当你调节淋浴水温时,你其实在做一件和神经网络训练本质相同的事情——根据当前"误差"(水太冷或太热)来调整"参数"(旋钮位置)。只不过神经网络的参数是几百万个数字,而调整它们的数学工具就是矩阵微积分。
引言:从一维到多维的求导革命
还记得高中学过的导数吗?
但当我们面对机器学习问题时,情况变得复杂了:
- 线性回归:
,这里 是一个向量甚至矩阵 - 神经网络:
,参数数以百万计 - 主成分分析:
,约束条件 这些问题的共同点是:变量不再是单个数字,而是向量或矩阵。我们需要一套新的数学语言来描述"当一个矩阵变化时,另一个量如何变化"——这就是矩阵微积分。
一个直观的类比
想象你在一座山上,手里拿着 GPS 显示的高度计。在一维情况下(只能沿着一条小路走),导数告诉你"往前走一步,高度变化多少"。但在二维山面上,你可以往任意方向走,这时你需要知道的不再是一个数字,而是一个向量——它告诉你"往哪个方向走下降最快,下降速度是多少"。
这个向量就是梯度,它是矩阵微积分最基础也是最重要的概念。
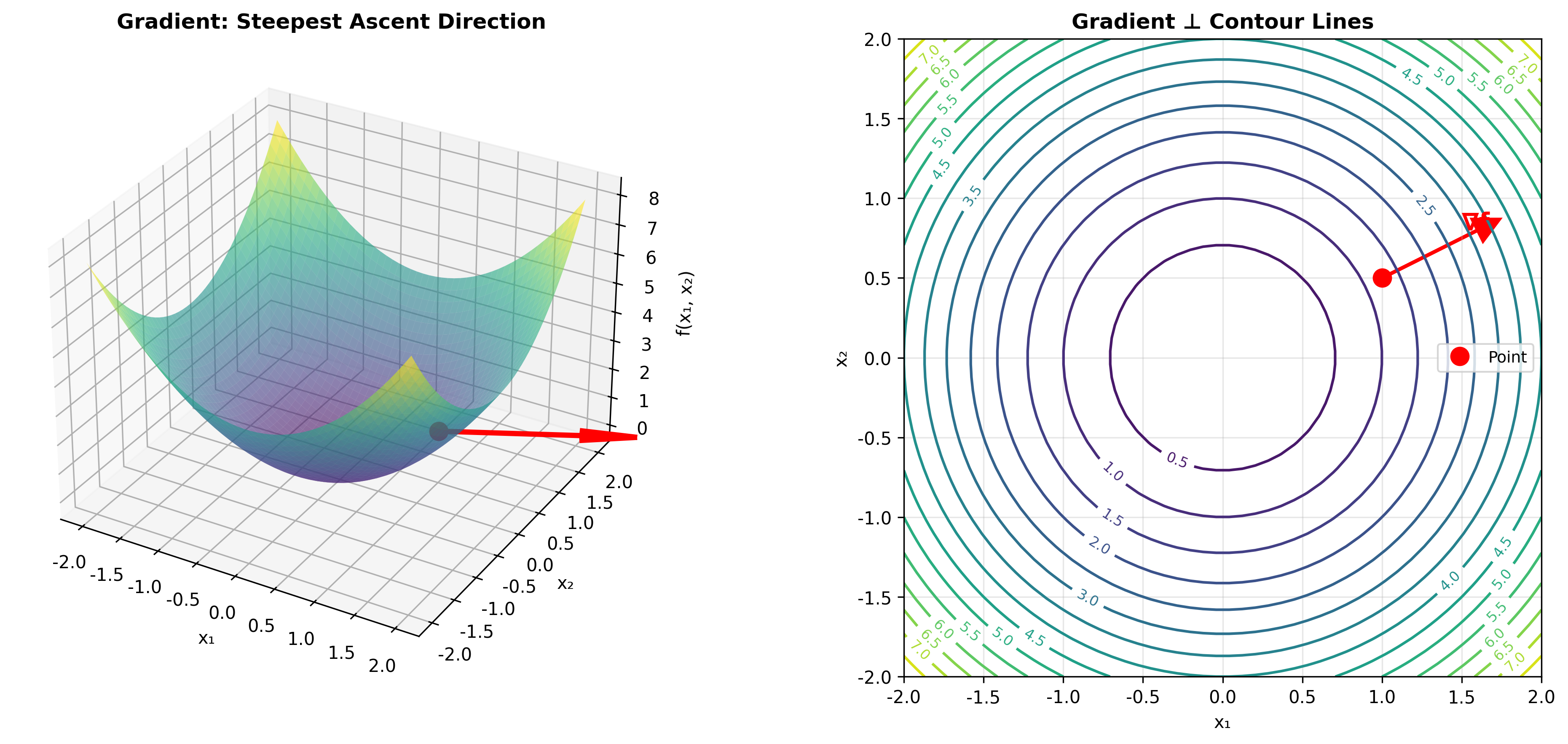
标量对向量的导数:梯度
从一维推广到多维
假设你经营一家奶茶店,利润
你想知道:如果稍微调整价格或广告投入,利润会怎么变?
