In 2005, Google Research published a paper claiming that their simple statistical models outperformed carefully engineered expert systems in machine translation tasks. This raised a profound question: Why can simple models learn effective patterns from data? The answer lies in the mathematical theory of machine learning.
The central problem in machine learning is: given finite training samples, how can we guarantee that the learned model will perform well on unseen data? This is not an engineering problem, but a mathematical one — involving deep structures from probability theory, functional analysis, and optimization theory. This series derives the theoretical foundations of machine learning from mathematical first principles.
Fundamental Concepts in Machine Learning
Mathematical Formalization of Learning Problems
Assume there exists an unknown data-generating distribution
Definition 1 (Loss Function): A loss function
- 0-1 loss (classification):
- Squared loss (regression):
- Hinge loss (SVM):
Definition 2 (Generalization Error): The
generalization error of hypothesis
This expectation is computed over all possible input-output pairs, representing the model's true performance on unseen data.
Definition 3 (Empirical Error): Given training set
This is the model's average loss on the training set, which can be directly computed.
The Core Paradox of Machine Learning: We can only
observe
Three Elements of Supervised Learning
Supervised learning can be completely described by a triple
Hypothesis Space
- Linear hypothesis space:
- Polynomial hypothesis space:
The choice of hypothesis space determines the model's expressive power. Larger spaces have stronger expressiveness but are harder to learn.
Loss Function
Learning Algorithm
Common learning algorithms include:
- Empirical Risk Minimization (ERM):
- Structural Risk Minimization (SRM):
, where is a complexity penalty term
Why Learning Theory Matters: The Generalization Gap
Consider a simple experiment: Train a 100-degree polynomial on 10
data points with Gaussian noise
Result:
- Training error:
(perfect fit) - Test error:
(catastrophic failure)
This massive gap (
- Predict when this gap will be small
- Quantify the gap using complexity measures (VC dimension, Rademacher complexity)
- Control the gap through regularization and model selection
Without learning theory, we would be:
- Blindly trying different models without understanding why some generalize and others don't
- Unable to predict how much data is needed for a given task
- Guessing hyperparameters without principled guidance
PAC Learning Framework: Mathematical Characterization of Learnability
Definition of PAC Learning
The Probably Approximately Correct (PAC) learning framework, proposed by Valiant in 1984, provides a mathematical answer to the fundamental question: "What kinds of problems are learnable?"
Definition 4 (PAC Learnability): A hypothesis
class
This definition contains three key elements:
- Probably (with high probability): The event occurs
with probability at least
- Approximately (near-optimal): The generalization
error is within
of the best hypothesis - Correct (measured correctly): Error is measured on
the true distribution
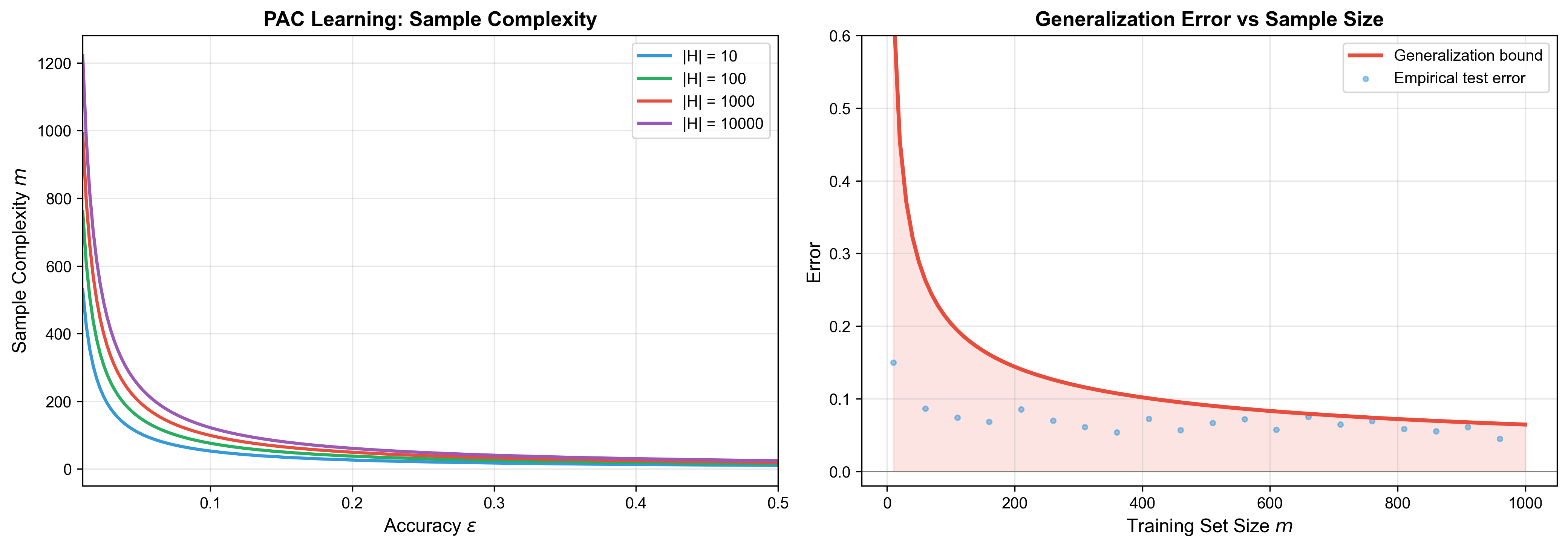
Sample Complexity
PAC Learnability of Finite Hypothesis Spaces
We first consider the simplest case: the hypothesis space
Theorem 1 (Sample Complexity for Finite Hypothesis
Spaces): Let
then the Empirical Risk Minimization algorithm is a PAC learning algorithm.
Proof:
Step 1: Define the set of bad hypotheses
For any
Our goal is to prove that: with high probability, the ERM algorithm will not select a bad hypothesis.
Step 2: Analyze the probability of a single bad hypothesis
For a fixed bad hypothesis
Since
Therefore, the probability that
Here we use the independence assumption:
Step 3: Use the Union Bound
Define event
Using the Union Bound (probability union inequality):
Step 4: Use the inequality
This is a standard exponential inequality. Therefore:
To make this probability less than
Taking logarithms on both sides and rearranging:
Step 5: Conclusion
When the sample size satisfies the above condition, with probability
at least
Intuition of the Theorem:
-
Example (Boolean Function Learning):
Consider learning conjunctions over
This is sample complexity linear in feature dimension, which is very efficient.
