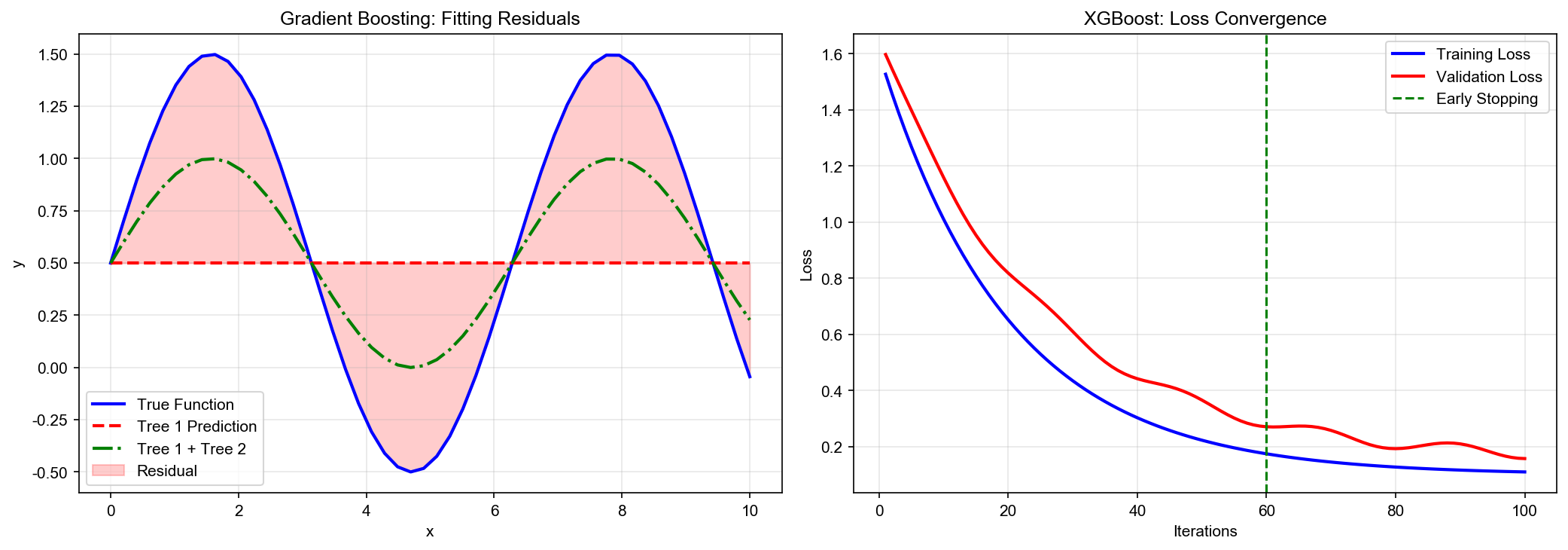
XGBoost 和 LightGBM 是工业界最流行的梯度提升框架——它们在 GBDT 基础上引入精妙的数学优化与工程创新,实现了精度与效率的完美平衡。XGBoost 通过二阶泰勒展开和正则化惩罚提升模型精度,LightGBM 则用直方图算法和梯度单边采样大幅加速训练。这些技术背后蕴含深刻的数学洞察:从目标函数的优化形式到分裂增益的精确计算,从特征绑定的互斥性分析到 Leaf-wise 生长的贪心策略。
XGBoost:极致优化的梯度提升
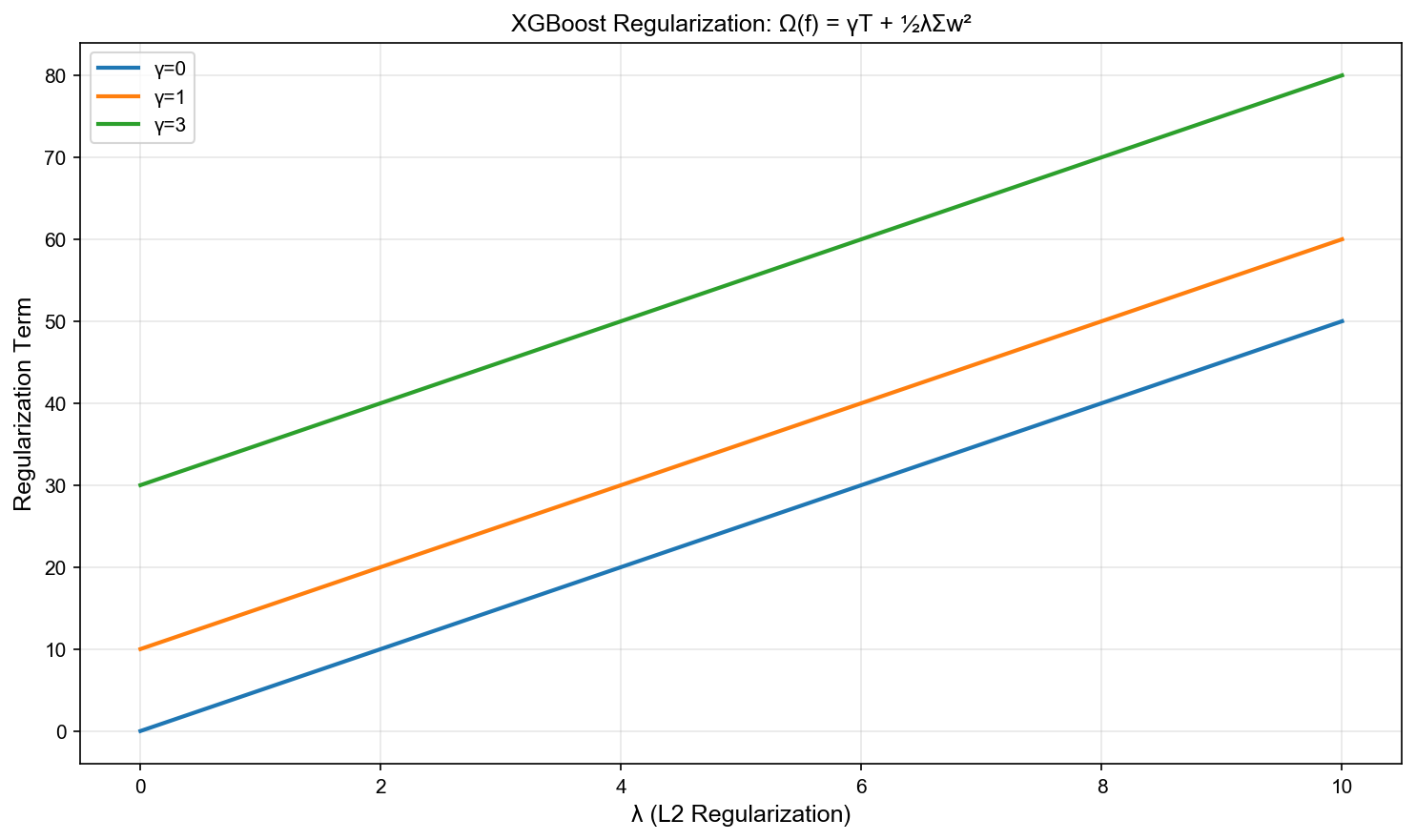
正则化目标函数
标准 GBDT 最小化损失:
XGBoost 目标:添加树复杂度正则化
其中: -
树的正则化:
其中: -
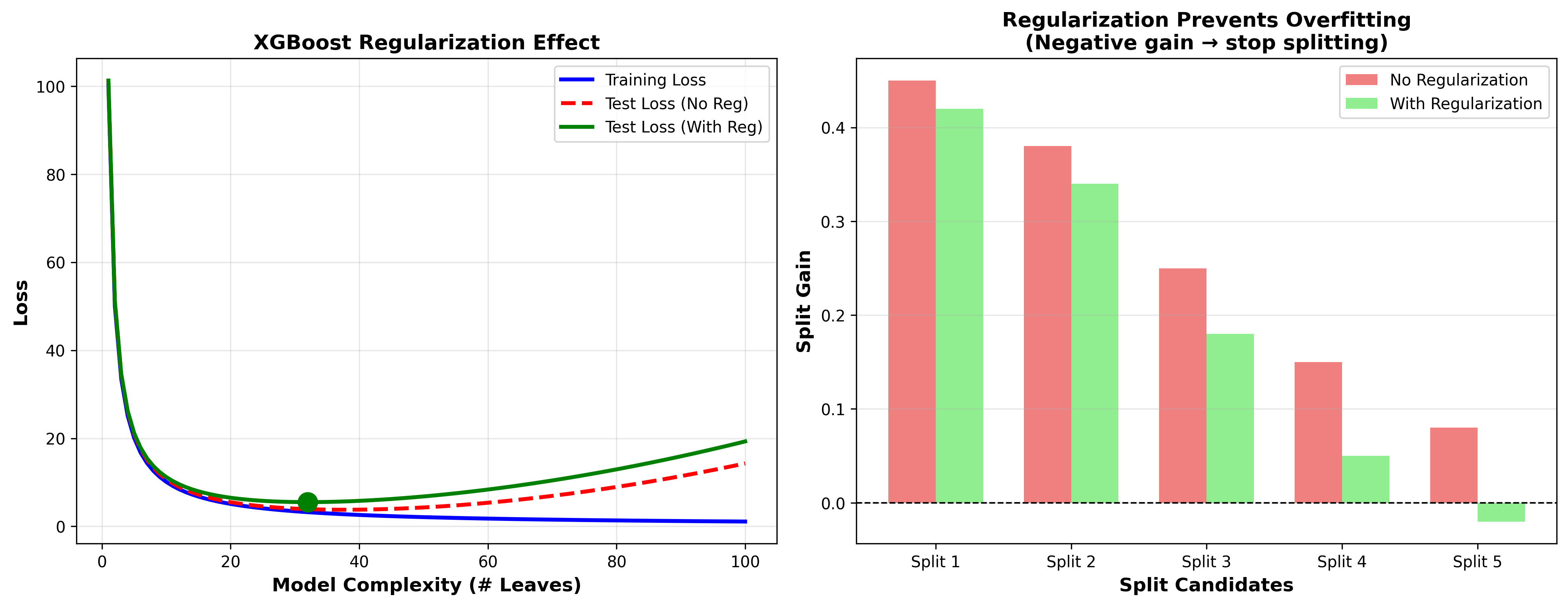
下图展示了 XGBoost 正则化对模型复杂度的控制效果:
二阶泰勒展开
在
其中: -$g_i =
目标函数简化:
(省略常数项
