磁盘相关的问题,很多时候不是“记几个命令”就能解决:分区表怎么选、文件系统怎么挂、扩容怎么尽量少停机、删文件为什么空间不立刻回来,背后都有明确的机制约束。本文从热/冷存储与磁盘结构切入,串起
RAID 与 LVM 的落地用法、 MBR/GPT 分区与
fdisk/gdisk
的实际操作、格式化与挂载的完整流程,并补上 /dev 特殊设备、
inode
与硬/软链接、文件删除原理这些最容易踩坑但又最“救命”的细节。读完建议能按步骤把一块新盘从“识别—分区—格式化—挂载—扩容—排障”走通。
网站存储
数据存储是网站架构的一大重点,关于存储方案我们通常需要考虑硬件角度和软件角度,本文我们只关注硬件角度。
1. 存储层的设计
热存储( Hot Storage):存储需要频繁访问的数据。通常使用 SSD(固态硬盘),例如数据库存储。
- SSD 基于 NAND 闪存技术,具有更快的读写速度和更高的耐用性。
- 通过电子电荷存储数据,每个单元存储一个或多个比特的数据。
- 和顺序读写比起来,固态硬盘的随机读写慢不了多少,随件写入效率略微降低,随机读取能力也就下降一半左右。
- 固态硬盘写入数据前要对齐,所以有独特的
trim指令。文件删除以后,操作系统会挑选空余时间自动执行trim,而不是下次使用的时候再对齐,机械硬盘不需要对齐,直接覆盖就行了。所以机械硬盘的数据在没有覆盖之前都是可以恢复了,固态硬盘一般在回收站里面删除以后很快就执行了trim命令,几乎不能再恢复数据了。
冷存储( Cold Storage):用于长期存储访问频率低的数据。可以使用 HDD(机械硬盘)或分布式存储系统。

HDD 通过磁性盘片和磁头来读取和写入数据,硬盘存储设备和电磁有关因此也被称为磁盘:磁头在盘片上移动,通过磁性变化来写入和读取数据。机械硬盘里有很多张磁盘。
数据存储分为多个扇区和轨道。
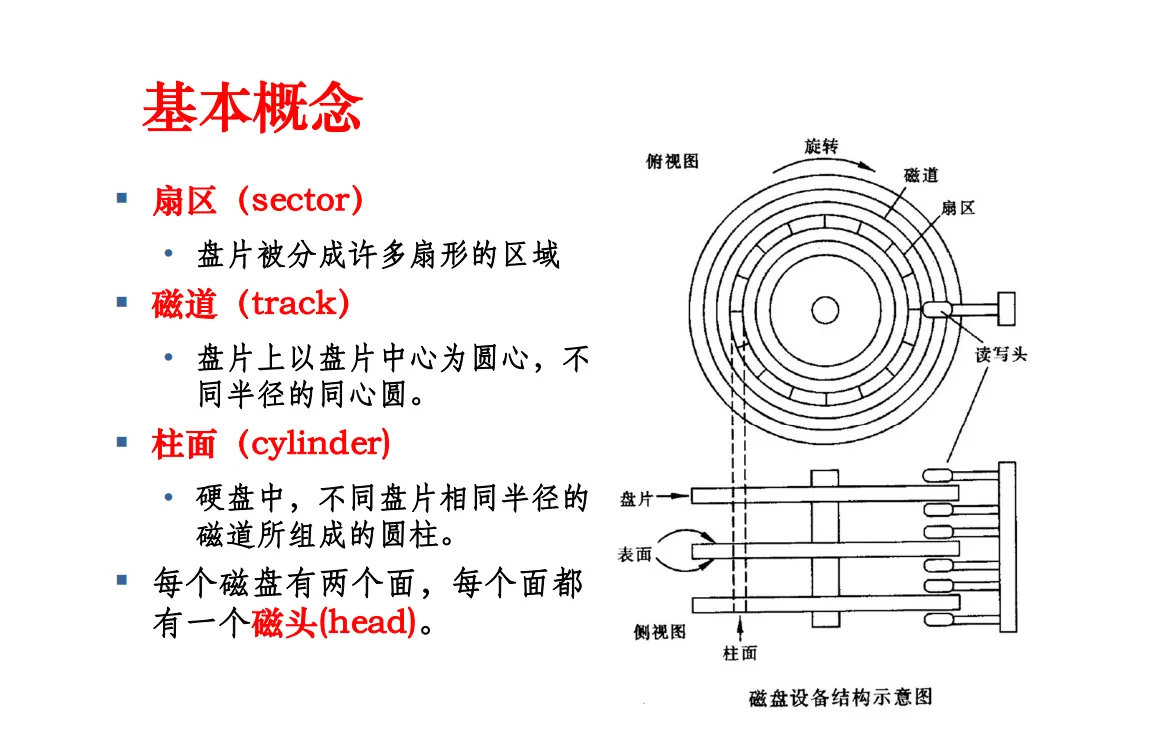
一个磁盘里面有一到多个盘片,盘片可以可以单面或者双面的。单面盘片只有一个面有磁头,双面盘片两个面都有磁头。多盘片,双盘面的磁盘,是协同工作的,这时候他们机械臂的位置相同,盘面相对位置恒定,理论上多盘片之间可以相互配合共同读写,多盘片的硬盘,也并不会成倍的提升读写性能,大概只能归结于工艺原因,并不能做到多盘片协同工作。
一个扇区模默认大小是 512 字节,也就是 0.5KB 。如下图,我们格式化硬盘的时候,可以指定分配单元大小,理论上一个分配单元最小值就是一个扇区。

操作系统的分配单元大小叫做簇(或者块 block),一个簇由一到多个连续扇区组成,一个文件只能被连续的存储在一个或者多个簇里面。比如我 4K 对齐(操作系统指定 1 个簇由 8 个扇区构成),那么我即便有的文件只有 1 个字节,那么它也会占用 4K 的存储空间。
有时候我们文件显示存储空间是 0,这是操作系统优化的结果,太小的文件,占用一个簇太浪费,可以公用区域存放,这个文件如果再大一点,或者公共区域放不下了,就会直接分配单独的一个簇存储。
对机械硬盘而言,转速和缓存是高性能的指标
- 常见的是 7200 rpm(转每分钟)+ 64 MB 的缓存配置
- 一些需要高负载和大型数据传输的高性能服务器会配置 10000 或 15000 rpm + 128 MB 甚至更高的缓存
磁盘读写过程:
- 通过地址确定需要读取的数据所在的磁道,和扇区。
- 机械摆臂移动磁头到指定磁道位置(等待机械结构移动)
- 等到磁盘扇区转到到磁头位置开始读取(等待机械结构转动)
- 如果数数据是在相邻扇区,或者相邻的蔟,那么就能连续的读取,这种叫做顺序读取
- 如果所需数据位于不同扇区,不同磁道,那么需要不断移动机械臂,和等待磁盘转动到指定扇区,这种就是随机读写。
机械硬盘随机读写慢的原因主要就是两次等待机械机构移动到指定位置。摆臂移动时间大概是 6-8 毫秒, 7200 转的硬盘一秒钟转 120 圈,每圈时间 8.3 毫秒,平均半圈是 4 毫秒的样子。所以 7200 转的机械银盘随机读取的平均延时在 10 多毫秒。机械硬盘顺序读写速度比随机读写快 80 倍以上,差异巨大。
对象存储:如 AWS S3 、阿里云 OSS,用于存储大量不常访问的文件和数据。
- 在 Hadoop 分布式文件系统( HDFS)中使用对象存储来处理大规模数据。
2. 存储的数据备份( RAID 磁盘阵列技术)
使用 raid
磁盘阵列技术进行磁盘备份,以保证数据安全性。
RAID 的基本概念
- RAID( Redundant Array of Independent Disks):将多个硬盘组合在一起形成一个逻辑单元,以提高数据冗余和/或性能。
- RAID 级别:
- RAID 0:数据条带化,分布到多个磁盘上,提高读写性能,但没有冗余,单个磁盘故障将导致数据丢失。
- RAID 1:镜像,数据在两个磁盘上完全复制,提高数据安全性,但存储空间减半。
- RAID 5:条带化+奇偶校验,至少需要三块磁盘,具有数据冗余和较好的性能平衡。
- RAID 6:类似 RAID 5,但使用双重奇偶校验,可以容忍两块磁盘同时故障。
- RAID 10:结合 RAID 0 和 RAID 1,先进行镜像再条带化,提供高性能和冗余,但成本较高。
软件 RAID(软 RAID)
软件 RAID 是由操作系统通过软件实现 RAID 功能,而不是依赖硬件 RAID
控制器。常见工具包括 Linux 下的 mdadm。优点是:
- 成本低,无需专用硬件。
