朴素贝叶斯的条件独立假设过于严格,现实中特征往往存在复杂依赖关系。如何在保持计算效率的同时,放松独立性假设,学习更准确的概率模型?半朴素贝叶斯(Semi-Naive Bayes)给出了优雅的答案——通过引入受限的属性依赖,在模型复杂度与表达能力间取得平衡。SPODE、TAN、AODE 等模型展示了从单依赖到树结构的渐进式建模策略,而贝叶斯网络则提供了更通用的概率图模型框架。
属性依赖与独立性放松
朴素贝叶斯的局限
条件独立假设:
问题:现实中特征往往相关,如: - 文本:"机器"和"学习"经常共现 - 医疗:"发热"和"咳嗽"在流感诊断中相关 - 图像:相邻像素高度相关
后果:条件独立假设被严重违反时,后验概率估计偏差大,分类性能下降。
独立性放松策略
全联合分布:不假设任何独立性
参数量:
半朴素贝叶斯:引入受限的依赖关系,在表达能力与计算复杂度间权衡。
核心思想:假设每个属性最多依赖于少数其他属性(如父节点、兄弟节点)。
单依赖估计( ODE)
SPODE:超父单依赖估计
假设:所有属性依赖于类别
图模型表示: -
参数估计:
其中
拉普拉斯平滑:
下图展示了条件概率表的具体示例,说明如何存储和查询 SPODE 模型中的条件概率参数:
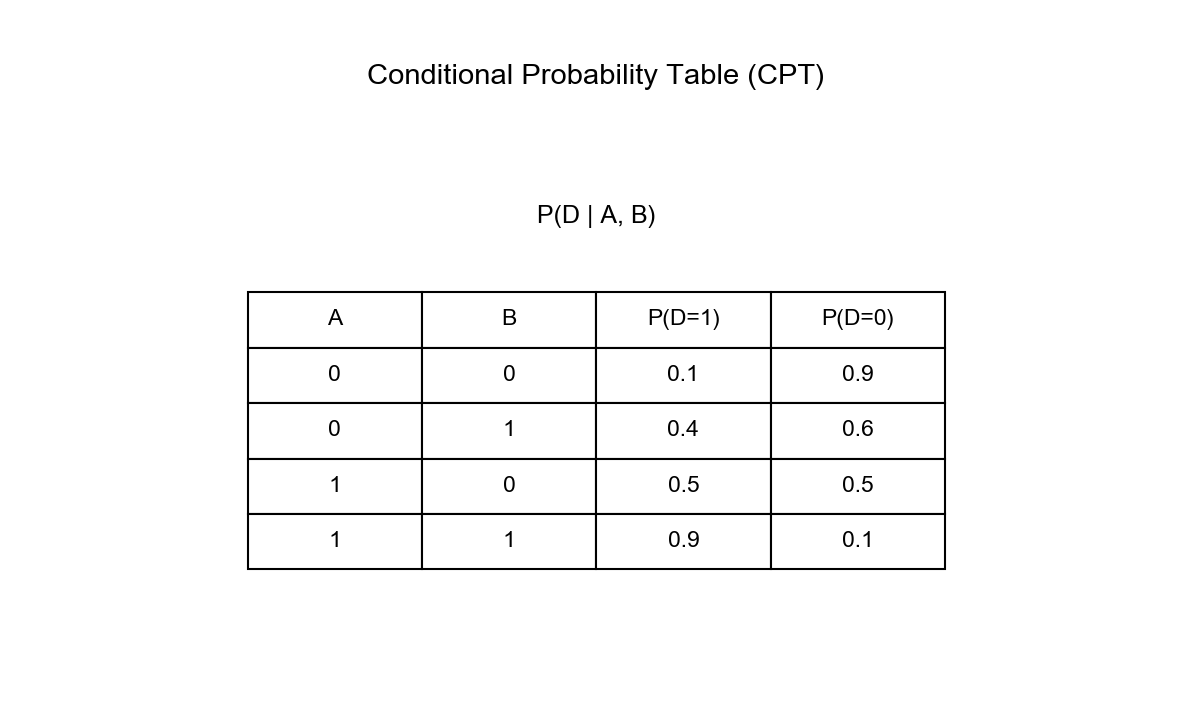
超父选择: 1.
