动态规划( Dynamic Programming,简称 DP)是算法竞赛和 LeetCode 中最重要也最常考的算法思想之一。很多看似复杂的问题,一旦识别出 DP 的本质,就能用简洁的状态转移方程优雅地解决。本文将从零开始,带你理解动态规划的核心思想,掌握 DP 的三步骤解题法,并通过经典一维、二维 DP 问题深入实践,最后探讨状态压缩、复杂度分析等进阶话题。
什么是动态规划
动态规划本质上是一种用空间换时间的优化技术。它通过保存已计算子问题的结果,避免重复计算,从而将指数级的时间复杂度降低到多项式级别。
核心思想:最优子结构与重叠子问题
动态规划能成立,需要满足两个关键性质:
1. 最优子结构( Optimal Substructure)
一个问题的最优解包含其子问题的最优解。换句话说,如果我们知道了所有子问题的最优解,就能构造出原问题的最优解。
举个例子:要计算从 A 到 C 的最短路径,如果路径经过 B,那么 A → B 和 B → C 都必须是各自段的最短路径。如果 A → B 不是最短的,那么整条路径 A → B → C 也不可能是最短的。
2. 重叠子问题( Overlapping Subproblems)
在递归求解过程中,同一个子问题会被多次计算。比如计算斐波那契数列时,fib(5)
需要计算 fib(4) 和 fib(3),而
fib(4) 又需要计算 fib(3) 和
fib(2),fib(3) 被重复计算了。
动态规划通过记忆化( Memoization)或自底向上的表格填充,确保每个子问题只计算一次。
动态规划 vs 递归 vs 记忆化
很多初学者会混淆这三个概念,这里做个清晰的对比:
递归( Recursion):函数调用自身,但可能重复计算子问题。
1 | def fib_recursive(n): |
时间复杂度:
记忆化递归( Memoization):在递归基础上加缓存,避免重复计算。
1 | memo = {} |
时间复杂度:
1 | def fib_dp(n): |
时间复杂度:
选择建议:
- 如果子问题重叠明显,优先考虑 DP
- 如果递归思路更直观,先用记忆化递归验证,再改写成 DP
- 自底向上的 DP 通常空间效率更高,且可以进一步优化
DP 解题三步骤
掌握这三步,大部分 DP 问题都能迎刃而解:
步骤一:定义状态
状态就是问题的子问题。通常用 dp[i] 或
dp[i][j] 表示某个条件下的最优值。
关键问题:dp[i] 到底表示什么?
常见模式:
dp[i]:前 i 个元素的最优解dp[i]:以第 i 个元素结尾的最优解dp[i][j]:前 i 个元素在 j 条件下的最优解
技巧:先想清楚“如果我知道
dp[i-1],我能推出 dp[i]
吗?”如果答案是肯定的,状态定义就对了。
步骤二:找状态转移方程
这是 DP 的核心。状态转移方程描述了如何从已知状态推导出未知状态。
一般形式:dp[i] = f(dp[i-1], dp[i-2], ..., 其他条件)
推导思路: 1. 考虑 dp[i] 的所有可能来源
2. 找出最优的选择 3. 用数学表达式表示
步骤三:确定初始值(边界条件)
初始值决定了 DP 的起点。通常是最小的子问题,或者边界情况。
常见初始值:
dp[0] = 0或dp[0] = 1dp[1] = 某个值dp[i][0] = 初始值(二维 DP)
注意:初始值设置错误会导致整个 DP 结果错误,务必仔细检查。
一维动态规划经典问题
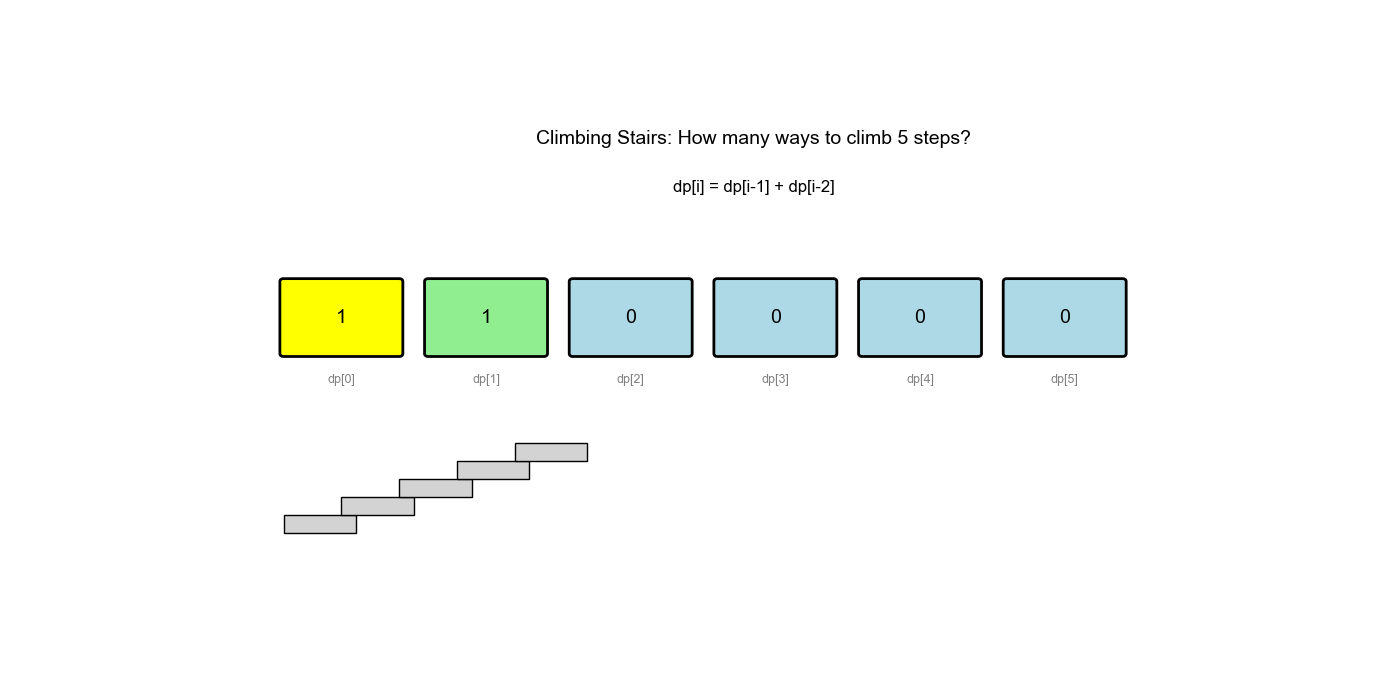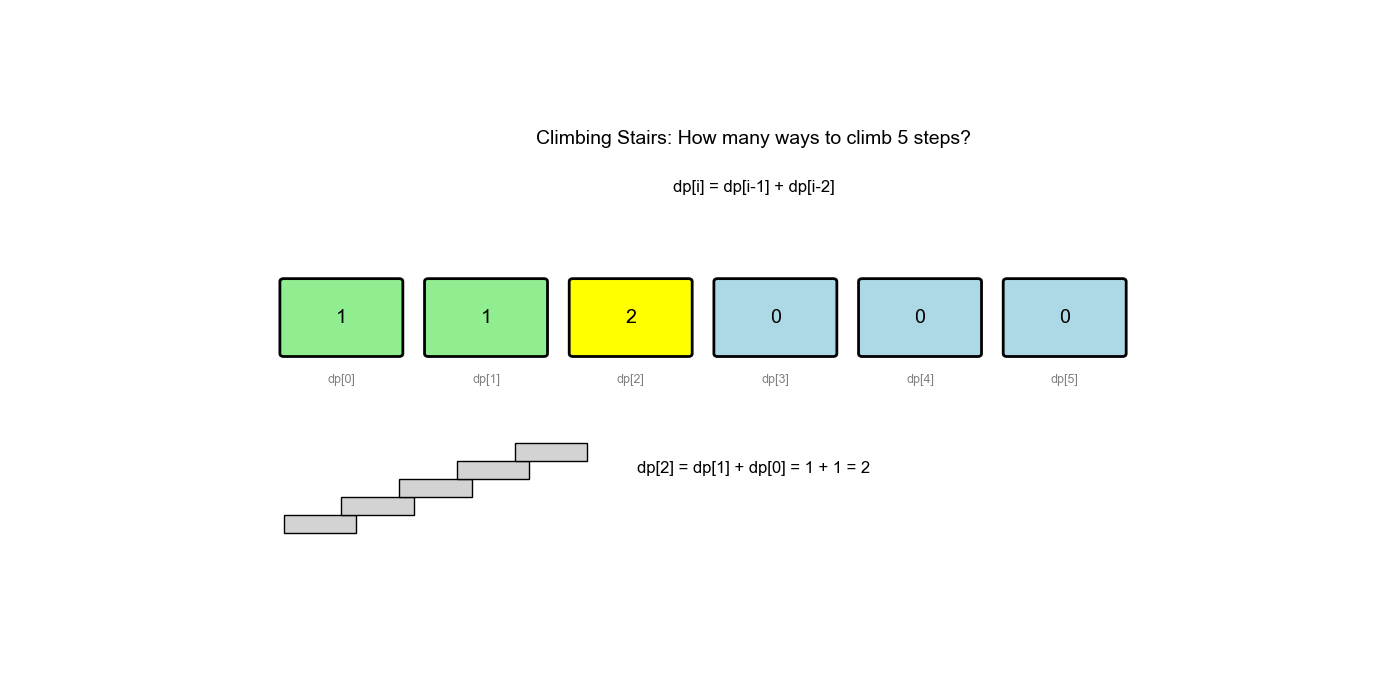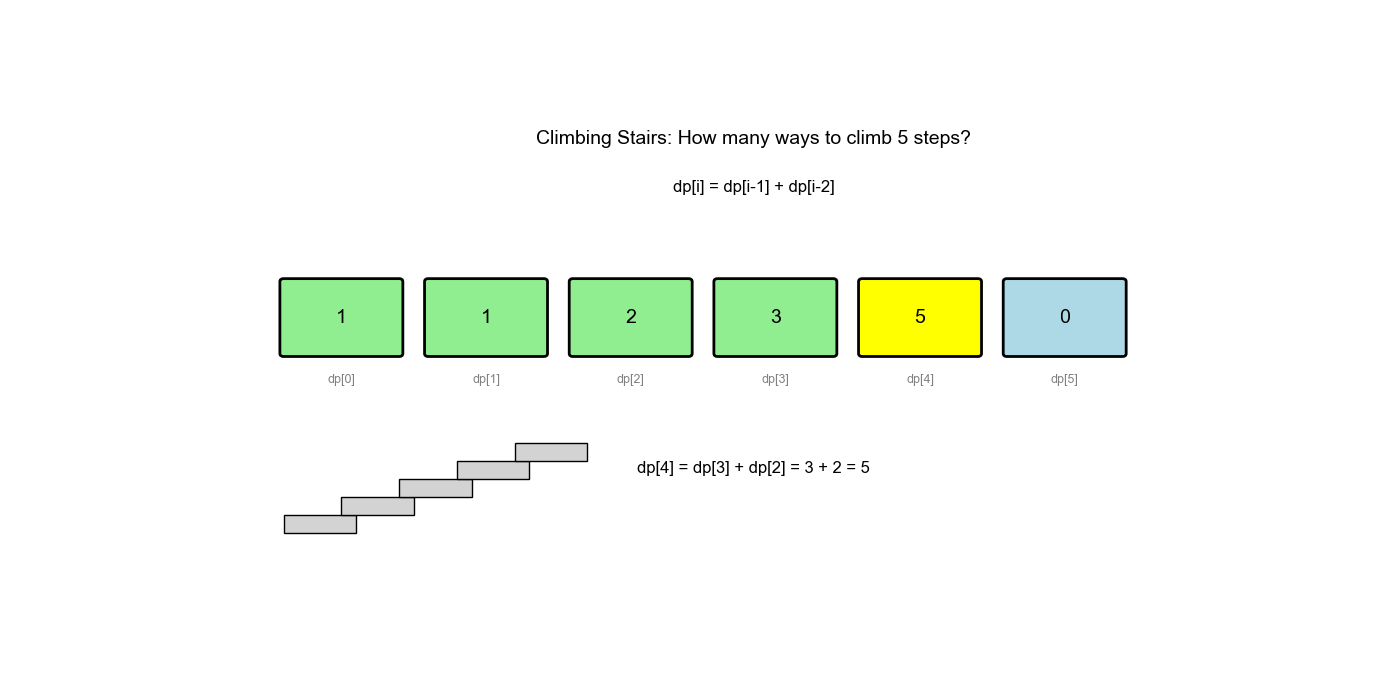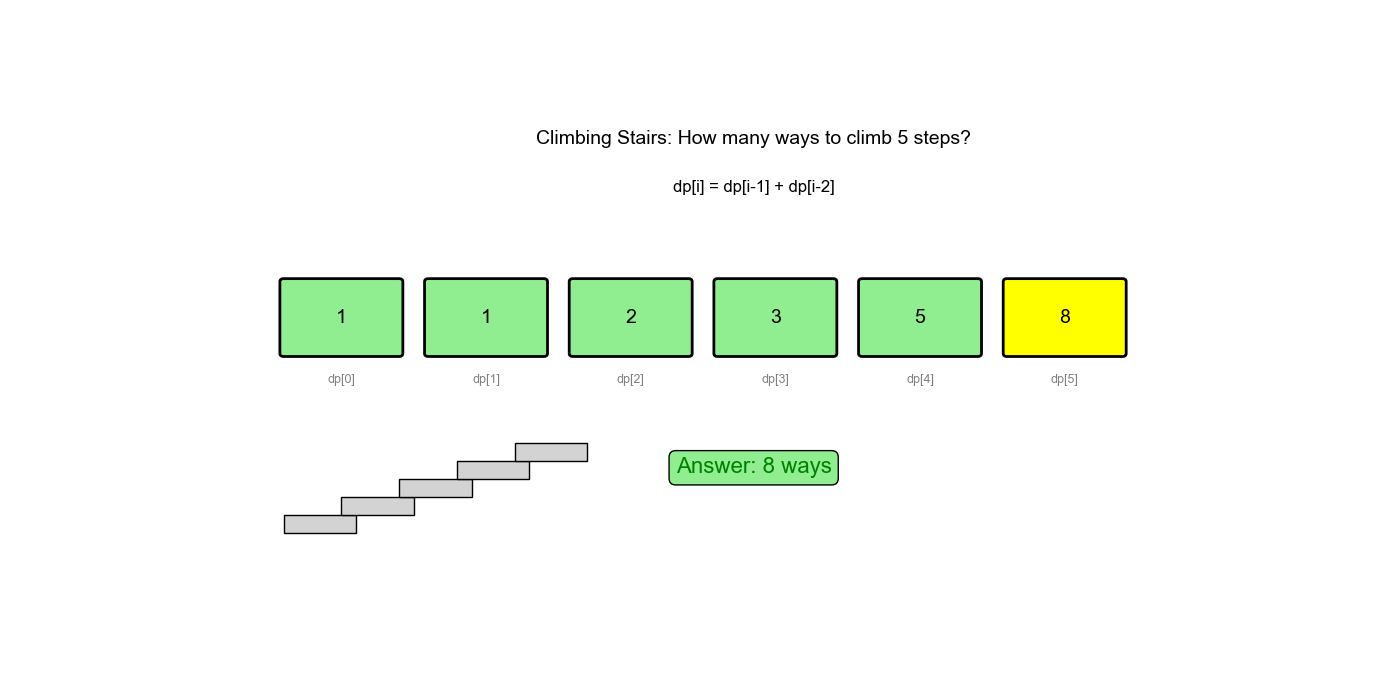
LeetCode 70: 爬楼梯( Climbing Stairs)
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。每次可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶?
示例:
- 输入:
n = 3 - 输出:
3( 1+1+1 、 1+2 、 2+1)
约束条件:
-
问题分析
爬楼梯是动态规划最经典的入门问题。要到达第
核心洞察:
到达第
这是因为: - 到达
解题思路
DP 三步骤分析:
- 状态定义:
dp[i]表示到达第阶的方法数 - 状态转移:
dp[i] = dp[i-1] + dp[i-2](从前一阶或前两阶到达) - 初始值:
dp[0] = 1(在起点,一种方法:不动)dp[1] = 1(到达第一阶,一种方法:爬 1 步)
为什么是斐波那契数列:
状态转移方程 dp[i] = dp[i-1] + dp[i-2]
与斐波那契数列的递推公式相同。因此,到达第
复杂度分析
基础版本:
- 时间复杂度:
,需要计算 dp[0]到dp[n],共个状态 - 空间复杂度:
,需要长度为 的数组
优化版本:
- 时间复杂度:
,不变 - 空间复杂度:
,只用两个变量存储前两个状态
复杂度证明:
每个状态 dp[i] 只计算一次,每次计算只需要
代码实现
1 | from typing import List |
空间优化版本:
1 | def climbStairs(self, n: int) -> int: |
算法原理:
为什么可以空间优化:
观察状态转移方程 dp[i] = dp[i-1] + dp[i-2],计算
dp[i] 时只需要知道 dp[i-1] 和
dp[i-2],不需要更早的状态。因此,只需要两个变量存储最近两个状态即可。
滚动更新机制:
1 | 初始: prev2=1(dp[0]), prev1=1(dp[1]) |
常见错误
错误一:初始值设置错误
1 | # ❌ 错误 |
错误二:滚动更新顺序错误
1 | # ❌ 错误 |
LeetCode 198: 打家劫舍( House Robber)
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。给定一个代表每个房屋存放金额的非负整数数组,计算你不触动警报装置的情况下,一夜之内能够偷窃到的最高金额。
示例:
- 输入:
nums = [2,7,9,3,1] - 输出:
12(偷窃 1 号、 3 号、 5 号房屋,金额 = 2 + 9 + 1 = 12)
约束条件:
-
问题分析
打家劫舍问题是典型的"选或不选"决策问题。对于每间房屋,需要在"偷"和"不偷"之间做出选择,目标是最大化总金额。
核心挑战:
- 约束条件:不能偷相邻的两间房屋(会触发警报)
- 最优决策:如何在满足约束的前提下最大化收益
- 状态转移:当前决策如何影响后续决策
关键洞察:
对于第nums[i],但不能偷第nums[i] + dp[i-2] 2.
