The leap from linear regression to logistic regression marks an important transition in machine learning from regression to classification tasks. Although named "regression," logistic regression is fundamentally a classification algorithm, establishing a bridge between linear models and probability predictions through the Sigmoid function. This chapter delves into the mathematical essence of logistic regression: from likelihood function construction to gradient computation details, from binary to multi-class extension, from optimization algorithms to regularization techniques, comprehensively revealing the probabilistic modeling approach to classification.
From Linear Models to Probabilistic Classification
Limitations of Linear Classification
Recall linear regression, which establishes a linear mapping between inputs and continuous outputs:
But classification task labels are discrete (e.g.,
- Unconstrained output:
can be any real number, but class labels must be in a finite set - Missing probability interpretation: Linear models cannot give "probability that sample belongs to a class"
Logistic regression solves this contradiction by introducing a
link function: mapping the linear model output to
the
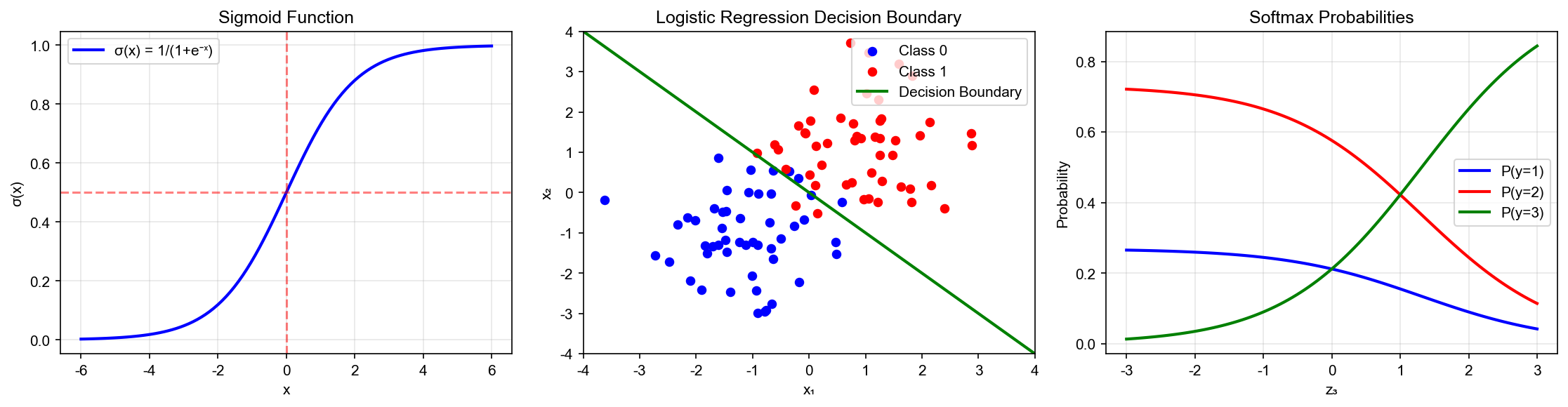
Sigmoid Function: From Real Numbers to Probabilities
The Sigmoid function is defined as:
It has elegant mathematical properties:
Property 1: Range Constraint
For any