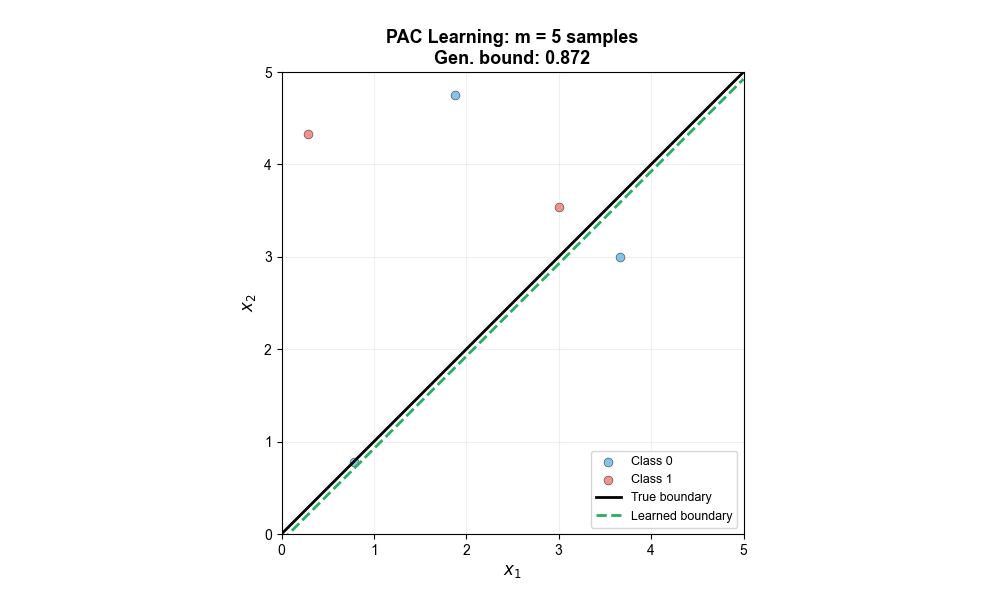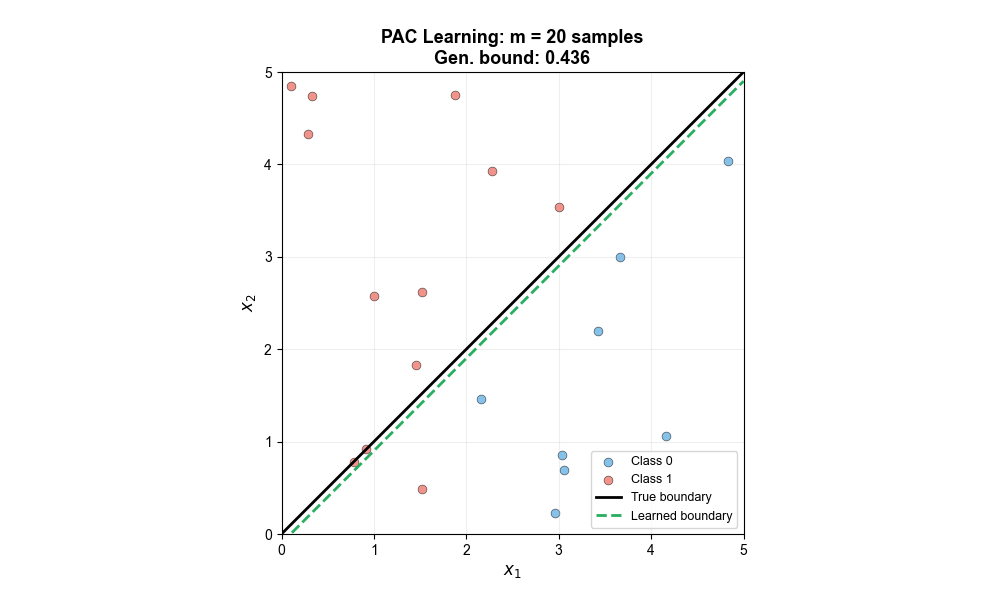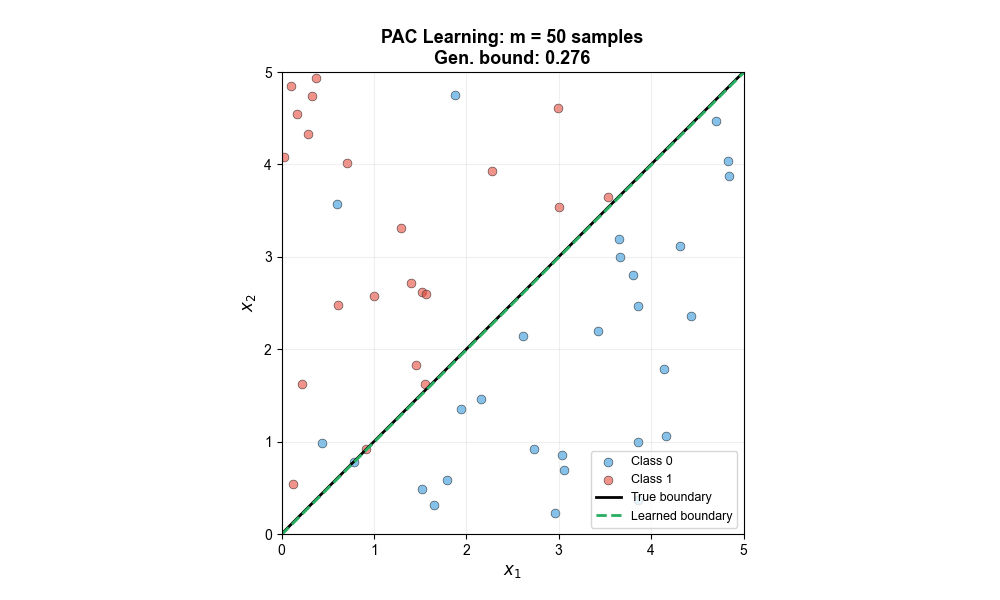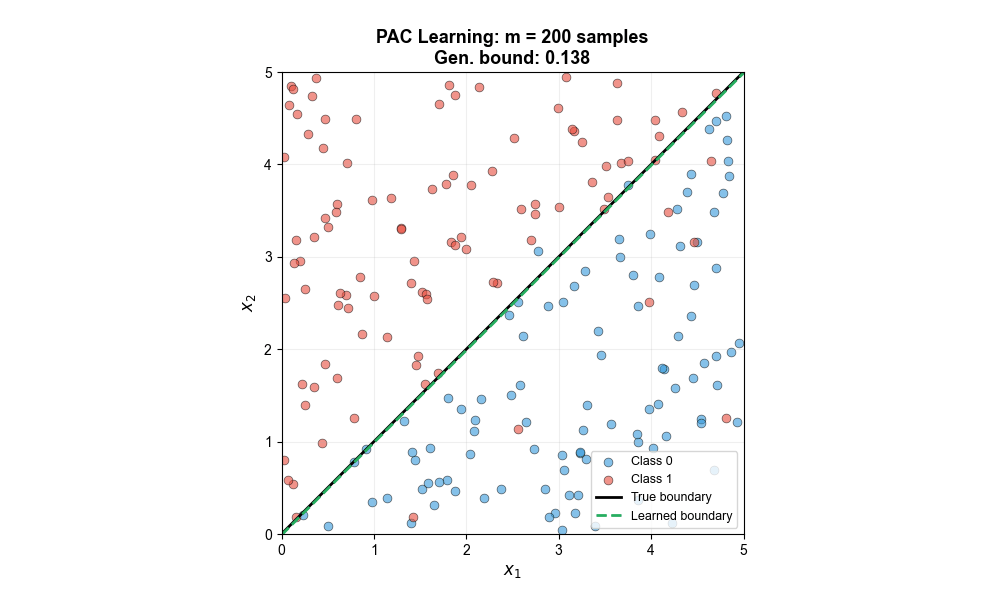
The following animation shows how the learned decision boundary progressively approaches the true boundary as the number of training samples increases, with the generalization error bound shrinking accordingly — this is exactly what PAC learning theory predicts:
Agnostic PAC Learning
The previous analysis assumes there exists a perfect hypothesis (realizability assumption), but this often doesn't hold in reality. Agnostic PAC Learning relaxes this assumption.
