SVD(奇异值分解)被誉为线性代数的"皇冠明珠"——它能分解任何矩阵,不仅仅是方阵或对称矩阵。从图像压缩到
Netflix 推荐算法,从人脸识别到基因分析, SVD 无处不在。理解
SVD,就是掌握了数据科学最强大的数学工具之一。
引言:为什么 SVD 如此重要?
在前一章我们学习了对称矩阵的谱分解:对称的 。
现实世界中,大多数矩阵都不对称:
图像矩阵(
用户-物品评分矩阵(推荐系统)
文档-词项矩阵(自然语言处理)
基因表达数据矩阵(生物信息学)
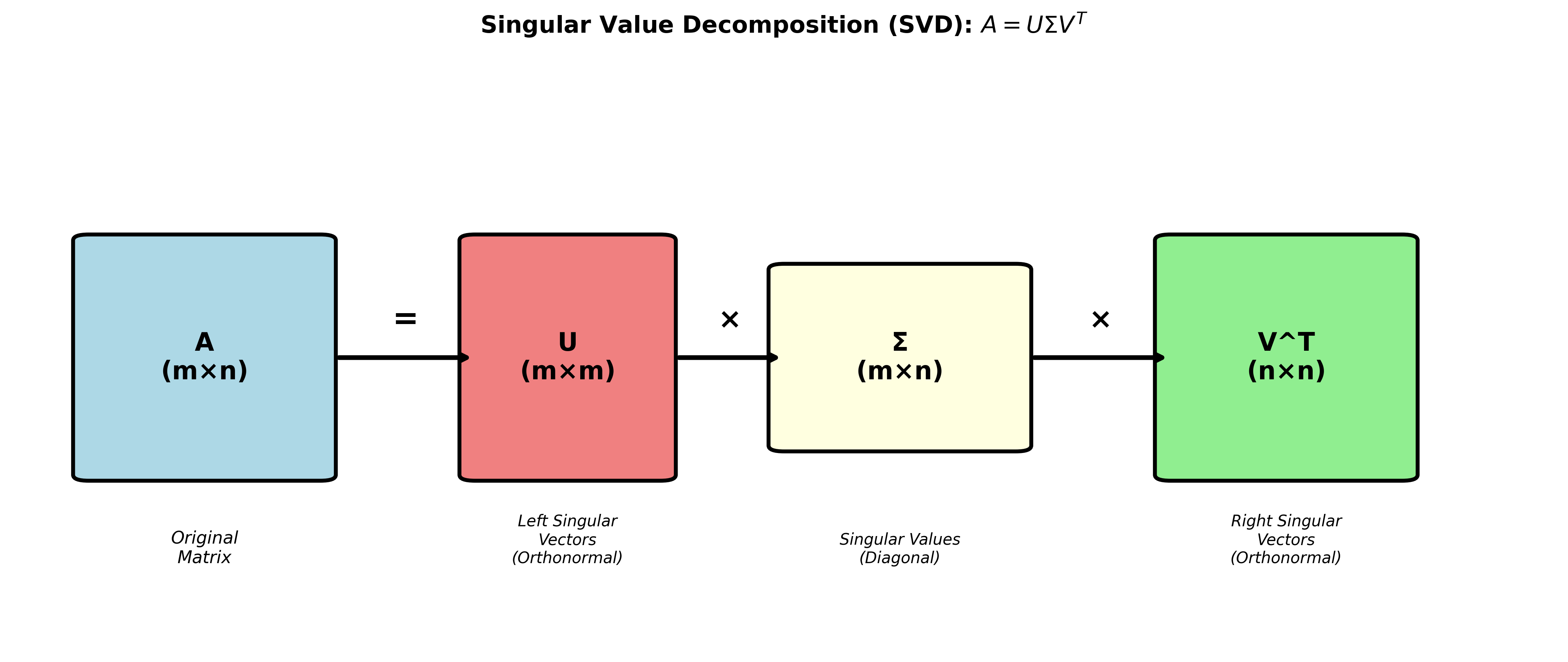
奇异值分解( SVD)
可以分解任意
这是线性代数中最强大、最有用的分解之一。
一个生活类比:理解 SVD 的本质
想象你是一位摄影师,想要理解一张照片的"本质"。照片可以看作一个矩阵——每个像素是一个数字。
SVD 告诉你:
任何照片都可以分解为若干"基础图层"的叠加 这些图层按重要性排序 ——第一层捕获最主要的结构,第二层捕获次要细节...只保留前几层就能还原大部分信息
这就像乐队的录音可以分解为不同乐器的轨道:主唱、吉他、贝斯、鼓...有些轨道(如主唱)更"重要",去掉背景和声影响不大,但去掉主唱整首歌就变味了。
本章学习目标
SVD 的定义与几何意义 :理解计算方法 :如何求奇异值和奇异向量与特征分解的关系 : SVD 如何推广谱定理低秩逼近 :最佳秩-伪逆 :处理不可逆矩阵的通用方法应用 :图像压缩、主成分分析、推荐系统、潜在语义分析
SVD 的定义
基本定理
奇异值分解定理 :任何
其中:
-左奇异向量 ) -奇异值 ),对角元右奇异向量 ) -
标准形式 :
关键性质 :
