当你把一堆随机数填进一个巨大的矩阵,然后计算它的特征值,你会发现一件神奇的事情:这些特征值的分布竟然有着惊人的规律性。这就像在混乱中发现秩序,在噪声中听见音乐。随机矩阵理论告诉我们,当维度足够高时,随机性本身会涌现出深刻的数学结构。
从直觉开始:为什么随机矩阵不"随机"?
想象你在一个巨大的音乐厅里,一万个人同时随机敲击键盘。直觉上,这应该产生纯粹的噪声。但如果你用傅里叶分析去看这些声音的频率分布,你会发现某些统计规律总是出现——这不是因为人们在协调,而是因为大数定律和中心极限定理在高维空间中的神奇体现。
随机矩阵也是如此。一个
随机矩阵的定义与分类
什么是随机矩阵?
随机矩阵是指矩阵的元素是随机变量的矩阵。听起来简单,但这个定义背后蕴含着丰富的数学结构。
设
最简单的例子:生成一个矩阵,每个元素独立地从标准正态分布
1 | import numpy as np |
核心问题
随机矩阵理论关心的核心问题是:当矩阵维度
这个问题的答案出人意料地普适——无论你用什么分布生成矩阵元素,只要满足一些基本条件,特征值分布就会收敛到同样的极限形状。
主要的随机矩阵模型
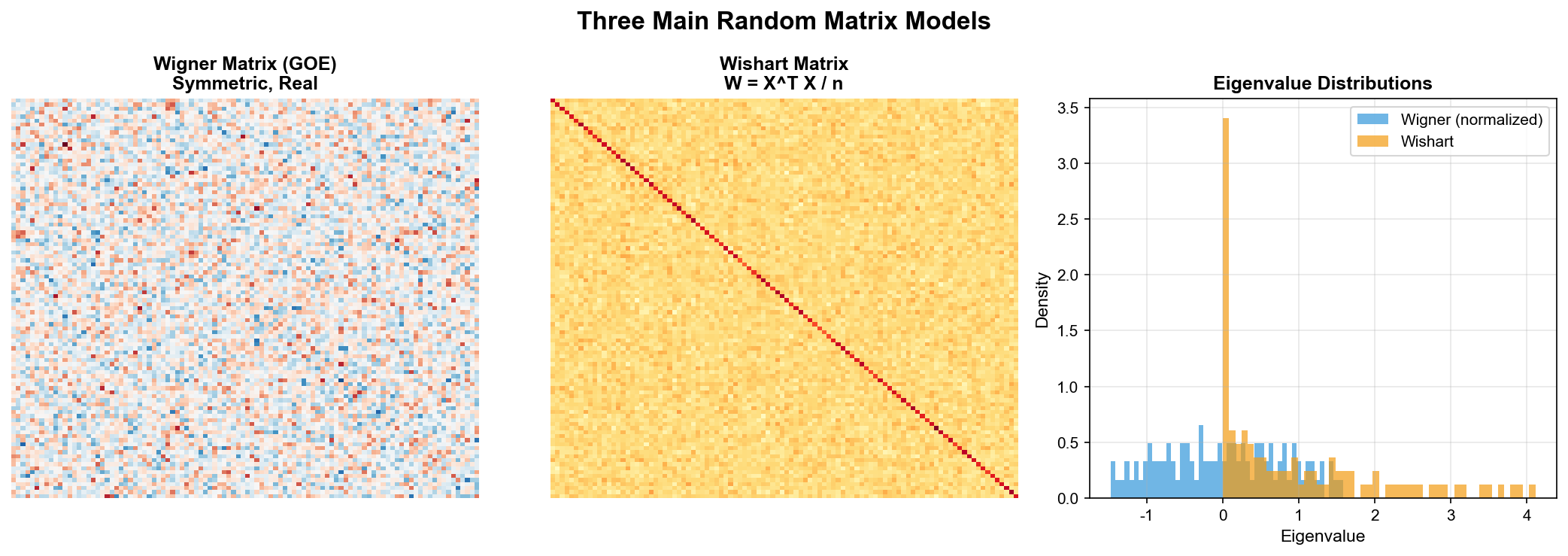
Wigner 矩阵(对称/Hermite 随机矩阵)
Wigner 矩阵是最经典的随机矩阵模型。设
- 对角元素
独立同分布,均值为 0,方差为 - 上三角元素
( )独立同分布,均值为 0,方差为 - 下三角元素由对称性确定:
最常见的例子是高斯正交系综( GOE),其中所有随机变量都服从高斯分布。
生活类比:想象一个社交网络,
