Learning rate (LR) is the knob that most often decides whether training converges, crawls, or blows up. This post builds an actionable mental model — from the simplest quadratic loss to modern large-scale training recipes — so you can choose schedules (warmup/cosine/WSD), debug instability, and tune LR systematically. We cover the math (why "too big explodes, too small stalls"), practical workflows (LR range test, schedule selection), failure mode diagnosis, recent research (schedule-free, power scheduler, warmup theory), and a troubleshooting checklist for common issues.
-
Learning Rate: From Basics to Large-Scale Training (2026 Complete Guide)
-
MoSLoRA: Mixture-of-Subspaces in Low-Rank Adaptation
LoRA is a simple and effective parameter-efficient fine-tuning (PEFT) method, but a single low-rank subspace can be too restrictive for complex tasks or heterogeneous domains. MoSLoRA increases LoRA ’ s expressivity by using a mixture of low-rank subspaces while keeping the operational simplicity of LoRA: small trainable parameters, low inference overhead, and practical deployability. The main idea is to represent the adaptation as multiple low-rank “ experts ” and combine them with a learnable mixer — without turning the model into a full Mixture-of-Experts (MoE) system with routing complexity.
-
Reinforcement Learning (3): Policy Gradient and Actor-Critic Methods
If value function methods learn policies indirectly by "evaluating action quality," then policy gradient methods directly optimize the policy itself. DQN's success proved deep learning's tremendous potential in reinforcement learning, but its limitations are also obvious — it can only handle discrete action spaces and struggles with continuous control tasks like robot control and autonomous driving. Policy Gradient methods parameterize policies as neural networks
and use gradient ascent to directly maximize expected returns, naturally supporting continuous actions. From the earliest REINFORCE algorithm to Actor-Critic architectures combining value functions, from asynchronous parallel A3C to breakthrough DDPG, from sample-efficient TD3 to industrially widespread PPO, to SAC under the maximum entropy framework — policy gradient methods have become the mainstream technical approach in deep reinforcement learning. This chapter systematically traces this evolution path, deeply analyzing each algorithm's design motivations, mathematical principles, and implementation details. -
Time Series Models (8): Informer for Long Sequence Forecasting
Long-sequence time series forecasting — predicting hundreds or thousands of steps ahead — has been a persistent challenge. Traditional models like ARIMA struggle with non-linear patterns, while vanilla Transformers face quadratic complexity that makes them computationally prohibitive for sequences beyond a few hundred timesteps. Informer, introduced in 2021, addresses this bottleneck through ProbSparse Self-Attention and a generative-style decoder, reducing complexity from
to while maintaining forecasting accuracy. Below we dive deep into Informer's architecture, mathematical foundations, implementation details, and real-world applications, providing both theoretical understanding and practical code. -
Reinforcement Learning (2): Q-Learning and Deep Q-Networks (DQN)
From board games to Atari video games, value function methods have been a cornerstone of reinforcement learning. Q-Learning learns to select optimal actions by iteratively updating state-action values, but faces the curse of dimensionality when dealing with high-dimensional state spaces (like an 84x84 pixel game screen). DeepMind's Deep Q-Network (DQN), proposed in 2013, broke through this barrier by using neural networks as function approximators, combined with two key innovations: experience replay and target networks. This enabled computers to achieve superhuman performance on multiple Atari games for the first time. This breakthrough not only accelerated the development of deep reinforcement learning but also spawned a series of improvements like Double DQN, Dueling DQN, and Prioritized Experience Replay, culminating in the Rainbow algorithm. This chapter starts from the mathematical foundations of Q-Learning, progressively deconstructs DQN's core mechanisms, and analyzes the design motivations and implementation details of various variants.
-
Reinforcement Learning (1): Fundamentals and Core Concepts
How should an intelligent agent learn optimal behavior in an environment? When AlphaGo defeats world champions on the Go board, when robots learn to walk and grasp objects, when recommendation systems continuously optimize suggestions based on user feedback — all of these share a common mathematical framework: reinforcement learning.
