线性代数的本质(十):矩阵范数与条件数
条件数告诉我们:解这个线性系统有多"危险"?
在数值计算中,有一个让无数工程师和科学家头疼的问题:明明方程写对了,算法也对了,为什么计算结果却完全是错的?答案往往藏在一个叫做条件数的概念里。条件数就像是线性系统的"健康体检报告"——它告诉你这个系统有多"敏感",输入的微小误差会不会被放大成灾难性的输出错误。而要理解条件数,我们首先要搞清楚如何度量向量和矩阵的"大小",这就是范数要解决的问题。
引言:为什么需要矩阵范数?
想象你是一个桥梁工程师,需要计算桥梁结构在各种载荷下的变形。你建立了有限元模型,得到一个包含 10 万个未知量的线性方程组。计算机给出了答案,但你怎么知道这个答案是否可靠?
再想象你是一个机器学习工程师,训练一个神经网络。某一层的权重矩阵更新后,网络的输出突然变得不稳定——梯度要么爆炸要么消失。这是为什么?
这些问题的答案都与矩阵范数和条件数密切相关。
在实际计算中,我们经常需要回答这样的问题:
- 矩阵有多"大"? 向量有长度,矩阵呢?
- 两个矩阵有多"接近"?
应该如何定义? - 解线性方程组有多可靠? 输入的小误差会放大多少?
- 迭代算法会收敛吗?
的条件是什么?
本章学习目标
- 向量范数回顾:
范数 - 矩阵范数定义: Frobenius 范数、诱导范数、谱范数
- 范数的性质:三角不等式、相容性
- 条件数:
- 数值稳定性分析:误差如何传播
- 应用:算法收敛性、病态矩阵识别
向量范数回顾
范数的定义与直觉