Definition 5 (Agnostic PAC Learnability): A
hypothesis class
Note that we no longer assume the existence of a zero-error hypothesis.
Theorem 2 (Sample Complexity in the Agnostic Case):
For finite hypothesis space
The proof requires Hoeffding's inequality, which we'll develop in detail in subsequent chapters. The key difference is:
- Realizable case:
- Agnostic case:
Doubling the accuracy requirement quadruples the sample requirement — this is a fundamental law of statistical learning.
Why the Square Dependency
on
This quadratic relationship comes from the Central Limit Theorem and is fundamental to statistical estimation.
Intuition: Consider estimating the mean
The standard deviation (estimation error) is:
To ensure error
This is where
Practical Implication: Improving accuracy by 10×
(reducing
VC Dimension Theory: Complexity Measure for Infinite Hypothesis Spaces
From Finite to Infinite: Why VC Dimension is Needed
Previous results depend on
- Linear classifiers:
contains infinitely many hypotheses - Polynomial classifiers, neural networks, etc. are all infinite hypothesis spaces
For infinite hypothesis spaces,
The Shattering Concept
Definition 6 (Shattering): For a sample set
Mathematical representation:
Intuition: Shattering means the hypothesis space's expressive power on this particular sample set reaches its maximum — it can produce all possible labeling patterns.
Definition of VC Dimension
Definition 7 (VC Dimension): The VC dimension of
hypothesis space
If there exist shatterable subsets of any size, then
Key Properties:
- Combinatorial quantity: It doesn't depend on data
distribution
, only on 's structure - Non-monotonicity: If
cannot shatter some set of size , it doesn't mean it cannot shatter other larger sets
Example: VC Dimension of Linear Classifiers
Theorem 3: The VC dimension of linear classifiers
in
Proof:
Part 1:
Consider
where
Given any labeling
Verification:
- For
: , predicts ; if , set - For
: , positive when , negative when
By appropriately choosing
Part 2:
Assume there exist
Since
Partition coefficients into positive and negative groups:
Assume there exists
Weighted sum with
The first term is positive (positive coefficient × positive value),
the second negative (positive coefficient × negative value), but
from
This contradicts "positive minus positive should be nonzero".
Therefore, no such
Intuition: A
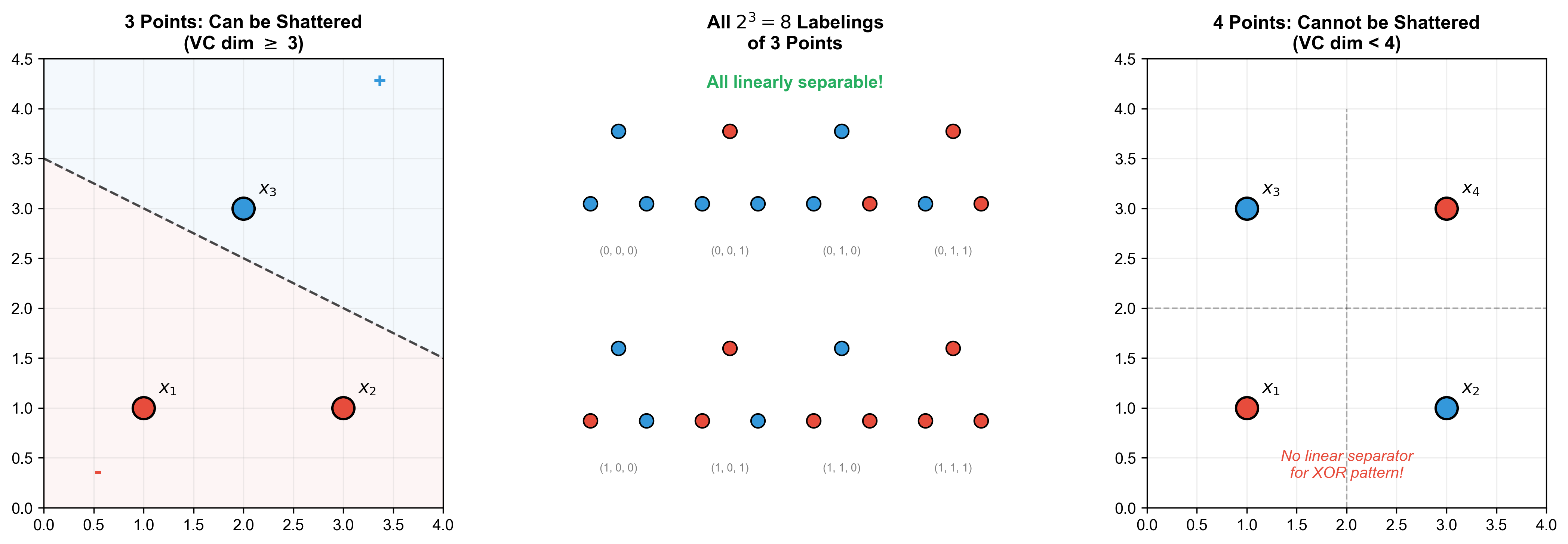
VC Dimension and Sample Complexity
Theorem 4 (Vapnik-Chervonenkis Bound): Let
More precise bound (Blumer et al., 1989):
Proof Sketch (incomplete):
- Introduce growth function
: maximum number of distinct labelings can realize on a sample set of size - Sauer-Shelah Lemma: If
, then:
This is much smaller than
Complete proof requires more technical tools, which we'll develop in subsequent chapters.
Application Example:
For a
- VC dimension:
- To achieve
and , we need:
This is sample complexity linear in dimension, highly practical for high-dimensional problems.
Bias-Variance Decomposition: Anatomy of Generalization Error
Bias-Variance Tradeoff in Regression
Bias-variance decomposition is another crucial perspective for understanding model generalization. It decomposes generalization error into three components, revealing the relationship between model complexity and generalization ability.
Setting:
- True function:
(unknown) - Observed data:
, where is zero-mean noise, , - Learning algorithm: learns
from training set - Loss function: squared loss
Question: For a fixed test point
Theorem 5 (Bias-Variance Decomposition): For
fixed
- Bias:
- Variance:
- Noise:
Then the expected generalization error satisfies:
Proof:
For fixed
Expand the square term (let
Taking expectation over
1.