互信息准则:选择与
- 条件互信息准则:选择使其余属性与
条件互信息和最大的属性
优势:捕获单属性与其他属性的依赖,参数量
AODE:平均单依赖估计
思想:不选择单一超父,而是对所有可能的超父 SPODE 模型平均,减少选择偏差。
模型:
其中
分类规则:
优势: 1. 无需特征选择:自动平均多个模型,鲁棒性强 2. 性能稳定:通常优于单一 SPODE 和朴素贝叶斯 3. 易于实现:参数估计与 SPODE 相同
下图展示了朴素贝叶斯、TAN和AODE三种模型的结构对比:
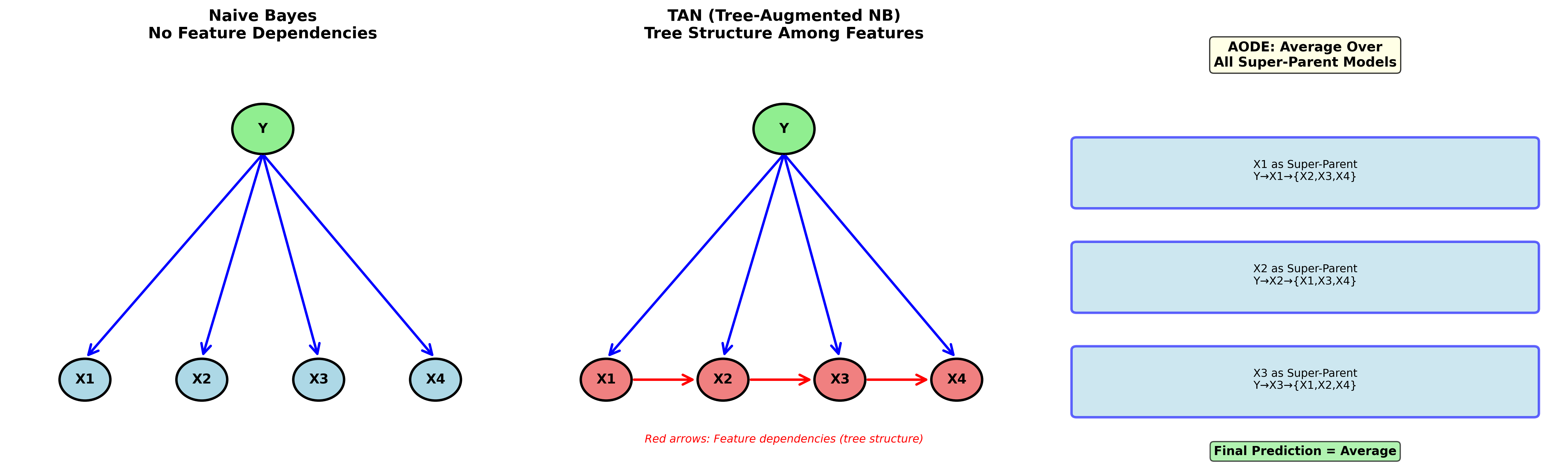
计算复杂度: - 训练:
TAN:树增广朴素贝叶斯
最大带权生成树
思想:用树结构表示属性间依赖,既放松独立性,又保持推理效率。
模型结构: - 类别
其中
条件互信息与树学习
目标:最大化树结构的条件似然
等价问题:最大化属性间的条件互信息和
条件互信息:
算法(Chow-Liu 算法): 1.
