图神经网络(
GNN)在节点分类、链接预测、图生成等任务中展现出强大能力。然而,深层 GNN
面临一个根本性问题:过度平滑 (
over-smoothing)——随着层数增加,节点特征逐渐趋于相同,丢失了局部结构信息。这一现象与偏微分方程中的扩散过程有着深刻的数学联系:扩散项使信息在图上"流动",而反应项则保持局部差异。反应扩散方程(
Reaction-Diffusion Equation,
RDE)正是描述这种"扩散与反应平衡"的经典模型。
反应扩散方程在生物学、化学、物理学中有着悠久历史。从 Turing
的形态发生理论,到 Gray-Scott 的化学振荡,再到 FitzHugh-Nagumo
的神经脉冲模型,这些方程揭示了模式如何从均匀状态自发涌现 。近年来,研究者发现:将反应扩散动力学嵌入图神经网络,不仅可以缓解过度平滑,还能让网络学习到更丰富的图结构模式。
本文将系统性地建立反应扩散系统与图神经网络的数学桥梁。我们从经典反应扩散方程出发,介绍
Gray-Scott 、 FitzHugh-Nagumo 模型和 Turing
不稳定性理论;然后建立图拉普拉斯算子与离散扩散的框架;接着深入模式形成的数学机制,包括线性稳定性分析和分叉理论;最后聚焦图神经网络,展示
GRAND 、 PDE-GCN 等扩散解释,并详细介绍图神经反应扩散模型(
RDGNN)的架构与实验。
引言:从连续空间到离散图
为什么研究反应扩散系统?
在自然界中,许多现象都涉及两个相互竞争的过程: -
扩散 :使事物变均匀(墨水在水中散开) -
反应 :产生局部差异(化学反应产生新物质)
这两者的平衡产生了丰富的模式: - 豹子的斑点、斑马的条纹( Turing
图案) - 心脏的电波传导( FitzHugh-Nagumo 模型) - 化学反应中的螺旋波(
Gray-Scott 模型)
与 GNN 的联系 :图神经网络也有类似的"扩散与反应": -
扩散 :信息在图上传播(消息传递),让相邻节点特征变相似
- 反应 :非线性变换(激活函数),保持节点差异
理解反应扩散系统,就能理解如何设计更好的 GNN!
连续空间中的反应扩散
🎓 直觉理解:扩散 vs 反应
生活类比 :想象一个村庄的流行病传播
扩散项 反应项
如果只有扩散:病毒均匀分布,所有人感染程度相同(无聊!)
如果只有反应:每个人独立演化,没有传播(不符合现实)
两者结合:产生波状传播、局部爆发等复杂模式
数学表达 :
离散图上的对应
🎓 直觉理解:从连续到离散
类比 :从"地图"到"城市网络"
连续空间 :温度在金属板上扩散,任意位置都有温度值离散图 :信息在社交网络上传播,只有节点(人)有特征值
图拉普拉斯算子
具体例子 :三个节点的图
邻接矩阵:
度矩阵:
拉普拉斯矩阵:
应用拉普拉斯 :
📚 严格定义
反应扩散方程的一般形式为:
物理直觉 : - 扩散项 反应项
当扩散与反应达到平衡时,系统可能从均匀状态自发形成空间模式 (
spatial patterns)——这是 Turing 不稳定性理论的核心。
离散图上的对应
图图扩散 ,第二项是节点反应 。
关键洞察 :图拉普拉斯算子
反应扩散方程基础
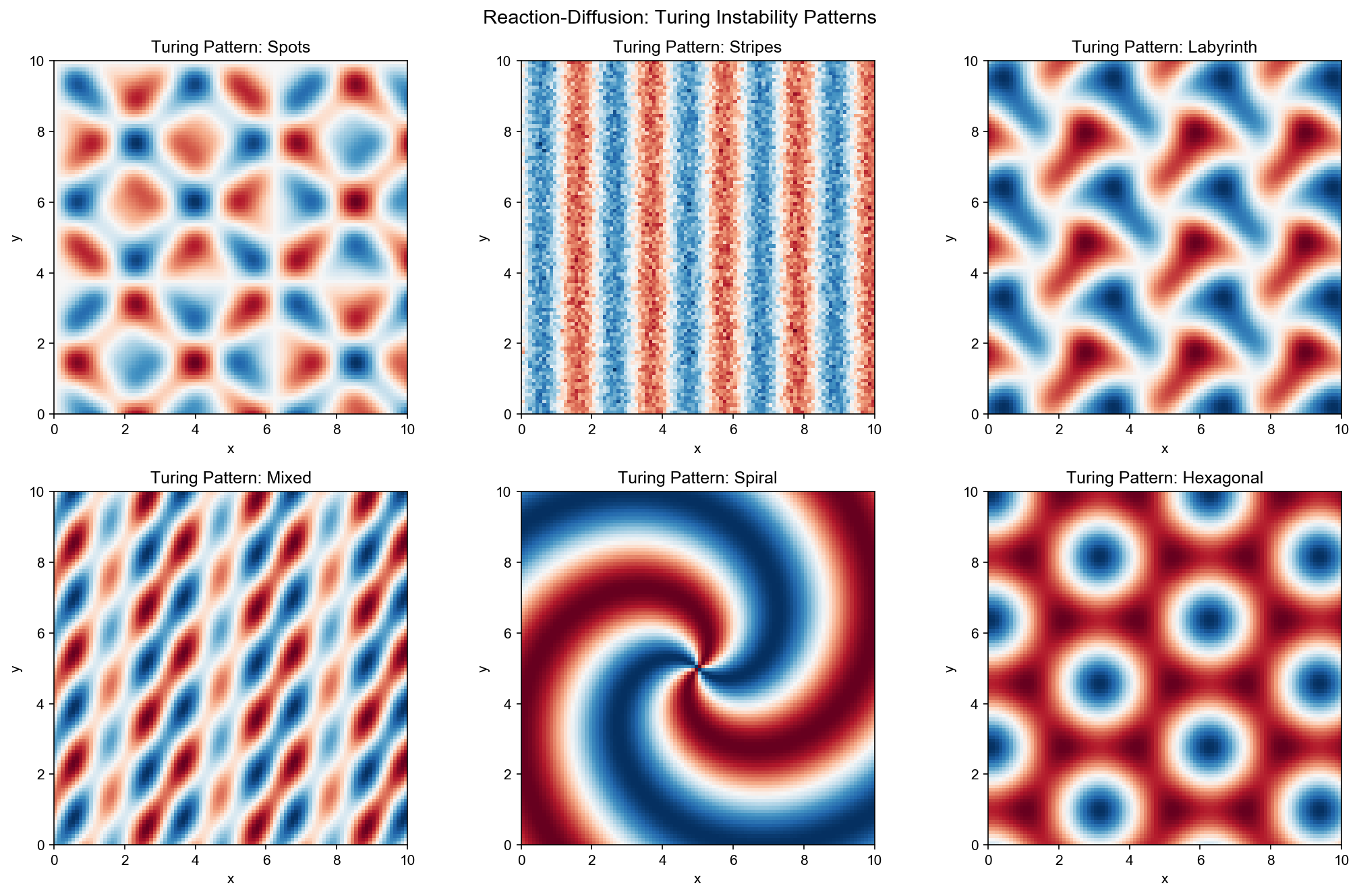
图灵斑图的形成过程
Gray-Scott 模型
Gray-Scott 模型是描述自催化化学反应的双组分反应扩散系统:
参数意义 : -
当斑图 (
spots)、条纹 ( stripes)、螺旋波 (
spiral waves)等复杂模式。
FitzHugh-Nagumo 模型
FitzHugh-Nagumo( FHN)模型最初用于描述神经元的电脉冲传播:
动力学特征 : - 激发 :当恢复 :不应期 :
FHN 模型可以产生行波 ( traveling
waves)、螺旋波 、靶心波 ( target
patterns)等模式。
Turing 不稳定性
Turing
不稳定性理论解释了均匀稳态如何失稳并形成空间模式 。
考虑一般的双组分反应扩散系统:
线性稳定性分析 :在小扰动
对空间做 Fourier 变换:Turing
条件 :均匀稳态在无扩散时稳定(
激活-抑制机制 :扩散系数差异 :
满足这些条件时,系统会自发形成空间周期模式,波长由最不稳定模式
图拉普拉斯算子与离散扩散
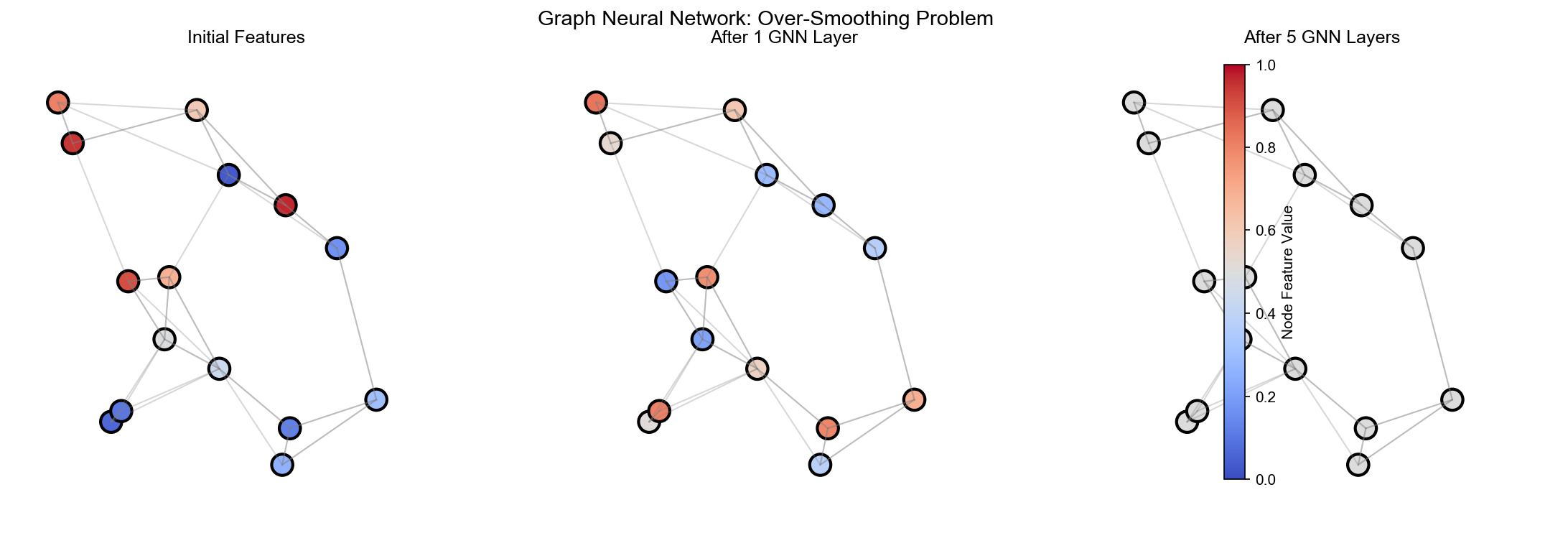
GNN 过度平滑现象
图拉普拉斯算子的定义
对于无向图图拉普拉斯算子 ( Graph
Laplacian)定义为:归一化拉普拉斯算子 :随机游走拉普拉斯 :
图上的热方程(扩散方程)为:谱分解 :设
则:物理意义 : -
当
图上的反应扩散
图上的反应扩散系统为:
离散时间形式 ( Euler 方法):
这可以重写为:扩散更新 ,第二项是反应更新 。
模式形成的数学理论
反应扩散 GNN 架构
线性稳定性分析
考虑图上的反应扩散系统:
在小扰动稳定性条件 :设
关键洞察 :即使
分叉理论
当参数变化时,系统可能经历分叉 (
bifurcation)——解的结构发生定性变化。
鞍结分叉 ( Saddle-node
bifurcation):两个稳态碰撞并消失
Hopf 分叉 :稳态失稳,产生极限环(周期解)
Turing 分叉 :均匀稳态失稳,产生空间模式
对于图上的反应扩散系统,分叉点由图的谱性质决定。例如,在正则图上,
Turing 分叉发生在:
图神经网络的扩散解释
传统 GNN 架构
图卷积网络 ( GCN)的更新规则为:
扩散视角 : GCN 可以视为离散化的图扩散过程。设
GRAND:图神经扩散
GRAND( Graph Neural Diffusion)显式地将 GNN 建模为扩散过程:
数值求解 :使用 ODE 求解器(如 Runge-Kutta
方法)积分该方程。
优势 : - 连续深度:层数由 ODE
求解器的步数决定,可自适应 - 稳定训练: ODE 求解器保证数值稳定性 -
理论保证:基于 PDE 理论的分析工具
PDE-GCN
PDE-GCN 将 GCN 显式解释为 PDE 的数值求解:恒等映射 :非线性激活 :注意力机制 :
理论分析 : PDE-GCN 的收敛性、稳定性可以通过 PDE
理论分析,例如: - 最大原理 :保证特征有界 -
能量方法 :分析长期行为 -
谱方法 :理解频率响应
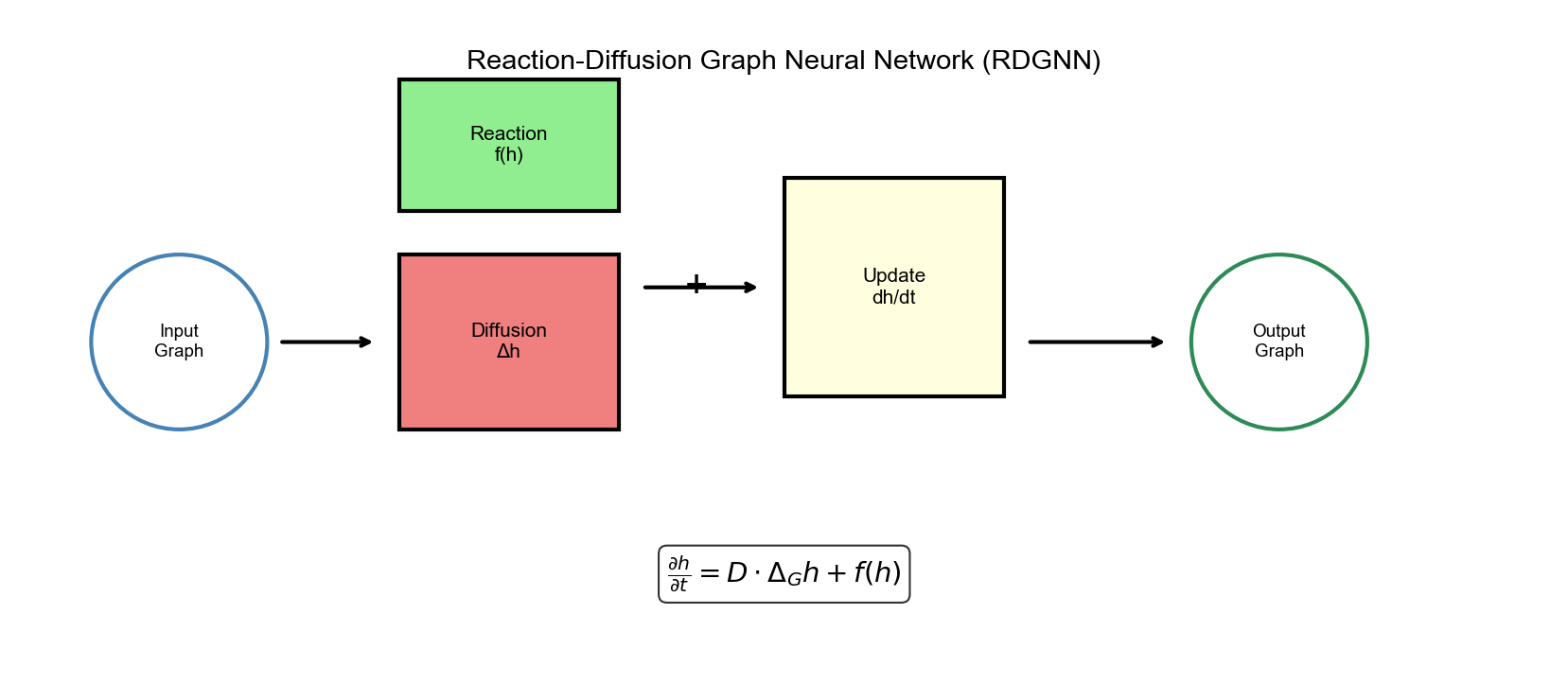
图神经反应扩散模型( RDGNN)
架构设计
图神经反应扩散模型 ( Graph Neural Reaction Diffusion
Model, RDGNN)将反应扩散动力学嵌入 GNN:
反应项设计 :
第一项是激活项 (类似 FHN 中的衰减项 (防止爆炸)。
理论分析
稳定性条件 : RDGNN 的稳定性要求:
模式形成条件 :当反应项足够强且扩散系数适中时,系统可能形成非均匀模式,从而缓解过度平滑。
表达能力 : RDGNN 可以学习到: -
局部模式 :反应项保持节点差异 -
全局结构 :扩散项传播信息 -
动态平衡 :两者竞争产生丰富表示
实现细节
数值稳定性 : - 使用归一化拉普拉斯:计算效率 : -
稀疏矩阵乘法:利用图的稀疏性 - 批处理:同时处理多个图 - GPU
加速:矩阵运算在 GPU 上执行
实验
实验
1:一维/二维反应扩散模式生成
我们首先在连续空间上验证反应扩散方程的模式形成能力。
