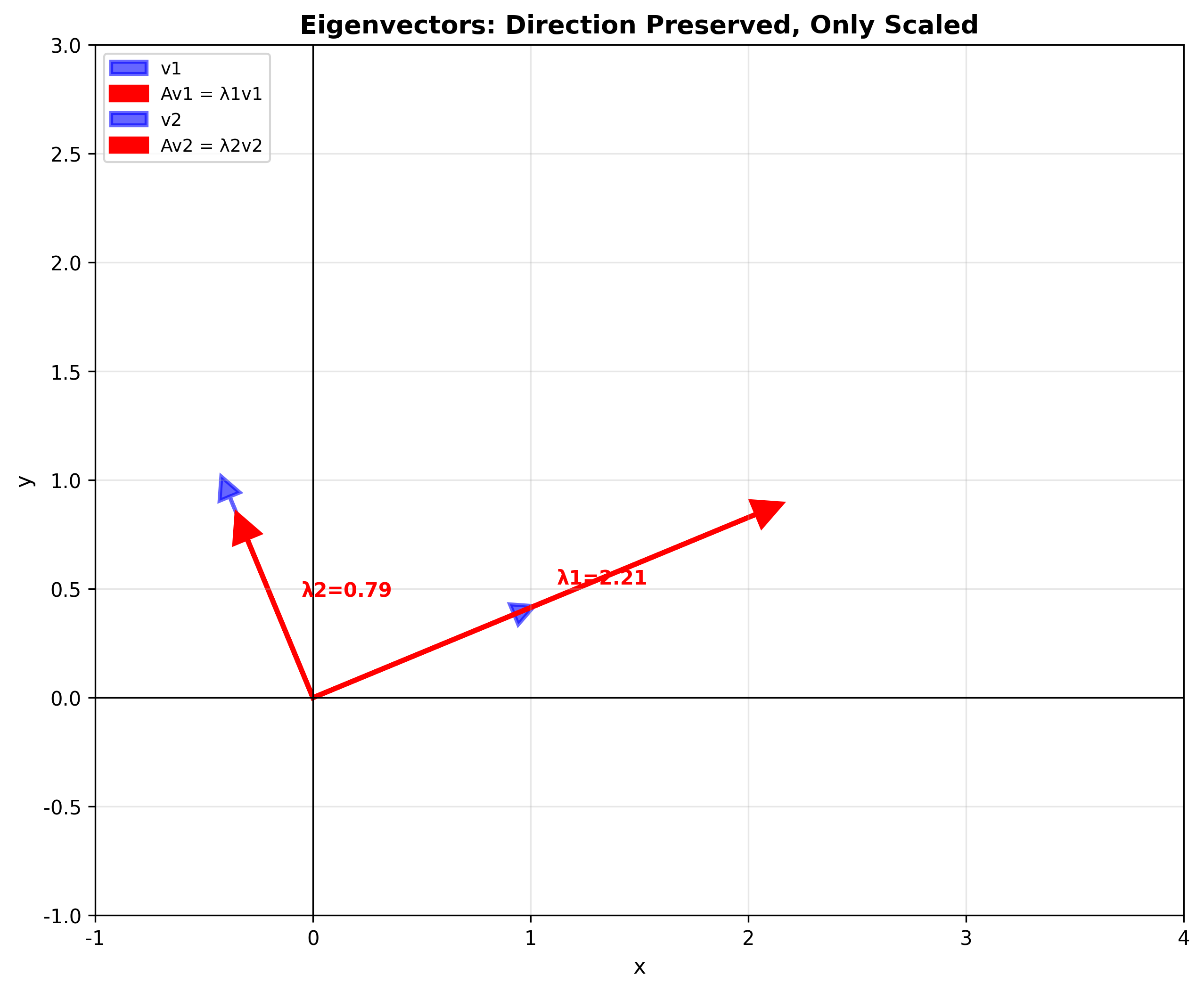
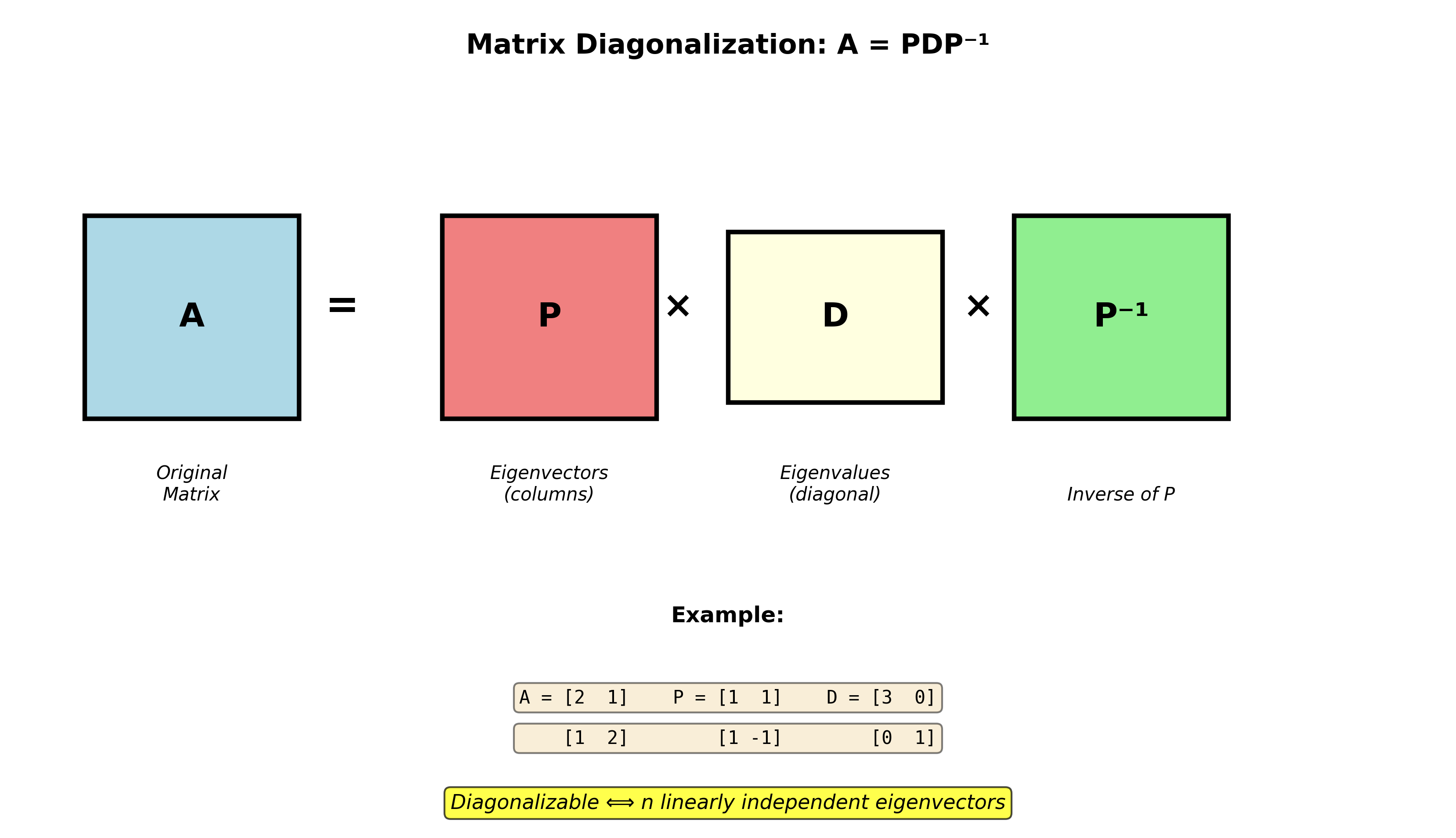
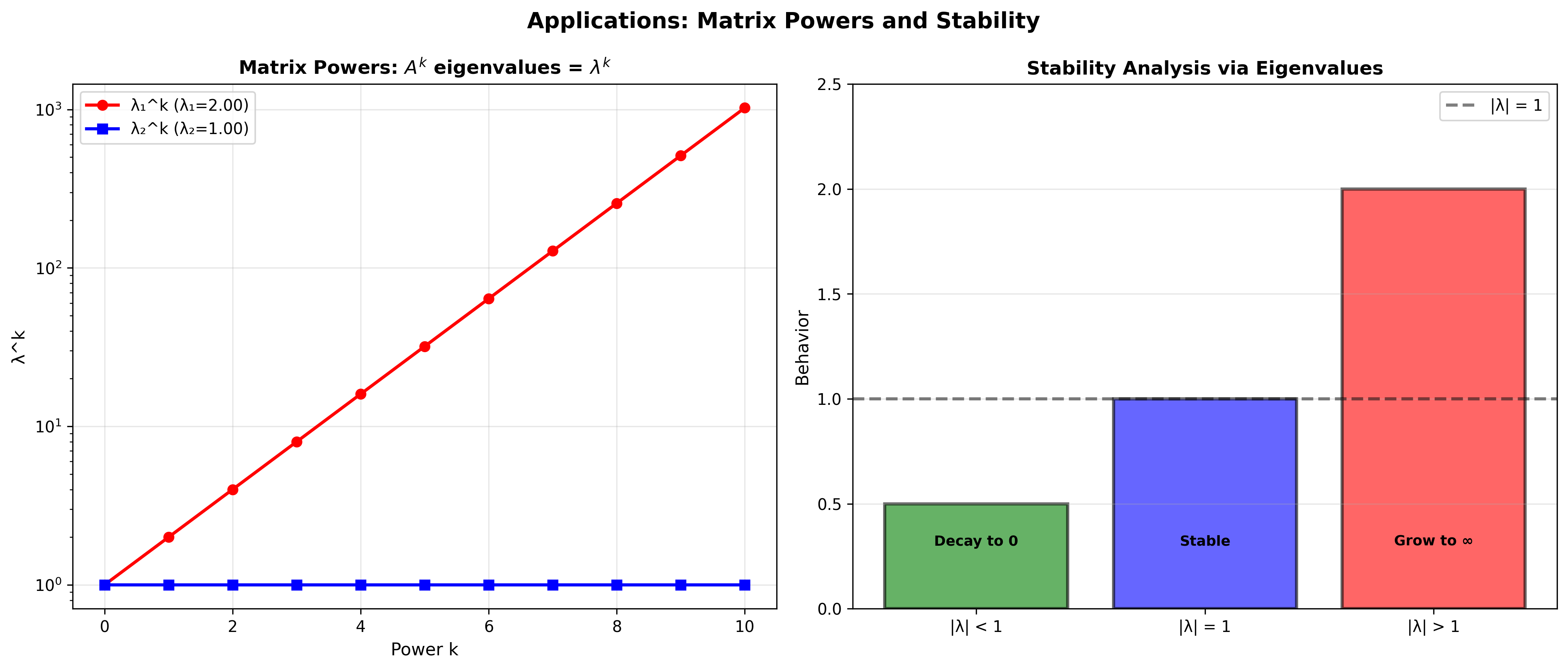
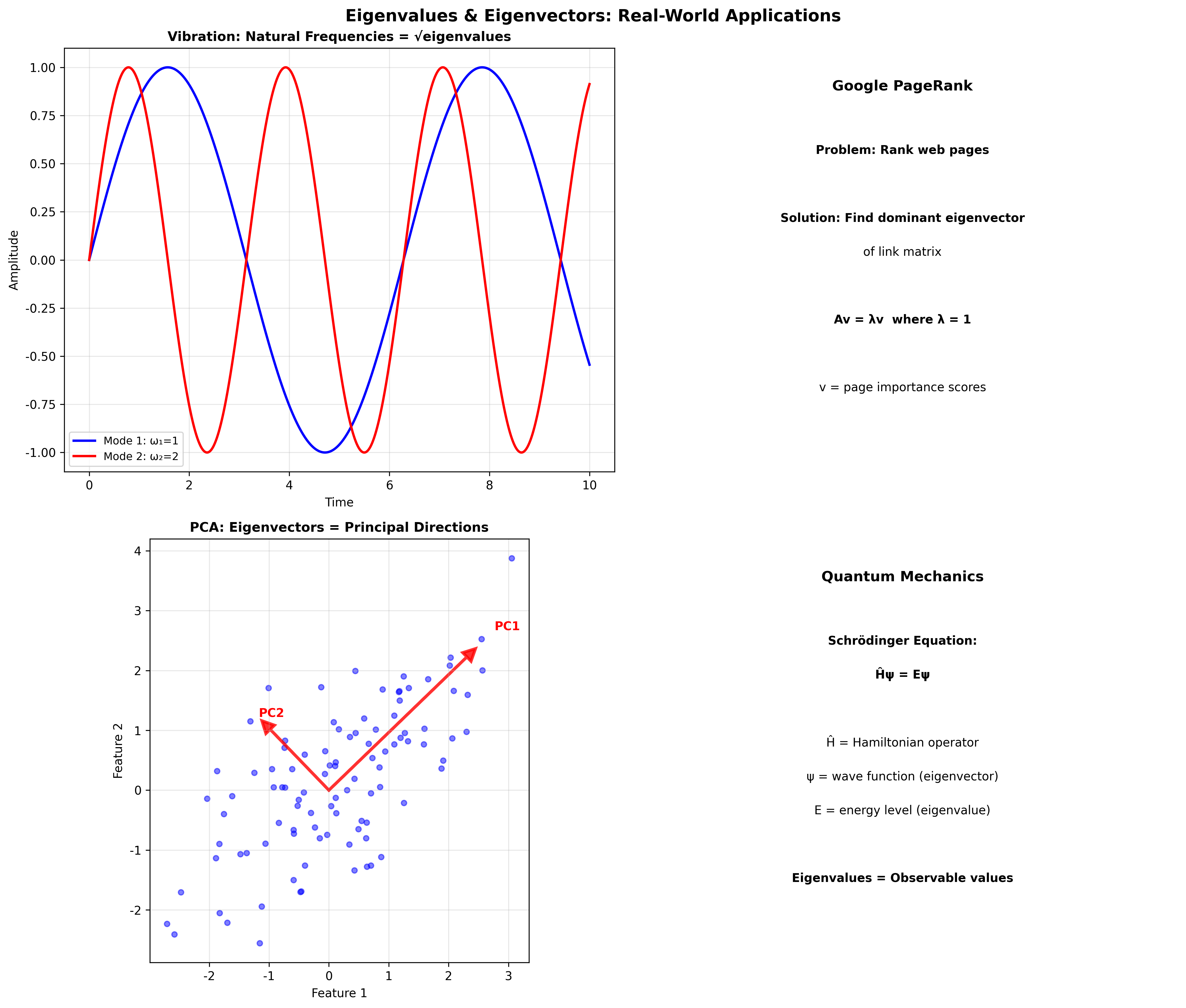
特征值与特征向量是线性代数中最深刻、最实用的概念之一。当我们对一个向量施加矩阵变换时,大多数向量会同时被"旋转"和"拉伸"。但有一类特殊的向量,在变换后只是被缩放,方向完全不变——这就是特征向量 。理解它们,就掌握了矩阵变换的"本质"。
从一个生活故事说起
想象你在厨房里揉面团。面团是一块柔软的三维物体,你每揉一下,它就会发生形变。大部分面团内部的"点"会被移动到完全不同的位置——既被拉伸,又被旋转。
但仔细观察,你会发现有一些特殊的方向:比如当你用擀面杖压面团时,沿着擀面杖方向的"纤维"只是被压扁(缩放),并没有旋转。这些特殊方向,就是面团变形的"本征方向"。
在线性代数中,矩阵描述的就是这种"揉面团"式的线性变换。而特征向量 就是那些在变换后"方向不变,只被缩放"的向量。特征值 则是缩放的倍数。
特征值与特征向量的定义
