如果你接触过深度学习,一定对"张量"这个词不陌生—— PyTorch 里叫
torch.Tensor, TensorFlow
更是直接把它写进了名字。但张量究竟是什么?为什么深度学习框架要用这个听起来很物理学的名词?
本章将从最熟悉的标量、向量、矩阵出发,带你理解张量的本质:它不过是把"数组"的概念推广到任意维度。我们会看到,张量运算如何自然地描述图像、视频、推荐系统中的多维数据,以及 CP 分解、 Tucker 分解等技术如何帮助我们压缩和理解这些高维结构。
从标量到张量:维度的自然推广
一个数、一排数、一张表、一个立方体
让我们从最简单的开始:
标量( 0 阶张量):就是一个数。比如气温
向量( 1
阶张量):一排数。比如你在地图上的位置需要两个数
矩阵( 2 阶张量):一张表。 Excel
表格就是典型的矩阵——有行有列。灰度图像也是矩阵,每个位置存储一个像素的亮度值。
3 阶张量:一个"数据立方体"。彩色图像就是这样的结构——高度 × 宽度 × 颜色通道( RGB 三通道)。
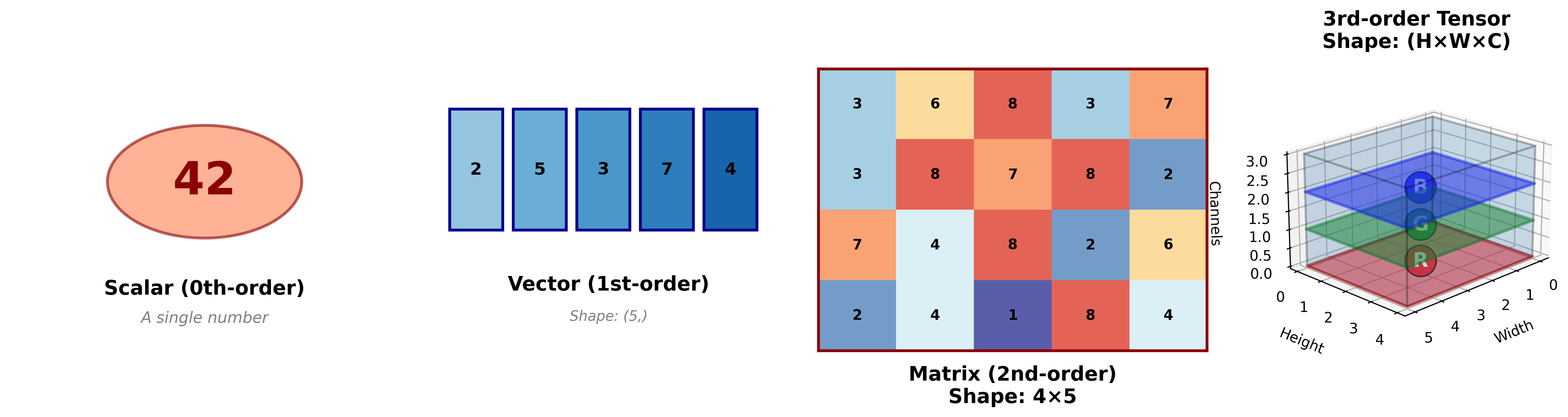
那么,张量的一般定义就呼之欲出了:
张量是向量和矩阵到任意维度的自然推广。一个
阶张量是一个 维数组,记作 ,其中 是各个维度的大小。
生活中的张量无处不在
你可能没意识到,日常生活中到处都是张量:
| 数据类型 | 张量形状 | 阶数 | 直观理解 |
|---|---|---|---|
| 一段话的情感得分 | 0(标量) | 一个数 | |
| 某城市一周气温 | 1 | 7 天,每天一个温度 | |
| 灰度照片 | 2 | 高×宽的像素矩阵 | |