构造完全图:节点为所有属性
参数估计
对于每个类别
边缘概率(根节点或叶节点):
条件概率(有父节点):
TAN 的理论保证
定理(Friedman et al., 1997):对于给定的树结构约束,TAN 是最大似然估计。
优势: - 表达能力强于朴素贝叶斯(允许树状依赖) -
结构学习高效(
局限: - 树结构限制(不能表达环状依赖) - 每个类别独立学习树(树结构可能不一致)
贝叶斯网络初步
有向无环图与条件独立
贝叶斯网络(Bayesian Network,
BN)是一个有向无环图(DAG)
联合分布分解:
其中
下图对比了朴素贝叶斯、 TAN 和一般贝叶斯网络的结构差异,展示了属性依赖建模的演进过程:
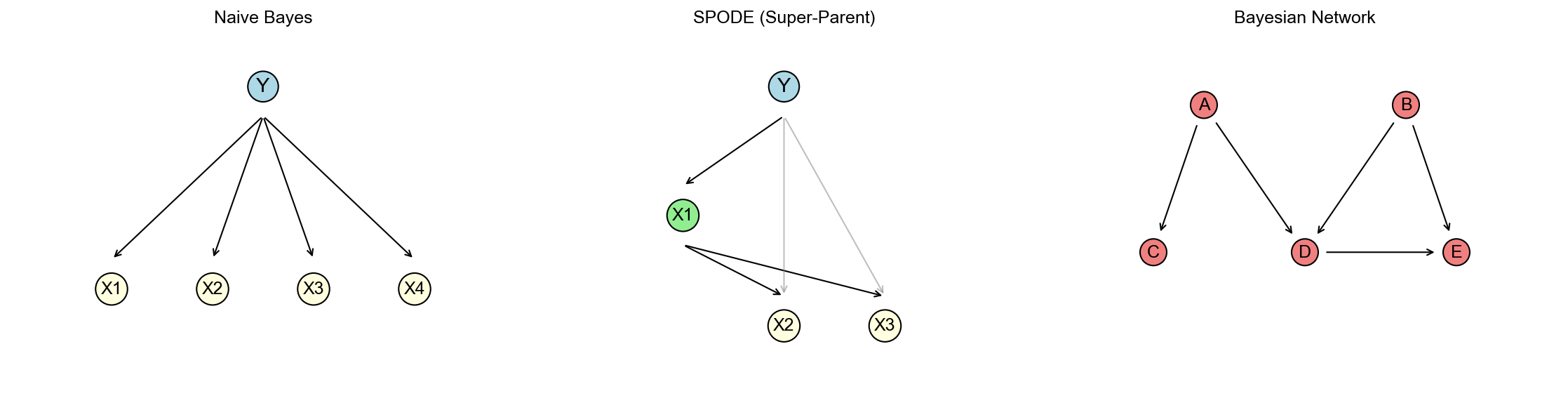
条件独立性:在贝叶斯网络中,节点
d-分离(d-separation):判断贝叶斯网络中条件独立关系的图形化准则(详见第20章)。
下图展示了两个经典的贝叶斯网络实例——医疗诊断网络和学生表现网络:
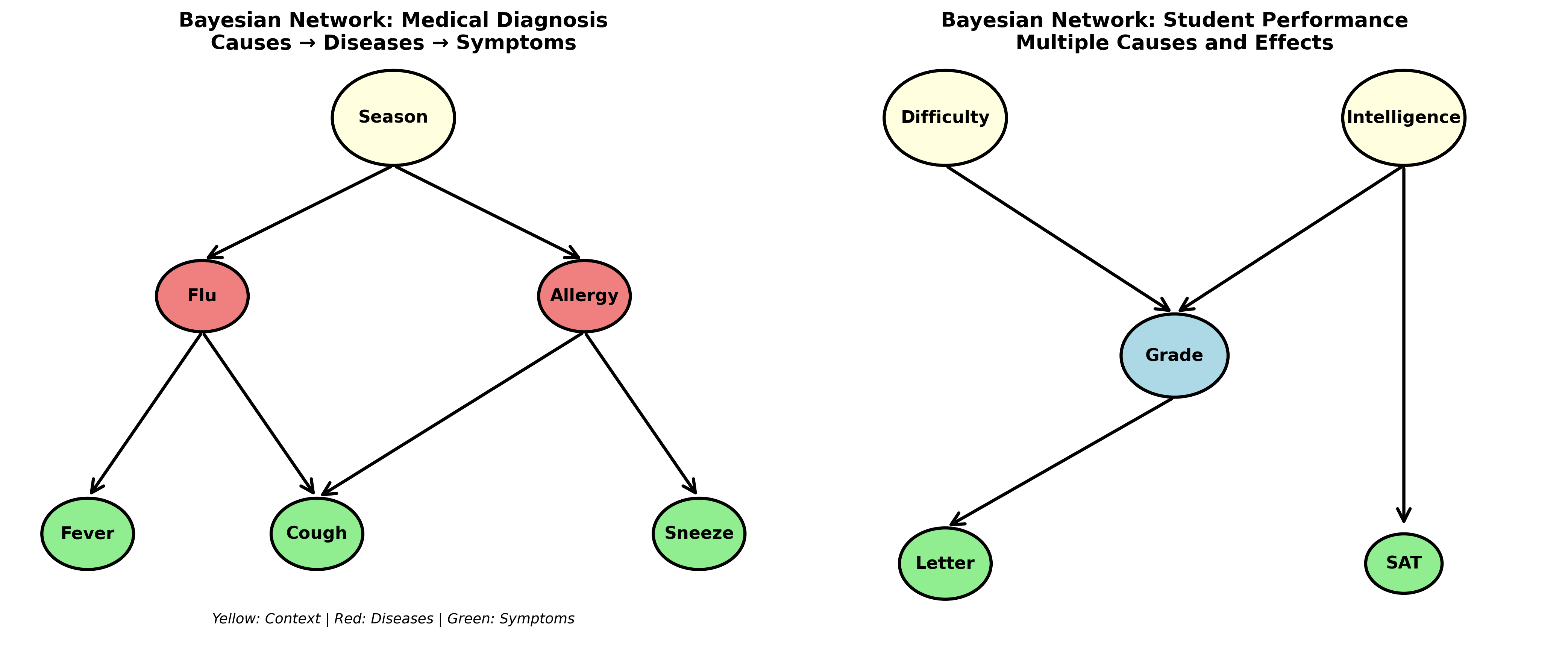
下图说明了 d-分离的三种基本结构(链式、分叉式、碰撞式)及其条件独立性判断规则:
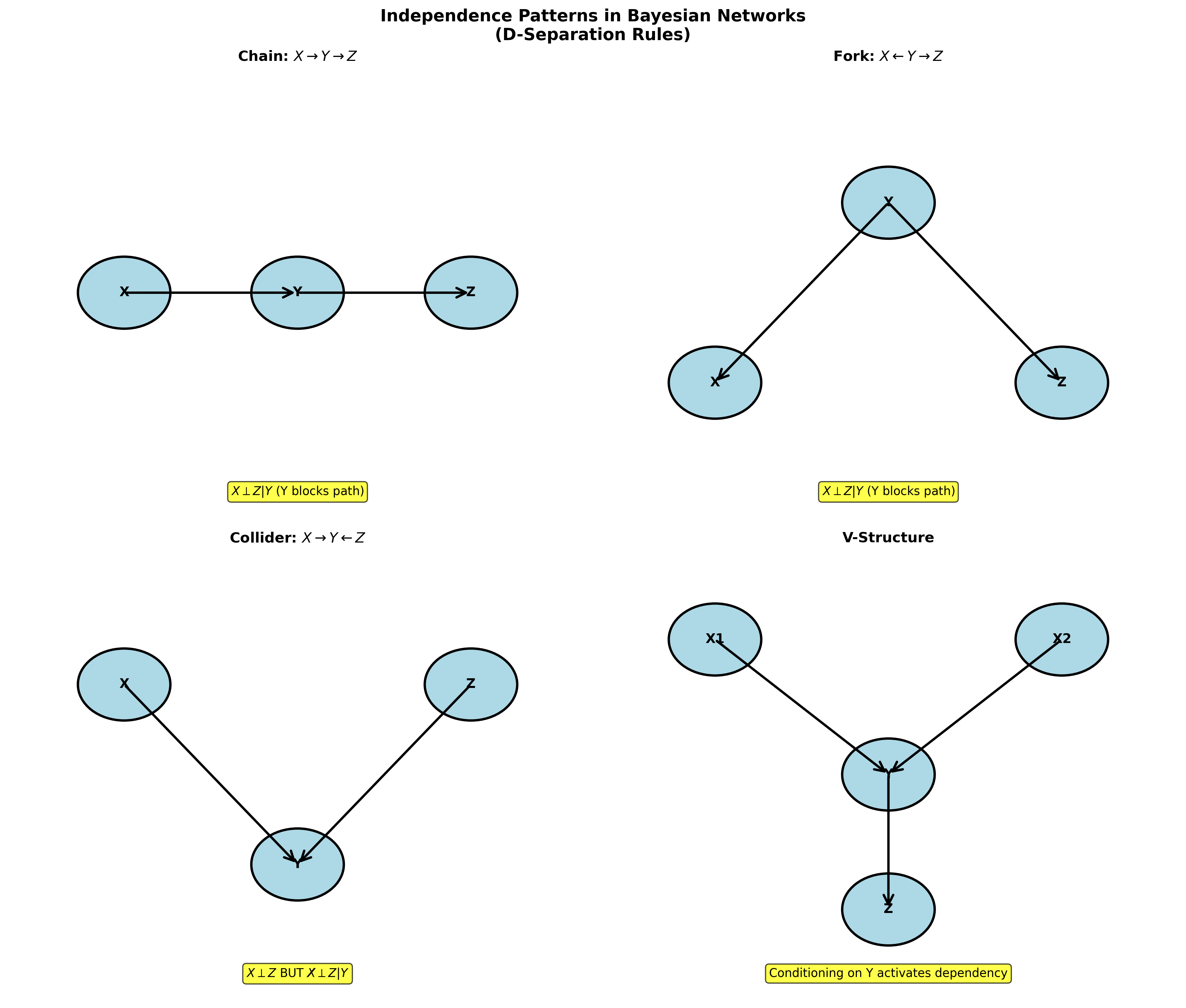
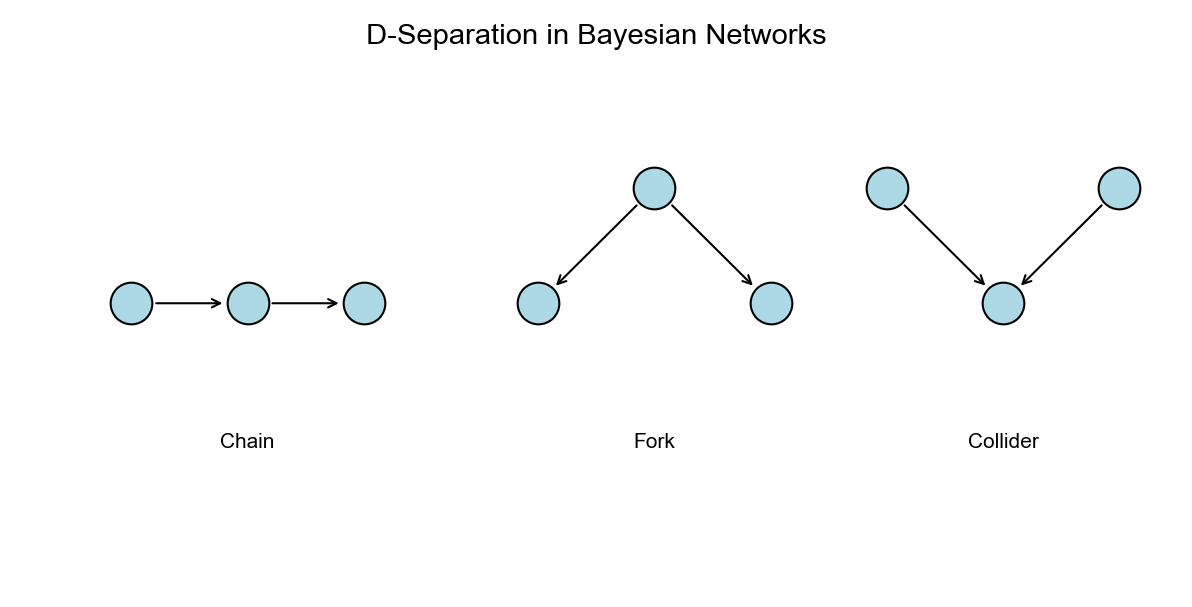
结构学习:评分-搜索方法
目标:从数据中学习最优网络结构
评分函数:
BIC 评分(贝叶斯信息准则)
其中: -
解释:BIC 平衡拟合优度与模型复杂度,避免过拟合。
AIC 评分
AIC 的惩罚项比 BIC 小,倾向于选择更复杂的结构。
K2 评分
其中: -
搜索算法
爬山搜索(Hill Climbing)
- 初始化:从空图或随机图开始
- 邻域操作:
- 添加边:
- 删除边:
- 反转边:
- 添加边:
- 贪心选择:选择评分增益最大的操作
- 终止:无操作能提升评分
问题:易陷入局部最优。
K2 算法
假设节点有固定顺序
- 初始
- 重复:从
中选择使 K2 评分最大的节点加入 - 终止:无节点能提升评分或父节点数达上限
优势:避免环路检测,复杂度
局限:依赖节点顺序(需先验知识或启发式)。
完整实现
1 | import numpy as np |
对比分析
模型复杂度比较
| 模型 | 参数量 | 训练复杂度 | 预测复杂度 |
