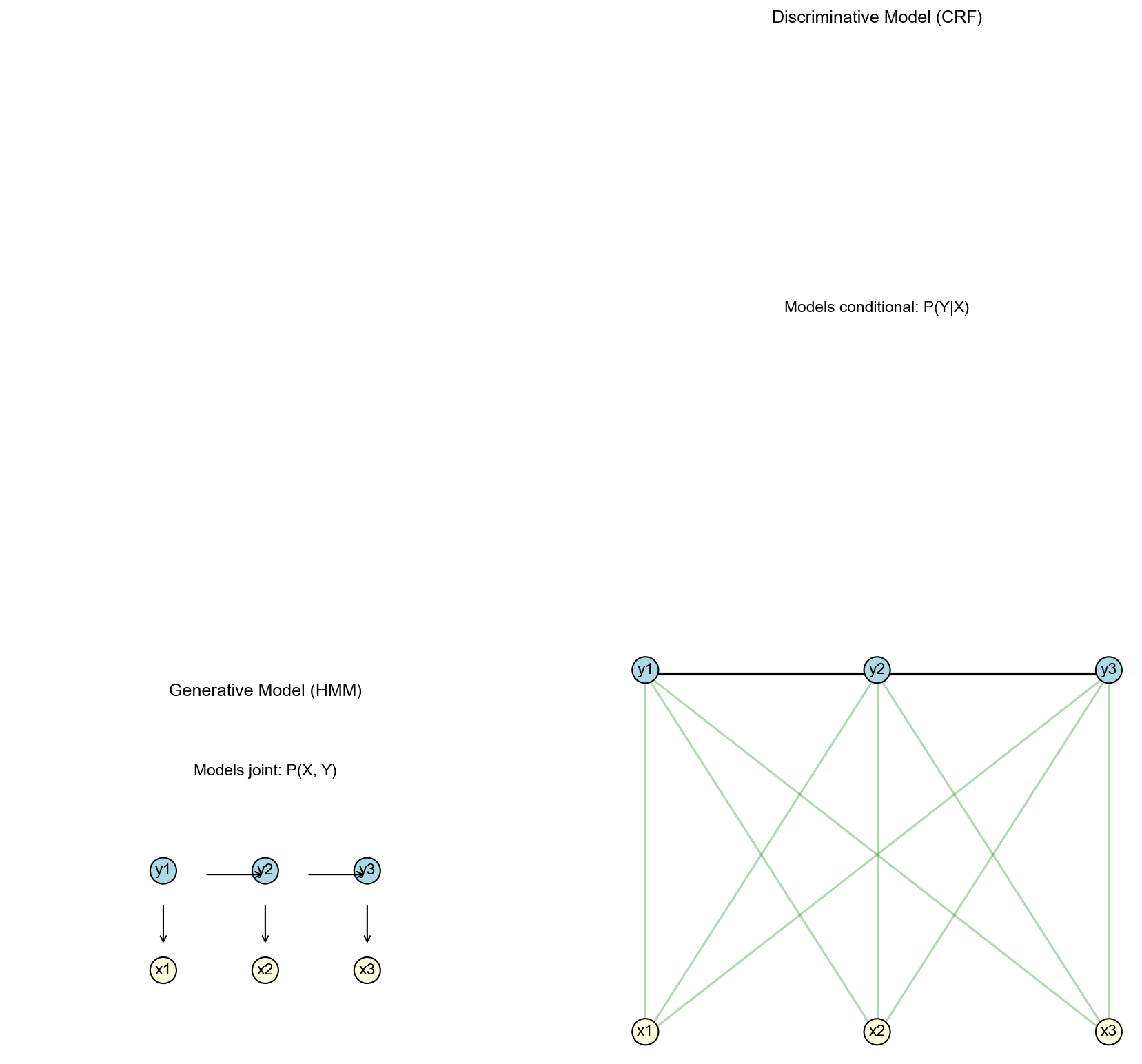
条件随机场(Conditional Random Field, CRF)是序列标注的判别式模型——与
HMM 不同, CRF 直接建模条件概率
从 HMM 到
CRF:生成式到判别式的跨越
HMM 的局限性回顾
HMM 建模 :联合概率
预测时使用贝叶斯公式 :
核心假设 (限制性):
观测独立性 :马尔可夫性 :
实际问题 :词性标注中,当前词的标签可能依赖于前一个词、后一个词、词的后缀等多种特征,观测独立性假设不合理!
