1947 年, George Dantzig 在美国空军工作时提出了线性规划的单纯形法,这一突破性工作标志着现代优化理论的诞生。七十多年后,优化理论已经成为机器学习的理论支柱——几乎所有的学习算法都可以表述为优化问题。而在众多优化问题中,凸优化问题具有独特的地位:局部最优解就是全局最优解,且有高效的算法保证收敛。
为什么神经网络训练可以找到好的解,即使损失函数是非凸的?为什么梯度下降在某些情况下能够快速收敛?这些问题的答案都深深植根于凸优化理论的数学结构中。本章从凸集和凸函数的定义出发,严格推导凸优化的核心理论和算法。
凸集与凸函数
凸集的定义与性质
定义 1(凸集):集合
这个定义说明:连接凸集中任意两点的线段完全包含在该集合内。几何上,凸集没有"凹陷"。
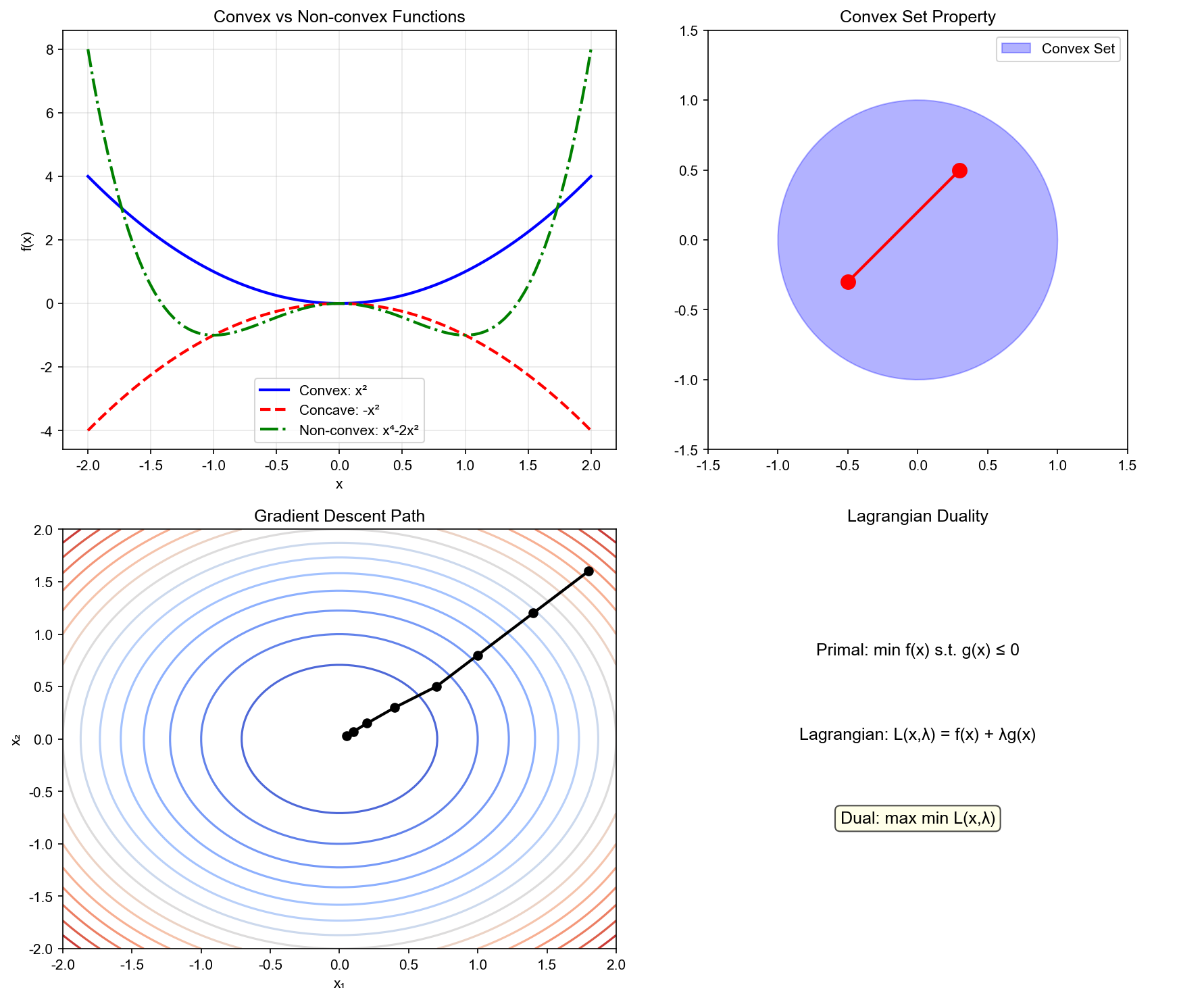
下图展示了凸优化的核心概念:凸函数与非凸函数的几何差异、梯度下降在凸函数上的收敛轨迹,以及 KKT 条件在约束优化中的应用。这些理论工具确保了优化算法的可靠性:
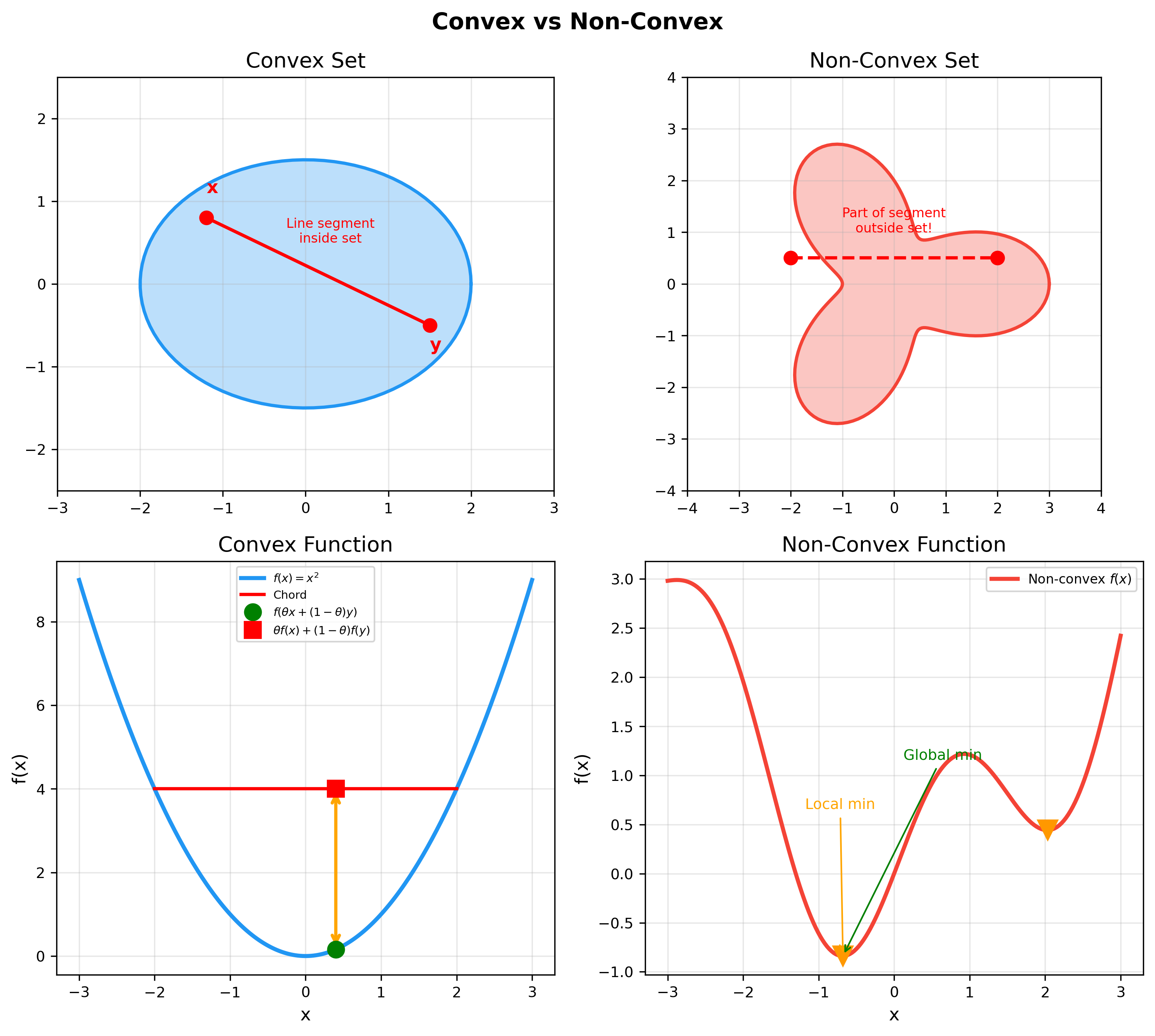
下图进一步对比了凸集与非凸集、凸函数与非凸函数的本质区别——凸性保证局部最优就是全局最优,这是凸优化在机器学习中不可替代的核心价值:
例 1(常见的凸集):
- 超平面:
,其中 - 半空间:
- 范数球:
,对于任意范数 - 椭球:
,其中 (正定矩阵)
证明超平面是凸集:设
因此
定理 1(凸集的交集仍是凸集):设
证明:设
因此
这个性质非常重要:它意味着我们可以通过有限个线性约束(半空间的交集)来描述复杂的凸集。
凸函数的定义与判别
定义 2(凸函数):函数
几何解释:函数图像上任意两点之间的线段位于函数图像的上方。
定义 3(严格凸函数):如果对于任意
定义 4(强凸函数):函数
强凸性是比凸性更强的条件,它保证函数有"严格的二次增长"。
定理 2(一阶条件):可微函数
这说明:凸函数的一阶泰勒展开是函数的全局下界(切线总在函数图像下方)。
证明(充分性):假设一阶条件成立。对于任意
将第一个不等式乘以
证明(必要性):假设
移项并除以
令
定理 3(二阶条件):二阶可微函数
如果
证明思路:利用泰勒展开。对于凸函数,二阶泰勒余项必须非负:
由一阶条件,
对所有
例 2(常见的凸函数):
仿射函数:
(既凸又凹) 指数函数:
幂函数:
,当 或 ( ) 负熵:
( ) 范数:
,对于任意范数
Jensen 不等式:凸函数的核心性质
定理 4(Jensen 不等式):设
如果
证明(离散情况):设
:这就是凸函数的定义 - 假设对
