Decision trees are among the most intuitive machine learning models — like human decision-making, they narrow down answers through a series of "yes/no" questions. But beneath them lies deep foundations in information theory and probability: How to choose the optimal split point? How to avoid overfitting? How to handle continuous features and missing values? This chapter systematically derives the mathematical principles of decision trees, from entropy definition to ID3, C4.5, and CART algorithm details, from pruning theory to random forest ensemble thinking, comprehensively revealing the inner logic of tree models.
Decision Tree Basics
Model Representation and Decision Process
A decision tree is a hierarchical classification/regression model consisting of nodes and edges:
- Root node: Contains all samples
- Internal nodes: Represent feature tests (e.g.,
) - Branches: Represent test outcomes
- Leaf nodes: Represent predictions (class or value)
Prediction process: For sample
Mathematical representation: A decision tree can be viewed as recursive partitioning of feature space:
where
Advantages and Limitations
Advantages: 1. High interpretability: Clear decision paths, similar to human thinking 2. No normalization needed: Insensitive to feature scales 3. Handles nonlinearity: Can capture complex interactions 4. Mixed data: Handles both numerical and categorical features
Limitations: 1. Overfitting tendency: Deep trees can perfectly fit training data 2. Instability: Small data changes can cause large structural changes 3. Greedy strategy: Local optima don't guarantee global optima 4. Difficulty with linear relationships: May perform poorly on linearly separable problems
Information Theory Foundations
Information Entropy: Measuring Uncertainty
For discrete random variable
where
Physical meaning: Entropy measures the uncertainty or disorder of a random variable. Higher entropy means higher uncertainty.
Property 1: Non-negativity
Equality holds only when
Property 2: Maximum value
For
Proof: Lagrange multipliers maximize
Property 3: Concavity
Conditional Entropy and Information Gain
Conditional entropy
Information Gain is the reduction in uncertainty of
Properties: -
Data mining interpretation: Select feature
Information Gain Ratio
Problem: Information gain tends to favor features with many values (extreme case: sample ID as feature gives maximum information gain but no generalization ability).
Solution: Introduce Gain Ratio:
where
Effect: Penalizes features with too many values. If
Splitting Criteria
Gini Index
Gini Index is another measure of data purity:
where
Physical meaning: Probability of randomly selecting two samples from the dataset and having them in different classes.
Properties: -
Gini Gain: Feature
Select feature that maximizes
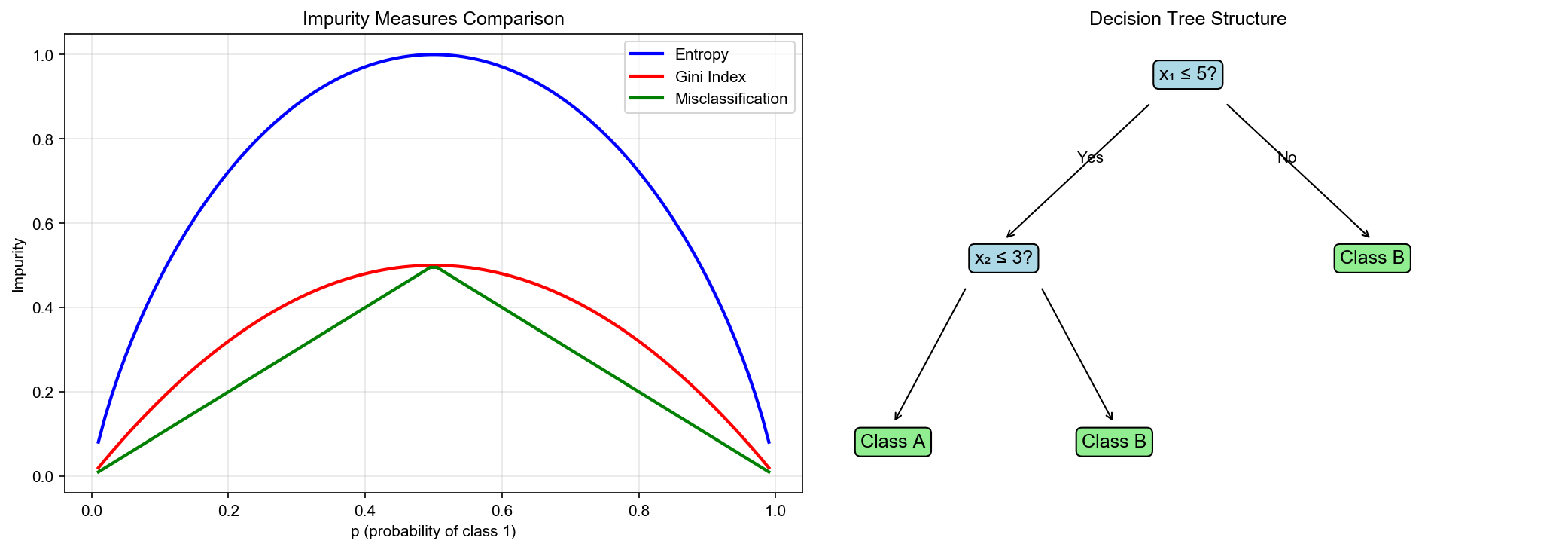
Relationship Between Entropy and Gini Index
For binary classification (
Taylor expansion: Near
Both have similar shapes, but Gini index is computationally simpler (no logarithm). CART algorithm uses Gini index.
The following figure compares how entropy and Gini index vary with class probability:

Mean Squared Error Criterion (Regression Trees)
For regression tasks, the goal is to minimize prediction error at
leaf nodes. If leaf node
Splitting criterion: Select feature
where
Optimal prediction values: Given split, optimal
Decision Tree Algorithms
ID3 Algorithm
ID3 (Iterative Dichotomiser 3) was proposed by Quinlan in 1986, using information gain as splitting criterion.
Algorithm:
- Stopping conditions: If current node
satisfies any of: - All samples belong to same class
- Feature set is empty, or all samples have same values on all features (majority vote)
- Node sample count below threshold
- Feature selection: Compute information gain
for each feature , select maximum:
Split: Split
into based on values of feature Recurse: Recursively build subtree for each subset
C4.5 Algorithm
C4.5 improves on ID3 with:
- Gain ratio: Use
instead of to avoid favoring multi-valued features - Continuous feature handling: Discretize continuous features (see below)
- Missing value handling: Allow missing feature values (see below)
- Pruning: Introduce post-pruning strategy
CART Algorithm
CART (Classification and Regression Tree) is the most widely used decision tree algorithm, proposed by Breiman et al. in 1984.
Features: - Binary tree: Each split produces two child nodes (ID3/C4.5 can produce multiple) - Gini index (classification) or MSE (regression) as splitting criterion - Cost-Complexity Pruning
Classification tree splitting:
For feature
Select
Regression tree splitting:
where
Continuous Features and Missing Values
Discretization of Continuous Features
For continuous feature
- Sort feature values:
- Consider all possible split points:
- For each split point
, compute criterion (Gini index or entropy) - Select optimal
Complexity: For
Optimization: Pre-sort feature values, reducing to
Missing Value Handling
For missing values, C4.5 uses these strategies:
Strategy 1: Handling during splitting
When computing information gain, only use non-missing samples:
where
Strategy 2: Handling during sample partitioning
For samples with missing feature
where
Strategy 3: Handling during prediction
If test sample has missing feature
Pruning Strategies
Why Pruning is Needed
Fully grown decision trees (until leaf nodes have only one sample or same-class samples) severely overfit: Training error is 0, but test error is high.
Causes of overfitting: - Tree too deep, captures noise in training data - Too few samples in leaf nodes, unreliable statistics
Solution: Pruning — simplify tree structure to improve generalization.
Pre-Pruning
Stop splitting early during construction. Common stopping conditions:
- Node sample threshold:
- Depth limit: Depth reaches
- Information gain threshold:
- Leaf sample threshold: Post-split child node
samples
Advantages: Computationally efficient, avoids building too-deep trees
Disadvantages: May stop too early, causing underfitting (some seemingly ineffective splits may be useful later)
Post-Pruning
Build complete tree first, then prune bottom-up.
Basic idea: For internal node
If performance doesn't decrease (or improves) after pruning, then prune.
Cost-Complexity Pruning (CART pruning):
Introduce tree complexity penalty. Define tree
where: -
Physical meaning:
Pruning process:
Generate pruning sequence: From full tree
, incrementally prune to get sequence ( is root node) For each internal node
, compute cost-complexity change:
where
- Cross-validation to select optimal
: Evaluate each tree in sequence on validation set, select with minimum validation error.
The following figure shows the effect of the complexity
parameter

Complete Implementation
1 | import numpy as np |
The following figure shows how decision tree depth affects overfitting — as depth increases, the decision boundary becomes more complex, transitioning from underfitting to overfitting:

The following animation shows the CART algorithm progressively splitting the feature space, selecting the optimal split point at each step:

The following figure shows the feature importance ranking from a decision tree trained on the Iris dataset:

Q&A Highlights
Q1: Why can decision trees handle nonlinear problems?
A: Decision trees recursively partition feature space into multiple
rectangular regions, each corresponding to a leaf node prediction.
Although each split is linear (
Q2: Why does information gain tend to favor multi-valued features?
A: Extreme case: If feature is sample ID (unique for each sample),
splitting by ID puts one sample in each subset,
Q3: Which is better, Gini index or entropy?
A: Theoretically equivalent (both concave functions with similar shapes), but slight practical differences: - Gini index: Faster computation (no logarithm), used by CART - Entropy: Better fits information theory interpretation, used by ID3/C4.5
Experiments show performance differences are small. Choice mainly based on computational efficiency and implementation preference.
Q4: How to handle categorical features?
A: For unordered categories (e.g., color: red, green, blue): -
Method 1: One-Hot encoding, convert to multiple binary
features - Method 2: Multi-way split (ID3 style), one
branch per category value - Method 3: Binary split
(CART style), divide categories into two subsets (need to traverse
For ordered categories (e.g., level: low, medium, high), treat as continuous feature.
Q5: Can decision trees handle multi-output tasks?
A: Yes. For multi-output regression (e.g., predict both height and weight), leaf nodes store mean of target vectors:
For multi-label classification, leaf nodes store probability distributions for each label.
Q6: Which is better, pre-pruning or post-pruning?
A: - Pre-pruning: Fast, but may stop too early (some seemingly ineffective splits may be useful later) - Post-pruning: More accurate (based on complete tree information), but higher computational cost
In practice, pre-pruning for quick prototypes, post-pruning for fine-tuning. Scikit-learn decision trees mainly use pre-pruning.
Q7: Why are decision trees insensitive to feature scales?
A: Decision tree split condition is
✏️ Exercises and Solutions
Exercise 1: Information Gain Calculation
Problem: Dataset
Solution:
Parent node entropy:
Child node entropies:
Conditional entropy:
Information gain:
Intrinsic value:
Gain ratio:
Exercise 2: Gini Index and Entropy Approximation
Problem: Prove that for binary classification with
natural logarithm,
Solution:
Let
Gini index:
Their ratio near
Thus
Exercise 3: Cost-Complexity Pruning
Problem: A decision tree has subtree
Solution:
Critical
When
Since
Exercise 4: Missing Value Correction
Problem: Dataset
Solution:
Non-missing proportion:
Corrected information gain:
More missing values lead to smaller
Exercise 5: Multivariate Decision Trees
Problem: A standard decision tree (univariate
splits) creates "staircase" decision boundaries in 2D. How many splits
are needed to approximate the line
Solution:
Standard decision tree: Each split produces
axis-aligned boundaries (
Multivariate decision tree: Using linear
combination
This is the advantage of multivariate decision trees: more compact
trees for diagonal boundaries. The trade-off is that finding
optimal
References
- Quinlan, J. R. (1986). Induction of decision trees. Machine Learning, 1(1), 81-106.
- Quinlan, J. R. (1993). C4.5: Programs for Machine Learning. Morgan Kaufmann.
- Breiman, L., Friedman, J., Stone, C. J., & Olshen, R. A. (1984). Classification and Regression Trees. Wadsworth.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning (2nd ed.). Springer. [Chapter 9: Additive Models, Trees, and Related Methods]
- Mitchell, T. M. (1997). Machine Learning. McGraw-Hill. [Chapter 3: Decision Tree Learning]
- Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5-32.
Decision trees, with their intuitive structure and powerful expressive capability, are important tools in machine learning. From information entropy to Gini index, from ID3 to CART, this chapter systematically derives theoretical foundations and algorithm details of decision trees. Understanding decision trees is not only needed for mastering classical algorithms, but prerequisite for understanding ensemble learning (Random Forest, GBDT, XGBoost)— these modern algorithms all center on combining and optimizing decision trees.
- Post title:Machine Learning Mathematical Derivations (7): Decision Trees
- Post author:Chen Kai
- Create time:2021-09-30 10:00:00
- Post link:https://www.chenk.top/Machine-Learning-Mathematical-Derivations-7-Decision-Trees/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.