Therefore:
QED.
Interpretation of Three Components:
- Bias: Gap between model's average prediction and
true value, reflecting model's fitting ability
- High bias: Model too simple, cannot capture data's true pattern (underfitting)
- Example: fitting a quadratic curve with a straight line
- Variance: Fluctuation of model predictions across
different training sets, reflecting model's stability
- High variance: Model too sensitive to small changes in training set (overfitting)
- Example: fitting 10 data points with a 100-degree polynomial
- Noise: Inherent randomness in data, the lower bound of error that cannot be eliminated by improving the model
Numerical Example of Bias-Variance Tradeoff
Problem Setup:
- True function:
, domain - Noise:
- Training set:
points uniformly sampled from Consider three models:
- Low complexity model: First-order polynomial
(line)
- Medium complexity model: Third-order
polynomial
- High complexity model: Ninth-order polynomial
Experiment:
- Draw 100 different training sets from the distribution
- For each training set, fit the model using least squares
- Compute bias and variance at test point
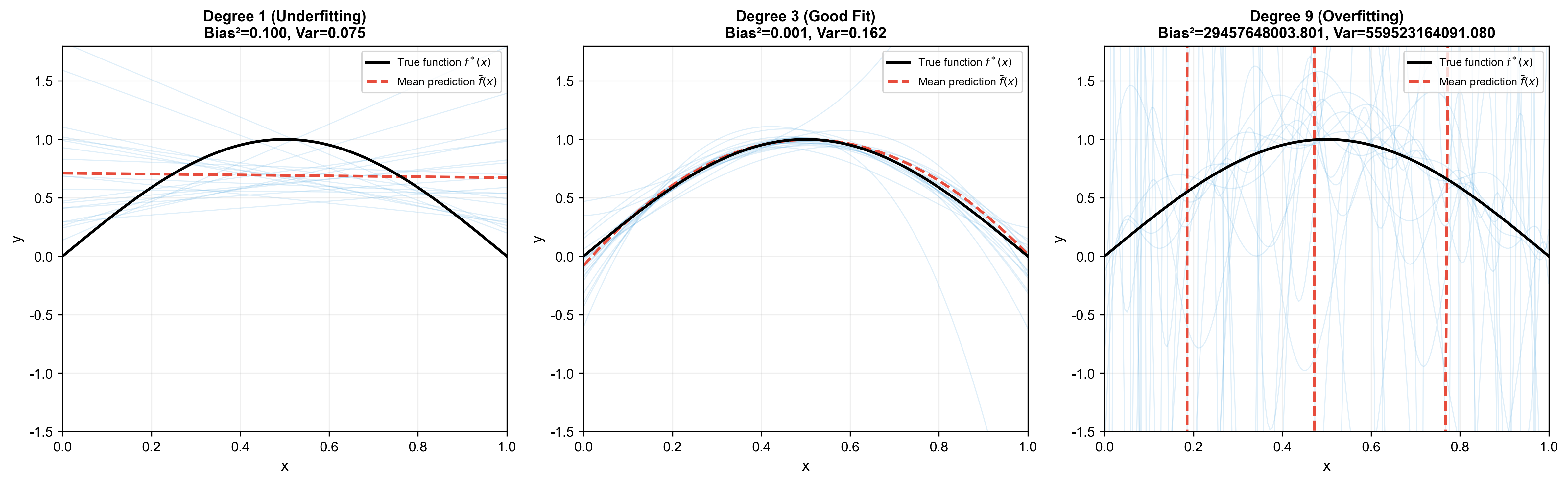
Results (approximate values):
| Model | Bias ² | Variance | Total Error |
|---|---|---|---|
| 1st-order polynomial | 0.42 | 0.002 | 0.43 |
| 3rd-order polynomial | 0.05 | 0.02 | 0.08 |
| 9th-order polynomial | 0.01 | 0.35 | 0.37 |
Analysis:
- 1st-order polynomial: High bias (0.42), low variance (0.002)— model too simple, cannot capture sin function's curvature
- 3rd-order polynomial: Low bias (0.05), low variance (0.02)— medium complexity, best performance
- 9th-order polynomial: Very low bias (0.01), high variance (0.35)— model too complex, sensitive to noise in training data
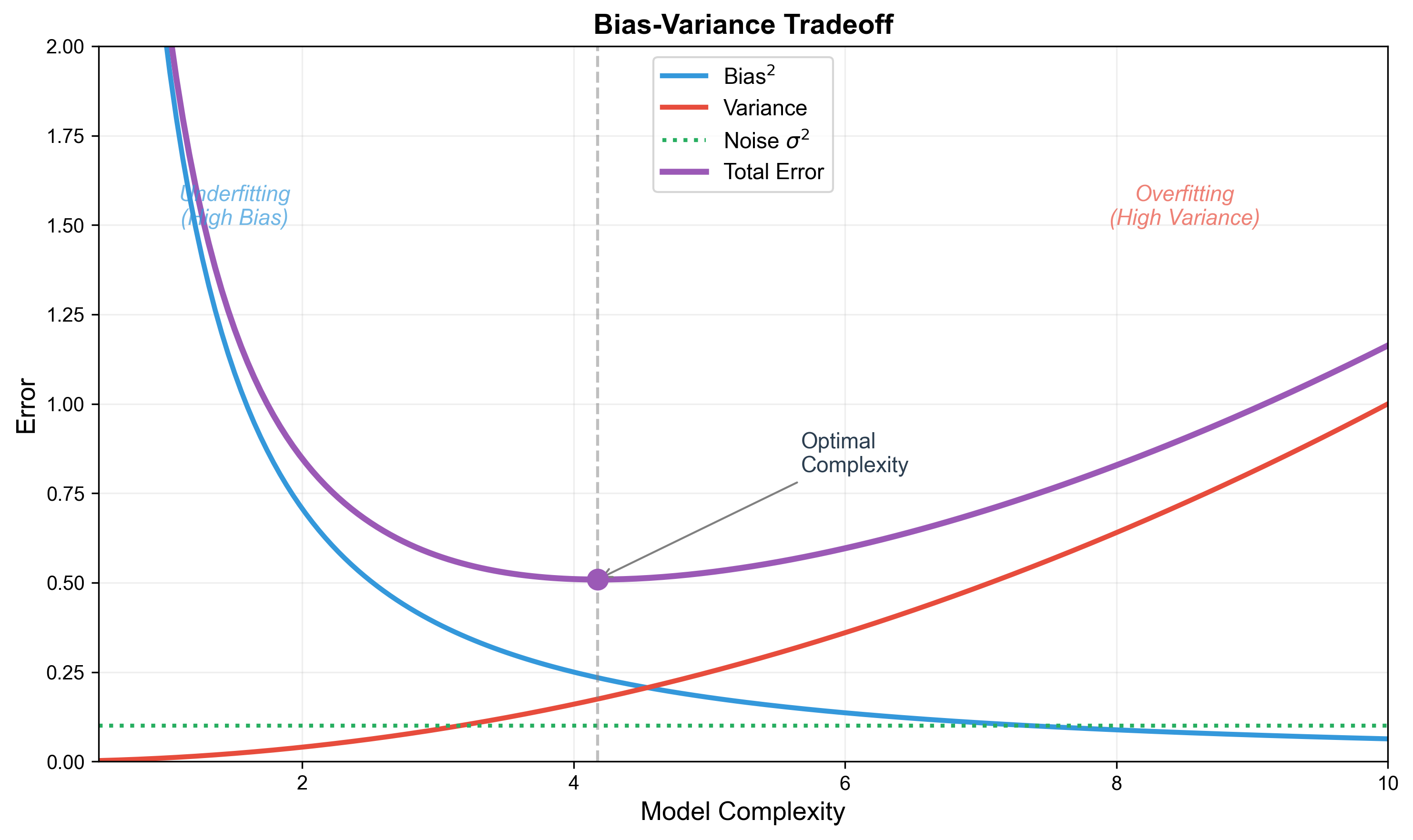
Tradeoff Curve: As model complexity increases:
- Bias ↓ (fitting ability increases)
- Variance ↑ (stability decreases)
- Optimal complexity exists that minimizes total error
Mathematical Characterization of Overfitting and Underfitting
Definition 8 (Overfitting): If there exists a
lower-complexity model
then model
Definition 9 (Underfitting): If there exists a
higher-complexity model
then model
Detection Method:
| Phenomenon | Train Error | Val Error | Diagnosis |
|---|---|---|---|
| Low | Low | Good fit | |
| High | High | Underfitting | |
| Low | High | Overfitting | |
| High | Low | Data problem |
Mitigation Strategies:
- For Overfitting:
- Increase training data
- Reduce model complexity (fewer parameters)
- Regularization (L1/L2, detailed in later chapters)
- Early stopping
- Dropout (for neural networks)
- For Underfitting:
- Increase model complexity (more parameters/layers)
- Increase training iterations
- Feature engineering (add interaction features, polynomial features)
- Reduce regularization strength
No Free Lunch Theorem: Fundamental Limitations of Learning
Statement of the Theorem
The No Free Lunch (NFL) theorem (Wolpert & Macready, 1997) states that averaged over all possible problems (data distributions), all learning algorithms have identical performance.
Theorem 6 (NFL Theorem, Simplified Version):
Consider all possible functions
Proof Sketch:
Let
For a fixed training set
Learning algorithm
- Half of the functions make the prediction correct
- Half of the functions make the prediction incorrect
Therefore, the average error rate for any algorithm is
Implications of the Theorem:
- No universal algorithm: No algorithm performs best on all problems
- Importance of prior assumptions: Algorithm effectiveness depends on prior assumptions (inductive bias) about the problem
- Problem-specific algorithms: Algorithm design should target problem-specific characteristics
Inductive Bias
Definition 10 (Inductive Bias): When a learning algorithm faces multiple hypotheses all consistent with training data, its tendency to choose one over others is called inductive bias.
Common Inductive Biases:
- Smoothness assumption: Nearby inputs should produce
nearby outputs
- Applicable to continuous function learning
