管道符是 Unix 哲学的最佳示例:将前一个命令的输出作为下一个命令输入。本篇深入介绍管道符的工作机制与典型用法,助你快速掌握文本处理与命令组合的强大威力。
一、管道符
¶1. 基本介绍
Linux 中,管道符 | 的功能是将前一个命令的输出传递给下一个命令作为输入。这样可以把多个小型命令拼装起来,让每个命令只专注做一件事(符合 UNIX 的哲学:单一命令,简单而强大),通过管道连接成一条完整的处理流程。
- 语法:
命令1 | 命令2 [| 命令3 …]

使用管道符的好处如下:
- 避免产生临时文件:数据无需先写入文件再读出。
- 提高效率:分步处理可以快速对结果进行再次筛选、统计、过滤等。
- 简化语句:一行命令即可串起多个操作。
¶2. 示例
-
基本使用示例:

从上图可以看到,
echo "I love you" | wc -m返回 11;另外当执行echo "I love you" | cat -E时,会在行末显示$符号,说明末尾还有换行符的存在。管道符让我们可以将echo命令输出,直接交给wc、cat或其他命令进行统计、格式化、过滤等操作,而无需中间文件。 -
查看日志内容时只取关键行
1
cat /var/log/syslog | grep 'error'
-
多级管道:
ls -l /etc | grep conf | wc -l(在/etc下查找带有conf的配置文件并统计数量) -
网络连接过滤:
netstat -an | grep LISTEN(查看处于监听状态的端口) -
循环生成随机数输出到文档里
1
for i in {1..30}; do echo `expr ${RANDOM} / 1000`; done > rand_1000.txt
可以
cat一下文档看看内容: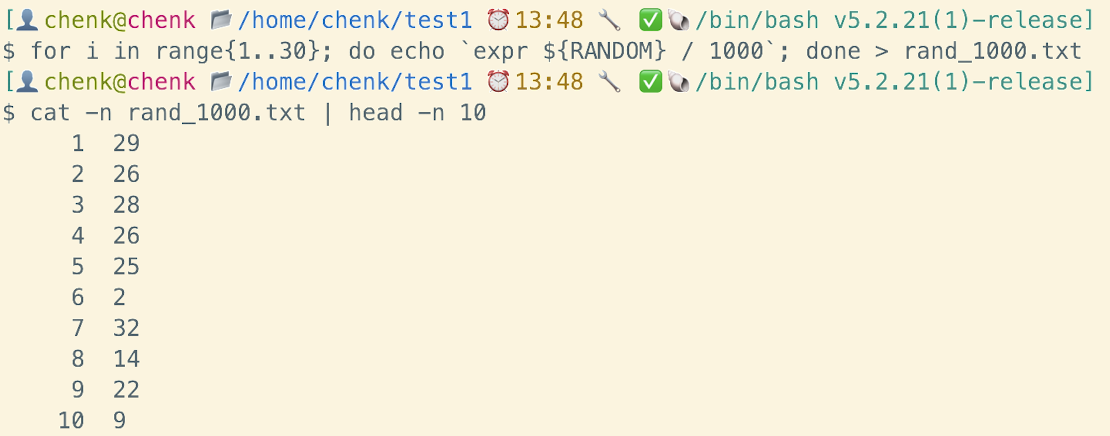
将随机数进行倒排:
1
cat rand_1000.txt | sort -nr

结果为:

去重排序:
将要使用到的命令是
uniq
我们需要首先对其排序后才能去重,还可以加
-c参数查看重复了多少次:
二、grep 的基本概念与使用
¶1. 基本介绍
grep 是 Linux 下极常用的文本搜索工具,通过模式匹配(包括正则表达式)筛选出符合条件的行。结合管道符,可以非常便捷地在输出数据中定位关键字。
