链表是技术面试的基石,测试你操作指针、处理边界情况和优化空间使用的能力。与数组不同,链表提供
系列导航
📚 LeetCode 算法精讲系列(共 10 篇):
- 哈希表完全指南
- 双指针技巧
- → 链表操作(反转、环检测、合并、相交、删除)← 当前文章
- 二叉树遍历与递归
- 动态规划基础
- 回溯算法
- 二分查找进阶
- 栈与队列
- 图算法
- 贪心与位运算
链表基础回顾
链表 vs 数组
| 特性 | 数组 | 链表 |
|---|---|---|
| 访问 | ||
| 插入/删除(已知位置) | ||
| 内存 | 连续 | 非连续 |
| 缓存局部性 | ✅ 高 | ❌ 低 |
| 动态增长 | ⚠️ 需要重新分配 | ✅ 自然支持 |
链表节点定义
1 | class ListNode: |
链表的思维模型
将链表想象成一列火车:
- 节点:每节车厢
- 指针:连接车厢的耦合器
- 头节点:机车
- 尾节点:最后一节车厢(
next = None)
操作直觉:
- 反转:让火车倒着运行
- 合并:按顺序合并两列火车
- 检测环:检查火车是否形成环路
- 删除节点:移除一节车厢并重新连接其余部分
LeetCode 206: 反转链表
问题分析
核心难点:如何在一次遍历中反转所有指针方向,而不使用额外的
解题思路:使用三指针技术(迭代)或递归。迭代方法维护三个指针:prev(前一个节点)、curr(当前节点)、next_node(下一个节点)。在遍历过程中,将
curr.next 指向
prev,然后三个指针向前移动。递归方法先递归反转剩余部分,然后调整当前节点的指针。两种方法都能在
复杂度分析: - 时间复杂度:
关键洞察:反转链表的本质是改变每个节点的
next
指针方向。关键是在修改指针之前保存下一个节点的引用,避免丢失后续节点。
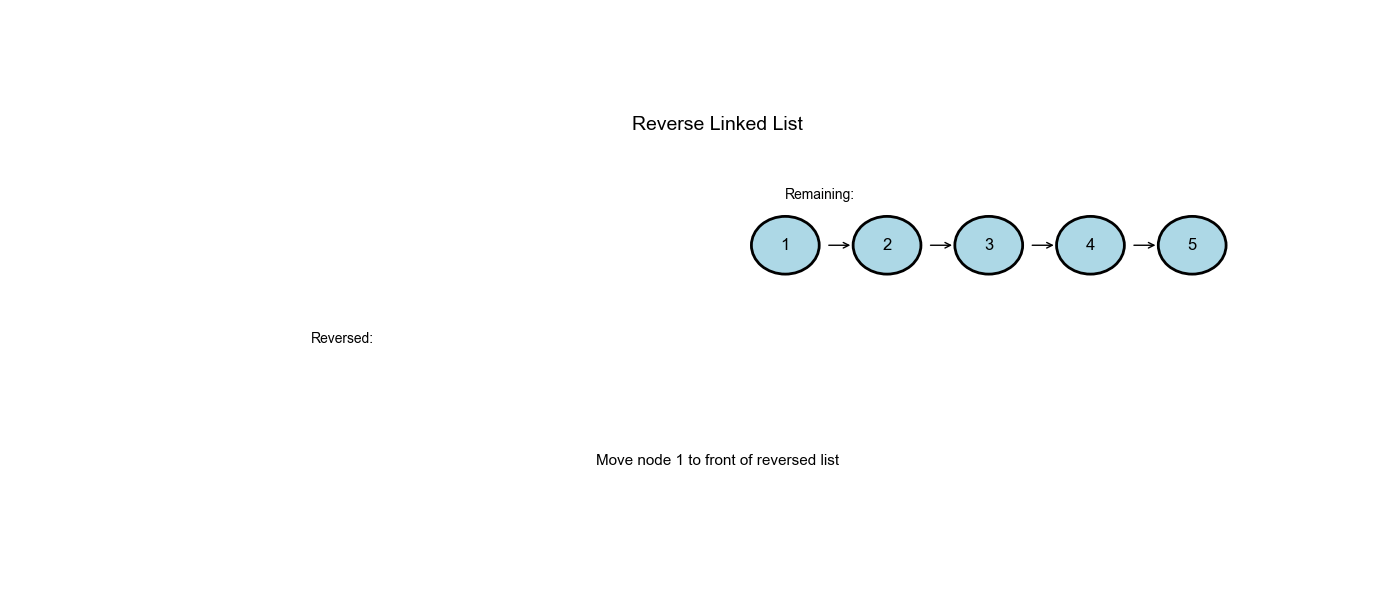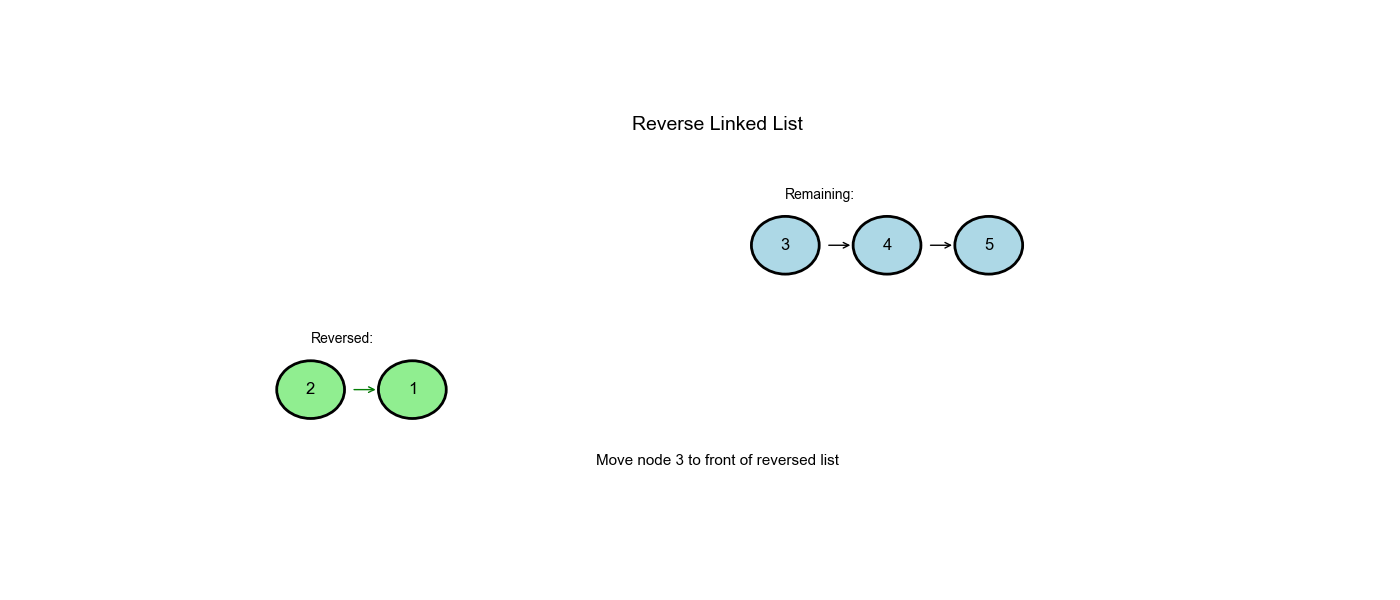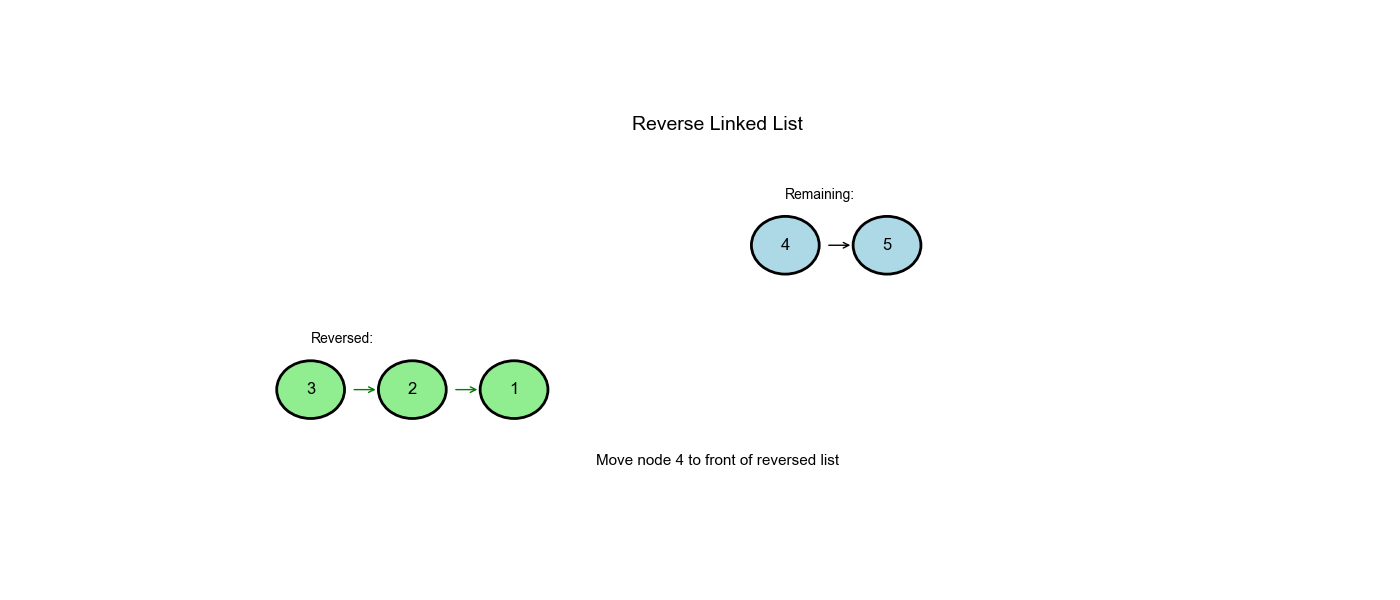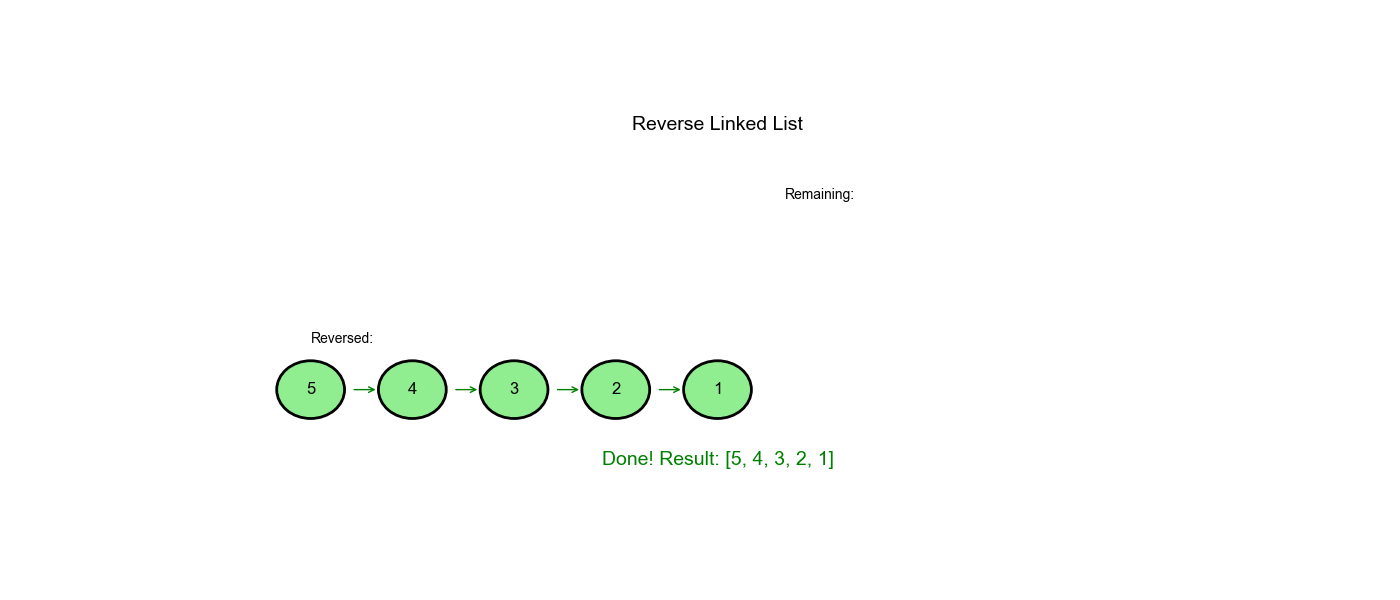
问题描述
给你单链表的头节点
head,请你反转链表,并返回反转后的链表。
示例:
- 输入:
head = [1,2,3,4,5] - 输出:
[5,4,3,2,1]
约束条件:
- 链表中节点的数目范围是
- 进阶:可以用迭代或递归两种方法解决这个问题吗?
方法一:迭代(三指针技术)
核心思想
维护三个指针:
prev:前一个节点curr:当前节点next_node:下一个节点(临时存储)
步骤:
初始化
prev = None,curr = head遍历链表,每次迭代:
- 将
curr.next保存到next_node - 反转指针:
curr.next = prev - 移动指针:
prev = curr,curr = next_node
