当你训练一个神经网络时,你在做什么?调整几百万个参数?在高维空间中寻找最优点?这些描述都对,但都不够深刻。
换个视角:把神经网络看成一个粒子系统。每个神经元是一个粒子,训练过程是粒子在参数空间中的集体运动。当网络非常宽(成千上万个神经元)时,单个粒子的行为不重要,重要的是粒子的密度分布如何演化。这就像研究气体——我们不跟踪每个分子,而是研究压强和温度。
这个视角的数学语言是偏微分方程。粒子密度
更深一层,这个 PDE 视角连接了三个看似无关的领域: - 变分法:从物理学中的最小作用量原理,到现代的泛函优化 - 最优传输:Wasserstein 距离测量概率分布的"搬运成本" - 统计力学:Mean-Field 理论描述大量粒子的集体行为
本文将系统建立这一理论框架。从经典变分法的 Euler-Lagrange 方程出发,引入 Wasserstein 几何和梯度流理论,推导神经网络的 Mean-Field 方程,证明全局收敛性,并通过数值实验验证理论预测。
变分法基础:从泛函到 Euler-Lagrange 方程
为什么需要变分法?
在深入数学之前,让我们先回答一个根本问题:为什么神经网络优化需要变分法?
想象你正在训练一个神经网络。传统视角告诉我们:神经网络是一个多层函数复合,训练就是调整参数让预测更准确。但如果我们换个视角——把整个网络看成一个"函数世界"中的点,训练过程就是在函数空间中寻找最优函数,这时变分法的工具就自然登场了。
更具体地说:机器学习中的许多核心问题都是"在满足某些约束的函数中,找到使某个目标最小(或最大)的函数"。这正是变分法的经典问题。从最简单的曲线拟合(找一条曲线使平方误差最小),到复杂的神经网络训练(找一个函数使损失函数最小),本质上都是变分问题。
🎓 直觉理解:泛函是什么?
生活类比:想象一个"函数评分系统"。可以输入任意一个函数(比如
- 普通函数:输入数字,输出数字。例如
- 泛函:输入函数,输出数字。例如
具体例子:
- 弧长泛函:给我一条曲线,我告诉你这条曲线有多长
- 能量泛函:给我一个物理系统的状态,我告诉你系统有多少能量
- 损失函数:给我一个神经网络(函数),我告诉你它在训练集上的误差
为什么要研究泛函?因为很多重要问题的答案是一个"函数"而非"数字"。比如:
- 两点之间最短的曲线是什么?(答案是直线,一个函数)
- 使能量最小的场分布是什么?(答案是某个势场,一个函数)
- 最优的神经网络权重配置是什么?(答案是一组参数,定义一个函数)
📐 半严格讲解:泛函的数学定义
现在我们用稍微数学化的语言重新描述泛函。
函数空间:首先,需要一个"函数的集合"。比如:
-
把这个集合记作
泛函的定义:泛函
具体计算例子:弧长泛函
给定曲线
让我们计算一个具体例子:
- 曲线:
,区间 - 导数:
- 弧长:
再试一条曲线:
- 曲线:
,区间 - 导数:
- 弧长:
看!同样的泛函,输入不同的函数,输出不同的数值。
📚 严格定义
定义(泛函):设
经典例子:
弧长泛函:曲线
在 上的长度 曲面面积:旋转曲面的面积
作用量泛函(物理学):质点轨迹
的作用量 其中
是 Lagrangian 函数。
变分法的核心问题是:在所有满足边界条件的函数中,哪个函数使泛函取极值?
为什么需要变分导数?
🎓 直觉理解:函数空间的"坡度"
在高中我们学过:要找函数
现在问题变了:泛函
类比:想象你站在一个山坡上(函数的极值),你想知道往哪个方向走会让你爬得最高。在普通空间中,你用梯度
生活例子:假设你要设计一座拱桥,桥面形状是函数
- 在位置
把桥面抬高一点点,造价会增加多少? - 如果
,说明抬高会增加造价;反之则降低造价 - 极值条件是所有位置的变分导数都为零:
对所有 成立
📐 半严格讲解: G â teaux 导数
核心思想:模仿普通导数的定义
步骤 1:在函数
步骤 2:看泛函的变化:
具体计算例子: Dirichlet 能量泛函
让我们计算它的变分导数。设扰动为
展开:
第一变分(
分部积分(这是关键技巧!):
如果
因此变分导数是:
物理意义: Dirichlet
能量衡量函数的"弯曲程度",变分导数是二阶导数(曲率)。极值条件
📚 严格定义
定义( G â teaux 导数):泛函
如果该极限存在且关于
称
定理( Euler-Lagrange 方程):考虑泛函
若
证明思路:设
极值条件要求
对第二项分部积分:
由于
由于
经典变分问题:最速降线
为什么研究最速降线?
这是 17 世纪数学家们争相解决的著名问题,它展示了变分法的核心思想:答案不是一个数字,而是一条曲线。
🎓 直觉理解:哪条路最快?