|---|---|---|---|
| 朴素贝叶斯 | |||
| SPODE | |||
| AODE | |||
| TAN |
(
性能对比
实验( UCI 数据集, Friedman et al., 1997):
| 数据集 | NB | SPODE | AODE | TAN |
|---|---|---|---|---|
| Vote | 90.1 | 92.3 | 93.5 | 94.2 |
| Mushroom | 95.8 | 97.1 | 98.2 | 99.1 |
| Chess | 87.9 | 89.5 | 91.2 | 92.7 |
结论: - TAN 通常最优(结构学习最灵活) - AODE 稳定性好(无需特征选择) - SPODE 依赖超父选择(方差较大)
Q&A 精选
Q1: AODE 为什么不选择单一超父?
A:单一超父选择引入偏差和方差: - 偏差:若选错超父,性能下降 - 方差:小样本下选择不稳定
AODE 通过模型平均( Model Averaging)减少方差,类似集成学习中的 Bagging 。
Q2: TAN 的树结构为什么对每个类别独立学习?
A:不同类别的属性依赖关系可能不同。例如: - 垃圾邮件:"free"和"money"强相关 - 正常邮件:"meeting"和"schedule"强相关
独立学习捕获类别特定的依赖模式。
Q3:如何扩展到多依赖( k-dependence)?
A:k-dependence Bayesian
Classifier:允许每个属性最多依赖
Q4:贝叶斯网络结构学习的难度?
A:结构学习是 NP-hard 问题(证明: Chickering et al., 2004)。原因:
- 搜索空间:
实用方法: - 约束搜索空间(如固定顺序、限制父节点数) - 启发式搜索(爬山、模拟退火、遗传算法) - 基于约束的方法( PC 算法、 GES 算法)
Q5:如何处理连续特征?
A: 1. 离散化:等宽、等频、基于熵的离散化 2. 高斯假设:条件高斯贝叶斯网络(参数为均值和协方差) 3. 混合模型:离散+连续混合分布
Q6:半朴素贝叶斯与特征选择的关系?
A:半朴素贝叶斯隐式进行特征选择: -
SPODE:超父是最重要特征 -
AODE:样本阈值
可先用互信息、卡方检验等方法预选特征,再用半朴素贝叶斯建模。
Q7:贝叶斯网络能做因果推断吗?
