聚类(Clustering)是无监督学习的核心任务——在没有标签的情况下,根据数据的相似性自动发现群组结构。从
K-means 的简洁优雅到 DBSCAN
的密度自适应,从层次聚类的树状结构到谱聚类的图论基础,聚类算法为探索性数据分析、客户分群、图像分割与异常检测提供了强大工具。K-means
通过 Lloyd 算法迭代优化,可用 EM
框架解释;层次聚类用链接准则构建树状图;DBSCAN
基于密度可达性发现任意形状簇;谱聚类则将图分割问题转化为拉普拉斯矩阵的特征分解。
聚类问题的形式化
聚类的目标
输入 :数据集
输出 :聚类分配
原则 :
高内聚 :同一簇内的点相似度高低耦合 :不同簇之间的点相似度低
相似度度量
欧氏距离 :
曼哈顿距离 :
余弦相似度 :
适用于文本、稀疏数据
马氏距离 :
其中
聚类质量评估
内部指标 (无需标签):
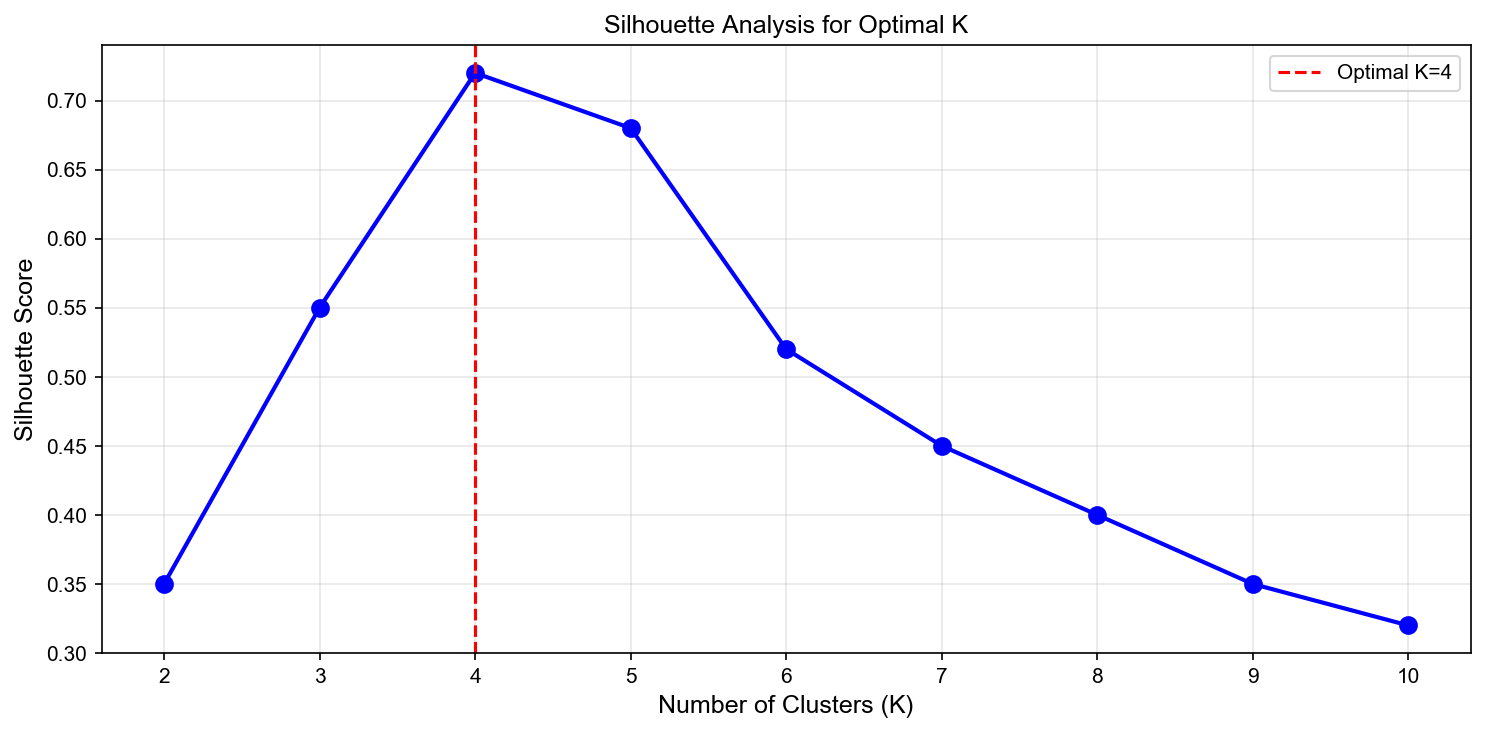
轮廓系数 (Silhouette Coefficient):
其中
取值
Figure 4
Calinski-Harabasz 指数 :
其中
外部指标 (需要真实标签):
调整兰德指数 (Adjusted Rand Index, ARI):
取值
归一化互信息 (Normalized Mutual Information,
NMI):
取值
