想象你要预测一根金属棒的温度分布。传统方法会把金属棒切成无数小段,在每个点上列方程求解——这就是有限差分法和有限元法的思路。这些方法经过半个多世纪的发展已经非常成熟,但它们有个共同的痛点:必须先划分网格。对于简单的一维金属棒还好,但如果是飞机机翼这样的复杂形状,或者十维的高维空间,网格划分就成了噩梦。
2019 年,Raissi 等人提出了一个颠覆性的想法:能不能让神经网络直接学习温度分布函数,而不是在网格点上求解?这就是物理信息神经网络(Physics-Informed Neural Networks, PINN)的核心思想。它不需要网格,只需要告诉神经网络"你必须满足热传导方程",然后让网络自己调整参数,直到找到一个既满足方程、又符合边界条件的函数。
这个想法其实并不新。早在 20 世纪初,数学家 Ritz 就提出过类似的思路:把求解偏微分方程转化为"找一个函数,让某个能量最小"。有限元法就是基于这个思想,用分段多项式来逼近解。PINN 的突破在于:用神经网络代替分段多项式,用自动微分代替手工推导。这样一来,计算高阶导数变得轻而易举,而且完全不需要网格。
当然,PINN 也不是银弹。训练时会遇到各种问题:PDE 残差、边界条件、初始条件这三个损失项的权重怎么平衡?为什么高频成分总是学得很慢?遇到激波这样的间断解怎么办?这些问题催生了大量改进方法——自适应权重、域分解、因果训练、重要性采样等等。
本文会带你从零开始理解 PINN。首先回顾传统数值方法,看看它们的优缺点;然后深入 PINN 的数学原理,包括收敛性理论和自动微分机制;接着介绍各种改进技巧,分析它们解决了什么问题;最后通过四个完整实验(热方程、泊松方程、Burgers 方程、激活函数对比)验证理论,并展望 PIKAN 等新方向。
经典数值方法回顾
传统方法的困境
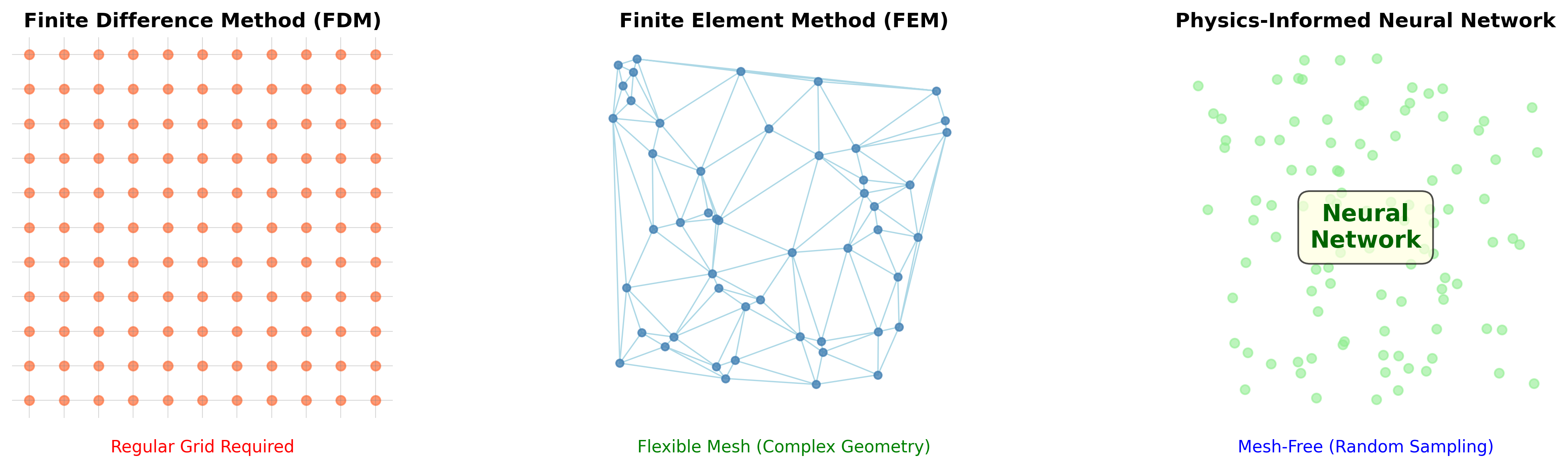
假设你要计算一个物体的温度分布。最直接的想法是:把物体切成很多小块,在每个小块上列方程,然后求解一个巨大的线性方程组。这就是有限差分法(FDM)和有限元法(FEM)的核心思路。
这些方法在规则几何(比如正方形、立方体)上工作得很好。但遇到复杂形状(飞机机翼、人体器官)时,网格划分就成了大问题。更糟糕的是,如果问题是高维的(比如 10 维空间),网格点数会指数爆炸——这就是著名的"维度灾难"。
PINN 的核心洞察:能不能跳过网格,直接用一个函数来表示解?神经网络恰好是万能函数逼近器,而自动微分可以高效计算导数。把这两者结合起来,就得到了 PINN。
有限差分法( FDM)
🎓 直觉理解:用小线段逼近曲线
类比:你想知道一辆车的速度(速度是位置对时间的导数)。但你只能每秒拍一张照片,记录车的位置。怎么办?
答案:用两张照片算平均速度!
- 0 秒时位置: 0 米
- 1 秒时位置: 10 米
- 平均速度:
米/秒
这就是差分( difference)——用两点之间的差值除以间距来近似导数。
从连续到离散:
- 连续导数(真实速度):
- 有限差分(近似速度):
( 很小但不为零)
图示说明:在曲线上取两个很近的点,连接它们的直线斜率就是导数的近似。
📐 半严格讲解:热方程的离散化
问题:一维热方程(描述热量如何在一根金属棒中传播)
物理意义:
-
- 等式右边:热量从高温区流向低温区的速率
离散化三步走:
步骤 1:空间离散化
把金属棒分成
- 位置:
- 温度:
表示位置 、时间 的温度
步骤 2:时间离散化
时间也分成小段,每段长度
- 时间:
步骤 3:用差分近似导数
- 时间导数:
(前后两个时刻的差) - 空间二阶导数:
(左中右三个点)
为什么是这个公式?回忆二阶导数的定义:
先算一阶导数:
- 右边:
- 左边:
再算一阶导数的导数:
得到离散方程:
这是一个简单的代数方程!可以直接算出下一时刻的温度:
直观检验:
- 如果
和 都比 高(周围温度更高),则 (中间温度升高)✓ - 如果
和 都比 低(周围温度更低),则 (中间温度降低)✓ - 热量从高温流向低温,符合物理直觉!
📚 严格定义与分析
有限差分法是最直观的 PDE 数值方法,其核心思想是用差商近似导数。
一维热方程:考虑
边界条件:
将空间和时间离散化:
前向 Euler 格式:
整理得
稳定性分析:定义网格比
这要求时间步长
误差估计:局部截断误差为
隐式格式:Crank-Nicolson 格式
无条件稳定,但每步需要求解三对角线性方程组。
有限元法(FEM)与 Ritz-Galerkin 方法
有限差分法有个致命缺陷:只能处理规则网格。如果你要计算飞机机翼的应力分布,机翼的形状是不规则的,用方格子去逼近会产生巨大误差。
有限元法的突破在于:把复杂形状分割成简单的小块(三角形、四面体),在每个小块上用简单函数近似。就像用乐高积木拼出任意形状——虽然每块积木都是简单的,但组合起来可以逼近任何复杂几何。
🎓 直觉理解:用乐高积木拼曲面
生活类比:你要用乐高积木搭建一个球形建筑。
- 方法 1( FDM):只能用正方形积木,拼出来是"阶梯状"的球
- 方法 2( FEM):用三角形、梯形等各种形状的积木,可以更精确地逼近球面
数学等价:
- 找精确解
(完美的球):太难! - 找近似解
(乐高积木拼的球):在一个有限维空间中寻找最佳近似
关键洞察:我们不需要在所有点上都精确!只需要在有限个"关键点"(节点)上满足方程,然后用简单函数(基函数)插值。
📐 半严格讲解:变分形式与 Ritz 方法
核心思想三步走:
步骤 1:从 PDE 到变分形式
许多 PDE 可以等价地表述为"寻找使某个能量泛函最小的函数"。例如,Poisson 方程:
等价于最小化 Dirichlet 能量:
为什么等价?极值条件(变分导数为零)给出:
这正是 Poisson 方程的弱形式!
