Linked lists are a cornerstone of technical interviews, testing your
ability to manipulate pointers, handle edge cases, and optimize space
usage. Unlike arrays, linked lists offer
Series Navigation
📚 LeetCode Algorithm Series (10 articles total): 1. Hash Tables Complete Guide 2. Two Pointers Technique 3. → Linked List Operations (Reversal, Cycle Detection, Merging, Intersection, Deletion) ← Current Article 4. Binary Tree Traversal and Recursion 5. Dynamic Programming Fundamentals 6. Backtracking Algorithms 7. Advanced Binary Search 8. Stacks and Queues 9. Graph Algorithms 10. Greedy and Bit Manipulation
Linked List Fundamentals Review
Linked List vs Array
| Feature | Array | Linked List |
|---|---|---|
| Access | ||
| Insert/Delete (known position) | ||
| Memory | Contiguous | Non-contiguous |
| Cache Locality | ✅ High | ❌ Low |
| Dynamic Growth | ⚠️ Requires reallocation | ✅ Natural support |
Linked List Node Definition
1 | class ListNode: |
The Mental Model of Linked Lists
Think of a linked list as a train:
- Node: Each train car
- Pointer: The coupling connecting cars
- Head node: The locomotive
- Tail node: The last car
(
next = None)
Operation Intuition:
- Reverse: Make the train run backward
- Merge: Combine two trains in sorted order
- Detect cycle: Check if the train forms a loop
- Delete node: Remove a car and reconnect the rest
LeetCode 206: Reverse Linked List
Problem Description
Given the head of a singly linked list, reverse the list and return the reversed list.
Example:
- Input:
head = [1,2,3,4,5] - Output:
[5,4,3,2,1]
Constraints:
- The number of nodes in the list:
- Follow-up: Can you solve it both iteratively and recursively?
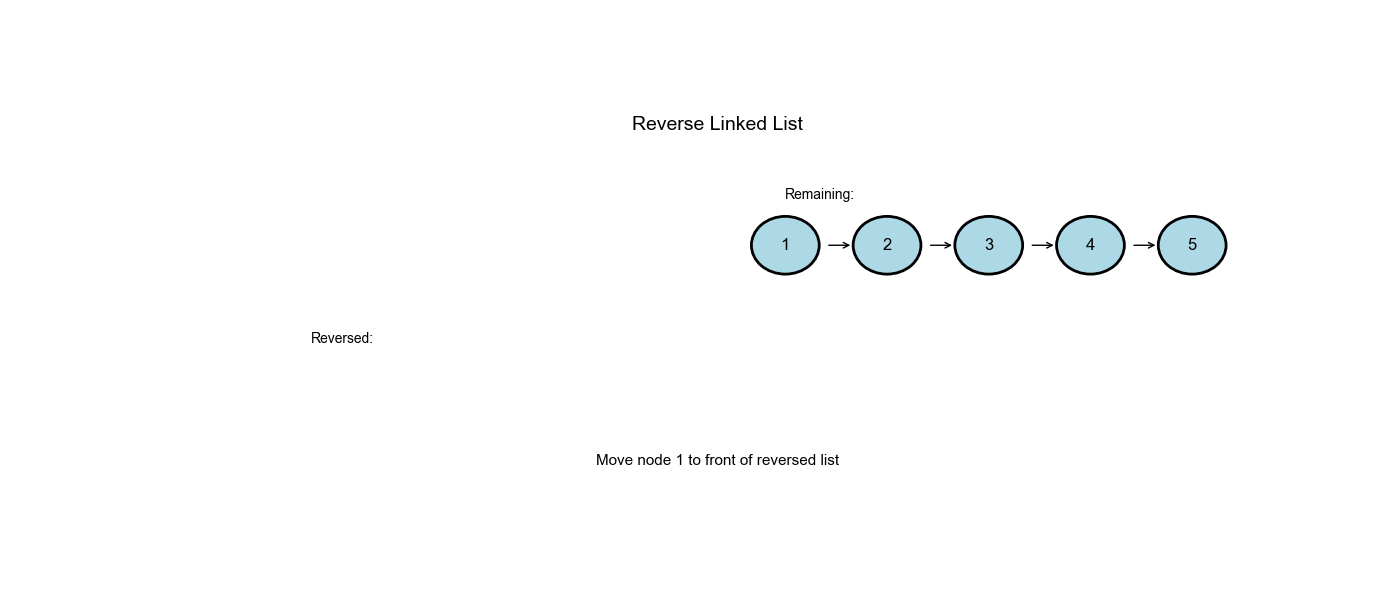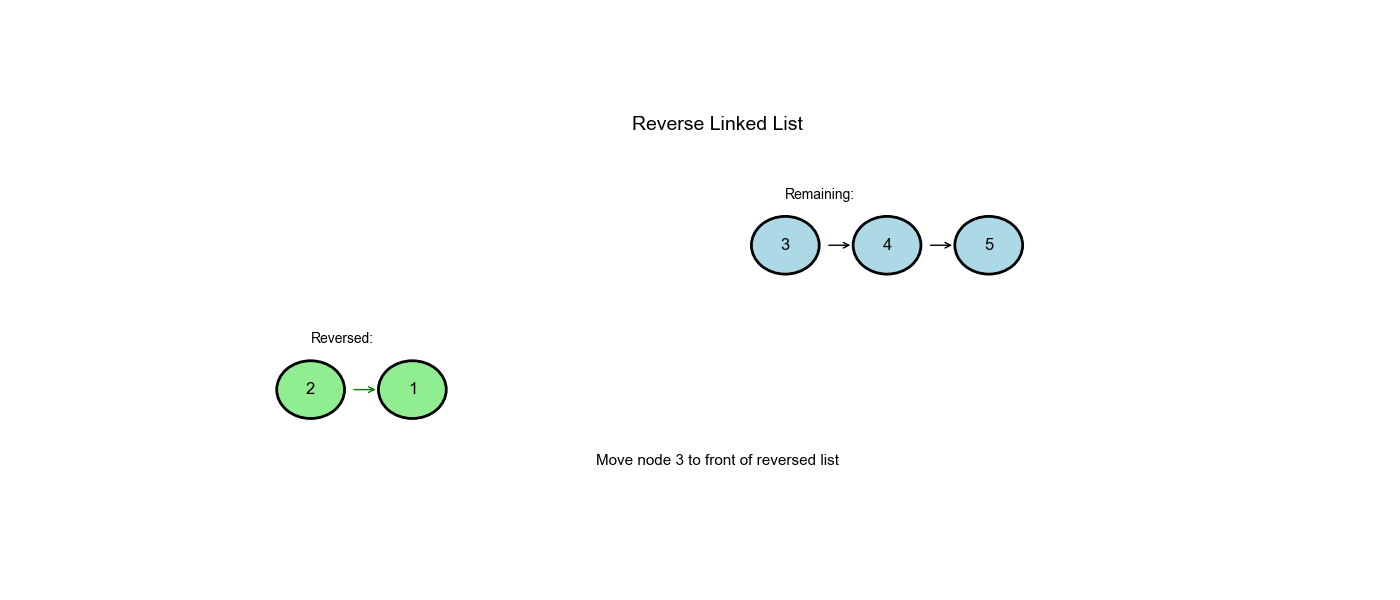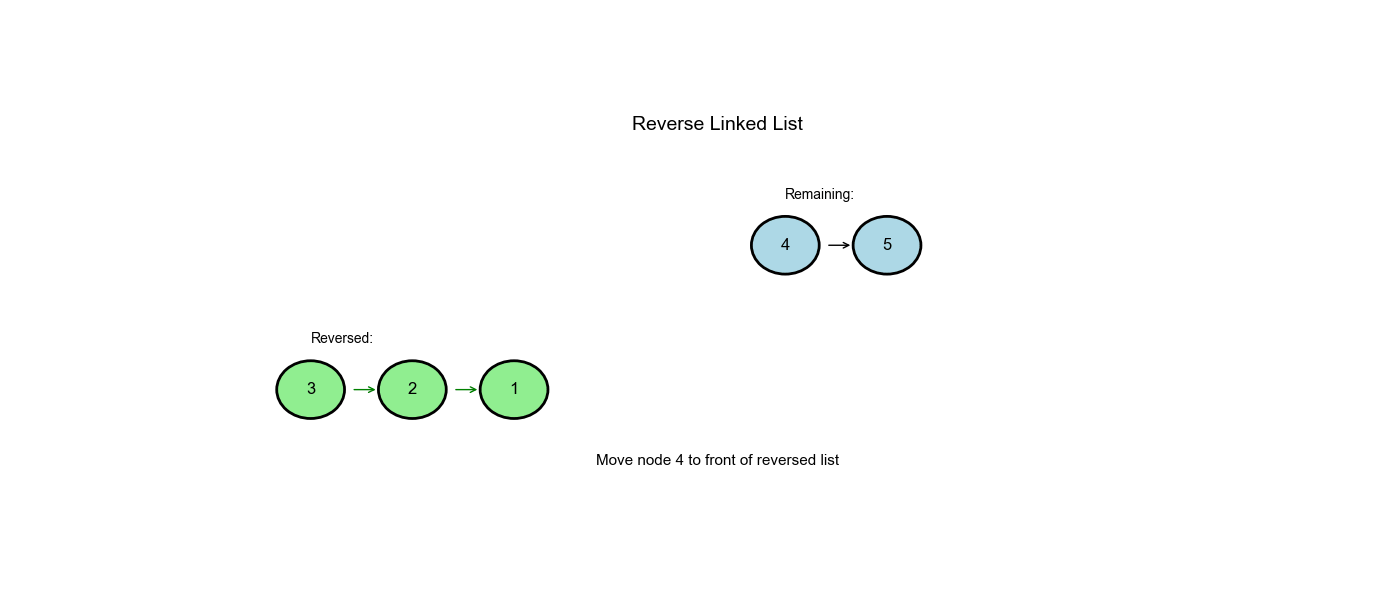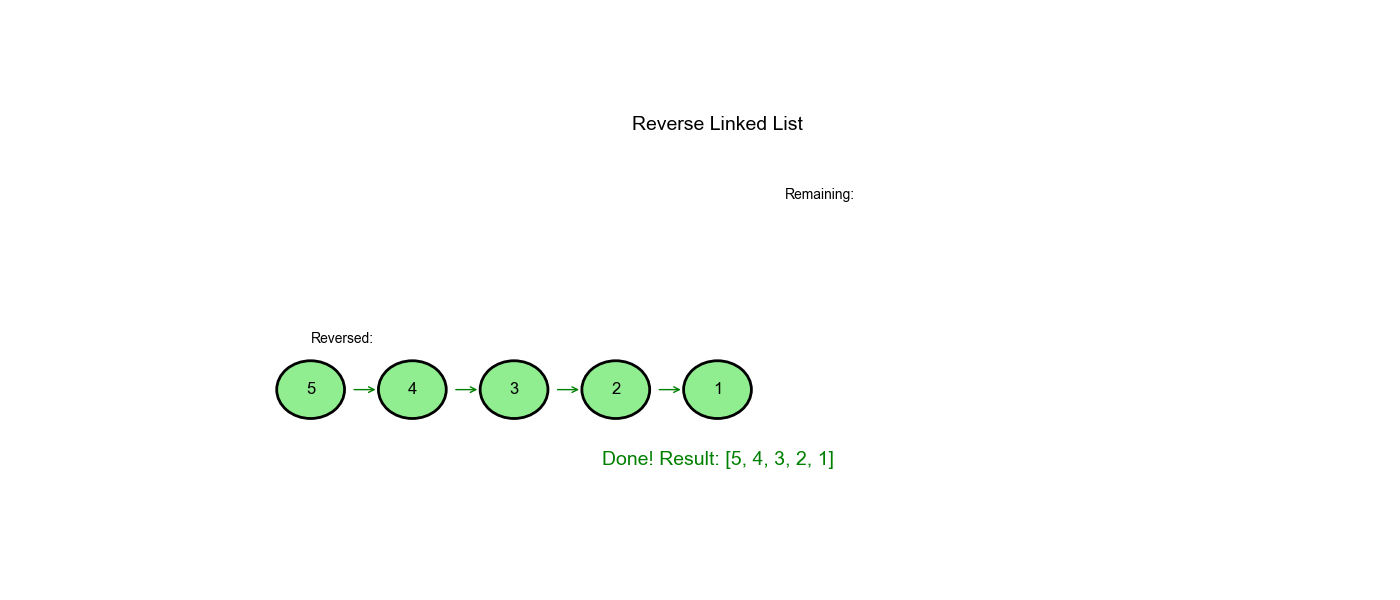
Approach One: Iterative (Three-Pointer Technique)
Core Idea
Maintain three pointers:
prev: The previous nodecurr: The current nodenext_node: The next node (temporary storage)
Steps: 1. Initialize prev = None,
curr = head 2. Traverse the list, for each iteration:
- Save
curr.nexttonext_node - Reverse the pointer:
curr.next = prev - Move pointers:
prev = curr,curr = next_node
- Return
prev(the new head)
Python Implementation
1 | def reverseList(head): |
Complexity Analysis
- Time Complexity:
, single traversal - Space Complexity:
, only constant extra pointers
Step-by-Step Walkthrough
Input: 1 → 2 → 3 → None
| Step | prev |
curr |
next_node |
Operation | List State |
|---|---|---|---|---|---|
| Initial | None |
1 |
- | - | 1 → 2 → 3 → None |
| 1 | None |
1 |
2 |
Save 2 |
- |
| 1 | None |
1 |
2 |
1.next = None |
None ← 1 2 → 3 → None |
| 1 | 1 |
2 |
2 |
Move pointers | - |
| 2 | 1 |
2 |
3 |
Save 3 |
- |
| 2 | 1 |
2 |
3 |
2.next = 1 |
None ← 1 ← 2 3 → None |
| 2 | 2 |
3 |
3 |
Move pointers | - |