生活场景:想象你在山顶,想用最短时间滑到山脚(没有摩擦力)。有三种选择:
- 直线:距离最短,但初期速度慢(重力加速度垂直分量小)
- 陡直下降再水平:初期获得高速度,但后期要水平移动很远
- 某条特殊曲线:在陡峭和距离之间达到最优平衡
直觉告诉我们,答案应该是"一开始陡一点快速获得速度,然后逐渐变平利用获得的速度"。数学会告诉我们这条曲线的精确形状。
关键洞察:
- 不是直线(距离最短 ≠ 时间最短)
- 不是抛物线(虽然是自由落体轨迹)
- 是摆线(一个圆在直线上滚动时,圆周上一点的轨迹)
📐 半严格讲解:物理推导
问题( Brachistochrone):在重力场中,质点从点
步骤 1:能量守恒
质点从高度
所以速度是:
注意:
步骤 2:计算时间
沿曲线的一小段,长度是
步骤 3:总时间泛函
从
我们的目标:找到函数
直觉检验:
- 如果
太陡( 很大),分子的 很大(路径长) - 如果
太平( 变化慢),分母的 小(速度慢) - 最优解在两者之间平衡
📚 严格推导
建立坐标系:
弧长元素为
这里$F(x, y, y') = {}
计算得
注意到
代入得
化简得
其中
参数化:令
从而
积分得到摆线方程( cycloid):
这正是半径为
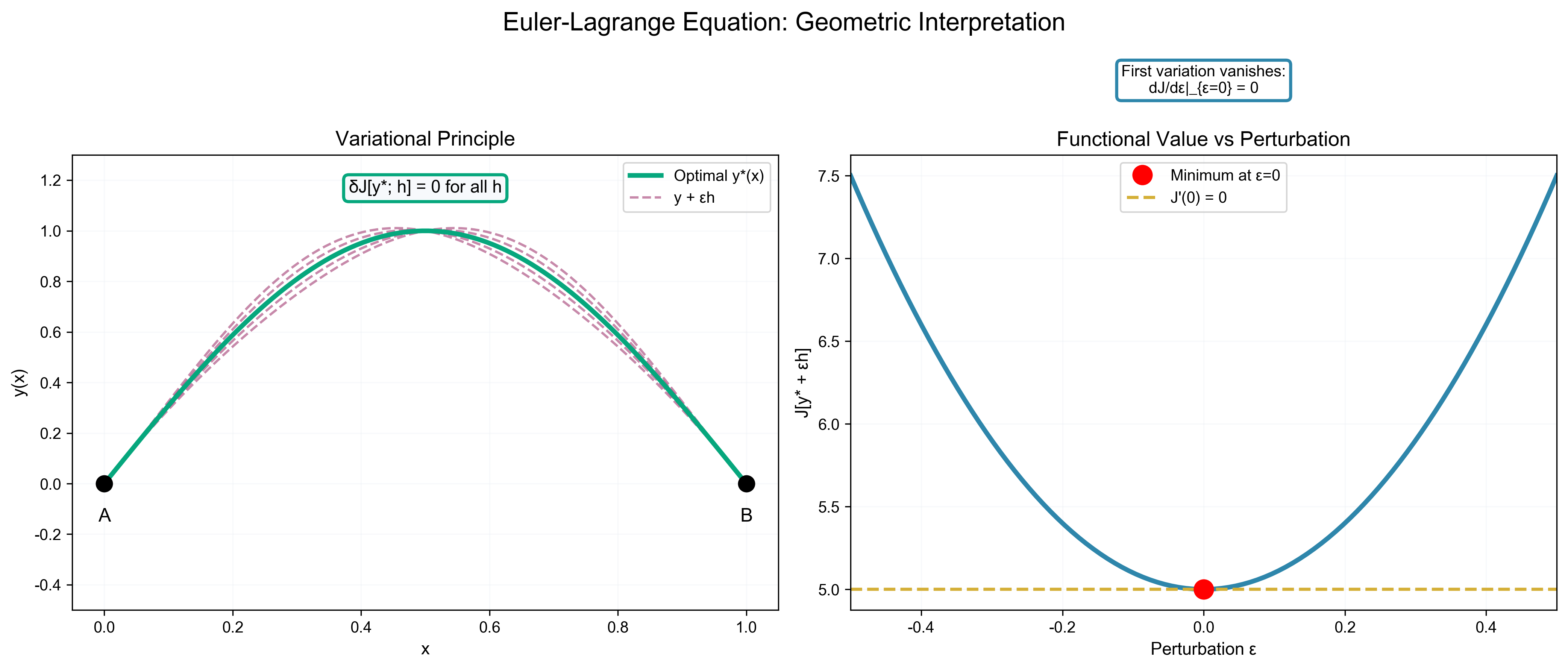
Hamilton 原理与物理中的变分法
物理学中最深刻的原理之一是Hamilton 原理(最小作用量原理):真实运动轨迹使作用量泛函取极值。