| 彩色照片 | 3 | 每个像素有 RGB 三个值 | |
| 一段视频 | 4 | T 帧图像叠在一起 | |
| 一批训练图片 | 4 | N 张图片打包 | |
| 用户-电影-时间评分 | 3 | 用户 u 在时间 t 对电影 m 的评分 | |
| 脑电图数据 | 4 | 通道×时间×频率×实验次数 |
一个具体例子:假设你在做视频推荐系统。你有 1000
个用户, 10000 部电影,用户的喜好还会随时间变化(比如按周统计, 52
周)。这个数据就是一个
张量的"阶"与"形状"
两个重要概念需要区分清楚:
阶( Order/Mode):张量的维度数量。向量是 1 阶,矩阵是 2 阶, RGB 图像是 3 阶。有时也叫"维度"或"模式数"。
形状( Shape):各个维度的大小。一张
的 RGB 图像,形状是 ,阶数是 3 。
注意:不要把"阶"和"秩( Rank)"混淆。秩是另一个概念,我们后面会详细讨论。
张量的内部结构:纤维与切片
要理解张量,必须学会"看穿"它的内部结构。我们有两个核心概念:纤维( Fiber)和切片( Slice)。
纤维:张量内部的"牙签"
想象你手里有一个魔方( 3 阶张量)。如果你用一根牙签穿过魔方,沿着某个方向穿透它,你得到的那一串小方块就是一根"纤维"。
数学定义:固定除一个索引外的所有索引,得到的向量就是纤维。
对于一个三阶张量
- 模式-1 纤维
:固定 和 ,沿着第一个维度穿过去,得到一个长度为 的向量 - 模式-2 纤维
:固定 和 ,得到长度为 的向量
- 模式-3 纤维
:固定 和 ,得到长度为 的向量
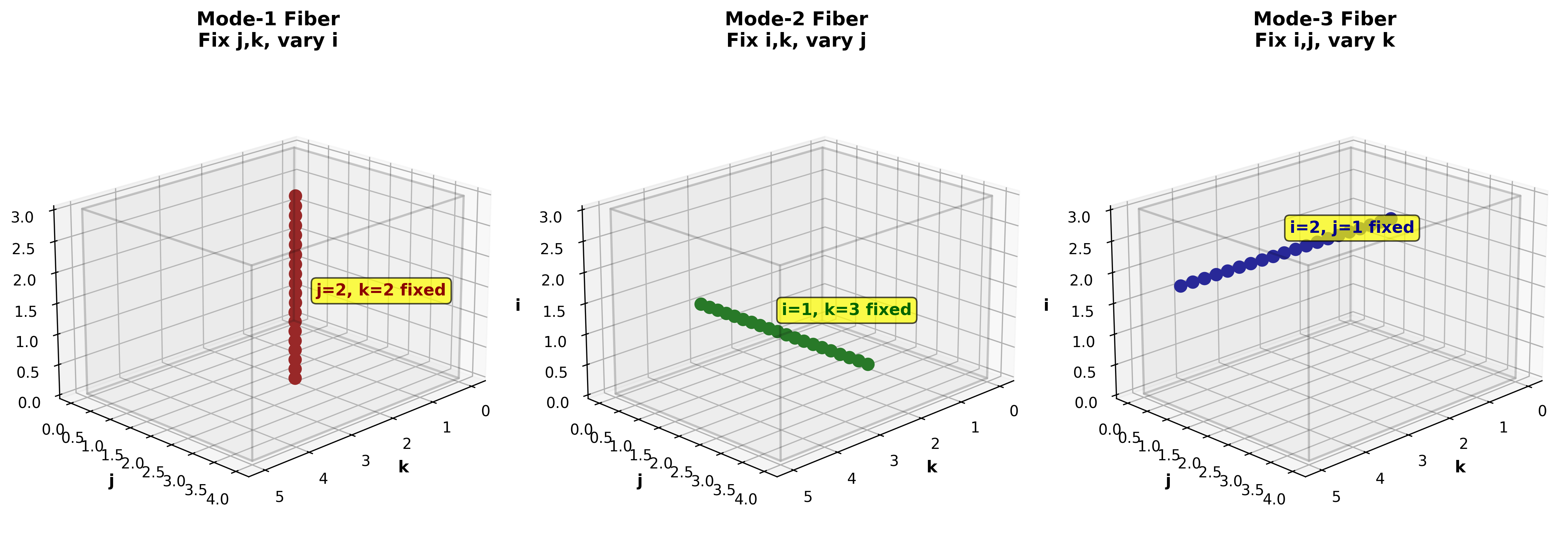
