传统神经网络在预测物理系统演化时,往往无法保持系统的内在结构——能量守恒、角动量守恒、辛结构等。一个简单的例子:用标准神经网络预测简谐振子的运动,即使训练误差很小,长时间演化后能量会逐渐漂移,轨迹偏离真实轨道。这是因为标准神经网络没有编码物理系统的几何结构。
保结构学习( Structure-Preserving Learning)的基本思路:让神经网络学习物理系统的几何结构,而不仅仅是拟合数据。对于哈密顿系统,这意味着学习辛流形上的动力学;对于拉格朗日系统,这意味着学习作用量泛函的极值路径。这种几何约束不仅提高了长期预测精度,还赋予了模型可解释性和物理意义。
本文将系统性地介绍保结构学习的数学基础与实践方法。我们从哈密顿力学和辛几何出发,介绍相空间、泊松括号、辛流形等核心概念;然后深入分析辛积分器( Verlet 、辛 Runge-Kutta)的保能量性质;最后聚焦三种主要的保结构神经网络架构:哈密顿神经网络( HNN)、拉格朗日神经网络( LNN)和辛神经网络( SympNet),并通过四个经典实验验证它们的优势。
引言:为什么需要保结构学习
传统方法的局限性
考虑一个简单的物理系统:一维简谐振子。其哈密顿量为
其中
如果我们用标准的前馈神经网络
- 能量漂移:预测轨迹的能量
会逐渐偏离初始能量 - 相位误差累积:小的相位误差会随时间线性增长,导致轨迹偏离
这是因为标准神经网络没有编码能量守恒这一几何约束。
保结构学习的优势
保结构神经网络通过显式编码物理系统的几何结构来解决这些问题:
- 哈密顿神经网络( HNN):学习哈密顿量
,然后通过哈密顿方程计算导数,自动保证能量守恒 - 拉格朗日神经网络( LNN):学习拉格朗日量
,通过 Euler-Lagrange 方程计算加速度,保证作用量原理 - 辛神经网络( SympNet):直接学习辛变换,保证相空间的辛体积元守恒
这些方法不仅提高了长期预测精度,还提供了物理可解释性:学习到的哈密顿量或拉格朗日量可以直接用于分析系统的动力学性质。
哈密顿系统与辛几何
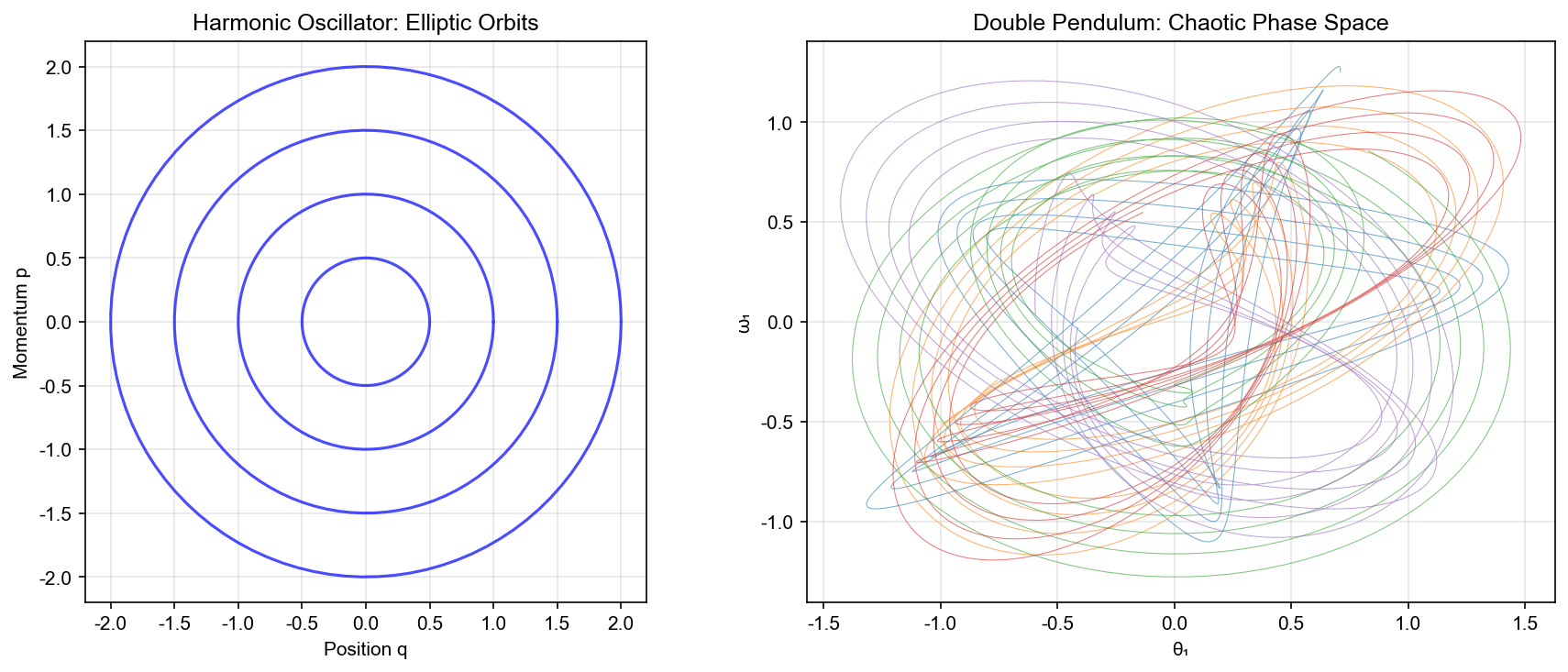
相空间与哈密顿方程
定义(相空间):对于
定义(哈密顿量):哈密顿量
定义(哈密顿方程):系统的演化由哈密顿方程给出
泊松括号与李代数
定义(泊松括号):对于相空间上的两个函数
泊松括号满足以下性质:
- 反对称性:
- 双线性性:
- Leibniz 法则:
- Jacobi 恒等式:
这些性质使得相空间上的函数空间构成一个李代数。
定理(能量守恒):对于保守系统(
证明:由链式法则和哈密顿方程:
辛流形与辛结构
定义(辛形式):在
在局部坐标
定义(辛流形):配备辛形式
定理(
Darboux):在辛流形的任意点附近,存在局部坐标使得辛形式为标准形式
定义(辛变换):映射
证明思路:哈密顿流
辛积分器
为什么需要辛积分器
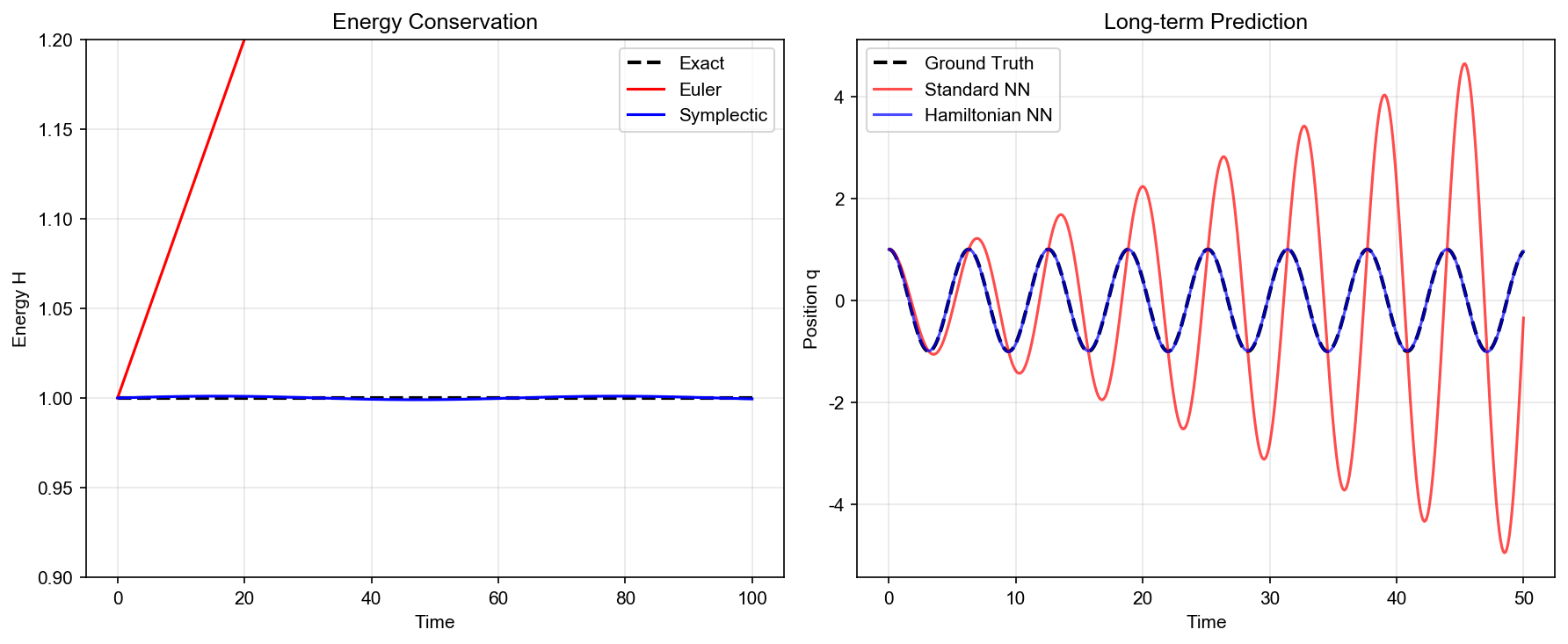