对每个变量分别求偏导数:
-
把这两个偏导数"打包"成一个向量,就是梯度:
正式定义
对于标量函数
梯度的三大几何意义
梯度不仅仅是"偏导数的集合",它有深刻的几何含义:
方向性:梯度指向函数增长最快的方向。回到奶茶店的例子,梯度方向告诉你"应该同时怎样调整价格和广告,才能让利润增长最快"。
大小性:梯度的模
正交性:梯度与函数的等高线(等值面)垂直。这就像地图上的等高线——如果你沿着等高线走,高度不变;而梯度方向则垂直于等高线,是"上坡"最陡的方向。
例子:线性函数的梯度
设
例子:二次函数的梯度
设
方向导数:不只是上下坡
在山上,你不一定要沿着最陡的方向走。你可以选择任意方向——那么这个方向上的"坡度"是多少呢?
定义
函数
其中
几何直觉
方向导数的公式
- 当
(沿梯度方向走)时, ,增长最快 - 当
(沿等高线走)时, ,函数值不变 - 当
(逆着梯度走)时, ,下降最快
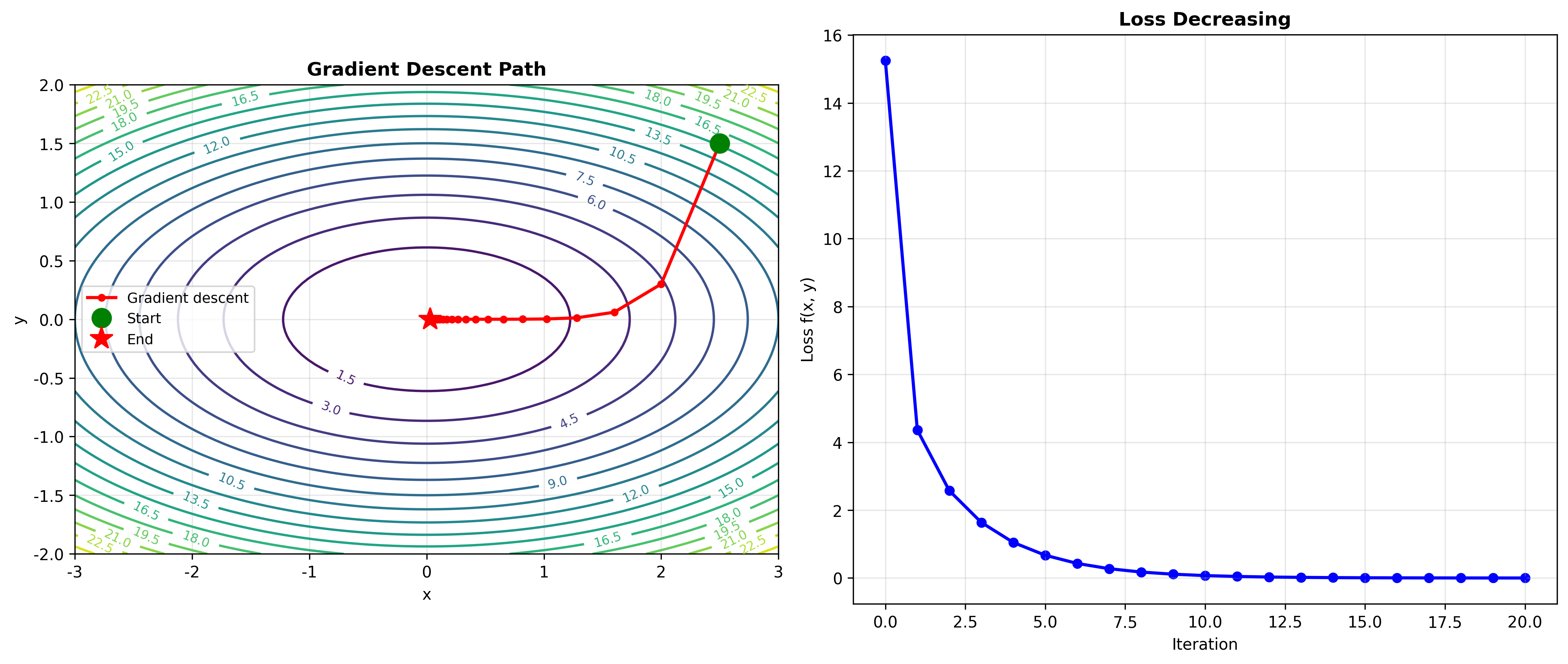
这就是梯度下降法的理论基础:要让函数值下降最快,就沿着负梯度方向走。
实际应用:登山策略
假设你是一个盲人登山者,只能感知脚下的坡度。你的策略可能是:
- 最速上升:永远沿着最陡的上坡方向走(梯度方向)
- 等高线漫步:沿着水平方向走,保持高度不变(垂直于梯度)
- Z 字形上山:比最陡方向稍微偏一点,这样不会太累
在优化算法中,这些策略都有对应物:梯度下降、约束优化、带动量的梯度下降等。
向量对向量的导数:雅可比矩阵
当输出也是向量时,情况变得更有趣了。
从一个生活案例说起
假设你在做菜,有三种调料的用量
现在问:如果所有调料用量都稍微变化一点,三个口味指标会怎么变?