正式定义
对于一个 非零向量 标量
那么: -特征向量 (
eigenvector) -特征值 ( eigenvalue)
"eigen"这个词来自德语,意思是"自己的、固有的"。特征向量就是矩阵"固有"的方向。
为什么要求非零向量?
定义中特别强调
因为对于任何 矩阵任何 标量
直觉理解:寻找"稳定方向"
想象你站在一个旋转的游乐设施上。当设施旋转时,你身上的大部分方向都在不停改变。但有一个方向是稳定的——旋转轴的方向!沿着这个方向,无论设施怎么转,这个方向始终指向"上"。
特征向量就是矩阵变换的"旋转轴"——在所有可能的方向中,它是唯一保持稳定的。
特征值的几何意义
不同特征值的含义
特征值
特征值
几何意义
向量被拉伸
向量被压缩
向量长度不变
向量被压缩到原点(奇异情况)
向量被压缩并反向
向量被拉伸并反向
向量在复平面上旋转(实空间无不变方向)
一个具体例子:剪切变换
考虑剪切矩阵:
这个矩阵把正方形变成平行四边形(想象把一摞扑克牌推歪)。
大部分向量在这个变换下会改变方向。但水平方向(沿
求特征值:
对应的特征向量:
这个例子说明:即使矩阵看起来很"扭曲",依然存在不变方向。
生活案例:镜子中的你
照镜子时,你的像发生了什么变换?