Wishart 矩阵(样本协方差矩阵)
设
这正是统计学中样本协方差矩阵的形式!如果你收集了
生活类比:假设你是一个基金经理,追踪 500
只股票,每天记录它们的收益率。一年下来你有大约 250
个交易日的数据。你计算的协方差矩阵就是一个
其他重要模型
- 高斯酉系综( GUE):元素是复数,满足 Hermite
条件
- 高斯辛系综( GSE):元素是四元数
- 循环系综:特征值分布在单位圆上
Wigner 半圆律:随机矩阵的"中心极限定理"
定理陈述
Wigner 半圆律是随机矩阵理论最基础、最优美的结果。它说的是:
设
在
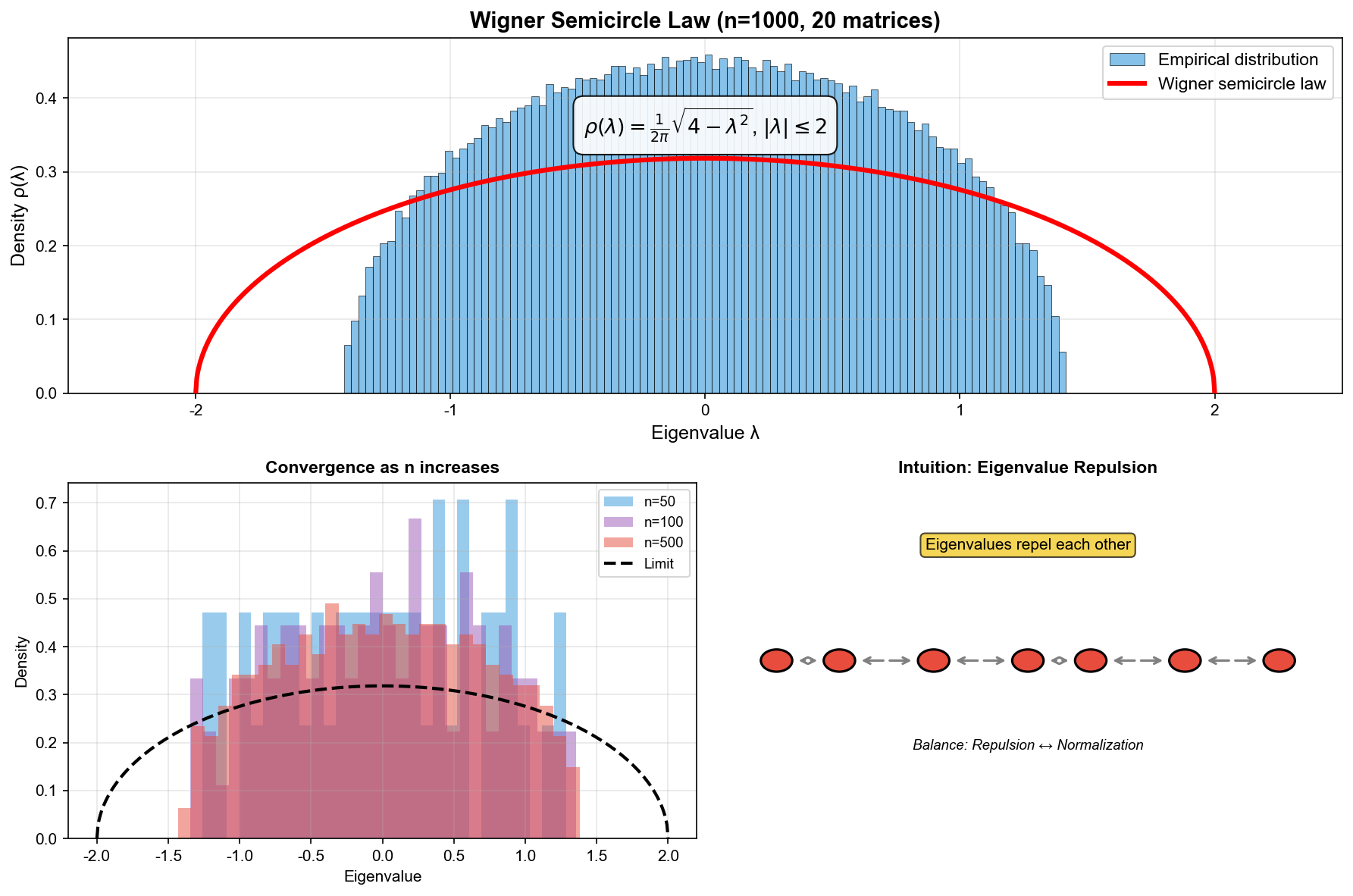
直觉理解
为什么是半圆?这里有几个直觉层面的解释:
直觉一:力学平衡
想象特征值是一条直线上的带电粒子,它们互相排斥(因为特征值不喜欢"聚堆")。同时有一个外力把它们往原点拉(归一化的效果)。排斥力和吸引力达到平衡时,粒子的密度分布就是半圆形。
直觉二:高维几何
在高维空间中,单位球的"体积"集中在赤道附近。随机矩阵的特征值分布反映了这种高维几何特性——大多数特征值既不会太大也不会太小,而是分布在"中间地带"。
直觉三:矩方法
数学上,证明半圆律的经典方法是矩方法。计算特征值分布的各阶矩,发现它们恰好等于半圆分布的矩。这就像通过均值和方差确定正态分布一样。
数值验证
让我们用代码验证 Wigner 半圆律:
1 | import numpy as np |
运行这段代码,你会看到经验分布与理论半圆曲线完美吻合。这种吻合的精确程度,每次都让人惊叹不已。