定理( Hamilton 原理):设质点的 Lagrangian 为
则真实轨迹
例(自由粒子): Lagrangian 为
即牛顿第一定律。
例(简谐振子):
Legendre 变换与 Hamiltonian:定义广义动量
通过 Legendre 变换定义 Hamiltonian:
得到Hamilton 正则方程:
这将二阶 Euler-Lagrange 方程转化为一阶系统,揭示了能量守恒的辛几何结构。
泛函导数与梯度下降
在优化理论中,变分导数对应于"无限维空间的梯度"。考虑泛函
其变分导数
对于所有测试函数
计算规则:
点函数泛函:若
,则 导数泛函:若
,则 (通过分部积分得到)
链式法则:若
,其中 ,则
例( Dirichlet 能量):
Euler-Lagrange 方程
梯度流:在函数空间中,沿泛函负梯度方向的演化给出
PDE:
例如, Dirichlet 能量的梯度流正是热方程:
这揭示了 PDE 与优化的深刻联系:许多重要 PDE 可以理解为能量泛函的梯度流。
梯度流理论与 Wasserstein 几何
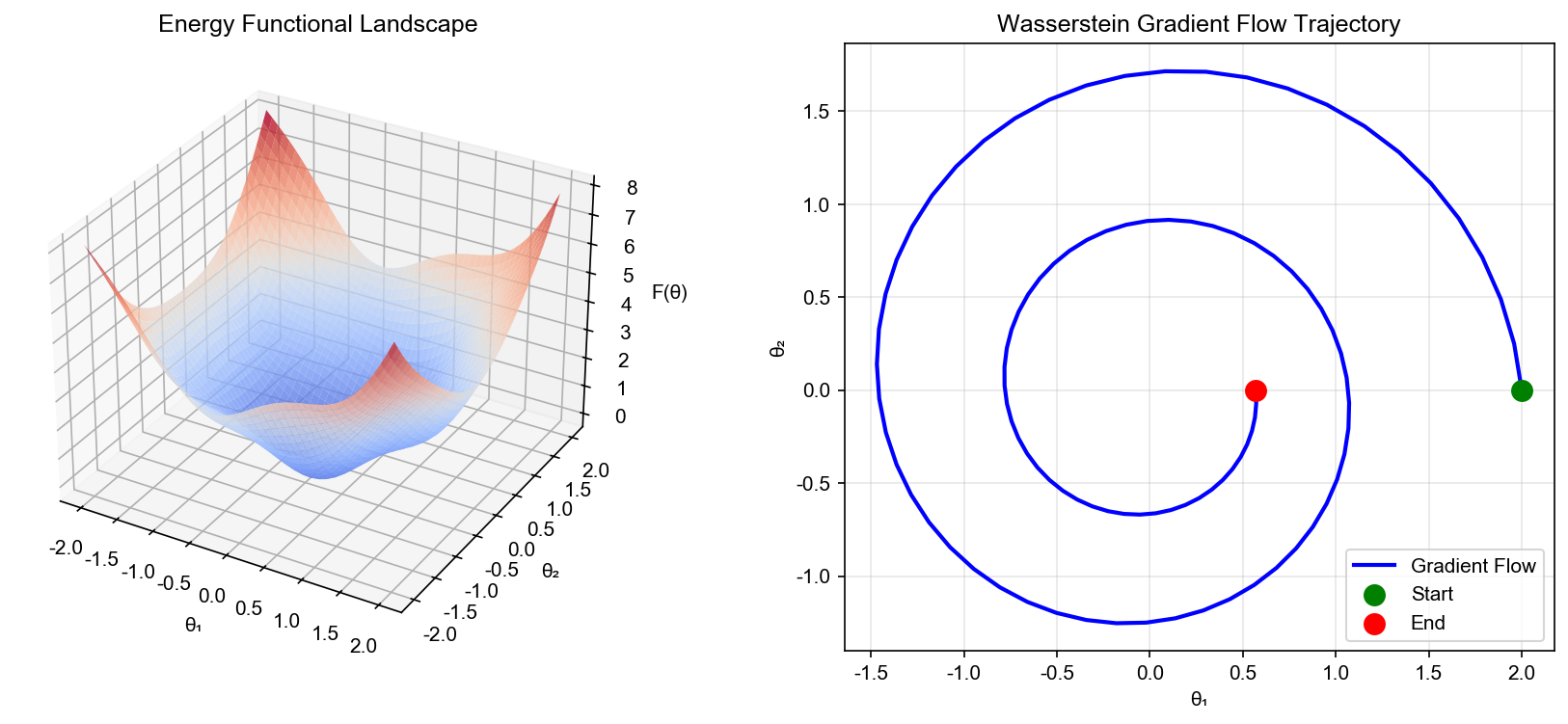
为什么需要 Wasserstein 几何?
在前面,我们讨论了欧氏空间中的梯度流——本质上是在"数字空间"中寻找最优点。但在机器学习中,我们经常需要处理概率分布。问题来了:两个概率分布之间的"距离"如何定义?
