我们走完了线性代数的漫长旅程。从最初的向量和矩阵,到特征值分解、 SVD 、张量分析,再到机器学习和深度学习中的应用——每一章都在揭示线性代数这门学科令人惊叹的普适性。现在,让我们把目光投向最前沿:量子计算、图神经网络、大语言模型,以及那些正在改变世界的技术。这些领域看似高深莫测,但其核心依然是我们熟悉的线性代数。
量子计算中的线性代数
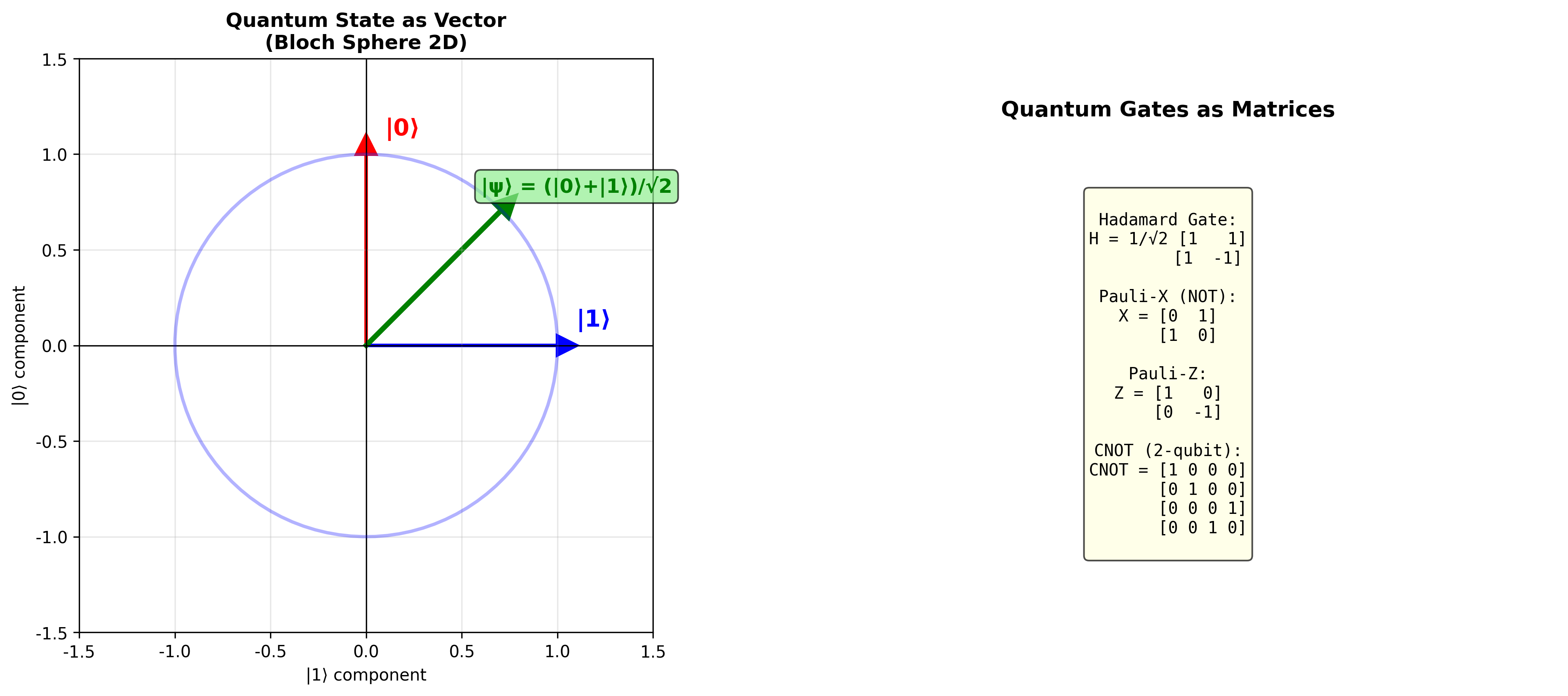
从经典比特到量子比特
经典计算机的基本单位是比特( bit),它只能处于
量子比特( qubit)完全不同。它可以同时处于
这里
系数

直觉理解:想象一个地球仪。经典比特只能在北极或南极,而量子比特可以在球面上的任何一点。这个球被称为Bloch
球,它完美地可视化了量子比特的状态空间。北极是
为什么叠加态如此强大?假设我们有
量子门:酉矩阵的物理实现
量子计算中的"操作"是通过量子门实现的。数学上,量子门就是酉矩阵(
unitary matrix)。一个矩阵
其中
最重要的单量子比特门:
Hadamard
门:这可能是量子计算中最常用的门,它创建叠加态:
作用效果是:
注意
Pauli 门:三个基本旋转
旋转门:参数化的旋转
类似地有
双量子比特门: CNOT
控制非门( CNOT)是双量子比特门的典型代表:
它的作用是:当控制比特为
著名的 Bell 态(最大纠缠态)可以这样制备:
这个态的神奇之处在于:无论两个量子比特相隔多远,测量其中一个会瞬间确定另一个的状态。这不是超光速通信,而是量子力学的非局域性。
量子算法的线性代数视角