-
Time Series Models (7): N-BEATS Deep Architecture
Deep learning models for time series forecasting often struggle with interpretability: you train a black box, get predictions, but can't explain why the model made those forecasts. Traditional methods like ARIMA decompose trends and seasonality explicitly, but they're limited to linear patterns. What if we could combine the expressiveness of deep neural networks with the interpretability of classical decomposition methods? N-BEATS (Neural Basis Expansion Analysis for Time Series) does exactly that — it's a deep architecture that won the M4 forecasting competition while providing interpretable components through basis function expansion. Below we dive deep into N-BEATS: how it uses stacked blocks with trend and seasonality decomposition, why double residual stacking enables hierarchical learning, how the interpretable architecture differs from the generic one, and practical PyTorch implementations with real-world case studies.
-
Time Series Models (6): Temporal Convolutional Networks (TCN)
When working with time series data, recurrent neural networks like LSTM and GRU have been the go-to architectures for capturing temporal dependencies. However, they come with inherent limitations: sequential processing prevents parallelization during training, vanishing gradients make it difficult to learn long-range dependencies, and the memory mechanism can be complex to tune.
Temporal Convolutional Networks (TCN) offer a compelling alternative. By leveraging causal convolutions and dilated convolutions, TCNs can capture long-range dependencies while maintaining parallelizable training, stable gradients, and a simple architecture. Unlike RNNs that process sequences step-by-step, TCNs apply convolutional filters across the entire sequence simultaneously, making them faster to train and often more effective for certain time series tasks.