- 将
返回
prev(新头节点)
Python 实现
1 | def reverseList(head): |
复杂度分析
- 时间复杂度:
,单次遍历 - 空间复杂度:
,仅使用常数额外指针
逐步解析
输入:1 → 2 → 3 → None
| 步骤 | prev |
curr |
next_node |
操作 | 链表状态 |
|---|---|---|---|---|---|
| 初始 | None |
1 |
- | - | 1 → 2 → 3 → None |
| 1 | None |
1 |
2 |
保存 2 |
- |
| 1 | None |
1 |
2 |
1.next = None |
None ← 1 2 → 3 → None |
| 1 | 1 |
2 |
2 |
移动指针 | - |
| 2 | 1 |
2 |
3 |
保存 3 |
- |
| 2 | 1 |
2 |
3 |
2.next = 1 |
None ← 1 ← 2 3 → None |
| 2 | 2 |
3 |
3 |
移动指针 | - |
| 3 | 2 |
3 |
None |
保存 None |
- |
| 3 | 2 |
3 |
None |
3.next = 2 |
None ← 1 ← 2 ← 3 |
| 3 | 3 |
None |
- | 循环结束 | - |
| 返回 | 3 |
- | - | - | 3 → 2 → 1 → None |
常见错误与边界情况
错误一:丢失下一个引用
1 | # ❌ 错误:我们丢失了对 curr.next 的引用 |
错误二:不处理空链表
1 | # ❌ 错误:如果 head 是 None,我们错误地返回 None |
边界情况:
- 空链表(
head = None):返回None✅ - 单节点(
head = [1]):返回[1]✅ - 两节点(
head = [1,2]):返回[2,1]✅
面试技巧
面试官看重的:
- 指针操作:你能安全地移动指针而不丢失引用吗?
- 边界情况处理:你检查空/单节点链表吗?
- 空间优化:你能用
空间完成吗?
后续问题:
- "你能递归地反转吗?"
- "如果链表有环怎么办?"
- "你能只反转链表的一部分吗?"
方法二:递归
核心思想
递归定义:反转链表 = 反转剩余部分 + 调整当前节点的指针
基本情况:空链表或单节点,原样返回
递归步骤:
- 递归反转
head.next并得到新头节点new_head - 使
head.next.next指向head(反转指针) - 断开
head.next(防止环) - 返回
new_head
Python 实现
1 | def reverseList_recursive(head): |
复杂度分析
- 时间复杂度:
,每个节点访问一次 - 空间复杂度:
,递归栈深度
递归过程可视化
输入:1 → 2 → 3 → None
1 | reverseList(1) |
