变分推断(Variational Inference)将贝叶斯推断转化为优化问题——当后验分布难以精确计算时,变分推断通过优化一个易处理的分布族来近似真实后验,将积分问题转化为优化问题。从变分 EM 到变分自编码器,从主题模型到深度生成模型,变分推断已成为现代机器学习的核心技术。ELBO(证据下界)提供了优化目标,平均场近似简化了分布族,坐标上升算法实现了高效求解,而黑盒变分推断则通过蒙特卡洛梯度估计扩展到任意模型。


贝叶斯推断与后验难题
贝叶斯推断框架
观测数据:
隐变量:
参数:
目标:计算后验分布
困难:边缘似然(证据)
通常无法解析计算,也难以数值积分(高维)。
精确推断 vs 近似推断
精确推断: - 共轭先验:某些模型后验有闭式解 - 图模型:变量消除、信念传播(树结构)
近似推断(大多数情况需要): 1. 采样方法: MCMC(马尔可夫链蒙特卡洛) - 优点:渐近精确 - 缺点:收敛慢,难以诊断 2. 变分方法:将推断转化为优化 - 优点:快速,确定性 - 缺点:有偏近似
变分推断的基本原理
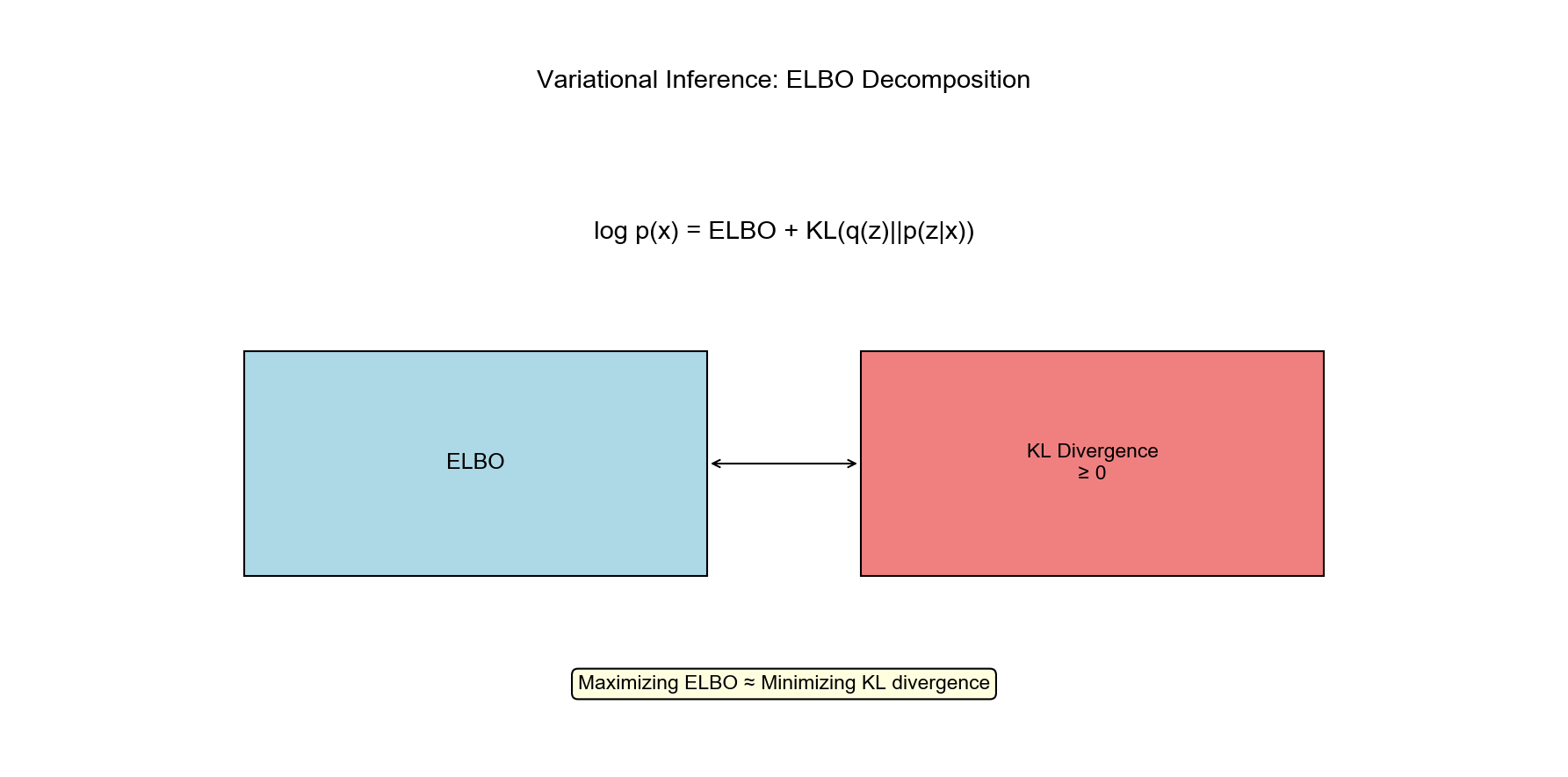
ELBO 推导
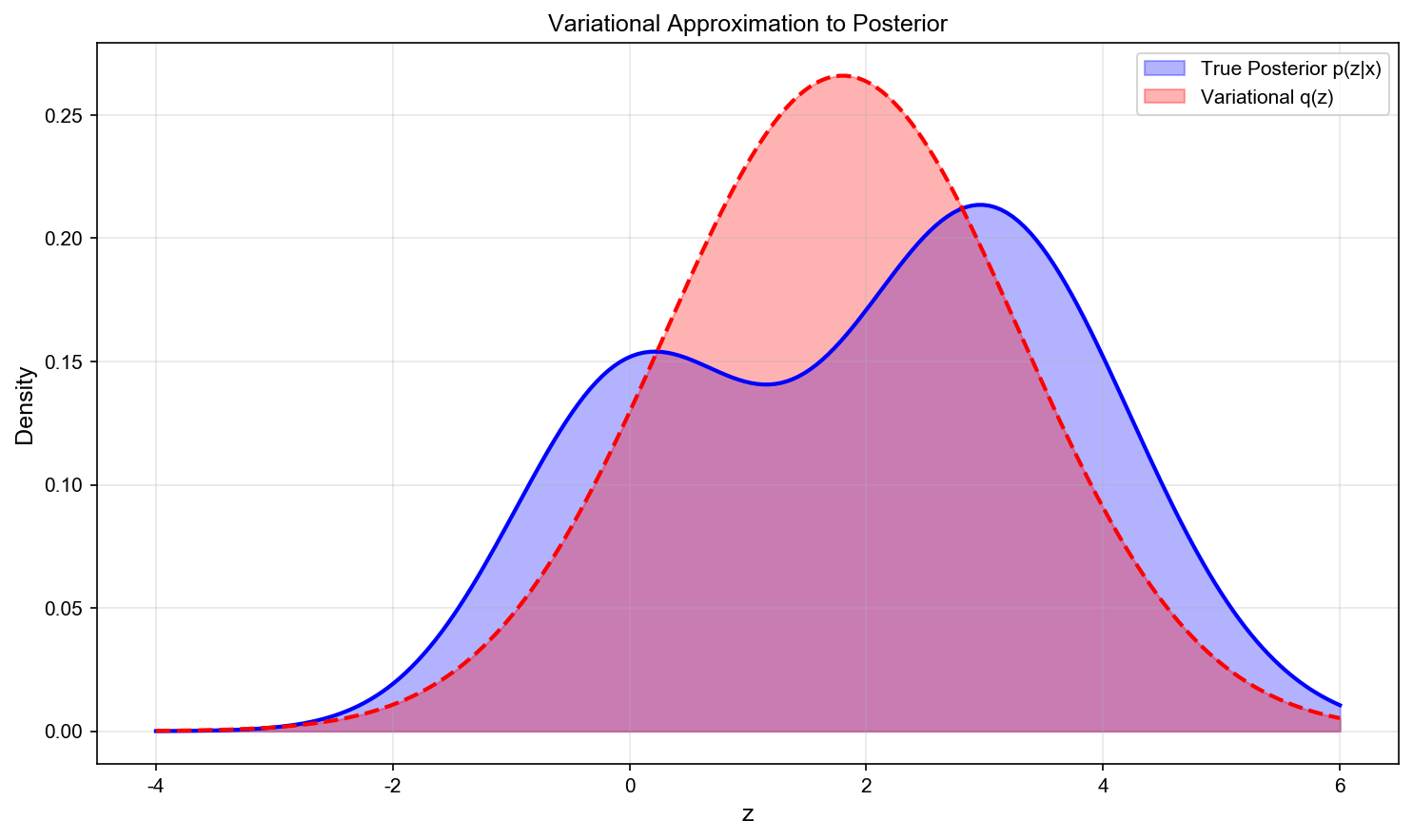
想法:用简单分布
优化目标:最小化 KL 散度
问题:包含未知的
转换:
其中证据下界(ELBO):
关键关系:
变分推断目标:
平均场近似
