如果你问一个机器学习工程师"日常用得最多的数学是什么",答案几乎必然是线性代数 。从数据的向量表示,到神经网络的前向传播,再到推荐系统的矩阵分解——线性代数就像机器学习的"母语"。本章将从直觉出发,深入理解这些核心算法背后的线性代数原理。
机器学习中的向量表示
数据就是向量
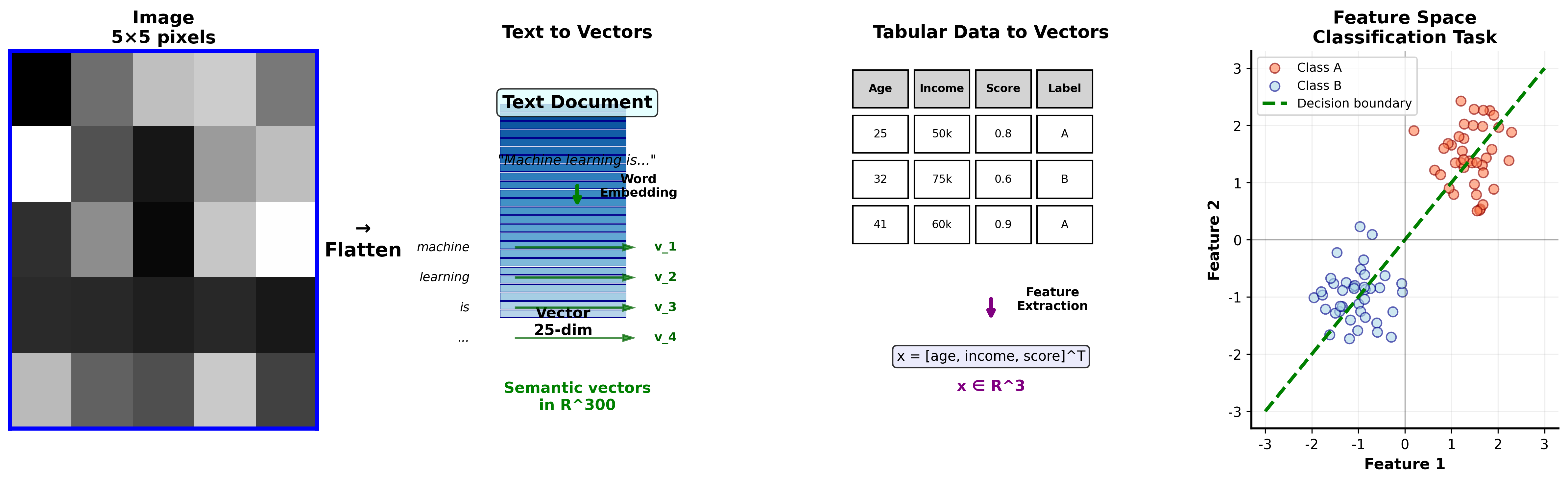
机器学习的第一步是把现实世界的对象转换成向量。一张
为什么要这么做?因为向量是线性代数的基本操作对象 。一旦数据变成向量,我们就可以:
计算距离(欧氏距离、余弦距离)
做线性组合(特征加权)
做投影(降维)
做矩阵乘法(特征变换)
特征空间的几何
假设有
其中
这个视角非常重要:机器学习的很多任务,本质上是在高维空间中做几何操作 :
分类 :找一个超平面把不同类别的点分开聚类 :找到点的自然分组降维 :把高维空间的点投影到低维子空间回归 :找一个超平面尽可能靠近所有点
词嵌入:语义的向量化
Word2Vec 、 GloVe
等词嵌入方法把单词映射到低维向量空间,使得语义相似的词在空间中距离更近。更神奇的是,这些向量还能做"语义算术":
这说明词嵌入捕捉到了某种线性结构:性别差异被编码成了一个方向向量
1 2 3 4 5 6 7 8 9 10 11 12 13 import numpy as npfrom gensim.models import KeyedVectorsmodel = KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin' , binary=True ) result = model.most_similar(positive=['king' , 'woman' ], negative=['man' ], topn=1 ) print (result) similarity = model.similarity('cat' , 'dog' ) print (f"cat 和 dog 的相似度: {similarity:.4 f} " )
主成分分析( PCA)
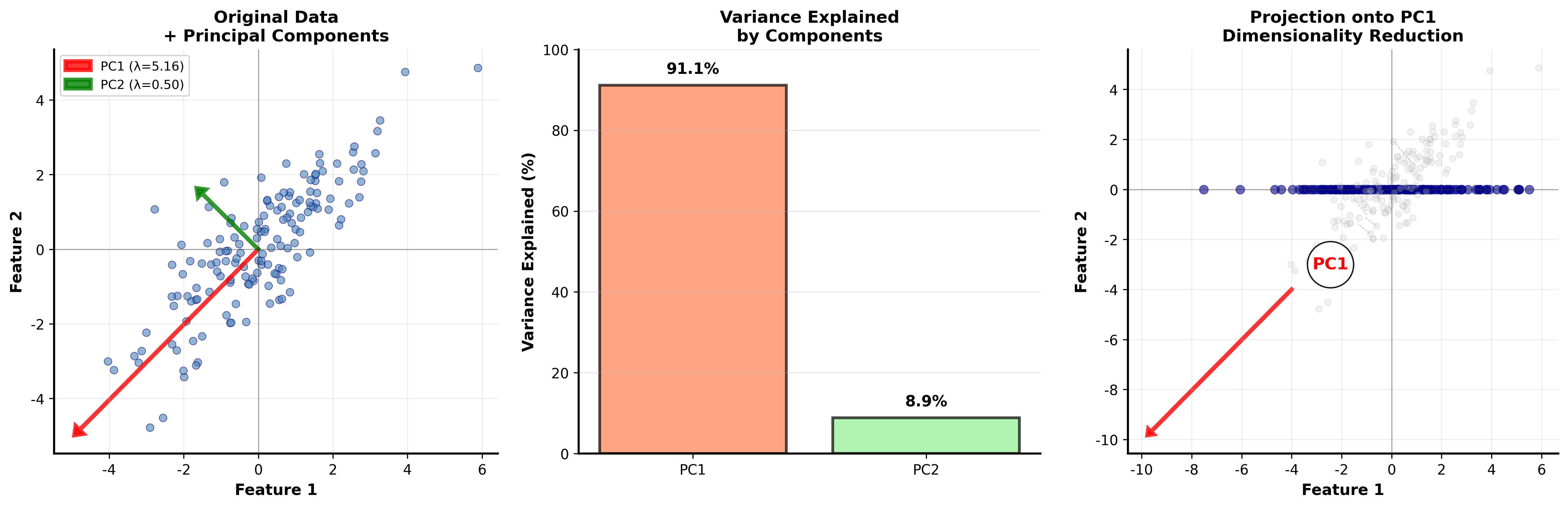
从直觉开始:找数据的"主轴"
想象桌上撒了一把回形针。如果俯视看它们,你会发现它们大致沿着某个方向排列(因为回形针是细长的)。
PCA 要做的就是找到这个"主方向"。
更正式地说:PCA
寻找数据方差最大的方向 。为什么关注方差?因为方差大的方向包含更多信息,方差小的方向可能只是噪声。
数学推导
设数据已经中心化(均值为零),我们要找一个单位向量
记协方差矩阵
用拉格朗日乘数法:
得到最优的 。
PCA 与 SVD 的关系
实际计算 PCA
时,通常不直接计算协方差矩阵(当特征很多时会很大),而是用 SVD
。对中心化的数据矩阵