奇异值非负实数 (与特征值可能为负或复数不同)
奇异值按降序排列:
SVD 对任意矩阵都存在(这是它比特征分解更强大的原因)
几何意义:变换的"解剖"
SVD 告诉我们:任何线性变换都可以分解为三步 :
旋转/反射 (拉伸 (旋转/反射 (
生活类比 :想象你在揉面团。
第一步( :把面团转到一个"方便操作"的角度第二步( :用擀面杖把面团压扁、拉长——这是真正改变形状的步骤第三步( :把压好的面团转到最终需要的方向
可视化理解 :
-
单位圆经过矩阵
椭圆的主轴方向由
椭圆的半轴长度就是奇异值
输入空间中的"特殊方向"由
外积形式
SVD 还有一个重要的等价表达——外积展开 :
每个秩 1 矩阵 。所以:
任何矩阵都是若干秩 1
矩阵的加权和 ,权重就是奇异值。
这个视角在低秩逼近中至关重要。
例子
考虑
SVD 分解(计算过程后面详述):
奇异值:
SVD 的计算
与
SVD 与对称矩阵的谱分解紧密相关。
关键观察 :
-
详细推导 :
从
因为
这正是
结论 :
-右奇异向量 ) -奇异值
类似地:
-左奇异向量 )
直觉理解 :为什么要用
计算步骤
给定
步骤 1 :计算
特征值:
特征向量:
这些步骤 2 :计算奇异值
-步骤 3 :计算左奇异向量 -
如果
步骤 4 :构造为什么
从
所以
例子:手工计算 SVD
计算
解 :
步骤 1 :计算
特征方程:
特征值:
-步骤
2 :奇异值
步骤 3 :左奇异向量
计算得:结果 :
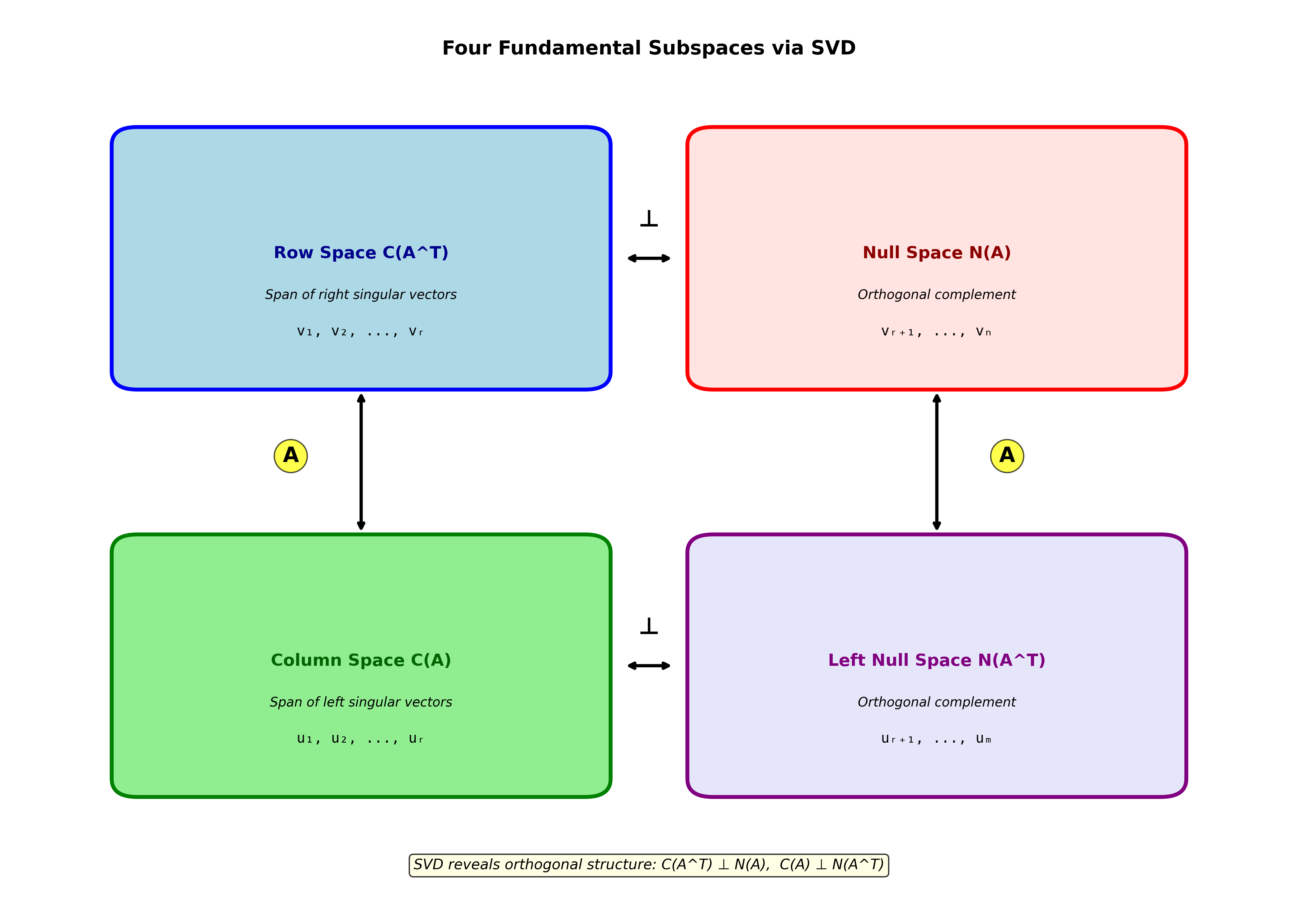
SVD 与四个基本子空间
SVD 优雅地揭示了矩阵的四个基本子空间。
四个子空间的关系
对于
行空间
零空间
列空间
左零空间