在日常生活中,我们经常需要描述事物的"大小":这个房间有多大?这袋米有多重?这段路有多长?在数学中,范数就是用来回答"这个向量有多大"这个问题的工具。
定义:向量空间
- 非负性:
,且 - 齐次性:
- 三角不等式:
生活类比:这三条公理非常符合我们对"大小"的直觉:
- 非负性:任何东西的"大小"都不能是负数,而且只有"什么都没有"才是零
- 齐次性:把一个东西放大 2 倍,它的"大小"也放大 2 倍
- 三角不等式:两点之间直线最短——绕路走不可能比直接走更近
常见向量范数
对于
生活案例:想象你在曼哈顿的街道上走路,只能沿着横向或纵向的街道行走,不能斜穿街区。从原点走到
生活案例:这是我们最熟悉的"直线距离"。如果一只乌鸦从原点飞到
生活案例:国际象棋中,国王每步可以向 8
个方向移动一格。从
一般
当
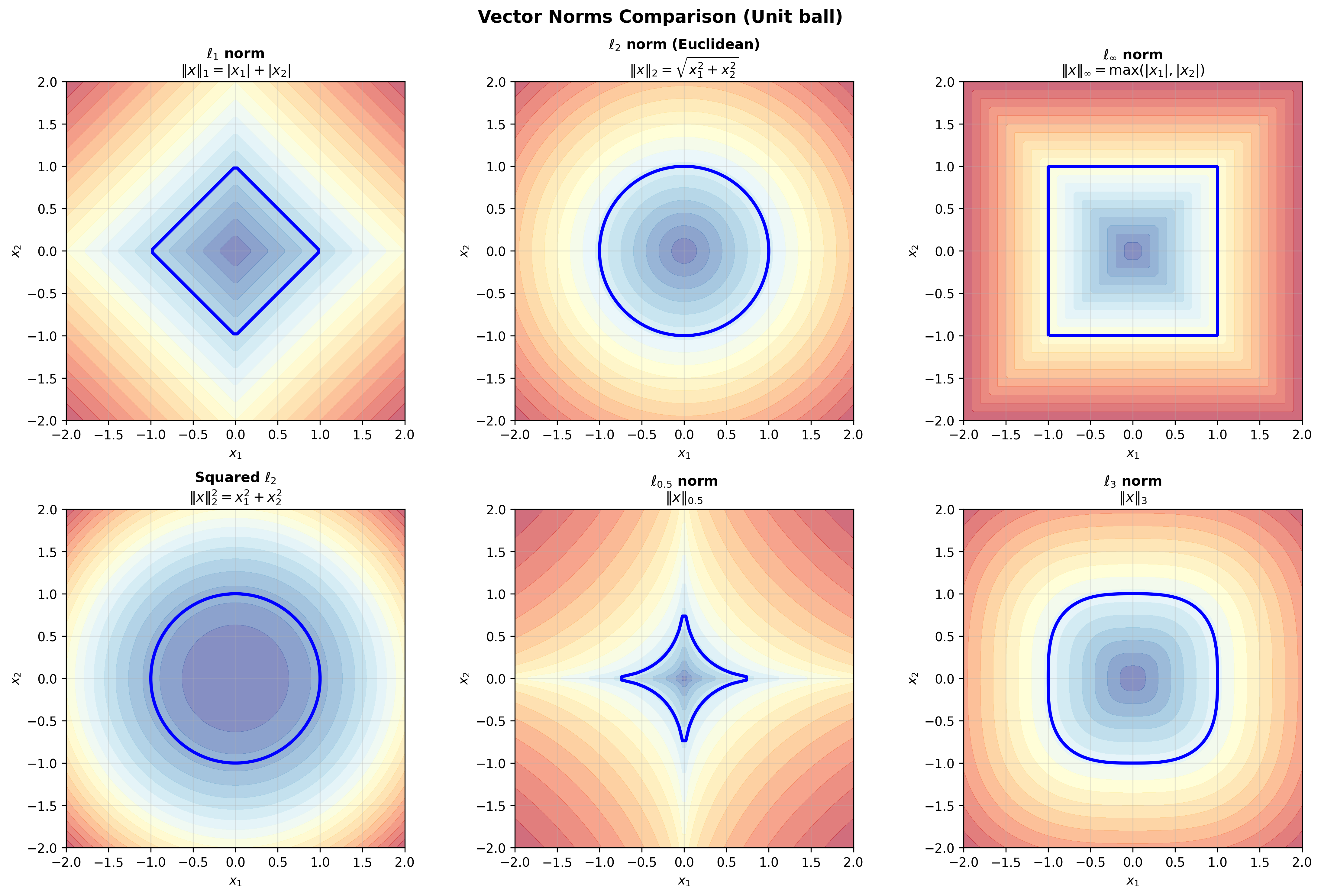
单位球的形状
不同范数定义不同的"单位球"
-
有趣的发现:随着
范数等价性定理
定理:在有限维空间
即:对于任意两个范数
具体关系(对
直觉解释:在有限维空间中,不同范数只是用不同的"尺子"测量同一个向量。虽然读数不同,但它们在本质上是一致的:如果一个向量在某个范数下"很大",那么在其他范数下也不会"太小"。
重要意义:
- 收敛性在所有范数下等价(一个序列在某个范数下收敛,在其他范数下也收敛)
- 但收敛速度可能不同
- 选择范数取决于问题的物理意义和计算便利性
矩阵范数
现在我们把范数的概念从向量推广到矩阵。矩阵范数要回答的问题是:这个线性变换有多"强"?
