贪心算法( Greedy Algorithm)是一种在每一步选择中都采取当前状态下最优选择的算法思想。虽然看似简单,但贪心算法的难点在于证明"局部最优能导致全局最优"。本文系统梳理贪心算法的核心思想、适用场景,通过区间调度、跳跃游戏、加油站等经典问题,帮助读者建立完整的贪心算法解题框架。
系列导航
📚 LeetCode 算法精讲系列(共 10 篇):
- 哈希表(两数之和、最长连续序列、字母异位词分组)
- 双指针技巧(对撞指针、快慢指针、滑动窗口)
- 链表操作(反转、环检测、合并)
- 滑动窗口技巧
- 二分查找
- 二叉树遍历与构造(前中后序、层序、构造)
- 动态规划入门(一维/二维 DP 、状态转移)
- 回溯算法(排列、组合、剪枝)
- → 贪心算法(区间调度、跳跃游戏)← 当前文章
- 栈与队列(括号匹配、单调栈)
什么是贪心算法?
核心思想
贪心算法( Greedy Algorithm)是一种在每一步选择中都采取当前状态下最优选择的算法思想。贪心算法不会考虑整体最优,只关注局部最优,期望通过局部最优选择达到全局最优。
贪心算法的特点:
- 局部最优性:每一步都做出当前看来最好的选择
- 不可撤销性:一旦做出选择,就不再改变(不同于回溯)
- 简单高效:通常时间复杂度较低(
或 ) - 需要证明:局部最优是否能导致全局最优需要严格证明
贪心 vs 动态规划 vs 回溯:
| 特性 | 贪心算法 | 动态规划 | 回溯算法 |
|---|---|---|---|
| 决策方式 | 局部最优 | 全局最优 | 尝试所有可能 |
| 时间复杂度 | |||
| 适用场景 | 满足贪心选择性质 | 最优子结构+重叠子问题 | 搜索所有解 |
| 可撤销性 | 不可撤销 | 不可撤销 | 可撤销 |
贪心算法的两个关键性质
1. 贪心选择性质( Greedy Choice Property)
问题的全局最优解可以通过一系列局部最优选择(贪心选择)来达到。换句话说,可以做出一个看起来最优的选择,然后求解剩余子问题。
示例:活动选择问题 - 问题:给定一组活动,每个活动有开始时间和结束时间,选择最多的不冲突活动 - 贪心策略:每次选择结束时间最早的活动 - 证明:选择结束时间最早的活动后,留给后续活动的时间最多
2. 最优子结构( Optimal Substructure)
问题的最优解包含其子问题的最优解。做出贪心选择后,原问题简化为一个规模更小的相似子问题。
贪心算法的设计步骤
- 理解问题:明确目标(最大化/最小化什么)和约束条件
- 确定贪心策略:找到每一步的"局部最优"选择标准
- 证明正确性:证明局部最优能导致全局最优(反证法、交换论证)
