In 1947, George Dantzig developed the simplex method for linear programming while working for the U.S. Air Force. This breakthrough marked the birth of modern optimization theory. Seven decades later, optimization has become the theoretical pillar of machine learning — nearly all learning algorithms can be formulated as optimization problems. Among all optimization problems, convex optimization holds a unique position: local optima are global optima, and efficient algorithms guarantee convergence.
Why can neural network training find good solutions even when the loss function is non-convex? Why does gradient descent converge rapidly in certain cases? The answers lie deeply embedded in the mathematical structure of convex optimization theory. This chapter rigorously derives the core theory and algorithms of convex optimization, starting from the definitions of convex sets and convex functions.
Convex Sets and Convex Functions
Definition and Properties of Convex Sets
Definition 1 (Convex Set): A set
This definition states that the line segment connecting any two points in a convex set is entirely contained within the set. Geometrically, convex sets have no "indentations."
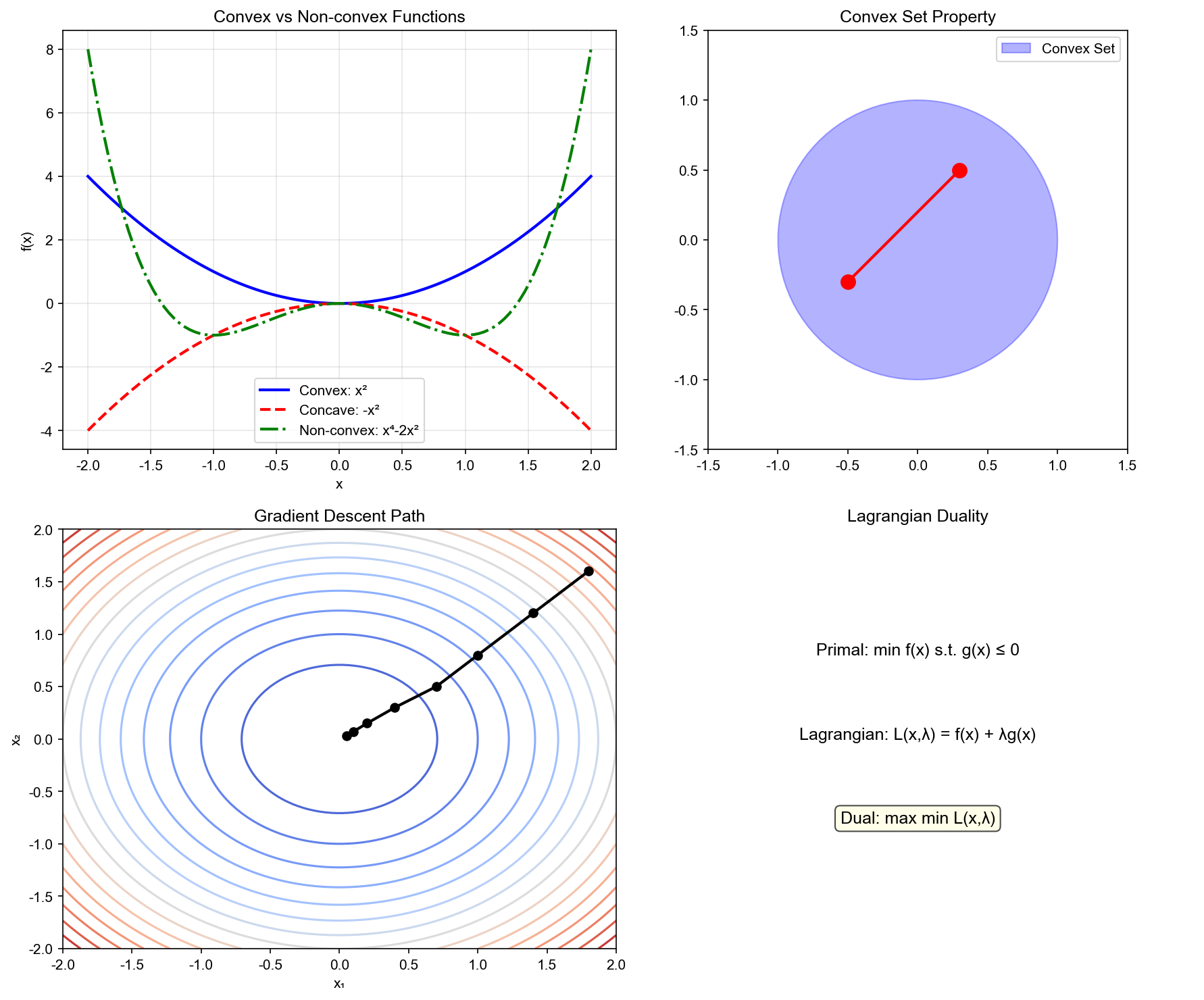
The following figure contrasts convex and non-convex sets/functions — convexity guarantees that local optima are global optima, which is the core value of convex optimization in machine learning:
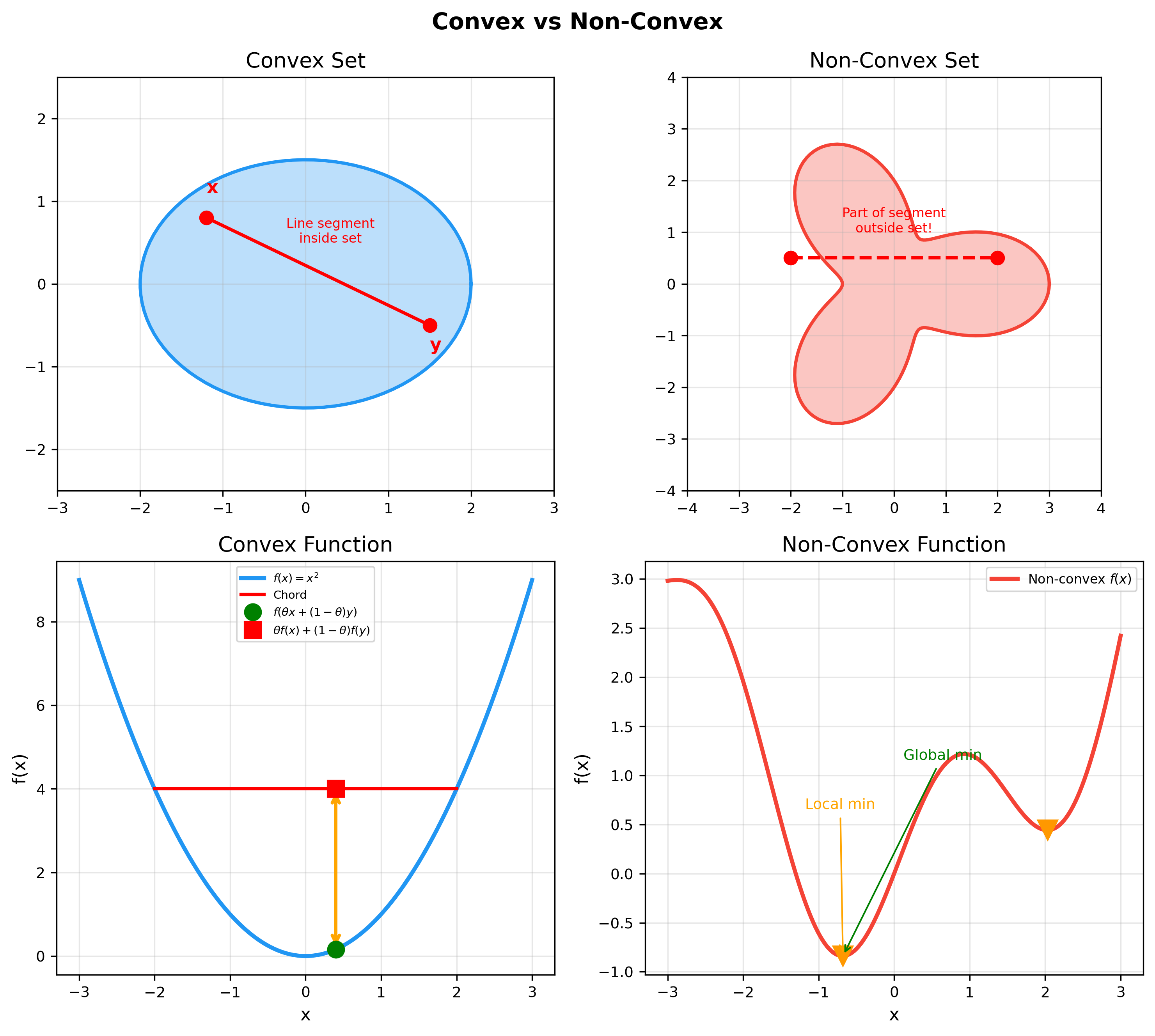
Example 1 (Common Convex Sets):
Hyperplane:
, where Halfspace:
Norm ball:
, for any norm Ellipsoid:
, where (positive definite)
Proof that hyperplane is convex: Let
Therefore
Theorem 1 (Intersection of Convex Sets): If
Proof: Let
Therefore
This property is crucial: it means we can describe complex convex sets through the intersection of finitely many linear constraints (halfspaces).