| 3 | 2 |
3 |
None |
Save None |
- |
| 3 | 2 |
3 |
None |
3.next = 2 |
None ← 1 ← 2 ← 3 |
| 3 | 3 |
None |
- | Loop ends | - |
| Return | 3 |
- | - | - | 3 → 2 → 1 → None |
Common Mistakes and Edge Cases
Mistake 1: Losing the next reference
1
2
3
4# ❌ Wrong: We lose the reference to curr.next
curr.next = prev
prev = curr
curr = curr.next # This is now prev, not the original next!
Mistake 2: Not handling empty list 1
2
3
4
5
6# ❌ Wrong: If head is None, we return None incorrectly
def reverseList(head):
prev = None
curr = head
while curr: # This handles None correctly, but be explicit
# ...
Edge Cases:
- Empty list (
head = None): ReturnsNone✅ - Single node (
head = [1]): Returns[1]✅ - Two nodes (
head = [1,2]): Returns[2,1]✅
Interview Tips
What interviewers look for: 1. Pointer
manipulation: Can you safely move pointers without losing
references? 2. Edge case handling: Do you check for
empty/single-node lists? 3. Space optimization: Can you
do it in
Follow-up questions:
- "Can you reverse it recursively?"
- "What if the list has a cycle?"
- "Can you reverse only a portion of the list?"
Approach Two: Recursive
Core Idea
Recursive definition: Reversing a list = reverse the rest + adjust current node's pointer
Base case: Empty list or single node, return as is
Recursive steps: 1. Recursively reverse
head.next and get the new head new_head 2.
Make head.next.next point to head (reverse the
pointer) 3. Break head.next (prevent cycle) 4. Return
new_head
Python Implementation
1 | def reverseList_recursive(head): |
Complexity Analysis
- Time Complexity:
, each node visited once - Space Complexity:
, recursion stack depth
Recursive Process Visualization
Input: 1 → 2 → 3 → None
1 | reverseList(1) |
Final result: 3 → 2 → 1 → None
Understanding the Recursive Magic
The recursive approach works backward: 1. It first reaches the tail node 2. Then, as the recursion unwinds, it reverses pointers one by one 3. Each level of recursion handles one node reversal
Why head.next.next = head?
- After reversing the sublist starting from
head.next, the node originally athead.nextis now the tail of the reversed sublist - We want this tail to point back to
head head.next.nextaccesses the node that was originallyhead.next, and we make it point tohead
Iterative vs Recursive Comparison
| Method | Time | Space | Pros | Cons |
|---|---|---|---|---|
| Iterative | Space optimal, easier to understand | Slightly longer code | ||
| Recursive | Concise, elegant | Stack space overhead, potential stack overflow |
Interview Strategy: Start with iterative (more practical), then mention recursive as an alternative approach.
LeetCode 21: Merge Two Sorted Lists
Problem Description
Merge two sorted linked lists and return it as a sorted list. The list should be made by splicing together the nodes of the first two lists.