- 实现算法:通常需要排序等预处理
- 分析复杂度:通常是
或 (排序)
常见的贪心策略
- 按结束时间排序:区间调度问题
- 按开始时间排序:会议室分配问题
- 按价值密度排序:背包问题(分数背包)
- 按长度排序:拼接字符串问题
- 按差值排序:任务分配问题
- 局部调整:跳跃游戏、加油站
LeetCode 435: 无重叠区间(区间调度)
给定一个区间的集合 intervals,其中
intervals[i] = [starti, endi]。返回需要移除区间的最小数量,使剩余区间互不重叠。
示例:
- 输入:
intervals = [[1,2],[2,3],[3,4],[1,3]] - 输出:
1(移除 [1,3],剩余 [[1,2],[2,3],[3,4]] 互不重叠)
约束条件:
-
问题分析
无重叠区间问题的本质是区间调度问题:在一组区间中,选择最多的互不重叠区间。移除区间的最小数量 = 总区间数 - 最多不重叠区间数。
核心挑战:
如何判断区间重叠:区间
和 重叠当且仅当 且 如何选择保留哪些区间:需要找到一个贪心策略
如何证明贪心策略的正确性:证明局部最优能导致全局最优
关键洞察:
贪心策略:按照区间的结束时间排序,每次选择结束时间最早且与已选区间不重叠的区间。
为什么按结束时间排序: - 选择结束时间最早的区间,能为后续区间留出最多的空间 - 结束越早,后面能容纳的区间越多 - 这是经典的"活动选择问题"( Activity Selection Problem)
解题思路
算法流程:
- 排序:按区间的结束时间升序排序
- 初始化:选择第一个区间(结束时间最早),记录当前区间的结束时间
- 遍历:从第二个区间开始
- 如果当前区间的开始时间 ≥ 上一个选中区间的结束时间:不重叠,选择当前区间
- 否则:重叠,跳过当前区间(即需要移除)
- 返回:总区间数 - 选中的区间数 = 需要移除的区间数
贪心策略的正确性证明:
使用交换论证( Exchange Argument):
假设存在最优解
- 将
中的 替换为 ,得到新解 - 因为
,所以 与其他区间的兼容性至少和 一样好 - 仍然是最优解,且第一个区间是结束时间最早的 - 因此,总是选择结束时间最早的区间不会影响最优性
复杂度分析
时间复杂度:sort() 是 Timsort,空间复杂度
复杂度证明:
排序是瓶颈,决定了总时间复杂度为
代码实现:
1 | from typing import List |
算法原理:
为什么按结束时间排序是最优的:
考虑两个重叠的区间
1 | A: [----] |
如果选择
如果选择
因此,选择结束时间早的区间总是更优。