Definition and Characterization of Convex Functions
Definition 2 (Convex Function): A function
Geometric interpretation: the line segment between any two points on the function's graph lies above the function's graph.
Definition 3 (Strictly Convex Function): For any
Definition 4 (Strongly Convex Function): Function
Strong convexity is a stronger condition than convexity, guaranteeing "strict quadratic growth."
Theorem 2 (First-Order Condition): A differentiable
function
This shows that the first-order Taylor expansion of a convex function is a global lower bound (tangent lines always lie below the function).
Proof (Sufficiency): Assume the first-order
condition holds. For any
Multiply the first inequality by
Proof (Necessity): Assume
Rearranging and dividing by
Taking
Theorem 3 (Second-Order Condition): A
twice-differentiable function
If
Proof sketch: Use Taylor expansion. For a convex function, the second-order remainder must be non-negative:
By the first-order condition,
This holds for all
Example 2 (Common Convex Functions):
Affine function:
(both convex and concave) Exponential function:
Power function:
, when or ( ) Negative entropy:
( ) Norm:
, for any norm
Jensen's Inequality: Core Property of Convex Functions
Theorem 4 (Jensen's Inequality): If
If
Proof (Discrete case): Let
-
Jensen's inequality is foundational for many inequalities in information theory, statistics, and machine learning. For instance, it directly implies the non-negativity of KL divergence.
Subgradients and Non-smooth Optimization
Definition of Subgradients
Convex functions may not be differentiable (e.g.,
Definition 5 (Subgradient): A vector
Geometric meaning: it defines a "supporting hyperplane" passing
through point
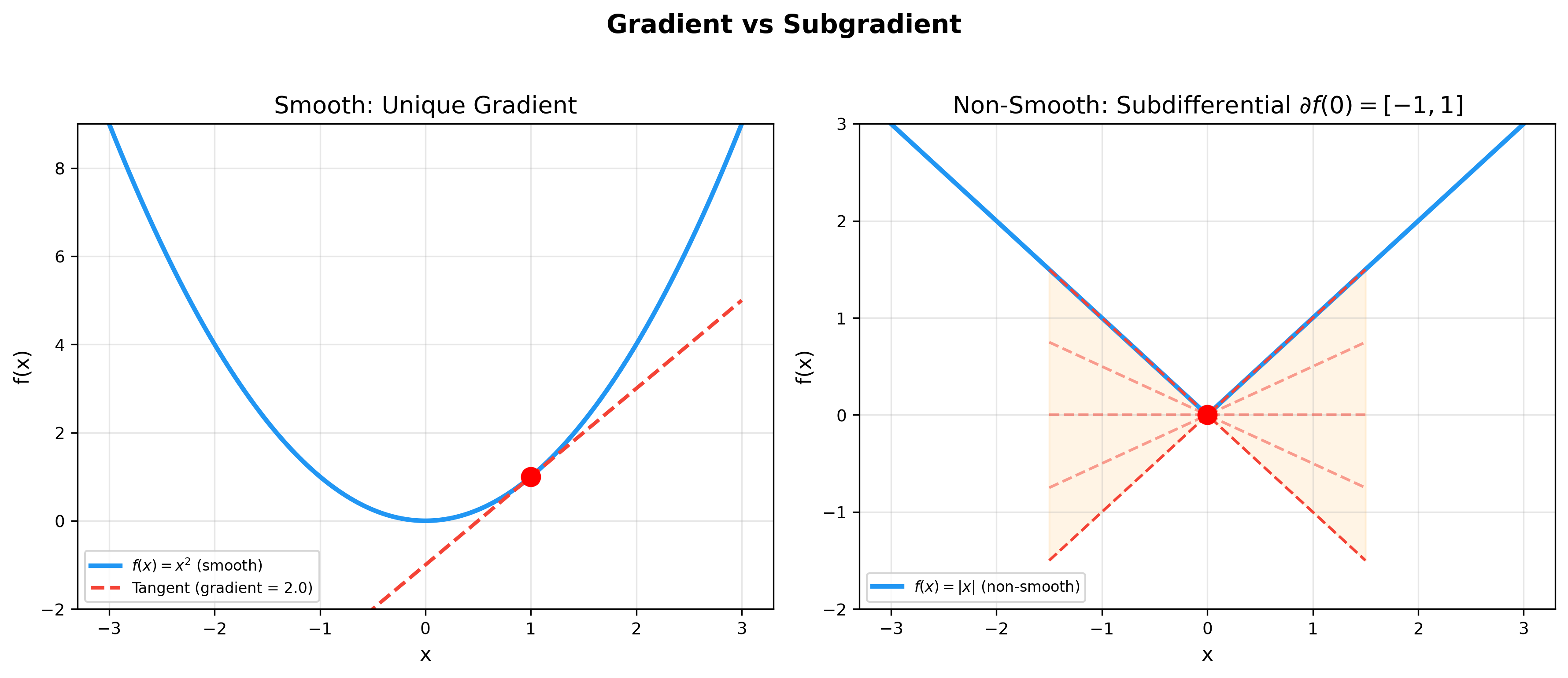
The figure below contrasts the gradient of smooth functions with subgradients of non-smooth functions — at non-differentiable points, the subdifferential is an interval, making non-smooth optimization possible:
Definition 6 (Subdifferential): The set of all
subgradients at point
Theorem 5 (Properties of Subdifferential):
- If
is differentiable at , then (singleton set) 2. is a closed convex set 3. is an optimal solution if and only if Proof of property 3:
- Sufficiency: If
, then for all : - Necessity: If
is optimal, then for all , so satisfies the subgradient condition
Example 3 (Computing Subdifferentials):
Absolute value function
:$$f(x) = L1 norm
:$$f(x) = {g : g_i = (x_i) x_i , |g_i| x_i = 0} Indicator function
( is a convex set):
This is called the normal cone of
Subgradient Method
For non-differentiable convex functions, we can use subgradients instead of gradients for optimization.
Algorithm 1 (Subgradient Descent): 1
2
3
4
5Initialize: x^(0)
for k = 0, 1, 2, ... do
Choose g^(k) ∈ ∂ f(x^(k))
x^(k+1) = x^(k) - α_k g^(k)
end for
where
Theorem 6 (Convergence of Subgradient Method):
Assume
then
Common step size choices include
Proof sketch: Define
Expanding and taking expectations establishes a recurrence relation,
ultimately yielding
First-Order Optimization Algorithms
Gradient Descent
Gradient descent is the most fundamental optimization algorithm, iteratively updating parameters in the direction of negative gradient.