图像处理中的例子:对于一张 RGB 图像
切片:张量内部的"薄片"
同样拿魔方做比喻:如果你用刀把魔方切成若干片,每一片就是一个"切片"。
数学定义:固定一个索引,得到的矩阵就是切片。
对于三阶张量
- 水平切片
:固定 ,得到 矩阵 - 侧面切片
:固定 ,得到 矩阵 - 正面切片
:固定 ,得到 矩阵
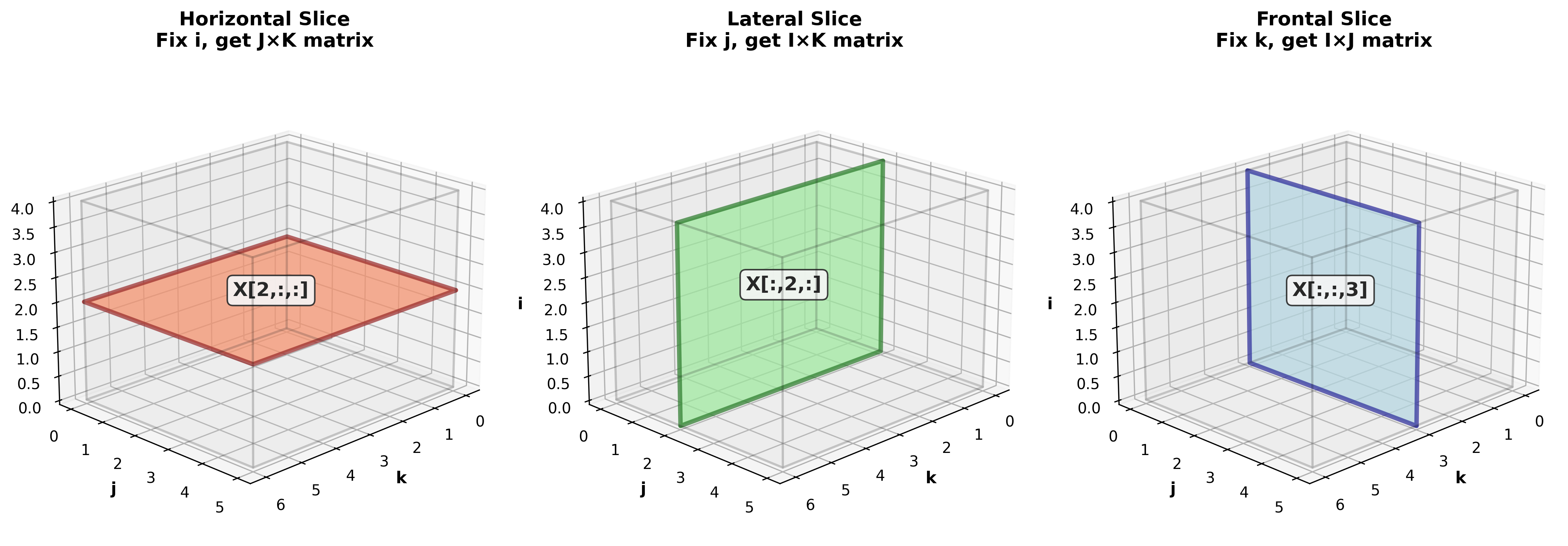
视频处理中的例子:对于一段视频
张量的展开( Matricization)
有时候,我们需要把高维张量"摊平"成矩阵来处理。这个操作叫做展开或矩阵化。
模式-n 展开:把张量沿着第
对于
具体例子:设
为什么展开有用?因为很多张量算法可以转化为矩阵运算,而矩阵运算我们已经非常熟悉了。
张量的基本运算
张量的加法与数乘
这是最简单的运算,和向量、矩阵完全类似:
加法:两个同形状的张量,对应元素相加。
数乘:每个元素乘以同一个标量。
在深度学习中,这些操作无处不在。比如残差网络中的跳跃连接
张量的缩并( Contraction)
缩并是张量中最重要的运算之一,它是矩阵乘法的推广。
核心思想:选择两个张量各自的一个维度,沿着这个维度求和,消除这个维度。
最熟悉的例子——矩阵乘法:
这里
张量的一般缩并:设
结果
直观理解:缩并就像是"配对求和"。想象
外积( Outer Product)——构建张量的基本方式
外积是缩并的"反操作",它把低阶张量组合成高阶张量。
两个向量的外积:
结果是一个矩阵,
三个向量的外积:
结果是一个三阶张量。
秩-1 张量:能写成向量外积形式的张量叫做秩-1 张量。它是最"简单"的张量,因为它的结构完全由几个向量决定。