grep 基础命令
grep pattern file:在文件中搜索pattern,打印匹配行。command | grep pattern:在命令输出中筛选包含pattern的行。
常用参数
-i:忽略大小写搜索。-v:反向匹配,只显示不包含关键字的行。-n:显示匹配结果所在行号。-E或-P:启用扩展正则或 Perl 风格正则。
¶2. 示例
¶基本示例
1 | # 在当前文件夹下检索含 "TODO" 的行 |
若要反向匹配:
1 | ls -l /etc | grep -v conf |
只显示不包含 conf 的行。
¶ps -ef | grep vim
在 Linux 下,ps -ef 通常用于查看当前所有进程;通过管道连接 grep 能快速查找特定的进程名或关键字。例如:
1 | # ps -ef | grep vim |
在某个终端运行 vim 编辑某文件,而在另一个终端使用 ps -ef | grep vim,我们可以看到当 vim 正在编辑某文件时,对该文件持有句柄,导致文件处于占用状态。当执行 :wq! 等命令退出 vim 后,vim 会释放对应文件句柄,不再占用系统资源。若一直不退出(不释放句柄),则有可能导致内存或资源泄露。下图示例演示了 ps -ef | grep vim 结果,vim 进程正在运行中:

文件占用示例里,只有在 vim 中执行 :wq! 或其他合理退出方式后,文件句柄才正式释放;否则文件会一直处于被 vim 进程占用状态。若长期不释放,系统会持续保留资源,占用内存,甚至导致“内存泄露”或类似的资源枯竭问题。
ps -ef的用法遍布各个场景,如日志分析、网络监控、系统排查等等,如
1 | ps -ef | grep ssh |
将查找系统中所有进程最后只输出带有 ssh 的进程行。ps 的其他参数如下:

¶查询进程
1 | ps aux | grep nginx |
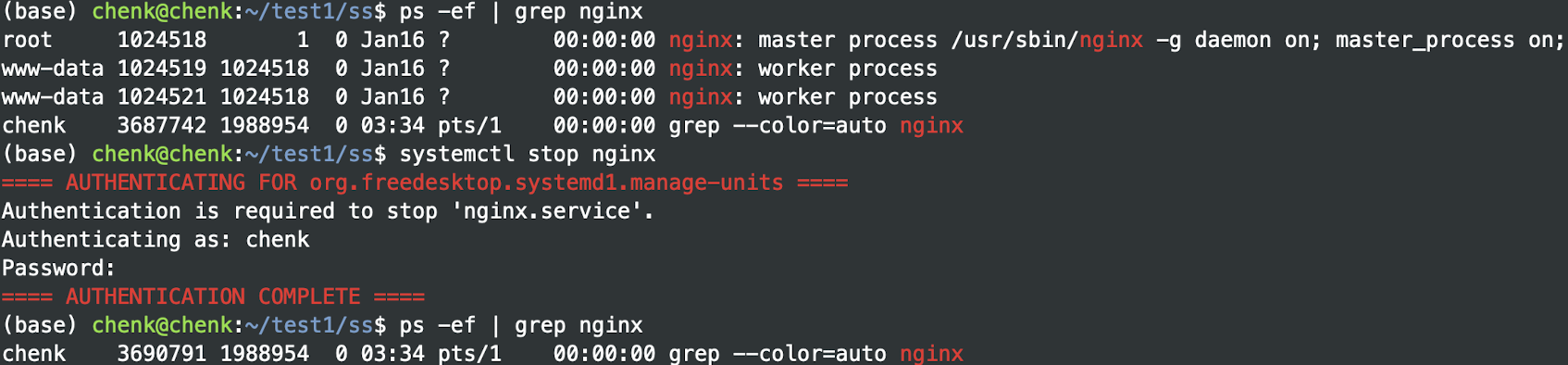
查找目前运行中的 nginx 进程,以便查看其 PID、运行用户等信息。
1 | ps aux | grep -v grep | grep vim |
有时 grep vim 本身也会被列入结果,可使用 -v grep 排除包含“grep”的行。
补充命令学习:
netstat -tunlp是查看系统中的所有端口信息,和ps -ef类似,都是查看系统中某资源信息的。LISTEN 代表监听中,即等待用户连接中。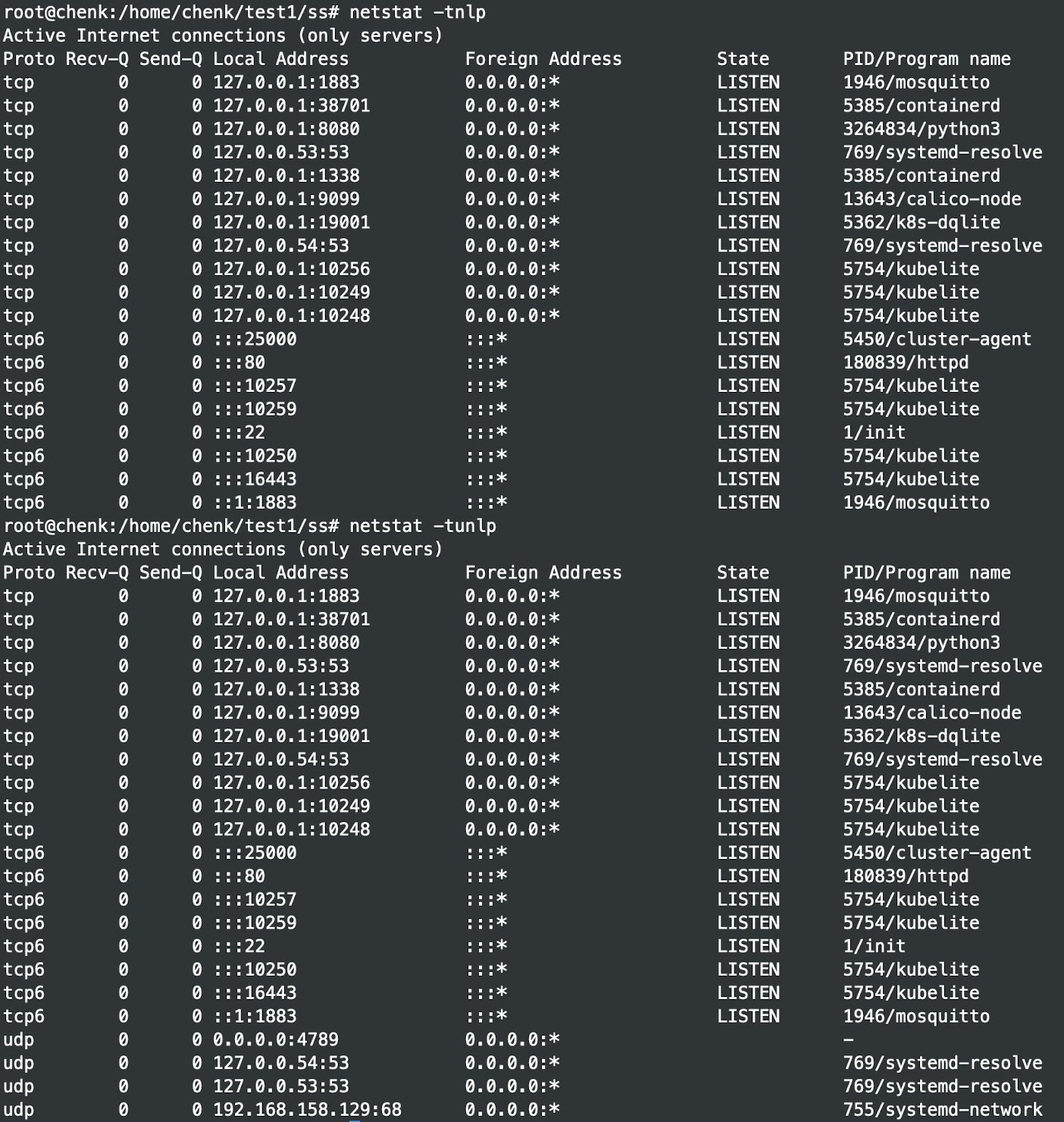
¶过滤日志
将系统日志(syslog)中所有包含 error 的行筛选出来
1 | cat /var/log/syslog | grep error |
实时查看日志变化,只显示包含 usb 的行,适合监控插拔事件或关键字出现
1 | tail -f /var/log/messages | grep usb |
找出 /var/log 目录下哪些文件含passwd信息
-R 是递归查找的命令
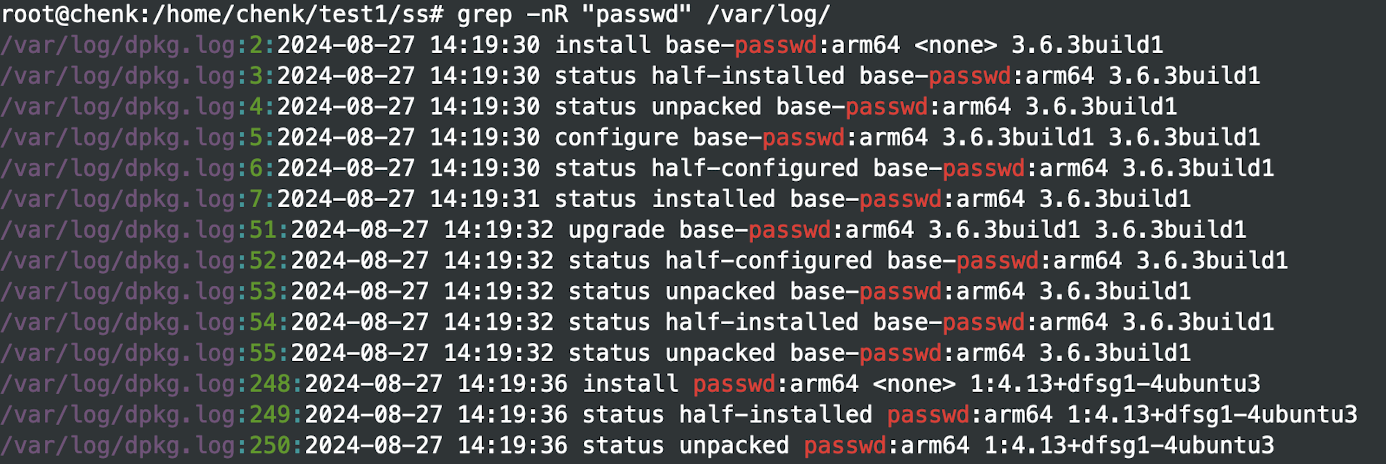
如果只想拿到文件名,加 -l 参数:
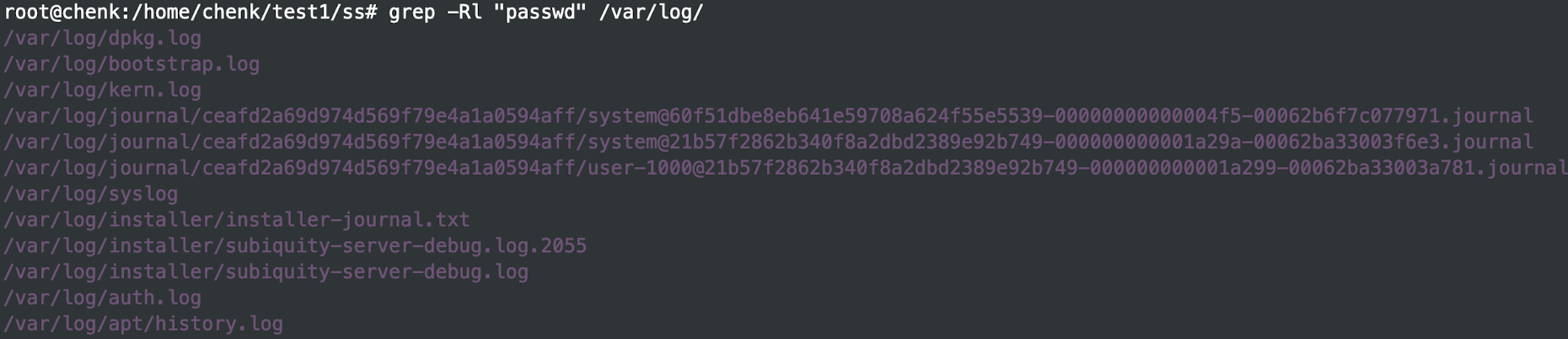
**找出 /var/log/ 下文件名包含 boot 的文件有哪些 **

¶多级筛选
1 | dmesg | grep 'eth0' | grep -i 'down' |
使用两次 grep 逐层过滤:先选含 eth0,再选含 down(不区分大小写可用 -i)。
¶结合 wc、sort、uniq 等命令
-
统计匹配次数:
1
cat file.log | grep "ERROR" | wc -l
显示 file.log 中包含“ERROR”的行数。
-
去重并统计:
1
cat /etc/passwd | grep '/bin/bash' | sort | uniq | wc -l
找出使用
/bin/bash作为 shell 的用户,去重后统计用户数。 -
灵活组合
1
netstat -an | grep ESTABLISHED | grep ':80' | wc -l
显示当前 80 端口处于已建立连接状态的连接数量。
¶3. grep 的高级搜索技巧
¶正则表达式
1 | # grep -E (extended regex) 示例 |
搜索以 d 或 l 开头的行(文件类型为目录 d 或链接 l),显示目录或链接。
¶显示上下文行
-A n:匹配行后面显示 n 行;-B n:匹配行前面显示 n 行;-C n:匹配行前后各显示 n 行;