Example:
- Input:
l1 = [1,2,4],l2 = [1,3,4] - Output:
[1,1,2,3,4,4]
Constraints:
- The number of nodes in both lists:
- - Both lists are sorted in non-decreasing order
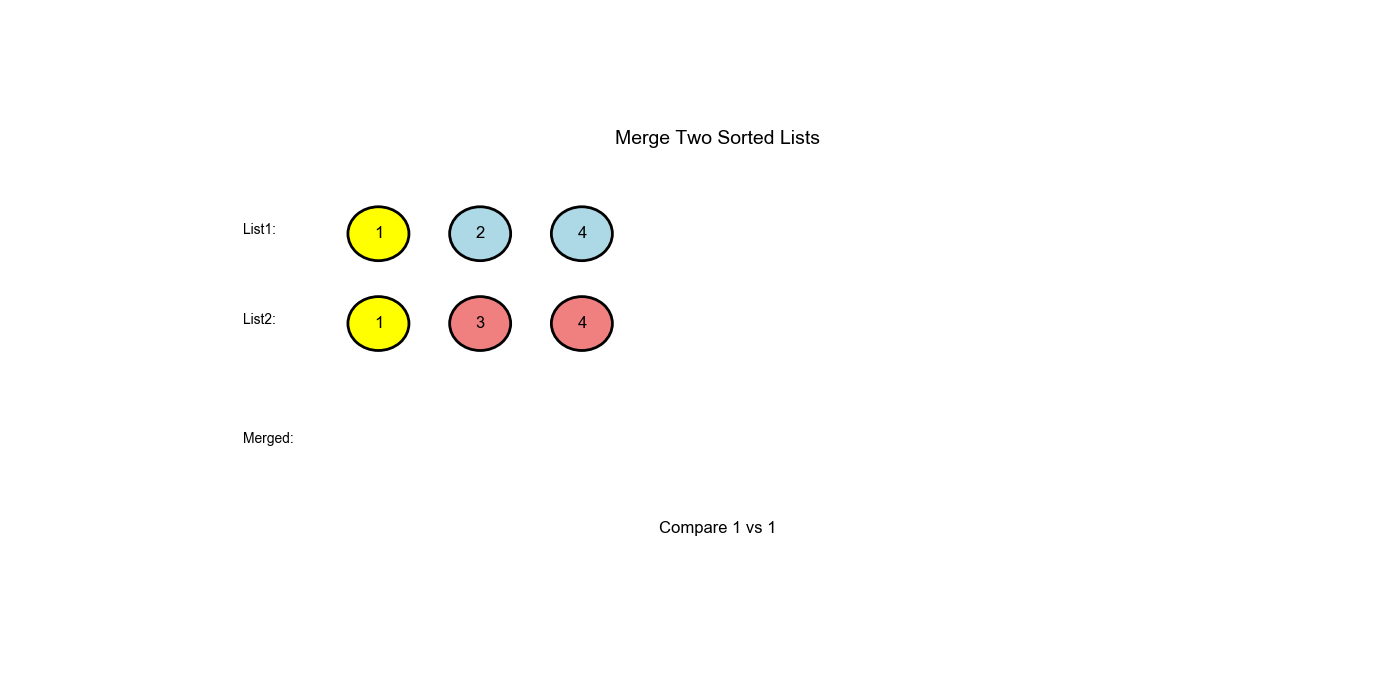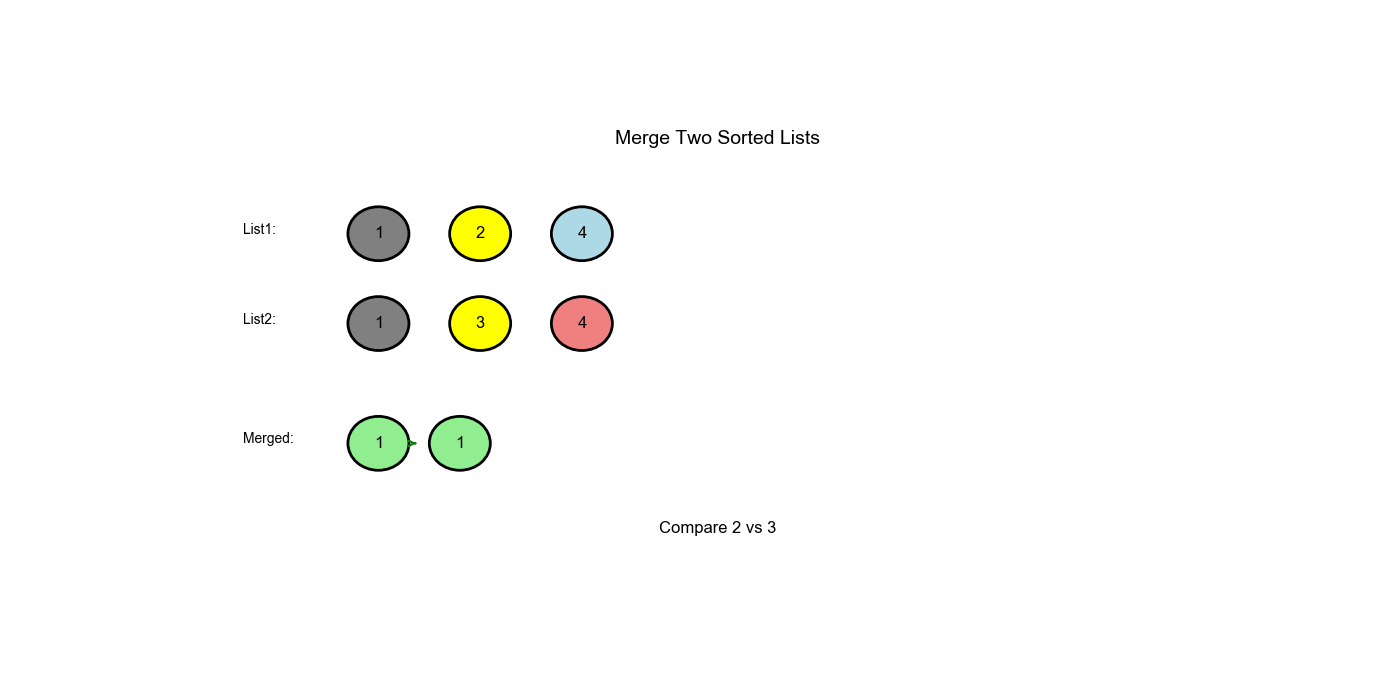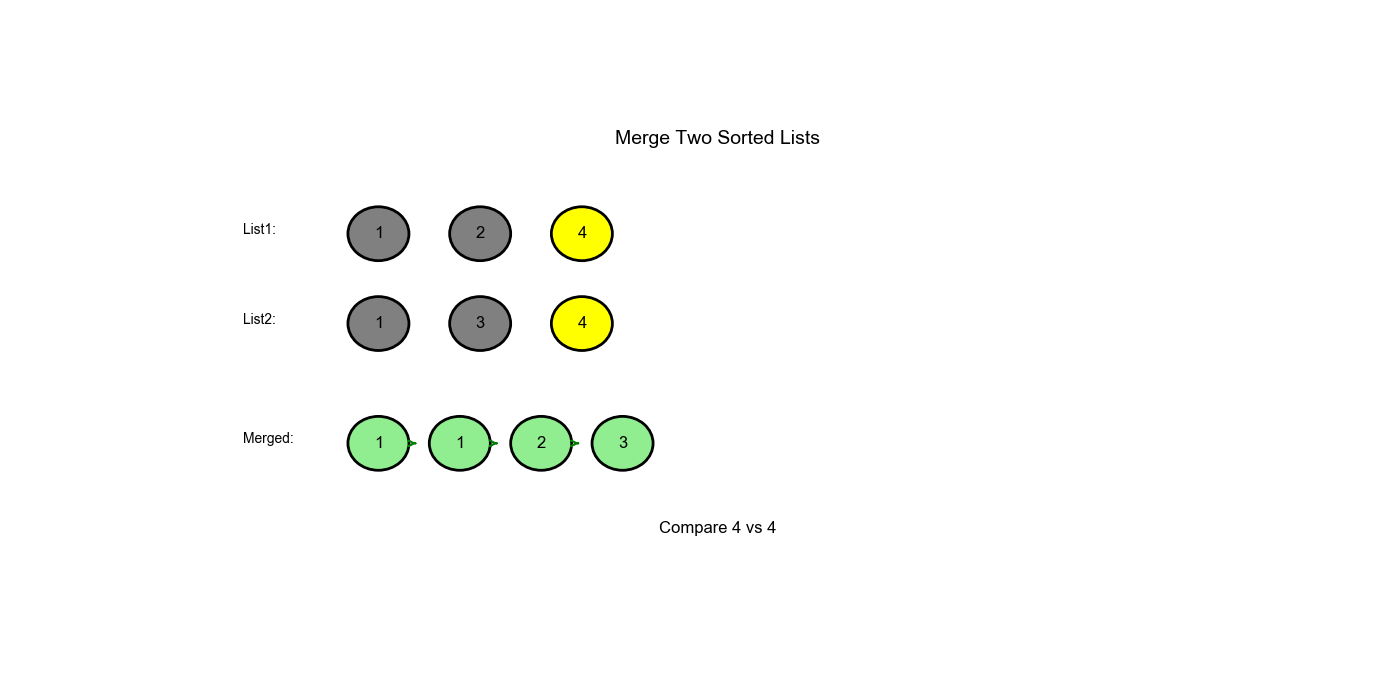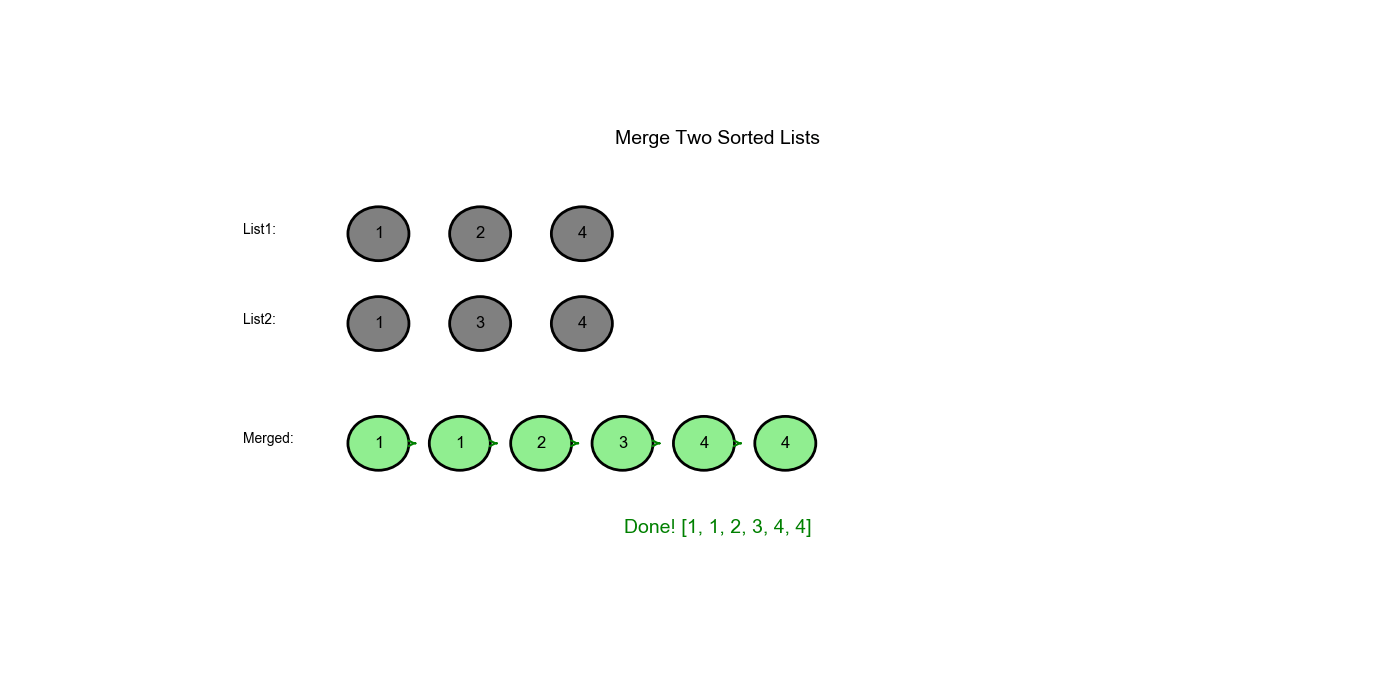
Approach One: Iterative (Dummy Node Technique)
Core Idea
Use a dummy node (sentinel node) to simplify
boundary handling: 1. Create a dummy node as the
predecessor of the result list 2. Use current pointer to
track the current build position 3. Compare values of l1
and l2, attach the smaller one to current 4.