Frobenius 范数:把矩阵当作大向量
定义:对于
直觉: Frobenius
范数的计算方式很简单粗暴——把矩阵的所有元素"拉直"成一个长向量,然后计算这个向量的
生活类比:想象矩阵是一张照片,每个像素的亮度是一个矩阵元素。 Frobenius 范数就是所有像素亮度平方和的平方根——它度量的是图像的"总能量"。在图像处理中,两张图片的差异经常用它们差矩阵的 Frobenius 范数来衡量。
性质:
- 计算简单,只需要遍历所有元素 -
(所有奇异值平方和) - 满足矩阵范数的所有公理
与奇异值的联系:上一章我们学习了 SVD, Frobenius
范数与奇异值有着优美的关系:
这说明 Frobenius 范数度量的是矩阵在所有方向上"拉伸能力"的某种平均。
诱导范数(算子范数):变换的最大放大倍数
定义:给定向量范数
几何意义:
生活类比:想象矩阵
常见诱导范数的计算公式:
(最大列绝对值之和)
计算技巧:计算每一列元素绝对值的和,取最大值。
(最大奇异值)
(最大行绝对值之和)
计算技巧:计算每一行元素绝对值的和,取最大值。
记忆口诀: 1-列和,
谱范数的几何意义
谱范数
- 椭圆半轴:
把单位球映射成椭圆, 是最长半轴的长度 - 最大奇异值:
- 能量观点:
能放大向量的最大倍数
SVD 视角:
生活案例:想象你有一个橡皮泥球,用手捏成椭球形。谱范数就是椭球最长轴的长度。如果你捏得很用力,球变成了一个扁扁的饼,那么谱范数就是饼的直径——它度量的是变形的"最大程度"。
