In Google's PageRank algorithm, the web ranking problem was transformed into a massive eigenvalue problem: finding the principal eigenvector of a transition matrix. Behind this elegant mathematical formulation lies the profound structure of linear algebra. Linear algebra is not merely the language of machine learning — it is the key to understanding the geometric structure of data.
Machine learning is fundamentally about finding optimal linear or
nonlinear transformations in high-dimensional spaces. From the simplest
linear regression (solving
Vector Spaces and Linear Transformations
Axiomatic Definition of Vector Spaces
Definition 1 (Vector Space): Let
Vector addition:
Scalar multiplication:
satisfying the following 8 axioms, then is called a vector space over :
Addition axioms:
Commutativity:
, Associativity:
, Zero element:
such that , Inverse element:
, such that
Scalar multiplication axioms:
Distributivity 1:
, Distributivity 2:
, Associativity:
, Identity:
,
Common vector space examples:
| Space | Elements | Dimension | Application |
|---|---|---|---|
| ML feature vectors | |||
| Quantum computing, signal processing | |||
| Data matrices, weight matrices | |||
| Continuous functions on |
Function approximation | ||
| Polynomials of degree |
Polynomial regression |
Linear Independence and Basis
Definition 2 (Linear Combination): A vector
Definition 3 (Linear Independence): A vector
set
Otherwise, it is linearly dependent.
Theorem 1 (Equivalent Condition for Linear
Dependence): A vector set
Proof:
Definition 4 (Basis and Dimension): A basis of
vector space
Standard basis example:
Standard basis of
Any
Linear Transformations and Matrices
Definition 5 (Linear Transformation): Let
Additivity:
, Homogeneity:
,
Theorem 2 (Matrix Representation of Linear
Transformations): Let
where
Proof:
Let
by linearity. Now,
Therefore:
This is exactly the
The
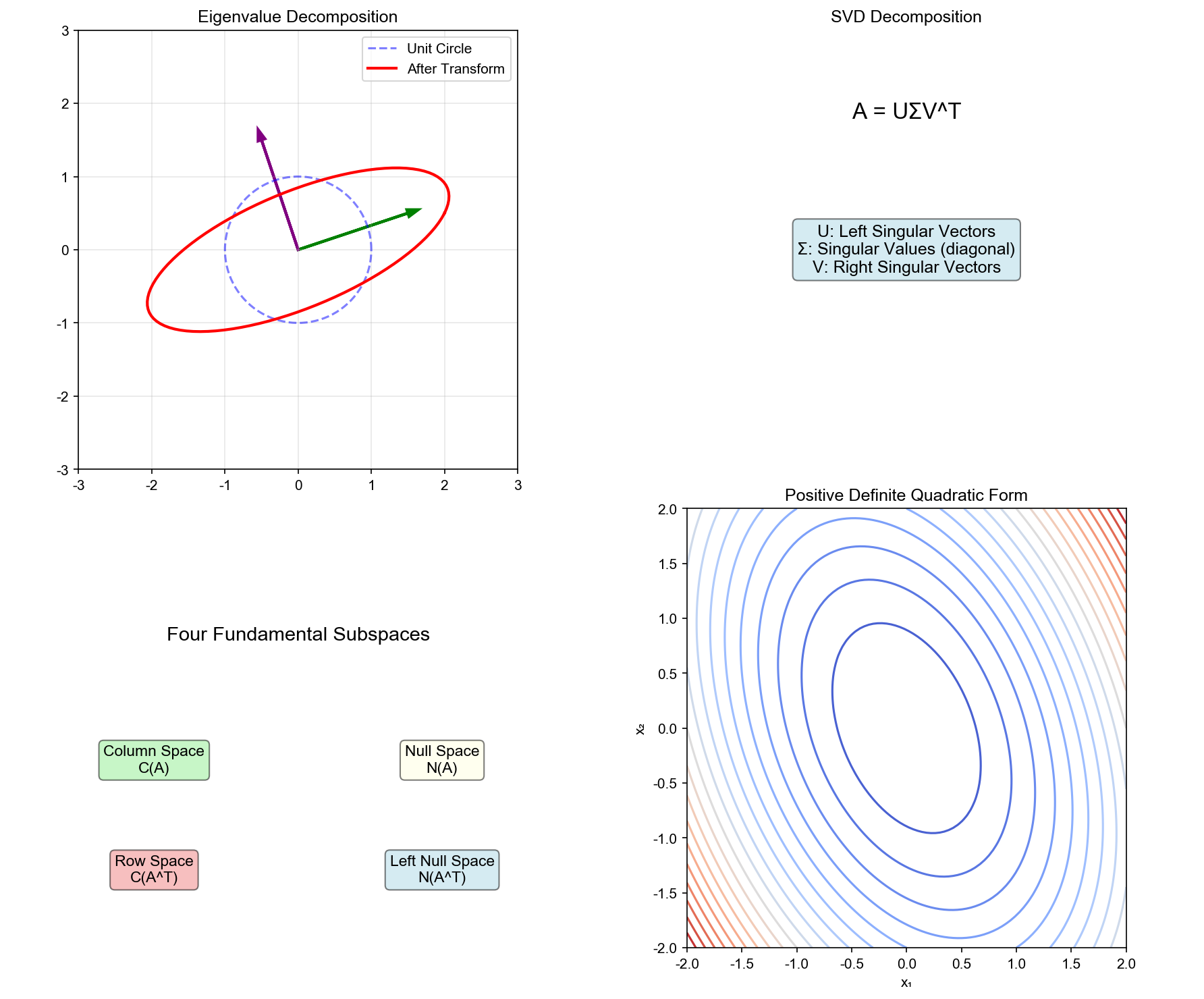
Four Fundamental Subspaces
For an
Definition 6 (Four Fundamental Subspaces):
- Column Space:
- Dimension:
- Geometric meaning: All vectors
can reach
- Dimension:
- Null Space:
- Dimension:
(by rank-nullity theorem) - Geometric meaning: All vectors mapped to zero by
- Dimension:
- Row Space:
- Dimension:
- Geometric meaning: All vectors
can reach
- Dimension:
- Left Null Space:
- Dimension:
- Geometric meaning: Vectors orthogonal to row space
- Dimension:
Theorem 3 (Orthogonality of Fundamental Subspaces):
(null space orthogonal to row space) (left null space orthogonal to column space)
Proof of property 1:
Let
Therefore
Dimension relations of fundamental subspaces:
These two equations show that
Inner Product Spaces and Norms
Definition and Properties of Inner Products
Definition 7 (Inner Product): Let
Symmetry:
Linearity:
Positive definiteness:
, and
Common inner products:
- Standard inner product (Euclidean inner product):
For
,
- Weighted inner product: Given positive definite
diagonal matrix
,
- Function space inner product: For
,
- Matrix Frobenius inner product: For
,
Definition and Properties of Norms
Definition 8 (Norm): A norm on vector space
Positive definiteness:
, and Homogeneity:
, Triangle inequality:
,
Common vector norms:
norm: For , ,
Special cases: -
- Inner product induced norm: For inner product
spaces,
Theorem 4 (Cauchy-Schwarz Inequality): For any
Equality holds if and only if
Proof:
For any
This is a quadratic function in
i.e.,
Corollaries of Cauchy-Schwarz inequality:
- Triangle inequality:
Proof:
Taking square roots gives the triangle inequality.