Handle remaining nodes 5. Return dummy.next (skip the
sentinel)
Python Implementation
1 | def mergeTwoLists(l1, l2): |
Complexity Analysis
- Time Complexity:
, where and are lengths of the two lists - Space Complexity:
, only constant extra pointers
The Power of Dummy Nodes
Why do we need a dummy node?
Without dummy: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# ❌ Need special handling for the first node
def mergeTwoLists_no_dummy(l1, l2):
if not l1:
return l2
if not l2:
return l1
# Determine the head
if l1.val <= l2.val:
head = l1
l1 = l1.next
else:
head = l2
l2 = l2.next
current = head
# Now merge the rest...
# More complex logic needed
With dummy: 1
2
3
4# ✅ Unified handling, no special cases
dummy = ListNode(-1)
current = dummy
# Uniform loop logic for all nodes
Real-world analogy: A dummy node is like a "construction marker"— removed after completion, but provides a fixed reference point during construction.
Step-by-Step Walkthrough
Input: l1 = [1,2,4],
l2 = [1,3,4]
| Step | l1 |
l2 |
current |
Operation | Result So Far |
|---|---|---|---|---|---|
| Initial | 1 |
1 |
dummy |
- | dummy → ... |
| 1 | 1 |
1 |
dummy |
Compare: 1 <= 1, attach l1 |
dummy → 1 |
| 1 | 2 |
1 |
1 |
Move l1 forward |
- |
| 2 | 2 |
1 |
1 |
Compare: 1 < 2, attach l2 |
dummy → 1 → 1 |
| 2 | 2 |
3 |
1 |
Move l2 forward |
- |
| 3 | 2 |
3 |
1 |
Compare: 2 < 3, attach l1 |
dummy → 1 → 1 → 2 |
| 3 | 4 |
3 |
2 |
Move l1 forward |
- |
| 4 | 4 |
3 |
2 |
Compare: 3 < 4, attach l2 |
dummy → 1 → 1 → 2 → 3 |
| 4 | 4 |
4 |
3 |
Move l2 forward |
- |
| 5 | 4 |
4 |
3 |
Compare: 4 <= 4, attach l1 |
dummy → 1 → 1 → 2 → 3 → 4 |
| 5 | None |
4 |
4 |
l1 exhausted, attach rest of l2 |
dummy → 1 → 1 → 2 → 3 → 4 → 4 |
| Return | - | - | - | Return dummy.next |
1 → 1 → 2 → 3 → 4 → 4 |
Edge Cases
- One list is empty:
l1 = [],l2 = [1,2]→ Returns[1,2]✅ - Both lists empty:
l1 = [],l2 = []→ Returns[]✅ - One list longer:
l1 = [1],l2 = [2,3,4]→ Returns[1,2,3,4]✅
Approach Two: Recursive
Core Idea
Recursive definition:
- If
l1.val <= l2.val, result isl1+ merge(l1.next,l2) - Otherwise, result is
l2+ merge(l1,l2.next)
Python Implementation
1 | def mergeTwoLists_recursive(l1, l2): |
Complexity Analysis
- Time Complexity:
- Space Complexity:
, recursion stack