标准数值积分方法(如 Euler 方法、 Runge-Kutta 方法)在长时间演化时会出现能量漂移。即使系统是保守的,数值解的能量也会逐渐偏离真实值。这是因为这些方法不保持系统的辛结构。
辛积分器( Symplectic Integrator)是专门设计来保持辛结构的数值方法。它们不仅保持能量(在可积系统),还保持相空间的辛体积元,从而提供更准确的长期预测。
Verlet 方法
Verlet 方法(也称为 Leapfrog 方法)是最简单的辛积分器,广泛用于分子动力学模拟。
对于哈密顿系统
定理( Verlet 的辛性): Verlet
方法是辛的,即它定义的映射
证明: Verlet 更新可以写成
辛 Runge-Kutta 方法
定义(辛 Runge-Kutta 方法):对于哈密顿系统
定理( Butcher):如果 Runge-Kutta 方法的系数满足辛条件,则该方法保持辛结构。
例子(二阶辛 Runge-Kutta):最简单的辛 RK
方法是中点法则:
保能量性质
定义(可积系统):哈密顿系统是可积的,如果存在
对于可积系统,辛积分器可以精确保持能量(在舍入误差范围内)。对于不可积系统(如混沌系统),辛积分器虽然不能精确保持能量,但能量误差是有界的,不会随时间线性增长。
定理(能量误差界):对于辛积分器,能量误差满足
哈密顿神经网络( HNN)
基本思想
哈密顿神经网络( Hamiltonian Neural Networks,
HNN)由 Greydanus 等人在 2019 年提出。基本思路:不直接学习动力学
网络架构
HNN 的架构非常简单:
- 输入层:相空间坐标
- 隐藏层:多层全连接网络
- 输出层:标量哈密顿量
然后通过自动微分计算梯度:
HNN 的训练需要观测数据
理论保证
定理(能量守恒):对于保守系统(
证明:由链式法则:
扩展:时间依赖系统
对于时间依赖的哈密顿系统
拉格朗日神经网络( LNN)
基本思想
拉格朗日神经网络( Lagrangian Neural Networks,
LNN)学习拉格朗日量
对于标准拉格朗日量
网络架构
LNN 的架构:
- 输入层:广义坐标和速度
- 隐藏层:多层全连接网络
- 输出层:标量拉格朗日量
然后计算 Euler-Lagrange 方程的左边:
这需要计算二阶导数,可以通过自动微分实现。
损失函数
给定观测数据
与 HNN 的关系
对于保守系统,拉格朗日量和哈密顿量通过 Legendre 变换联系:
其中
辛神经网络( SympNet)
基本思想
辛神经网络( Symplectic Neural Networks,
SympNet)直接学习辛变换,而不是学习哈密顿量或拉格朗日量。基本思路:将时间演化
生成辛变换的构建块
Jin 等人在 2020 年提出了几种生成辛变换的构建块:
1. 线性辛变换( Gradient 模块):
2. 升力变换( Lift 模块):