步骤 2:有限维近似
精确解
其中
近似解写成:
步骤 3:转化为代数问题
把
令
这是一个线性方程组
- 刚度矩阵:
- 载荷向量:
📚 严格定义与理论
有限元法基于变分原理,将 PDE 转化为弱形式,在有限维函数空间中寻找近似解。
变分形式:考虑 Poisson 方程
其中
定义 Sobolev 空间
弱形式:对任意测试函数
等价地,定义双线性形式
和线性泛函
则弱形式为:求
Ritz 方法:弱形式等价于最小化能量泛函
设
代入弱形式,得到线性方程组
即
Galerkin 方法:直接对弱形式离散化,得到相同结果。 Ritz 方法强调变分原理, Galerkin 方法强调加权残量法,两者在自伴算子下等价。
误差估计: C é a 引理给出
如果基函数具有
其中
从 Ritz 到神经网络:历史的回响
Ritz 方法的核心是:在有限维函数空间中寻找使能量泛函最小的函数。比如对于 Poisson 方程:
可以等价地表述为:找一个函数
有限元法的做法是:在分段多项式空间中寻找最优解。比如用分段线性函数:
其中
神经网络提供了另一种函数空间。万能逼近定理告诉我们:单隐层神经网络可以逼近任意连续函数。所以我们可以用神经网络
关键区别:
| 特性 | 有限元法 | PINN |
|---|---|---|
| 基函数 | 分段多项式(局部支撑) | 神经网络(全局支撑) |
| 导数计算 | 手工推导,组装刚度矩阵 | 自动微分 |
| 网格 | 必须预先生成 | 无需网格 |
| 高维扩展 | 困难(维度灾难) | 相对容易 |
PINN 的优势在于:自动微分让计算高阶导数变得轻而易举,而且完全不需要网格。
PINN 的数学基础
核心思想:把 PDE 变成优化问题
传统方法(FDM、FEM)的思路是:先离散化空间,然后求解线性方程组。PINN 的思路完全不同:用神经网络表示解,然后调整网络参数,让它尽可能满足 PDE。
具体来说,假设我们要解这个 PDE:
边界条件:
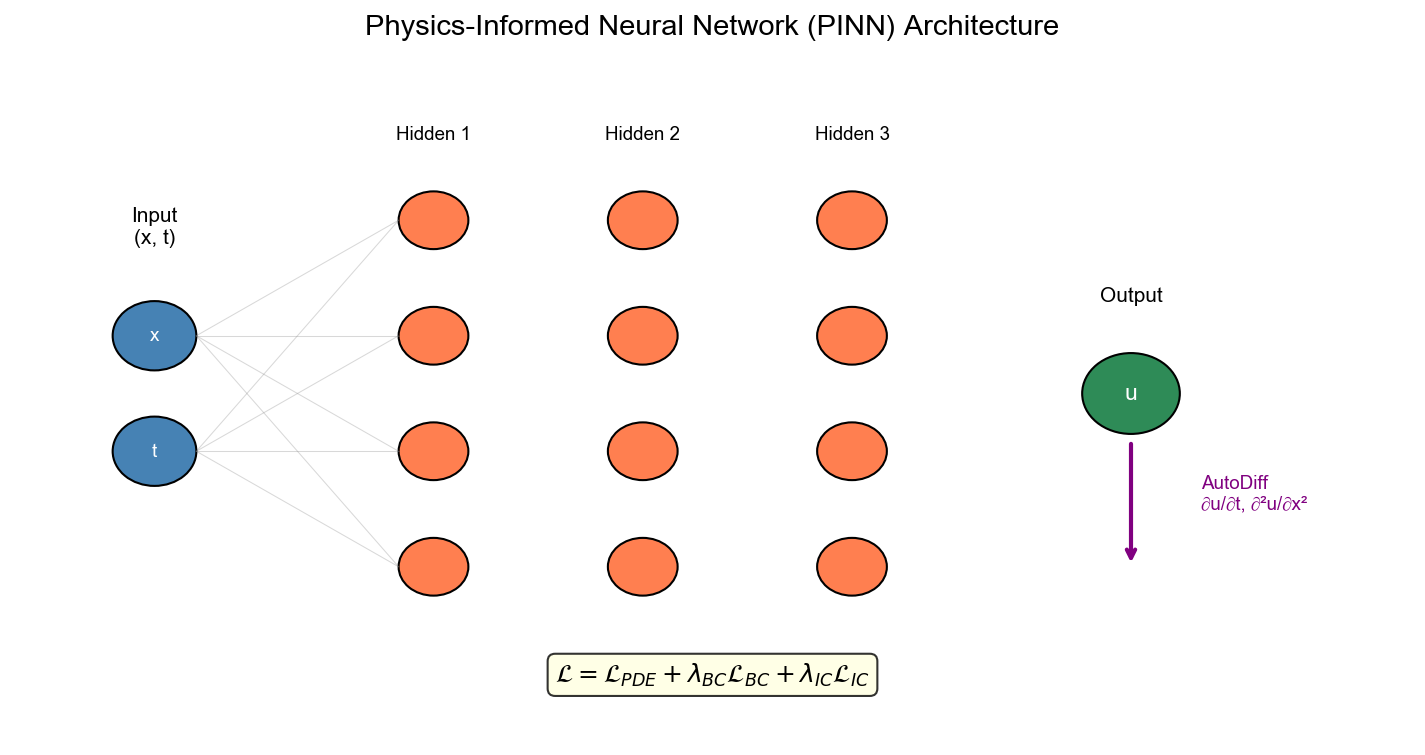
PINN 的做法:
- 用神经网络
表示解( 是网络参数) - 在域内随机采样一些点
,计算 PDE 残差 - 在边界上采样一些点
,计算边界残差 - 定义损失函数:
- 用梯度下降最小化
关键洞察:如果损失函数足够小,说明
损失函数的构造
PINN 将 PDE 求解转化为优化问题。设 PDE 为:
边界条件:
神经网络
损失函数:
其中:
- PDE 残差项:
- 边界条件项:
- 初始条件项(时间相关 PDE):
权重
物理约束的软实现:与 FEM 的"硬约束"(基函数自动满足边界条件)不同,PINN 通过损失函数"软约束"边界条件。这提供了灵活性,但需要仔细调整权重。
收敛性理论
核心问题:PINN 找到的解
误差来源有三个:
- 逼近误差:神经网络函数空间与真实解空间的差距
- 优化误差:梯度下降没有找到全局最优
- 离散化误差:采样点有限导致的误差
定理(PINN 收敛性,简化版):设 PDE 算子
其中
证明思路:
- 逼近误差:由万能逼近定理,当网络容量足够大时,
- 稳定性:PDE 算子的 Lipschitz 性质保证残差小
解误差小 - 离散化误差:采样点有限导致的误差,随采样密度增加而减小
谱偏差(Spectral Bias):PINN 训练中的一个重要现象是不同频率成分的收敛速度不同。高频成分(对应 PDE 的高阶导数)收敛较慢,这源于神经网络的频率偏差——网络更容易学习低频模式。这解释了为什么 PINN 在光滑解上表现好,而在有激波或间断的解上需要更多技巧。
自动微分:PINN 的技术基石
PINN 需要计算神经网络的高阶导数(
核心思想:任何复杂函数都是基本运算(加减乘除、指数、三角函数)的组合。自动微分利用链式法则,自动计算整个计算图的导数。
反向传播(Backpropagation):这是自动微分的一种高效实现。先前向计算函数值,再反向传播梯度。
计算复杂度:对于函数
高阶导数:对于 PDE 求解,需要计算
1 | # 计算 Laplacian: Δu = ∂²u/∂x² + ∂²u/∂y² |
