神经网络(Neural
Network)是深度学习的基石——从生物神经元的启发到多层非线性变换,神经网络通过反向传播算法实现端到端学习。从感知机的收敛定理到万能逼近定理,从梯度消失问题到
He 初始化,从 Sigmoid 到
ReLU,神经网络的数学原理为理解深度模型提供了坚实基础。前向传播用矩阵运算高效计算输出,反向传播通过链式法则计算梯度,梯度消失/爆炸源于激活函数和权重的连乘效应,而合理的权重初始化能保持信号在各层的方差稳定。
Figure 5
感知机:神经网络的起点
感知机模型
输入 :
权重 :
偏置 :
线性组合 :
激活函数 (阶跃函数):
几何解释 :超平面
感知机学习算法
训练数据 :
目标 :找到
损失函数 :误分类点到超平面的距离和
其中
更新规则 (随机梯度下降):选择一个误分类点
感知机收敛定理
定理 (Novikoff, 1962):如果数据线性可分(存在
证明思路 :
定义
步骤 1 :与最优权重的内积单调增
归纳得
步骤 2 :权重范数增长有界
由于
步骤 3 :结合两式
化简:
结论 :最多更新
感知机的局限性
XOR 问题 :
数据:
线性不可分 !单层感知机无法解决
解决方案 :多层感知机(引入隐藏层)
多层感知机与前向传播
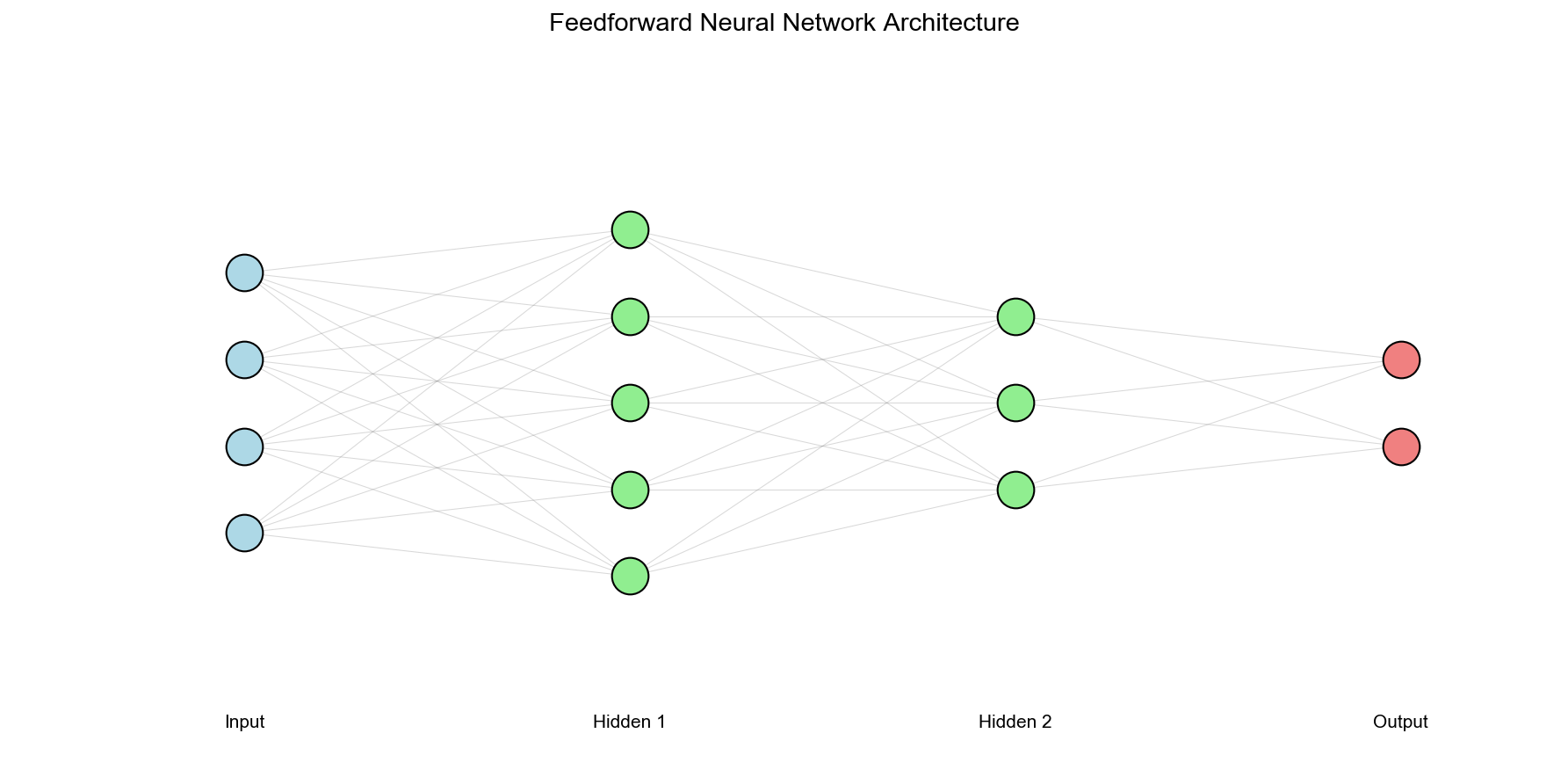
MLP 架构
Figure 1
层结构 :
输入层 :隐藏层 1 :隐藏层 2 :输出层 :
前向传播推导
第 :
线性变换 :
其中:
非线性激活 :
完整前向传播 :
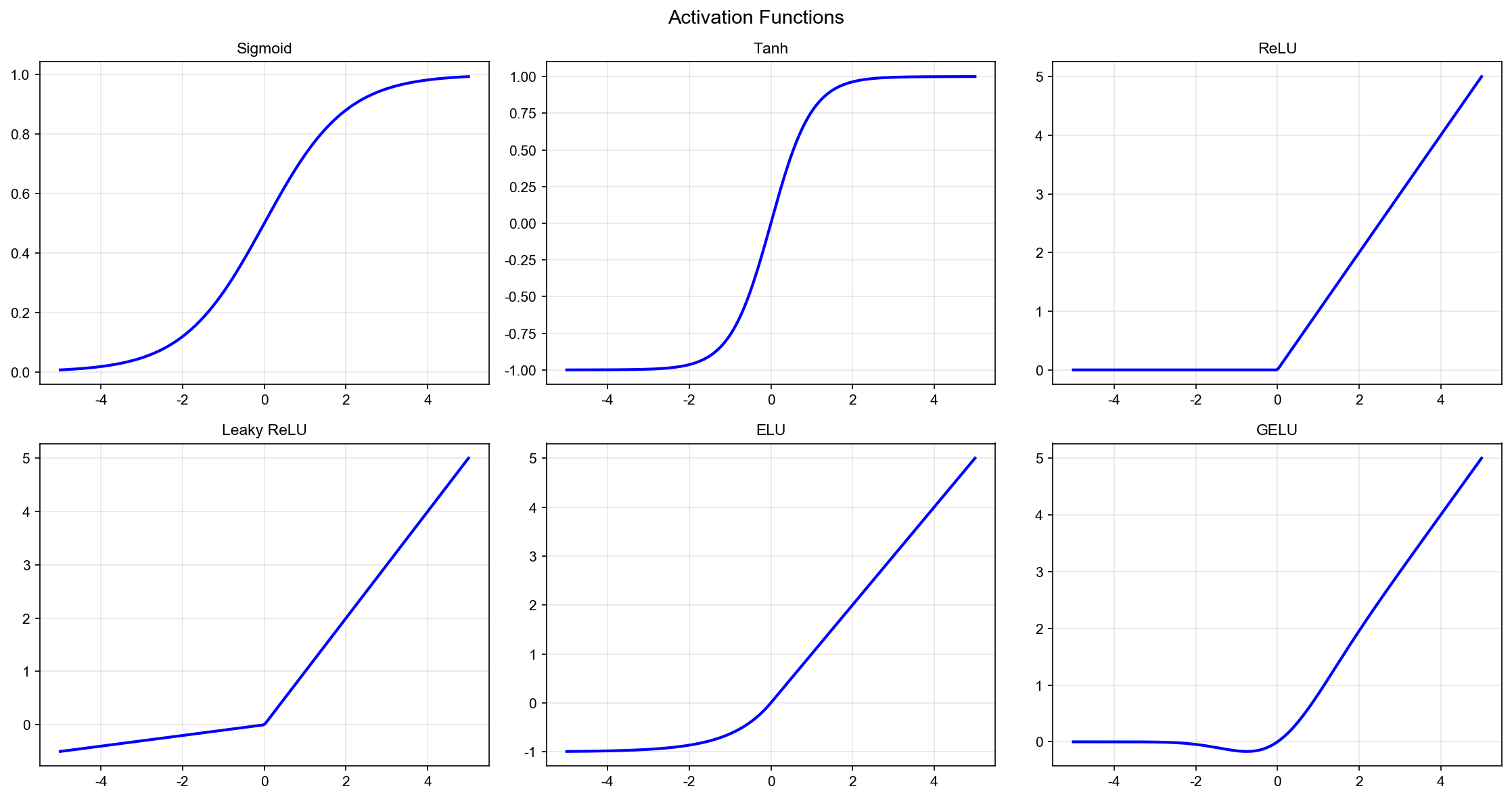
激活函数详解
Figure 2
1. Sigmoid 函数 :
导数 :
性质 :
2. Tanh 函数 :
导数 :
性质 :
输出范围
问题 :仍有梯度消失
3. ReLU (Rectified Linear Unit) :