这就需要一个矩阵来描述,因为有
正式定义
对于向量函数
维度:
雅可比矩阵的几何意义
雅可比矩阵描述了函数
换句话说,雅可比矩阵是"用线性函数逼近非线性函数"的最佳系数矩阵。
另一个视角:雅可比矩阵描述了函数如何"变形空间"。如果你在输入空间画一个小正方形,通过函数
经典例子:极坐标变换
极坐标到直角坐标的变换
行列式的意义:
海森矩阵:曲率的完整描述
梯度告诉我们函数的"坡度",但它没有告诉我们坡度是否在变化。为此,我们需要二阶导数。
一维情况的回顾
在一维微积分中,二阶导数
-
多维情况:海森矩阵
对于多变量函数
海森矩阵的性质
对称性:如果
曲率描述:海森矩阵描述了函数表面的"弯曲程度"。想象一个碗状曲面,海森矩阵告诉你这个碗在各个方向上有多"陡"。
二阶泰勒展开
海森矩阵出现在函数的二阶泰勒展开中:
这个展开式是理解优化算法的基础。第一项是当前函数值,第二项是线性近似(梯度方向),第三项是二次修正(曲率影响)。
临界点分类
在临界点
函数的局部行为完全由海森矩阵决定:
| 海森矩阵性质 | 临界点类型 | 直观理解 |
|---|---|---|
| 正定 | 局部极小值 | 各个方向都是"碗底" |
| 负定 | 局部极大值 | 各个方向都是"山顶" |
| 不定 | 鞍点 | 有些方向上升,有些方向下降 |
| 半正定/半负定 | 需要更高阶分析 | 某些方向是"平的" |