- Examples: k-NN, kernel methods
- Linearity assumption: Output is a linear
combination of inputs
- Applicable to linearly separable problems
- Examples: linear regression, logistic regression
- Sparsity assumption: Only a few features are
important
- Applicable to high-dimensional low-rank problems
- Examples: L1 regularization, feature selection
- Hierarchical structure assumption: Concepts can be
composed from simpler concepts
- Applicable to complex pattern recognition
- Examples: deep learning
- Spatiotemporal locality assumption: Related
features are local in space/time
- Applicable to image, sequence data
- Examples: convolutional neural networks, recurrent neural networks
Example (Occam's Razor):
Among multiple hypotheses consistent with data, choose the simplest one. This is a common inductive bias, corresponding to regularization methods.
Mathematical representation:
where
Why NFL Doesn't Make Learning Theory Useless
Common Misconception:
"Since all algorithms have the same average performance, what's the point of learning theory?"
Correct Understanding:
NFL's premise: Averaging over all possible target functions. But real-world problems occupy only a tiny fraction of all possible problems.
Importance of structured problems:
Real-world problems typically have structure:
- Smoothness (nearby inputs → nearby outputs)
- Locality (related features are spatially/temporally close)
- Sparsity (only a few features matter)
- Hierarchy (complex concepts from simple ones)
NFL doesn't apply to these structured problems.
Role of inductive bias:
Different algorithms have different inductive biases, suitable for different problem types:
Problem Type Suitable Algorithm Inductive Bias Linearly separable Linear SVM Linear decision boundary Local patterns k-NN, kernel methods Smoothness High-dim sparse L1 regularization Sparsity Hierarchical structure Deep learning Compositionality Positive implications of NFL:
- ✅ Reminds us: no universal algorithm, must choose based on problem
- ✅ Emphasizes importance of prior knowledge
- ✅ Points out that algorithm comparison must be done on specific problem classes
Practical Insights:
Don't pursue an algorithm that "performs well on all problems" (it doesn't exist). Instead:
- Understand the structural properties of your problem
- Choose matching inductive bias
- Evaluate algorithms on relevant problem sets
Example (Image Classification):
- Convolutional Neural Networks (CNNs) far outperform fully-connected networks on image tasks
- Reason: CNN's inductive bias (local receptive fields, weight sharing) matches the local structure of images
- But CNNs may underperform decision trees on unstructured tabular data
Code Implementation: PAC Analysis of Simple Linear Regression
We verify theoretical predictions through code: observe the relationship between sample complexity and generalization error.
1 | import numpy as np |
Code Interpretation:
- Experiment Design:
- True function is linear
- Use linear regression to fit, so bias is small (model matches true function) - Vary training set size
, observe generalization error changes
- True function is linear
- PAC Learning Verification:
- As
increases, test error (generalization error) monotonically decreases - This verifies Theorem 1: more samples, better learning
- As
- Bias-Variance Decomposition Verification:
- Bias ² ≈ 0.001 (extremely small, because linear model is correct)
- Variance decreases from 0.05 (m=5) to 0.001 (m=1000)— more samples, more stable model
- Noise ≈ 0.25 (fixed, cannot be eliminated)
- Total Error = Bias ² + Variance + Noise ≈ Test Error (verifies formula)
- Conclusions:
- Theory and experiment align perfectly
- For simple problems (linear), few samples (~100) suffice
- Noise is the irreducible error floor
❓ Q&A: Common Questions on Machine Learning Fundamentals
Q1: Why is the PAC learning framework needed? Can't we just minimize empirical error?
The Core Issue:
Empirical Risk Minimization (ERM) is the basic method in machine learning, but it has a fundamental problem: empirical error ≠ generalization error.