Deutsch-Jozsa 算法:量子并行性的展示
假设有一个函数
核心思想是利用 Hadamard 变换创建所有输入的叠加,然后让量子干涉放大正确答案、消除错误答案。
Grover 搜索算法
在
Grover 算法的核心是两个操作的迭代:
- Oracle 翻转:标记目标态的相位
- 扩散变换:绕均值反射
用矩阵语言,扩散变换是
Shor 算法与 RSA 的危机
Shor 算法可以在多项式时间内分解大整数,这直接威胁了 RSA
加密(其安全性基于大数分解的困难)。算法的关键步骤是量子傅里叶变换(
QFT):
这正是离散傅里叶变换的量子版本。经典 FFT 需要
量子机器学习
量子计算与机器学习的交叉点是一个活跃的研究领域。几个重要方向:
变分量子特征求解器( VQE):用于求解分子的基态能量,这是化学和药物设计中的核心问题。 VQE 使用参数化量子电路,通过经典优化器调整参数以最小化能量期望值。
量子神经网络:用参数化量子门构建神经网络。理论上可能实现某些任务的量子加速,但目前受限于量子硬件的噪声。
量子核方法:利用量子态空间作为特征空间,可能访问经典难以计算的核函数。
图神经网络中的线性代数
图的矩阵表示
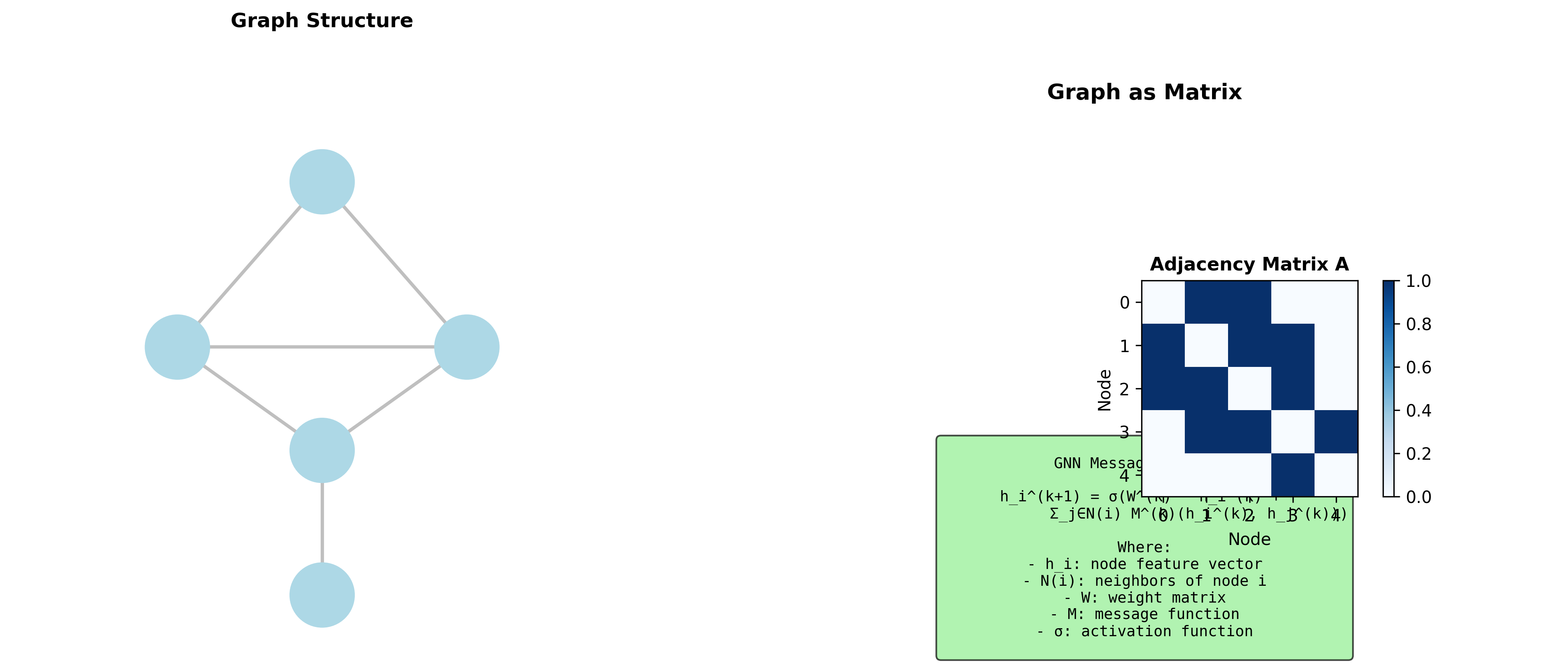
图( graph)是描述关系和连接的基本数据结构。社交网络、分子结构、交通系统、互联网——都可以用图来建模。
一个图
邻接矩阵
度矩阵
图拉普拉斯矩阵
-
归一化拉普拉斯
谱图论:图上的傅里叶分析
傅里叶变换将时间信号分解为不同频率的正弦波。那么,如何在图上定义"频率"?