导数 :
性质 :
计算简单
缓解梯度消失(正区间梯度恒为 1)
问题 : Dead ReLU(负区间永远不激活)
4. Leaky ReLU :
通常
性质 :解决 Dead ReLU 问题
5. ELU (Exponential Linear Unit) :
性质 :负值有非零梯度,零中心化
万能逼近定理
定理 ( Cybenko, 1989; Hornik, 1991):
给定任意连续函数
使得
意义 :神经网络理论上可以逼近任意连续函数!
但注意 :
不保证能高效学习(样本复杂度、训练时间) -
深度网络实践中比宽度网络更高效
反向传播:链式法则的艺术
损失函数
回归任务 (均方误差):
分类任务 (交叉熵):
其中
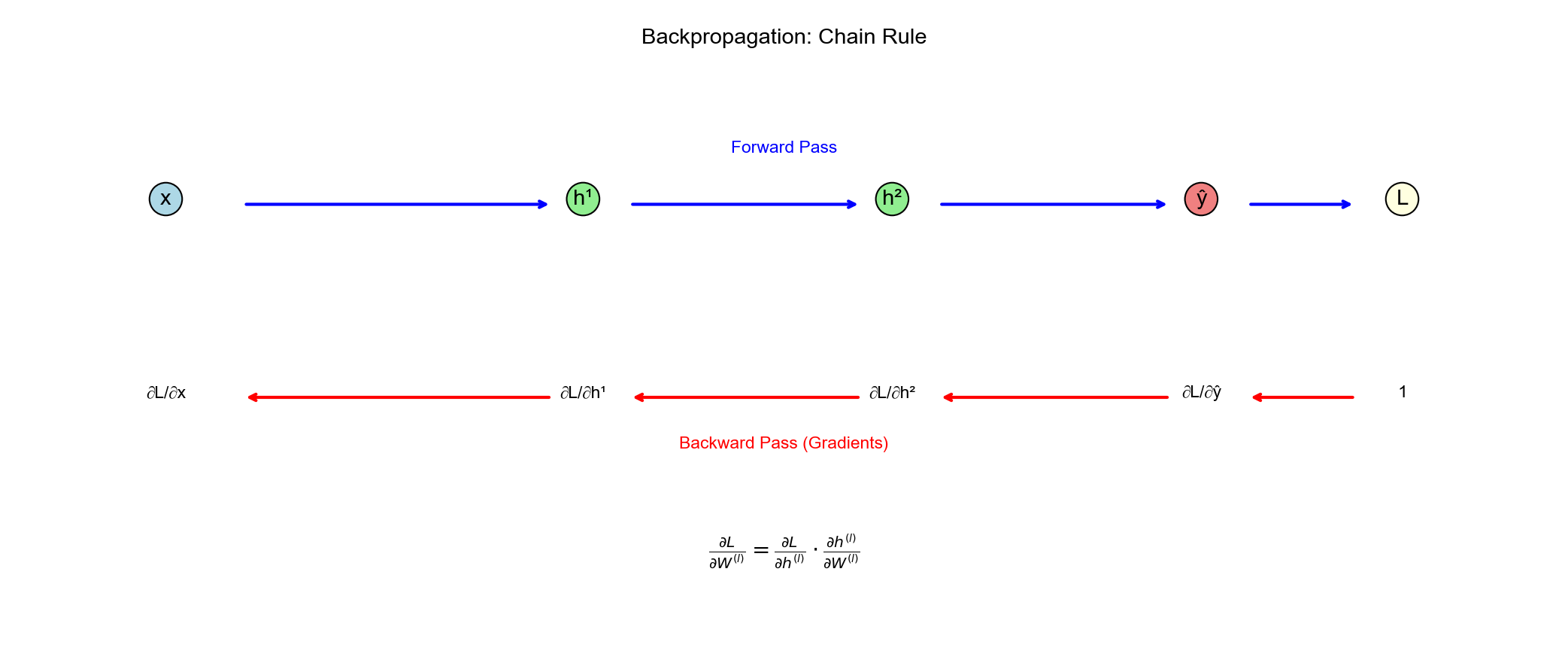
反向传播推导(输出层)
Figure 3
目标 :计算
定义误差项 :
输出层 (
对于均方误差:
链式法则:
向量形式 :
其中
对于 Softmax + 交叉熵 (特殊简化):
反向传播推导(隐藏层)
递推关系 :
展开链式法则:
中间项 :
代入 :
向量形式 :
物理意义 :第
权重梯度计算
权重梯度 :
矩阵形式 :
偏置梯度 :
矩阵形式 :
反向传播算法完整流程
输入 :训练样本
前向传播 :
对
计算损失
反向传播 :
输出层 :
隐藏层 (
梯度 :
参数更新 (梯度下降):
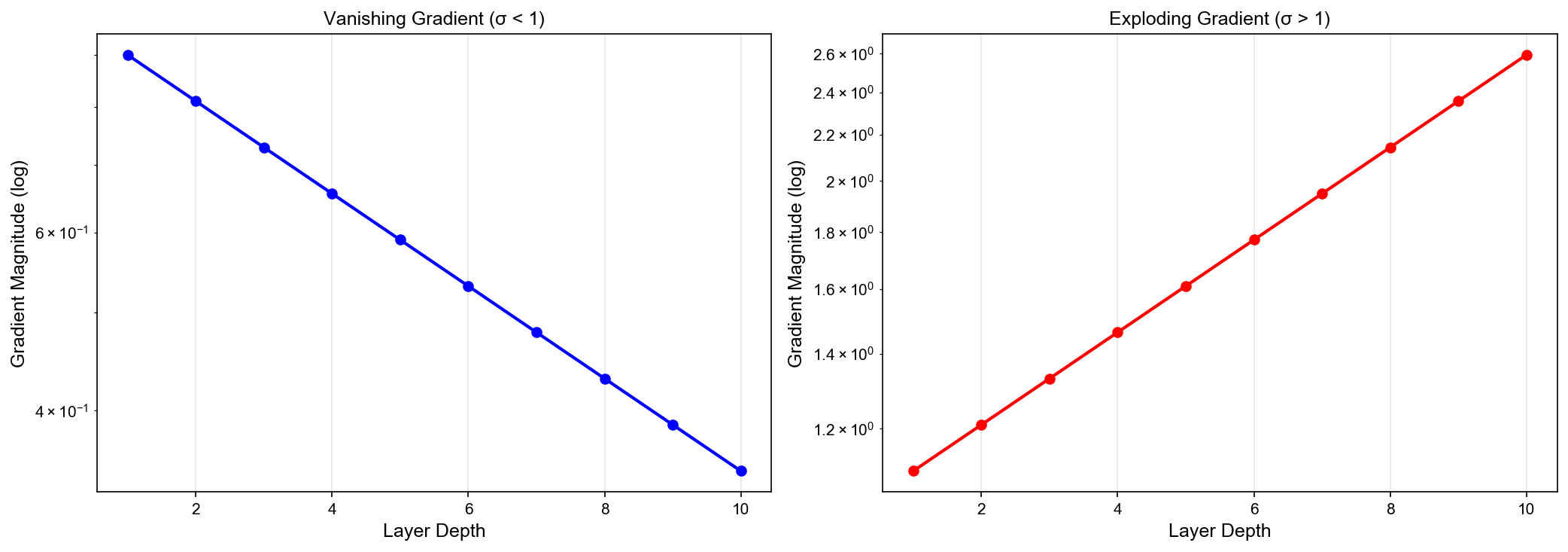
梯度消失与梯度爆炸
梯度消失问题
Figure 4
现象 :深层网络训练时,前面层的梯度趋近于
0,参数几乎不更新
数学分析 :
考虑
其中
关键观察 :
Sigmoid 导数 :
如果权重矩阵的谱范数
指数衰减 !当
梯度爆炸问题
现象 :梯度指数级增长,参数更新幅度巨大,导致数值溢出
条件 :权重矩阵的特征值
数学分析 :
如果
指数增长 !