树结构下的目标函数
树的表示:第
其中
重新组织目标:将样本按叶节点分组
其中
最优叶权重:对
其中
代入最优权重:
这是给定树结构下的最优损失。
分裂增益计算
问题:如何选择最优分裂点?
对于叶节点
分裂前的损失:
分裂后的损失:
分裂增益( Gain):
分裂准则: - 若
常用损失函数的梯度
平方损失(回归)
Logistic 损失(二分类)
令
Softmax 损失(多分类)
对于类别
其中
分裂算法
精确贪心算法
输入:当前节点的样本集
算法: 1. 初始化:
复杂度:
近似算法(分位数 sketch)
精确算法在大数据上不可行。近似算法:用分位数代替所有可能阈值。
分位数候选生成: -
全局:在树构建前,一次性计算所有特征的分位数(如
加权分位数:考虑二阶梯度
寻找候选分裂点
稀疏感知算法
问题:现实数据常含缺失值或稀疏特征(如 one-hot 编码)。
默认方向:为每个节点学习默认分裂方向(左或右)。
算法: 1. 将非缺失样本分别尝试分到左、右子节点 2. 缺失样本分到默认方向 3. 选择增益最大的分裂和默认方向
实现:只遍历非缺失值,
LightGBM:高效梯度提升
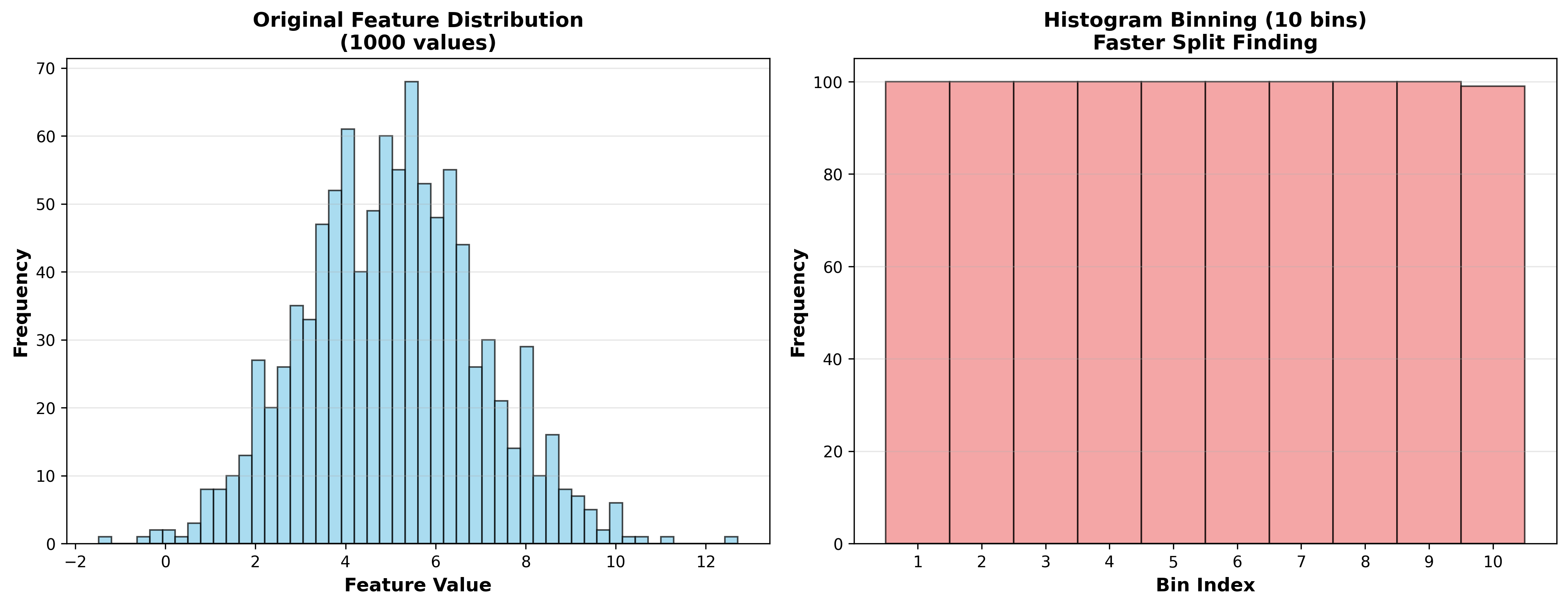
Histogram 算法
核心思想:将连续特征离散化为
优势: -
内存:存储直方图而非原始数据,
算法: 1. 特征离散化:将特征
- 遍历桶:计算每个桶的分裂增益(
而非 )
下图展示了直方图离散化加速分裂查找的过程:
Histogram 差分:对于兄弟节点,只需计算一个直方图,另一个通过父节点减法得到:
减少一半计算量。
Leaf-wise 生长策略
Level-wise( XGBoost):每次分裂所有叶节点(同一层)
Leaf-wise( LightGBM):每次分裂增益最大的单个叶节点
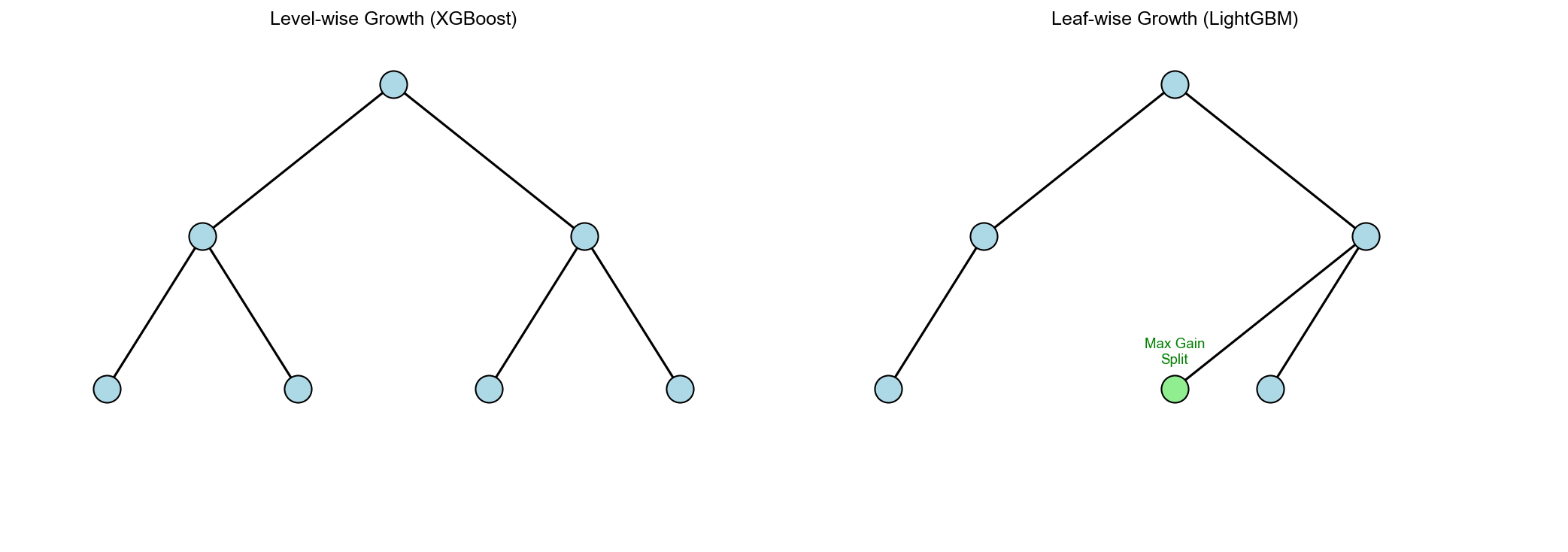
优势: - 更高的精度(优先分裂最有价值的节点) - 更快的收敛(不浪费计算在低增益节点)
风险: - 易过拟合(树更深更不平衡) - 需要 max_depth 限制
GOSS:梯度单边采样
动机:不同样本对梯度的贡献不同,梯度大的样本更重要。