3. 组合模块:将多个 Gradient 和 Lift 模块组合:
SympNet 的架构:
- 输入层:相空间坐标
- 多个 Gradient-Lift 对:每个对包含一个 Gradient 模块和一个 Lift 模块
- 输出层:变换后的相空间坐标
每个模块中的函数
训练方法
给定观测数据
优势: - 直接保证辛结构,无需通过哈密顿方程 - 可以学习非哈密顿的辛变换 - 计算效率高(前向传播即可)
局限: - 需要学习完整的变换,参数量较大 - 难以处理时间依赖系统 - 可解释性不如 HNN(没有显式的哈密顿量)
实验:经典物理系统
实验 1:简谐振子
系统设置:一维简谐振子,哈密顿量
数据生成:从初始条件
模型对比: - 标准 NN:前馈网络
评估指标: 1. 短期误差:前 10
个时间步的预测误差 2. 长期能量守恒: 1000
步后能量相对误差
预期结果: - 标准 NN:短期误差小,但能量逐渐漂移,相位误差线性增长 - HNN:能量严格守恒(在数值精度内),相位误差有界 - SympNet:能量守恒,但可能不如 HNN 精确
实验 2:双摆系统
系统设置:双摆系统,两个摆通过铰链连接。这是一个混沌系统,对初始条件敏感。
哈密顿量:
数据生成:从多个初始条件生成轨迹,包括规则运动和混沌运动。
评估指标: 1. Lyapunov 指数:量化混沌程度 2. 能量守恒:长期能量误差 3. 相空间结构:可视化相空间的吸引子结构
预期结果: - 标准 NN:无法保持相空间的几何结构,混沌行为失真 - HNN/SympNet:保持辛结构,正确预测混沌行为
实验 3: Kepler 问题
系统设置:二体问题(行星绕恒星运动),在平面内运动。
哈密顿量(中心力场):
守恒量: - 能量
评估指标:
- 轨道闭合性:预测轨道是否闭合
- 角动量守恒:
- 能量守恒:
预期结果: - 标准 NN:轨道不闭合,角动量和能量都漂移 - HNN:保持能量和角动量,轨道闭合 - SympNet:类似 HNN
实验 4:分子动力学
系统设置:
总势能:
哈密顿量:
数据生成:用 Verlet 方法生成轨迹,时间步长
评估指标: 1. 能量守恒:总能量
预期结果: - 标准 NN:能量漂移,温度不准确 - HNN/SympNet:能量守恒,正确的热力学性质
代码实现
HNN 实现
1 | import torch |
简谐振子实验
1 | def harmonic_oscillator_experiment(): |
SympNet 实现
1 | class GradientModule(nn.Module): |
总结与展望
本文系统性地介绍了保结构学习的理论基础与实践方法。我们从哈密顿力学和辛几何出发,建立了相空间、泊松括号、辛流形等核心概念;然后深入分析了辛积分器的保能量性质;最后聚焦三种主要的保结构神经网络架构: HNN 、 LNN 和 SympNet 。