成立。对于 个点:
Jensen 不等式是信息论、统计学和机器学习中许多不等式的基础。例如,它直接导出了 KL 散度的非负性。
次梯度与非光滑优化
次梯度的定义
凸函数可能不可微(如
定义 5(次梯度):向量
次梯度的几何意义:它定义了一个过点
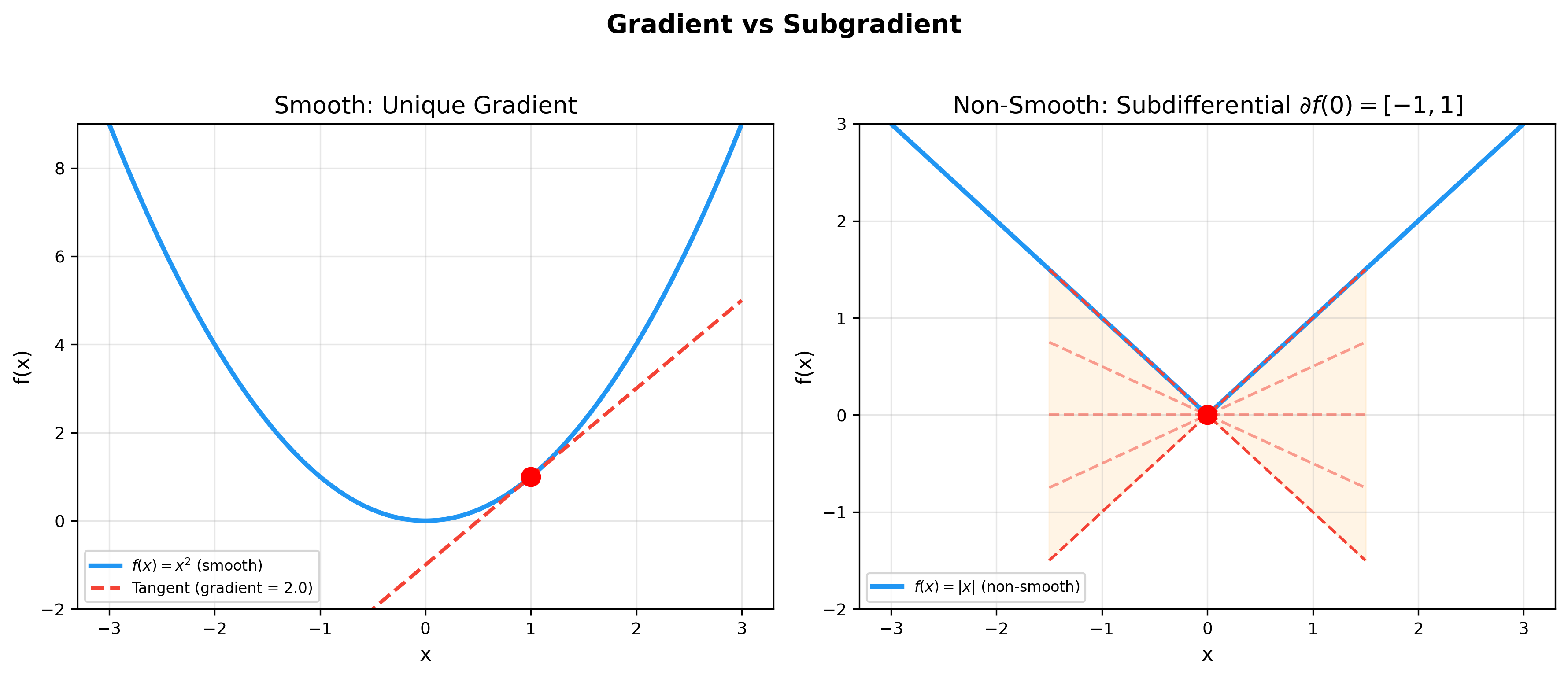
下图对比了光滑函数的梯度与非光滑函数的次梯度——在不可微点处,次梯度集合是一个区间,这使得非光滑优化成为可能:
定义 6(次微分):点
定理 5(次微分的性质):
- 如果
在 处可微,则 (单点集) 2. 是闭凸集 3. 是最优解当且仅当
证明性质 3: - 充分性:如果
例 3(计算次微分):
绝对值函数
: L1 范数
: 指示函数
( 为凸集):
这称为$C
次梯度法
对于不可微的凸函数,可以用次梯度替代梯度进行优化。
算法 1(次梯度下降): 1
2
3
4
5初始化: x^(0)
for k = 0, 1, 2, ... do
选择 g^(k) ∈ ∂ f(x^(k))
x^(k+1) = x^(k) - α_k g^(k)
end for
其中
定理 6(次梯度法收敛性):假设
则
常见的步长选择包括
证明思路:定义
展开并取期望,可以建立递推关系,最终得出
一阶优化算法
梯度下降法
梯度下降是最基础的优化算法,它沿着负梯度方向迭代更新参数。
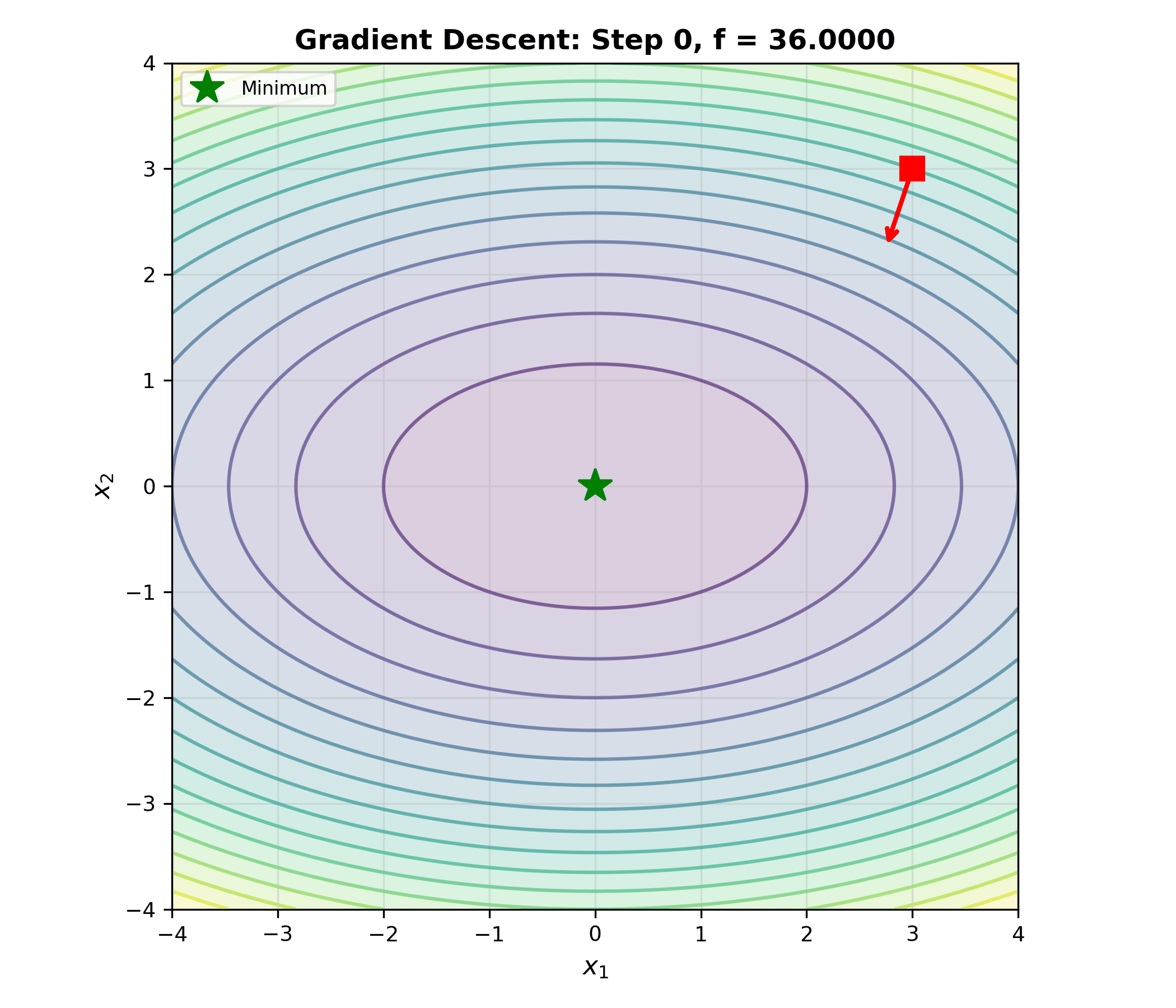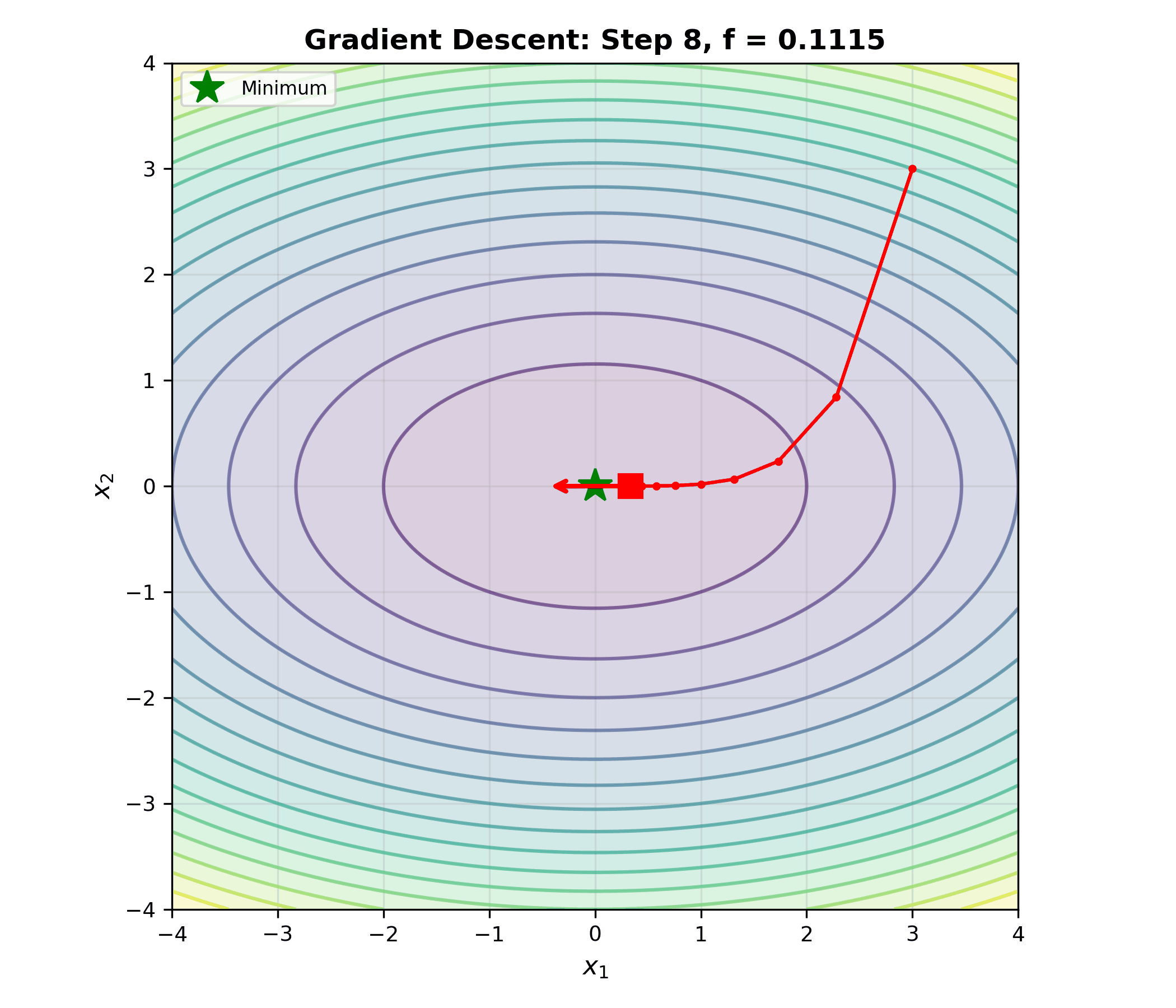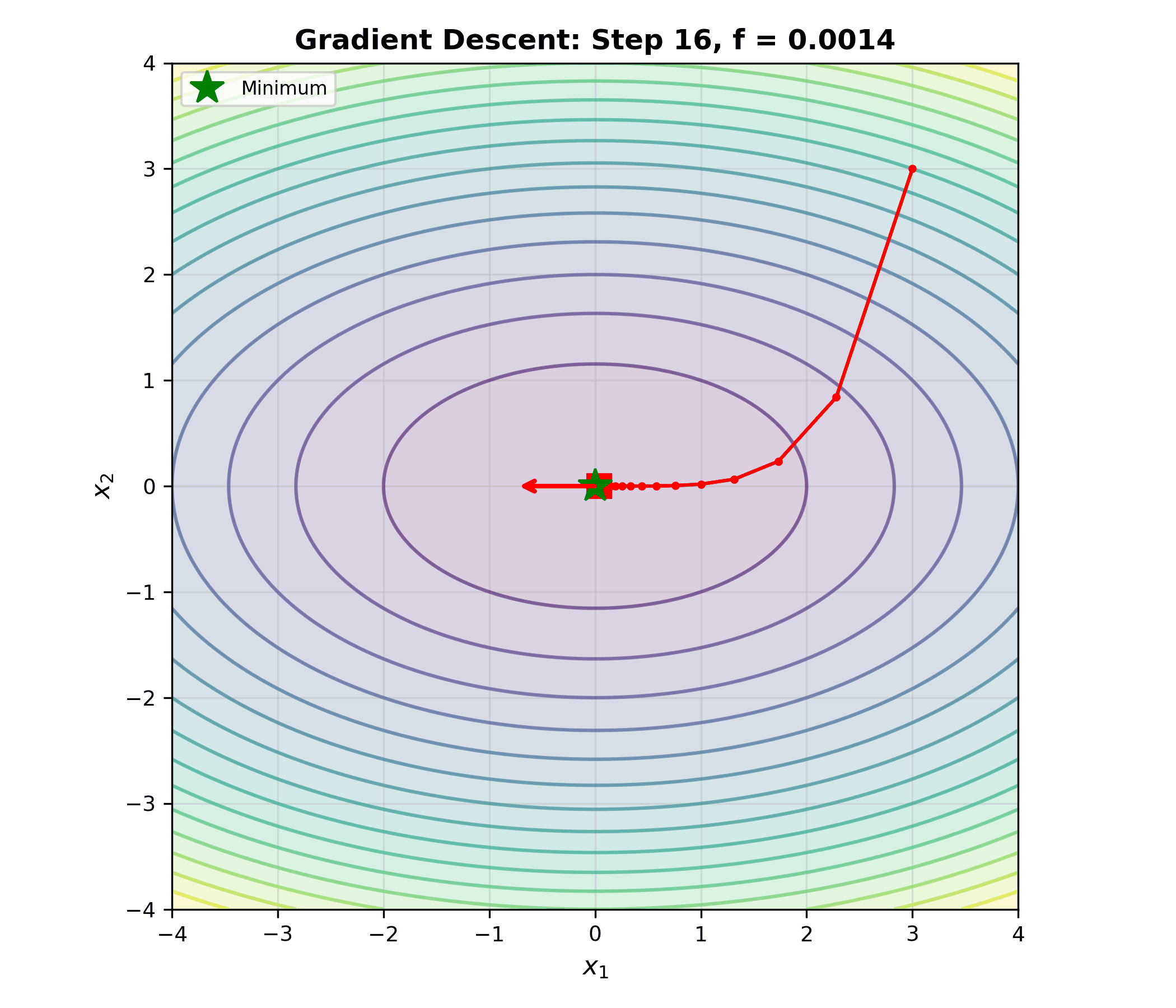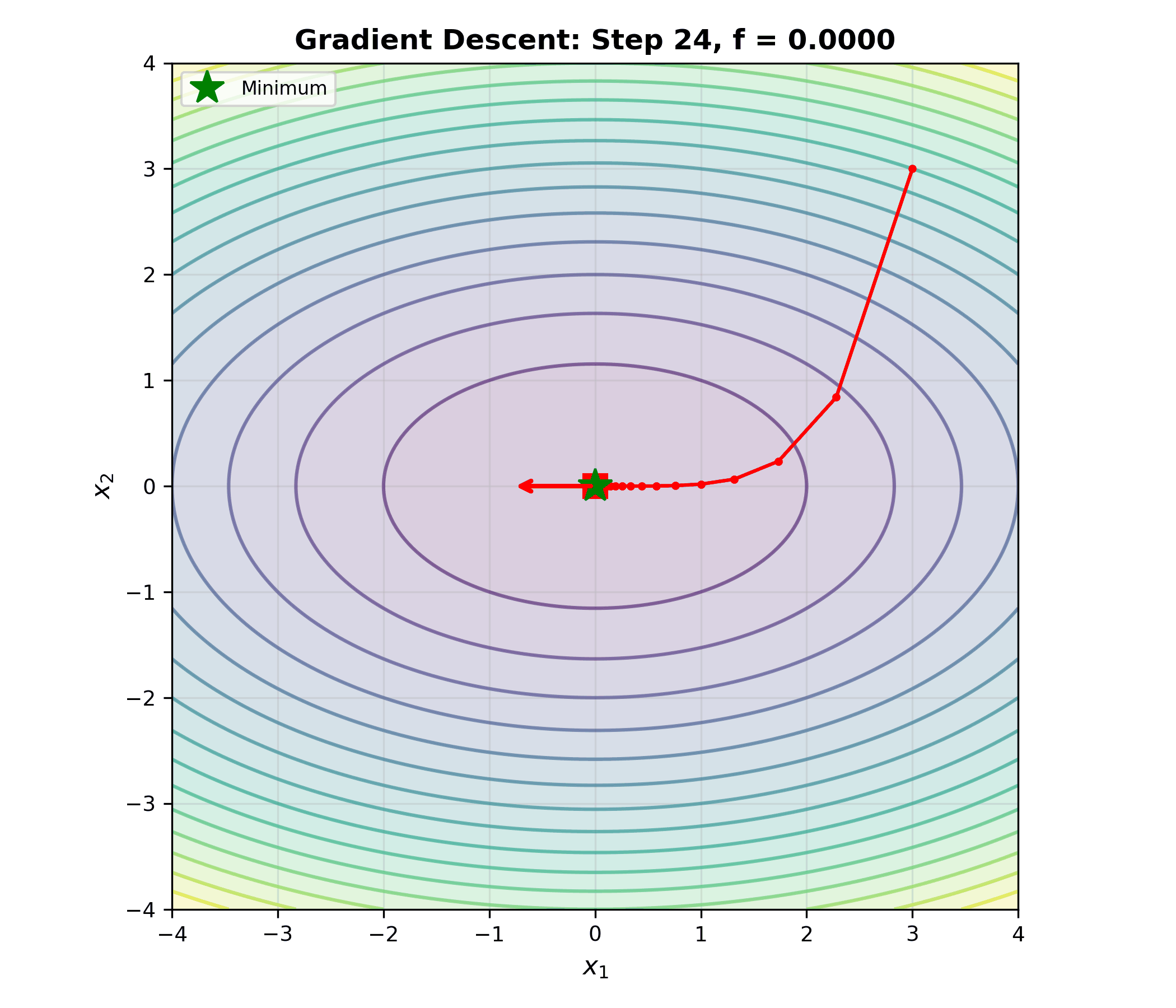
下面的动画展示了梯度下降在二维凸函数等高线上的优化轨迹——每一步沿负梯度方向移动,逐步逼近最优解:
算法 2(梯度下降): 1
2
3
4初始化: x^(0)
for k = 0, 1, 2, ... do
x^(k+1) = x^(k) - α_k ∇ f(x^(k))
end for
定理 7(梯度下降收敛性-凸且光滑情况):假设
使用固定步长
即收敛速率为
证明:
取
由凸性的一阶条件:
结合
定理 8(强凸情况):如果
收敛速率依赖于条件数
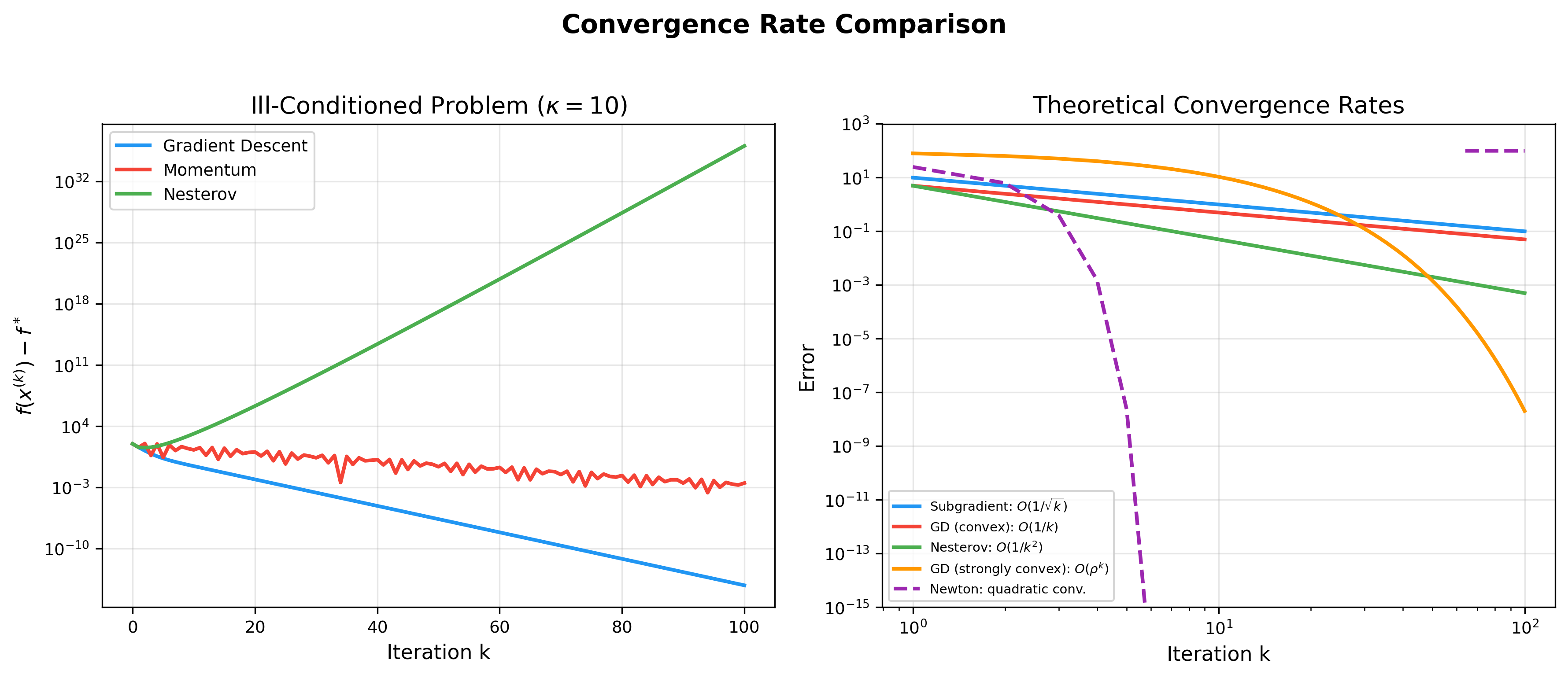
动量法与 Nesterov 加速
标准梯度下降在"峡谷"地形(一个方向曲率很大,另一个方向曲率很小)上收敛缓慢。动量法通过累积历史梯度来加速。
算法 3(动量梯度下降): 1
2
3
4