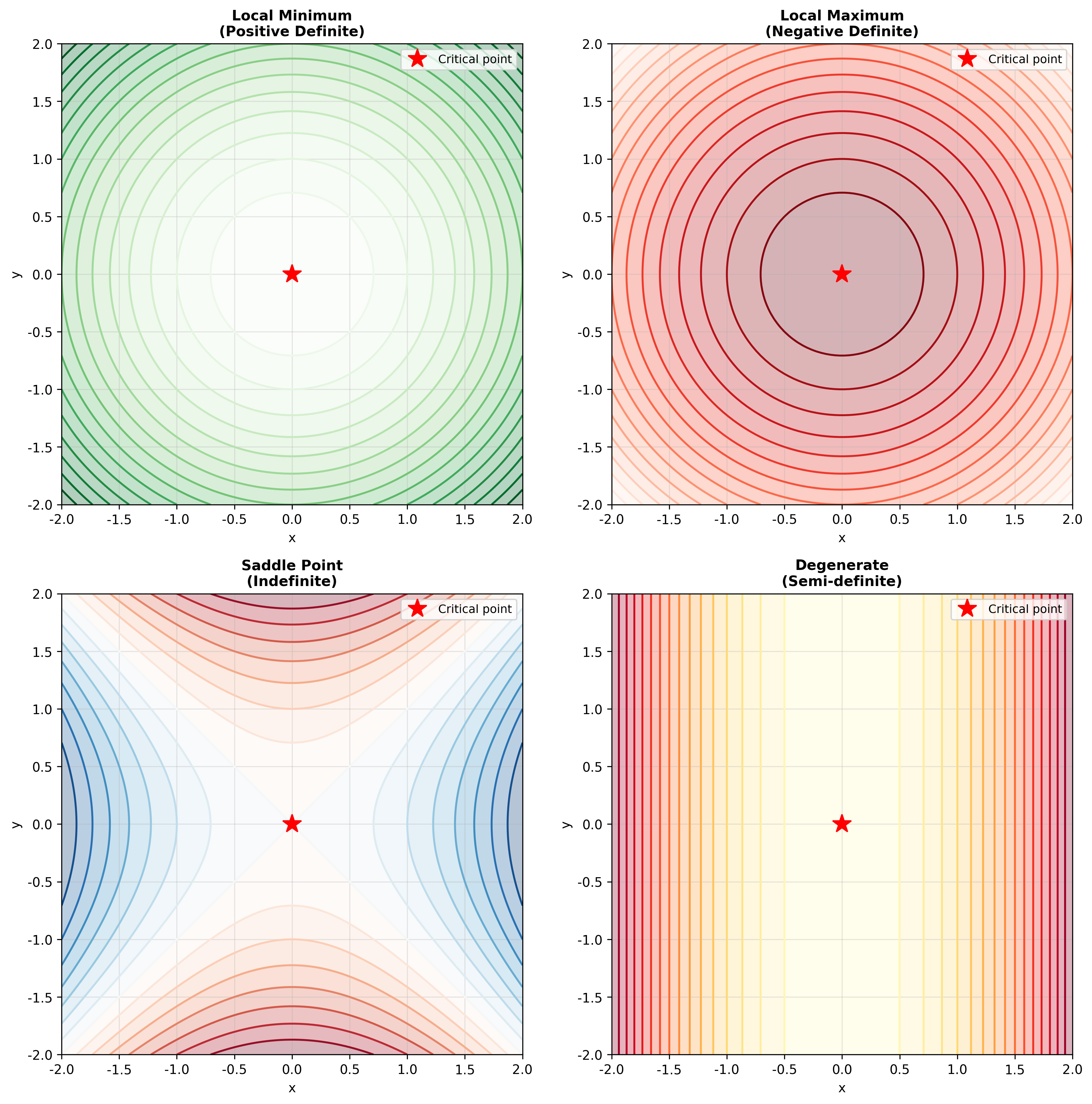
例子:二维二次函数
设
海森矩阵
再看
海森矩阵特征值为
标量对矩阵的导数
在机器学习中,参数往往是矩阵形式。例如神经网络的权重矩阵
定义与记号
对于标量函数
结果是一个与
迹函数的导数
矩阵的迹
基本公式:
证明技巧:利用迹的循环性质
行列式的导数
行列式对矩阵的导数有一个优美的公式:
其中
进一步,对于对数行列式:
这个公式在统计学的最大似然估计中非常有用,特别是在处理多元正态分布时。
逆矩阵的导数
当
证明:从
解出
矩阵微积分的链式法则
链式法则是微积分最强大的工具之一。它告诉我们如何计算复合函数的导数。
回顾标量情况
设
这是微积分入门时就学过的公式。但当变量变成向量和矩阵时,情况会复杂一些。
向量链式法则
设
其中
维度分析:
向量对向量的链式法则
设
即雅可比矩阵相乘:
一个直观的理解
链式法则的本质是"微小变化的传递"。想象一条河流的污染物传播:
- 上游工厂排放量变化
→ - 中游污染物浓度变化
→ - 下游生态指数变化
最终: 这就是链式法则!每个环节的"放大系数"相乘,就是总的放大系数。
反向传播算法
反向传播是深度学习的核心算法,它是链式法则在计算图上的高效实现。
计算图:把复杂函数拆解成简单步骤
任何复杂的数学表达式都可以拆解成基本运算的组合。例如:
可以拆解为:
1.