Property 2: Symmetry
Proof:
Property 3: Self-Expressing Derivative
Proof:
This property is key to the simplicity of gradient computation.
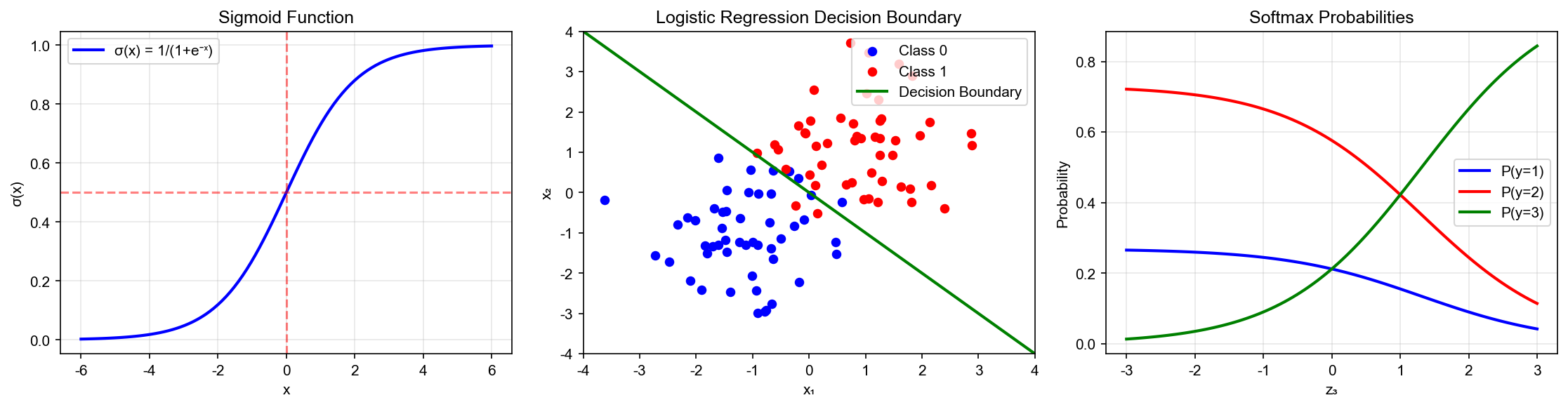
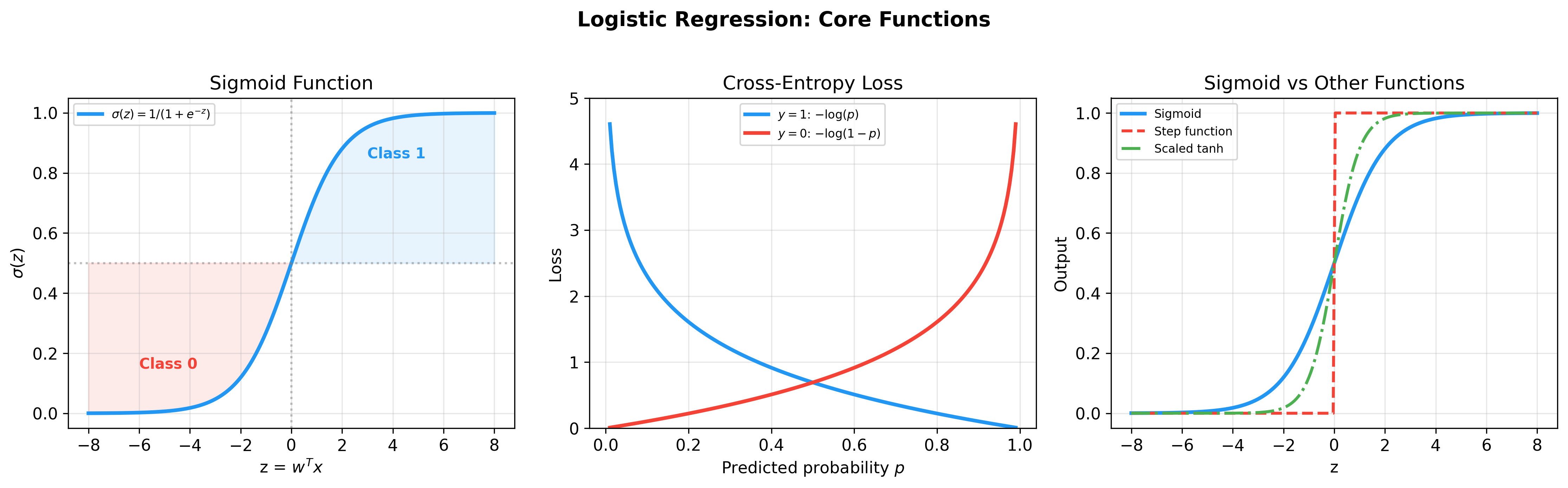
Logistic Regression Model Definition
For binary classification (
Correspondingly:
Unified Representation: Using exponential form, both probabilities can be combined as:
When
Maximum Likelihood Estimation and Loss Function
Likelihood Function Construction
Given training set
Substituting the logistic regression model:
Log-Likelihood and Cross-Entropy
Taking logarithm gives log-likelihood:
Maximizing log-likelihood is equivalent to minimizing negative log-likelihood:
where