5初始化: x^(0), v^(0) = 0
for k = 0, 1, 2, ... do
v^(k+1) = β v^(k) - α ∇ f(x^(k))
x^(k+1) = x^(k) + v^(k+1)
end for
其中
Nesterov 加速梯度法( NAG) 做了一个巧妙的改进:先根据动量"预测"下一步位置,再在预测位置计算梯度:
算法 4( Nesterov 加速): 1
2
3
4
5初始化: x^(0), y^(0) = x^(0)
for k = 0, 1, 2, ... do
x^(k+1) = y^(k) - α ∇ f(y^(k))
y^(k+1) = x^(k+1) + β_k(x^(k+1) - x^(k))
end for
定理 9( Nesterov 加速收敛性):对于$L
这是
下图对比了各优化算法的收敛速度——从次梯度法的
下图展示了凸二次函数的三维表面和等高线,以及梯度下降路径在等高线上的轨迹:
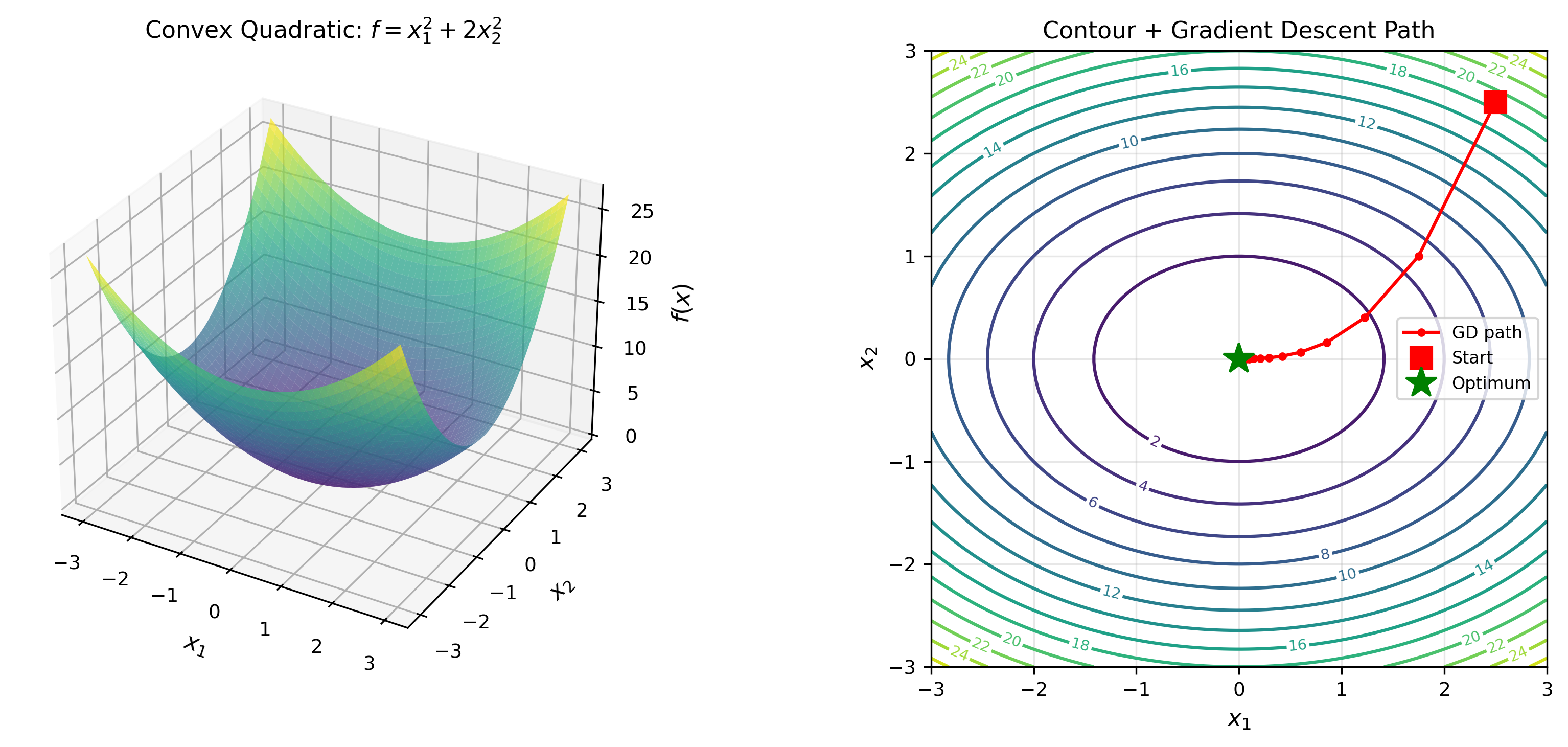
自适应学习率算法
AdaGrad、RMSProp、Adam 等算法根据历史梯度自动调整每个参数的学习率。
算法 5( Adam): 1
2
3
4
5
6
7
8
9初始化: x^(0), m^(0) = 0, v^(0) = 0
for k = 0, 1, 2, ... do
g^(k) = ∇ f(x^(k))
m^(k+1) = β_1 m^(k) + (1-β_1) g^(k) // 一阶矩估计
v^(k+1) = β_2 v^(k) + (1-β_2) (g^(k))^2 // 二阶矩估计
m ̂^(k+1) = m^(k+1) / (1 - β_1^{k+1}) // 偏差修正
v ̂^(k+1) = v^(k+1) / (1 - β_2^{k+1})
x^(k+1) = x^(k) - α m ̂^(k+1) / (√ v ̂^(k+1)} + ε)
end for
典型参数:
Adam 结合了动量(一阶矩)和自适应学习率(二阶矩),在深度学习中被广泛使用。
二阶优化算法
牛顿法
牛顿法利用二阶信息( Hessian 矩阵)来构造二次近似,从而实现更快的收敛。
推导:在点
对右侧关于
解得牛顿方向:
算法 6(牛顿法): 1
2
3
4
5
6
7初始化: x^(0)
for k = 0, 1, 2, ... do
计算 g^(k) = ∇ f(x^(k))
计算 H^(k) = ∇² f(x^(k))
解线性系统: H^(k) Δ x^(k) = -g^(k)