这里的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import numpy as npfrom sklearn.preprocessing import StandardScalerfrom sklearn.decomposition import PCAimport matplotlib.pyplot as pltnp.random.seed(42 ) n_samples = 200 theta = np.pi / 6 X = np.random.randn(n_samples, 2 ) @ np.array([[2 , 0 ], [0 , 0.5 ]]) rotation = np.array([[np.cos(theta), -np.sin(theta)], [np.sin(theta), np.cos(theta)]]) X = X @ rotation pca = PCA(n_components=2 ) X_pca = pca.fit_transform(X) print ("主成分方向:\n" , pca.components_)print ("方差解释比例:" , pca.explained_variance_ratio_)X_centered = X - X.mean(axis=0 ) U, S, Vt = np.linalg.svd(X_centered, full_matrices=False ) print ("\nSVD 得到的主成分方向:\n" , Vt)print ("方差:" , S**2 / n_samples)fig, axes = plt.subplots(1 , 2 , figsize=(12 , 5 )) axes[0 ].scatter(X[:, 0 ], X[:, 1 ], alpha=0.5 ) for i, (comp, var) in enumerate (zip (pca.components_, pca.explained_variance_)): axes[0 ].arrow(0 , 0 , comp[0 ]*np.sqrt(var)*2 , comp[1 ]*np.sqrt(var)*2 , head_width=0.2 , head_length=0.1 , fc=['r' , 'b' ][i], ec=['r' , 'b' ][i]) axes[0 ].set_title('原始数据与主成分方向' ) axes[0 ].set_xlabel('x1' ) axes[0 ].set_ylabel('x2' ) axes[0 ].axis('equal' ) axes[1 ].scatter(X_pca[:, 0 ], X_pca[:, 1 ], alpha=0.5 ) axes[1 ].set_title('PCA 变换后的数据' ) axes[1 ].set_xlabel('PC1' ) axes[1 ].set_ylabel('PC2' ) axes[1 ].axis('equal' ) plt.tight_layout() plt.savefig('pca_visualization.png' , dpi=150 )
