In 1886, Francis Galton discovered a peculiar phenomenon while studying the relationship between parents' and children's heights: parents with extreme heights tended to have children whose heights were closer to the average. He coined the term "regression toward the mean," which is where "regression" comes from. However, the true power of linear regression lies not in statistical description, but in its role as the mathematical foundation for almost all machine learning algorithms — from neural networks to support vector machines, all can be viewed as generalizations of linear regression.
The essence of linear regression is finding the optimal hyperplane in data space. This seemingly simple problem conceals deep connections between linear algebra, probability theory, and optimization. This chapter provides complete mathematical derivations of linear regression from multiple perspectives.
Basic Form of Linear Regression
Problem Definition
Given training dataset
-
Objective: Find parameter vector
best fits the training data.
Notation Simplification: To unify notation, we absorb the bias into the weight vector. Define the augmented feature vector:
Then the model simplifies to:
For brevity, we omit the tildes and write
Matrix Form
Organize all training samples into matrix form:
Design Matrix:
Output Vector:
Prediction Vector:
Our goal is to find optimal
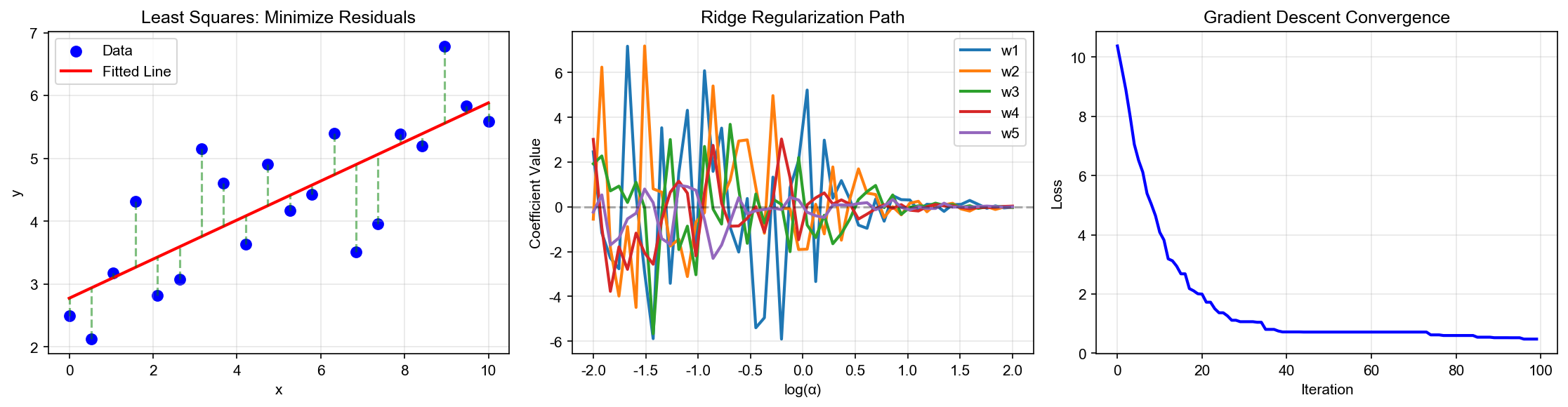
Least Squares: Algebraic Derivation
Loss Function
Using squared loss (L2 loss) to measure prediction error:
The coefficient
Objective:
Gradient Derivation
Calculate the gradient of the loss function with respect to
Expanding:
Taking derivatives with respect to
Therefore:
Normal Equation
Setting the gradient to zero:
This is the famous Normal Equation.
Theorem 1 (Least Squares Solution): If
Proof:
First-order necessary condition:
gives Second-order sufficient condition: Computing the Hessian matrix:
For any non-zero vector
If
- Positive definite Hessian + zero gradient = global minimum. QED.
Invertibility Conditions for
- Necessary and sufficient condition:
has full column rank, i.e., - Equivalent condition:
is positive definite - Practical interpretation:
- Number of samples
(at least as many samples as features) - Features are linearly independent (no perfect collinearity)
- Number of samples
Moore-Penrose Pseudoinverse
When
where
Properties:
- When
is invertible, (degenerates to ordinary inverse) - is the minimum norm solution among all solutions satisfying :
Computation: Via Singular Value Decomposition (SVD).
Let
where
Geometric Interpretation: Projection Perspective
Column Space and Projection
The geometric essence of linear regression is orthogonal projection.
Definitions:
-
This is exactly the normal equation!