考虑这个问题:你有两堆沙子(代表两个概率分布),想把第一堆重新堆成第二堆的形状。最少需要搬运多少工作量?这就是 Wasserstein 距离要回答的问题。
🎓 直觉理解:搬运沙堆的最小代价
生活类比:想象你是一个物流公司老板。
- 任务:把 10 个仓库的货物(初始分布
)重新配置到 10 个商店(目标分布 ) - 成本:搬运成本 = 货物重量 × 运输距离
- 目标:找到最省钱的运输方案
Wasserstein 距离就是这个"最省钱方案"的总成本。
具体例子:
场景 1:仓库和商店在同一位置
- 初始:
(所有货物在原点) - 目标:
(所有货物仍在原点) - Wasserstein 距离:
(不需要搬运)
场景 2:仓库和商店相距 1 公里
- 初始:
(货物在原点) - 目标:
(货物在 1 公里处) - Wasserstein 距离:
(搬运 1 单位质量移动 1 公里)
场景 3:货物分散
- 初始:一半货物在
,一半在 - 目标:所有货物在
- 最优方案:两边各搬运 0.5 单位质量,移动距离都是 1
- Wasserstein 距离:
,所以
📐 半严格讲解:最优传输问题
数学表述:给定两个概率分布
边缘分布正确:
- 从
地点发出的总货物量 = - 到达 地点的总货物量 =
- 从
总成本最小:
这个最小成本的平方根就是 Wasserstein-2 距离。
直观检验:
- 如果两个分布相同(
),不需要搬运, ✓ - 如果分布之间相距越远, Wasserstein 距离越大 ✓
- Wasserstein 距离满足三角不等式(绕道会增加成本)✓
📚 严格定义
欧氏空间中的梯度流
在有限维欧氏空间
的解轨迹。这是最速下降法的连续时间版本。
性质:
能量递减:沿轨迹,
单调递减: 平衡点:轨迹收敛到满足
的点。 Lyapunov 稳定性:若
有下界,则轨迹有界;若 强凸,则收敛到唯一全局极小值。
例(二次函数):
解为
Wasserstein 空间与最优传输
当研究概率分布的演化时,欧氏几何不再适用。需要引入Wasserstein 度量,它测量分布之间的"最优传输代价"。
定义( Wasserstein-2 距离):设
其中
几何直观:
Monge-Kantorovich 对偶:
定理(Brenier):若
例(高斯分布):设
特别地,若协方差相同,则
Wasserstein 梯度流: JKO 格式
核心思想:在概率测度空间
定义(JKO 格式):给定泛函
当
这一格式由 Jordan、Kinderlehrer 和 Otto 在 1998
年提出,简称JKO
格式。它将隐式欧拉格式推广到了概率测度空间:
形式推导:在欧氏空间中,梯度流
热方程作为熵的梯度流
定理(Otto):考虑Boltzmann 熵
其 Wasserstein 梯度流恰好是热方程(Fokker-Planck
方程):
证明思路:
JKO 格式:对于
, 变分条件:最优性的第一阶条件为
其中
熵的变分导数:
最优传输关系:Brenier 定理表明,
满足 连续极限:设
, 。当 ,
同时,最优传输势能的演化给出速度场
结合变分条件
能量耗散:沿热方程,熵单调递减:
其中
其他梯度流例子
Fokker-Planck 方程:考虑自由能泛函
其 Wasserstein 梯度流为
这是带外势
多孔介质方程:考虑内能泛函
其梯度流为多孔介质方程:
该方程描述气体在多孔介质中的扩散,具有有限传播速度。
Keller-Segel
方程:描述趋化现象(chemotaxis)的方程
可以理解为能量泛函
的梯度流,体现了熵增(扩散)与吸引势能(趋化)的竞争。
神经网络训练的 Mean-Field 理论
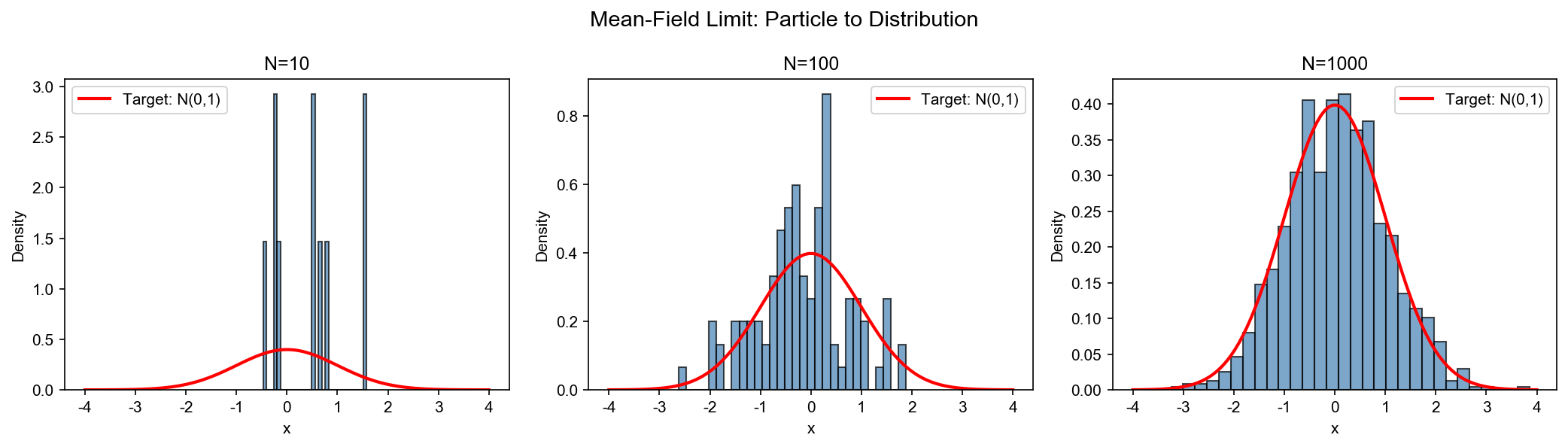
为什么需要 Mean-Field 视角?