K-means:质心驱动的聚类
Lloyd 算法
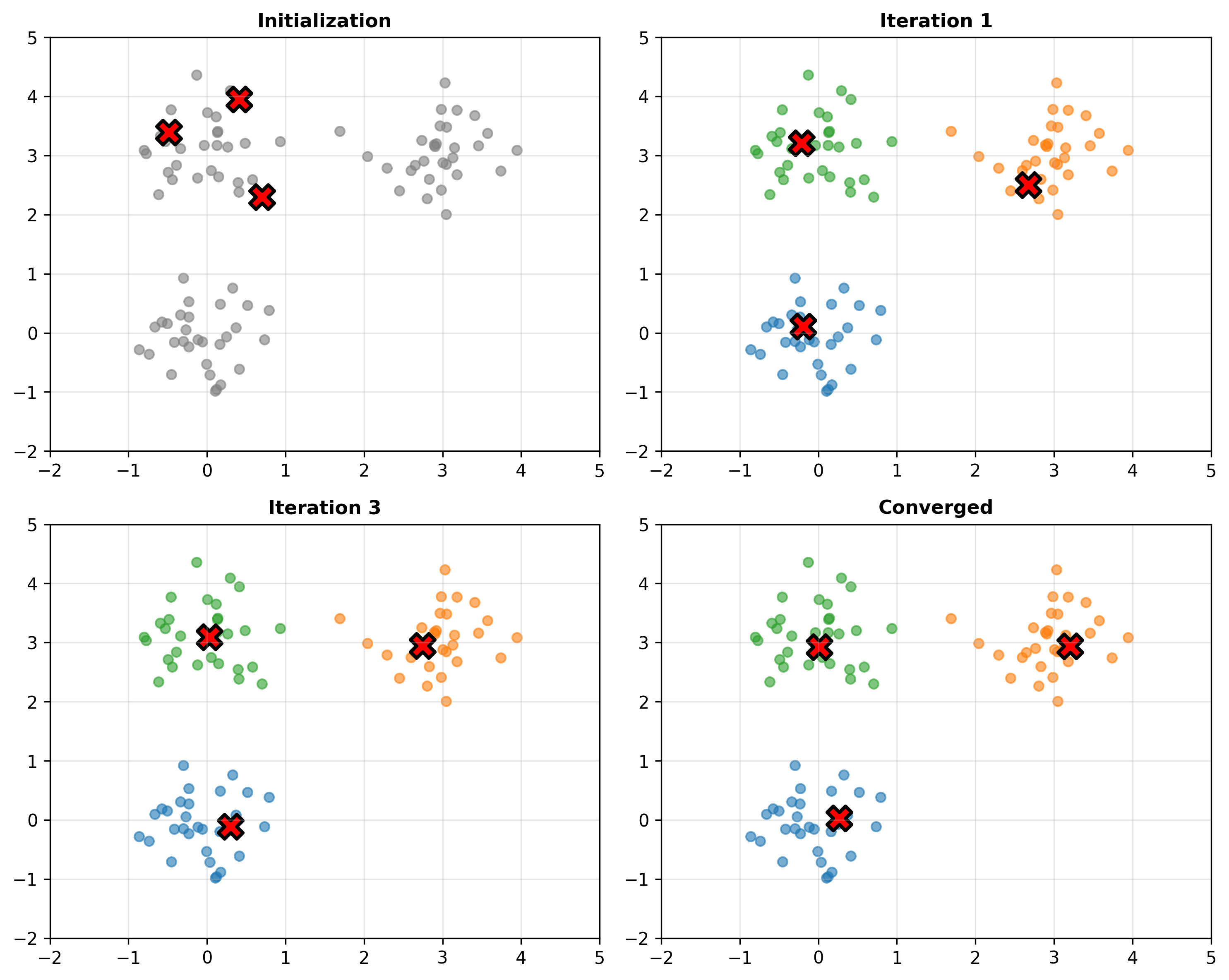
Figure 1
目标 :最小化簇内平方误差和(Within-Cluster Sum of
Squares, WCSS)
其中
优化问题 :
困难 :联合优化离散变量
解决方案 :坐标下降法( Lloyd 算法)
Lloyd 算法推导
步骤 1(分配步) :固定{_k}, 优 化
物理意义 :将每个点分配给最近的质心
步骤 2(更新步) :固定
解得:
其中
物理意义 :质心是簇内所有点的平均值
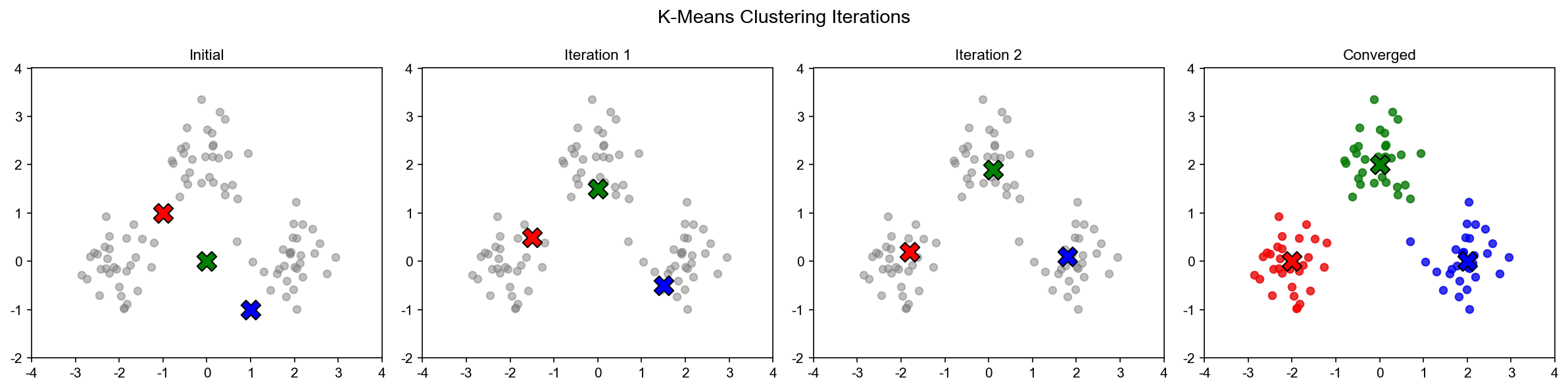
完整算法流程
输入 :数据
初始化 :随机选择
迭代 (
分配步 :对每个点
更新步 :对每个簇
收敛检查 :如果
下图展示了 K-means 算法的收敛过程:
K-means Convergence
输出 :聚类分配
复杂度 :
收敛性分析
定理 : Lloyd 算法保证目标函数
证明 :
分配步后 :每个点被分配给最近质心,更新步后 :质心设为簇平均值,这是使簇内平方误差最小的选择
求导得
局限性 :收敛到的是局部最优,依赖初始化
K-means 的 EM 解释
生成模型视角 :假设数据由
硬分配版本 :每个点只属于一个簇(
对数似然 :
忽略
等价于 K-means 目标!