最终结果:3 → 2 → 1 → None
理解递归的魔法
递归方法向后工作:
- 它首先到达尾节点
- 然后,随着递归展开,它逐个反转指针
- 递归的每一层处理一个节点的反转
为什么 head.next.next = head?
- 反转从
head.next开始的子链表后,原本在head.next的节点现在是反转子链表的尾节点 - 我们希望这个尾节点指回
head head.next.next访问原本在head.next的节点,我们让它指向head
迭代 vs 递归对比
| 方法 | 时间 | 空间 | 优点 | 缺点 |
|---|---|---|---|---|
| 迭代 | 空间最优,更容易理解 | 代码稍长 | ||
| 递归 | 简洁,优雅 | 栈空间开销,潜在栈溢出 |
面试策略:从迭代开始(更实用),然后提及递归作为替代方法。
LeetCode 21: 合并两个有序链表
问题分析
核心难点:如何高效地合并两个有序链表,同时处理边界情况(空链表、一个链表先耗尽等)。需要维护结果链表的构建过程,确保节点按升序连接。
解题思路:使用虚拟节点( dummy
node)技术简化边界处理。虚拟节点作为结果链表的前驱,避免处理"第一个节点"的特殊情况。使用
current
指针跟踪当前构建位置,比较两个链表的当前节点值,将较小的节点连接到结果链表,然后移动相应指针。当一个链表耗尽时,直接将另一个链表的剩余部分连接到结果。
复杂度分析: - 时间复杂度:
关键洞察:虚拟节点消除了"第一个节点"的特殊情况,使代码更简洁统一。这是链表问题中常用的技巧。
问题描述
将两个升序链表合并为一个新的升序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例:
- 输入:
l1 = [1,2,4],l2 = [1,3,4] - 输出:
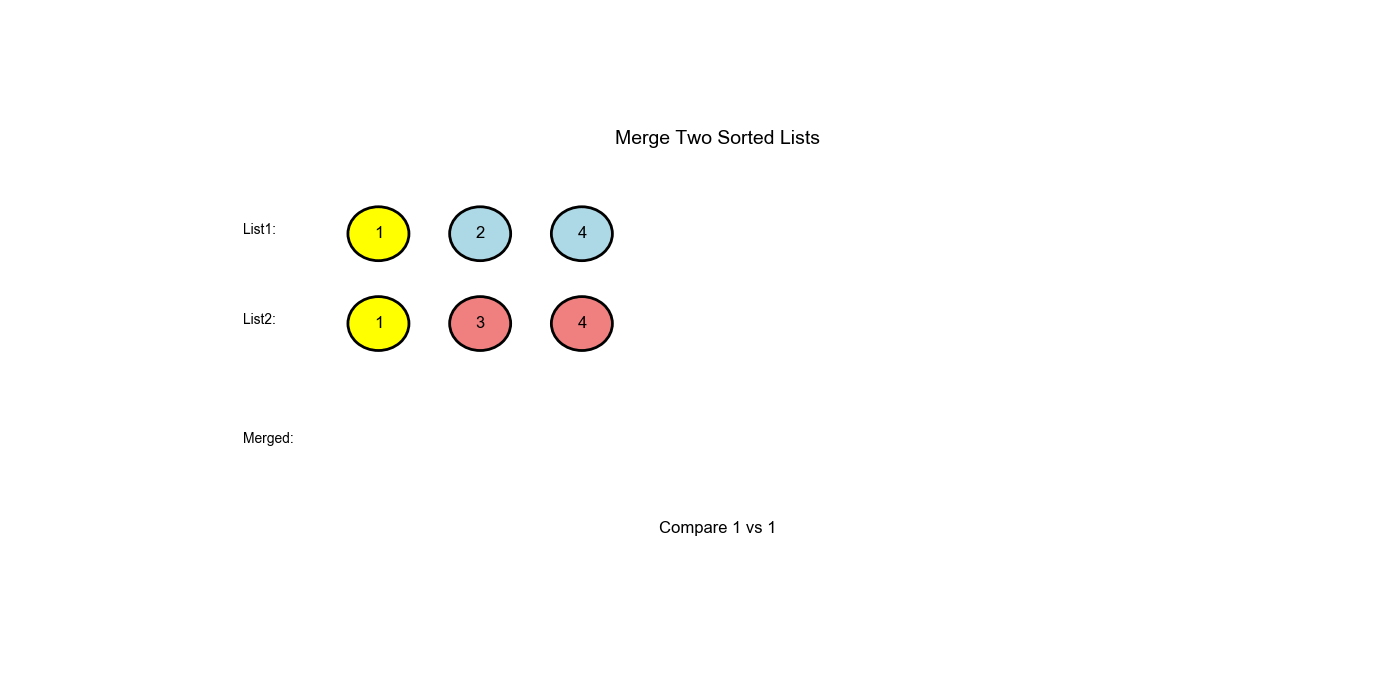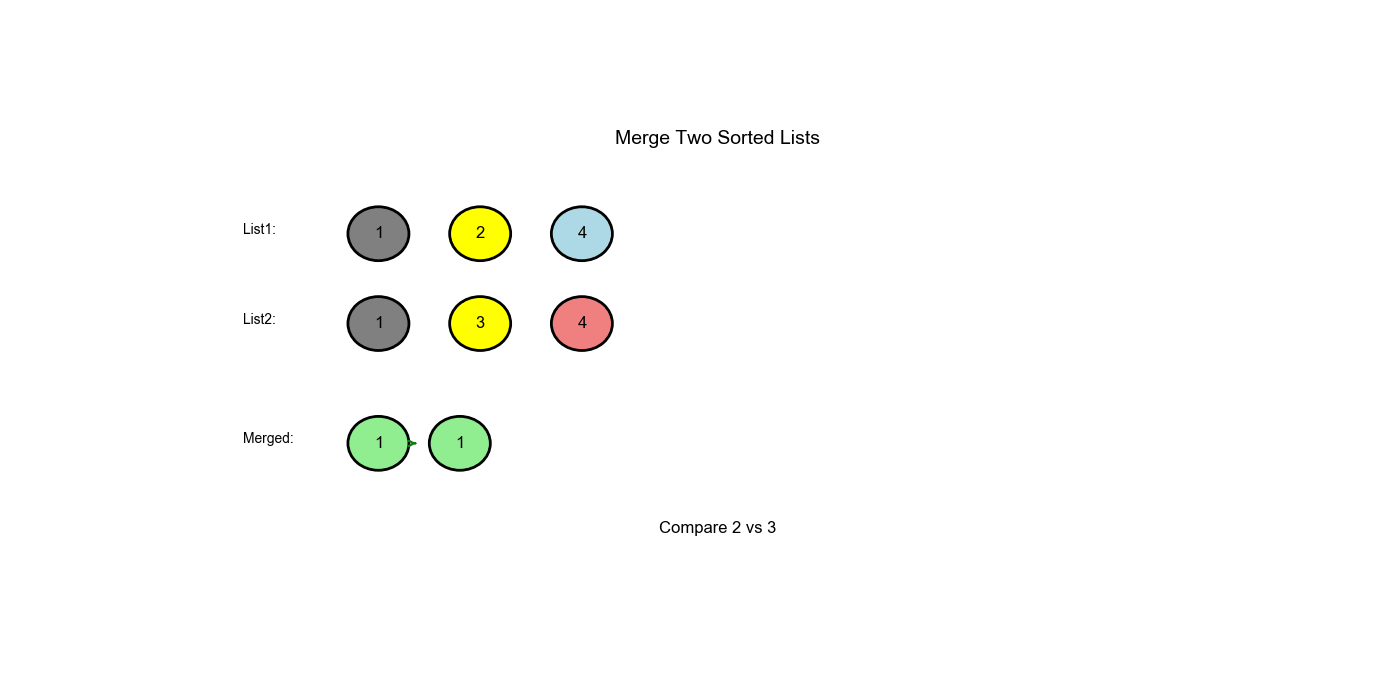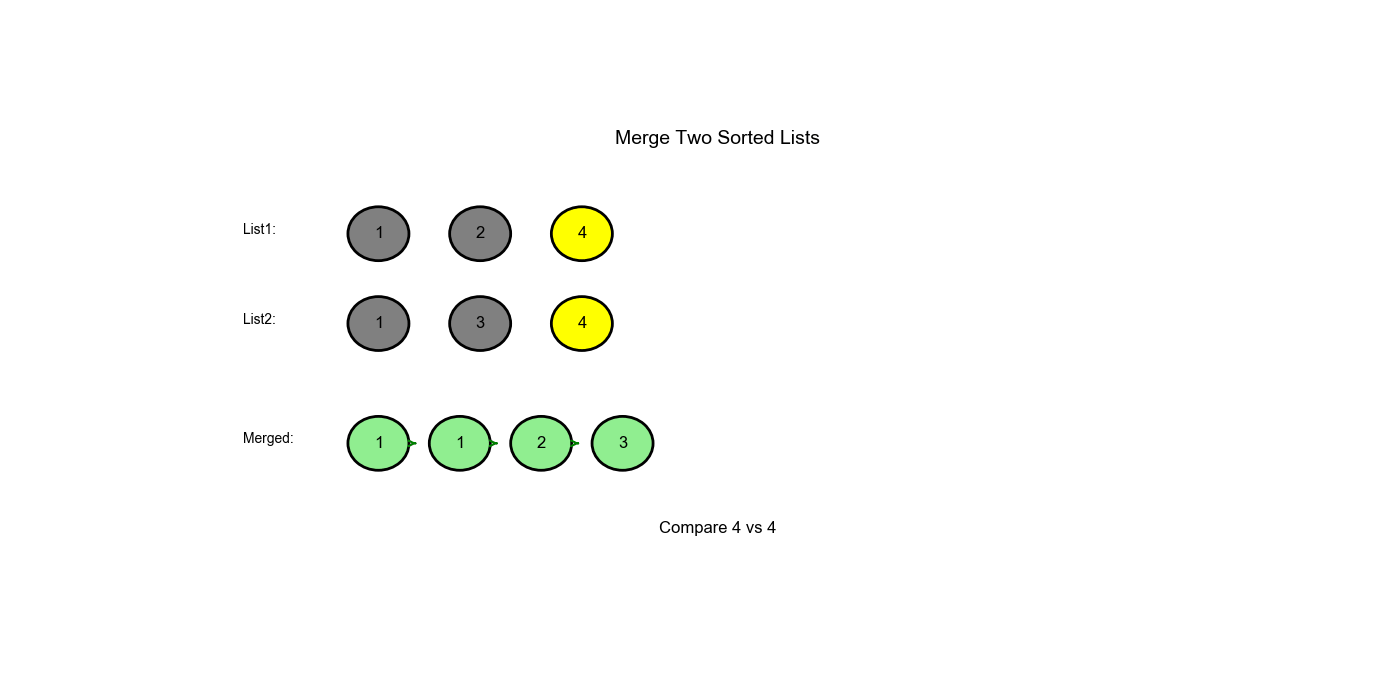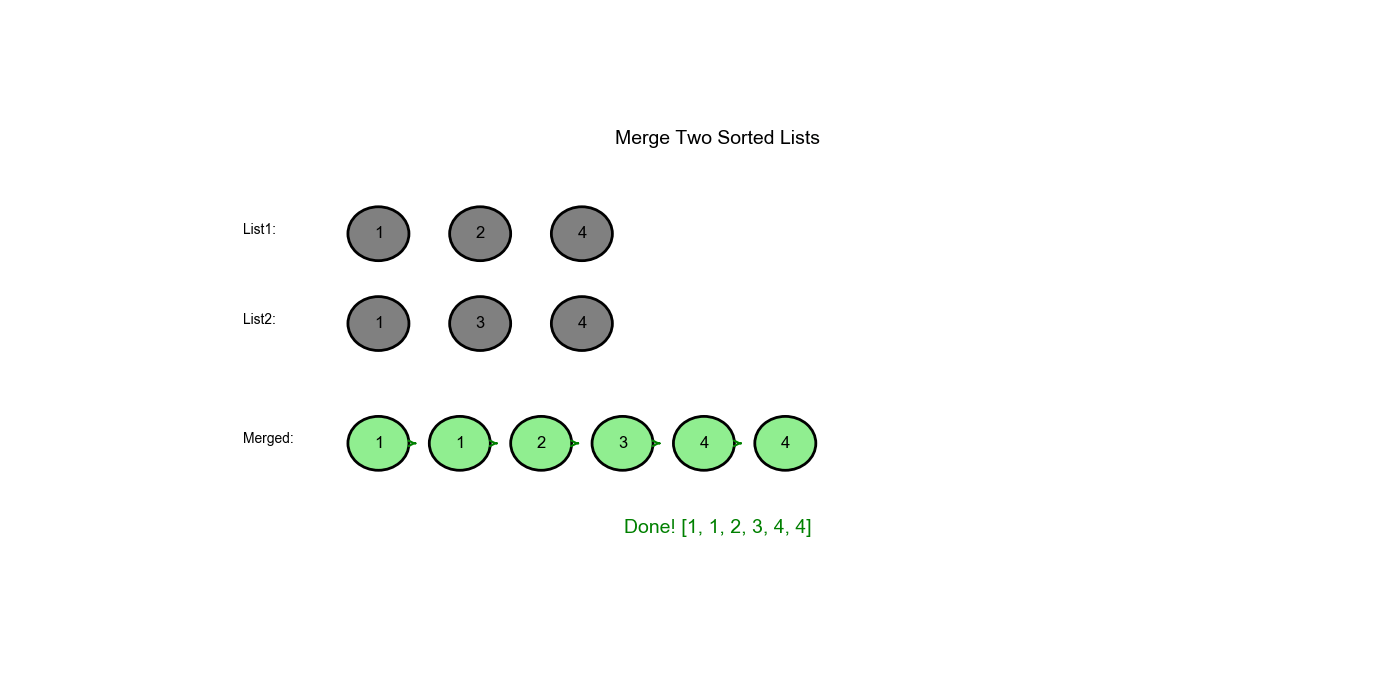
[1,1,2,3,4,4]
约束条件:
- 两个链表的节点数目范围是
- - 两个链表均为非递减顺序
方法一:迭代(虚拟节点技术)
核心思想
使用虚拟节点(哨兵节点)简化边界处理:
- 创建一个
dummy节点作为结果链表的前驱 - 使用
current指针跟踪当前构建位置 - 比较
l1和l2的值,将较小的附加到current - 处理剩余节点
- 返回
dummy.next(跳过哨兵)
Python 实现
1 | def mergeTwoLists(l1, l2): |
复杂度分析
- 时间复杂度:
,其中 和 是两个链表的长度 - 空间复杂度:
,仅使用常数额外指针
深入解读
算法原理:为什么虚拟节点能简化代码?