Proof:
For any
Using the Pythagorean theorem (when two vectors are orthogonal):
Let
Therefore:
Equality holds if and only if
Projection Matrix
Definition: The projection matrix
Properties:
Idempotent:
(projecting twice equals projecting once) Symmetric:
Effect:
is the projection of onto the column space
Residual Projection Matrix:
Satisfying:
Properties:
-
Geometric Intuition
In
-
Imagine in 3D space, the perpendicular distance from a point
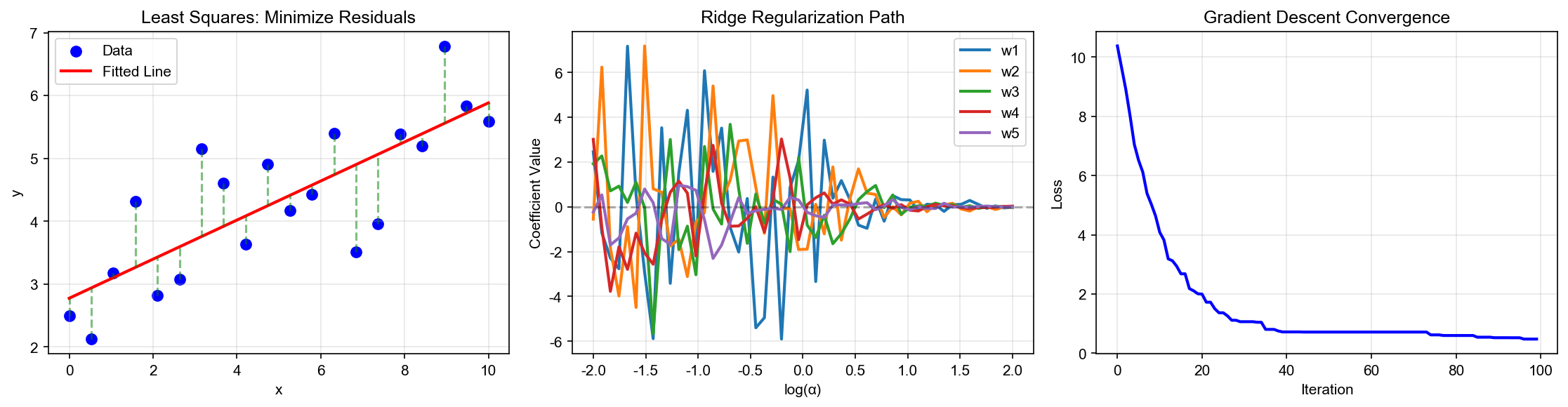
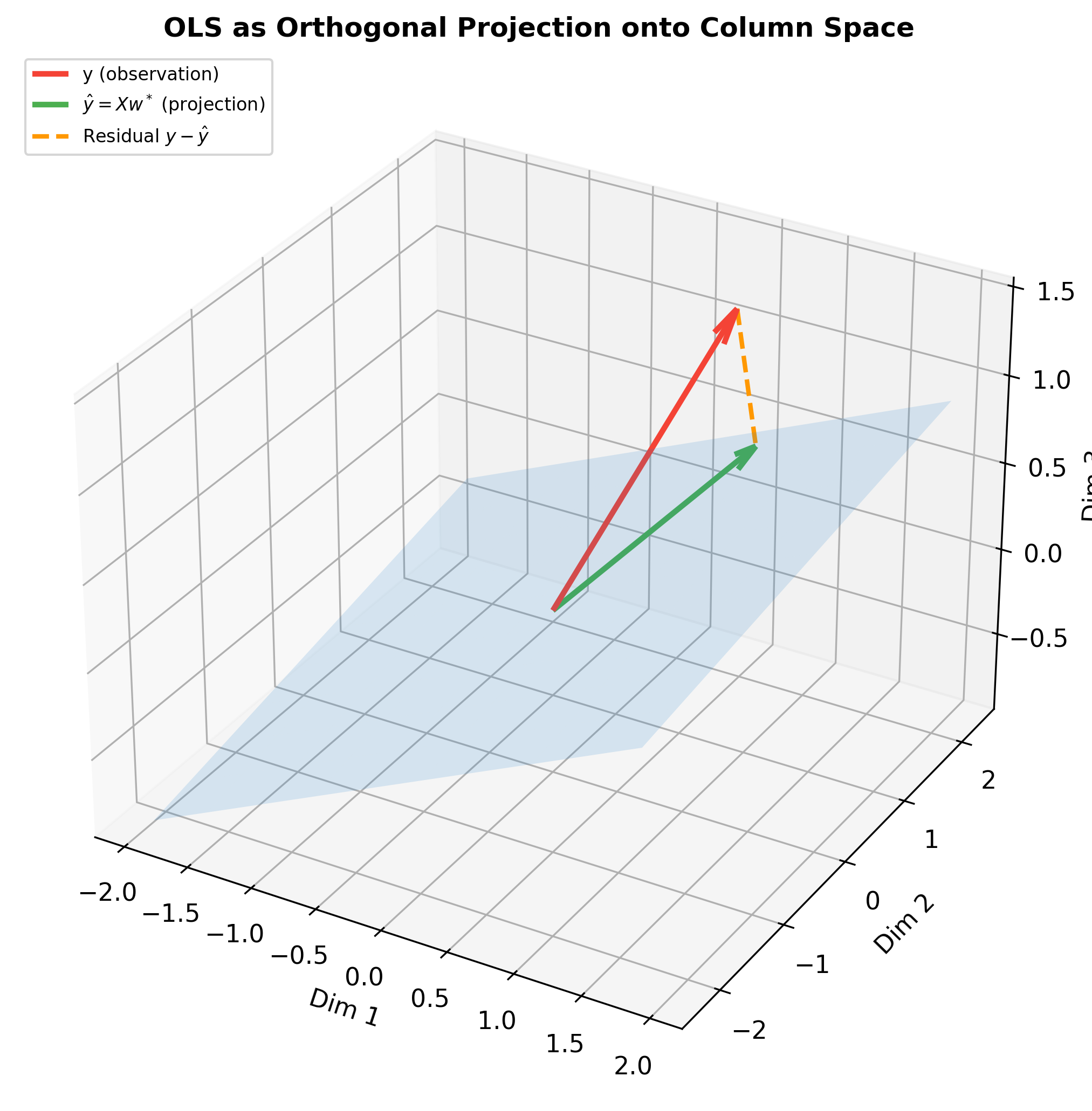
The figure below shows OLS as orthogonal projection in 3D —
observation vector
Probabilistic Perspective: Maximum Likelihood Estimation
Linear Gaussian Model
Assume the data generating process is:
where
Equivalent form:
That is, given
Likelihood Function
Given training data
Log-Likelihood
Taking logarithm (monotonic transformation doesn't change the maximum
point):
Maximum Likelihood Estimation
Optimization with respect to
Maximizing
This is exactly the least squares objective!