答案来自拉普拉斯矩阵的特征分解。设
图傅里叶变换定义为:
其中
特征值
- 小特征值对应"低频":特征向量在相邻节点有相似的值(平滑变化)
- 大特征值对应"高频":特征向量在相邻节点有剧烈变化
谱聚类就是利用这个思想:用拉普拉斯矩阵最小的几个非零特征向量来嵌入图节点,然后在嵌入空间中做 K-means 聚类。直觉上,同一社区的节点在低频特征向量上有相似的值。
图卷积网络( GCN)
传统卷积神经网络( CNN)在规则网格(如图像)上工作得很好,但无法直接应用于图结构数据。图卷积网络解决了这个问题。
谱卷积的定义:
这相当于在频域做逐元素乘法,然后变换回来。问题是需要计算整个拉普拉斯矩阵的特征分解,复杂度是
ChebNet 的近似:用切比雪夫多项式近似滤波器:
其中
GCN 的简化:取
这里
直觉理解:每一层 GCN 做的事情是:
- 聚合邻居的特征(
) - 对称归一化(避免度大的节点主导)
- 线性变换(
) - 非线性激活(
)
多层 GCN 可以聚合多跳邻居的信息。
消息传递神经网络
GCN 可以看作消息传递框架的特例。在这个框架中,每一层的更新分为三步:
- 消息计算:
- 消息聚合:
- 节点更新:
不同的 GNN 变体对应不同的 MSG、AGG、UPD 函数选择:
- GraphSAGE:使用采样和不同的聚合器( mean, max, LSTM)
- GAT(图注意力网络):用注意力机制加权聚合
- GIN(图同构网络):理论上最强大的消息传递 GNN
图神经网络的应用
分子性质预测:分子可以看作图(原子是节点,化学键是边)。 GNN 可以预测分子的各种性质,如溶解度、毒性、药物活性。 AlphaFold 预测蛋白质结构时也使用了类似技术。
推荐系统:用户-物品交互可以建模为二部图。 GNN 可以学习用户和物品的嵌入,用于推荐。
知识图谱:实体是节点,关系是边。 GNN 可以做链接预测(预测缺失的关系)和节点分类(实体分类)。
物理仿真:粒子系统可以建模为动态图。 Graph Network Simulator 可以学习复杂的物理动力学。
大模型时代的线性代数
Transformer 的数学结构
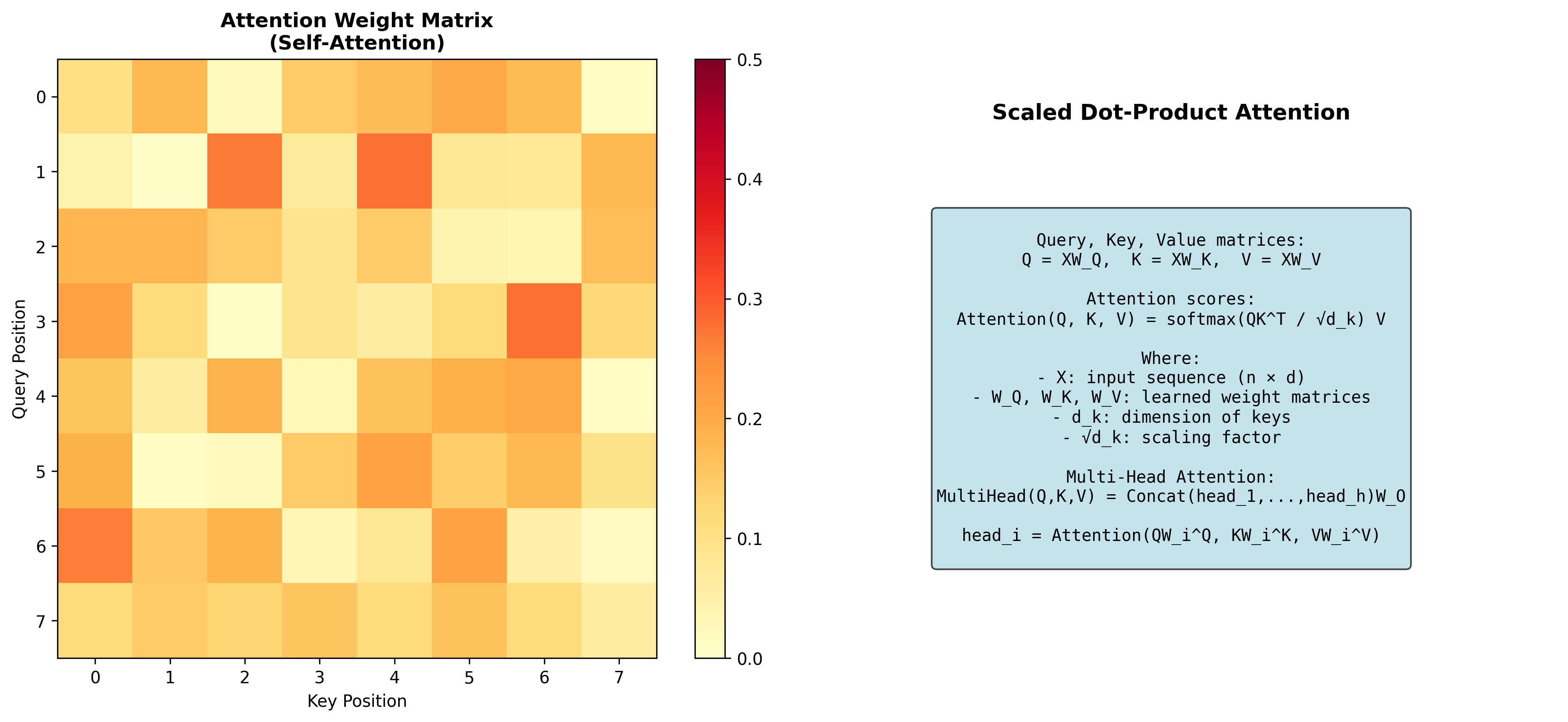