执行过程示例(intervals = [[1,2],[2,3],[3,4],[1,3]]):
1 | 排序后:[[1,2], [2,3], [1,3], [3,4]] # 按结束时间排序 |
常见错误:
错误一:按开始时间排序
1 | # ❌ 错误:按开始时间排序 |
错误二:重叠判断错误
1 | # ❌ 错误:使用 > 判断不重叠 |
变体扩展:
变体一:最多不重叠区间数
LeetCode 452:直接返回保留的区间数(不需要减法)
1 | def findMinArrowShots(self, points: List[List[int]]) -> int: |
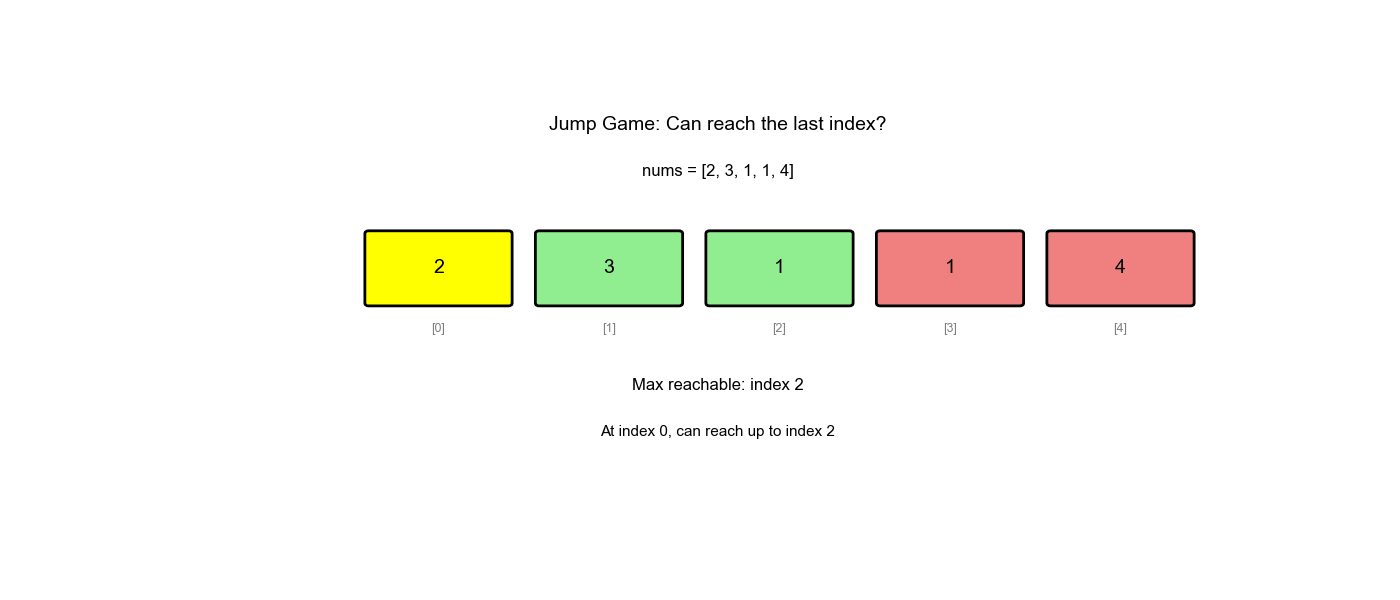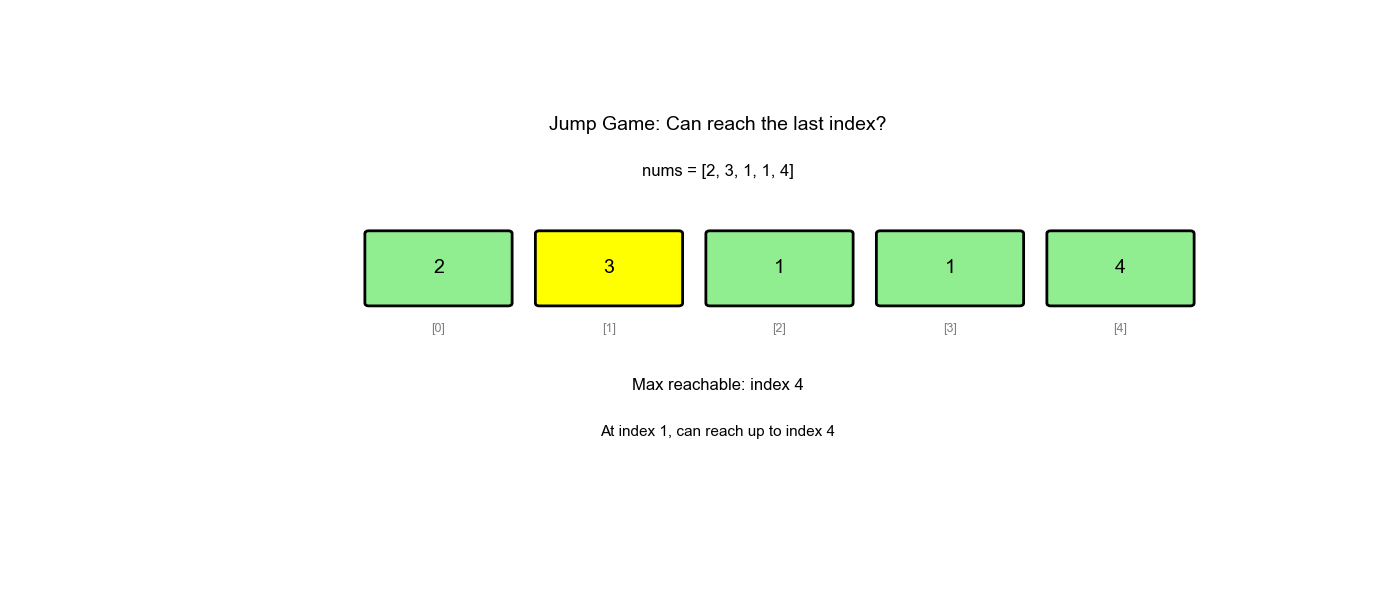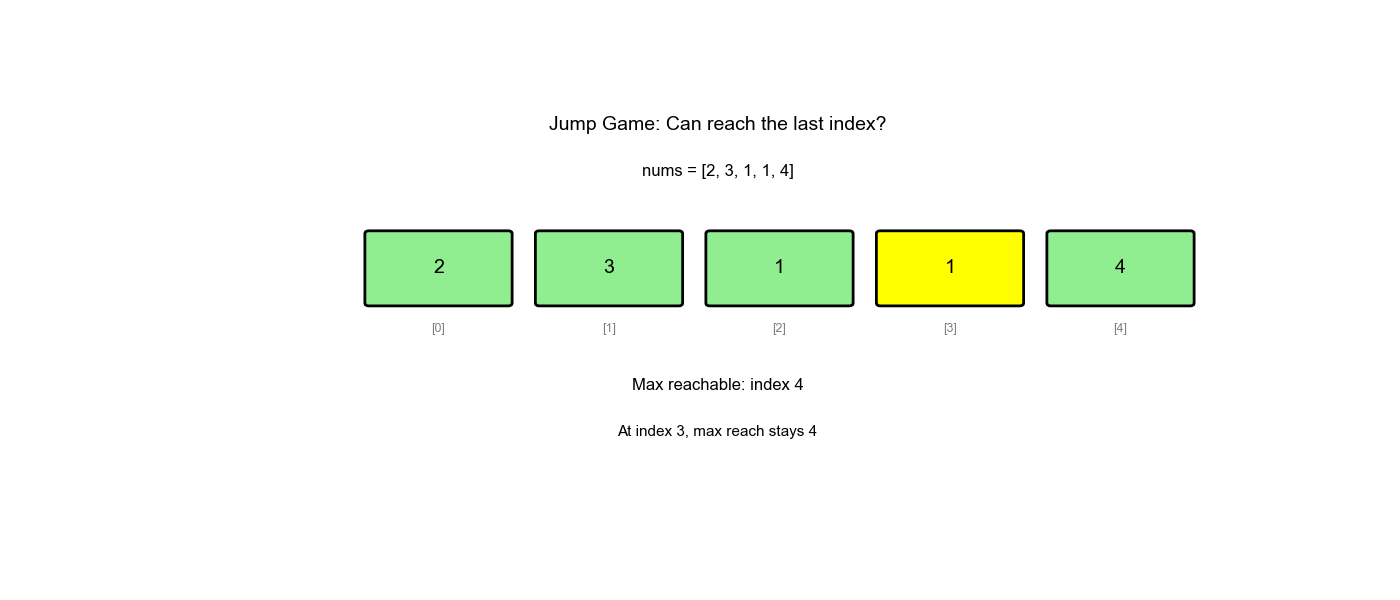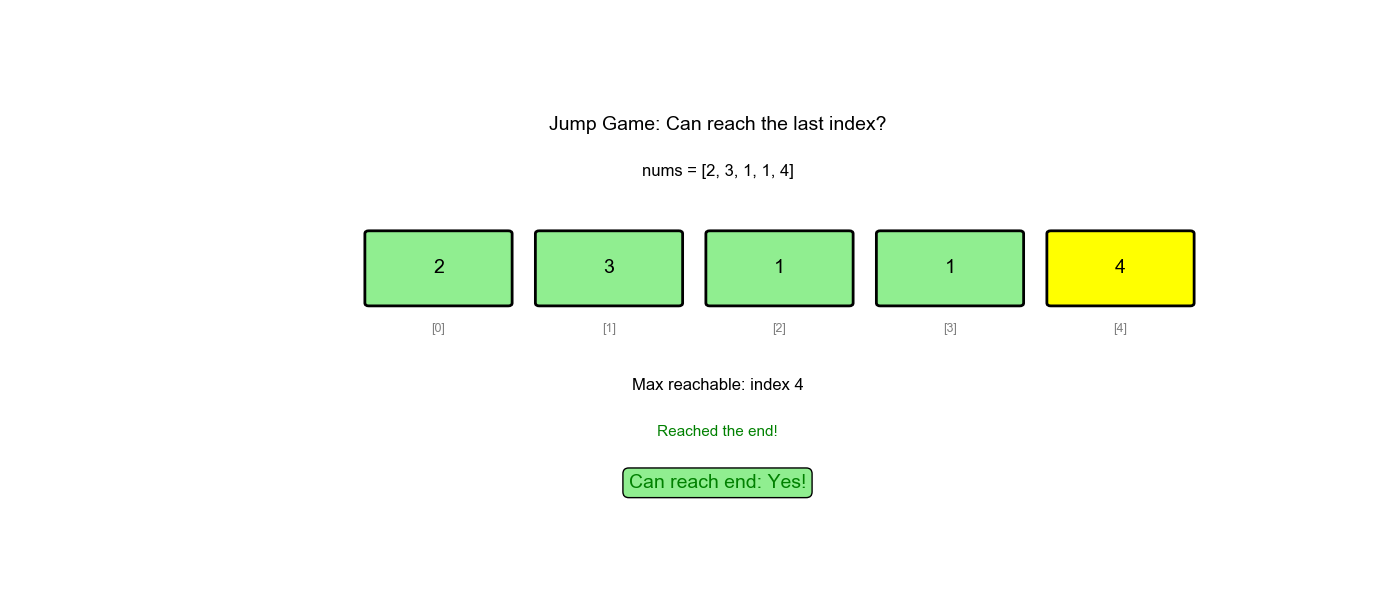
LeetCode 55: 跳跃游戏
给定一个非负整数数组
nums,你最初位于数组的第一个下标。数组中的每个元素代表你在该位置可以跳跃的最大长度。判断你是否能够到达最后一个下标。
示例:
- 输入:
nums = [2,3,1,1,4] - 输出:
true(跳 1 步到下标 1,再跳 3 步到最后) - 输入:
nums = [3,2,1,0,4] - 输出:
false(无法越过下标 3 的 0)
约束条件:
-
问题分析
跳跃游戏的核心是判断能否到达终点。需要维护一个"能够到达的最远位置"。
核心挑战:
- 0 的陷阱:如果在某个位置跳跃距离为 0,可能无法前进
- 最远距离的维护:如何高效地更新和判断最远可达位置
- 遍历策略:是否需要遍历所有位置
关键洞察:
贪心策略:维护一个变量 max_reach
表示当前能到达的最远位置。遍历数组,不断更新
max_reach,如果当前位置max_reach,说明无法到达。
为什么贪心可行: - 我们不需要知道具体怎么跳,只需要知道"能不能到" - 只要当前位置可达,就更新从该位置能跳到的最远位置 - 如果最远位置 ≥ 数组末尾,说明可达
解题思路
算法流程:
- 初始化:
max_reach = 0(从第 0 个位置开始,最远能到 0) - 遍历:对于每个位置
(从 0 到 n-1) - 如果
:说明无法到达位置 ,返回 false - 更新:
max_reach = max(max_reach, i + nums[i])(从位置能跳到的最远位置) - 如果
max_reach >= n-1:已经能到达终点,返回true