Recursive Visualization
Input: l1 = [1,2],
l2 = [3,4]
1 | mergeTwoLists([1,2], [3,4]) |
LeetCode 142: Linked List Cycle II
Problem Description
Given the head of a linked list, return the node where the cycle
begins. If there is no cycle, return null.
Follow-up: Can you solve it using
Example:
- Input:
head = [3,2,0,-4], tail connects to node index 1 - Output: Node at index 1
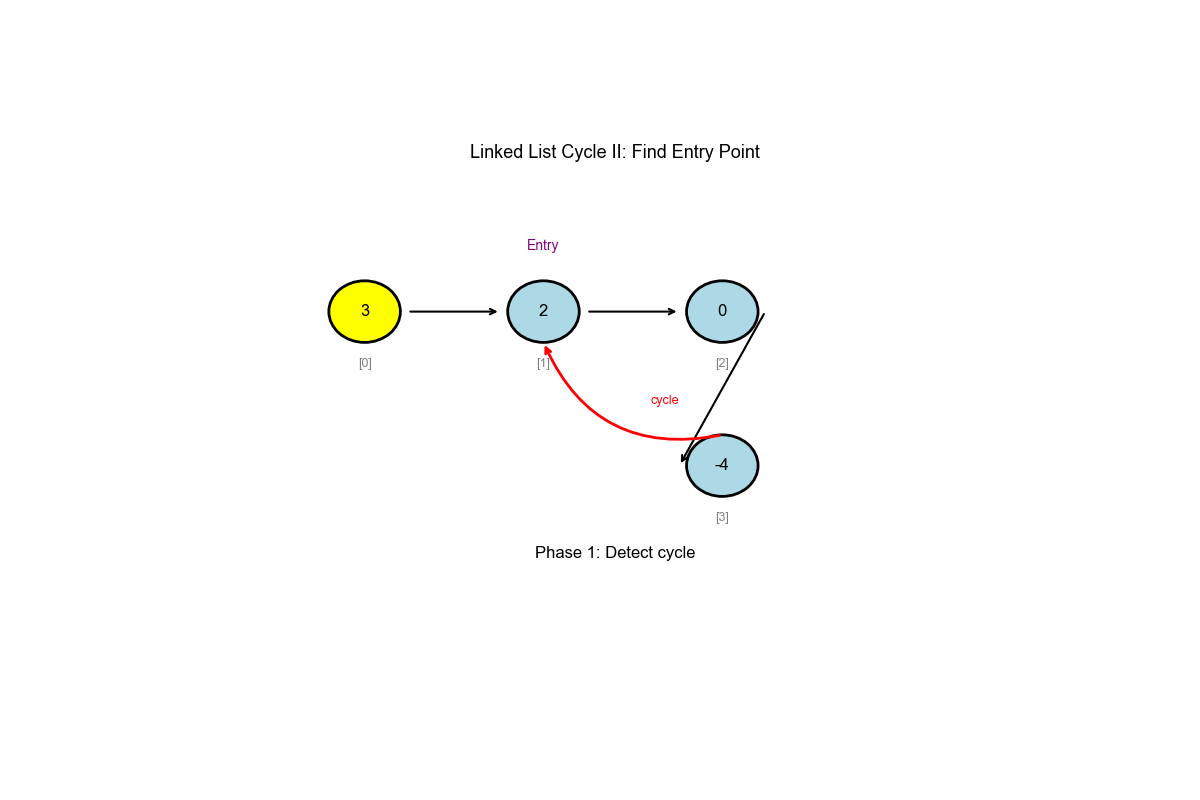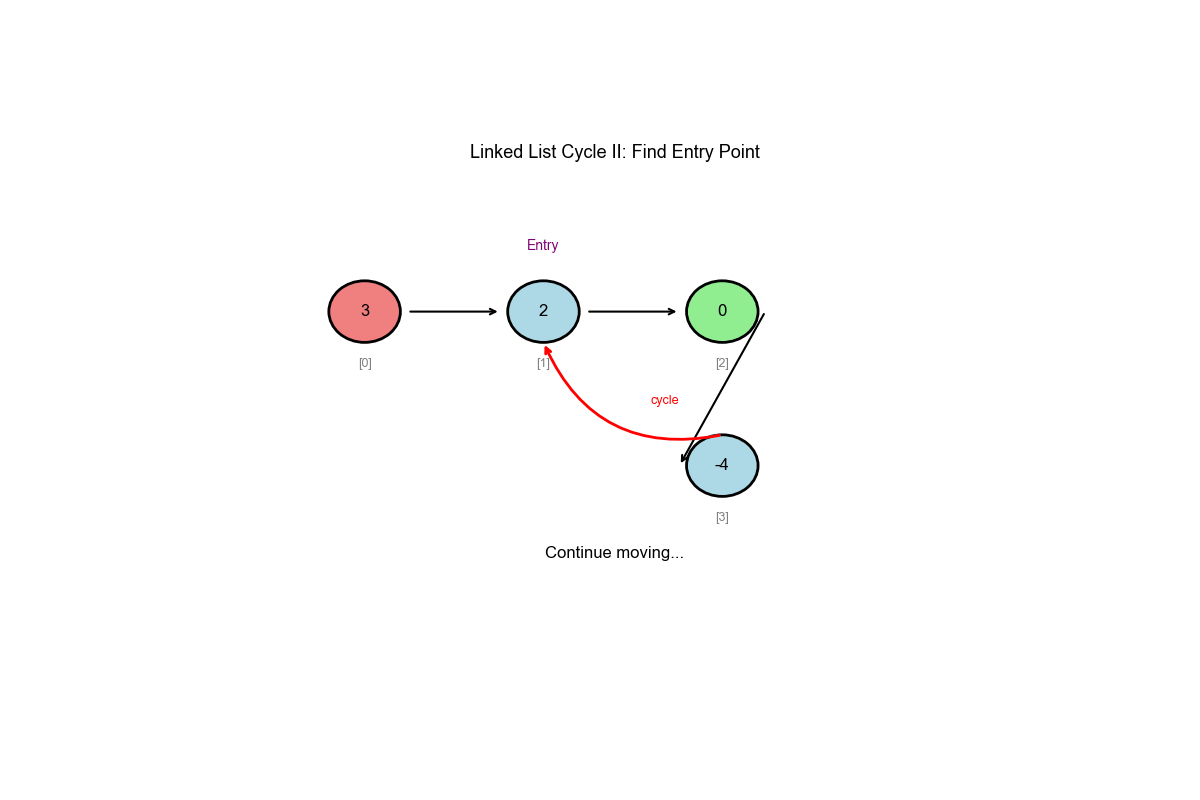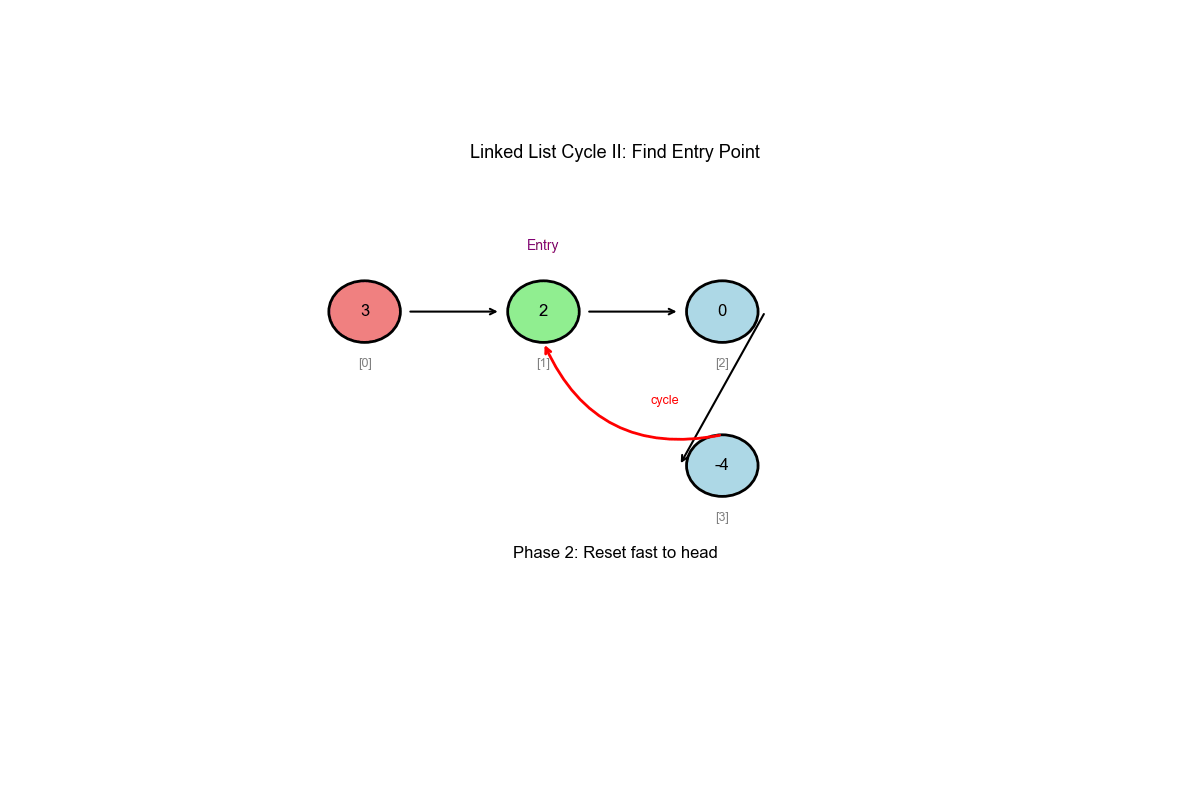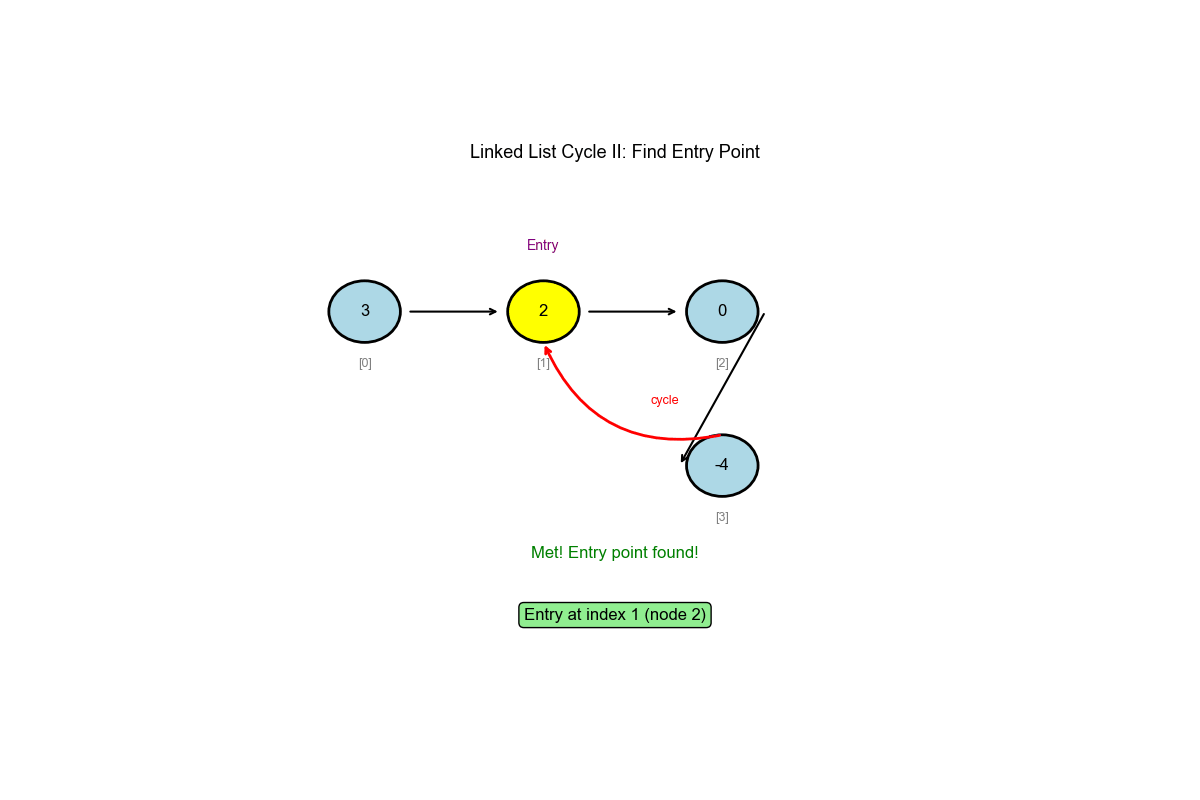
Core Idea: Floyd's Cycle Detection Algorithm (Extended)
Phase 1: Detect if there's a cycle using fast and slow pointers
Phase 2: Find the cycle entrance 1. After meeting, move one pointer back to the start 2. Both pointers move at the same speed (1 step each) 3. The meeting point is the cycle entrance
Python Implementation
1 | def detectCycle(head): |
Mathematical Proof
Let:
Distance from start to cycle entrance:
Distance from cycle entrance to meeting point:
Distance from meeting point to cycle entrance:
Cycle length:
When they meet: Slow pointer has traveled:
Fast pointer has traveled:
(where is the number of extra cycles)
Since fast pointer is twice as fast:
Key insight: Walking
Since
Visual Explanation
1 | Start → [a steps] → Entrance → [b steps] → Meeting Point |
When slow and fast meet:
- Slow: traveled
- Fast: traveled
(where )
From the equation
- If we move slow back to start and both move 1 step at a time
- Slow will travel
steps to reach entrance - Fast will travel
steps, which also reaches entrance (since is full cycles)
Complexity Analysis
- Time Complexity:
- Space Complexity:
Common Mistakes
Mistake 1: Not checking for cycle existence
1
2
3
4
5# ❌ Wrong: Assumes cycle exists
slow = fast = head
while slow != fast: # This might never terminate if no cycle!
slow = slow.next
fast = fast.next.next
Mistake 2: Wrong pointer reset 1
2
3
4# ❌ Wrong: Reset fast instead of slow
fast = head # Should be slow = head
while slow != fast:
# ...
LeetCode 160: Intersection of Two Linked Lists
Problem Description
Given the heads of two singly linked lists headA and
headB, return the node at which the two lists intersect. If
the two linked lists have no intersection, return null.