普适性:为什么分布无关紧要?
Wigner 半圆律的一个惊人特点是普适性:无论矩阵元素服从什么分布(高斯、均匀、离散……),只要满足均值为 0 、方差有限、独立性等基本条件,极限分布都是半圆。
这就像中心极限定理——无论原始分布是什么,足够多独立随机变量的和趋向于正态分布。半圆律是随机矩阵领域的"中心极限定理"。
Marchenko-Pastur 分布:样本协方差矩阵的极限
问题背景
在统计学和数据科学中,我们经常需要估计协方差矩阵。假设有
其中
关键问题:当
定理陈述
设
当
其中边界为:
当
当
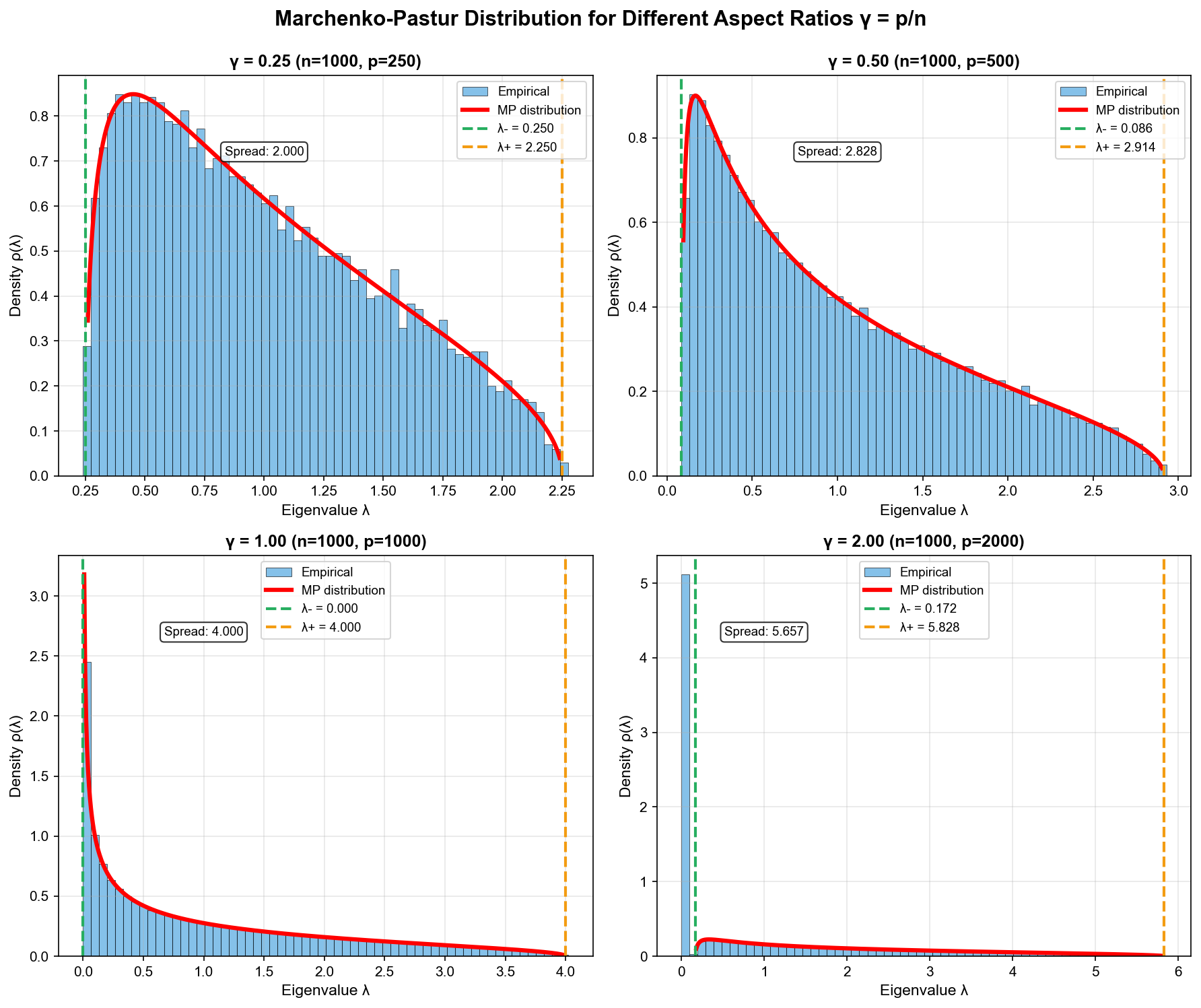
直觉理解
为什么特征值不集中在 1 附近?
如果总体协方差矩阵是单位阵
纵横比
生活类比:这就像用有限的观测来估计一个复杂系统。观测越少、系统越复杂,你的估计误差越大。 Marchenko-Pastur 分布精确地量化了这种误差。
数值验证
1 | import numpy as np |
特征值的精细结构
经验特征值分布
设矩阵
其中
直观地说,经验特征值分布就是把每个特征值当作一个"点质量",然后求平均。
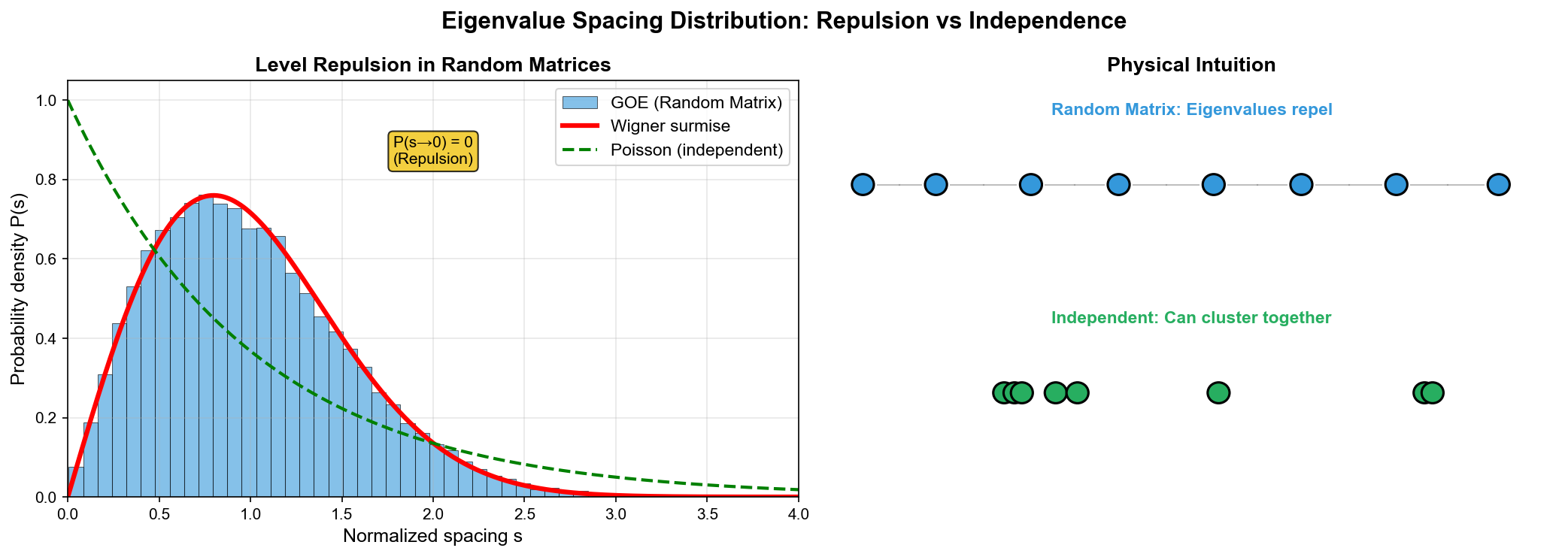
特征值间距分布
除了整体分布,特征值之间的间距也有深刻的规律。
定义相邻特征值间距
关键观察:当
这与独立随机变量完全不同!如果特征值是独立的,间距应该服从指数分布
Tracy-Widom 分布:最大特征值的极限
对于标准 Wigner 矩阵,最大特征值
具体地,存在一个标准化因子,使得:
其中