核心思想:虚拟节点作为"占位符",使得所有节点的处理逻辑统一。如果没有虚拟节点,需要特殊处理第一个节点(确定哪个链表提供头节点),代码会变得复杂。
为什么 current.next = l1 if l1 else l2
能正确处理剩余节点: - 如果 l1 和 l2
都非空:循环继续 - 如果 l1 为空:l2
的剩余部分(可能为空)直接连接到结果 - 如果 l2
为空:l1 的剩余部分(可能为空)直接连接到结果 -
如果两者都为空:current.next = None,正确结束
时间复杂度证明:为什么是 O(m+n)?
- 循环次数:最多
次(每个节点最多被访问一次) - 每次迭代操作:
(比较、连接、移动指针) - 总时间:
空间优化:有没有更省空间的方法?
这个问题已经是空间最优的: - 虚拟节点:current,
l1, l2) -
无法进一步优化:必须构建新链表
注意:结果链表本身需要
常见错误分析
| 错误类型 | 错误代码 | 问题 | 正确做法 |
|---|---|---|---|
| 忘记移动 current | current.next = l1; l1 = l1.next |
current 不更新 | current = current.next |
| 不使用虚拟节点 | 直接确定头节点 | 需要特殊处理 | 使用 dummy |
| 剩余节点处理错误 | if l1: current.next = l1 |
可能遗漏 l2 | current.next = l1 if l1 else l2 |
变体扩展
- 合并 K 个有序链表:使用分治或优先队列
- 合并两个有序链表(原地):不创建新节点,修改原链表
- 合并两个有序数组:类似思路,但数组需要移动元素
虚拟节点的威力
为什么需要虚拟节点?
不使用虚拟节点:
1 | # ❌ 需要特殊处理第一个节点 |
使用虚拟节点:
1 | # ✅ 统一处理,无特殊情况 |
现实类比:虚拟节点就像"施工标记"——完成后移除,但在施工过程中提供固定参考点。
逐步解析
输入:l1 = [1,2,4],
l2 = [1,3,4]
| 步骤 | l1 |
l2 |
current |
操作 | 当前结果 |
|---|---|---|---|---|---|
| 初始 | 1 |
1 |
dummy |
- | dummy → ... |
| 1 | 1 |
1 |
dummy |
比较:1 <= 1,附加 l1 |
dummy → 1 |
| 1 | 2 |
1 |
1 |
移动 l1 向前 |
- |
| 2 | 2 |
1 |
1 |
比较:1 < 2,附加 l2 |
dummy → 1 → 1 |
| 2 | 2 |
3 |
1 |
移动 l2 向前 |
- |
| 3 | 2 |
3 |
1 |
比较:2 < 3,附加 l1 |
dummy → 1 → 1 → 2 |
| 3 | 4 |
3 |
2 |
移动 l1 向前 |
- |
| 4 | 4 |
3 |
2 |
比较:3 < 4,附加 l2 |
dummy → 1 → 1 → 2 → 3 |
| 4 | 4 |
4 |
3 |
移动 l2 向前 |
- |
| 5 | 4 |
4 |
3 |
比较:4 <= 4,附加 l1 |
dummy → 1 → 1 → 2 → 3 → 4 |
| 5 | None |
4 |
4 |
l1 耗尽,附加 l2 的剩余部分 |
dummy → 1 → 1 → 2 → 3 → 4 → 4 |
| 返回 | - | - | - | 返回 dummy.next |
1 → 1 → 2 → 3 → 4 → 4 |
边界情况
- 一个链表为空:
l1 = [],l2 = [1,2]→ 返回[1,2]✅ - 两个链表都为空:
l1 = [],l2 = []→ 返回[]✅ - 一个链表更长:
l1 = [1],l2 = [2,3,4]→ 返回[1,2,3,4]✅
方法二:递归
核心思想
递归定义:
- 如果
l1.val <= l2.val,结果是l1+ merge(l1.next,l2) - 否则,结果是
l2+ merge(l1,l2.next)