Constraints:
- The linked lists have no cycles
- The lists must retain their original structure after the function returns
- Follow-up:
time, space
Example: 1
2
3A: a1 → a2 ↘
c1 → c2 → c3
B: b1 → b2 → b3 ↗
Intersection point is c1.
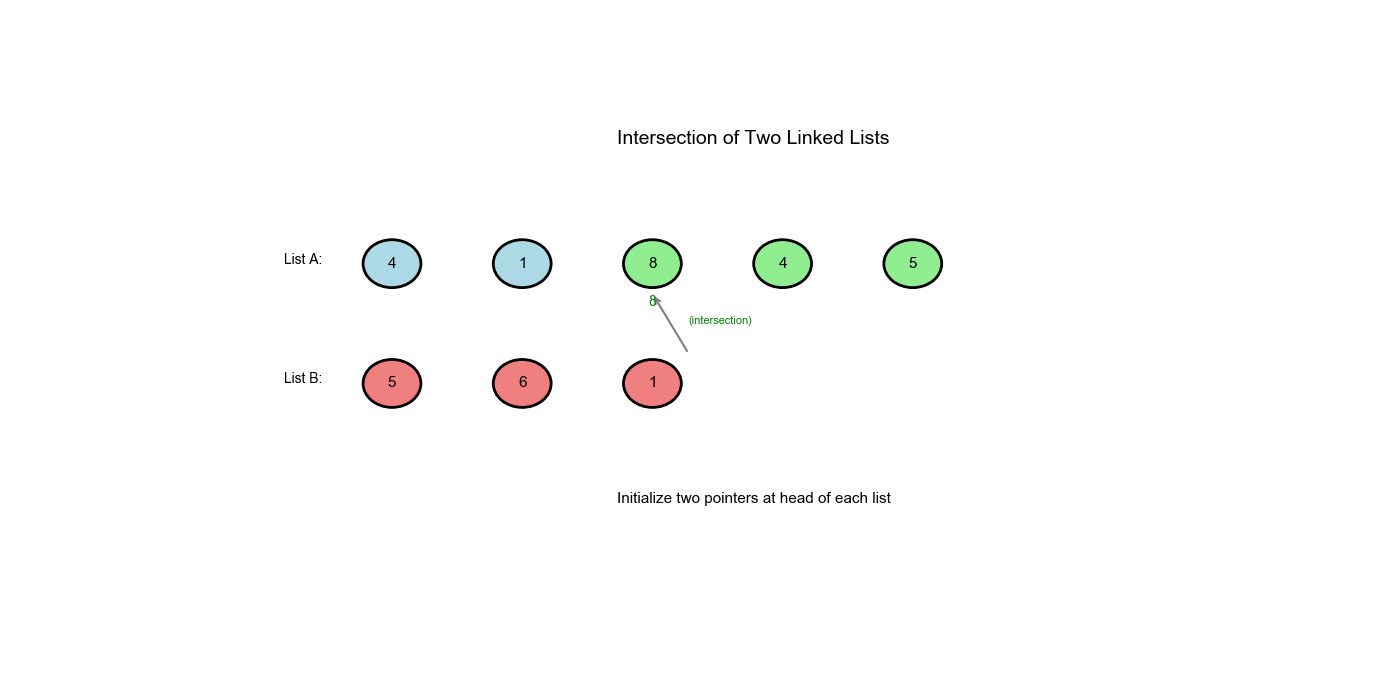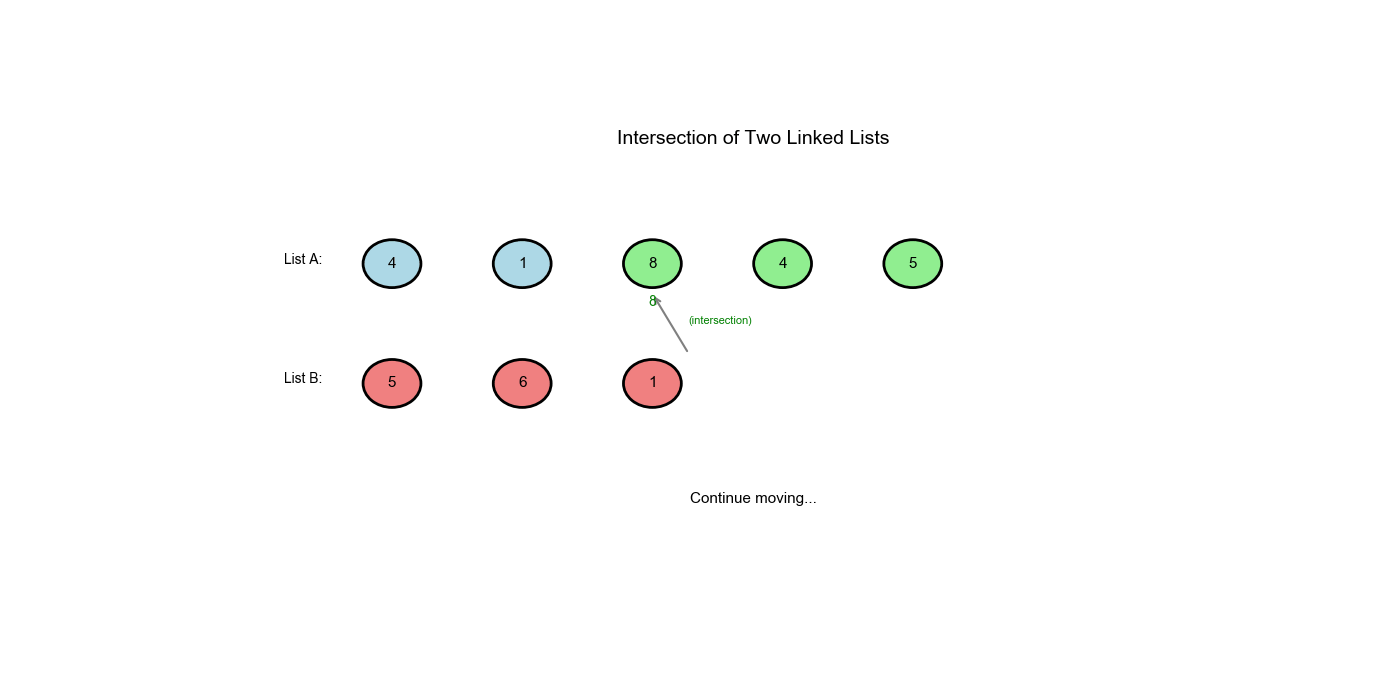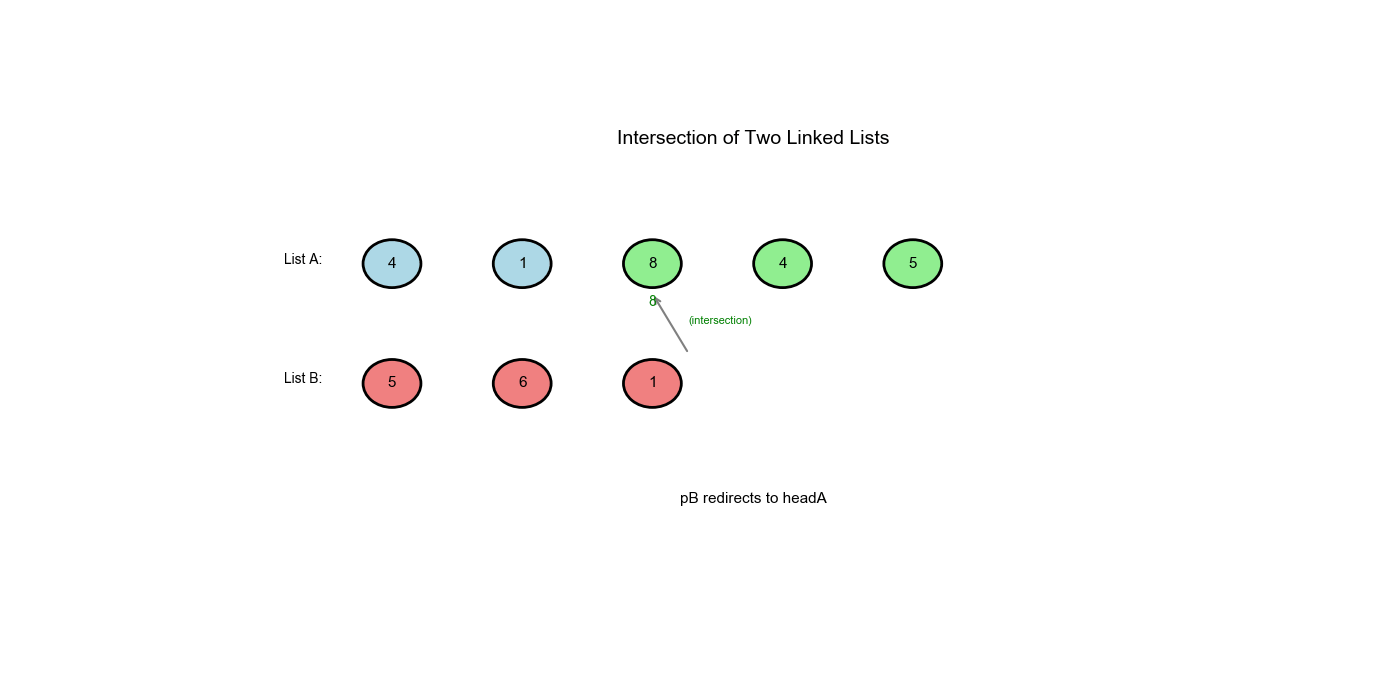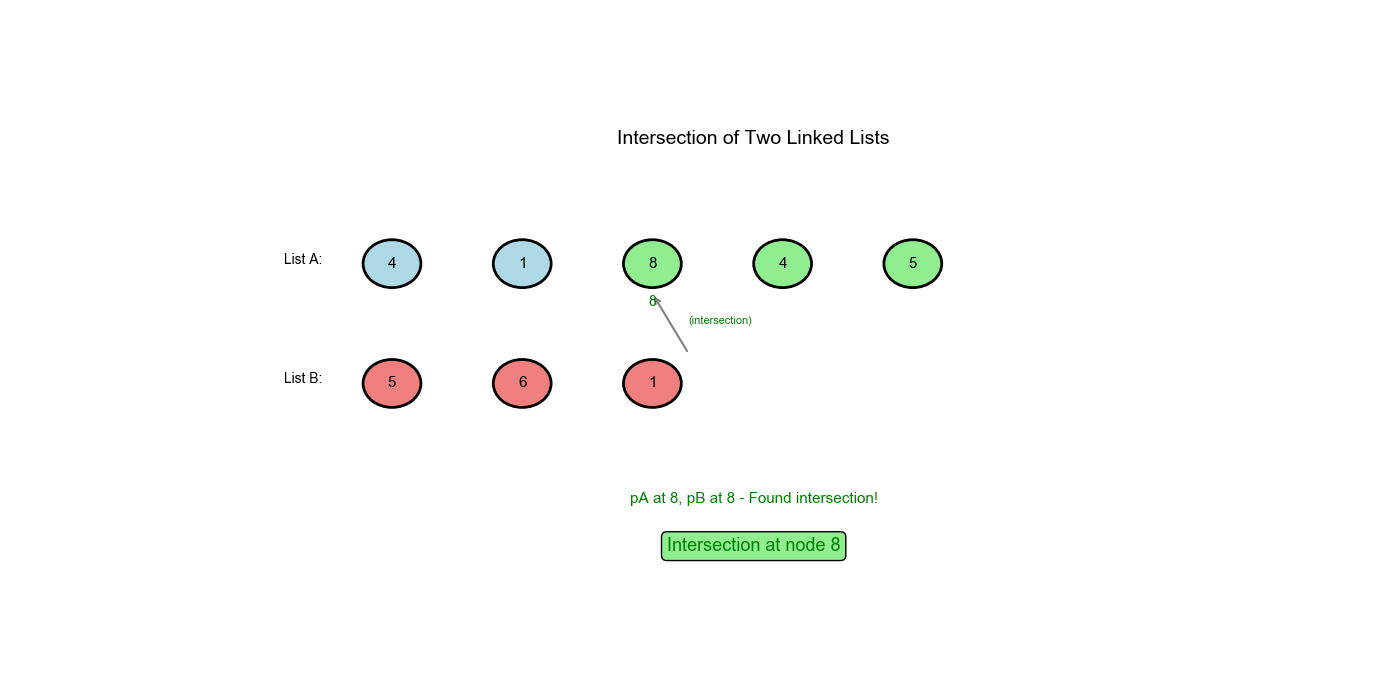
Approach One: Two Pointers (Path Alignment)
Core Idea
Key observation: If two lists intersect, the path from intersection to end has the same length.
Clever trick: 1. Pointer pA traverses
A, then jumps to B's start when reaching end 2. Pointer pB
traverses B, then jumps to A's start when reaching end 3. The two
pointers will meet at intersection (or both reach None)
Why does this work?
Let:
- Length of A's unique part:
- Length of B's unique part:
- Length of common part:
pApath:pBpath:They're equal! So they'll reach intersection (or None) simultaneously.
Python Implementation
1 | def getIntersectionNode(headA, headB): |
Complexity Analysis
- Time Complexity:
- Space Complexity:
Step-by-Step Walkthrough
Input: 1
2A: 1 → 2 → 8 → 9
B: 3 → 8 → 9
| Step | pA |
pB |
pA == pB? |
|---|---|---|---|
| 0 | 1 |
3 |
❌ |
| 1 | 2 |
8 |
❌ |
| 2 | 8 |
9 |
❌ |
| 3 | 9 |
None |
❌ |
| 4 | None |
1 (switch to A) |
❌ |
| 5 | 3 (switch to B) |
2 |
❌ |
| 6 | 8 |
8 |
✅ Meet! |
Why This Works: Mathematical Proof
Let:
- Length of list A:
- Length of list B:
- Where
= A's unique part, = B's unique part, = common part
After switching:
pAtravels:pBtravels:Both travel the same distance! If they intersect, they meet at the intersection point. If not, both become Nonesimultaneously.
Approach Two: Hash Set
Python Implementation
1 | def getIntersectionNode_hash(headA, headB): |
Complexity
- Time:
- Space:
or Comparison: Two-pointer method is space-optimal!
LeetCode 19: Remove Nth Node From End of List
Problem Description
Given the head of a linked list, remove the
Follow-up: Could you do this in one pass?
Example:
- Input:
head = [1,2,3,4,5],n = 2 - Output:
[1,2,3,5](remove the 2nd node from end, which is4)
Constraints:
- The number of nodes in the list:
- 
Core Idea: Two Pointers (Gap of n)