算法: 1. 排序:按梯度绝对值
分裂增益估计:
其中
理论保证: GOSS 的估计误差有界(证明见 LightGBM 论文)。
EFB:互斥特征绑定
动机:稀疏特征间互斥(如 one-hot 编码),可绑定为单个特征。
问题形式:将
这是图着色问题( NP-hard)。
近似算法: 1. 构造冲突图:节点为特征,边权重为特征间冲突度(非零值同时出现的次数) 2. 贪心着色:按冲突度降序,依次分配特征到组(冲突度最小的组)
特征绑定:将组内特征合并,通过偏移避免冲突:
其中
示例:特征 A( 3 个桶)、特征 B( 5 个桶)绑定后: - A 的桶 0, 1, 2 映射到 0, 1, 2 - B 的桶 0, 1, 2, 3, 4 映射到 3, 4, 5, 6, 7
总共 8 个桶。
XGBoost vs LightGBM 对比
| 维度 | XGBoost | LightGBM |
|---|---|---|
| 分裂策略 | Level-wise | Leaf-wise |
| 基本算法 | 预排序 | Histogram |
| 采样 | 行列采样 | GOSS + EFB |
| 内存 | 高(存储排序后数据) | 低(直方图) |
| 速度 | 中等 | 快 |
| 精度 | 高 | 高 |
| 过拟合风险 | 低 | 高(需调参) |
| 稀疏特征 | 稀疏感知 | EFB 优化 |
| 分布式 | 支持 | 支持(更高效) |
完整实现(简化版)
1 | import numpy as np |
工程优化技巧
并行化
特征并行:不同特征的最优分裂点搜索并行化
数据并行:样本分布到多机,各机计算局部直方图,再聚合
树并行:多棵树并行训练(需要独立性假设,如随机森林)
缓存优化
预排序缓存: XGBoost 将排序后的特征索引缓存,避免重复排序
直方图缓存: LightGBM 缓存父节点直方图,子节点通过差分计算
GPU 加速
直方图构建:在 GPU 上并行计算所有特征的直方图
分裂搜索: GPU 并行计算所有候选分裂的增益
减少 CPU-GPU 传输:只传输梯度而非原始数据
Q&A 精选
Q1:为什么 XGBoost 用二阶信息?
