In 1912, Fisher proposed the idea of Maximum Likelihood Estimation (MLE), fundamentally transforming statistics. His core insight was: The best estimate of parameters should maximize the probability of observed data. Behind this seemingly simple idea lies profound mathematical structure — from the axiomatic definition of probability spaces, to asymptotic properties of statistical inference, to philosophical disputes between Bayesian and frequentist schools.
The core of machine learning is uncertainty modeling. Linear regression assumes errors follow Gaussian distribution; logistic regression assumes labels follow Bernoulli distribution; Hidden Markov Models assume state transitions follow Markov chains. All these models are built on the solid foundation of probability theory. This chapter derives the mathematical theory of statistical inference starting from Kolmogorov axioms.
Probability Spaces and Measure Theory Foundations
Axiomatic Definition of Probability Spaces
Definition 1 (Probability Space): A probability
space is a triplet
- Sample space
: set of all possible outcomes - Event σ-algebra
: collection of subsets of satisfying σ-algebra properties: - If
, then (closed under complement) - If
, then (closed under countable union)
- Probability measure
, satisfying Kolmogorov axioms: - Non-negativity:
, - Normalization:
- Countable additivity: If
are disjoint, then
- Non-negativity:
Why do we need σ-algebra?
In infinite sample spaces, not all subsets are measurable. For
example, there exist non-measurable sets (Vitali sets) on real
interval
Theorem 1 (Basic Properties of Probability):
- If
, then (inclusion-exclusion)
Proof of property 1:
By countable additivity, let
This holds if and only if
Conditional Probability and Independence
Definition 2 (Conditional Probability): Let
Theorem 2 (Multiplication Rule):
Theorem 3 (Law of Total Probability): Let
Proof:
Since
QED.
Theorem 4 (Bayes' Theorem): Let
where the second equality uses law of total probability.
Meaning of Bayes' Theorem:
-
Bayes' theorem is the core of Bayesian statistics, providing mathematical framework for updating beliefs from data.
Definition 3 (Independence): Events
Equivalently, if
Definition 4 (Conditional Independence): Events
Note: Independence does not imply conditional independence, and conditional independence does not imply independence.
Counterexample: Consider flipping two coins:
-
Clearly
Random Variables and Distributions
Definition 5 (Random Variable): A random variable is
a measurable function from sample space
Measurability requires: for any Borel set
Definition 6 (Cumulative Distribution Function,
CDF): The CDF of random variable
Properties of CDF:
Monotone non-decreasing:
Right-continuous:
Limit properties:
,
Definition 7 (Probability Density Function, PDF): If
there exists non-negative function
then
Definition 8 (Probability Mass Function, PMF): For
discrete random variable
Definition 9 (Joint Distribution): The joint CDF of
random variables
Joint PDF (if exists):
Definition 10 (Marginal Distribution):
Definition 11 (Conditional Distribution):
Definition 12 (Independence of Random Variables):
Random variables
Expectation, Variance, and Characteristic Functions
Definition and Properties of Expectation
Definition 13 (Expectation): The expectation of
random variable
- Discrete:
- Continuous:
Theorem 5 (Linearity of Expectation):
for any constants
Proof (continuous case):
QED.
Theorem 6 (Law of Total Expectation):
Proof:
QED.
Variance and Covariance
Definition 14 (Variance):
Theorem 7 (Properties of Variance):
- If
and are independent, then Proof of property 2:
If
Definition 15 (Covariance):
Properties:
1.$(X, X) = (X)
Definition 16 (Correlation Coefficient):
Theorem 8 (Cauchy-Schwarz Inequality):
i.e.,
Proof: Consider any
This is quadratic in
QED.
Characteristic Functions
Definition 17 (Characteristic Function): The
characteristic function of random variable
Properties of characteristic functions:
(conjugate) - If
, then - If
and are independent, then
Theorem 9 (Uniqueness of Characteristic Function):
Distribution is uniquely determined by characteristic function. I.e.,
if
Theorem 10 (Moment Generating Property): If
Proof:
Taking
Setting
QED.
Common Probability Distributions
Discrete Distributions
1. Bernoulli Distribution
Definition:
Expectation and Variance:
Application: Binary classification, output distribution of logistic regression.
2. Binomial Distribution
Definition:
Expectation and Variance:
Derivation of expectation:
Let
Derivation of variance:
By independence additivity of variance:
3. Poisson Distribution
Definition:
Expectation and Variance:
Derivation of expectation:
Poisson's Theorem: When
Proof:
As
So
Application: Counting rare events (e.g., website visits, radioactive decay).
Continuous Distributions
1. Uniform Distribution
Definition:
Expectation and Variance:
2. Exponential Distribution
Definition:
Expectation and Variance:
Memoryless property:
Proof:
QED.