1 | grep -C 2 "error" syslog |
匹配到 “error” 的行,并显示上下各 2 行上下文,以便快速定位问题。
¶反向匹配
1 | ls -l /etc | grep -v conf |
列表中排除包含“conf”的文件行。
三、xargs
在 Linux/UNIX 环境中,很多命令(如 rm、cp、mv 等)可以一次接受较多参数,但是有时我们需要先通过 grep、find 等命令查到很多结果,再把这些结果逐个传给另外的命令去执行;若结果很多,直接把输出用 | command 有可能出现“参数列表过长”或命令无法正确解析的情况。
xargs 则是专门设计来解决这个需求的:它能从标准输入读取一行行或多行数据,再把它们当作参数传给指定命令。这样我们就能轻松地把“输出流”接给下一个命令,实现批量操作。
¶1. 基础用法
1 | echo "file1 file2 file3" | xargs rm |
这代表将 file1 file2 file3 交给 rm 命令,一次删除这些文件。
¶2. -i 与替换符 {}
1 | find /tmp/ -name '*.log' | xargs -i cp {} {}.bak |
在示例 find /tmp/ -name '*.log' | xargs -i cp {} {}.bak 中:
• -i 选项允许我们使用占位符 {} 来表示从上一个命令输出中得到的每一行文本;
• cp {} {}.bak 表示对于每一个 log 文件,用它自己的文件名作为 {},然后再在后面补 .bak,形成新文件名。
如果没有 -i,则 xargs 默认把所有输出的文件拼成一行一行或多行参数传给命令,不会像替换符 {} 这样灵活地组合不同的目标和源路径。
1 | # 另一个示例:将所有 .txt 文件复制到 ~/backup/ 下 |
¶3. 批量查询文本是否包含某信息
当我们想要在一堆文件里搜索某字符串、某信息或某正则模式时,最直接的工具往往是 grep。如果我们已经有了一份文件列表(如在某个文本文件里,或通过 find 找到),也可以配合 xargs 来实现批量查询。
¶使用 grep 自带的批量搜索
其实最简单的是,直接在 grep 后面跟多个文件参数,如:
1 | grep "关键字" file1 file2 file3 ... |