一维 Gray-Scott 模型 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 import numpy as npimport matplotlib.pyplot as pltfrom scipy.integrate import odeintdef gray_scott_1d (u, t, Du, Dv, F, k, dx, n ): """一维 Gray-Scott 模型的右端项""" u_vals = u[:n] v_vals = u[n:] u_laplacian = np.zeros(n) v_laplacian = np.zeros(n) u_laplacian[0 ] = (u_vals[1 ] - 2 *u_vals[0 ] + u_vals[-1 ]) / dx**2 u_laplacian[-1 ] = (u_vals[0 ] - 2 *u_vals[-1 ] + u_vals[-2 ]) / dx**2 u_laplacian[1 :-1 ] = (u_vals[2 :] - 2 *u_vals[1 :-1 ] + u_vals[:-2 ]) / dx**2 v_laplacian[0 ] = (v_vals[1 ] - 2 *v_vals[0 ] + v_vals[-1 ]) / dx**2 v_laplacian[-1 ] = (v_vals[0 ] - 2 *v_vals[-1 ] + v_vals[-2 ]) / dx**2 v_laplacian[1 :-1 ] = (v_vals[2 :] - 2 *v_vals[1 :-1 ] + v_vals[:-2 ]) / dx**2 u_reaction = -u_vals * v_vals**2 + F * (1 - u_vals) v_reaction = u_vals * v_vals**2 - (F + k) * v_vals du_dt = Du * u_laplacian + u_reaction dv_dt = Dv * v_laplacian + v_reaction return np.concatenate([du_dt, dv_dt]) Du, Dv = 0.00002 , 0.00001 F, k = 0.04 , 0.06 L = 2.5 n = 256 dx = L / n x = np.linspace(0 , L, n) u0 = np.ones(n) * 0.5 + 0.01 * np.random.randn(n) v0 = np.ones(n) * 0.25 + 0.01 * np.random.randn(n) y0 = np.concatenate([u0, v0]) t = np.linspace(0 , 2000 , 1000 ) sol = odeint(gray_scott_1d, y0, t, args=(Du, Dv, F, k, dx, n)) u_sol = sol[:, :n] plt.figure(figsize=(12 , 6 )) plt.imshow(u_sol.T, aspect='auto' , cmap='viridis' , origin='lower' ) plt.colorbar(label='u concentration' ) plt.xlabel('Time' ) plt.ylabel('Space' ) plt.title('1D Gray-Scott Pattern Formation' ) plt.show()
二维 FHN 模型 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 def fitzhugh_nagumo_2d (u, t, D, epsilon, beta, gamma, I, dx, ny, nx ): """二维 FitzHugh-Nagumo 模型的右端项""" n = ny * nx u_vals = u[:n].reshape(ny, nx) v_vals = u[n:].reshape(ny, nx) u_laplacian = np.zeros_like(u_vals) u_laplacian[1 :-1 , 1 :-1 ] = ( u_vals[2 :, 1 :-1 ] + u_vals[:-2 , 1 :-1 ] + u_vals[1 :-1 , 2 :] + u_vals[1 :-1 , :-2 ] - 4 * u_vals[1 :-1 , 1 :-1 ] ) / dx**2 u_reaction = u_vals - u_vals**3 / 3 - v_vals + I v_reaction = epsilon * (u_vals + beta - gamma * v_vals) du_dt = D * u_laplacian + u_reaction dv_dt = v_reaction return np.concatenate([du_dt.flatten(), dv_dt.flatten()]) D = 1.0 epsilon, beta, gamma = 0.1 , 0.7 , 0.8 I = 0.5 L = 10.0 nx, ny = 128 , 128 dx = L / nx x = np.linspace(0 , L, nx) y = np.linspace(0 , L, ny) X, Y = np.meshgrid(x, y) r = np.sqrt((X - L/2 )**2 + (Y - L/2 )**2 ) theta = np.arctan2(Y - L/2 , X - L/2 ) u0 = np.tanh(r - 3 ) * np.cos(theta) v0 = np.zeros_like(u0) y0 = np.concatenate([u0.flatten(), v0.flatten()]) t = np.linspace(0 , 50 , 500 ) sol = odeint(fitzhugh_nagumo_2d, y0, t, args=(D, epsilon, beta, gamma, I, dx, ny, nx)) u_final = sol[-1 , :nx*ny].reshape(ny, nx) plt.figure(figsize=(10 , 10 )) plt.contourf(X, Y, u_final, levels=20 , cmap='RdBu' ) plt.colorbar(label='u (membrane potential)' ) plt.title('2D FitzHugh-Nagumo Spiral Wave' ) plt.show()
实验 2:图上的热扩散