范数的相容性
矩阵范数有一个重要性质叫做相容性(或次乘性):
直觉:两次变换的"放大倍数"不超过各自放大倍数的乘积。
这个性质对于分析迭代算法的收敛性至关重要。注意 Frobenius 范数不满足次乘性,这是它与诱导范数的重要区别。
条件数:线性系统的健康指标
什么是条件数?
条件数是衡量矩阵"病态程度"的指标,它回答了一个关键问题:解这个线性方程组有多"危险"?
定义:对于可逆矩阵
谱条件数(最常用):
即:最大奇异值除以最小奇异值。
生活类比:想象条件数是一个系统的"过敏程度"。
- 条件数小(比如
):系统很"健壮",就像一个身体好的人,稍微着点凉也不会生病 - 条件数大(比如
):系统极度"敏感",就像严重过敏的人,空气中一点花粉就会引发剧烈反应
条件数的性质
下界:
(等号当且仅当 是正交矩阵的倍数) 证明:
正交不变性:
( 正交) 意义:正交变换不改变条件数,因为它只是"旋转"不改变"形状"
缩放不变性:
意义:整体放大或缩小矩阵不影响其病态程度 逆矩阵:
意义:解方程和求逆的难度是一样的 乘积上界:
条件数的几何意义
条件数描述了矩阵变换的"形变程度":
:正交变换,等比例缩放(圆→圆) 大:椭圆变得很"扁",接近降秩 :矩阵奇异(不可逆)
几何公式:
案例:考虑两个
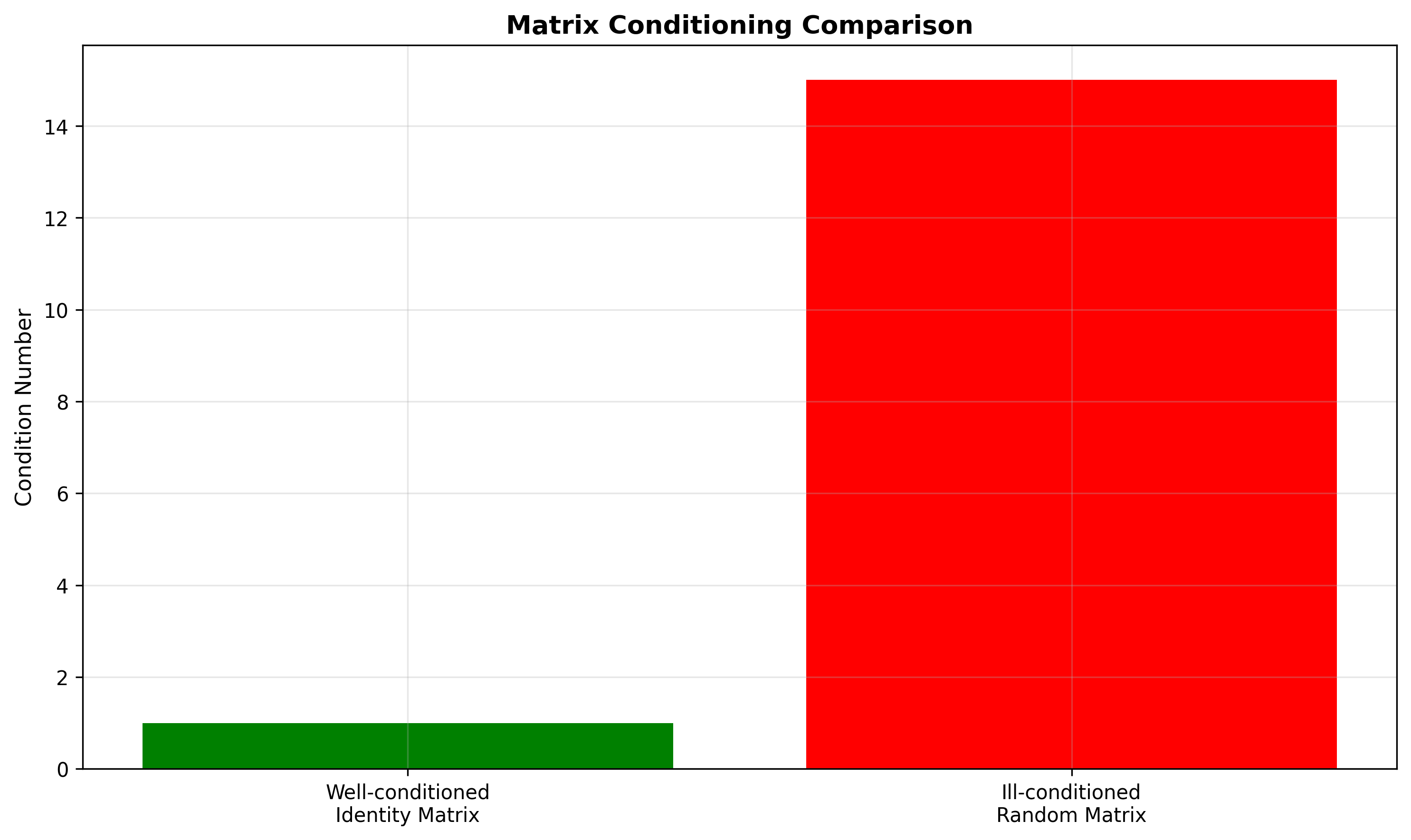
病态矩阵:数值计算的噩梦
什么是病态矩阵?