- 灵活性高,可动态调整 RAID 配置。
对应的缺点是占用 CPU 资源,对系统性能有一定影响(现代 CPU 通常能很好地应对)。
软件 RAID 命令实践
创建 RAID:例如,创建一个 RAID 1 镜像:
1
mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/sda1 /dev/sdb1
/dev/md0:新创建的 RAID 设备--level=1:指定 RAID 1(镜像)--raid-devices=2:使用两个磁盘分区/dev/sda1 /dev/sdb1:参与 RAID 的设备
查看 RAID 状态:使用如下命令检查 RAID 设备状态:
1
cat /proc/mdstat
管理 RAID:添加、移除、重建等操作都可以使用
mdadm进行管理。例如:停止 RAID:
1
mdadm --stop /dev/md0
移除设备:
1
mdadm /dev/md0 --fail /dev/sda1 --remove /dev/sda1
配置文件:将 RAID 配置信息写入配置文件(如
/etc/mdadm.conf),以便系统启动时自动组装 RAID 设备:1
mdadm --detail --scan >> /etc/mdadm.conf
3. 存储的数据扩容
磁盘的数据满了怎么办,需要涉及存储的设备扩容
- 保证数据库数据完整的情况下,将用户数据迁移到另一个硬盘中
- 考虑到用户数据会不断增长,新磁盘采用
lvm逻辑卷管理,方便日后动态扩容
扩容业务整体流程
需要一块新硬盘(虚拟机可添加)
新硬盘需要做
lvm管理数据库迁移(夜间停机维护,凌晨 2 点)
- 停止数据库监控
- 停止前端(关闭前端数据入口,比如停用博客发表功能):
systemctl stop apache - 停止后端(可选)
- 停止 MySQL 数据库(防止数据还在写入,或者锁表)
- 备份数据库(全备)
- 迁移数据到新硬盘(使用
rsync【比cp命令更强大】),新硬盘已经做好了lvm,且挂载好了 - 启动数据库
- 启动前端入口
- 测试数据读写
- 博客功能重新恢复上线
- 开启数据库监控
lvm 技术
LVM(逻辑卷管理器, Logical Volume Manager)是一种将物理存储设备抽象为逻辑存储单元的技术,允许系统管理员更加灵活地管理存储设备。与传统的分区方式(如直接将磁盘划分为固定大小的分区)不同, LVM 提供了更高的灵活性,能够在系统运行时动态地调整存储空间。
LVM 技术包括以下几个核心概念:
物理卷( Physical Volume, PV)
物理卷是 LVM 中的最底层存储单元,通常是磁盘或者磁盘分区。 LVM 会将一个或多个物理卷组织在一起,形成一个“卷组”( Volume Group, VG)。物理卷不一定是整个磁盘,可以是磁盘的一个分区,也可以是整个磁盘。
创建物理卷:
1 | pvcreate /dev/sdb1 # 创建一个物理卷 |
卷组( Volume Group, VG)
卷组是由多个物理卷组成的逻辑容器。它可以将多个物理卷中的存储空间汇聚到一起,形成一个大的池,供逻辑卷使用。一个卷组可以包含多个物理卷,也可以只有一个物理卷。
创建卷组:
1 | vgcreate my_volume_group /dev/sdb1 /dev/sdc1 # 创建一个卷组,包含 /dev/sdb1 和 /dev/sdc1 |
逻辑卷( Logical Volume, LV)
逻辑卷是实际存储数据的地方,它类似于传统分区。逻辑卷是从卷组中分配的存储空间,可以根据需要进行扩展或缩减。 LVM 提供了动态创建、删除和调整逻辑卷大小的能力。
创建逻辑卷:
1 | lvcreate -L 10G -n my_logical_volume my_volume_group # 创建一个大小为 10GB 的逻辑卷 |
逻辑卷的扩展与收缩
LVM 允许在逻辑卷中增加或减少存储空间。对于增加存储空间,可以将新的物理卷加入到卷组中,并扩展逻辑卷的大小;对于减少存储空间,需要先对文件系统进行缩减,确保数据的安全。
扩展逻辑卷:
1 | lvextend -L +5G /dev/my_volume_group/my_logical_volume # 将逻辑卷扩展 5GB |
缩小逻辑卷:
1 | e2fsck -f /dev/my_volume_group/my_logical_volume # 检查文件系统 |
快照( Snapshot)
LVM 还支持创建快照。快照是某个逻辑卷的时间点副本,可以用于数据备份或在对逻辑卷进行修改之前进行保护。快照是增量的,仅记录自创建快照以来的变化。
创建和删除快照:
1 | lvcreate -L 1G -s -n my_snapshot /dev/my_volume_group/my_logical_volume # 创建快照 |
LVM 的优点
- 灵活性:可以动态增加、缩小卷的大小,无需重新分区和格式化磁盘。
- 卷扩展性:可以将多个物理卷合并为一个卷组,增加存储池的空间。
- 数据保护:通过快照功能,可以在修改数据之前创建数据副本,保护数据不被误删。
- 性能优化: LVM 支持多种策略,如镜像( Mirroring)、条带化( Striping)等,来提高性能或容错性。
LVM 的常用命令
查看物理卷、卷组、逻辑卷的状态:
1 | pvs # 查看物理卷 |
删除物理卷、卷组、逻辑卷:
1 | lvremove /dev/my_volume_group/my_logical_volume # 删除逻辑卷 |
将物理卷加入卷组:
1 | vgextend my_volume_group /dev/sdd1 # 向卷组添加物理卷 |
移除物理卷:
1 | vgreduce my_volume_group /dev/sdb1 # 从卷组中移除物理卷 |
举个例子,在 Mac 系统上,硬盘空间的增加会被自动识别为新的分区或逻辑卷( LVM),而不需要手动进行分区。
可以首先进行硬盘空间分配来验证之(注意这里的硬盘空间分配了之后,主机的硬盘空间不会立刻少这么多,而是慢慢减少直到用满了这新增的空间)。
然后我们查看 lablk:
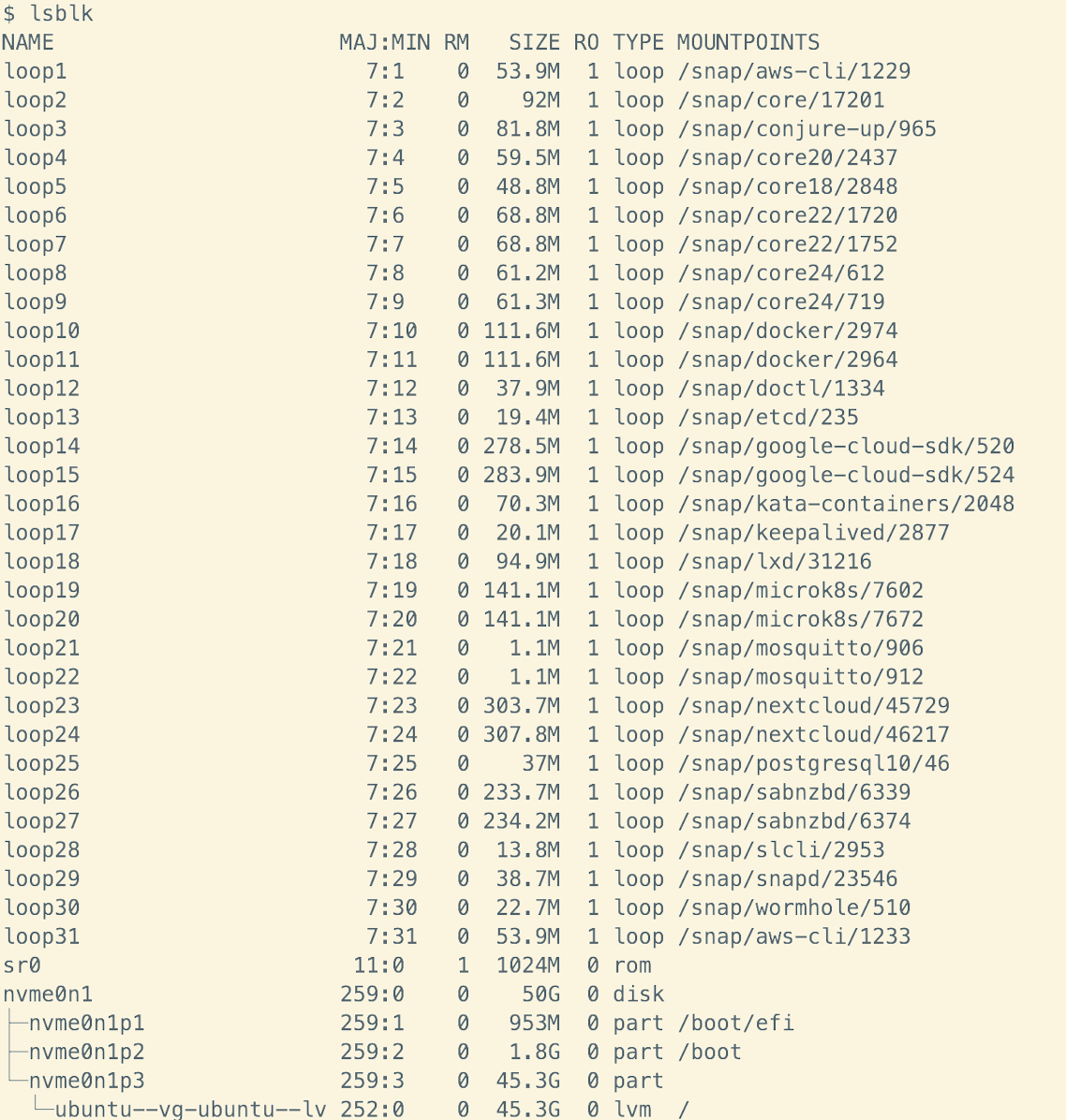
nvme0n1 硬盘是我的物理硬盘,大小为 50GB 。这个硬盘上有三个分区:
- /dev/nvme0n1p1: EFI 系统分区,大小 953MB 。
- /dev/nvme0n1p2:启动分区,大小 1.8GB 。
- /dev/nvme0n1p3:剩余的分区,大小 45.3GB 。
- 在 /dev/nvme0n1p3 上,系统使用了 LVM,具体来说是 ubuntu--vg-ubuntu--lv 这个逻辑卷,大小为 45.3GB,挂载在 /(根目录)下。
- 当我们增加硬盘空间时,LVM(逻辑卷管理)在已经有的物理分区(如 /dev/nvme0n1p3)上自动扩展了空间。因此我们无需手动分区, LVM 可以动态调整卷的大小以适应新加入的空间。
- LVM 使得可以动态管理存储,不需要像传统的分区方式那样手动分区。
进一步地,可以通过 lvdisplay 命令查看逻辑卷的详细信息,确认新的硬盘空间是否已正确分配给逻辑卷:
1 | # lvdisplay |
磁盘管理业务背景与流程
磁盘管理确保硬件存储的健康和可靠性。磁盘的使用涉及到磁盘健康监控、备份、恢复等多个方面。可以与 Windows 的磁盘管理做一个对比,在 Windows 系统中,磁盘的管理包括分区、格式化、磁盘检查等。
- 磁盘分区:可以通过“磁盘管理”工具创建、删除、格式化磁盘分区。
- 磁盘碎片整理: Windows 提供磁盘碎片整理工具。
- 查看磁盘信息:
1 | diskpart # 启动磁盘管理工具 |
在 Linux 下,具体的内容为:
硬盘健康检查:定期运行
smartctl检查硬盘状态,提前发现潜在问题,如坏道、读写错误等。1
2smartctl -a /dev/sda # 查看硬盘健康状态
df -h # 显示磁盘空间使用情况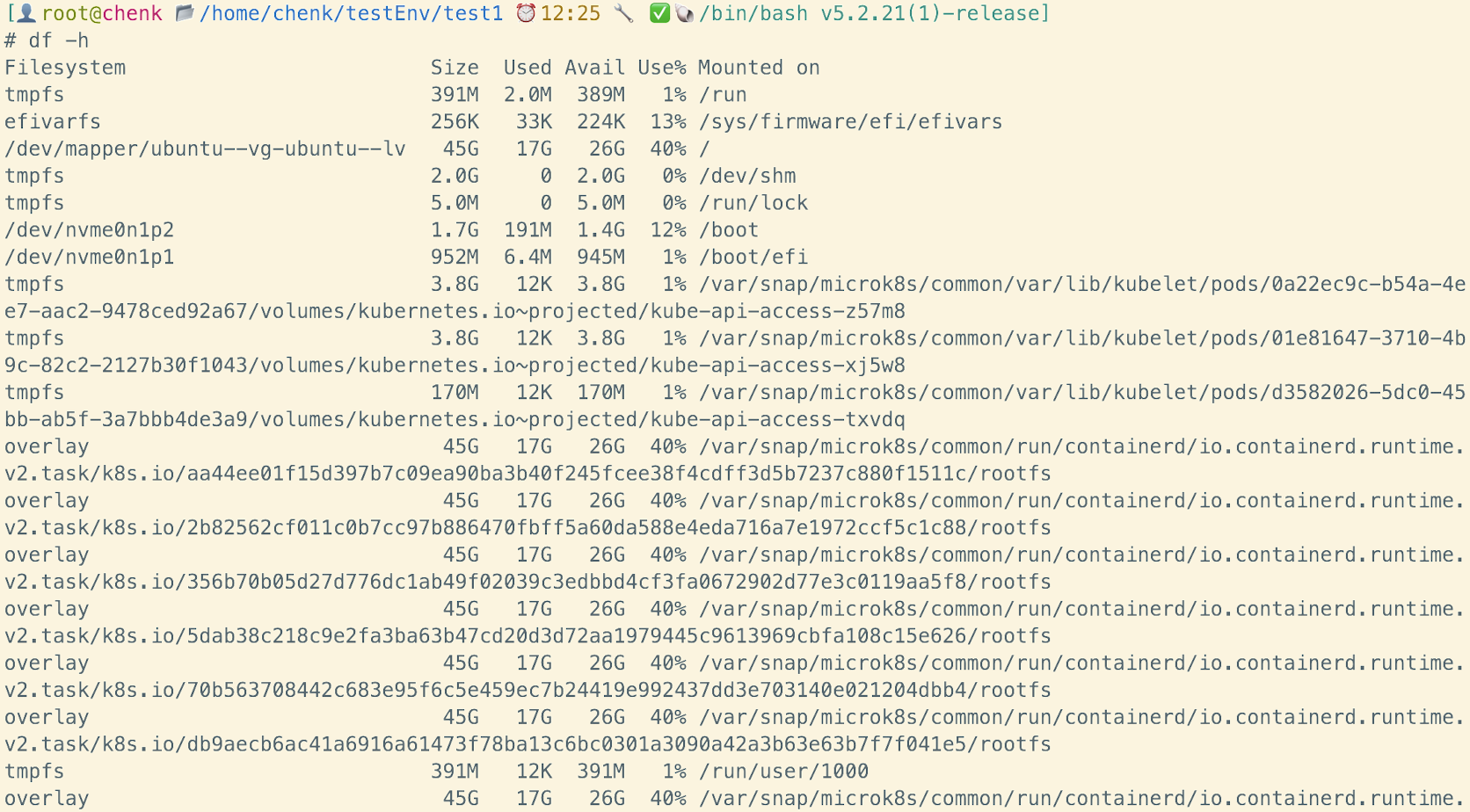
磁盘碎片整理:对于机械硬盘( HDD),可以使用工具如
bleachbit或ncdu进行磁盘清理,释放磁盘空间。并使用e4defrag碎片整理工具进行整理:1
e4defrag /dev/sda # 对 /dev/sda 分区进行碎片整理
数据备份与恢复:使用工具如
rsync或tar进行定期备份。
磁盘使用流程
磁盘在计算机中是用来存储数据的设备,磁盘的使用包括挂载、分区以及对文件系统的访问。 Linux 系统中的磁盘挂载是磁盘和文件系统连接的过程, Linux 系统通过挂载将磁盘分区与文件系统连接,使得用户可以通过路径访问磁盘上的文件。
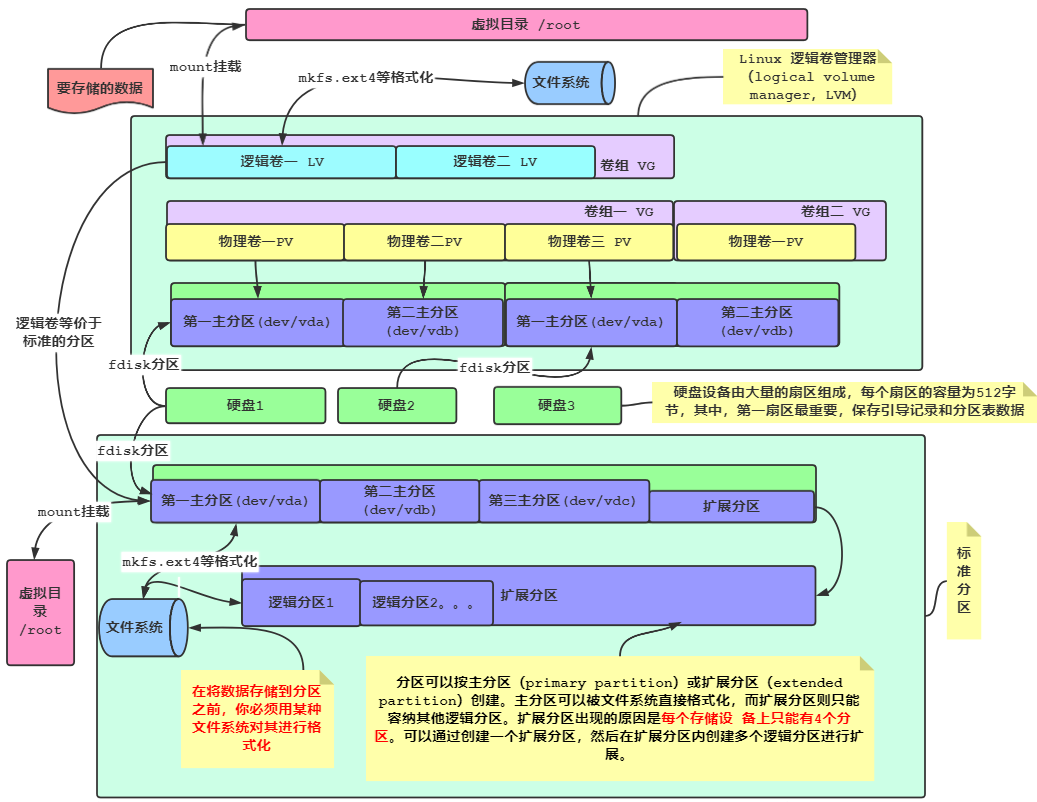
可以将磁盘从被识别到可以使用的过程与实际生活中房子类比:
- 磁盘准备存储数据:类比为人盖房子。磁盘需要在计算机系统中准备好,才能进行数据存储。
- 磁盘分区:类比为房子改好后需要隔断。磁盘需要分区,才能将磁盘空间划分为不同的区域(例如:卧室、厨房、卫生间等),不同区域用于存储不同类型的数据。
- 磁盘格式化与创建文件系统:类比为房子装修。分区后,磁盘还需要格式化并创建文件系统,不同的文件系统有不同的功能和用途,就像房子的装修风格(欧式、中式等)决定了居住体验。
- 磁盘挂载到文件夹:类比为安装门窗,确保进出。格式化并创建文件系统后,磁盘需要挂载到系统的文件夹中,才能通过操作系统进行数据存储和读取,就像房子需要安装门窗才能与外界沟通。
1. 磁盘分区
分区方案指的是磁盘布局的特定基础结构、分区的实际排列方式、功能以及限制。
| 特性 | MBR(主引导记录) | GPT( GUID 分区表) |
|---|---|---|
| 最大存储空间 | 最大支持 2TB | 支持大于 2TB,最大支持 9.4ZB(远超当前硬盘技术) |
| 最大分区数量 | 最多支持 4 个主分区,或 3 个主分区 + 1 个扩展分区 | 最多支持 128 个主分区 |
| 分区表大小 | 固定为 512 字节 | 可自定义,支持更大规模的分区表 |
| 冗余与备份 | 无冗余备份,一旦损坏可能导致数据丢失 | 提供冗余备份,分区表存储在磁盘的开始和结尾部分 |
| 支持的引导模式 | 传统 BIOS 引导模式 | 与 UEFI 配合使用,支持更现代的引导方式 |
| 操作系统兼容性 | 支持所有 32 位和 64 位 Windows 操作系统 | 支持大多数 Windows 版本,但需要 UEFI 支持 |
| 使用场景 | 适用于小容量磁盘( 2TB 以下)和老旧系统 | 适用于大容量磁盘( 2TB 以上)和现代系统 |