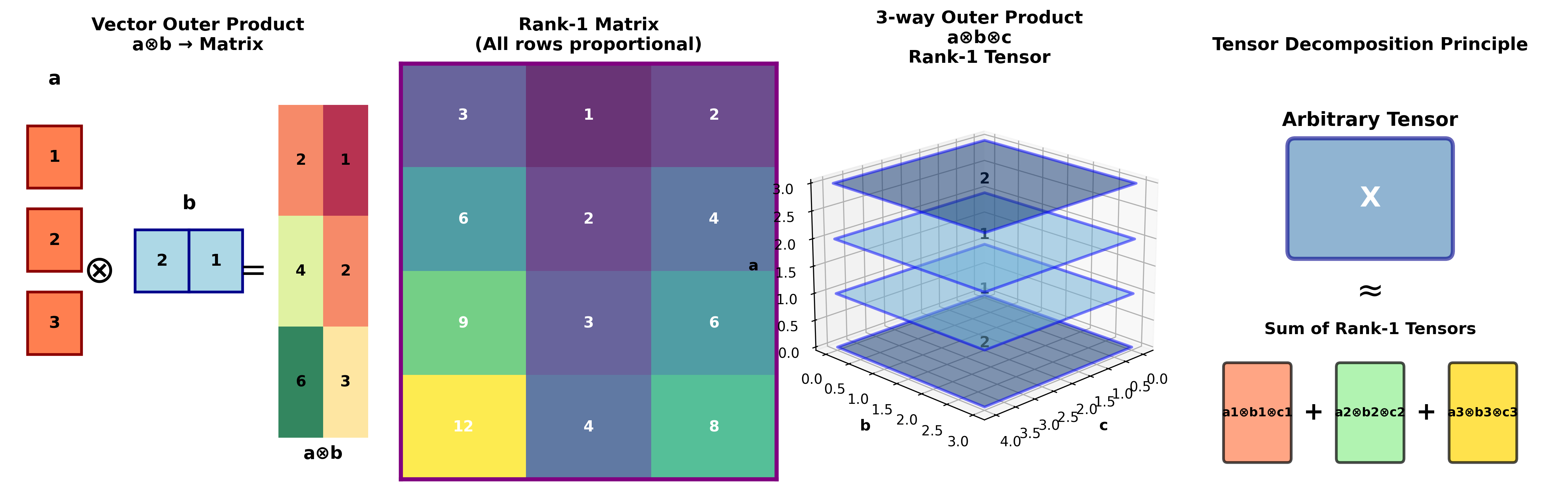
一个重要事实:任何张量都可以写成秩-1 张量的和。这就是张量分解的理论基础。
n-模乘积( n-mode Product)
n-模乘积是将矩阵作用到张量某个模式上的运算。
定义:张量
其中
结果
矩阵语言描述:用展开来看更清晰:
直观理解: n-模乘积就是"沿着第 n 个维度做线性变换"。
例子:对于彩色图像
这就是对每个像素的颜色向量做线性变换(比如调整白平衡、色调映射等)。
重要性质:
不同模式的乘积可以交换顺序:
(当 ) 同一模式的连续乘积:
Kronecker 积与 Khatri-Rao 积
这两个积在张量分解中经常出现。
Kronecker 积
设
直观理解:把
Khatri-Rao 积
设
张量范数
Frobenius 范数
张量的 Frobenius 范数是所有元素平方和的平方根:
重要性质:对于任意模式-n 展开,
这意味着我们可以把张量展开成矩阵来计算范数,结果不变。
内积
两个同形状张量的内积:
显然,
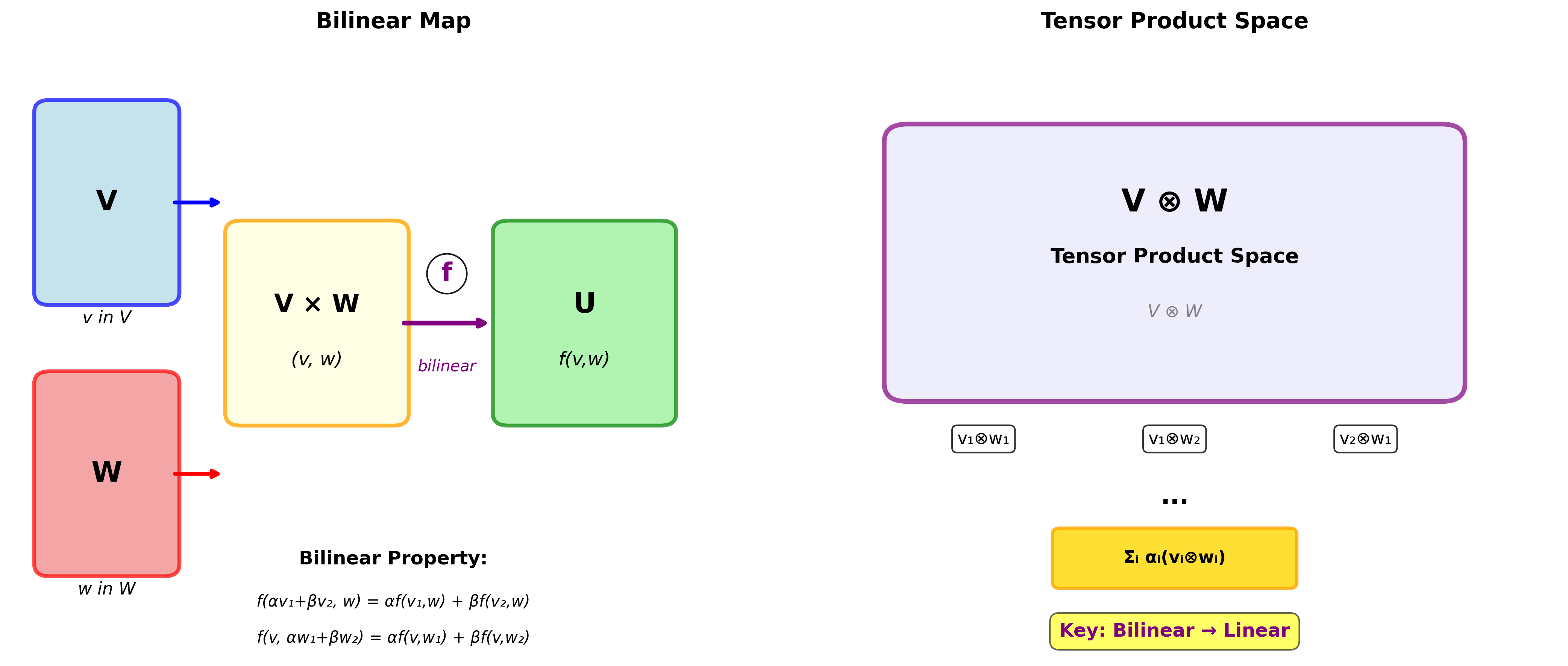
张量积:多重线性映射的观点
从更抽象的角度看,张量其实是多重线性映射的表示。
多重线性映射
线性映射大家都熟悉:
双线性映射接收两个向量,对每个变量分别线性:
满足: -
多重线性映射是双线性映射的推广,接收
张量积空间
给定向量空间
对任何双线性映射
通俗理解:张量积空间把"双线性"问题转化为"线性"问题。这就是为什么张量如此有用——它让我们可以用线性代数的工具处理多重线性问题。
CP 分解:将张量拆成简单成分
什么是 CP 分解?
