permalink: "en/recommendation-systems-4-ctr-prediction/" date: 2024-05-17 15:45:00 tags: - Recommendation Systems - CTR Prediction - Click-Through Rate categories: Recommendation Systems mathjax: true--- When you scroll through your social media feed, click on a product recommendation, or watch a suggested video, you're interacting with one of the most critical components of modern recommendation systems: the CTR (Click-Through Rate) prediction model. These models answer a deceptively simple question: "What's the probability this user will click on this item?" But behind this simplicity lies a complex machine learning challenge that directly impacts billions of dollars in revenue for platforms like Facebook, Google, Amazon, and Alibaba.
CTR prediction sits at the heart of the ranking stage in recommendation systems. After candidate generation retrieves thousands of potential items, CTR models score each candidate to determine the final ranking order. A 1% improvement in CTR prediction accuracy can translate to millions of dollars in additional revenue for large-scale platforms. This makes CTR prediction one of the most researched and optimized problems in machine learning.
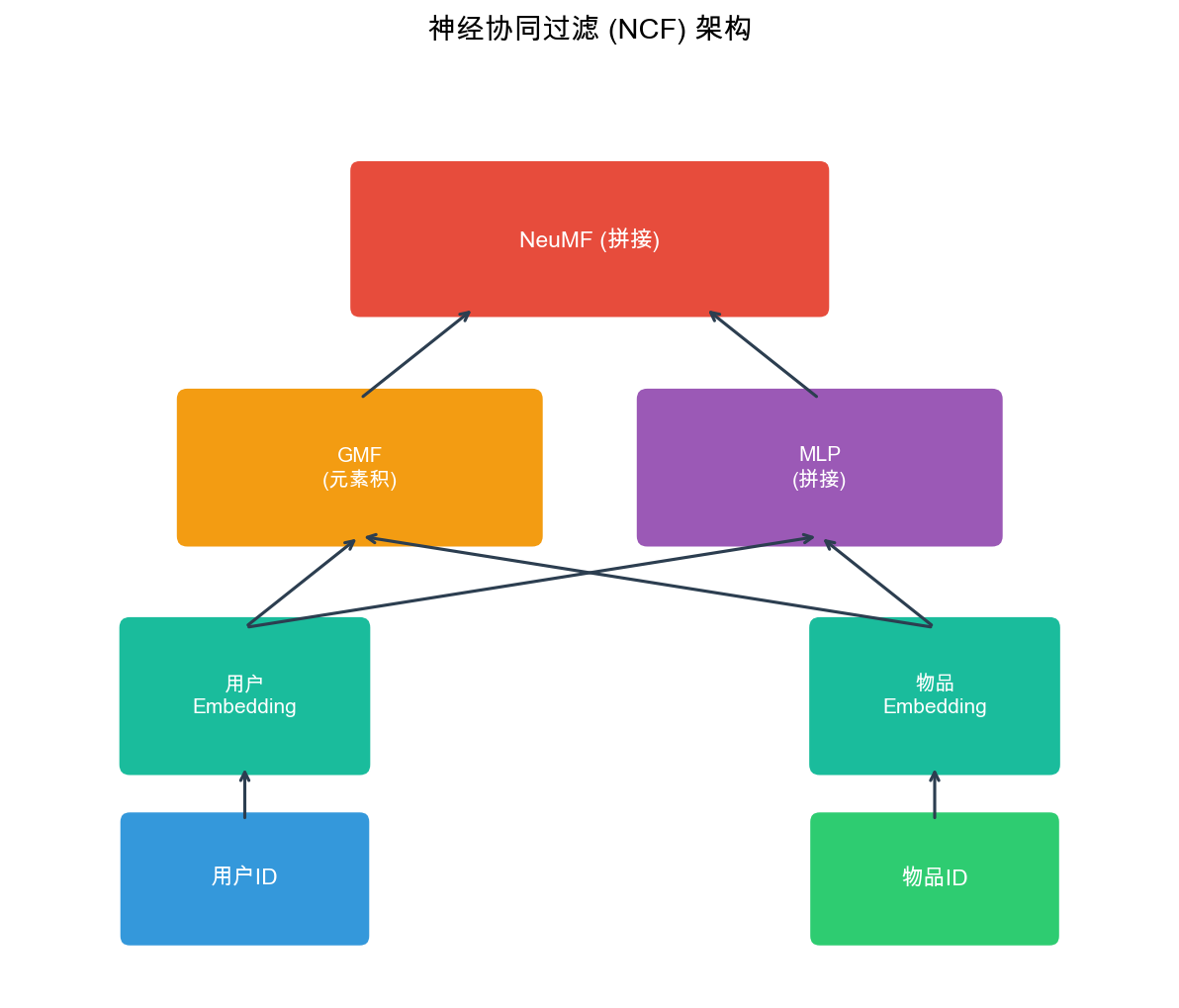
This article takes you on a journey through the evolution of CTR prediction models, from the foundational Logistic Regression baseline to state-of-the-art deep learning architectures like DeepFM, xDeepFM, DCN, AutoInt, and FiBiNet. We'll explore not just how these models work mathematically, but why they were designed the way they were, what problems they solve, and how to implement them from scratch. Along the way, we'll cover feature engineering techniques, training strategies, and practical considerations that separate academic prototypes from production-ready systems.
Whether you're building a recommendation system for the first time or optimizing an existing one, understanding CTR prediction models is essential. These models have evolved dramatically over the past decade, incorporating insights from factorization machines, deep learning, attention mechanisms, and feature interaction modeling. By the end of this article, you'll have a comprehensive understanding of the field and the practical skills to implement these models yourself.