PCA 的应用场景
数据可视化 :把高维数据投影到 2D 或
3D,方便人眼观察。例如,把 MNIST 数据集的 784 维图片投影到
2D,看不同数字的分布。
降维与压缩 :保留前
去噪 :假设信号在主要成分上,噪声在次要成分上。保留主要成分就能滤除噪声。
特征去相关 : PCA
后的新特征是正交的(不相关的),这对某些算法(如朴素贝叶斯)有帮助。
核 PCA:处理非线性结构
标准 PCA
只能发现线性结构。如果数据分布在弯曲的流形上(比如"瑞士卷"), PCA
就无能为力了。
核 PCA 的思路是:先把数据映射到高维特征空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from sklearn.decomposition import KernelPCAfrom sklearn.datasets import make_moonsX, y = make_moons(n_samples=200 , noise=0.1 , random_state=42 ) pca = PCA(n_components=2 ) X_pca = pca.fit_transform(X) kpca = KernelPCA(n_components=2 , kernel='rbf' , gamma=10 ) X_kpca = kpca.fit_transform(X) fig, axes = plt.subplots(1 , 3 , figsize=(15 , 4 )) axes[0 ].scatter(X[:, 0 ], X[:, 1 ], c=y, cmap='viridis' ) axes[0 ].set_title('原始数据' ) axes[1 ].scatter(X_pca[:, 0 ], X_pca[:, 1 ], c=y, cmap='viridis' ) axes[1 ].set_title('线性 PCA' ) axes[2 ].scatter(X_kpca[:, 0 ], X_kpca[:, 1 ], c=y, cmap='viridis' ) axes[2 ].set_title('核 PCA (RBF)' ) plt.savefig('kernel_pca.png' , dpi=150 )
线性判别分析( LDA)
有监督的降维
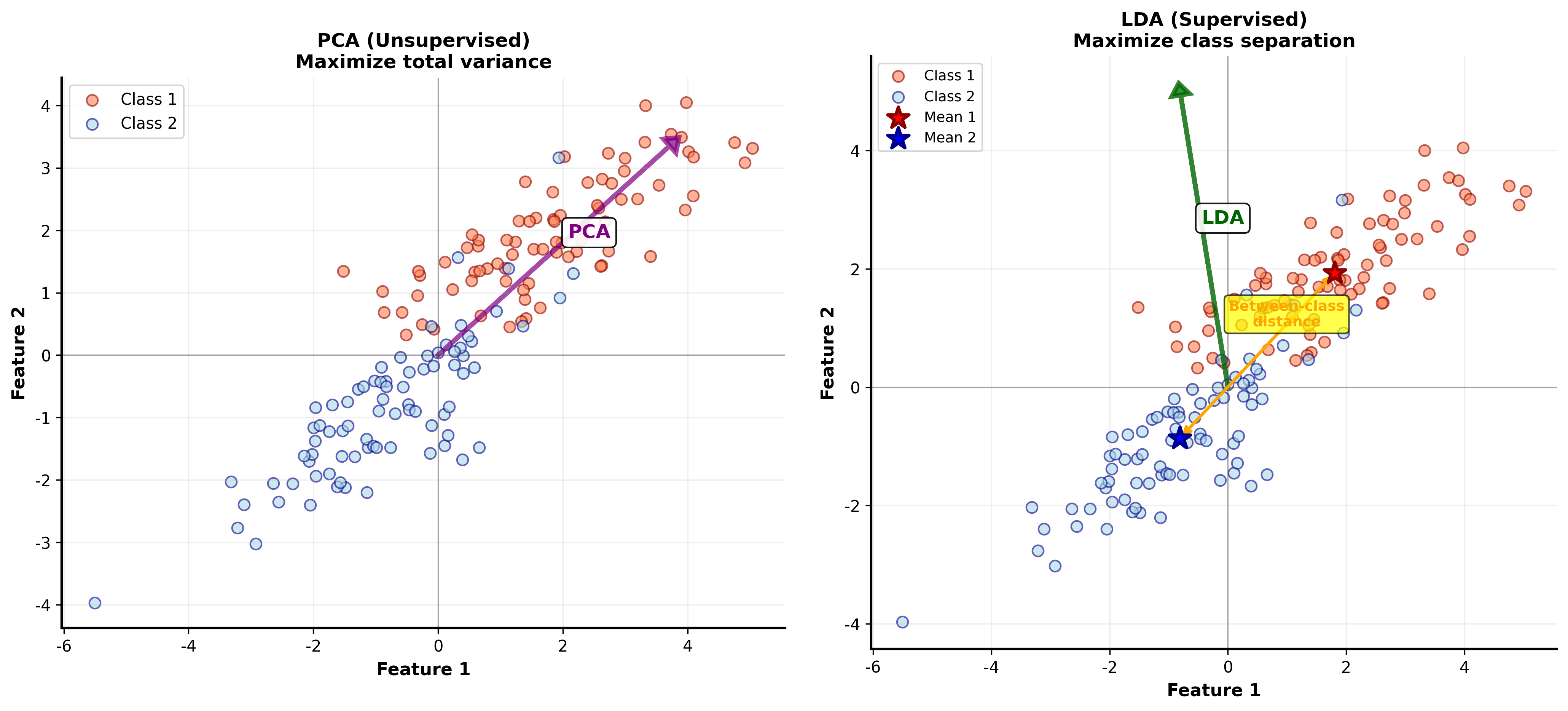
PCA 是无监督的——它不知道数据的类别标签。 LDA
则是有监督的:它利用类别信息,寻找最能区分不同类别的投影方向。
直觉上, LDA 要找一个方向,使得: 1.