或结合 find:
1 | find /path -name '*.txt' -exec grep "关键字" {} \; |
这里 -exec 命令是跟着shell的命令,结尾必须以分号结束,考虑到系统差异,加上转义符 \;
这是 find + grep 直接搭配的一种写法。
¶通过 xargs 把文件列表交给 grep
有时我们需要先过滤或组合出文件列表,再进行搜索。如下示例先找所有 .log 文件,然后查它们是否包含 “ERROR”:
1 | find /var/log/ -name '*.log' | xargs grep "ERROR" |
若想在搜索结果中显示文件名、行号等信息,可以再加 grep 参数:
1 | find /var/log/ -name '*.log' | xargs grep -Hn "ERROR" |
其中:
H:显示匹配所在文件名;-n:显示匹配行号。
避免 “Argument list too long” 问题
如果文件特别多,可能出现“Argument list too long”的报错。xargs 默认一次性传递给命令的参数数量是有限的,但 xargs 会自动分批提交给命令。另一个常见做法是加 -print0 / -0 参数组合,保证文件名中若有空格或特殊字符,也能被安全识别。
1 | # 避免空格破坏 |
-print0:让 find 用 NULL 字符做分隔符;xargs -0:xargs 以 NULL 作为分隔符,防止空格或换行导致分割错误。
¶4. 更多实用示例
为每个文件创建一个备份
1 | find /data/ -type f -name '*.conf' | xargs -i cp {} {}.bak |
为所有 .conf 文件都复制一份 .bak 结尾的备份文件。
大批量删除指定文件
1 | # 比如要删除所有 .tmp 文件 |
组合 grep 与 xargs
1 | # 显示 /etc/ 下所有 .cfg 文件中包含 "port" 的行 |
-H 让 grep 显示匹配所在的文件名。
查找所有报错的日志文件

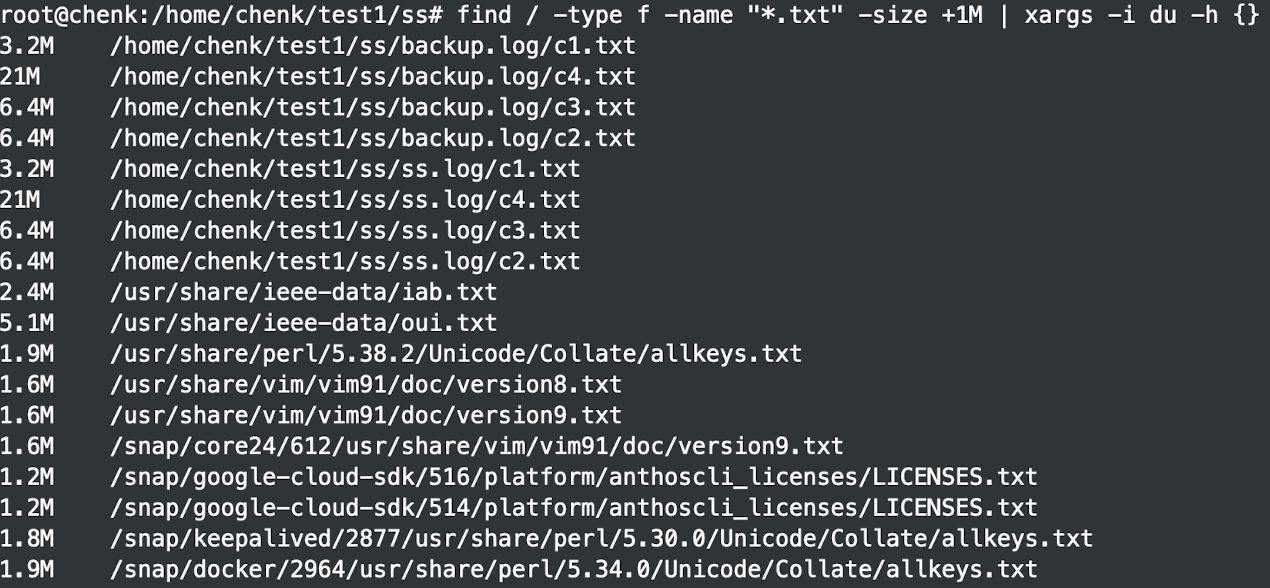
找出系统中超过1M的txt,并且显示其文件具体的容量信息
四、exec 与 ok
