计算机视觉的核心任务是让机器"看懂"图像和视频。令人惊讶的是,这门学科几乎完全建立在线性代数之上:图像本身就是矩阵,几何变换是矩阵乘法,相机成像是投影变换,三维重建是求解线性方程组。掌握了线性代数,你就掌握了计算机视觉的数学核心。
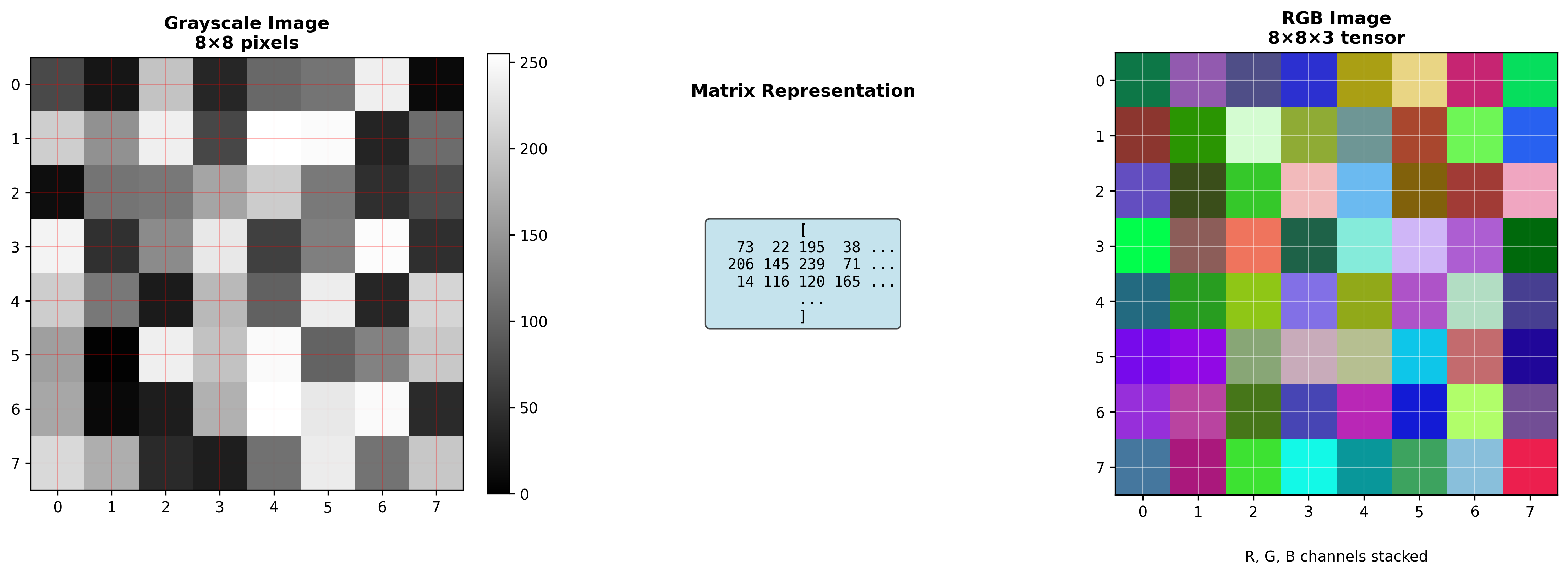
图像的向量与矩阵表示
从像素到矩阵
当你用手机拍一张照片时,传感器捕获的是一个个小方格(像素)的亮度值。一张灰度图像可以直接表示为一个矩阵:
其中
直觉理解 :把图像想象成一张电子表格,每个单元格填了一个数字。数字越大,那个位置越亮。
彩色图像的张量表示
彩色图像通常用 RGB 三通道表示,每个通道都是一个矩阵:
这构成了一个三维张量,形状为
1 2 3 4 5 6 7 8 9 10 11 12 13 import numpy as npimport cv2img = cv2.imread('photo.jpg' ) print (f"图像形状: {img.shape} " ) B, G, R = cv2.split(img) print (f"单通道形状: {R.shape} " ) gray = 0.299 * R + 0.587 * G + 0.114 * B
图像作为高维向量
有时候,把图像"拉平"成一个长向量更方便处理。一张
为什么要这样做?
很多机器学习算法期望输入是向量形式。比如, PCA
降维、支持向量机、全连接神经网络的输入层,都需要把图像展平。
1 2 3 4 5 6 img_flat = gray.flatten() print (f"向量维度: {img_flat.shape} " ) img_restored = img_flat.reshape(480 , 640 )
图像的内积与相似度
既然图像可以看作向量,那么向量的内积就可以用来衡量图像相似度。两幅图像
这在图像检索、人脸识别中广泛使用。两幅相似的图像,它们对应的向量夹角小,余弦值接近
1 。
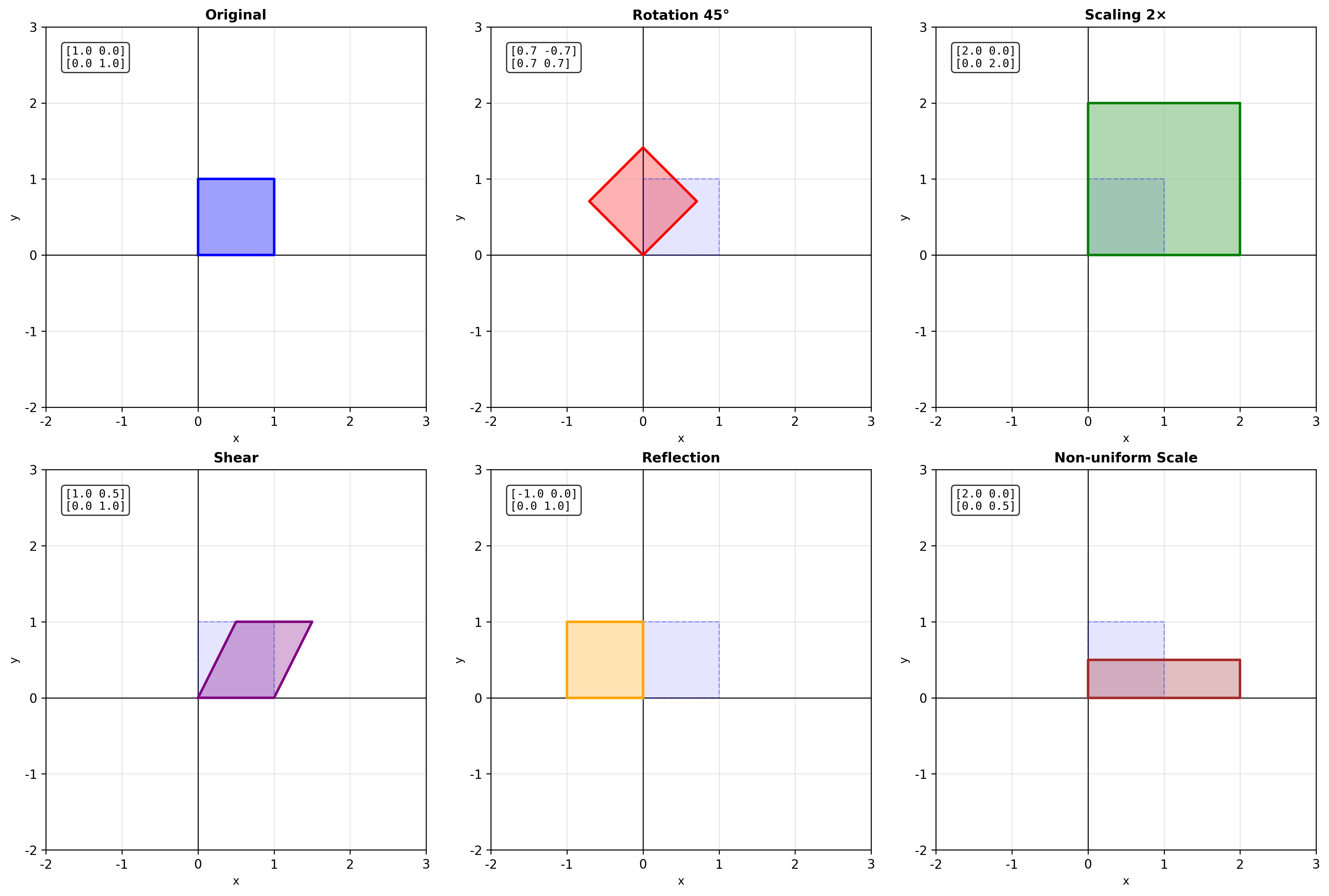
几何变换矩阵
为什么用矩阵表示变换?