Application: Waiting times, lifetime distributions, inter-arrival times in Poisson processes.
3. Gaussian Distribution (Normal)
Definition:
Expectation and Variance:
Standard Normal Distribution:
Standardization: If
Multivariate Gaussian Distribution:
Properties:
Invariance under linear transformation: If
, then Marginals are Gaussian: If
jointly Gaussian, then marginals and are Gaussian Conditionals are Gaussian: If
jointly Gaussian, then and are Gaussian Uncorrelated implies independent: For Gaussian random variables,
Why is Gaussian distribution so important? Central Limit Theorem: Sum of i.i.d. random variables tends to Gaussian
Maximum Entropy Principle: Among all distributions with given mean and variance, Gaussian has maximum entropy
Analytical tractability: Convolution and linear transformation of Gaussians are Gaussian
Ubiquity: Many natural phenomena approximately Gaussian (e.g., measurement errors)
4. Gamma Distribution
Definition:
where
Expectation and Variance:
Special cases:
-
5. Beta Distribution
Definition:
Expectation and Variance:
Application: Conjugate prior in Bayesian inference (prior for Bernoulli/Binomial distribution).
Relationships Between Distributions
Theorem 11 (Relationship Between Gamma and Beta
Functions):
Theorem 12 (Chi-squared Distribution): If
Theorem 13 (t Distribution): If
where
Theorem 14 (F Distribution): If
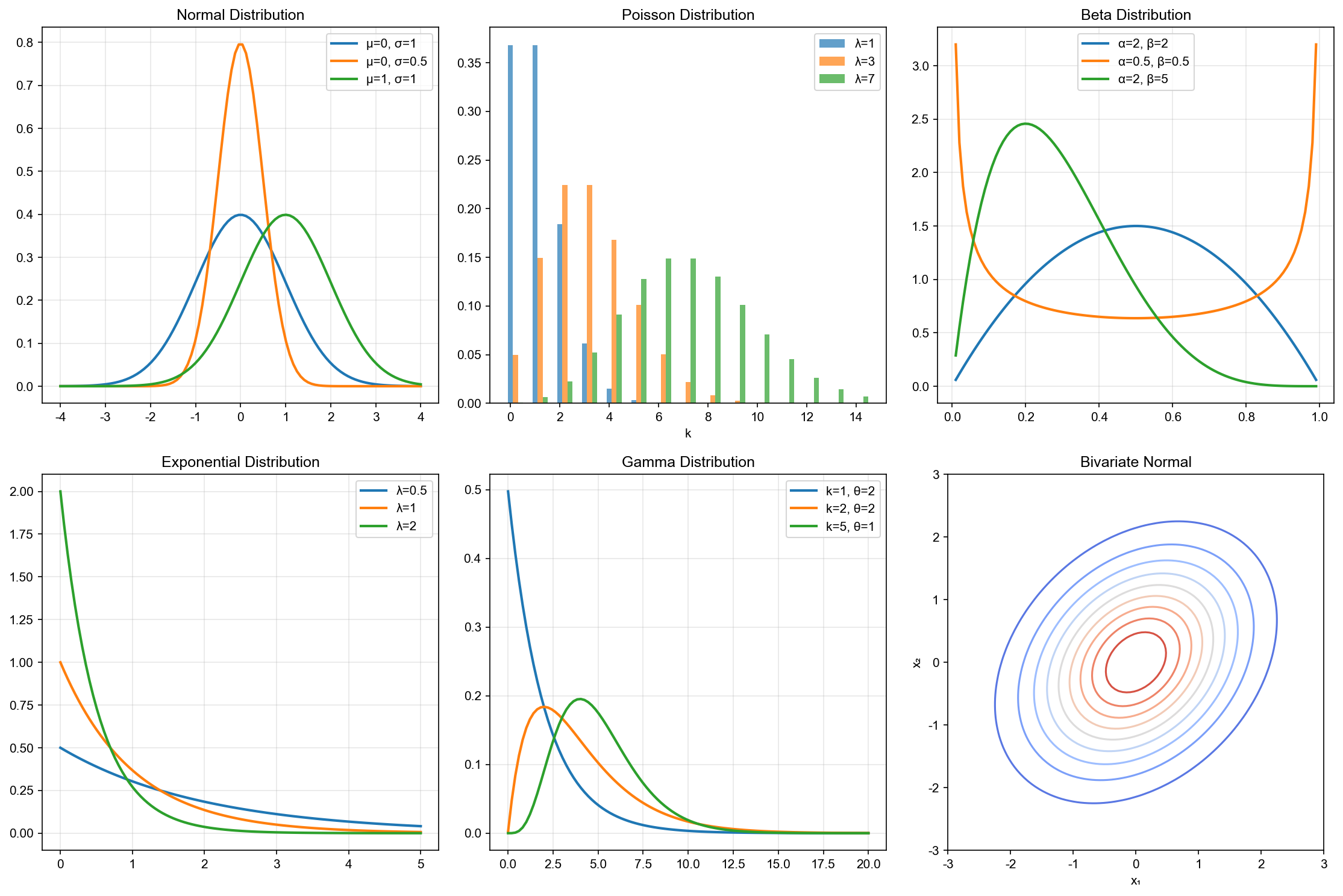
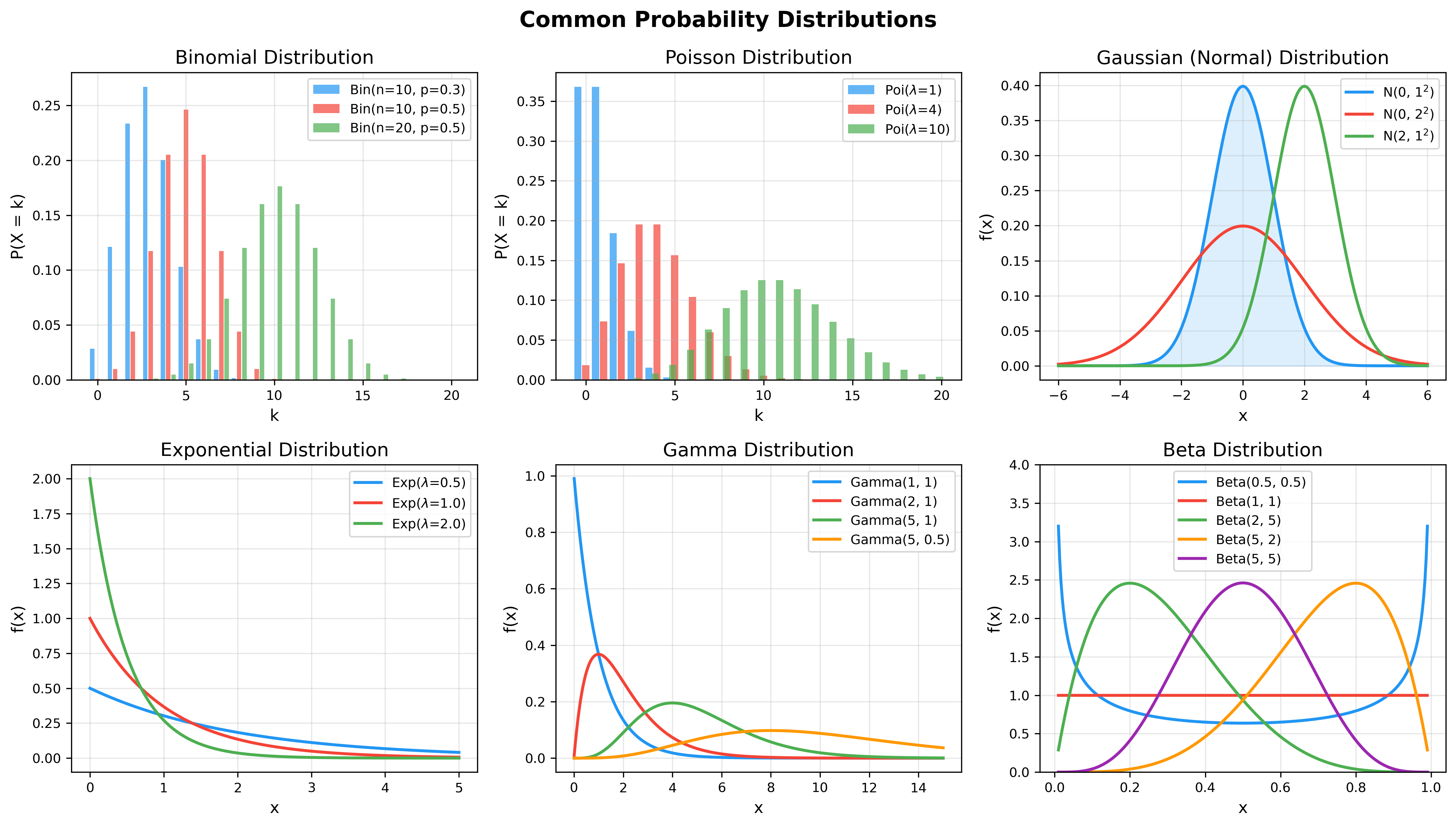
The following figure shows how distribution shapes change with different parameters — understanding parameter effects is key to choosing appropriate models:
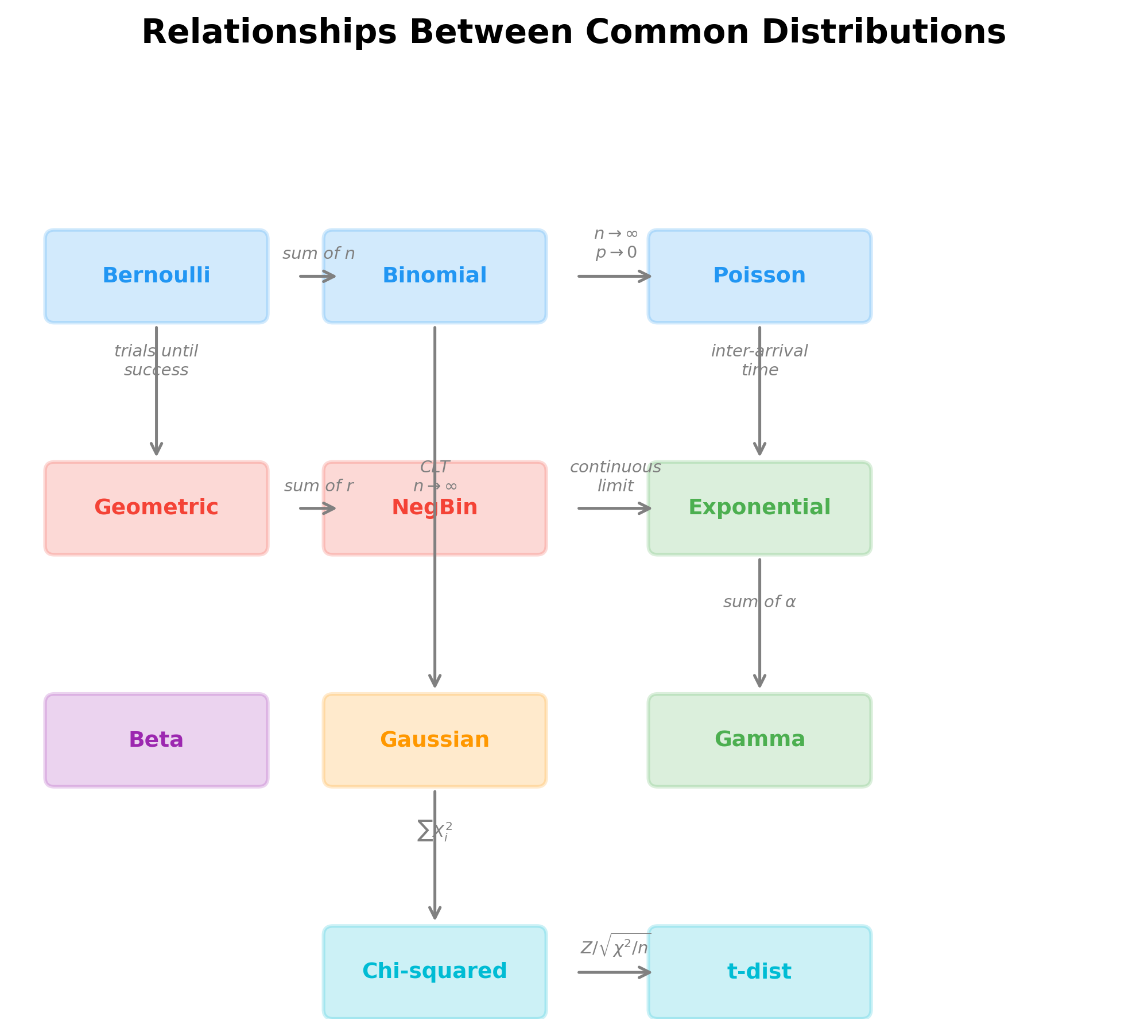
The diagram below illustrates the mathematical relationships between common distributions — these connections reveal deep structural ties in distribution theory:
Limit Theorems
Law of Large Numbers
Definition 18 (Convergence in Probability): Random
variable sequence
Theorem 15 (Markov's Inequality): If
Proof:
QED.
Theorem 16 (Chebyshev's Inequality): If
Proof: Apply Markov's inequality to
QED.
Theorem 17 (Weak Law of Large Numbers, WLLN): Let
Proof:
By Chebyshev's inequality:
QED.
Theorem 18 (Strong Law of Large Numbers, SLLN): Under WLLN conditions:
i.e.,
Almost sure convergence vs convergence in probability:
- Almost sure convergence (a.s.): sample path convergence
- Convergence in probability: concentration of probability mass
Almost sure convergence is stronger than convergence in probability.