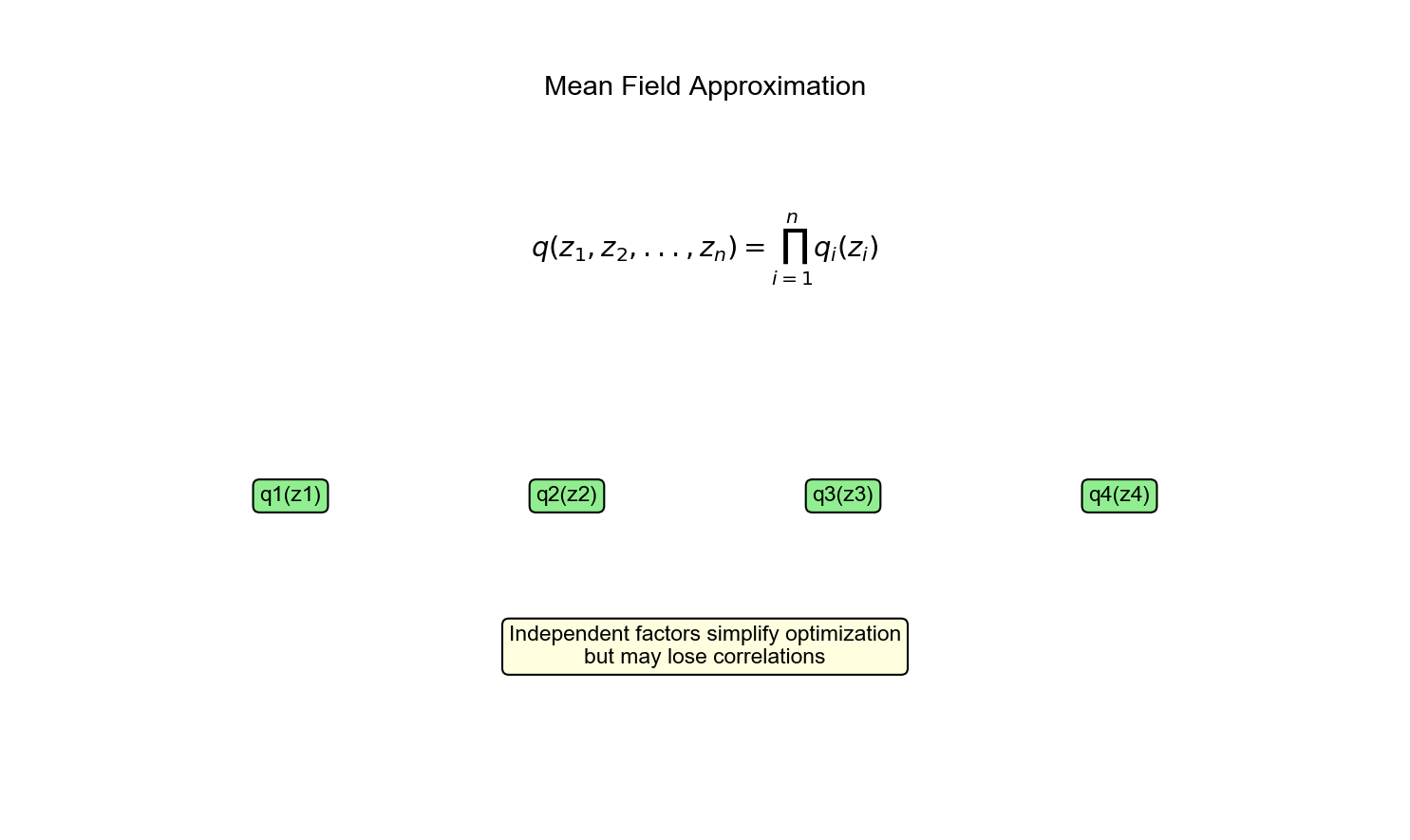
假设:变分分布完全分解
或更简洁地,假设隐变量和参数划分为
优化:对每个因子
坐标上升变分推断
ELBO 展开:
其中
对
最优
算法:循环更新每个因子直至收敛
变分 EM 算法
EM 与变分推断的联系
标准 EM: - E 步:
变分 EM: - E 步:
变分贝叶斯 EM: - VE 步:
变分贝叶斯 GMM
模型:
- 先验:
, , - 似然:
,
变分分布:
更新公式(共轭性质):
黑盒变分推断(BBVI)
梯度估计问题
ELBO:
梯度:
困难:梯度与期望不可交换(
REINFORCE 梯度估计器
对数导数技巧:
ELBO 梯度:
蒙特卡洛估计:
其中
问题:高方差
重参数化技巧
想法:将随机性从
重参数化:
示例(高斯):
ELBO 梯度:
蒙特卡洛估计:
优势:低方差,可自动微分
实现示例
1 | import numpy as np |
Q&A 精选
Q1: 变分推断 vs MCMC?
A: - 变分: 快速、确定性、有偏(KL 散度非零) - MCMC: 慢、随机、渐近无偏
变分适合大规模数据和在线学习,MCMC 适合精确推断。
Q2: 为什么用 KL(q||p)而非 KL(p||q)?
A: KL(q||p)是"反向 KL",使
Q3: 平均场假设何时失效?
A: 当变量强相关时。解决方法: - 结构化变分(保留部分依赖) - 更 rich 的变分族(normalizing flows)