在使用 find 命令时,我们常见到 -exec 和 -ok 这两个选项,均可对匹配到的每一个结果(文件或目录)执行某条命令。它们的区别在于 是否需要交互式确认。以下是它们的具体用法与示例。
¶1. 基本语法
1 | find <path> [条件] -exec <命令> {} \; |
其中:
{}:表示当前匹配到的文件或目录的占位符,find会用实际文件名替换它。\;:语句结尾标识,告诉find结束当前命令。-exec:对每个搜索结果直接执行指定命令,无需用户确认。-ok:与-exec类似,但在执行命令前会提示用户确认,按 y 或 n 决定是否对该项执行命令。
¶2. -exec 用法示例
¶删除匹配的所有文件
1 | find /tmp -type f -name '*.tmp' -exec rm -f {} \; |
在 /tmp 目录下查找所有后缀为 .tmp 的文件,并直接删除(rm -f),不需用户确认。
¶给所有匹配到的文件改权限
1 | find /var/www -type f -exec chmod 644 {} \; |
¶批量移动/复制文件
1 | find /home/user -name '*.jpg' -exec mv {} /home/user/pictures/ \; |
将所有 .jpg 文件移动到指定目录 /home/user/pictures/。
注意:若匹配结果过多,一次执行可能出现 “参数列表过长” 的情况,可改用
-exec ... + 语法或xargs处理。
¶3. -ok 用法示例
¶交互式删除
1 | find /tmp -type f -name '*.log' -ok rm -i {} \; |
- 查找 /tmp 下所有 .log 文件,针对每个文件执行
rm -i,删除前会提示“确认是否删除”。 - 因为用了
-ok,在执行rm -i前,find也会先询问一次:- 类似于:
< rm … ./filename > ? y/n - 选择 y 或 n 决定是否对当前匹配文件执行命令。
- 类似于:
¶安全操作
如果你想对某些关键目录下的文件执行敏感操作又不确定匹配范围是否准确,就可以用 -ok 来逐一确认,如:
1 | find /etc -type f -name '*.bak' -ok rm {} \; |