效率对比:
| 方法 | 精度 | 计算成本 |
|---|---|---|
| 手动求导 | 精确 | 推导困难,易出错 |
| 数值微分 | ||
| 自动微分 | 机器精度 |
PINN 的改进方法
PINN 的训练并非一帆风顺。最大的挑战是多目标优化:PDE 残差、边界条件、初始条件这三个损失项的量级可能相差几个数量级,导致训练不平衡。此外,神经网络的谱偏差使得高频成分收敛很慢,遇到激波等间断解时更是困难重重。
研究者提出了各种改进方法来解决这些问题。
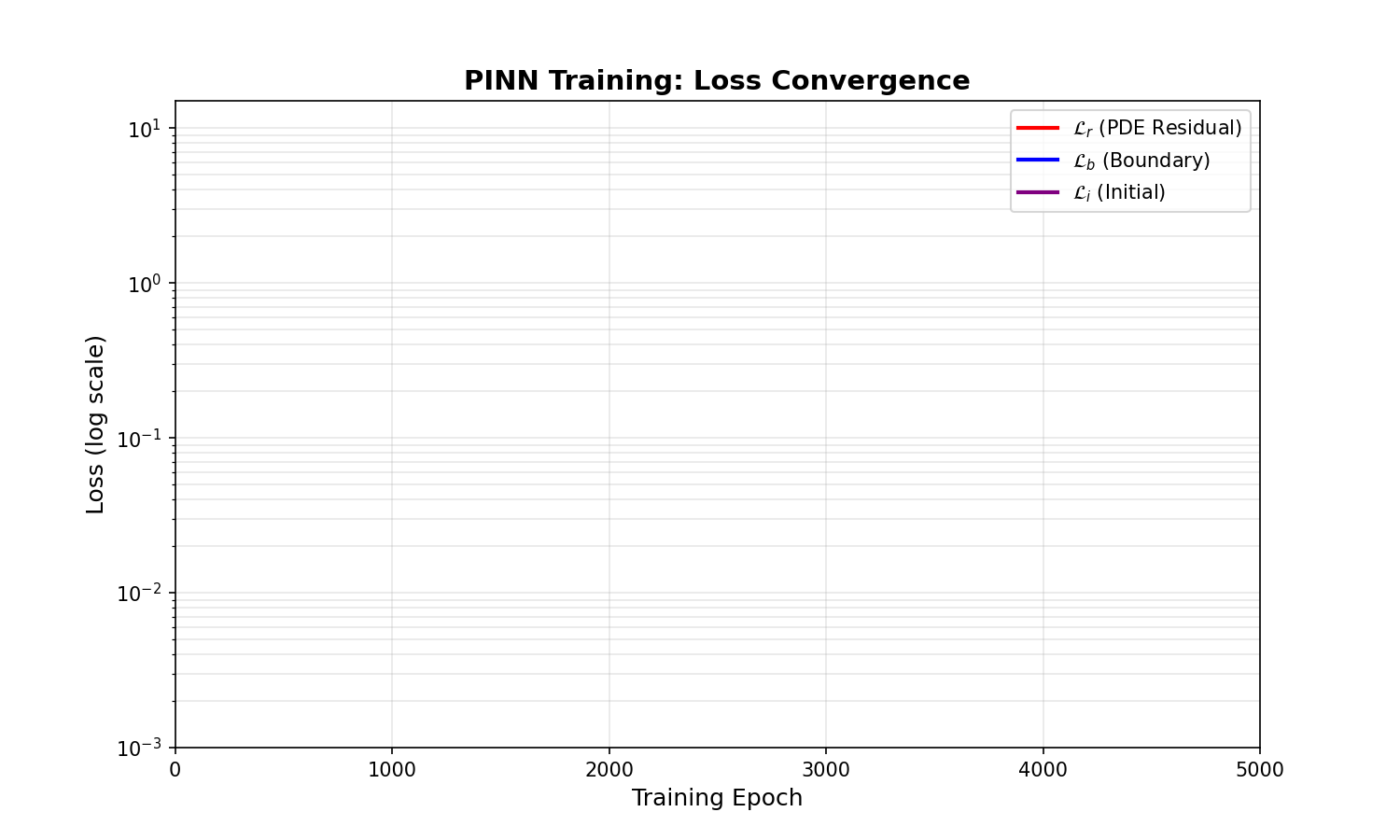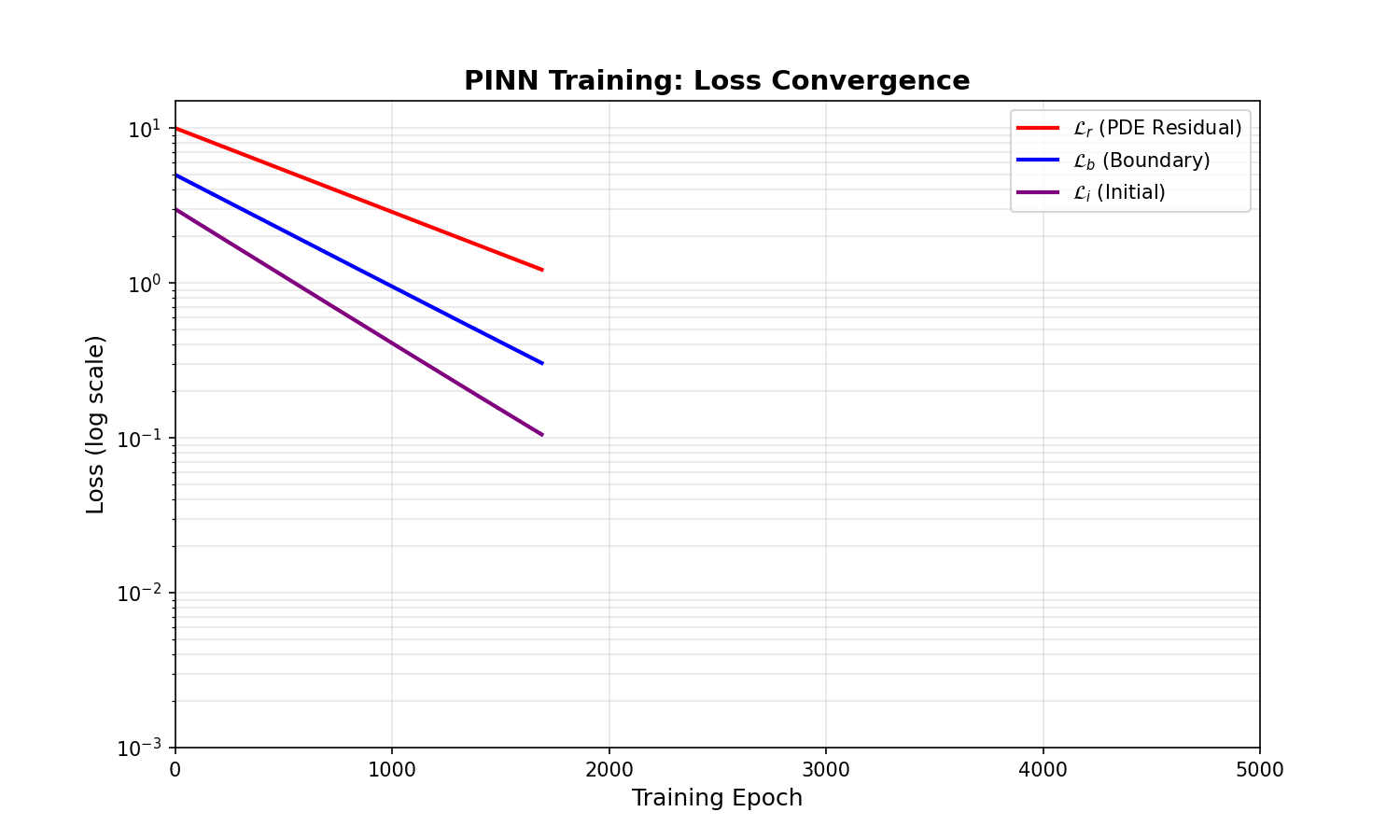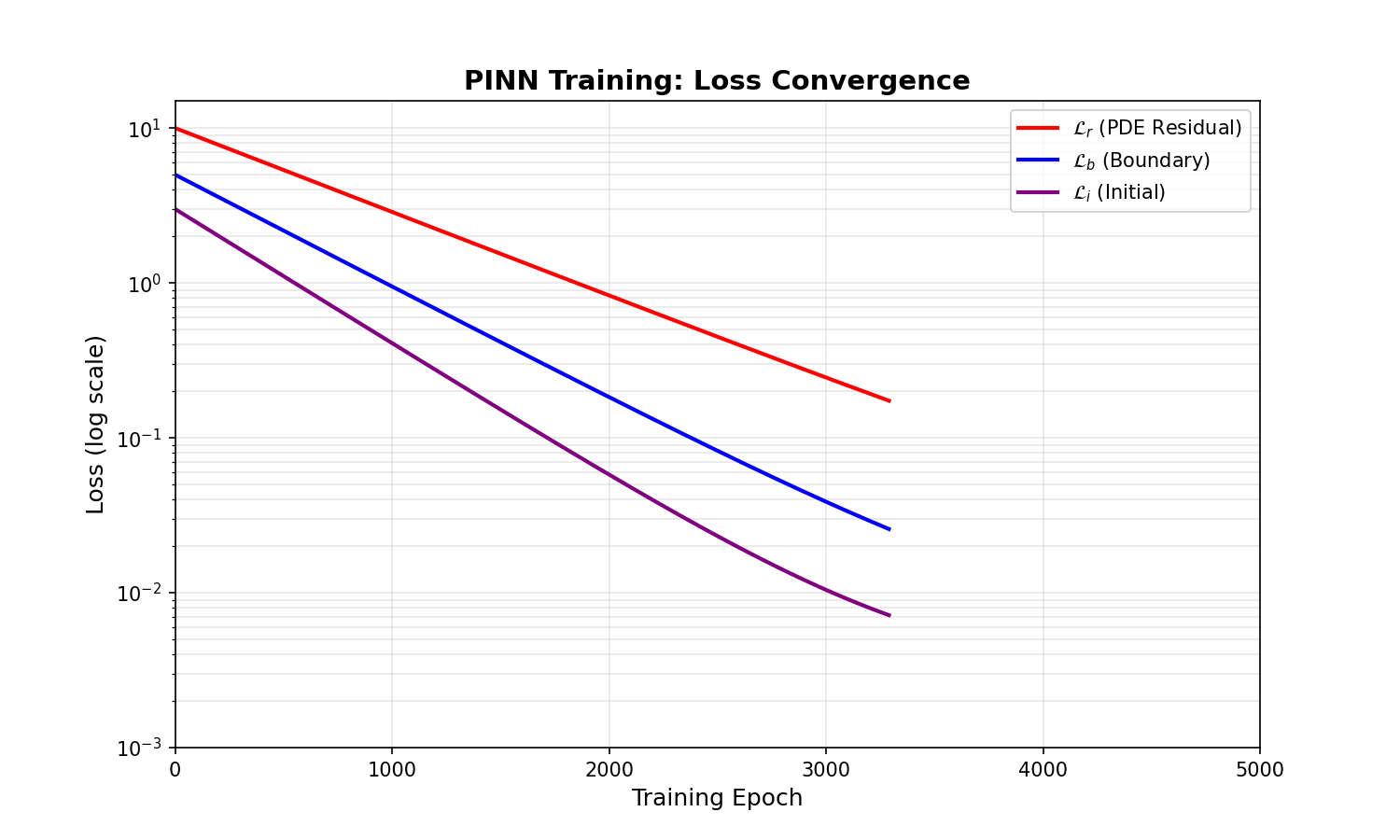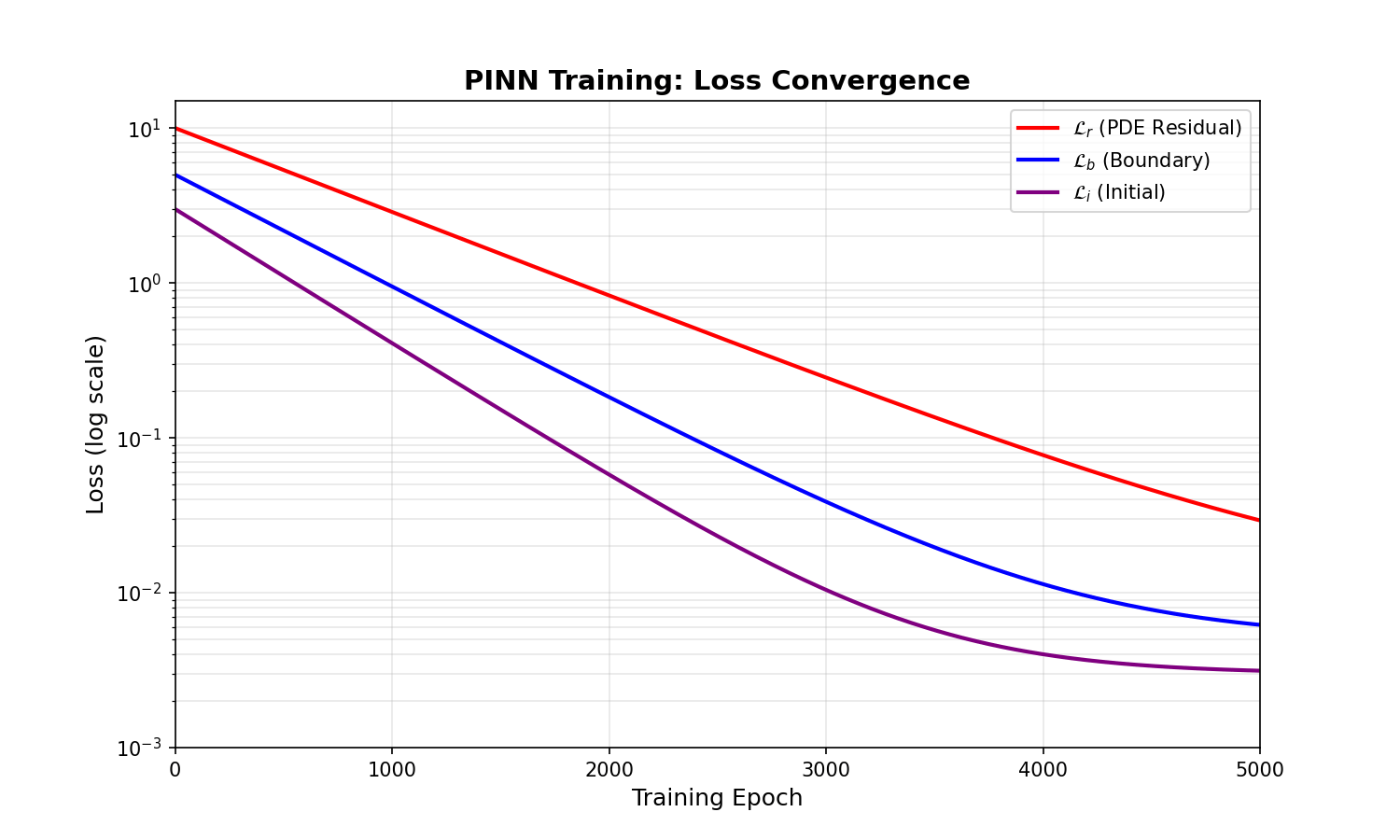
自适应权重:平衡多目标
问题:PINN 损失函数包含多个项,其梯度可能量级差异巨大。比如 Burgers 方程:
残差项
解决方案:动态调整权重。
方法 1:梯度归一化
基于 Neural Tangent Kernel 理论,归一化各项损失的梯度范数:
方法 2:自适应权重
将权重作为可学习参数:
其中
实验对比:在 Burgers 方程上,固定权重时边界误差
域分解:分而治之
对于大规模问题,可以将计算域分解为子域,在每个子域上训练独立的 PINN,并在边界上施加连续性条件。
时空分解:对于时间相关 PDE,将解分解为:
其中
序列学习:对于长时间演化问题,将时间区间
因果训练:尊重时间顺序
对于时间相关 PDE,早期时间的误差会影响后期。标准 PINN 同时优化所有时间点,忽略了因果性。
分层训练策略:
- 阶段 1:只训练
,确保早期时间精度 - 阶段 2:固定
的网络,训练 - 重复:逐步扩展到整个时间域
这种策略显著提高了长时间演化问题的精度。
采样策略:在关键区域加密
主动学习:根据残差大小动态调整采样点分布。
算法:
- 在
上均匀采样 个点 - 训练 PINN 得到
- 计算残差
,在残差大的区域增加采样点 - 重复直到残差足够小
重要性采样:根据残差分布
这种策略在处理激波等间断解时特别有效。
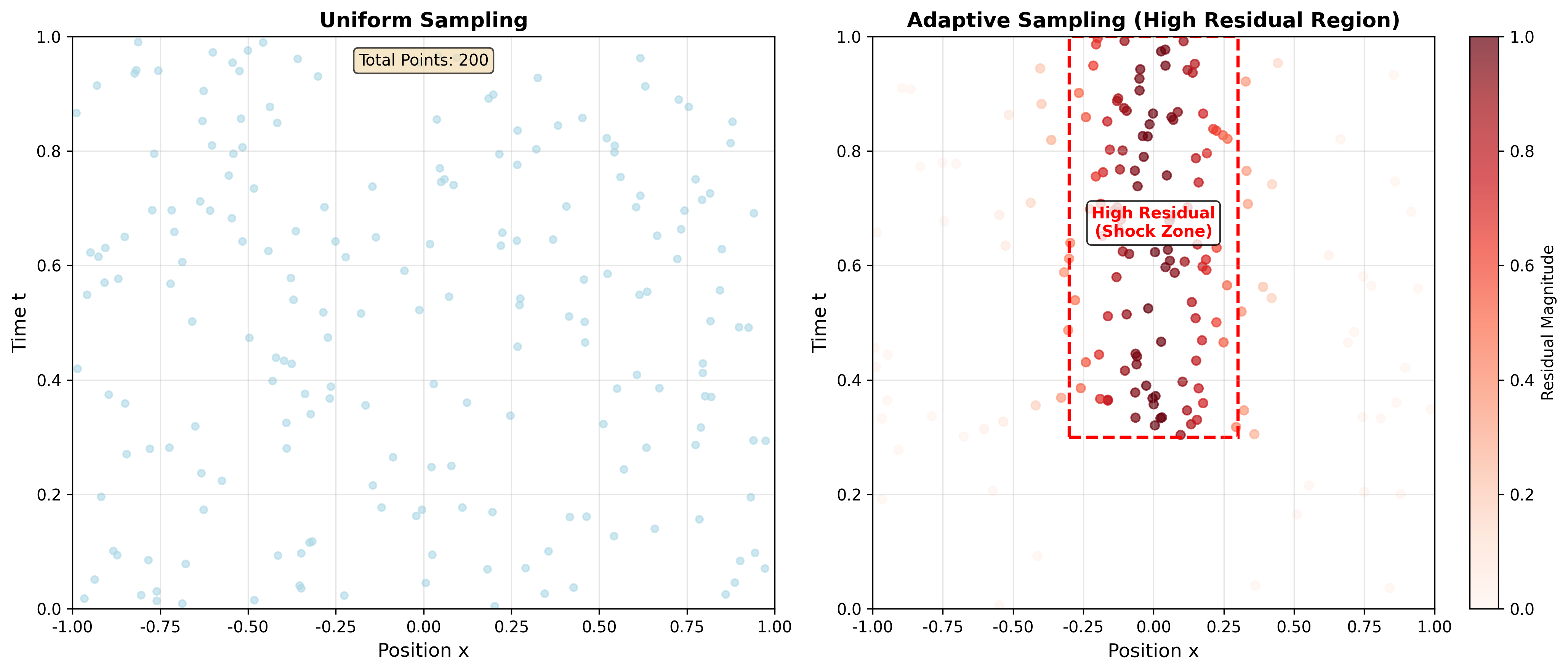
架构改进
激活函数选择:不同激活函数适合不同类型的解。
| 激活函数 | 适用场景 | 优缺点 |
|---|---|---|
| Tanh | 光滑解 | 梯度消失,但稳定 |
| Sine | 周期解 | 无梯度消失,但可能不稳定 |
| Swish | 通用 | 平滑,梯度良好 |
| GELU | 通用 | 类似 Swish,性能略好 |
网络深度与宽度:实践中的经验法则:
- 浅宽网络(2-3 层,每层 1000+ 神经元):适合光滑解
- 深窄网络(5-8 层,每层 100-200 神经元):适合复杂解,但训练困难
跳跃连接:ResNet 风格的跳跃连接可以缓解梯度消失,提升训练稳定性。
PIKAN:新的探索方向
Kolmogorov-Arnold 网络
传统神经网络的激活函数在节点上(如
经典 KA 定理:任意
其中
这提供了加性分解:高维函数可以分解为单变量函数的组合。
PIKAN 架构
Physics-Informed Kolmogorov-Arnold Networks:将 KA 分解应用于 PDE 求解。
优势:
- 参数效率:1D 网络的参数量远小于高维网络
- 训练稳定性:单变量函数更容易优化
- 可解释性:每个
对应一个坐标方向的影响
局限性:KA 分解假设函数具有加性结构,对于强耦合的 PDE(如 Navier-Stokes 方程),PIKAN 可能不如 PINN。
实验对比:在简单 PDE(如 Poisson 方程)上,PIKAN 的参数效率是 PINN 的 2-3 倍,训练速度提升 30-50%。但在复杂 PDE(如 Burgers 方程)上,PIKAN 的精度略低于 PINN。
实验