- Cosine formula:
where
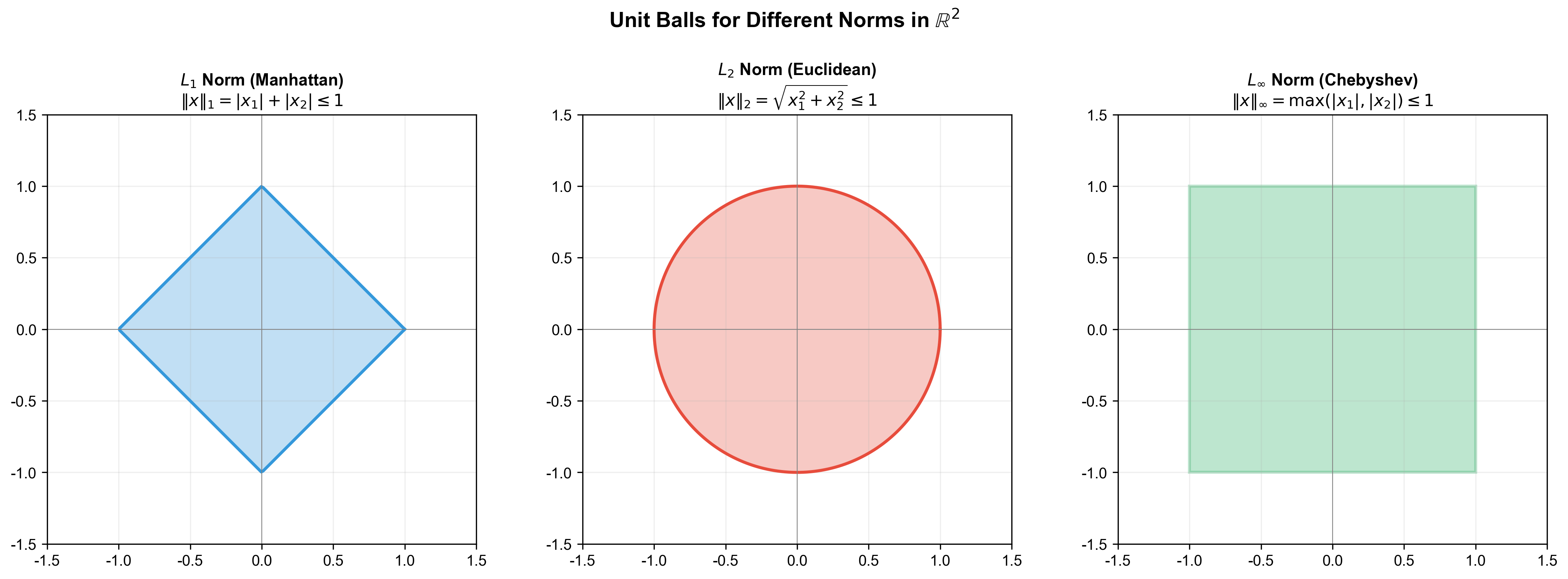
The figure below visualizes the unit balls of different norms in
Common Matrix Norms
Definition 9 (Matrix Norm): A matrix norm is a norm
defined on matrix space
Common matrix norms:
- Frobenius norm:
- Induced norm (operator norm): Induced by vector norms,
Special cases: - Spectral norm (2-norm):
- Nuclear norm (trace norm):
where
Theorem 5 (Properties of Matrix Norms):
Submultiplicativity:
(Frobenius norm doesn't satisfy this, but satisfies ) Submultiplicativity of induced norms:
Compatibility with vector norms:
# Eigenvalues and Eigenvectors
Definition of Eigenvalue Problem
Definition 10 (Eigenvalues and Eigenvectors): Let
then
Computing eigenvalues:
Eigenvalues satisfy the characteristic equation:
This is an
Theorem 6 (Properties of Eigenvalues):
(sum of eigenvalues equals trace) (product of eigenvalues equals determinant) is invertible all eigenvalues are non-zero - Eigenvalues of
are - Similar matrices have same eigenvalues
Proof of properties 1 and 2:
The leading coefficient of characteristic polynomial is
By Vieta's formulas, polynomial
- Coefficient of
: - Constant term:
Comparing coefficients gives
Spectral Theorem for Symmetric Matrices
Theorem 7 (Spectral Theorem for Symmetric Matrices):
Let
- All eigenvalues of
are real - Eigenvectors corresponding to different eigenvalues are orthogonal
can be orthogonally diagonalized, i.e., there exist orthogonal matrix and diagonal matrix such that:
where
Proof:
Step 1: Eigenvalues are real
Let
Therefore