这样在删除每个 .bak 文件之前都会询问,可避免误操作带来的损失。
¶4. 其他相关技巧
¶用 + 替代 \; 提升效率
在较新的 find 版本里,可以使用 -exec / -ok 并以 + 结尾,将多个匹配结果一次性传给命令,而不是针对每个文件执行一次。例如:
1 | find /logs -name '*.log' -exec rm {} + |
此时 find 会把所有匹配文件收集后,一次性执行 rm file1 file2 file3 …,通常比单次执行效率高。
¶与管道符、xargs 结合
对于极多匹配结果或需要分批处理,可改用管道符及 xargs 实现类似效果。例如:
1 | find /data -name '*.tar.gz' | xargs rm -f |
或结合 -ok 功能用 xargs -p(交互式询问)也可以实现安全删除等操作。
五、文件时间
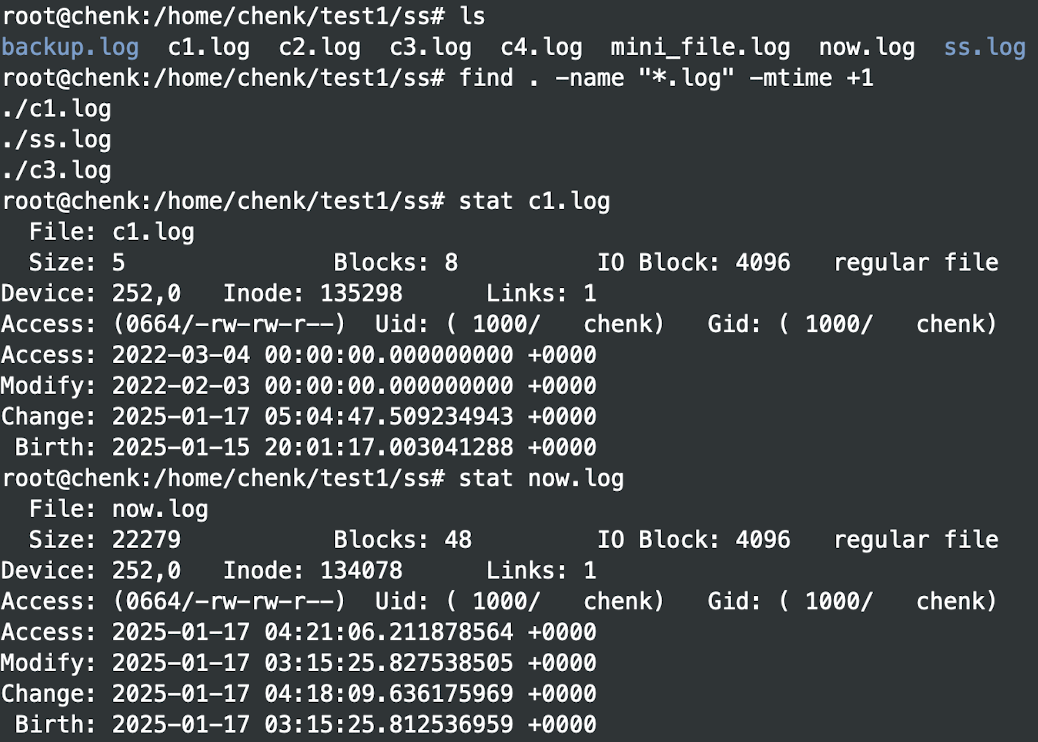
我们知道 stat 文件路径 能显示文件的 Access、Modify 和 Change 的时间:
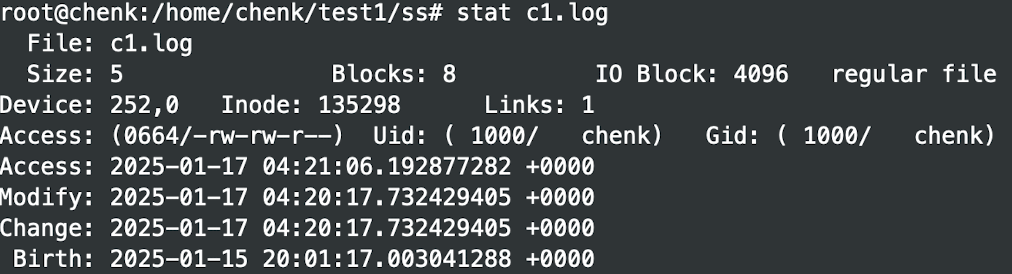
这个时间是可以被修改的,修改方法为:
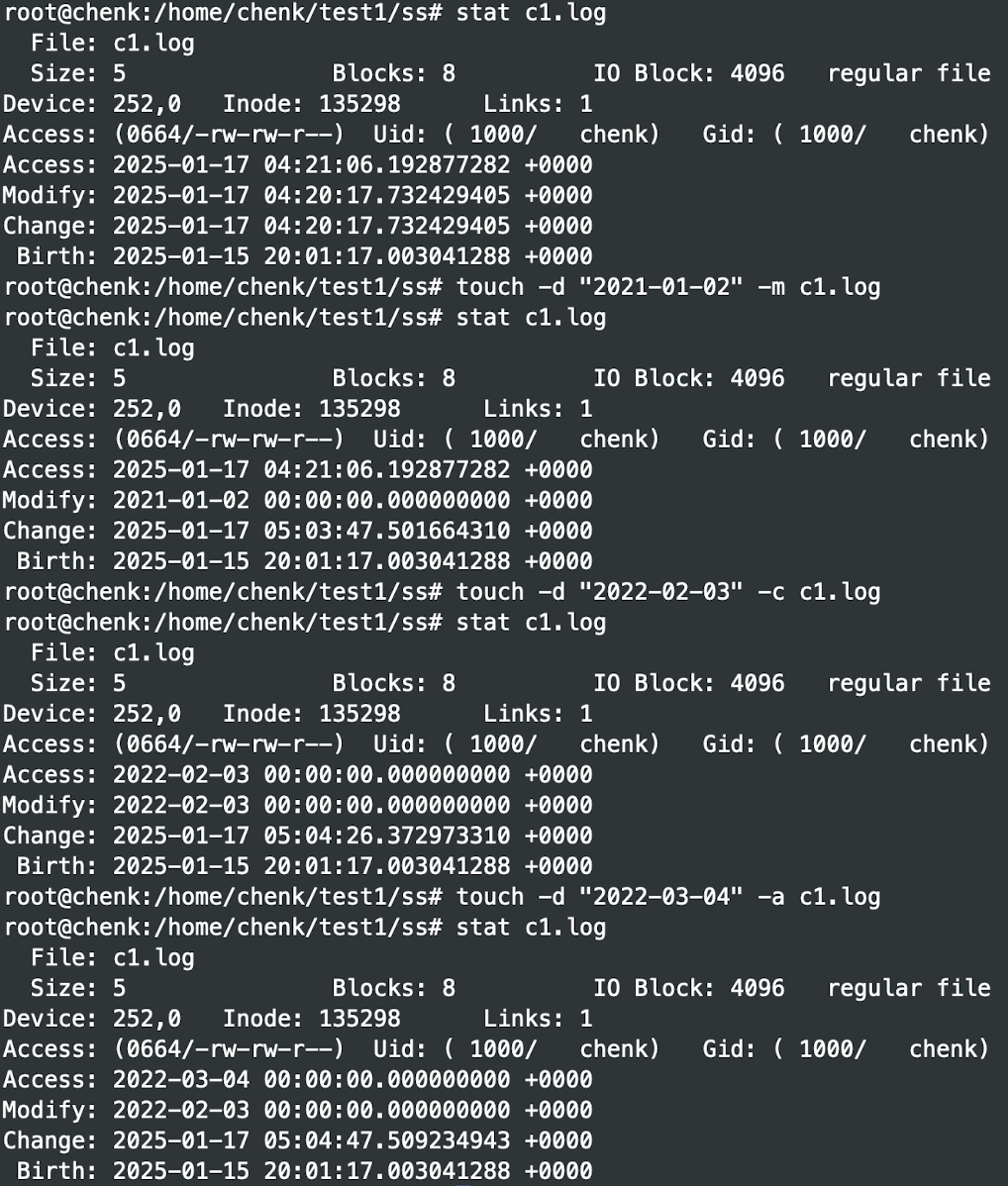
要查看最近几天 Modify 过的文件时间,可以这么写:
1 | find 文件路径 -name "xxx" -mtime +1 (+n 代表 n 天前,不加代表第 n 天,-n 代表 n 天内) |
六、Linux 数据流和重定向
Linux 系统的标准输入、输出和错误输出可以通过文件描述符来管理。数据流通过这三个标准流进行输入和输出,通常我们会将数据流重定向到不同的文件或命令中,以便更好地管理和调试程序。
¶1. 标准输入输出与错误输出重定向
- 标准输入(stdin):通常来自用户的键盘输入,也可以通过重定向从文件或其他命令获取,描述符为 0。
- 标准输出(stdout):程序的输出结果,默认显示在屏幕上,也可以重定向到文件中,描述符为 1。
- 标准错误输出(stderr):程序运行过程产生的错误信息,默认显示在屏幕上,可重定向到文件,描述符为 2。
¶2. 重定向的常见用法与示例
常见用法:
| 操作符 | 含义 | 示例 |