不同类别的中心投影后尽可能远(类间距离大) 2.
同一类别的点投影后尽可能近(类内方差小)
数学表述
设有
类内散度矩阵 (衡量每个类内部的分散程度):
类间散度矩阵 (衡量类别中心之间的分散程度):
这等价于求解广义特征值问题
二分类的 Fisher 判别
对于二分类问题, Fisher
给出了一个更直接的推导。投影后的类间距离是
最优解是
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from sklearn.discriminant_analysis import LinearDiscriminantAnalysisfrom sklearn.datasets import load_irisimport numpy as npimport matplotlib.pyplot as pltiris = load_iris() X, y = iris.data, iris.target lda = LinearDiscriminantAnalysis(n_components=2 ) X_lda = lda.fit_transform(X, y) pca = PCA(n_components=2 ) X_pca = pca.fit_transform(X) fig, axes = plt.subplots(1 , 2 , figsize=(12 , 5 )) for i, (X_transformed, title) in enumerate ([(X_pca, 'PCA' ), (X_lda, 'LDA' )]): for label in np.unique(y): axes[i].scatter(X_transformed[y==label, 0 ], X_transformed[y==label, 1 ], label=iris.target_names[label], alpha=0.7 ) axes[i].set_title(f'{title} 降维结果' ) axes[i].legend() plt.tight_layout() plt.savefig('lda_vs_pca.png' , dpi=150 ) print (f"LDA 解释方差比: {lda.explained_variance_ratio_} " )
PCA vs LDA:何时用哪个?
特性
PCA
LDA
监督性
无监督
有监督
目标
最大化方差
最大化类间可分性
最大维度
适用场景
数据探索、压缩、去噪
分类预处理
假设
线性结构
类内高斯分布、协方差相同
一个重要限制: LDA 最多只能降到
支持向量机与核方法
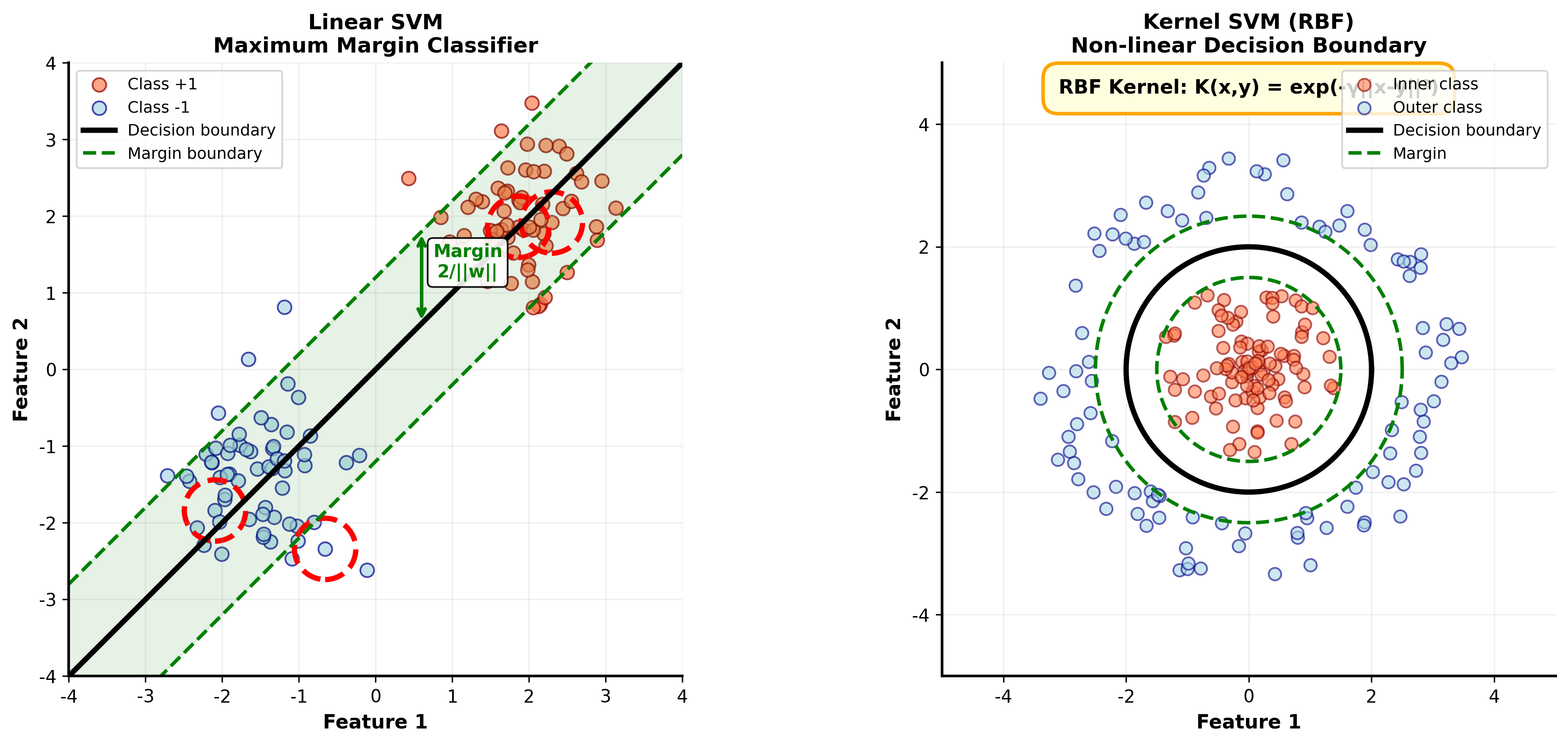
线性 SVM:最大间隔分类器
支持向量机要找一个超平面间隔 (
margin)最大。
间隔是什么?直观地说,是超平面到最近数据点的距离。点
通过适当缩放
优化问题
原问题 :
用拉格朗日乘数法,引入
对偶问题 (对
注意对偶问题只涉及数据点之间的内积
核技巧
如果数据线性不可分,一个办法是把数据映射到更高维的空间。例如,对于二维数据
原来的圆形边界在新空间中可能变成线性的。
问题是:高维映射计算代价很大。核技巧 的妙处在于,我们只需要计算内积
常用核函数 :
线性核 :多项式核 :RBF 核(高斯核) :sigmoid 核 :
核矩阵与正定性
给定核矩阵 ( Gram 矩阵)定义为:
一个函数是合法的核函数,当且仅当对任意数据集,核矩阵都是半正定的(所有特征值Mercer
条件 。
直觉上,核矩阵的第
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from sklearn.svm import SVCfrom sklearn.datasets import make_circlesimport numpy as npimport matplotlib.pyplot as pltX, y = make_circles(n_samples=200 , noise=0.1 , factor=0.3 , random_state=42 ) svm_linear = SVC(kernel='linear' ) svm_linear.fit(X, y) svm_rbf = SVC(kernel='rbf' , gamma=2 ) svm_rbf.fit(X, y) def plot_decision_boundary (ax, clf, X, y, title ): xx, yy = np.meshgrid(np.linspace(X[:, 0 ].min ()-0.5 , X[:, 0 ].max ()+0.5 , 200 ), np.linspace(X[:, 1 ].min ()-0.5 , X[:, 1 ].max ()+0.5 , 200 )) Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape) ax.contourf(xx, yy, Z, alpha=0.3 , cmap='coolwarm' ) ax.scatter(X[:, 0 ], X[:, 1 ], c=y, cmap='coolwarm' , edgecolors='black' ) ax.set_title(title) ax.scatter(clf.support_vectors_[:, 0 ], clf.support_vectors_[:, 1 ], s=100 , facecolors='none' , edgecolors='green' , linewidths=2 ) fig, axes = plt.subplots(1 , 2 , figsize=(12 , 5 )) plot_decision_boundary(axes[0 ], svm_linear, X, y, '线性 SVM' ) plot_decision_boundary(axes[1 ], svm_rbf, X, y, 'RBF 核 SVM' ) plt.tight_layout() plt.savefig('svm_kernels.png' , dpi=150 ) print (f"线性 SVM 准确率: {svm_linear.score(X, y):.2 f} " )print (f"RBF 核 SVM 准确率: {svm_rbf.score(X, y):.2 f} " )print (f"支持向量数量: {len (svm_rbf.support_vectors_)} " )
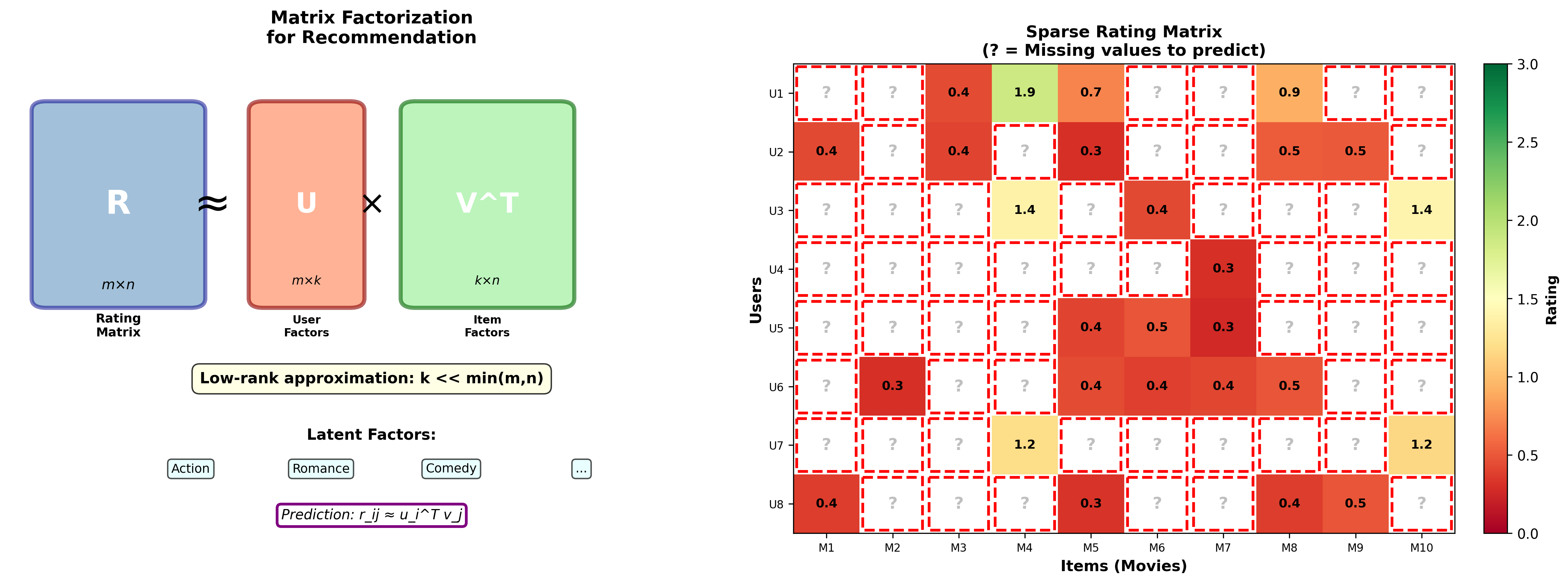
矩阵分解与推荐系统
Netflix 问题
推荐系统的经典问题:有一个用户-电影评分矩阵预测缺失的评分 ,从而向用户推荐他可能喜欢的电影。
低秩假设
核心假设:用户的偏好和电影的特性都可以用少数几个"隐因子"来描述。比如,隐因子可能对应"动作程度"、"浪漫程度"、"是否有明星"等。
数学上,假设
用户
优化目标
只在观测到的评分上优化(带正则化):
其中
交替最小二乘( ALS)
这个问题关于
固定
固定
重复直到收敛
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 import numpy as npfrom scipy.sparse import random as sparse_randomfrom scipy.sparse.linalg import svdsnp.random.seed(42 ) n_users, n_items, k = 100 , 50 , 5 U_true = np.random.randn(n_users, k) V_true = np.random.randn(n_items, k) R_true = U_true @ V_true.T mask = np.random.rand(n_users, n_items) < 0.2 R_observed = np.where(mask, R_true + 0.1 * np.random.randn(n_users, n_items), 0 ) def als (R_observed, mask, k, n_iter=50 , lambda_reg=0.1 ): n_users, n_items = R_observed.shape U = np.random.randn(n_users, k) * 0.1 V = np.random.randn(n_items, k) * 0.1 for iteration in range (n_iter): for i in range (n_users): items_rated = np.where(mask[i, :])[0 ] if len (items_rated) > 0 : V_sub = V[items_rated, :] r_sub = R_observed[i, items_rated] U[i, :] = np.linalg.solve(V_sub.T @ V_sub + lambda_reg * np.eye(k), V_sub.T @ r_sub) for j in range (n_items): users_rated = np.where(mask[:, j])[0 ] if len (users_rated) > 0 : U_sub = U[users_rated, :] r_sub = R_observed[users_rated, j] V[j, :] = np.linalg.solve(U_sub.T @ U_sub + lambda_reg * np.eye(k), U_sub.T @ r_sub) if iteration % 10 == 0 : R_pred = U @ V.T loss = np.sum ((R_observed[mask] - R_pred[mask])**2 ) print (f"Iteration {iteration} , Loss: {loss:.4 f} " ) return U, V U_learned, V_learned = als(R_observed, mask, k) R_pred = U_learned @ V_learned.T rmse = np.sqrt(np.mean((R_true[~mask] - R_pred[~mask])**2 )) print (f"\n 在未观测位置的 RMSE: {rmse:.4 f} " )
非负矩阵分解( NMF)
有时候我们希望分解结果是非负的,这样更容易解释。比如在文档-词矩阵分解中,非负的因子可以解释为"主题"。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from sklearn.decomposition import NMFfrom sklearn.datasets import fetch_20newsgroupsfrom sklearn.feature_extraction.text import TfidfVectorizercategories = ['rec.sport.baseball' , 'sci.med' , 'comp.graphics' ] newsgroups = fetch_20newsgroups(subset='train' , categories=categories) vectorizer = TfidfVectorizer(max_features=1000 , stop_words='english' ) X = vectorizer.fit_transform(newsgroups.data) n_topics = 5 nmf = NMF(n_components=n_topics, random_state=42 ) W = nmf.fit_transform(X) H = nmf.components_ feature_names = vectorizer.get_feature_names_out() for topic_idx, topic in enumerate (H): top_words = [feature_names[i] for i in topic.argsort()[:-10 :-1 ]] print (f"Topic {topic_idx} : {', ' .join(top_words)} " )
线性回归的矩阵形式
从标量到矩阵
大家熟悉的简单线性回归
把所有
其中
最小二乘解的几何意义
最小二乘的目标是最小化残差平方和:
几何上,
最优的
解得正规方程 :
数值稳定性问题
直接计算
当
当特征高度相关时,
更好的方法是用 QR 分解:
岭回归:解决病态问题
岭回归在损失函数中加入
解为:
加上
小的奇异值对应的分量被"压缩"了,减少了过拟合。
LASSO:稀疏特征选择
LASSO 用稀疏解 :很多
为什么?几何上,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import numpy as npfrom sklearn.linear_model import LinearRegression, Ridge, Lassofrom sklearn.preprocessing import StandardScalerimport matplotlib.pyplot as pltnp.random.seed(42 ) n, p = 100 , 20 X = np.random.randn(n, p) beta_true = np.zeros(p) beta_true[:3 ] = [3 , -2 , 1.5 ] y = X @ beta_true + 0.5 * np.random.randn(n) scaler = StandardScaler() X_scaled = scaler.fit_transform(X) ols = LinearRegression(fit_intercept=False ) ols.fit(X_scaled, y) ridge = Ridge(alpha=1.0 , fit_intercept=False ) ridge.fit(X_scaled, y) lasso = Lasso(alpha=0.1 , fit_intercept=False ) lasso.fit(X_scaled, y) fig, ax = plt.subplots(figsize=(12 , 5 )) x_pos = np.arange(p) width = 0.25 ax.bar(x_pos - width, beta_true, width, label='真实系数' , alpha=0.7 ) ax.bar(x_pos, ols.coef_, width, label='OLS' , alpha=0.7 ) ax.bar(x_pos + width, lasso.coef_, width, label='LASSO' , alpha=0.7 ) ax.axhline(y=0 , color='black' , linestyle='-' , linewidth=0.5 ) ax.set_xlabel('特征索引' ) ax.set_ylabel('系数值' ) ax.set_title('不同回归方法的系数比较' ) ax.legend() plt.tight_layout() plt.savefig('regression_comparison.png' , dpi=150 ) print (f"OLS 非零系数数量: {np.sum (np.abs (ols.coef_) > 0.01 )} " )print (f"LASSO 非零系数数量: {np.sum (np.abs (lasso.coef_) > 0.01 )} " )
神经网络中的线性层
全连接层就是矩阵乘法
神经网络中的全连接层( Dense 层)本质上就是一个仿射变换:
其中
如果没有激活函数,多层全连接网络等价于单层:
批量处理:矩阵乘矩阵
实际训练时,我们一次处理一批( batch)数据。设输入是
这是一个矩阵乘法,可以高效地在 GPU 上并行计算。
反向传播的线性代数
反向传播计算梯度时,大量用到矩阵微分。设损失函数
批量情况下:
这就是为什么深度学习框架底层是大量的矩阵运算。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 import numpy as npclass LinearLayer : """手写一个线性层,展示矩阵运算""" def __init__ (self, in_features, out_features ): self.W = np.random.randn(out_features, in_features) * np.sqrt(2.0 / in_features) self.b = np.zeros(out_features) self.x = None def forward (self, x ): """前向传播: h = Wx + b""" self.x = x return x @ self.W.T + self.b def backward (self, grad_output, learning_rate=0.01 ): """反向传播""" grad_W = grad_output.T @ self.x grad_b = grad_output.sum (axis=0 ) grad_input = grad_output @ self.W self.W -= learning_rate * grad_W self.b -= learning_rate * grad_b return grad_input class ReLU : def forward (self, x ): self.mask = (x > 0 ) return np.maximum(0 , x) def backward (self, grad_output ): return grad_output * self.mask np.random.seed(42 ) layer1 = LinearLayer(10 , 20 ) relu = ReLU() layer2 = LinearLayer(20 , 1 ) X = np.random.randn(100 , 10 ) y = np.random.randn(100 , 1 ) h1 = layer1.forward(X) h1_relu = relu.forward(h1) output = layer2.forward(h1_relu) grad_output = 2 * (output - y) / len (y) grad_h1_relu = layer2.backward(grad_output) grad_h1 = relu.backward(grad_h1_relu) grad_input = layer1.backward(grad_h1) print (f"输出形状: {output.shape} " )print (f"损失: {np.mean((output - y)**2 ):.4 f} " )