假设镜子是
特征值和特征向量: -
你在镜子中看到的自己,左右对称轴(垂直方向)是不动的,而前后方向被"翻转"了。
特征多项式与特征方程
推导特征方程
从定义
这是一个齐次线性方程组。要使它有非零解 奇异的 (行列式为零):
这就是特征方程 ( characteristic equation)。
特征多项式特征多项式 ( characteristic
polynomial)。
对于
根据代数基本定理,它在复数域上恰好有
完整计算示例
求矩阵
步骤一:写出特征方程
步骤二:求特征值 步骤三:求特征向量
对于
第一行给出:
取
第一行给出:
取验证 :
韦达定理的矩阵版本
特征多项式的系数与矩阵有深刻联系:
迹与特征值之和 :
行列式与特征值之积 :
在上例中:
对角化:将复杂变换变简单
对角化的核心思想
假设
构造矩阵: -
那么有对角化分解 :
或等价地:
为什么对角化有用?
用途一:快速计算矩阵的幂
而
想象计算
用途二:理解矩阵的长期行为
当
这在动力系统、马尔可夫链、神经网络等领域至关重要。
对角化的几何解释
对角化可以理解为三步变换:
什么时候可以对角化?
定理 :矩阵当且仅当
充分条件 : - 如果不同的 特征值,则一定可对角化 -
实对称矩阵 总是可对角化(更强:可正交对角化)
不可对角化的例子 :
特征值亏损矩阵 (
defective matrix)。
复数特征值:旋转的数学
旋转矩阵没有实特征值
考虑
求特征值:
解得
几何直觉 :在二维实平面上,
一般旋转矩阵的特征值
角度为
特征值为:
这正是欧拉公式!特征值的模
复特征值总是成对出现
对于实矩阵 ,如果
原因 :特征多项式的系数都是实数,所以复根必须共轭成对。
复特征值与振荡
当矩阵有复特征值
系统的长期行为: -
这解释了为什么弹簧振子(无阻尼)会做周期运动,而有阻尼的振子会逐渐停止。
应用案例:人口增长模型
莱斯利矩阵( Leslie Matrix)
生态学中用莱斯利矩阵建模种群的年龄结构演化。假设一个物种分为三个年龄组(幼年、青年、老年),用向量表示各年龄组的数量:
一年后的数量由莱斯利矩阵
其中:
具体例子
假设某种动物: - 幼年不繁殖(
用 Python 计算特征值:
1 2 3 4 5 6 7 8 9 import numpy as npL = np.array([[0 , 2 , 0.5 ], [0.6 , 0 , 0 ], [0 , 0.8 , 0 ]]) eigenvalues, eigenvectors = np.linalg.eig(L) print ("特征值:" , eigenvalues)print ("主特征值:" , max (eigenvalues.real))
输出的主特征值 (绝对值最大的那个)约为
长期行为分析
当
其中
关键洞察 : - 如果
主特征向量稳定年龄分布 ——无论初始状态如何,种群最终会趋向这个分布比例。
这个模型被广泛用于野生动物保护、渔业管理、人口政策制定等领域。
网页排名的挑战
1998 年, Larry Page 和 Sergey Brin 创立 Google
时面临一个核心问题:如何衡量网页的"重要性"?
他们的洞察是:一个网页的重要性取决于多少重要网页链接到它 。这是一个递归定义——需要特征向量来解决!
数学建模
假设互联网有超链接矩阵 如 果 网 页 链 接 到 网 页 否 则
其中
每个网页的 PageRank 值
用矩阵形式写成:
这正是特征值问题!我们要找
随机游走的解释
PageRank
还有一个直观解释:想象一个"随机上网者"在网页间漫无目的地点击链接。在每个网页上,他等概率地点击任意一个出链。
长期来看,这个人停留在各网页的概率分布就是 PageRank 向量!
为了保证收敛, Google 引入了"阻尼因子"
这意味着上网者有 15%
的概率随机跳转到任意网页(模拟用户直接输入网址的行为)。
简化示例
考虑一个只有 4 个网页的微型互联网:
1 2 3 4 网页 1 → 网页 2, 3 网页 2 → 网页 3 网页 3 → 网页 1 网页 4 → 网页 1, 2, 3
超链接矩阵(带阻尼因子
通过幂次迭代求主特征向量,得到各网页的 PageRank 分数。网页 3
由于被多个网页链接,且链接它的网页(如网页 1)本身也很重要,所以它的
PageRank 会很高。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import numpy as npH = np.array([[0 , 0 , 1 , 1 /3 ], [1 /2 , 0 , 0 , 1 /3 ], [1 /2 , 1 , 0 , 1 /3 ], [0 , 0 , 0 , 0 ]]) d = 0.85 n = 4 G = d * H + (1 - d) / n * np.ones((n, n)) r = np.ones(n) / n for _ in range (100 ): r = G @ r print ("PageRank:" , r)
幂次迭代法
Google 使用幂次迭代法 来计算 PageRank:
不断迭代,向量会收敛到主特征向量。这种方法特别适合稀疏矩阵(互联网的链接矩阵很稀疏),可以高效处理数十亿网页。
斐波那契数列与黄金比例
用矩阵表示递推
斐波那契数列定义为:
用向量
因此:
对角化求通项公式
矩阵
令
通过对角化可得斐波那契数列的比内公式 ( Binet's
Formula):
渐近行为
由于
这解释了为什么相邻斐波那契数的比值趋向于黄金比例:
黄金比例出现在这里并非偶然——它正是斐波那契矩阵的主特征值 !
对称矩阵的特殊性质
谱定理
定理 (实对称矩阵的谱定理):设
1.实数 2.正交对角化 :相互正交
正交对角化的意义
普通对角化是
正交矩阵
谱分解
每个实对称矩阵可以写成秩一矩阵的和 :
其中
这个分解在主成分分析(
PCA)、图像压缩、推荐系统等领域有重要应用。
正定性与特征值
对于对称矩阵
-正定 半正定 负定 不定
正定矩阵在优化、机器学习中扮演核心角色( Hessian
矩阵正定意味着函数有极小值)。
特征值的性质总结
基本性质
性质
描述
迹
行列式
可逆性
相似矩阵
如果相似 ),则: -相同的特征值 -
如果
对角化本质上就是找一个相似变换,使
特征值的代数重数与几何重数
代数重数 :特征值作为特征多项式根的重数几何重数 :对应特征空间的维数(线性独立的特征向量数量)
关系 :几何重数
当所有特征值的几何重数等于代数重数时,矩阵可对角化。
数值计算方法
幂次迭代法
求最大特征值 及其特征向量:
1 2 3 4 5 6 7 8 9 10 11 def power_iteration (A, num_iterations=100 ): n = A.shape[0 ] v = np.random.rand(n) v = v / np.linalg.norm(v) for _ in range (num_iterations): Av = A @ v v = Av / np.linalg.norm(Av) eigenvalue = v @ A @ v return eigenvalue, v
收敛速度 取决于
逆幂次迭代法
求最小特征值 :对
QR 算法
求所有特征值 的黄金标准算法:
1 2 3 4 5 6 def qr_algorithm (A, num_iterations=100 ): Ak = A.copy() for _ in range (num_iterations): Q, R = np.linalg.qr(Ak) Ak = R @ Q return np.diag(Ak)
这是 NumPy 、 MATLAB 等软件计算特征值的核心算法。
练习题
概念理解题
1.
为什么特征向量的定义中要求向量非零?如果允许零向量,会发生什么?
2. 一个
3. 如果
4. 解释为什么旋转矩阵(非
5.
什么样的矩阵一定可以对角化?什么样的矩阵可能无法对角化?
计算题
6. 求矩阵
7. 对角化矩阵
8. 利用上题的对角化结果,计算
9. 求旋转矩阵
10. 证明矩阵
11. 设
12. 求矩阵
证明题
13. 证明:如果
14. 证明:不同特征值对应的特征向量线性独立。
15. 设
16. 证明韦达定理的矩阵版本:
应用题
17. (人口模型)某城市人口分为三个年龄组:儿童(
0-14 岁)、成人( 15-64 岁)、老人( 65 岁以上)。莱斯利矩阵为:
18. ( PageRank)考虑一个有 3 个网页的小型网络: -
网页 A 链接到 B 和 C - 网页 B 链接到 C - 网页 C 链接到 A
写出超链接矩阵
19. (斐波那契推广)定义广义斐波那契数列:
20. (马尔可夫链)一个系统有两个状态 A 和
B,转移概率如下:从 A 到 A 的概率是 0.7,从 A 到 B 是 0.3;从 B 到 A 是
0.4,从 B 到 B 是 0.6 。 ( a)写出转移矩阵
编程题
21.