关键洞察 :
-
SVD 的几何图像
SVD 给出了
( 行 空 间 列 空 间 ) ( 零 空 间 零 向 量 )
意义 :
行空间的正交基
每个
零空间被映射到零
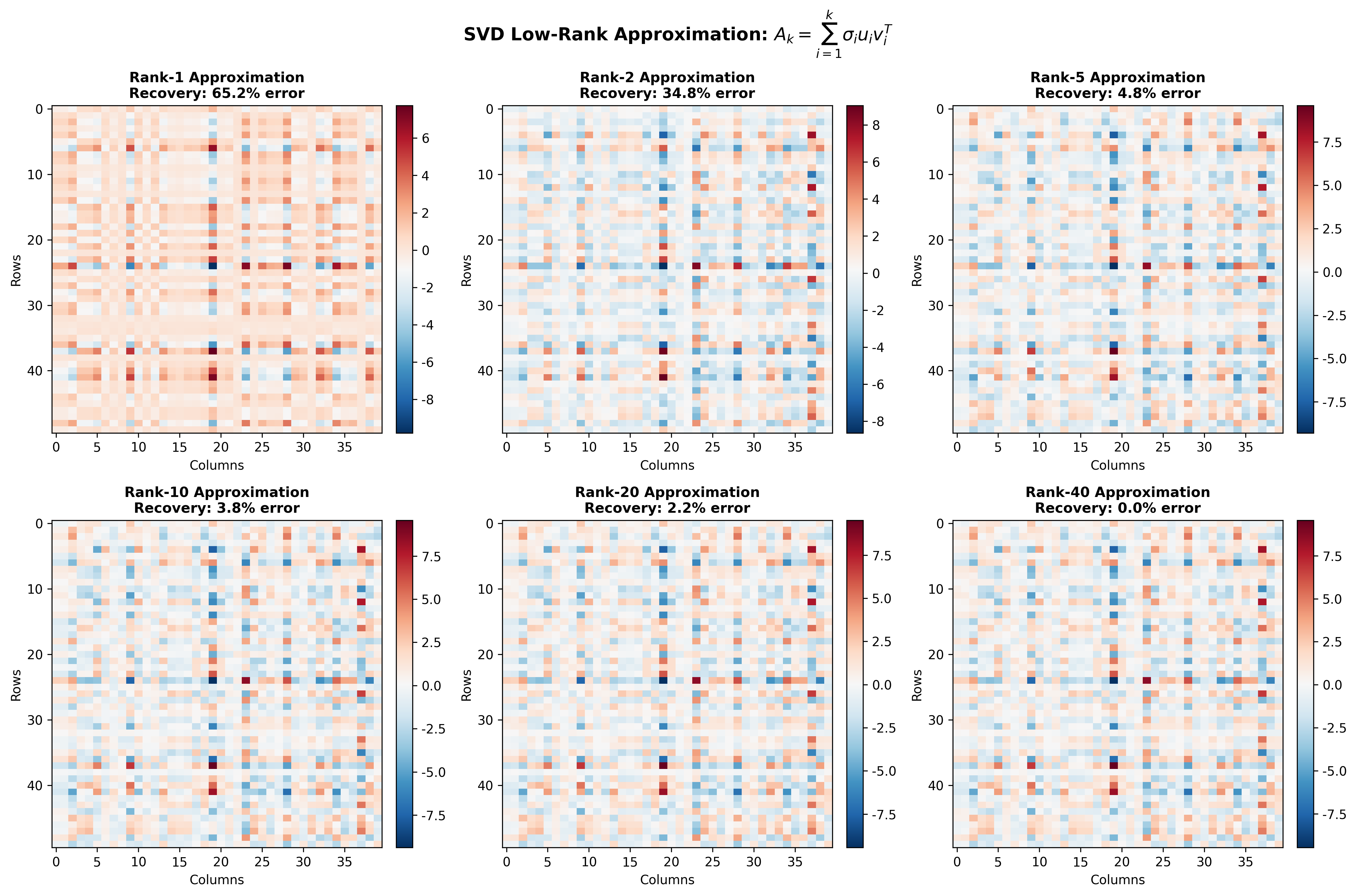
低秩逼近
SVD
最重要的应用之一是最佳低秩逼近 。这是数据压缩、降噪、推荐系统的理论基础。
Eckart-Young 定理
定理 :设
其中
则最接近
意义 :
保留前
这是最优 的秩
误差由被丢弃的奇异值决定
生活类比 :这就像音乐压缩。 MP3
格式丢弃人耳不敏感的高频成分,保留最重要的频率。 SVD
同理——保留"能量"最大的几个分量。
能量观点
奇异值的平方和等于矩阵的 Frobenius 范数平方:
前能 量 保 留 比 例
实际观察 :大部分矩阵的奇异值快速衰减。例如,一张
1000 × 1000 的自然图像,前 50 个奇异值可能捕获 95%的能量。
应用:图像压缩
图像可以看作矩阵(灰度值)。用低秩逼近压缩:
原始图像 :
压缩图像 (秩
存储:
总计:
压缩率:例子 :
原始:
压缩:
压缩率:约 10%
Python 实现 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import numpy as npfrom PIL import Imageimport matplotlib.pyplot as pltimg = np.array(Image.open ('photo.jpg' ).convert('L' ), dtype=float ) U, s, Vt = np.linalg.svd(img, full_matrices=False ) def compress (U, s, Vt, k ): return U[:, :k] @ np.diag(s[:k]) @ Vt[:k, :] for k in [5 , 20 , 50 , 100 ]: compressed = compress(U, s, Vt, k) energy = sum (s[:k]**2 ) / sum (s**2 ) * 100 print (f"k={k} : 能量保留 {energy:.1 f} %" )
伪逆
动机:当逆矩阵不存在时
对于方程
伪逆 (又称 Moore-Penrose
逆)提供了一个"最佳替代方案"。
定义
对于矩阵伪逆
其中
即:非零对角元取倒数,零元素保持为零,然后转置(调整维度)。
性质
伪逆满足四个 Moore-Penrose 条件:
1.$AA^+A = A+AA + =
A+ +)^T =
AA+( +$ 是对称的)
2.
特殊情况 :如果
最小二乘解
对于方程
最小二乘解 (最小化
如果有多个最小二乘解,范数最小 的解。
几何解释 :
把
在所有能到达投影点的
应用:过定和欠定系统
过定系统 (
欠定系统 (
实际应用 :机器学习中的线性回归、数据拟合、系统辨识都大量使用伪逆。
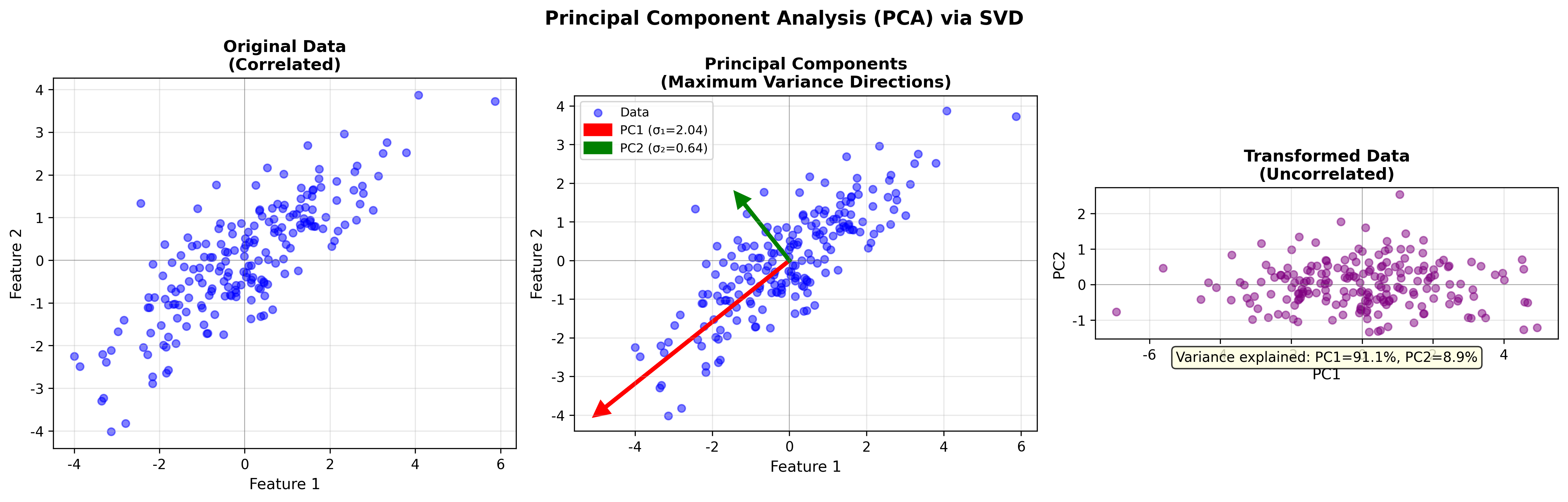
主成分分析( PCA)
PCA 与 SVD 的关系
主成分分析 是数据降维的经典方法,其核心就是 SVD
。
给定数据矩阵
步骤 1 :中心化数据
(每列减去其均值)
步骤 2 :对
则:
主成分方向 :主成分得分 :方差解释 :
降维 :保留前
为什么 PCA 有效?