判别式模型的优势
CRF 思想 :直接建模
优势 :
无需观测独立性假设 :特征可以任意重叠灵活特征工程 :可引入全局特征、词典特征、形态特征等理论性能保证 :判别式模型在标注任务上通常优于生成式
代价 :训练复杂度更高(需要计算归一化因子)
Figure 1
CRF vs HMM
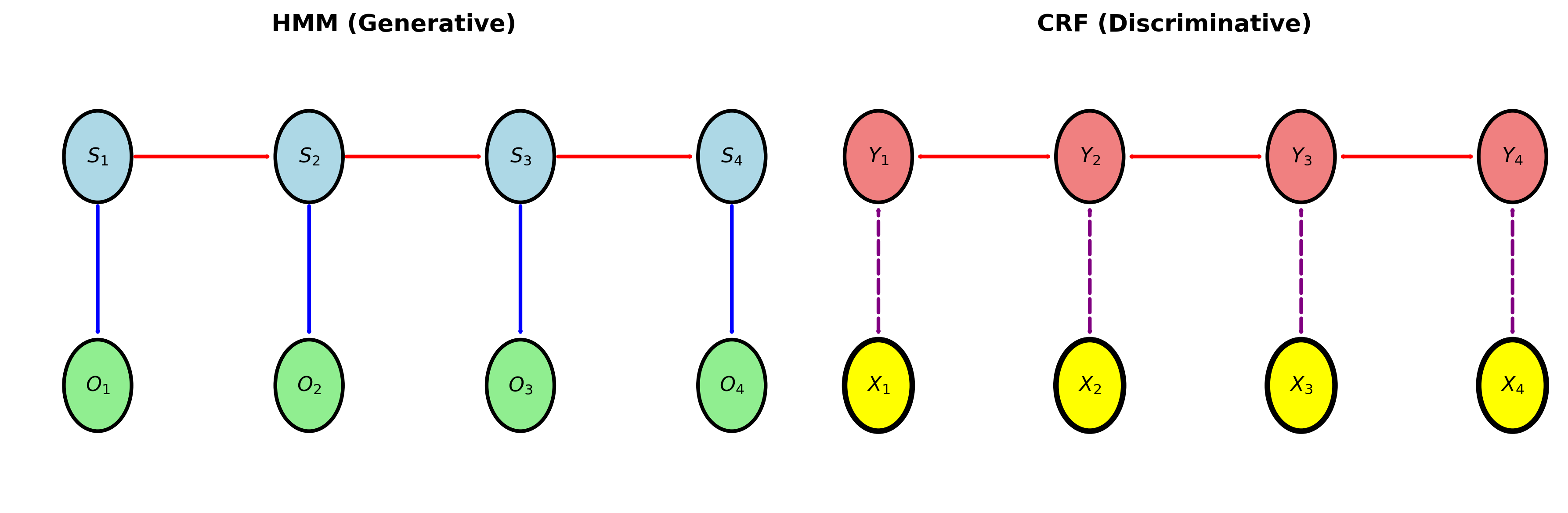
从 HMM 到 MEMM 到 CRF
最大熵马尔可夫模型 (MEMM):
问题 :标注偏置(Label
Bias)——局部归一化导致模型倾向于选择转移选项少的状态
CRF 解决方案 :全局归一化
线性链 CRF 的数学框架
基本定义
Figure 2
输入 :观测序列
输出 :标签序列
条件概率 :
其中:
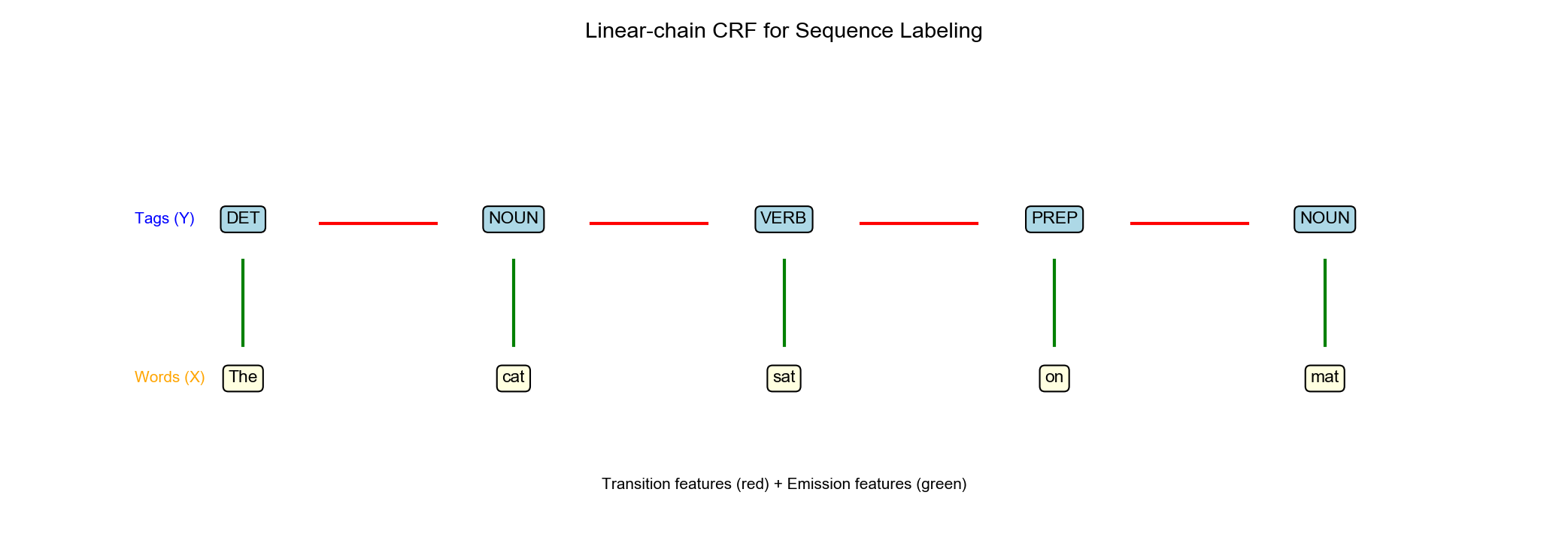
特征函数分解
Figure 3
转移特征 ( Transition
Features):依赖于前一标签和当前标签
例子:𝟙
状态特征 ( Emission
Features):依赖于当前标签和观测
例子:𝟙
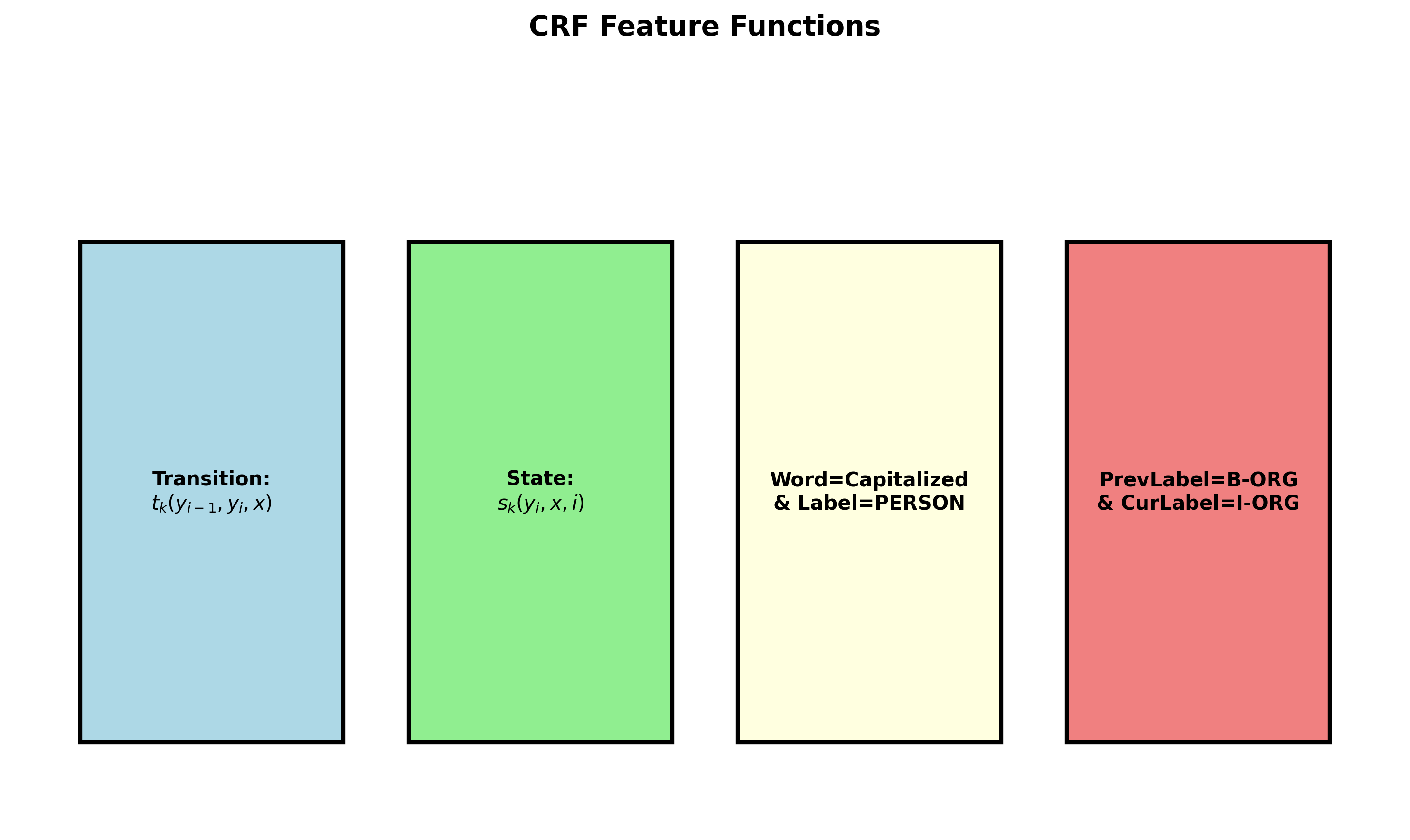
下图展示了 CRF 的特征函数类型:
Feature Functions
势函数展开 :
参数化形式
统一表示 :合并所有特征函数
势函数简化 :
全局得分 :
其中
CRF 完整形式 :
矩阵形式表示
**定义
序列得分的矩阵连乘 :
配分函数 :
其中
前向后向算法: CRF 版本
前向算法推导
前向变量 :
初始化 (
其中
递推 (
终止 :
物理意义 :
后向算法推导
后向变量 :
初始化 (
其中
递推 (
验证 :
边缘概率计算
单个标签的边缘概率 :
相邻标签的边缘概率 :
这些边缘概率是参数学习的核心!
对数空间计算
数值稳定性 :使用
使用
参数学习:极大似然估计
目标函数
训练数据 :
对数似然 :
展开:
加入 L2 正则化 :
优化目标 :
梯度计算详解
对数似然的梯度 :
第一项 (简单):
第二项 (需要推导):
因此:
梯度最终形式 :
物理解释 :经验特征期望 - 模型特征期望
期望的高效计算
问题 :直接计算
解决 :利用线性链结构和边缘概率
利用前向后向算法 :
复杂度 :
梯度下降与 LBFGS 优化
梯度下降 :
问题 :收敛慢,需要调学习率
LBFGS 算法 ( Limited-memory BFGS):
二阶优化方法,利用 Hessian 矩阵近似
有限内存版本,适合高维参数
CRF 训练的标准选择
伪代码 :
1 2 3 4 5 6 初始化 w = 0 while 未收敛: 计算 g = ∇ L(w)(通过前向后向算法) 用 LBFGS 更新 w if |L(w_new) - L(w_old)| < ε: break
工程实现 :使用 scipy.optimize.fmin_l_bfgs_b
Viterbi 解码: CRF 版本
最优序列预测
目标 :
等价于:
Viterbi 算法推导
动态规划变量 :
递推公式 :
回溯指针 :
算法流程
初始化 (
递推 (
终止 :
回溯 (
复杂度 :
代码实现:完整 CRF 框架
特征工程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 import numpy as npfrom collections import defaultdictclass CRFFeatures : """CRF 特征提取器""" def __init__ (self, labels ): """ 参数: labels: 标签集合(不含 START/END) """ self.labels = ['<START>' ] + list (labels) + ['<END>' ] self.label_to_idx = {l: i for i, l in enumerate (self.labels)} self.L = len (self.labels) self.feature_templates = [ self._word_identity, self._word_suffix, self._word_prefix, self._word_is_capitalized, self._word_is_numeric, self._prev_word, self._next_word, ] self.feature_to_idx = {} self.next_feature_idx = 0 def _get_feature_id (self, feature_name ): """获取特征 ID,不存在则创建""" if feature_name not in self.feature_to_idx: self.feature_to_idx[feature_name] = self.next_feature_idx self.next_feature_idx += 1 return self.feature_to_idx[feature_name] def _word_identity (self, X, t, prev_label, curr_label ): """当前词特征""" return [(f"word={X[t]} ,label={curr_label} " , 1.0 )] def _word_suffix (self, X, t, prev_label, curr_label ): """词后缀特征""" word = X[t] if len (word) >= 3 : return [(f"suffix={word[-3 :]} ,label={curr_label} " , 1.0 )] return [] def _word_prefix (self, X, t, prev_label, curr_label ): """词前缀特征""" word = X[t] if len (word) >= 3 : return [(f"prefix={word[:3 ]} ,label={curr_label} " , 1.0 )] return [] def _word_is_capitalized (self, X, t, prev_label, curr_label ): """首字母大写特征""" if X[t][0 ].isupper(): return [(f"capitalized=True,label={curr_label} " , 1.0 )] return [] def _word_is_numeric (self, X, t, prev_label, curr_label ): """数字特征""" if X[t].isdigit(): return [(f"numeric=True,label={curr_label} " , 1.0 )] return [] def _prev_word (self, X, t, prev_label, curr_label ): """前一个词特征""" if t > 0 : return [(f"prev_word={X[t-1 ]} ,label={curr_label} " , 1.0 )] return [] def _next_word (self, X, t, prev_label, curr_label ): """后一个词特征""" if t < len (X) - 1 : return [(f"next_word={X[t+1 ]} ,label={curr_label} " , 1.0 )] return [] def extract_features (self, X, t, prev_label, curr_label ): """ 提取位置 t 的所有特征 返回: feature_vector: 稀疏特征向量 {feature_id: value} """ features = {} trans_feat = f"transition={prev_label} ->{curr_label} " features[self._get_feature_id(trans_feat)] = 1.0 for template in self.feature_templates: for feat_name, feat_val in template(X, t, prev_label, curr_label): feat_id = self._get_feature_id(feat_name) features[feat_id] = feat_val return features def extract_global_features (self, X, Y ): """ 提取全局特征向量 F(X, Y) 返回: 稀疏向量 {feature_id: count} """ features = defaultdict(float ) T = len (X) Y_with_boundary = ['<START>' ] + list (Y) + ['<END>' ] for t in range (T): local_feats = self.extract_features( X, t, Y_with_boundary[t], Y_with_boundary[t+1 ] ) for feat_id, val in local_feats.items(): features[feat_id] += val return dict (features)
CRF 模型实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 from scipy.special import logsumexpfrom scipy.optimize import fmin_l_bfgs_bclass LinearChainCRF : """线性链条件随机场""" def __init__ (self, labels, l2_lambda=0.1 ): """ 参数: labels: 标签集合 l2_lambda: L2 正则化系数 """ self.feature_extractor = CRFFeatures(labels) self.labels = self.feature_extractor.labels self.L = self.feature_extractor.L self.l2_lambda = l2_lambda self.weights = None def _compute_scores (self, X, Y=None ): """ 计算得分矩阵 M_t(i, j) 返回: 如果 Y 为 None: list of (L, L) matrices 如果 Y 给定: scalar score """ T = len (X) if Y is None : M = [] for t in range (T): M_t = np.zeros((self.L, self.L)) for i in range (self.L): for j in range (self.L): if t == 0 and self.labels[i] != '<START>' : M_t[i, j] = -np.inf continue features = self.feature_extractor.extract_features( X, t, self.labels[i], self.labels[j] ) score = sum (self.weights[f_id] * val for f_id, val in features.items() if f_id < len (self.weights)) M_t[i, j] = score M.append(M_t) return M else : global_features = self.feature_extractor.extract_global_features(X, Y) score = sum (self.weights[f_id] * count for f_id, count in global_features.items() if f_id < len (self.weights)) return score def _forward (self, X ): """ 前向算法计算 alpha 和 log Z 返回: alpha: (T, L)数组 log_Z: 对数配分函数 """ T = len (X) M = self._compute_scores(X) log_alpha = np.full((T, self.L), -np.inf) start_idx = self.labels.index('<START>' ) log_alpha[0 , start_idx] = 0.0 for j in range (self.L): if M[0 ][start_idx, j] > -np.inf: log_alpha[0 , j] = M[0 ][start_idx, j] for t in range (1 , T): for j in range (self.L): log_alpha[t, j] = logsumexp( log_alpha[t-1 ] + M[t][:, j] ) end_idx = self.labels.index('<END>' ) log_Z = logsumexp(log_alpha[-1 ]) return log_alpha, log_Z def _backward (self, X ): """ 后向算法计算 beta 返回: beta: (T, L)数组 """ T = len (X) M = self._compute_scores(X) log_beta = np.full((T, self.L), -np.inf) log_beta[-1 , :] = 0.0 for t in range (T-2 , -1 , -1 ): for i in range (self.L): log_beta[t, i] = logsumexp( M[t+1 ][i, :] + log_beta[t+1 ] ) return log_beta def _compute_gradient (self, X_list, Y_list ): """ 计算梯度 返回: gradient: 梯度向量 neg_log_likelihood: 负对数似然 """ num_features = self.feature_extractor.next_feature_idx empirical_counts = np.zeros(num_features) expected_counts = np.zeros(num_features) log_likelihood = 0.0 for X, Y in zip (X_list, Y_list): global_features = self.feature_extractor.extract_global_features(X, Y) for f_id, count in global_features.items(): empirical_counts[f_id] += count score = self._compute_scores(X, Y) log_alpha, log_Z = self._forward(X) log_beta = self._backward(X) log_likelihood += score - log_Z T = len (X) M = self._compute_scores(X) for t in range (T): for i in range (self.L): for j in range (self.L): if t == 0 : log_marginal = M[t][i, j] + log_beta[t, j] - log_Z else : log_marginal = (log_alpha[t-1 , i] + M[t][i, j] + log_beta[t, j] - log_Z) marginal = np.exp(log_marginal) features = self.feature_extractor.extract_features( X, t, self.labels[i], self.labels[j] ) for f_id, val in features.items(): expected_counts[f_id] += marginal * val gradient = empirical_counts - expected_counts - self.l2_lambda * self.weights neg_log_likelihood = -log_likelihood + 0.5 * self.l2_lambda * np.sum (self.weights**2 ) return -gradient, neg_log_likelihood def fit (self, X_list, Y_list, max_iter=100 ): """ 训练 CRF 模型 参数: X_list: 观测序列列表 Y_list: 标签序列列表 max_iter: 最大迭代次数 """ num_features = self.feature_extractor.next_feature_idx self.weights = np.zeros(num_features) def objective (w ): self.weights = w neg_grad, neg_ll = self._compute_gradient(X_list, Y_list) return neg_ll, neg_grad print ("Training CRF with LBFGS..." ) self.weights, f_min, info = fmin_l_bfgs_b( objective, self.weights, maxiter=max_iter, disp=1 ) print (f"Training finished. Final negative log-likelihood: {f_min:.4 f} " ) return self def viterbi (self, X ): """ Viterbi 解码 返回: best_labels: 最优标签序列 """ T = len (X) M = self._compute_scores(X) delta = np.full((T, self.L), -np.inf) psi = np.zeros((T, self.L), dtype=int ) start_idx = self.labels.index('<START>' ) delta[0 , :] = M[0 ][start_idx, :] for t in range (1 , T): for j in range (self.L): scores = delta[t-1 ] + M[t][:, j] psi[t, j] = np.argmax(scores) delta[t, j] = scores[psi[t, j]] best_path = np.zeros(T, dtype=int ) best_path[-1 ] = np.argmax(delta[-1 ]) for t in range (T-2 , -1 , -1 ): best_path[t] = psi[t+1 , best_path[t+1 ]] best_labels = [self.labels[idx] for idx in best_path if self.labels[idx] not in ['<START>' , '<END>' ]] return best_labels def predict (self, X_list ): """批量预测""" return [self.viterbi(X) for X in X_list]
命名实体识别应用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 def ner_example (): """ 命名实体识别示例 """ X_train = [ ['Barack' , 'Obama' , 'was' , 'born' , 'in' , 'Hawaii' ], ['Apple' , 'Inc.' , 'is' , 'located' , 'in' , 'Cupertino' ], ['The' , 'company' , 'was' , 'founded' , 'in' , '1976' ] ] Y_train = [ ['B-PER' , 'I-PER' , 'O' , 'O' , 'O' , 'B-LOC' ], ['B-ORG' , 