Step 2: Eigenvectors for different eigenvalues are orthogonal
Let
Therefore
Step 3: Orthogonal diagonalization
Since
Therefore we can find
Multiplying both sides by
Geometric meaning of spectral decomposition:
This shows that
Positive Definite Matrices
Definition 11 (Positive Definite Matrix): A
symmetric matrix
Similarly, we define positive semi-definite (
Theorem 8 (Equivalent Conditions for Positive Definiteness): The following are equivalent:
is positive definite - All eigenvalues of
are positive - All leading principal minors of
are positive - There exists an invertible matrix
such that - Cholesky decomposition of
exists: , where is lower triangular
Proof
Therefore
because at least one
Properties of positive definite matrices:
- Positive definite matrices are always invertible
- Inverse of positive definite matrix is also positive definite
- Sum of two positive definite matrices is positive definite
- Diagonal elements of positive definite matrix are all positive
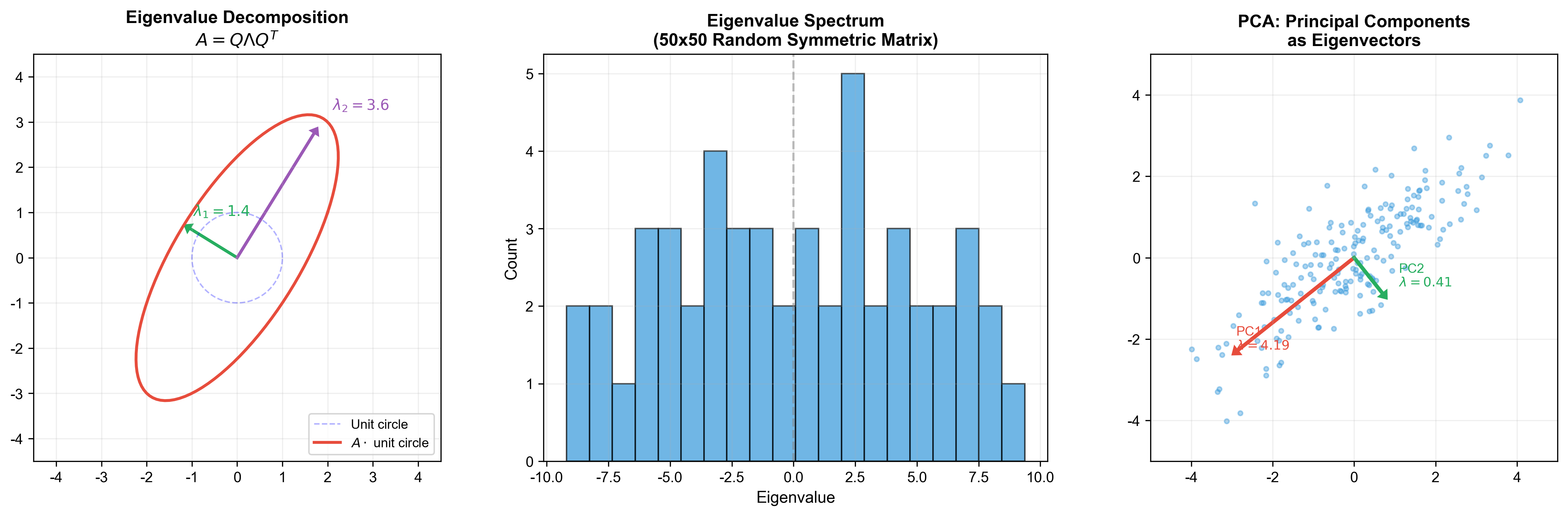
The figure below illustrates the geometric meaning of eigenvalue
decomposition: matrix
Singular Value Decomposition (SVD)
SVD Theorem and Geometric Meaning
Theorem 9 (Singular Value Decomposition): Let
where diagonal elements
Full form:
Compact form (economy SVD):
where
Proof sketch:
Step 1: Inspiration from eigenvalue decomposition
Consider
is symmetric positive semi-definite is symmetric positive semi-definite
By spectral theorem, they can be orthogonally diagonalized.
Step 2: Right singular vectors (from