Transformer 是现代大语言模型(如 GPT 、 BERT 、 LLaMA)的基础架构。它的核心是自注意力机制( self-attention),这完全是线性代数运算。
给定输入序列的嵌入矩阵
分解这个公式:
1.
几何直觉:注意力机制在做的是软检索。 Query 是"我想找什么", Key 是"我有什么", Value 是"我能提供什么"。通过内积匹配 query 和 key,然后从相关的 value 中聚合信息。
多头注意力将输入投影到多个子空间:
每个头关注不同的"模式"(如语法关系、语义关系、位置关系)。
位置编码的数学
Transformer 没有递归或卷积,如何感知位置信息?答案是位置编码。
正弦位置编码(原始 Transformer):
旋转位置编码(
RoPE)是更现代的方法,通过复数旋转编码位置:
大模型的参数高效微调
大语言模型有数十亿甚至上万亿参数,全量微调成本极高。线性代数提供了优雅的解决方案。
LoRA( Low-Rank
Adaptation):假设微调时的权重变化是低秩的。不直接更新
这样,可训练参数从
直觉:神经网络的权重矩阵往往是"内在低秩"的。微调只需要在这个低维子空间中调整,而不需要改变所有参数。
QLoRA 进一步结合量化:基础模型用 4-bit 量化存储,只有 LoRA 部分是全精度。这让在消费级 GPU 上微调 65B 模型成为可能。
KV 缓存与推理优化
自回归生成时,每生成一个 token 都需要计算对之前所有 token
的注意力。朴素实现中,生成第
KV 缓存利用了这样的事实:之前 token 的 Key 和 Value
不变。我们缓存它们,每步只计算新 token 的 Q 、 K 、
V,然后与缓存拼接。这将每步计算降到
这是典型的空间换时间策略。 KV 缓存的大小是
稀疏计算和高效推理
稀疏注意力
标准注意力的复杂度是
稀疏注意力通过只计算部分位置对的注意力来降低复杂度:
局部注意力:每个位置只关注附近的窗口。复杂度
膨胀注意力:关注间隔
Longformer/BigBird:结合局部注意力、全局注意力(某些特殊 token 可以看到所有位置)和随机注意力。
数学上,稀疏注意力相当于将
线性注意力与核近似
另一个思路是用核方法近似 softmax 注意力:
通过先计算
Performer 使用随机特征来近似 softmax 核。Linear Transformer 直接去掉 softmax,但可能损失表达能力。
模型量化
量化是将高精度(如 FP32 、 FP16)的权重和激活转换为低精度(如 INT8 、 INT4)表示。
线性代数视角:量化可以看作找一个离散网格来近似连续值。设原始权重是
对称量化:
非对称量化:
按通道量化 vs 按张量量化:不同通道(或不同层)的数值范围可能差异很大。按通道量化为每个通道使用不同的缩放因子,精度更高但开销也更大。
GPTQ 是一种基于二阶信息的量化方法。它考虑 Hessian
矩阵来最小化量化误差:
这是一个加权的矩阵近似问题,可以用 Cholesky 分解高效求解。
模型剪枝
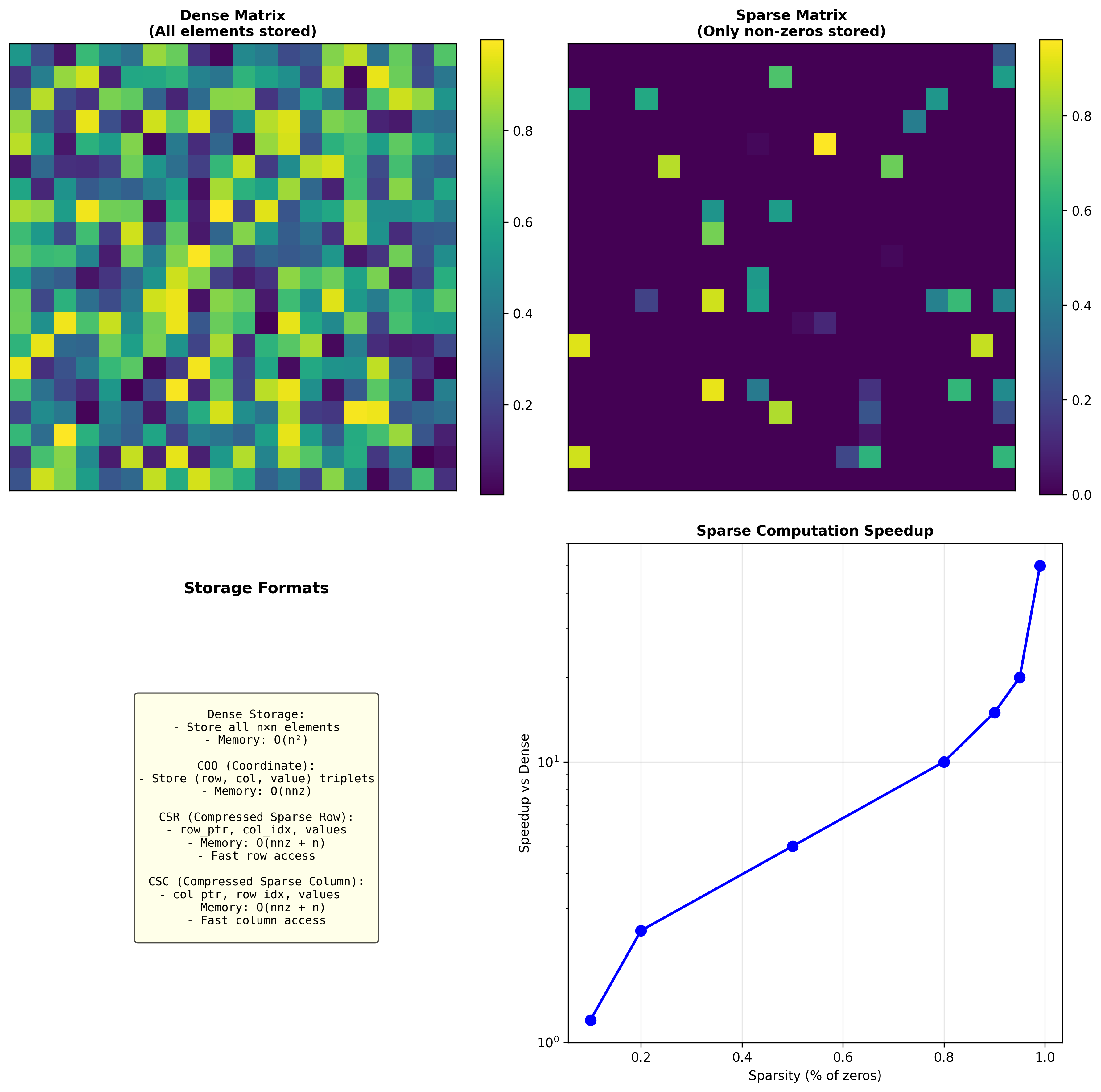
剪枝移除不重要的权重(置为零),创造稀疏性。
非结构化剪枝:任意位置的权重都可以剪掉。稀疏度可以很高( 90%+),但硬件加速困难。
结构化剪枝:剪掉整行、整列、或整个卷积核。更容易加速,但稀疏度通常较低。
重要性度量:
- 幅度:
小的权重不重要 - 梯度:
小的权重不重要 - 二阶:考虑 Hessian 对角线
稀疏矩阵存储: CSR 、 CSC 、 COO 等格式可以高效存储稀疏矩阵。现代 GPU(如 NVIDIA Ampere)有专门的稀疏张量核,支持 2:4 稀疏(每 4 个元素中最多 2 个非零)。
混合精度训练
混合精度训练结合 FP32 和 FP16(或 BF16)来加速训练:
- 主权重保持 FP32
- 前向和反向传播用 FP16
- 梯度缩放防止下溢
这依赖于线性代数运算(矩阵乘法、卷积)在低精度下仍足够准确的事实。现代 GPU 的 Tensor Core 对 FP16/BF16 矩阵乘法有专门优化。
线性代数的前沿研究方向
张量网络与量子态表示
张量网络是表示高维张量的紧凑方式。一个
矩阵乘积态( MPS)是最简单的张量网络:
存储从
MPS 在量子物理中用于表示一维量子系统的基态。DMRG(密度矩阵重正化群)算法是基于 MPS 的变分方法。
更复杂的张量网络包括 PEPS(二维)、MERA(多尺度纠缠重正化)等。它们在量子多体物理和量子机器学习中有重要应用。