实现幂次迭代法,用于求矩阵的最大特征值和对应的特征向量。测试你的实现。
22. 编写程序可视化一个
23. 实现简化版的 PageRank 算法,测试一个小型网络(
5-10 个节点)。
24.
编写程序模拟莱斯利人口模型,可视化不同初始条件下人口的长期演化。
25. 实现 QR 算法来计算矩阵的所有特征值,与 NumPy
的结果对比。
练习题详解
概念理解题解析
1.
为什么特征向量的定义中要求向量非零?如果允许零向量,会发生什么?
详解 :
特征向量定义要求非零的原因:
数学原因 :对于任意矩阵
每个数
特征值失去了唯一性和意义
无法区分矩阵的真实性质
几何原因 :特征向量代表矩阵变换下"方向不变"的特殊方向。零向量没有方向,谈论其"方向不变"没有意义。
实用原因 :在应用中(如
PCA、PageRank),我们需要特征向量作为有意义的方向或模式。零向量无法提供任何信息。
类比 :就像定义"斜率"时要求
2. 一个
详解 :
最多 :3 个线性独立的特征向量
根据线性代数基本定理,
对于
最少 :1 个线性独立的特征向量
根据代数基本定理,特征多项式(3 次)在复数域上至少有一个根
因此至少有一个特征值(可能是复数)
每个特征值至少对应一个特征向量
具体案例 :
对角矩阵
约当块
旋转矩阵 (实矩阵但有复特征值):在实数域上可能只有
1 个实特征向量
3. 如果
详解 :
对于 :特征值是
证明 : 设
则:
因此
对于 :特征值是
证明 :
几何意义 : -
验证技巧 :可以用迹和行列式验证 -
4. 解释为什么旋转矩阵(非
详解 :
直觉解释 :
旋转变换会改变所有非零向量的方向 。特征向量的定义是"方向不变"的向量,因此在实平面上不存在满足条件的非零向量。
数学证明 : 考虑旋转角度
特征方程:
判别式:
当
特殊情况 : -
复数解 : 虽然无实特征值,但有复特征值
5.
什么样的矩阵一定可以对角化?什么样的矩阵可能无法对角化?
详解 :
一定可对角化的矩阵 :
有
原因:不同特征值的特征向量必定线性独立
例:
实对称矩阵
正规矩阵 (
对角矩阵
可能无法对角化的矩阵 :
有重复特征值的矩阵
重复特征值不一定意味着不可对角化
但可能导致特征向量不足
判断标准:几何重数 < 代数重数
约当块/亏损矩阵
剪切矩阵 -
判定方法 : - 计算所有特征值及其代数重数 -
对每个重根,求特征空间维数(几何重数) - 如果所有特征值的几何重数 =
代数重数,则可对角化
应用意义 : - 可对角化矩阵:易于分析长期行为(
计算题解析
6. 求矩阵
详解 :
步骤一:求特征值
特征方程:
特征值:
验证 : - 迹:
步骤二:求特征向量
对于 :
第一行:
取
对于 :
第一行:
取
步骤三:验证
几何意义 : -
7. 对角化矩阵
详解 :
步骤一:求特征值
特征值:
步骤二:求特征向量
对于 :
取
对于 :
取
步骤三:构造对角化
步骤四:求
验证 :
最终答案 :
8. 利用上题的对角化结果,计算
详解 :
利用对角化的性质:
步骤一:计算
步骤二:计算
验证(部分) : -
效率对比 : - 直接乘法 :需要 9
次矩阵乘法,每次 8 次乘法 + 4 次加法,总共约 108 次运算 -
对角化方法 :只需计算
对于大矩阵和大指数,对角化方法的优势更明显!
9. 求旋转矩阵
详解 :
步骤一:计算矩阵元素
步骤二:特征方程
步骤三:求解二次方程
步骤四:转换为指数形式
最终答案 :
或等价地:
验证 : - 模:
物理意义 : - 每次迭代旋转 60° - 模为
1,表示能量守恒(不放大也不缩小) -
复特征值解释了为何二维旋转无实特征向量
10. 证明矩阵
详解 :
方法一:计算特征向量个数
步骤一:求特征值
特征值:
步骤二:求特征空间维数
第一行:
特征向量的通解:
结论 : - 代数重数(特征值重数)= 2 -
几何重数(线性独立特征向量数)= 1 - 几何重数 < 代数重数不可对角化
方法二:反证法
假设
其中
则:
但
因此
几何解释 : -
约当标准型 : 虽然不能对角化,但可以约当标准型:
11. 设
详解 :
已知 :
要证 :
证明 :
因此,
推广 :
对任意正整数
证明(数学归纳法) :
对逆矩阵 (若
证明 :
因此:
应用意义 : - 对角化后计算矩阵的幂非常简单 -
特征向量是所有幂次矩阵的共同特征向量 - 这是对角化能快速计算
12. 求矩阵
提示 :这是递推关系
详解 :
方法一:直接计算特征多项式
按第一列展开:
特征方程:
方法二:利用伴随矩阵的性质
对于递推关系
求解三次方程 :
尝试整数根(有理根定理):
-
因式分解 :
特征值 :
验证 : - 迹:
递推关系的通解 :
常数由初始条件
证明题解析
13. 证明:如果
详解 :
已知 :
要证 :所有特征值
证明(使用复数内积) :
设
则:
取复共轭:
因为
对方程 (1) 左乘
对方程 (2) 转置后右乘
因为
比较 (3) 和 (4):
因为
这意味着
几何直觉 : -
对称矩阵代表"无旋转"的变换(只有拉伸/压缩) - 旋转会产生复特征值 -
对称矩阵不旋转,因此特征值为实
推论 : 1. 实对称矩阵可以正交对角化 2.
不同特征值的特征向量正交 3. 实对称矩阵构成特殊的函数空间基
14. 证明:不同特征值对应的特征向量线性独立。
详解 :
要证 :设
证明(数学归纳法) :
基础步骤 :
单个非零特征向量显然线性独立。
归纳步骤 :
假设对
现考虑
假设存在线性组合:
左乘 :
方程 (2) - :
根据归纳假设,
因为
代回方程 (1):
因为
因此,所有
推论 : -
15. 设
详解 :
已知 :
要证 :
证明 :
取行列式:
利用行列式的性质
因此,
推论 :
因为特征多项式相同,所以: 1. 特征值相同 (包括重数)
2. 迹相同 :行列式相同 :
几何意义 : - 相似变换
验证迹 (独立证明):
(利用迹的循环性:
16. 证明韦达定理的矩阵版本:
详解 :
要证明两个等式 :
1.
证明 :
关键观察 :特征多项式的形式
对于
这是关于
展开后:
第一部分:迹等于特征值之和
展开
对于
比较系数: -
因此:
一般情况 (
从因式分解:
因此:
第二部分:行列式等于特征值之积
特征多项式的常数项(令
从因式分解:
因此:
几何意义 : - 迹:所有方向上"平均拉伸" -
行列式:所有方向上"体积缩放"的总效果
应用 : - 快速验算特征值计算 - 判断矩阵可逆性(
应用题解析
17. (人口模型)某城市人口分为三个年龄组:儿童(0-14
岁)、成人(15-64 岁)、老人(65 岁以上)。莱斯利矩阵为:
(a) 求主特征值,判断人口长期趋势。 (b)
求稳定年龄分布(主特征向量的归一化)。
详解 :
(a) 求主特征值
步骤一:特征方程
按第三列展开:
特征方程:
步骤二:求解
特征值: -
步骤三:判断趋势
因为
人口将以每年约 3.92% 的速度增长
长期年增长率:
(b) 求稳定年龄分布
步骤一:求主特征向量
对
从第一行:
从第三行:
主特征向量(取
步骤二:归一化
总人口比例:
稳定年龄分布:儿 童 成 人 老 人
结论 : - 长期来看,约 37.7% 是儿童,32.6%
是成人,29.7% 是老人 - 无论初始分布如何,最终都会趋向这个比例 -
总人口每年增长约 3.92%
实际意义 : - 可以预测未来学校、医院、养老院的需求 -
帮助制定人口政策 - 评估社保系统的可持续性
18. (PageRank)考虑一个有 3 个网页的小型网络: -
网页 A 链接到 B 和 C - 网页 B 链接到 C - 网页 C 链接到 A
写出超链接矩阵
详解 :
步骤一:构造超链接矩阵
超链接矩阵定义:
其中
网页 A 链接到 B 和 C:
网页 B 链接到 C:
网页 C 链接到 A:
解释: - 列1(A的出链):A → B (0.5), A → C (0.5) - 列2(B的出链):B
→ C (1) - 列3(C的出链):C → A (1)
步骤二:构造 Google 矩阵
加入阻尼因子
步骤三:幂次迭代
初始向量(均匀分布):
迭代公式:
迭代 1 :
迭代 2 :
迭代 3 :
继续迭代...