Eigenvalue decomposition of
where columns of
Define
Step 3: Construction of left singular vectors
For
Verify orthogonality of
For
Step 4: Verify
For
For
(because
Therefore:
Multiplying both sides by
Geometric meaning of SVD:
Any linear transformation
Rotation (or reflection):
rotates 's standard orthonormal basis to eigenvector basis of Scaling:
scales along directions, with scaling factors being singular values Rotation (or reflection):
rotates result to 's standard orthonormal basis
Applications of SVD
1. Low-Rank Approximation
Theorem 10 (Eckart-Young Theorem): Let
Proof sketch (spectral norm):
Let
But they are both subspaces of
Since
More refined arguments (using minimax principle) prove
Application: Principal Component Analysis (PCA)
Given centered data matrix
Take first
This is the best rank
The figure below visualizes the geometric meaning of SVD
decomposition: any matrix
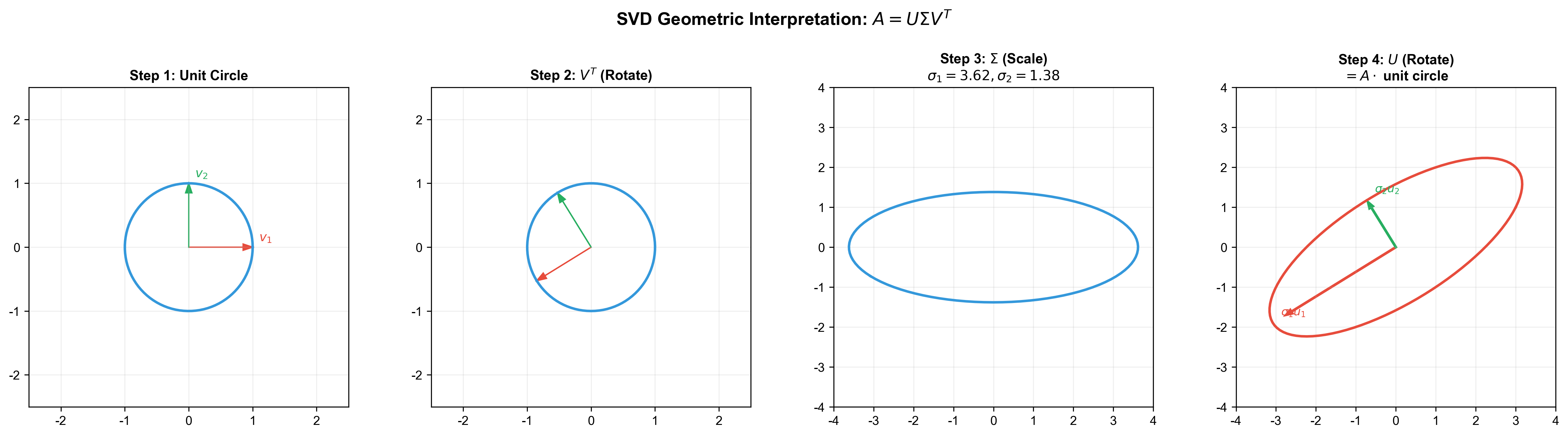
The following animation intuitively demonstrates the SVD low-rank
approximation process — as the number of retained singular values
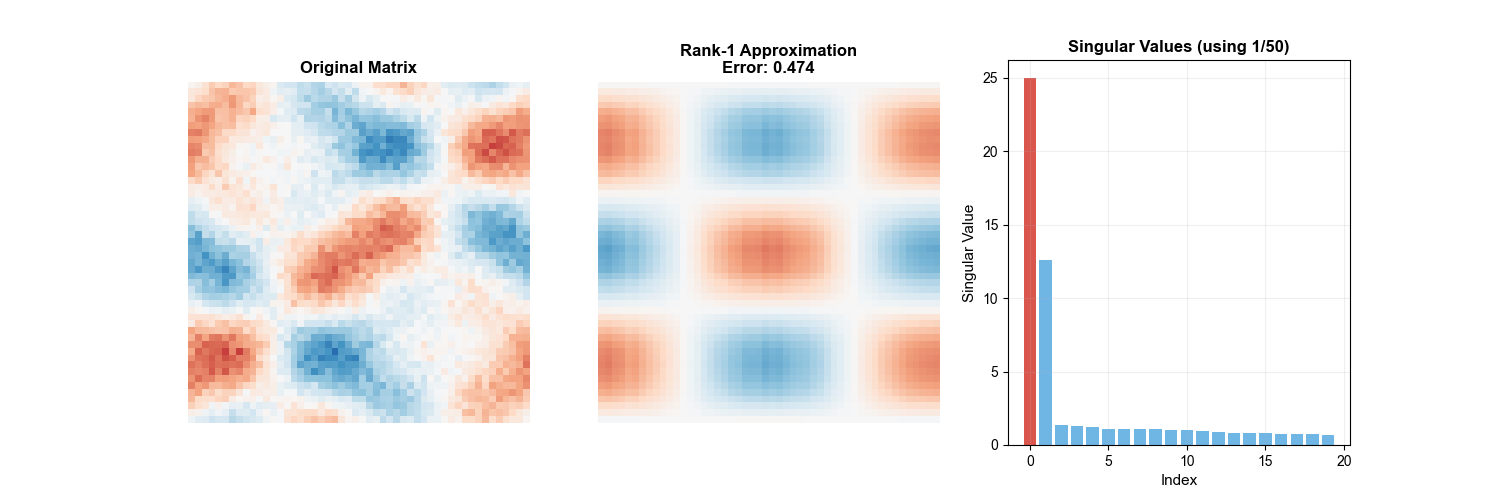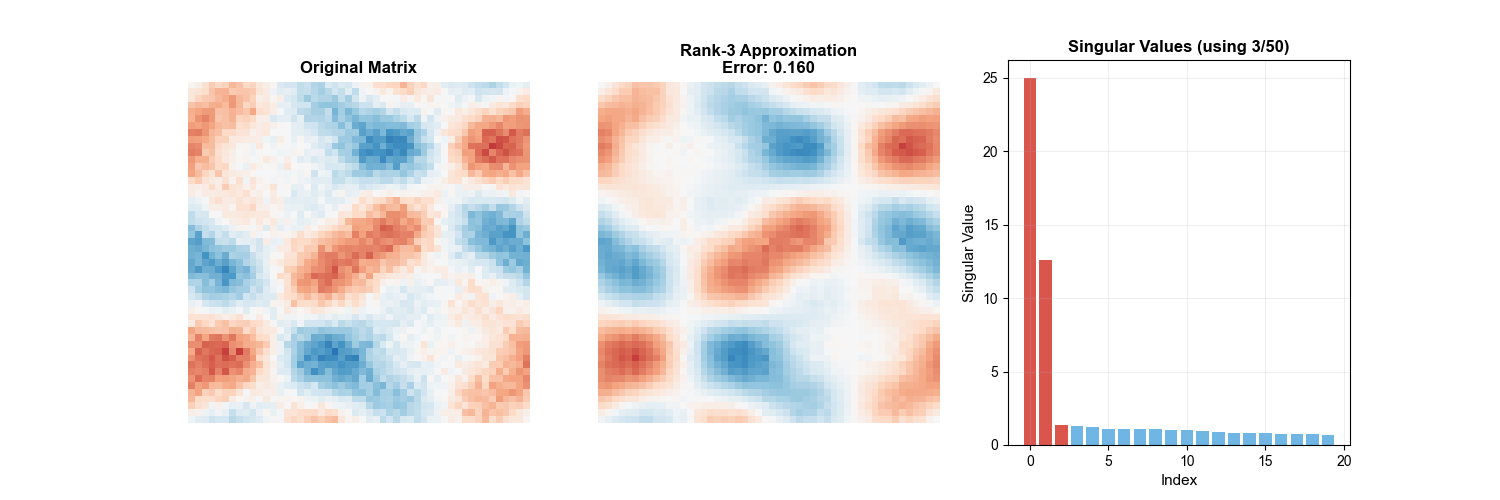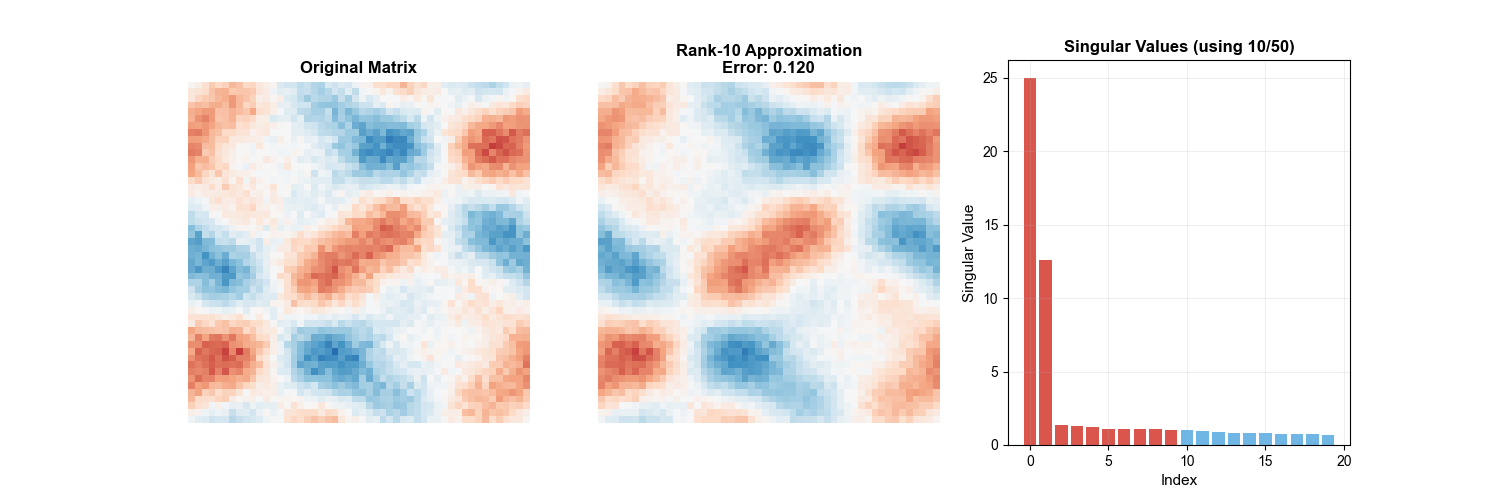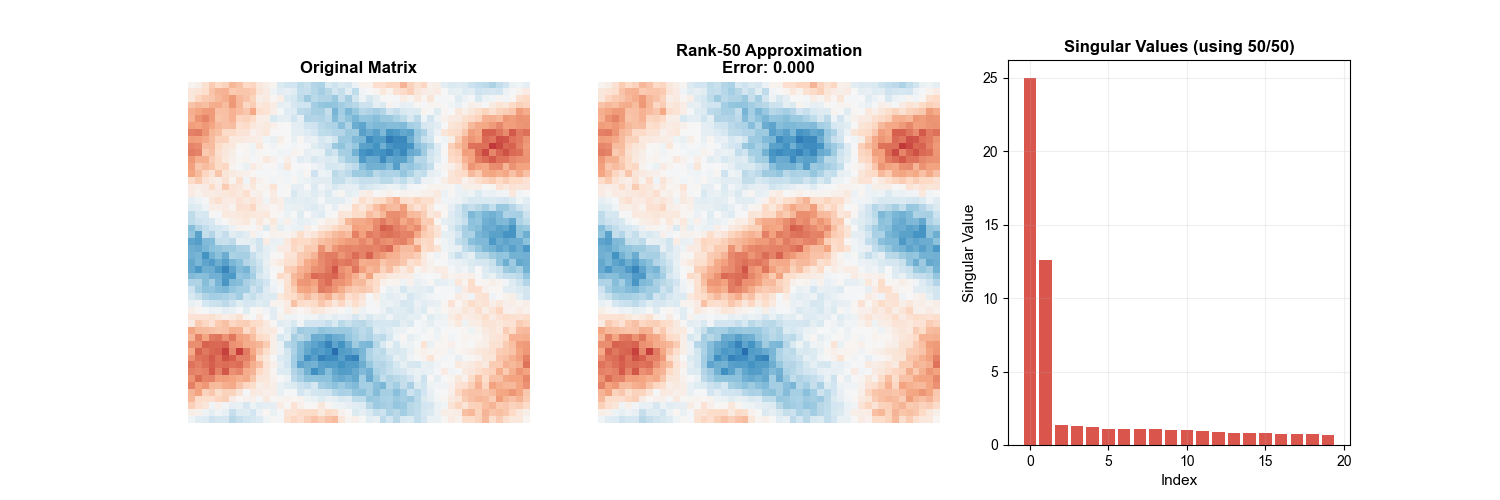
2. Pseudoinverse Matrix
Definition 12 (Moore-Penrose Pseudoinverse): The
pseudoinverse
Theorem 11 (Computing Pseudoinverse via SVD): Let
where
i.e.,
Verification:
Verify that
because
Least squares solution:
For inconsistent system
This is the minimum norm least squares solution among all solutions
minimizing