E 步 :给定
M 步 :给定
𝟙 𝟙
结论 : K-means 是 GMM
的硬分配特例(协方差为单位矩阵)
K-means++初始化
问题 :随机初始化可能导致糟糕的局部最优
K-means++策略 :
随机选择第一个质心
对
计算每个点
以概率
直觉 :倾向于选择远离已有质心的点,使初始质心分散
理论保证 :K-means++的期望目标函数值
K-means 的局限性
**1. 需要预先指定
解决方案:
肘部法则(Elbow Method):绘制
轮廓系数:选择使轮廓系数最大的
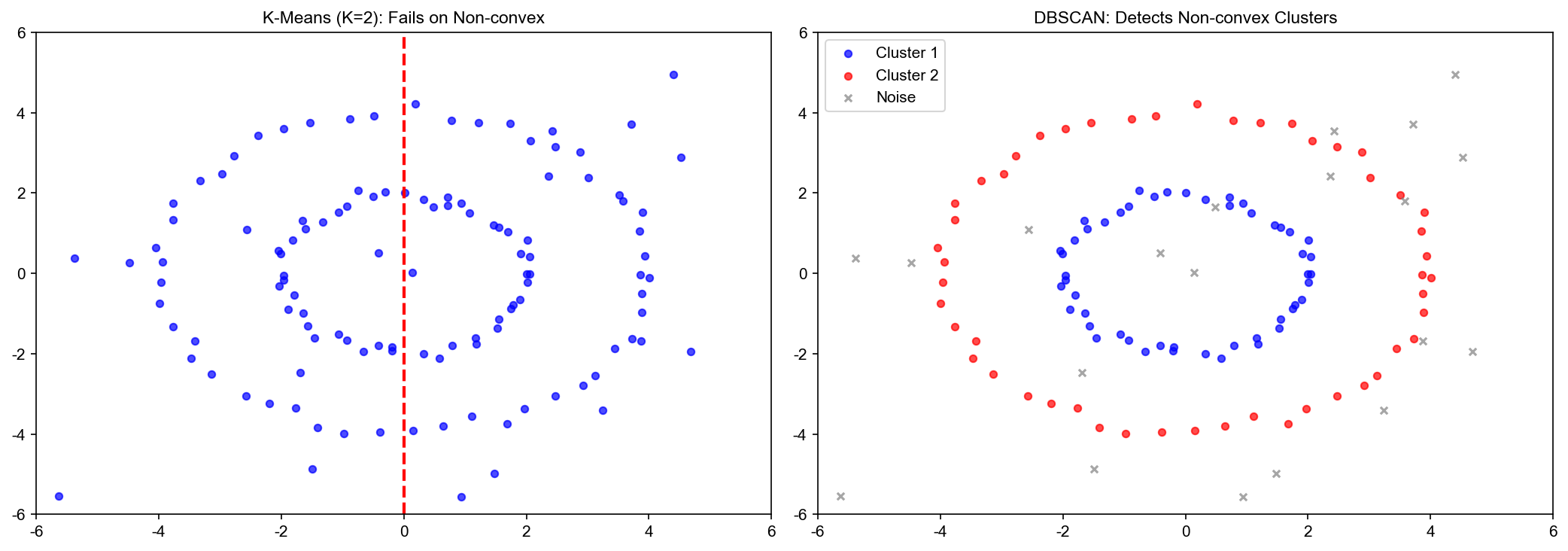
2. 假设簇是凸的、各向同性的
反例:环形簇、椭圆簇
解决方案:核 K-means 、谱聚类
3. 对离群点敏感
解决方案: K-medoids(使用中位数而非均值)
4. 对特征尺度敏感
解决方案:标准化数据
层次聚类:从树到簇
凝聚层次聚类
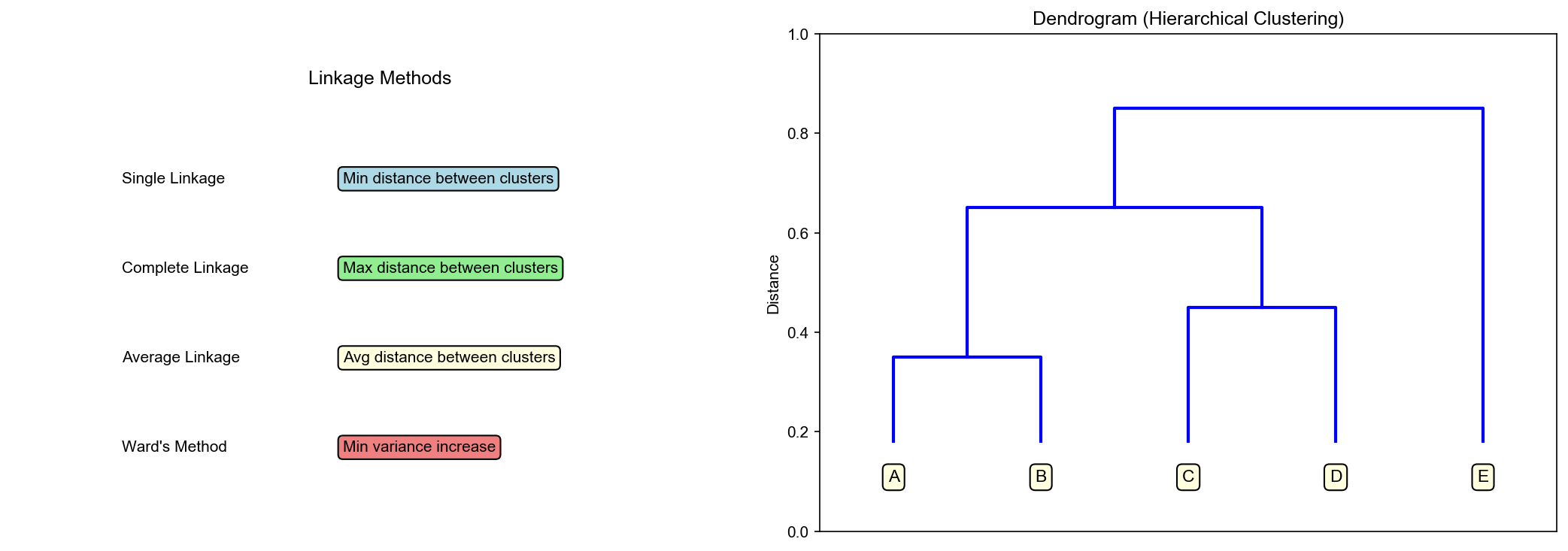
Figure 2
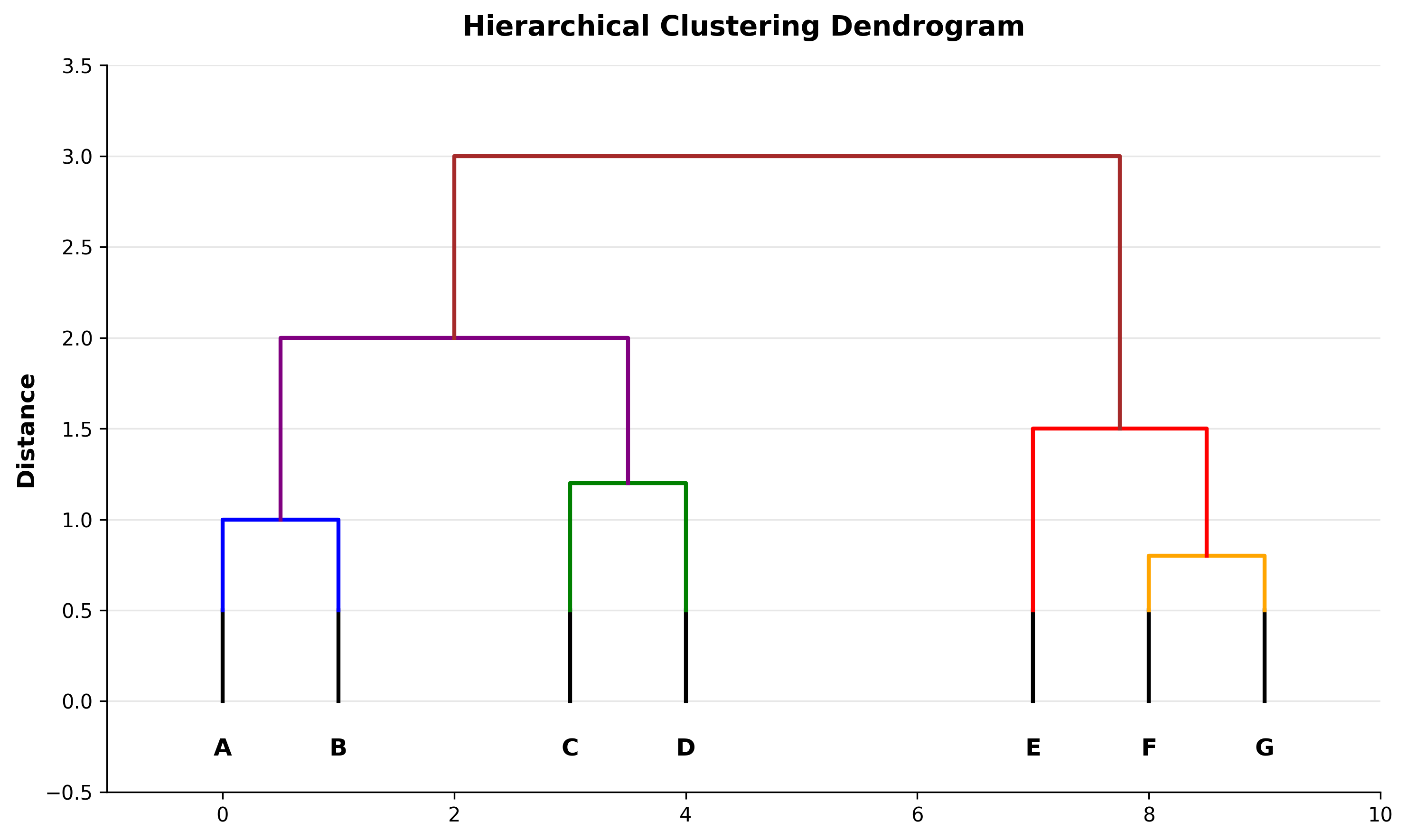
思想 :自底向上合并簇,构建树状图(Dendrogram)
下图展示了层次聚类的树状图结构:
Hierarchical Dendrogram
算法流程 :
初始化 :每个点是一个簇,
迭代 :
找到距离最近的两个簇
合并:
更新距离矩阵
重复直到只剩
关键 :如何定义簇间距离
链接准则
1. 单链接 (Single Linkage):最小距离
特点 :
2. 全链接 (Complete Linkage):最大距离
特点 :
3. 平均链接 (Average Linkage):平均距离
特点 :介于单链接和全链接之间
4. Ward 链接 :最小化合并后的方差增量
特点 :与 K-means
目标一致,倾向于产生大小相近的簇
树状图与簇切割
树状图 :展示合并顺序和距离
切割策略 :
固定高度 :在某个距离阈值处水平切割固定簇数 :切割出
优势 :
不需要预先指定
可解释性强
劣势 :
分裂层次聚类
思想 :自顶向下分裂簇
算法 :
初始化:所有点在一个簇
迭代:
选择最大的簇(或其他准则)
用 K-means(
重复直到达到
优势 :可以提前停止,适合只需要粗粒度聚类
劣势 :计算量大
DBSCAN:密度驱动的聚类
核心概念
邻域 :点
核心点 :邻域内至少有
边界点 :不是核心点,但在某个核心点的邻域内
噪声点 :既不是核心点也不是边界点
密度可达性
直接密度可达 :
密度可达 :存在链
密度连通 :存在点
簇定义 :
最大性 :如果连通性 :簇内任意两点密度连通
DBSCAN 算法流程
Figure 3
输入 :数据, 最 小 点 数
初始化 :所有点标记为未访问
主循环 :
随机选择一个未访问的点
标记为已访问
找到邻域
如果 :
否则 :
重复直到所有点被访问
输出 :簇集合
复杂度 :
DBSCAN 的优势与局限
优势 :
不需要指定簇数 可发现任意形状的簇 自动识别噪声点 对离群点鲁棒
局限 :
参数敏感 :难以处理不同密度的簇
高维数据困难 :维度灾难导致距离集中
参数选择策略
对每个点,计算到第
将所有点的
找到"肘部"(曲线急剧上升处)作为
谱聚类:图论视角
图构建
将数据看作图 :
相似度矩阵 :
稀疏化 (可选):
度矩阵 :
图拉普拉斯矩阵
未归一化拉普拉斯 :
性质 :
对称半正定:
最小特征值为 0,对应特征向量是全 1 向量
第二小特征值(Fiedler 值)衡量图的连通性
归一化拉普拉斯 (对称版本):
归一化拉普拉斯 (随机游走版本):
谱聚类的优化目标
RatioCut (未归一化):
其中
NCut (归一化):
其中
目标 :最小化簇间连接,同时平衡簇的大小/体积
谱聚类算法推导
RatioCut 的松弛 :
引入指示矩阵
可以证明:
约束:
松弛 :允许
解 :
NCut 的松弛 :类似推导,使用归一化拉普拉斯
谱聚类算法流程
输入 :数据
步骤 :
构建相似度矩阵 :
计算度矩阵 :
计算拉普拉斯矩阵 :
特征分解 :计算
构建嵌入矩阵 :
归一化 (对于
K-means 聚类 :对
分配簇标签 :如果 K-means 将第
输出 :聚类分配
复杂度 :
谱聚类的优势与局限
优势 :
可发现非凸簇 基于图论的坚实理论基础 只需要相似度矩阵,不需要原始特征
局限 :
复杂度高 :参数敏感 :**仍需指定簇数
GMM 聚类:软分配与概率视角
高斯混合模型
生成过程 :
选择成分
生成数据
概率密度 :
参数 :
EM 算法求解
E 步 :计算后验概率(责任)
M 步 :更新参数
聚类分配 :
GMM vs K-means
维度
K-means
GMM
分配
硬分配( 0/1)
软分配(概率)
簇形状
球形
椭圆形(任意协方差)
概率解释