Python 实现
1 | def mergeTwoLists_recursive(l1, l2): |
复杂度分析
- 时间复杂度:
- 空间复杂度:
,递归栈
递归可视化
输入:l1 = [1,2],
l2 = [3,4]
1 | mergeTwoLists([1,2], [3,4]) |
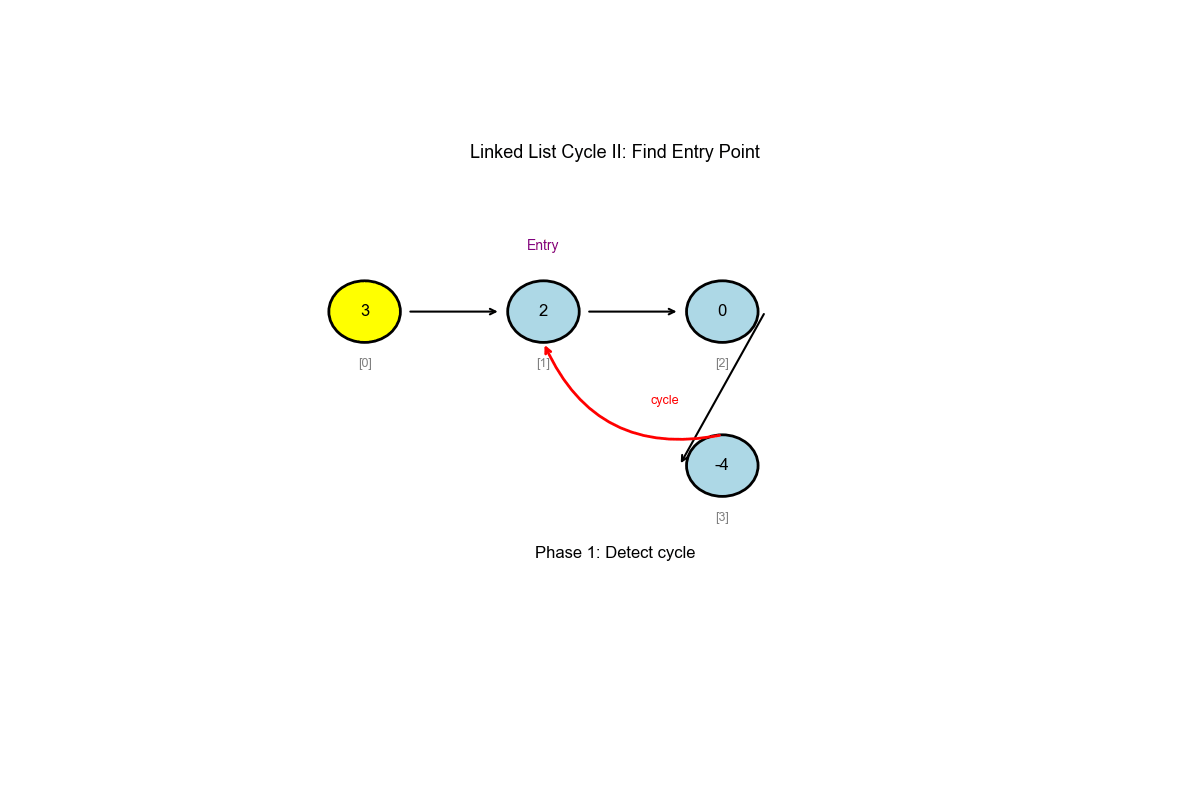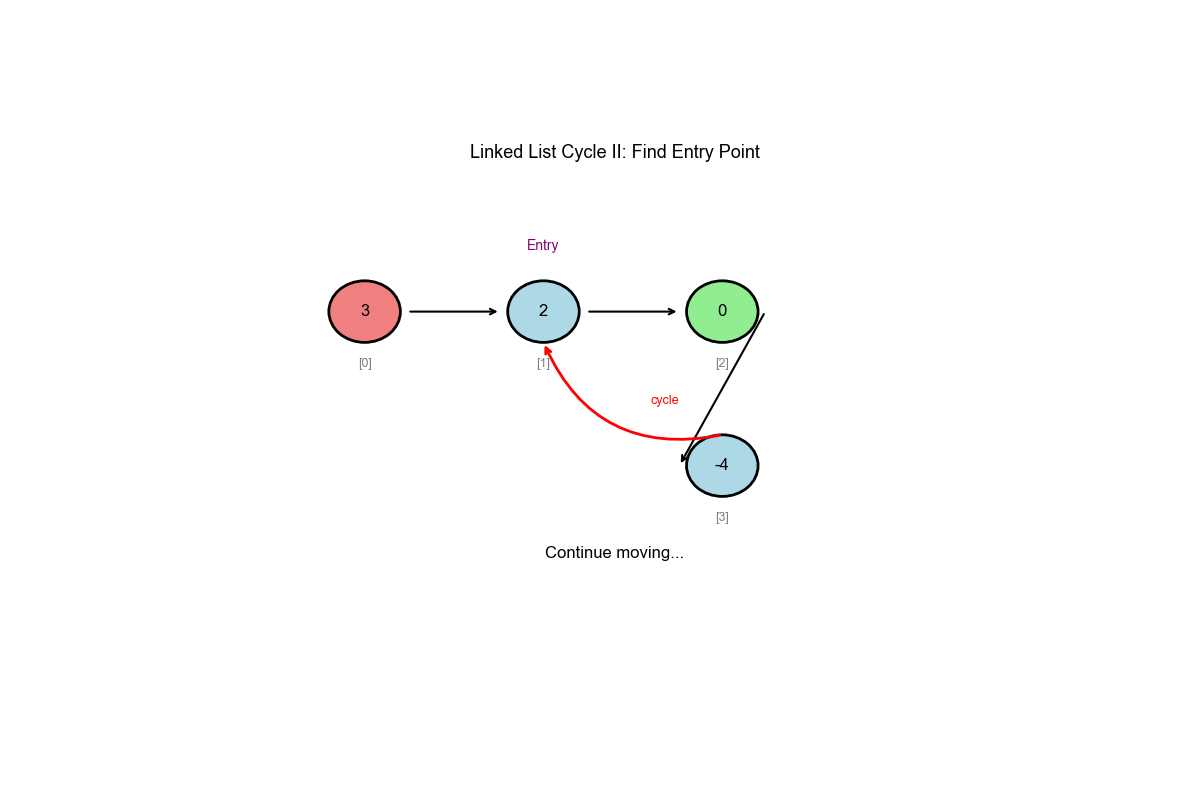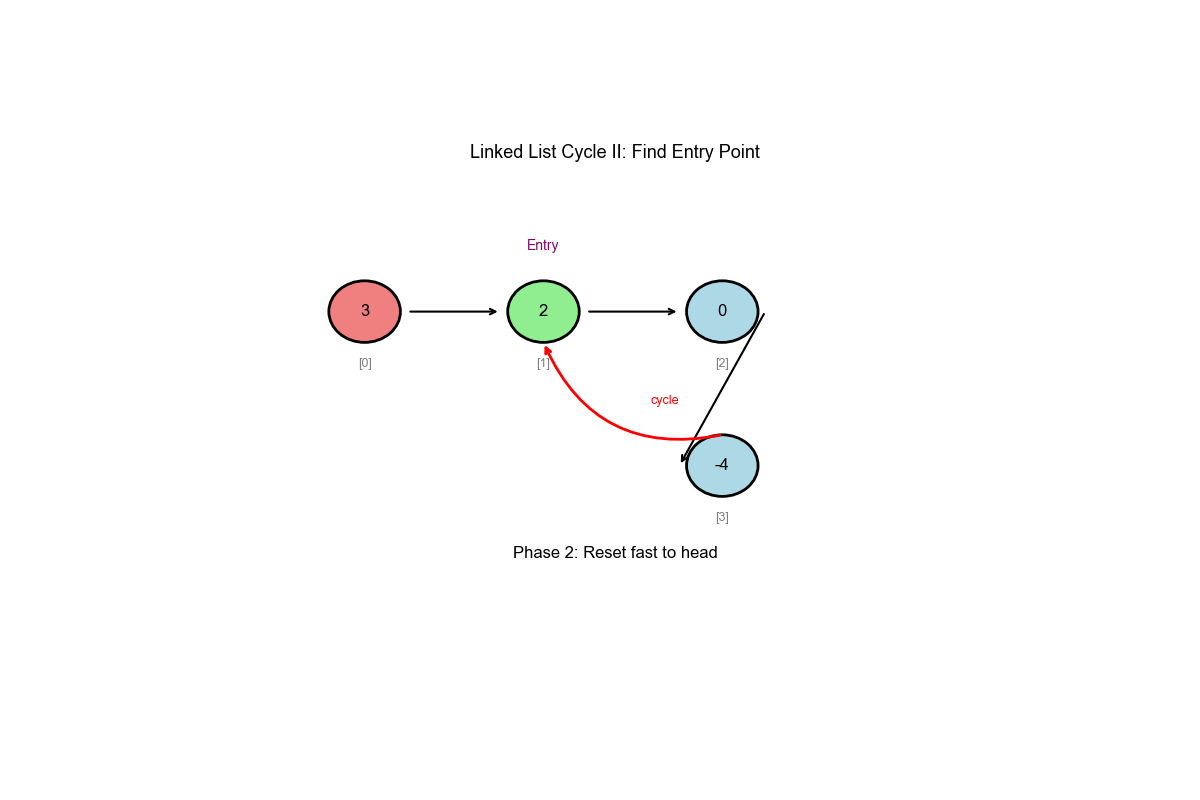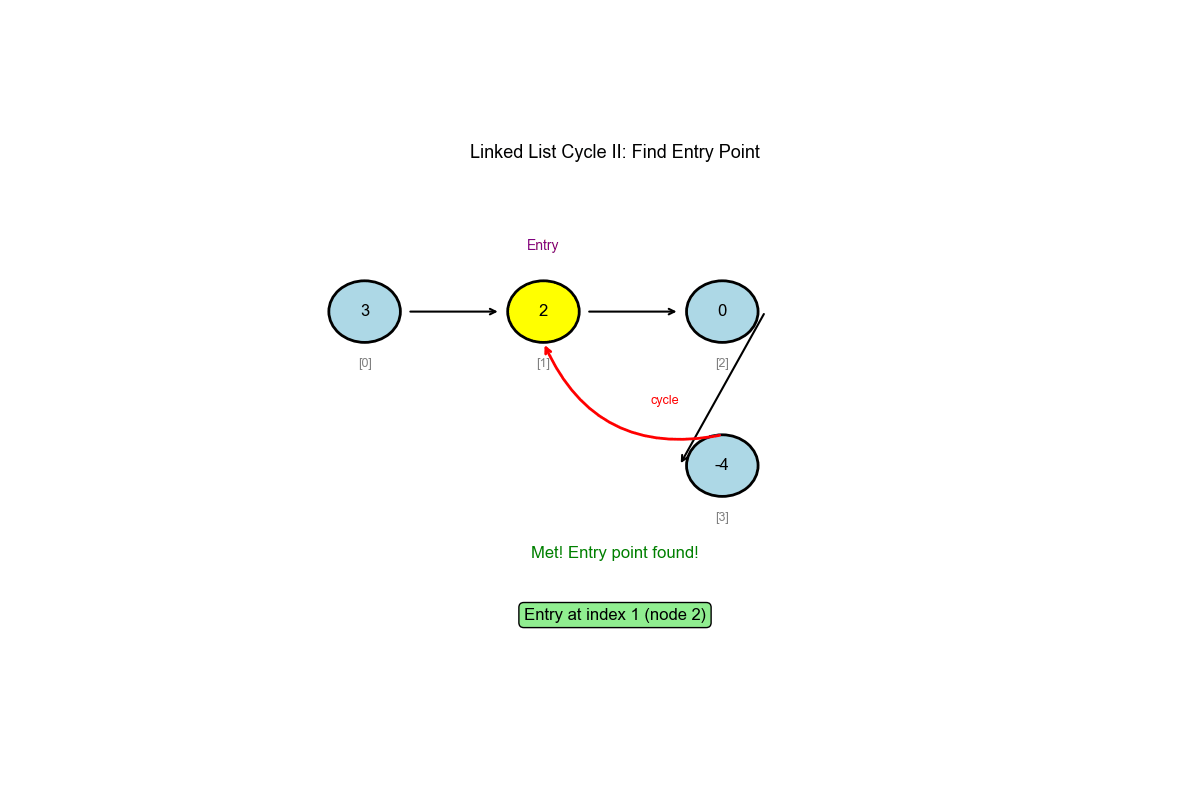
LeetCode 142: 环形链表 II
问题分析
核心难点:这道题在检测环的基础上,还需要找到环的入口节点。使用哈希集合需要
解题思路:使用 Floyd 算法的两阶段方法。阶段一:使用快慢指针检测环并找到相遇点。阶段二:将一个指针移回头部,两个指针以相同速度移动,它们会在环入口相遇。这个方法的正确性基于数学证明:从头部到入口的距离等于从相遇点到入口的距离。
复杂度分析: - 时间复杂度:
关键洞察: Floyd
算法的数学性质:当快慢指针相遇时,从头部到入口的距离等于从相遇点到入口的距离。这允许我们在
问题描述
给定一个链表的头节点
head,返回链表开始入环的第一个节点。如果链表无环,则返回
null。
进阶:你能用
示例:
- 输入:
head = [3,2,0,-4],尾节点连接到索引 1 的节点 - 输出:索引 1 的节点
核心思想: Floyd 环检测算法(扩展)
阶段一:使用快慢指针检测是否存在环
阶段二:找到环入口
- 相遇后,将一个指针移回起点
- 两个指针以相同速度移动(每次 1 步)
- 相遇点就是环入口
Python 实现
1 | def detectCycle(head): |
数学证明
设:
从起点到环入口的距离:
从环入口到相遇点的距离:
从相遇点回到环入口的距离:
环长度:
当它们相遇时: 慢指针移动了:
快指针移动了:
(其中 是额外循环数)
因为快指针是慢指针的 2 倍:
关键洞察:从起点走
因为
可视化解释
1 | 起点 → [a 步] → 入口 → [b 步] → 相遇点 |
当慢指针和快指针相遇时:
- 慢指针:移动了
- 快指针:移动了
(其中 )
从方程
- 如果我们将 slow 移回起点,两者都以 1 步移动
- Slow 将移动
步到达入口 - Fast 将移动
步,这也到达入口(因为 是完整循环)
复杂度分析
- 时间复杂度:
- 空间复杂度:
常见错误
错误一:不检查环是否存在
1 | # ❌ 错误:假设环存在 |
错误二:错误的指针重置
1 | # ❌ 错误:重置 fast 而不是 slow |
LeetCode 160: 相交链表
问题分析
核心难点:如何在
解题思路:使用路径切换的双指针技巧。让指针
pA 遍历链表 A,到达末尾时切换到链表 B 的起点;让指针
pB 遍历链表 B,到达末尾时切换到链表 A
的起点。这样两个指针会走过相同的总距离( A 的唯一部分 + 公共部分 + B
的唯一部分),如果相交,它们会在交点相遇;如果不相交,它们会同时到达
None。
复杂度分析: - 时间复杂度:
关键洞察:路径切换使得两个指针走过相同的总距离,这是找到交点的关键。这个技巧避免了计算链表长度或使用额外空间。
问题描述
给你两个单链表的头节点 headA 和
headB,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回
null。
约束条件:
- 链表无环
- 函数返回后,链表必须保持其原始结构
- 进阶:
时间, 空间
示例:
1 | A: a1 → a2 ↘ |
相交点是 c1。
方法一:双指针(路径对齐)
核心思想
关键观察:如果两个链表相交,从交点到末尾的路径长度相同。
巧妙技巧:
- 指针
pA遍历 A,到达末尾时跳到 B 的起点 - 指针
pB遍历 B,到达末尾时跳到 A 的起点 - 两个指针将在交点相遇(或都到达
None)
为什么这样可行?