实践中, RNN 更容易梯度爆炸(权重共享)
解决梯度消失的方法
1. 使用 ReLU 激活函数
正区间梯度恒为 1,不会指数衰减
2. 残差连接 (ResNet)
梯度可以直接通过恒等映射传播:
3. 批归一化 (Batch Normalization)
归一化激活值,稳定梯度
4. 使用 LSTM/GRU (RNN 专用)
门控机制控制信息流
解决梯度爆炸的方法
1. 梯度裁剪 (Gradient Clipping)
2. 权重正则化
添加 L2 惩罚
3. 合理初始化 (见下节)
权重初始化策略
为什么初始化重要?
问题 1:全零初始化
所有神经元计算相同,对称性导致无法学习不同特征
问题 2:随机初始化太大
激活值饱和,梯度消失
问题 3:随机初始化太小
激活值接近 0,信息损失
方差保持原则
目标 :前向传播和反向传播时,保持激活值和梯度的方差稳定
假设 :
权重
输入
激活函数线性区域(
Xavier 初始化
推导 ( Glorot & Bengio, 2010):
第
假设
前向传播 :
要求
反向传播 :
类似分析,要求:
折中 :
Xavier 初始化 :
或均匀分布:
适用 : Sigmoid 、 Tanh 激活函数
He 初始化
推导 ( He et al., 2015):
对于 ReLU,
方差变为原来的一半:
要求方差不变:
He 初始化 :
适用 : ReLU 及其变体
初始化总结
激活函数
初始化方法
方差
Sigmoid/Tanh
Xavier
ReLU
He
Leaky ReLU
He (修改)
代码实现:从零构建神经网络
激活函数实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import numpy as npclass ActivationFunction : """激活函数基类""" def forward (self, z ): raise NotImplementedError def backward (self, z ): """返回导数""" raise NotImplementedError class Sigmoid (ActivationFunction ): def forward (self, z ): return 1 / (1 + np.exp(-np.clip(z, -500 , 500 ))) def backward (self, z ): s = self.forward(z) return s * (1 - s) class Tanh (ActivationFunction ): def forward (self, z ): return np.tanh(z) def backward (self, z ): return 1 - np.tanh(z)**2 class ReLU (ActivationFunction ): def forward (self, z ): return np.maximum(0 , z) def backward (self, z ): return (z > 0 ).astype(float ) class LeakyReLU (ActivationFunction ): def __init__ (self, alpha=0.01 ): self.alpha = alpha def forward (self, z ): return np.where(z > 0 , z, self.alpha * z) def backward (self, z ): return np.where(z > 0 , 1 , self.alpha)
全连接层实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 class FullyConnectedLayer : """全连接层""" def __init__ (self, input_dim, output_dim, activation='relu' , initialization='he' ): """ 参数: input_dim: 输入维度 output_dim: 输出维度 activation: 激活函数类型 initialization: 权重初始化方法 """ self.input_dim = input_dim self.output_dim = output_dim if initialization == 'xavier' : std = np.sqrt(2.0 / (input_dim + output_dim)) elif initialization == 'he' : std = np.sqrt(2.0 / input_dim) else : std = 0.01 self.W = np.random.randn(output_dim, input_dim) * std self.b = np.zeros((output_dim, 1 )) if activation == 'sigmoid' : self.activation = Sigmoid() elif activation == 'tanh' : self.activation = Tanh() elif activation == 'relu' : self.activation = ReLU() elif activation == 'leaky_relu' : self.activation = LeakyReLU() else : self.activation = None self.cache = {} def forward (self, X ): """ 前向传播 参数: X: (input_dim, batch_size) 返回: A: (output_dim, batch_size) """ Z = self.W @ X + self.b A = self.activation.forward(Z) if