特殊情况(单位协方差)
完整概率模型
复杂度
代码实现:完整聚类工具包
K-means 实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 import numpy as npimport matplotlib.pyplot as pltclass KMeans : """K-means 聚类""" def __init__ (self, n_clusters=3 , max_iter=300 , tol=1e-4 , init='k-means++' ): """ 参数: n_clusters: 簇数 K max_iter: 最大迭代次数 tol: 收敛阈值 init: 初始化方法 ('random' 或 'k-means++') """ self.n_clusters = n_clusters self.max_iter = max_iter self.tol = tol self.init = init self.centroids = None self.labels = None self.inertia_ = None def _initialize_centroids (self, X ): """初始化质心""" N = X.shape[0 ] if self.init == 'random' : indices = np.random.choice(N, self.n_clusters, replace=False ) return X[indices] elif self.init == 'k-means++' : centroids = [] centroids.append(X[np.random.randint(N)]) for _ in range (1 , self.n_clusters): distances = np.array([min ([np.linalg.norm(x - c)**2 for c in centroids]) for x in X]) probabilities = distances / distances.sum () cumulative_probs = np.cumsum(probabilities) r = np.random.rand() for i, cum_prob in enumerate (cumulative_probs): if r < cum_prob: centroids.append(X[i]) break return np.array(centroids) def _assign_clusters (self, X ): """分配步:将每个点分配给最近的质心""" distances = np.zeros((X.shape[0 ], self.n_clusters)) for k in range (self.n_clusters): distances[:, k] = np.linalg.norm(X - self.centroids[k], axis=1 ) return np.argmin(distances, axis=1 ) def _update_centroids (self, X, labels ): """更新步:重新计算质心""" centroids = np.zeros((self.n_clusters, X.shape[1 ])) for k in range (self.n_clusters): if np.sum (labels == k) > 0 : centroids[k] = X[labels == k].mean(axis=0 ) else : centroids[k] = X[np.random.randint(X.shape[0 ])] return centroids def fit (self, X ): """训练 K-means 模型""" self.centroids = self._initialize_centroids(X) for iteration in range (self.max_iter): labels = self._assign_clusters(X) new_centroids = self._update_centroids(X, labels) centroid_shift = np.linalg.norm(new_centroids - self.centroids) self.centroids = new_centroids if centroid_shift < self.tol: print (f"Converged at iteration {iteration+1 } " ) break self.labels = self._assign_clusters(X) self.inertia_ = 0 for k in range (self.n_clusters): cluster_points = X[self.labels == k] self.inertia_ += np.sum ((cluster_points - self.centroids[k])**2 ) return self def predict (self, X ): """预测新样本的簇标签""" distances = np.zeros((X.shape[0 ], self.n_clusters)) for k in range (self.n_clusters): distances[:, k] = np.linalg.norm(X - self.centroids[k], axis=1 ) return np.argmin(distances, axis=1 )
DBSCAN 实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 from scipy.spatial.distance import pdist, squareformclass DBSCAN : """DBSCAN 密度聚类""" def __init__ (self, eps=0.5 , min_samples=5 ): """ 参数: eps: 邻域半径 min_samples: 核心点的最小邻居数 """ self.eps = eps self.min_samples = min_samples self.labels = None def _get_neighbors (self, X, point_idx ): """获取点的邻域""" distances = np.linalg.norm(X - X[point_idx], axis=1 ) return np.where(distances <= self.eps)[0 ] def fit (self, X ): """训练 DBSCAN 模型""" N = X.shape[0 ] self.labels = -np.ones(N, dtype=int ) cluster_id = 0 for point_idx in range (N): if self.labels[point_idx] != -1 : continue neighbors = self._get_neighbors(X, point_idx) if len (neighbors) < self.min_samples: self.labels[point_idx] = -1 continue self.labels[point_idx] = cluster_id seed_set = list (neighbors) i = 0 while i < len (seed_set): current_point = seed_set[i] if self.labels[current_point] == -1 : self.labels[current_point] = cluster_id elif self.labels[current_point] != -1 : i += 1 continue self.labels[current_point] = cluster_id current_neighbors = self._get_neighbors(X, current_point) if len (current_neighbors) >= self.min_samples: seed_set.extend(current_neighbors) i += 1 cluster_id += 1 return self def fit_predict (self, X ): """训练并返回标签""" self.fit(X) return self.labels
谱聚类实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 class SpectralClustering : """谱聚类""" def __init__ (self, n_clusters=3 , sigma=1.0 , use_normalized=True ): """ 参数: n_clusters: 簇数 K sigma: 高斯核参数 use_normalized: 是否使用归一化拉普拉斯 """ self.n_clusters = n_clusters self.sigma = sigma self.use_normalized = use_normalized self.labels = None def _compute_affinity_matrix (self, X ): """计算相似度矩阵""" distances = squareform(pdist(X, 'sqeuclidean' )) W = np.exp(-distances / (2 * self.sigma**2 )) np.fill_diagonal(W, 0 ) return W def fit (self, X ): """训练谱聚类模型""" N = X.shape[0 ] W = self._compute_affinity_matrix(X) D = np.diag(W.sum (axis=1 )) if self.use_normalized: D_inv_sqrt = np.diag(1.0 / np.sqrt(np.diag(D))) L = np.eye(N) - D_inv_sqrt @ W @ D_inv_sqrt else : L = D - W eigenvalues, eigenvectors = np.linalg.eigh(L) idx = np.argsort(eigenvalues)[:self.n_clusters] U = eigenvectors[:, idx] if self.use_normalized: U = U / np.linalg.norm(U, axis=1 , keepdims=True ) kmeans = KMeans(n_clusters=self.n_clusters, init='k-means++' ) self.labels = kmeans.fit(U).labels return self def fit_predict (self, X ): """训练并返回标签""" self.fit(X) return self.labels
聚类评估与可视化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 from sklearn.metrics import silhouette_score, calinski_harabasz_scoredef evaluate_clustering (X, labels ): """评估聚类质量""" mask = labels != -1 X_filtered = X[mask] labels_filtered = labels[mask] if len (np.unique(labels_filtered)) < 2 : print ("簇数少于 2,无法计算评估指标" ) return silhouette = silhouette_score(X_filtered, labels_filtered) ch_score = calinski_harabasz_score(X_filtered, labels_filtered) print (f"Silhouette Score: {silhouette:.4 f} " ) print (f"Calinski-Harabasz Score: {ch_score:.4 f} " ) return silhouette, ch_score def visualize_clustering (X, labels, title='Clustering Result' ): """可视化聚类结果( 2D)""" plt.figure(figsize=(8 , 6 )) unique_labels = np.unique(labels) colors = plt.cm.Spectral(np.linspace(0 , 1 , len (unique_labels))) for label, color in zip (unique_labels, colors): if label == -1 : color = 'k' marker = 'x' else : marker = 'o' mask = labels == label plt.scatter(X[mask, 0 ], X[mask, 1 ], c=[color], marker=marker, s=50 , edgecolor='k' , linewidth=0.5 , label=f'Cluster {label} ' if label != -1 else 'Noise' ) plt.title(title) plt.xlabel('Feature 1' ) plt.ylabel('Feature 2' ) plt.legend() plt.grid(True , alpha=0.3 ) plt.show()