- 如果
- 返回:
true(遍历完成,说明所有位置都可达)
为什么是贪心:
我们不关心具体的跳跃路径,只关心"能到达的最远位置"。每一步都尽可能扩大可达范围,这是局部最优策略,也能保证全局最优(要么到达终点,要么无法到达)。
复杂度分析
时间复杂度:max_reach)
复杂度证明:
遍历数组一次,每次更新 max_reach 只需要
代码实现:
1 | from typing import List |
算法原理:
为什么更新
max_reach = max(max_reach, i + nums[i])
是正确的:
i是当前位置nums[i]是从当前位置能跳的最大距离i + nums[i]是从当前位置能到达的最远位置max(max_reach, i + nums[i])确保max_reach始终是"到目前为止能到达的最远位置"
执行过程示例(nums = [2,3,1,1,4]):
1 | 初始: max_reach = 0 |
执行过程示例(nums = [3,2,1,0,4]):
1 | 初始: max_reach = 0 |
常见错误:
错误一:没有检查当前位置是否可达
1 | # ❌ 错误:直接更新 max_reach,没有检查 i 是否可达 |
错误二:提前返回条件错误
1 | # ❌ 错误:检查 max_reach == n-1 |
变体扩展:
变体一:跳跃游戏 II(最少跳跃次数)
LeetCode 45:给定数组
nums,保证一定能到达最后一个位置,返回到达最后一个位置的最少跳跃次数。
思路:使用贪心 + 双指针
1 | def jump(self, nums: List[int]) -> int: |
示例(nums = [2,3,1,1,4]):
1 | 初始: jumps=0, current_end=0, farthest=0 |
LeetCode 134: 加油站
在一条环路上有gas[i] 升。你有一辆油箱容量无限的汽车,从第cost[i]
升。你从其中的一个加油站出发,开始时油箱为空。给定两个整数数组
gas 和
cost,如果可以按顺序绕环路行驶一周,则返回出发时加油站的编号,否则返回
-1。如果存在解,则保证它是唯一的。
示例:
- 输入:
gas = [1,2,3,4,5],cost = [3,4,5,1,2] - 输出:
3(从加油站 3 出发:油量 3 →到 4 油量 2 →到 0 油量 0 →到 1 油量 1 →到 2 油量 2 →到 3 油量 3)
约束条件:
-
问题分析
加油站问题的核心是判断从哪个加油站出发能完成一圈。
核心挑战:
- 环形结构:需要考虑从任意位置出发绕一圈
- 无解的判断:何时确定无解
- 起点的选择:如何快速找到正确的起点
关键洞察:
贪心策略: 1. 如果总油量 < 总消耗,一定无解 2. 如果总油量 ≥ 总消耗,一定有解(且解唯一) 3. 从某个起点出发,如果在中途某个位置油量不足,说明起点到该位置之间的所有站点都不能作为起点(因为从起点到该位置的累计油量一直在下降) 4. 因此,将起点设置为下一个加油站,继续尝试
为什么贪心可行: - 如果从
解题思路
算法流程:
- 判断无解:如果
sum(gas) < sum(cost),返回 -1 - 初始化:
start = 0(起始加油站),total_tank = 0(当前油量),current_tank = 0(从 start 出发的累计油量) - 遍历:对于每个加油站
- 计算净油量: current_tank += gas[i] - cost[i]- 如果
current_tank < 0:无法从 start 到达,将 start 设为 ,重置 current_tank = 0
- 如果
- 返回:
start
复杂度分析
时间复杂度:
空间复杂度:
代码实现:
1 | from typing import List |
算法原理:
为什么如果总油量够就一定有解:
假设总油量 ≥ 总消耗,即
如果从某个起点
根据贪心策略,我们将起点设为
常见错误:
错误一:暴力尝试每个起点
1 | # ❌ 错误:时间复杂度 O(n^2) |
总结
核心要点
- 贪心算法的本质:在每一步选择中都采取当前状态下最优的选择,期望通过局部最优达到全局最优
- 贪心算法的难点:证明局部最优能导致全局最优(需要数学证明)
- 常见贪心策略:
- 排序:按某种属性排序后贪心选择
- 维护最优值:动态更新和维护最优值(如最远距离)
- 局部调整:根据当前状态做出最优调整
解题清单
区间调度类:
- ✅ 无重叠区间(按结束时间排序)
- ✅ 用最少数量的箭引爆气球(区间重叠)
- 会议室问题(区间调度)
跳跃游戏类:
- ✅ 跳跃游戏(判断能否到达)
- ✅ 跳跃游戏 II(最少跳跃次数)
加油站类:
- ✅ 加油站(环形数组)
- 分发糖果(局部调整)
其他经典问题:
- 买卖股票的最佳时机 II(多次交易)
- 分发饼干(排序贪心)
- 摆动序列(局部调整)
常见错误
- 错误的贪心策略:没有正确选择贪心标准(如按开始时间排序而不是结束时间)
- 忘记证明正确性:贪心算法需要证明局部最优能导致全局最优
- 边界条件处理:没有处理空数组、单元素等边界情况
- 提前返回条件:没有在满足条件时提前返回,导致效率降低
学习建议