病态矩阵是指条件数非常大的矩阵。用它来解线性方程组就像在走钢丝——任何微小的抖动都可能让你摔下去。
经典案例: Hilbert 矩阵
Hilbert 矩阵是数值分析中最著名的病态矩阵:
通式:
| 可靠位数(双精度) | ||
|---|---|---|
| 5 | 约 10 位 | |
| 10 | 约 3 位 | |
| 12 | 约 0 位! | |
| 15 | 完全不可靠 |
实验演示:用 Python 体验 Hilbert 矩阵的病态性:
1 | import numpy as np |
警告:在双精度浮点数(约 16 位有效数字)下,用
病态矩阵的来源
在实际应用中,病态矩阵可能来自:
- 多项式拟合:高次多项式拟合会产生 Vandermonde 矩阵,通常很病态
- 有限差分/有限元:细密的网格会导致更大的条件数
- 最小二乘问题:过定系统的正规方程
条件数是 的平方 - 接近奇异:矩阵的行或列"几乎"线性相关
误差分析:条件数如何放大误差
右端项扰动分析
考虑线性系统
问题:如果
设:
- 精确解:
- 扰动解:
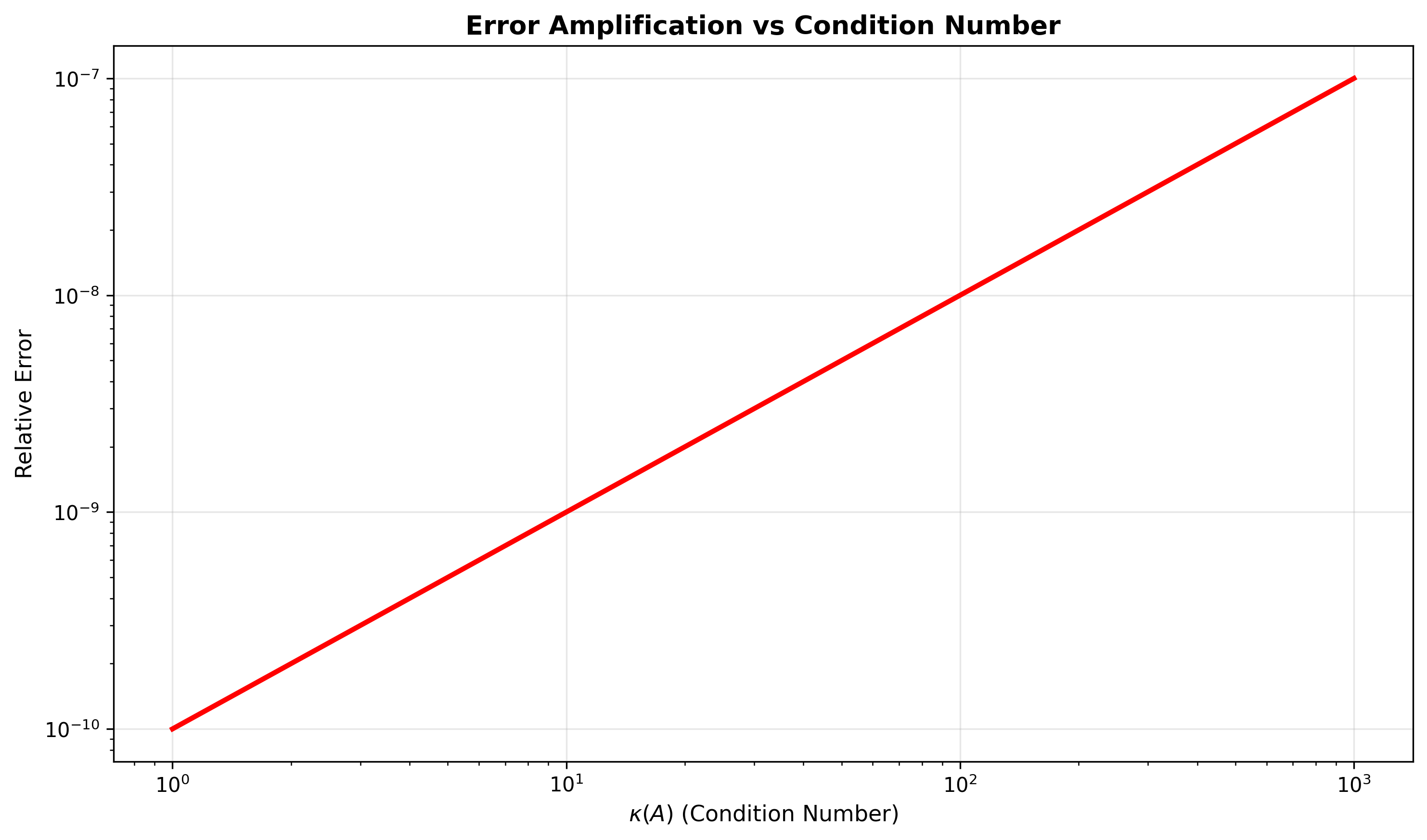
则: ,即 相对误差界:
推导过程:
因此:
直觉解释:
- 输入相对误差:
- 输出相对误差:
- 条件数是误差放大因子的上界
数值例子:
-
矩阵扰动分析
更一般地,如果矩阵
相对误差界(当
结论:条件数大的矩阵对矩阵元素的扰动也非常敏感!