CP 分解( CANDECOMP/PARAFAC)把张量表示为秩-1
张量的加权和:
或者用更简洁的记号:
其中
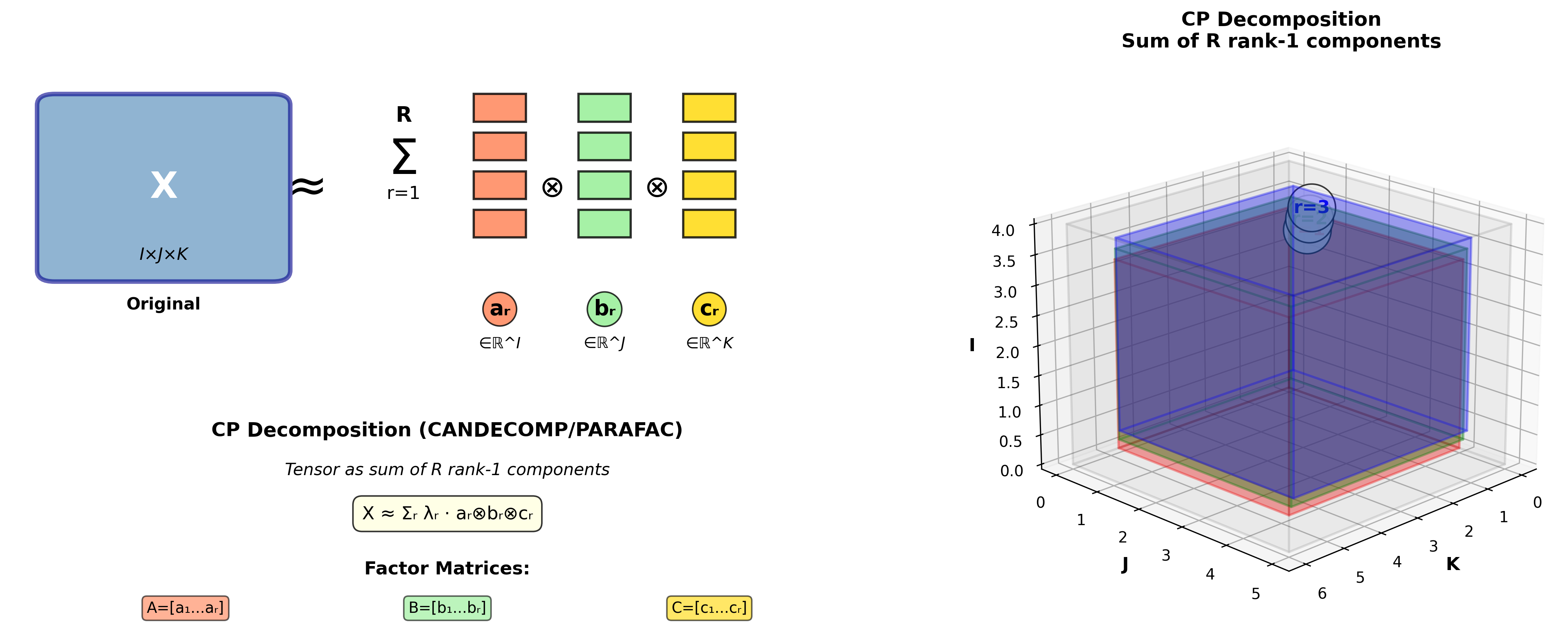
直观理解:叠加简单模式
想象你在分析一个"用户-电影-时间"的评分张量。 CP 分解告诉你:
每个成分
- 成分 1 可能是"喜欢动作片的年轻用户,周末看得多"
- 成分 2 可能是"喜欢文艺片的中年用户,晚上看得多"
- ...