不偷:不获得金额,但可以偷第dp[i-1]
选择两者中的最大值。
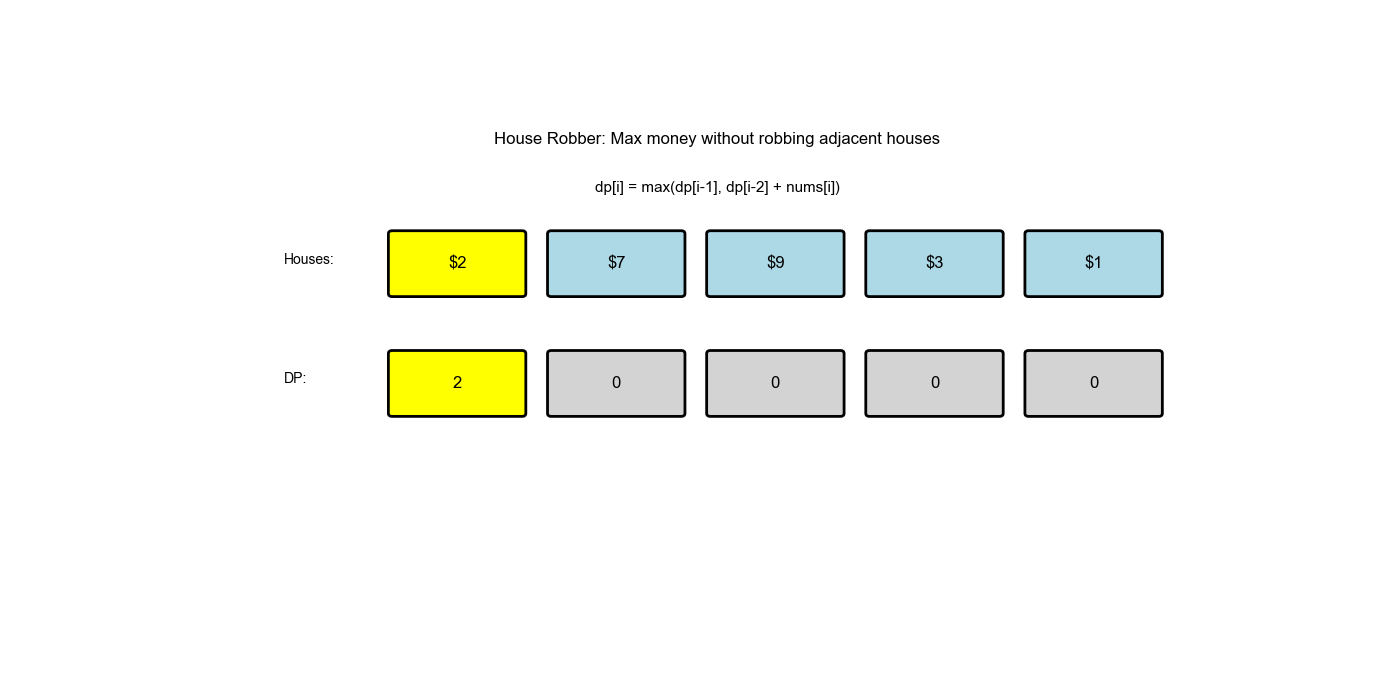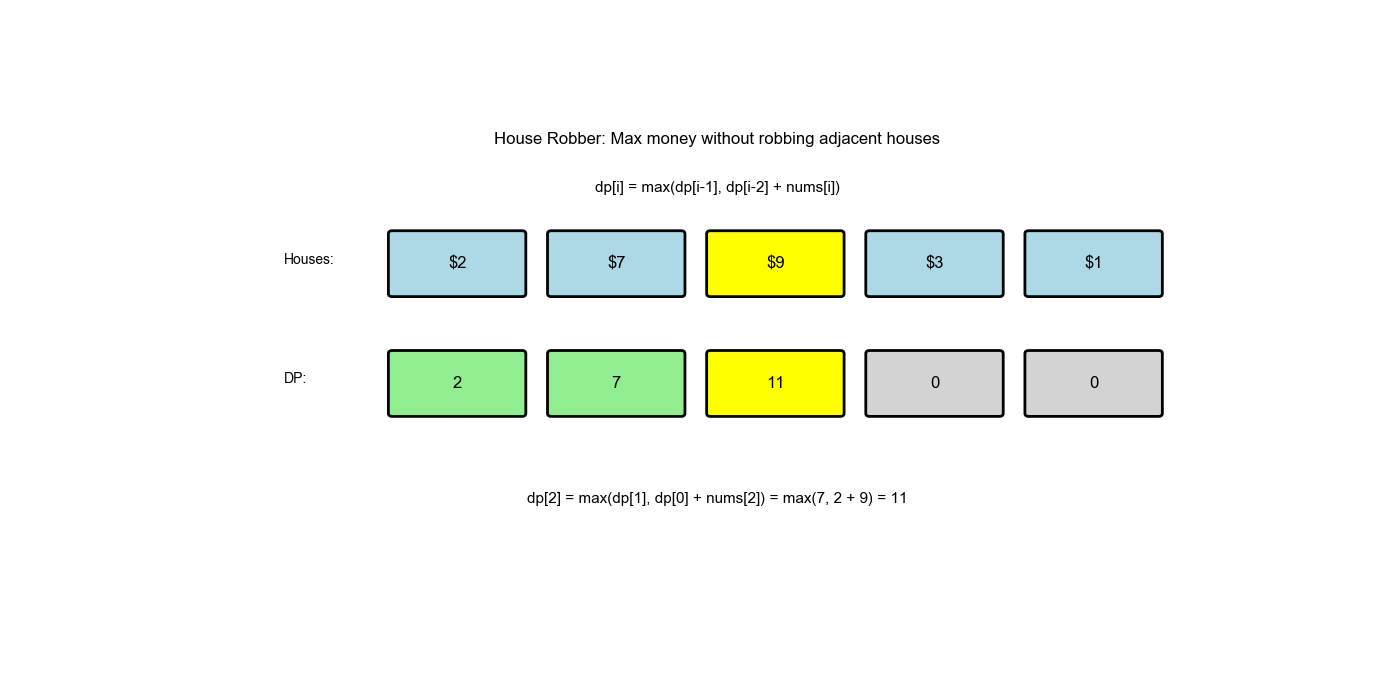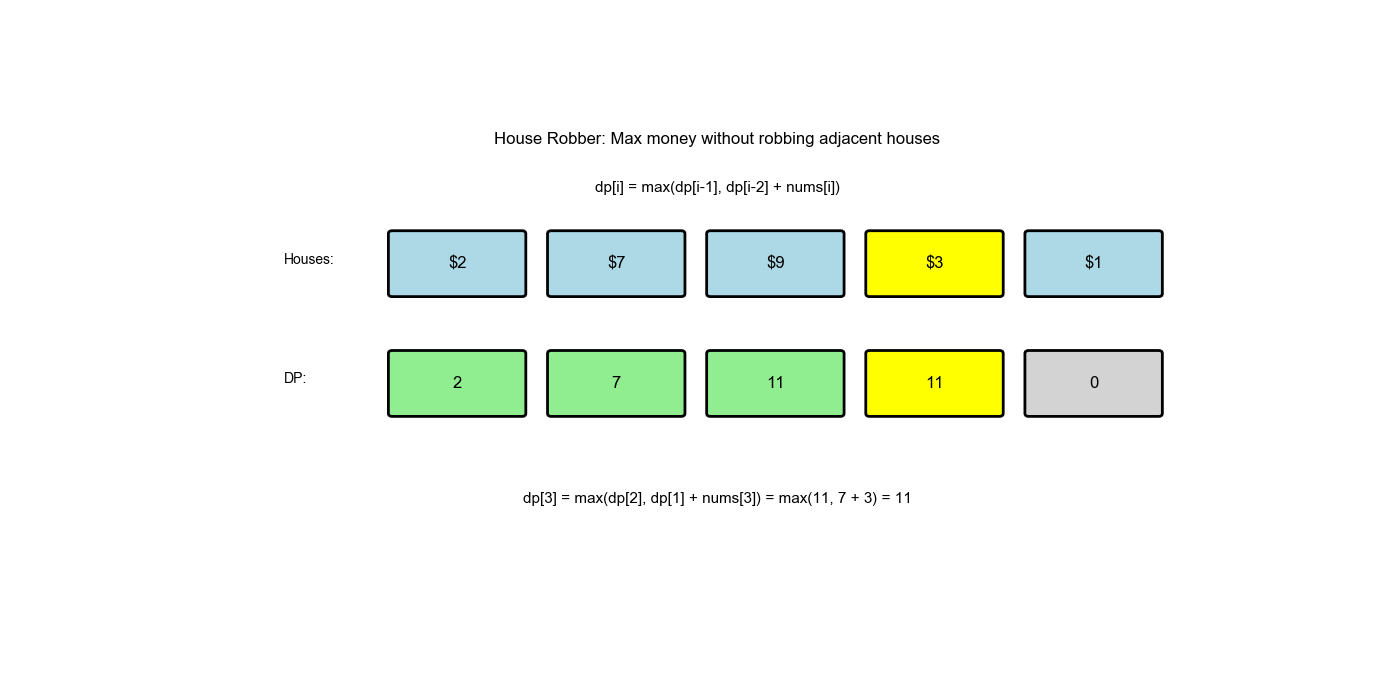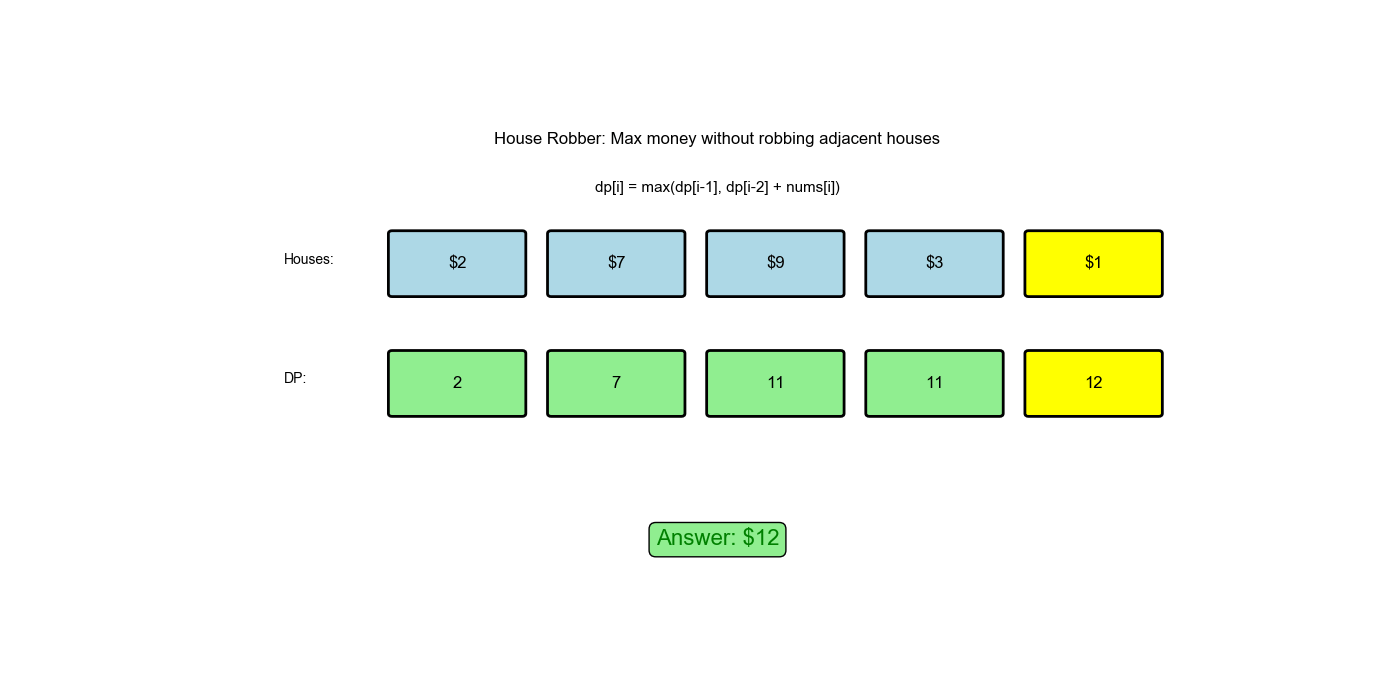
解题思路
DP 三步骤分析:
- 状态定义:
dp[i]表示偷窃前间房屋能获得的最大金额 - 状态转移:
dp[i] = max(dp[i-1], nums[i-1] + dp[i-2])dp[i-1]:不偷第间,继承前 间的最优解 nums[i-1] + dp[i-2]:偷第间,加上前 间的最优解
- 初始值:
dp[0] = 0(没有房屋,金额为 0)dp[1] = nums[0](只有一间房屋,偷它)
为什么这样可行:
动态规划的核心是最优子结构。如果我们知道了偷窃前
复杂度分析
基础版本:
- 时间复杂度:
,需要计算 个状态 - 空间复杂度:
,需要长度为 的数组
优化版本:
- 时间复杂度:
,不变 - 空间复杂度:
,只用两个变量
复杂度证明:
每个状态只计算一次,每次计算只需要
代码实现:
1 | from typing import List |
常见错误
错误一:状态定义错误
1 | # ❌ 错误: dp[i]表示"是否偷第 i 间" |
变种:打家劫舍 II(环形)
LeetCode
213:如果房屋围成一圈(第一间和最后一间相邻),需要分两种情况:
1. 偷第一间,不偷最后一间:计算 nums[0:n-1] 2.