聚类算法对比示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 from sklearn.datasets import make_moons, make_circles, make_blobsdef clustering_comparison (): """对比不同聚类算法""" n_samples = 300 datasets = [ make_blobs(n_samples=n_samples, centers=3 , random_state=42 ), make_moons(n_samples=n_samples, noise=0.05 , random_state=42 ), make_circles(n_samples=n_samples, factor=0.5 , noise=0.05 , random_state=42 ) ] dataset_names = ['Blobs' , 'Moons' , 'Circles' ] algorithms = [ ('K-means' , KMeans(n_clusters=3 , init='k-means++' )), ('DBSCAN' , DBSCAN(eps=0.2 , min_samples=5 )), ('Spectral' , SpectralClustering(n_clusters=3 , sigma=0.5 )) ] fig, axes = plt.subplots(3 , 3 , figsize=(15 , 12 )) for i, (X, y) in enumerate (datasets): for j, (name, algorithm) in enumerate (algorithms): ax = axes[i, j] if hasattr (algorithm, 'fit_predict' ): labels = algorithm.fit_predict(X) else : algorithm.fit(X) labels = algorithm.labels unique_labels = np.unique(labels) colors = plt.cm.Spectral(np.linspace(0 , 1 , len (unique_labels))) for label, color in zip (unique_labels, colors): if label == -1 : color = 'k' marker = 'x' else : marker = 'o' mask = labels == label ax.scatter(X[mask, 0 ], X[mask, 1 ], c=[color], marker=marker, s=30 , edgecolor='k' , linewidth=0.5 ) ax.set_title(f'{dataset_names[i]} - {name} ' ) ax.set_xticks([]) ax.set_yticks([]) plt.tight_layout() plt.savefig('clustering_comparison.png' , dpi=300 ) plt.show()
深入问答
Q1: K-means 为什么假设簇是球形的?
A: K-means
使用欧氏距离,将点分配给最近的质心。这隐含假设每个簇的协方差矩阵是单位矩阵(各向同性)。如果簇是椭圆形或不规则形状,
K-means 会失败。解决方案: GMM(允许不同协方差)或谱聚类。
Q2:如何确定最优的 K 值?
A:常用方法: 1. 肘部法则 :绘制 WCSS vs K
曲线,找拐点 2. 轮廓系数 :选择使平均轮廓系数最大的 K 3.
Gap 统计量 :比较 WCSS 与随机数据的 WCSS 4.
领域知识 :结合实际问题
实践中,通常结合多种方法并考虑可解释性。
Q3: DBSCAN 如何处理不同密度的簇?
A:DBSCAN 难以处理密度差异大的簇,因为单一的HDBSCAN :层次 DBSCAN,自适应不同密度 -
OPTICS :生成可达性图,允许多尺度分析 -
多次运行 :对不同密度区域分别运行 DBSCAN
Q4:谱聚类为什么需要最后一步 K-means?
A:特征分解给出的嵌入向量
理论上,离散化是松弛优化的必要步骤。
Q5:为什么归一化拉普拉斯比未归一化的更好?
A:归一化拉普拉斯
实践中,归一化版本通常性能更好。
Q6: GMM vs K-means,何时选择 GMM?
A:选择 GMM 当: - 簇形状是椭圆的(不同方向方差不同) -
需要软分配(点属于多个簇的概率) - 需要概率解释(生成模型)
选择 K-means 当: - 簇近似球形 - 需要速度( K-means 快得多) -
数据量大( GMM 的协方差估计需要更多样本)
Q7:层次聚类何时优于 K-means?
