隐马尔可夫模型(Hidden Markov Model,
HMM)是序列建模的经典工具——当我们观察到一系列可见的输出时,如何推断背后隐藏的状态序列?从语音识别到词性标注,从生物信息学到金融时间序列,
HMM
通过巧妙的动态规划算法解决概率计算、学习与预测三大基本问题。前向后向算法高效计算观测序列概率,Viterbi
算法找到最优状态路径,Baum-Welch 算法在 EM
框架下学习模型参数——这三者构成了 HMM 的完整理论体系。
马尔可夫链:从无记忆到有限记忆
一阶马尔可夫假设
经典马尔可夫链 :状态序列
物理解释 :未来只依赖于现在,与历史无关
齐次性假设 :转移概率与时间无关
转移矩阵 :
约束条件 :
天气预测示例
状态空间 :晴 天 , 雨 天
转移矩阵 :
解读:晴天后仍晴天的概率 80%,雨天后放晴的概率 40%
初始分布 :
T 步后的状态分布 :
稳态分布 :当
对于上述天气例子,稳态分布为
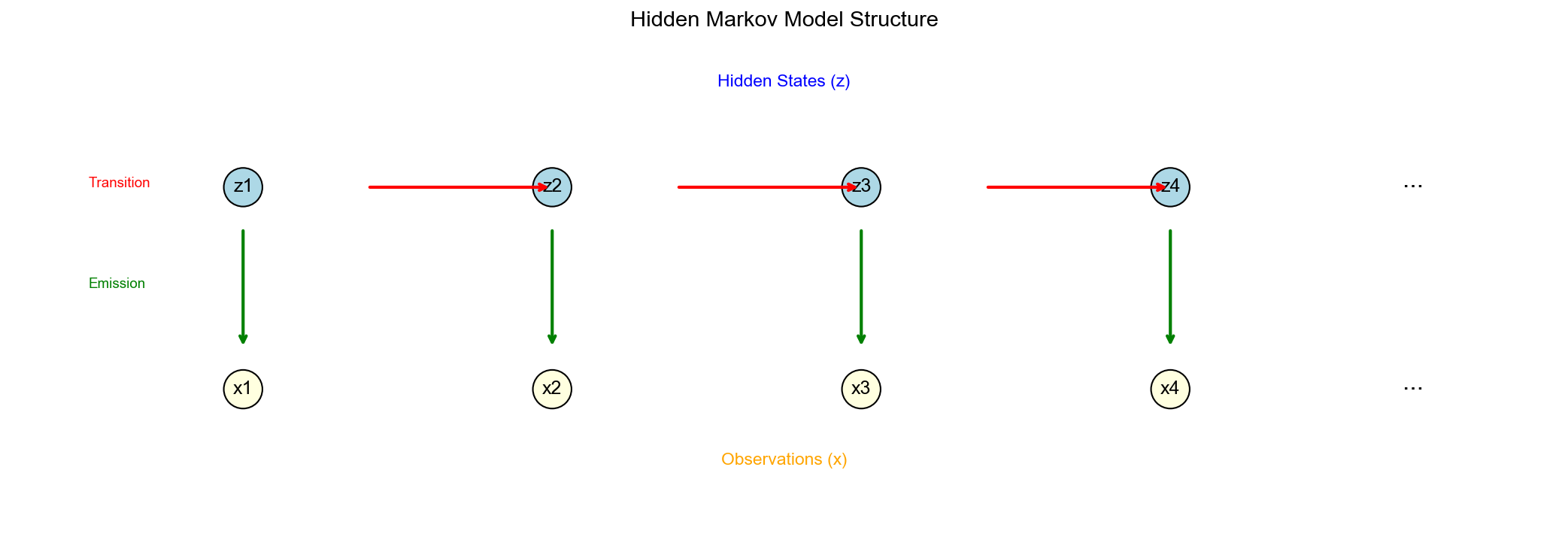
HMM 的三要素与基本架构
Figure 1
核心组件
状态序列 (不可观测):
观测序列 (可观测):
三大参数 :
初始状态概率 :
状态转移概率矩阵 :
发射概率矩阵 (观测概率):
紧凑表示 :
两个基本假设
齐次马尔可夫假设 :
观测独立性假设 :
联合概率分解 :
词性标注示例
观测序列 :["我", "爱", "自然", "语言", "处理"]
隐状态 :[代词, 动词, 形容词, 名词, 名词]
状态空间 :
观测空间 :
发射概率 :名 词 处 理
HMM 的三个基本问题
问题 1:概率计算问题
输入 :模型
输出 :观测序列概率
应用 :模型评估、序列分类
直接计算 (暴力枚举):
复杂度 :
问题 2:学习问题
输入 :观测序列
输出 :模型参数
应用 :从数据学习模型
算法 : Baum-Welch 算法( HMM 的 EM 算法)
问题 3:预测问题(解码)
输入 :模型
输出 :最可能的状态序列
应用 :词性标注、语音识别
算法 : Viterbi 算法(动态规划)
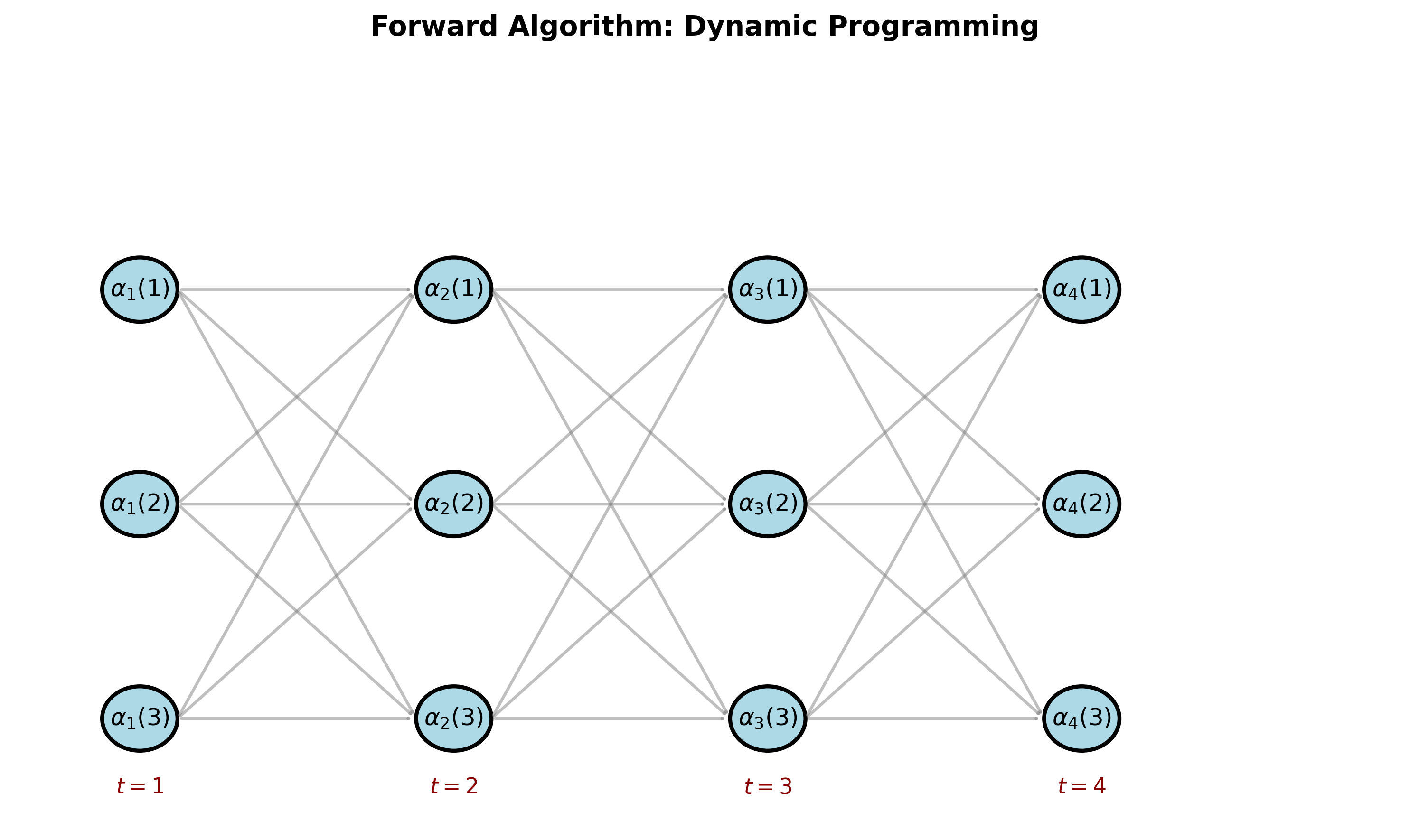
前向算法:从左到右的概率累积
前向概率定义
前向变量 :
终止目标 :
下图展示了前向算法的动态规划结构:
Forward Algorithm
递推公式推导
初始化 (
递推 (
应用 HMM 假设 :
得到:
物理意义 :从所有可能的前一状态
前向算法完整流程
输入 :
步骤 1(初始化) :对
步骤 2(递推) :对
步骤 3(终止) :
复杂度 :
数值稳定性:对数空间计算
问题 :连乘导致下溢(概率太小)
解决 :使用
递推变为 :
使用
后向算法:从右到左的概率回溯
后向概率定义
后向变量 :
与前向的关系 :
递推公式推导
初始化 (
约定:没有未来观测时概率为 1
递推 (
应用 HMM 假设 :