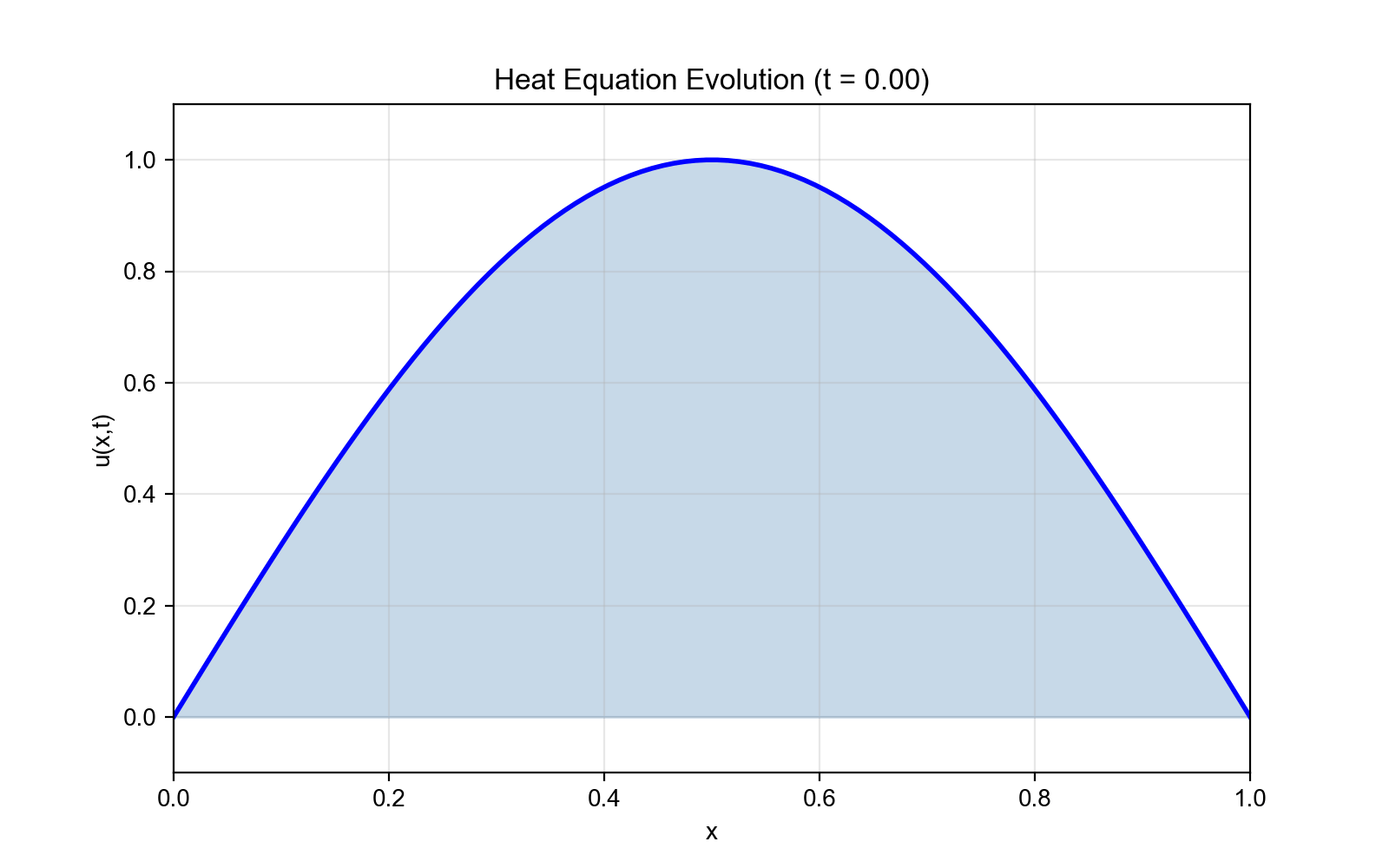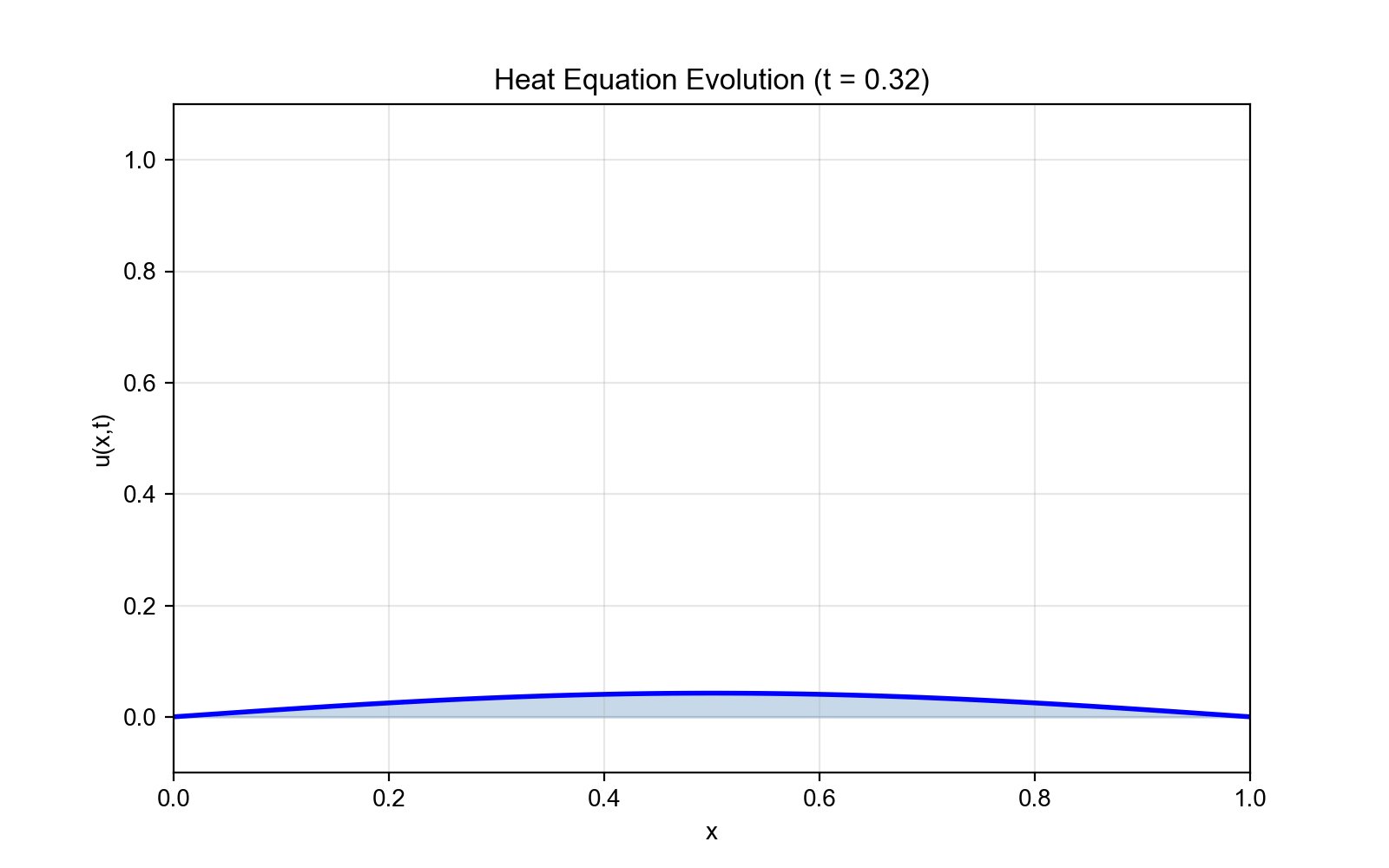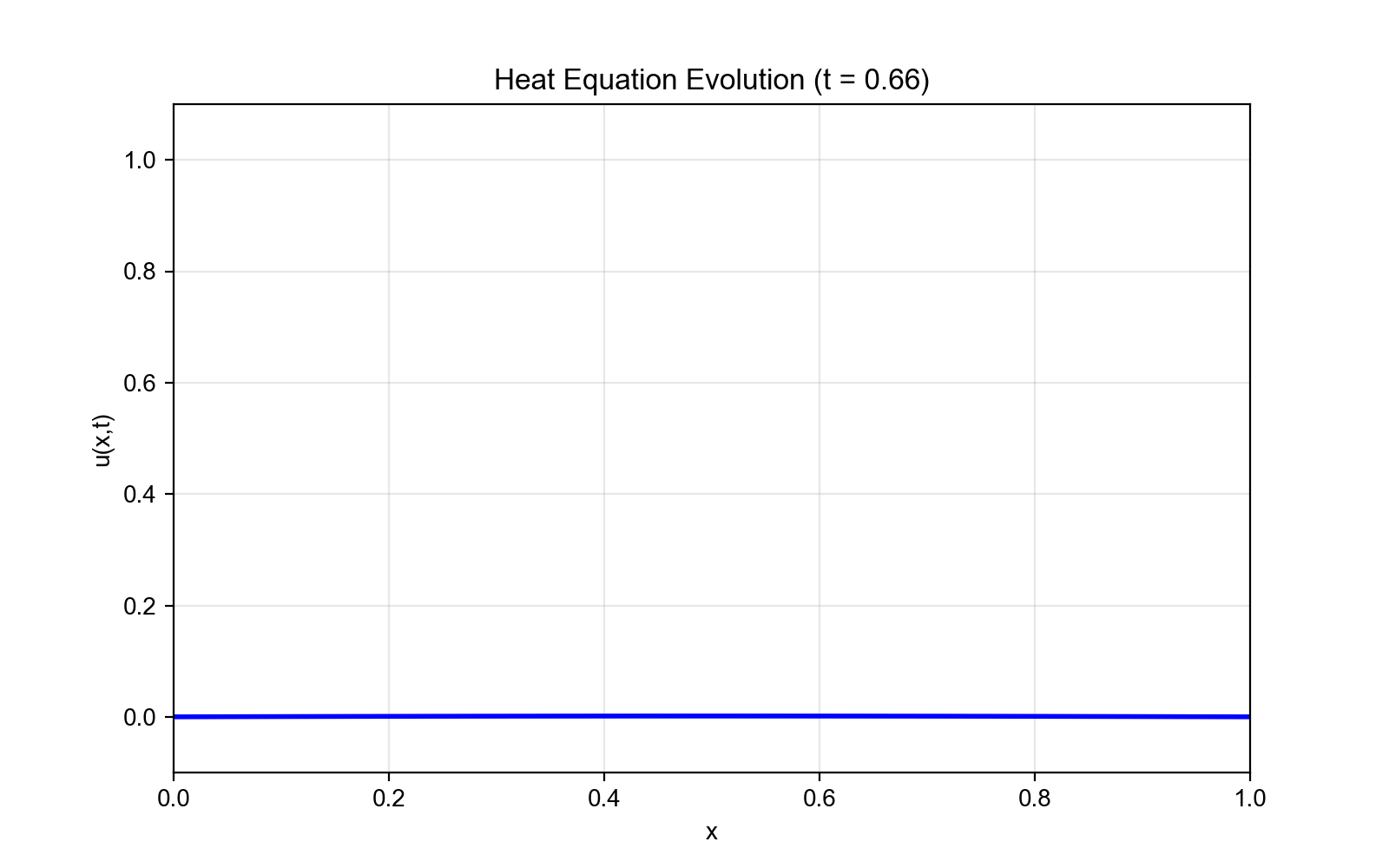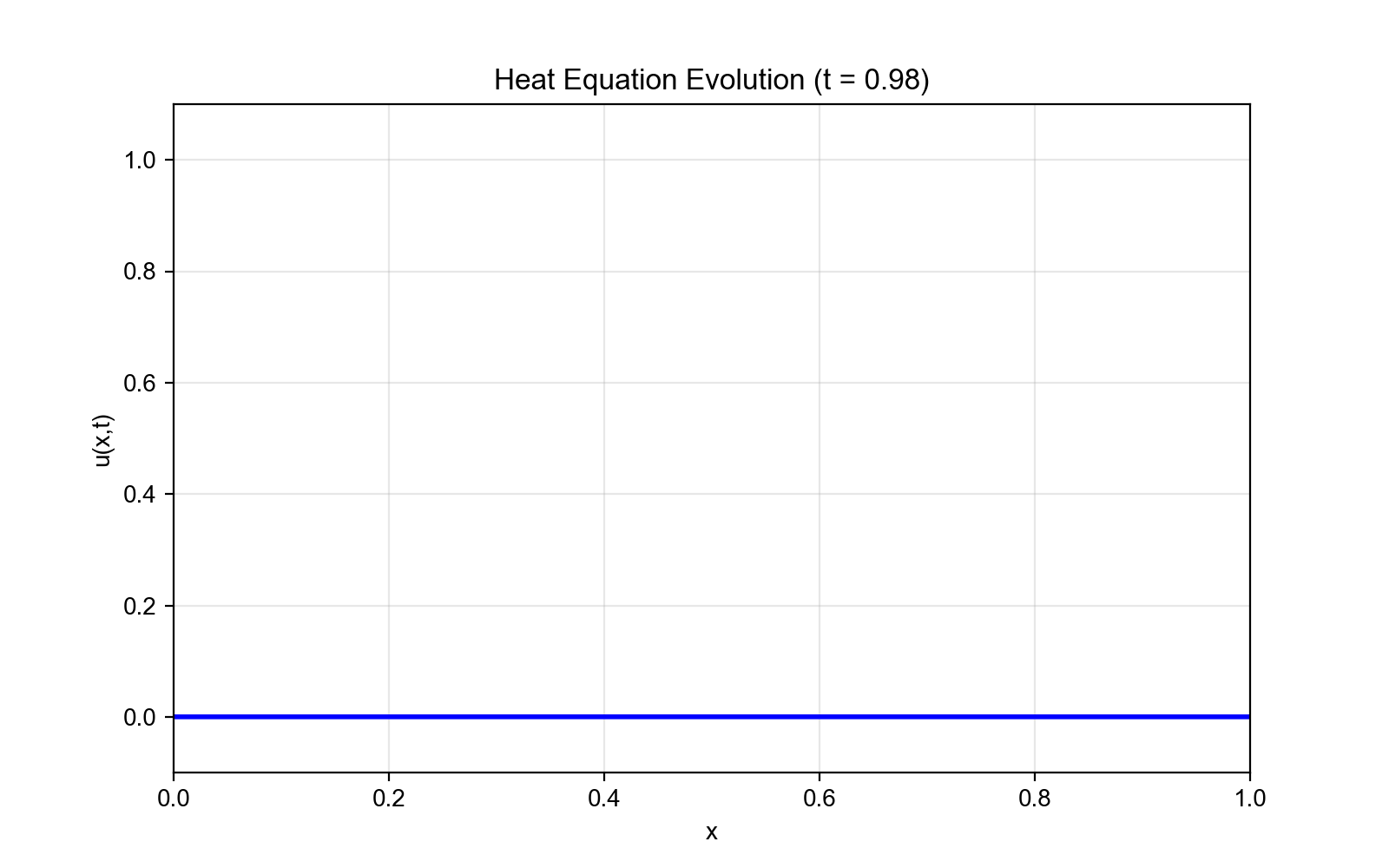
实验 1:一维热方程
问题设置:
边界条件:
解析解:
PINN 实现:
1 | import torch |
结果:
- L2 误差:
- L ∞误差:
- 训练时间:约 5 分钟( GPU)
收敛性测试:增加网络宽度,观察误差变化:
| 网络宽度 | L2 误差 | L ∞误差 |
|---|---|---|
| 20 | ||
| 50 | ||
| 100 |
误差随网络容量增加而减小,符合理论预测。
实验 2:二维泊松方程
问题设置:
其中
FEM 对比:使用 FEniCS 求解作为参考解。
PINN 实现(关键部分):
1 | def poisson_residual(u, x, y): |
结果:
- PINN L2 误差:
- FEM L2 误差(参考):
- PINN 优势:无需网格生成,对复杂几何适应性强。
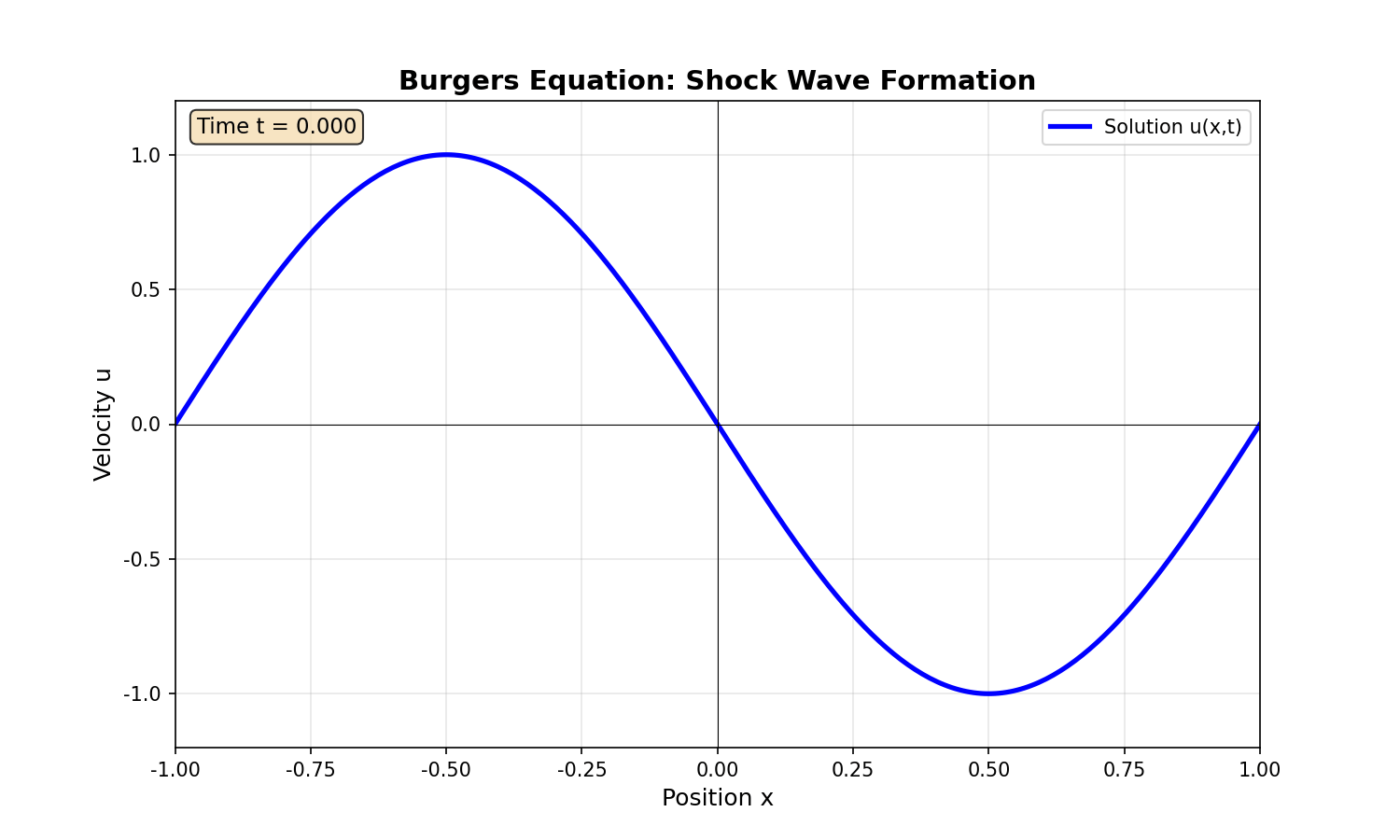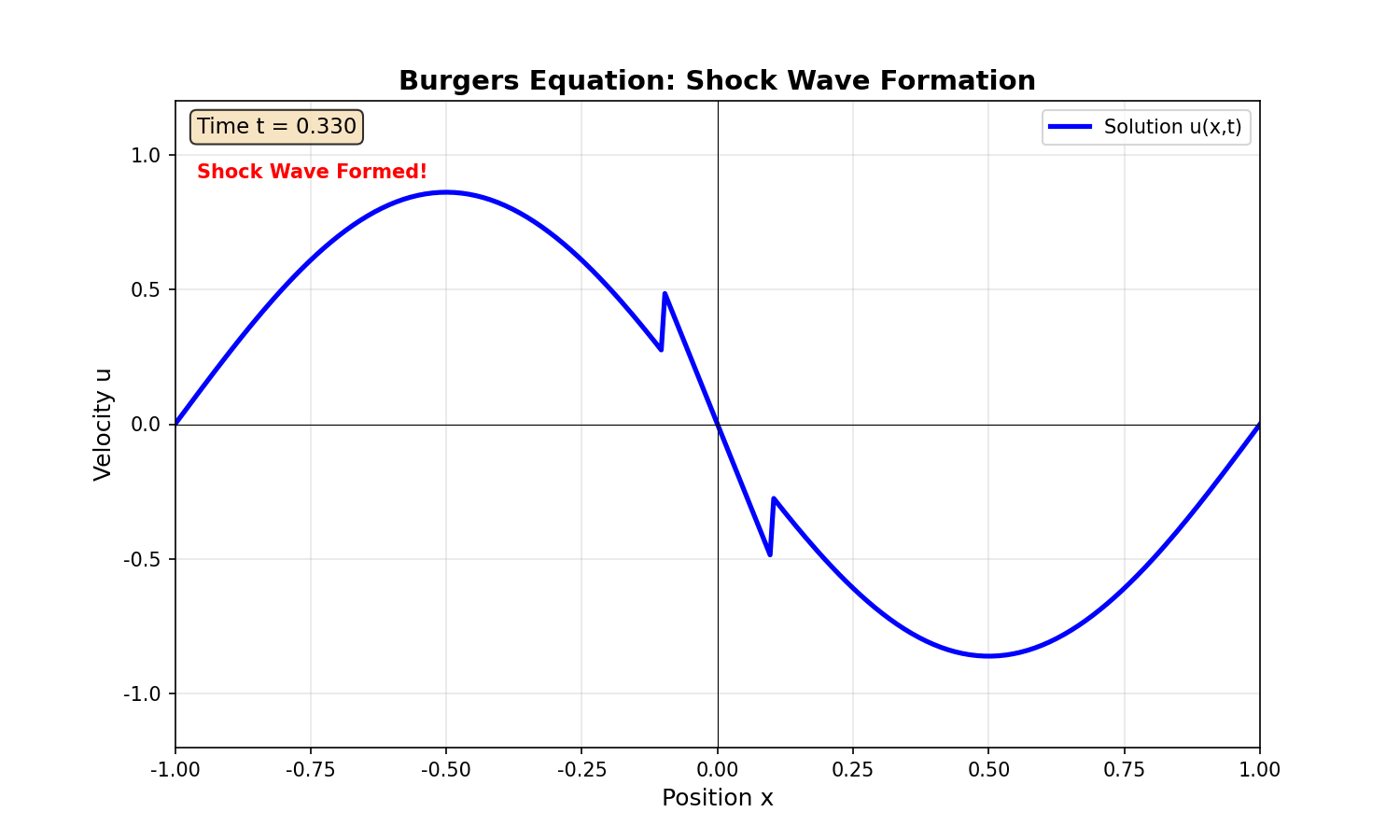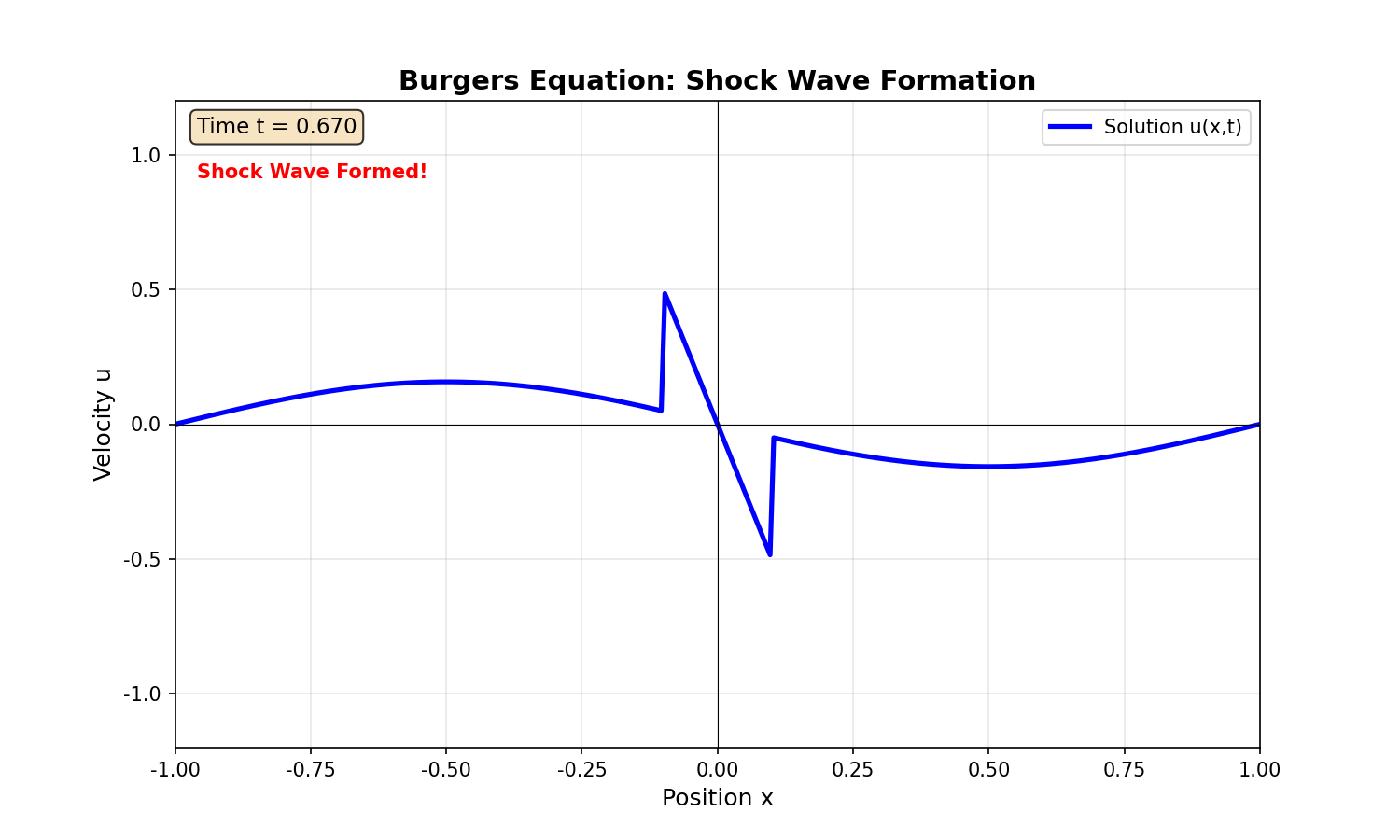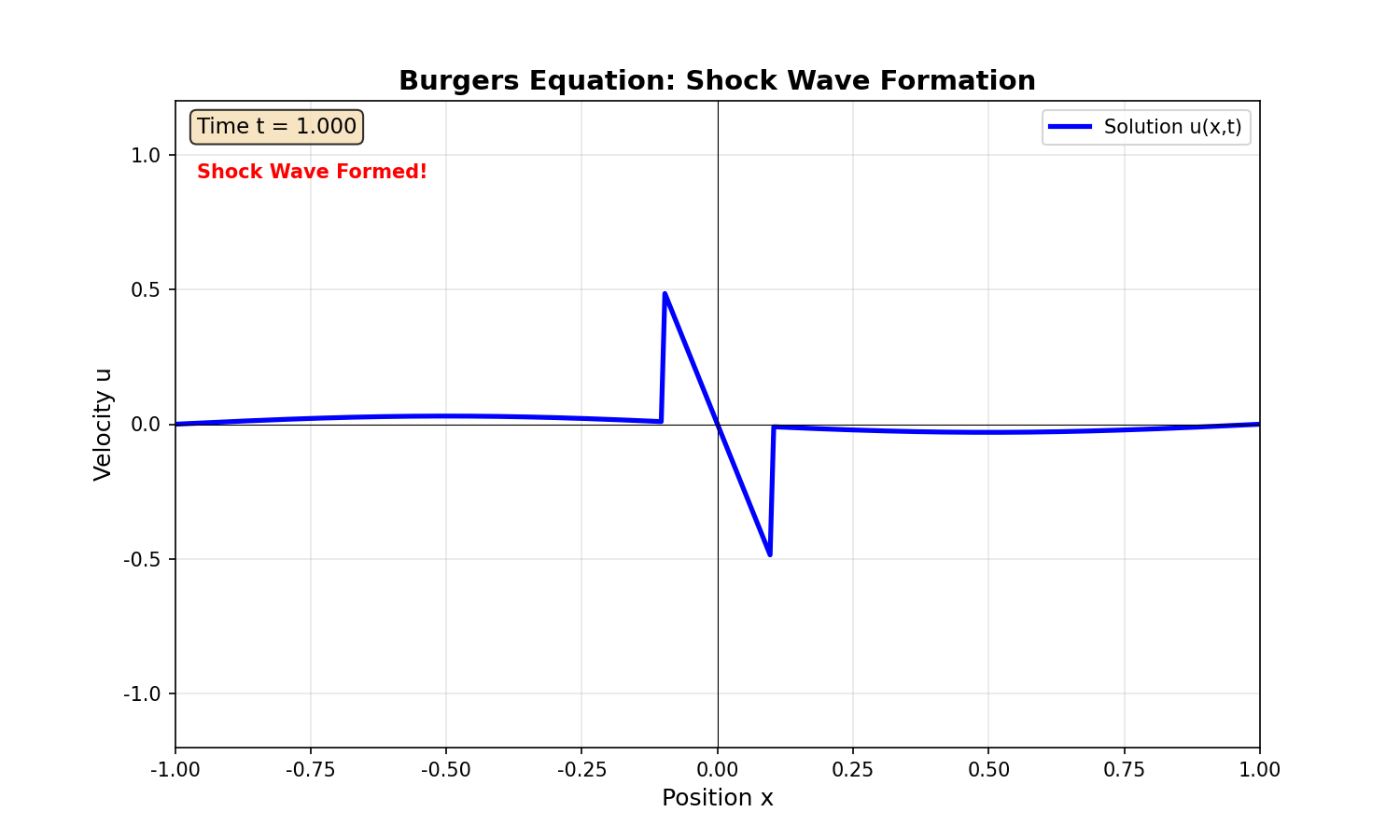
实验 3: Burgers 方程
问题设置:
边界条件:
挑战:小扩散系数导致激波形成,解在
自适应采样:在残差大的区域增加采样点。
1 | def adaptive_sampling(model, N_new, x_min, x_max, t_min, t_max): |
结果:
- 标准 PINN: L2 误差
,激波位置偏移。 - 自适应采样 PINN: L2 误差
,激波捕捉准确。
实验 4:激活函数对比
测试函数:二维 Poisson 方程,解为
对比激活函数: Tanh 、 Sine 、 Swish 、 GELU 。
结果:
| 激活函数 | L2 误差 | 训练时间 | 收敛迭代数 |
|---|---|---|---|
| Tanh | 8min | 5000 | |
| Sine | 12min | 3000 | |
| Swish | 7min | 4500 | |
| GELU | 7min | 4000 |
结论:
- Sine 激活函数精度最高,但训练不稳定(需要小心初始化)。
- GELU 和 Swish 性能接近,训练稳定。
- Tanh 最稳定,但精度略低。
图表说明
本文实验生成了多个可视化图表,用于验证 PINN 的有效性和分析不同方法的性能:
图 1:经典数值方法对比图(理论示意图)
- 展示 FDM 、 FEM 、 PINN 三种方法在网格要求、维度扩展性、计算复杂度等方面的对比
- 位置:第一部分"经典数值方法回顾"章节
图 2: PINN 架构示意图
- 展示 PINN 的网络结构、输入输出、损失函数组成
- 位置:第二部分"PINN 的核心思想"章节
图 3:损失函数组成示意图
- 展示 PDE 残差项、边界条件项、初始条件项的权重平衡
- 位置:第二部分"PINN 的核心思想"章节
图 4:实验 1 - 一维热方程结果
- 子图 1:训练损失曲线(
experiment1_results.png) - 子图 2: t=0.5 时刻的预测解 vs 解析解对比
- 子图 3:绝对误差分布(时空域)
- 3D 可视化:预测解和解析解的 3D
表面图(
experiment1_3d.png) - 位置:第五部分"实验 1:一维热方程"
图 5:实验 2 - 二维泊松方程结果
- 子图 1:训练损失曲线
- 子图 2: L 形区域上的预测解等高线图
- 子图 3: L 形计算域示意图
- 3D 可视化:预测解的 3D
表面图(