x^(k+1) = x^(k) + Δ x^(k)
end for
定理 10(牛顿法二次收敛性):假设
证明思路:利用泰勒展开和隐函数定理。在最优点
牛顿迭代:
代入上式并化简,可得二次收敛。
牛顿法的缺点:
- 每次迭代需要计算和求逆
Hessian 矩阵,计算复杂度 - Hessian 可能不正定,导致搜索方向不是下降方向
- 需要存储
的矩阵
拟牛顿法:BFGS 算法
拟牛顿法的思想是用一个矩阵
拟牛顿条件(Secant 条件):希望
记
这模拟了真实 Hessian 满足的性质(沿着搜索方向的曲率信息)。
BFGS 更新公式:BFGS(Broyden-Fletcher-Goldfarb-Shanno)算法使用如下更新:
或者更新逆矩阵
其中
算法 7( BFGS): 1
2
3
4
5
6
7
8
9
10初始化: x^(0), H^(0) = I
for k = 0, 1, 2, ... do
计算 g^(k) = ∇ f(x^(k))
d^(k) = -H^(k) g^(k)
线搜索: 选择 α_k 使 f(x^(k) + α_k d^(k)) 足够小
x^(k+1) = x^(k) + α_k d^(k)
s_k = x^(k+1) - x^(k)
y_k = ∇ f(x^(k+1)) - ∇ f(x^(k))
更新 H^(k+1) 使用上述公式
end for
定理 11(BFGS 超线性收敛):对于强凸函数,如果线搜索满足 Wolfe 条件,BFGS 算法超线性收敛:
BFGS 是实践中最成功的拟牛顿算法之一,广泛应用于中小规模优化问题。
L-BFGS(Limited-memory
BFGS):对于大规模问题,存储
约束优化与对偶理论
拉格朗日对偶
考虑一般的约束优化问题:
拉格朗日函数:引入拉格朗日乘子
定义 7(拉格朗日对偶函数):
其中
定理 12(弱对偶性):对于任意
其中
证明:设
因此:
由于
对偶问题:
记对偶问题最优值为
定义 8(对偶间隙):
定理 13( Slater
条件):如果原问题是凸优化问题(
这个条件保证了对偶间隙为零,使得我们可以通过求解对偶问题来解原问题。
KKT 条件:最优性的必要和充分条件
定理 14(KKT 条件):假设
- 原始可行性:
- 对偶可行性:
- 互补松弛:
- 稳定性:
定理 15:如果原问题是凸优化问题且满足 Slater 条件,则 KKT 条件是最优性的充分必要条件。
证明思路(互补松弛):由于
最后一个不等号利用了
由于
下图展示了 KKT 条件的几何意义——在最优点处,目标函数梯度
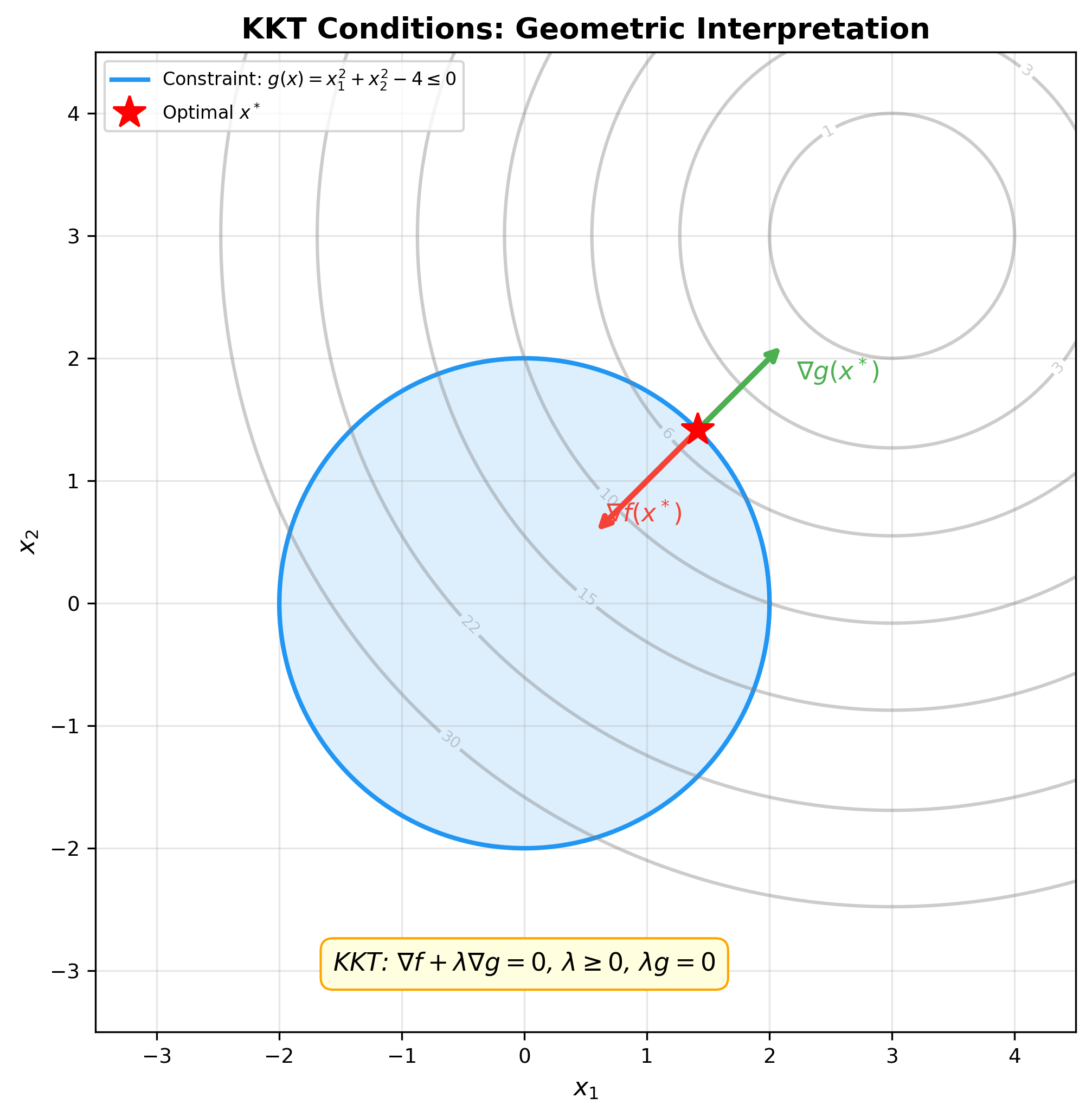