3. Condition Number
Definition 13 (Condition Number): The condition
number of matrix
Condition number measures the "ill-conditioning" of a matrix.
Larger
Theorem 12 (Perturbation Bound): Let
This shows relative error is amplified by condition number.
Matrix Calculus
Matrix calculus is ubiquitous in machine learning optimization. This section derives common matrix calculus formulas from first principles.
Notation for Matrix Calculus
Scalar with respect to vector:
Let
This is called the gradient vector, denoted
Scalar with respect to matrix:
Let
Vector with respect to vector:
Let
Note: Matrix calculus notation conventions may differ across literatures (numerator layout vs denominator layout). This chapter uses numerator layout, where derivative shape matches numerator (function being differentiated) shape.
Basic Derivative Formulas
1. Linear Functions
Formula 1:
Proof:
Therefore:
i.e.,
2. Quadratic Form
Formula 2:
In particular, if
Proof:
Differentiating with respect to
Therefore
3. Matrix Multiplication
Formula 3:
Proof:
Differentiating with respect to
Therefore
4. Trace of Matrix
Formula 4:
In particular, if
Proof:
Using cyclic property of trace
Direct computation:
Therefore
5. Determinant and Inverse
Formula 5:
Proof:
Using chain rule and
For determinant differential, there is formula (Jacobi's formula):
Therefore:
By relation between differential and derivative
QED.
Formula 6:
where
Chain Rule and Backpropagation
Theorem 13 (Chain Rule for Scalar Functions): Let
where
Proof:
By multivariate chain rule:
In matrix form:
QED.