所有简单模式叠加起来,就近似了复杂的原始数据。
张量秩
张量的秩是精确表示它所需的最少秩-1 成分数:
与矩阵秩的关键区别:
- 矩阵秩可以通过 SVD 精确计算,但张量秩的计算是 NP-hard 的!
- 矩阵的最佳低秩近似由 SVD 给出,但张量的最佳低秩近似可能不存在(逼近但达不到)
- 张量秩可能超过任何一个维度的大小(而矩阵秩不超过行列数的较小者)
CP 分解的唯一性
CP 分解的一个重要优势是本质唯一性。在温和条件下( Kruskal 条件), CP 分解是唯一的(仅差列的排列和缩放)。
Kruskal 条件:如果
这个唯一性是相对于矩阵分解(如 SVD)的重要优势。 SVD 得到的
交替最小二乘( ALS)算法
CP 分解最常用的算法是交替最小二乘( ALS):
思想:固定其他因子矩阵,优化一个因子矩阵,这变成普通的最小二乘问题。
算法步骤:
- 随机初始化
- 重复直到收敛:
- 固定
,更新 : - 固定 ,更新 : - 固定 ,更新 : 其中 表示 Hadamard(逐元素)积, 表示伪逆。
- 固定
注意: ALS 不保证收敛到全局最优,但实践中通常表现良好。可以多次随机初始化,选择最好的结果。
1 | import numpy as np |
Tucker 分解:更灵活的张量表示
Tucker 分解的定义
Tucker 分解是比 CP 分解更一般的形式:
或者用元素形式:
其中
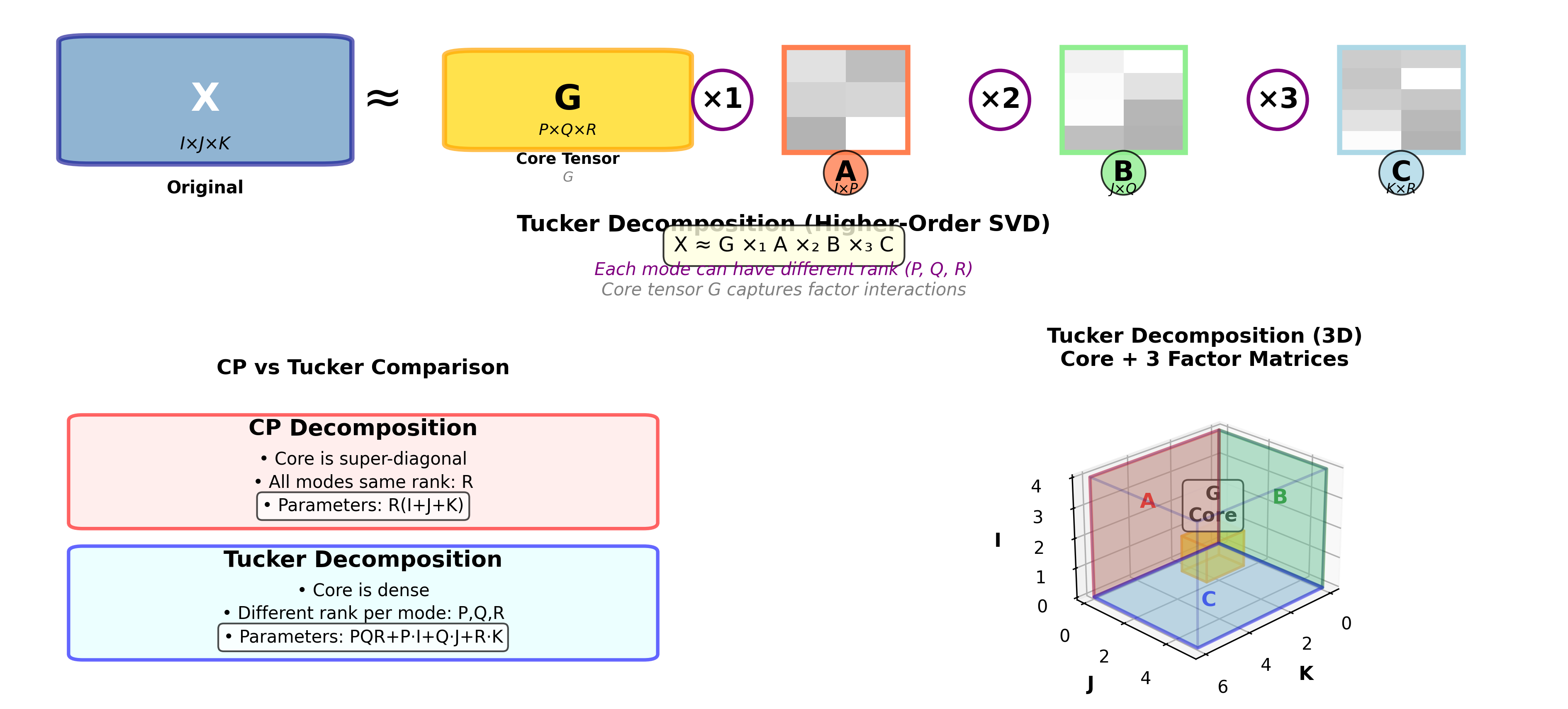
Tucker 与 CP 的关系
CP 是 Tucker 的特殊情况:当核心张量
Tucker 更灵活: CP
要求三个因子矩阵的列数相同(都是秩
HOSVD:高阶奇异值分解
HOSVD( Higher-Order SVD)是 Tucker 分解的一种特殊形式,它保证因子矩阵是正交的。
计算步骤:
- 对每个模式-n 展开
,计算其 SVD - 取左奇异向量的前
个作为因子矩阵 - 核心张量
与矩阵 SVD 的类比:
| 矩阵 SVD | HOSVD |
|---|---|
| 每个 |
HOSVD 的应用:
- 数据压缩:保留核心张量的主要成分
- 初始化:为更精细的 Tucker 分解提供好的起点
- 降噪:截断小的核心张量元素
1 | from tensorly.decomposition import tucker |
多线性秩
Tucker 分解引出了多线性秩的概念:
多线性秩告诉你,沿着每个模式看,数据本质上是几维的。
深度学习中的张量:以 CNN 为例
深度学习框架为什么叫"TensorFlow"或使用"Tensor"?因为神经网络的计算本质上就是张量运算。