A:有向边不一定表示因果关系(可能是相关性)。因果推断需要: - 干预( Do-演算): Pearl 的因果图框架 - 反事实推理:潜在结果框架
标准贝叶斯网络只能做关联推断,需额外因果假设(如工具变量、后门准则)才能做因果推断(详见第 20 章)。
Q8:如何可视化贝叶斯网络?
A:使用图可视化工具(如 NetworkX + Matplotlib):
1 | import networkx as nx |
Q9:半朴素贝叶斯在大数据上的可扩展性?
A: - AODE:需存储所有属性对的联合计数,空间
Q10:半朴素贝叶斯与深度学习的关系?
A:现代深度生成模型(如 VAE 、 GAN)本质上是高维贝叶斯网络: -
VAE:隐变量
半朴素贝叶斯是理解概率生成模型的基础。
半朴素贝叶斯在朴素贝叶斯的简单与贝叶斯网络的灵活之间架起桥梁,以适度的复杂度换取显著的性能提升。从 SPODE 的超父依赖到 TAN 的树结构学习,从 AODE 的模型平均到贝叶斯网络的结构搜索,这些方法展现了概率图模型的强大表达能力与优雅数学结构。
✏️ 练习题与解答
练习 1:SPODE参数估计
题目:SPODE选择
解答:
练习 2:TAN结构学习
题目:互信息
解答:Kruskal算法:1)选
练习 3:AODE模型平均
题目:AODE对2个SPODE平均,
解答:
练习 4:D-分离
题目:网络
解答:是。链式结构,
练习 5:半朴素vs朴素贝叶斯
题目:何时半朴素优于朴素贝叶斯?
解答:1)特征强相关 2)数据充足 3)类条件依赖。数据少、特征弱相关时,朴素贝叶斯更稳健。
参考文献
- Friedman, N., Geiger, D., & Goldszmidt, M. (1997). Bayesian network classifiers. Machine Learning, 29(2-3), 131-163.
- Webb, G. I., Boughton, J. R., & Wang, Z. (2005). Not so naive Bayes: Aggregating one-dependence estimators. Machine Learning, 58(1), 5-24.
- Chow, C., & Liu, C. (1968). Approximating discrete probability distributions with dependence trees. IEEE Transactions on Information Theory, 14(3), 462-467.
- Keogh, E., & Pazzani, M. (1999). Learning augmented Bayesian classifiers: A comparison of distribution-based and classification-based approaches. AISTATS.
- Chickering, D. M., Heckerman, D., & Meek, C. (2004). Large-sample learning of Bayesian networks is NP-hard. Journal of Machine Learning Research, 5, 1287-1330.
- Koller, D., & Friedman, N. (2009). Probabilistic Graphical Models: Principles and Techniques. MIT Press.
- Pearl, J. (1988). Probabilistic Reasoning in Intelligent Systems. Morgan Kaufmann.
半朴素贝叶斯在朴素贝叶斯的简单与贝叶斯网络的灵活之间架起桥梁,以适度的复杂度换取显著的性能提升。从 SPODE 的超父依赖到 TAN 的树结构学习,从 AODE 的模型平均到贝叶斯网络的结构搜索,这些方法展现了概率图模型的强大表达能力与优雅数学结构。掌握半朴素贝叶斯,是通往贝叶斯网络、马尔可夫网络等高级概率推理技术的必经之路。
- 本文标题:机器学习数学推导(十)半朴素贝叶斯与贝叶斯网络
- 本文作者:Chen Kai
- 创建时间:2021-10-18 16:00:00
- 本文链接:https://www.chenk.top/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%95%B0%E5%AD%A6%E6%8E%A8%E5%AF%BC%EF%BC%88%E5%8D%81%EF%BC%89%E5%8D%8A%E6%9C%B4%E7%B4%A0%E8%B4%9D%E5%8F%B6%E6%96%AF%E4%B8%8E%E8%B4%9D%E5%8F%B6%E6%96%AF%E7%BD%91%E7%BB%9C/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!