Information Theory Interpretation: Cross-entropy
measures the difference between true distribution
In binary classification, true distribution
Comparison with Mean Squared Error
If using MSE as loss:
Computing gradient:
Note the extra term
Cross-entropy loss gradient (derived below) is:
Without the
Gradient Derivation and Optimization Algorithms
Exact Gradient Computation
For single sample loss:
where
Step 1:
Step 2: Using Sigmoid derivative property
Step 3:
Combining:
Total gradient:
where
Hessian Matrix and Second-Order Methods
For second-order optimization like Newton's method, we need the Hessian matrix:
Taking derivative of single-sample gradient
Total Hessian:
where
Positive Definiteness Analysis: For any
Since
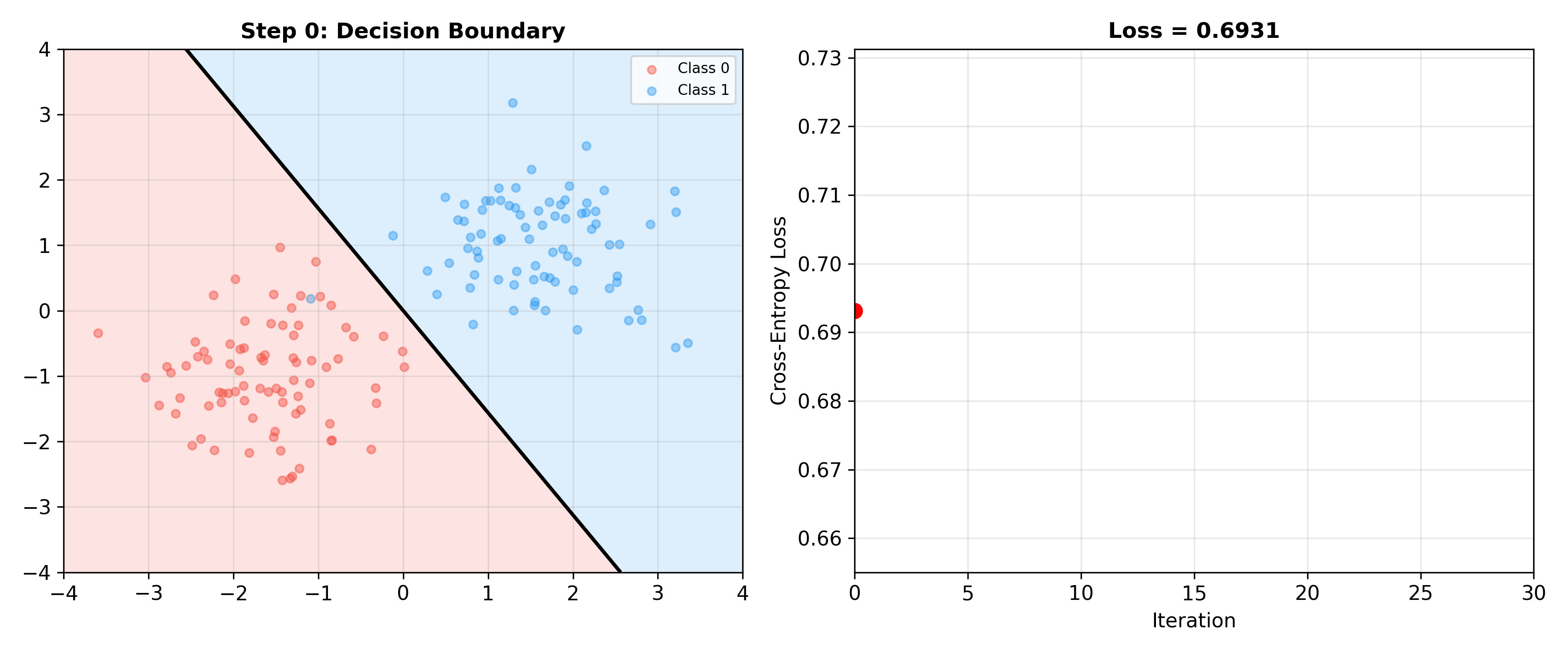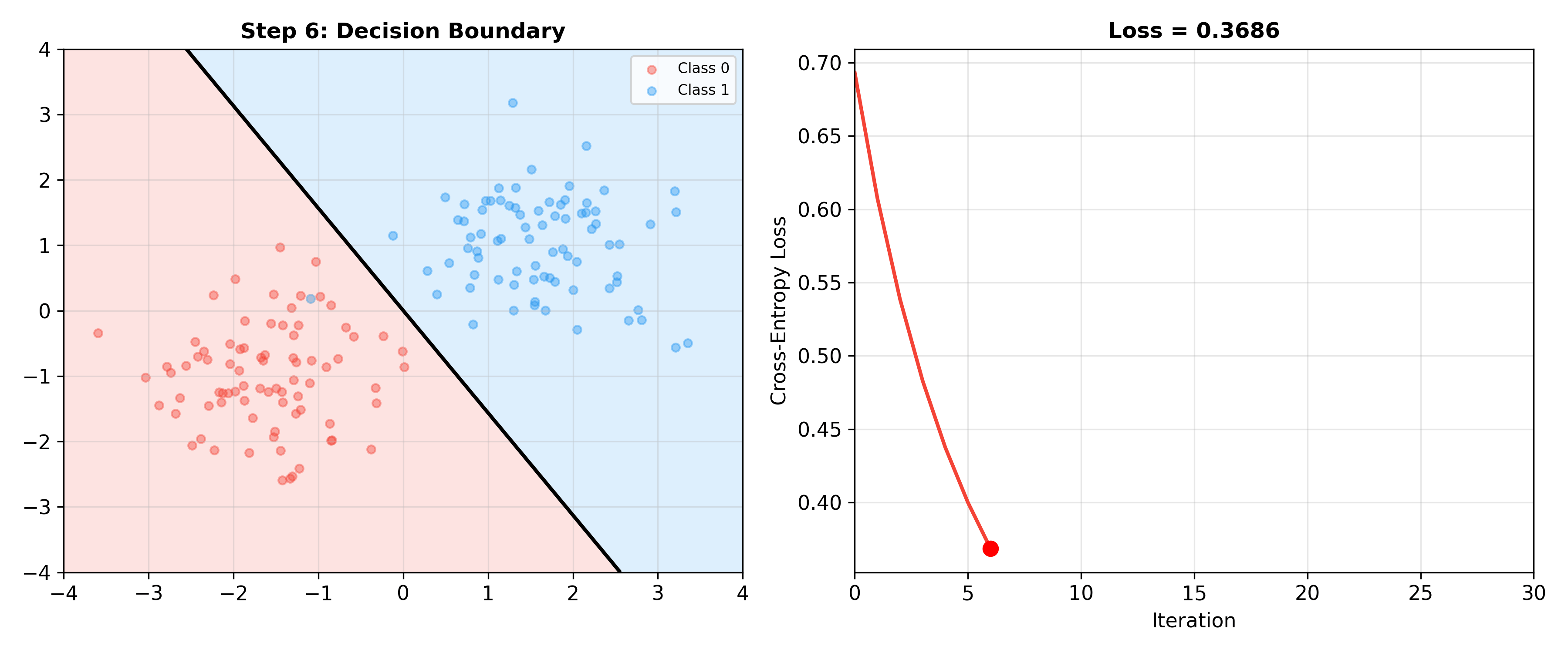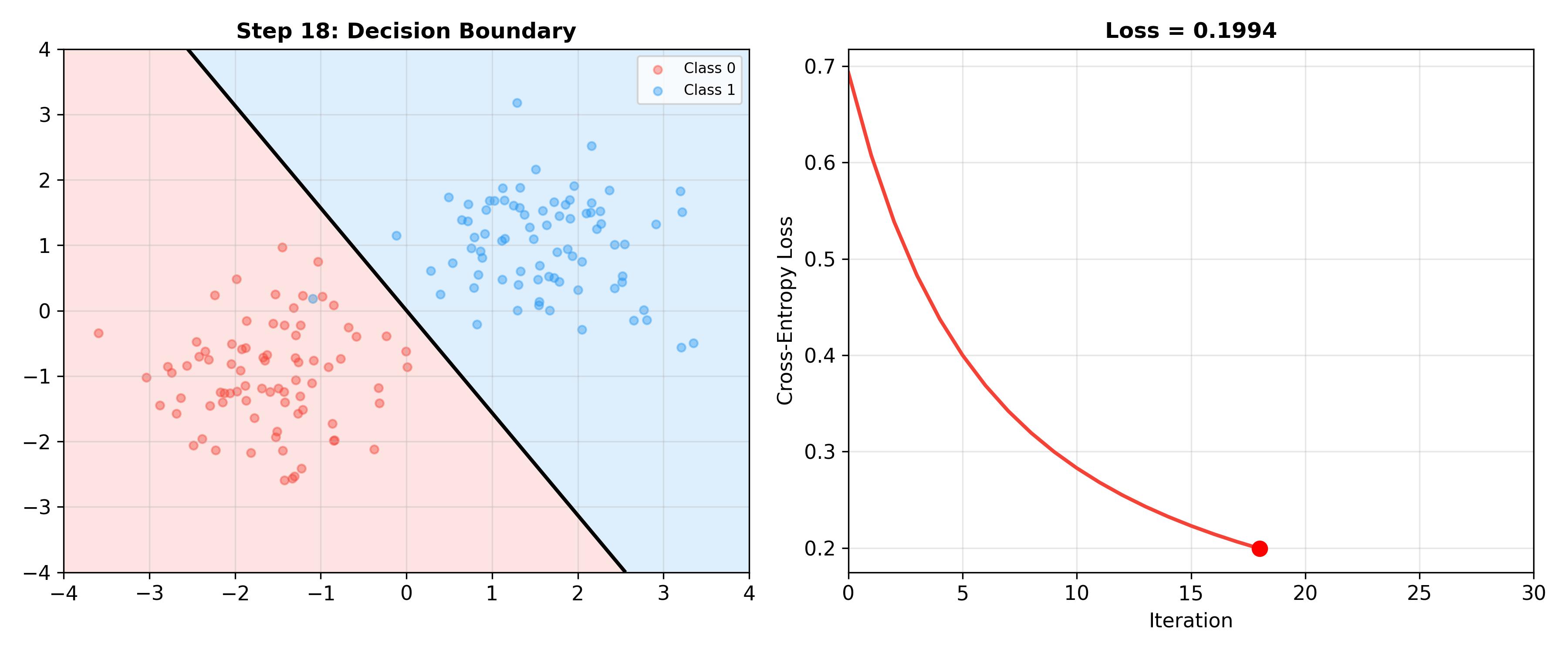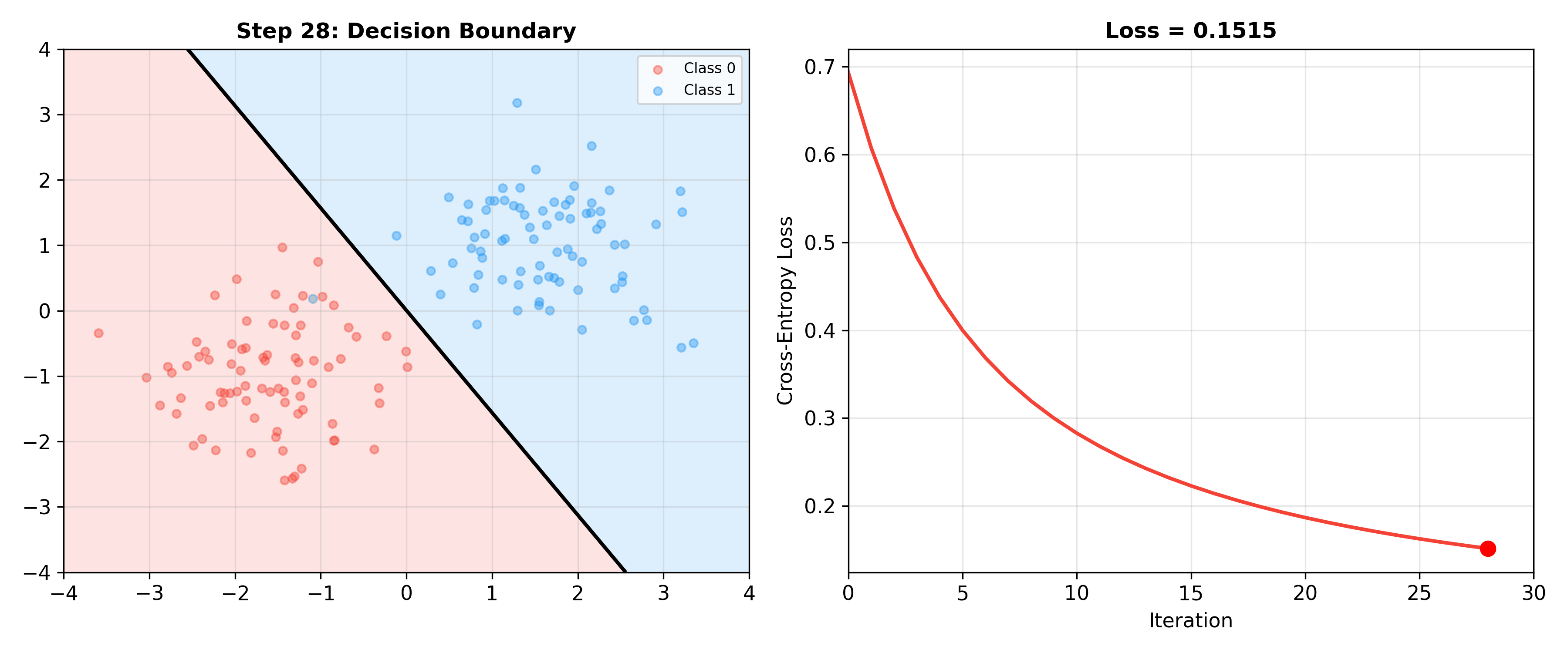
Gradient Descent and Stochastic Optimization
Batch Gradient Descent (BGD):
Stochastic Gradient Descent (SGD): Randomly select
one sample
Mini-batch Gradient Descent: Select batch size
Multi-class Extension: Softmax Regression
From Binary to Multi-class
For
Use Softmax function to normalize scores into probabilities:
where
Normalization Verification:
Cross-Entropy Loss and One-Hot Encoding
Introduce One-Hot encoding: If true class is
where
Simplification: Since each sample has only one
This is the Negative Log-Likelihood (NLL) for multi-class.