self.activation else Z self.cache['X' ] = X self.cache['Z' ] = Z self.cache['A' ] = A return A def backward (self, dA, learning_rate=0.01 ): """ 反向传播 参数: dA: 来自上一层的梯度 (output_dim, batch_size) learning_rate: 学习率 返回: dX: 传递给下一层的梯度 (input_dim, batch_size) """ X = self.cache['X' ] Z = self.cache['Z' ] batch_size = X.shape[1 ] if self.activation: dZ = dA * self.activation.backward(Z) else : dZ = dA dW = (1 / batch_size) * (dZ @ X.T) db = (1 / batch_size) * np.sum (dZ, axis=1 , keepdims=True ) dX = self.W.T @ dZ self.W -= learning_rate * dW self.b -= learning_rate * db return dX
神经网络实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 class NeuralNetwork : """多层感知机""" def __init__ (self, layer_dims, activations='relu' , initialization='he' ): """ 参数: layer_dims: 列表,每层的维度 [D0, D1, ..., DL] activations: 激活函数(字符串或列表) initialization: 初始化方法 """ self.num_layers = len (layer_dims) - 1 self.layers = [] if isinstance (activations, str ): activations = [activations] * (self.num_layers - 1 ) + ['linear' ] for l in range (self.num_layers): layer = FullyConnectedLayer( input_dim=layer_dims[l], output_dim=layer_dims[l+1 ], activation=activations[l], initialization=initialization ) self.layers.append(layer) def forward (self, X ): """ 前向传播 参数: X: (D0, batch_size) 返回: Y_hat: (DL, batch_size) """ A = X for layer in self.layers: A = layer.forward(A) return A def backward (self, Y, Y_hat, learning_rate=0.01 ): """ 反向传播 参数: Y: 真实标签 (DL, batch_size) Y_hat: 预测值 (DL, batch_size) learning_rate: 学习率 """ batch_size = Y.shape[1 ] dA = -(Y - Y_hat) / batch_size for layer in reversed (self.layers): dA = layer.backward(dA, learning_rate) def train (self, X_train, Y_train, epochs=100 , batch_size=32 , learning_rate=0.01 ): """ 训练神经网络 参数: X_train: (D0, N) Y_train: (DL, N) epochs: 训练轮数 batch_size: 批大小 learning_rate: 学习率 """ N = X_train.shape[1 ] losses = [] for epoch in range (epochs): indices = np.random.permutation(N) X_shuffled = X_train[:, indices] Y_shuffled = Y_train[:, indices] epoch_loss = 0 for i in range (0 , N, batch_size): X_batch = X_shuffled[:, i:i+batch_size] Y_batch = Y_shuffled[:, i:i+batch_size] Y_hat = self.forward(X_batch) loss = 0.5 * np.sum ((Y_batch - Y_hat)**2 ) / batch_size epoch_loss += loss self.backward(Y_batch, Y_hat, learning_rate) avg_loss = epoch_loss / (N // batch_size) losses.append(avg_loss) if (epoch + 1 ) % 10 == 0 : print (f"Epoch {epoch+1 } /{epochs} , Loss: {avg_loss:.6 f} " ) return losses def predict (self, X ): """预测""" return self.forward(X)