| 系统安装和维护 | 适合传统的磁盘管理方式 | 支持多重操作系统安装和复杂的硬件配置 |
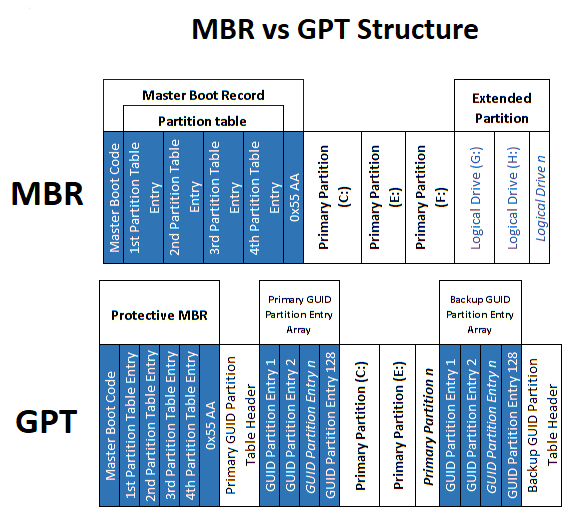
MBR
MBR ( master boot record - 主引导记录)支持最多 4 个主分区( 3 个主分区+1 个扩展分区),最大支持 2 TB 的磁盘。

- 简单来说, MBR 是磁盘里的第一个扇区,作用是告诉操作系统怎么加载磁盘顺序,如何开机
- 优点是兼容性好,缺点是不支持管理大硬盘结构。对于大于 2TB 的硬盘, MBR 会无法识别,导致硬盘空间浪费。这是因为 MBR 使用 32 位寻址方式,限制了可寻址的空间。
- 主引导扇区位于整个磁盘的 0 磁头 0 柱头 1 扇面,包括硬盘主引导记录 MBR 和分区表 DPT( Disk Partition Table)。主引导记录用于检查分区表是否正确以及哪个分区为引导分区,也就是操作系统引导扇区调入内存加以执行。
从原理上说:
- MBR 分区方案使用硬盘的第一个物理扇区中的 64 个字节作为分区表的空间保存硬盘分区信息,每个分区的信息要占 16 个字节。所以, MBR 分区表最多只能保存 4 个分区的分区信息。
- MBR 分区方案中,有三种类型的分区,主分区、扩展分区和逻辑分区。扩展分区与逻辑分区是为了突破分区表中只能保存 4 个分区的限制而出现的
- MBR 分区表中保存的分区信息都是主分区与扩展分区的分区信息,扩展分区不能直接使用,需要在扩展分区内划分一个或多个逻辑分区后才能使用,逻辑分区的分区信息保存在扩展分区内,而不是保存在 MBR 分区表内,这样就可以突破 MBR 分区表只能保存 4 个分区的限制。
- 16 个字节的分区信息保存有分区活动状态标志、文件系统标识、起止柱面号、磁头号、扇区号、起始扇区位置( 4 个字节)、分区总扇区数目( 4 个字节)等内容。这里核心::分区的起始扇区位置与分区的总扇区数,都是用 4 个字节表示的。一般每个廓区的容量是 512 字节, 4 个字节的扇区能表示的最大容量是 2 TB,由此可知,在 MBR 分区表中,分区的起始位置不能大于 2 TB,分区的最大容量,也不能大于 2 TB,所以,对 2 TB 以上容量的物理硬盘,不适合使用 MBR 分区方案。
GPT
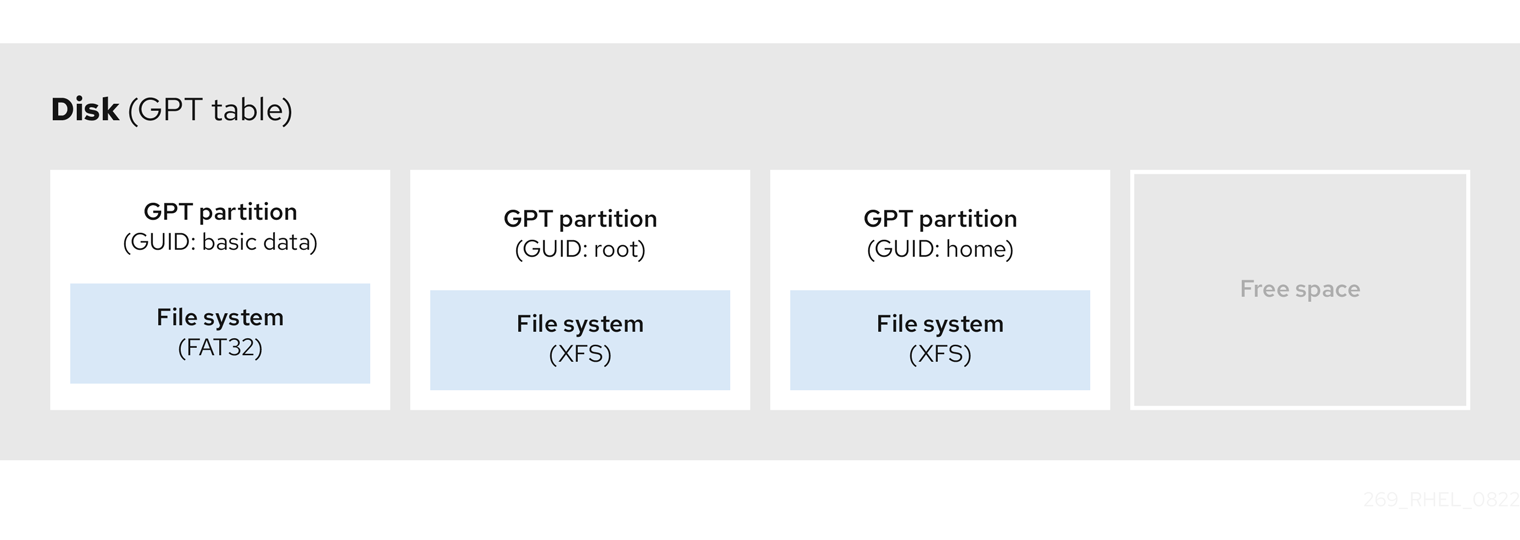
GPT( GUID 分区表)可以给超过 2 TB 的硬盘使用,支持更多分区(最多 128 个),且没有大小限制。 GPT 使用 64 位寻址方式,支持最大 9.4ZB( zettabytes)的硬盘空间,远超当前硬盘技术的需求。
新购电脑的主板类型:
- 如果电脑使用传统的 BIOS 主板,建议使用 MBR 格式。
- 如果电脑使用现代的 UEFI 主板,建议使用 GPT 格式。 UEFI 模式可以更好地支持 GPT,提供更快速、更安全的启动过程。
重装操作系统时的兼容性:
- 在重装操作系统前,了解所安装的操作系统版本是否支持 MBR 或者 UEFI 模式(即 GPT 格式)。大多数操作系统,特别是 Windows 7 及以后的版本,都支持 GPT 格式,但老旧版本的 Windows(如 XP)可能不支持 GPT 。
- 注意:虽然 MBR 格式支持大部分操作系统版本,但并非所有 Windows 版本都兼容 GPT 格式。例如, Windows XP 不支持 GPT,而 Windows 10 和 Windows 11 则完全支持 GPT 格式,尤其是在 UEFI 启动模式下。
磁盘类型选择:
- 对于传统硬盘( HDD)和容量较小( 2TB 以下)的硬盘,使用 MBR 可以满足基本需求。
- 对于大容量硬盘(大于 2TB), SSD,以及希望获得更高可靠性和灵活性的用户,使用 GPT 是更优的选择。
系统安装和维护:
- 如果计划使用 RAID 、加密、或者多重操作系统的安装, GPT 格式会提供更多的优势,尤其是在支持 UEFI 的系统上。
- 由于 GPT 格式支持更多的分区,它适合多重操作系统的安装或大型磁盘的管理。
fdisk 和 gdisk

fdisk 是管理 MBR
分区表的命令行工具,常用来创建、删除和修改分区。常见操作是:
1 | # 创建新分区 |
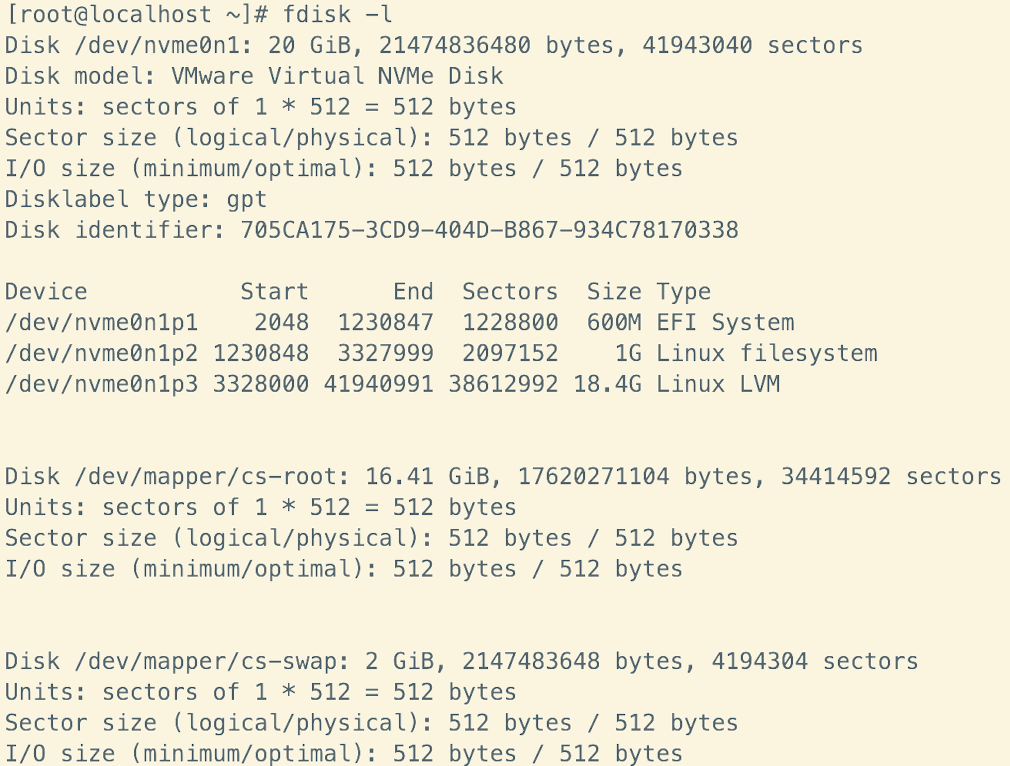
我的系统显示是 GPT 类型,因此不支持 fdisk
分区,需要用到 gdisk。gdisk 是一个用于 GPT
分区表的工具,适用于支持 UEFI 启动的系统。
1 | # 创建新分区 |
要将分区类型做修改,可以参考如下操作:
1 | # mbr ----> gpt |
硬盘接口与命名规则
在 Linux 系统中,磁盘设备的命名规则通常采用 /dev/sdX 或
/dev/nvmeX 的格式。
常见命名规则:
- /dev/sda:第一个 SATA 硬盘
- /dev/nvme0n1:第一个 NVMe 固态硬盘
- /dev/sr0:光盘驱动器
更具体一点的命名规则其实得追溯到硬盘接口
硬盘接口主要分为以下几种:
- SATA:常见的消费级接口,速度适中,广泛使用。
- SAS:企业级接口,速度较快且稳定性好,常用于服务器。 SAS 比 SATA 多了一个金手指。
- NVMe:最现代的存储接口,专为固态硬盘设计,提供超高速数据传输。
- PCIe:不仅适用于硬盘,还用于显卡等高性能设备,是一个高速的通用接口。
- IDE:老旧的接口,现已几乎完全被 SATA 替代。