物理意义 :从当前状态
后向算法完整流程
输入 :
步骤 1(初始化) :对
步骤 2(递推) :对
步骤 3(验证) :
应与前向算法结果一致
前向后向的协同作用
Figure 2
联合概率分解 :
状态占据概率 ( Smoothing):
状态转移概率 :
这些概率是 Baum-Welch 算法的核心!
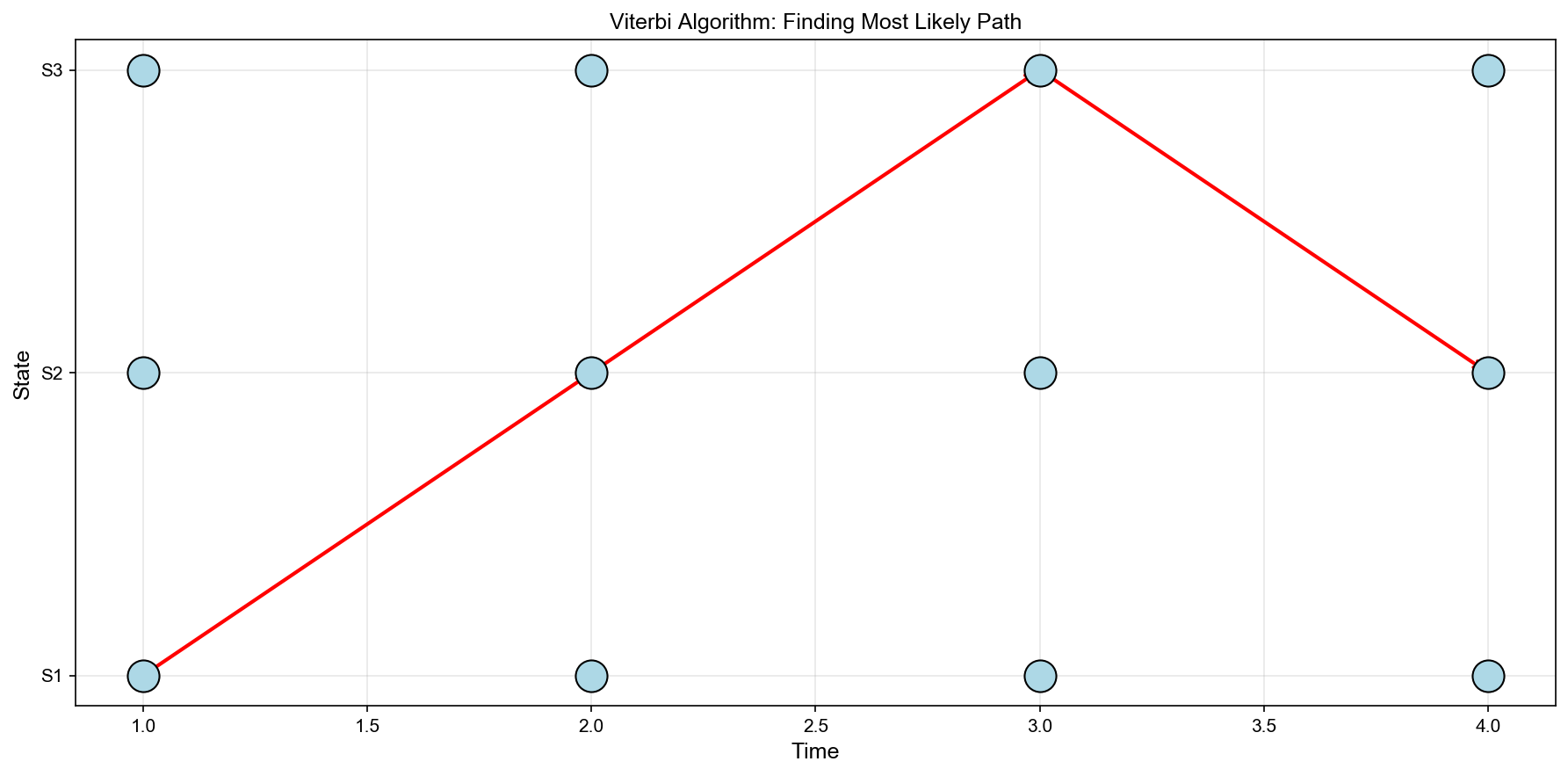
Viterbi
算法:动态规划求解最优路径
问题形式化
目标 :找到最可能的状态序列
与前向算法的区别 : - 前向算法:对所有路径求和
Viterbi 变量定义
Figure 3
Viterbi Path
递推公式推导
初始化 (
递推 (
回溯指针 :
物理意义 :在所有到达状态
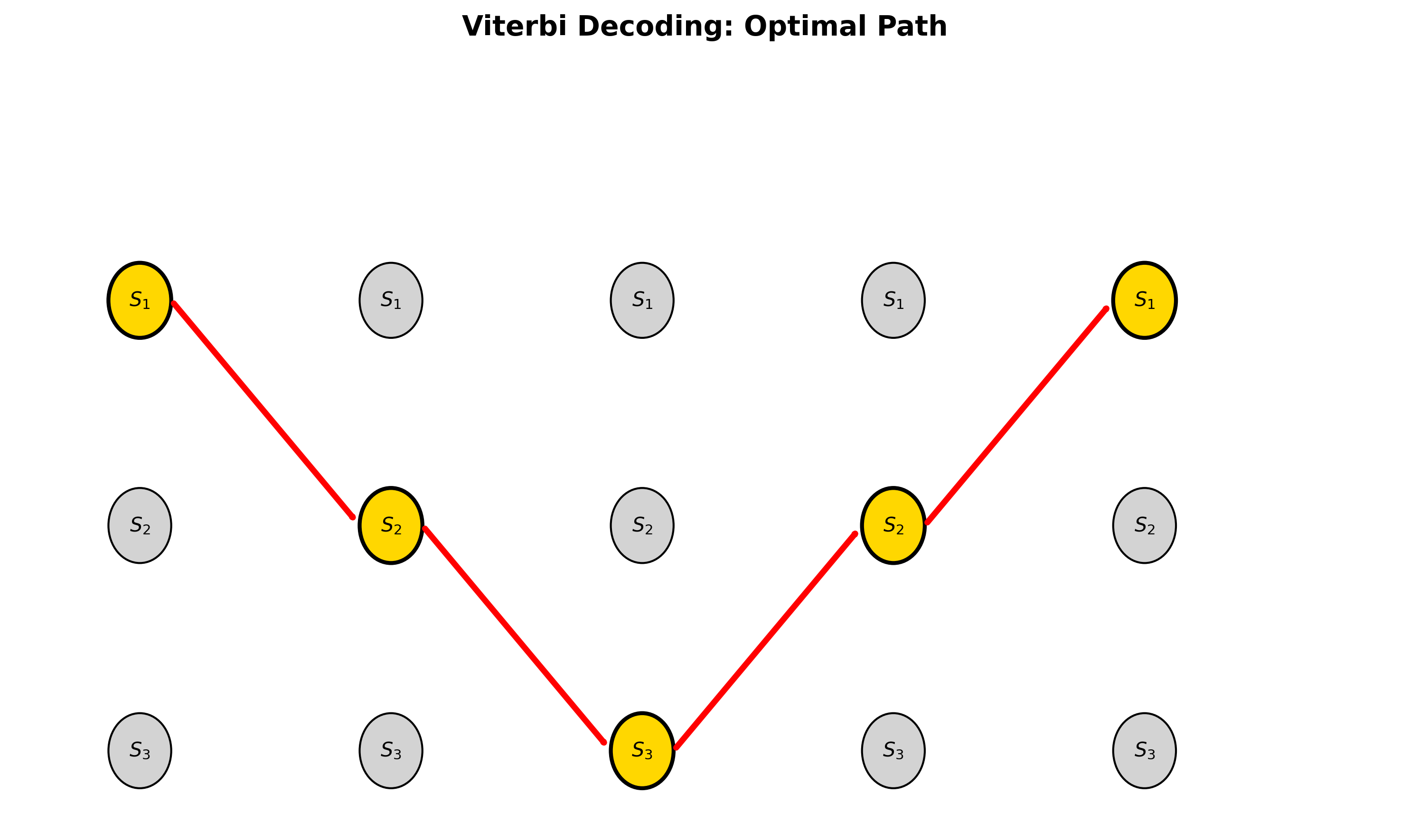
Viterbi 算法完整流程
输入 :
步骤 1(初始化) :对
步骤 2(递推) :对
步骤 3(终止) :
步骤 4(回溯) :对
输出 :最优状态序列
对数 Viterbi 算法
数值稳定版本 :
避免了连乘导致的下溢问题
Viterbi vs 前向算法
前向算法 :
Viterbi 算法 :
仅仅是
Baum-Welch 算法: HMM 的 EM
框架
学习问题的形式化
观测数据 :
隐变量 :
参数 :
目标 :最大化似然
困难 :对数似然含有隐变量的求和
无法直接求导优化!
EM 算法框架应用
E 步 :计算 Q 函数
M 步 :最大化 Q 函数
E 步详细推导
完全数据对数似然 :
Q 函数展开 :
引入期望统计量 :
这些正是前向后向算法计算的!
Q 函数简化为 :
M 步详细推导
参数独立优化 : Q 函数可分解为三部分
优化
目标 :
拉格朗日函数 :
求导 :
约束条件 :
最优解 :
因为
优化
目标 :对每个
拉格朗日函数 :
求导 :
最优解 :
物理意义 :从状态
优化
离散观测情况 :对每个状态
物理意义 :在状态
连续观测情况 (高斯分布):
更新公式:
Baum-Welch 算法完整流程
输入 :观测序列
初始化 :随机初始化
迭代 (直到收敛):
E 步 :使用当前参数
M 步 :更新参数
收敛判断 :
代码实现:完整 HMM 工具包
前向后向算法实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 import numpy as npclass HMM : def __init__ (self, n_states, n_observations ): """ 初始化 HMM 模型 参数: n_states: 隐状态数量 N n_observations: 观测符号数量 M """ self.n_states = n_states self.n_observations = n_observations self.pi = np.random.rand(n_states) self.pi /= self.pi.sum () self.A = np.random.rand(n_states, n_states) self.A /= self.A.sum (axis=1 , keepdims=True ) self.B = np.random.rand(n_states, n_observations) self.B /= self.B.sum (axis=1 , keepdims=True ) def forward (self, observations ): """ 前向算法计算 alpha 参数: observations: 观测序列[o1, o2, ..., oT],取值 0 到 M-1 返回: alpha: shape (T, N) log_prob: 对数似然 """ T = len (observations) alpha = np.zeros((T, self.n_states)) alpha[0 ] = self.pi * self.B[:, observations[0 ]] for t in range (1 , T): for j in range (self.n_states): alpha[t, j] = np.sum (alpha[t-1 ] * self.A[:, j]) * self.B[j, observations[t]] log_prob = np.log(alpha[-1 ].sum ()) return alpha, log_prob def backward (self, observations ): """ 后向算法计算 beta 参数: observations: 观测序列[o1, o2, ..., oT] 返回: beta: shape (T, N) """ T = len (observations) beta = np.zeros((T, self.n_states)) beta[-1 ] = 1.0 for t in range (T-2 , -1 , -1 ): for i in range (self.n_states): beta[t, i] = np.sum (self.A[i] * self.B[:, observations[t+1 ]] * beta[t+1 ]) return beta def forward_log (self, observations ): """ 数值稳定的对数空间前向算法 """ T = len (observations) log_alpha = np.zeros((T, self.n_states)) log_alpha[0 ] = np.log(self.pi) + np.log(self.B[:, observations[0 ]]) for t in range (1 , T): for j in range (self.n_states): log_alpha[t, j] = self._logsumexp( log_alpha[t-1 ] + np.log(self.A[:, j]) ) + np.log(self.B[j, observations[t]]) log_prob = self._logsumexp(log_alpha[-1 ]) return log_alpha, log_prob def _logsumexp (self, x ): """数值稳定的 log(sum(exp(x)))""" max_x = np.max (x) return max_x + np.log(np.sum (np.exp(x - max_x)))
Viterbi 算法实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 def viterbi (self, observations ): """ Viterbi 算法求最优状态序列 参数: observations: 观测序列[o1, o2, ..., oT] 返回: states: 最优状态序列 log_prob: 最优路径的对数概率 """ T = len (observations) log_delta = np.zeros((T, self.n_states)) psi = np.zeros((T, self.n_states), dtype=int ) log_delta[0 ] = np.log(self.pi) + np.log(self.B[:, observations[0 ]]) psi[0 ] = 0 for t in range (1 , T): for j in range (self.n_states): temp = log_delta[t-1 ] + np.log(self.A[:, j]) psi[t, j] = np.argmax(temp) log_delta[t, j] = temp[psi[t, j]] + np.log(self.B[j, observations[t]]) states = np.zeros(T, dtype=int ) states[-1 ] = np.argmax(log_delta[-1 ]) log_prob = log_delta[-1 , states[-1 ]] for t in range (T-2 , -1 , -1 ): states[t] = psi[t+1 , states[t+1 ]] return states, log_prob