例 4(支持向量机的 KKT 条件):SVM 的原始问题:
KKT 条件给出:
互补松弛条件说明:只有位于边界上的点(支持向量)才有
ADMM 算法
交替方向乘子法( Alternating Direction Method of Multipliers, ADMM) 是一种强大的分布式优化算法,特别适合求解带有可分离结构的凸优化问题。
问题形式
考虑如下问题:
其中
增广拉格朗日函数:
其中
ADMM 算法步骤
算法 8( ADMM): 1
2
3
4
5
6初始化: x^(0), z^(0), y^(0)
for k = 0, 1, 2, ... do
x^(k+1) = argmin_x L_ρ(x, z^(k), y^(k))
z^(k+1) = argmin_z L_ρ(x^(k+1), z, y^(k))
y^(k+1) = y^(k) + ρ(Ax^(k+1) + Bz^(k+1) - c)
end for
算法解释:
- 更新:固定 和 ,关于 最小化增广拉格朗日函数 - 更新:固定 和 ,关于 最小化 - 更新:对偶变量的梯度上升
ADMM 的巧妙之处在于:即使
收敛性分析
定理 16(ADMM 收敛性):假设
- 残差收敛:
- 目标值收敛:
- 对偶变量收敛:
证明思路:构造一个 Lyapunov 函数来证明序列的收敛性。定义:
可以证明
应用例子:Lasso 回归
Lasso 问题:
重写为 ADMM 形式:
增广拉格朗日函数:
ADMM 更新:
- **
^{(k+1)} = (X^T X + I){-1}(XT y + z^{(k)} - u^{(k)}) $$
这是一个岭回归问题,有闭式解。
- 更新:
其中
- 更新:
这个算法非常高效,且易于分布式实现。
实现代码
下面给出梯度下降、牛顿法、 BFGS 和 ADMM 的完整实现。
1 | import numpy as np |
代码说明:
- ConvexOptimizer 类:实现了多种优化算法
gradient_descent: 固定步长梯度下降gradient_descent_backtracking: 带回溯线搜索的梯度下降newton_method: 牛顿法bfgs: BFGS 拟牛顿法momentum_gd: 动量梯度下降nesterov_accelerated_gd: Nesterov 加速
- ADMMSolver 类:实现 ADMM 算法求解 Lasso 问题
- 使用 Cholesky 分解加速
更新 - 软阈值算子用于
更新 - 跟踪原始残差和对偶残差
- 使用 Cholesky 分解加速