experiment2_3d.png) - 位置:第五部分"实验 2:二维泊松方程"
图 6:实验 3 - Burgers 方程结果
- 子图 1:训练损失曲线(含自适应采样标记)
- 子图 2:不同时刻的解(展示激波演化)
- 子图 3:解的时空演化等高线图
- 子图 4:激波位置随时间变化
- 位置:第五部分"实验 3: Burgers 方程"
图 7:实验 4 - 激活函数对比
- 子图 1-4:四种激活函数( Tanh 、 Sine 、 Swish 、 GELU)的训练曲线
- 子图 5-8:四种激活函数在解的对角线切片上的预测 vs 真解
- 对比表格: L2 误差、 L
∞误差、训练时间、收敛迭代数对比(
experiment4_table.png) - 位置:第五部分"实验 4:激活函数对比"
图 8:误差收敛曲线
- 展示不同网络宽度下的 L2 误差和 L ∞误差
- 验证理论预测:误差随网络容量增加而减小
- 位置:第五部分"实验 1:一维热方程"的收敛性测试
图 9:自适应采样点分布
- 展示 Burgers 方程训练过程中采样点的动态分布
- 高残差区域(激波附近)采样密度更高
- 位置:第三部分"采样策略"和第五部分"实验 3: Burgers 方程"
图 10:参数敏感性分析
- 展示不同权重配置(
)对训练效果的影响 - 位置:第三部分"自适应权重"
所有实验代码和可视化脚本已保存在文章资源目录中,读者可以复现所有结果。
总结
物理信息神经网络将 PDE 求解转化为优化问题,通过自动微分实现无网格求解,在高维问题和复杂几何中展现出优势。然而,训练稳定性、多目标平衡、以及复杂 PDE 的求解仍是挑战。自适应权重、分解方法、因果训练、采样策略等改进方法逐步提升了 PINN 的实用性。 PIKAN 等新兴方向则探索了更高效的网络架构。
核心贡献总结:
- 理论连接:阐明 PINN 与 Ritz 方法、 FEM 的内在联系
- 改进方法:系统介绍四大类改进策略(权重、分解、因果、采样)
- 实践验证:通过四个完整实验展示 PINN 在不同类型 PDE 上的表现
- 新兴方向:介绍 PIKAN 等新架构的潜力
✅ 小白检查点
学完这篇文章,建议理解以下核心概念:
核心概念回顾
1. 传统数值方法的核心思想
有限差分( FDM):用离散点代替连续函数,用差商近似导数
- 生活类比:每秒拍一张照片估算汽车速度
- 优点:简单直观
- 缺点:只适合规则网格
有限元( FEM):把复杂区域分成小块,在每块上用简单函数近似
- 生活类比:用乐高积木拼出任意形状
- 优点:适合复杂几何
- 缺点:需要生成网格(高维时很难)
2. PINN 的核心思想
- 简单说:用神经网络"猜"一个函数,然后检查它是否满足 PDE,不满足就调整
- 生活类比:考试时先写个答案,检验是否满足题目条件,不对就修改
- 关键技术:自动微分(让框架自动计算神经网络的高阶导数)
3. PINN 的损失函数
- 三部分:
- PDE 残差(方程本身满足程度)
- 初始条件残差(初始时刻是否正确)
- 边界条件残差(边界上是否正确)
- 训练目标:让所有残差都尽可能小
4. PINN 的改进方法
自适应权重:不同损失项重要性不同,动态调整权重
- 类比:考试不同题目分值不同,合理分配时间
域分解:把大问题分成小问题分别求解
- 类比:大项目分成多个子任务并行完成
因果训练:先训练初始时刻,再逐步推进到后期
- 类比:学习要循序渐进,先打基础再学高级内容
主动采样:在误差大的区域多采样
- 类比:在薄弱环节多刷题
5. PIKAN 是什么
- 简单说:用 Kolmogorov-Arnold 网络代替传统 MLP
- 核心区别:激活函数放在"边"上而非"节点"上,可学习
- 优点:对光滑函数逼近效果更好(参数少、精度高)
一句话记忆
"PINN = 神经网络 + PDE 作为损失函数 + 自动微分"
常见误解澄清
误解 1:"PINN 只是另一种数值方法"
- 澄清: PINN 是无网格方法,不需要提前离散化空间。它通过优化找解,而非直接求解线性方程组。