Baum-Welch 算法实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 def baum_welch (self, observations, max_iter=100 , tol=1e-6 ): """ Baum-Welch 算法学习 HMM 参数 参数: observations: 观测序列[o1, o2, ..., oT] max_iter: 最大迭代次数 tol: 收敛阈值 返回: log_probs: 每次迭代的对数似然 """ T = len (observations) log_probs = [] for iteration in range (max_iter): alpha, log_prob = self.forward(observations) beta = self.backward(observations) log_probs.append(log_prob) gamma = np.zeros((T, self.n_states)) xi = np.zeros((T-1 , self.n_states, self.n_states)) for t in range (T): denominator = np.sum (alpha[t] * beta[t]) gamma[t] = (alpha[t] * beta[t]) / denominator for t in range (T-1 ): denominator = 0.0 for i in range (self.n_states): for j in range (self.n_states): xi[t, i, j] = alpha[t, i] * self.A[i, j] * \ self.B[j, observations[t+1 ]] * beta[t+1 , j] denominator += xi[t, i, j] xi[t] /= denominator self.pi = gamma[0 ] for i in range (self.n_states): denominator = np.sum (gamma[:-1 , i]) for j in range (self.n_states): self.A[i, j] = np.sum (xi[:, i, j]) / denominator for j in range (self.n_states): denominator = np.sum (gamma[:, j]) for k in range (self.n_observations): mask = (observations == k) self.B[j, k] = np.sum (gamma[mask, j]) / denominator if iteration > 0 and abs (log_probs[-1 ] - log_probs[-2 ]) < tol: print (f"Converged after {iteration+1 } iterations" ) break return log_probs