Softmax Gradient Derivation
For single-sample loss
First term:
Second term:
Combining:
Further differentiating with respect to
Total gradient:
Matrix form:
where
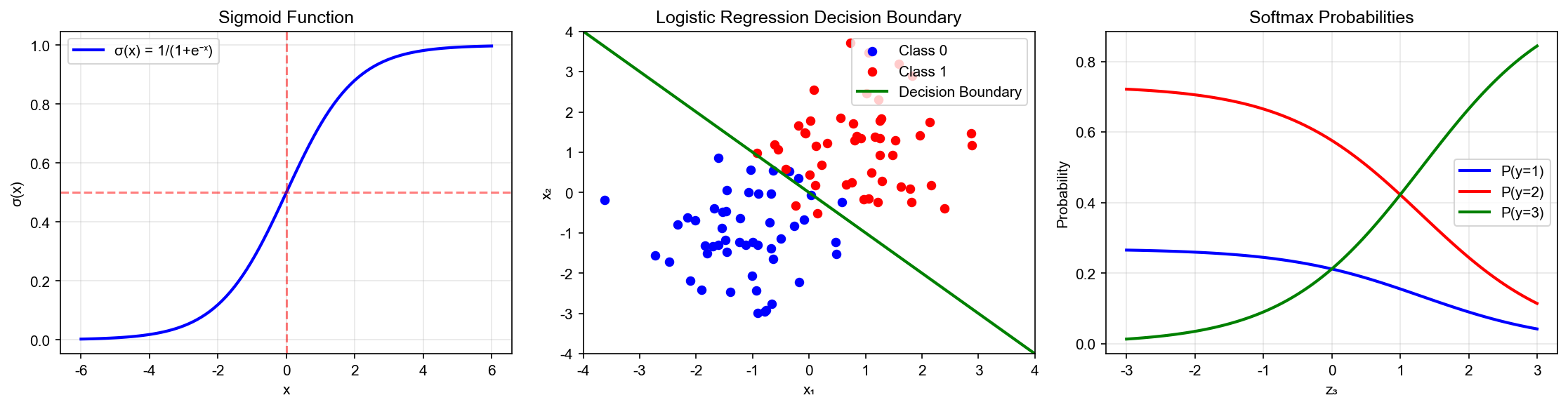
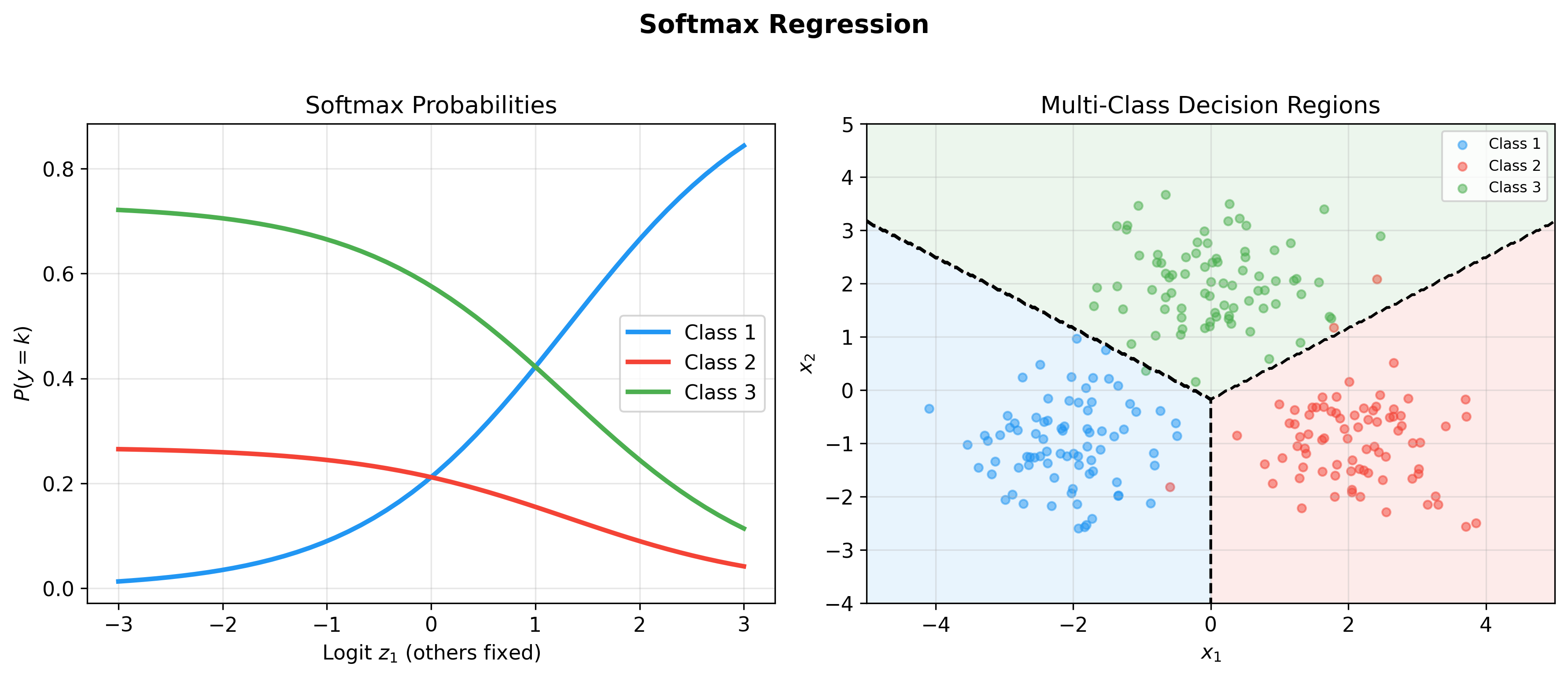
Regularization Techniques
L2 Regularization (Ridge Logistic Regression)
Add L2 penalty:
Gradient becomes:
Update formula:
The
L1 Regularization (Lasso Logistic Regression)
Add L1 penalty:
L1 norm is not differentiable at 0, use subgradient:
where
Sparsity: L1 regularization tends to produce sparse solutions (many weights exactly zero), achieving feature selection.
Elastic Net
Combining L1 and L2:
Combining sparsity with stability.