卷积操作的张量视角
考虑一个标准的 2D 卷积层:
输入:
卷积核:
输出:
卷积操作可以写成:
这就是一个复杂的张量缩并操作!
用张量分解压缩神经网络
神经网络的权重是巨大的张量。通过张量分解,我们可以大幅减少参数量。
卷积核的 CP 分解:
原始卷积核
这等价于用 4 个更小的卷积层替代原来的 1 个大卷积层:
1.
压缩效果:
- 原始参数量:
- 分解后参数量:
当 较小时,压缩比可以非常大。
实际例子: VGG-16 中一个
Tucker 分解用于网络压缩
Tucker 分解在 CNN
压缩中也很常用,因为它允许输入/输出通道有不同的压缩率:
这等价于:
1.
推荐系统中的张量分解
从矩阵到张量:引入上下文
传统推荐系统用用户-物品矩阵:
其中
其中
问题:用户偏好会随时间变化,也受场景影响。比如你周末和工作日想看的电影可能不同。
张量解决方案:引入时间维度,变成用户-物品-时间张量:
其中
处理稀疏数据
实际推荐系统中,大部分用户只评价了很少的物品。张量极度稀疏(可能只有 0.1%的元素被观测到)。
带缺失值的 CP 分解:只在观测到的位置计算损失:
其中
多维上下文推荐
可以加入更多维度:
- 用户 × 物品 × 时间 × 地点 × 设备
- 用户 × 物品 × 标签 × 评分类型
每个维度都可能提供有价值的信息。张量方法自然地处理这种多维交互。
1 | # 模拟一个简单的推荐系统张量分解 |
其他张量分解方法
张量链( Tensor Train)分解
对于非常高阶的张量(比如量子物理中的多体系统), CP 和 Tucker
分解的复杂度可能爆炸。张量链(
TT)分解是一种更可扩展的方法:
其中
TT 分解的优势:
- 参数量线性增长:
,而不是指数增长 - 存在稳定的算法( TT-SVD)
- 特别适合高阶张量
非负张量分解( NTF)
当张量元素非负且需要可解释因子时,使用非负张量分解:
应用:
- 图像分析(像素值非负)
- 文本挖掘(词频非负)
- 化学计量学(浓度非负)
非负约束使得因子更容易解释为"部分"或"成分"。
练习题
概念理解题
练习 1:判断以下数据结构的张量阶数:
一首 MP3 歌曲(单声道,采样率 44.1kHz)
一首立体声歌曲
一个 5 分钟的 1080p RGB 视频( 30fps)
ImageNet 数据集( 100 万张
RGB 图片) 一个 Transformer 模型的注意力权重
练习 2:对于张量 : 有多少个模式-1 纤维?每个纤维长度是多少?
有多少个正面切片?每个切片的形状是什么?
模式-2 展开
的形状是什么?