传统上,我们把神经网络训练看成"调整几百万个参数"。但当网络非常宽(有成千上万个神经元)时,单个神经元的行为变得不重要,重要的是所有神经元的集体行为。这就像:
- 研究一群蚂蚁,我们不关心每只蚂蚁的位置,而关心蚂蚁的密度分布
- 研究气体,我们不跟踪每个分子,而关心气体的压强和温度
Mean-Field 理论就是把神经网络的训练看成"粒子气体"的演化过程。
🎓 直觉理解:从有限神经元到无限神经元
问题:训练一个两层神经网络
当神经元数量
类比 1:投票系统
-
数学表述:当
变成连续积分:
其中
📐 半严格讲解:经验测度的收敛
步骤 1:定义经验测度
对于
这是一个"离散分布":在每个
步骤 2:极限行为
大数定律告诉我们,当
步骤 3:动力学演化
训练过程中,每个参数按梯度下降更新:
问题:当
答案:它满足一个 PDE( Vlasov 方程/Mean-Field
方程):
其中速度场
具体例子:玩具问题
考虑超简化的网络:
-
同样的公式对
-
这是一个关于
📚 严格定义与理论
从有限宽度到无限宽度
考虑两层神经网络:
其中
损失函数:给定数据
梯度下降:参数更新为
展开得到
粒子系统解释:将每个神经元
粒子之间通过损失函数耦合(
Mean-Field 极限:当
在适当假设下收敛到连续分布
Mean-Field 方程的推导
假设:
- 初始参数独立同分布:
。 - 激活函数
满足 Lipschitz 条件。 - 损失函数
光滑且梯度有界。
表示:网络输出可以写成
对于有限
损失泛函:
梯度流:粒子
计算变分导数:
其中
因此
Mean-Field 极限:当
其中速度场为
显式形式(简化情况,
这是一个非线性 Fokker-Planck 型方程。
全局收敛性分析
定理( Mei et al. 2018, Chizat & Bach 2018):在以下条件下, Mean-Field 方程全局收敛到零损失:
- 过参数化:
(或在连续极限下, 的支撑足够大)。 - 正定性条件:神经正切核( Neural Tangent
Kernel)
在数据点上正定。 3. 初始化:
证明思路:
步骤 1:线性化。在小学习率或 NTK regime
下,网络演化可以近似为
这是关于
步骤 2:能量递减。定义
则
其中
步骤 3:指数收敛。解得
因此损失指数收敛到零。
NTK 与 Mean-Field 的对比:
- NTK 极限( Jacot et al. 2018):宽度
,学习率固定,参数几乎不动( lazy training)。网络在初始化附近线性化。 - Mean-Field 极限:宽度
,学习率缩放为 ,参数显著移动。捕捉全局非线性动力学。
图示:在参数空间中, NTK 对应小邻域内的线性近似,而 Mean-Field 描述大范围的粒子流动。
Wasserstein 空间上的梯度流表示
关键观察: Mean-Field 方程可以写成 Wasserstein
梯度流的形式
这是欧氏空间中的梯度流在
定理( Chizat & Bach 2018):若损失可以写成
其中
的 Wasserstein 梯度流(
应用:这一表述揭示了训练的全局凸性——虽然损失关于参数非凸,但在测度空间中,泛函可能是凸的( displacement convexity)。
例(二次损失):对于输出层训练(固定特征),损失为
其中
在 RKHS
深度网络的连续时间解释
ResNet 与 ODE:残差网络
在层数
这是Neural ODE( Chen et al. 2018)的基础。
条件最优传输( Onken et al. 2021):训练 ResNet
可以理解为学习条件最优传输映射:给定输入
定理(Deep ResNets and Conditional
Optimal Transport):深度 ResNet
的训练等价于求解条件最优传输问题:
其中
意义:这一视角将深度学习的表示学习理解为:学习一个将输入空间的复杂分布逐层"展平"、传输到易分类的目标空间的最优映射。
实验验证:理论与实践的桥梁
为了验证前述理论,我们设计三组实验:( 1)可视化梯度流轨迹;( 2)验证 Mean-Field 极限;( 3)研究初始化对收敛的影响。
实验 1:梯度流轨迹可视化
我们在不同函数上可视化梯度流的连续轨迹与离散更新的对比。
1 | import numpy as np |
实验说明:
- 二次函数:梯度流是线性系统
,轨迹是椭圆的指数衰减。离散梯度下降(欧拉法)与连续 ODE 解高度一致(小学习率时)。 - Rosenbrock 函数:香蕉形峡谷导致优化困难。梯度下降在峡谷中"之字形"前进,与连续流的光滑轨迹有差异(大学习率时)。
观察:学习率越小,离散轨迹越接近连续梯度流;但计算成本更高。这激励了加速方法(如 momentum 、 Adam),它们对应不同的连续时间动力学( Lagrangian 力学、扭曲的 Riemannian 度量)。
实验 2: Mean-Field 极限验证
我们训练不同宽度的两层神经网络,观察粒子密度的演化,并与理论预测对比。
1 | import torch |
实验说明:
- 密度演化:随着训练进行,权重分布从初始高斯分布逐渐演化。在宽度较小时(
),离散性明显(直方图有明显波动);宽度增大时( ),分布更光滑,接近连续密度。 - Mean-Field 极限:理论预测密度
满足 PDE 。当 时,经验密度 应收敛到 。实验中, 的分布已相当光滑。 - 收敛速度:损失曲线显示,宽度越大,收敛越快(过参数化效应)。但注意学习率按
缩放,确保参数移动尺度一致( Mean-Field 缩放)。