- U.2 和 M.2:适用于现代高性能固态硬盘, M.2 更适合笔记本, U.2 多用于企业级 SSD 。
| 接口类型 | 数据传输速度 | 主要特点 | 使用场景 |
|---|---|---|---|
| SATA (Serial ATA) | 最高 6Gb/s | - 最常见的硬盘接口,适用于台式机和笔记本 - 适合机械硬盘和一些固态硬盘 |
适用于大多数消费级硬盘,兼容性好 |
| SAS (Serial Attached SCSI) | 最高 12Gb/s | - 专为企业级存储设计,支持多设备连接 - 提供更高的稳定性和可靠性 |
企业级存储,服务器,数据中心 |
| NVMe (Non-Volatile Memory Express) | 最高 32Gb/s | - 基于 PCIe,总线速度更快 - 主要用于固态硬盘,低延迟 |
高性能计算、大型数据应用、游戏 |
| PCIe (Peripheral Component Interconnect Express) | 取决于版本,最大可达 64Gb/s( PCIe 4.0 x16) | - 高速数据传输接口,用于显卡、存储设备等 - 非常适合高性能存储设备 |
高端工作站、服务器、快速 SSD 存储 |
| IDE (Integrated Drive Electronics) | 最高 133MB/s | - 较老的硬盘接口,速度较慢 - 现已被 SATA 取代 |
主要用于老旧设备,不推荐用于现代系统 |
| U.2 (previously SFF-8639) | 最高 32Gb/s | - 连接方式类似于 SATA,但基于 PCIe 协议 - 用于高性能企业级固态硬盘 |
企业级 SSD,数据中心、高端服务器 |
| M.2 | 最高 32Gb/s (取决于协议,如 SATA 或 PCIe) | - 小型接口,用于笔记本、主板上 - 支持 SATA 和 NVMe 协议 |
笔记本电脑、主板上的固态硬盘 |
硬盘在不同操作系统和不同接口类型中有不同的命名规则,主要依赖于硬盘的接口类型、顺序以及分区情况。以下是一些常见的命名规则和详细说明。
| 操作系统 | 硬盘命名规则 | 描述 |
|---|---|---|
| Linux (RHEL) | /dev/hda, /dev/sda |
- /dev/hda: IDE 接口硬盘(早期版本) - /dev/sda: SATA 或 SCSI 接口硬盘 |
| IDE 接口 | /dev/hda |
IDE 接口的硬盘,较旧的命名方式 |
| SATA 接口 | /dev/sda, /dev/sdb |
SATA 接口硬盘命名规则,a 为第一块硬盘,b
为第二块硬盘 |
| SCSI 接口 | /dev/sda, /dev/sdb |
SCSI 接口硬盘命名,类似 SATA,但在服务器环境中常见 |
| 多块硬盘 | /dev/sda1, /dev/sdb1 |
多块硬盘时,根据硬盘顺序命名,如第一块硬盘为
/dev/sda,第二块为
/dev/sdb,每个硬盘的分区由数字表示,/dev/sda1
表示第一块硬盘的第一个分区 |
| 惠普服务器硬盘 | /dev/cciss/c0d0,/dev/cciss/c0d0p1,/dev/cciss/c0d0p2 |
|
| 虚拟硬盘 | /dev/vd |
阿里云服务器等可能会用 |
总结来说:
- 硬盘命名:硬盘的名字通常由接口类型(如 SATA 、
SCSI)、硬盘的顺序(
a,b,c等)以及分区编号组成。/dev/sda:第一块硬盘。/dev/sdb:第二块硬盘。/dev/sdc:第三块硬盘。- 以此类推,字母递增。
- 分区命名:每个硬盘上的分区通过数字表示:
/dev/sda1:第一块硬盘的第一个分区。/dev/sda2:第一块硬盘的第二个分区。/dev/sda3:第一块硬盘的第三个分区。/dev/sda4:第一块硬盘的第四个分区。
虚拟硬盘格式:
格式 描述 主要应用 VMDK VMware 使用的虚拟硬盘格式。它能够模拟物理硬盘的特性,用于 VMware 虚拟机中。 VMware 虚拟化平台 VHD Microsoft 的虚拟硬盘格式,支持微软 Hyper-V 虚拟化平台。 Hyper-V 虚拟化平台 VHDX VHD 的增强版本,支持更大的虚拟硬盘和更高的可靠性。 Hyper-V 虚拟化平台 QCOW2 QEMU 的虚拟硬盘格式,支持快照和压缩,适用于 KVM 和 QEMU 虚拟机。 QEMU/KVM 虚拟化平台 VDI VirtualBox 使用的虚拟硬盘格式。 VirtualBox 虚拟化平台
在 Windows 中,硬盘分区命名类似:
- C: 代表硬盘的第一个分区(通常是操作系统分区)。
- D: 代表第二个分区。
- E: 代表第三个分区。
- F: 代表第四个分区。
这和 Linux 中的硬盘命名规则 /dev/sda1,
/dev/sda2 等相对应。
2. 格式化文件系统
常见的文件系统有 EXT4 、 XFS 和 NTFS 等,可以对分区在格式化的时候进行选择:
- EXT4: Linux 常用的文件系统,支持大文件和较高的性能。
- XFS:高性能文件系统,常用于大型数据库和大规模存储。
- NTFS: Windows 操作系统的标准文件系统,支持文件压缩、加密等功能。
- ExFAT: MacOS 下的文件系统,在 MacOS 和 Windows 之间都可以读写