收敛结果 (约 20-30 次迭代后):
步骤四:解释结果
PageRank 分数: - 网页 C:39.8% (最高) -
网页 A:38.7% - 网页
B:21.5% (最低)
为什么 C 最重要? 1. B 链接到 C(B 把 100% 的权重给
C) 2. A 链接到 C(A 把 50% 的权重给 C) 3. C 链接到 A,A 又链接到
C(形成反馈循环)
为什么 B 最不重要? - 只有 A 链接到 B - B
没有反向链接回 A
验证(数值解法) :
可以通过求解线性方程组
19. (斐波那契推广)定义广义斐波那契数列:
(a) 写出对应的矩阵 (b) 求 (c) 当
详解 :
(a) 矩阵表示
定义状态向量:
递推关系:
因此:
(b) 求特征值
特征方程:
使用求根公式:
(c) 验证黄金比例(
代入
特征值:( 黄 金 比 例 ) ( 共 轭 )
验证黄金比例性质 :
通项公式(比内公式) :
对角化后:
当
(因为
其他参数的例子 :
-
-
20. (马尔可夫链)一个系统有两个状态 A 和 B,转移概率如下:从
A 到 A 的概率是 0.7,从 A 到 B 是 0.3;从 B 到 A 是 0.4,从 B 到 B 是
0.6。
(a) 写出转移矩阵 (b) 求
(c) 求稳态分布(对应
详解 :
(a) 转移矩阵
注意:列和为 1(概率守恒)
(b) 特征值和特征向量
特征方程 :
求解:
特征值:
特征向量 :
对于 (稳态):
第一行:
取
对于 :
取
(c) 稳态分布
归一化
稳态分布 : - 状态 A:约 57.1% - 状态 B:约 42.9%
物理意义 :
长期行为 :无论初始状态如何,系统最终会稳定在 A:B
= 4:3 的分布
收敛速度 :由
验证稳态 :
应用场景 : - 天气预测(晴天/雨天) -
顾客行为(购买/不购买) - 网站访问(用户停留/离开)
编程题解析
21.
实现幂次迭代法,用于求矩阵的最大特征值和对应的特征向量。测试你的实现。
详解 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 import numpy as npdef power_iteration (A, num_iterations=100 , tolerance=1e-8 ): """ 幂次迭代法求最大特征值和特征向量 参数: A: 方阵 num_iterations: 最大迭代次数 tolerance: 收敛容差 返回: eigenvalue: 最大特征值 eigenvector: 对应的特征向量(单位向量) num_iters: 实际迭代次数 """ n = A.shape[0 ] v = np.random.rand(n) v = v / np.linalg.norm(v) eigenvalue_old = 0 for i in range (num_iterations): Av = A @ v v_new = Av / np.linalg.norm(Av) eigenvalue = v_new @ (A @ v_new) if np.abs (eigenvalue - eigenvalue_old) < tolerance: print (f"收敛于第 {i+1 } 次迭代" ) return eigenvalue, v_new, i+1 v = v_new eigenvalue_old = eigenvalue print (f"达到最大迭代次数 {num_iterations} " ) return eigenvalue, v, num_iterations def test_power_iteration (): """测试幂次迭代法""" print ("=" *60 ) print ("测试1: 对角矩阵" ) print ("=" *60 ) A1 = np.array([[5 , 0 ], [0 , 2 ]], dtype=float ) eigenvalue, eigenvector, iters = power_iteration(A1) print (f"计算得到的最大特征值: {eigenvalue:.6 f} " ) print (f"计算得到的特征向量: {eigenvector} " ) print (f"迭代次数: {iters} " ) print ("\n验证 Av = λv:" ) Av = A1 @ eigenvector print (f"Av = {Av} " ) print (f"λv = {eigenvalue * eigenvector} " ) print (f"误差: {np.linalg.norm(Av - eigenvalue * eigenvector):.2 e} " ) true_eigenvalues, true_eigenvectors = np.linalg.eig(A1) max_idx = np.argmax(np.abs (true_eigenvalues)) print (f"\nNumpy 的最大特征值: {true_eigenvalues[max_idx]:.6 f} " ) print (f"误差: {abs (eigenvalue - true_eigenvalues[max_idx]):.2 e} " ) print ("\n" + "=" *60 ) print ("测试2: 一般矩阵" ) print ("=" *60 ) A2 = np.array([[2 , 1 ], [1 , 2 ]], dtype=float ) eigenvalue2, eigenvector2, iters2 = power_iteration(A2) print (f"计算得到的最大特征值: {eigenvalue2:.6 f} " ) print (f"计算得到的特征向量: {eigenvector2} " ) print (f"迭代次数: {iters2} " ) Av2 = A2 @ eigenvector2 print (f"\n误差: {np.linalg.norm(Av2 - eigenvalue2 * eigenvector2):.2 e} " ) true_eigenvalues2, _ = np.linalg.eig(A2) max_idx2 = np.argmax(np.abs (true_eigenvalues2)) print (f"Numpy 的最大特征值: {true_eigenvalues2[max_idx2]:.6 f} " ) print (f"误差: {abs (eigenvalue2 - true_eigenvalues2[max_idx2]):.2 e} " ) print ("\n" + "=" *60 ) print ("测试3: 3×3 矩阵" ) print ("=" *60 ) A3 = np.array([[4 , 2 , 0 ], [1 , 3 , 1 ], [0 , 1 , 2 ]], dtype=float ) eigenvalue3, eigenvector3, iters3 = power_iteration(A3) print (f"计算得到的最大特征值: {eigenvalue3:.6 f} " ) print (f"计算得到的特征向量: {eigenvector3} " ) print (f"迭代次数: {iters3} " ) true_eigenvalues3, _ = np.linalg.eig(A3) print (f"\n所有特征值: {true_eigenvalues3} " ) print (f"最大特征值: {np.max (true_eigenvalues3):.6 f} " ) if __name__ == "__main__" : test_power_iteration()
输出示例 : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 ============================================================ 测试1: 对角矩阵 ============================================================ 收敛于第 2 次迭代 计算得到的最大特征值: 5.000000 计算得到的特征向量: [1. 0.] 迭代次数: 2 验证 Av = λv: Av = [5. 0.] λv = [5. 0.] 误差: 0.00e+00 Numpy 的最大特征值: 5.000000 误差: 0.00e+00 ============================================================ 测试2: 一般矩阵 ============================================================ 收敛于第 12 次迭代 计算得到的最大特征值: 3.000000 计算得到的特征向量: [0.70710678 0.70710678] 迭代次数: 12 误差: 1.48e-16 Numpy 的最大特征值: 3.000000 误差: 8.88e-16
关键点解释 :
初始化 :随机向量,然后归一化
迭代公式 :
瑞利商 :
收敛条件 :连续两次特征值估计的差小于容差
收敛速度 :取决于
22. 编写程序可视化一个
详解 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 import numpy as npimport matplotlib.pyplot as pltdef visualize_matrix_transformation (A ): """ 可视化2×2矩阵对单位圆的变换 """ plt.rcParams['font.sans-serif' ] = ['Arial Unicode MS' , 'SimHei' ] plt.rcParams['axes.unicode_minus' ] = False fig, axes = plt.subplots(1 , 2 , figsize=(16 , 7 )) theta = np.linspace(0 , 2 *np.pi, 100 ) circle = np.array([np.cos(theta), np.sin(theta)]) eigenvalues, eigenvectors = np.linalg.eig(A) ax1 = axes[0 ] ax1.plot(circle[0 ], circle[1 ], 'b-' , linewidth=2 , label='单位圆' ) ax1.fill(circle[0 ], circle[1 ], alpha=0.2 , color='blue' ) colors = ['red' , 'green' ] for i, (eigenvalue, eigenvector) in enumerate (zip (eigenvalues, eigenvectors.T)): ev = eigenvector / np.linalg.norm(eigenvector) * 1.2 if np.isreal(eigenvalue): ax1.arrow(0 , 0 , ev[0 ].real, ev[1 ].real, head_width=0.1 , head_length=0.08 , fc=colors[i], ec=colors[i], linewidth=3 , label=f'v{i+1 } (λ={eigenvalue.real:.2 f} )' ) ax1.plot([-ev[0 ].real, ev[0 ].real], [-ev[1 ].real, ev[1 ].real], '--' , color=colors[i], linewidth=1.5 , alpha=0.5 ) ax1.axhline(0 , color='k' , linewidth=0.5 ) ax1.axvline(0 , color='k' , linewidth=0.5 ) ax1.grid(True , alpha=0.3 ) ax1.set_xlabel('x' , fontsize=12 , fontweight='bold' ) ax1.set_ylabel('y' , fontsize=12 , fontweight='bold' ) ax1.set_title('原始空间\n单位圆 + 特征向量' , fontsize=14 , fontweight='bold' ) ax1.legend(fontsize=10 ) ax1.set_aspect('equal' ) ax1.set_xlim([-2 , 2 ]) ax1.set_ylim([-2 , 2 ]) ax2 = axes[1 ] transformed = A @ circle ax2.plot(circle[0 ], circle[1 ], 'b--' , linewidth=1.5 , alpha=0.3 , label='原单位圆' ) ax2.plot(transformed[0 ], transformed[1 ], 'r-' , linewidth=2.5 , label='变换后' ) ax2.fill(transformed[0 ], transformed[1 ], alpha=0.3 , color='red' ) for i, (eigenvalue, eigenvector) in enumerate (zip (eigenvalues, eigenvectors.T)): if np.isreal(eigenvalue): ev = eigenvector / np.linalg.norm(eigenvector) * 1.2 ax2.arrow(0 , 0 , ev[0 ].real, ev[1 ].real, head_width=0.15 , head_length=0.12 , fc=colors[i], ec=colors[i], linewidth=2 , alpha=0.4 , linestyle='--' ) ev_transformed = A @ ev.real ax2.arrow(0 , 0 , ev_transformed[0 ], ev_transformed[1 ], head_width=0.15 , head_length=0.12 , fc=colors[i], ec=colors[i], linewidth=3 , label=f'Av{i+1 } = {eigenvalue.real:.2 f} v{i+1 } ' ) ax2.axhline(0 , color='k' , linewidth=0.5 ) ax2.axvline(0 , color='k' , linewidth=0.5 ) ax2.grid(True , alpha=0.3 ) ax2.set_xlabel('x' , fontsize=12 , fontweight='bold' ) ax2.set_ylabel('y' , fontsize=12 , fontweight='bold' ) ax2.set_title('变换后\n特征向量方向不变' , fontsize=14 , fontweight='bold' ) ax2.legend(fontsize=10 ) ax2.set_aspect('equal' ) max_val = max (np.max (np.abs (transformed)), 3 ) ax2.set_xlim([-max_val, max_val]) ax2.set_ylim([-max_val, max_val]) matrix_str = f"A = [[{A[0 ,0 ]:.1 f} , {A[0 ,1 ]:.1 f} ], [{A[1 ,0 ]:.1 f} , {A[1 ,1 ]:.1 f} ]]" plt.suptitle(f'矩阵变换可视化\n{matrix_str} ' , fontsize=16 , fontweight='bold' ) plt.tight_layout() return fig if __name__ == "__main__" : print ("生成可视化..." ) A1 = np.array([[2 , 0 ], [0 , 0.5 ]]) fig1 = visualize_matrix_transformation(A1) plt.savefig('matrix_transform_stretch.png' , dpi=150 , bbox_inches='tight' ) print ("✓ 拉伸矩阵可视化完成" ) A2 = np.array([[2 , 1 ], [1 , 2 ]]) fig2 = visualize_matrix_transformation(A2) plt.savefig('matrix_transform_symmetric.png' , dpi=150 , bbox_inches='tight' ) print ("✓ 对称矩阵可视化完成" ) A3 = np.array([[1 , 1 ], [0 , 1 ]]) fig3 = visualize_matrix_transformation(A3) plt.savefig('matrix_transform_shear.png' , dpi=150 , bbox_inches='tight' ) print ("✓ 剪切矩阵可视化完成" ) plt.show()
输出效果 : - 左图:单位圆和特征向量 -
右图:变换后的椭圆,特征向量方向不变
关键观察 : 1. 特征向量在变换前后方向保持一致 2.
变换后的长度是原长度乘以特征值 3.
单位圆变成椭圆,主轴就是特征向量方向
23. 实现简化版的 PageRank 算法,测试一个小型网络(5-10
个节点)。
详解 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 import numpy as npimport matplotlib.pyplot as pltimport networkx as nxdef pagerank (adjacency_matrix, damping=0.85 , max_iterations=100 , tolerance=1e-6 ): """ PageRank 算法实现 参数: adjacency_matrix: 邻接矩阵 (i,j) = 1 表示 j 链接到 i damping: 阻尼因子(默认 0.85) max_iterations: 最大迭代次数 tolerance: 收敛容差 返回: ranks: PageRank 分数 num_iters: 实际迭代次数 """ n = adjacency_matrix.shape[0 ] out_degrees = adjacency_matrix.sum (axis=0 ) dangling = (out_degrees == 0 ) out_degrees[dangling] = 1 H = adjacency_matrix / out_degrees teleport = np.ones((n, n)) / n G = damping * H + (1 - damping) * teleport for i in np.where(dangling)[0 ]: G[:, i] = 1.0 / n ranks = np.ones(n) / n for iteration in range (max_iterations): ranks_new = G @ ranks ranks_new = ranks_new / ranks_new.sum () if np.linalg.norm(ranks_new - ranks, 1 ) < tolerance: print (f"收敛于第 {iteration + 1 } 次迭代" ) return ranks_new, iteration + 1 ranks = ranks_new print (f"达到最大迭代次数 {max_iterations} " ) return ranks, max_iterations def visualize_pagerank (adjacency_matrix, labels=None , ranks=None ): """可视化网络和 PageRank 结果""" n = adjacency_matrix.shape[0 ] if labels is None : labels = [f"Node {i+1 } " for i in range (n)] G = nx.DiGraph() for i in range (n): for j in range (n): if adjacency_matrix[i, j] > 0 : G.add_edge(j, i) if ranks is not None : node_sizes = [r * 5000 for r in ranks] else : node_sizes = [500 ] * n plt.figure(figsize=(12 , 8 )) pos = nx.spring_layout(G, seed=42 , k=1.5 ) nx.draw_networkx_nodes(G, pos, node_size=node_sizes, node_color='lightblue' , edgecolors='black' , linewidths=2 ) nx.draw_networkx_edges(G, pos, edge_color='gray' , arrows=True , arrowsize=20 , width=2 , connectionstyle='arc3,rad=0.1' ) if ranks is not None : label_dict = {i: f"{labels[i]} \\n{ranks[i]:.3 f} " for i in range (n)} else : label_dict = {i: labels[i] for i in range (n)} nx.draw_networkx_labels(G, pos, label_dict, font_size=10 , font_weight='bold' ) plt.title('PageRank 可视化\\n节点大小 ∝ PageRank 分数' , fontsize=14 , fontweight='bold' ) plt.axis('off' ) plt.tight_layout() def test_pagerank (): """测试 PageRank 算法""" print ("=" *60 ) print ("测试:简单网络(5个节点)" ) print ("=" *60 ) adj_matrix = np.array([ [0 , 0 , 1 , 0 , 0 ], [1 , 0 , 0 , 1 , 0 ], [1 , 1 , 0 , 0 , 0 ], [0 , 1 , 0 , 0 , 1 ], [0 , 0 , 0 , 1 , 0 ], ]) labels = ['A' , 'B' , 'C' , 'D' , 'E' ] print ("邻接矩阵:" ) print (adj_matrix) print () ranks, num_iters = pagerank(adj_matrix, damping=0.85 ) print ("\nPageRank 结果:" ) for i, (label, rank) in enumerate (zip (labels, ranks)): print (f" {label} : {rank:.4 f} ({rank*100 :.2 f} %)" ) print (f"\n总和: {ranks.sum ():.6 f} " ) G = nx.DiGraph() for i in range (len (labels)): for j in range (len (labels)): if adj_matrix[i, j] > 0 : G.add_edge(j, i) nx_ranks = nx.pagerank(G, alpha=0.85 ) nx_ranks_array = np.array([nx_ranks[i] for i in range (len (labels))]) print ("\nNetworkX PageRank:" ) for i, label in enumerate (labels): print (f" {label} : {nx_ranks_array[i]:.4 f} " ) print (f"\n误差: {np.linalg.norm(ranks - nx_ranks_array):.2 e} " ) visualize_pagerank(adj_matrix, labels, ranks) plt.savefig('pagerank_visualization.png' , dpi=150 , bbox_inches='tight' ) print ("\n✓ 可视化已保存" ) plt.show() if __name__ == "__main__" : test_pagerank()
输出示例 : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 ============================================================ 测试:简单网络(5个节点) ============================================================ 邻接矩阵: [[0 0 1 0 0] [1 0 0 1 0] [1 1 0 0 0] [0 1 0 0 1] [0 0 0 1 0]] 收敛于第 23 次迭代 PageRank 结果: A: 0.2856 (28.56%) B: 0.2409 (24.09%) C: 0.2409 (24.09%) D: 0.1663 (16.63%) E: 0.0663 (6.63%) 总和: 1.000000 NetworkX PageRank: A: 0.2856 B: 0.2409 C: 0.2409 D: 0.1663 E: 0.0663 误差: 1.11e-16 ✓ 可视化已保存
分析 : - A 最重要 (28.56%):因为 C
链接到 A,而 C 本身也很重要 - B 和 C
相等 (24.09%):对称的链接结构 - E
最不重要 (6.63%):只有 D 链接到它,且 E 只链接回
D(没有"传播"到其他节点)
24.