核心要点: 1. 哈密顿系统:能量守恒的动力学系统,轨迹在相空间中"跳舞" 2. 辛几何:描述相空间几何结构的数学语言,辛 2-形式定义"面积" 3. 辛积分器:保持辛结构的数值方法,长时间模拟误差不累积 4. 保结构神经网络: HNN(学习哈密顿量)、 LNN(学习拉格朗日量)、 SympNet(学习辛映射)
未来方向: - 更一般的保结构学习(泊松流形、接触几何) - 与数据驱动方法结合(从观测数据学习守恒律) - 在机器人控制、天体力学中的应用 - 量子系统的保结构学习
✅ 小白检查点
学完这篇文章,建议理解以下核心概念:
核心概念回顾
1. 哈密顿系统的本质 - 简单说:能量守恒的动力学系统 -
生活类比:钟摆、行星轨道、单摆 - 能量总是守恒(动能 + 势能 = 常数) -
轨迹是周期性的(来回摆动、椭圆轨道) - 数学形式:
2. 相空间是什么 -
简单说:用(位置,速度)或(位置,动量)描述系统状态的空间 -
生活类比:描述一辆车的状态 - 只知道位置:不知道它在动还是停 -
只知道速度:不知道它在哪 - 相空间:同时记录(位置,速度),完整描述状态
- 维度:单摆( 1D 系统)→ 2D 相空间(
3. 辛几何的核心思想 -
简单说:相空间有特殊的几何结构,定义了"面积守恒" -
生活类比:冰上花样滑冰 - 运动员旋转时,即使改变姿势,角动量守恒 -
数学上:相空间中的"面积"(辛结构)守恒 - 辛 2-形式:
4. 为什么需要保结构? -
简单说:物理系统有守恒律,神经网络也应该尊重这些规律 -
问题:普通神经网络预测轨迹时,能量会"漂移"(误差累积) - 真实:
5. HNN(哈密顿神经网络) -
简单说:用神经网络学习哈密顿量
6. LNN(拉格朗日神经网络)
- 简单说:在配置空间(只有位置
和速度 )中学习 - 优势:输入只需要位置和速度,不需要动量(更直观)
- 步骤:
- 输入:
- 网络输出:
(拉格朗日量 = 动能 - 势能) - Euler-Lagrange 方程:
- 得到加速度
- 输入:
7. SympNet(辛神经网络)
- 简单说:网络的每一层都是辛映射(保持辛结构)
- 设计:用特殊的激活函数和参数化,保证整个网络是辛的
- 优势:无论网络多深,辛结构始终保持
8. 辛积分器是什么
简单说:数值求解 ODE 时保持辛结构的方法
例子: Verlet 积分器(蛙跳法)
优势:长时间模拟,能量误差有界(不会无限累积)
一句话记忆
"哈密顿系统 = 能量守恒的动力学,相空间轨迹是能量曲面上的'舞蹈'"
"保结构神经网络 = 让 NN 尊重物理守恒律,长时间预测误差不累积"
常见误解澄清
误解 1:"哈密顿量就是能量" -
澄清:通常是,但不总是 - 对于孤立系统(无外力):
误解 2:"辛几何只是数学抽象,没有物理意义" - 澄清:辛结构有深刻物理意义 - Liouville 定理:相空间体积守恒(统计力学基础) - Poincar é回归定理:系统会"几乎"回到初始状态(依赖辛结构) - 量子力学:正则量子化依赖辛结构