| 文件系统 | 最大分区 | 最大文件 | 支持的操作系统 | 备注 |
|---|---|---|---|---|
| FAT32 | 128GB | 4GB | Windows, Linux, Mac, 其他 | 适用于 U 盘和老旧设备,不支持大文件和大分区 |
| NTFS | 2TB | 2TB | Windows, Linux (通过第三方软件支持) | 常用于 Windows 操作系统,支持较大的文件和分区 |
| FAT16 | 2GB | 2GB | Windows, Linux, 其他 | 较老的文件系统,适合小容量设备,常见于早期的 Windows 版本 |
| HPFS | 2TB | 2GB | OS/2 | 主要用于 OS/2 系统,适合较大的分区和文件 |
| EXT2 | 4TB | 2GB | Linux | 早期 Linux 的标准文件系统,支持大文件,但没有日志功能 |
| EXT3 | 4TB | 2GB | Linux | EXT2 的升级版,加入了日志功能,提高了可靠性 |
| JFS | 4PB | 4PB | AIX | 高性能文件系统,常用于大型企业级服务器,支持极大分区和文件大小 |
| XFS | 9EB( 2^63) | 9EB( 2^63) | IRIX, Linux | 64 位文件系统,支持非常大的分区和文件,常用于高性能和大数据场景 |
| exFAT | 无限制(但实际应用中通常为 256TB) | 16EB | Windows, Mac, Linux (通过第三方软件支持) | 适合闪存和移动存储设备,克服了 FAT32 的文件大小限制,不适合磁盘存储 |
CentOS 4/5/6 都采用 Ext 2/3/4 文件系统,到了 CentOS 7 采用了 XFS 系统,因为 CentOS 7 是容器的时代, docker 不支持原来的文件系统。但都支持日志系统,日志系统指的是不会因为突然断电造成磁盘数据损坏,能够通过日志恢复磁盘文件。
Windows 10 使用 NTFS,支持加密、压缩、权限控制等等,且还支持日志保持数据一致性,主流硬盘都是 NTFS,专门给闪存使用的 ExFAT 属于是 FAT32 和 NTFS 的折中,同时支持 Windows 和 Mac 。
不同的文件系统区别在于
- 兼容性:不同系统平台不一定识别,可能无法进行读写操作。例如 Windows 上可能无法读取 XFS 文件系统的 U 盘;
- 容量大小:不同的文件系统对分区容量的支持以及文件数量及单个文件的容量支持有区别。例如以前的 Windows 机械硬盘使用 FAT32 文件系统,该文件系统不支持单个文件超过 4G 。
可以通过 mkfs 然后 TAB
查看当前支持什么操作系统(实际上这个是进行分区文件系统格式化的命令):

以 mkfs.xfs 为例:

3. 挂载目录到分区
什么是挂载( Mount)?
想象你的电脑是一个大房子,房子里有很多房间(文件夹),比如
/home(你的卧室)、/etc(工具箱)等。但房子里原本没有连接外部设备(比如
U
盘、硬盘、光盘)。挂载就像是在墙上开一扇门,把外部设备(比如
U 盘)连接到房子的某个房间(比如
/mnt/usb),这样你就能通过这个房间访问外部设备的内容。
- 设备: U 盘、硬盘、光盘等(物理存储介质)。
- 挂载点:房子里的一扇门(比如
/mnt/usb这个空文件夹)。 - 挂载操作:把设备通过这扇门连接到房子。
挂载的基本操作
假设你插入一个 U 盘,系统识别它为
/dev/sdb1(设备名可能不同)。你要把它挂载到
/mnt/usb 这个空文件夹:
1 | sudo mount /dev/sdb1 /mnt/usb |
其结果就是我们进入 /mnt/usb 就能看到 U
盘里的文件。但要注意,当我们挂载后,/mnt/usb
不再是普通文件夹,而是 U 盘的“入口”。
1 | sudo umount /mnt/usb |
卸载后,/mnt/usb 恢复成普通空文件夹, U
盘可以安全拔出。
挂载后新建的文件在哪?
场景 1:挂载后创建文件
- 挂载 U 盘到
/mnt/usb。 - 在
/mnt/usb新建文件test.txt。 - 卸载 U 盘。
问题:test.txt 存在哪里?
答案:文件实际保存在 U 盘中!卸载后,文件依然在 U
盘里,下次挂载还能看到。
场景 2:换一个挂载点
- 将 U 盘挂载到
/mnt/usb,创建文件test.txt。 - 卸载后,重新挂载到
/media/myusb。 - 进入
/media/myusb,依然能看到test.txt。
结论:文件存储在设备( U 盘)中,和挂载点无关。换挂载点只是换了一个“入口”。
挂载点原有内容会怎样?
场景:挂载到非空文件夹
假设 /mnt/usb 原本有一个文件 old.txt:
- 挂载 U 盘到
/mnt/usb。 - 此时访问
/mnt/usb,只能看到 U 盘的内容,old.txt被“隐藏”。 - 卸载后,
old.txt重新出现。
结论:挂载到非空文件夹时,原内容会被临时隐藏(但不会被删除!)。
常见挂载类型
挂载光盘
1 | sudo mount /dev/cdrom /mnt/cd |
光盘内容会出现在 /mnt/cd。
挂载硬盘分区
假设硬盘分区是 /dev/sda2,挂载到
/data:
1 | sudo mount /dev/sda2 /data |
所有存到 /data 的文件实际保存在硬盘分区中。