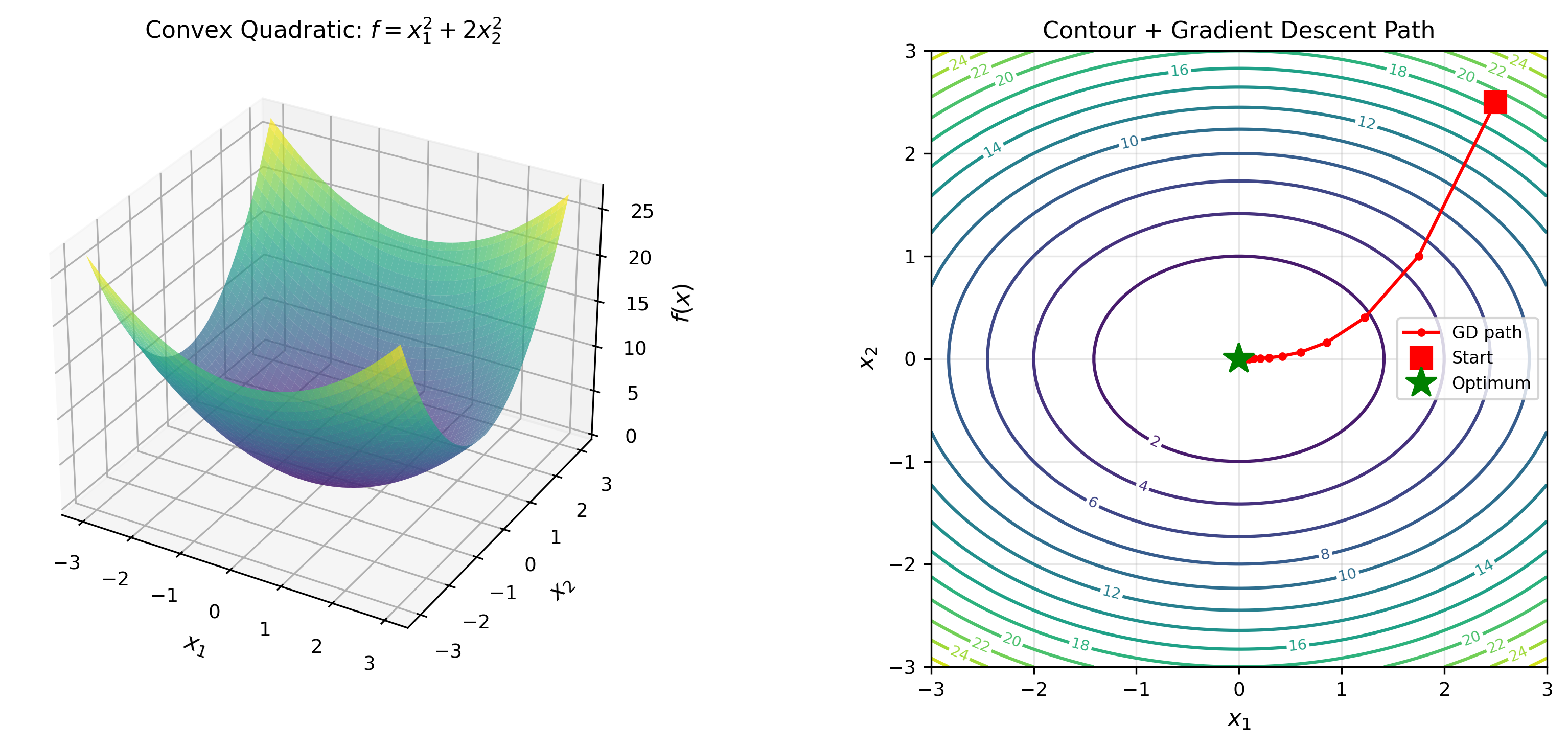
The animation below shows the gradient descent trajectory on 2D convex function contours — each step moves along the negative gradient direction, progressively approaching the optimum:
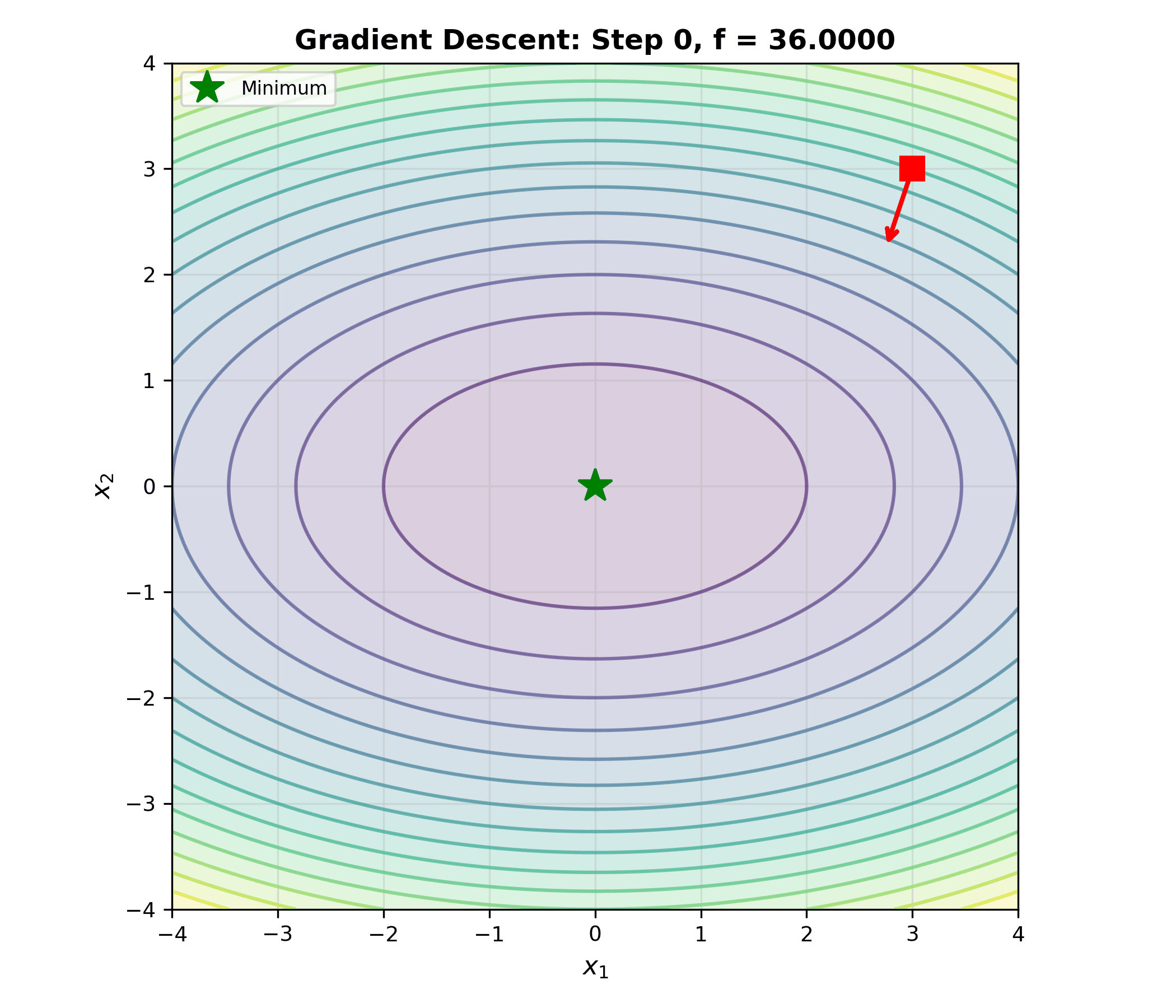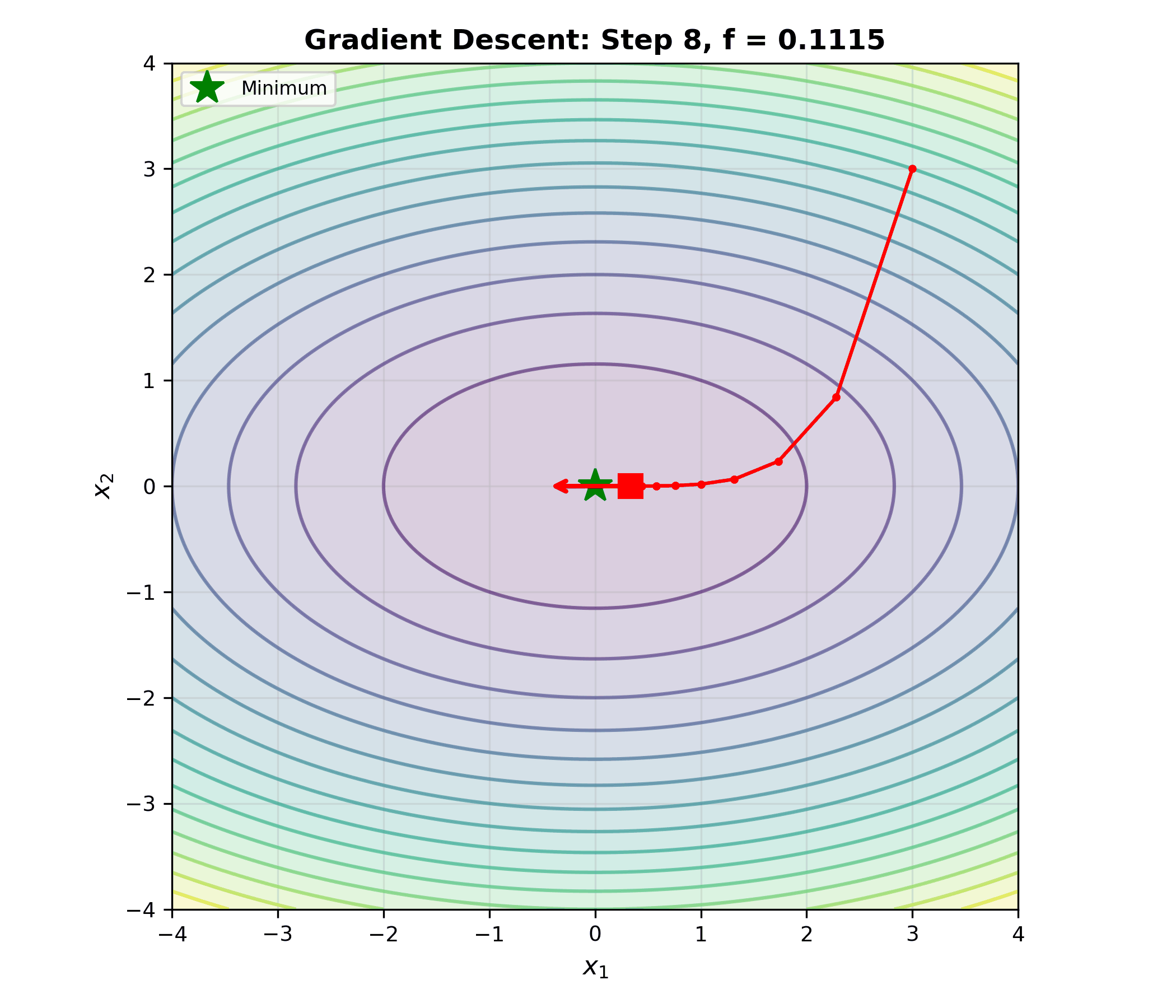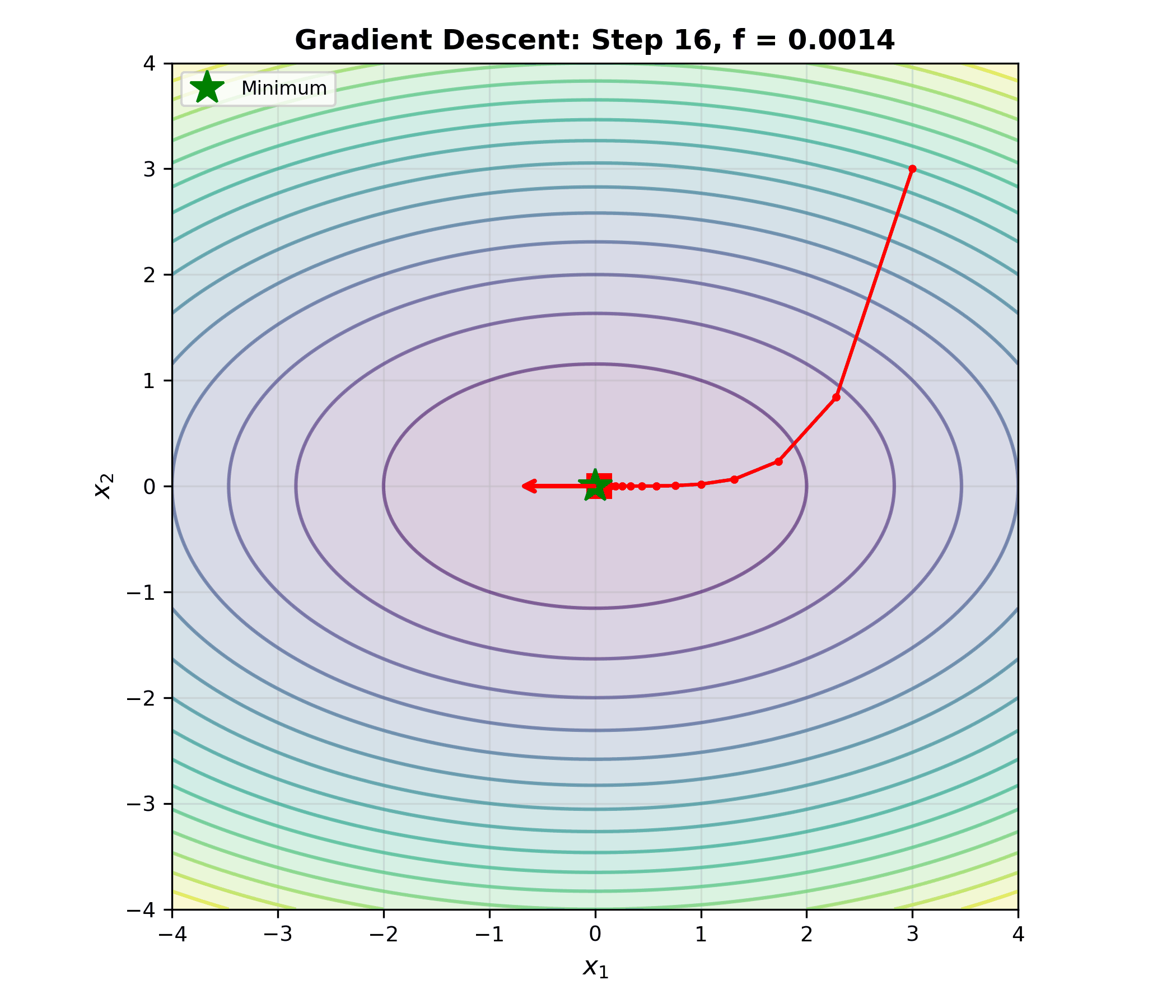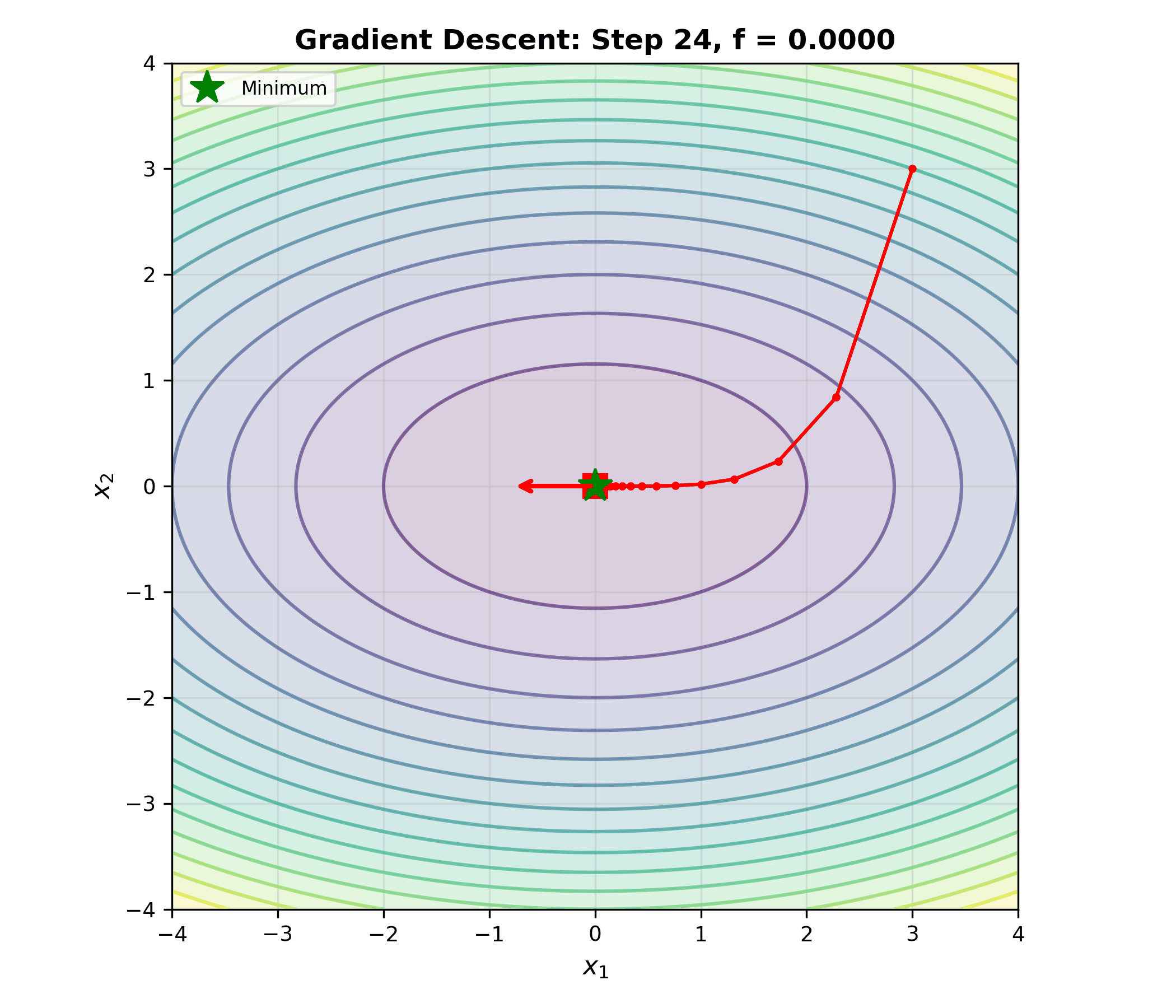
Algorithm 2 (Gradient Descent): 1
2
3
4Initialize: x^(0)
for k = 0, 1, 2, ... do
x^(k+1) = x^(k) - α_k ∇ f(x^(k))
end for
Theorem 7 (Convergence of Gradient Descent - Convex and
Smooth Case): Assume
Using fixed step size
This is a convergence rate of
Proof:
Taking