不偷第一间,可以偷最后一间:计算 nums[1:n]
取两者最大值。
LeetCode 121: 买卖股票的最佳时机( Best Time to Buy and Sell Stock)
给定一个数组 prices,它的第 i 个元素
prices[i] 表示一支给定股票第 i
天的价格。你只能选择某一天买入这只股票,并选择在未来的某一个不同的日子卖出该股票。设计一个算法来计算你所能获取的最大利润。
分析:
对于第 i 天,有两种状态: 1. 持有股票:可能是今天买入,或者之前就持有 2. 不持有股票:可能是今天卖出,或者之前就不持有
状态定义:
dp[i][0]:第 i 天不持有股票的最大利润dp[i][1]:第 i 天持有股票的最大利润
状态转移方程:
dp[i][0] = max(dp[i-1][0], dp[i-1][1] + prices[i])(今天不持有 = 昨天不持有 或 今天卖出)dp[i][1] = max(dp[i-1][1], -prices[i])(今天持有 = 昨天持有 或 今天买入)
初始值:
dp[0][0] = 0(第一天不持有,利润为 0)dp[0][1] = -prices[0](第一天持有,即买入,利润为负)
代码实现:
1 | def maxProfit(prices): |
空间优化:由于只依赖前一天的状态,可以用两个变量:
1 | def maxProfit(prices): |
更直观的解法:记录到第 i 天为止的最低买入价,计算今天卖出的利润:
1 | def maxProfit(prices): |
复杂度分析:
- 时间复杂度:
- 空间复杂度:
二维动态规划经典问题
LeetCode 1143: 最长公共子序列( Longest Common Subsequence)
给定两个字符串 text1 和
text2,返回这两个字符串的最长公共子序列的长度。如果不存在公共子序列,返回
0 。
子序列定义:字符串的一个子序列是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
问题分析
对于两个字符串,比较 text1[i] 和
text2[j]:
- 如果相等:公共子序列长度 +1,继续比较
text1[i+1]和text2[j+1] - 如果不等:要么跳过
text1[i],要么跳过text2[j],取最大值
解题思路
状态定义:dp[i][j] 表示
text1[0:i] 和 text2[0:j]
的最长公共子序列长度。
状态转移方程:
初始值:
dp[0][j] = 0(空字符串与任何字符串的公共子序列长度为 0)dp[i][0] = 0
代码实现:
1 | def longestCommonSubsequence(text1, text2): |
空间优化:由于 dp[i][j] 只依赖
dp[i-1][j-1]、dp[i-1][j] 和
dp[i][j-1],可以用一维数组:
1 | def longestCommonSubsequence(text1, text2): |
复杂度分析
- 时间复杂度:
- 空间复杂度:
(优化后)
LeetCode 72: 编辑距离( Edit Distance)
给你两个单词 word1 和 word2,请返回将
word1 转换成 word2
所使用的最少操作数。可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
问题分析
对于 word1[i] 和 word2[j],有三种操作: 1.
插入:在 word1 中插入
word2[j],相当于 word2
前移,dp[i][j] = dp[i][j-1] + 1 2.
删除:删除 word1[i],相当于
word1 前移,dp[i][j] = dp[i-1][j] + 1 3.
替换:如果 word1[i] != word2[j],替换
word1[i] 为
word2[j],dp[i][j] = dp[i-1][j-1] + 1;如果相等,不需要操作,dp[i][j] = dp[i-1][j-1]
解题思路
状态定义:dp[i][j] 表示将
word1[0:i] 转换成 word2[0:j]
所需的最少操作数。
状态转移方程:
初始值:
dp[0][j] = j(将空字符串转换为word2[0:j]需要 j 次插入)dp[i][0] = i(将word1[0:i]转换为空字符串需要 i 次删除)
代码实现:
1 | def minDistance(word1, word2): |
空间优化:
1 | def minDistance(word1, word2): |
复杂度分析
- 时间复杂度:
- 空间复杂度:
(优化后)
0-1 背包问题( 0-1 Knapsack)
有 n 个物品,第 i 个物品的重量为 weight[i],价值为
value[i]。有一个容量为 W
的背包,问如何选择物品放入背包,使得背包中物品的总价值最大?每个物品只能选择一次(
0-1 背包)。
问题分析
对于第 i 个物品,有两种选择: 1.
不选:价值不变,dp[i][w] = dp[i-1][w] 2.
选:如果
w >= weight[i],dp[i][w] = dp[i-1][w-weight[i]] + value[i]
选择两者中的最大值。
解题思路
状态定义:dp[i][w] 表示前 i
个物品在容量为 w 的背包中能获得的最大价值。
状态转移方程:
初始值:
dp[0][w] = 0(没有物品,价值为 0)dp[i][0] = 0(容量为 0,价值为 0)
代码实现:
1 | def knapsack_01(weight, value, W): |
空间优化(一维数组):
关键点:需要逆序遍历容量,避免覆盖还未使用的
dp[w-weight[i]]。
1 | def knapsack_01(weight, value, W): |
为什么逆序?