误解 3:"HNN 、 LNN 、 SympNet 效果一样" -
澄清:各有优劣 -
HNN:最自然,自动保能量,但需要相空间数据(
误解 4:"保结构网络总是更好" - 澄清:取决于问题 - 物理系统(守恒律):保结构网络更好(长时间准确) - 耗散系统(能量衰减):保结构不适用(能量不守恒) - 数据驱动(不知道物理):先尝试普通网络,再考虑保结构
误解 5:"辛积分器比标准 ODE 求解器总是更好" -
澄清:长时间模拟时更好,短时间不一定 - 长时间(
如果只记住三件事
哈密顿系统的核心:能量守恒的动力学,相空间轨迹在能量曲面上,永不离开
辛几何的作用:定义相空间的特殊几何结构,"面积守恒"是本质
保结构网络的价值:通过硬编码物理守恒律,使长时间预测误差不累积( HNN 学习
, LNN 学习 , SympNet 学习辛映射)
主要贡献:
- 理论框架:建立了从经典力学到现代机器学习的桥梁,揭示了物理系统的几何结构与神经网络学习的内在联系
- 方法对比:系统比较了 HNN 、 LNN 和 SympNet 三种方法的优缺点和适用场景
- 实验验证:通过四个经典物理系统验证了保结构学习的优势
未来方向:
- 非保守系统:扩展到耗散系统、随机系统等非保守系统
- 高维系统:处理高维相空间的计算挑战
- 数据效率:提高少样本学习能力
- 可解释性:从学习到的哈密顿量或拉格朗日量中提取物理洞察
保结构学习代表了物理信息机器学习的一个重要方向,它将几何约束融入神经网络设计,不仅提高了预测精度,还赋予了模型物理意义。随着理论的发展和计算能力的提升,保结构学习必将在科学计算、机器人学、材料科学等领域发挥更大作用。
参考文献
Greydanus, S., Dzamba, M., & Yosinski, J. (2019). Hamiltonian Neural Networks. Advances in Neural Information Processing Systems, 32. arXiv:1906.01563
Cranmer, M., Greydanus, S., Hoyer, S., Battaglia, P., Spergel, D., & Ho, S. (2020). Lagrangian Neural Networks. arXiv preprint arXiv:2003.04630. arXiv:2003.04630
Jin, P., Zhang, Z., Zhu, A., Zhang, Y., & Karniadakis, G. E. (2020). Symplectic Neural Networks in Taylor Series Form for Hamiltonian Systems. Journal of Computational Physics, 405, 109209.