想象你在修图软件中旋转、缩放、移动一张图片。这些操作本质上都是对像素坐标的变换。用矩阵表示变换有两大好处:
组合简单 :多个变换的组合就是矩阵连乘逆变换简单 :变换的逆就是矩阵的逆
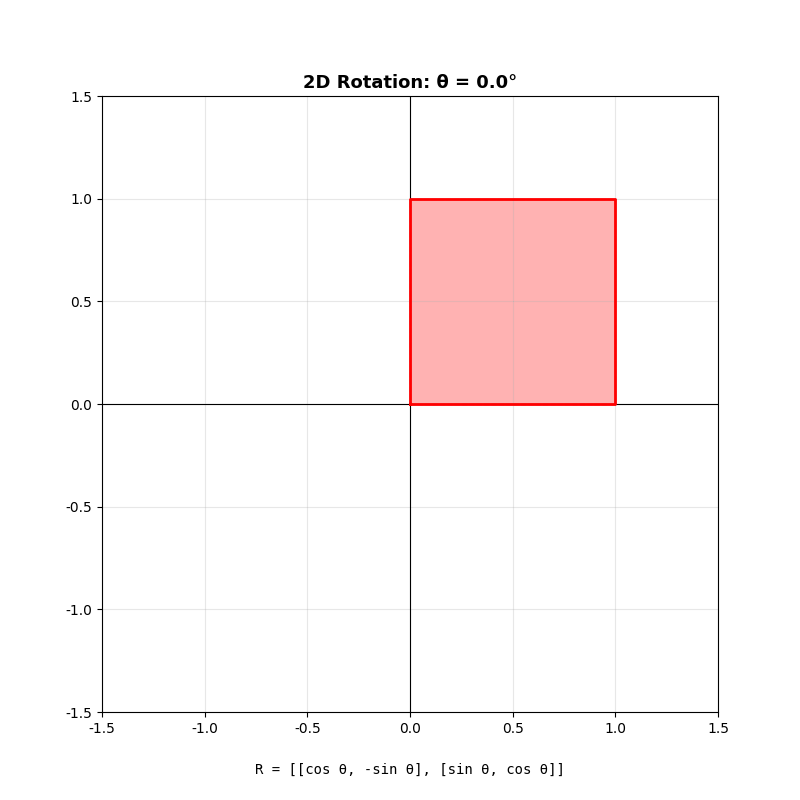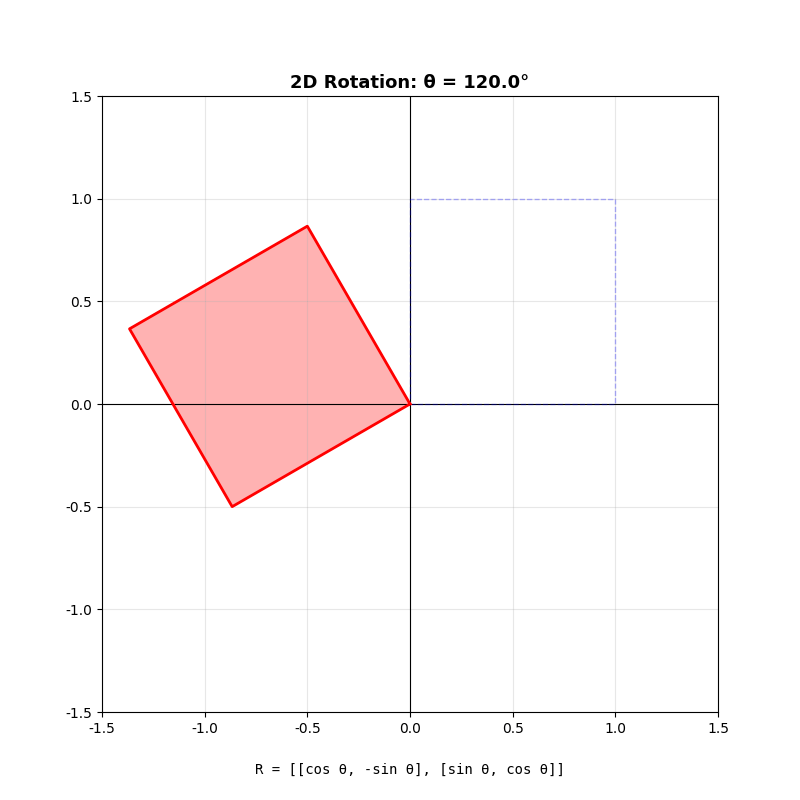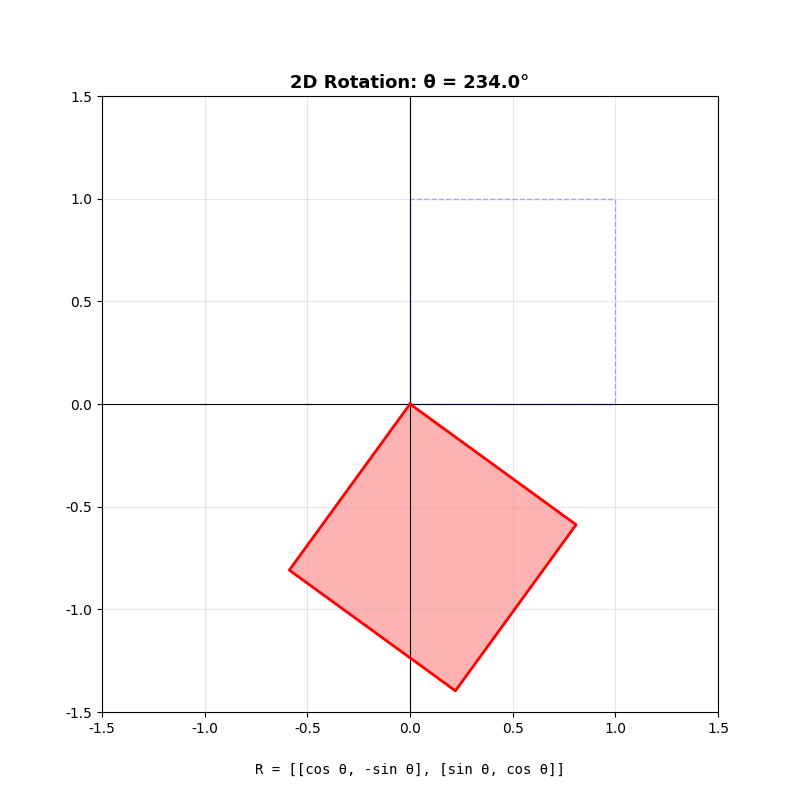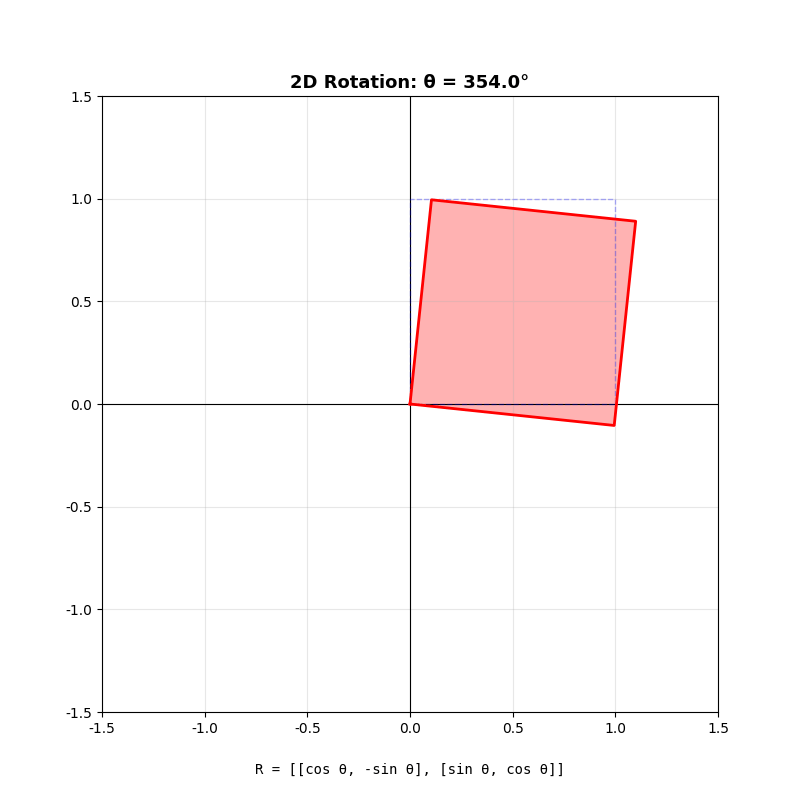
二维旋转矩阵
绕原点逆时针旋转角度
几何直觉 :旋转矩阵把基向量
关键性质 :
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import numpy as npdef rotation_matrix (theta ): """创建 2D 旋转矩阵""" c, s = np.cos(theta), np.sin(theta) return np.array([[c, -s], [s, c]]) theta = np.pi / 4 R = rotation_matrix(theta) point = np.array([1 , 0 ]) rotated = R @ point print (f"旋转后: ({rotated[0 ]:.3 f} , {rotated[1 ]:.3 f} )" )
缩放矩阵
沿 x 轴缩放
特殊情况 :
-
剪切(错切)矩阵
剪切变换让图像"倾斜",像斜体字一样:
水 平 剪 切 垂 直 剪 切
参数
变换的组合
多个变换依次作用,对应矩阵从右向左相乘:
表示先缩放(
1 2 3 4 5 6 7 8 9 10 11 12 13 scale = 2 theta = np.pi / 4 S = np.array([[scale, 0 ], [0 , scale]]) R = rotation_matrix(theta) T = R @ S points = np.array([[1 , 0 ], [0 , 1 ], [1 , 1 ]]).T transformed = T @ points
齐次坐标系统
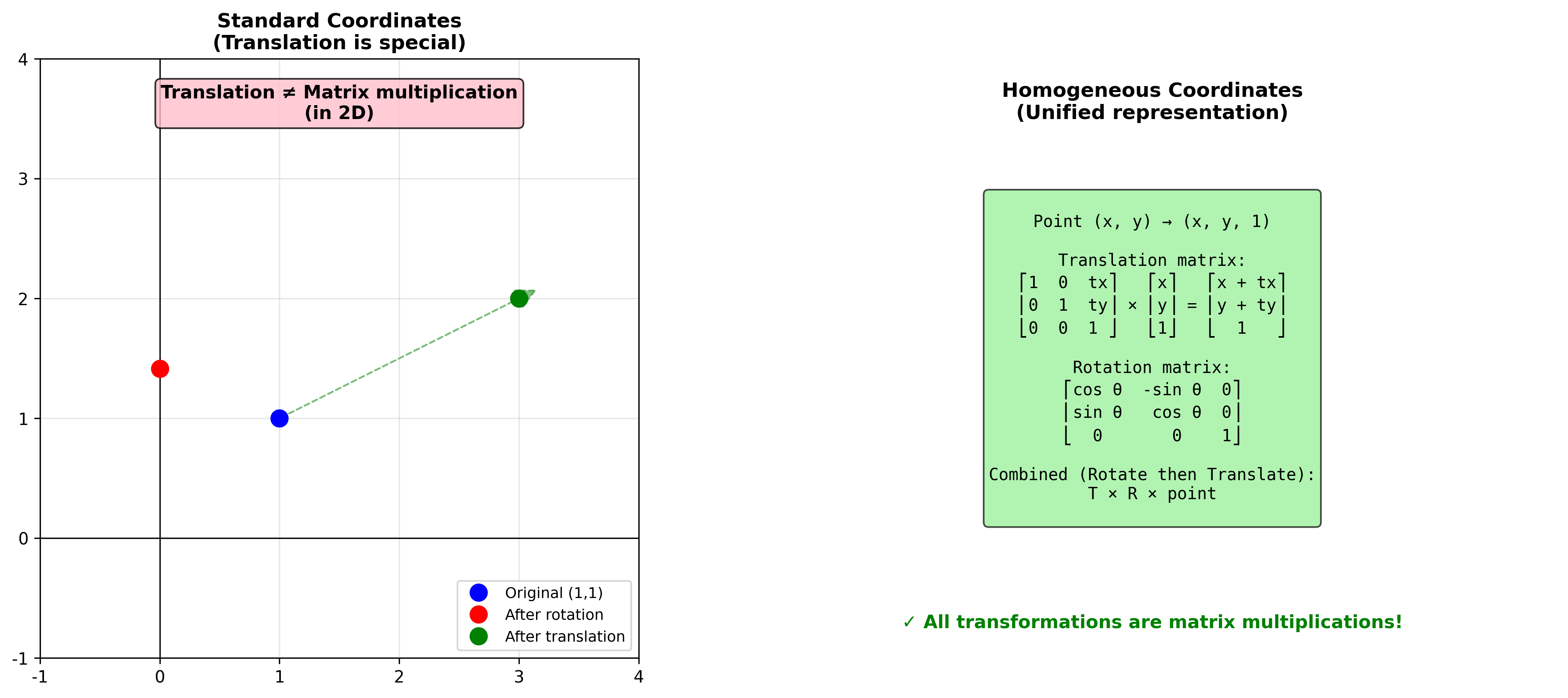
平移的难题
前面的变换(旋转、缩放、剪切)都是线性变换,可以写成
这是仿射变换,不是线性变换(因为它不保持原点不动)。如果我们想把所有变换统一成矩阵乘法的形式,就需要引入齐次坐标。
齐次坐标的魔法
在 2D 点
现在,平移可以写成矩阵乘法了:
直觉理解 :我们把 2D 平面"嵌入"到 3D
空间中(放在
一般的仿射变换矩阵
旋转、缩放、剪切、平移都可以用
其中左上角
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import cv2import numpy as npdef affine_matrix (rotation_deg, scale, translation ): """构建仿射变换矩阵""" theta = np.radians(rotation_deg) c, s = np.cos(theta), np.sin(theta) sx, sy = scale tx, ty = translation return np.array([ [sx * c, -sy * s, tx], [sx * s, sy * c, ty], [0 , 0 , 1 ] ]) M = affine_matrix(30 , (1.5 , 1.5 ), (100 , 50 )) img = cv2.imread('input.jpg' ) rows, cols = img.shape[:2 ] M_cv = M[:2 , :] result = cv2.warpAffine(img, M_cv, (cols, rows))
绕任意点旋转
绕原点旋转很简单,但如果要绕图像中心或任意点
平移,把旋转中心移到原点
绕原点旋转
平移回去
组合起来:
1 2 3 4 5 6 def rotation_around_center (img, angle_deg ): """绕图像中心旋转""" h, w = img.shape[:2 ] center = (w // 2 , h // 2 ) M = cv2.getRotationMatrix2D(center, angle_deg, 1.0 ) return cv2.warpAffine(img, M, (w, h))
透视变换与单应性矩阵
仿射变换的局限
仿射变换保持平行线平行,但现实世界中,平行的铁轨在远方会"交汇"。这种近大远小的透视效果,需要更一般的透视变换(投影变换)来描述。
单应性矩阵
单应性( Homography)用
最终的 2D 坐标通过除以
关键区别 :仿射变换的最后一行是
估计单应性矩阵
给定两幅图像中的对应点对
每对点提供两个约束( x 和 y 方向)。
DLT