Central Limit Theorem
Theorem 19 (Central Limit Theorem, CLT): Let
then:
where
Proof sketch (using characteristic functions):
Let
Characteristic function of
Taylor expansion of
Therefore:
And
Significance of CLT:
The animation below demonstrates the magic of the Central Limit
Theorem — even when the original distribution is a highly skewed
exponential distribution, as sample size
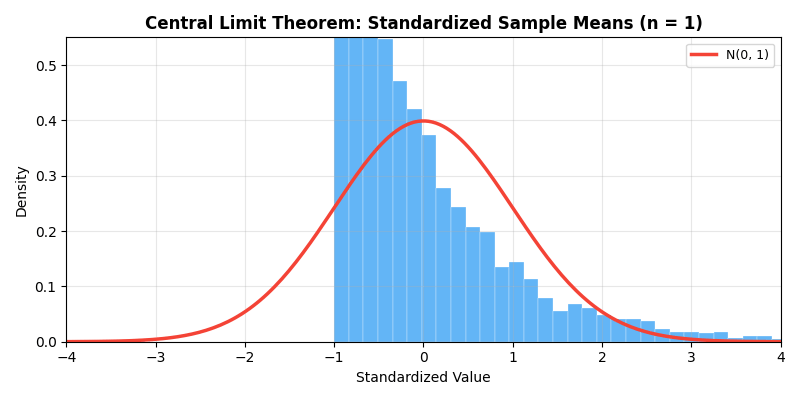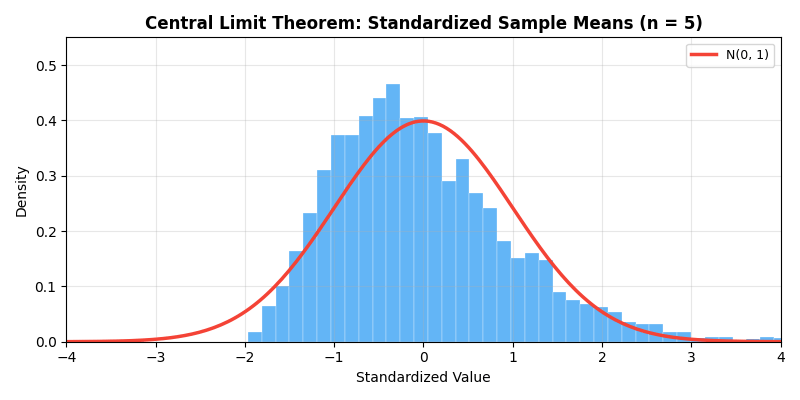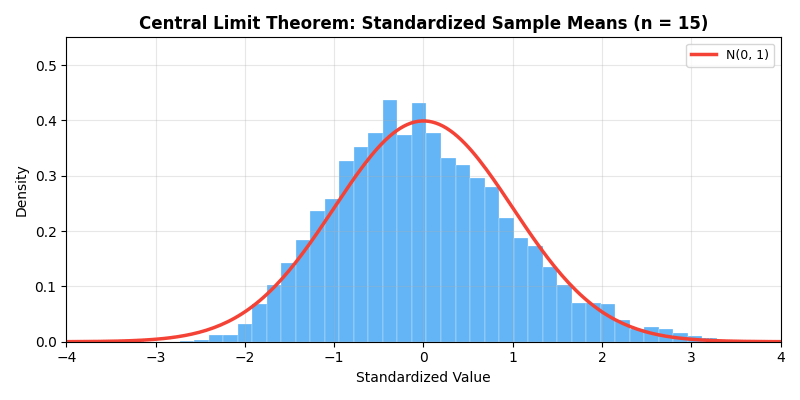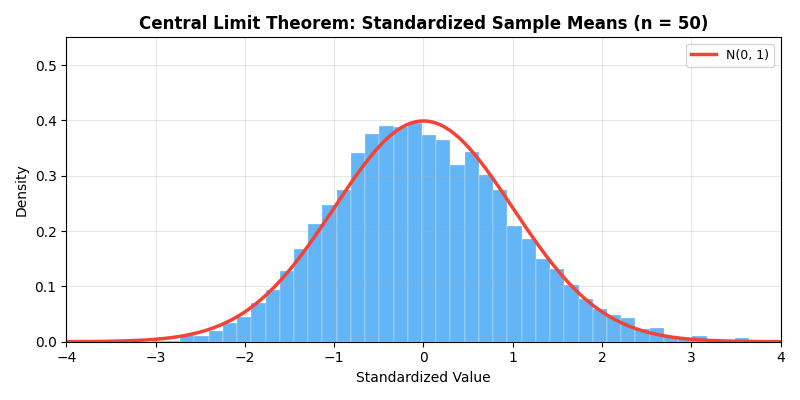
- Explains why normal distribution is so prevalent: many phenomena are superposition of many small random effects
- Provides theoretical foundation for statistical inference: distribution of sample mean approximately normal
- Gives approximation error bound:
Multivariate Central Limit Theorem: Let be i.i.d. with , . Then:
Parameter Estimation
Point Estimation
Definition 19 (Estimator): Let
Definition 20 (Unbiasedness): If
Examples:
- Sample mean
is unbiased estimator of population mean - Sample variance
is unbiased estimator of population variance
Why does sample variance divide by
Proof of unbiasedness of sample variance:
Key step:
Dividing by
Definition 21 (Consistency): If
Definition 22 (Mean Squared Error, MSE):
where
Bias-variance decomposition:
- Bias: systematic error of estimation
- Variance: randomness of estimation
- Tradeoff between them is core of statistical learning
Maximum Likelihood Estimation (MLE)
Definition 23 (Likelihood Function): Given sample
Log-likelihood function:
Definition 24 (Maximum Likelihood Estimator): MLE is defined as:
Example 1: MLE for Bernoulli Distribution
Let
Log-likelihood:
Taking derivative:
Solving:
Example 2: MLE for Gaussian Distribution
Let
Taking partial derivative with respect to
Taking partial derivative with respect to
Solving:
Note: This is biased! Unbiased estimator divides by
Theorem 20 (Asymptotic Properties of MLE): Under regularity conditions, MLE has following properties:
Consistency:
(true parameter) Asymptotic normality:
Asymptotic efficiency: Among all consistent estimators, MLE achieves Cramér-Rao lower bound on asymptotic variance
where
Bayesian Estimation
Bayesian paradigm: Treat parameter
Posterior distribution: By Bayes' theorem:
Definition 25 (Posterior Mean Estimator):
Definition 26 (Maximum A Posteriori, MAP):
Example: Beta-Bernoulli Conjugacy
Prior:
Likelihood:
Posterior:
This is
Posterior mean:
Interpretation:
- Prior parameters
can be viewed as "pseudo-observations": prior believes there are successes, failures - Posterior combines prior and data:
successes, failures - As
, posterior mean (MLE)
Bayesian vs Frequentist:
| Feature | Frequentist | Bayesian |
|---|---|---|
| Parameter | Fixed but unknown | Random variable |
| Inference basis | Repeated sampling | Conditional probability |
| Prior knowledge | Not used | Explicitly modeled |
| Uncertainty | Confidence interval | Credible interval |
| Computation | Usually simpler | May need MCMC |
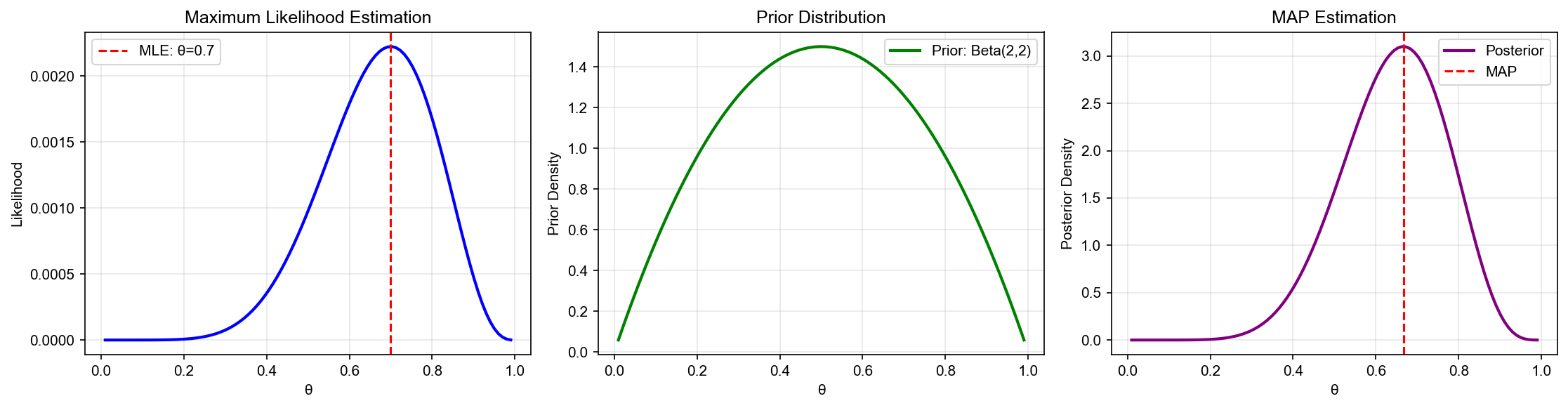
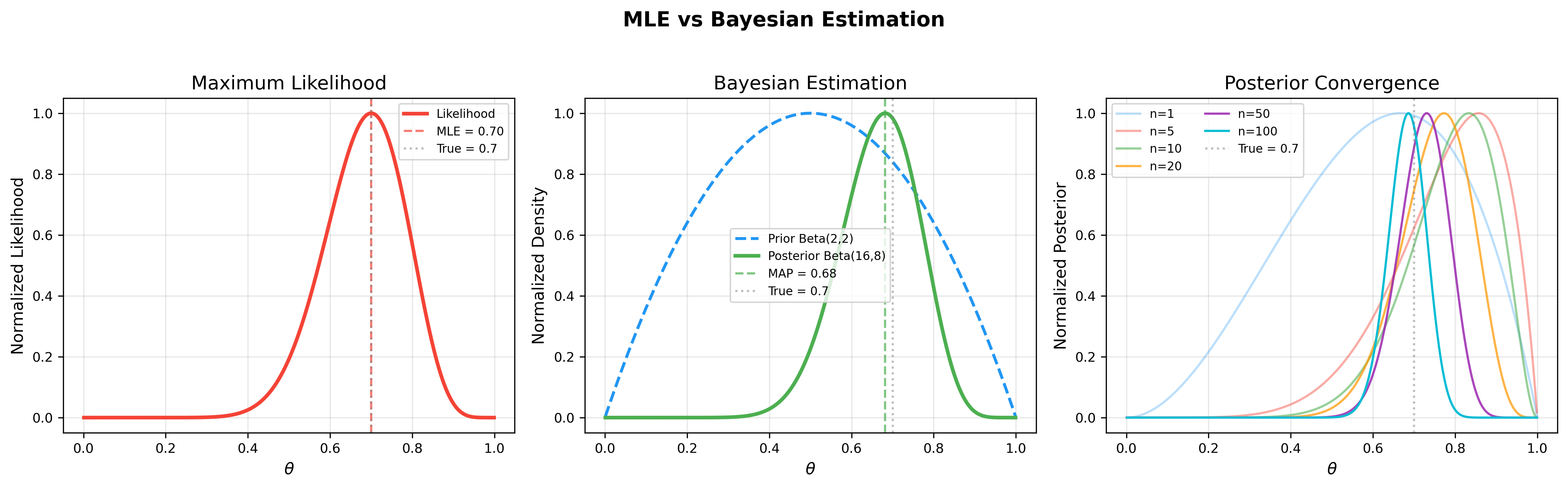
The figure below further illustrates the core Bayesian estimation workflow: the left panel shows the likelihood function, the middle panel shows how the prior distribution combines with the likelihood to produce the posterior, and the right panel demonstrates posterior convergence as data increases:
Hypothesis Testing and Confidence Intervals
Hypothesis Testing
Definition 27 (Statistical Hypothesis): Statement about population distribution.
- Null hypothesis
: default hypothesis (usually "no effect") - Alternative hypothesis
: hypothesis researcher hopes to prove
Definition 28 (Test Statistic): Random variable
Definition 29 (Rejection Region): If
Two types of errors:
| True State | Accept |
Reject |
|---|---|---|
| ✓ | Type I error ( |
|
| Type II error ( |
✓ (power |
Definition 30 (Significance Level):
Definition 31 (p-value): Under condition
Decision rule: If p-value
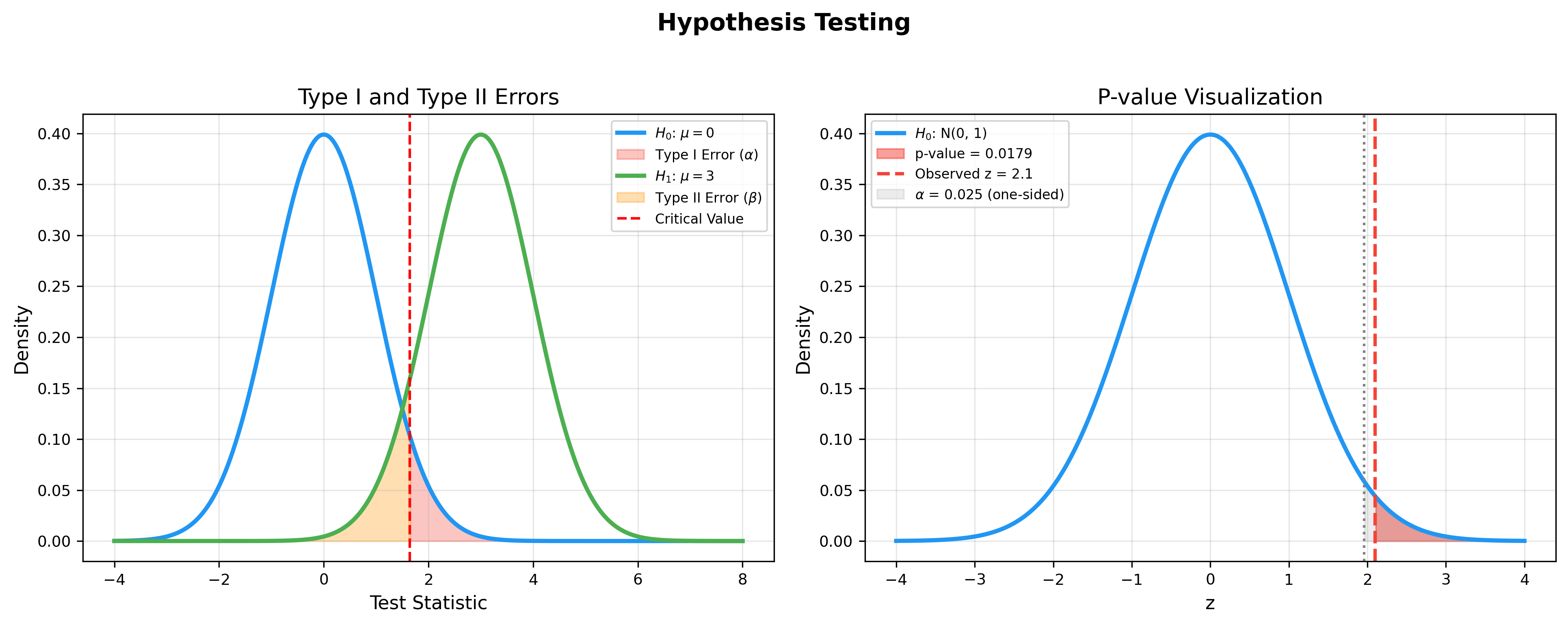
The figure below visualizes the core concepts of hypothesis testing:
the left panel shows the trade-off between Type I error (rejecting a
true
Example: One-sample t-test
Hypothesis:
Test statistic:
Under
Rejection region:
Confidence Intervals
Definition 32 (Confidence Interval): Random
interval
Note: This is probability statement about random interval, not about parameter (frequentist view).
Example: Confidence interval for mean
Let
Therefore:
Rearranging:
is
If
Exercise 1: Conditional Probability and Bayes' Formula
Problem: A disease has a prevalence of 0.1%. A test has sensitivity (true positive rate) of 99% and specificity (true negative rate) of 95%. If a person tests positive, what is the probability they actually have the disease?
Solution:
Let
By Bayes' formula:
Even with a positive test, the actual probability of disease is only about 1.94%. This is a classic case of the "base rate fallacy" — when disease prevalence is very low, even an accurate test has low positive predictive value.
Exercise 2: Maximum Likelihood Estimation
Problem: Let
Solution:
Likelihood function:
where
To maximize
Checking unbiasedness: The CDF of
Therefore
Unbiased correction:
Exercise 3: Central Limit Theorem Application
Problem: A machine produces screws with mean length
10mm and standard deviation 0.2mm. A random sample of 100 screws is
taken. Find the probability that the sample mean falls in
Solution:
Let
By CLT,
The probability of the sample mean falling in
Exercise 4: Bayesian Estimation with Conjugate Prior
Problem: A possibly unfair coin is flipped. Assume
the prior for the probability of heads
Solution:
Prior:
Likelihood:
By Beta-Binomial conjugacy, the posterior is:
Posterior mean:
Compare with MLE:
The posterior mean (0.643) is closer to 0.5 than the MLE (0.7),
reflecting the "pull-back" effect of the
Exercise 5: Hypothesis Testing
Problem: A factory claims its products have mean
weight 500g. A random sample of 25 products yields
Solution:
Set
Test statistic:
Under
Critical value:
Since
p-value:
Conclusion: There is insufficient statistical evidence to conclude
the mean product weight differs significantly from 500g. Note: failing
to reject
Next chapter preview: Chapter 4 will delve into optimization theory foundations, including convex optimization, gradient descent, Newton's method, quasi-Newton methods, constrained optimization, etc., providing mathematical tools for training machine learning algorithms.
- Post title:Machine Learning Mathematical Derivations (3): Probability Theory and Statistical Inference
- Post author:Chen Kai
- Create time:2021-09-06 10:45:00
- Post link:https://www.chenk.top/Machine-Learning-Mathematical-Derivations-3-Probability-Theory-and-Statistical-Inference/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.