词性标注应用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 def pos_tagging_example (): """ 词性标注示例 """ states = ['N' , 'V' , 'ADJ' ] observations_vocab = ['I' , 'love' , 'natural' , 'language' , 'processing' ] state_to_idx = {s: i for i, s in enumerate (states)} obs_to_idx = {o: i for i, o in enumerate (observations_vocab)} hmm = HMM(n_states=len (states), n_observations=len (observations_vocab)) hmm.pi = np.array([0.6 , 0.3 , 0.1 ]) hmm.A = np.array([ [0.3 , 0.5 , 0.2 ], [0.6 , 0.1 , 0.3 ], [0.7 , 0.2 , 0.1 ] ]) hmm.B = np.array([ [0.1 , 0.05 , 0.05 , 0.6 , 0.2 ], [0.05 , 0.7 , 0.05 , 0.1 , 0.1 ], [0.05 , 0.05 , 0.8 , 0.05 , 0.05 ] ]) sentence = ['I' , 'love' , 'natural' , 'language' , 'processing' ] obs_seq = [obs_to_idx[w] for w in sentence] state_seq, log_prob = hmm.viterbi(obs_seq) predicted_tags = [states[s] for s in state_seq] print ("Sentence:" , sentence) print ("Predicted POS tags:" , predicted_tags) print ("Log probability:" , log_prob) alpha, log_prob_forward = hmm.forward(obs_seq) print ("Forward log probability:" , log_prob_forward)
模型训练示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 def train_hmm_example (): """ 训练 HMM 模型示例 """ np.random.seed(42 ) true_hmm = HMM(n_states=3 , n_observations=5 ) observations = generate_sequence(true_hmm, length=1000 ) learned_hmm = HMM(n_states=3 , n_observations=5 ) log_probs = learned_hmm.baum_welch(observations, max_iter=50 ) import matplotlib.pyplot as plt plt.figure(figsize=(10 , 5 )) plt.plot(log_probs, marker='o' ) plt.xlabel('Iteration' ) plt.ylabel('Log Likelihood' ) plt.title('Baum-Welch Convergence' ) plt.grid(True ) plt.show() return learned_hmm def generate_sequence (hmm, length ): """ 从 HMM 生成观测序列 """ observations = [] state = np.random.choice(hmm.n_states, p=hmm.pi) for _ in range (length): obs = np.random.choice(hmm.n_observations, p=hmm.B[state]) observations.append(obs) state = np.random.choice(hmm.n_states, p=hmm.A[state]) return np.array(observations)
实战问题与优化技巧
初始化策略
问题 : Baum-Welch 是局部优化,初始化很关键
方案 :
均匀初始化 :所有参数相等随机初始化 + 多次重启 :选择似然最高的K-means 预训练 :用聚类结果初始化状态专家知识 :利用语言学规则初始化词性标注
平滑技术
零概率问题 :未见过的转移/发射概率为 0
Laplace 平滑 :
通常取
缩放技术
问题 :
前向算法缩放版本 :
定义缩放因子:
缩放后的前向变量:
对数似然:
高阶 HMM
二阶 HMM :
状态爆炸 :二阶需要
简化方案 :插值平滑
深入问答
Q1:前向算法和 Viterbi 算法的本质区别是什么?
A:两者都是动态规划,但前向算法对所有可能路径求和
仅仅是求和与求最大值的差异,导致前者给出边缘概率,后者给出 MAP
估计。
Q2:为什么 Baum-Welch 能保证似然单调上升?
A:这是 EM 算法的理论保证。EM 算法每次迭代都保证:
关键在于 E 步构造的 Q 函数是对数似然的下界( ELBO), M
步最大化这个下界会推高真实似然。具体证明依赖于 Jensen 不等式和 KL
散度的非负性。
Q3: HMM 的局限性是什么?
A:三大局限: 1.
马尔可夫假设过强 :未来只依赖当前状态,忽略长距离依赖 2.
观测独立性假设 :当前观测只依赖当前状态,现实中观测可能相互依赖
3.