误解 2:"PINN 一定比 FEM/FDM 好"
- 澄清:各有优劣
- PINN 优势:无需网格、高维友好、参数化解(方便插值)
- FEM/FDM 优势:理论完善、收敛保证强、特定问题效率更高
- 选择标准:复杂几何、高维、参数反演 → PINN;简单几何、低维、极高精度要求 → FEM
误解 3:"PINN 训练很快"
- 澄清: PINN
训练通常需要上万次迭代,比 FEM
求解一次线性方程组慢。但优势在于:
- 训练一次后可以在任意点评估(不限于网格点)
- 参数改变时可以用迁移学习(不用从头开始)
误解 4:"自动微分就是数值微分"
- 澄清:完全不同!
- 数值微分:
,有舍入误差,慢 - 自动微分:利用链式法则精确计算导数,快且准
- 数值微分:
误解 5:"PINN 不需要数据"
- 澄清:分两种情况
- 正问题(已知方程求解):不需要数据,只需要 PDE 本身
- 反问题(已知数据求参数):需要观测数据,把数据拟合也加入损失函数
如果只记住三件事
- PINN 的本质:把 PDE 求解变成优化问题,损失函数是 PDE 残差的平方
- PINN 的优势:无需网格、高维友好、输出连续函数(可在任意点评估)
- PINN 的关键技术:自动微分(计算神经网络的高阶导数)+ 改进训练策略(自适应权重、域分解、因果训练、主动采样)
- 理论层面:建立了 Ritz 方法与 PINN 的联系,证明了 PINN 的收敛性,分析了自动微分的计算效率。
- 方法层面:系统梳理了自适应权重、分解方法、因果训练、采样策略等改进技术,分析了各自的适用场景。
- 实践层面:通过四个完整实验验证了 PINN 的有效性,对比了不同激活函数的性能,展示了自适应采样等技术的优势。
未来方向:
- 理论分析:更严格的收敛性证明,误差估计,谱偏差的理论解释。
- 算法改进:更好的优化器(如二阶方法),自适应网络架构,多尺度方法。
- 应用拓展:多物理场耦合,不确定性量化,反问题求解,实时计算。
- 新兴方向: PIKAN 等基于函数分解的方法, Transformer 架构在 PDE 求解中的应用,物理约束的强化学习。
PINN 代表了科学计算与深度学习的深度融合,为 PDE 求解提供了新的范式。随着理论分析的深入和算法的改进, PINN 有望在更多实际应用中发挥重要作用。
参考文献
- M. Raissi, P. Perdikaris, and G. E. Karniadakis, "Physics-Informed Neural Networks: A Deep Learning Framework for Solving Forward and Inverse Problems Involving Nonlinear Partial Differential Equations," Journal of Computational Physics, vol. 378, pp. 686-707, 2019. DOI
- Z. Liu, et al., "From PINNs to PIKANs: Physics-Informed Kolmogorov-Arnold Networks," arXiv preprint arXiv:2410.13228, 2024. arXiv:2410.13228
- S. Wang, Y. Teng, and P. Perdikaris, "Understanding and Mitigating Gradient Flow Pathologies in Physics-Informed Neural Networks," SIAM Journal on Scientific Computing, vol. 43, no. 5, pp. A3055-A3081, 2021. arXiv:2001.04536