A:二阶泰勒展开提供曲率信息,类似牛顿法相比梯度下降: - 更精确:二次近似比一次近似更接近真实损失 - 更快收敛:考虑 Hessian 的方向,步长自适应 - 统一框架:不同损失函数(平方、 logistic 、 Huber 等)统一处理
Q2: Leaf-wise 为什么比 Level-wise 快?
A: Leaf-wise 每次只分裂一个节点,计算量更小。 Level-wise 分裂所有同层节点,可能包括增益很小的节点(浪费计算)。
但: Leaf-wise 易过拟合,需要 max_depth 和 min_data_in_leaf 约束。
Q3: GOSS 为什么有效?
A:梯度大的样本对损失贡献大,保留它们保证精度;梯度小的样本也含信息,通过采样+重加权近似。理论上, GOSS 的方差增加有界,而计算减少显著。
Q4:如何选择超参数?
A:经验法则: - learning_rate: 0.01-0.3(小值+大 n_estimators 更好) - max_depth: 3-10( LightGBM 可更深) - min_child_weight: 1-10(防止过拟合) - gamma: 0-5(剪枝阈值) - lambda: 0-10( L2 正则化)
调优策略:先粗调 learning_rate 和 n_estimators,再细调树结构参数。
Q5: XGBoost/LightGBM 能处理类别特征吗?
A: - XGBoost:需手动编码( one-hot 、 label encoding) - LightGBM:原生支持类别特征(用最优分割算法,无需编码)
LightGBM 的类别特征处理更高效(避免 one-hot 维度爆炸)。
Q6:如何防止过拟合?
A: 1. 树复杂度:降低 max_depth 、增加 min_child_weight 2. 正则化:增大 gamma 、 lambda 3. 学习率:降低 learning_rate(配合增加 n_estimators) 4. 采样:子采样( subsample < 1)、列采样( colsample_bytree < 1) 5. 早停:监控验证集,设置 early_stopping_rounds
Q7: XGBoost/LightGBM 与深度学习的对比?
A: | 维度 | GBDT | 深度学习 | |------|------|----------| | 表格数据 | 优秀 | 一般 | | 图像/文本 | 差 | 优秀 | | 特征工程 | 需要 | 自动 | | 可解释性 | 高 | 低 | | 训练速度 | 快 | 慢 | | 调参难度 | 中等 | 高 |
表格数据( Kaggle 常见): GBDT 通常更好;非结构化数据:深度学习碾压。
Q8:如何可视化 XGBoost 模型?
A: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import xgboost as xgb
import matplotlib.pyplot as plt
# 单棵树可视化
xgb.plot_tree(model, num_trees=0)
plt.show()
# 特征重要性
xgb.plot_importance(model, importance_type='gain')
plt.show()
# SHAP 值(可解释性)
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
shap.summary_plot(shap_values, X)
Q9: XGBoost 的缺失值处理原理?
A:学习最优默认方向: 1. 将缺失样本分别尝试到左、右子树 2. 选择增益最大的方向作为默认 3. 预测时,缺失值自动走默认方向
这相当于自动学习缺失值的最优填充策略。
Q10:如何在生产环境部署 GBDT 模型?