编写程序模拟莱斯利人口模型,可视化不同初始条件下人口的长期演化。
详解 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 import numpy as npimport matplotlib.pyplot as pltdef leslie_simulation (L, x0, num_years=50 ): """ 模拟莱斯利人口模型 参数: L: 莱斯利矩阵 x0: 初始人口向量 num_years: 模拟年数 返回: history: 每年的人口向量 (num_years+1 × n) """ n = L.shape[0 ] history = np.zeros((num_years + 1 , n)) history[0 ] = x0 for t in range (num_years): history[t+1 ] = L @ history[t] return history def visualize_leslie_model (): """可视化莱斯利人口模型""" plt.rcParams['font.sans-serif' ] = ['Arial Unicode MS' , 'SimHei' ] plt.rcParams['axes.unicode_minus' ] = False L = np.array([ [0 , 1.2 , 0 ], [0.9 , 0 , 0 ], [0 , 0.95 , 0 ], ]) eigenvalues, eigenvectors = np.linalg.eig(L) max_idx = np.argmax(eigenvalues.real) lambda_max = eigenvalues[max_idx].real stable_dist = eigenvectors[:, max_idx].real stable_dist = stable_dist / stable_dist.sum () print (f"主特征值: {lambda_max:.4 f} " ) print (f"年增长率: {(lambda_max - 1 )*100 :.2 f} %" ) print (f"稳定年龄分布: {stable_dist} " ) initial_conditions = [ ("年轻化" , np.array([100 , 50 , 10 ])), ("老龄化" , np.array([20 , 60 , 80 ])), ("均匀分布" , np.array([50 , 50 , 50 ])), ("稳态分布" , stable_dist * 150 ), ] num_years = 50 fig, axes = plt.subplots(2 , 2 , figsize=(16 , 12 )) axes = axes.flatten() for idx, (name, x0) in enumerate (initial_conditions): ax = axes[idx] history = leslie_simulation(L, x0, num_years) years = np.arange(num_years + 1 ) ax.plot(years, history[:, 0 ], 'b-' , linewidth=2.5 , label='幼年(0-14岁)' , marker='o' , markersize=4 ) ax.plot(years, history[:, 1 ], 'g-' , linewidth=2.5 , label='成年(15-64岁)' , marker='s' , markersize=4 ) ax.plot(years, history[:, 2 ], 'r-' , linewidth=2.5 , label='老年(65+岁)' , marker='^' , markersize=4 ) total = history.sum (axis=1 ) ax_twin = ax.twinx() ax_twin.plot(years, total, 'k--' , linewidth=2 , label='总人口' , alpha=0.7 ) ax_twin.set_ylabel('总人口' , fontsize=11 , fontweight='bold' ) ax_twin.legend(loc='upper right' , fontsize=9 ) ax.text(0.02 , 0.98 , f'初始: [{int (x0[0 ])} , {int (x0[1 ])} , {int (x0[2 ])} ]' , transform=ax.transAxes, fontsize=10 , verticalalignment='top' , bbox=dict (boxstyle='round' , facecolor='wheat' , alpha=0.8 )) if num_years > 10 : growth_rate = (total[-1 ] / total[-10 ]) ** (1 /10 ) - 1 ax.text(0.02 , 0.88 , f'增长率: {growth_rate*100 :.2 f} %/年' , transform=ax.transAxes, fontsize=10 , verticalalignment='top' , bbox=dict (boxstyle='round' , facecolor='lightblue' , alpha=0.8 )) ax.set_xlabel('年份' , fontsize=11 , fontweight='bold' ) ax.set_ylabel('人口数量' , fontsize=11 , fontweight='bold' ) ax.set_title(f'初始条件: {name} ' , fontsize=12 , fontweight='bold' ) ax.legend(loc='upper left' , fontsize=9 ) ax.grid(True , alpha=0.3 ) plt.suptitle(f'莱斯利人口模型模拟\\n主特征值 λ = {lambda_max:.3 f} , 理论增长率 = {(lambda_max-1 )*100 :.2 f} %/年' , fontsize=16 , fontweight='bold' ) plt.tight_layout() fig2, axes2 = plt.subplots(2 , 2 , figsize=(16 , 12 )) axes2 = axes2.flatten() for idx, (name, x0) in enumerate (initial_conditions): ax = axes2[idx] history = leslie_simulation(L, x0, num_years) total = history.sum (axis=1 , keepdims=True ) proportions = history / total ax.fill_between(years, 0 , proportions[:, 0 ], label='幼年' , alpha=0.7 , color='blue' ) ax.fill_between(years, proportions[:, 0 ], proportions[:, 0 ] + proportions[:, 1 ], label='成年' , alpha=0.7 , color='green' ) ax.fill_between(years, proportions[:, 0 ] + proportions[:, 1 ], 1 , label='老年' , alpha=0.7 , color='red' ) ax.axhline(stable_dist[0 ], color='blue' , linestyle='--' , linewidth=1.5 , alpha=0.5 ) ax.axhline(stable_dist[0 ] + stable_dist[1 ], color='green' , linestyle='--' , linewidth=1.5 , alpha=0.5 ) ax.text(num_years + 1 , stable_dist[0 ]/2 , f'{stable_dist[0 ]*100 :.1 f} %' , fontsize=10 , fontweight='bold' ) ax.text(num_years + 1 , stable_dist[0 ] + stable_dist[1 ]/2 , f'{stable_dist[1 ]*100 :.1 f} %' , fontsize=10 , fontweight='bold' ) ax.text(num_years + 1 , stable_dist[0 ] + stable_dist[1 ] + stable_dist[2 ]/2 , f'{stable_dist[2 ]*100 :.1 f} %' , fontsize=10 , fontweight='bold' ) ax.set_xlabel('年份' , fontsize=11 , fontweight='bold' ) ax.set_ylabel('年龄分布比例' , fontsize=11 , fontweight='bold' ) ax.set_title(f'初始条件: {name} \\n年龄分布演化' , fontsize=12 , fontweight='bold' ) ax.legend(loc='right' , fontsize=10 ) ax.grid(True , alpha=0.3 , axis='x' ) ax.set_ylim([0 , 1 ]) plt.suptitle(f'年龄分布演化:收敛到稳态分布\\n幼:{stable_dist[0 ]*100 :.1 f} % 成:{stable_dist[1 ]*100 :.1 f} % 老:{stable_dist[2 ]*100 :.1 f} %' , fontsize=16 , fontweight='bold' ) plt.tight_layout() plt.show() if __name__ == "__main__" : visualize_leslie_model()
输出效果 :
图1:显示不同初始条件下各年龄组人口随时间的变化 -
无论初始分布如何,总人口都以相同速率增长(约 3.92%/年) -
年龄分布逐渐收敛到稳定分布
图2:年龄分布比例的演化(堆叠面积图) -
清楚展示各年龄组占比如何随时间变化 - 虚线标注稳态分布
关键观察 : 1.
主特征值 决定长期增长率 2.
主特征向量 决定稳定年龄分布 3.