如果正序遍历,dp[w] 更新时会用到
dp[w-weight[i]],但这个值可能已经被当前物品更新过了,相当于同一个物品被用了两次(完全背包问题)。逆序可以保证
dp[w-weight[i]] 是上一轮(前 i-1 个物品)的结果。
复杂度分析:
- 时间复杂度:
- 空间复杂度:
(优化后)
变种:完全背包
如果每个物品可以选择无限次,只需将容量循环改为正序:
1 | def knapsack_unbounded(weight, value, W): |
状态压缩优化
当 DP 状态只依赖前几个状态时,可以用滚动数组或位运算压缩空间。
滚动数组
一维压缩:如果 dp[i] 只依赖
dp[i-1] 和 dp[i-2],用两个变量即可。
1 | # 爬楼梯的空间优化版本 |
二维压缩:如果 dp[i][j] 只依赖
dp[i-1][...],用两个一维数组交替使用。
1 | # LCS 的空间优化版本 |
位运算压缩
当状态可以用布尔值表示时(如“选或不选”),可以用整数的二进制位表示状态集合。
例子:旅行商问题( TSP)的简化版
dp[mask][i] 表示访问过 mask
表示的城市的集合,当前在城市 i 的最短路径。
1 | def tsp_dp(graph): |
时间空间复杂度分析
时间复杂度
DP 的时间复杂度通常是:状态数 × 每个状态的转移次数
一维 DP:通常
或 ( k 是转移时需要考虑的状态数) 二维 DP:通常
或 优化技巧: 减少状态数:合并等价状态
减少转移次数:用数据结构(如单调队列、线段树)优化转移
空间复杂度
基础版本:
或 空间优化后:通常可以降到
或 优化技巧: 滚动数组:只保留必要的状态
状态压缩:用位运算表示状态集合
降维:将二维 DP 优化为一维
动态规划解题技巧总结
1. 识别 DP 问题
特征:
- 求最优解(最大值、最小值)
- 可以分解为子问题
- 子问题有重叠
- 满足最优子结构
常见题型:
- 路径问题(不同路径、最小路径和)
- 序列问题(最长递增子序列、最长公共子序列)
- 背包问题( 0-1 背包、完全背包)
- 字符串问题(编辑距离、回文串)
- 区间 DP(石子合并、括号匹配)
2. 状态定义技巧
一维状态:
dp[i]:以第 i 个元素结尾dp[i]:前 i 个元素
二维状态:
dp[i][j]:两个序列的前 i/j 个元素dp[i][j]:区间 [i, j]dp[i][j]:在位置 (i, j)
多维状态:
dp[i][j][k]:三个维度(如:天数、交易次数、持有状态)
3. 状态转移方程推导
思考步骤: 1. 考虑 dp[i] 的所有可能来源
2. 列出所有转移方式 3. 找出最优选择 4. 用数学表达式表示
常见转移模式:
- 线性转移:
dp[i] = f(dp[i-1], dp[i-2], ...) - 区间转移:
dp[i][j] = f(dp[i][k], dp[k+1][j]) - 树形转移:
dp[u] = f(dp[v1], dp[v2], ...)(树形 DP)
4. 边界条件处理
常见边界:
- 空序列:
dp[0] = 0或dp[0] = 1 - 单个元素:
dp[1] = 初始值 - 二维 DP:第一行和第一列
注意:边界条件错误会导致整个 DP 失败,务必仔细检查。
5. 空间优化
何时优化:
- 状态只依赖前几个状态
- 内存限制严格
- 需要提升代码效率
优化方法:
- 滚动数组
- 降维(二维→一维)
- 状态压缩(位运算)
❓ Q&A: 动态规划常见问题
Q1: 如何判断一个问题是否可以用动态规划解决?
A: 检查是否满足两个条件: 1. 最优子结构:问题的最优解包含子问题的最优解 2. 重叠子问题:递归求解时会有重复计算
如果满足,就可以用 DP 。如果不确定,先写递归版本,如果发现大量重复计算,就改用 DP 。
Q2: 动态规划和贪心算法有什么区别?
A:
- 贪心:每一步都做当前最优选择,不回溯。适用于局部最优能导致全局最优的问题(如最小生成树、最短路径的某些变种)。
- DP:会考虑所有可能的选择,通过比较得出最优解。适用于需要全局最优的问题。
关键区别:贪心不需要保存子问题的解, DP 需要。
Q3: 什么时候用记忆化递归,什么时候用自底向上的 DP?
A:
- 记忆化递归:思路更直观,适合验证想法。但递归有栈空间开销,可能栈溢出。
- 自底向上 DP:效率更高,可以空间优化。适合生产环境。
建议:先用记忆化递归验证,再改写成 DP 。
Q4: 如何优化 DP 的空间复杂度?
A: 1. 滚动数组:如果只依赖前几个状态,用变量或小数组代替大数组 2. 降维:二维 DP 优化为一维(注意遍历顺序) 3. 状态压缩:用位运算表示状态集合 4. 只保留必要状态:如果某些状态永远不会用到,不计算它们
Q5: 为什么 0-1 背包的空间优化要逆序遍历?
A:
因为每个物品只能选一次。如果正序遍历,dp[w] 更新时会用到
dp[w-weight[i]],但这个值可能已经被当前物品更新过了,相当于同一个物品被用了两次。逆序可以保证
dp[w-weight[i]] 是上一轮(前 i-1 个物品)的结果。
Q6: 如何调试 DP 问题?
A: 1. 打印 DP 表:看每个状态的值是否正确 2. 检查初始值:确保边界条件正确 3. 验证转移方程:手动计算几个小例子 4. 对比递归版本:如果递归版本正确, DP 版本应该得到相同结果
Q7: DP 的时间复杂度可以进一步优化吗?
A: 可以。常见优化方法:
- 单调队列/栈:优化转移的查找过程(如滑动窗口最大值)
- 线段树/树状数组:快速查询区间最值
- 斜率优化:将转移方程转化为斜率形式,用单调队列维护凸包
- 四边形不等式:区间 DP 的优化技巧
Q8: 如何确定状态定义的维度?
A: 看问题需要哪些信息才能唯一确定一个子问题:
- 如果只需要位置信息:一维
dp[i] - 如果需要两个序列的位置:二维
dp[i][j] - 如果需要额外条件(如背包容量、交易次数):增加维度
原则:维度越少越好,但必须能完整描述子问题。
Q9: 遇到 DP 问题没有思路怎么办?
A: 1. 先写暴力递归:理解问题的本质 2. 找规律:观察小规模例子的解 3. 画状态转移图:可视化状态之间的关系 4. 类比经典问题:看看是否类似背包、 LCS 、编辑距离等 5. 从简单到复杂:先解决简化版本,再逐步增加约束
Q10: 动态规划可以解决所有最优化问题吗?