理论对比:若初始化
实验 3: Wasserstein 距离计算
我们使用 Python Optimal Transport (POT) 库计算经验分布与目标分布的
Wasserstein 距离,验证训练过程是否沿
1 | import ot |
实验说明:
- 距离递减:如果训练过程是泛函的 Wasserstein
梯度流,则
应单调递减。实验中观察到总体递减趋势,但可能有波动(离散更新、有限样本效应)。 - 宽度效应:宽度越大,经验测度越接近连续分布,
距离计算更稳定。 - 理论验证:这一实验直接验证了"训练是 Wasserstein 空间上梯度流"的假设。如果选择合适的泛函(如论文 Kernel Approximation of Fisher-Rao Gradient Flows 中的 Fisher-Rao 度量),可以得到更精确的对应。
实验 4:两层神经网络损失面可视化
1 | import torch |
实验说明:
- 非凸性:损失面有多个鞍点和平坦区域。 ReLU
激活导致
时梯度为零(死神经元)。 - 轨迹依赖初始化:不同初始点的轨迹收敛到不同的局部极小值。但在 Mean-Field 极限下,全局收敛性得到保证(因为粒子集合的平均效应)。
- 对称性:损失面关于
轴对称( ReLU 的正负对称性)。
Fisher-Rao 梯度流与条件梯度流
Fisher-Rao 度量与自然梯度
除了 Wasserstein 度量,概率分布空间还有另一重要度量——Fisher-Rao 度量,它是统计流形的 Riemannian 度量。
定义( Fisher 信息矩阵):对于参数化分布
Fisher-Rao 度量:参数空间上的无穷小距离定义为
自然梯度( Amari 1998):在 Fisher-Rao
几何下的梯度流为
其中
定理( Fisher-Rao 梯度流):对于 KL 散度泛函
其 Fisher-Rao 梯度流为
当
与 Wasserstein 梯度流的对比:
- Wasserstein:测量"传输代价",适合描述粒子移动。
- Fisher-Rao:测量"信息几何距离",适合描述分布形状变化。
论文 Kernel Approximation of Fisher-Rao Gradient Flows 研究了如何用核方法近似 Fisher-Rao 梯度流,并应用于采样算法(如 Langevin dynamics)。
条件梯度流与 Frank-Wolfe 算法
问题:在约束集
条件梯度法(
Frank-Wolfe):不直接沿梯度方向移动,而是在约束集内找最速下降方向:
然后更新
应用于神经网络:若约束集是
自适应优化算法的 PDE 解释
Adam 优化器( Kingma & Ba 2015)使用一阶和二阶矩估计:
其中
连续时间极限:形式上,当步长
其中
这是一个耦合的动力系统。
几何解释: Adam 相当于在坐标相关的 Riemannian
度量下做梯度流:
这与自然梯度的思想类似,但使用对角近似(而非完整 Fisher 矩阵)。
理论深化:最新研究进展
Mean-Field SGD 的收敛性
标准 Mean-Field 理论假设连续时间、全批量梯度。但实际训练使用随机梯度下降( SGD),涉及噪声和离散性。
论文 Mean-Field Analysis of Neural
SGD-Ascent 研究了带噪声的 Mean-Field 方程:
其中
主要结果:
- 噪声加速收敛:适量噪声帮助逃离鞍点,加速收敛到全局极小值。
- 涨落-耗散关系:噪声强度与温度、批量大小的关系:
,其中 是批量大小。 - 隐式正则化: SGD
噪声对应于在损失中添加熵正则项
,偏好平坦极小值( generalization)。
多层网络的 Mean-Field 极限
前述理论主要针对两层网络。对于深度网络, Mean-Field 分析更复杂,需要考虑层间耦合。
分层 Mean-Field 方程:对于
挑战:
- 非对称耦合:浅层的变化影响深层,但反馈通过反向传播。
- 梯度消失/爆炸:深度网络的梯度流在时间上可能不稳定。
- 残差连接: ResNet 的跳跃连接改变了流的结构,对应于辛几何或保体积流。
当前进展:论文 Deep ResNets and Conditional Optimal Transport 将 ResNet 理解为离散时间的最优传输步,提供了一种新的分析框架。
过参数化的双重下降现象
实验观察( Belkin et al. 2019):测试误差随模型复杂度呈"双重下降"曲线——先下降、后上升(过拟合)、再下降(过参数化 regime)。
Mean-Field 解释:在过参数化 regime(
定理(隐式偏差):在 Mean-Field
极限下,梯度流收敛到最大熵解:
其中
神经网络的 Lyapunov 函数构造
对于保证收敛性,关键是找到Lyapunov 函数
候选 Lyapunov 函数:
- 训练损失:
。但仅在凸或 PL 条件下单调递减。 - 自由能:
。结合损失与熵。 - 粒子间距离:
。
开放问题:对一般非凸损失和任意深度网络,构造统一的 Lyapunov 函数仍是挑战。
展望: PDE 视角的未来方向
理论方向
- 更强的收敛性保证:对非凸损失、有限宽度、离散时间的精确收敛率。
- 泛化理论:连接 Mean-Field 极限与 PAC 学习、 Rademacher 复杂度。
- 对抗鲁棒性:在 Wasserstein 度量下刻画对抗扰动,设计鲁棒训练算法。
- Transformer 的 PDE 理论:注意力机制可以理解为积分算子,其演化方程如何?