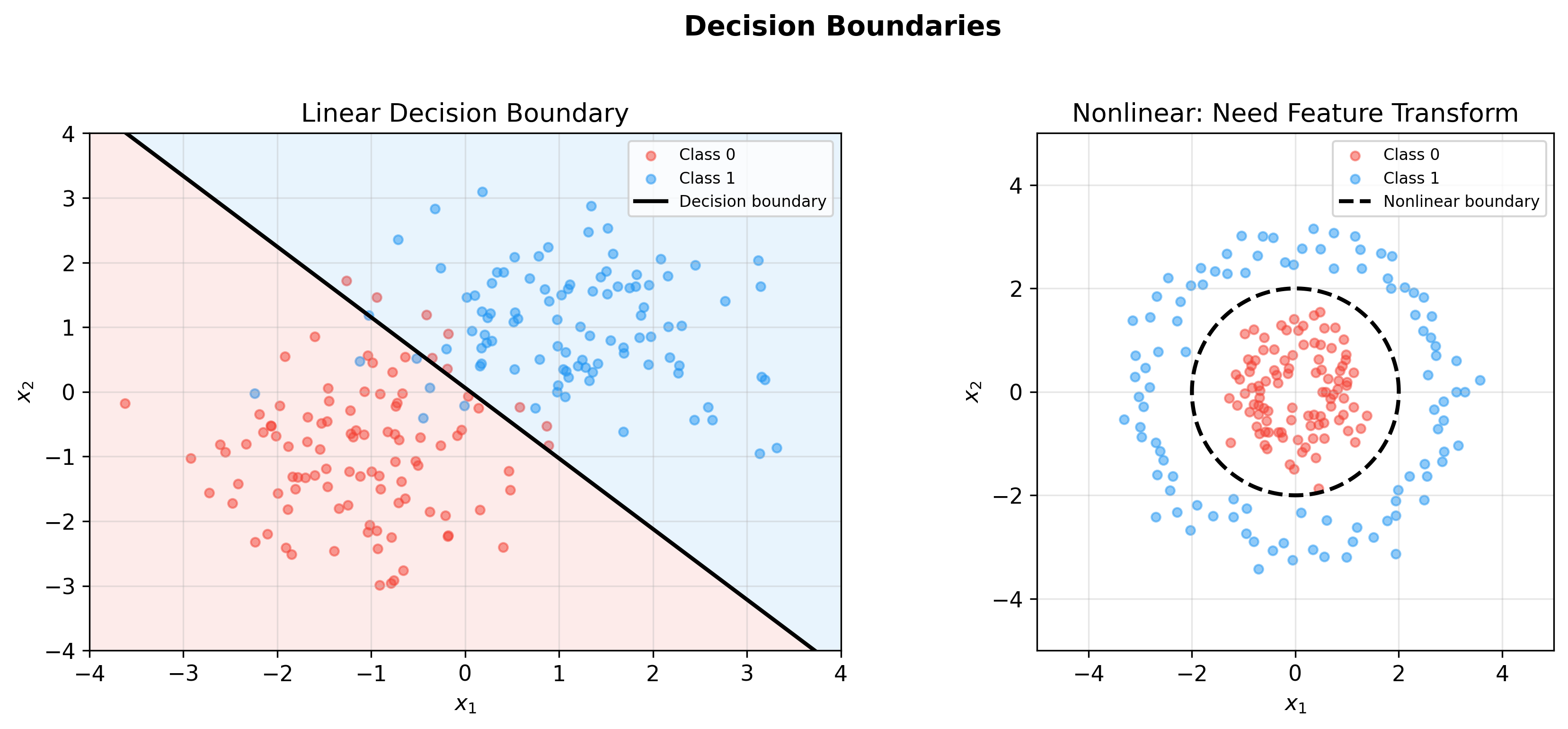
Decision Boundary and Geometric Interpretation
Binary Classification Decision Boundary
Logistic regression decision rule:
Since
This is a hyperplane in feature space.
Distance to Boundary: For sample
The larger the distance, the more confident the classification.
Multi-class Decision Regions
In
Feature space is divided into
Model Evaluation and Diagnostics
Confusion Matrix and Performance Metrics
For binary classification, define:
- TP (True Positive): True positive, predicted positive
- FP (False Positive): True negative, predicted positive
- TN (True Negative): True negative, predicted negative
- FN (False Negative): True positive, predicted negative
Accuracy:
Precision:
Recall:
F1 Score:
ROC Curve and AUC
Varying decision threshold
- True Positive Rate (TPR):
- False Positive Rate (FPR):
ROC Curve: Curve with FPR as x-axis, TPR as y-axis.
AUC (Area Under Curve): Area under ROC curve, measures ranking ability. AUC=1 is perfect classifier, AUC=0.5 is random guessing.
Probabilistic Interpretation: AUC equals the probability that a randomly selected positive sample scores higher than a randomly selected negative sample.