- 示例:
- 二次函数优化:展示不同算法的收敛性能
- Lasso 回归:展示 ADMM 在稀疏优化中的应用
深度 Q&A
Q1: 为什么凸优化如此重要?非凸优化不是更常见吗?
A1: 凸优化的重要性体现在三个层面:
理论层面:凸优化是唯一一类我们能够完全刻画最优性条件的问题。 KKT 条件给出了充要条件,这在非凸情况下是不可能的。
算法层面:凸优化有多项式时间算法(如内点法),且收敛性有严格保证。梯度下降在凸情况下保证收敛到全局最优,而在非凸情况下只能保证局部最优。
应用层面:许多实际问题本身就是凸的(线性回归、支持向量机、许多统计估计问题)。即使原问题非凸,凸松弛( convex relaxation)技术可以提供有用的近似解和下界。
对于深度学习等非凸问题,凸优化理论仍然提供了重要的直觉和工具。例如, Adam 等自适应算法的设计灵感来自凸优化的对偶平均( dual averaging)方法。
Q2: Jensen 不等式与 KL 散度的非负性有什么关系?
A2: KL 散度的非负性是 Jensen 不等式的直接推论。 KL
散度定义为:
要证明
等号成立当且仅当
这个证明揭示了信息论与凸优化的深层联系。 KL 散度可以看作是概率分布空间上的"距离"(虽然不对称),而 Jensen 不等式保证了这个"距离"总是非负的。
Q3: 为什么牛顿法比梯度下降快,但实际应用中反而用得少?
A3: 这是一个经典的理论与实践的权衡问题:
牛顿法的优势: - 二次收敛:每次迭代误差平方级减少,接近最优解时极快 - 步长自适应:自动根据曲率调整步长,不需要调参 - 仿射不变性:对坐标变换不敏感
牛顿法的劣势: 1.
计算成本:每次迭代需要
实践中的解决方案: - 小规模问题(
Q4: BFGS 的更新公式是如何推导出来的?
A4: BFGS 更新公式的推导基于两个原则:
原则 1:满足拟牛顿条件(Secant equation)
原则 2:最小化
具体推导:考虑优化问题
这是一个约束优化问题。构造拉格朗日函数并求解,得到:
第一项是"移除"
对称秩 1( SR1)公式是另一种选择:
但 SR1 可能不保持正定性,而 BFGS 在
Q5: ADMM 为什么能够分布式实现?
A5:ADMM 的分布式能力源于其"分而治之"的结构。考虑多个智能体协同优化的问题:
每个智能体只知道自己的
全局共识 ADMM: 1
2
3
4
5
6
7
8// 智能体 i 的局部更新(并行)
x_i^(k+1) = argmin_{x_i} [f_i(x_i) + y_i^(k)T x_i + (ρ/2)||x_i - z^(k)||^2]