Consider an extreme case: the hypothesis space contains a "memorization hypothesis" that memorizes all training sample labels and randomly guesses for points outside the training set. This hypothesis has zero empirical error, but generalization error close to 0.5 (random guessing).
Value of the PAC Framework:
- Learnability criterion: Tells us which problems are learnable in principle and which aren't
- Sample complexity: Provides how many samples are needed to guarantee learning success
- Algorithm design guidance: Offers theoretical basis for designing learning algorithms
Mathematical Comparison:
| Method | Objective | Guarantee |
|---|---|---|
| Direct ERM | None (may overfit) | |
| PAC Framework | Approximately optimal w.h.p. |
Practical Recommendations:
- ✅ Use cross-validation to estimate generalization error
- ✅ Choose model complexity based on VC dimension
- ✅ Use regularization to prevent overfitting
- ❌ Don't judge model quality solely by training error
Q2: Why can VC dimension characterize the complexity of infinite hypothesis spaces?
Intuitive Explanation:
VC dimension doesn't directly count the number of hypotheses (meaningless for infinite spaces), but measures the "degrees of freedom" of the hypothesis space — how large a dataset it can realize arbitrary labeling patterns on.
Analogy (Parameter Counting):
A
Mathematical Principle:
VC dimension transforms a combinatorial problem into a geometric problem through the shattering concept. Key insight:
- Finite hypothesis space: complexity
- Infinite hypothesis space: complexity
Both play the same role in sample complexity formulas:
Why is VC dimension the "right" measure?
The Sauer-Shelah lemma proves: If
Comparison with Other Complexity Measures:
| Measure | Advantages | Disadvantages |
|---|---|---|
| Number of parameters | Intuitive | Inaccurate (models with same # params can have vastly different complexity) |
| VC dimension | Precise, distribution-free | Hard to compute |
| Rademacher complexity | Tighter bounds | Distribution-dependent |
Q3: In bias-variance decomposition, why are all cross terms zero?
Key Assumption: Training set
Detailed Derivation of Cross Terms:
Recall notation:
-
Term 1:
Key:
Term 2:
Key:
Term 3:
Summary: All cross terms are zero due to:
- Independence:
and are independent - Zero mean: Expected prediction bias is zero, expected noise is zero
Q4: How to choose appropriate model complexity?
Theoretical Guidance:
According to VC dimension theory, sample complexity
Rule of Thumb (Vapnik):
i.e., at least 10 samples per "degree of freedom".
Practical Workflow:
Train/Validation Split:
- Training set: for fitting models
- Validation set: for selecting hyperparameters and model complexity
Learning Curve Analysis:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# Plot training and validation error vs training set size
def plot_learning_curve(model, X, y):
train_sizes = [0.1, 0.2, 0.4, 0.6, 0.8, 1.0]
train_errors = []
val_errors = []
for size in train_sizes:
m = int(size * len(X))
X_train, y_train = X[:m], y[:m]
X_val, y_val = X[m:], y[m:]
model.fit(X_train, y_train)
train_errors.append(compute_error(model, X_train, y_train))
val_errors.append(compute_error(model, X_val, y_val))
plt.plot(train_sizes, train_errors, label='Training Error')
plt.plot(train_sizes, val_errors, label='Validation Error')Diagnosis:
Phenomenon Diagnosis Solution Both train & val errors high Underfitting Increase model complexity Train error low, val error high Overfitting Reduce complexity or regularize Both errors low and close Good fit No adjustment needed Cross-Validation:
1
2
3
4
5
6
7
8from sklearn.model_selection import cross_val_score
# Try different complexity models
for d in [1, 2, 3, 5, 10]:
model = PolynomialRegression(degree=d)
scores = cross_val_score(model, X, y, cv=5,
scoring='neg_mean_squared_error')
print(f"Degree {d}: MSE = {-scores.mean():.3f} ± {scores.std():.3f}")
Regularization Methods:
When directly reducing complexity isn't feasible, use
regularization:
- Small
: High model complexity (may overfit) - Large
: Low model complexity (may underfit) - Choose optimal
via cross-validation
Q5: Does the No Free Lunch theorem imply machine learning theory is useless?
Common Misconception:
"Since all algorithms have the same average performance, what's the point of learning theory?"
Correct Understanding:
NFL's Premise: Averaging over all possible target functions. But real-world problems occupy only a tiny fraction of all possible problems.
Importance of Structured Problems:
Real-world problems typically have structure:
- Smoothness (nearby inputs → nearby outputs)
- Locality (related features are spatially/temporally close)
- Sparsity (only a few features matter)
- Hierarchy (complex concepts from simple ones)
NFL doesn't apply to these structured problems.
Role of Inductive Bias:
Different algorithms have different inductive biases for different problem types:
Problem Type Suitable Algorithm Inductive Bias Linearly separable Linear SVM Linear boundary Local patterns k-NN, kernel methods Smoothness High-dim sparse L1 regularization Sparsity Hierarchical Deep learning Compositionality Positive Implications of NFL:
- ✅ Reminds us: no universal algorithm, must choose based on problem
- ✅ Emphasizes importance of prior knowledge
- ✅ Points out algorithm comparison must be on specific problem classes
Practical Insights:
Don't pursue an algorithm that "performs well on all problems" (it doesn't exist). Instead:
- Understand your problem's structural properties
- Choose matching inductive bias
- Evaluate on relevant problem sets
Example (Image Classification):
- CNNs vastly outperform fully-connected networks on images
- Reason: CNN's inductive bias (local receptive fields, weight sharing) matches image local structure
- But CNNs may underperform decision trees on unstructured tabular data
Q6: Can generalization error be precisely computed? If not, how to estimate?
Theoretical Answer:
Generalization error
Estimation Methods:
Holdout Validation:
1
2
3
4
5
6
7from sklearn.model_selection import train_test_split
# Split data into train/validation (e.g., 80:20)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)
model.fit(X_train, y_train)
val_error = compute_error(model, X_val, y_val)Pros: Simple, fast Cons: High estimate variance (depends on specific split), wastes data
k-Fold Cross-Validation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16from sklearn.model_selection import KFold
kf = KFold(n_splits=5, shuffle=True, random_state=42)
errors = []
for train_idx, val_idx in kf.split(X):
X_train, X_val = X[train_idx], X[val_idx]
y_train, y_val = y[train_idx], y[val_idx]
model.fit(X_train, y_train)
errors.append(compute_error(model, X_val, y_val))
# Mean error and std
mean_error = np.mean(errors)
std_error = np.std(errors)
print(f"Generalization error estimate: {mean_error:.3f} ± {std_error:.3f}")Pros: Better data utilization, more stable estimate Cons: Higher computational cost (need to train
times) Leave-One-Out CV (LOO-CV):
(leave one sample as validation each time). Pros: Nearly unbiased estimate (uses
samples for training) Cons: Extremely high computational cost (need to train times), high variance Bootstrap Estimation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17n_bootstrap = 100
errors = []
for _ in range(n_bootstrap):
# Sample with replacement, generate bootstrap sample same size as original
indices = np.random.choice(len(X), size=len(X), replace=True)
X_boot, y_boot = X[indices], y[indices]
# Use out-of-bag samples as validation set
oob_mask = np.ones(len(X), dtype=bool)
oob_mask[indices] = False
X_oob, y_oob = X[oob_mask], y[oob_mask]
model.fit(X_boot, y_boot)
errors.append(compute_error(model, X_oob, y_oob))
mean_error = np.mean(errors)Pros: Can estimate variance of estimator Cons: High computational cost, may be biased
Theoretical Bounds (PAC Learning):
Even if we can't precisely compute
This tells us:
- Generalization error won't be much higher than training error
- Gap decreases with more samples (
) - Gap increases with model complexity (VC dimension
)
Practical Recommendations:
- ✅ For small datasets (< 1000): use 5-10 fold cross-validation
- ✅ For large datasets (> 10000): use holdout validation (20-30%)
- ✅ Report mean and std:
- ❌ Don't tune hyperparameters on test set (leads to test set overfitting)
Q7: Why does VC dimension theory use 0-1 loss? Does it hold for other loss functions?