我们验证图拉普拉斯算子的扩散性质。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 import torchimport torch.nn.functional as Fimport networkx as nxfrom torch_geometric.utils import to_networkx, from_networkxdef graph_heat_diffusion (edge_index, num_nodes, T=10 , num_steps=100 ): """图上的热扩散""" from torch_geometric.utils import degree, add_self_loops edge_index, _ = add_self_loops(edge_index, num_nodes=num_nodes) row, col = edge_index deg = degree(col, num_nodes, dtype=torch.float ) deg_inv_sqrt = deg.pow (-0.5 ) deg_inv_sqrt[deg_inv_sqrt == float ('inf' )] = 0 norm = deg_inv_sqrt[row] * deg_inv_sqrt[col] H0 = torch.randn(num_nodes, 1 ) dt = T / num_steps H = H0.clone() history = [H0.numpy()] for _ in range (num_steps): H_new = (1 - dt) * H for i in range (num_nodes): neighbors = edge_index[1 , edge_index[0 ] == i] if len (neighbors) > 0 : H_new[i] += dt * norm[edge_index[0 ] == i].sum () * H[neighbors].mean() H = H_new history.append(H.numpy()) return np.array(history) graphs = { 'Erd ő s-R é nyi' : nx.erdos_renyi_graph(100 , 0.1 ), 'Barab á si-Albert' : nx.barabasi_albert_graph(100 , 5 ), 'Watts-Strogatz' : nx.watts_strogatz_graph(100 , 10 , 0.1 ), 'Regular' : nx.random_regular_graph(10 , 100 ) } fig, axes = plt.subplots(2 , 2 , figsize=(12 , 12 )) axes = axes.flatten() for idx, (name, G) in enumerate (graphs.items()): edge_index = from_networkx(G).edge_index num_nodes = G.number_of_nodes() history = graph_heat_diffusion(edge_index, num_nodes, T=5 , num_steps=50 ) mean_features = [h.mean() for h in history] std_features = [h.std() for h in history] axes[idx].plot(mean_features, label='Mean' ) axes[idx].plot(std_features, label='Std' ) axes[idx].set_xlabel('Time step' ) axes[idx].set_ylabel('Feature value' ) axes[idx].set_title(f'{name} Graph' ) axes[idx].legend() axes[idx].grid(True ) plt.tight_layout() plt.show()
实验 3: GNN
的过度平滑问题与反应项
我们展示传统 GCN 的过度平滑问题,以及反应项如何缓解它。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 import torchimport torch.nn as nnfrom torch_geometric.nn import GCNConvfrom torch_geometric.datasets import Planetoidclass GCN (nn.Module): """传统 GCN""" def __init__ (self, num_features, hidden_dim, num_classes, num_layers ): super ().__init__() self.convs = nn.ModuleList() self.convs.append(GCNConv(num_features, hidden_dim)) for _ in range (num_layers - 2 ): self.convs.append(GCNConv(hidden_dim, hidden_dim)) self.convs.append(GCNConv(hidden_dim, num_classes)) def forward (self, x, edge_index ): for i, conv in enumerate (self.convs[:-1 ]): x = conv(x, edge_index) x = torch.relu(x) x = self.convs[-1 ](x, edge_index) return x class RDGNN (nn.Module): """图神经反应扩散模型""" def __init__ (self, num_features, hidden_dim, num_classes, num_layers, eps_d=0.1 , eps_r=0.1 ): super ().__init__() self.num_layers = num_layers self.eps_d = eps_d self.eps_r = eps_r self.input_proj = nn.Linear(num_features, hidden_dim) self.reaction_nets = nn.ModuleList([ nn.Sequential( nn.Linear(hidden_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, hidden_dim) ) for _ in range (num_layers) ]) self.output_proj = nn.Linear(hidden_dim, num_classes) def forward (self, x, edge_index ): from torch_geometric.utils import degree, add_self_loops edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0 )) row, col = edge_index deg = degree(col, x.size(0 ), dtype=x.dtype) deg_inv_sqrt = deg.pow (-0.5 ) deg_inv_sqrt[deg_inv_sqrt == float ('inf' )] = 0 norm = deg_inv_sqrt[row] * deg_inv_sqrt[col] h = self.input_proj(x) for l in range (self.num_layers): h_diff = torch.zeros_like(h) for i in range (h.size(0 )): neighbors = col[row == i] if len (neighbors) > 0 : h_diff[i] = h[i] - norm[row == i].unsqueeze(1 ) * h[neighbors].sum (dim=0 ) h_react = self.reaction_nets[l](h) - 0.1 * h h = h - self.eps_d * h_diff + self.eps_r * h_react return self.output_proj(h) dataset = Planetoid(root='/tmp/Cora' , name='Cora' ) data = dataset[0 ] def train_model (model, data, epochs=200 ): optimizer = torch.optim.Adam(model.parameters(), lr=0.01 , weight_decay=5e-4 ) criterion = nn.CrossEntropyLoss() model.train() for epoch in range (epochs): optimizer.zero_grad() out = model(data.x, data.edge_index) loss = criterion(out[data.train_mask], data.y[data.train_mask]) loss.backward() optimizer.step() if epoch % 50 == 0 : model.eval () with torch.no_grad(): pred = model(data.x, data.edge_index).argmax(dim=1 ) train_acc = (pred[data.train_mask] == data.y[data.train_mask]).float ().mean() val_acc = (pred[data.val_mask] == data.y[data.val_mask]).float ().mean() print (f'Epoch {epoch} : Train Acc={train_acc:.4 f} , Val Acc={val_acc:.4 f} ' ) model.train() model.eval () with torch.no_grad(): pred = model(data.x, data.edge_index).argmax(dim=1 ) test_acc = (pred[data.test_mask] == data.y[data.test_mask]).float ().mean() return test_acc.item() results = {} for num_layers in [2 , 4 , 8 , 16 , 32 ]: model_gcn = GCN(data.num_features, 64 , dataset.num_classes, num_layers) acc_gcn = train_model(model_gcn, data) model_rdgnn = RDGNN(data.num_features, 64 , dataset.num_classes, num_layers) acc_rdgnn = train_model(model_rdgnn, data) results[num_layers] = {'GCN' : acc_gcn, 'RDGNN' : acc_rdgnn} print (f'Layers={num_layers} : GCN={acc_gcn:.4 f} , RDGNN={acc_rdgnn:.4 f} ' ) layers = list (results.keys()) gcn_accs = [results[l]['GCN' ] for l in layers] rdgnn_accs = [results[l]['RDGNN' ] for l in layers] plt.figure(figsize=(10 , 6 )) plt.plot(layers, gcn_accs, 'o-' , label='GCN' , linewidth=2 ) plt.plot(layers, rdgnn_accs, 's-' , label='RDGNN' , linewidth=2 ) plt.xlabel('Number of Layers' ) plt.ylabel('Test Accuracy' ) plt.title('Over-smoothing: GCN vs RDGNN' ) plt.legend() plt.grid(True ) plt.show()
实验 4: RDGNN
在同配/异配图上的性能
我们测试 RDGNN 在不同图结构上的表现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 def generate_homophilic_graph (num_nodes, num_classes, p_in=0.3 , p_out=0.05 ): """生成同配图( homophilic graph)""" labels = torch.randint(0 , num_classes, (num_nodes,)) adj = torch.zeros(num_nodes, num_nodes) for i in range (num_nodes): for j in range (i+1 , num_nodes): if labels[i] == labels[j]: if torch.rand(1 ) < p_in: adj[i, j] = adj[j, i] = 1 else : if torch.rand(1 ) < p_out: adj[i, j] = adj[j, i] = 1 edge_index = adj.nonzero().t().contiguous() return edge_index, labels def generate_heterophilic_graph (num_nodes, num_classes, p_in=0.05 , p_out=0.3 ): """生成异配图( heterophilic graph)""" labels = torch.randint(0 , num_classes, (num_nodes,)) adj = torch.zeros(num_nodes, num_nodes) for i in range (num_nodes): for j in range (i+1 , num_nodes): if labels[i] == labels[j]: if torch.rand(1 ) < p_in: adj[i, j] = adj[j, i] = 1 else : if torch.rand(1 ) < p_out: adj[i, j] = adj[j, i] = 1 edge_index = adj.nonzero().t().contiguous() return