训练示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 def train_xor_example (): """训练 XOR 问题""" X_train = np.array([[0 , 0 , 1 , 1 ], [0 , 1 , 0 , 1 ]]) Y_train = np.array([[0 , 1 , 1 , 0 ]]) nn = NeuralNetwork( layer_dims=[2 , 4 , 1 ], activations=['relu' , 'sigmoid' ], initialization='he' ) losses = nn.train(X_train, Y_train, epochs=1000 , batch_size=4 , learning_rate=0.1 ) Y_pred = nn.predict(X_train) print ("\nPredictions:" ) print (Y_pred) print ("\nTrue labels:" ) print (Y_train) import matplotlib.pyplot as plt plt.figure(figsize=(10 , 5 )) plt.plot(losses) plt.xlabel('Epoch' ) plt.ylabel('Loss' ) plt.title('Training Loss' ) plt.grid(True ) plt.show() def train_regression_example (): """训练回归问题""" np.random.seed(42 ) X_train = np.random.randn(1 , 500 ) * 2 Y_train = X_train**2 + np.random.randn(1 , 500 ) * 0.1 nn = NeuralNetwork( layer_dims=[1 , 16 , 16 , 1 ], activations=['relu' , 'relu' , 'linear' ], initialization='he' ) losses = nn.train(X_train, Y_train, epochs=200 , batch_size=32 , learning_rate=0.01 ) X_test = np.linspace(-3 , 3 , 100 ).reshape(1 , -1 ) Y_pred = nn.predict(X_test) import matplotlib.pyplot as plt plt.figure(figsize=(12 , 5 )) plt.subplot(1 , 2 , 1 ) plt.plot(losses) plt.xlabel('Epoch' ) plt.ylabel('Loss' ) plt.title('Training Loss' ) plt.grid(True ) plt.subplot(1 , 2 , 2 ) plt.scatter(X_train.flatten(), Y_train.flatten(), alpha=0.5 , label='Training data' ) plt.plot(X_test.flatten(), Y_pred.flatten(), 'r-' , linewidth=2 , label='Predictions' ) plt.plot(X_test.flatten(), X_test.flatten()**2 , 'g--' , label='True function' ) plt.xlabel('X' ) plt.ylabel('Y' ) plt.title('Regression Result' ) plt.legend() plt.grid(True ) plt.tight_layout() plt.show()
深入问答
Q1:为什么需要激活函数?
A:如果没有激活函数,多层线性变换仍是线性变换:
无法学习非线性函数!激活函数引入非线性,使得网络能逼近任意复杂函数。
Q2:为什么 ReLU 比 Sigmoid 更流行?
A:三大优势: 1. 缓解梯度消失 :正区间梯度恒为 1 2.
计算高效 :仅需比较和取最大值 3.
稀疏激活 :约 50%神经元输出 0,类似生物神经元
但注意 Dead ReLU 问题:一旦进入负区间,永远输出 0 。
Q3:反向传播与数值微分的区别?
A: - 数值微分 :
实践中,用反向传播训练,用数值微分验证实现正确性。
Q4:如何检测梯度消失/爆炸?
A:监控梯度的统计量:
1 2 3 4 for name, param in model.named_parameters(): if param.grad is not None : grad_norm = param.grad.norm() print (f"{name} : grad_norm = {grad_norm:.6 f} " )
梯度消失 :前面层的grad_norm远小于后面层梯度爆炸 :grad_norm非常大(>100)
Q5:为什么深度网络比浅层网络更强大?
A:理论与实践双重原因: 1.
表达能力 :深度网络可用指数级少的参数表示函数 -
例子:计算特征层次 :低层学简单特征(边缘),高层学复杂特征(物体)
3.
优化景观 :深度网络的损失函数虽非凸,但局部最优质量较好
Q6: Batch Normalization 为什么有效?
A:三个作用: 1.
减少内部协变量偏移 :每层输入分布稳定,加速收敛 2.
正则化效果 :引入噪声( mini-batch 统计量),类似
Dropout 3. 允许更大学习率 :梯度更稳定
数学上,归一化使得损失函数的 Lipschitz 常数更小,优化更 smooth 。
Q7: Dropout 如何防止过拟合?
A:两种解释: 1.
集成学习 :训练时每次随机丢弃神经元,相当于训练正则化 :迫使网络不依赖任何单个神经元,学习更鲁棒特征
数学上, Dropout 近似 L2 正则化(对权重的期望值)。
Q8:为什么要使用 Mini-batch 而不是 Full-batch?