挂载网络存储
1 | sudo mount -t nfs 192.168.1.100:/shared /mnt/nfs |
通过网络访问远程文件夹。
自动挂载(开机自动挂载)
编辑 /etc/fstab 文件,添加一行配置:
1 | /dev/sdb1 /mnt/usb ext4 defaults 0 0 |
系统启动时会自动挂载设备到指定位置。另外还有一种方法,通过
blkid 获取要挂载设备的 UUID,然后使用
UUID 挂载。
4. 取消挂载
取消挂载使用 umount
命令,需要注意的是,要取消挂载需要退出挂载点所在的目录,我们结合报错例子来学习,例如在执行下面的取消挂载命令时:
1
umount /data
可能会出现下面的报错:
1 | umount: target is busy |
原因解析
文件系统被占用
- 打开文件:有进程正在
/data目录下打开文件(例如日志文件、数据文件等),导致文件系统处于“忙”状态。 - 当前工作目录:某个用户或服务的当前工作目录设置在
/data下。如果用户的 shell 或程序正处于该目录,也会阻止卸载。
- 打开文件:有进程正在
多用户环境的影响
- 多用户使用:在多用户系统中,不同用户可能同时在
/data挂载点下运行应用程序或脚本。即使你自己不在使用,其他用户的进程也可能占用该目录。 - 服务使用:某些服务(如数据库、 Web
服务器或其他网络服务)可能将
/data用作数据存储目录,并且这些服务可能由不同用户启动。
- 多用户使用:在多用户系统中,不同用户可能同时在
后台进程和网络端口
- 某些后台进程或守护进程可能绑定了特定端口,并且其配置文件或数据存放在
/data下。使用ps -ef | grep <端口号>可帮助定位这些进程。
- 某些后台进程或守护进程可能绑定了特定端口,并且其配置文件或数据存放在
解决方法
使用 lsof 命令查看占用情况
运行以下命令,查看哪些进程正在访问
/data1
lsof /data
此命令会列出所有打开
/data下文件的进程及其详细信息。
使用 fuser 命令确认进程
通过 fuser 命令可以直接看到占用挂载点的进程 ID:
1
fuser -m /data
使用 ps 命令查找特定端口进程(如有需要)
如果怀疑某个服务在使用特定端口(例如数据库或 Web 服务),可以使用:
1
ps -ef | grep <端口号>
这样可以帮助你定位使用该端口的进程,从而确认它们是否涉及到
/data目录的使用。
停止或终止相关进程
根据上面的命令输出,确认占用
/data的进程后,可以采取以下措施:
通知用户:在多用户环境中,先通知使用者退出或切换工作目录,确保不再访问
/data。终止进程:如果确认进程可以安全终止,使用以下命令(注意要谨慎操作):
1
kill -9 <PID>
使用延迟卸载( Lazy Unmount)
如果确定暂时无法中止所有进程,也可以采用延迟卸载的方法:
1
umount -l /data
此方法会立即断开挂载点,但会在进程不再使用时真正卸载。但需注意,这种方式可能会导致数据同步问题。
特殊设备文件
1. /dev/null ——
空设备(黑洞)
特点
- 读取时总是返回 EOF( End of File)。
- 写入的数据会被直接丢弃,不占用存储空间。
应用
丢弃输出:常用于忽略命令的标准输出(
stdout)或错误输出(stderr)。例如:
1
2
3ls > /dev/null # 丢弃 ls 命令的标准输出
ls 2> /dev/null # 丢弃 ls 命令的错误输出
ls > /dev/null 2>&1 # 同时丢弃标准输出和错误输出作为空文件输入:
1
cat /dev/null > file.txt # 清空 file.txt
2. /dev/zero ——
无限输出零字节
特点
- 读取时会不断返回
0x00(空字节)。 - 适用于生成填充数据(例如创建大文件)。
- 读取时会不断返回
应用
创建特定大小的文件:
1
dd if=/dev/zero of=file.bin bs=1M count=100
该命令创建一个 100MB 的全零文件
1
file.bin
初始化文件系统:
1
mkfs.ext4 /dev/zero # 格式化磁盘时用于填充数据
用于共享内存(如
mmap)或虚拟内存文件系统(如tmpfs)。
3. /dev/random ——
高质量随机数生成器
特点
- 读取时返回加密安全的随机数据(由环境噪声等熵源提供)。
- 如果熵池( entropy pool)不足,读取可能会阻塞(等待更多随机熵)。
- 适用于生成高质量的加密密钥。
应用
生成安全随机数:
1
head -c 16 /dev/random | base64 # 生成 16 字节的随机数据并编码
生成随机密码:
1
cat /dev/random | tr -dc 'A-Za-z0-9' | head -c 12
4. /dev/urandom ——
非阻塞随机数生成器
特点
- 读取时返回伪随机数,熵不足时不会阻塞(不同于
/dev/random)。 - 适用于大多数非极端安全需求的随机数生成场景。
- 读取时返回伪随机数,熵不足时不会阻塞(不同于
应用
生成随机文件:
1
dd if=/dev/urandom of=random.bin bs=1M count=10
生成一个 10MB 的随机文件。
生成随机密码:
1