设:
- A 的唯一部分长度:
- B 的唯一部分长度:
- 公共部分长度:
pA路径:pB路径:它们相等!所以它们会同时到达交点(或 None)。
Python 实现
1 | def getIntersectionNode(headA, headB): |
复杂度分析
- 时间复杂度:
- 空间复杂度:
逐步解析
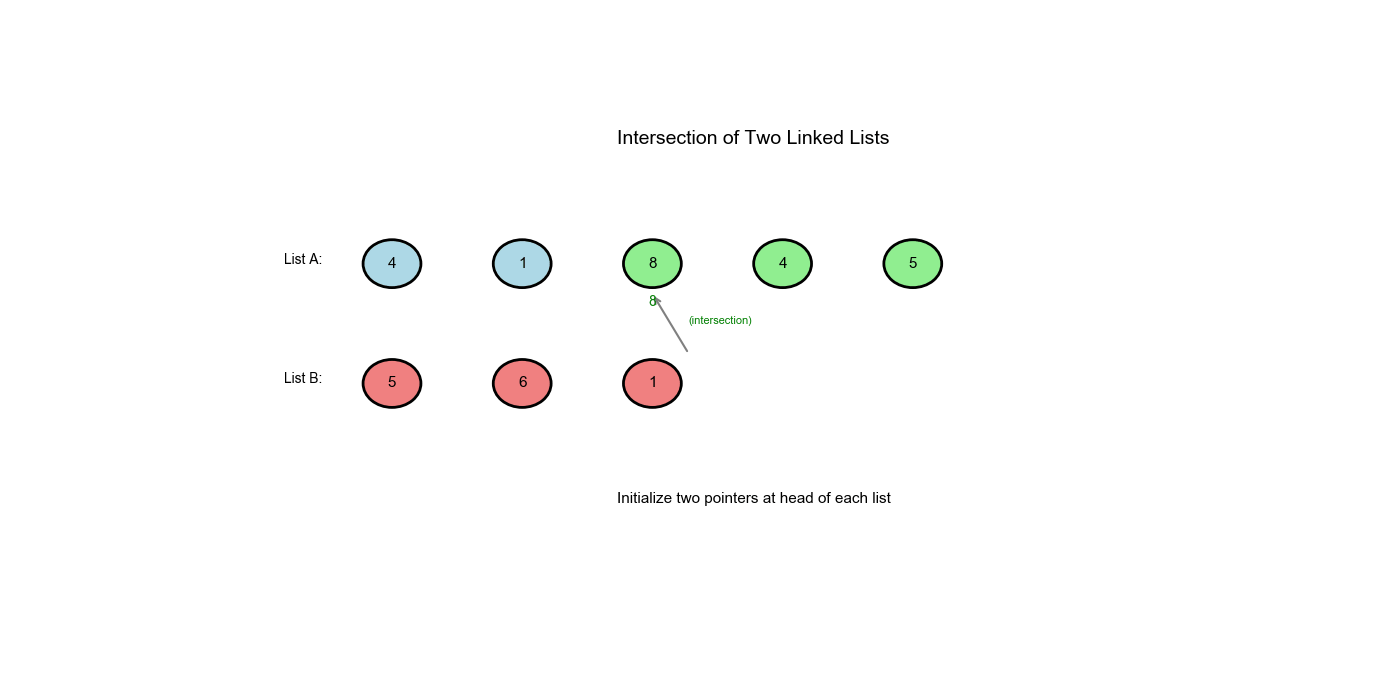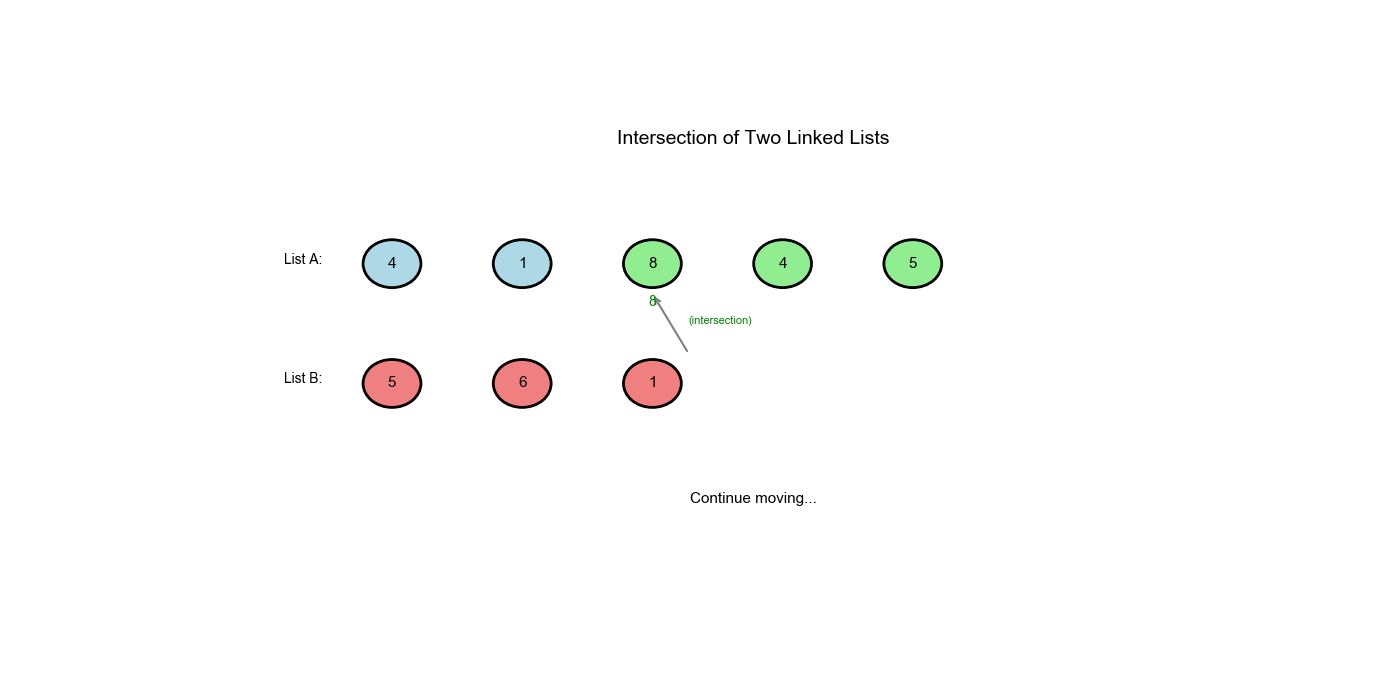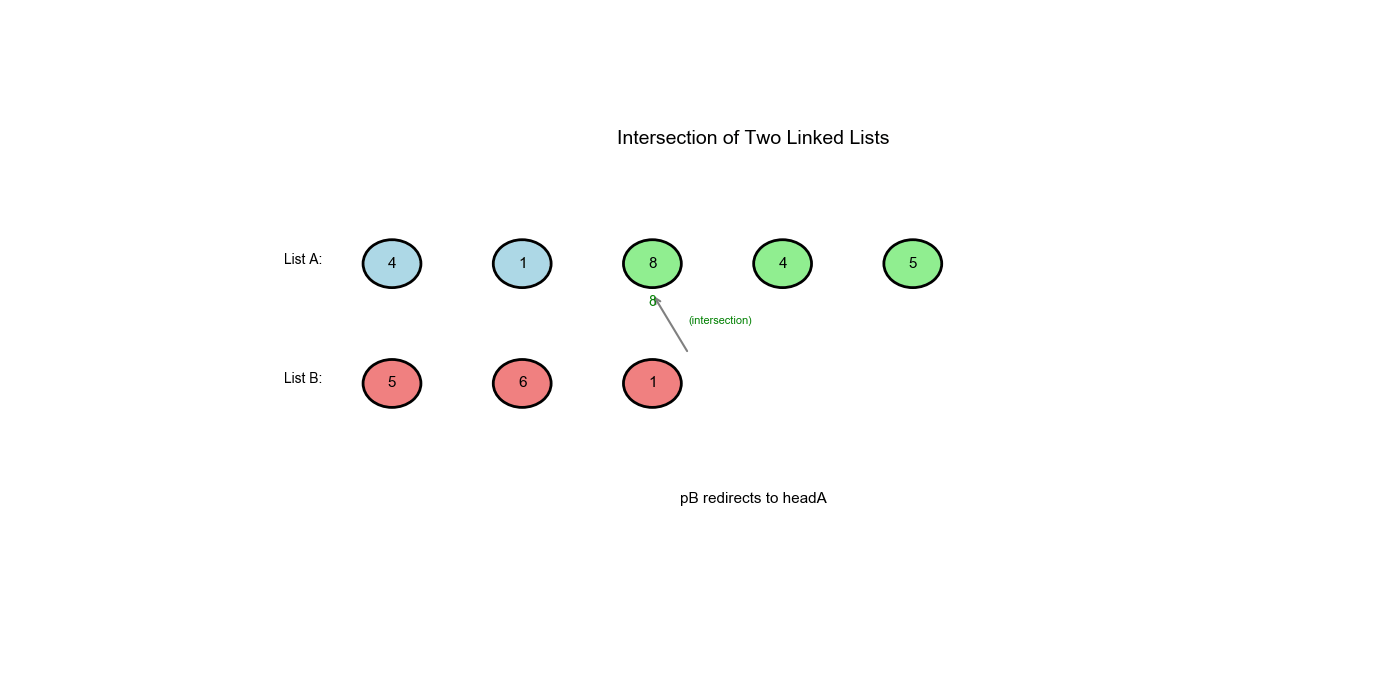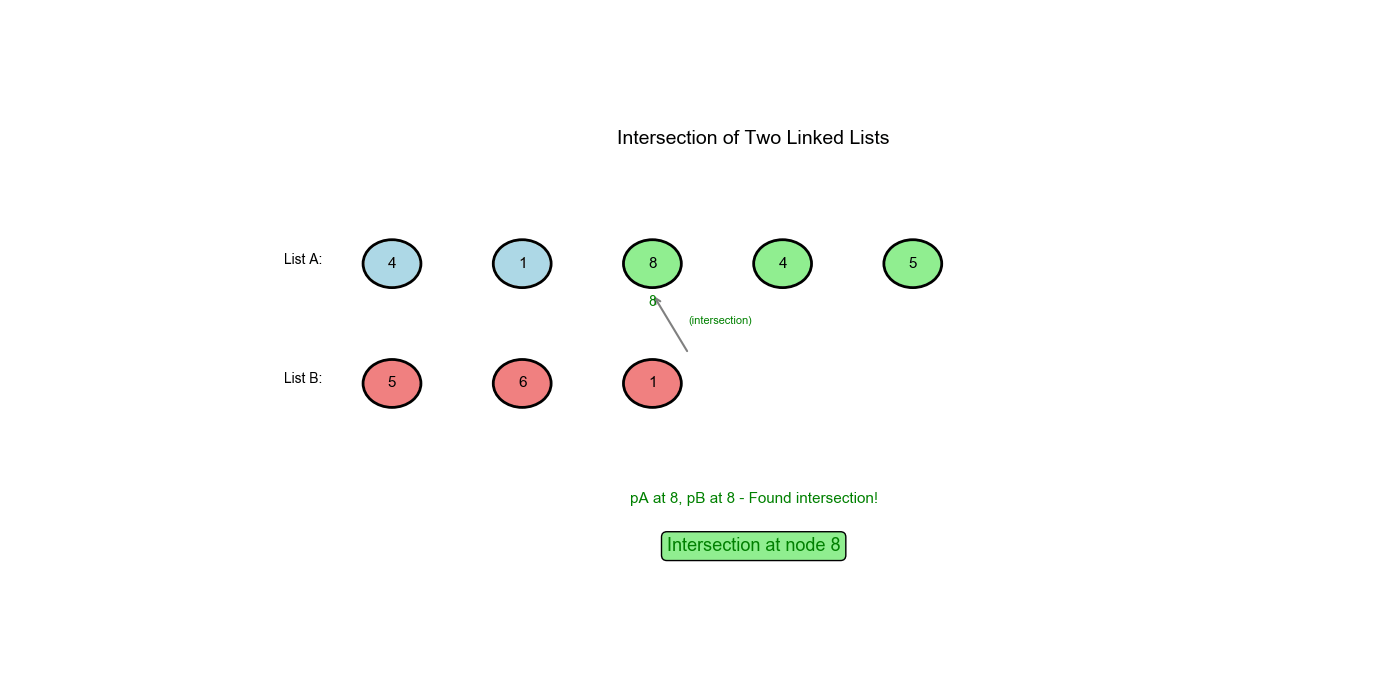
输入:
1 | A: 1 → 2 → 8 → 9 |
| 步骤 | pA |
pB |
pA == pB? |
|---|---|---|---|
| 0 | 1 |
3 |
❌ |
| 1 | 2 |
8 |
❌ |
| 2 | 8 |
9 |
❌ |
| 3 | 9 |
None |
❌ |
| 4 | None |
1(切换到 A) |
❌ |
| 5 | 3(切换到 B) |
2 |
❌ |
| 6 | 8 |
8 |
✅相遇! |
为什么这样可行:数学证明
设:
- 链表 A 长度:
- 链表 B 长度:
- 其中
= A 的唯一部分, = B 的唯一部分, = 公共部分
切换后:
pA行进:pB行进:两者行进相同距离!如果它们相交,它们在交点相遇。如果不相交,两者同时变为 None。
方法二:哈希集合
Python 实现
1 | def getIntersectionNode_hash(headA, headB): |
复杂度
- 时间:
- 空间:
或 对比:双指针方法是空间最优的!
LeetCode 19: 删除链表的倒数第 N 个结点
问题分析
核心难点:如何在一次遍历中找到倒数第
解题思路:使用双指针保持
复杂度分析: - 时间复杂度:
关键洞察:双指针的间隔技巧是解决"倒数第 k 个"问题的经典方法。虚拟节点统一处理了删除头节点的特殊情况。

