MTL in recommendation
systems.
Conclusion
Multi-task learning has become essential for modern recommendation
systems, enabling us to optimize multiple objectives simultaneously
while leveraging shared patterns across tasks. From the simple
Shared-Bottom architecture to sophisticated models like MMoE and PLE,
MTL provides a principled framework for handling the complex,
multi-objective nature of real-world recommendation problems.
Key takeaways: 1. Start simple: Begin with
Shared-Bottom, move to MMoE/PLE if needed 2. Balance
losses: Use appropriate weighting strategies 3.
Understand task relationships: Know which tasks benefit
from sharing 4. Monitor all tasks: Don't optimize for
average performance alone 5. Consider business
priorities: Align technical choices with business goals
As recommendation systems continue to evolve, multi-task learning
will remain a crucial tool for building systems that balance multiple
objectives while delivering great user experiences.
Post title:Recommendation Systems (9): Multi-Task Learning and Multi-Objective Optimization
Post author:Chen Kai
Create time:2024-06-11 09:45:00
Post link:https://www.chenk.top/en/recommendation-systems-9-multi-task-learning/
Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.