Backpropagation example:
Consider one layer of neural network:
where
Let loss function be
Let
But this involves matrix-to-matrix differentiation, requiring more careful treatment. Actually:
Note that
Therefore:
where
In matrix form:
where
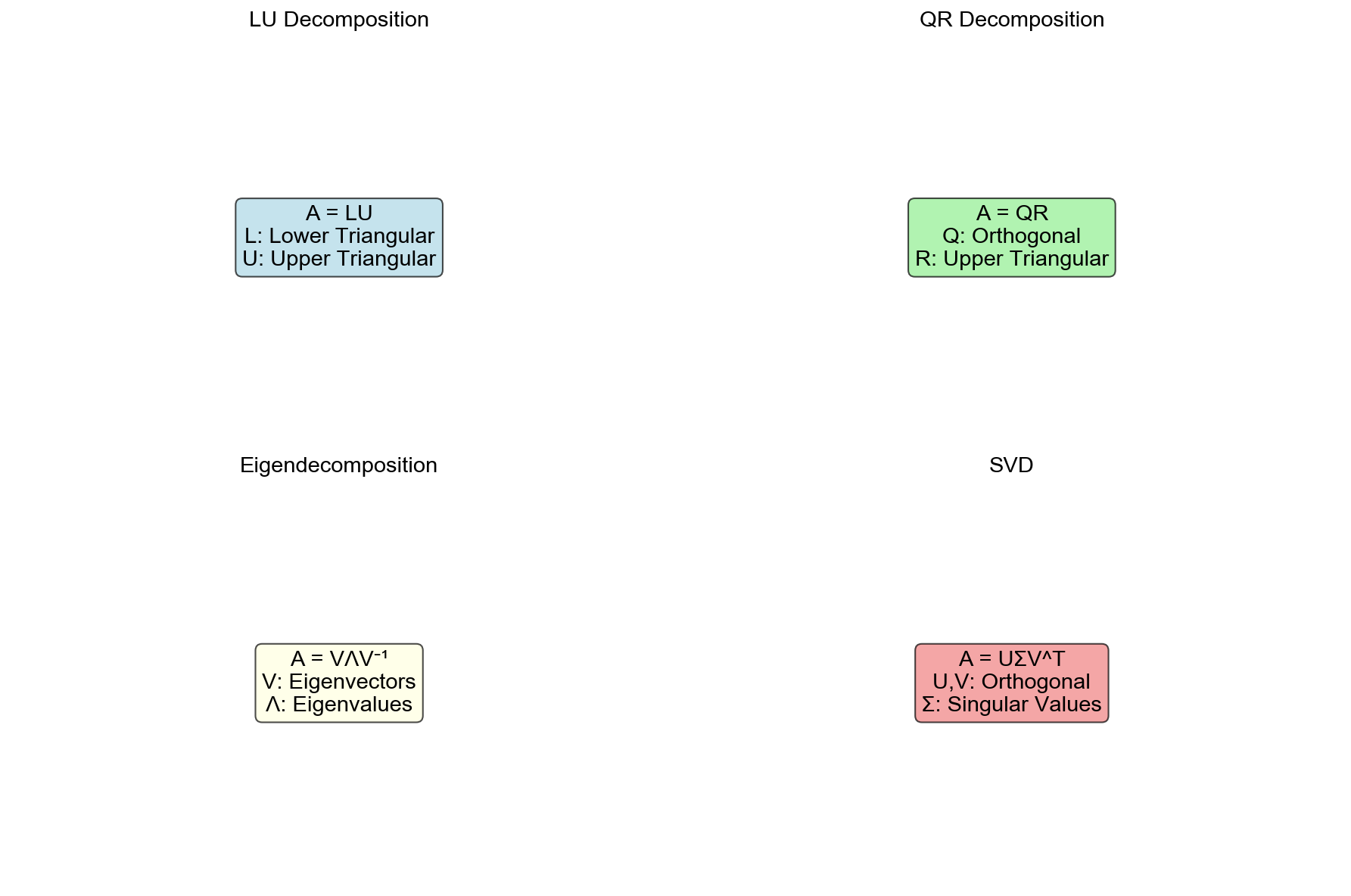
Numerical Computation of Matrix Decompositions
QR Decomposition
Theorem 14 (QR Decomposition): Let
Gram-Schmidt orthogonalization algorithm:
Given linearly independent vectors
Then:
In matrix form:
where
Applications of QR decomposition:
Solving least squares:
Solution is (using ). Computing eigenvalues: QR iteration algorithm
Repeat:
Under certain conditions,
Cholesky Decomposition
Theorem 15 (Cholesky Decomposition): Let
Algorithm:
Recursively compute elements of
Computational complexity:
Applications:
- Solving linear system
: - Decompose
- Solve
(forward substitution) - Solve
(backward substitution)
- Decompose
- Testing positive definiteness: If Cholesky decomposition succeeds
(all
positive), then is positive definite.
Code Implementation: Matrix Decompositions and Applications
1 | import numpy as np |
Code walkthrough:
- SVD demonstration:
- Verifies Eckart-Young theorem: rank-
approximation error equals sum of squares from -th singular value onwards - Shows singular value spectrum: true signal's singular values decay rapidly, noise singular values are flat
- Verifies Eckart-Young theorem: rank-
- QR decomposition demonstration:
- Compares three methods for solving least squares: normal equations, QR decomposition, SVD pseudoinverse
- Shows numerical stability advantage of QR decomposition (no need to
compute
, condition number doesn't square)
- Cholesky decomposition demonstration:
- Verifies accuracy of
- Shows speed advantage of Cholesky decomposition for solving positive definite linear systems
- Verifies accuracy of
- Matrix calculus demonstration:
- Verifies analytic gradient formula for linear regression matches numerical gradient
- Implements gradient descent and compares with analytic solution
❓ Q&A: Common Questions on Linear Algebra
Q1: Why does SVD always exist while eigenvalue decomposition may not?