随机数值线性代数
随机化方法正在改变数值线性代数。传统算法是确定性的,随机算法用概率方法实现更快的速度。
随机 SVD:不计算完整 SVD,而是用随机投影找到近似的低秩分解:
- 生成随机矩阵
- 计算
(矩阵-矩阵乘法) - 对
做 QR 分解: - 计算
(投影到低维) - 对
做 SVD
复杂度从
Johnson-Lindenstrauss 引理是随机方法的理论基础:高维点可以随机投影到低维,同时近似保持点对距离。
隐式神经表示
隐式神经表示( INR)用神经网络表示连续信号(图像、 3D 形状、视频)。给定坐标,网络输出该点的值。
例如,NeRF(神经辐射场)用 MLP 表示 3D 场景:
输入是 3D 位置
INR
的核心是学习一个从坐标到值的映射函数。位置编码(傅里叶特征)帮助网络学习高频细节:
这与正弦位置编码的思想一脉相承。
微分方程的神经求解器
Physics-Informed Neural Networks(PINN)
用神经网络求解偏微分方程。网络直接参数化解函数,训练时优化:
其中 PDE 损失惩罚方程残差, BC/IC 损失惩罚边界/初始条件违反。
自动微分让我们可以轻松计算任意阶导数。这依赖于链式法则——线性代数中的矩阵乘法。
Neural ODE 将神经网络看作连续动力系统:
全系列回顾和知识图谱
线性代数的三大视角
整个系列贯穿着三种看待线性代数的视角:
代数视角:矩阵是数的阵列,运算遵循特定规则。这是计算的基础。
几何视角:矩阵是线性变换,向量是空间中的箭头。这是直觉的来源。
抽象视角:向量空间是满足公理的集合,线性映射保持结构。这是推广的钥匙。
三种视角相辅相成。代数告诉我们"怎么算",几何告诉我们"什么意思",抽象告诉我们"为什么成立"。
核心概念网络
1 | 向量空间 |
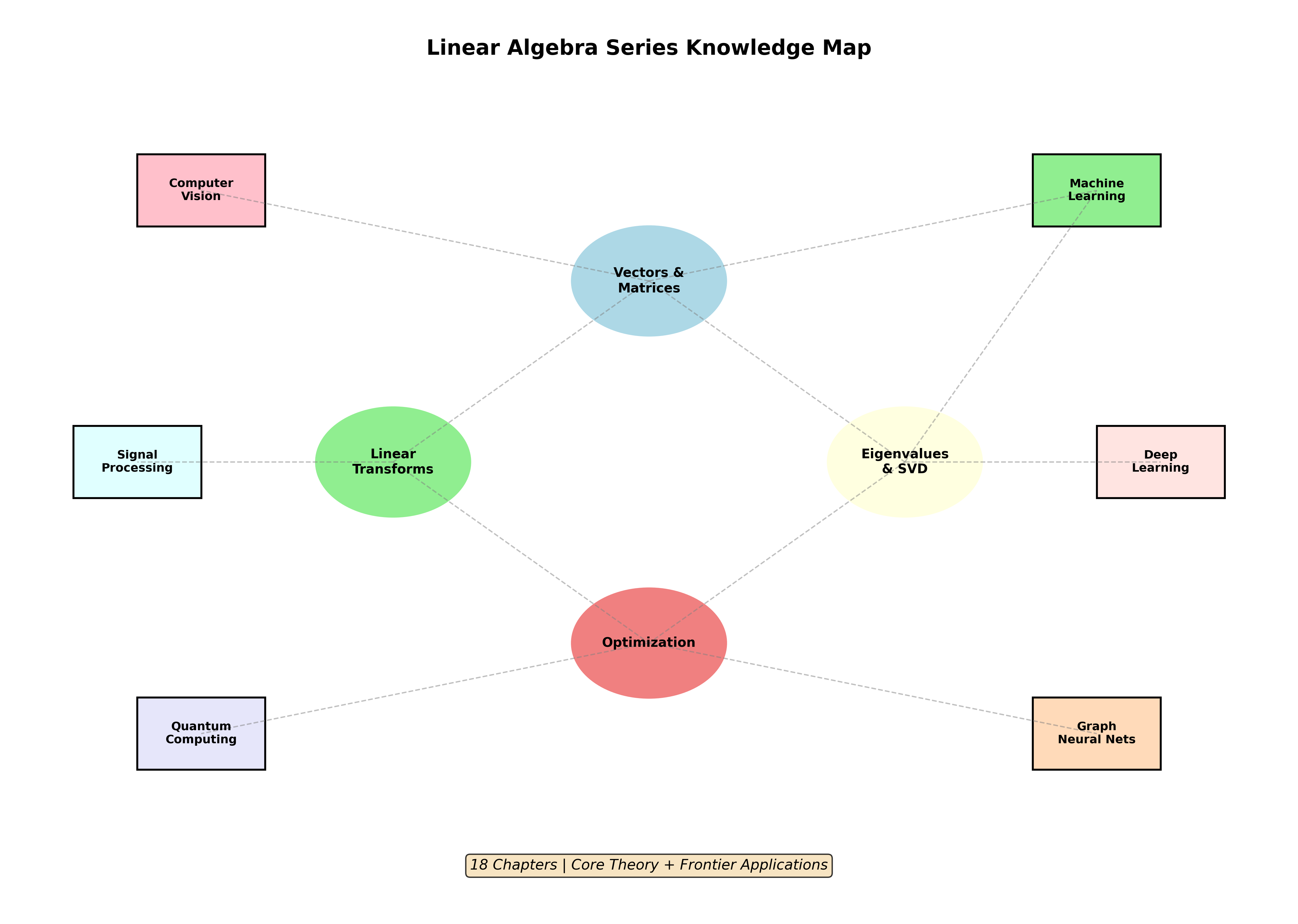
各章关键收获
| 章节 | 主题 | 核心洞见 |
|---|---|---|
| 1 | 向量 | 向量是有大小和方向的量,也是函数空间的元素 |
| 2 | 向量空间 | 八条公理定义了可以做线性组合的空间 |
| 3 | 线性变换 | 矩阵和线性变换一一对应,选基是关键 |