Implementation Details and Numerical Stability
Sigmoid Function Numerical Overflow
When
1 | def stable_sigmoid(z): |
Softmax Numerical Stability
Direct computation of
Taking
1 | def stable_softmax(z): |
Complete Training Code
1 | import numpy as np |
Multi-class Implementation
1 | class SoftmaxRegression: |
Q&A Highlights
Q1: Why called "logistic regression" instead of "logistic classification"?
A: Historical reasons. Logistic regression was originally used for probabilistic modeling in regression problems, mapping linear model output to probability through the Logistic function (i.e., Sigmoid). Later it was found more suitable for classification, but the name persists.
Q2: What is the essential difference between logistic and linear regression?
A: The core difference lies in output space and loss
function: - Linear regression:
Both are special cases of Generalized Linear Models (GLM), differing only in link function and assumed distribution.
Q3: Why is cross-entropy better than MSE for classification?
A: MSE gradient contains the
Q4: Can logistic regression fit nonlinear boundaries?
A: Original logistic regression is a linear classifier with
hyperplane decision boundary. But through: - Feature
engineering: Adding polynomial features (e.g.,
nonlinear classification can be achieved.
Q5: Difference between Softmax and multiple independent Sigmoids?
A: - Softmax: Class probabilities are
normalized,
For example, news classification (single category) uses Softmax; tag recommendation (multi-label) uses multiple Sigmoids.
Q6: How to choose regularization parameter
A: Through cross-validation grid search: 1.
Candidate values:
Generally, larger
Q7: Why is logistic regression a convex optimization problem?
A: Hessian matrix
This is an important advantage of logistic regression.
Q8: Can logistic regression handle missing values?
A: Standard logistic regression doesn't directly support this. Common approaches: - Deletion: Delete samples with missing values (loses information) - Imputation: Fill with mean/median/mode - Indicator variables: Add binary indicator for missing features - Model prediction: Predict missing values using other features
Or use algorithms that support missing values (like XGBoost).
Q9: Why is feature standardization needed?
A: Different feature scales (e.g., age [0,100] vs income [0,1e6]) cause: 1. Large numerical range differences in gradients, requiring very small learning rate 2. Some features dominate weight updates 3. Unfair regularization (penalizes large-scale features)
Standardization (
Q10: Difference between logistic regression and SVM?
A: | Dimension | Logistic Regression | SVM | |-----------|--------------------|----| | Loss | Cross-Entropy | Hinge Loss | | Output | Probability | Decision value | | Support vectors | All samples participate | Only boundary samples | | Kernel trick | Not directly supported | Naturally supported | | Convexity | Strictly convex | Convex |
Logistic regression suits probability prediction; SVM suits hard classification and nonlinear boundaries.
Q11: How to interpret logistic regression coefficients?
A: Weight
Odds ratio: When
Q12: What is the time complexity of logistic regression?
A: - Single iteration:
For large-scale data, use SGD or mini-batch gradient descent,
reducing single iteration to
✏️ Exercises and Solutions
Exercise 1: Sigmoid Function Properties
Problem: Prove that
Solution:
Derivative:
Symmetry:
Exercise 2: Cross-Entropy Loss Derivation
Problem: Derive the binary cross-entropy loss from maximum likelihood estimation.
Solution:
Likelihood:
Negative log-likelihood gives cross-entropy:
Exercise 3: Softmax Gradient
Problem: Derive
Solution:
With
This elegant result (
Exercise 4: Regularization as Bayesian Prior
Problem: What prior distributions do L2 and L1 regularization correspond to?
Solution:
L2: Gaussian prior
L1: Laplace prior
Exercise 5: Decision Boundary Geometry
Problem: Prove that the decision boundary
Solution:
This is a hyperplane with normal vector
References
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer. [Chapter 4: Linear Models for Classification]
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning (2nd ed.). Springer. [Chapter 4: Linear Methods for Classification]
- Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. MIT Press. [Chapter 8: Logistic Regression]
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press. [Chapter 5: Machine Learning Basics]
- Ng, A. Y., & Jordan, M. I. (2002). On discriminative vs. generative classifiers: A comparison of logistic regression and naive Bayes. Advances in Neural Information Processing Systems, 14.
- Hosmer, D. W., Lemeshow, S., & Sturdivant, R. X. (2013). Applied Logistic Regression (3rd ed.). Wiley.
Logistic regression, with its concise mathematical form, clear probabilistic interpretation, and efficient optimization algorithms, becomes the baseline model for classification tasks. From Sigmoid to Softmax, from gradient descent to regularization, this chapter provides complete derivation of the theoretical framework. Understanding logistic regression is not only fundamental to mastering classical machine learning, but also the gateway to neural networks and deep learning — after all, every layer of a deep neural network contains the essence of logistic regression.
- Post title:Machine Learning Mathematical Derivations (6): Logistic Regression and Classification
- Post author:Chen Kai
- Create time:2021-09-24 15:30:00
- Post link:https://www.chenk.top/Machine-Learning-Mathematical-Derivations-6-Logistic-Regression-and-Classification/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.