// 中心节点的全局更新
z^(k+1) = (1/N) Σ_i x_i^(k+1)
// 对偶变量更新
y_i^(k+1) = y_i^(k) + ρ(x_i^(k+1) - z^(k+1))
每次迭代,智能体只需向中心发送
这使得 ADMM 特别适合: - 联邦学习:每个客户端训练本地模型,服务器聚合 - 传感器网络:分布式状态估计 - 大规模机器学习:数据分布在多个节点
Q6: 强凸性的实际意义是什么?为什么要关心条件数?
A6:强凸性决定了优化问题的"病态"程度,直接影响算法收敛速度。
条件数
(完美条件):函数是球形的,各方向曲率相同。梯度下降一步收敛。 :函数是椭球,长轴是短轴的 10 倍。梯度下降以 的速率收敛。 (病态):函数是极扁的椭球。梯度下降以 的速率收敛,需要百万次迭代才能显著减小误差。
实例:岭回归的条件数
Hessian 矩阵
当
预条件技术:对于病态问题,可以通过变量替换改善条件数。如果
新问题的 Hessian 接近单位矩阵,条件数接近 1。这是预条件共轭梯度法(Preconditioned CG)的思想。
Q7: 次梯度法的收敛速度为什么比梯度下降慢?
A7: 这源于不可微性导致的信息损失:
梯度下降(光滑函数): -
梯度提供了"最陡下降方向"的精确信息 - 步长可以根据 Lipschitz 常数精确选择
- 收敛速率:
次梯度法(非光滑函数): -
次梯度只是一个"支撑方向",不一定是下降方向 -
函数值可能在某些迭代中上升! - 必须使用递减步长(如
直觉解释:考虑
改进方法: 1. 近端梯度法:对于
Q8: 拉格朗日对偶在机器学习中有什么实际应用?
A8: 对偶理论在机器学习中有多个关键应用:
1. 支持向量机( SVM) -
原始问题:在高维甚至无限维空间中优化(使用核函数时) -
对偶问题:只依赖于样本之间的内积
2. 神经网络的理论分析 - 对偶范数用于分析泛化能力:权重矩阵的谱范数、 Frobenius 范数等 - 拉格朗日松弛用于神经网络验证(证明某个性质在所有输入上成立)
3. 分布式优化 - 原始问题可能有复杂的全局约束 - 对偶问题可以分解为多个独立的子问题,适合并行计算 - 这是 ADMM 的理论基础
4. 模型压缩与剪枝 - 稀疏优化( L0 范数最小化)是非凸的 - L1 范数的凸松弛及其对偶提供了可计算的近似
5. 生成对抗网络( GAN) - GAN 的训练是一个 min-max 问题(鞍点问题) - 对偶理论帮助理解 GAN 的收敛性和均衡点 - Wasserstein GAN 直接优化对偶形式
Q9: 在实践中如何选择优化算法?