Key difference:
| Property | Eigenvalue Decomposition | Singular Value Decomposition |
|---|---|---|
| Applicable matrices | Square |
Any |
| Decomposition form | ||
| Left/right vectors | Same ( |
Different ( |
| Existence | Only for diagonalizable matrices | Always exists |
| Value properties | Eigenvalues may be complex | Singular values always non-negative real |
Why does SVD always exist?
SVD construction doesn't depend on
-
Spectral theorem for symmetric matrices guarantees they can be orthogonally diagonalized, so SVD always exists.
When doesn't eigenvalue decomposition exist?
Non-symmetric square matrices may not be diagonalizable. For example:
Eigenvalues:
Eigenvectors: Only one linearly independent eigenvector
Therefore
Practical applications:
- SVD applies to any data matrix, widely used in PCA, recommender systems, image compression
- Eigenvalue decomposition used for symmetric matrices (covariance matrices, graph Laplacians) or iterative solving problems
Q2: When should QR decomposition be used instead of normal equations for least squares?
Numerical stability issue of normal equations:
Normal equations
Numerical example:
Suppose
-
In finite precision arithmetic (e.g., double precision floating
point, relative precision
- Using normal equations: lose about 6 significant digits, result may have only 10 significant digits
- Using QR decomposition: lose about 3 significant digits, result has 13 significant digits
Practical example:
Consider matrix:
In double precision,
But QR decomposition works directly on
Recommendations:
- ✅ For ill-conditioned problems with
, use QR decomposition or SVD - ✅ For tall-thin matrices with
, QR decomposition is more efficient - ⚠️ Only use normal equations when
has small condition number ( ) and not too large
Q3: How to understand matrix rank? Why is rank important?
Multiple equivalent definitions of rank:
Column space dimension:
Row space dimension:
Number of linearly independent columns: Size of maximal linearly independent column set
Number of non-zero singular values:
Geometric meaning:
Rank is the "effective dimension" of matrix
-
Why is rank important?
Invertibility: -
is invertible Equation solvability: -
has solution - Solution unique
- Solution unique
Degrees of freedom:
- General solution of homogeneous equation
has free parameters
- General solution of homogeneous equation
Data dimensionality reduction:
- PCA projects data onto rank-
subspace, preserving maximum variance
- PCA projects data onto rank-
Practical applications:
| Domain | Meaning of Rank |
|---|---|
| Machine Learning | Effective dimension of features |
| Recommender Systems | Number of latent factors in user-item interaction matrix |
| Image Compression | Low-rank approximation of image matrix |
| Control Theory | Controllability/observability of system |
Numerical rank:
Due to floating point errors, numerical rank is defined as:
where
Q4: What's the relationship between inner products and norms? Why do we need different norms?
Inner product induced norm:
For inner product spaces, inner product naturally induces a norm:
For example, standard inner product
Not all norms come from inner products:
Testing if norm comes from inner product: Parallelogram law
Norm
Applications of different norms:
| Norm | Geometric Meaning | Application |
|---|---|---|
| Manhattan distance, diamond contours | Sparse regularization (Lasso) | |
| Euclidean distance, circular contours | Ridge regression, SVM | |
| Chebyshev distance, square contours | Robust optimization, minimax | |
| Number of non-zero elements (not a norm) | Feature selection, compressed sensing |
Why does
Illustration:
1 | L1 constraint (diamond) L2 constraint (circle) |
L1 constraint's corners more easily touch coordinate axes (sparse solutions).
Q5: Why are positive definite matrices so important in machine learning?
Core properties of positive definite matrices:
Symmetric positive definite matrix
- All eigenvalues
- For all
, - Can be written as
(e.g., Cholesky decomposition )
Role in optimization:
Theorem: Function
Proof: Hessian matrix
Strictly convex function (unique optimal
solution):
Practical applications:
- Normal equations in linear regression:
Kernel matrices: Gram matrix
corresponding to kernel function must be positive definite (Mercer's theorem). Covariance matrices: Data covariance matrix
is always positive semi-definite. Second-order optimization: Newton's method, conjugate gradient method depend on Hessian positive definiteness.
Meaning of negative definite matrices:
Function
Testing positive definiteness:
Eigenvalues: All eigenvalues
Sylvester's criterion: All leading principal minors
Cholesky decomposition: Try decomposition, success means positive definite
Numerical method: Compute minimum eigenvalue
Q6: What's the difference between "numerator layout" and "denominator layout" in matrix calculus?
Two layout conventions:
| Layout | Rule | Common in | |
|---|---|---|---|
| Numerator | Derivative shape matches numerator | Same as |
Statistics, ML |
| Denominator | Derivative shape matches denominator | Same as |
Physics, engineering |
Example:
Let
- Numerator layout:
- Denominator layout:
Scalar with respect to vector:
Let
- Numerator layout:
(column vector) - Denominator layout:
(row vector)
Comparison of important formulas:
| Formula | Numerator Layout | Denominator Layout |
|---|---|---|
Convention in this chapter:
This chapter uses numerator layout, because:
- Consistent with natural vector/matrix shape
- More common in ML literature
- Gradient is column vector, convenient for gradient descent
Practical recommendations:
- ✅ When reading papers, first determine author's layout convention
- ✅ Stay consistent in your own code/derivations
- ✅ Use automatic differentiation libraries (PyTorch, JAX) to avoid manual derivation
Q7: How to quickly determine if a matrix is invertible?
Theoretical criteria:
Matrix
1.
Numerical criteria (practical computation):
Due to floating point errors, use:
- Condition number:
: numerically invertible : numerically singular
- Minimum singular value:
(where ): invertible
- LU decomposition: Try LU decomposition, if encounter zero pivot (or extremely small pivot), matrix singular
Quick checks (without full computation):
1 | def is_invertible_quick(A, tol=1e-10): |
Invertibility of special matrices:
| Matrix Type | Invertibility Condition |
|---|---|
| Diagonal | All diagonal elements non-zero |
| Triangular | All diagonal elements non-zero |
| Orthogonal | Always invertible ( |
| Symmetric positive definite | Always invertible |
| Idempotent ( |
Only when |
Q8: What's the relationship between SVD and PCA? Why does PCA use eigenvalue decomposition of covariance matrix?