Steps: 1. Create a dummy node
(handles deletion of head node) 2. Fast pointer movesslow.next = slow.next.next
Python Implementation
1 | def removeNthFromEnd(head, n): |
Complexity Analysis
- Time Complexity:
, where is list length, one pass - Space Complexity:
Why Does Fast Pointer Move n+1 Steps?
Goal: Make slow stop at the node
before the target node.
Example: head = [1,2,3,4,5],
n = 2 (delete 4)
| Fast Position | Slow Position | Explanation |
|---|---|---|
dummy → 1 → 2 → 3 |
dummy |
Fast moved 3 steps (n+1) |
3 → 4 → 5 → None |
dummy → 1 → 2 → 3 |
Move synchronously |
None |
3 |
Slow at 3, can delete
4 |
Edge Case: Deleting Head Node
Input: head = [1,2], n = 2
(delete 1)
- Fast moves 3 steps:
dummy → 1 → 2 → None - Slow still at
dummy - Delete:
dummy.next = 1.next = 2 - Return:
dummy.next = 2✅
Without dummy: Need special handling for head deletion, code becomes complex!
Common Mistakes
Mistake 1: Wrong gap size 1
2
3
4# ❌ Wrong: Only n steps, slow will be AT target, not before
for _ in range(n):
fast = fast.next
# Now slow.next = slow.next.next will delete wrong node
Mistake 2: Not using dummy 1
2
3
4# ❌ Wrong: Need special case for head deletion
if n == length:
return head.next
# More complex code...
LeetCode 23: Merge K Sorted Lists
Problem Description
You are given an array of
Example:
- Input:
lists = [[1,4,5],[1,3,4],[2,6]] - Output:
[1,1,2,3,4,4,5,6]
Constraints:
-
Approach One: Divide and Conquer
Core Idea
Merge lists in pairs recursively, similar to merge sort: 1. Divide: Split the array of lists into two halves 2. Conquer: Recursively merge each half 3. Combine: Merge the two merged halves
Python Implementation
1 | def mergeKLists(lists): |
Complexity Analysis
- Time Complexity:
, where is total nodes, is number of lists - Space Complexity:
, recursion stack depth
Why Divide and Conquer?
Naive approach: Merge lists one by one
- Time:
(each merge is , done times)
Divide and conquer: Merge in pairs
- Time:
(merge tree has levels, each level processes nodes)
Approach Two: Priority Queue (Heap)
Python Implementation
1 | import heapq |
LeetCode 138: Copy List with Random Pointer
Problem Description
A linked list of lengthnull.
Construct a deep copy of the list.