这种拆解形成一个有向无环图( DAG),称为计算图。
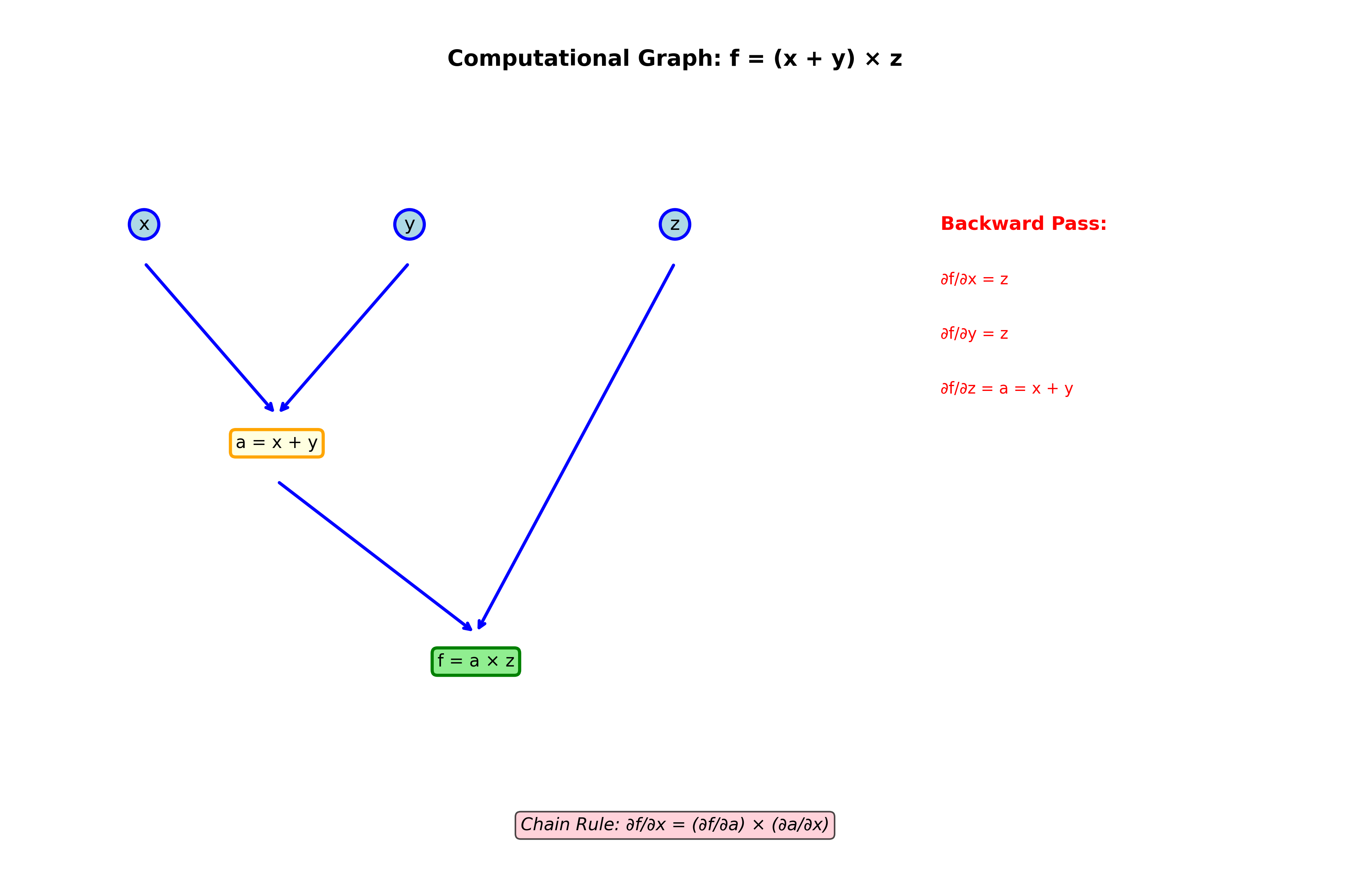
前向传播与反向传播
前向传播:从输入开始,沿着计算图一步步计算到输出。
反向传播:从输出开始,沿着计算图反向一步步计算梯度。
反向传播的核心思想是:每个节点只需要知道"输出对自己的偏导",就能计算出"输出对自己所有输入的偏导"。
为什么反向传播比前向模式更高效?