A:层次聚类优势: - 不需要预先指定 K - 提供多层次的簇结构(树状图) -
可解释性强
劣势: - 复杂度高(
适用场景:中小规模数据、需要层次结构、探索性分析。
Q8:如何评估聚类结果的好坏?
A:两类指标:
内部指标 (无需标签): - 轮廓系数:高内聚低耦合 - CH
指数:簇间/簇内散度比 - Davies-Bouldin 指数:簇间距离/簇内距离
外部指标 (需要真实标签): - ARI:调整兰德指数 -
NMI:归一化互信息 - F1 分数:精确率与召回率的调和平均
实践中,结合多个指标和可视化。
Q9:聚类算法对特征尺度敏感吗?
A:非常敏感(基于距离的算法)!如果特征尺度差异大(如身高 cm vs
工资元),大尺度特征会主导距离计算。解决方案: -
标准化 :归一化 :鲁棒缩放 :使用中位数和 IQR
基于图的算法(谱聚类)相对不敏感,因为相似度矩阵已经归一化。
Q10: Mini-batch K-means vs 标准 K-means?
A: Mini-batch K-means: - 每次迭代只使用随机子集更新质心 -
复杂度从
适用于:超大规模数据(百万级样本)、在线学习、流数据。
权衡:速度 vs 精度。实践中, Mini-batch 通常只损失 1-5%的精度,但快
10-100 倍。
Q11:如何处理高维数据的聚类?
A:高维聚类挑战: - 维度灾难:距离集中,所有点等距 -
稀疏性:数据变得稀疏 - 噪声维度:许多维度无关
解决方案: 1. 降维预处理 : PCA/t-SNE 后聚类 2.
子空间聚类 :每个簇在不同子空间(如 CLIQUE) 3.
特征选择 :只保留相关特征 4. 基于密度 :
DBSCAN 在局部邻域工作,对维度稍鲁棒
Q12:聚类在实际应用中有哪些坑?
A:常见陷阱: 1. 过度依赖默认参数 : K/eps 等需要调优
2. 忽略特征工程 :聚类对特征选择和缩放极度敏感 3.
误解聚类结果 :聚类总能给出结果,但不一定有意义 4.
忽略可视化 :低维投影可视化验证聚类合理性 5.
错误评估 :只看内部指标,忽略领域知识
最佳实践:多个算法对比、参数搜索、可视化验证、领域专家评估。
参考文献
[1] Lloyd, S. (1982). Least squares quantization in PCM. IEEE
Transactions on Information Theory , 28(2), 129-137.
[2] Arthur, D., & Vassilvitskii, S. (2007). k-means++: The
advantages of careful seeding. SODA , 1027-1035.
[3] Ester, M., Kriegel, H. P., Sander, J., & Xu, X. (1996). A
density-based algorithm for discovering clusters in large spatial
databases with noise. KDD , 226-231.
[4] Ng, A. Y., Jordan, M. I., & Weiss, Y. (2002). On spectral
clustering: Analysis and an algorithm. NIPS , 849-856.
[5] Von Luxburg, U. (2007). A tutorial on spectral clustering.
Statistics and Computing , 17(4), 395-416.
[6] Shi, J., & Malik, J. (2000). Normalized cuts and image
segmentation. IEEE Transactions on Pattern Analysis and Machine
Intelligence , 22(8), 888-905.
[7] Ward, J. H. (1963). Hierarchical grouping to optimize an
objective function. Journal of the American Statistical
Association , 58(301), 236-244.
[8] Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum
likelihood from incomplete data via the EM algorithm. Journal of the
Royal Statistical Society: Series B , 39(1), 1-22.
[9] Campello, R. J., Moulavi, D., & Sander, J. (2013).
Density-based clustering based on hierarchical density estimates.
PAKDD , 160-172.
[10] Jain, A. K. (2010). Data clustering: 50 years beyond K-means.
Pattern Recognition Letters , 31(8), 651-666.
✏️ 练习题与解答
练习 1:K-means 目标函数
题目 :证明 K-means 的更新步使目标函数
解答 :对
令导数为0:
这是二阶导数为正的极小值点,故更新步使
练习 2:DBSCAN 参数影响
题目 :
解答 :是核心点 。
若改为边界点 或噪声点 (取决于是否在其他核心点的邻域内)。
练习 3:GMM vs K-means
题目 :比较 GMM 和 K-means 的异同。
解答 :
维度 K-means GMM
假设 硬分配(每点属于1个簇)
软分配(概率分布)
簇形状 球形(等方差)
椭圆形(协方差矩阵)
优化 Lloyd算法
EM算法
目标函数 最小化平方误差
最大化对数似然
输出 簇标签
后验概率
关键 :GMM 是 K-means
的概率化推广,更灵活但计算更复杂。
练习 4:层次聚类链接方式
题目 :单链接和全链接在处理噪声时的表现。
解答 :
单链接 (Min):
优点 :可识别任意形状簇缺点 :对噪声敏感,易产生"链式效应"(两个簇通过单个噪声点连接)
全链接 (Max):
实践 :Ward链接(最小化簇内方差增量)综合性能最佳。
练习 5:轮廓系数计算
题目 :点
解答 :
解读 :
整体评估 :平均轮廓系数