Theorem 3: Under the linear Gaussian model, maximum
likelihood estimation is equivalent to least squares estimation:
Optimization with respect to
Fixing
Solving:
The MLE of noise variance is the mean of squared residuals.
Bayesian Perspective
Introducing a prior distribution
Gaussian Prior: Assuming
Maximizing the posterior probability (MAP) is equivalent to minimizing:
This is the Ridge Regression objective function! The
regularization term
Regularization: Ridge Regression and Lasso
Ridge Regression (L2 Regularization)
Objective Function:
where
Gradient:
Setting gradient to zero:
Analytical Solution:
Key Observations:
- Adding
guarantees invertibility of (even if is not invertible) - When
, degenerates to ordinary least squares - When
, (extreme regularization)
Matrix Perspective: Ridge regression "stabilizes"
the matrix
Lasso Regression (L1 Regularization)
Objective Function:
where
Characteristics:
- No analytical solution (L1 norm is not differentiable)
- Requires iterative algorithms (e.g., coordinate descent, proximal gradient)
- Sparsity: Some parameters are compressed exactly to zero, achieving feature selection
Geometric Interpretation:
In constrained form:
The L1 constraint ball is a diamond (hyperdiamond in high dimensions), whose corners are more likely to intersect with contour lines on coordinate axes, leading to sparse solutions.
Elastic Net
Combining L1 and L2:
Advantages:
- Retains L1 sparsity
- Retains L2 stability (friendly to collinear features)