|---|---|---|
> |
将输出重定向到文件,覆盖原文件内容 | echo "Hello, World!" > output.txt |
>> |
将输出重定向到文件,追加内容到文件末尾 | echo "Hello again!" >> output.txt |
2> |
将错误输出重定向到文件,覆盖原文件内容 | ls non_existent_file 2> error.log |
2>> |
将错误输出重定向到文件,追加内容到文件末尾 | ls non_existent_file 2>> error.log |
< |
从文件中读取输入,将文件内容作为标准输入 | sort < input.txt |
&> |
同时将标准输出和标准错误输出重定向到文件 | command &> output.log |
2>&1 |
将标准错误输出重定向到标准输出的位置 | command > output.log 2>&1 |
| ` | ` | 管道符,用于将一个命令的输出作为另一个命令的输入 |
常见操作:
-
将标准输出重定向到文件:
1
echo "Hello, World!" > output.txt
这条命令将 “Hello, World!” 输出到 output.txt 文件中。
-
将标准错误输出重定向到文件:
1
ls non_existent_file 2> error.log
如果文件不存在,错误信息会被写入 error.log 文件中。
-
将标准输出和标准错误输出同时重定向到同一文件:
1
command > output.txt 2>&1
这条命令将标准输出和标准错误输出都重定向到 output.txt 文件。
-
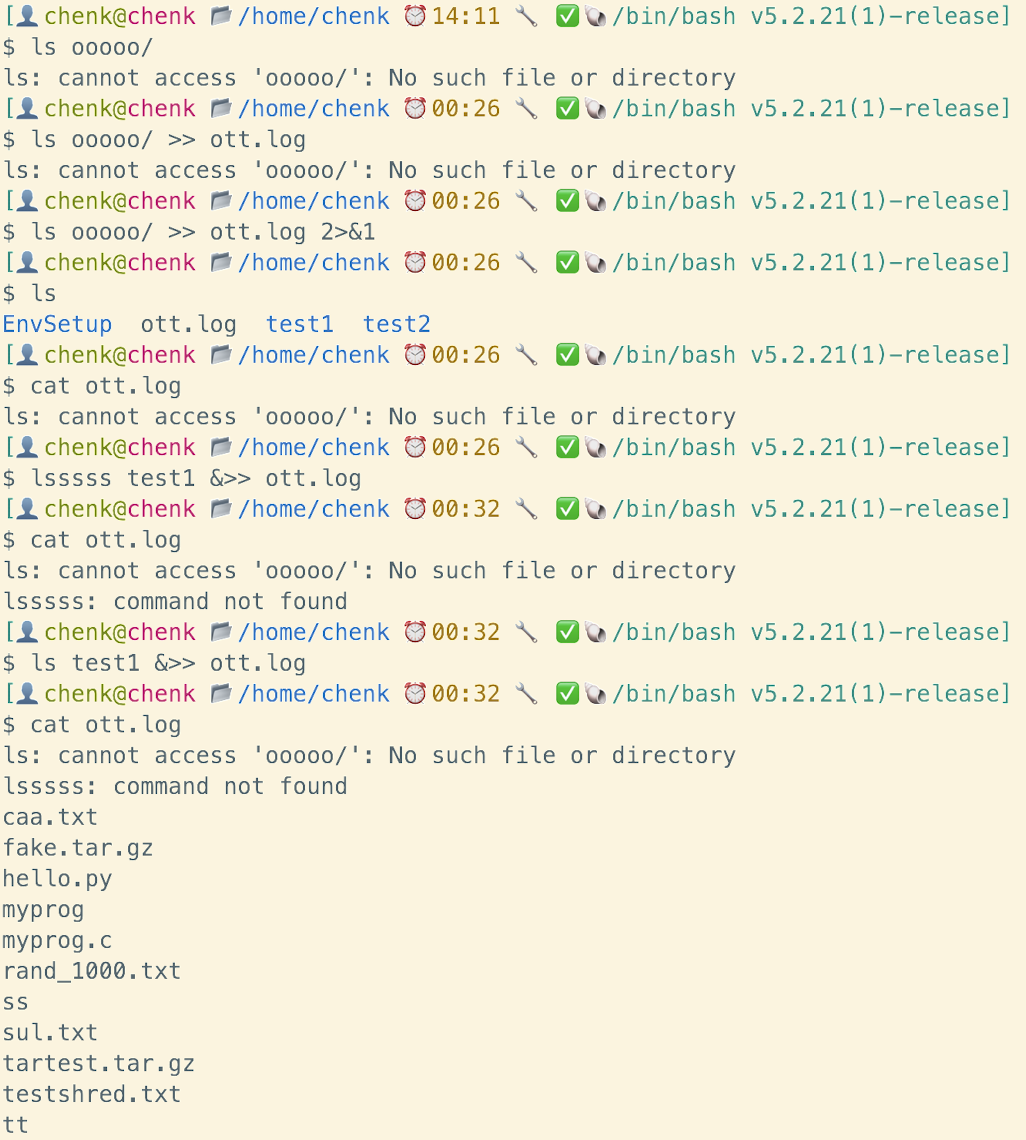
输入重定向:
1
cat < file.txt
将 file.txt 文件的内容作为标准输入传递给
cat命令。
示例:
- 本文标题:Linux 文件操作深入解析
- 本文作者:Chen Kai
- 创建时间:2025-01-18 00:00:00
- 本文链接:https://www.chenk.top/Linux 文件操作深入解析/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!