Tracy-Widom 分布是高度不对称的:它的左尾衰减很快(超指数),右尾衰减较慢。这反映了最大特征值有小概率出现异常大的值。
在无线通信中的应用
MIMO 系统简介
MIMO( Multiple-Input
Multiple-Output)是现代无线通信的核心技术。发射端有
其中
在丰富散射环境中(如城市环境),信道矩阵
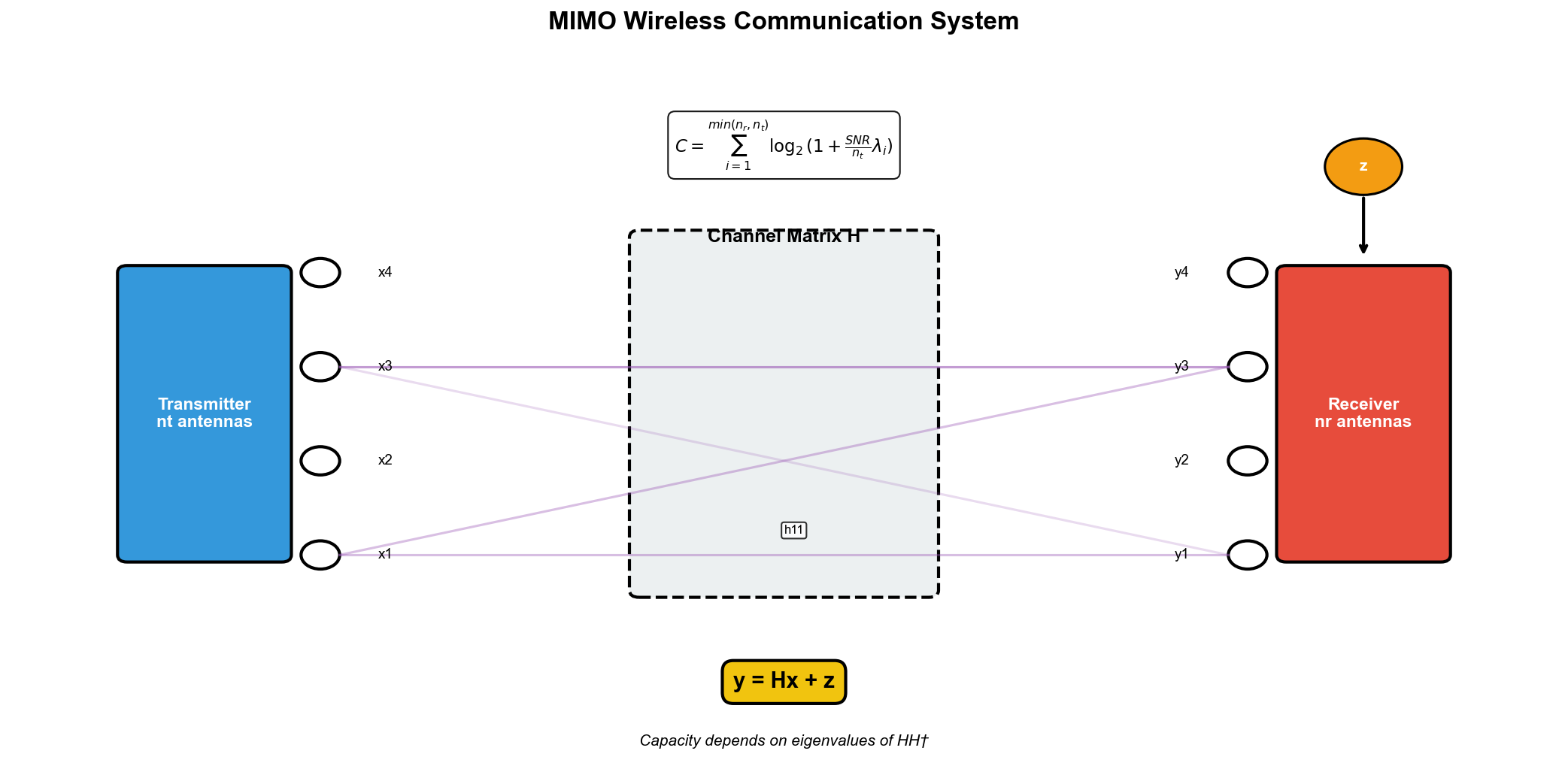
信道容量与特征值
MIMO 信道的容量(理论上能传输的最大信息速率)由下式给出:
其中
关键洞察:信道容量完全由特征值决定!
随机矩阵理论的应用
当天线数目很大时,可以用 Marchenko-Pastur 分布来分析信道特征值分布,进而预测系统容量。
设
这说明 MIMO 可以实现线性增长的容量——天线数目翻倍,容量也翻倍!这是 MIMO 的核心优势。
实际设计启示
- 天线配置:纵横比
影响特征值分布的"形状",进而影响容量 - 功率分配:知道特征值分布后,可以优化在各个"信道模式"上的功率分配
- 大规模 MIMO:当天线数目趋向无穷时,随机矩阵理论给出精确的性能预测
1 | import numpy as np |
在金融中的应用
投资组合与协方差矩阵
现代投资组合理论( Markowitz 理论)的核心是协方差矩阵。设有
其中
问题:我们不知道真实的
噪声的诅咒
假设你跟踪 500 只股票,收集 5 年(约 1250
个交易日)的数据。样本协方差矩阵是
纵横比
- 真实特征值 = 1 时,样本特征值分布在
- 这意味着最大特征值被高估约 126%,最小特征值被低估约 86%!