Effects of Regularization
Bias-Variance Tradeoff:
- No regularization (
): Low bias, high variance (overfitting) - Strong regularization (large
): High bias, low variance (underfitting) - Optimal
: Selected via cross-validation
Ridge Trace:
Plot
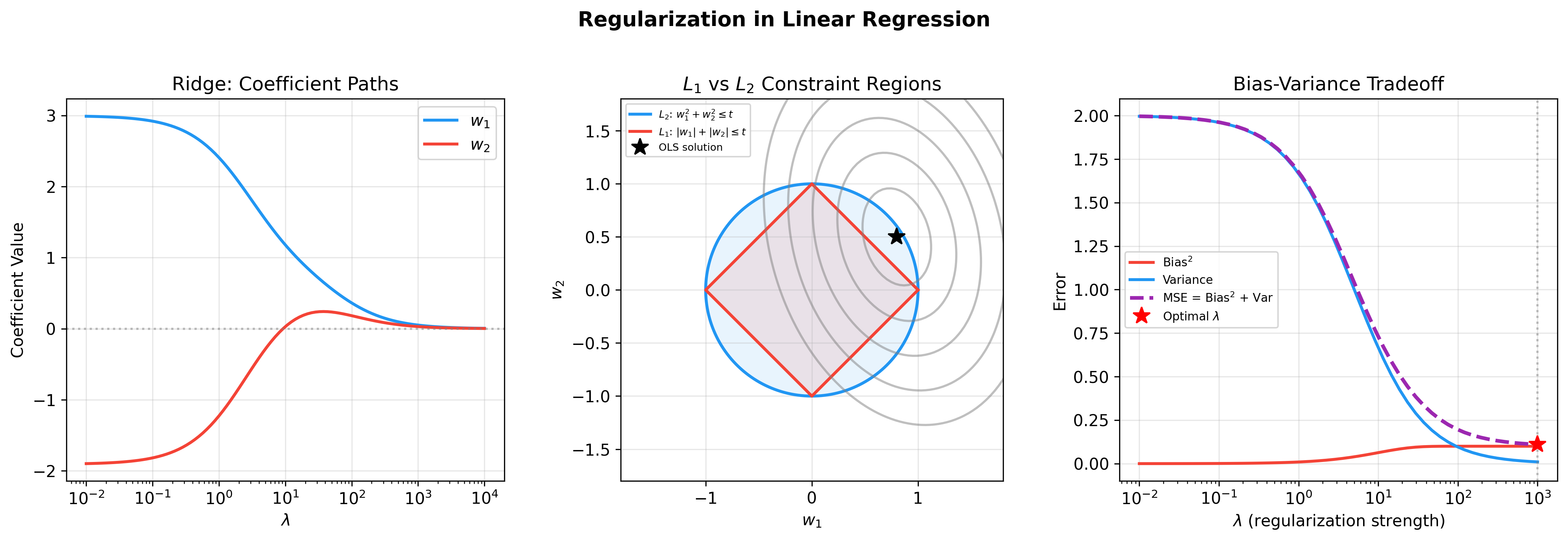
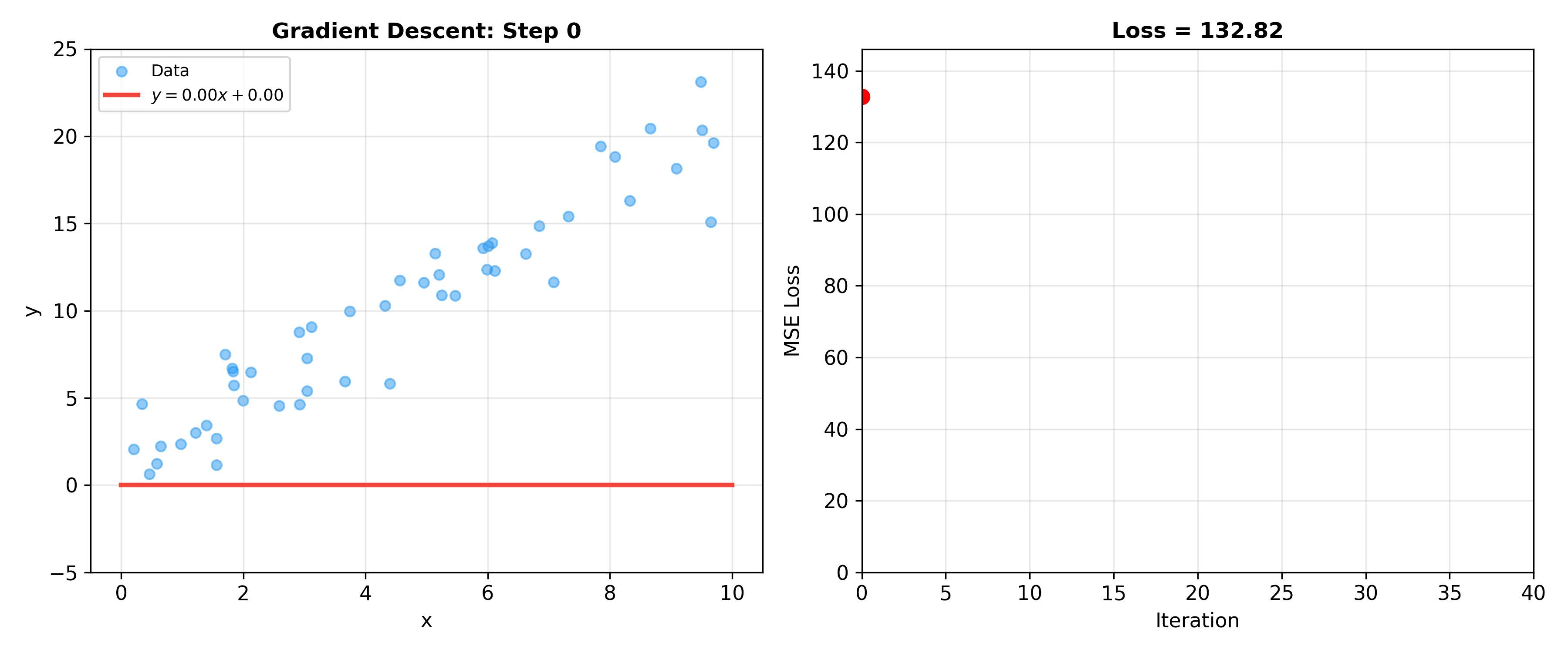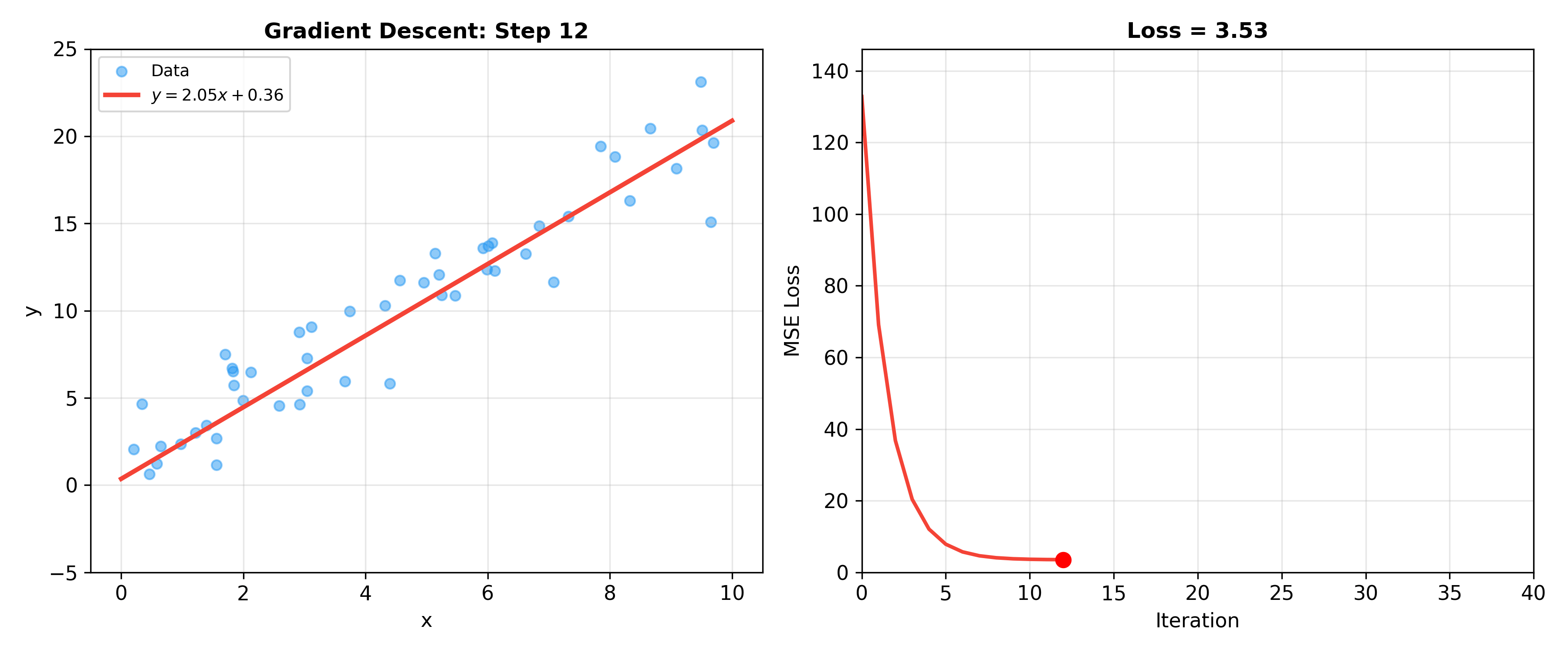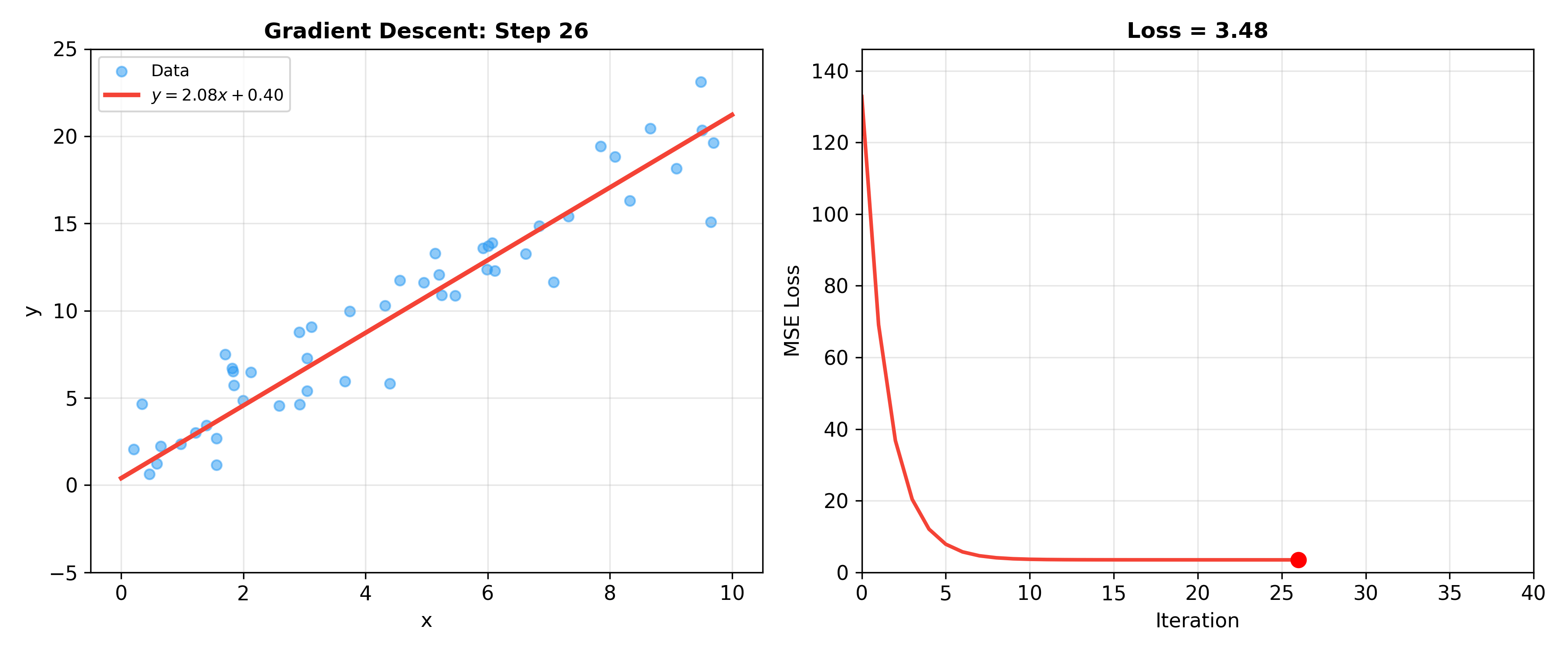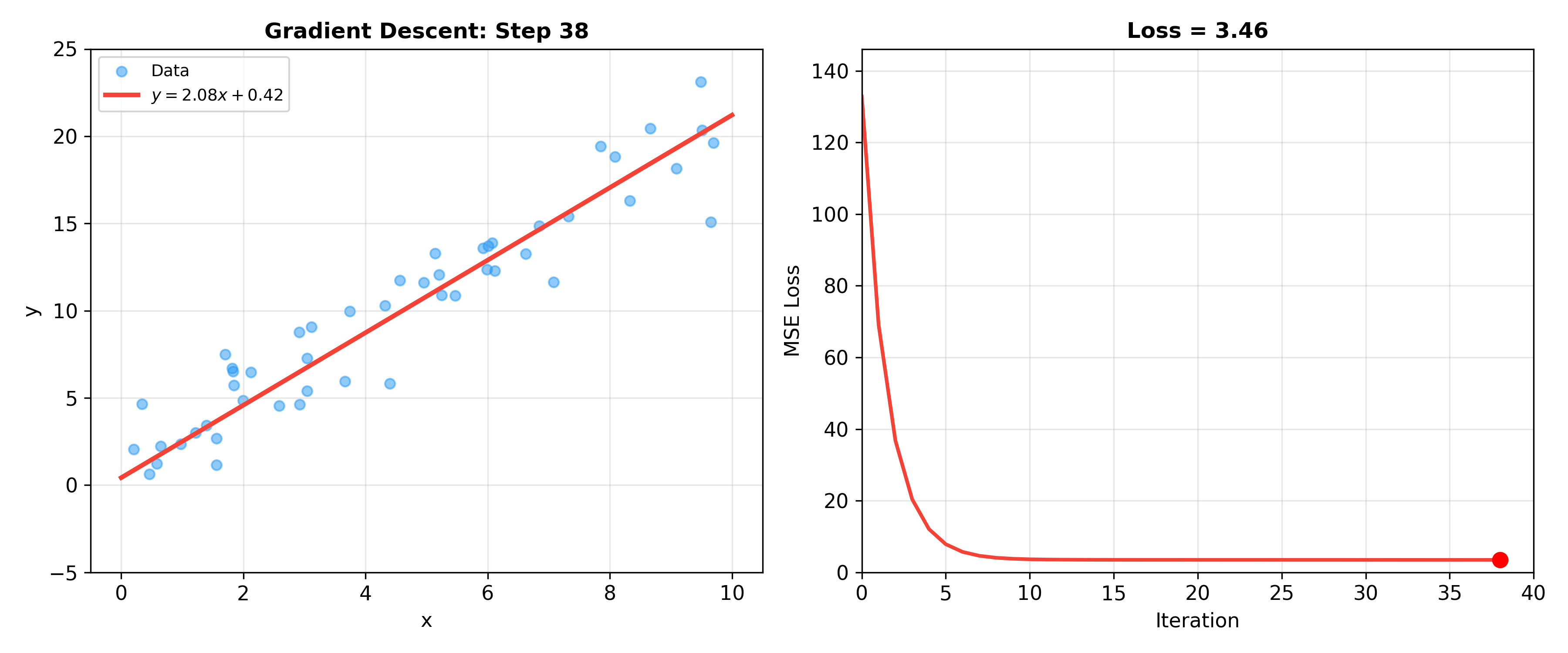
Gradient Descent Algorithms
Batch Gradient Descent (BGD)
When data is large, directly computing
Algorithm:
- Initialize
- Repeat until convergence:
where
Complete Form:
Computational Complexity:
Stochastic Gradient Descent (SGD)
Update parameters using only one sample at a time.
Algorithm:
- Initialize
- For
: - Randomly select sample
- Update:
- Randomly select sample
Advantages:
- Fast per iteration (
) - Suitable for large-scale data
- Ability to escape local minima (for non-convex problems)
Disadvantages:
- Unstable convergence (high variance)
- Requires careful learning rate tuning
Mini-batch Gradient Descent
Compromise: Use
where
Typical choices:
Convergence Analysis
Theorem 4 (BGD Convergence): For learning rate
where
Proof Sketch:
- Loss function is strongly convex (Hessian is positive definite)
- Gradient is Lipschitz continuous
- Apply convergence theorem for strongly convex functions
Practical Recommendations:
- Learning rate:
(conservative choice) - Adaptive learning rates: Adam, RMSprop, etc.
- Learning rate decay:
Model Evaluation and Selection
Evaluation Metrics
Mean Squared Error (MSE):
Root Mean Squared Error (RMSE):
Mean Absolute Error (MAE):
Coefficient of Determination (R ²):
where
Interpretation:
-
Adjusted R ²
Penalizing model complexity:
Advantage: Adding useless features decreases
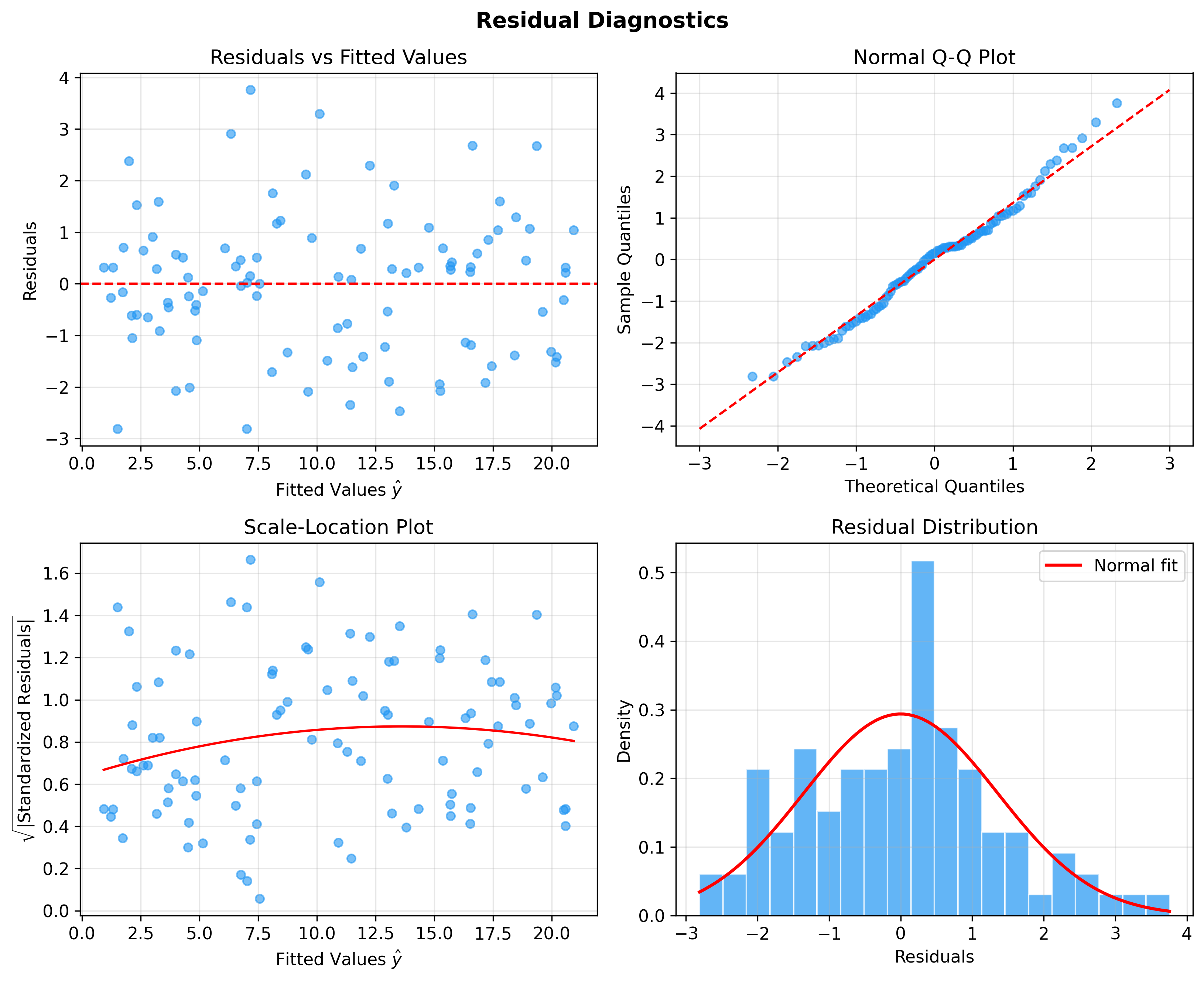
The figure below shows four classic residual diagnostic plots — residuals vs fitted values, Q-Q plot, Scale-Location plot, and residual histogram — for checking model assumptions:
Cross-Validation
k-fold Cross-Validation:
- Split data into
folds - For
: - Train on all data except fold
- Test on fold
- Train on all data except fold
- Average the
test errors
Python Implementation:
1 | from sklearn.model_selection import cross_val_score |
Complete Code Implementation
1 | import numpy as np |
Q&A: Core Linear Regression Questions
Q1: Why use squared loss instead of absolute value loss?
Mathematical Reasons:
- Differentiability:
is differentiable everywhere, facilitating optimization - Analytical solution: Squared loss leads to quadratic optimization problem with closed-form solution
- Statistical significance: Under Gaussian noise assumption, squared loss corresponds to maximum likelihood estimation
Absolute Value Loss (L1 loss):
Comparison:
| Loss Function | Differentiability | Analytical Solution | Outlier Robustness | Noise Distribution |
|---|---|---|---|---|
| Squared (L2) | Everywhere | Yes | Weak | Gaussian |
| Absolute (L1) | Not at 0 | No | Strong | Laplacian |