运算练习
练习 3:设
计算外积
计算三阶张量
,写出 的值 计算
练习 4:设 , 。 计算 Kronecker 积
验证
(设 为合适大小的矩阵)
分解练习
练习 5:考虑秩-2 张量
计算
的具体元素 写出三个模式的因子矩阵
计算模式-1 展开
练习 6:对于
计算其 Frobenius 范数
它的 CP 秩是多少?(提示:考虑它是否可以写成少于 3 个秩-1 张量的和)
它的多线性秩是多少?
应用题
练习 7(推荐系统):某视频平台有 3 个用户、 4 部电影、 2 个时间段。观测到的评分如下:
| 用户 | 电影 | 时间段 | 评分 |
|---|---|---|---|
| 1 | 1 | 1 | 5 |
| 1 | 2 | 1 | 4 |
| 2 | 1 | 2 | 3 |
| 2 | 3 | 1 | 5 |
| 3 | 2 | 2 | 2 |
| 3 | 4 | 1 | 4 |
构造评分张量
(未观测位置设为 0) 如果用秩-2 的 CP 分解,需要估计多少个参数?
讨论:用秩-1 分解 vs 秩-2 分解,可能存在什么 trade-off?
练习 8(图像压缩):一张
原始存储需要多少字节(假设每个像素值用 1 字节)?
使用 Tucker 分解,设
,压缩后需要存储多少字节? 计算压缩比
如果用 CP 分解,秩为 100,压缩后需要多少字节?
编程题
练习 9:用 Python 实现以下功能:
1 | # (a) 实现三阶张量的模式-n 展开 |
练习 10:使用 tensorly
库完成以下任务:
生成一个秩-3 的随机
张量(先生成因子,再用外积构造) 对这个张量进行 CP 分解,分别用秩 2 、 3 、 4 、 5,比较重构误差
画出重构误差随秩变化的曲线
用 HOSVD 对同一张量分解,比较结果
证明题
练习 11:证明张量 Frobenius
范数与展开的关系:对任意模式
练习 12:证明 n-模乘积的性质:
(a)
(a)
开放题
练习 14:你手上有一个"用户-商品-标签-时间"的四阶张量(来自电商平台的用户行为数据)。
讨论 CP 分解和 Tucker 分解各自的优缺点
设计一个方案,利用这个张量预测某用户下周可能购买什么商品
讨论数据稀疏性可能带来的问题及解决方案
练习 15:研究一篇使用张量分解压缩神经网络的论文,回答:
作者使用了什么分解方法?为什么选择这种方法?
压缩比和精度损失分别是多少?
你认为还有什么可以改进的地方?
本章总结
这一章我们从最基本的概念出发,系统学习了张量与多线性代数:
核心概念: - 张量是向量和矩阵到任意维度的推广 - 纤维、切片、展开是分析张量结构的基本工具 - 张量运算包括加法、数乘、缩并、外积、 n-模乘积等
张量分解: - CP 分解把张量表示为秩-1 成分的和,具有本质唯一性 - Tucker 分解更灵活,允许不同模式有不同秩 - HOSVD 是正交的 Tucker 分解,常用于初始化和数据压缩
实际应用: - 深度学习:卷积核压缩、网络加速 - 推荐系统:多维上下文建模 - 信号处理、化学计量学等领域
张量方法的核心思想是:把高维数据的复杂结构分解为简单成分的组合。这让我们能够压缩数据、提取特征、发现隐藏模式。随着数据维度越来越高,张量方法的重要性只会继续增长。
参考资料
Kolda, T. G., & Bader, B. W. (2009). Tensor decompositions and applications. SIAM Review, 51(3), 455-500.
Sidiropoulos, N. D., et al. (2017). Tensor decomposition for signal processing and machine learning. IEEE Transactions on Signal Processing, 65(13), 3551-3582.
Cichocki, A., et al. (2015). Tensor decompositions for signal processing applications. IEEE Signal Processing Magazine, 32(2), 145-163.
TensorLy 文档: Python 张量学习库
Strang, G. (2019). Linear Algebra and Learning from Data. 第 7 章.
下一章预告:我们将学习线性代数在优化问题中的应用——从最小二乘到凸优化,看线性代数如何帮助我们找到最优解。
上一章回顾:第十二章:矩阵分解与特征值应用
本文是《线性代数的本质与应用》系列的第十三章。
- 本文标题:线性代数(十三)张量与多线性代数
- 本文作者:Chen Kai
- 创建时间:2019-03-09 10:15:00
- 本文链接:https://www.chenk.top/%E7%BA%BF%E6%80%A7%E4%BB%A3%E6%95%B0%EF%BC%88%E5%8D%81%E4%B8%89%EF%BC%89%E5%BC%A0%E9%87%8F%E4%B8%8E%E5%A4%9A%E7%BA%BF%E6%80%A7%E4%BB%A3%E6%95%B0/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!