注意力机制中的线性代数
Transformer 中的自注意力机制本质上也是线性代数操作:
其中
优化算法的线性代数基础
梯度与 Hessian 矩阵
对于多变量函数
在极值点附近,函数可以用二次函数近似:
梯度下降的收敛性
梯度下降条件数
条件数越大,收敛越慢。直觉上,条件数大意味着函数在某些方向陡峭、在其他方向平缓,梯度下降会"之字形"前进。
预处理与 Adam
预处理的思想是:用一个矩阵
Adam
优化器维护梯度的一阶矩(动量)和二阶矩(用于自适应学习率):
这相当于对每个参数自适应地调整学习率,缓解了条件数大带来的问题。
练习题
概念理解题
第 1 题 :解释为什么 PCA
找到的主成分方向是正交的。提示:思考协方差矩阵的性质。
第 2 题 : LDA 最多能把数据降到
第 3 题 :核函数
第 4 题 :为什么
计算题
第 5 题 :设数据矩阵
计算协方差矩阵
数据投影到第一主成分后的坐标是什么?
第 6 题 :考虑二分类问题,两类的均值分别是
第 7 题 :证明岭回归解
编程题
第 8 题 :用 NumPy 从零实现 PCA,不使用 sklearn 。在
MNIST 数据集上测试,可视化前两个主成分。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def my_pca (X, n_components ): """ X: (n_samples, n_features) 数据矩阵 n_components: 保留的主成分数 返回: X_transformed: (n_samples, n_components) 变换后的数据 components: (n_components, n_features) 主成分方向 explained_variance_ratio: 各主成分解释的方差比例 """ pass
第 9
题 :实现一个简单的矩阵分解推荐系统。生成一个
第 10 题 :用 PyTorch
实现一个简单的两层神经网络(不使用
nn.Linear,手动写矩阵乘法),在 MNIST 上训练并达到 95%
以上准确率。
证明题
第 11 题 :证明核矩阵
第 12 题 :证明 PCA 的主成分方向与 SVD
的右奇异向量相同(对于中心化的数据)。
第 13 题 :证明对于线性回归最佳线性无偏估计 (
BLUE),即在所有线性无偏估计中方差最小( Gauss-Markov 定理)。
应用题
第 14 题 :你有一个包含 10000 个用户、 1000
部电影的评分数据集,每个用户平均评价了 50 部电影。设计一个推荐系统:
选择合适的隐因子数
如何评估推荐效果?
第 15 题 :在图像分类任务中,你有 50000 张
是否应该先做 PCA 降维?降到多少维合适?
PCA 降维与卷积神经网络的特征提取有何本质区别?
本章总结
本章我们深入探讨了线性代数在机器学习中的核心应用:
向量表示 :把数据转化为向量是机器学习的起点。词嵌入、图像展平、特征工程都是向量化的过程。
PCA :通过协方差矩阵的特征分解,找到数据方差最大的方向。实际计算时用
SVD 更稳定。核 PCA 可以处理非线性结构。
LDA :有监督的降维方法,最大化类间距离与类内距离的比值。最多降到
SVM
与核方法 :核技巧让我们能在高维(甚至无限维)特征空间中计算内积,而不需要显式构造特征。核矩阵必须是半正定的。
矩阵分解推荐 :假设评分矩阵是低秩的,可以分解成用户因子和物品因子的乘积。
ALS 是常用的优化算法。
线性回归 :矩阵形式揭示了最小二乘解的几何意义(投影)。岭回归和
LASSO 通过正则化处理病态问题和特征选择。
神经网络 :全连接层就是矩阵乘法加激活函数。反向传播本质上是矩阵微分。注意力机制也是大量的矩阵运算。
理解这些线性代数基础,你就能更深刻地理解机器学习算法的工作原理,而不只是当黑箱使用。
参考资料
Strang, G. Linear Algebra and Learning from Data .
Wellesley-Cambridge Press, 2019.
Murphy, K. P. Machine Learning: A Probabilistic
Perspective . MIT Press, 2012.
Goodfellow, I., Bengio, Y., & Courville, A. Deep
Learning . MIT Press, 2016.
Bishop, C. M. Pattern Recognition and Machine Learning .
Springer, 2006.
Golub,
G. H., & Van Loan, C. F. Matrix Computations . Johns Hopkins
University Press, 2013.
本文是《线性代数的本质与应用》系列的第十五章。