Example: 1
2
3
4Original: 7 → 13 → 11 → 10 → 1 → None
↓ ↓ ↓ ↓ ↓
- 7 1 11 7
Approach: Two-Pass with Hash Map
Core Idea
- First pass: Create all new nodes and map old → new
- Second pass: Connect
nextandrandompointers using the map
Python Implementation
1 | def copyRandomList(head): |
Complexity Analysis
- Time Complexity:
, two passes - Space Complexity:
, hash map storage
The Power of Dummy Nodes
When to Use Dummy Nodes?
Signals:
- Might delete head node
- Need to return new head node
- Building new linked list
Benefits:
- Unified handling of head and other nodes
- No special cases for empty lists
- Cleaner code
Comparison Example: Delete Node
Without dummy: 1
2
3
4
5
6
7
8
9
10
11
12def deleteNode(head, val):
# ❌ Special case for head
if head.val == val:
return head.next
curr = head
while curr.next:
if curr.next.val == val:
curr.next = curr.next.next
break
curr = curr.next
return head
With dummy: 1
2
3
4
5
6
7
8
9
10
11
12
13def deleteNode_dummy(head, val):
dummy = ListNode(0)
dummy.next = head
curr = dummy
# ✅ Unified handling
while curr.next:
if curr.next.val == val:
curr.next = curr.next.next
break
curr = curr.next
return dummy.next
Common Pitfalls and Debugging Tips
Pitfall 1: Null Pointer Access
1 | # ❌ curr might be None |
Fix: 1
2
3
4# ✅ Check if curr.next exists
while curr and curr.next:
if curr.next.val == target:
# ...
Pitfall 2: Losing Node Reference After Pointer Modification
1 | # ❌ Wrong example |
Correct approach:
- If you need to access the deleted node, save it first:
1
2
3to_delete = curr.next
curr.next = curr.next.next
# Can still use to_delete
Pitfall 3: Forgetting to Move Pointer
1 | # ❌ Infinite loop |
Debugging Tips
Tip 1: Print Linked List
1 | def print_list(head): |
Tip 2: Draw Diagrams
Draw the linked list state at each step, especially when modifying pointers.
Tip 3: Step-by-Step Debugging
For complex operations (like reversal, merging), execute step by step and check pointer state after each step.
Linked List Interview Communication Templates
Template 1: Identify Linked List Characteristics
"This problem involves linked list manipulation. Linked lists have
insertion/deletion but access. I'll use [iterative/recursive] approach with [two pointers/dummy node] technique to [reverse/merge/detect] the list."
Template 2: Choose Iterative vs Recursive
"I can implement this iteratively with
space, or recursively with cleaner code but space. For production, I prefer iterative to avoid stack overflow; for interviews, I'll show iterative first, then mention recursive as an alternative."
Template 3: Explain Dummy Node
"I'll use a dummy node as a sentinel to unify handling of head node special cases, avoiding complex boundary checks. Finally, return
dummy.next."
Template 4: Fast-Slow Pointers
"I'll use fast-slow pointers: fast moves 2 steps, slow moves 1 step. This solves the problem in one pass with
time and space."
❓ Q&A: Linked List Interview Tips
Q1: When should I use recursion vs iteration for linked lists?
A: Use iteration when:
- Space optimization matters (
vs ) - Production code (avoid stack overflow risk)
- Long lists (recursion depth concerns)
Use recursion when:
- Code clarity is priority
- Demonstrating multiple approaches in interviews
- Natural recursive structure (e.g., tree-like problems)
Interview tip: Always mention both approaches, but implement iteration first.
Q2: How do I handle edge cases systematically?
A: Check these systematically: 1. Empty
list: head == None 2. Single
node: head.next == None 3. Two
nodes: Special cases for operations 4. Head
modification: Use dummy node 5. Cycle
detection: Check fast and fast.next
before accessing
Pattern: Always check node before
accessing node.next.
Q3: What's the best way to find the middle of a linked list?
A: Use fast-slow pointers:
1
2
3
4
5
6def findMiddle(head):
slow = fast = head
while fast and fast.next:
slow = slow.next
fast = fast.next.next
return slow
When fast reaches end, slow is at middle (or second middle if even length).
Q4: How do I detect a cycle without using extra space?
A: Use Floyd's algorithm (fast-slow pointers):
- Fast moves 2 steps, slow moves 1 step
- If they meet, cycle exists
- To find entrance: move one pointer to start, both move 1 step
Time:
Q5: What's the trick to deleting a node when you only have access to that node?
A: Copy next node's data, then delete next
node: 1
2
3
4
5
6
7
8
9def deleteNode(node):
# Can't delete if it's the last node
if not node.next:
return
# Copy next node's value
node.val = node.next.val
# Delete next node
node.next = node.next.next
Note: This doesn't work for the last node (requires
None).
Q6: How do I reverse a linked list in groups of k?
A: Use recursion: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def reverseKGroup(head, k):
# Check if we have k nodes
curr = head
count = 0
while curr and count < k:
curr = curr.next
count += 1
if count == k:
# Reverse first k nodes
curr = reverseKGroup(curr, k) # Recurse for rest
while count > 0:
next_node = head.next
head.next = curr
curr = head
head = next_node
count -= 1
head = curr
return head
Q7: What's the most common mistake in linked list problems?
A: Accessing node.next when
node might be None.
Always check: 1
2if node and node.next:
# Safe to access node.next
Q8: How do I merge k sorted lists efficiently?
A: Two main approaches:
Divide and Conquer:
time, space - Merge pairs recursively
Priority Queue:
time, space - Use min heap to always get smallest element
Both are optimal. Choose based on space constraints.
Q9: Can I modify a linked list in-place without extra space?
A: Yes! Most operations can be done in
- Reversal: Three pointers
- Cycle detection: Fast-slow pointers
- Merging: Dummy node + pointers
- Deletion: Two pointers
Key: Use pointers cleverly, avoid extra data structures.
Q10: What should I say when asked about time/space complexity?
A: Be specific:
- Time: Count operations (traversals, comparisons)
- Space: Count extra variables (pointers =
, recursion stack = , hash map = )
Example: "This uses two pointers, so space is
Practice Problems (10 Recommended)
Basic Operations
- Reverse Linked List (LeetCode 206) ← Covered in this article Easy
- Merge Two Sorted Lists (LeetCode 21) ← Covered in this article Easy
- Remove Nth Node From End (LeetCode 19) ← Covered in this article Medium
Cycle Detection and Intersection
- Linked List Cycle (LeetCode 141) Easy
- Linked List Cycle II (LeetCode 142) ← Covered in this article Medium
- Intersection of Two Linked Lists (LeetCode 160) ← Covered in this article Easy
Advanced Operations
- Palindrome Linked List (LeetCode 234) Easy
- Sort List (LeetCode 148) Medium
- Reorder List (LeetCode 143) Medium
- Copy List with Random Pointer (LeetCode 138) ← Covered in this article Medium
Summary: Linked List Operations Cheat Sheet
Core Techniques Quick Reference
| Technique | Use Case | Example Problems |
|---|---|---|
| Two Pointers | Find middle, cycle detection, nth from end | Cycle detection, remove nth node |
| Dummy Node | Delete head, build new list | Merge lists, delete node |
| Recursion | Reverse, merge (clean code) | Reverse list, merge lists |
| Iteration | All operations (space optimal) | Reverse list, detect cycle |
When to Use What?
Two Pointers:
- Need to track multiple positions simultaneously
- Cycle detection (fast-slow)
- Find middle, nth from end
Dummy Node:
- Might modify head node
- Building new linked list
- Simplify boundary conditions
Recursion vs Iteration:
- Recursion: Clean code, good for demonstrating algorithm thinking
- Iteration: Space optimal, better for production
Common Pitfalls
- Null pointer: Check
nodebefore accessingnode.next - Lost reference: Save necessary references before modifying pointers
- Forgot to move pointer: Every loop branch must move pointer
- Edge cases: Empty list, single node, head node operations
Interview Golden Phrases
"The core of linked lists is pointer manipulation. I'll use [two pointers/dummy/recursion] technique, ensure boundary safety, achieving
time, space (or explain stack space for recursion)."
Memory Mnemonic
Two pointers find cycles and middle, dummy simplifies boundaries, iteration saves space recursion is elegant, pointer operations avoid nulls and pitfalls!
Next Article Preview
In LeetCode (4): Binary Tree Traversal and Recursion, we'll explore:
- Four traversal methods: Preorder, inorder, postorder, level-order
- Recursive patterns: Subtree problem decomposition
- Morris traversal:
space traversal - Classic problems: Lowest common ancestor, path sum, tree serialization
Food for thought: How to perform inorder traversal without recursion or stack? Answer in the next article!
Further Reading
- Books:
- Introduction to Algorithms Chapter 10: Linked Lists
- Cracking the Coding Interview — Linked List Chapter
- Visualization:
- VisuAlgo - Linked Lists: https://visualgo.net/en/list
- LeetCode: Linked List tag (100+ problems)
Linked lists aren't the "hard part" of data structures — they're the touchstone of pointer thinking. Master them, and you'll easily handle trees, graphs, and more complex structures!
- Post title:LeetCode (3): Linked List Operations - Reversal, Cycle Detection & Merging
- Post author:Chen Kai
- Create time:2023-05-08 00:00:00
- Post link:https://www.chenk.top/en/leetcode-linked-list-operations/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.