算法 (直接线性变换):将约束改写成齐次线性方程组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import cv2import numpy as npsrc_pts = np.array([[100 , 100 ], [200 , 100 ], [200 , 200 ], [100 , 200 ]], dtype=np.float32) dst_pts = np.array([[120 , 90 ], [220 , 110 ], [210 , 220 ], [90 , 210 ]], dtype=np.float32) H, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0 ) img = cv2.imread('input.jpg' ) h, w = img.shape[:2 ] result = cv2.warpPerspective(img, H, (w, h))
单应性的应用
图像拼接 :估计相邻图像间的单应性,把它们对齐到同一坐标系平面矫正 :把倾斜拍摄的文档/白板变成正视图增强现实 :把虚拟物体"贴"到检测到的平面上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def rectify_document (img, corners ): """ 文档矫正:将四边形区域变换为矩形 corners: 文档四个角的坐标,顺序为[左上, 右上, 右下, 左下] """ width, height = 595 , 842 src = np.array(corners, dtype=np.float32) dst = np.array([[0 , 0 ], [width, 0 ], [width, height], [0 , height]], dtype=np.float32) H = cv2.getPerspectiveTransform(src, dst) rectified = cv2.warpPerspective(img, H, (width, height)) return rectified
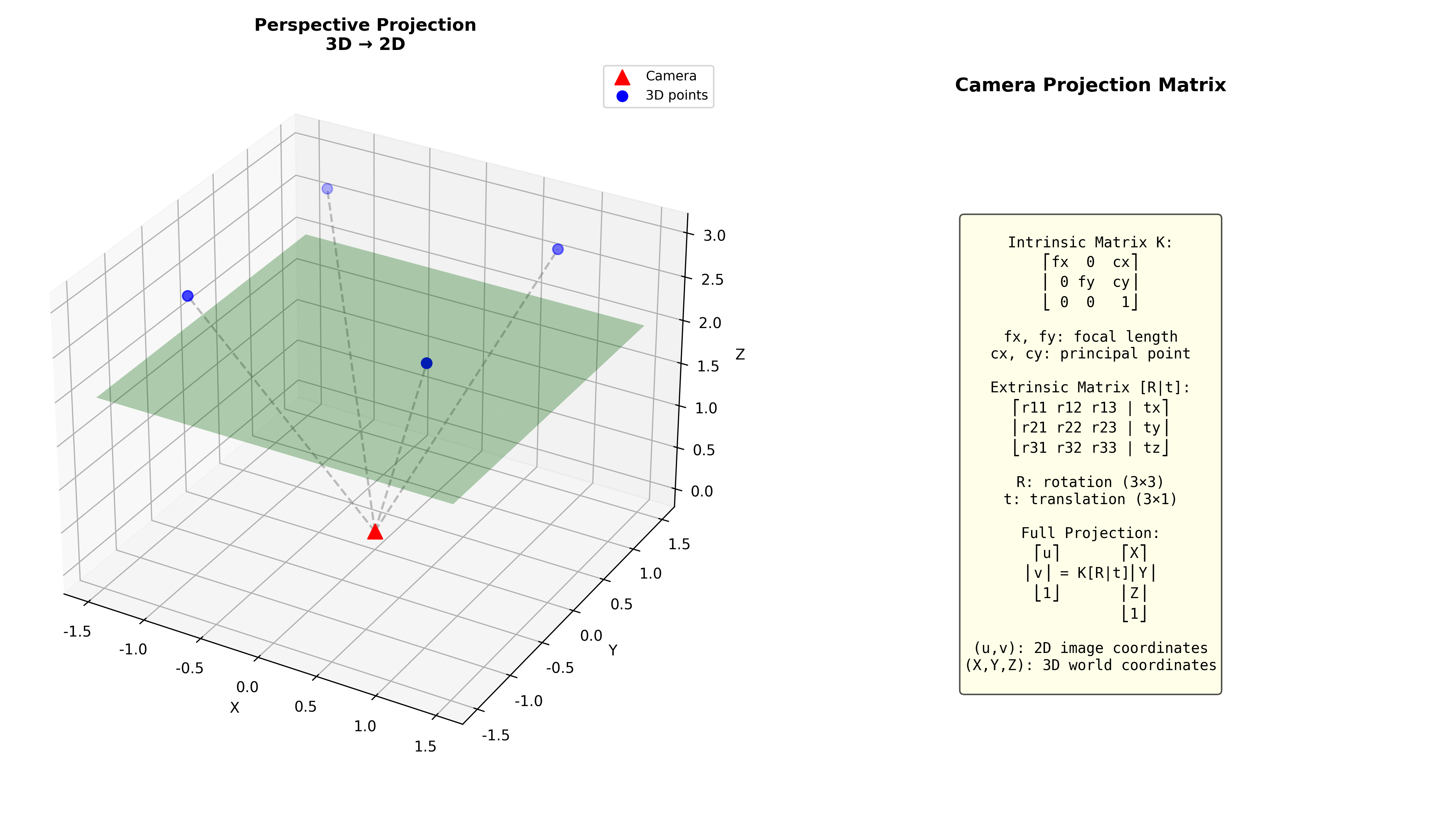
相机模型与投影矩阵
针孔相机模型
相机的工作原理可以用一个简化模型描述:场景中的 3D
点通过一个小孔(针孔),投影到相机后方的成像平面上。
设 3D 点在相机坐标系下的坐标为
这就是透视投影 的基本公式。除以
相机内参矩阵
实际相机还有一些额外参数:
焦距可能在 x 、 y 方向不同:
像平面原点(主点)不在图像中心:
可能有像素倾斜( skew,通常为 0)
这些参数组成内参矩阵
其中
相机外参
外参描述相机在世界坐标系中的位置和朝向,包括:
完整的投影方程
世界坐标系中的 3D 点
其中投影矩阵 。
物理意义 :
1.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def project_3d_to_2d (X_world, K, R, t ): """ 将 3D 点投影到 2D 图像平面 X_world: (N, 3) 世界坐标系中的点 K: (3, 3) 内参矩阵 R: (3, 3) 旋转矩阵 t: (3,) 平移向量 """ X_cam = (R @ X_world.T).T + t x = X_cam[:, 0 ] / X_cam[:, 2 ] y = X_cam[:, 1 ] / X_cam[:, 2 ] u = K[0 , 0 ] * x + K[0 , 2 ] v = K[1 , 1 ] * y + K[1 , 2 ] return np.stack([u, v], axis=1 )
相机标定
相机标定的目标是估计内参
拍摄多张棋盘格图像(不同角度)
检测棋盘格角点
建立 2D-3D 对应关系
用非线性优化求解内参
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import cv2import numpy as npimport globCHESS_SIZE = (9 , 6 ) SQUARE_SIZE = 25.0 objp = np.zeros((CHESS_SIZE[0 ] * CHESS_SIZE[1 ], 3 ), np.float32) objp[:, :2 ] = np.mgrid[0 :CHESS_SIZE[0 ], 0 :CHESS_SIZE[1 ]].T.reshape(-1 , 2 ) objp *= SQUARE_SIZE objpoints = [] imgpoints = [] images = glob.glob('calibration/*.jpg' ) for fname in images: img = cv2.imread(fname) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) ret, corners = cv2.findChessboardCorners(gray, CHESS_SIZE, None ) if ret: corners2 = cv2.cornerSubPix(gray, corners, (11 , 11 ), (-1 , -1 ), criteria=(cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30 , 0.001 )) objpoints.append(objp) imgpoints.append(corners2) ret, K, dist, rvecs, tvecs = cv2.calibrateCamera( objpoints, imgpoints, gray.shape[::-1 ], None , None ) print ("内参矩阵 K:" )print (K)print (f"\n 畸变系数: {dist.ravel()} " )
畸变校正
实际镜头不是理想的针孔,会产生畸变:
径向畸变 (桶形/枕形):
切向畸变 (镜头与传感器不平行):
其中
1 2 3 4 5 6 undistorted = cv2.undistort(img, K, dist) map1, map2 = cv2.initUndistortRectifyMap(K, dist, None , K, (w, h), cv2.CV_32FC1) undistorted = cv2.remap(img, map1, map2, cv2.INTER_LINEAR)
对极几何与基础矩阵
对极约束
假设同一个 3D 点被两个相机拍到,在两幅图像中的位置分别是对极约束 :
其中基础矩阵 (
Fundamental Matrix)。
几何直觉 :
3D 点、两个相机光心、两个像点,这 5 个点共面(对极平面)
对极约束就是说这 5 点共面的代数表达
本质矩阵与基础矩阵
本质矩阵 标定 相机之间的关系(使用归一化坐标)
其中
基础矩阵 未标定 相机之间的关系(使用像素坐标)
两者的关系:
本质矩阵的分解
本质矩阵可以分解为旋转和平移:
其中
意义 :从本质矩阵可以恢复两个相机之间的相对位姿(旋转和平移方向,平移尺度不确定)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import cv2import numpy as npdef compute_fundamental_matrix (pts1, pts2 ): """ 从对应点计算基础矩阵 pts1, pts2: (N, 2) 对应点坐标 """ F, mask = cv2.findFundamentalMat(pts1, pts2, cv2.FM_RANSAC, 3.0 , 0.99 ) return F, mask.ravel().astype(bool ) def compute_essential_matrix (pts1, pts2, K ): """ 从对应点计算本质矩阵 """ E, mask = cv2.findEssentialMat(pts1, pts2, K, cv2.RANSAC, 0.999 , 1.0 ) return E, mask.ravel().astype(bool ) def recover_pose (E, pts1, pts2, K ): """ 从本质矩阵恢复相机位姿 """ _, R, t, mask = cv2.recoverPose(E, pts1, pts2, K) return R, t
对极线
给定第一幅图像中的一点对极线 :
反过来,给定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def draw_epipolar_lines (img1, img2, pts1, pts2, F ): """绘制对极线""" lines1 = cv2.computeCorrespondEpilines(pts2.reshape(-1 , 1 , 2 ), 2 , F).reshape(-1 , 3 ) lines2 = cv2.computeCorrespondEpilines(pts1.reshape(-1 , 1 , 2 ), 1 , F).reshape(-1 , 3 ) h, w = img1.shape[:2 ] for r, pt in zip (lines1, pts1): color = tuple (np.random.randint(0 , 255 , 3 ).tolist()) x0, y0 = map (int , [0 , -r[2 ]/r[1 ]]) x1, y1 = map (int , [w, -(r[2 ] + r[0 ]*w)/r[1 ]]) cv2.line(img1, (x0, y0), (x1, y1), color, 1 ) cv2.circle(img1, tuple (pt.astype(int )), 5 , color, -1 ) return img1, img2