| Huber | Everywhere | No | Medium | Mixed |
Huber Loss (compromise):
Quadratic when
Q2: Normal equation vs gradient descent — when to use which?
Decision Tree:
1 | Data Scale? |
Detailed Comparison:
| Dimension | Normal Equation | Gradient Descent |
|---|---|---|
| Time Complexity | ||
| Space Complexity | ||
| Convergence | One step | Requires multiple iterations |
| Hyperparameters | None | Learning rate, iterations |
| Feature Count | Arbitrary | |
| Invertibility | Not required | |
| Regularization | Easy to add | Easy to add |
| Online Learning | Not supported | Supported (SGD) |
Practical Recommendations:
- Default choice: Use normal equation for
, otherwise gradient descent - Big data: Must use SGD or Mini-batch GD
- Real-time updates: Must use SGD (supports online learning)
Q3: Why does Ridge regression solution always exist?
Core Reason: Adding
Theorem: For any
Proof:
For any non-zero vector
Since
Therefore
Intuition:
-
Geometric Interpretation:
In feature space, the null space of
Q4: How to
choose regularization parameter
Method 1: Cross-Validation (Recommended)
1 | from sklearn.linear_model import RidgeCV |
Method 2: Grid Search
1 | from sklearn.model_selection import GridSearchCV |
Method 3: Theoretical Guidance
Based on bias-variance tradeoff:
where
Practical Experience:
- Starting point:
(on standardized data) - Range:
(logarithmic scale search) - Fine-tuning: Narrow range around optimal value
- Early stopping: Stop if validation error keeps increasing