| 4 | 行列式 | 行列式是有向体积的缩放因子,零当且仅当不可逆 |
| 5 | 线性方程组 | 解空间结构由四个基本子空间决定 |
| 6 | 特征值 | 特征向量是不变方向,特征值是缩放因子 |
| 7 | 正交性 | 内积提供长度和角度,正交基最好 |
| 8 | 对称矩阵 | 实对称矩阵可以正交对角化,特征值全实 |
| 9 | SVD | 任何矩阵都可以分解为旋转-缩放-旋转 |
| 10 | 范数与条件数 | 条件数衡量问题的敏感性 |
| 11 | 矩阵微积分 | 梯度是函数变化最快的方向,链式法则是基础 |
| 12 | 稀疏性 | L1 正则化诱导稀疏,压缩感知打破香农极限 |
| 13 | 张量 | 张量是多维数组,分解揭示隐藏结构 |
| 14 | 随机矩阵 | 高维随机有惊人的规律性( Marchenko-Pastur 、半圆律) |
| 15 | 机器学习 | PCA 是方差最大化,核方法是隐式高维映射 |
| 16 | 深度学习 | 神经网络是分层的矩阵乘法加非线性 |
| 17 | 计算机视觉 | 相机是投影矩阵, 3D 重建是反问题 |
| 18 | 前沿应用 | 量子门是酉矩阵,图卷积是拉普拉斯上的滤波 |

最重要的定理
- 维度定理:
- 秩-零化度定理:
- 谱定理:实对称矩阵可以正交对角化
- SVD 存在性:任何矩阵都有 SVD 分解
- Eckart-Young 定理:截断 SVD 是最优低秩逼近
- Johnson-Lindenstrauss 引理:高维点可以低失真地嵌入低维
学习建议和资源推荐
建立直觉的方法
可视化:使用 GeoGebra 、 Manim( 3Blue1Brown 使用的库)或自己写代码来可视化线性变换。看到矩阵如何扭曲网格,比任何公式都直观。
小例子先行:在学习新概念时,先用 2x2 或 3x3 矩阵手算几个例子。只有亲手算过,才能真正理解。
问"为什么":不要满足于"这个公式是这样"。问:为什么行列式的定义要这样?为什么特征值和迹、行列式有关系?为什么 SVD 总是存在?
联系应用:每学一个概念,想想它在哪里有用。特征值分解用于 PageRank, SVD 用于推荐系统,正交矩阵用于计算机图形学...