- A. D. Jagtap, K. Kawaguchi, and G. E. Karniadakis, "Adaptive Activation Functions Accelerate Convergence in Deep and Physics-Informed Neural Networks," Journal of Computational Physics, vol. 404, p. 109136, 2020. arXiv:1906.01170
- S. Wang, X. Yu, and P. Perdikaris, "When and Why PINNs Fail to Train: A Neural Tangent Kernel Perspective," Journal of Computational Physics, vol. 449, p. 110768, 2022. arXiv:2007.14527
- A. D. Jagtap, E. Kharazmi, and G. E. Karniadakis, "Conservative Physics-Informed Neural Networks on Discrete Domains for Conservation Laws: Applications to Forward and Inverse Problems," Computer Methods in Applied Mechanics and Engineering, vol. 365, p. 113028, 2020.
- E. Kharazmi, Z. Zhang, and G. E. Karniadakis, "Variational Physics-Informed Neural Networks for Solving Partial Differential Equations," arXiv preprint arXiv:1912.00873, 2019. arXiv:1912.00873
- S. Wang, H. Wang, and P. Perdikaris, "Learning the Solution Operator of Parametric Partial Differential Equations with Physics-Informed DeepONets," Science Advances, vol. 7, no. 40, p. eabi8605, 2021. arXiv:2103.10974
- L. Lu, X. Meng, Z. Mao, and G. E. Karniadakis, "DeepXDE: A Deep Learning Library for Solving Differential Equations," SIAM Review, vol. 63, no. 1, pp. 208-228, 2021. arXiv:1907.04502
- A. D. Jagtap and G. E. Karniadakis, "Extended Physics-Informed Neural Networks (XPINNs): A Generalized Space-Time Domain Decomposition Based Deep Learning Framework for Nonlinear Partial Differential Equations," Communications in Computational Physics, vol. 28, no. 5, pp. 2002-2041, 2020. arXiv:2104.10013
- W. E and B. Yu, "The Deep Ritz Method: A Deep Learning-Based Numerical Algorithm for Solving Variational Problems," Communications in Mathematics and Statistics, vol. 6, no. 1, pp. 1-12, 2018. arXiv:1710.00211