head -c 16 /dev/urandom | base64
/dev/random vs
/dev/urandom
| 特性 | /dev/random |
/dev/urandom |
|---|---|---|
| 是否阻塞 | 是(熵池不足时) | 否 |
| 安全性 | 高(适用于加密密钥) | 较高(但不适用于极端安全需求) |
| 适用场景 | 需要高质量随机数,如密钥生成 | 普通随机需求,如随机 ID 、随机测试数据 |
结论:
/dev/random适用于生成高安全性密钥(如 GPG/SSH 密钥)。/dev/urandom适用于一般随机数需求(如 session ID)。
文件系统、链接与 RAID 技术详解
下面将详细介绍 inode 、块( block)、硬链接、文件删除原理、软链接、硬链接。
1. inode 与文件系统
inode( Index Node):是 Unix/Linux
文件系统中用于存储文件元数据(
metadata)的数据结构。它记录了文件的所有属性信息(如所有者、权限、时间戳、文件大小、数据块指针等),但不包含文件名。换句话说,
Linux 的文件内容其实是包含了文件名和元数据两个部分的,元数据可以通过
stat
命令查看得到。一个新的磁盘在格式化文件系统后存在两个存储空间,一个叫做
inode 存储空间(存储元数据),一个叫做 block
存储空间(存储文件数据),创建文件系统之后 inode 和
block 的数量就会固定下来。 Linux 读取文件内容是通过
文件名 > inode 编号 > block 的顺序 来读取的。

文件与 inode 的关系
- 文件数据与 inode:
- 每个文件在创建时都会分配一个 inode, inode 存储文件的元数据。
- 文件的数据实际存放在数据块中,而 inode 中包含指向这些数据块的指针。
- 目录与 inode:
- 目录本身也是一个特殊类型的文件,其内容是文件名和对应 inode 编号的映射表。
- 当你通过文件名访问文件时,系统实际上先通过目录查找对应的 inode 编号,再根据 inode 获取文件的相关信息和数据。
块( block)
- 块的概念:
- 硬盘上的数据以块为单位存储。块是文件系统读写的基本单位,其大小通常在 512 字节到 4KB 之间,具体取决于文件系统的设置。
- inode 中的指针正是指向这些块的位置。
- 块在性能上的影响:
- 块的大小会影响文件存储的效率与性能。过小可能导致大量索引;过大则可能浪费存储空间(内部碎片)。

2. 链接( Link):硬链接与软链接
硬链接( Hard Link)
硬链接是多个目录项(文件名)指向同一个 inode 。也就是说,同一个文件的多个名字都指向同一组数据和属性,其特点是:
- 共享 inode:硬链接和原始文件共享同一个 inode,所以它们是完全等价的。
- 不能跨文件系统:硬链接只能在同一个文件系统内建立。
- 不能对目录建立硬链接(防止循环引用)。
- 当删除一个硬链接时,只是删除了目录中的一个引用。如果该 inode 的链接计数不为 0,则文件数据仍然保留。
- 只有当所有指向该 inode 的硬链接都被删除后,系统才真正回收 inode 和数据块。
软链接(符号链接, Symbolic Link)
软链接是一个特殊类型的文件,其中存储了另一个文件或目录的路径,其特点是:
- 不共享 inode:软链接有自己的 inode,其内容指向目标文件的路径。
- 可以跨文件系统:软链接可以引用其他文件系统上的文件或目录。
- 如果目标文件被删除,软链接就会变成“悬挂链接”( dangling link),即指向不存在的目标。

3. 目录的链接数
在 Linux 中,目录的链接数( link
count)表示有多少个硬链接指向该目录。可以通过 ls -ld
来查看:
1 | ls -ld 目录名 |
目录的硬链接数
普通目录
(非空目录):硬链接数 = 2 + 该目录下的子目录个数
.指向自身( 1 个链接)..存在于每个子目录(父目录的链接数 +1)- 目录下的每个子目录都会在父目录中创建一个
..,增加父目录的链接数。
根目录
/:其硬链接数等于 2 +/下的一级子目录数量。
示例:
1 | mkdir test_dir |
子目录的影响
1 | mkdir test_dir/sub_dir |
总结:
- 空目录的硬链接数是 2(自身
.+ 父目录的..)。 - 每增加一个子目录,父目录的硬链接数增加 1。
4. 文件删除原理
目录项删除:当删除文件时,实际上是从目录中移除了对该文件 inode 的引用(即减少了 inode 的链接计数)。
数据实际删除:只有当 inode 的链接计数归零时,操作系统才会将该 inode 和对应的数据块标记为可回收,从而真正释放磁盘空间。
缓存与文件句柄:如果某个进程已打开文件,即使目录项被删除,该文件仍可被进程读取或写入,直到文件描述符关闭后,数据才会最终释放。
移动和删除文件对软硬链接的影响:

- 本文标题:Linux 磁盘管理
- 本文作者:Chen Kai
- 创建时间:2019-12-01 10:30:00
- 本文链接:https://www.chenk.top/Linux-%E7%A3%81%E7%9B%98%E7%AE%A1%E7%90%86/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!