有效数字的损失
经验法则:如果
| 条件数 | 损失有效数字 | 双精度下可靠位数 |
|---|---|---|
| 4 位 | 约 12 位 | |
| 8 位 | 约 8 位 | |
| 12 位 | 约 4 位 | |
| 16 位 | 0 位(完全不可靠) |
谱半径与迭代收敛性
谱半径定义
谱半径是矩阵特征值的最大模:
名称由来:"谱"是指矩阵的特征值集合(谱),"半径"是指这个集合在复平面上能被包含在以原点为圆心的最小圆的半径。
与范数的关系:
对任意矩阵范数成立。
精确关系( Gelfand 公式):
直觉:谱半径是所有范数的"下界"。虽然任何单个范数都可能高估矩阵的"大小",但谱半径是最紧的界。
迭代法收敛性
考虑迭代格式:
证明要点:
- 如果
,则 ,误差逐渐衰减 - 如果
,存在某个特征方向上误差不衰减或增长
收敛速度:由
每次迭代误差缩小的比例约为
- 达到误差
需要约 次迭代
生活类比:想象你在调节淋浴水温。如果系统是"稳定的"(
幂级数收敛与 Neumann 级数
Neumann 级数:如果
证明:这是几何级数
应用:
- 近似计算逆矩阵:当
接近零矩阵时,只需取前几项 - 迭代求解器的理论基础
- 摄动分析
数值技巧:如果
数值稳定性:算法设计的核心考量
前向误差与后向误差
理解数值稳定性需要区分两种误差概念:
前向误差:计算结果
后向误差:使得
类比:
- 前向误差:你的答案离正确答案有多远
- 后向误差:你的答案对于某个"差不多正确"的问题是精确的
稳定算法的特征:后向误差很小(与机器精度同量级)。
为什么正规方程不稳定?
最小二乘问题
问题:
推导:
解决方案:使用 QR 分解或 SVD 而非正规方程。
QR 分解的数值优势
最小二乘问题用 QR 分解求解:
优势:
-
SVD:最稳定但最贵
SVD 求解最小二乘:
优势:
- 对秩亏问题也适用
- 可以自动识别和处理近似奇异
- 条件数信息直接可得
代价:计算量比 QR 大约 2-3 倍
预条件技术:驯服病态矩阵
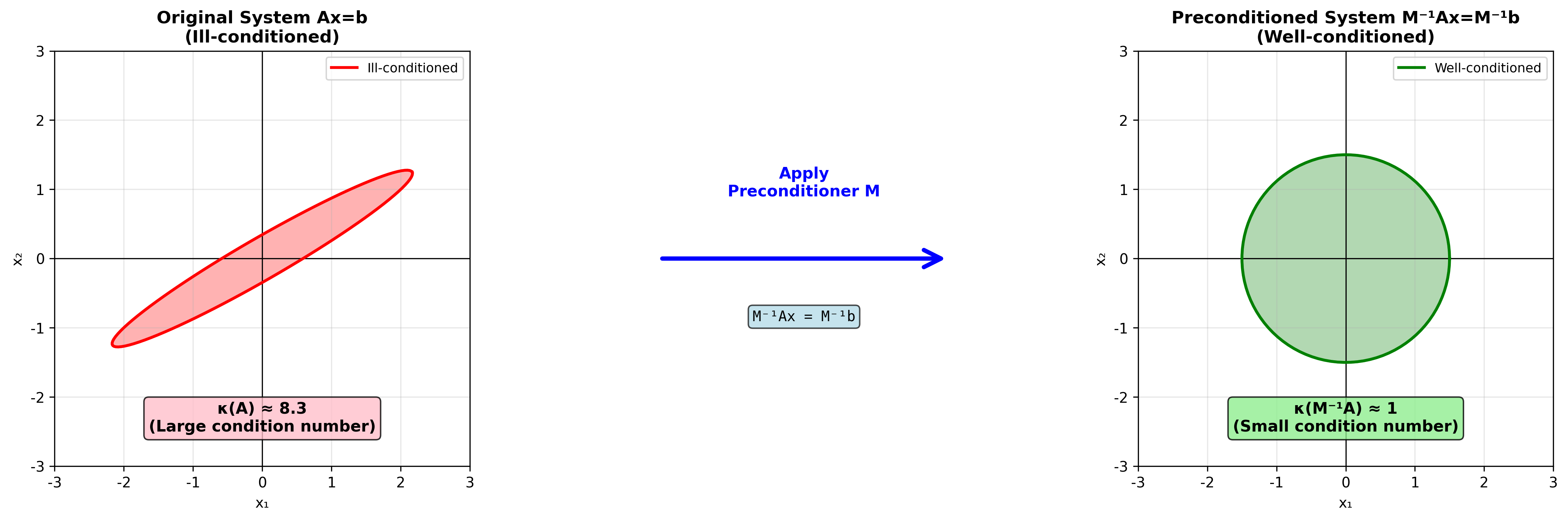
预条件的基本思想
问题:求解
想法:找一个矩阵
如果
生活类比:想象你要测量一个非常大的物体,但你的尺子太短了。预条件就像是先用一个粗略的估计把物体"缩小"到尺子能测量的范围,测量后再"放大"回去。
常见预条件子
Jacobi 预条件(对角预条件):
- 优点:实现简单,计算代价最小
- 缺点:效果有限,只能处理对角占优的情况
Gauss-Seidel 预条件:
- 优点:效果比 Jacobi 好
- 缺点:不易并行化
不完全 LU 分解( ILU):
- 优点:效果好,适用范围广
- 缺点:可能填入非零元,需要控制填入