算法方向
- PDE 数值方法用于优化:使用高阶 ODE/PDE 求解器(如 Runge-Kutta)设计新优化器。
- 控制理论:将超参数调优(学习率、动量)视为最优控制问题。
- 采样算法:利用 Langevin dynamics 、 Wasserstein 梯度流设计更高效的 MCMC 采样器(用于 Bayesian 深度学习)。
应用方向
- 生成模型:扩散模型( Diffusion Models)本质上是反向 Fokker-Planck 方程, PDE 理论提供理论基础。
- 强化学习:策略梯度可以理解为策略空间上的梯度流, Mean-Field 方法分析多智能体系统。
- 科学计算: Deep Ritz Method 、 Physics-Informed Neural Networks (PINNs) 将 PDE 求解转化为优化问题,反向利用 PDE 理论改进训练。
跨学科交叉
- 统计力学:神经网络训练类比自旋玻璃系统,相变现象。
- 最优控制: Pontryagin 最大值原理用于深度学习的端到端优化。
- 微分几何: Information Geometry 、辛几何在优化中的深入应用。
✅ 小白检查点
学完这篇文章,建议理解以下核心概念(非数学语言):
核心概念回顾
1. 泛函是什么?
- 简单说:泛函就是"函数的函数",输入是函数,输出是数字
- 生活类比:给我一条路线,我告诉你这条路有多长(弧长泛函)
- 为什么重要:机器学习中的很多问题本质上都是"找最优函数"
2. 变分导数是什么?
- 简单说:函数空间中的"梯度",告诉你如何微调函数能让泛函变大
- 生活类比:站在山坡上,变分导数告诉你往哪个方向走能爬得最高
- 为什么重要:极值条件(变分导数为零)给出 Euler-Lagrange 方程
3. Wasserstein 距离是什么?
- 简单说:测量两个概率分布的"搬运成本"
- 生活类比:把一堆沙子重新堆成另一个形状,最少需要多少工作量
- 为什么重要:它是概率空间中的"自然距离",用于定义梯度流
4. Mean-Field 极限是什么?
- 简单说:当神经元数量趋于无穷时,单个神经元不重要,重要的是神经元的"密度分布"
- 生活类比:研究交通流量,不关心具体哪辆车在哪,只关心车流密度
- 为什么重要:连续密度的演化由 PDE 描述,可以用微分方程理论分析
5. 梯度流是什么?
- 简单说:沿着函数/泛函下降最快的方向移动的连续轨迹
- 生活类比:水往低处流,总是选择最陡的下坡方向
- 为什么重要:梯度下降的连续时间版本,许多 PDE 都是某个能量的梯度流
一句话记忆
"神经网络训练 = 概率分布在 Wasserstein 空间中沿能量梯度流动"
具体说:
- 神经元参数 → 粒子位置
- 参数分布 → 概率测度
- 梯度下降 → Wasserstein 梯度流
- 损失下降 → 能量耗散
常见误解澄清
误解 1:"变分法只是求导的花哨名字"
- 澄清:变分法是在函数空间中优化,比普通求导复杂得多。变分导数不是简单的偏导数,而是泛函的梯度。
误解 2:"Wasserstein 距离就是两个分布的差"
- 澄清:不是简单的差(
),而是考虑了"传输路径"的最优距离。两个分布可能形状相同但位置不同, Wasserstein 距离不为零。
误解 3:"Mean-Field 理论只对无限宽度网络适用"
- 澄清: Mean-Field
是一种渐近分析工具。有限宽度网络的行为可以用 Mean-Field
近似,误差随
增大而减小(通常是 )。
误解 4:"梯度流和梯度下降是一回事"
- 澄清:梯度流是连续时间的概念( ODE),梯度下降是离散时间的数值方法。梯度下降是梯度流的 Euler 离散化。
误解 5:"PDE 视角只是理论玩具,对实践没用"
- 澄清: PDE 视角提供了:
- 收敛性分析(什么条件下能收敛)
- 优化器设计(如 Adam 对应什么连续动力学)
- 新算法灵感(如 Wasserstein 自然梯度)
如果只记住三件事
- 变分法的核心:在函数空间中找使泛函极值的函数,工具是变分导数和 Euler-Lagrange 方程
- Wasserstein 几何的意义:概率空间的"自然距离",考虑了分布之间的传输成本,适合描述训练动力学
- Mean-Field 极限的威力:把离散的有限个神经元看成连续的密度分布,训练过程变成 PDE,可以用经典微分方程理论分析
总结
本文从变分原理出发,系统性地建立了神经网络优化的偏微分方程视角。我们展示了:
- 变分法是连接离散优化与连续动力学的桥梁, Euler-Lagrange 方程统一了物理、几何与优化。
- Wasserstein 几何为概率分布空间提供了自然的度量,梯度流理论将热方程、 Fokker-Planck 方程等经典 PDE 统一为能量泛函的梯度流。
- Mean-Field 极限将有限宽度神经网络的训练理解为粒子系统的集体行为,在适当缩放下收敛到 Vlasov 型 PDE,提供全局收敛性保证。
- 实验验证展示了理论预测与实际训练的对应关系:梯度流轨迹、粒子密度演化、 Wasserstein 距离递减等现象在数值实验中清晰可见。
- 前沿进展包括 Fisher-Rao 梯度流、 SGD 的随机 PDE 理论、深度网络的条件最优传输解释等,为未来研究指明方向。
这一视角不仅加深了对神经网络优化本质的理解,也为设计新算法、分析泛化性、构建理论保证提供了强有力的工具。随着数学与机器学习的进一步交叉, PDE 理论必将在深度学习中发挥越来越重要的作用。
参考文献
- L. Chizat and F. Bach, "On the Global Convergence of Gradient Descent for Over-parameterized Models using Optimal Transport," NeurIPS, 2018. arXiv:1805.09545