A: 1. 模型导出:保存为 JSON/文本格式(可读、跨语言) 2. 推理优化: TreeLite 编译为 C 代码,降低延迟 3. 特征工程:预计算特征,避免在线计算 4. 批量预测:批处理提升吞吐 5. A/B 测试:逐步灰度新模型
✏️ 练习题与解答
练习 1:XGBoost 二阶近似
题目:在回归问题中使用平方损失
解答:
一阶梯度:
二阶梯度:
代入
负梯度表示当前预测偏小,需要增加预测值。
练习 2:分裂增益计算
题目:某叶节点有10个样本,
解答:
分裂增益公式:
代入数值:
增益为正,值得分裂。
练习 3:GOSS 采样策略
题目:LightGBM 使用 GOSS 采样,保留所有大梯度样本(梯度前20%)和随机采样小梯度样本(剩余80%中随机选10%)。数据集有1000个样本,计算:(1) 保留样本数;(2) 小梯度样本的权重放大因子。
解答:
(1) 保留样本数: - 大梯度样本:
(2) 权重放大因子:
小梯度样本占比从 80% 被采样到 8%,需要放大
GOSS 的核心:用少量样本(28%)近似完整梯度分布,显著加速训练。
练习 4:Leaf-wise vs Level-wise
题目:某数据集训练决策树,Level-wise 策略生长到深度3(共15个节点),Leaf-wise 策略生长15个节点但最大深度5。两者训练误差相同。哪种策略泛化更好?
解答:
Level-wise(XGBoost默认): - 平衡树结构,深度3,每层节点数均匀增长 - 计算资源分配均匀,不易过拟合
Leaf-wise(LightGBM默认): - 优先分裂增益最大的叶节点,深度可达5 - 树不平衡,部分分支很深(可能过拟合)
结论: - 在小数据上,Level-wise 更稳健(深度受限,防过拟合) - 在大数据上,Leaf-wise 更高效(快速逼近最优结构)
实践建议:LightGBM 的 Leaf-wise 需配合
max_depth 和 min_data_in_leaf
限制,防止过深的树。
练习 5:XGBoost vs LightGBM 选择
题目:比较以下场景应该选择 XGBoost 还是 LightGBM:(1) 100万样本,1000特征;(2) 1万样本,50特征;(3) 含大量类别特征的推荐系统。
解答:
(1) 100万样本,1000特征: - 推荐 LightGBM - 原因:Histogram算法对大规模数据优势明显,内存和速度都优于XGBoost。GOSS采样进一步加速。
(2) 1万样本,50特征: - 推荐 XGBoost - 原因:小数据集,Level-wise 生长更稳健,二阶信息利用充分,不易过拟合。LightGBM 的 Leaf-wise 可能过拟合。
(3) 类别特征的推荐系统: - 推荐 LightGBM 或 CatBoost - 原因: - LightGBM 对类别特征有原生支持(无需 one-hot) - CatBoost 的 Ordered Boosting 和 Target Statistics 专门优化类别特征 - XGBoost 需要手动 one-hot,维度爆炸
总结:大规模数据选 LightGBM,小数据/需稳定选 XGBoost,类别特征多选 LightGBM/CatBoost。
参考文献
- Chen, T., & Guestrin, C. (2016). XGBoost: A scalable tree boosting system. KDD, 785-794.
- Ke, G., Meng, Q., Finley, T., et al. (2017). LightGBM: A highly efficient gradient boosting decision tree. NeurIPS, 3146-3154.
- Prokhorenkova, L., Gusev, G., Vorobev, A., et al. (2018). CatBoost: Unbiased boosting with categorical features. NeurIPS, 6638-6648.
- Friedman, J. H., Hastie, T., & Tibshirani, R. (2000). Additive logistic regression: A statistical view of boosting. Annals of Statistics, 28(2), 337-407.
- Mitchell, R., & Frank, E. (2017). Accelerating the XGBoost algorithm using GPU computing. PeerJ Computer Science, 3, e127.
XGBoost 和 LightGBM 代表了梯度提升算法的工程巅峰——从数学优化(二阶信息、正则化)到算法创新(直方图、 GOSS 、 EFB),从系统优化(并行化、缓存)到实战技巧(超参数调优、可解释性)。它们在工业界的成功证明:扎实的数学理论与精妙的工程实现相结合,能创造出既高效又强大的机器学习系统。掌握这些技术,是成为机器学习工程师的关键里程碑。
- 本文标题:机器学习数学推导(十二) XGBoost 与 LightGBM
- 本文作者:Chen Kai
- 创建时间:2021-10-30 15:15:00
- 本文链接:https://www.chenk.top/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%95%B0%E5%AD%A6%E6%8E%A8%E5%AF%BC%EF%BC%88%E5%8D%81%E4%BA%8C%EF%BC%89XGBoost%E4%B8%8ELightGBM/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!