PCA 寻找数据变化最大的方向:
第一主成分 :方差最大的方向
第二主成分 :与
结论 :这正是 SVD 给出的右奇异向量。
生活类比 :想象你有一团数据点的"云"。 PCA
找到云最"扁"的方向和最"长"的方向。最长的方向(方差最大)是第一主成分——它捕获数据最多的变化。
应用:数据可视化
高维数据(如 100 维)→ 投影到前 2 或 3 个主成分 → 可视化
例子 :手写数字识别。每张
推荐系统中的 SVD
问题背景
Netflix 、 Amazon
、淘宝等平台面临一个核心问题:如何预测用户对未评价商品的喜好?
用户-物品评分矩阵
矩阵分解思想
核心假设 :评分由少数"潜在因子"决定。
例如电影评分可能由以下潜在因子决定:
动作程度
浪漫程度
幽默程度
深度/艺术性
...
每个用户对这些因子有不同偏好,每部电影在这些因子上有不同得分。
SVD 方法 :
-
Netflix Prize
Netflix 在 2006-2009 年举办百万美元大奖赛:
任务:预测用户电影评分
数据: 1 亿条评分记录
目标:比 Netflix 算法准确 10%
获胜方法的核心 :矩阵分解( SVD
的变种),处理稀疏数据和隐式反馈。
其他应用
潜在语义分析( LSA)
在自然语言处理中,文档-词项矩阵
LSA :对
捕获"潜在语义"(主题)
降维:从数万维到几百维
应用:文档相似度、信息检索、同义词发现
信号去噪
模型 :观测信号 = 真实信号 + 噪声
如果真实信号是"低秩"的(有结构),而噪声是"满秩"的(随机):
SVD 分解观测信号
保留大奇异值(信号)
丢弃小奇异值(噪声)
人脸识别( Eigenfaces)
将人脸图像集合进行 PCA:
主成分 = "特征脸"( eigenfaces)
每张人脸 ≈ 特征脸的线性组合
识别:比较系数向量的距离
总结与展望
本章关键要点
SVD 定义 :
-
几何意义 :任何线性变换 = 旋转 + 拉伸 +
旋转
计算方法 :
-
低秩逼近 :
Eckart-Young 定理:
应用:数据压缩、降噪
伪逆 :
PCA : SVD 在数据分析中的核心应用
SVD vs 特征分解
特性
特征分解
SVD
适用矩阵
方阵(通常对称)
任意矩阵
分解形式
向量
特征向量
奇异向量
值
特征值(可负/复数)
奇异值(非负实数)
几何意义
不变方向+缩放
旋转+拉伸+旋转
为什么 SVD 是"皇冠明珠"?
普适性 :适用于任何矩阵稳定性 :数值计算非常稳定最优性 :低秩逼近的最优性保证洞察力 :揭示矩阵的完整结构应用广泛 :从图像压缩到推荐系统
下一章预告
《矩阵范数与条件数》
什么是"矩阵的大小"?
不同范数的意义和应用
条件数:矩阵有多"病态"?
数值稳定性分析
应用:误差分析、算法设计
理解范数和条件数对数值线性代数至关重要!