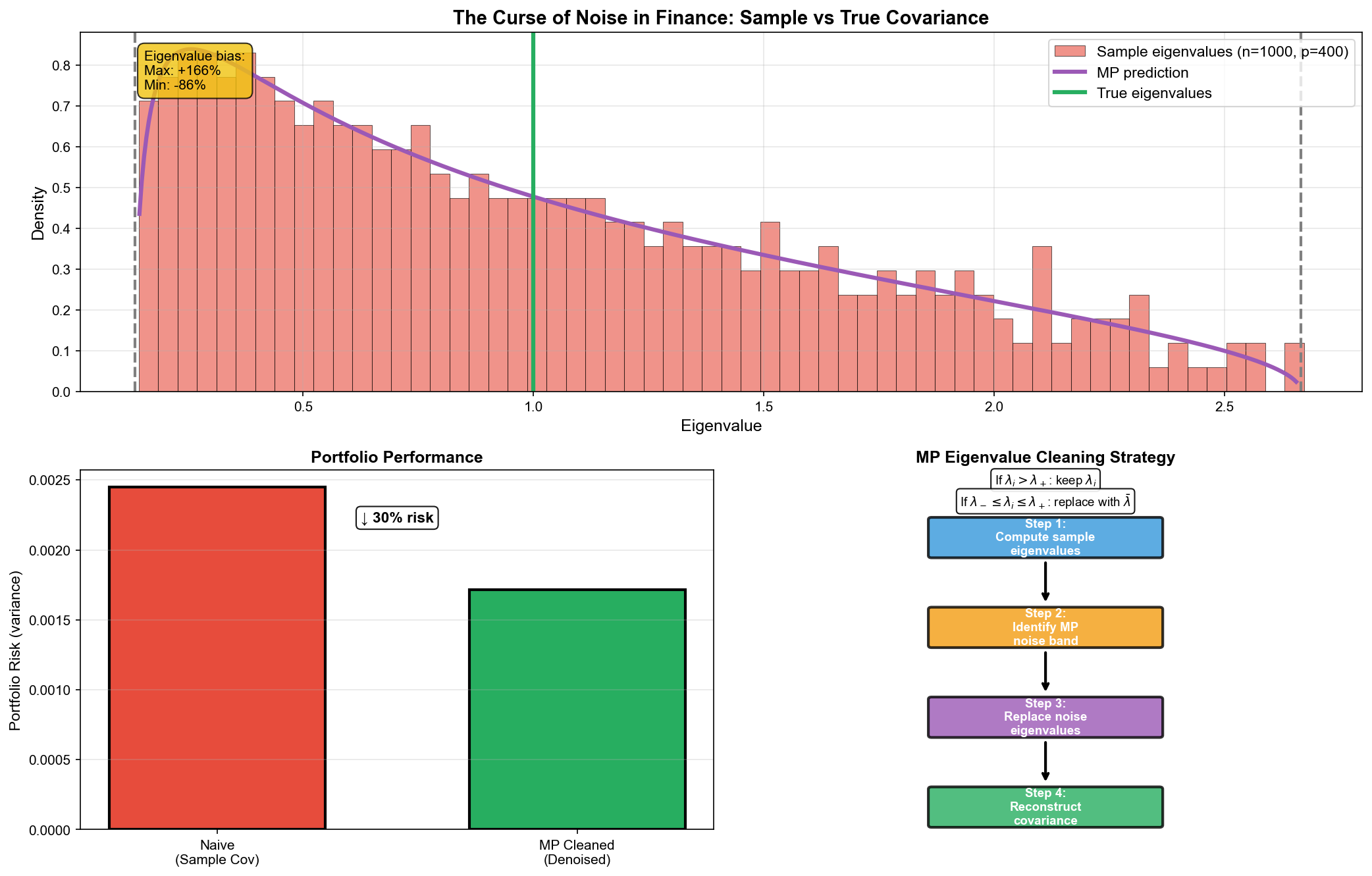
特征值清洗
随机矩阵理论提供了一种"清洗"噪声特征值的方法:
步骤 1:计算样本协方差矩阵的特征值分解
步骤 4:重构协方差矩阵1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41import numpy as np
def clean_covariance_matrix(returns, method='average'):
"""
使用随机矩阵理论清洗协方差矩阵
Parameters:
returns: n x p 收益率矩阵( n 个样本, p 个资产)
method: 清洗方法
Returns:
清洗后的协方差矩阵
"""
n, p = returns.shape
gamma = p / n
# 计算样本协方差矩阵
S = np.cov(returns, rowvar=False)
# 特征值分解
eigenvalues, eigenvectors = np.linalg.eigh(S)
# Marchenko-Pastur 边界
sigma_sq = np.mean(eigenvalues) # 估计噪声方差
lambda_minus = sigma_sq * (1 - np.sqrt(gamma))**2
lambda_plus = sigma_sq * (1 + np.sqrt(gamma))**2
# 识别噪声特征值
noise_mask = (eigenvalues >= lambda_minus) & (eigenvalues <= lambda_plus)
# 清洗
cleaned_eigenvalues = eigenvalues.copy()
if method == 'average':
# 将噪声特征值替换为平均值
noise_avg = np.mean(eigenvalues[noise_mask])
cleaned_eigenvalues[noise_mask] = noise_avg
# 重构协方差矩阵
cleaned_S = eigenvectors @ np.diag(cleaned_eigenvalues) @ eigenvectors.T
return cleaned_S, lambda_minus, lambda_plus
实证效果
使用清洗后的协方差矩阵构建的投资组合,在样本外测试中通常表现更好: - 夏普比率提升:约 10-30% - 波动率更稳定:减少极端波动 - 换手率降低:投资组合更稳定