问题描述
给你一个链表,删除链表的倒数第
进阶:你能尝试使用一趟扫描实现吗?
示例:
- 输入:
head = [1,2,3,4,5],n = 2 - 输出:
[1,2,3,5](删除倒数第 2 个节点,即4)
约束条件:
- 链表中结点的数目为
-
核心思想:双指针(间隔 n)
步骤:
- 创建一个虚拟节点(处理删除头节点的情况)
- 快指针向前移动
步 - 两个指针同步移动直到快指针到达末尾
- 慢指针现在位于要删除节点的前一个节点
- 删除:
slow.next = slow.next.next
Python 实现
1 | def removeNthFromEnd(head, n): |
复杂度分析
- 时间复杂度:
,其中 是链表长度,一次遍历 - 空间复杂度:
深入解读
算法原理:为什么双指针间隔技巧能 work?
核心思想:要删除倒数第
数学证明:设链表长度为
时间复杂度证明:为什么是 O(L)?
- 快指针移动:先移动
步,然后移动 步到达末尾 - 总移动:
步 - 慢指针移动:
步 - 总时间:
空间优化:有没有更省空间的方法?
这个问题已经是空间最优的: - 虚拟节点:
对比其他方法: | 方法 | 时间 | 空间 | 遍历次数 |
|------|------|------|---------| | 双指针 |
常见错误分析
| 错误类型 | 错误代码 | 问题 | 正确做法 |
|---|---|---|---|
| 间隔错误 | for _ in range(n) |
慢指针停在目标节点 | range(n + 1) |
| 不使用虚拟节点 | 直接处理头节点 | 需要特殊处理 | 使用 dummy |
| 忘记检查边界 | 不检查 n 是否有效 |
可能越界 | 先验证 n |
变体扩展
- 删除链表的倒数第 N 个结点(一次遍历):当前方法
- 找到链表的中间节点:快指针移动 2 步,慢指针移动 1 步
- 找到链表的第 k 个节点:快指针先移动 k 步
为什么快指针移动 n+1 步?