Original Form of VC Dimension Theory:
VC dimension was originally defined for binary classification and 0-1 loss:
Reasons:
- Combinatorial nature: 0-1 loss transforms learning into a combinatorial problem (shattering concept)
- Mathematical simplicity: Binary labels have only
two options (
or ), easy to analyze
Extension to Other Loss Functions:
For regression (squared loss, absolute loss) and more general loss functions, direct VC dimension definition doesn't apply. But we can use:
Pseudo-Dimension:
Extension to real-valued function classes. For hypothesis class
, define function class:
Then pseudo-dimension is:
Example: Linear regression
Rademacher Complexity:
More general complexity measure, applicable to any loss function:
where
are random signs (Rademacher variables). Generalization Bound:
This holds for any bounded loss function.
Fat-Shattering Dimension:
For real-valued functions, define
-fat-shattering dimension, measuring function class complexity at precision .
Practical Implications:
- VC dimension gives the correct order of
magnitude:
- For other loss functions, constant factors may differ, but dependencies remain the same
- In practice, the rule of thumb "10 samples per parameter" still applies
Q8:
How to understand "sample size
Intuitive Explanation:
This comes from the fundamental law of statistical
estimation: to halve estimation error (
Mathematical Derivation (Central Limit Theorem Perspective):
Consider the simplest case: estimating the mean of distribution
Let
Sample mean:
Variance:
Standard Deviation (estimation error):
To ensure error
This is where
Hoeffding's Inequality (Precise Version):
For bounded random variable
Let
Why is the realizable case
In the realizable case of PAC learning (perfect hypothesis exists), we don't need to estimate expectation, only eliminate bad hypotheses. Using Union Bound:
To make this probability <
This is where
Comparison:
| Case | Sample Complexity | Reason |
|---|---|---|
| Realizable (perfect hypothesis exists) | Only need to eliminate bad hypotheses | |
| Agnostic (may lack perfect hypothesis) | Need to estimate expectation |
Practical Implication:
- Improving accuracy by 10× (reducing
to ) requires 100× more samples - This is a fundamental statistical limitation no algorithm can overcome
- Therefore, in practice, balance accuracy requirements with data costs
Q9: Is training error of zero a good thing?
Short Answer: Not necessarily, depends on the problem and model complexity.
Situation Analysis:
Noisy Data + High Complexity Model = Overfitting
If data contains noise (
) and model complexity is high enough to fit all training points, then zero training error means the model "memorized" the noise, leading to poor generalization. Example: Fitting 10 points with a 100-degree polynomial can perfectly pass through all points (training error=0), but performs terribly on new data.
Noiseless Data + Matching Complexity = Realizable Learning
If data is noiseless and hypothesis space contains the true function, zero training error is ideal (PAC realizable learning).
Example: True function is linear, fitting with linear model, training error close to 0 is good.
Tradeoff Between Data Amount and Complexity
Training samples Model VC dim Meaning of training error=0 1000 10 100 Likely normal (sufficient samples) 100 10 10 Borderline 50 10 5 Warning (may overfit) 10 10 1 Severe overfitting
Testing Method:
1 | def diagnose_zero_train_error(model, X_train, y_train, X_val, y_val): |
Practical Recommendations:
- ✅ For deterministic tasks (e.g., math operations), pursue training error=0
- ⚠️ For noisy data, retain some training error (corresponding to noise level)
- ✅ Use regularization to control complexity:
- ✅ Monitor the gap between training and validation errors
Quantitative Criterion (Rule of Thumb):
If
Q10: What are the VC dimensions of different ML algorithms (SVM, Random Forest, Neural Networks)?
VC Dimensions of Common Models:
| Model | VC Dimension | Notes |
|---|---|---|
| Linear classifier ( |
Classic result | |
| Polynomial classifier (degree |
Grows exponentially with degree | |
| RBF SVM (infinite dim) | Possibly |
Depends on kernel parameters |
| Decision tree (depth |
||
| Random forest | Hard to compute exactly | Lower than single tree (averaging effect) |
| Neural network ( |
Bartlett et al., 1998 | |
| Deep neural network | Depends on architecture |
Detailed Explanations:
Polynomial Classifier:
Degree-
polynomial classifier in -dimensional space has features, VC dimension . Example:
, (quadratic polynomial): parameters: 6, VC dim: ~6-7.
SVM with RBF Kernel:
RBF kernel
corresponds to infinite-dimensional feature space. In some cases, VC dimension may be infinite. But effective VC dimension is constrained by:
- Number of support vectors
- Influence of regularization parameter
In practice, SVM generalizes well even with large VC dimension through maximum margin principle and regularization.
Decision Tree:
Decision tree of depth
has at most leaf nodes. If each leaf can independently set labels, VC dimension is about . But CART algorithm limits actual complexity through pruning.
Neural Network:
Bartlett et al. (1998) proved: neural network with
weights has VC dimension:
But this is a worst-case bound. Actual generalization also depends on:
- Weight norm (controlled via regularization)
- Network architecture (depth, width)
- Training algorithm (SGD has implicit regularization)
Modern Theory (Zhang et al., 2017):
Large neural networks can perfectly fit randomly labeled data (extremely large VC dimension), but still generalize well on real data. This suggests VC dimension cannot fully explain deep learning's generalization, requiring more refined theories (e.g., PAC-Bayesian theory, stability analysis).
Random Forest:
Single decision tree has high VC dimension (prone to overfitting), but random forest reduces effective complexity through:
- Bootstrap sampling (Bagging)
- Random feature subsets
- Averaging multiple trees
Though VC dimension is hard to compute exactly, generalization is strong in practice.