三维重建
三角测量原理
知道两个相机的位姿和一对对应点,就可以通过三角测量恢复 3D 点。
设两个相机的投影矩阵为
这给出 4 个方程(实际独立的是 3 个),可以求解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def triangulate_points (pts1, pts2, P1, P2 ): """ 三角测量恢复 3D 点 pts1, pts2: (N, 2) 像点坐标 P1, P2: (3, 4) 投影矩阵 """ pts1_h = pts1.T pts2_h = pts2.T X_4d = cv2.triangulatePoints(P1, P2, pts1_h, pts2_h) X_3d = X_4d[:3 ] / X_4d[3 ] return X_3d.T
Structure from Motion (SfM)
SfM 是从一组图像重建场景 3D 结构和相机位姿的技术。基本流程:
特征提取与匹配 :在所有图像中检测 SIFT/ORB
特征,进行两两匹配初始化 :选取两幅图像,估计基础矩阵/本质矩阵,三角测量初始点增量重建 :逐步加入新图像
Bundle Adjustment :全局优化所有参数
Bundle Adjustment
Bundle Adjustment 是 SfM 的核心优化步骤,同时优化所有相机参数和 3D
点位置,最小化重投影误差:
其中:
-
这是一个大规模非线性最小二乘问题,通常用 Levenberg-Marquardt
算法求解。由于 Jacobian 矩阵具有稀疏结构(每个观测只涉及一个相机和一个
3D 点),可以高效求解。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from scipy.optimize import least_squaresfrom scipy.sparse import lil_matrixdef bundle_adjustment (camera_params, points_3d, points_2d, camera_indices, point_indices, K ): """ Bundle Adjustment 优化 camera_params: (n_cameras, 6) [rvec, tvec] points_3d: (n_points, 3) points_2d: (n_observations, 2) camera_indices: (n_observations,) 每个观测对应的相机索引 point_indices: (n_observations,) 每个观测对应的 3D 点索引 """ def residual (params ): n_cameras = len (camera_indices) // (len (point_indices) // len (np.unique(point_indices))) n_points = len (np.unique(point_indices)) cam_params = params[:n_cameras * 6 ].reshape(-1 , 6 ) pts_3d = params[n_cameras * 6 :].reshape(-1 , 3 ) residuals = [] for i, (cam_idx, pt_idx) in enumerate (zip (camera_indices, point_indices)): rvec = cam_params[cam_idx, :3 ] tvec = cam_params[cam_idx, 3 :6 ] R, _ = cv2.Rodrigues(rvec) pt_cam = R @ pts_3d[pt_idx] + tvec pt_proj = K @ pt_cam pt_2d_pred = pt_proj[:2 ] / pt_proj[2 ] residuals.extend(pt_2d_pred - points_2d[i]) return np.array(residuals) x0 = np.hstack([camera_params.ravel(), points_3d.ravel()]) result = least_squares(residual, x0, method='lm' ) return result
SLAM 中的线性代数
SLAM 问题概述
SLAM( Simultaneous Localization and
Mapping)要解决的问题是:机器人在未知环境中移动,同时估计自己的位置和构建环境地图。
这涉及到大量的线性代数:
位姿表示(旋转矩阵、四元数)
状态估计(卡尔曼滤波中的矩阵运算)
图优化(稀疏线性方程组求解)
位姿的李群表示
三维刚体变换可以用
其中李群 ,其对应的李代数
指数映射将李代数映射到李群:
为什么用李代数?