Using the first-order condition from convexity:
Combined with the recurrence for
Theorem 8 (Strongly Convex Case): If
The convergence rate depends on the condition number
Momentum and Nesterov Acceleration
Standard gradient descent converges slowly on "canyon" terrain (high curvature in one direction, low in another). Momentum methods accelerate by accumulating historical gradients.
Algorithm 3 (Momentum Gradient Descent):
1
2
3
4
5Initialize: x^(0), v^(0) = 0
for k = 0, 1, 2, ... do
v^(k+1) = β v^(k) - α ∇ f(x^(k))
x^(k+1) = x^(k) + v^(k+1)
end for
where
Nesterov Accelerated Gradient (NAG) makes a clever improvement: first "predict" the next position using momentum, then compute gradient at the predicted position:
Algorithm 4 (Nesterov Acceleration):
1
2
3
4
5Initialize: x^(0), y^(0) = x^(0)
for k = 0, 1, 2, ... do
x^(k+1) = y^(k) - α ∇ f(y^(k))
y^(k+1) = x^(k+1) + β_k(x^(k+1) - x^(k))
end for
Theorem 9 (Nesterov Acceleration Convergence):
For
This is a convergence rate of
The figure below compares convergence rates of various optimization
algorithms — from subgradient method's
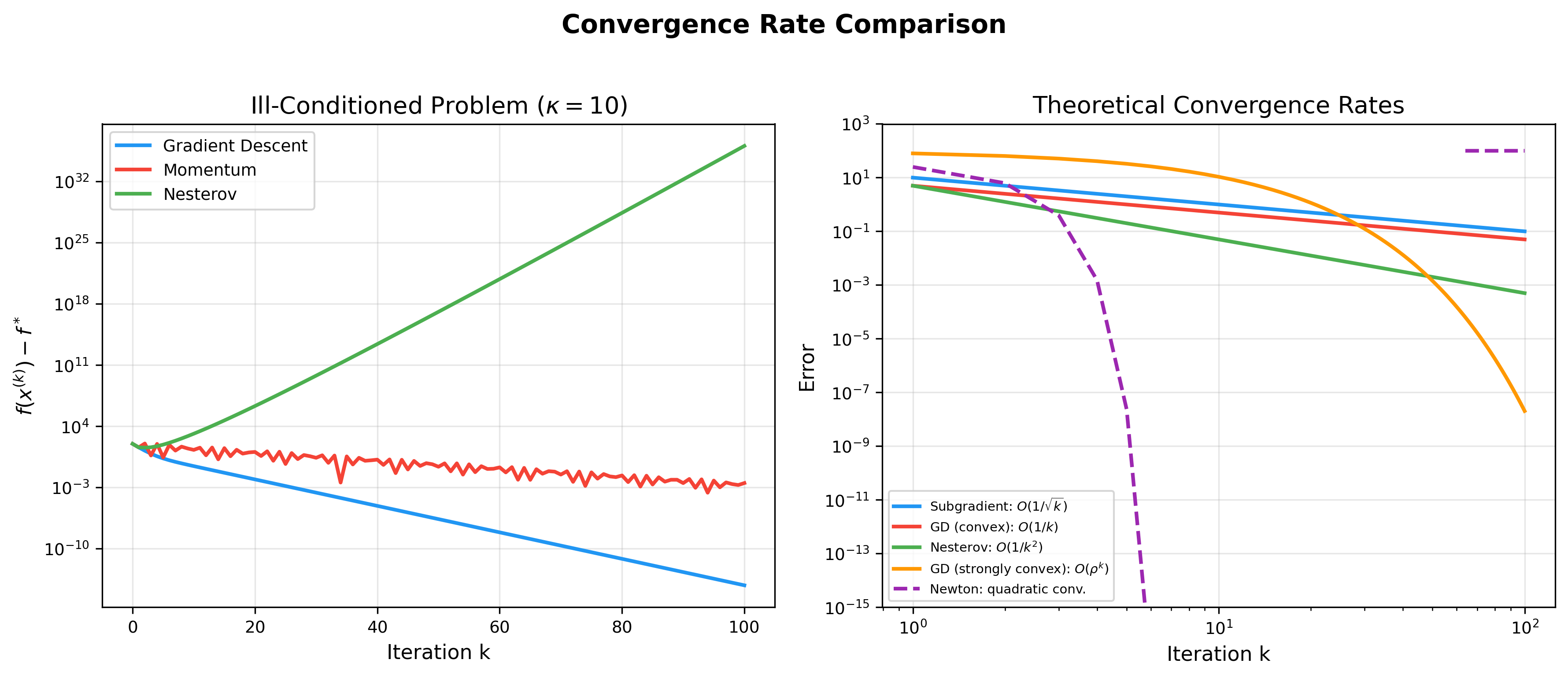
Adaptive Learning Rate Algorithms
Algorithms like AdaGrad, RMSProp, and Adam automatically adjust learning rates for each parameter based on historical gradients.