不完全 Cholesky( ICC):
- 优点:利用对称性,存储量减半
- 缺点:只适用于 SPD 矩阵
预条件的效果评估
好的预条件应该满足:
1.
实际选择:
- 对角占优矩阵: Jacobi 或 Gauss-Seidel
- 一般稀疏矩阵: ILU(0)或 ILU(k)
- 对称正定: ICC
- 特殊结构:利用问题特性设计专门预条件
科学计算中的应用
有限元分析中的条件数
在结构力学的有限元分析中,刚度矩阵
其中
实际意义:
- 网格太不均匀会导致条件数很大
- 材料性质差异大(如钢筋混凝土)也会增加条件数
- 需要使用自适应网格和预条件技术
图像处理中的反问题
图像去模糊问题
解决方案: Tikhonov 正则化
这等价于求解
当
机器学习中的正则化
Ridge 回归(岭回归):
正则化参数
- 防止过拟合:约束模型复杂度
- 改善条件数:使问题数值稳定
- 处理多重共线性:当特征高度相关时
条件数与泛化:高条件数往往意味着模型对训练数据的微小变化过于敏感,这与过拟合密切相关。
深度学习中的梯度问题
神经网络中的梯度消失/爆炸问题与条件数密切相关。
权重矩阵
- 如果
:信号在前向传播中指数增长 - 如果
:信号在前向传播中指数衰减 - 梯度反传时情况相反
解决方案:
- 批归一化( Batch Normalization)
- 权重初始化( Xavier, He 初始化)
- 残差连接( ResNet)
- 梯度裁剪
总结与展望
本章关键要点
向量范数:
-
范数对应不同的"距离"概念 - 单位球的几何形状反映范数的特性
- 有限维空间中所有范数等价
矩阵范数:
- Frobenius 范数:元素平方和的平方根,计算简单
- 谱范数:最大奇异值,几何意义明确
- 诱导范数:变换的最大放大倍数
条件数:
- 定义:
- 谱条件数:
- 误差放大因子,衡量问题的敏感度
- 定义:
病态矩阵:
- Hilbert 矩阵是经典例子
- 条件数大意味着数值计算不可靠
- 需要特殊技术(正则化、预条件)处理
谱半径:
- 定义:
- 迭代收敛条件:
- Neumann 级数
- 定义:
数值稳定性:
- 正规方程会使条件数平方
- QR 分解和 SVD 更稳定
- 预条件技术可以改善条件数
实践建议
| 条件数 | 风险级别 | 建议 |
|---|---|---|
| 低 | 安全,标准方法可用 | |
| 中 | 小心,验证结果,考虑换方法 | |
| 高 | 使用正则化或预条件 | |
| 极高 | 重新建模,考虑问题是否 well-posed |
下一章预告
《矩阵微积分与优化》
- 矩阵函数的导数
- 梯度和 Hessian
- 矩阵微分公式
- 应用:神经网络反向传播
矩阵微积分是机器学习优化的数学基础!