进阶学习路径
如果你想深入数学:
- 学习抽象代数(群、环、域、模)
- 学习泛函分析(无限维向量空间)
- 学习代数几何(多项式方程的几何)
如果你想专注应用:
- 数值线性代数( Trefethen & Bau)
- 凸优化( Boyd & Vandenberghe)
- 统计学习理论( Hastie, Tibshirani, Friedman)
如果你想做研究:
- 随机矩阵理论
- 张量分解和多线性代数
- 量子信息和量子计算
推荐资源
经典教材:
- Gilbert Strang 的 Introduction to Linear Algebra:直觉优先,适合入门
- Sheldon Axler 的 Linear Algebra Done Right:优雅的证明,抽象视角
- Trefethen & Bau 的 Numerical Linear Algebra:数值方法必读
- Golub & Van Loan 的 Matrix Computations:工程师的圣经
在线课程:
- MIT 18.06( Gilbert Strang): YouTube 免费,经典中的经典
- 3Blue1Brown 的 Essence of Linear Algebra:视觉化入门,强烈推荐先看
- Stanford CS229(机器学习):线性代数在 ML 中的应用
软件工具:
- NumPy/SciPy: Python 科学计算
- MATLAB/Octave:传统数值计算
- Julia:现代科学计算语言
- PyTorch/JAX:深度学习框架,提供自动微分
论文和综述:
- "The Matrix Cookbook":矩阵公式大全
- "Randomized Numerical Linear Algebra"综述
- "Attention is All You Need"( Transformer 原论文)
练习题
量子计算基础
练习 1:证明 Hadamard 门
练习 2:计算
练习 3:证明 Pauli 矩阵
练习 4: Bell 态
练习 5:设计一个量子电路,将
图神经网络
练习 6:对于下图,写出其邻接矩阵
1 | 1 -- 2 |
练习 7:计算上述图的拉普拉斯矩阵的特征值,验证最小特征值为 0,并解释其意义。
练习 8:证明对于任何图信号
练习 9:解释为什么归一化拉普拉斯
练习 10:在 GCN 层
大模型与高效计算
练习 11:在自注意力
练习 12: LoRA 中,如果原权重矩阵
- 原参数量
- LoRA 可训练参数量
- 参数量减少的比例
练习 13:解释为什么 KV
缓存可以加速自回归生成。如果序列长度为
练习 14:对于一个权重范围在
练习 15:稀疏注意力(如只关注前后各
综合应用题
练习 16:设计一个简单的图神经网络来预测分子的极性。
- 输入:分子图(原子是节点,化学键是边)
- 输出:极性( 0 或 1)
- 描述你会用什么节点特征、边特征,以及网络结构
练习 17:假设你要在一个只有 8GB 显存的 GPU 上运行一个 7B 参数的语言模型进行推理。计算:
- 模型权重占用多少空间( FP16)?
- 如果使用 INT4 量化呢?
- 是否可行?还需要考虑什么?
练习 18:推导 GCN 层可以看作谱卷积的 1
阶切比雪夫近似。从谱图卷积定义出发,说明如何得到
练习 19:比较以下三种处理长序列的方法:
- 稀疏注意力(局部窗口)
- 线性注意力(核近似)
- 滑动窗口 + 全局 token
分析它们的优缺点和适用场景。
练习 20:设计一个结合 GNN 和 Transformer 的架构来处理分子性质预测任务。说明如何利用分子的图结构和原子序列信息。
编程实践题
练习 21:用 NumPy 实现:
- Hadamard 门和 CNOT 门
- 模拟一个简单量子电路:
练习 22:用 PyTorch 实现一个简单的 GCN 层,在 Karate Club 数据集上做节点分类。
练习 23:实现 LoRA 层,并验证当
练习 24:实现 INT8 对称量化和反量化函数,在一个预训练模型的权重上测试量化误差。
练习 25:比较标准注意力和稀疏注意力(窗口大小
结语
线性代数是一门古老而又年轻的学科。古老,因为它的基本概念——向量、矩阵、线性变换——已经有两百多年的历史;年轻,因为它在每一代新技术中都焕发出新的生命力。
从 19 世纪的方程组求解,到 20 世纪的量子力学,再到 21 世纪的机器学习和人工智能,线性代数始终是科学技术的通用语言。量子计算机用酉矩阵描述量子门,图神经网络用拉普拉斯矩阵传播信息,大语言模型用注意力矩阵捕捉语义关联——底层的数学本质始终如一。
学习线性代数,不仅仅是学习一套计算技巧,更是学习一种思维方式:
- 用向量表示状态
- 用矩阵表示变换
- 用分解揭示结构
- 用优化求解问题
希望这个系列能够帮助你:
- 建立坚实的概念基础和几何直觉
- 看到线性代数与现代技术的深刻联系
- 获得继续深入学习的动力和方向
数学不是记忆,而是理解。线性代数的美在于其简洁的结构和强大的应用。
感谢你阅读完整个《线性代数的本质与应用》系列!
本文是《线性代数的本质与应用》系列的第十八章,也是最后一章。
- 本文标题:线性代数(十八)前沿应用与总结
- 本文作者:Chen Kai
- 创建时间:2019-03-30 16:15:00
- 本文链接:https://www.chenk.top/%E7%BA%BF%E6%80%A7%E4%BB%A3%E6%95%B0%EF%BC%88%E5%8D%81%E5%85%AB%EF%BC%89%E5%89%8D%E6%B2%BF%E5%BA%94%E7%94%A8%E4%B8%8E%E6%80%BB%E7%BB%93/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!