Algorithm 5 (Adam): 1
2
3
4
5
6
7
8
9Initialize: x^(0), m^(0) = 0, v^(0) = 0
for k = 0, 1, 2, ... do
g^(k) = ∇ f(x^(k))
m^(k+1) = β_1 m^(k) + (1-β_1) g^(k) // First moment estimate
v^(k+1) = β_2 v^(k) + (1-β_2) (g^(k))^2 // Second moment estimate
m ̂^(k+1) = m^(k+1) / (1 - β_1^{k+1}) // Bias correction
v ̂^(k+1) = v^(k+1) / (1 - β_2^{k+1})
x^(k+1) = x^(k) - α m ̂^(k+1) / (√ v ̂^(k+1)} + ε)
end for
Typical parameters:
Adam combines momentum (first moment) and adaptive learning rates (second moment), making it widely used in deep learning.
Second-Order Optimization Algorithms
Newton's Method
Newton's method uses second-order information (Hessian matrix) to construct a quadratic approximation, achieving faster convergence.
Derivation: At point
Taking derivative with respect to
Solving for the Newton direction:
Algorithm 6 (Newton's Method): 1
2
3
4
5
6
7Initialize: x^(0)
for k = 0, 1, 2, ... do
Compute g^(k) = ∇ f(x^(k))
Compute H^(k) = ∇² f(x^(k))
Solve linear system: H^(k) Δ x^(k) = -g^(k)
x^(k+1) = x^(k) + Δ x^(k)
end for
Theorem 10 (Quadratic Convergence of Newton's
Method): Assume
Proof sketch: Use Taylor expansion and implicit
function theorem. At optimal point
Newton iteration:
Substituting and simplifying yields quadratic convergence.
Disadvantages of Newton's method:
- Each iteration requires computing and inverting an
Hessian matrix, computational complexity - Hessian may not be positive definite, causing search direction to not be a descent direction
- Requires storing
matrix
Quasi-Newton Methods: BFGS Algorithm
Quasi-Newton methods approximate the Hessian matrix
Quasi-Newton Condition (Secant Condition): We
want
Let
This mimics a property satisfied by the true Hessian (curvature information along the search direction).
BFGS Update Formula: The BFGS (Broyden-Fletcher-Goldfarb-Shanno) algorithm uses the following update:
Or update the inverse matrix
where
Algorithm 7 (BFGS): 1
2
3
4
5
6
7
8
9
10Initialize: x^(0), H^(0) = I
for k = 0, 1, 2, ... do
Compute g^(k) = ∇ f(x^(k))
d^(k) = -H^(k) g^(k)
Line search: choose α_k such that f(x^(k) + α_k d^(k)) is small enough
x^(k+1) = x^(k) + α_k d^(k)
s_k = x^(k+1) - x^(k)
y_k = ∇ f(x^(k+1)) - ∇ f(x^(k))
Update H^(k+1) using formula above
end for
Theorem 11 (Superlinear Convergence of BFGS): For strongly convex functions, if line search satisfies Wolfe conditions, BFGS converges superlinearly:
BFGS is one of the most successful quasi-Newton algorithms in practice, widely applied to small and medium-scale optimization problems.
L-BFGS (Limited-memory BFGS): For large-scale
problems, storing
Constrained Optimization and Duality Theory
Lagrangian Duality
Consider a general constrained optimization problem:
Lagrangian Function: Introduce Lagrange
multipliers
Definition 7 (Lagrangian Dual Function):
where
Theorem 12 (Weak Duality): For any
where
Proof: Let
Therefore:
Since
Dual Problem:
Let the optimal value of the dual problem be
Definition 8 (Duality Gap):
Theorem 13 (Slater's Condition): If the primal
problem is a convex optimization problem (
This condition guarantees zero duality gap, allowing us to solve the primal problem through the dual problem.
KKT Conditions: Necessary and Sufficient Conditions for Optimality
Theorem 14 (KKT Conditions): Assume
Primal feasibility:
Dual feasibility:
Complementary slackness:
Stationarity:
The figure below shows the geometric interpretation of KKT conditions
— at the optimum, the objective gradient
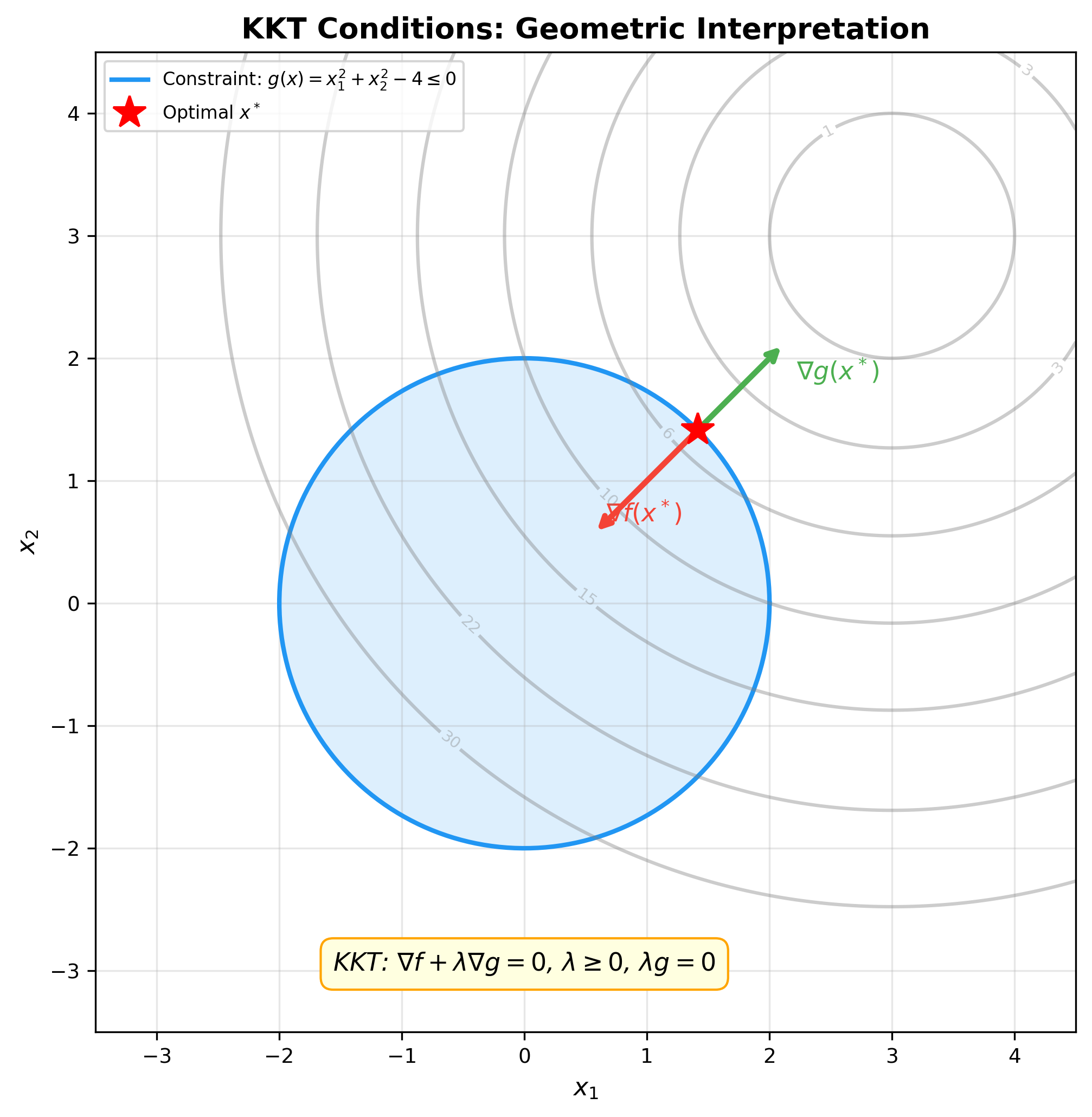
Theorem 15: If the primal problem is convex and satisfies Slater's condition, KKT conditions are necessary and sufficient for optimality.