练习题
基础题
- 计算向量
的 范数。 - 计算矩阵
的 Frobenius 范数和谱范数。 - 证明:
,并说明何时等号成立。 - 对于对角矩阵
,证明 。 - 计算
和 诱导范数:
进阶题
- 证明:
对任意矩阵范数成立。 - 设
是 实矩阵,证明 。 - 证明:如果
是正交矩阵,则 。 - 设
可逆且 ,证明 也可逆。 - 推导
Hilbert 矩阵的条件数(可用编程验证)。 - 证明 Neumann 级数收敛的充分条件:如果
(对某个矩阵范数),则 存在。
编程题
实现函数计算矩阵的
, , 诱导范数和 Frobenius 范数。 可视化 Hilbert 矩阵条件数随维数
的增长(用对数坐标)。 比较正规方程、 QR 分解、 SVD 求解最小二乘问题的数值稳定性:
- 生成一个病态设计矩阵
- 用三种方法求解 - 比较解的精度
- 生成一个病态设计矩阵
实现 Jacobi 迭代法和 Gauss-Seidel 迭代法,比较收敛速度与谱半径的关系。
实现 Jacobi 预条件的共轭梯度法,对比有无预条件的迭代次数。
应用题
分析 Ridge 回归中正则化参数
对条件数的影响: - 生成一个近似奇异的设计矩阵
- 画出
随 变化的曲线
研究有限差分离散 Laplace 算子的条件数与网格大小的关系:
- 对于一维问题
- 用二阶中心差分离散 - 分析条件数如何随网格点数
增长
- 对于一维问题
神经网络权重初始化实验:
- 比较不同初始化方法(随机、 Xavier 、 He)
- 观察前向传播中信号范数的变化
- 分析与权重矩阵谱范数的关系
图像去模糊问题:
- 用高斯模糊生成模糊图像
- 尝试直接求逆和 Tikhonov 正则化
- 分析条件数和正则化参数的关系
思考题
- 为什么说"条件数大的问题本身就困难",而不只是"算法不好"?
- 在什么情况下, Frobenius 范数比谱范数更合适?反过来呢?
- 预条件技术的本质是什么?为什么它能加速迭代收敛?
- 机器学习中的正则化和数值线性代数中的条件数有什么联系?
参考资料
Golub, G. H., & Van Loan, C. F. (2013). Matrix Computations. 4th ed.
- 数值线性代数的圣经,条件数分析的权威来源
Trefethen, L. N., & Bau, D. (1997). Numerical Linear Algebra. SIAM.
- 条件数和稳定性的深入讲解,几何直观丰富
Higham, N. J. (2002). Accuracy and Stability of Numerical Algorithms. 2nd ed. SIAM.
- 数值稳定性的权威参考,涵盖各种算法
Demmel, J. W. (1997). Applied Numerical Linear Algebra. SIAM.
- 理论与实践结合,有大量应用案例
Saad, Y. (2003). Iterative Methods for Sparse Linear Systems. 2nd ed. SIAM.
- 迭代方法和预条件技术的详细介绍
本文是《线性代数的本质与应用》系列的第 10 章,共 18 章。
- 本文标题:线性代数(十)矩阵范数与条件数
- 本文作者:Chen Kai
- 创建时间:2019-02-23 09:00:00
- 本文链接:https://www.chenk.top/%E7%BA%BF%E6%80%A7%E4%BB%A3%E6%95%B0%EF%BC%88%E5%8D%81%EF%BC%89%E7%9F%A9%E9%98%B5%E8%8C%83%E6%95%B0%E4%B8%8E%E6%9D%A1%E4%BB%B6%E6%95%B0/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!