目标:使 slow
停在目标节点的前一个节点。
示例:head = [1,2,3,4,5],
n = 2(删除 4)
| 快指针位置 | 慢指针位置 | 解释 |
|---|---|---|
dummy → 1 → 2 → 3 |
dummy |
快指针移动了 3 步( n+1) |
3 → 4 → 5 → None |
dummy → 1 → 2 → 3 |
同步移动 |
None |
3 |
Slow 在 3,可以删除
4 |
边界情况:删除头节点
输入:head = [1,2],
n = 2(删除 1)
- 快指针移动 3 步:
dummy → 1 → 2 → None - 慢指针仍在
dummy - 删除:
dummy.next = 1.next = 2 - 返回:
dummy.next = 2✅
不使用虚拟节点:需要特殊处理头删除,代码变得复杂!
常见错误
错误一:错误的间隔大小
1 | # ❌ 错误:仅 n 步, slow 将在目标节点,而不是之前 |
错误二:不使用虚拟节点
1 | # ❌ 错误:需要头删除的特殊情况 |
LeetCode 23: 合并 K 个有序链表
问题描述
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例:
- 输入:
lists = [[1,4,5],[1,3,4],[2,6]] - 输出:
[1,1,2,3,4,4,5,6]
约束条件:
-
方法一:分治
核心思想
递归地成对合并链表,类似于归并排序:
- 分:将链表数组分成两半
- 治:递归合并每一半
- 合:合并两个合并后的半部分
Python 实现
1 | def mergeKLists(lists): |
复杂度分析
- 时间复杂度:
,其中 是总节点数, 是链表数 - 空间复杂度:
,递归栈深度
为什么分治?
朴素方法:逐个合并链表
- 时间:
(每次合并是 ,执行 次)
分治:成对合并
- 时间:
(合并树有 层,每层处理 个节点)
方法二:优先队列(堆)
Python 实现
1 | import heapq |
LeetCode 138: 复制带随机指针的链表
问题描述
给你一个长度为random,该指针可以指向链表中的任何节点或空节点。
构造这个链表的深拷贝。
示例:
1 | 原始: 7 → 13 → 11 → 10 → 1 → None |
方法:两次遍历与哈希映射
核心思想
- 第一次遍历:创建所有新节点并建立旧 → 新映射
- 第二次遍历:使用映射连接
next和random指针
Python 实现
1 | def copyRandomList(head): |
复杂度分析
- 时间复杂度:
,两次遍历 - 空间复杂度:
,哈希映射存储
虚拟节点的威力
何时使用虚拟节点?
信号:
- 可能删除头节点
- 需要返回新头节点
- 构建新链表
好处:
- 统一处理头节点和其他节点
- 无空链表的特殊情况
- 代码更简洁
对比示例:删除节点
不使用虚拟节点:
1 | def deleteNode(head, val): |
使用虚拟节点:
1 | def deleteNode_dummy(head, val): |
常见陷阱与调试技巧
陷阱一:空指针访问
1 | # ❌ curr 可能是 None |
修复:
1 | # ✅ 检查 curr.next 是否存在 |
陷阱二:修改指针后丢失节点引用
1 | # ❌ 错误示例 |
正确方法:
- 如果需要访问删除的节点,先保存:
1
2
3to_delete = curr.next
curr.next = curr.next.next
# 仍可使用 to_delete
陷阱三:忘记移动指针
1 | # ❌ 无限循环 |
调试技巧
技巧一:打印链表
1 | def print_list(head): |
技巧二:画图
在每一步绘制链表状态,特别是在修改指针时。
技巧三:逐步调试
对于复杂操作(如反转、合并),逐步执行并检查每一步后的指针状态。
链表面试沟通模板
模板一:识别链表特征
"这个问题涉及链表操作。链表具有
插入/删除但 访问。我将使用[迭代/递归]方法,采用[双指针/虚拟节点]技术来[反转/合并/检测]链表。"
模板二:选择迭代 vs 递归
"我可以用迭代实现,空间复杂度
,或者用递归实现,代码更简洁但空间复杂度 。对于生产环境,我倾向于迭代以避免栈溢出;对于面试,我先展示迭代,然后提及递归作为替代。"
模板三:解释虚拟节点
"我将使用虚拟节点作为哨兵来统一处理头节点特殊情况,避免复杂的边界检查。最后,返回
dummy.next。"
模板四:快慢指针
"我将使用快慢指针:快指针移动 2 步,慢指针移动 1 步。这以一次遍历解决,时间复杂度
,空间复杂度 。"
❓ Q&A:链表面试技巧
Q1:什么时候应该对链表使用递归 vs 迭代?
答案:当以下情况使用迭代:
- 空间优化重要(
vs ) - 生产代码(避免栈溢出风险)
- 长链表(递归深度担忧)
当以下情况使用递归:
- 代码清晰度优先
- 在面试中展示多种方法
- 自然递归结构(例如,类似树的问题)
面试提示:总是提及两种方法,但先实现迭代。
Q2:如何系统地处理边界情况?
答案:系统地检查这些:
- 空链表:
head == None - 单节点:
head.next == None - 两节点:操作的特殊情况
- 头节点修改:使用虚拟节点
- 环检测:访问前检查
fast和fast.next
模式:访问 node.next 前总是检查
node。
Q3:找链表中间的最佳方法是什么?
答案:使用快慢指针:
1 | def findMiddle(head): |
当快指针到达末尾时,慢指针在中点(或偶数长度时的第二个中点)。
Q4:如何在不使用额外空间的情况下检测环?
答案:使用Floyd 算法(快慢指针):
- 快指针移动 2 步,慢指针移动 1 步
- 如果它们相遇,存在环
- 找入口:将一个指针移到起点,两者都移动 1 步
时间:
Q5:当你只能访问该节点时,删除节点的技巧是什么?
答案:复制下一个节点的数据,然后删除下一个节点:
1 | def deleteNode(node): |
注意:这对最后一个节点不起作用(需要
None)。
Q6:如何按 k 组反转链表?
答案:使用递归:
1 | def reverseKGroup(head, k): |
Q7:链表问题中最常见的错误是什么?
答案:当 node 可能是
None 时访问 node.next。
总是检查:
1 | if node and node.next: |
Q8:如何高效合并 k 个有序链表?
答案:两种主要方法:
分治:
时间, 空间 - 递归成对合并
优先队列:
时间, 空间 - 使用最小堆总是获取最小元素
两者都是最优的。根据空间约束选择。
Q9:能否在不使用额外空间的情况下原地修改链表?
答案:可以!大多数操作可以在
- 反转:三指针
- 环检测:快慢指针
- 合并:虚拟节点 + 指针
- 删除:双指针
关键:巧妙地使用指针,避免额外数据结构。
Q10:被问及时间/空间复杂度时应该说什么?
答案:要具体:
- 时间:计算操作(遍历、比较)
- 空间:计算额外变量(指针 =
,递归栈 = ,哈希映射 = )
示例:"这使用两个指针,所以空间是
练习题目( 10 道推荐)
基本操作
- 反转链表( LeetCode 206)← 本文已覆盖 简单
- 合并两个有序链表( LeetCode 21)← 本文已覆盖 简单
- 删除链表的倒数第 N 个结点( LeetCode 19)← 本文已覆盖 中等
环检测与相交
- 环形链表( LeetCode 141)简单
- 环形链表 II( LeetCode 142)← 本文已覆盖 中等
- 相交链表( LeetCode 160)← 本文已覆盖 简单
高级操作
- 回文链表( LeetCode 234)简单
- 排序链表( LeetCode 148)中等
- 重排链表( LeetCode 143)中等
- 复制带随机指针的链表( LeetCode 138)← 本文已覆盖 中等
总结:链表操作速查表
核心技术快速参考
| 技术 | 用例 | 示例问题 |
|---|---|---|
| 双指针 | 找中点、环检测、倒数第 n 个 | 环检测、删除倒数第 n 个节点 |
| 虚拟节点 | 删除头节点、构建新链表 | 合并链表、删除节点 |
| 递归 | 反转、合并(代码简洁) | 反转链表、合并链表 |
| 迭代 | 所有操作(空间最优) | 反转链表、检测环 |
何时使用什么?
双指针:
- 需要同时跟踪多个位置
- 环检测(快慢)
- 找中点、倒数第 n 个
虚拟节点:
- 可能修改头节点
- 构建新链表
- 简化边界条件
递归 vs 迭代:
- 递归:代码简洁,适合展示算法思维
- 迭代:空间最优,更适合生产环境
常见陷阱
- 空指针:访问
node.next前检查node - 丢失引用:修改指针前保存必要引用
- 忘记移动指针:每个循环分支必须移动指针
- 边界情况:空链表、单节点、头节点操作
面试黄金短语
"链表的核心是指针操作。我将使用[双指针/虚拟/递归]技术,确保边界安全,实现
时间, 空间(或解释递归的 栈空间)。"
记忆口诀
双指针找环和中点,虚拟简化边界,迭代节省空间递归优雅,指针操作避免空指针和陷阱!
下一篇文章预览
在LeetCode(四):二叉树遍历与递归中,我们将探索:
- 四种遍历方法:前序、中序、后序、层序
- 递归模式:子树问题分解
- Morris 遍历:
空间遍历 - 经典问题:最近公共祖先、路径和、树序列化
思考题:如何在不使用递归或栈的情况下执行中序遍历?下一篇文章见答案!
链表不是数据结构的"困难部分"——它们是指针思维的试金石。掌握它们,你将轻松处理树、图和更复杂的结构!
- 本文标题:LeetCode(三)—— 链表操作
- 本文作者:Chen Kai
- 创建时间:2020-01-18 10:45:00
- 本文链接:https://www.chenk.top/LeetCode%EF%BC%88%E4%B8%89%EF%BC%89%E2%80%94%E2%80%94-%E9%93%BE%E8%A1%A8%E6%93%8D%E4%BD%9C/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!