Proof sketch (Complementary slackness): Since
The last inequality uses
Since
Example 4 (KKT Conditions in SVM): SVM primal problem:
KKT conditions yield:
Complementary slackness shows: only points on the margin (support
vectors) have
ADMM Algorithm
Alternating Direction Method of Multipliers (ADMM) is a powerful distributed optimization algorithm, particularly suited for solving convex optimization problems with separable structure.
Problem Formulation
Consider the following problem:
where
Augmented Lagrangian Function:
where
ADMM Algorithm Steps
Algorithm 8 (ADMM): 1
2
3
4
5
6Initialize: x^(0), z^(0), y^(0)
for k = 0, 1, 2, ... do
x^(k+1) = argmin_x L_ρ(x, z^(k), y^(k))
z^(k+1) = argmin_z L_ρ(x^(k+1), z, y^(k))
y^(k+1) = y^(k) + ρ(Ax^(k+1) + Bz^(k+1) - c)
end for
Algorithm explanation:
-update: Fix and , minimize augmented Lagrangian with respect to -update: Fix and , minimize with respect to -update: Gradient ascent on dual variable
ADMM's cleverness: even if joint optimization of
Convergence Analysis
Theorem 16 (ADMM Convergence): Assume
Residual convergence:
Objective convergence:
Dual variable convergence:
Proof sketch: Construct a Lyapunov function to prove sequence convergence. Define:
We can prove
Application Example: Lasso Regression
Lasso problem:
Rewrite in ADMM form:
Augmented Lagrangian function:
ADMM updates:
-update:
This is a ridge regression problem with closed-form solution.
-update:
where
-update:
This algorithm is very efficient and easily distributed.
Implementation Code
Below is a complete implementation of gradient descent, Newton's method, BFGS, and ADMM.
1 | import numpy as np |
Code explanation:
- ConvexOptimizer class: Implements multiple
optimization algorithms
gradient_descent: Fixed step size gradient descentgradient_descent_backtracking: Gradient descent with backtracking line searchnewton_method: Newton's methodbfgs: BFGS quasi-Newton methodmomentum_gd: Momentum gradient descentnesterov_accelerated_gd: Nesterov acceleration
- ADMMSolver class: Implements ADMM algorithm for
Lasso
- Uses Cholesky decomposition to accelerate
update - Soft thresholding operator for
update - Tracks primal and dual residuals
- Uses Cholesky decomposition to accelerate
- Examples:
- Quadratic function optimization: Demonstrates convergence performance of different algorithms
- Lasso regression: Demonstrates ADMM application in sparse optimization
In-Depth Q&A
Q1: Why is convex optimization so important? Isn't non-convex optimization more common?
A1: The importance of convex optimization manifests in three layers:
Theoretical level: Convex optimization is the only class of problems where we can completely characterize optimality conditions. KKT conditions provide necessary and sufficient conditions, which is impossible in non-convex cases.
Algorithmic level: Convex optimization has polynomial-time algorithms (like interior-point methods), with strict convergence guarantees. Gradient descent in convex cases guarantees convergence to global optimum, while in non-convex cases it only guarantees local optimum.
Application level: Many practical problems are inherently convex (linear regression, support vector machines, many statistical estimation problems). Even when the original problem is non-convex, convex relaxation techniques can provide useful approximate solutions and lower bounds.
For non-convex problems like deep learning, convex optimization theory still provides important intuition and tools. For instance, adaptive algorithms like Adam draw design inspiration from dual averaging methods in convex optimization.
Q2: What is the relationship between Jensen's inequality and the non-negativity of KL divergence?
A2: The non-negativity of KL divergence is a direct consequence of Jensen's inequality. KL divergence is defined as:
To prove
Equality holds if and only if
This proof reveals the deep connection between information theory and convex optimization. KL divergence can be viewed as a "distance" in probability distribution space (though asymmetric), and Jensen's inequality guarantees this "distance" is always non-negative.
Q3: Why is Newton's method faster than gradient descent, but less commonly used in practice?
A3: This is a classic theory-practice trade-off:
Advantages of Newton's method: - Quadratic convergence: Error decreases quadratically per iteration, extremely fast near optimum - Adaptive step size: Automatically adjusts step size based on curvature, no parameter tuning needed - Affine invariance: Insensitive to coordinate transformations
Disadvantages of Newton's method: 1.
Computational cost: Each iteration requires
Practical solutions: - Small-scale problems (
Q4: How is the BFGS update formula derived?
A4: BFGS update formula derivation is based on two principles:
Principle 1: Satisfy quasi-Newton condition (Secant equation)
Principle 2: Minimize
Specific derivation: Consider optimization problem
This is a constrained optimization problem. Construct Lagrangian and solve to get:
The first term "removes"
Symmetric rank-1 (SR1) formula is another choice:
But SR1 may not maintain positive definiteness, while BFGS guarantees
positive definiteness when
Q5: Why can ADMM be implemented in a distributed manner?
A5: ADMM's distributed capability stems from its "divide and conquer" structure. Consider multi-agent collaborative optimization:
Each agent only knows its own
Global consensus ADMM: 1
2
3
4
5
6
7
8// Agent i's local update (parallel)
x_i^(k+1) = argmin_{x_i} [f_i(x_i) + y_i^(k)T x_i + (ρ/2)||x_i - z^(k)||^2]
// Central node's global update
z^(k+1) = (1/N) Σ_i x_i^(k+1)
// Dual variable update
y_i^(k+1) = y_i^(k) + ρ(x_i^(k+1) - z^(k+1))
Each iteration, agents only send
This makes ADMM particularly suitable for: - Federated learning: Each client trains local model, server aggregates - Sensor networks: Distributed state estimation - Large-scale machine learning: Data distributed across multiple nodes
Q6: What is the practical significance of strong convexity? Why care about condition number?
A6: Strong convexity determines the optimization problem's "ill-conditioning" degree, directly affecting algorithm convergence speed.
Condition number
-
Example: Ridge regression condition number
Hessian matrix
When
Preconditioning techniques: For ill-conditioned
problems, variable substitution can improve condition number. If
New problem's Hessian approaches identity matrix, condition number approaches 1. This is the idea behind Preconditioned Conjugate Gradient (PCG).
Q7: Why does subgradient method converge slower than gradient descent?
A7: This stems from information loss due to non-smoothness:
Gradient descent (smooth functions): - Gradient
provides precise information about "steepest descent direction" - Step
size can be precisely chosen based on Lipschitz constant - Convergence
rate:
Subgradient method (non-smooth functions): -
Subgradient is only a "supporting direction," not necessarily descent
direction - Function value may increase in some iterations! - Must use
decreasing step size (like
Improvement methods: 1. Proximal gradient
method: For
Q8: What are the practical applications of Lagrangian duality in machine learning?