状态数固定 :需要预先指定,难以自动确定(可用贝叶斯非参数方法如
iHMM 解决)
Q4: CRF 相比 HMM 有什么优势?
A: CRF 是判别式模型,直接建模
劣势是训练复杂度更高(需要计算配分函数)。
Q5:如何选择 HMM 的状态数?
A:三种方法: 1. 交叉验证 :在验证集上测试不同信息准则 :使用 AIC/BIC 平衡拟合度与复杂度
其中贝叶斯非参数 :使用 iHMM( infinite
HMM)自动推断状态数
Q6:前向后向算法的时间复杂度如何分析?
A:前向算法每个时刻和
Q7: Viterbi 算法为什么不直接用
A:因为
但
Q8:如何处理连续观测(如语音信号)?
A:使用连续观测 HMM( CHMM),发射概率改为连续分布:
或高斯混合模型( GMM):
Q9: HMM 能处理变长序列吗?
A:可以。对于不同长度的序列
Baum-Welch 算法对每个序列分别进行 E 步,M
步时累加所有序列的期望统计量。
Q10:前向算法能用于实时解码吗?
A:可以!前向算法天然支持在线计算,每次新观测到
不需要未来信息。但 Viterbi
需要回溯,必须等序列结束。对于实时应用,可以用在线
Viterbi 或beam search 近似。
Q11: HMM 与 RNN 的关系是什么?
A: HMM 可以看作 RNN 的离散概率版本。两者都建模序列,但: -
HMM:离散隐状态,转移概率固定,推断用动态规划 -
RNN:连续隐状态,转移函数参数化(神经网络),推断用前向传播
现代深度学习中, RNN/LSTM 已基本替代 HMM,但 HMM 的推断算法(如
CTC)仍在语音识别中使用。
Q12:如何评估 HMM 模型质量?
A:三种方式: 1. 对数似然 :解码准确率 : Viterbi 预测的状态序列与真实标签的匹配度
3. 困惑度 ( perplexity):
越低越好
✏️ 练习题与解答
练习 1:前向算法计算
题目 :HMM有2状态(晴、雨),观测干 湿
解答 :晴 雨 晴 雨
练习 2:Viterbi解码
题目 :使用练习1参数,找最可能状态序列。
解答 :雨 晴 雨
练习 3:前向算法复杂度
题目 :
解答 :前向算法
练习 4:Baum-Welch更新
题目 :推导
解答 :
练习 5:HMM vs朴素贝叶斯
题目 :比较两者异同。
解答 :HMM建模序列依赖(状态转移),朴素贝叶斯假设样本独立。HMM推理用动态规划
参考文献
[1] Rabiner, L. R. (1989). A tutorial on hidden Markov models and
selected applications in speech recognition. Proceedings of the
IEEE , 77(2), 257-286.
[2] Baum, L. E., & Petrie, T. (1966). Statistical inference for
probabilistic functions of finite state Markov chains. The Annals of
Mathematical Statistics , 37(6), 1554-1563.
[3] Viterbi, A. (1967). Error bounds for convolutional codes and an
asymptotically optimum decoding algorithm. IEEE Transactions on
Information Theory , 13(2), 260-269.
[4] Jelinek, F. (1997). Statistical methods for speech
recognition . MIT Press.
[5] Eddy, S. R. (1998). Profile hidden Markov models.
Bioinformatics , 14(9), 755-763.
[6] Lafferty, J., McCallum, A., & Pereira, F. C. (2001).
Conditional random fields: Probabilistic models for segmenting and
labeling sequence data. ICML .
[7] Murphy, K. P. (2012). Machine Learning: A Probabilistic
Perspective . MIT Press. (Chapter 17: Hidden Markov Models)
[8] Bishop, C. M. (2006). Pattern Recognition and Machine
Learning . Springer. (Chapter 13: Sequential Data)
[9] Ghahramani, Z., & Jordan, M. I. (1997). Factorial hidden
Markov models. Machine Learning , 29(2-3), 245-273.
[10] Teh, Y. W., Jordan, M. I., Beal, M. J., & Blei, D. M.
(2006). Hierarchical Dirichlet processes. Journal of the American
Statistical Association , 101(476), 1566-1581.