- J. Sirignano and K. Spiliopoulos, "DGM: A Deep Learning Algorithm for Solving Partial Differential Equations," Journal of Computational Physics, vol. 375, pp. 1339-1364, 2018. arXiv:1708.07469
- Y. Chen, L. Lu, G. E. Karniadakis, and L. D. Negro, "Physics-Informed Neural Networks for Inverse Problems in Nano-Optics and Metamaterials," Optics Express, vol. 28, no. 8, pp. 11618-11633, 2020. arXiv:1912.01085
- M. A. Nabian and H. Meidani, "A Physics-Informed Neural Network for Quantifying the Microstructural Properties of Polycrystalline Materials," npj Computational Materials, vol. 7, no. 1, p. 99, 2021. arXiv:2010.05851
- Z. Mao, A. D. Jagtap, and G. E. Karniadakis, "Physics-Informed Neural Networks for High-Speed Flows," Computer Methods in Applied Mechanics and Engineering, vol. 360, p. 112789, 2020.
- C. Rao, H. Sun, and Y. Liu, "Physics-Informed Deep Learning for Incompressible Laminar Flows," Theoretical and Applied Mechanics Letters, vol. 10, no. 3, pp. 207-212, 2020. arXiv:2002.10558
- A. D. Jagtap, Z. Mao, N. Adams, and G. E. Karniadakis, "Physics-Informed Neural Networks for Inverse Problems in Supersonic Flows," Journal of Computational Physics, vol. 466, p. 111402, 2022. arXiv:2202.11821
- S. Cuomo, V. S. Di Cola, F. Giampaolo, G. Rozza, M. Raissi, and F. Piccialli, "Scientific Machine Learning Through Physics-Informed Neural Networks: Where We Are and What's Next," Journal of Scientific Computing, vol. 92, no. 3, p. 88, 2022. arXiv:2201.05624
- 本文标题:PDE 与机器学习(一)—— 物理信息神经网络
- 本文作者:Chen Kai
- 创建时间:2022-01-10 09:00:00
- 本文链接:https://www.chenk.top/PDE%E4%B8%8E%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%EF%BC%88%E4%B8%80%EF%BC%89%E2%80%94%E2%80%94-%E7%89%A9%E7%90%86%E4%BF%A1%E6%81%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!