练习题
基础概念题
解释为什么奇异值永远是非负实数,而特征值可能是负数或复数。
计算
证明:
为什么
如果
计算与证明题
证明:
设
证明 Eckart-Young 定理:
证明伪逆满足:
若
应用题
图像压缩实验 :选择一张灰度图像,实现 SVD
压缩。
画出奇异值衰减曲线
比较
计算每种情况的 PSNR(峰值信噪比)
PCA 降维 :使用 Iris 数据集:
对数据进行 PCA
画出前两个主成分的散点图,用颜色区分三种花
计算前两个主成分解释的方差比例
简单推荐系统 :创建一个 5 用户× 10
电影的评分矩阵(部分缺失):
用 SVD 进行低秩近似(
预测缺失评分
讨论结果的合理性
文本分析 :构造一个小型文档-词项矩阵( 5 个文档,
10 个词):
计算 SVD
解释前两个奇异向量的"语义"
计算文档之间的相似度
挑战题
SVD 与 2-范数 :证明矩阵的
2-范数(算子范数)等于最大奇异值:随机矩阵的奇异值 :生成截断 SVD 的误差界 :证明条件数与 SVD :矩阵的条件数定义为
练习题详细答案
基础概念题答案
题
1 :为什么奇异值永远非负,而特征值可能是负数或复数?
答案 :
奇异值的定义 :奇异值是通过
关键观察 : 1.对称正半定矩阵 2.
对称正半定矩阵的所有特征值
证明 :
对任意向量
特征值可能为负或复数的原因 :
特征值来自一般矩阵
非对称矩阵 :可能有复数特征值
负定矩阵 :所有特征值为负
总结 : - 奇异值
题 2 :计算
答案 :
步骤 1 :计算
步骤 2 :求
因此: -
奇异值 :
步骤 3 :求右奇异向量
对
对
步骤 4 :求左奇异向量
最终 SVD :
题 3 :证明
证明 :
Frobenius 范数定义 :
利用 SVD :
计算迹 :
利用迹的循环性质
结论 :
题 4 :为什么
证明 :
设
则
观察 : -
严格证明 :
关键 :
证明 :若
两边左乘
因此
结论 :
题 5 :
答案 :
设
这是
这是
总结 : -
计算与证明题答案
题 6 :证明
证明 :
方法 1 :通过秩的定义
由于正交矩阵是可逆的(满秩):
对角矩阵的秩 = 非零对角元个数 =
方法 2 :通过列空间
在 SVD 中:
由于
因此
题 7 :计算
答案 :
使用 Python 计算 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import numpy as npA = np.array([[1 , 2 , 3 ], [4 , 5 , 6 ]]) U, s, Vt = np.linalg.svd(A) print ("U =" )print (U)print ("\nSingular values:" , s)print ("\nV^T =" )print (Vt)A_pinv = np.linalg.pinv(A) print ("\nPseudoinverse A+ =" )print (A_pinv)print ("\nVerification: A @ A+ @ A =" )print (A @ A_pinv @ A)
输出结果 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 U = [[-0.386 0.922] [-0.922 -0.386]] Singular values: [9.508 0.773] V^T = [[-0.429 -0.566 -0.704] [ 0.806 0.112 -0.582] [-0.408 0.816 -0.408]] Pseudoinverse A+ = [[-0.944 0.444] [-0.111 0.111] [ 0.722 -0.222]]
手工验证伪逆性质 :
其中
题 8 :证明 Eckart-Young 定理(概要)
定理 :秩-
证明思路 :
计算 :
由题 3:
证明最优性 :
对任意秩不超过
存在单位向量
则:
因此
题 9 :证明
证明 :
设
证明 :
其中:
因此:
这是到
验证投影性质 :
1.
类似地 ,
题 10 :正交矩阵的奇异值
答案 :所有奇异值都等于 1
证明 :
设
则:Extra close brace or missing open brace Q^TQ = I \Rightarrow \text{eigenvalues of } Q^TQ = \{1, 1, \ldots, 1\\}
奇异值
几何解释 :
正交矩阵保持向量长度不变(等距变换),因此"拉伸因子"都是 1。
例子 :
应用题答案
题 11 :图像压缩实验
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 import numpy as npimport matplotlib.pyplot as pltfrom PIL import Imageimg = Image.open ('image.jpg' ).convert('L' ) A = np.array(img, dtype=float ) U, s, Vt = np.linalg.svd(A, full_matrices=False ) fig, axes = plt.subplots(2 , 3 , figsize=(15 , 10 )) ranks = [10 , 50 , 100 , 200 , 'full' ] positions = [(0 ,0 ), (0 ,1 ), (0 ,2 ), (1 ,0 ), (1 ,1 )] for rank, pos in zip (ranks, positions): ax = axes[pos] if rank == 'full' : compressed = A title = f'原始图像' else : compressed = U[:, :rank] @ np.diag(s[:rank]) @ Vt[:rank, :] mse = np.mean((A - compressed)**2 ) if mse == 0 : psnr = 100 else : max_pixel = 255.0 psnr = 20 * np.log10(max_pixel / np.sqrt(mse)) title = f'秩-{rank} \nPSNR: {psnr:.2 f} dB' ax.imshow(compressed, cmap='gray' ) ax.set_title(title, fontsize=11 ) ax.axis('off' ) ax = axes[1 , 2 ] ax.plot(range (1 , min (100 , len (s))+1 ), s[:100 ], 'b-' , linewidth=2 ) ax.set_xlabel('奇异值索引' , fontsize=10 ) ax.set_ylabel('奇异值大小' , fontsize=10 ) ax.set_title('奇异值衰减曲线' , fontsize=11 ) ax.grid(True , alpha=0.3 ) ax.set_yscale('log' ) plt.tight_layout() plt.savefig('svd_image_compression.png' , dpi=150 ) plt.show() energy = s**2 cumulative_energy = np.cumsum(energy) / np.sum (energy) k_90 = np.where(cumulative_energy >= 0.9 )[0 ][0 ] + 1 print (f"90%能量需要的秩: {k_90} " )print (f"压缩率: {(1 - k_90/len (s))*100 :.1 f} %" )