优化问题需要对参数求导。旋转矩阵有约束(
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import numpy as npfrom scipy.spatial.transform import Rotationdef skew_symmetric (v ): """向量的反对称矩阵""" return np.array([ [0 , -v[2 ], v[1 ]], [v[2 ], 0 , -v[0 ]], [-v[1 ], v[0 ], 0 ] ]) def so3_exp (phi ): """so(3)到 SO(3)的指数映射""" theta = np.linalg.norm(phi) if theta < 1e-10 : return np.eye(3 ) a = phi / theta A = skew_symmetric(a) R = np.eye(3 ) + np.sin(theta) * A + (1 - np.cos(theta)) * A @ A return R def se3_exp (xi ): """se(3)到 SE(3)的指数映射""" rho = xi[:3 ] phi = xi[3 :6 ] R = so3_exp(phi) theta = np.linalg.norm(phi) if theta < 1e-10 : J = np.eye(3 ) else : a = phi / theta A = skew_symmetric(a) J = np.sin(theta)/theta * np.eye(3 ) + (1 - np.sin(theta)/theta) * np.outer(a, a) + (1 - np.cos(theta))/theta * A t = J @ rho T = np.eye(4 ) T[:3 , :3 ] = R T[:3 , 3 ] = t return T
扩展卡尔曼滤波 (EKF-SLAM)
EKF-SLAM 将 SLAM
问题建模为状态估计问题。状态向量包含机器人位姿和所有路标位置:
预测步骤 (运动模型):
更新步骤 (观测模型):
其中
图优化 SLAM
现代 SLAM 更多采用图优化方法。将 SLAM 问题建模为因子图:
节点 :机器人位姿、路标位置边 :运动约束、观测约束
优化目标是最小化所有约束的误差平方和:
这是一个非线性最小二乘问题,可以迭代求解。每次迭代需要求解一个稀疏线性系统:
其中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class PoseGraphOptimization : def __init__ (self ): self.vertices = {} self.edges = [] def add_vertex (self, id , pose ): self.vertices[id ] = pose def add_edge (self, id1, id2, measurement, information ): """ 添加位姿-位姿约束 measurement: 相对位姿测量 information: 信息矩阵(协方差的逆) """ self.edges.append({ 'from' : id1, 'to' : id2, 'measurement' : measurement, 'information' : information }) def optimize (self, n_iterations=10 ): """Gauss-Newton 优化""" for _ in range (n_iterations): H, b = self._build_linear_system() delta = np.linalg.solve(H, -b) self._update_vertices(delta) def _build_linear_system (self ): pass
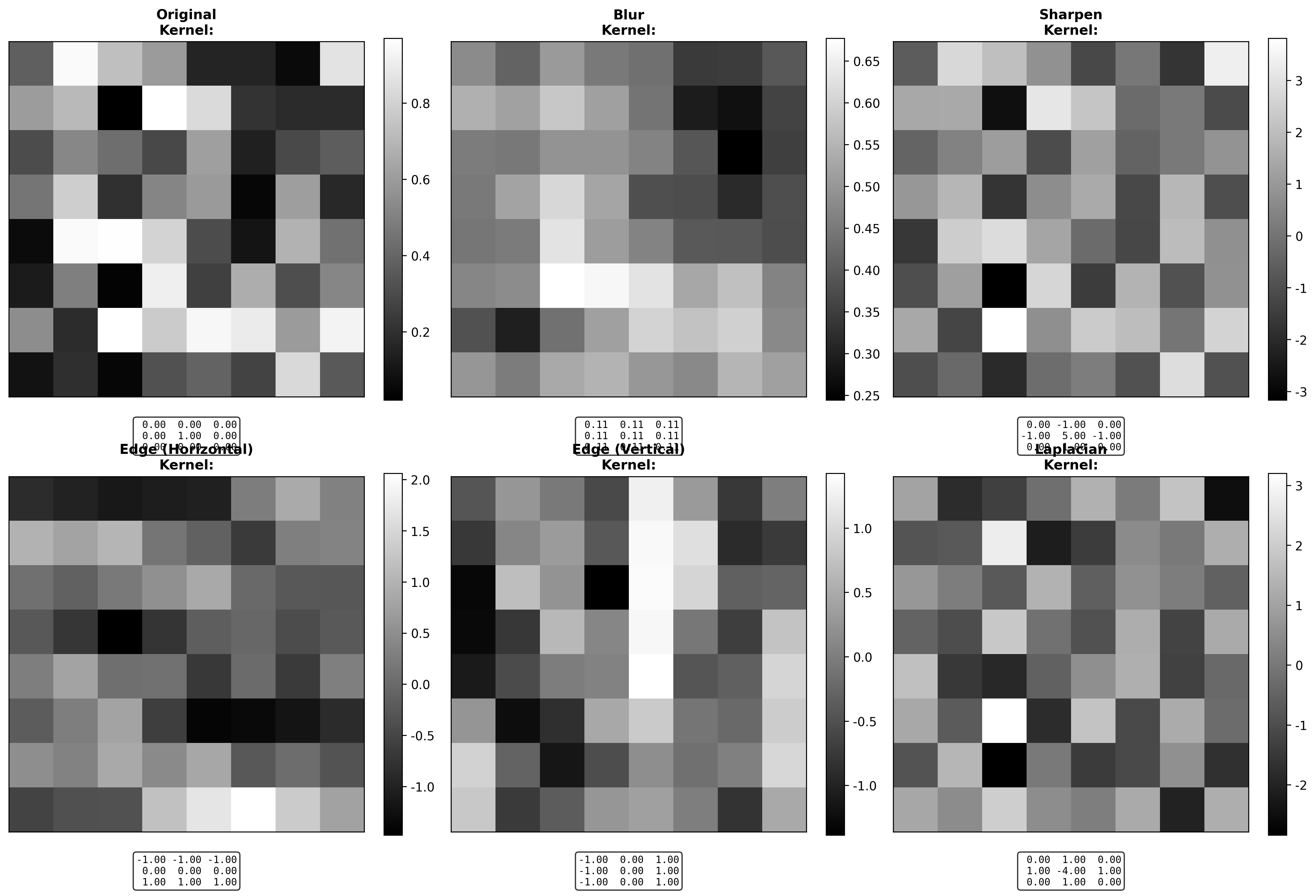
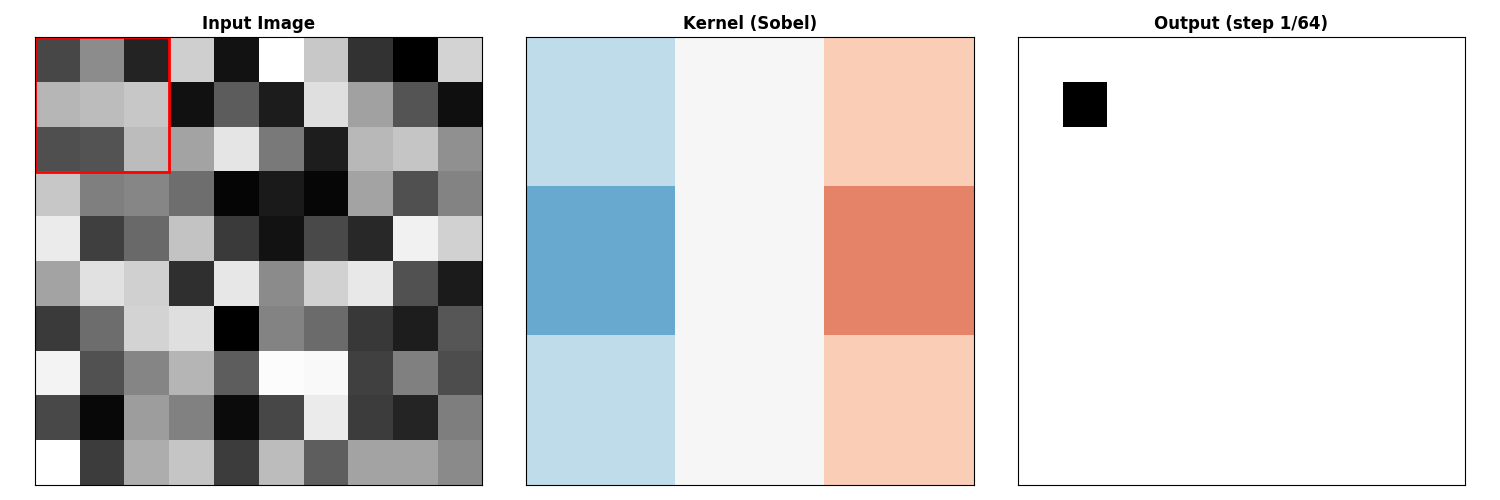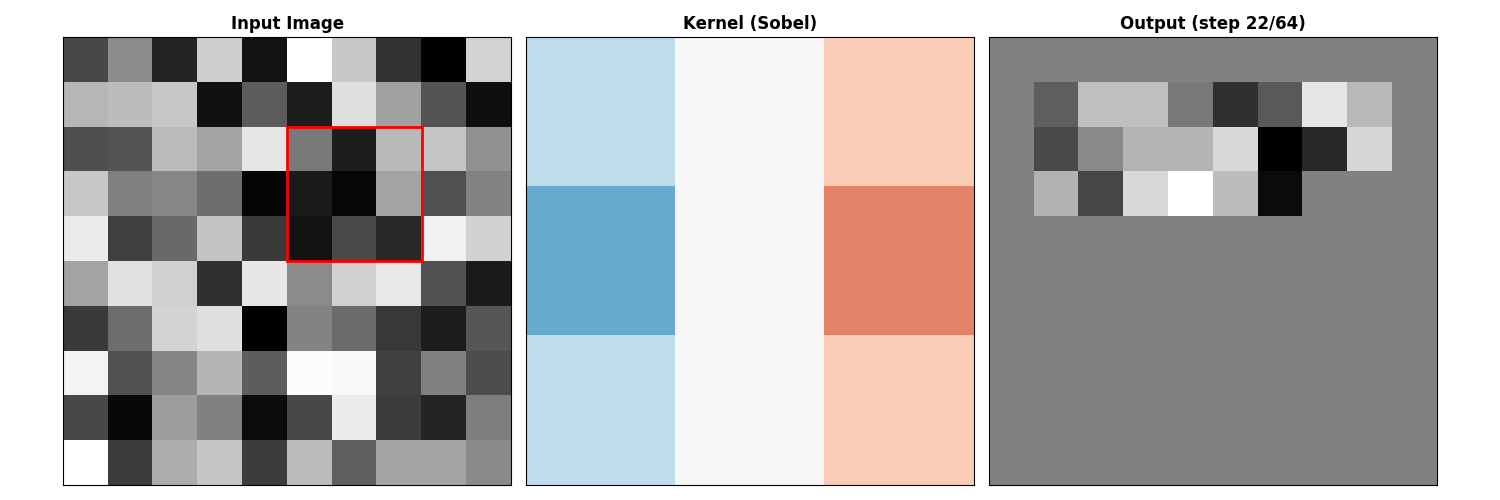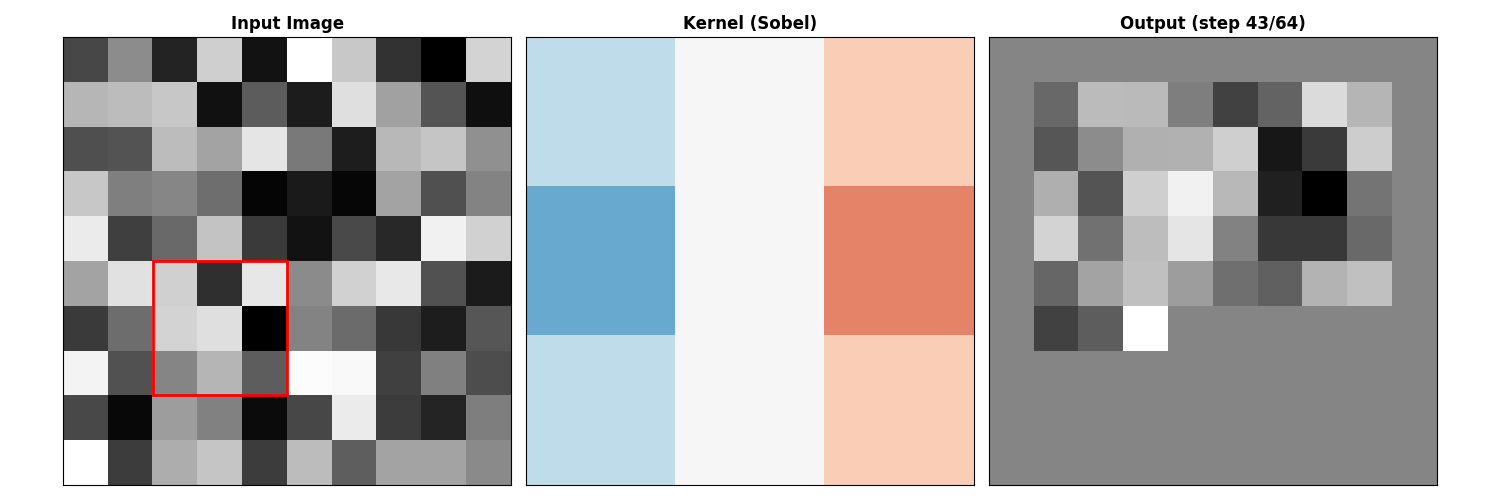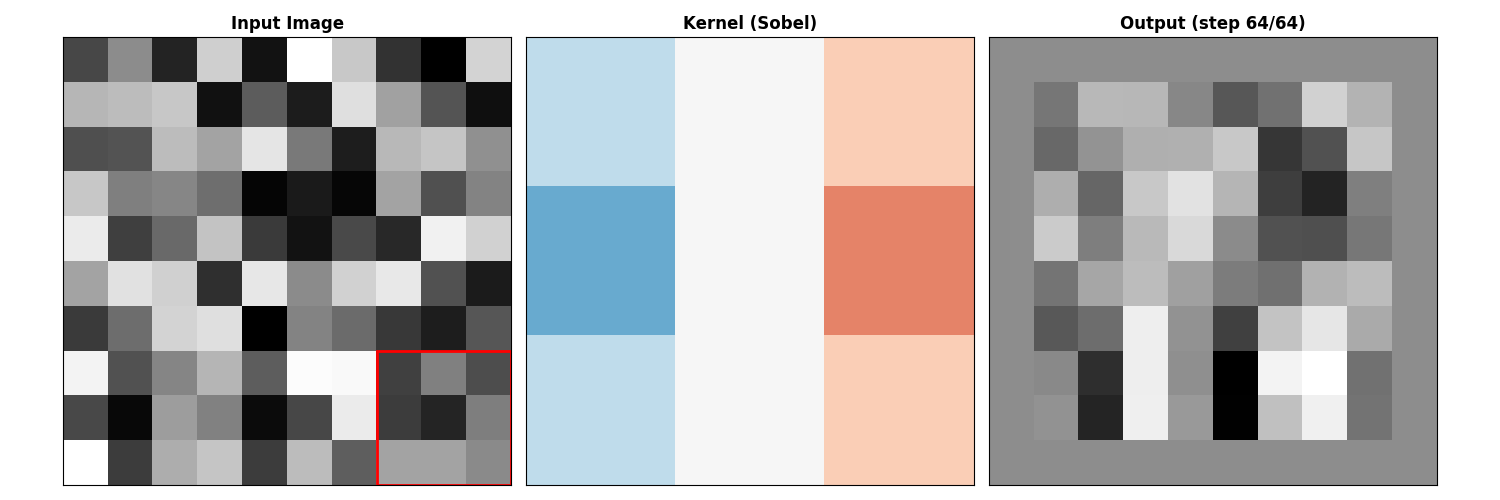
图像滤波的矩阵形式
卷积作为矩阵乘法
图像卷积通常写成:
但它也可以表示为矩阵乘法。把图像展平成向量
为什么这很重要?