L-curve Method:
Plot
Q5: Why is feature standardization important?
Problem: Different feature scales cause:
- Slow GD convergence: Parameter space is ellipsoidal, gradient doesn't point to optimum
- Unfair regularization:
penalizes large-scale features more
Example:
Suppose two features:
-
Weights
Standardization Methods:
Z-score Standardization (Recommended):
where
Min-Max Standardization:
Effect Comparison:
| Method | Mean | Std/Range | Outlier Sensitivity |
|---|---|---|---|
| Raw data | Any | Any | - |
| Z-score | 0 | 1 | Medium |
| Min-Max | - | [0,1] | High |
Code:
1 | from sklearn.preprocessing import StandardScaler |
Note:
After standardization, weight interpretation changes. To recover
original-scale weights:
Q6: How does multicollinearity affect linear regression?
Definition: Multicollinearity refers to high linear correlation among features.
Detection Method:
Variance Inflation Factor (VIF):
where
Guidelines:
-
Effects:
Numerical instability:
near singular, large errors in High parameter variance: Standard errors increase, confidence intervals widen
Uninterpretable parameters: Weight signs may be opposite to expectations
Solutions:
- Remove redundant features: Identify and remove via VIF
- PCA dimensionality reduction: Transform correlated features into orthogonal principal components
- Ridge regression:
penalty mitigates collinearity - Collect more data: Larger sample size reduces estimation variance
Q7: What are the assumptions of linear regression? What if violated?