A: - Full-batch :每次用全部数据计算梯度 -
准确但慢,内存消耗大 - 容易陷入锐利局部最优(泛化差) -
Mini-batch :每次用小批量数据 - 快速,可并行 -
梯度噪声充当正则化,帮助跳出锐利最优 - 通常 batch_size = 32/64/128
最佳实践: batch_size
太小(<8)噪声过大不稳定,太大(>1024)失去正则化效果。
Q9:学习率如何选择?
A:学习率是最重要的超参数!
选择策略 : 1.
网格搜索 :对数尺度搜索学习率预热 :训练初期线性增加学习率 3.
学习率衰减 : - Step decay:每自适应优化器 : Adam 、
RMSprop 自动调整
经验法则: SGD 初始学习率 0.01-0.1, Adam 初始学习率 0.001 。
Q10:如何诊断过拟合 vs 欠拟合?
A:绘制学习曲线(训练 loss vs 验证 loss):
欠拟合 :训练 loss 高,验证 loss 高,两者接近
过拟合 :训练 loss 低,验证 loss 高,差距大
良好拟合 :训练 loss 低,验证 loss 低,差距小
Q11:如何理解反向传播的计算图?
A:计算图是有向无环图,节点是变量/操作,边是依赖关系。
前向传播:从输入到输出计算值 反向传播:从输出到输入计算梯度
链式法则的递归应用 :
现代框架( PyTorch/TensorFlow)自动构建计算图并执行反向传播。
Q12:权重初始化为何不能全相同?
A:对称性破缺问题!如果所有权重相同: -
同一层的所有神经元计算相同的函数 - 梯度相同,更新相同 -
永远无法学习不同特征
随机初始化打破对称性,使每个神经元学习不同的特征。
✏️ 练习题与解答
练习 1:反向传播计算
题目 :解答 :链式法则:
练习 2:梯度消失
题目 :为什么深层sigmoid网络易梯度消失?
解答 :
练习 3:批归一化
题目 :BatchNorm如何加速训练?
解答 :规范化层输入分布,减少内部协变量偏移,允许更大学习率,加速收敛,兼具正则化效果。
练习 4:Dropout正则化
题目 :训练时Dropout率0.5,测试时如何处理?
解答 :测试时保留所有神经元,权重乘以0.5(或训练时除以0.5),保持期望输出一致。
练习 5:Xavier初始化
题目 :为什么Xavier初始化权重为解答 :保持前向传播方差稳定(输入输出方差相等),避免梯度爆炸/消失,适合tanh/sigmoid。ReLU用He初始化。
参考文献
[1] Rosenblatt, F. (1958). The perceptron: A probabilistic model for
information storage and organization in the brain. Psychological
Review , 65(6), 386-408.
[2] Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986).
Learning representations by back-propagating errors. Nature ,
323(6088), 533-536.
[3] Cybenko, G. (1989). Approximation by superpositions of a
sigmoidal function. Mathematics of Control, Signals and
Systems , 2(4), 303-314.
[4] Hornik, K., Stinchcombe, M., & White, H. (1989). Multilayer
feedforward networks are universal approximators. Neural
Networks , 2(5), 359-366.
[5] Glorot, X., & Bengio, Y. (2010). Understanding the difficulty
of training deep feedforward neural networks. AISTATS ,
249-256.
[6] He, K., Zhang, X., Ren, S., & Sun, J. (2015). Delving deep
into rectifiers: Surpassing human-level performance on ImageNet
classification. ICCV , 1026-1034.
[7] Nair, V., & Hinton, G. E. (2010). Rectified linear units
improve restricted Boltzmann machines. ICML , 807-814.
[8] Ioffe, S., & Szegedy, C. (2015). Batch normalization:
Accelerating deep network training by reducing internal covariate shift.
ICML , 448-456.
[9] Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., &
Salakhutdinov, R. (2014). Dropout: A simple way to prevent neural
networks from overfitting. Journal of Machine Learning
Research , 15(1), 1929-1958.
[10] Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep
Learning . MIT Press. (Chapter 6: Deep Feedforward Networks)