在机器学习中的应用
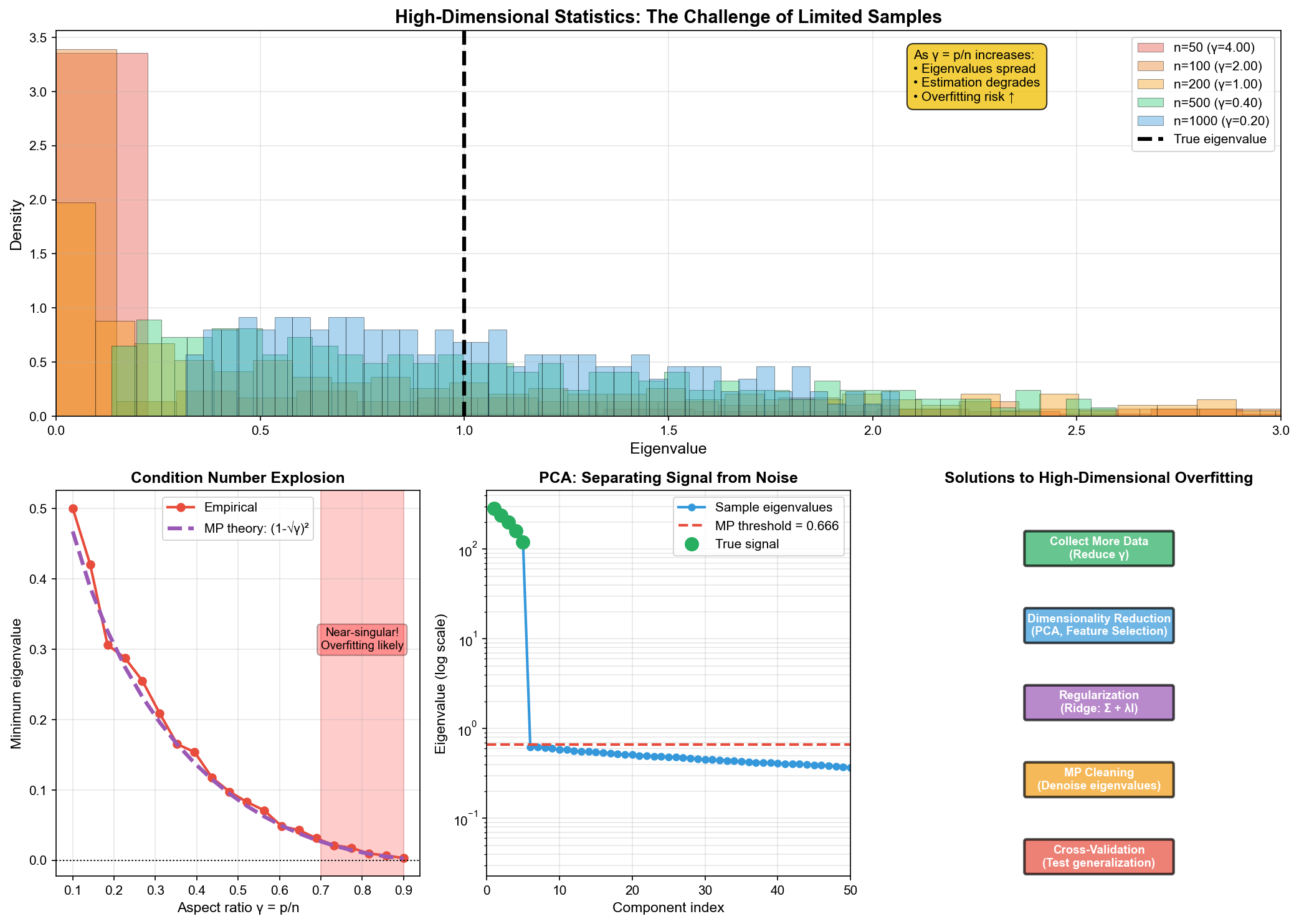
高维统计的挑战
现代机器学习经常处理"高维小样本"问题:特征数
在这种情况下,传统统计方法会失效。例如: -
样本协方差矩阵是奇异的(当
随机矩阵理论为这些问题提供了理论框架和实用工具。
PCA 与随机矩阵
主成分分析( PCA)是最常用的降维方法。它提取协方差矩阵的主特征值对应的方向。
问题:在高维情况下,哪些主成分是"真实的",哪些只是噪声?
随机矩阵答案:使用 Marchenko-Pastur
分布作为"零假设"。超出
1 | import numpy as np |
神经网络初始化
深度学习中,权重矩阵的初始化至关重要。随机矩阵理论帮助理解不同初始化策略的效果。
Xavier 初始化的原理:保持各层输出的方差稳定,避免梯度消失/爆炸。
设
这使得
过拟合的理论理解
随机矩阵理论揭示了高维统计中过拟合的本质:
当
解决方案: 1. 正则化:添加
核心数学工具
Stieltjes 变换
Stieltjes 变换是研究特征值分布的强大工具。设
其中
为什么有用?
恢复分布:
可以从 通过逆变换恢复 方程简化:许多随机矩阵问题在 Stieltjes 变换的语言下变得简洁
自由概率论
自由概率论是 Voiculescu 在 1980 年代发展的理论,研究"非交换概率空间"中的随机变量。
与经典概率中的"独立性"类似,自由概率引入了自由独立的概念。两个随机矩阵是自由独立的,当且仅当它们"尽可能不交换"。
关键定理:大型随机矩阵在极限下是自由独立的。
这允许我们像处理独立随机变量一样处理随机矩阵的和与积的特征值分布。
半圆律的证明思路
使用矩方法证明 Wigner 半圆律:
步骤 1:计算特征值的第
步骤 2:使用独立性和均值为 0 的性质,只有"配对"的求和项不为 0
步骤 3:对非零项计数,发现数目等于 Catalan 数
步骤 4: Catalan 数恰好是半圆分布的矩
这完成了证明的骨架。严格化需要处理误差项和收敛性。
深入理解:为什么随机矩阵理论如此普适?
普适性现象
随机矩阵理论最神奇的特点是普适性: - 无论元素分布如何,极限特征值分布相同 - 不同物理系统(原子核、量子混沌、等等)展现相同的统计规律
这种普适性源于高维概率的一个深刻事实:当维度趋于无穷时,细节被"平均掉",只有宏观结构保留下来。
与物理学的联系
随机矩阵理论最初由 Wigner 在 1950 年代为研究原子核能级统计而发展。
观察:复杂原子核的能级间距分布与 GOE 随机矩阵的特征值间距分布惊人相似!