Below we explore TCN from the ground up: starting with 1D convolution fundamentals for time series, explaining causal convolutions that prevent information leakage, diving into dilated convolutions that exponentially expand the receptive field, and covering residual connections and normalization techniques. We'll compare TCN with LSTM/RNN architectures, discuss their advantages in parallel training and gradient stability, provide a complete PyTorch implementation, and walk through two practical case studies on traffic flow prediction and sensor data forecasting.
-
Recommendation Systems (9): Multi-Task Learning and Multi-Objective Optimization
In real-world recommendation systems, optimizing for a single objective is rarely sufficient. When you browse an e-commerce platform, the system needs to predict not just whether you'll click on a product, but also whether you'll add it to cart, make a purchase, return it, or write a review. Each of these actions represents a different task with distinct patterns, yet they're all interconnected — a user who clicks is more likely to purchase, and someone who purchases is more likely to return. Multi-task learning (MTL) provides a powerful framework for jointly optimizing multiple objectives by sharing representations across related tasks, leading to improved performance on each individual task while reducing computational overhead.
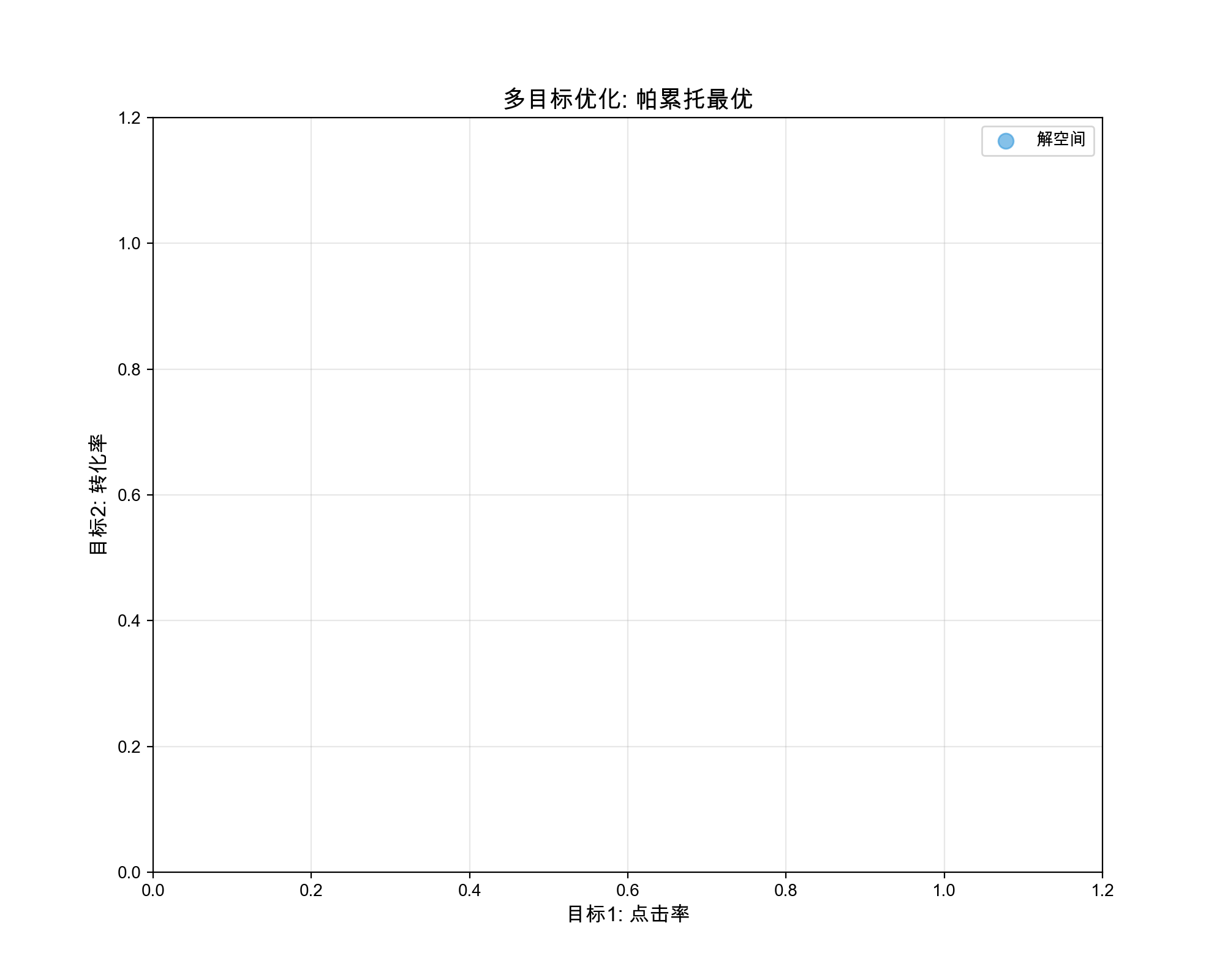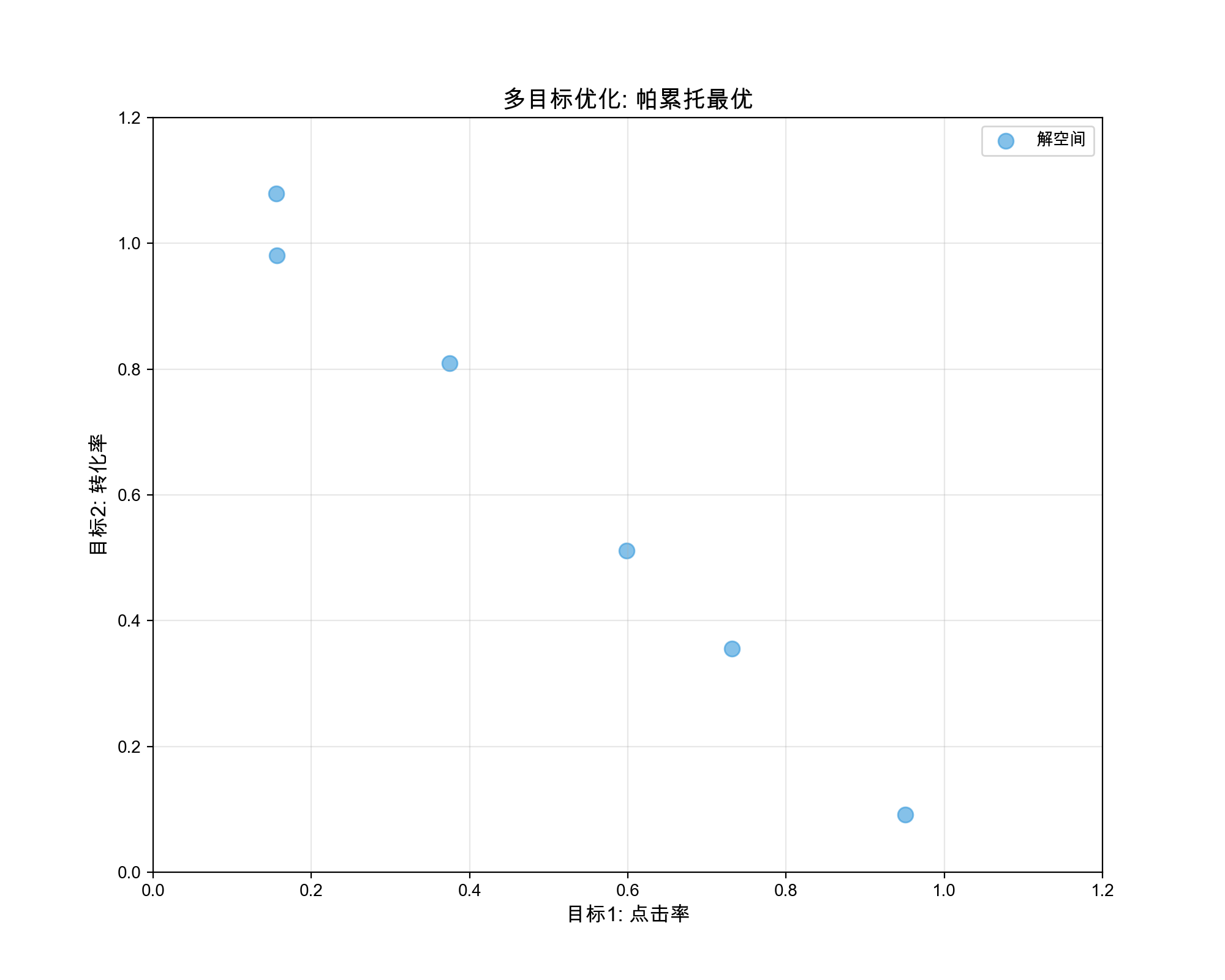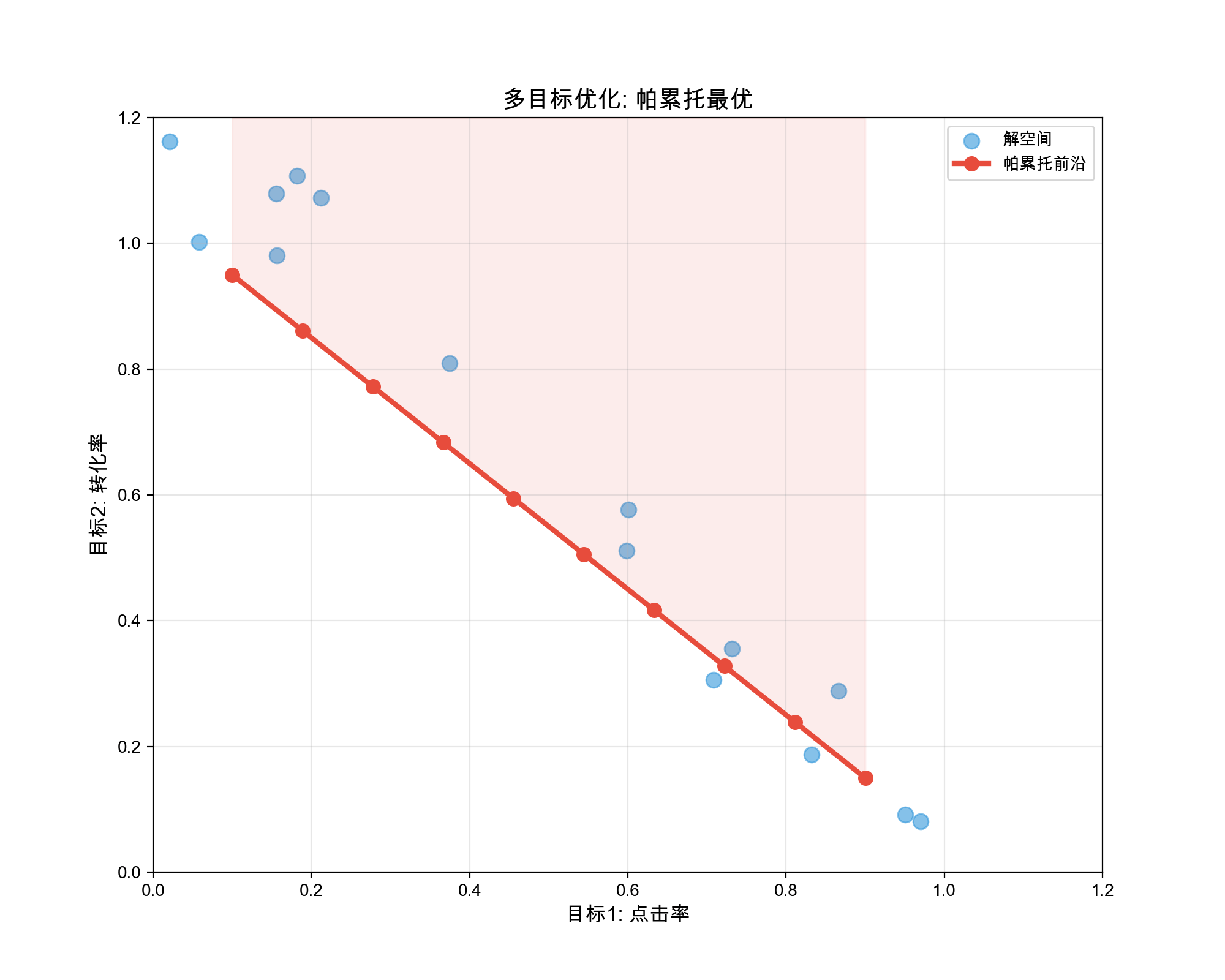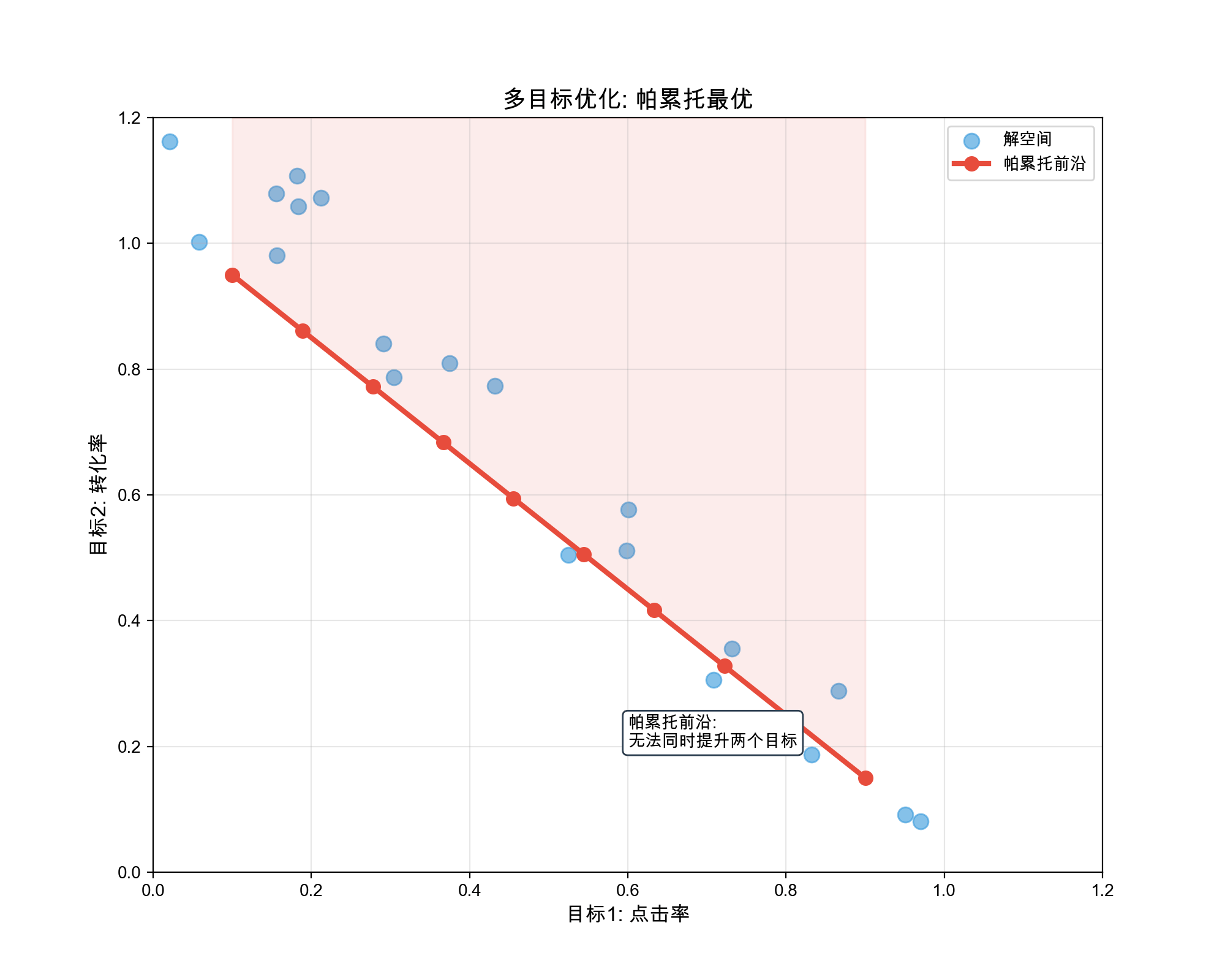
Multi-task learning has become a cornerstone of modern recommendation systems, from Google's MMoE (Multi-gate Mixture-of-Experts) that handles conflicting objectives, to Alibaba's ESMM (Entire Space Multi-Task Model) that addresses sample selection bias in conversion prediction, to Tencent's PLE (Progressive Layered Extraction) that explicitly separates shared and task-specific knowledge. These architectures have demonstrated significant improvements over single-task models by leveraging the commonalities between tasks while preserving task-specific nuances.
This article provides a comprehensive exploration of multi-task learning for recommendation systems, covering foundational architectures (Shared-Bottom, ESMM, MMoE, PLE, STEM-Net), task relationship modeling techniques, loss balancing strategies, industrial applications and case studies, implementation details with 10+ code examples, and detailed Q&A sections addressing common challenges and best practices.
-
Time Series (5): Transformer Architecture
Traditional RNN-based models like LSTM and GRU process sequences sequentially, creating bottlenecks in parallelization and struggling with very long-range dependencies. The Transformer architecture, originally designed for natural language processing, has revolutionized time series forecasting by enabling parallel computation and direct attention to any temporal position. Below we explore how Transformers work for time series, their advantages over recurrent models, specialized adaptations for temporal data, and practical implementation strategies.