Two equivalent derivations of PCA:
Method 1: Maximum variance (eigenvalue decomposition of covariance matrix)
Given centered data matrix
Objective: Find direction
Variance:
Optimization problem:
By Lagrange multipliers, optimal solution
i.e.,
Method 2: Minimum reconstruction error (SVD of data matrix)
Objective: Find rank-
By Eckart-Young theorem, optimal solution is rank-
where
Equivalence of two methods:
i.e.:
- Right singular vectors of
= eigenvectors of (PCA principal directions) - Squared singular values of
= eigenvalues of (explained variance)
Choice in practical computation:
| Method | Formula | Applicable Scenario |
|---|---|---|
| Eigenvalue decomposition of covariance matrix | ||
| SVD of data matrix |
Why is SVD better for high dimensions?
- Covariance matrix:
, requires time - Data matrix SVD:
, economy SVD only requires time
When
Q9: Why are rank-1 matrices called "atoms of matrices"?
Definition of rank-1 matrix:
Matrix
Equivalent condition:
Why called "atoms"?
Any matrix can be decomposed as sum of rank-1 matrices. This is analogous to:
- Vectors can be decomposed as linear combinations of basis vectors
- Functions can be decomposed as Fourier series (sum of sine/cosine functions)
SVD rank-1 decomposition:
Each term
Properties of rank-1 matrices:
- Simple structure:
completely determined by two vectors - Low storage: Storing
matrix requires numbers, rank-1 matrix only needs numbers - Fast multiplication:
, first compute inner product (O(n)), then scale (O(m)), total O(m+n), much less than O(mn)
Applications:
- Low-rank matrix completion (recommender systems):
User-item rating matrix approximated as rank-
matrix (k small):
Neural network compression: Weight matrix
approximated by rank- , parameters reduced from to . Fast matrix multiplication: If
, then , computation from to .
Q10:
What's the relationship between Gram matrix (
Definition of Gram matrix:
Given matrix
Elements:
i.e., inner products between column vectors.
Properties of Gram matrix:
Symmetric:
Positive semi-definite:
Rank:
Invertibility:
invertible full column rank
Gram-Schmidt orthogonalization:
Objective: Transform
Process:
Relationship:
Gram-Schmidt orthogonalization essentially "removes projection
of
- Compute projection:
- Compute orthogonal component:
- Normalize
Cholesky decomposition of Gram matrix:
If
where
Numerical stability:
Classical Gram-Schmidt (CGS) is numerically unstable: subsequent vectors may not be orthogonal.
Modified Gram-Schmidt (MGS) is more stable: orthogonalize one vector at a time.
Relationship between QR decomposition and Gram-Schmidt:
QR decomposition
- Columns of
are orthogonalized vectors is upper triangular, elements are
Conversely, Gram matrix can be expressed through QR:
This is exactly Cholesky decomposition of Gram matrix!
🎓 Summary: Core Points of Linear Algebra
Key formulas to remember:
- Four fundamental subspaces:
- SVD decomposition:
- Spectral theorem (symmetric matrices):
- Matrix calculus:
Memory mnemonic:
SVD is universal key (any matrix decomposable)
Symmetric matrices have real eigenvalues (spectral theorem guarantees orthogonality)
Positive definite matrices optimize well (convex functions have unique solutions)
QR decomposition is numerically stable (first choice for least squares)
Practical checklist:
✏️ Exercises and Solutions
Exercise 1: Eigenvalues and Eigenvectors
Problem: Let
Solution:
Characteristic equation
Solving:
For
For
Verification of diagonalization:
We can verify
Exercise 2: SVD and Low-Rank Approximation
Problem: Let
Solution:
First compute
Eigenvalues of
Singular values:
Right singular vectors
Best rank-1 approximation:
Exercise 3: Matrix Calculus
Problem: Let
Solution:
Gradient:
(Since
Hessian matrix:
When
Minimum value:
Exercise 4: Positive Definite Matrices and Cholesky Decomposition
Problem: Prove that a symmetric positive definite
matrix
Solution:
Existence proof (by induction on matrix order
Assume the result holds for order
Let
By positive definiteness,
Uniqueness: If
Verification:
Exercise 5: Condition Number and Numerical Stability
Problem: For matrix
Solution:
Eigenvalues of
Since
The condition number is approximately
- Small perturbations
in the right-hand side vector can cause changes in the solution amplified by a factor of : - In floating-point arithmetic, even without errors in
, rounding errors can be amplified by approximately times, resulting in a loss of about 4 significant digits in the solution - In practice, regularization should be considered (e.g., Tikhonov
regularization:
) to improve numerical stability
📚 References
Strang, G. (2006). Linear Algebra and Its Applications (4th ed.). Cengage Learning.
Golub, G. H., & Van Loan, C. F. (2013). Matrix Computations (4th ed.). Johns Hopkins University Press.
Horn, R. A., & Johnson, C. R. (2012). Matrix Analysis (2nd ed.). Cambridge University Press.
Trefethen, L. N., & Bau III, D. (1997). Numerical Linear Algebra. SIAM.
Axler, S. (2015). Linear Algebra Done Right (3rd ed.). Springer.
Petersen, K. B., & Pedersen, M. S. (2012). The Matrix Cookbook. Technical University of Denmark.
Eckart, C., & Young, G. (1936). The approximation of one matrix by another of lower rank. Psychometrika, 1(3), 211-218.
Meyer, C. D. (2000). Matrix Analysis and Applied Linear Algebra. SIAM.
Boyd, S., & Vandenberghe, L. (2004). Convex Optimization. Cambridge University Press.
Magnus, J. R., & Neudecker, H. (2019). Matrix Differential Calculus with Applications in Statistics and Econometrics (3rd ed.). Wiley.
Next chapter preview: Chapter 3 will delve into probability theory and statistical inference, including common distributions, maximum likelihood estimation, Bayesian estimation, etc., laying the foundation for probabilistic models.
- Post title:Machine Learning Mathematical Derivations (2): Linear Algebra and Matrix Theory
- Post author:Chen Kai
- Create time:2021-08-31 14:00:00
- Post link:https://www.chenk.top/Machine-Learning-Mathematical-Derivations-2-Linear-Algebra-and-Matrix-Theory/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.