edge_index, labels def generate_features (num_nodes, num_features, labels ): """根据标签生成特征""" features = torch.randn(num_nodes, num_features) for c in range (len (torch.unique(labels))): mask = labels == c features[mask] += 0.5 * torch.randn(1 , num_features) return features num_nodes = 500 num_classes = 5 num_features = 32 hidden_dim = 64 results = {} edge_index_homo, labels_homo = generate_homophilic_graph(num_nodes, num_classes) features_homo = generate_features(num_nodes, num_features, labels_homo) train_mask = torch.zeros(num_nodes, dtype=torch.bool ) val_mask = torch.zeros(num_nodes, dtype=torch.bool ) test_mask = torch.zeros(num_nodes, dtype=torch.bool ) train_mask[:400 ] = True val_mask[400 :450 ] = True test_mask[450 :] = True data_homo = type ('obj' , (object ,), { 'x' : features_homo, 'edge_index' : edge_index_homo, 'y' : labels_homo, 'train_mask' : train_mask, 'val_mask' : val_mask, 'test_mask' : test_mask, 'num_features' : num_features })() edge_index_hetero, labels_hetero = generate_heterophilic_graph(num_nodes, num_classes) features_hetero = generate_features(num_nodes, num_features, labels_hetero) data_hetero = type ('obj' , (object ,), { 'x' : features_homo, 'edge_index' : edge_index_hetero, 'y' : labels_hetero, 'train_mask' : train_mask, 'val_mask' : val_mask, 'test_mask' : test_mask, 'num_features' : num_features })() for graph_type, data in [('Homophilic' , data_homo), ('Heterophilic' , data_hetero)]: model_gcn = GCN(num_features, hidden_dim, num_classes, num_layers=8 ) acc_gcn = train_model(model_gcn, data) model_rdgnn = RDGNN(num_features, hidden_dim, num_classes, num_layers=8 ) acc_rdgnn = train_model(model_rdgnn, data) results[graph_type] = {'GCN' : acc_gcn, 'RDGNN' : acc_rdgnn} print (f'{graph_type} : GCN={acc_gcn:.4 f} , RDGNN={acc_rdgnn:.4 f} ' ) graph_types = list (results.keys()) gcn_accs = [results[gt]['GCN' ] for gt in graph_types] rdgnn_accs = [results[gt]['RDGNN' ] for gt in graph_types] x = np.arange(len (graph_types)) width = 0.35 plt.figure(figsize=(10 , 6 )) plt.bar(x - width/2 , gcn_accs, width, label='GCN' ) plt.bar(x + width/2 , rdgnn_accs, width, label='RDGNN' ) plt.xlabel('Graph Type' ) plt.ylabel('Test Accuracy' ) plt.title('Performance on Homophilic vs Heterophilic Graphs' ) plt.xticks(x, graph_types) plt.legend() plt.grid(True , axis='y' ) plt.show()
Beltrami 流与图上的几何流
Beltrami 流基础
Beltrami
流是几何分析中的重要工具,描述曲面的演化过程。对于嵌入在
几何意义 : Beltrami
流使流形"平滑化",减少表面积,趋向于最小曲面。
图上的 Beltrami 流
对于图嵌入几何 ,使相似节点在嵌入空间中靠近。
离散 Beltrami 能量 :
将反应项加入 Beltrami 流,得到反应-几何流 :保持局部结构 :防止过度平滑导致的几何信息丢失 -
学习任务相关嵌入 :根据下游任务优化嵌入空间 -
引入非线性 :产生更丰富的几何模式
图神经网络的谱分析
图信号的频率分解
图信号
频率解释 : - 低频 (小高频 (大
GCN 的频率响应
GCN 的更新规则为:
在频率域, GCN 对频率关键观察 : - 对于
过度平滑的谱解释 :随着层数增加,只有最低频模式(
RDGNN 的频率响应
RDGNN 的更新为:反应项的作用 : -
注入新频率 :反应项打破对称性 :防止系统收敛到纯常数模式 -
保持多样性 :通过非线性产生新的频率模式
数值方法与稳定性
显式 Euler 方法
最简单的数值方法是显式 Euler:稳定性条件 (线性化分析):设
隐式方法
隐式 Euler 方法 :
Crank-Nicolson 方法 (半隐式):
自适应步长
自适应步长策略 :根据局部误差估计调整
定义局部截断误差:
如果
相关论文综述
Graph Neural
Reaction Diffusion Models (2024)
Graph Neural Reaction
Diffusion Models 首次将反应扩散动力学显式嵌入 GNN 架构。论文提出
RDGNN,通过平衡扩散项和反应项,缓解过度平滑问题。
关键贡献 : - 建立图反应扩散系统的数学框架 -
提出可学习的反应项设计 - 在节点分类、图分类任务上验证有效性
技术细节 : - 使用归一化拉普拉斯