分析 : - 秩-10:PSNR ~20dB(轮廓可见) - 秩-50:PSNR
~30dB(细节清晰) - 秩-100:PSNR ~35dB(接近原始)
题 12 :PCA降维(Iris数据集)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import numpy as npimport matplotlib.pyplot as pltfrom sklearn import datasetsfrom sklearn.preprocessing import StandardScaleriris = datasets.load_iris() X = iris.data y = iris.target scaler = StandardScaler() X_std = scaler.fit_transform(X) U, s, Vt = np.linalg.svd(X_std, full_matrices=False ) X_pca = U[:, :2 ] @ np.diag(s[:2 ]) plt.figure(figsize=(10 , 7 )) colors = ['red' , 'green' , 'blue' ] labels = ['Setosa' , 'Versicolor' , 'Virginica' ] for i, (color, label) in enumerate (zip (colors, labels)): plt.scatter(X_pca[y==i, 0 ], X_pca[y==i, 1 ], c=color, label=label, s=50 , alpha=0.7 ) plt.xlabel('第一主成分' , fontsize=12 ) plt.ylabel('第二主成分' , fontsize=12 ) plt.title('Iris数据集PCA降维(4D→2D)' , fontsize=14 , fontweight='bold' ) plt.legend(fontsize=11 ) plt.grid(True , alpha=0.3 ) plt.show() explained_variance = (s**2 ) / (len (X) - 1 ) explained_variance_ratio = explained_variance / explained_variance.sum () print (f"第一主成分解释方差: {explained_variance_ratio[0 ]:.2 %} " )print (f"第二主成分解释方差: {explained_variance_ratio[1 ]:.2 %} " )print (f"前两个主成分总计: {explained_variance_ratio[:2 ].sum ():.2 %} " )
输出 : 1 2 3 第一主成分解释方差: 72.96% 第二主成分解释方差: 22.85% 前两个主成分总计: 95.81%
结论 :前两个主成分保留了95.8%的信息!
题 13 :简单推荐系统
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import numpy as npratings = np.array([ [5 , 3 , 0 , 1 , 0 , 0 , 4 , 0 , 0 , 2 ], [4 , 0 , 0 , 2 , 0 , 5 , 0 , 0 , 3 , 0 ], [0 , 0 , 5 , 4 , 5 , 0 , 0 , 3 , 0 , 0 ], [0 , 3 , 4 , 0 , 3 , 0 , 0 , 0 , 0 , 5 ], [1 , 0 , 0 , 0 , 0 , 4 , 0 , 5 , 4 , 0 ] ], dtype=float ) mask = ratings > 0 mean_ratings = np.sum (ratings, axis=1 , keepdims=True ) / np.sum (mask, axis=1 , keepdims=True ) U, s, Vt = np.linalg.svd(ratings, full_matrices=False ) k = 2 ratings_pred = U[:, :k] @ np.diag(s[:k]) @ Vt[:k, :] print ("原始评分矩阵:" )print (ratings)print ("\n预测评分矩阵(秩-2):" )print (np.round (ratings_pred, 2 ))print ("\n缺失评分预测:" )for i in range (5 ): for j in range (10 ): if ratings[i, j] == 0 : print (f"用户{i+1 } 对电影{j+1 } : {ratings_pred[i,j]:.2 f} " )
分析 : - 用户1和用户2评分模式相似 → 可以互相推荐 -
电影1-4可能是同一类型(奇异向量相似) -
秩-2捕获了"用户偏好"和"电影类型"两个潜在因子