解释:复杂量子系统的哈密顿量"看起来像"随机矩阵,因为它极其复杂,我们无法追踪每个细节。
这是统计力学思想在量子物理中的体现。
与信息论的联系
从信息论角度,随机矩阵可以看作"最大熵"矩阵——在给定约束下,熵最大的矩阵分布。
半圆分布是满足一定约束条件下的"最无信息"分布,类似于正态分布在一维情况下的地位。
练习题
基础概念题
练习 1:设
练习 2:解释为什么 Wigner 矩阵需要归一化因子
练习 3:设
计算与证明题
练习 4:验证半圆分布
练习 5:计算半圆分布的二阶矩
练习 6:设
练习 7:对于
其中
编程题
练习 8:编写程序验证特征值排斥现象。 - 生成大量 GOE
矩阵 - 计算相邻特征值间距 - 绘制间距分布直方图 - 与理论 Wigner 猜测
练习 9:实现 Marchenko-Pastur 分布的数值验证。 -
生成
练习 10:编写 MIMO 信道容量仿真程序。 - 实现不同天线配置下的容量计算 - 绘制容量随信噪比变化的曲线 - 比较与随机矩阵理论预测的差异
应用题
练习 11:某投资者跟踪 100 只股票,收集了 200
天的收益率数据。 1. 计算纵横比
练习 12:在一个
练习 13:你有一个数据集,包含 1000 个样本,每个样本有 500 个特征。 1. 应该保留多少个主成分?使用 Marchenko-Pastur 准则。 2. 如果希望保留更多主成分,应该如何调整实验设计?
进阶研究题
练习 14:研究 Tracy-Widom 分布。 1. 查阅文献,写出 Tracy-Widom 分布的定义 2. 解释为什么最大特征值的极限分布不是高斯分布 3. Tracy-Widom 分布在统计假设检验中有什么应用?
练习 15:探索自由概率论。 1.
什么是自由独立性?与经典独立性有什么区别? 2. 设
练习 16:随机矩阵与量子混沌。 1. 什么是量子混沌?它与经典混沌有什么关系? 2. 为什么量子混沌系统的能级统计服从 GOE 分布? 3. 如何从能级间距分布判断一个量子系统是"可积的"还是"混沌的"?
练习题答案
基础概念题答案
练习 1 答案:
期望矩阵:
因为所有元素的期望都是 0。
协方差结构: -
这是标准的 Wigner 矩阵(GOE)结构。
练习 2 答案:
需要归一化因子
特征值尺度:如果不归一化,
随机矩阵的最大特征值大约是 (每行元素平方和约为 )。 极限分布存在性:为了得到非平凡的极限分布,需要将特征值除以
,使它们落在固定区间内。 半圆律:归一化后,特征值收敛到半圆分布,支撑在
。
如果不归一化: - 特征值会随
数学上,定义
练习 3 答案:
给定
支撑区间为
密度函数:
草图特点: - 在
计算与证明题答案
练习 4 答案:
证明:
使用三角代换:
当
使用
证毕。
练习 5 答案:
二阶矩:
使用对称性和三角代换
所以
四阶矩(通过类似计算):
这些矩对应 Catalan 数:
练习 6 答案:
证明:
由于
- 当
时: ,所以 - 当
时:
因此
这说明样本协方差矩阵(在总体协方差为单位阵时)是无偏估计。
练习 7 答案:
特征值
联合概率密度函数(通过 Jacobian 变换):
原始变量的联合密度:
变换到
其中
这展现了特征值排斥:因子
编程题答案
练习 8 答案:
1 | import numpy as np |
观察: - 经验分布与 Wigner 猜测完美吻合 -
练习 9 答案:
1 | import numpy as np |
观察
练习 10 答案:
1 | import numpy as np |
理论对比: - 高信噪比下:
应用题答案
练习 11 答案:
纵横比:
样本特征值分布区间:
大部分样本特征值会落在
区间。 特征值 3.5 的意义:
- 3.5 > 2.914(超出 MP 噪声带)
- 这很可能是真实的市场因子,而非噪声
- 可能代表:
- 市场整体走势(市场因子)
- 行业相关性(某个行业的共同因子)
- 宏观经济因素
建议:保留这个主成分作为投资组合构建的基础。
练习 12 答案:
容量表达式:
其中
是信道矩阵 的特征值。 30dB 下的容量估计:
- SNR = 30dB = 1000(线性尺度)
- 高信噪比近似:
增至 16×16 MIMO:
- 容量约为:
bits/s/Hz - 增加量:
bits/s/Hz(约增加 71%) - 天线数翻倍,容量约翻倍(线性扩展性)
- 容量约为:
练习 13 答案:
主成分数量: -
- MP 阈值:
- 标准化后,计算样本协方差矩阵的特征值
- 保留所有超过 2.914(相对于噪声方差)的特征值对应的主成分
- 经验法则:约保留 5-15 个主成分(取决于数据的真实低秩结构)
- MP 阈值:
调整实验设计: 为了保留更多真实主成分,可以:
方法 1:收集更多样本
- 增加
,降低 - 例如:
,则 , (阈值降低)
方法 2:特征选择
- 通过领域知识减少无关特征
- 降低
,同时降低
方法 3:正则化
- 使用岭回归式的收缩:
- 提高小特征值的稳定性
最优策略:确保
,给予充足的样本余量。 - 增加
进阶研究题答案
练习 14 答案:
Tracy-Widom 分布定义:
对于 GOE 随机矩阵,最大特征值
的波动服从: 其中
, 是 Tracy-Widom GOE 分布。 累积分布函数可以用 Painlevé II 方程的解表示:
其中
满足 。 为什么不是高斯分布?