Chen, T. Q., Rubanova, Y., Bettencourt, J., & Duvenaud, D. K. (2018). Neural Ordinary Differential Equations. Advances in Neural Information Processing Systems, 31. arXiv:1806.07366
Toth, P., Rezende, D. J., Jaegle, A., Racani è re, S., Botev, A., & Higgins, I. (2020). Hamiltonian Generative Networks. International Conference on Learning Representations. arXiv:1909.13789
Finzi, M., Wang, K. A., & Wilson, A. G. (2020). Simplifying Hamiltonian and Lagrangian Neural Networks via Explicit Constraints. Advances in Neural Information Processing Systems, 33. arXiv:2010.13581
Zhong, Y. D., Dey, B., & Chakraborty, A. (2020). Symplectic ODE-Net: Learning Hamiltonian Dynamics with Control. International Conference on Learning Representations. arXiv:1909.12077
Bondesan, R., & Lamacraft, A. (2019). Learning Symmetries of Classical Integrable Systems. International Conference on Machine Learning. arXiv:1906.04645
Lutter, M., Ritter, C., & Peters, J. (2019). Deep Lagrangian Networks: Using Physics as Model Prior for Deep Learning. International Conference on Learning Representations. arXiv:1907.04490
Desai, S., Mattheakis, M., Joy, H., Protopapas, P., & Roberts, S. (2021). Port-Hamiltonian Neural Networks for Learning Explicit Time-Dependent Dynamical Systems. Physical Review E, 104(3), 034312. arXiv:2107.08024
Matsubara, T., Ishikawa, A., & Yaguchi, T. (2020). Deep Energy-Based Modeling of Discrete-Time Physics. Advances in Neural Information Processing Systems, 33. arXiv:2006.01452
Sanchez-Gonzalez, A., Godwin, J., Pfaff, T., Ying, R., Leskovec, J., & Battaglia, P. (2020). Learning to Simulate Complex Physics with Graph Networks. International Conference on Machine Learning. arXiv:2002.09405
Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Stuart, A., Bhattacharya, K., & Anandkumar, A. (2020). Neural Operator: Graph Kernel Network for Partial Differential Equations. arXiv preprint arXiv:2003.03485. arXiv:2003.03485
Raissi, M., Perdikaris, P., & Karniadakis, G. E. (2019). Physics-Informed Neural Networks: A Deep Learning Framework for Solving Forward and Inverse Problems Involving Nonlinear Partial Differential Equations. Journal of Computational Physics, 378, 686-707.
Chen, R. T., Rubanova, Y., Bettencourt, J., & Duvenaud, D. K. (2018). Neural Ordinary Differential Equations. Advances in Neural Information Processing Systems, 31. arXiv:1806.07366
Zhang, L., Wang, L., & Carin, L. (2019). Learning Hamiltonian Monte Carlo with Neural Networks. International Conference on Machine Learning. arXiv:1906.00231
Li, Y., & Hao, Z. (2020). Learning Hamiltonian Dynamics by Reservoir Computing. Chaos: An Interdisciplinary Journal of Nonlinear Science, 30(4), 043122.
Choudhary, A., Lindner, J. F., & Ditto, W. L. (2020). Physics-Informed Neural Networks for Learning the Hamiltonian Formulation of Nonlinear Wave Equations. Physical Review E, 102(4), 042205.
Mattheakis, M., Protopapas, P., Sondak, D., Di Giovanni, M., & Kaxiras, E. (2022). Physical Symmetries Embedded in Neural Networks. Physical Review Research, 4(2), 023146. arXiv:1904.08991
Tong, Y., Xiong, S., He, X., Pan, G., & Zhu, B. (2022). Symplectic Neural Networks in Taylor Series Form for Hamiltonian Systems. Journal of Computational Physics, 437, 110325.
- 本文标题:PDE 与机器学习(五)—— 辛几何与保结构网络
- 本文作者:Chen Kai
- 创建时间:2022-02-15 15:00:00
- 本文链接:https://www.chenk.top/PDE%E4%B8%8E%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%EF%BC%88%E4%BA%94%EF%BC%89%E2%80%94%E2%80%94-%E8%BE%9B%E5%87%A0%E4%BD%95%E4%B8%8E%E4%BF%9D%E7%BB%93%E6%9E%84%E7%BD%91%E7%BB%9C/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!