Q4: 变分贝叶斯 vs 点估计(MAP/MLE)?
A: 变分贝叶斯保留不确定性,防止过拟合。代价:计算复杂度高。小数据/正则化需求高→变分贝叶斯;大数据/速度需求→点估计。
Q5: 重参数化技巧的适用范围?
A: 需要连续可微的分布。适用:高斯、 Logistic 、 Laplace 。不适用:离散分布(需 REINFORCE 或 Gumbel-Softmax)。
✏️ 练习题与解答
练习 1:ELBO推导
题目:证明
练习 2:平均场近似
题目:
练习 3:变分EM
题目:变分EM的E步和M步分别优化什么?
解答:E步:固定
练习 4:VAE重参数化
题目:为什么VAE用
练习 5:变分推断 vs MCMC
题目:何时用变分推断,何时用MCMC? 解答:变分推断快但有偏(近似假设),适合大数据。MCMC渐近无偏但慢,适合精确推断小规模问题。
参考文献
- Jordan, M. I., et al. (1999). An introduction to variational methods for graphical models. Machine Learning, 37(2), 183-233.
- Blei, D. M., Kucukelbir, A., & McAuliffe, J. D. (2017). Variational inference: A review for statisticians. JASA, 112(518), 859-877.
- Kingma, D. P., & Welling, M. (2014). Auto-encoding variational Bayes. ICLR.
- Ranganath, R., Gerrish, S., & Blei, D. (2014). Black box variational inference. AISTATS.
变分推断将贝叶斯推断的积分难题转化为优化问题,以确定性算法换取计算效率。从经典的平均场近似到现代的黑盒变分推断,从 VAE 到深度生成模型,变分方法已成为机器学习的基础工具。理解变分推断,是通往概率编程、贝叶斯深度学习的必经之路。
- 本文标题:机器学习数学推导(十四)变分推断与变分 EM
- 本文作者:Chen Kai
- 创建时间:2021-11-11 14:30:00
- 本文链接:https://www.chenk.top/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%95%B0%E5%AD%A6%E6%8E%A8%E5%AF%BC%EF%BC%88%E5%8D%81%E5%9B%9B%EF%BC%89%E5%8F%98%E5%88%86%E6%8E%A8%E6%96%AD%E4%B8%8E%E5%8F%98%E5%88%86EM/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!