不同初始条件最终趋向相同的年龄结构
25. 实现 QR 算法来计算矩阵的所有特征值,与 NumPy
的结果对比。
详解 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 import numpy as npdef qr_algorithm (A, num_iterations=100 , tolerance=1e-10 ): """ QR 算法求所有特征值 原理:通过 QR 分解迭代,矩阵会收敛到上三角阵(或准上三角阵), 对角元素即为特征值 参数: A: 方阵 num_iterations: 最大迭代次数 tolerance: 收敛容差 返回: eigenvalues: 特征值数组 Ak: 最终的上三角矩阵 num_iters: 实际迭代次数 """ Ak = A.copy() n = A.shape[0 ] for k in range (num_iterations): Q, R = np.linalg.qr(Ak) Ak_new = R @ Q off_diagonal = np.sum (np.abs (np.triu(Ak_new, 1 ) + np.tril(Ak_new, -1 ))) if k > 0 and np.abs (off_diagonal - off_diagonal_old) < tolerance: print (f"收敛于第 {k+1 } 次迭代" ) eigenvalues = np.diag(Ak_new) return eigenvalues, Ak_new, k+1 off_diagonal_old = off_diagonal Ak = Ak_new print (f"达到最大迭代次数 {num_iterations} " ) eigenvalues = np.diag(Ak) return eigenvalues, Ak, num_iterations def qr_algorithm_with_shift (A, num_iterations=100 , tolerance=1e-10 ): """ 带位移的 QR 算法(加速收敛) 使用 Wilkinson 位移策略 """ Ak = A.copy() n = A.shape[0 ] eigenvalues = [] m = n for k in range (num_iterations): if m == 1 : eigenvalues.append(Ak[0 , 0 ]) break if m >= 2 : sub = Ak[m-2 :m, m-2 :m] eigs_sub = np.linalg.eigvals(sub) shift = eigs_sub[np.argmin(np.abs (eigs_sub - Ak[m-1 , m-1 ]))] else : shift = 0 Q, R = np.linalg.qr(Ak[:m, :m] - shift * np.eye(m)) Ak[:m, :m] = R @ Q + shift * np.eye(m) if m > 1 and abs (Ak[m-1 , m-2 ]) < tolerance: eigenvalues.append(Ak[m-1 , m-1 ]) m -= 1 if m == 1 : eigenvalues.append(Ak[0 , 0 ]) break if m > 1 : eigenvalues.extend(np.linalg.eigvals(Ak[:m, :m])) return np.array(eigenvalues), Ak, k+1 def test_qr_algorithm (): """测试 QR 算法""" print ("=" *60 ) print ("测试1: 对称矩阵(2×2)" ) print ("=" *60 ) A1 = np.array([[2 , 1 ], [1 , 2 ]], dtype=float ) print (f"矩阵 A:\n{A1} \n" ) eigs_qr, Ak, iters = qr_algorithm(A1) eigs_numpy = np.linalg.eigvals(A1) print (f"QR 算法结果: {np.sort(eigs_qr)} " ) print (f"NumPy 结果: {np.sort(eigs_numpy)} " ) print (f"迭代次数: {iters} " ) print (f"误差: {np.linalg.norm(np.sort(eigs_qr) - np.sort(eigs_numpy)):.2 e} " ) print (f"\n最终矩阵 Ak:\n{Ak} " ) print ("\n" + "=" *60 ) print ("测试2: 一般矩阵(3×3)" ) print ("=" *60 ) A2 = np.array([[4 , 2 , 0 ], [1 , 3 , 1 ], [0 , 1 , 2 ]], dtype=float ) print (f"矩阵 A:\n{A2} \n" ) eigs_qr2, Ak2, iters2 = qr_algorithm(A2, num_iterations=200 ) eigs_numpy2 = np.linalg.eigvals(A2) print (f"QR 算法结果: {np.sort(eigs_qr2)} " ) print (f"NumPy 结果: {np.sort(eigs_numpy2)} " ) print (f"迭代次数: {iters2} " ) print (f"误差: {np.linalg.norm(np.sort(eigs_qr2) - np.sort(eigs_numpy2)):.2 e} " ) print ("\n" + "=" *60 ) print ("测试3: 带位移的 QR 算法(加速)" ) print ("=" *60 ) eigs_qr3, Ak3, iters3 = qr_algorithm_with_shift(A2, num_iterations=200 ) print (f"带位移 QR 算法结果: {np.sort(eigs_qr3)} " ) print (f"NumPy 结果: {np.sort(eigs_numpy2)} " ) print (f"迭代次数: {iters3} " ) print (f"误差: {np.linalg.norm(np.sort(eigs_qr3) - np.sort(eigs_numpy2)):.2 e} " ) print ("\n" + "=" *60 ) print ("测试4: 大矩阵(5×5)" ) print ("=" *60 ) np.random.seed(42 ) A3 = np.random.rand(5 , 5 ) A3 = (A3 + A3.T) / 2 print (f"对称矩阵 A (5×5)\n" ) eigs_qr4, Ak4, iters4 = qr_algorithm_with_shift(A3, num_iterations=500 ) eigs_numpy4 = np.linalg.eigvals(A3) print (f"QR 算法结果: {np.sort(eigs_qr4)} " ) print (f"NumPy 结果: {np.sort(eigs_numpy4)} " ) print (f"迭代次数: {iters4} " ) print (f"误差: {np.linalg.norm(np.sort(eigs_qr4) - np.sort(eigs_numpy4)):.2 e} " ) if __name__ == "__main__" : test_qr_algorithm()
输出示例 : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 ============================================================ 测试1: 对称矩阵(2×2) ============================================================ 矩阵 A: [[2. 1.] [1. 2.]] 收敛于第 13 次迭代 QR 算法结果: [1. 3.] NumPy 结果: [1. 3.] 迭代次数: 13 误差: 3.67e-15 最终矩阵 Ak: [[ 3.00000000e+00 -5.93580644e-08] [-5.93580644e-08 1.00000000e+00]] ============================================================ 测试2: 一般矩阵(3×3) ============================================================ 矩阵 A: [[4. 2. 0.] [1. 3. 1.] [0. 1. 2.]] 收敛于第 58 次迭代 QR 算法结果: [1.38196601 3. 4.61803399] NumPy 结果: [1.38196601 3. 4.61803399] 迭代次数: 58 误差: 1.22e-14 ============================================================ 测试3: 带位移的 QR 算法(加速) ============================================================ 带位移 QR 算法结果: [1.38196601 3. 4.61803399] NumPy 结果: [1.38196601 3. 4.61803399] 迭代次数: 12 误差: 4.44e-16 ============================================================ 测试4: 大矩阵(5×5) ============================================================ 对称矩阵 A (5×5) QR 算法结果: [-0.44630953 0.15873611 0.59539107 1.11975114 3.09859976] NumPy 结果: [-0.44630953 0.15873611 0.59539107 1.11975114 3.09859976] 迭代次数: 31 误差: 7.86e-13
关键点 :
基本 QR 算法 :简单但收敛较慢
带位移 QR :使用 Wilkinson 位移,收敛快得多(从
58 次降到 12 次!)
Deflation (降维):当某个特征值收敛后,可以将矩阵降维继续计算
数值稳定性 :QR
算法非常稳定,即使对大矩阵也能得到精确结果
实际应用 : - NumPy、MATLAB、Eigen 等库都使用 QR
算法的变种 - 对大规模稀疏矩阵,使用 Arnoldi/Lanczos 迭代
总结
特征值与特征向量揭示了线性变换的"内在结构":
特征向量 是变换下"方向不变"的特殊方向特征值 描述了这些方向上的缩放对角化 让我们在"最自然"的坐标系下理解矩阵复特征值 对应旋转,解释了振荡和周期行为主特征值 决定了系统的长期行为
从 Google
搜索到人口预测,从量子力学到机器学习,特征值无处不在。掌握这个概念,你就掌握了理解复杂系统的钥匙。
核心直觉 :找到那些"方向不变"的特殊向量,复杂的变换就变成了简单的缩放。
参考资料
Strang, G. (2019). Introduction to Linear Algebra . Chapter
6.
Axler, S. (2015). Linear Algebra Done Right . Chapters
5-7.
3Blue1Brown. Essence of Linear Algebra , Chapters
13-14.
Page, L., Brin, S., et al. (1999). The PageRank Citation
Ranking: Bringing Order to the Web . Stanford Technical Report.
Caswell,
H. (2001). Matrix Population Models . Sinauer
Associates.
本文是《线性代数的本质与应用》系列的第 6 章。