'I-ORG' , 'O' , 'O' , 'O' , 'B-LOC' ], ['O' , 'O' , 'O' , 'O' , 'O' , 'B-DATE' ] ] X_test = [ ['Steve' , 'Jobs' , 'founded' , 'Apple' ], ['Google' , 'is' , 'in' , 'California' ] ] labels = set (label for seq in Y_train for label in seq) crf = LinearChainCRF(labels, l2_lambda=0.1 ) crf.fit(X_train, Y_train, max_iter=50 ) Y_pred = crf.predict(X_test) for X, Y in zip (X_test, Y_pred): print (f"Sentence: {' ' .join(X)} " ) print (f"Predicted labels: {' ' .join(Y)} " ) print ()
高级话题与优化
特征模板设计
窗口特征 :
1 2 3 4 for offset in [-2 , -1 , 0 , 1 , 2 ]: if 0 <= t + offset < T: features.append(f"word[{offset} ]={X[t+offset]} ,label={y_t} " )
词典特征 :
1 2 if word in person_dict: features.append(f"in_person_dict=True,label={y_t} " )
正则表达式特征 :
1 2 3 import reif re.match (r'\d{4}-\d{2}-\d{2}' , word): features.append(f"date_pattern=True,label={y_t} " )
半马尔可夫 CRF
允许段级标注 :标签跨越多个位置
应用 :中文分词、命名实体识别
结构化感知机
在线学习版本 :不需要计算配分函数
更新规则 :
优势 :训练快,但不如 CRF 概率化
深入问答
Q1: CRF 相比 HMM 的核心优势是什么?
A: CRF 是判别式模型,直接建模无观测独立性假设 : HMM
假设灵活特征工程 :
CRF 可以使用全局特征、重叠特征(如前后词、词典匹配) 3.
序列标注性能更优 :在 NER 、词性标注任务上, CRF 通常比
HMM 高 5-10 个百分点
Q2:为什么 CRF 需要前向后向算法计算梯度?
A:梯度包含期望项
边缘概率
Q3:配分函数 Z(X)为什么难计算?
A:配分函数定义为
需要对所有
Q4: CRF 的 L2 正则化为什么重要?
A:两个原因: 1.
防止过拟合 :特征数量通常很大(几万到几百万),L2
惩罚保证凸性 :原始目标函数是凸的,加入 L2
后仍是强凸,保证 LBFGS 收敛到全局最优
通常取
Q5: Viterbi 解码与边缘解码的区别?
A:两种解码策略: - Viterbi
解码 :找到联合概率最大的序列边缘解码 :每个位置独立选择边缘概率最大的标签
Viterbi 保证全局一致性(如 BIO
标注约束),边缘解码可能产生非法序列。实践中 Viterbi 更常用。
Q6:如何处理大规模标签集?
A:当标签数Beam Search 近似 :只保留 top-K 个候选状态 2.
分层标注 :先粗粒度标注,再细粒度 3. 神经
CRF :用神经网络学习转移矩阵,减少参数
Q7: CRF 能处理非序列结构吗?
A:可以!通用 CRF 可以定义在任意图结构上: - 树形
CRF :依存句法分析 - 网格 CRF :图像分割( 2D
CRF) - 完全图 CRF :全局归一化分类
但非链式结构的推断复杂度更高,通常需要近似算法(如 loopy belief
propagation)。
Q8: MEMM 为什么有标注偏置问题?
A: MEMM 局部归一化:
问题:转移选项少的状态(如确定性状态)归一化分母小,概率倾向于
1,模型偏向选择这些状态。 CRF 通过全局归一化解决:
所有路径竞争同一个分母,避免局部偏置。
Q9:特征数量对 CRF 性能的影响?