A9: 选择优化算法需要考虑多个因素:
| 因素 | 建议算法 |
|---|---|
| 问题规模 | |
| 小规模 ( |
BFGS 、牛顿法 |
| 中等规模 ( |
L-BFGS 、共轭梯度 |
| 大规模 ( |
SGD 、 Adam 、 AdaGrad |
| 函数性质 | |
| 光滑凸函数 | 梯度下降、 Nesterov 加速 |
| 非光滑凸函数 | 次梯度法、近端梯度法 |
| 强凸函数 | 牛顿法、 BFGS(快速收敛) |
| 病态问题(大条件数) | 预条件方法、自适应算法 |
| 约束 | |
| 无约束 | 上述一阶/二阶方法 |
| 简单约束(如 |
投影梯度法、 Frank-Wolfe |
| 复杂约束 | 增广拉格朗日法、内点法 |
| 可分离结构 | ADMM |
| 计算资源 | |
| 梯度易计算, Hessian 困难 | 一阶方法、拟牛顿法 |
| 分布式环境 | ADMM 、分布式 SGD |
| 在线学习(流式数据) | SGD 、在线梯度下降 |
实践建议: 1. 从简单开始:先用梯度下降 + 线搜索,确保实现正确 2. 监控收敛:绘制目标函数值、梯度范数的变化曲线 3. 调参策略:学习率是最关键的参数,使用学习率衰减或自适应算法 4. 组合使用:先用一阶方法快速接近最优解,再用二阶方法精细优化
Q10: 凸优化理论对深度学习(非凸优化)有什么启示?
A10: 尽管深度学习的损失函数是非凸的,凸优化理论仍然提供了重要的指导:
1. 算法设计灵感 - Adam 的设计借鉴了凸优化中的对偶平均和自适应步长 - Batch Normalization 可以看作一种隐式的预条件,改善优化的条件数 - Residual connection(残差连接)使得优化曲面更接近凸(减少了梯度消失)
2. 局部凸性分析 - 虽然全局非凸,但在局部极小值附近,损失函数近似强凸 - 可以用凸优化的收敛速率来分析算法在局部的行为 - 这解释了为什么梯度下降能够在接近极小值时快速收敛
3. 泛化理论 - 凸优化的正则化理论( L1 、 L2)直接应用于深度学习 - PAC-Bayes 界、 Rademacher 复杂度等工具都基于凸分析
4. 损失函数设计 - 理解为什么交叉熵比均方误差更适合分类(源于凸优化的对数障碍函数) - Hinge loss 、 smoothed hinge loss 的设计来自凸优化
5. 理论保证的退化情况 - 某些深度学习问题可以证明是凸的(如单隐层线性网络的矩阵分解形式) - 过参数化( over-parameterization)理论表明,足够宽的网络优化曲面在某种意义上"接近凸"
6. 优化陷阱的识别 - 凸优化告诉我们鞍点、局部极小值的特征 - 在非凸情况下,我们可以用类似的分析来理解为什么 SGD 能够逃离鞍点(噪声帮助跨越势垒)
最新研究方向: - 隐式偏置( Implicit bias):梯度下降在非凸问题中倾向于找到什么样的解?答案涉及凸分析。 - 神经正切核( NTK)理论:极宽网络的训练动力学可以用线性(凸)模型近似。 - 景观理论( Landscape theory):研究非凸损失曲面的几何结构,识别"易优化"的非凸问题类别。
✏️ 练习题与解答
练习 1:判断凸性
题目:判断以下函数是否为凸函数,并证明你的结论: (a)
解答:
恒成立,因此 是凸函数。 , ( ),因此 是凸函数。 Hessian 矩阵为
,特征值为 和 。Hessian 不半正定,因此 不是凸函数。
练习 2:KKT 条件求解
题目:求解以下约束优化问题:
解答:
转化为标准形式:
KKT 条件: 1. 驻点条件:
由条件 1:
若
因此
最优解:
练习 3:梯度下降收敛分析
题目:对于
解答:
梯度下降更新:
因此
收敛条件:
需要
由于
最优步长
练习 4:对偶问题推导
题目:推导线性规划
解答:
引入拉格朗日乘子
对偶函数:
对偶问题(消去
这正是线性规划的经典对偶形式。由于线性规划满足 Slater 条件,强对偶性成立。
练习 5:Jensen 不等式应用
题目:利用 Jensen
不等式证明算术-几何均值不等式:对于
解答:
由于
即:
取负号并利用
由
参考文献
本章推导和理论主要基于以下经典文献:
Boyd, S., & Vandenberghe, L. (2004). Convex Optimization. Cambridge University Press. [经典教材,凸优化的标准参考]
Nocedal, J., & Wright, S. J. (2006). Numerical Optimization (2nd ed.). Springer. [数值优化的权威教材,详细介绍了各种算法]
Nesterov, Y. (2004). Introductory Lectures on Convex Optimization: A Basic Course. Springer. [Nesterov 加速的原始文献]
Duchi, J., Hazan, E., & Singer, Y. (2011). Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. Journal of Machine Learning Research, 12, 2121-2159. [AdaGrad 算法]
Kingma, D. P., & Ba, J. (2015). Adam: A Method for Stochastic Optimization. ICLR. [Adam 算法,深度学习中最常用的优化器]
Boyd, S., Parikh, N., Chu, E., Peleato, B., & Eckstein, J. (2011). Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Foundations and Trends in Machine Learning, 3(1), 1-122. [ADMM 的权威综述]
Bottou, L., Curtis, F. E., & Nocedal, J. (2018). Optimization Methods for Large-Scale Machine Learning. SIAM Review, 60(2), 223-311. [大规模机器学习优化的现代综述]
Bubeck, S. (2015). Convex Optimization: Algorithms and Complexity. Foundations and Trends in Machine Learning, 8(3-4), 231-357. [凸优化算法复杂度的理论分析]
Beck, A., & Teboulle, M. (2009). A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems. SIAM Journal on Imaging Sciences, 2(1), 183-202. [FISTA 算法,加速近端梯度法]
Rockafellar, R. T. (1970). Convex Analysis. Princeton University Press. [凸分析的数学基础]
Shalev-Shwartz, S., & Ben-David, S. (2014). Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press. [机器学习中的优化理论]
Polyak, B. T. (1964). Some methods of speeding up the convergence of iteration methods. USSR Computational Mathematics and Mathematical Physics, 4(5), 1-17. [动量法的原始文献]
总结:凸优化理论是机器学习的数学基石。本章从凸集和凸函数的定义出发,严格推导了凸优化的核心理论( Jensen 不等式、次梯度、 KKT 条件)和主要算法(梯度下降、牛顿法、 BFGS 、 ADMM)。理解这些理论不仅能帮助我们设计更好的算法,也能为分析非凸优化(如深度学习)提供重要的直觉和工具。在后续章节中,我们将看到这些优化技术如何应用于具体的机器学习模型。
- 本文标题:机器学习数学推导(四)凸优化理论
- 本文作者:Chen Kai
- 创建时间:2021-09-12 16:15:00
- 本文链接:https://www.chenk.top/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%95%B0%E5%AD%A6%E6%8E%A8%E5%AF%BC%EF%BC%88%E5%9B%9B%EF%BC%89%E5%87%B8%E4%BC%98%E5%8C%96%E7%90%86%E8%AE%BA/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!