对于
- 前向模式需要
次遍历(对每个输入变量单独计算) - 反向模式需要
次遍历(对每个输出变量单独计算)
神经网络通常
这就是反向传播算法的魔力——它把计算复杂度从
全连接层的反向传播
前向传播:
其中
反向传播:假设我们已知
步骤 1:通过激活函数
其中
步骤 2:对权重求导
步骤 3:对偏置求导
步骤 4:对输入求导(传给前面层)
常见激活函数及其导数
ReLU(修正线性单元):
优点:计算简单,不会饱和(正区间)。缺点:负区间梯度为零("死亡 ReLU")。
Sigmoid:
优点:输出在
Tanh:
优点:输出在
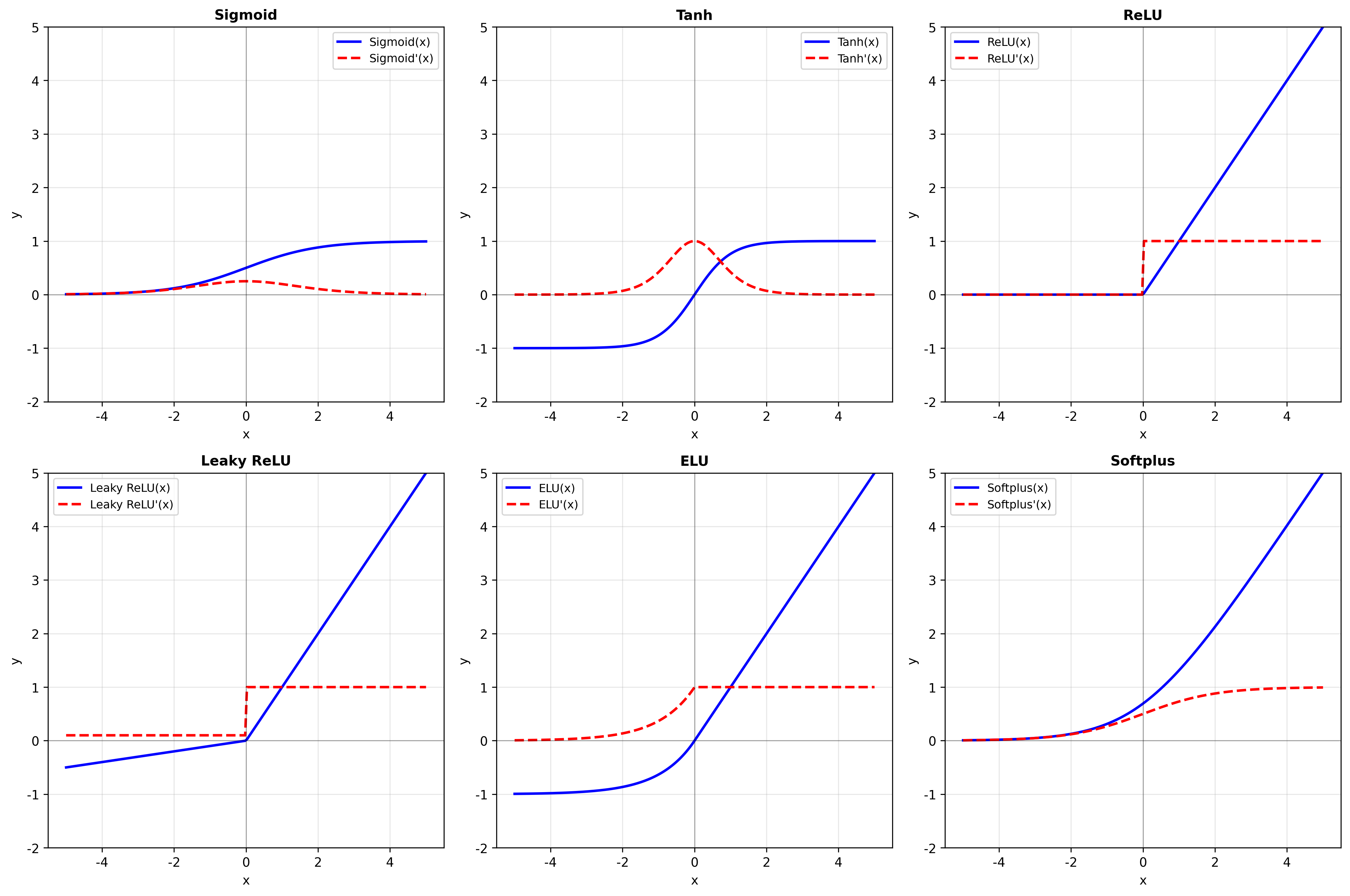
Softmax 与交叉熵
Softmax 函数将任意实数向量转换为概率分布:
交叉熵损失衡量预测分布与真实分布的差距:
重要简化: Softmax +