A: 不能。 DP 只适用于满足最优子结构和重叠子问题的问题。以下情况不适合 DP:
- 贪心可解:局部最优即全局最优(如最小生成树)
- 无重叠子问题:分治法更合适(如归并排序)
- 状态空间太大:需要其他方法(如启发式算法、近似算法)
总结: DP 是强大的工具,但不是万能的。要根据问题特点选择最合适的算法。
变体与扩展问题
变体一:区间 DP
区间 DP 是二维 DP 的一种特殊形式,状态定义为 dp[i][j]
表示区间 [i, j] 的最优解。
特点:
- 状态转移通常从小区间到大区间
- 需要枚举分割点
k,将区间[i, j]分割为[i, k]和[k+1, j]
经典问题:
- 戳气球:
dp[i][j]表示戳破区间[i, j]内所有气球能获得的最大分数
- 戳气球:
- 最长回文子序列:
dp[i][j]表示s[i:j+1]的最长回文子序列长度
- 最长回文子序列:
- 最长回文子串:也可以用区间 DP 解决
模板代码: 1
2
3
4
5
6
7
8
9
10
11# 区间 DP 模板
n = len(nums)
dp = [[0] * n for _ in range(n)]
# 枚举区间长度
for length in range(2, n + 1):
for i in range(n - length + 1):
j = i + length - 1
# 枚举分割点
for k in range(i, j):
dp[i][j] = max(dp[i][j], dp[i][k] + dp[k+1][j] + cost(i, k, j))
变体二:树形 DP
树形 DP 是在树结构上进行的动态规划,通常需要 DFS 遍历树。
特点:
- 状态定义与树的节点相关
- 状态转移需要考虑子节点的状态
- 通常需要后序遍历(先处理子节点,再处理当前节点)
经典问题:
- 打家劫舍 III:在二叉树上打家劫舍
- 二叉树中的最大路径和:
dp[node]表示以node为起点的最大路径和
- 二叉树中的最大路径和:
- 二叉树的直径:通过树形 DP 计算最长路径
模板代码: 1
2
3
4
5
6
7
8
9
10
11
12def tree_dp(node):
if not node:
return base_case
# 处理左子树和右子树
left_result = tree_dp(node.left)
right_result = tree_dp(node.right)
# 根据子节点状态更新当前节点状态
dp[node] = combine(left_result, right_result, node.val)
return dp[node]
变体三:状态压缩 DP
当状态可以用布尔值表示时,可以用整数的二进制位压缩状态,常用于旅行商问题( TSP)等。
特点:
- 状态数是指数级的,但可以通过位运算优化
- 适用于状态空间较小但需要枚举所有状态的问题
经典问题:
- 旅行商问题( TSP):
dp[mask][i]表示访问过mask中的城市,当前在城市i的最短路径 - 我能赢吗:用位压缩表示已选择的数字
- 划分为 k 个相等的子集:用位压缩表示已选择的元素
技巧:
- 用
mask & (1 << i)检查第i位是否为 1 - 用
mask | (1 << i)将第i位设为 1 - 用
mask ^ (1 << i)翻转第i位
变体四:数位 DP
数位 DP 用于解决与数字的每一位相关的问题,如统计满足条件的数字个数。
特点:
- 通常需要处理数字的上界
- 状态包括:当前位数、是否达到上界、前导零等
经典问题:
- 数字 1 的个数:统计 1 到 n 中数字 1 出现的次数
- 最大为 N 的数字组合:统计可以用给定数字组合成的数字个数
常见错误与调试技巧
错误一:状态定义不清晰
问题:dp[i]
的含义不明确,导致状态转移方程错误。
解决方法:
- 明确
dp[i]表示什么(以第 i 个元素结尾?前 i 个元素?) - 用注释说明状态定义
- 先写递归版本,再改写成 DP
错误二:状态转移方程遗漏情况
问题:只考虑了部分转移情况,导致结果错误。
解决方法:
- 列出所有可能的转移方式
- 检查是否考虑了所有边界情况
- 用具体例子验证转移方程
错误三:初始值设置错误
问题:初始值设置不当,导致后续计算错误。
解决方法:
- 明确最小子问题的解
- 检查边界条件(空数组、单个元素等)
- 用具体例子验证初始值
错误四:数组越界
问题:访问 dp[i-k] 时,i-k
可能为负数。
解决方法:
- 检查数组访问是否越界
- 使用条件判断保护数组访问
- 考虑是否需要调整数组大小(如
dp[n+1])
调试技巧
打印 DP 表:
1
2for i in range(len(dp)):
print(f"dp[{i}] = {dp[i]}")对比递归版本:如果递归版本正确, DP 版本应该得到相同结果
手动计算小例子:用纸笔计算几个小规模例子,验证 DP 过程
使用断言:
1
2assert dp[i] >= 0, f"dp[{i}] should be non-negative"
assert dp[i] <= max_value, f"dp[{i}] exceeds maximum"
实战建议
如何快速识别 DP 问题
看到以下特征时,考虑动态规划: 1. 求最优解:最大值、最小值、最长、最短等 2. 可以分解为子问题:问题可以分解为相似的子问题 3. 有重叠子问题:递归求解时会有重复计算 4. 满足最优子结构:子问题的最优解能构成原问题的最优解
解题步骤总结
- 理解问题:明确问题要求什么
- 定义状态:
dp[i]或dp[i][j]表示什么 - 找状态转移:如何从已知状态推导出未知状态
- 确定初始值:最小子问题的解
- 写代码:实现 DP 算法
- 优化空间:如果可能,进行空间优化
经典问题分类
一维 DP:
- 爬楼梯
- 打家劫舍
- 买卖股票的最佳时机
二维 DP:
- 最长公共子序列
- 编辑距离
- 最小路径和
背包问题:
- 0-1 背包
- 完全背包
- 多重背包
区间 DP:
- 戳气球
- 最长回文子序列
树形 DP:
- 打家劫舍 III
- 二叉树中的最大路径和
性能优化建议
空间优化:
- 如果只依赖前几个状态,用滚动数组
- 二维 DP 优化为一维(注意遍历顺序)
时间优化:
- 减少不必要的状态计算
- 使用数据结构优化状态转移(如单调队列、线段树)
代码优化:
- 合并相似逻辑
- 使用更高效的数据结构
总结
动态规划是算法竞赛和 LeetCode 中的核心技能。掌握 DP 的要点:
- 理解核心思想:最优子结构和重叠子问题
- 掌握三步骤:定义状态、找转移方程、确定初始值
- 多练习经典问题:从一维到二维,从简单到复杂
- 学会优化:空间优化、时间优化、状态压缩
希望本文能帮助你建立对动态规划的清晰认识。记住, DP 不是死记硬背模板,而是理解问题的本质,找到状态之间的转移关系。多练习,多思考,你一定能掌握这门艺术!
- 本文标题:LeetCode(七)—— 动态规划入门
- 本文作者:Chen Kai
- 创建时间:2020-02-16 10:15:00
- 本文链接:https://www.chenk.top/LeetCode%EF%BC%88%E4%B8%83%EF%BC%89%E2%80%94%E2%80%94-%E5%8A%A8%E6%80%81%E8%A7%84%E5%88%92%E5%85%A5%E9%97%A8/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!