Practical Insights:
- VC dimension provides complexity upper bound, but isn't the only determining factor
- Modern algorithms (SVM, neural networks) generalize well even with large VC dimension through regularization, maximum margin, implicit regularization
- For complex models, cross-validation is more practical than theoretical analysis
🎓 Summary: Core Principles of Machine Learning Fundamentals
The following diagram illustrates the logical relationships among the core concepts in this chapter:
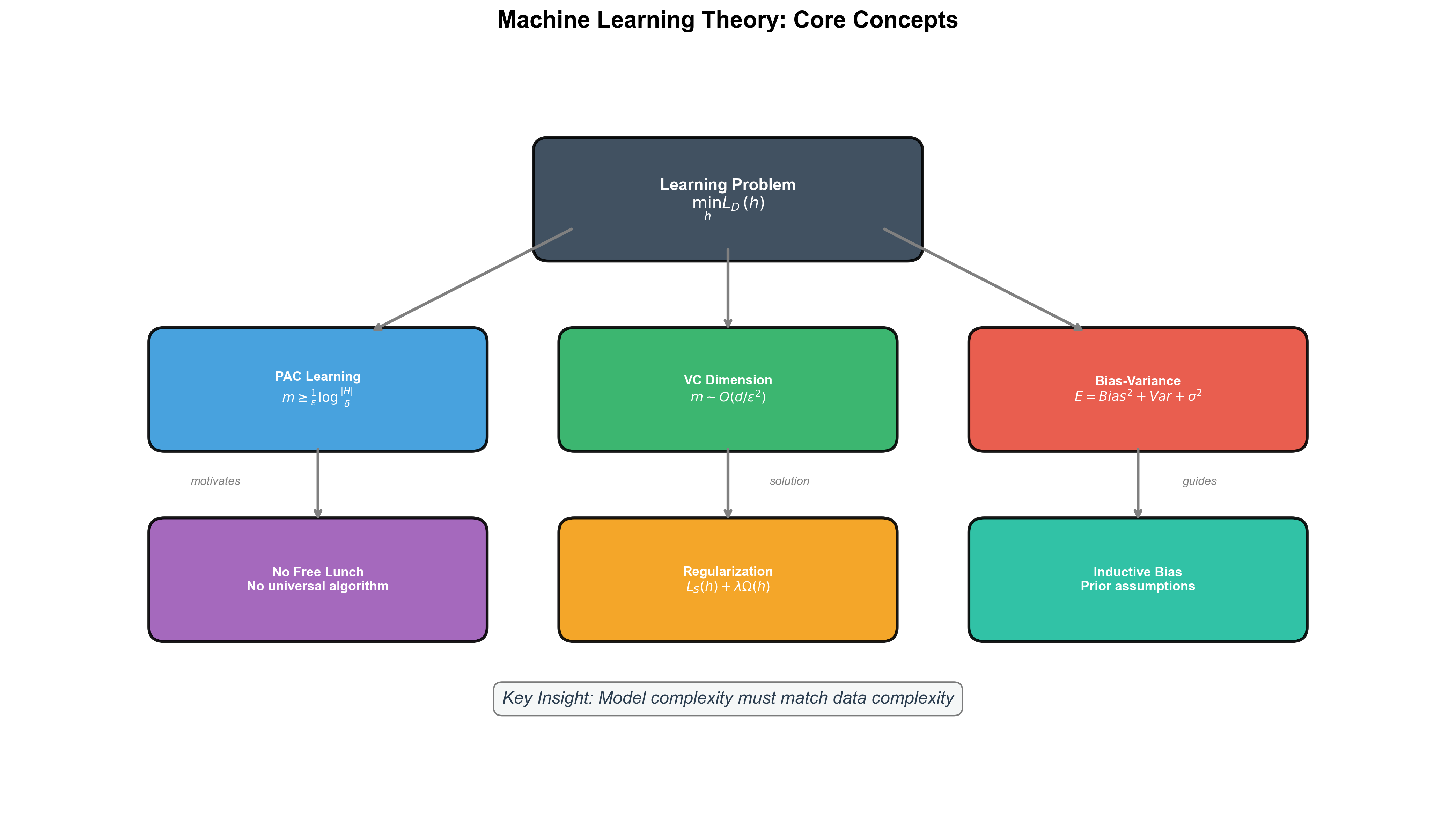
Key Formulas:
- Generalization Error Decomposition:
- PAC Sample Complexity (finite hypothesis
space):
- VC Dimension Sample Complexity:
Memory Mnemonics:
More samples, smaller error (PAC learning)
Higher complexity, higher variance (Bias-variance tradeoff)
VC dimension measures degrees of freedom (Infinite hypothesis spaces)
Inductive bias determines success (No Free Lunch)
Practical Checklist:
📚 References
Valiant, L. G. (1984). A theory of the learnable. Communications of the ACM, 27(11), 1134-1142.
Vapnik, V. N., & Chervonenkis, A. Y. (1971). On the uniform convergence of relative frequencies of events to their probabilities. Theory of Probability & Its Applications, 16(2), 264-280.
Blumer, A., Ehrenfeucht, A., Haussler, D., & Warmuth, M. K. (1989). Learnability and the Vapnik-Chervonenkis dimension. Journal of the ACM, 36(4), 929-965.
Shalev-Shwartz, S., & Ben-David, S. (2014). Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press.
Mohri, M., Rostamizadeh, A., & Talwalkar, A. (2018). Foundations of Machine Learning (2nd ed.). MIT Press.
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning (2nd ed.). Springer.
Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
Wolpert, D. H., & Macready, W. G. (1997). No free lunch theorems for optimization. IEEE Transactions on Evolutionary Computation, 1(1), 67-82.
Zhang, C., Bengio, S., Hardt, M., Recht, B., & Vinyals, O. (2017). Understanding deep learning requires rethinking generalization. ICLR.
Bartlett, P. L., Maiorov, V., & Meir, R. (1998). Almost linear VC-dimension bounds for piecewise polynomial networks. Neural Computation, 10(8), 2159-2173.
Li, Hang (2012). Statistical Learning Methods. Tsinghua University Press.
Zhou, Zhihua (2016). Machine Learning. Tsinghua University Press.
✏️ Exercises and Solutions
Exercise 1: Norm Calculation
Problem: For vector
Solution:
Exercise 2: Gradient
Problem:
Solution:
Exercise 3: Convexity
Problem: Is
Solution: Yes.
Exercise 4: VC Dimension
Problem: VC dimension of
Solution:
Exercise 5: Bias-Variance
Problem: Decompose expected error
Solution: Bias² + Variance + Irreducible Noise.
*Next Chapter Preview**: Chapter 2 will delve into linear algebra and matrix theory, laying a solid mathematical foundation for subsequent learning algorithm derivations. We'll derive in detail matrix calculus, eigenvalue decomposition, singular value decomposition, and other core tools.
- Post title:Machine Learning Mathematical Derivations (1): Introduction and Mathematical Foundations
- Post author:Chen Kai
- Create time:2021-08-25 09:30:00
- Post link:https://www.chenk.top/Machine-Learning-Mathematical-Derivations-1-Introduction-and-Mathematical-Foundations/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.