交叉熵的组合有一个非常简洁的梯度:
这个简洁的形式使得 Softmax+交叉熵成为分类问题的标准选择。它告诉我们:梯度就是"预测概率减去真实概率",直观且高效。
凸优化基础
为什么我们总是追求"凸"问题?因为凸问题只有一个极值点,而且是全局最优。
凸集与凸函数
凸集:集合
直观理解:凸集内任意两点的连线完全在集合内部。圆盘是凸的,月牙形不是凸的。
凸函数:函数
直观理解:函数图像上任意两点的连线在函数图像上方。碗是凸的,波浪不是凸的。
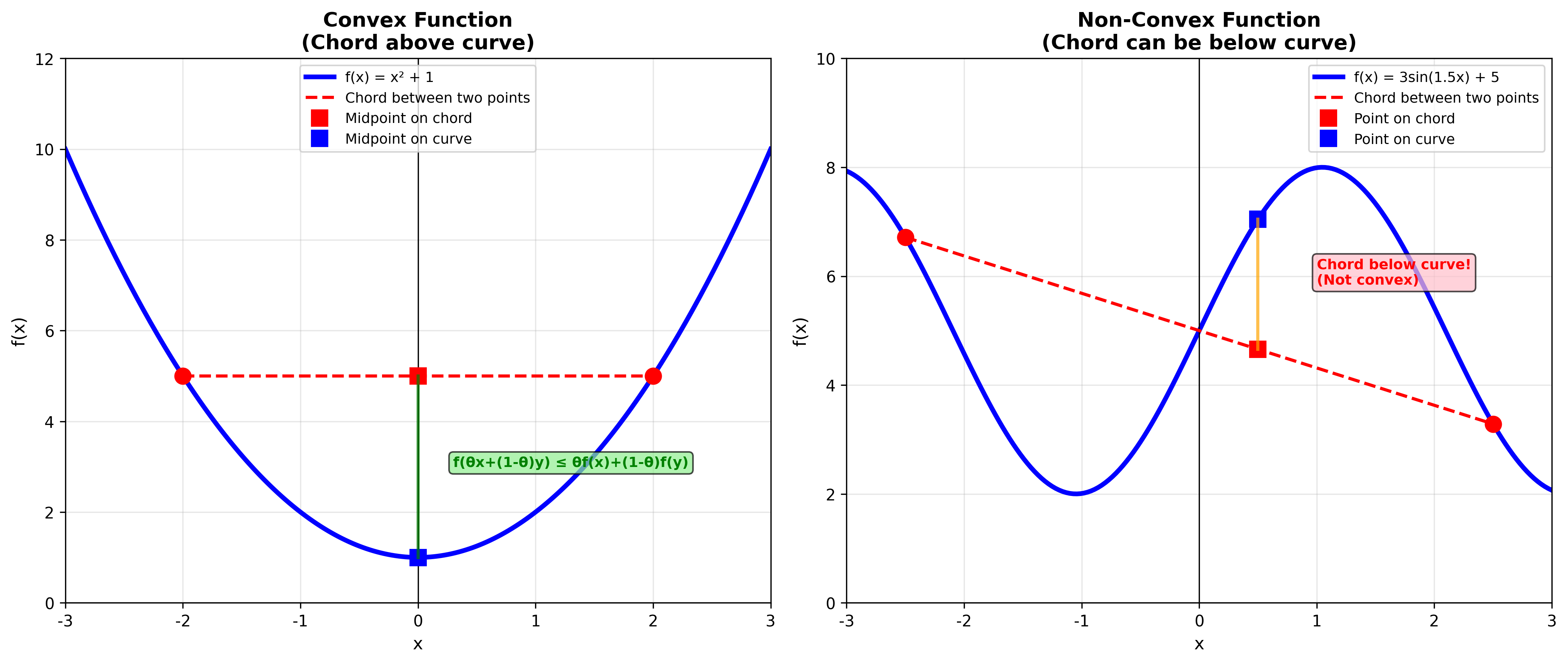
凸函数的等价刻画
以下条件等价(对于可微函数):
1.
对于严格凸函数,条件 3 变为
为什么凸很重要?
定理:凸函数的任何局部最小值都是全局最小值。
证明思路:假设
这意味着对于凸问题,梯度下降找到的任何极值点都是全局最优!