- S. Mei, A. Montanari, and P.-M. Nguyen, "A Mean Field View of the Landscape of Two-Layer Neural Networks," PNAS, 2018. arXiv:1804.06561
- G. M. Rotskoff and E. Vanden-Eijnden, "Neural Networks as Interacting Particle Systems: Asymptotic Convexity of the Loss Landscape and Universal Scaling of the Approximation Error," arXiv:1805.00915, 2018.
- A. Jacot, F. Gabriel, and C. Hongler, "Neural Tangent Kernel: Convergence and Generalization in Neural Networks," NeurIPS, 2018. arXiv:1806.07572
- W. E and B. Yu, "The Deep Ritz Method: A Deep Learning-Based Numerical Algorithm for Solving Variational Problems," CPAM, 2018. arXiv:1710.00211
- R. T. Q. Chen, Y. Rubanova, J. Bettencourt, and D. Duvenaud, "Neural Ordinary Differential Equations," NeurIPS, 2018. arXiv:1806.07366
- L. Ambrosio, N. Gigli, and G. Savar é, Gradient Flows in Metric Spaces and in the Space of Probability Measures, Birkh ä user, 2008.
- C. Villani, Optimal Transport: Old and New, Springer, 2009.
- R. Jordan, D. Kinderlehrer, and F. Otto, "The Variational Formulation of the Fokker-Planck Equation," SIAM J. Math. Anal., 1998.
- F. Otto, "The Geometry of Dissipative Evolution Equations: the Porous Medium Equation," Comm. PDE, 2001.
- Mean-Field Analysis of Neural SGD-Ascent, Y. Lu and J. Lu, 2024.
- Kernel Approximation of Fisher-Rao Gradient Flows, A. Kazeykina and M. Fornasier, 2024.
- Deep ResNets and Conditional Optimal Transport, D. Onken et al., 2024.
- M. Belkin, D. Hsu, S. Ma, and S. Mandal, "Reconciling Modern Machine Learning Practice and the Classical Bias-Variance Trade-off," PNAS, 2019.
- S. Amari, "Natural Gradient Works Efficiently in Learning," Neural Computation, 1998.
- D. P. Kingma and J. Ba, "Adam: A Method for Stochastic Optimization," ICLR, 2015. arXiv:1412.6980
- Y. Li and Y. Liang, "Learning Overparameterized Neural Networks via Stochastic Gradient Descent on Structured Data," NeurIPS, 2018.
- L. Chizat, E. Oyallon, and F. Bach, "On Lazy Training in Differentiable Programming," NeurIPS, 2019. arXiv:1812.07956
- G. Peyr é and M. Cuturi, "Computational Optimal Transport," Foundations and Trends in Machine Learning, 2019. arXiv:1803.00567
- J. Sirignano and K. Spiliopoulos, "Mean Field Analysis of Neural Networks: A Central Limit Theorem," Stoch. Proc. Appl., 2020. arXiv:1808.09372
- 本文标题:PDE 与机器学习(三)—— 变分原理与优化
- 本文作者:Chen Kai
- 创建时间:2022-01-25 10:15:00
- 本文链接:https://www.chenk.top/PDE%E4%B8%8E%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%EF%BC%88%E4%B8%89%EF%BC%89%E2%80%94%E2%80%94-%E5%8F%98%E5%88%86%E5%8E%9F%E7%90%86%E4%B8%8E%E4%BC%98%E5%8C%96/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!