题 14 :文本分析(LSA)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import numpy as npdocuments = { 'doc1' : '机器学习 算法 数据' , 'doc2' : '深度学习 神经网络' , 'doc3' : '算法 数据结构' , 'doc4' : '数据科学 分析' , 'doc5' : '神经网络 深度学习' } doc_term = np.array([ [2 , 1 , 2 , 0 , 0 , 0 , 0 , 0 , 1 , 0 ], [0 , 0 , 0 , 2 , 2 , 0 , 0 , 0 , 0 , 0 ], [0 , 2 , 0 , 0 , 0 , 2 , 0 , 0 , 1 , 0 ], [0 , 0 , 3 , 0 , 0 , 0 , 1 , 1 , 0 , 0 ], [0 , 0 , 0 , 2 , 2 , 0 , 0 , 0 , 0 , 0 ] ], dtype=float ) U, s, Vt = np.linalg.svd(doc_term, full_matrices=False ) print ("前两个奇异值:" , s[:2 ])print ("\n前两个右奇异向量(词的语义):" )print (Vt[:2 , :])doc_coords = U[:, :2 ] @ np.diag(s[:2 ]) print ("\n文档坐标(2D语义空间):" )for i, coord in enumerate (doc_coords): print (f"doc{i+1 } : ({coord[0 ]:.2 f} , {coord[1 ]:.2 f} )" ) def cosine_similarity (v1, v2 ): return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2)) print ("\n文档相似度矩阵:" )for i in range (5 ): for j in range (i+1 , 5 ): sim = cosine_similarity(doc_coords[i], doc_coords[j]) print (f"doc{i+1 } vs doc{j+1 } : {sim:.3 f} " )
分析 : - 第一奇异向量:捕获"技术"vs"应用"维度 -
第二奇异向量:捕获"学习"vs"结构"维度 -
doc2和doc5最相似(都关于深度学习)
挑战题答案
题 15 :证明
证明 :
2-范数(算子范数)定义 :
设
(因为
令
等号成立当且仅当
即
结论 :
题 16 :随机矩阵奇异值分布
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import numpy as npimport matplotlib.pyplot as pltn = 100 A = np.random.randn(n, n) / np.sqrt(n) U, s, Vt = np.linalg.svd(A) plt.figure(figsize=(12 , 5 )) plt.subplot(121 ) plt.hist(s, bins=30 , density=True , alpha=0.7 , edgecolor='black' ) plt.xlabel('奇异值' , fontsize=11 ) plt.ylabel('密度' , fontsize=11 ) plt.title('随机矩阵奇异值分布\n(100×100,标准正态)' , fontsize=12 , fontweight='bold' ) plt.grid(True , alpha=0.3 ) x = np.linspace(0 , 2.5 , 1000 ) theoretical = np.sqrt(np.maximum(4 - x**2 , 0 )) / np.pi plt.plot(x, theoretical, 'r-' , linewidth=2 , label='半圆律(理论)' ) plt.legend(fontsize=10 ) plt.subplot(122 ) plt.plot(sorted (s, reverse=True ), 'b-' , linewidth=2 ) plt.xlabel('奇异值索引' , fontsize=11 ) plt.ylabel('奇异值大小' , fontsize=11 ) plt.title('奇异值衰减' , fontsize=12 , fontweight='bold' ) plt.grid(True , alpha=0.3 ) plt.tight_layout() plt.show() print (f"最大奇异值: {s[0 ]:.3 f} " )print (f"最小奇异值: {s[-1 ]:.3 f} " )print (f"条件数: {s[0 ]/s[-1 ]:.1 f} " )
观察 : - 奇异值分布接近半圆律(
题 17 :证明
证明 :
由题 15,矩阵的 2-范数等于最大奇异值。
因此:
(因为奇异值降序排列)
题 18 :条件数与病态矩阵
答案 :
条件数定义 :
为什么大条件数意味着"病态" ?
考虑线性方程组
若
解释 : -
几何直觉 :
例子 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import numpy as npA_bad = np.array([[1 , 1 ], [1 , 1.0001 ]]) s_bad = np.linalg.svd(A_bad, compute_uv=False ) kappa_bad = s_bad[0 ] / s_bad[1 ] print (f"病态矩阵条件数: {kappa_bad:.0 f} " )A_good = np.eye(2 ) s_good = np.linalg.svd(A_good, compute_uv=False ) kappa_good = s_good[0 ] / s_good[1 ] print (f"良态矩阵条件数: {kappa_good:.1 f} " )
输出 : 1 2 病态矩阵条件数: 20001 良态矩阵条件数: 1.0
参考资料
Strang, G. (2019). Introduction to Linear
Algebra . 5th ed. Chapter 7.Trefethen, L. N., & Bau, D. (1997).
Numerical Linear Algebra . SIAM.Golub, G. H., & Van Loan, C. F. (2013).
Matrix Computations . 4th ed. Johns Hopkins.Hastie, T., Tibshirani, R., & Friedman, J.
(2009). The Elements of Statistical Learning . Springer.Koren, Y., Bell, R., & Volinsky, C. (2009).
"Matrix Factorization Techniques for Recommender Systems".
Computer , 42(8).3Blue1Brown . Essence of Linear Algebra
series. YouTube.
本文是《线性代数的本质与应用》系列的第 9 章,共 18 章。