常见的凸函数
| 函数 | 凸性条件 |
|---|---|
| 既凸又凹 | |
| 凸 | |
| 凸 | |
| 凸 | |
| 凸 |
凸优化的 KKT 条件
对于约束优化问题:
KKT 条件( Karush-Kuhn-Tucker)是最优性的必要条件(凸问题时也是充分条件):
- 原问题可行:
, - 对偶可行:
- 互补松弛:
- 驻点条件:
优化算法
梯度下降
更新规则:
其中
收敛性:对于凸函数,梯度下降收敛到全局最优。收敛速度取决于函数的条件数
学习率选择:太大会发散,太小收敛太慢。实践中常用学习率衰减策略。
牛顿法
更新规则:
直观理解:牛顿法用二次函数近似原函数,然后一步跳到二次函数的极值点。
优点:二次收敛(误差平方级减少),不需要选择学习率。
缺点:需要计算和求逆海森矩阵(
随机梯度下降( SGD)
当目标函数是大量样本损失的和时:
其中
优点:计算效率高(每步只用一个样本),有助于逃离局部极小值。
缺点:更新方向有噪声,需要仔细调节学习率。
动量法( Momentum)
SGD
的更新方向可能"抖动"很厉害。动量法通过累积历史梯度来平滑更新方向:
直观理解:想象一个小球在山坡上滚动。小球有惯性,不会立即改变方向,而是累积之前的速度。这样可以冲过小的"坑",更快地到达谷底。
Adam 优化器
Adam 结合了动量和自适应学习率的优点:
直观理解:
应用实例
线性回归的解析解
目标函数:
展开:
梯度:
最优解(令梯度为零):
这就是著名的正规方程( Normal Equation)。
Ridge 回归:正则化的威力
当
目标函数:
梯度:
最优解:
好处:
主成分分析:优化视角
PCA 可以表述为以下优化问题:
其中
使用拉格朗日乘数法:
对
这正是特征值问题!最优的
公式速查表
向量导数
| 函数 | 导数 | 备注 |
|---|---|---|
| 线性 | ||
| 平方范数 | ||
| 一般二次型 | ||
| L2 范数 |
矩阵导数
| 函数 | 导数 | 备注 |
|---|---|---|
| 迹 | ||
| 迹 | ||
| 行列式 | ||
| 对数行列式 | ||
| 逆矩阵 |
练习题
基础题
1. 计算以下函数的梯度:
- (a)
- (b)
- (c)
2. 设 ,找出所有临界点并分类(极大、极小、鞍点)。
3. 证明:
5. 证明 Softmax 函数的雅可比矩阵为
进阶题
6. 证明:
7. 推导两层神经网络
8. 证明牛顿法对二次函数
9. 证明凸函数的任何局部极小值都是全局极小值。
10. 设
应用题
11. 对于 Logistic 回归的目标函数
- 计算梯度
- 计算梯度
- 计算海森矩阵
- 计算海森矩阵
- 证明
是凸函数
- 证明
12. 对于带 L2 正则化的线性回归:
- 推导最优解的闭式表达式
- 分析正则化参数
对解的影响
- 分析正则化参数
- 从贝叶斯角度解释正则化
编程题
13. 实现梯度检验函数,比较解析梯度和数值梯度:
1 | def gradient_check(f, grad_f, x, epsilon=1e-5): |
14. 从零实现一个支持自动微分的简单计算图,支持加法、乘法、 ReLU 操作。
15. 实现并比较 SGD 、 Momentum 、 Adam
在二次函数
16. 在 MNIST 数据集上实现一个两层神经网络,手动实现反向传播(不使用深度学习框架的自动微分)。
总结
矩阵微积分是连接微积分和线性代数的桥梁,也是机器学习和深度学习的数学基础。
核心要点:
- 梯度是标量函数对向量的导数,指向函数增长最快的方向
- 雅可比矩阵描述向量函数的线性近似
- 海森矩阵描述函数的曲率,用于判断极值点类型
- 链式法则是反向传播的理论基础
- 凸优化保证找到的极值是全局最优
掌握这些工具后,你就能理解现代深度学习框架的核心原理,也能设计和分析新的优化算法。
下一章预告
《稀疏矩阵与压缩感知》
- 稀疏表示的数学原理
- L1 正则化为何促进稀疏
- 压缩感知理论
- RIP 条件与恢复保证
参考资料
Petersen & Pedersen - The Matrix Cookbook
- 矩阵微积分公式大全,必备参考
Goodfellow et al. - Deep Learning, Chapter 6
- 深度学习中的反向传播算法
Boyd & Vandenberghe - Convex Optimization
- 凸优化理论的经典教材
Nocedal & Wright - Numerical Optimization
- 数值优化算法的权威参考
本文是《线性代数的本质与应用》系列的第 11 章,共 18 章。
- 本文标题:线性代数(十一)矩阵微积分与优化
- 本文作者:Chen Kai
- 创建时间:2019-02-28 16:00:00
- 本文链接:https://www.chenk.top/%E7%BA%BF%E6%80%A7%E4%BB%A3%E6%95%B0%EF%BC%88%E5%8D%81%E4%B8%80%EF%BC%89%E7%9F%A9%E9%98%B5%E5%BE%AE%E7%A7%AF%E5%88%86%E4%B8%8E%E4%BC%98%E5%8C%96/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!