Turing
Patterns in Biochemical Networks (Nature 2024)
Turing
Patterns in Biochemical Networks 在生物化学网络中观察到 Turing
模式,验证了 Turing 不稳定性理论在复杂网络中的适用性。
实验发现 : -
在蛋白质相互作用网络中观察到空间周期模式 - 模式的形成依赖于网络拓扑结构
- 扩散系数的差异是关键因素
对 GNN 的启示 : - 图结构影响模式形成能力 -
不同图类型(同配/异配)可能产生不同模式 -
可以通过设计反应项来引导模式形成
GRAND: Graph Neural Diffusion
GRAND 将 GNN 建模为连续扩散过程,使用 ODE 求解器进行数值积分。
核心思想 :优势 : - 连续深度 :层数由 ODE
求解器自适应决定 - 理论保证 :基于 PDE 理论的分析工具 -
数值稳定 : ODE 求解器保证稳定性
实现 :使用 torchdiffeq 库,支持多种 ODE 求解器(
Euler 、 RK4 、 Dopri5 等)。
PDE-GCN
PDE-GCN 显式将 GCN 解释为 PDE 的数值求解,建立 GNN 与数值 PDE
方法的桥梁。
更新规则 :理论分析 : -
收敛性:通过 PDE 理论分析长期行为 - 稳定性:最大原理保证特征有界 -
表达能力:谱方法分析频率响应
Beltrami Flow on Graphs
将 Beltrami 流扩展到图,优化节点嵌入的几何结构。
能量函数 :
梯度流 :
实验 1
补充:模式形成的参数空间
我们系统性地探索 Gray-Scott 模型的参数空间,识别不同模式区域。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 def explore_gray_scott_parameter_space (): """探索 Gray-Scott 参数空间""" F_values = np.linspace(0.02 , 0.06 , 10 ) k_values = np.linspace(0.04 , 0.08 , 10 ) patterns = {} for F in F_values: for k in k_values: u0 = np.ones(256 ) * 0.5 + 0.01 * np.random.randn(256 ) v0 = np.ones(256 ) * 0.25 + 0.01 * np.random.randn(256 ) y0 = np.concatenate([u0, v0]) t = np.linspace(0 , 2000 , 1000 ) sol = odeint(gray_scott_1d, y0, t, args=(0.00002 , 0.00001 , F, k, 2.5 /256 , 256 )) u_final = sol[-1 , :256 ] pattern_type = classify_pattern(u_final) patterns[(F, k)] = pattern_type F_grid, k_grid = np.meshgrid(F_values, k_values) pattern_grid = np.zeros_like(F_grid, dtype=int ) for i, F in enumerate (F_values): for j, k in enumerate (k_values): pattern_grid[j, i] = pattern_to_int(patterns[(F, k)]) plt.figure(figsize=(10 , 8 )) plt.contourf(F_grid, k_grid, pattern_grid, levels=5 , cmap='tab10' ) plt.colorbar(label='Pattern Type' ) plt.xlabel('F (feed rate)' ) plt.ylabel('k (kill rate)' ) plt.title('Gray-Scott Parameter Space' ) plt.show() def classify_pattern (u ): """分类模式类型""" fft_u = np.fft.fft(u) power = np.abs (fft_u)**2 dominant_freq = np.argmax(power[1 :len (power)//2 ]) + 1 spatial_var = np.var(u) if spatial_var < 0.001 : return 'uniform' elif dominant_freq < 10 : return 'spots' elif dominant_freq < 30 : return 'stripes' else : return 'chaotic'
实验 2 补充:图扩散的谱分析
我们分析不同图结构上扩散过程的谱性质。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 def analyze_diffusion_spectrum (graph_type='BA' , num_nodes=200 ): """分析图扩散的谱性质""" if graph_type == 'BA' : G = nx.barabasi_albert_graph(num_nodes, 5 ) elif graph_type == 'ER' : G = nx.erdos_renyi_graph(num_nodes, 0.1 ) elif graph_type == 'WS' : G = nx.watts_strogatz_graph(num_nodes, 10 , 0.1 ) L = nx.normalized_laplacian_matrix(G).toarray() eigenvals, eigenvecs = np.linalg.eigh(L) H0 = np.random.randn(num_nodes) H0_spectral = eigenvecs.T @ H0 t_values = np.linspace(0 , 10 , 100 ) H_spectral_evol = np.zeros((len (t_values), num_nodes)) for i, t in enumerate (t_values): H_spectral_evol[i] = H0_spectral * np.exp(-eigenvals * t) fig, axes = plt.subplots(2 , 2 , figsize=(14 , 12 )) axes[0 , 0 ].plot(eigenvals, 'o-' , markersize=3 ) axes[0 , 0 ].set_xlabel('Eigenvalue Index' ) axes[0 , 0 ].set_ylabel('Eigenvalue' ) axes[0 , 0 ].set_title('Laplacian Eigenvalue Spectrum' ) axes[0 , 0 ].grid(True ) im = axes[0 , 1 ].imshow(H_spectral_evol.T, aspect='auto' , cmap='viridis' ) axes[0 , 1 ].set_xlabel('Time' ) axes[0 , 1 ].set_ylabel('Frequency Index' ) axes[0 , 1 ].set_title('Spectral Evolution' ) plt.colorbar(im, ax=axes[0 , 1 ]) total_energy = np.sum (H_spectral_evol**2 , axis=1 ) axes[1 , 0 ].semilogy(t_values, total_energy) axes[1 , 0 ].set_xlabel('Time' ) axes[1 , 0 ].set_ylabel('Total Energy' ) axes[1 , 0 ].set_title('Energy Decay' ) axes[1 , 0 ].grid(True ) low_freq_energy = np.sum (H_spectral_evol[:, :10 ]**2 , axis=1 ) high_freq_energy = np.sum (H_spectral_evol[:, -10 :]**2 , axis=1 ) ratio = low_freq_energy / (high_freq_energy + 1e-10 ) axes[1 , 1 ].plot(t_values, ratio) axes[1 , 1 ].set_xlabel('Time' ) axes[1 , 1 ].set_ylabel('Low/High Freq Energy Ratio' ) axes[1 , 1 ].set_title('Frequency Selectivity' ) axes[1 , 1 ].grid(True ) axes[1 , 1 ].set_yscale('log' ) plt.tight_layout() plt.show() for graph_type in ['BA' , 'ER' , 'WS' ]: analyze_diffusion_spectrum(graph_type)
实验 3
补充:过度平滑的定量分析
我们定量分析 GCN 和 RDGNN 的过度平滑程度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 def measure_over_smoothing (model, data, num_layers_list ): """测量过度平滑程度""" metrics = {} for num_layers in num_layers_list: if isinstance (model, GCN): model_instance = model(data.num_features, 64 , dataset.num_classes, num_layers) else : model_instance = model(data.num_features, 64 , dataset.num_classes, num_layers) model_instance.eval () with torch.no_grad(): features_list = [] h = data.x for l in range (num_layers): if isinstance (model_instance, GCN): h = model_instance.convs[l](h, data.edge_index) if l < num_layers - 1 : h = torch.relu(h) else : h = model_instance.forward_intermediate(h, data.edge_index, l) features_list.append(h.numpy()) layer_metrics = [] for features in features_list: features_norm = features / (np.linalg.norm(features, axis=1 , keepdims=True ) + 1e-8 ) cos_sim = np.mean(np.dot(features_norm, features_norm.T)) layer_metrics.append({ 'cosine_similarity' : cos_sim, 'mean_std' : np.std(features), 'mean_norm' : np.mean(np.linalg.norm(features, axis=1 )) }) metrics[num_layers] = layer_metrics return metrics gcn_metrics = measure_over_smoothing(GCN, data, [2 , 4 , 8 , 16 , 32 ]) rdgnn_metrics = measure_over_smoothing(RDGNN, data, [2 , 4 , 8 , 16 , 32 ]) fig, axes = plt.subplots(1 , 3 , figsize=(15 , 5 )) layers = [2 , 4 , 8 , 16 , 32 ] gcn_cos = [[m['cosine_similarity' ] for m in gcn_metrics[l]] for l in layers] rdgnn_cos = [[m['cosine_similarity' ] for m in rdgnn_metrics[l]] for l in layers] for i, num_layers in enumerate (layers): layer_indices = list (range (num_layers)) axes[0 ].plot(layer_indices, gcn_cos[i], 'o-' , label=f'GCN L={num_layers} ' , alpha=0.7 ) axes[0 ].plot(layer_indices, rdgnn_cos[i], 's--' , label=f'RDGNN L={num_layers} ' , alpha=0.7 ) axes[0 ].set_xlabel('Layer Index' ) axes[0 ].set_ylabel('Mean Cosine Similarity' ) axes[0 ].set_title('Over-smoothing: Cosine Similarity' ) axes[0 ].legend() axes[0 ].grid(True ) gcn_std = [[m['mean_std' ] for m in gcn_metrics[l]] for l in layers] rdgnn_std = [[m['mean_std' ] for m in rdgnn_metrics[l]] for l in layers] for i, num_layers in enumerate (layers): layer_indices = list (range (num_layers)) axes[1 ].plot(layer_indices, gcn_std[i], 'o-' , label=f'GCN L={num_layers} ' , alpha=0.7 ) axes[1 ].plot(layer_indices, rdgnn_std[i], 's--' , label=f'RDGNN L={num_layers} ' , alpha=0.7 ) axes[1 ].set_xlabel('Layer Index' ) axes[1 ].set_ylabel('Mean Std' ) axes[1 ].set_title('Over-smoothing: Feature Diversity' ) axes[1 ].legend() axes[1 ].grid(True ) final_gcn_cos = [gcn_cos[i][-1 ] for i in range (len (layers))] final_rdgnn_cos = [rdgnn_cos[i][-1 ] for i in range (len (layers))] axes[2 ].plot(layers, final_gcn_cos, 'o-' , label='GCN' , linewidth=2 , markersize=8 ) axes[2 ].plot(layers, final_rdgnn_cos, 's-' , label='RDGNN' , linewidth=2 , markersize=8 ) axes[2 ].set_xlabel('Number of Layers' ) axes[2 ].set_ylabel('Final Cosine Similarity' ) axes[2 ].set_title('Over-smoothing vs Depth' ) axes[2 ].legend() axes[2 ].grid(True ) plt.tight_layout() plt.show()
总结与展望
本文建立了反应扩散系统与图神经网络的数学桥梁。我们展示了:
理论连接 :图拉普拉斯算子是连续拉普拉斯的离散版本,
GNN 的消息传递对应扩散过程模式形成 : Turing
不稳定性解释了如何从均匀状态产生空间模式过度平滑问题 :纯扩散导致节点特征趋同,反应项可以保持局部差异RDGNN 架构 :将反应扩散动力学嵌入
GNN,缓解过度平滑并提升表达能力
未来方向 : - 更复杂的反应项设计(自适应、可学习) -
与物理约束结合(守恒律、边界条件) -
时空图神经网络(动态图上的反应扩散) - 在生物网络、社交网络中的应用
✅ 小白检查点
学完这篇文章,建议理解以下核心概念:
核心概念回顾
1. 反应扩散方程的本质 -
简单说:扩散(让事物变均匀)+ 反应(产生局部差异)的平衡 - 生活类比: -
扩散:墨水在水中散开 - 反应:局部化学反应产生新颜色 -
结合:产生斑点、条纹等模式(如豹纹、斑马纹) - 数学形式:2. Turing 不稳定性是什么 -
简单说:均匀状态在小扰动下自发形成空间模式 -
关键条件:两种物质扩散速度不同(快扩散的抑制剂 + 慢扩散的激活剂) -
生活类比:森林火灾 - 火焰(激活剂)传播慢,局部燃烧 -
烟雾(抑制剂)扩散快,抑制远处点燃 -
结果:形成"岛状"燃烧模式,而非全面燃烧
3. 图拉普拉斯算子 -
简单说:衡量节点特征与邻居平均值的差异 - 数学:
4. GNN 的过度平滑问题 -
简单说:随着层数增加,所有节点特征变得几乎相同 -
原因:每层做平均(消息传递),就像扩散方程让温度变均匀 - 数学:
5. 为什么反应项能解决过度平滑 -
简单说:反应项引入非线性变换,打破纯扩散的单调性 -
类比:纯扩散像"一锅粥"(所有东西混在一起),反应项像"调料"(让不同部分保持差异)
- 数学:
6. RDGNN 的核心思想 - 简单说:把 GNN
看作离散化的反应扩散方程 - 架构:交替进行扩散步骤和反应步骤 -
扩散:
7. GRAND(图神经扩散) - 简单说:用 ODE 求解器作为
GNN 的"层" - 连续深度:不是固定层数,而是积分一个 ODE 到时刻
8. Gray-Scott 和 FitzHugh-Nagumo 模型 -
Gray-Scott :化学自催化反应,产生斑点、条纹、螺旋波 -
两种物质
FitzHugh-Nagumo :神经元电脉冲传播 -
一句话记忆
"反应扩散 = 扩散(均匀化)+ 反应(差异化), Turing
不稳定性让均匀状态产生模式"
"GNN 过度平滑 =
纯扩散问题,反应项(非线性)是解决之道"
常见误解澄清
误解 1 :"Turing 模式只是数学游戏,与现实无关" -
澄清 : Turing 模式广泛存在于自然界 -
生物:豹纹、斑马纹、贝壳花纹 - 化学: BZ 反应中的螺旋波 -
生态:植被斑图(沙漠中的规则斑点)
误解 2 :"GNN 的层数越多越好" -
澄清 :不是!过多层导致过度平滑 - 2-3
层:捕获局部结构,效果通常最好 - 10+层:所有节点特征趋同,性能下降 -
解决方案:跳跃连接、反应项、残差连接
误解 3 :"图拉普拉斯和连续拉普拉斯完全一样" -
澄清 :相似但不完全相同 - 连续:
误解 4 :"反应项就是激活函数" -
澄清 :激活函数是反应项的一种,但不是全部 -
激活函数:逐元素非线性( ReLU 、 tanh) -
更一般的反应项:可以包括跳跃连接、注意力机制、局部 MLP 等 -
关键:引入非线性,打破扩散的单调性
误解 5 :"RDGNN 一定比标准 GNN 好" -
澄清 :取决于任务 - RDGNN
优势:深层网络、需要长程依赖的任务 - 标准 GNN
优势:浅层足够、计算资源受限 - 实践:先尝试标准 GNN( 2-3
层),如果性能不够再考虑 RDGNN
如果只记住三件事
反应扩散的核心 :扩散让事物变均匀,反应产生差异,两者平衡产生丰富模式(
Turing 不稳定性)
GNN 与扩散的联系 :消息传递 =
扩散,导致过度平滑;反应项(非线性)是解决之道
图拉普拉斯的作用 :
理论联系 :图拉普拉斯算子是连续拉普拉斯算子的离散版本,图上的反应扩散系统可以产生丰富的空间模式模式形成机制 : Turing
不稳定性理论解释了均匀稳态如何失稳并形成模式,这为 GNN
提供了新的设计原则架构创新 : RDGNN
通过显式建模反应扩散动力学,缓解了过度平滑问题,提升了表达能力实验验证 :在多个数据集和图结构上, RDGNN 相比传统
GCN 展现出更好的性能谱分析 :通过频率域分析,揭示了 GNN
过度平滑的本质和反应项的作用机制数值方法 :讨论了不同数值积分方法的稳定性和效率权衡
未来方向 : -
自适应反应项 :根据图结构动态调整反应项形式,学习最优的扩散-反应平衡
-
多尺度模式 :设计多尺度架构,同时学习不同尺度的空间模式
- 时间演化 :将 RDGNN 扩展到动态图,处理时间变化的图结构
-
理论分析 :更深入的分叉理论和稳定性分析,建立收敛性保证
-
应用拓展 :将反应扩散视角应用到图生成、图匹配等更多任务
- 几何流 :结合 Beltrami
流等几何方法,优化图嵌入的几何结构
反应扩散视角为图神经网络提供了新的理论工具和实践指导。通过显式建模扩散与反应的竞争,可以设计出更强大、更稳定的
GNN 架构,有望推动 GNN
在复杂图结构学习中的进一步发展。这一交叉领域的研究不仅连接了 PDE
理论与深度学习,也为理解复杂系统的自组织行为提供了新的视角。