- 不同的波动尺度:最大特征值波动尺度为
,而非通常的 - 边界效应:最大特征值受到谱边界的约束,不能"自由波动"
- 长程相关性:特征值之间存在强相关(排斥),最大特征值受到所有其他特征值的影响
- 非线性统计量:
是非线性的,中心极限定理不适用
Tracy-Widom 分布是非对称的:
- 左尾衰减极快(超指数)
- 右尾衰减较慢(
)
- 不同的波动尺度:最大特征值波动尺度为
统计假设检验应用:
应用 1:协方差矩阵检验
- 零假设:数据来自白噪声(协方差为
) - 检验统计量:最大特征值
- 临界值由 Tracy-Widom 分布给出
应用 2:尖峰检测
- 问题:样本协方差矩阵的最大特征值是否显著大于 MP 噪声带?
- 阈值:
,其中 来自 TW 分布的分位数
应用 3:因子数量选择
- 在金融中:检验有几个真实的风险因子
- 逐个检验特征值是否超过 TW 阈值
- 零假设:数据来自白噪声(协方差为
练习 15 答案:
自由独立性定义:
在非交换概率空间
中,两个子代数 是自由独立的,当且仅当对所有 中心化的元素 , : (交替乘积的期望为零)
与经典独立的区别:
- 经典独立:
(交换代数) - 自由独立:
(非交换代数)
直观理解:
- 经典独立:随机变量没有相关性
- 自由独立:随机矩阵"尽可能不对易"
- 经典独立:
自由卷积:
如果
和 是自由独立的大随机矩阵,它们的和 的特征值分布是: 其中
是自由加法卷积。 例子:两个半圆分布的自由卷积仍是半圆分布(方差相加)。
乘积:对于
,特征值分布由自由乘法卷积 给出。 自由卷积 vs 经典卷积:
性质 经典卷积 自由卷积 适用对象 独立随机变量 自由独立随机矩阵 加法 的分布 = 的谱 = 不变量 特征函数相乘 Stieltjes 变换相加(经变换) 极限定理 高斯分布(CLT) 半圆分布(自由 CLT) 计算方法:
- 经典:
- 自由:通过
-变换计算( )
- 经典:
练习 16 答案:
量子混沌定义:
经典混沌:
- 对初值极端敏感(蝴蝶效应)
- Lyapunov 指数 > 0
- 遍历性、混合性
量子混沌:
- 经典混沌系统的量子版本
- 由于不确定性原理,无法定义"轨道"
- 通过能级统计来表征
Bohigas-Giannoni-Schmit(BGS)猜想: 量子混沌系统的能级统计与 GOE 随机矩阵相同。
为什么服从 GOE?
直观解释:
- 混沌系统极其复杂,哈密顿量
有大量非零矩阵元 - 在适当基下,
"看起来像"随机对称矩阵 - 时间反演对称性(实哈密顿量)→ GOE
- 如果破缺时间反演对称(如加磁场)→ GUE
更深层原因:
- 遍历性:混沌系统遍历整个相空间
- 典型性:大多数满足对称性的哈密顿量都产生 GOE 统计
- 普适性:细节无关,只要足够混沌
- 混沌系统极其复杂,哈密顿量
可积 vs 混沌判据:
能级间距分布:
- 可积系统:
- 间距分布 ~ Poisson:
- (允许能级简并) - 能级统计上"独立"
- 间距分布 ~ Poisson:
- 混沌系统:
- 间距分布 ~ Wigner:
- (能级排斥) - 能级强相关
- 间距分布 ~ Wigner:
实际判断方法:
- 计算大量能级
- 统计归一化间距分布
- 拟合 Poisson 或 Wigner
- 计算统计量如
: - 可积:~ 1
- 混沌:~ 0.5
其他判据:
- 光谱刚性(
统计量) - 数值方差
- 能级速度分布
- 可积系统:
本章总结
随机矩阵理论是线性代数与概率论的美妙交汇点。我们学习了:
核心概念 - 随机矩阵的定义与主要模型( Wigner 、 Wishart) - 经验特征值分布的概念
基本定理 - Wigner 半圆律:对称随机矩阵特征值的极限分布 - Marchenko-Pastur 分布:样本协方差矩阵特征值的极限分布 - Tracy-Widom 分布:最大特征值的极限分布 - 普适性:不同模型具有相同的极限行为
应用领域 - 无线通信: MIMO 系统容量分析 - 金融:协方差矩阵去噪、投资组合优化 - 机器学习:高维统计、 PCA 、神经网络初始化
核心洞察 - 高维随机性会涌现出精确可预测的结构 - 噪声可以被系统地识别和去除 - 普适性使理论具有广泛的适用性
随机矩阵理论仍是一个活跃的研究领域,不断有新的发现和应用涌现。掌握这些基础概念,将为你进入更深层次的研究打下坚实基础。
参考资料
- Bai, Z., & Silverstein, J. W. Spectral Analysis of Large Dimensional Random Matrices. Springer, 2010.
- Anderson, G. W., Guionnet, A., & Zeitouni, O. An Introduction to Random Matrices. Cambridge University Press, 2010.
- Mehta, M. L. Random Matrices. Academic Press, 2004.
- Tulino, A. M., & Verd ú, S. "Random Matrix Theory and Wireless Communications." Foundations and Trends in Communications and Information Theory, 2004.
- Bouchaud, J. P., & Potters, M. "Financial Applications of Random Matrix Theory: A Short Review." arXiv:0910.1205, 2009.
Couillet, R., & Debbah, M. Random Matrix Methods for Wireless Communications. Cambridge University Press, 2011.
本文是《线性代数的本质与应用》系列的第十四章。
- 本文标题:线性代数(十四)随机矩阵理论
- 本文作者:Chen Kai
- 创建时间:2019-03-14 15:00:00
- 本文链接:https://www.chenk.top/%E7%BA%BF%E6%80%A7%E4%BB%A3%E6%95%B0%EF%BC%88%E5%8D%81%E5%9B%9B%EF%BC%89%E9%9A%8F%E6%9C%BA%E7%9F%A9%E9%98%B5%E7%90%86%E8%AE%BA/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!