因为我们可以用线性代数的工具来分析滤波器的性质。
常见滤波器
均值滤波 (模糊):
高斯滤波 (更平滑的模糊):
拉普拉斯算子 (边缘检测):
Sobel 算子 (梯度):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import cv2import numpy as npimg = cv2.imread('image.jpg' , cv2.IMREAD_GRAYSCALE) blurred = cv2.GaussianBlur(img, (5 , 5 ), 1.0 ) grad_x = cv2.Sobel(img, cv2.CV_64F, 1 , 0 , ksize=3 ) grad_y = cv2.Sobel(img, cv2.CV_64F, 0 , 1 , ksize=3 ) gradient_magnitude = np.sqrt(grad_{x*}*2 + grad_{y*}*2 ) laplacian = cv2.Laplacian(img, cv2.CV_64F) kernel = np.array([[0 , -1 , 0 ], [-1 , 5 , -1 ], [0 , -1 , 0 ]]) sharpened = cv2.filter2D(img, -1 , kernel)
滤波的频域分析
卷积定理告诉我们:空域的卷积等于频域的乘法。
这意味着我们可以通过分析卷积核的频率响应来理解滤波器:
低通滤波器 (如高斯):保留低频,去除高频噪声高通滤波器 (如拉普拉斯):保留高频,提取边缘
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def frequency_response (kernel, size=(256 , 256 ): """计算卷积核的频率响应""" padded = np.zeros(size) kh, kw = kernel.shape padded[:kh, :kw] = kernel padded = np.roll(padded, (-kh//2 , -kw//2 ), axis=(0 , 1 )) freq_response = np.fft.fft2(padded) return np.abs (np.fft.fftshift(freq_response)) gaussian_kernel = cv2.getGaussianKernel(5 , 1.0 ) @ cv2.getGaussianKernel(5 , 1.0 ).T response = frequency_response(gaussian_kernel)
特征检测中的线性代数
Harris 角点检测
Harris
角点检测的核心是分析图像在一个点附近的自相关矩阵(结构张量):
其中
关键观察 :
两个特征值都大 → 角点(各方向都有变化)
一个大一个小 → 边缘(只在一个方向变化)
两个都小 → 平坦区域
Harris 响应函数避免直接计算特征值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def harris_corner_detector (img, k=0.04 , block_size=2 , ksize=3 ): """Harris 角点检测的手动实现""" Ix = cv2.Sobel(img, cv2.CV_64F, 1 , 0 , ksize=ksize) Iy = cv2.Sobel(img, cv2.CV_64F, 0 , 1 , ksize=ksize) Ixx = Ix ** 2 Iyy = Iy ** 2 Ixy = Ix * Iy Sxx = cv2.GaussianBlur(Ixx, (block_size*2 +1 , block_size*2 +1 ), 0 ) Syy = cv2.GaussianBlur(Iyy, (block_size*2 +1 , block_size*2 +1 ), 0 ) Sxy = cv2.GaussianBlur(Ixy, (block_size*2 +1 , block_size*2 +1 ), 0 ) det_M = Sxx * Syy - Sxy ** 2 trace_M = Sxx + Syy R = det_M - k * trace_M ** 2 return R gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY).astype(np.float32) harris = cv2.cornerHarris(gray, blockSize=2 , ksize=3 , k=0.04 )
PCA 与特征描述子
SIFT 等特征描述子会对局部梯度直方图进行统计。
PCA(主成分分析)可以用来降维或提取主方向。
对于一组数据点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def pca_orientation (patch ): """用 PCA 确定图像块的主方向""" Ix = cv2.Sobel(patch, cv2.CV_64F, 1 , 0 ) Iy = cv2.Sobel(patch, cv2.CV_64F, 0 , 1 ) gradients = np.stack([Ix.ravel(), Iy.ravel()], axis=1 ) mean = gradients.mean(axis=0 ) centered = gradients - mean cov = centered.T @ centered / len (gradients) eigenvalues, eigenvectors = np.linalg.eig(cov) main_direction = eigenvectors[:, np.argmax(eigenvalues)] orientation = np.arctan2(main_direction[1 ], main_direction[0 ]) return orientation
深度学习视觉中的线性代数
卷积神经网络中的矩阵运算
CNN 的核心操作——卷积,可以重写为矩阵乘法( im2col 技术):
把输入特征图的局部块"展开"成列向量
把卷积核也展开成行向量
用矩阵乘法完成所有卷积
这让 GPU 能高效并行计算。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def im2col (img, kernel_size, stride=1 ): """将图像转换为列矩阵形式""" H, W = img.shape kH, kW = kernel_size out_H = (H - kH) // stride + 1 out_W = (W - kW) // stride + 1 col = np.zeros((kH * kW, out_H * out_W)) idx = 0 for i in range (0 , H - kH + 1 , stride): for j in range (0 , W - kW + 1 , stride): patch = img[i:i+kH, j:j+kW] col[:, idx] = patch.ravel() idx += 1 return col def conv2d_as_matmul (img, kernel, stride=1 ): kH, kW = kernel.shape col = im2col(img, (kH, kW), stride) kernel_row = kernel.ravel().reshape(1 , -1 ) result = kernel_row @ col out_H = (img.shape[0 ] - kH) // stride + 1 out_W = (img.shape[1 ] - kW) // stride + 1 return result.reshape(out_H, out_W)
批归一化的线性变换
BatchNorm 层对每个特征通道做仿射变换:
在推理时,
注意力机制中的矩阵运算
Transformer 的自注意力机制完全基于矩阵运算:
其中
练习题
基础题
1. 图像矩阵运算
一张
上下翻转图像
左右翻转图像
将图像亮度增加 50(像素值加 50)
将图像对比度提高 1.5 倍(像素值乘 1.5)
2. 旋转矩阵性质
证明:
二维旋转矩阵的行列式等于 1
二维旋转矩阵的逆等于其转置
两个旋转矩阵的乘积仍是旋转矩阵,且3. 齐次坐标
用
进阶题
4. 单应性矩阵
给定四对对应点:
说明为什么需要 4 对点来确定单应性矩阵
用 DLT 方法列出求解
5. 本质矩阵分解
已知本质矩阵
提示:对
6. 三角测量
两个相机的投影矩阵分别为:
一对对应点为
编程题
7. 实现图像仿射变换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def affine_transform (img, rotation_deg, scale, translation, center=None ): """ 实现图像仿射变换 参数: - img: 输入图像 - rotation_deg: 旋转角度(度) - scale: 缩放因子 (sx, sy) - translation: 平移 (tx, ty) - center: 旋转中心,默认为图像中心 返回: - 变换后的图像 要求: - 手动构建变换矩阵(不使用 cv2.getRotationMatrix2D) - 使用 cv2.warpAffine 应用变换 """ pass
8. 实现基础矩阵估计
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def estimate_fundamental_matrix (pts1, pts2 ): """ 八点法估计基础矩阵 参数: - pts1: (N, 2) 第一幅图像中的点 - pts2: (N, 2) 第二幅图像中的点 返回: - F: (3, 3) 基础矩阵 要求: - 实现八点法(构建约束矩阵, SVD 求解) - 对结果强制 rank-2 约束 - 不使用 cv2.findFundamentalMat """ pass
9. 实现 Harris 角点检测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def harris_corners (img, block_size=2 , ksize=3 , k=0.04 , threshold=0.01 ): """ Harris 角点检测 参数: - img: 灰度图像 - block_size: 邻域大小 - ksize: Sobel 核大小 - k: Harris 参数 - threshold: 响应阈值(相对于最大响应) 返回: - corners: (M, 2) 角点坐标 要求: - 手动计算结构张量 - 手动计算 Harris 响应 - 非极大值抑制 """ pass
应用题
10. 全景图像拼接
设计一个全景图像拼接系统:
需要实现的步骤:
特征检测与匹配
估计相邻图像间的单应性
图像变换与融合
讨论:
为什么可以用单应性矩阵来描述不同视角的图像关系?
累积误差如何处理?
曝光差异如何处理?
11. 简单的视觉里程计
实现一个简单的单目视觉里程计:
需要实现:
帧间特征跟踪
本质矩阵估计与位姿恢复
轨迹累积
讨论:
单目视觉里程计的尺度漂移问题
如何检测和处理跟踪失败?
本章总结
计算机视觉与线性代数的关系密不可分:
图像表示 :
图像是矩阵,彩色图像是张量
图像可以展平为向量,用于机器学习
几何变换 :
旋转、缩放、剪切是线性变换
齐次坐标让平移也能用矩阵表示
透视变换用单应性矩阵描述
相机与三维 :
投影矩阵将 3D 点映射到 2D 图像
对极几何约束对应点关系
三角测量和 SfM 恢复 3D 结构
优化与估计 :
SLAM 中的状态估计依赖矩阵运算
李群/李代数处理旋转的优化
Bundle Adjustment 求解稀疏线性系统
信号处理 :
卷积可以写成矩阵乘法
傅里叶变换分析滤波器
深度学习大量使用矩阵运算
掌握这些内容,你就掌握了计算机视觉的数学基础。下一步可以深入学习多视图几何、视觉
SLAM 、三维重建等专题。
参考资料
Hartley, R., & Zisserman, A. Multiple View Geometry in
Computer Vision . Cambridge University Press.
Szeliski, R. Computer Vision: Algorithms and Applications .
Springer.
Forsyth, D. A., & Ponce, J. Computer Vision: A Modern
Approach . Pearson.
Strang, G. Introduction to Linear Algebra .
Wellesley-Cambridge Press.
Barfoot, T. D. State Estimation for Robotics . Cambridge
University Press.
本文是《线性代数的本质与应用》系列的第十七章。