Four Classic Assumptions:
Assumption 1: Linearity
Test: Residual plot should show no obvious pattern.
When Violated:
- Add polynomial features:
- Feature transformation:
- Use nonlinear models: Decision trees, neural networks
Assumption 2: Independence
Test: Durbin-Watson test statistic:
When Violated (common in time series):
- Use autoregressive models (AR, ARIMA)
- Add lagged terms as features
Assumption 3: Homoscedasticity
Test: In residual plot, spread of residuals should
remain constant with
When Violated (heteroscedasticity):
- Weighted Least Squares (WLS): Different weights for different samples
- Robust Standard Errors
- Log-transform target variable
Assumption 4: Normality
Tests:
- QQ plot (Quantile-Quantile Plot)
- Shapiro-Wilk test
When Violated:
- Transform target variable (Box-Cox transformation)
- Use nonparametric methods or generalized linear models
Q8: How to handle categorical features?
Problem: Linear regression requires numerical inputs, but many features are categorical (e.g., "color": red, green, blue).
Wrong Approach: Directly encode as integers (red=1, green=2, blue=3).
Problem: Introduces spurious ordinal relationship (model thinks blue is "larger" than red by 2).
Correct Methods:
One-Hot Encoding:
Convert
Example:
| Original | Red | Green | Blue |
|---|---|---|---|
| Red | 1 | 0 | 0 |
| Green | 0 | 1 | 0 |
| Blue | 0 | 0 | 1 |
Code:
1 | from sklearn.preprocessing import OneHotEncoder |
Notes:
- Multicollinearity:
one-hot columns are perfectly collinear (sum to 1). Solution: Drop one column ( drop='first') or use Ridge regression. - High cardinality features: If
is large (e.g., zip codes), consider: - Target Encoding
- Embeddings
Q9: Can linear regression handle nonlinear relationships?
Answer: Yes, through feature engineering.
Key Insight: "Linear" in linear regression refers to linearity in parameters, not features.
This is still a linear model with respect to
Method 1: Polynomial Features
1 | from sklearn.preprocessing import PolynomialFeatures |
Method 2: Interaction Features
1 | from sklearn.preprocessing import PolynomialFeatures |
Method 3: Custom Transformations
1 | import numpy as np |
Caution:
- Overfitting risk: Feature count grows rapidly
(
features with degree polynomial has terms) - Regularization necessary: Use Ridge or Lasso to control complexity
- Reduced interpretability: High-degree terms are hard to interpret
Q10: How to interpret linear regression coefficients?
Basic Interpretation:
For model
Meaning of
Caveats:
Standardization effect: If features are standardized, weight magnitudes cannot directly compare importance.
Collinearity effect: Multicollinearity makes weights unstable.
Causal relationship: Correlation ≠ causation. Weights only indicate statistical association, not causal inference.
Standardized Coefficients:
Fitting on standardized data yields coefficients that can compare
relative importance:
Interpretation: When
Significance Testing:
Use t-test to determine if
where
Python Implementation:
1 | import statsmodels.api as sm |
Confidence Interval:
95% confidence interval:
If the interval does not contain 0, the parameter is significant.
Summary and Outlook
Key Points:
Three perspectives: Algebraic (normal equation), geometric (projection), probabilistic (MLE) all lead to same result
Least squares solution:
Regularization: Ridge (L2) ensures invertibility, Lasso (L1) achieves sparsity
Optimization algorithms: Normal equation for small data, gradient descent for large data
Model diagnostics: Check linearity, independence, homoscedasticity, normality
Practical Tips:
- Feature standardization
- Handle collinearity
- Select regularization parameter
- Cross-validation for evaluation
Next Chapter Preview: Chapter 6 will explore logistic regression and classification, extending linear models to discrete output spaces. We will derive the origin of the sigmoid function, mathematical foundations of cross-entropy loss, and geometric interpretation of decision boundaries.
✏️ Exercises and Solutions
Exercise 1: Normal Equation Derivation
Problem: Derive the normal equation
Solution:
Loss:
Gradient:
Setting
Exercise 2: Bayesian Interpretation of Ridge
Problem: Prove that Ridge regression is equivalent
to MAP estimation with Gaussian prior
Solution:
MAP minimizes:
Comparing with Ridge:
Therefore
Exercise 3: Projection Matrix Properties
Problem: Prove that
Solution:
Symmetry:
Idempotency:
Geometric meaning:
Exercise 4: MLE of Noise Variance
Problem: Under
Solution:
Log-likelihood:
Setting
This is biased:
Exercise 5: Multicollinearity and Ridge
Problem: When
Solution:
VIF
Ridge:
References
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning (2nd ed.). Springer.
Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. MIT Press.
Shalev-Shwartz, S., & Ben-David, S. (2014). Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press.
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An Introduction to Statistical Learning. Springer.
Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B, 58(1), 267-288.
Hoerl, A. E., & Kennard, R. W. (1970). Ridge regression: Biased estimation for nonorthogonal problems. Technometrics, 12(1), 55-67.
Zou, H., & Hastie, T. (2005). Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society: Series B, 67(2), 301-320.
Huber, P. J. (1964). Robust estimation of a location parameter. The Annals of Mathematical Statistics, 35(1), 73-101.
- Post title:Machine Learning Mathematical Derivations (5): Linear Regression
- Post author:Chen Kai
- Create time:2021-09-18 09:00:00
- Post link:https://www.chenk.top/Machine-Learning-Mathematical-Derivations-5-Linear-Regression/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.