- 理解贪心的适用场景:不是所有问题都能用贪心,需要满足贪心选择性质和最优子结构
- 学会证明正确性:使用反证法、交换论证等方法证明贪心策略的正确性
- 对比动态规划:有些问题既可以用贪心也可以用 DP,理解两者的区别和适用场景
- 积累常见模式:区间调度、跳跃问题、分配问题等都有固定的贪心模式
常见问题 Q&A
Q1:如何判断一个问题是否可以用贪心算法?
A1:满足以下条件时可以考虑贪心: 1. 问题可以分解为子问题 2. 局部最优选择能导致全局最优(需要证明) 3. 问题具有最优子结构 4. 通常求最大值/最小值/计数问题
Q2:贪心算法和动态规划有什么区别?
A2: -
贪心:每一步做出当前最优选择,不可撤销,通常
Q3:为什么区间调度要按结束时间排序而不是开始时间?
A3:按结束时间排序能为后续区间留出最多空间。选择结束早的区间,后面能容纳的区间越多。按开始时间排序可能选择一个很长的区间,导致后续无法选择更多区间。
Q4:跳跃游戏为什么只需要维护最远距离?
A4:我们只关心"能否到达",不关心"如何到达"。只要当前位置可达,就更新从该位置能跳到的最远位置。如果最远位置 ≥ 终点,说明可达。
Q5:加油站问题为什么如果总油量够就一定有解?
A5:如果总油量 ≥ 总消耗,说明整体是有盈余的。如果从某个起点出发在中途油量不足,说明起点到该位置的累计油量 < 0(有亏损)。将起点设为下一个加油站,由于总油量 ≥ 0,后续的盈余一定能补偿之前的亏损,最终完成一圈。
Q6:贪心算法一定需要排序吗?
A6:不一定。有些贪心问题需要排序(如区间调度),有些不需要(如跳跃游戏、加油站)。关键是找到合适的贪心策略。
Q7:如何证明贪心算法的正确性?
A7:常用方法: 1. 反证法:假设存在更优解,推导出矛盾 2. 交换论证:证明将非贪心选择替换为贪心选择不会变差 3. 归纳法:证明每一步贪心选择后问题规模缩小,且保持最优性
Q8:贪心算法的时间复杂度一般是多少?
A8: - 不需要排序:
希望通过本文,你对贪心算法有了深入的理解。继续练习,逐步建立贪心算法的直觉和解题框架!🎯
- 本文标题:LeetCode(九)—— 贪心算法
- 本文作者:Chen Kai
- 创建时间:2020-03-02 09:45:00
- 本文链接:https://www.chenk.top/LeetCode%EF%BC%88%E4%B9%9D%EF%BC%89%E2%80%94%E2%80%94-%E8%B4%AA%E5%BF%83%E7%AE%97%E6%B3%95/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!