A:特征数量与性能关系: - 太少:欠拟合,捕捉不到复杂模式 -
太多:过拟合,训练慢,泛化差
经验法则: - 基础特征(词、 POS 、词缀):几千到几万 -
加入词典特征:几万到几十万 - 使用正则化+特征选择(如 L1)控制复杂度
Q10: CRF 与深度学习的结合?
A:现代序列标注通常使用BiLSTM-CRF : -
BiLSTM:学习上下文表示 - CRF:建模标签依赖、约束合法性
结构:
BiLSTM 输出作为 CRF 的发射得分,CRF
层学习转移矩阵。训练时联合优化,推断时仍用 Viterbi。
Q11:如何评估 CRF 模型?
A:序列标注任务评估指标: 1. Token
级准确率 :单个标签正确率 2. Span 级
F1 :实体级别的精确率、召回率、 F1(更重要) - Precision =
正确实体数 / 预测实体数 - Recall = 正确实体数 / 真实实体数 3.
混淆矩阵 :分析哪些标签容易混淆
Q12: CRF 的训练时间如何优化?
A:优化策略: 1. 特征哈希 :用哈希函数减少特征维度 2.
小批量梯度 :不用全量数据计算梯度 3.
并行化 :多个序列的前向后向算法可并行 4.
早停 :监控验证集性能,避免过拟合 5.
预训练初始化 :用感知机快速预训练权重
参考文献
[1] Lafferty, J., McCallum, A., & Pereira, F. C. (2001).
Conditional random fields: Probabilistic models for segmenting and
labeling sequence data. ICML .
[2] Sutton, C., & McCallum, A. (2012). An introduction to
conditional random fields. Foundations and Trends in Machine
Learning , 4(4), 267-373.
[3] Sha, F., & Pereira, F. (2003). Shallow parsing with
conditional random fields. NAACL-HLT .
[4] Wallach, H. M. (2004). Conditional random fields: An
introduction. Technical Report MS-CIS-04-21, University of
Pennsylvania .
[5] Sarawagi, S., & Cohen, W. W. (2005). Semi-Markov conditional
random fields for information extraction. NIPS .
[6] Collins, M. (2002). Discriminative training methods for hidden
Markov models: Theory and experiments with perceptron algorithms.
EMNLP .
[7] Huang, Z., Xu, W., & Yu, K. (2015). Bidirectional LSTM-CRF
models for sequence tagging. arXiv preprint
arXiv:1508.01991 .
[8] Ma, X., & Hovy, E. (2016). End-to-end sequence labeling via
bi-directional LSTM-CNNs-CRF. ACL .
[9] Lample, G., Ballesteros, M., Subramanian, S., Kawakami, K., &
Dyer, C. (2016). Neural architectures for named entity recognition.
NAACL-HLT .
[10] Kr ä henb ü hl, P., & Koltun, V. (2011). Efficient inference
in fully connected CRFs with Gaussian edge potentials.
NIPS .
✏️ 练习题与解答
练习 1:CRF vs HMM
题目 :比较 CRF 和 HMM
在词性标注任务中的建模差异。
解答 :
维度 HMM CRF
模型类型 生成式
判别式
假设 观测独立性
无观测独立性假设
特征 局部特征
任意重叠特征
归一化 局部归一化
全局归一化
标注偏置 MEMM有,HMM无
无
关键 :CRF
的全局归一化和灵活特征使其在序列标注任务上优于 HMM。
练习 2:特征函数设计
题目 :为命名实体识别设计3个特征函数。
解答 :
转移特征 :𝟙
状态特征 :𝟙
全局特征 :𝟙
优势 :这些特征可以重叠 (如同时考虑大写和词典),HMM
的观测独立性无法做到!
练习
3:前向算法计算归一化因子
题目 :CRF 序列长度
解答 :
初始化 (
递推 (
终止 :
复杂度 :
练习 4:梯度计算
题目 :推导 CRF 负对数似然
解答 :
其中
含义 :梯度 = 模型期望特征 -
观测特征,这是最大熵原理的体现!
练习 5:Viterbi解码
题目 :CRF 的 Viterbi 解码与 HMM 的区别。
解答 :
相同点 :都用动态规划找最优标签序列
不同点 :
维度 HMM Viterbi CRF Viterbi
得分
转移
特征 局部观测
全局观测
关键 :CRF Viterbi 使用全局特征,HMM
只用当前观测!