A8: Duality theory has multiple key applications in machine learning:
1. Support Vector Machines (SVM) - Primal problem:
Optimize in high-dimensional or even infinite-dimensional space (when
using kernels) - Dual problem: Only depends on inner products
3. Distributed Optimization - Primal problem may have complex global constraints - Dual problem can decompose into multiple independent subproblems, suitable for parallel computation - This is the theoretical basis of ADMM
4. Model Compression and Pruning - Sparse optimization (L0 norm minimization) is non-convex - L1 norm convex relaxation and its dual provide computable approximations
5. Generative Adversarial Networks (GAN) - GAN training is a min-max problem (saddle point problem) - Duality theory helps understand GAN convergence and equilibrium points - Wasserstein GAN directly optimizes dual form
Q9: How to choose optimization algorithms in practice?
A9: Choosing optimization algorithms requires considering multiple factors:
| Factor | Recommended Algorithm |
|---|---|
| Problem Scale | |
| Small-scale ( |
BFGS, Newton's method |
| Medium-scale ( |
L-BFGS, Conjugate Gradient |
| Large-scale ( |
SGD, Adam, AdaGrad |
| Function Properties | |
| Smooth convex | Gradient descent, Nesterov acceleration |
| Non-smooth convex | Subgradient method, Proximal gradient |
| Strongly convex | Newton, BFGS (fast convergence) |
| Ill-conditioned (large condition number) | Preconditioning, Adaptive algorithms |
| Constraints | |
| Unconstrained | Above first/second-order methods |
| Simple constraints (e.g., |
Projected gradient, Frank-Wolfe |
| Complex constraints | Augmented Lagrangian, Interior-point |
| Separable structure | ADMM |
| Computational Resources | |
| Gradient easy, Hessian hard | First-order methods, Quasi-Newton |
| Distributed environment | ADMM, Distributed SGD |
| Online learning (streaming data) | SGD, Online gradient descent |
Practical recommendations: 1. Start simple: Begin with gradient descent + line search, ensure correct implementation 2. Monitor convergence: Plot objective value, gradient norm curves 3. Tuning strategy: Learning rate is most critical parameter, use learning rate decay or adaptive algorithms 4. Combined use: First use first-order methods to quickly approach optimum, then second-order methods for fine optimization
Q10: What insights does convex optimization theory provide for deep learning (non-convex optimization)?
A10: Although deep learning loss functions are non-convex, convex optimization theory still provides important guidance:
1. Algorithm Design Inspiration - Adam's design borrows from dual averaging and adaptive step sizes in convex optimization - Batch Normalization can be viewed as implicit preconditioning, improving optimization condition number - Residual connections make optimization surface more convex-like (reducing gradient vanishing)
2. Local Convexity Analysis - Though globally non-convex, loss functions are approximately strongly convex near local minima - Can analyze algorithm behavior locally using convex optimization convergence rates - This explains why gradient descent converges quickly approaching minima
3. Generalization Theory - Regularization theory from convex optimization (L1, L2) directly applies to deep learning - Tools like PAC-Bayes bounds, Rademacher complexity all based on convex analysis
4. Loss Function Design - Understanding why cross-entropy is better than mean squared error for classification (from log-barrier functions in convex optimization) - Hinge loss, smoothed hinge loss design comes from convex optimization
5. Theoretical Guarantees in Degenerate Cases - Some deep learning problems provably convex (like single hidden layer linear network's matrix factorization form) - Over-parameterization theory shows sufficiently wide networks' optimization surfaces are "near-convex" in some sense
6. Identifying Optimization Traps - Convex optimization tells us characteristics of saddle points, local minima - In non-convex cases, we can use similar analysis to understand why SGD escapes saddle points (noise helps cross barriers)
Latest Research Directions: - Implicit bias: What kind of solutions does gradient descent tend to find in non-convex problems? Answer involves convex analysis. - Neural Tangent Kernel (NTK) theory: Extremely wide networks' training dynamics can be approximated by linear (convex) models. - Landscape theory: Study geometric structure of non-convex loss surfaces, identify "easy to optimize" non-convex problem classes.
✏️ Exercises and Solutions
Exercise 1: Convexity Verification
Problem: Determine whether the following functions
are convex and prove your conclusions: (a)
Solution:
always holds, so is convex. , ( ), so is convex. The Hessian is
, with eigenvalues and . The Hessian is not positive semidefinite, so is not convex.
Exercise 2: KKT Conditions
Problem: Solve the following constrained optimization problem:
Solution:
Standard form:
KKT conditions: 1. Stationarity:
From condition 1:
If
Therefore
Optimal solution:
Exercise 3: Gradient Descent Convergence
Problem: For
Solution:
GD update:
Therefore
Convergence requires spectral radius
Eigenvalues of
Since
Optimal step size
Exercise 4: Dual Problem Derivation
Problem: Derive the dual of linear program
Solution:
Lagrangian with multipliers
Dual function:
Dual problem (eliminating
This is the classic LP dual form. Strong duality holds since LP satisfies Slater's condition.
Exercise 5: Jensen's Inequality Application
Problem: Use Jensen's inequality to prove the AM-GM
inequality: for
Solution:
Since
Taking negatives and using monotonicity of
QED.
References
This chapter's derivations and theory are primarily based on the following classic literature:
Boyd, S., & Vandenberghe, L. (2004). Convex Optimization. Cambridge University Press. [Classic textbook, standard reference for convex optimization]
Nocedal, J., & Wright, S. J. (2006). Numerical Optimization (2nd ed.). Springer. [Authoritative textbook on numerical optimization, detailed algorithm descriptions]
Nesterov, Y. (2004). Introductory Lectures on Convex Optimization: A Basic Course. Springer. [Original literature on Nesterov acceleration]
Duchi, J., Hazan, E., & Singer, Y. (2011). Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. Journal of Machine Learning Research, 12, 2121-2159. [AdaGrad algorithm]
Kingma, D. P., & Ba, J. (2015). Adam: A Method for Stochastic Optimization. ICLR. [Adam algorithm, most commonly used optimizer in deep learning]
Boyd, S., Parikh, N., Chu, E., Peleato, B., & Eckstein, J. (2011). Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Foundations and Trends in Machine Learning, 3(1), 1-122. [Authoritative ADMM survey]
Bottou, L., Curtis, F. E., & Nocedal, J. (2018). Optimization Methods for Large-Scale Machine Learning. SIAM Review, 60(2), 223-311. [Modern survey on large-scale machine learning optimization]
Bubeck, S. (2015). Convex Optimization: Algorithms and Complexity. Foundations and Trends in Machine Learning, 8(3-4), 231-357. [Theoretical analysis of convex optimization algorithm complexity]
Beck, A., & Teboulle, M. (2009). A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems. SIAM Journal on Imaging Sciences, 2(1), 183-202. [FISTA algorithm, accelerated proximal gradient]
Rockafellar, R. T. (1970). Convex Analysis. Princeton University Press. [Mathematical foundations of convex analysis]
Shalev-Shwartz, S., & Ben-David, S. (2014). Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press. [Optimization theory in machine learning]
Polyak, B. T. (1964). Some methods of speeding up the convergence of iteration methods. USSR Computational Mathematics and Mathematical Physics, 4(5), 1-17. [Original literature on momentum method]
Summary: Convex optimization theory is the mathematical cornerstone of machine learning. This chapter rigorously derives the core theory (Jensen's inequality, subgradients, KKT conditions) and main algorithms (gradient descent, Newton's method, BFGS, ADMM) of convex optimization, starting from the definitions of convex sets and convex functions. Understanding these theories not only helps us design better algorithms, but also provides important intuition and tools for analyzing non-convex optimization (like deep learning). In subsequent chapters, we will see how these optimization techniques apply to specific machine learning models.
- Post title:Machine Learning Mathematical Derivations (4): Convex Optimization Theory
- Post author:Chen Kai
- Create time:2021-09-12 16:15:00
- Post link:https://www.chenk.top/Machine-Learning-Mathematical-Derivations-4-Convex-Optimization-Theory/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.